stable-diffusion-webui
https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.2.1
- RuntimeError: Detected that PyTorch and torchvision were compiled with different CUDA versions
- Stable Diffusion WebUI部署过程踩坑记录
- 中文插件
1 | |
lora 训练
参考技巧
大致步骤
- 底模选择
- 图片预处理
- lora训练
- 对比lora效果
底模选择
底模,尽量选祖宗级别的模型练出来的LoRA会更通用。如果在融合模型上训练可能会仅仅在你训练的底模上生成图片拥有不错的效果 但是失去了通用性。可以自己抉择
什么是祖宗级别的模型?
sd1.5 2.0、novelai 原版泄露模型。也就是非融合模型。融合模型比如 anything 系列融合了一大堆,orangemix系列融合了 anything 和 basil 更灵车了等等。在他们上面训练的会迁移性更差一些。
图片预处理
找素材,切素材,生成对应的关键词 就三步
- 不少于 15 张的高质量图片,一般可以准备 20-50 张图
- 图片主体内容清晰可辨、特征明显,图片构图简单,避免其它杂乱元素
- 如果是人物照,尽可能以脸部特写为主(多角度、多表情),再放几张全身像(不同姿势、不同服装)
- 减少重复或相似度高的图片。
- 选择高清,或者大尺寸,特大尺寸。点进去之后看看有没有套图。
具体的筛选标准:
- 脸部有遮挡的不要(比如麦克风、手指、杂物等)
- 背景太复杂的不要(比如一堆字的广告板,或夜市太乱的背景)
- 分辨率太低的不要(例如希望画
512x512,则训练至少需要用 2 倍分辨率1024x1024), - 光影比较特殊的不要(比如暗光,背光等)
- 不像本人特征的不要(比如大部分训练集都是长发,那么短发显脸大的不要,大笑毁形象的不要)
- 化妆太浓重的、美颜太严重的不要
直接用sd,就可以完成切素材,生成对应的关键词,(人物可以选择自动焦点裁切)
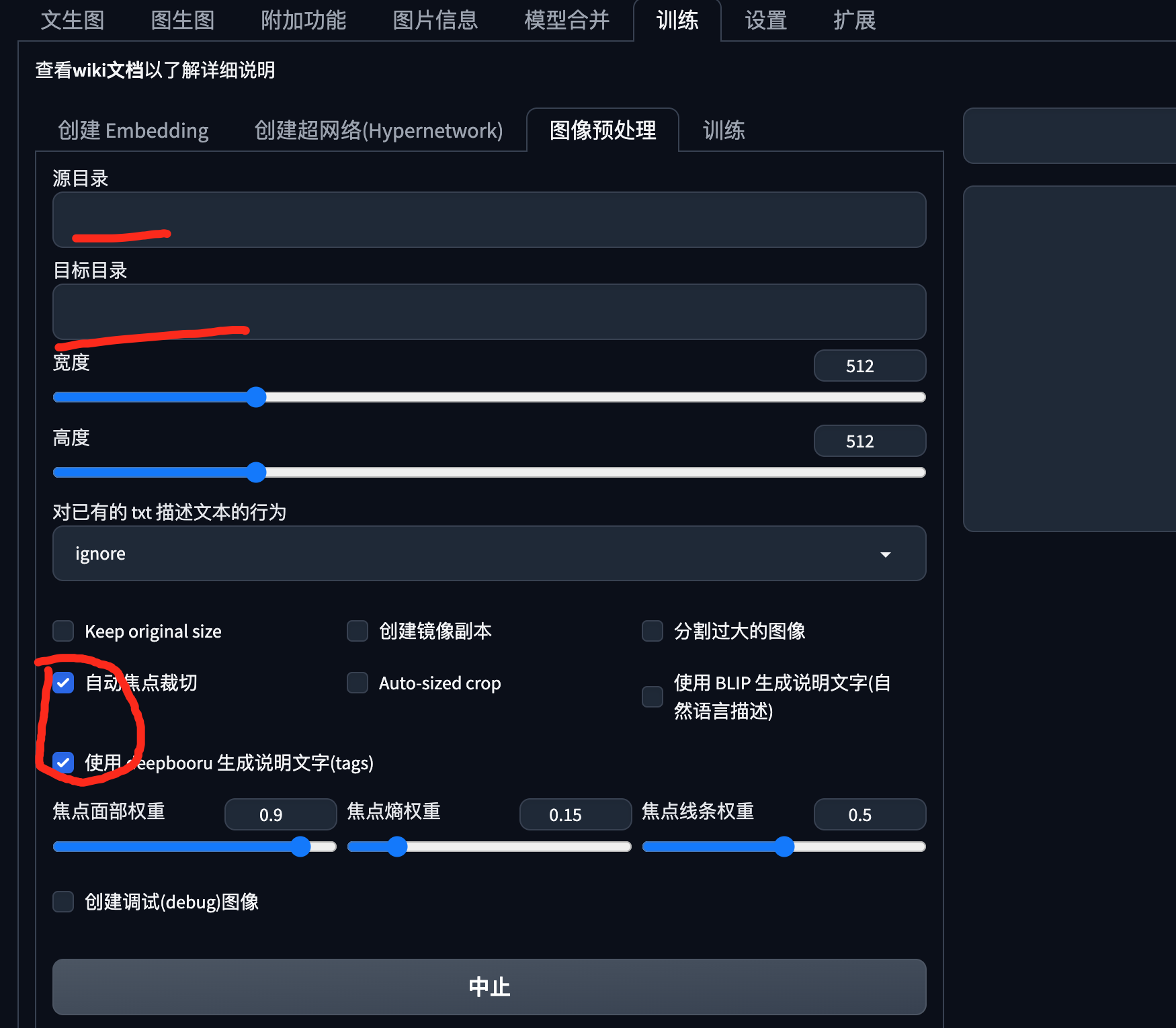
生产图片.png-关键词tag.txt的训练集,例如
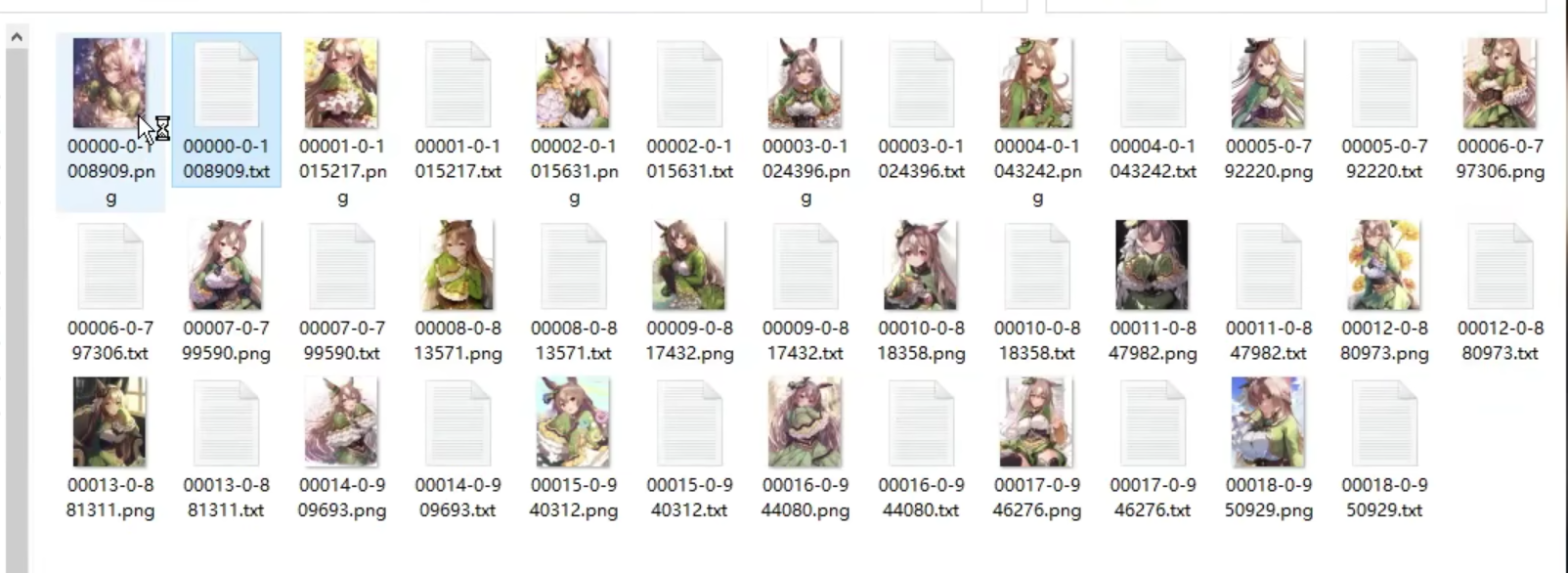
预处理生成 tags 打标文件后,就需要对文件中的标签再进行优化,一般有两种优化方法:
-
方法一:保留全部标签
就是对这些标签不做删标处理, 直接用于训练。一般在训练画风,或想省事快速训练人物模型时使用。
- 优点:不用处理 tags 省时省力,过拟合的出现情况低。
- 缺点:风格变化大,需要输入大量 tag 来调用、训练时需要把 epoch 训练轮次调高,导致训练时间变长。
-
方法二:删除部分特征标签
比如训练某个特定角色,要保留蓝眼睛作为其自带特征,那么就要将 blue eyes 标签删除,以防止将基础模型中的 blue eyes 引导到训练的 LoRA 上。简单来说删除标签即将特征与 LoRA 做绑定,保留的话画面可调范围就大。
一般需要删掉的标签:如人物特征 long hair,blue eyes 这类。
不需要删掉的标签:如人物动作 stand,run 这类,人物表情 smile,open mouth 这类,背景 simple background,white background 这类,画幅位置等 full body,upper body,close up 这类。
- 优点:调用方便,更精准还原特征。
- 缺点:容易导致过拟合,泛化性降低。
什么是过拟合:过拟合会导致画面细节丢失、画面模糊、画面发灰、边缘不齐、无法做出指定动作、在一些大模型上表现不佳等情况。
批量打标:有时要优化等标签会比较多,可以尝试使用批量打标工具
炼丹炉
使用秋葉aaaki参考视频
使用项目https://github.com/Akegarasu/lora-scripts
1 | |
1 | |
根据页面提示去填参数就好,预估效果。
-
根据页面提示填写,主要修改的参数 http://xxx.xx:7860/ lora 训练页面 ,参数详解http://xxxx:7860/lora/params.html
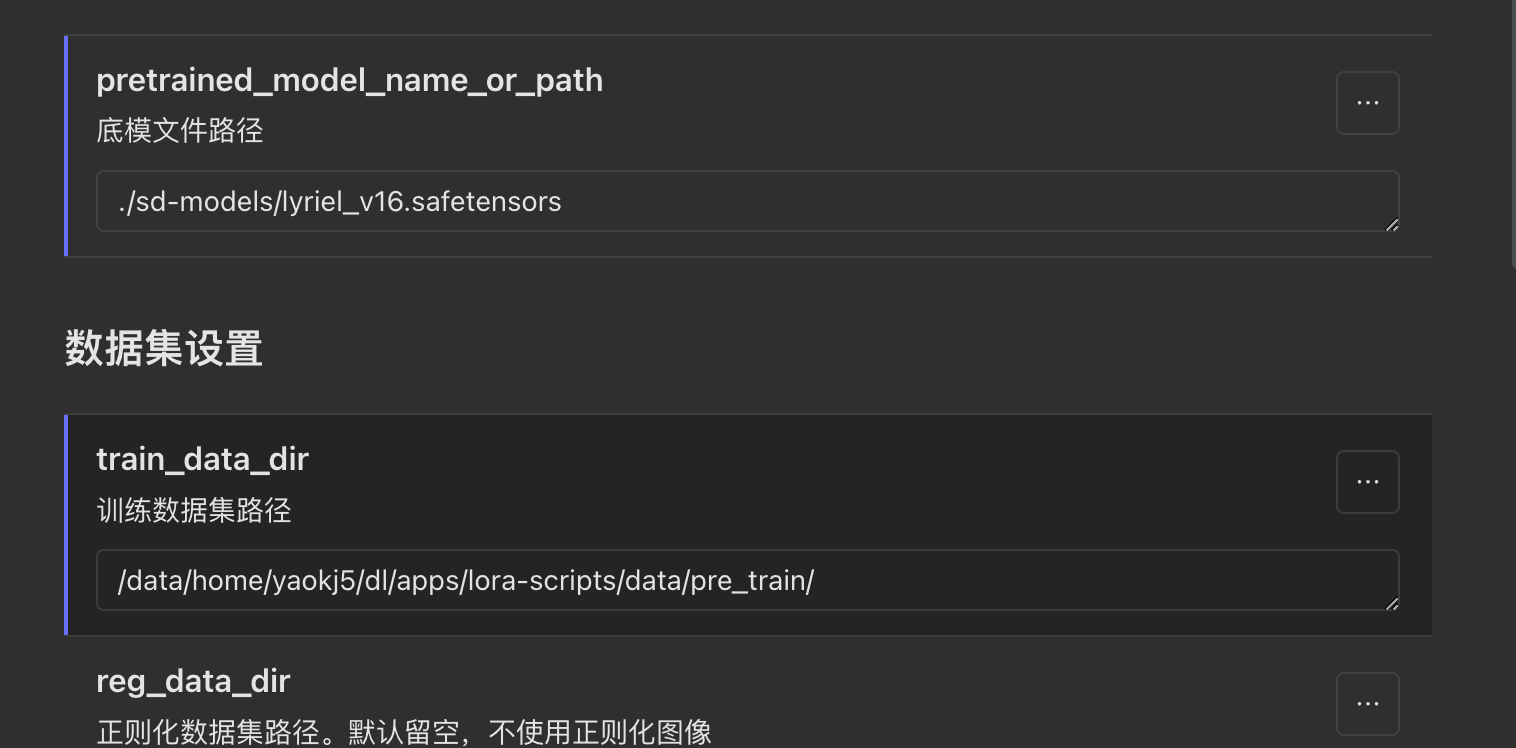
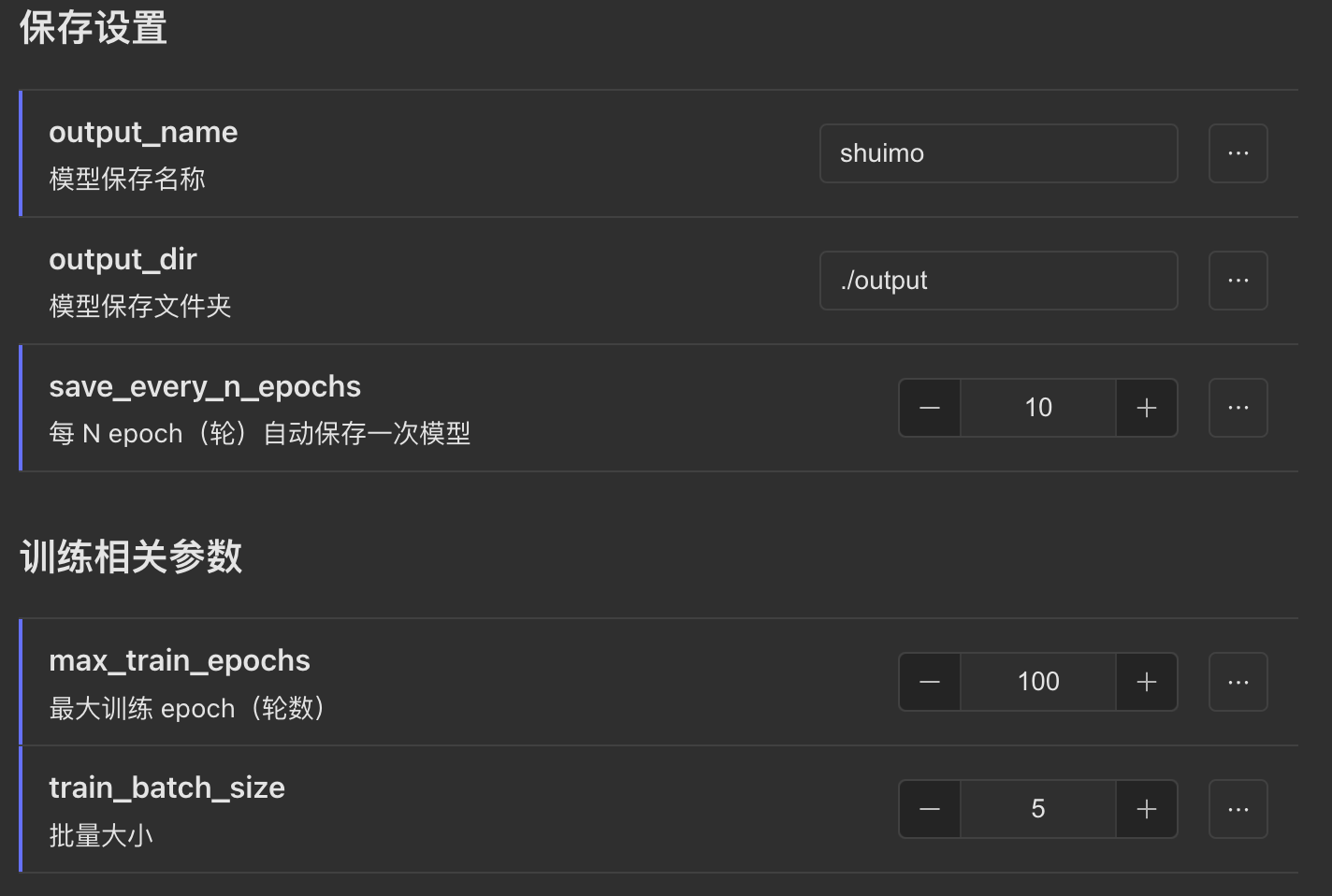
- 看控制台报错信息,训练进度。
- tensorboard 的loss http://xxx.xxx:7861/ tensorboard页面
- 启用UI的训练预览图设置 , 在输出目录的sample目录
训练好后在output目录生成对应名字的lora文件,.safetensors后缀,然后复制到stable-diffusion-webui/models/Lora
底模放到stable-diffusion-webui/models/Stable-diffusion,就可以给sd使用,看不到相关的模型或者lora,可以按一下刷新。
对比Lora之间效果
对比多个lora效果,找出效果比较好的lora版本和权重。

在 Stable Diffusion WebUI 页面最底部的脚本栏中调用 XYZ plot 脚本,设置模型对比参数。
划重点:其中 X 轴类型和 Y 轴类型都选择「提示词搜索/替换」Prompt S/R。
-
X 轴值输入:NUM,000001,000002,000003,000004,000005,对应模型序号
-
Y 轴值输入:STRENGTH,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1,对应模型权重值
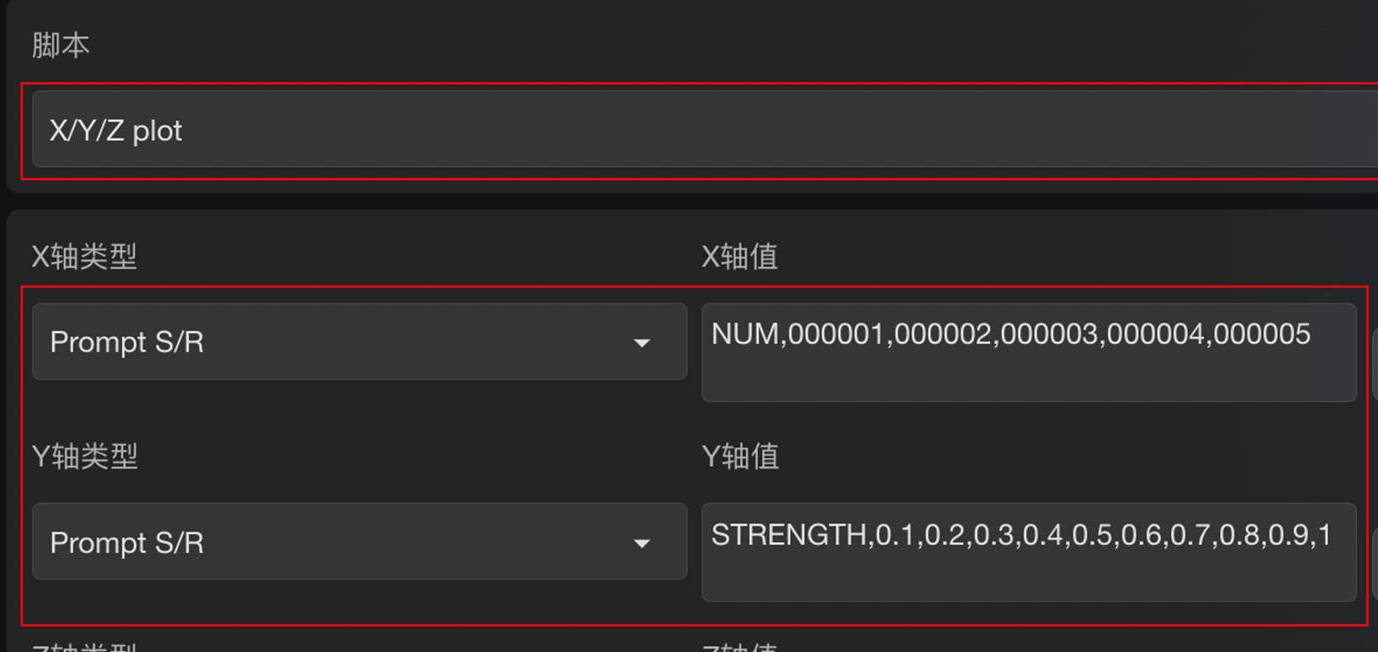
通过对比生成结果,选出表现最佳的模型和权重值。

sdapi
加上--api的参数,访问the /docs endpoint,其他参数值的获取参考官方wiki api
1 | |