测量不同特征值之间的距离方法 选择特征最相似的K个实例 选择K个实例的多数作为新数据的分类
K-近邻算法必须保存全部数据集,如果训练数据集的很大,必须使用大量的存储空间。此外, 由于必须对数据集中的每个数据计算距离值,实际使用时可能非常耗时。


三个要素
距离度量、K 、分类决策规则

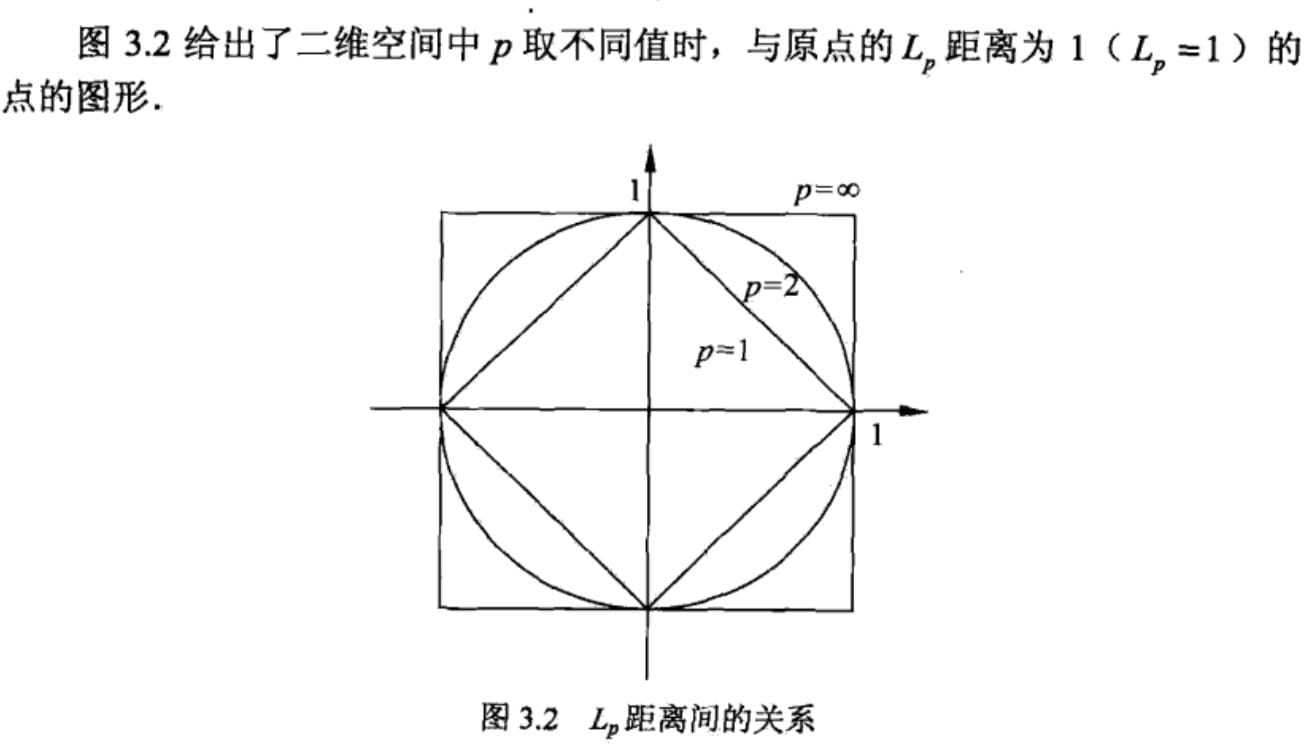
距离度量
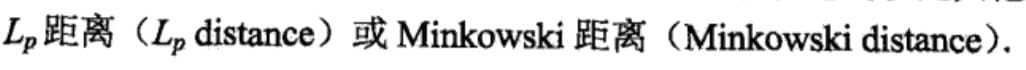


K
k 减小 过拟合 通常使用较小的 交叉验证
分类决策
多数表决
K邻近算法优化 线性扫描 kdtree 训练实例»空间维数 接近的 == 线性扫描
测量不同特征值之间的距离方法 选择特征最相似的K个实例 选择K个实例的多数作为新数据的分类
K-近邻算法必须保存全部数据集,如果训练数据集的很大,必须使用大量的存储空间。此外, 由于必须对数据集中的每个数据计算距离值,实际使用时可能非常耗时。
距离度量、K 、分类决策规则
k 减小 过拟合 通常使用较小的 交叉验证
多数表决
K邻近算法优化 线性扫描 kdtree 训练实例»空间维数 接近的 == 线性扫描