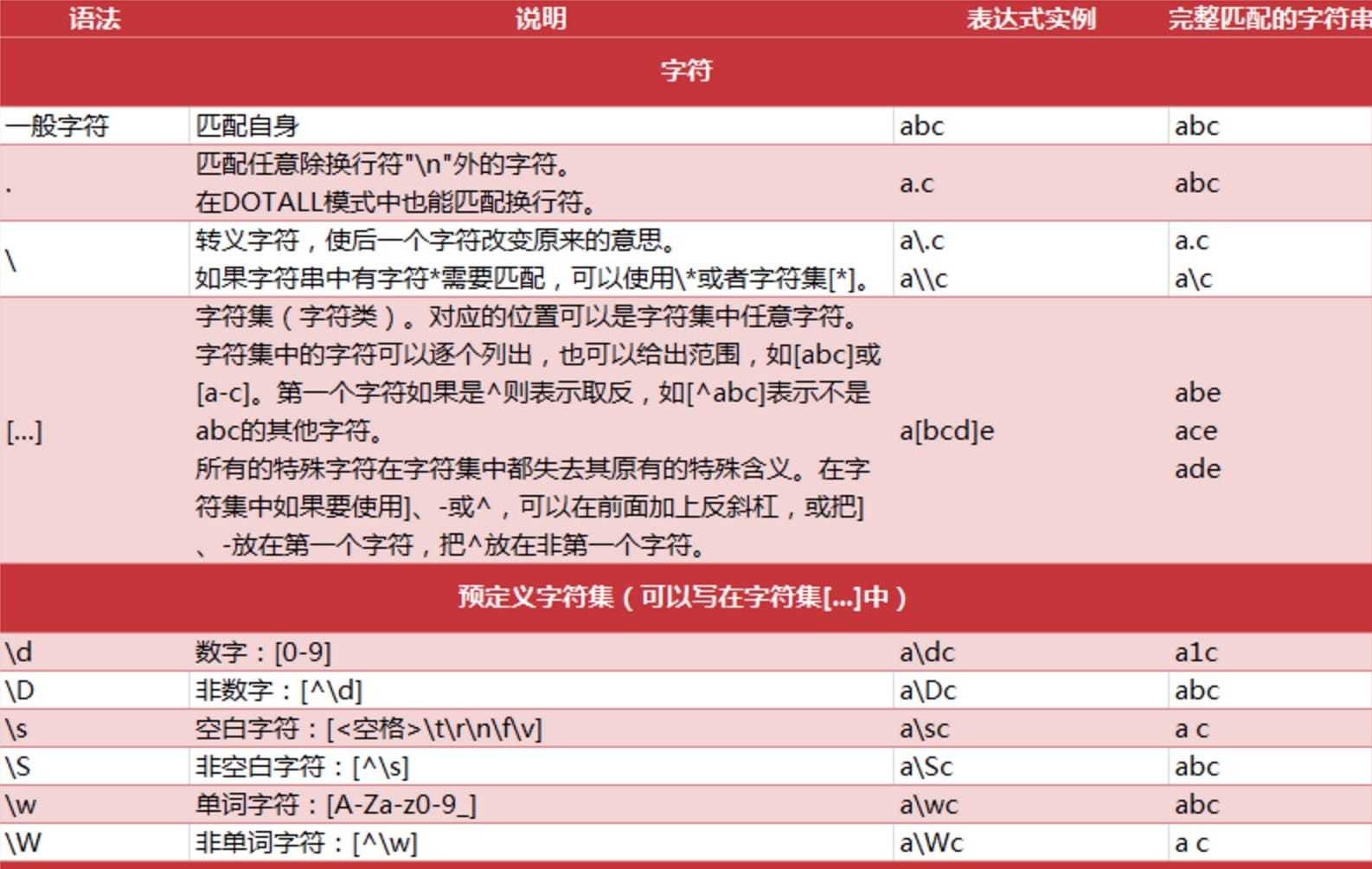
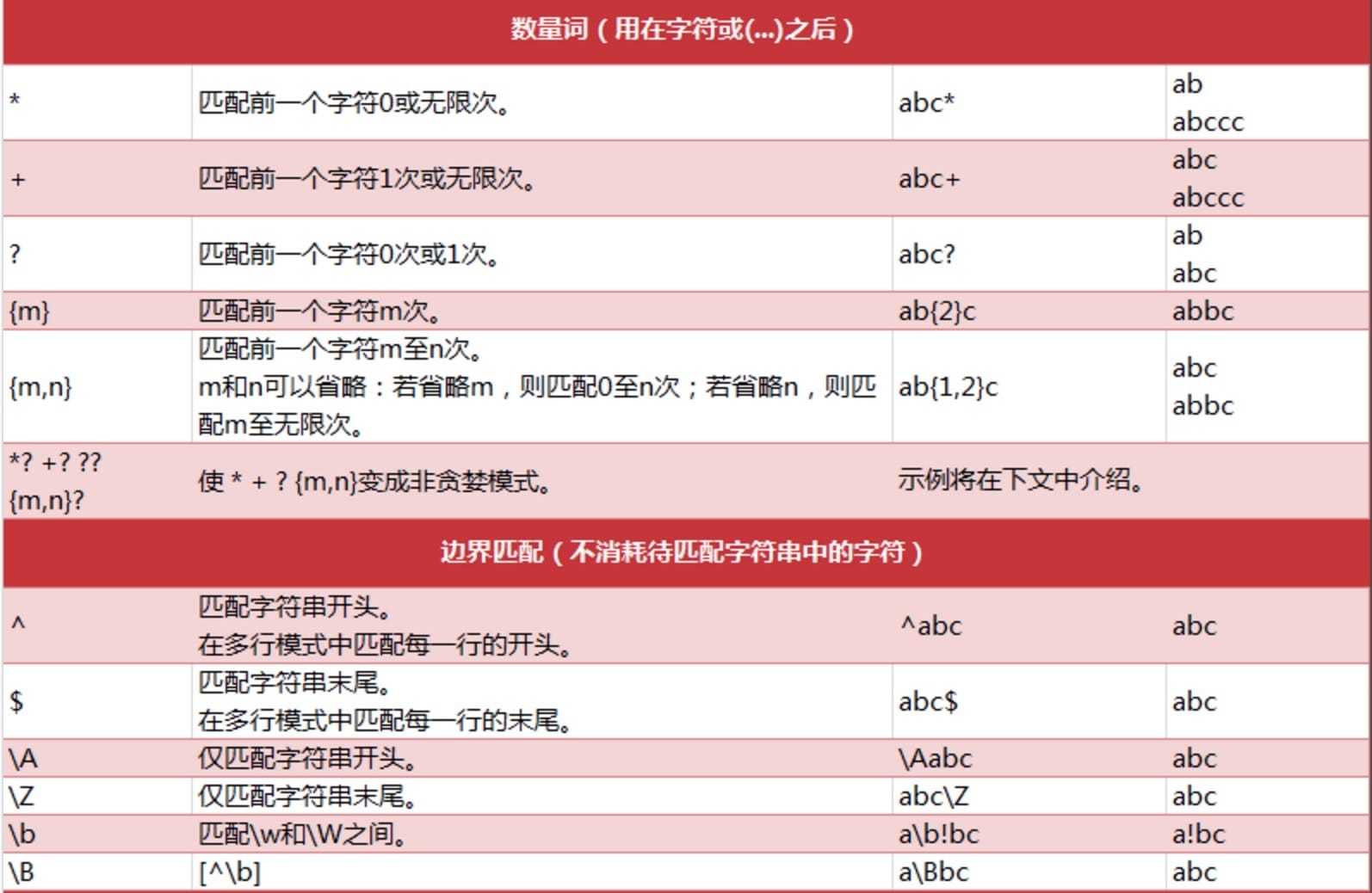
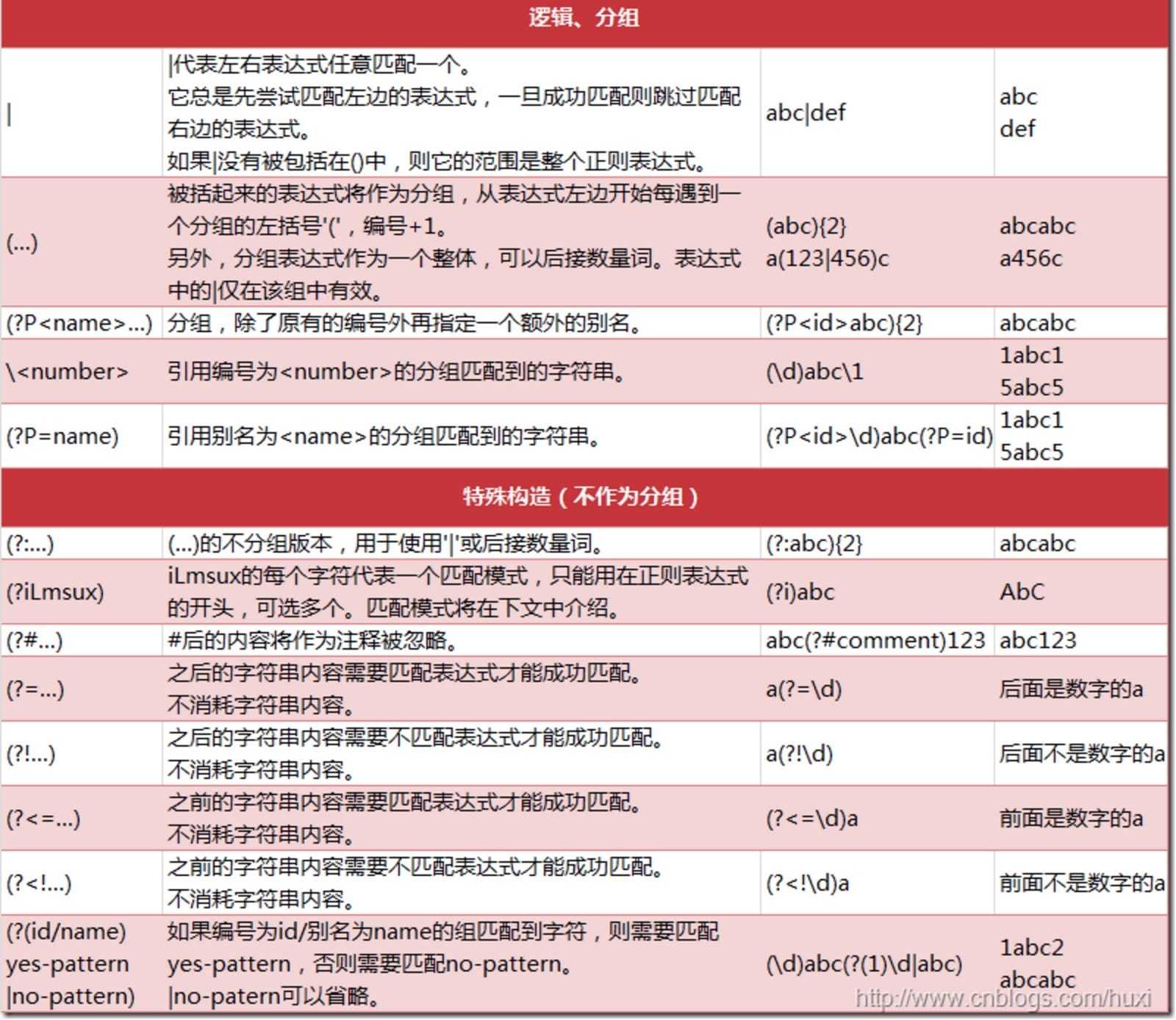
Python 正则 发表于 2018-06-03 | 分类于 正则 | 阅读次数 re 正则 1234567891011121314151617181920import re #返回pattern对象 re.compile(string[,flag]) #以下为匹配所用函数 re.match(pattern, string[, flags]) re.search(pattern, string[, flags]) re.split(pattern, string[, maxsplit]) re.findall(pattern, string[, flags]) re.finditer(pattern, string[, flags]) re.sub(pattern, repl, string[, count]) re.subn(pattern, repl, string[, count]) re.I(全拼:IGNORECASE): 忽略大小写(括号内是完整写法,下同) re.M(全拼:MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图) re.S(全拼:DOTALL): 点任意匹配模式,改变'.'的行为 re.L(全拼:LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定 re.U(全拼:UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性 re.X(全拼:VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。 总结: 尽量使用.*?匹配 使用()获取匹配目标 有换行用re.S 尽量用re.search 扫描整个字符串返回第一个匹配 不用match因为pattern参数里面第一个不匹配就直接None 本文作者: wyx 本文链接: https://github.com/blog/2018/06/03/%E6%AD%A3%E5%88%99 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 许可协议。转载请注明出处!