文字和图像有什么共同之处?乍一看,很少。 但是都可以表示成矩阵Matrix。图像的基本单位(cell)是像素(pixel)。
我们如何将文本表示为矩阵?嗯,这很简单:矩阵的每一行都是一个向量,代表文本的基本单位。
To define what a basic unit is , aggregate similar words together and then denote each aggregation (sometimes called cluster or embedding) with a representative symbol.
文本实际上不是矩阵,而是更多的向量,因为位于相邻文本行中的两个单词几乎没有共同之处。实际上,对于图像存在显着差异,其中位于相邻列中的两个像素最可能具有一些相关性。
if we have a document with 10 lines of text and each line is a 100-dimensional embedding, then we will represent our text with a matrix 10 x 100. In this very particular image, a pixel is turned on if that sentence x contains the embedding represented by position y.
为数据集中包含的文本构建嵌入。就目前而言,将此步骤视为一个黑框,它将单词并将它们映射到聚合(聚类),以便相似的单词可能出现在同一个聚类中。 请注意,前面步骤的词汇表是离散的和稀疏的。通过嵌入,我们将创建一个将每个单词嵌入连续密集向量空间的地图。
Word Embedding
特征向量表述
one-hot表征单词的方法最大的缺点就是每个单词都是独立的、正交的,无法知道不同单词之间的相似程度,这样使得算法对相关词的泛化能力不强。
使用特征表征(Featurized representation)的方法对每个单词进行编码。也就是使用一个特征向量表征单词,
特征向量的每个元素都是对该单词某一特征的量化描述,量化范围可以是[-1,1]之间。
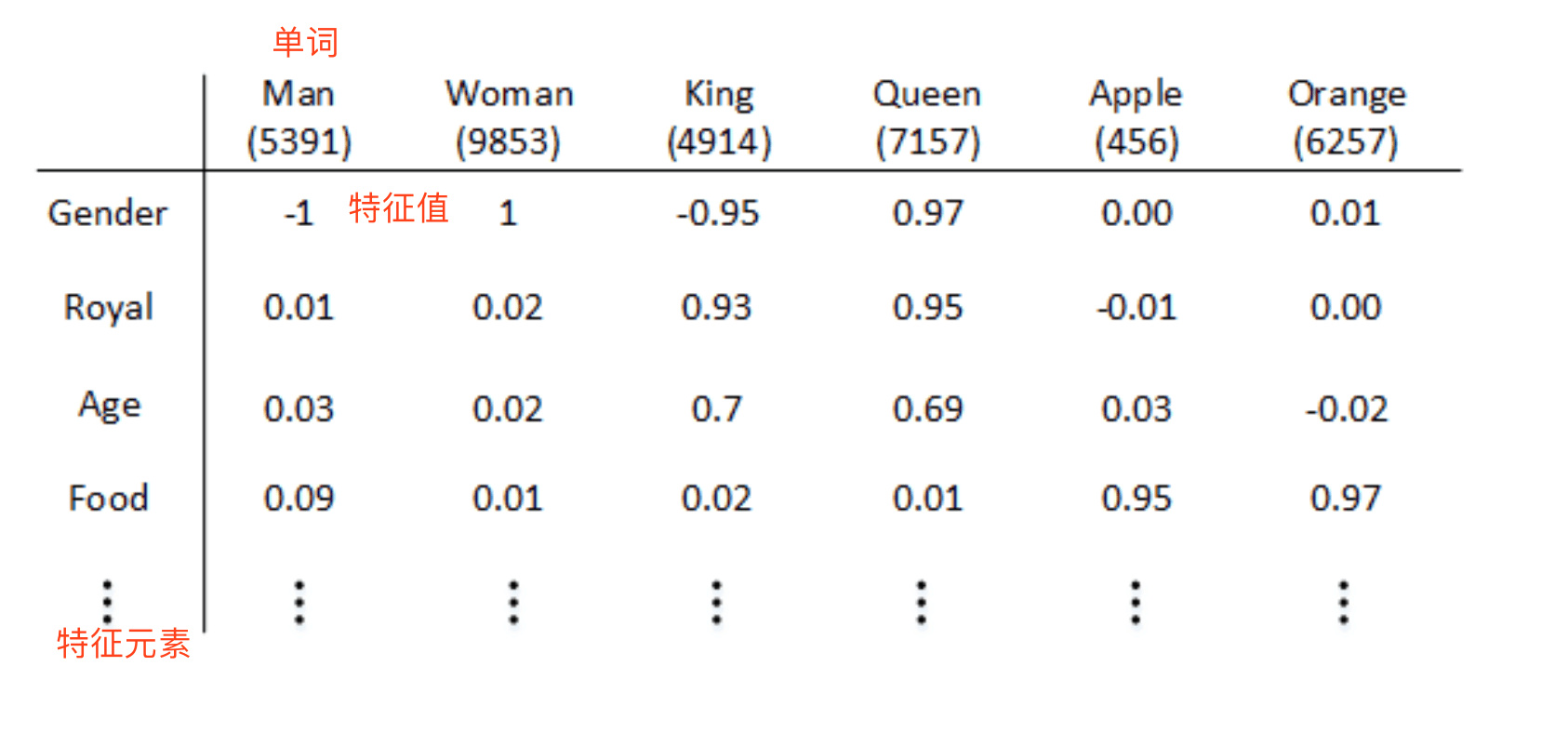
举个例子,对于这些词,比如我们想知道这些词与Gender(性别)的关系。假定男性的性别为-1, 女性的性别为+1,那么man的性别值可能就是-1,而woman就是-1。最终根据经验king就是-0.95,queen是+0.97,apple和orange没有性别可言。
特征向量的长度依情况而定,特征元素越多则对单词表征得越全面。该向量的每个元素表示该单词对应的某个特征值。 这种特征表征的优点是根据特征向量能清晰知道不同单词之间的相似程度。这种单词“类别”化的方式,大大提高了有限词汇量的泛化能力。 这种特征化单词的操作被称为Word Embeddings,即单词嵌入。每个单词都由高维特征向量表征,为了可视化不同单词之间的相似性,可以使用降维操作。
featurized representation的优点是可以减少训练样本的数目,前提是对海量单词建立特征向量表述(word embedding), 即使是训练样本中没有的单词,也可以根据word embedding的结果得到与其词性相近的单词,从而得到与该单词相近的结果,有效减少了训练样本的数量。
Properties of word embeddings
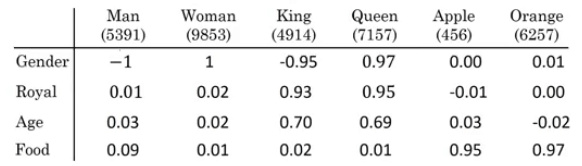
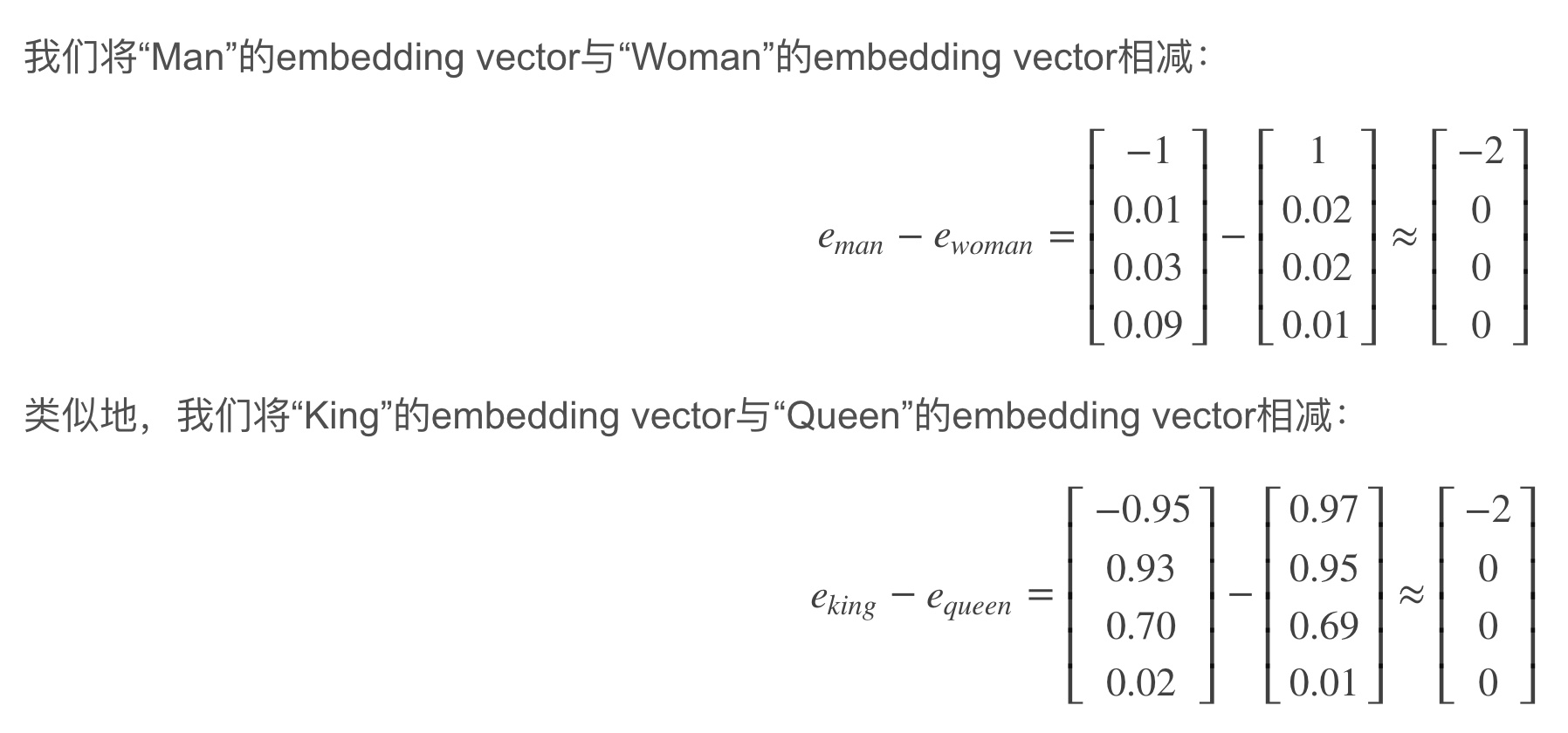
如上图所示,根据等式$e_{man}-e_{woman}\approx e_{king}-e_?$得:
\(e_?=e_{king}-e_{man}+e_{woman}\)
\(sim(e_w,e_{king}-e_{man}+e_{woman})\)
余弦相似度 平方距离或者欧氏距离

Embedding matrix

Get E
E 未知待求,每个单词可用embedding vector ew表示
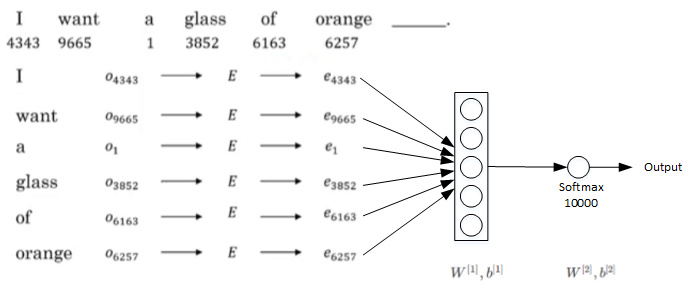 神经网络输入层包含6个embedding vactors,每个embedding vector维度是300,则输入层总共有1800个输入。
Softmax层有10000个概率输出,与词汇表包含的单词数目一致。
其中$E,W^{[1]},b^{[1]},W^{[2]},b^{[2]}$为待求值。对足够的训练例句样本,
运用梯度下降算法,迭代优化,最终求出embedding matrix E。
神经网络输入层包含6个embedding vactors,每个embedding vector维度是300,则输入层总共有1800个输入。
Softmax层有10000个概率输出,与词汇表包含的单词数目一致。
其中$E,W^{[1]},b^{[1]},W^{[2]},b^{[2]}$为待求值。对足够的训练例句样本,
运用梯度下降算法,迭代优化,最终求出embedding matrix E。

Word2Vec
词向量就是一个二维矩阵,维度为 V × d,V 是词的总个数,d是词向量的维度。
- Skip-Gram:根据当前词预测上下文词语
- CBOW(Continuous Bag-of-Words): 根据上下文词语预测当前词
Skip-Gram
context和target的选择方法,比较流行的是采用Skip-Gram模型,
I want a glass of orange juice to go along with my cereal.
首先随机选择一个单词作为context,例如orange; 然后使用一个宽度为5或10(自定义)的滑动窗,在context附近选择一个单词作为target, 可以是juice、glass、my等等。最终得到了多个context—target对作为监督式学习样本。
训练的过程是构建自然语言模型,经过softmax单元的输出为:
\[\hat y=\frac{e^{\theta_t^T\cdot e_c}}{\sum_{j=1}^{10000}e^{\theta_j^T\cdot e_c}}\]其中,$\theta_t$为target对应的参数,$e_c$为context的embedding vector,且$e_c=E\cdot O_c$。
相应的loss function为:
\[L(\hat y,y)=-\sum_{i=1}^{10000}y_ilog\ \hat y_i\]然后,运用梯度下降算法,迭代优化,最终得到embedding matrix E。
然而,这种算法计算量大,影响运算速度。主要因为softmax输出单元为10000个,$\hat y$计算公式中包含了大量的求和运算。
解决方案:分级(hierarchical)的softmax分类器和负采样(Negative Sampling)
hierarchical softmax classifier
树形分类器,与之前的softmax分类器不同,它在每个数节点上对目标单词进行区间判断, 最终定位到目标单词,通常选择把比较常用的单词放在树的顶层,而把不常用的单词放在树的底层。这样更能提高搜索速度。
关于context的采样,需要注意的是如果使用均匀采样,那么一些常用的介词、冠词, 例如the, of, a, and, to等出现的概率更大一些。 但是,这些单词的embedding vectors通常不是我们最关心的,我们更关心例如orange, apple, juice等这些名词等。 所以,实际应用中,一般不选择随机均匀采样的方式来选择context,而是使用其它算法来处理这类问题。
Negative Sampling
判断选取的context word和target word是否构成一组正确的context-target对,一般包含一个正样本和k个负样本。
例如,“orange”为context word,“juice”为target word,很明显“orange juice”是一组context-target对,为正样本, 相应的target label为1。若“orange”为context word不变,target word随机选择“king”、“book”、“the”或者“of”等。 这些都不是正确的context-target对,为负样本,相应的target label为0。
一般地,固定某个context word对应的负样本个数k一般遵循:
- 若训练样本较小,k一般选择5~20;
- 若训练样本较大,k一般选择2~5即可。
Negative sampling的数学模型为:
\[P(y=1|c,t)=σ(θTt⋅ec)P(y=1|c,t)=σ(θtT⋅ec)P(y=1|c,t)=\sigma(\theta^T_t\cdot e_c)\]其中,$\sigma$表示sigmoid激活函数。
很明显,negative sampling某个固定的正样本对应k个负样本,即模型总共包含了k+1个binary classification。 对比之前介绍的10000个输出单元的softmax分类,negative sampling转化为k+1个二分类问题,计算量要小很多,大大提高了模型运算速度。
最后提一点,关于如何选择负样本对应的target单词,可以使用随机选择的方法。但有资料提出一个更实用、效果更好的方法, 就是根据该词出现的频率进行选择,相应的概率公式为:
\[P(w_i)=\frac{f(w_i)^{\frac34}}{\sum_j^{10000}f(w_j)^{\frac34}}\]其中,$f(w_i)$表示单词$w_i$在单词表中出现的概率。
CBOW
连续词袋模型(Continuous Bag-Of-Words Model)它获得中间词两边的的上下文,然后用周围的词去预测中间的词, 这个模型也很有效,也有一些优点和缺点。
CBOW是从原始语句推测目标字词;而Skip-Gram正好相反,是从目标字词推测出原始语句。 CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。 通常情况下,Skip-Gram模型用到更多点
GloVe word vectors
GloVe算法引入了一个新的参数:
\[X_{ij}: 表示i和j同时出现的次数。\]其中,i表示context,j表示target。一般地,如果不限定context一定在target的前面,则有对称关系$X_{ij}=X_{ji}$;如果有限定先后, 则$X_{ij}\neq X_{ji}$。接下来的讨论中,我们默认存在对称关系$X_{ij}=X_{ji}$。
GloVe模型的loss function为:
\[L=\sum_{i=1}^{10000}\sum_{j=1}^{10000}(\theta_i^Te_j-log X_{ij})^2\]从上式可以看出,若两个词的embedding vector越相近,同时出现的次数越多,则对应的loss越小。
为了防止出现“log 0”,即两个单词不会同时出现,无相关性的情况,对loss function引入一个权重因子$f(X_{ij})$:
\[L=\sum_{i=1}^{10000}\sum_{j=1}^{10000}f(X_{ij})(\theta_i^Te_j-log X_{ij})^2\]当$X_{ij}=0$时,权重因子$f(X_{ij})=0$。这种做法直接忽略了无任何相关性的context和target,只考虑$X_{ij}>0$的情况。
出现频率较大的单词相应的权重因子$f(X_{ij})$较大,出现频率较小的单词相应的权重因子$f(X_{ij})$较小一些。 具体的权重因子f(X_{ij})$选取方法可查阅相关论文资料。
一般地,引入偏移量,则loss function表达式为:
\[L=\sum_{i=1}^{10000}\sum_{j=1}^{10000}f(X_{ij})(\theta_i^Te_j+b_i+b_j'-log X_{ij})^2\]值得注意的是,参数θiθi\theta_i和ejeje_j是对称的。使用优化算法得到所有参数之后,最终的$e_w$可表示为:
\[e_w=\frac{e_w+\theta_w}{2}\]最后提一点的是,无论使用Skip-Gram模型还是GloVe模型等等,计算得到的embedding matrix EEE的每一个特征值不一定对应有实际物理意义的特征值,如gender,age等。
Sentiment Classification
情感分类问题的一个主要挑战是缺少足够多的训练样本。而Word embedding恰恰可以帮助解决训练样本不足的问题。不同单词出现的次序直接决定了句意。
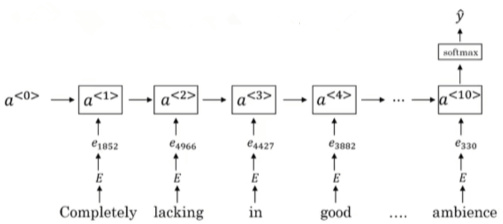 该RNN模型是典型的many-to-one模型,考虑单词出现的次序,能够有效识别句子表达的真实情感。
值得一提的是使用word embedding,能够有效提高模型的泛化能力,即使训练样本不多,也能保证模型有不错的性能。
该RNN模型是典型的many-to-one模型,考虑单词出现的次序,能够有效识别句子表达的真实情感。
值得一提的是使用word embedding,能够有效提高模型的泛化能力,即使训练样本不多,也能保证模型有不错的性能。
词模型
词袋模型:(词,出现次数)统计词频 CountVectorize 词频统计
TF-IDF模型
评估某一字词对于一个文件集或一个语料库的重要程度 如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征
\[W_{tf-idf}=W_{tf}\;\ast\;\lg({\textstyle\frac1{W_{df}}})\]$W_{tf}$ text frequency (TF) 某文档词频 $W_{df}$ 在所有的文档总词频
1 | |
词汇表模型
词袋模型:文本由哪些单词组成 无法表达出单词之间的前后关系 生成的词汇表对原有句子按照单词逐个进行编码
Word2Vec
生成词向量 显示词间关系 采用的模型有 CBOW(Continuous Bag-Of-Words,即连续的词袋模型) Skip-Gram 两种
CBOW模型能够根据输入周围n-1个词来预测出这个词本身,而Skip-gram模型能够根据词本身来预测周围有哪些词。也就是说, CBOW模型的输入是某个词A周围的n个单词的词向量之和,输出是词A本身的词向量,而Skip-gram模型的输入是词A本身,输出是词A周围的n个单词的词向量。

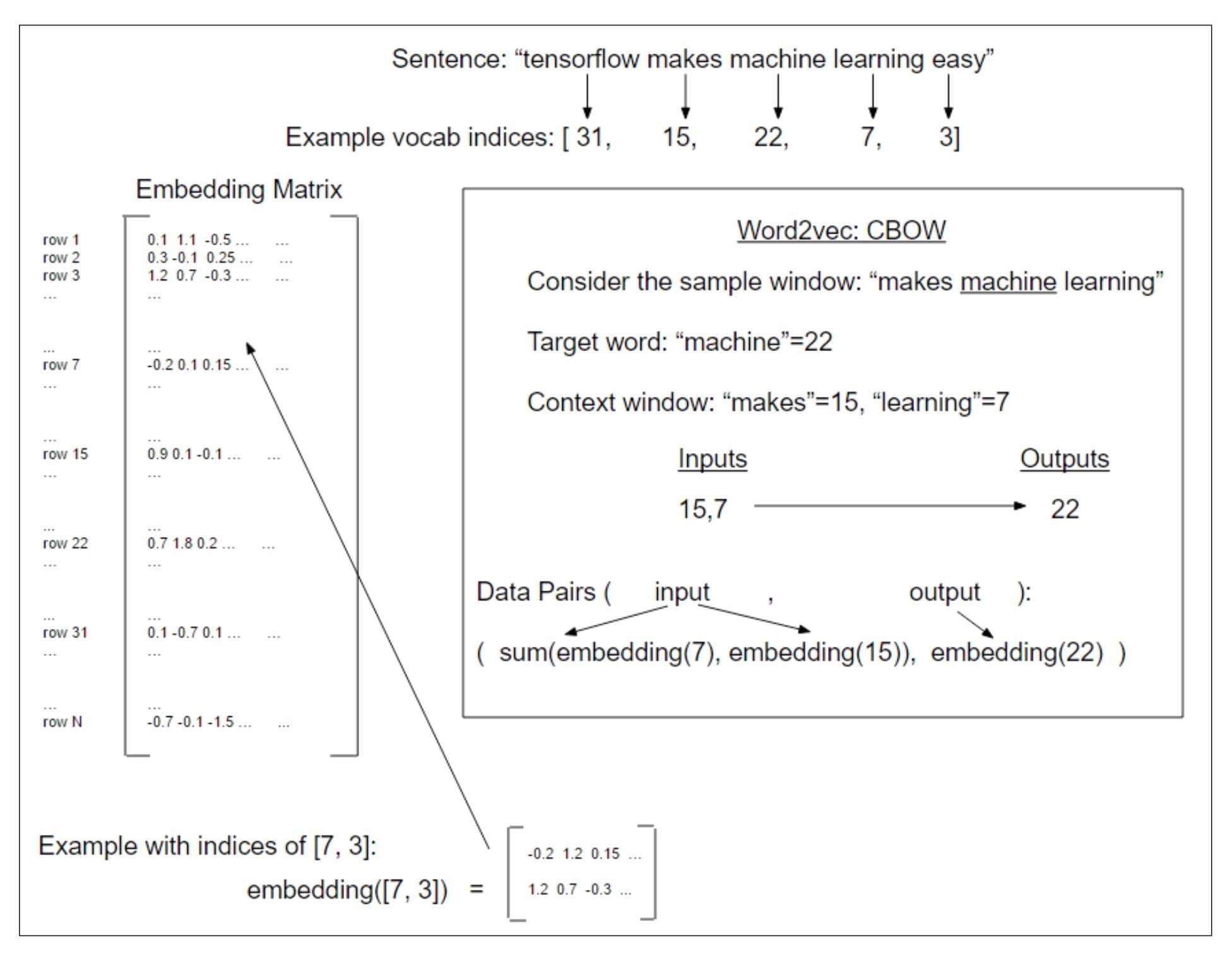
Doc2Vec
分为Distributed Memory (DM) 和Distributed Bag of Words (DBOW)。
fasttext
有效且快速的方式生成词向量以及进行文档分类 高效
LDA
一种文档主题模型,包含词、主题和文档三层结构
LDA认为一篇文档由一些主题按照一定概率组成,一个主题又由一些词语按照一定概率组成。

Why 主题: 主题的个数通常为几百,这就把文档使用了维数为几百的向量进行了表示,大大加快了训练速度,并且相对不容易造成过拟合。从某种程度上来说,主题是对若干词语的抽象表示。
TextRank TF-IDF
使用TextRank提取关键字
计算文档相似度
simhash
- n个(关键词,权重)对
- 计算关键词的hash,生成(hash,weight),并将hash和weight相乘,这一过程是对hash值加权
- 将hash和weight相乘的值相加,比如图中的[13, 108, -22, -5, -32, 55],并最终转换成simhash值110001,转换的规则为正数为1负数为0
评论预处理
文本去重
- 原因

- 做法
尽量保留有用的
压缩去词
 短句删除
短句删除
