Pig
- 高级数据流语言 Pig Latin
- 运行Pig Latin程序的执行环境
Pig能够让你专心于数据及业务本身,而不是纠结于数据的格式转换以及MapReduce程序的编写。

Execution Modes
local
only requires a single machine. Pig will run on the local host and access the local filesystem.
pig -x local ...
MapReduce
pig ...
Interactive Mode
Pig can be run interactively in the Grunt shell.
1 | |
Batch Mode
use pig script
pig -x local id.pig
pig 语法
Each statement is an operator that takes a relation as an input, performs a transformation on that relation,
and produces a relation as an out‐ put. Statements can span multiple lines,;结尾。
- A LOAD statement that reads the data from the filesystem
- One or more statements to transform the data
- A DUMP or STORE statement to view or store the results
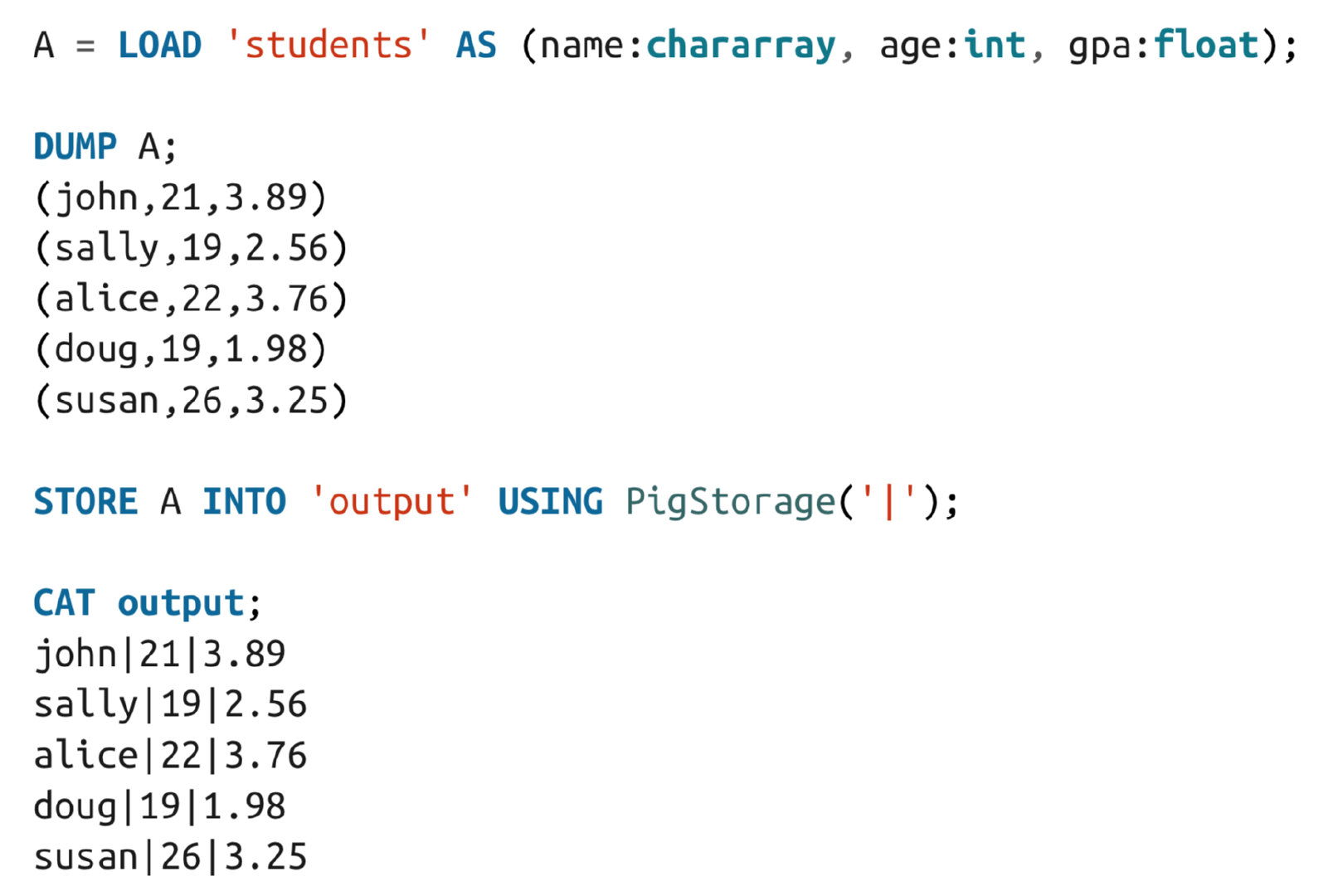
load
USING default keyword \t
AS default not named and type bytearray
LOAD 'data' [USING function] [AS schema];
A = LOAD 'students' AS (name:chararray, age:int);
DUMP A;
(john,21,3.89)
(sally,19,2.56)
(alice,22,3.76)
(doug,19,1.98)
(susan,26,3.25)
Transforming Data
条件关系 and or not
FILTER
处理列
1 | |
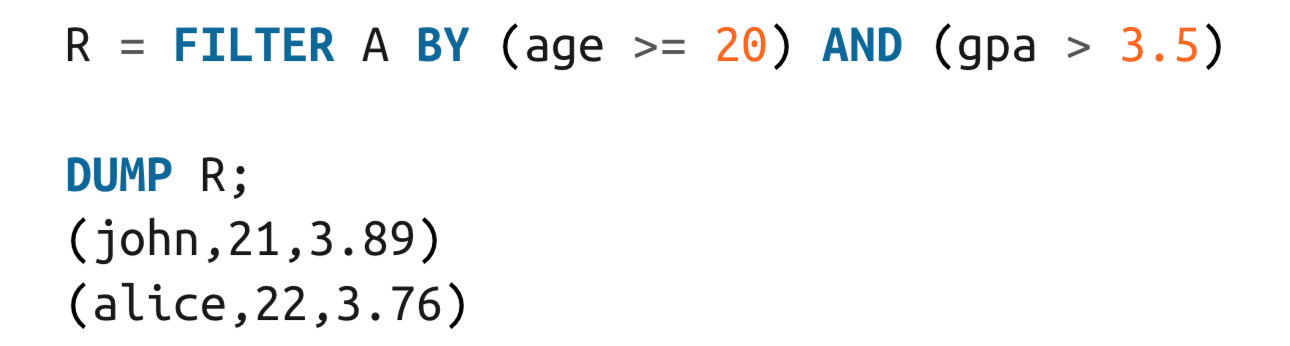
FOREACH
处理行 有点像select
1 | |


GROUP
1 | |


STORE
1 | |
1 | |
UDF
1 | |
1 | |
Hive
HBase
数据模型概念



表

行

列族

限定字符

单元格

时间戳

列族存储

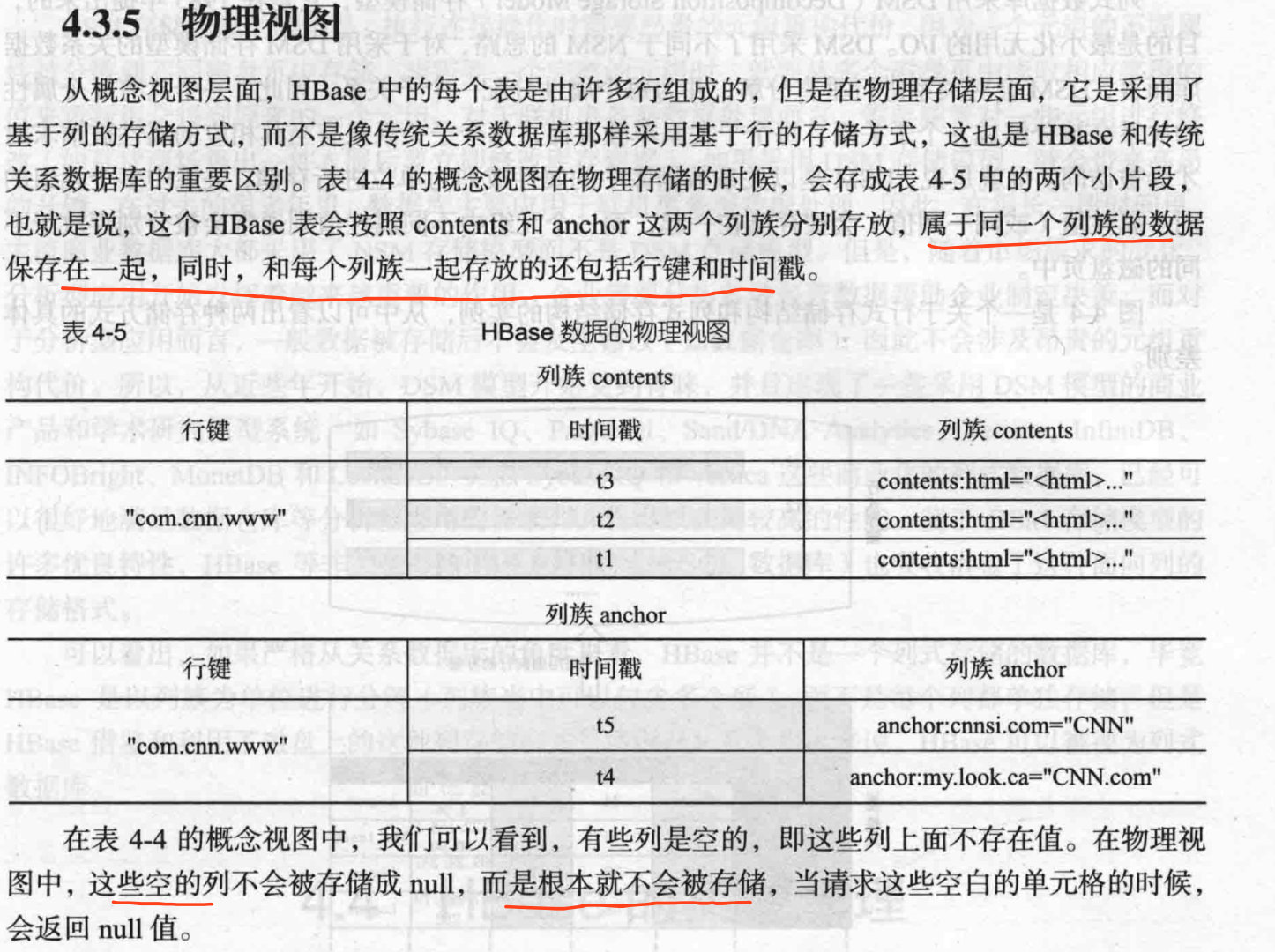

- 降低IO
- 大并发查询
- 高数据压缩比
架构
与Hadoop访问过程,结构有点像

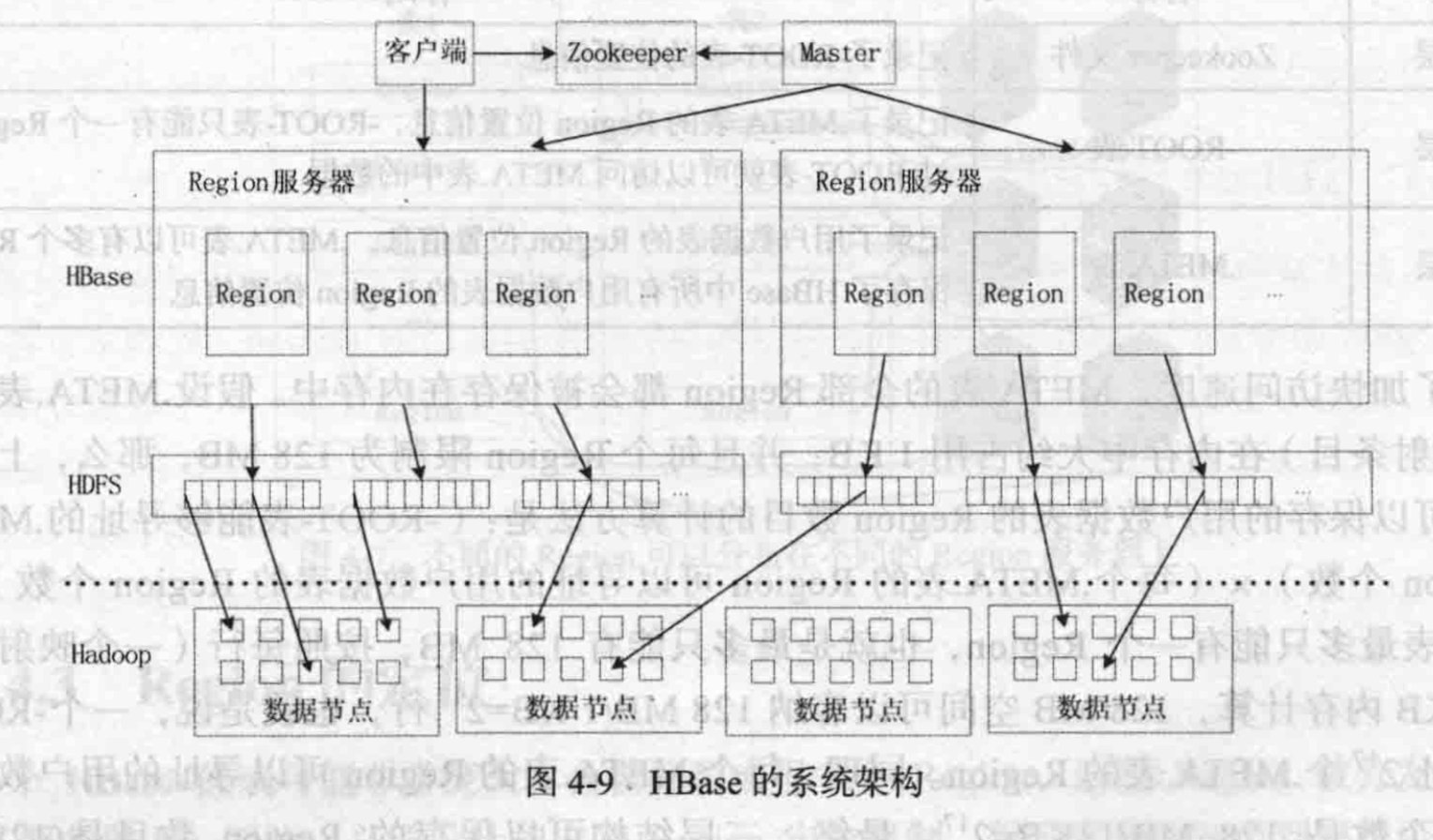
zookeeper

master

region

表 Region
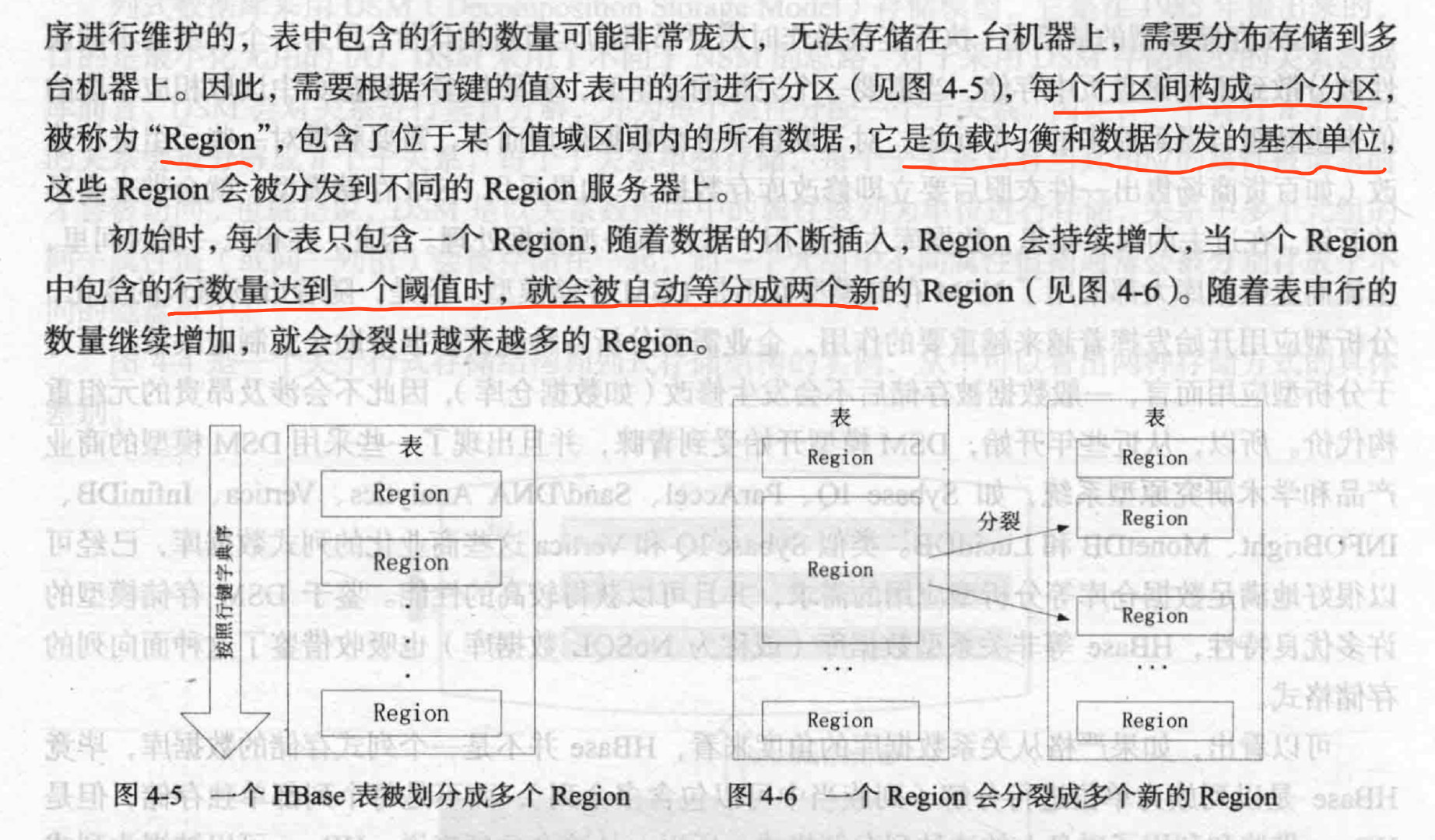

Region 定位
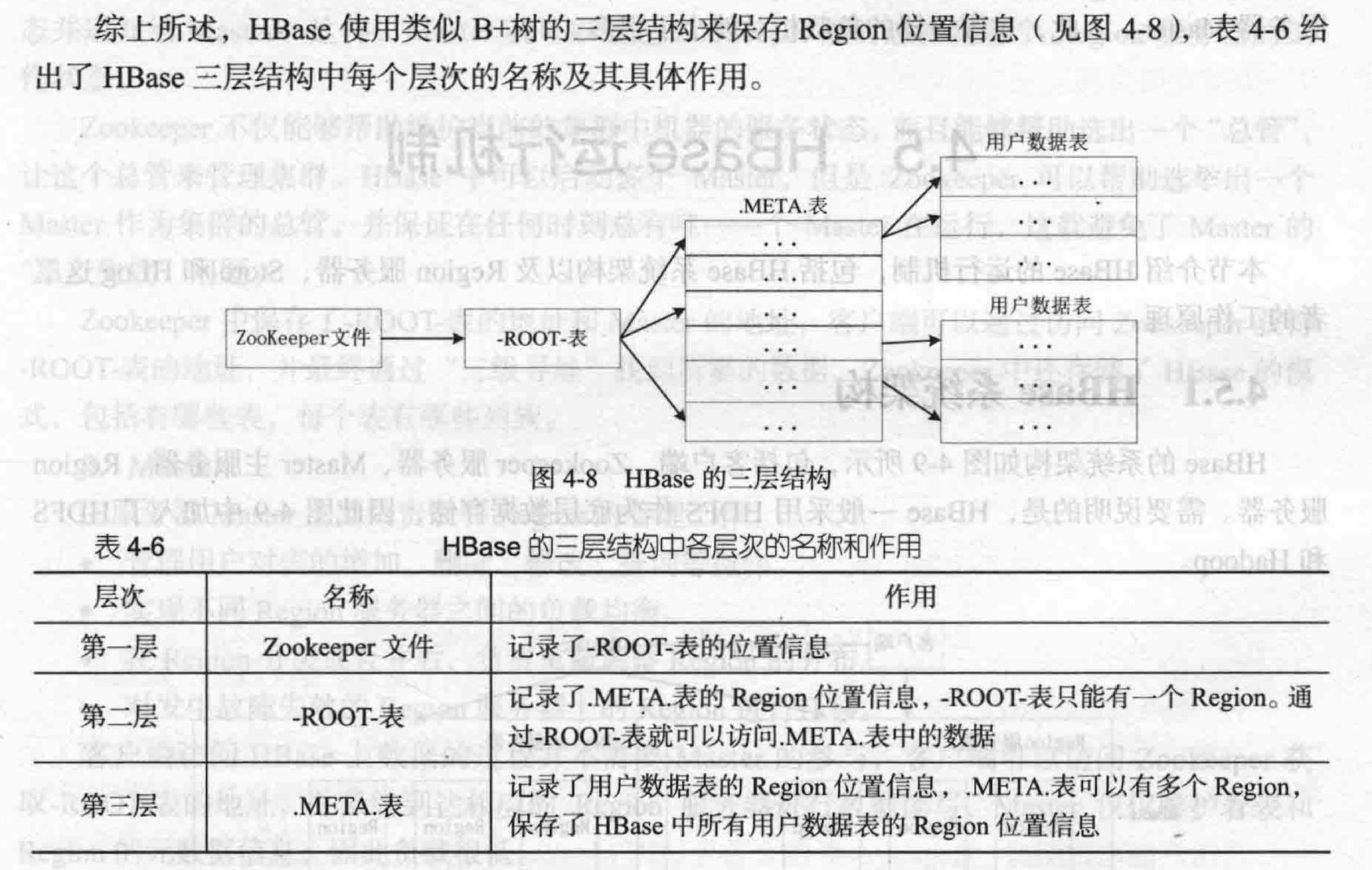


结构
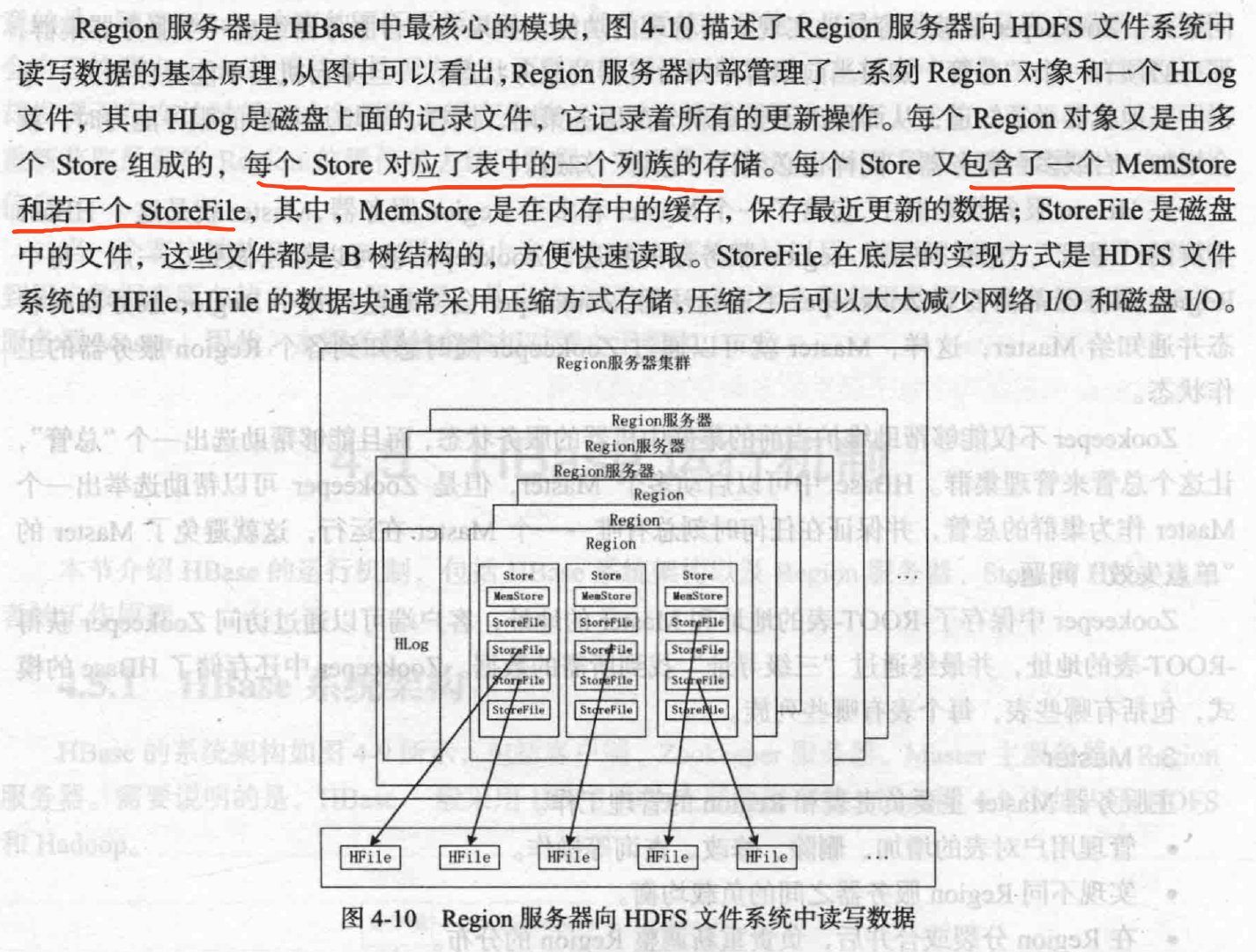
MemStore容量有限,周期性写入到StoreFile,HLog写入一个标记。每次缓存刷新生成新的StoreFile,
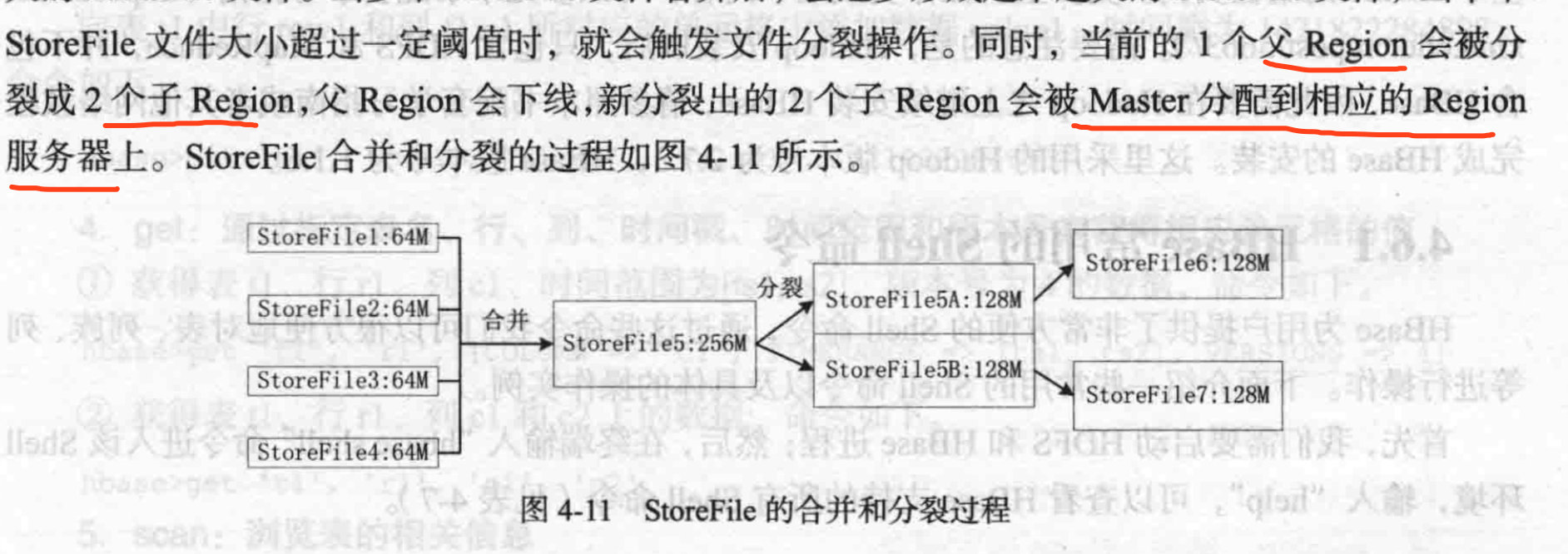
当StoreFile数量到达某个阈值,会合并一个大StoreFile。当大StoreFile大小到达某个阈值,会分裂。


读写

局限

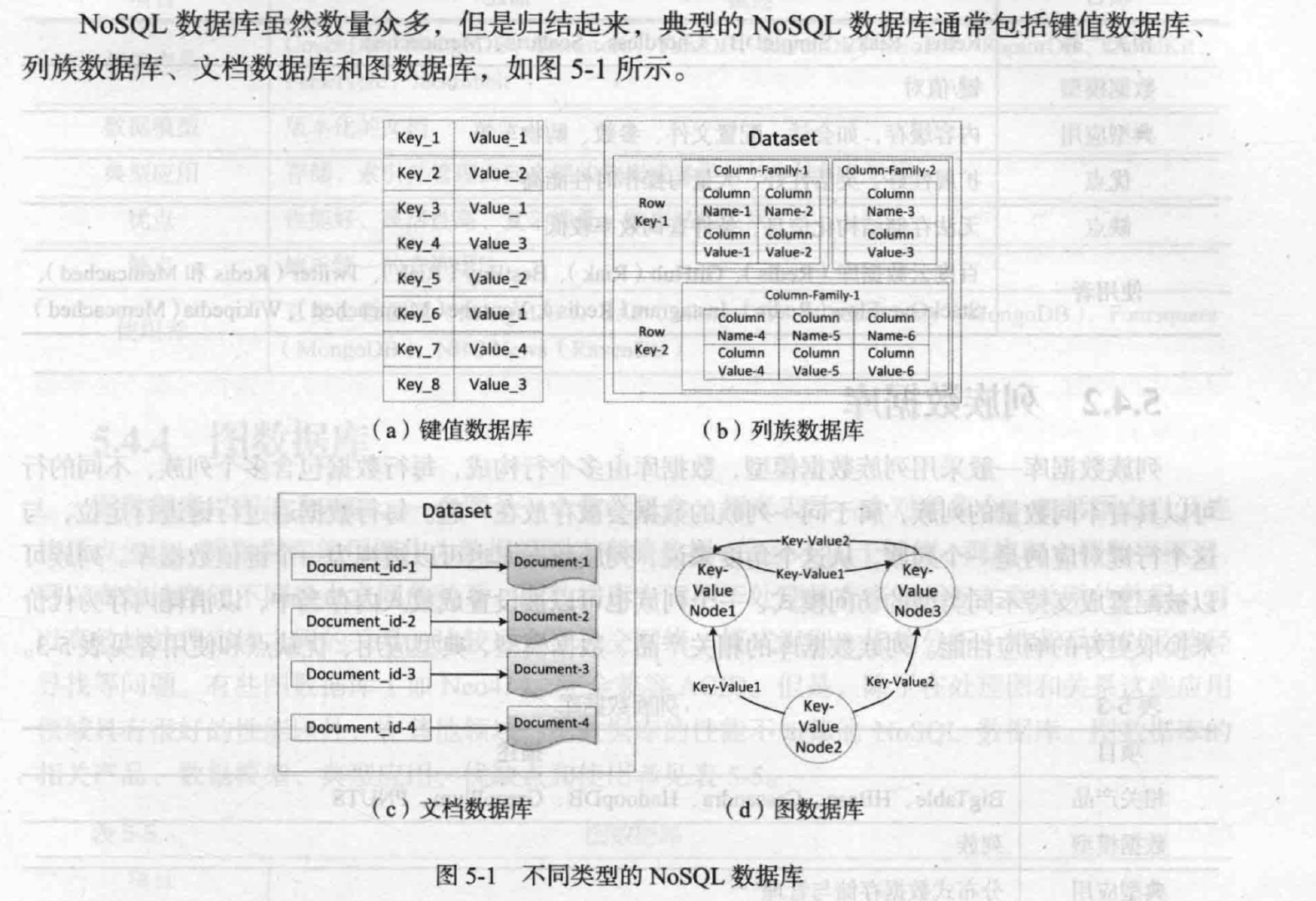
NoSQL
不需要事务,读写实时性,没有复杂SQL查询。
种类
Spark
流计算
- 静态数据 批量计算 时间充足批量处理海量数据
- 流数据 实时计算

流数据特征

实时采集
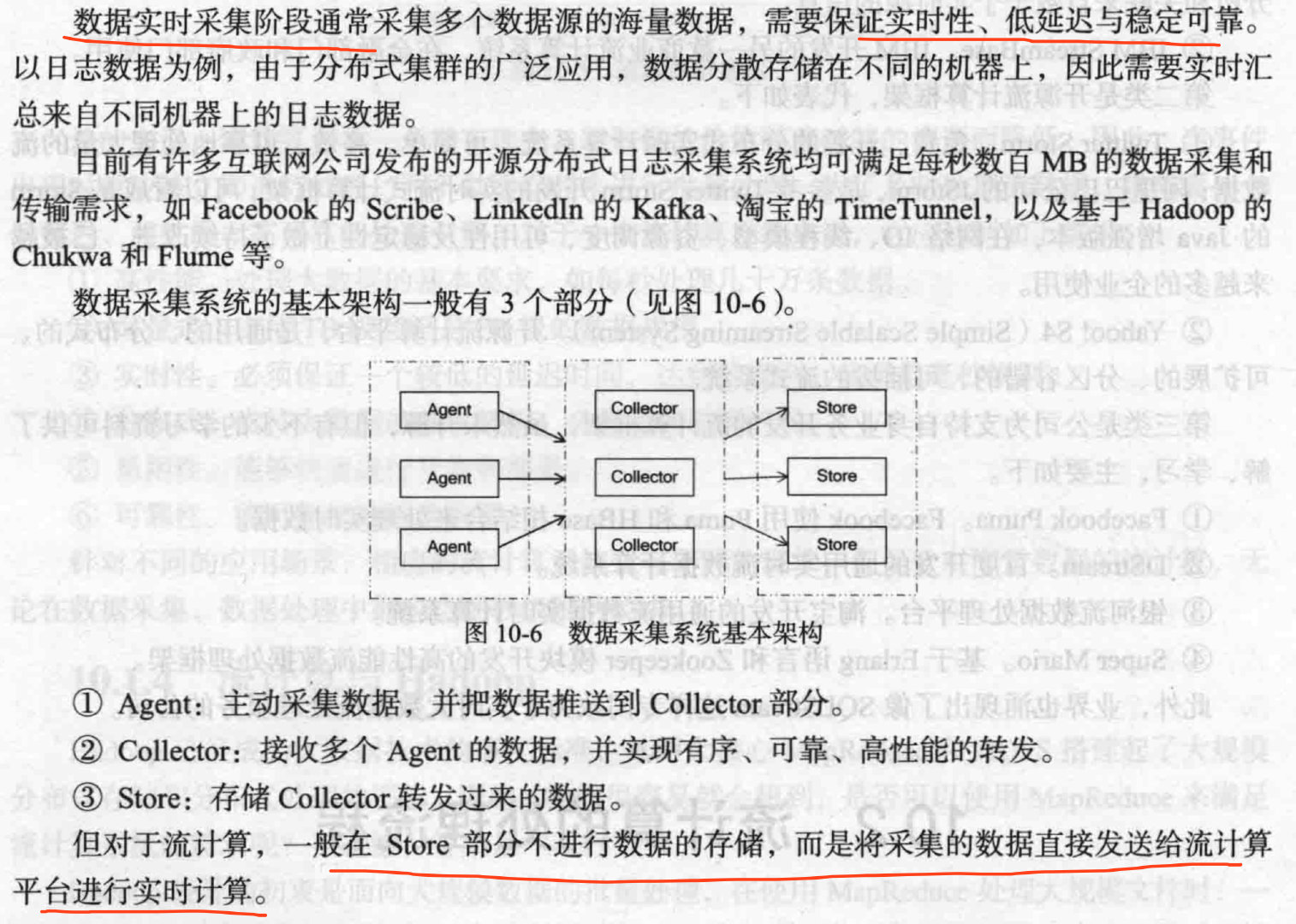
实时计算

实时查询

Storm
Spark Streaming
将stream拆分成小量批处理, 做不到毫秒级别,storm 可以

对比storm
做不到毫秒级别,storm 可以
