what is OLAP Online analytical processing
- 大多数是读请求
- 数据总是以相当大的批(> 1000 rows)进行写入
- 不修改已添加的数据
- 每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列
- 宽表,即每个表包含着大量的列
- 较少的查询(通常每台服务器每秒数百个查询或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小: 数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每一个查询除了一个大表外都很小
- 查询结果明显小于源数据,换句话说,数据被过滤或聚合后能够被盛放在单台服务器的内存中
vs mysql
数据压缩空间大,减少IO;处理单查询高吞吐量每台服务器每秒最多数十亿行;Data compression saves storage space and reduces IO. It enables high throughput for single queries, with each server capable of processing billions of rows per second.
高效的使用CPU,数据不仅仅按列存储,同时还按向量进行处理。Efficient CPU utilization is achieved by storing data not only in columnar format but also processing it in vectors.
索引非B树结构,不需要满足最左原则;只要过滤条件在索引列中包含即可;即使在使用的数据不在索引中,由于各种并行处理机制ClickHouse全表扫描的速度也很快 ClickHouse uses non-B-tree index structures, eliminating the need for the “leftmost prefix rule.” As long as the filtering conditions are present in the indexed columns, ClickHouse can quickly perform full table scans even if the queried data is not in the index.
写入速度非常快,50-200M/s,对于大量的数据更新非常适用 Write speed is exceptionally fast, ranging from 50-200 MB/s, making it suitable for handling large data updates.
1,不支持事务,不支持真正的删除/更新; ClickHouse does not support transactions or true delete/update operations.
2,不支持高并发,官方建议qps为100,可以通过修改配置文件增加连接数,但是在服务器足够好的情况下;It is not designed for high concurrency. The recommended QPS is 100, although you can increase the connection count through configuration changes if your server can handle it.
3,SQL满足日常使用80%以上的语法,join写法比较特殊;最新版已支持类似SQL的join,但性能不好;ClickHouse supports more than 80% of SQL syntax commonly used in daily operations, but its join syntax is unique. The latest version does support SQL-like joins, but their performance may not be optimal.
4,尽量做1000条以上批量的写入,避免逐行insert或小批量的insert,update,delete操作,因为ClickHouse底层会不断的做异步的数据合并,会影响查询性能,这个在做实时数据写入的时候要尽量避开;It is advisable to perform batch writes of 1000 or more rows to avoid slow insert/update/delete operations. ClickHouse continuously performs asynchronous data merges, which can impact query performance. Real-time data ingestion should be done with caution.
5,Clickhouse快是因为采用了并行处理机制,即使一个查询,也会用服务器一半的CPU去执行,所以ClickHouse不能支持高并发的使用场景,默认单查询使用CPU核数为服务器核数的一半,安装时会自动识别服务器核数,可以通过配置文件修改该参数。ClickHouse’s speed is achieved through parallel processing. Even a single query utilizes half of the server’s CPU cores. By default, ClickHouse uses half of the available CPU cores for single query execution. This can be adjusted through configuration changes.
1,MySQL单条SQL是单线程的,只能跑满一个core,ClickHouse相反,有多少CPU,吃多少资源,所以飞快;MySQL executes single SQL statements in a single thread, utilizing only one core. ClickHouse, on the other hand, utilizes as many CPU resources as available, resulting in faster performance.
2,ClickHouse不支持事务,不存在隔离级别。ClickHouse的定位是分析性数据库,而不是严格的关系型数据库。ClickHouse does not support transactions or isolation levels. Its focus is on analytical processing rather than strict relational database functionality.
3,IO方面,MySQL是行存储,ClickHouse是列存储,后者在count()这类操作天然有优势,同时,在IO方面,MySQL需要大量随机IO,ClickHouse基本是顺序IO。In terms of IO, MySQL uses row-based storage, while ClickHouse uses columnar storage. This gives ClickHouse a natural advantage in operations like count(). Additionally, MySQL requires a significant amount of random IO, while ClickHouse primarily relies on sequential IO.
vs ES
分布式
经过这么多年的打磨,Elasticsearch的Meta同步协议也是相当成熟了。依托于此,Elasticsearch具有非常易用的多角色划分,auto schema inference等功能。值得一提的是Elasticsearch的多副本数据同步,并没有复用Meta同步协议,而是采用传统的主备同步机制,由主节点负责同步到备节点,这种方式会更加简单高效。
ClickHouse引入了外置的ZooKeeper集群,来进行分布式DDL任务(节点Meta变更)、主备同步任务等操作的下发。多副本之间的数据同步(data shipping)任务下发也是依赖于ZooKeeper集群,但最终多副本之间的数据传输还是通过Http协议来进行点对点的数据拷贝
写入
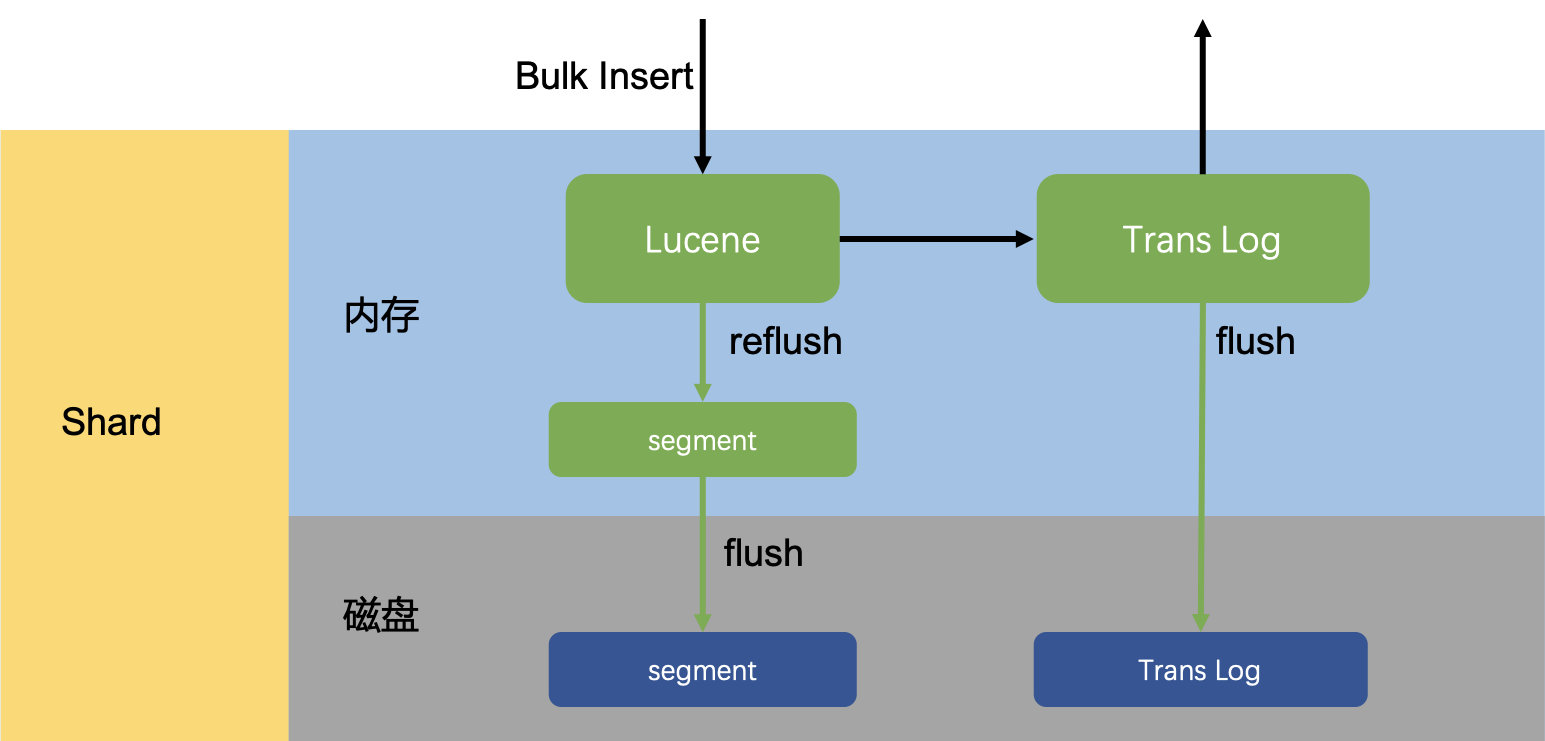
ClickHouse的写入方式更加“简单直接”、极致,上面已经讲过Elasticsearch是一个近实时系统,内存存储引擎中新写入的数据需要定时refresh才可见。而ClickHouse则是干脆彻底放弃了内存存储引擎这一功能,所有的数据写入时直接落盘,同时也就省略了传统的写redo日志阶段。
ClickHouse’s approach to data writing is more straightforward and extreme. As mentioned before, Elasticsearch is a near-real-time system where newly written data in the memory storage engine needs to be periodically refreshed to become visible. In contrast, ClickHouse completely abandons the functionality of a memory storage engine. All data is directly written to disk without the traditional write redo log phase.
Elasticsearch和ClickHouse都需要为了提升吞吐而放弃部分写入实时可见性。只不过ClickHouse主推的做法是把数据延迟攒批写入交给客户端来实现。另外在多副本同步上,Elasticsearch要求的是实时同步,也就是写入请求必须写穿多个副本才会返回,而ClickHouse是依赖于ZooKeeper做异步的磁盘文件同步(data shipping)。在实战中ClickHouse的写入吞吐能力可以远远超过同规格的Elasticsearch。
Both Elasticsearch and ClickHouse sacrifice some real-time visibility for improved throughput. However, ClickHouse’s preferred approach is to accumulate data and batch write it, leaving the responsibility of implementation to the client. Additionally, in terms of multi-replica synchronization, Elasticsearch requires real-time synchronization, meaning that a write request must be written to multiple replicas before returning. On the other hand, ClickHouse relies on ZooKeeper for asynchronous disk file synchronization (data shipping). In practical scenarios, ClickHouse’s writing throughput can far exceed that of Elasticsearch with the same specifications.
底层存储
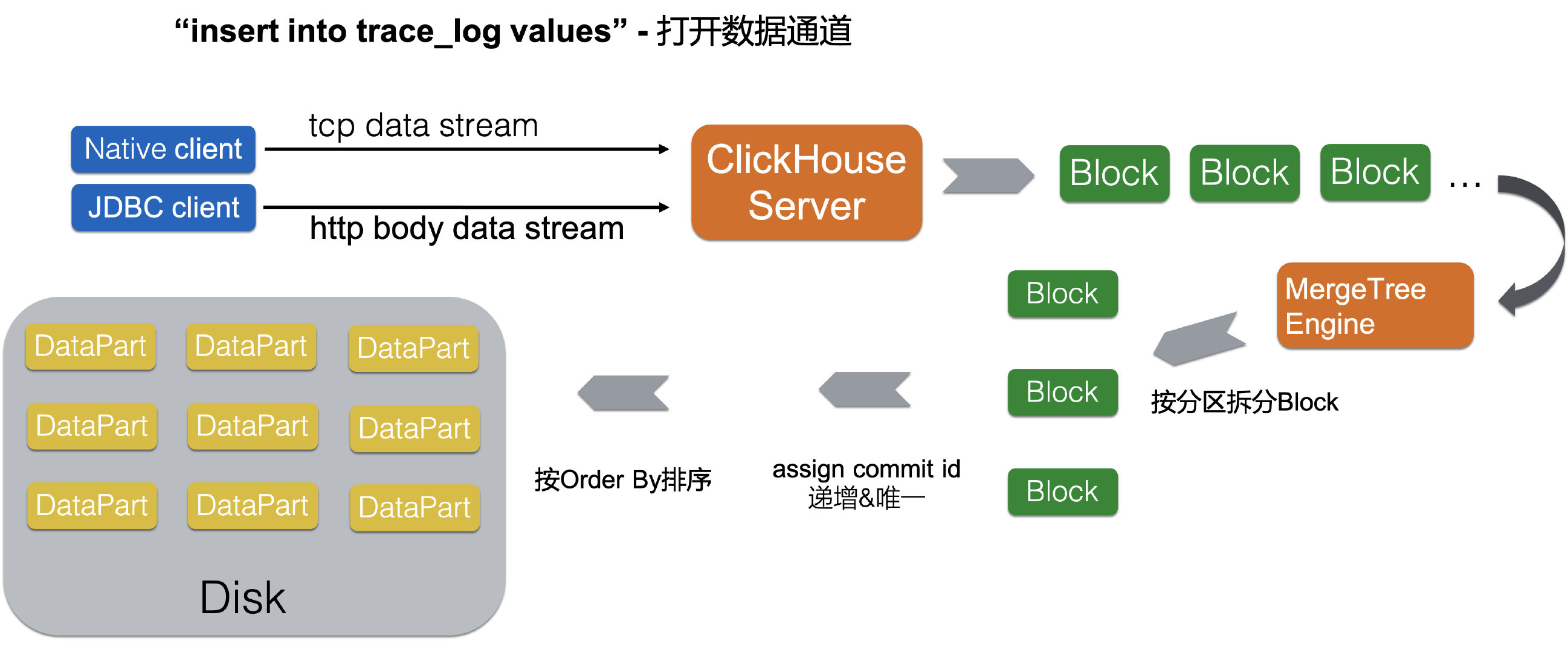
对比Elasticsearch中的Segment,ClickHouse存储中的最小单位是DataPart,一次批量写入的数据会落盘成一个DataPart。DataPart内部的数据存储是完全有序的状态(按照表定义的order by排序,加速数据扫描)
Compared to Elasticsearch’s segments, ClickHouse’s smallest storage unit is called a DataPart. When data is written in batches, it is stored on disk as a DataPart. The data within a DataPart is stored in a completely ordered state, sorted according to the table’s defined order by clause. This ordering accelerates data scanning operations.
ClickHouse也会对DataPart进行异步合并
- 让数据存储更加有序 Making data storage more ordered: By merging DataParts, ClickHouse can reorganize scattered data into a more ordered form, improving query performance and data continuity.
- 完成主键数据变更 Completing primary key data changes: When there are changes to the primary key data, ClickHouse applies these changes to the relevant DataParts through asynchronous merging, ensuring data consistency and correctness.
DataPart在合并存储数据时表现出的是merge-sorted的方式,合并后产生的DataPart仍然处于完全有序状态。
This asynchronous merging approach effectively enhances data storage efficiency and performance, enabling ClickHouse to efficiently manage and query large-scale data.
Elasticsearch是支持主键删除更新的,这都是依托于Lucene索引的删除功能来实现的,更新操作会被转换成删除操作加写入操作。当Lucene索引的Segment里存在多条删除记录时,系统就需要通过Segment合并来剔除这些记录。在多个Segment进行合并的时候,Lucene索引中的存储数据表现出的是append-only的合并,这种方式下二级索引的合并就不需要进行“重排序”。Elasticsearch在变更主键时,采用的是“先查原纪录-生成新记录-删除原纪录-写入新纪录”的方式,这种方式完全限制住了主键更新的效率,主键更新写入和append-only写入的效率差异非常大。
ClickHouse的主键更新是完全异步进行的,主键相同的多条记录在异步合并的时候会产生最新的记录结果。这种异步批量的主键更新方式比Elasticsearch更加高效。
Segment完全就是Lucene索引的存储格式,Lucene索引在倒排文件上的存储毋庸置疑是做到极致的,Lucene索引同时也提供了行存、列存等不同格式的原数据存储。Elasticsearch默认都会把原数据存两份,一份在行存里,一份在列存里。Elasticsearch会根据查询的pattern,选择扫描的合适的存储文件。原生ClickHouse的DataPart中并没有任何二级索引文件,数据完全按列存储,ClickHouse实现的列存在压缩率、扫描吞吐上都做到了极致。相对而言Elasticsearch中的存储比较中庸,并且成本至少翻倍。
Schema
Elasticsearch的存储其实是需要schema的,甚至是强绑定schema的,因为它是以二级索引为核心的存储,没有类型的字段又如何能构建索引呢,变更Elasticsearch index中的某个字段类型,那只有一种方法:就是把整份数据数据reindex。
ClickHouse的存储反而不是强绑定schema的,因为ClickHouse的分析能力是以存储扫描为核心的,它是可以在数据扫描进行动态类型转换,也可以在DataPart合并的时候慢慢异步调整字段的类型,在查询的时候字段类型变更引起的代价也就是运行时增加cast算子的开销,用户不会感受到急剧的性能下降。
搜索计算
Elasticsearch实现的只是一个通用化搜索引擎,搜索引擎能处理的查询复杂度是确定的、有上限的,所有的搜索查询经过确定的若干个阶段就可以得出结果。不支持的数据分析行为。
-
query_and_fetch
每个分布式节点独立搜索然后把得到的结果返回给客户端
-
query_then_fetch
每个分布式存储节点先搜索到各自TopN的记录Id和对应的score,汇聚到查询请求节点后做重排得到最终的TopN结果,最后再请求存储节点去拉取明细数据 (尽量减少拉取明细的数量,也就是磁盘扫描的次数)
-
dfs_query_then_fetch
均衡各个存储节点打分的标准,先统计全局的TF(Term Frequency)和DF(Document Frequency),再进行query_then_fetch
Elasticsearch的搜索引擎完全不具备数据库计算引擎的流式处理能力,它是完全回合制的request-response数据处理。当用户需要返回的数据量很大时,就很容易出现查询失败,或者触发GC。一般来说Elasticsearch的搜索引擎能力上限就是两阶段的查询,像多表关联这种查询是完全超出其能力上限的。
Elasticsearch的数据扫描,主要发生在query和fetch阶段。其中query阶段主要是扫描Lucene的索引文件获取查询命中的DocId,也包括扫描列存文件进行聚合计算。而fetch阶段主要是点查Lucene索引中的行存文件读取明细结果。表达式计算和聚合计算在两个阶段都有可能发生,其计算逻辑都是以行为单位进行运算。总的来说Elasticsearch的数据扫描和计算都没有向量化的能力,而且是以二级索引结果为基础,当二级索引返回的命中行数特别大时(涉及大量数据的分析查询),其搜索引擎就会暴露出数据处理能力不足的短板。
ClickHouse是完全列式的存储计算引擎,而且是以有序存储为核心,在查询扫描数据的过程中,首先会根据存储的有序性、列存块统计信息、分区键等信息推断出需要扫描的列存块,然后进行并行的数据扫描,像表达式计算、聚合算子都是在正规的计算引擎中处理。从计算引擎到数据扫描,数据流转都是以列存块为单位,高度向量化的。轻松就可以把机器资源跑满。ClickHouse的计算引擎能力在分析查询支持上可以完全覆盖住Elasticsearch的搜索引擎,有完备SQL能力的计算引擎可以让用户在处理数据分析时更加灵活、自由。
高并发
从Cache设计层面来看,Elasticsearch的Cache包括Query Cache, Request Cache,Data Cache,Index Cache,从查询结果到索引扫描结果层层的Cache加速,就是因为Elasticsearch认为它的场景下存在热点数据,可能被反复查询。但是Elasticsearch具备二级索引,并发能力就一定会好么?也不尽然,当二级索引搜索得到的结果集很大时,查询还是会伴随大量的IO扫描,高并发就无从谈起,除非Elasticsearch的Data Cache足够大,把所有原数据都加载到内存里来。
反观ClickHouse,只有一个面向IO的UnCompressedBlockCache和系统的PageCache,为什么呢?因为ClickHouse立足于分析查询场景,分析场景下的数据和查询都是多变的,查询结果等Cache都不容易命中,所以ClickHouse的做法是始终围绕磁盘数据,具备良好的IO Cache能力。
Why is that? It’s because ClickHouse is focused on analytical query scenarios, where both the data and queries are constantly changing. Caches like query results are not easily hit. Therefore, ClickHouse’s approach is to always revolve around disk data and possess strong IO caching capabilities.
其次回到数据扫描粒度,Elasticsearch具备全列的二级索引能力,这些索引一般都是预热好提前加载到内存中的,即使在多变的查询条件下索引查询得到结果的代价也很低,拿到索引结果就可以按行读取数据进行计算。而原生ClickHouse并没有二级索引的能力,在多变的查询条件下只能大批量地去扫描数据过滤出结果。查询需要扫描的数据量和计算复杂度摆在那,ClickHouse只是每次都老老实实计算而已,机器的硬件能力就决定了它的并发上限。部分场景下用户可以通过设置合适的系统参数来提升并发能力,比如max_threads等。
总结来说,Elasticsearch只有在完全搜索场景下面(where过滤后的记录数较少),并且内存足够的运行环境下,才能展现出并发上的优势。而在分析场景下(where过滤后的记录数较多),ClickHouse凭借极致的列存和向量化计算会有更加出色的并发表现。两者的侧重不同而已,同时ClickHouse并发处理能力立足于磁盘吞吐,而Elasticsearch的并发处理能力立足于内存Cache。ClickHouse更加适合低成本、大数据量的分析场景,它能够充分利用磁盘的带宽能力。
why clickhouse

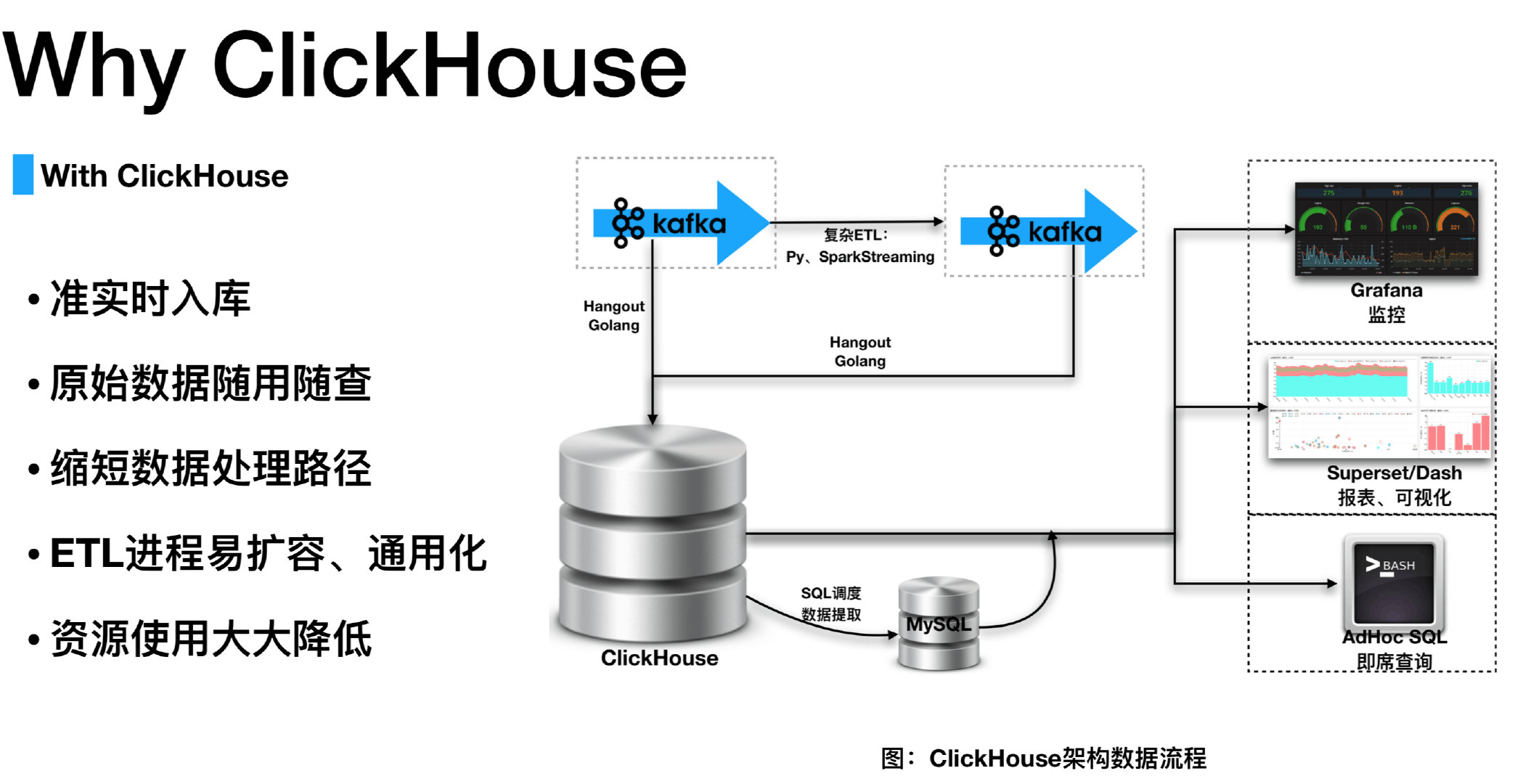

what is clickhouse
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)
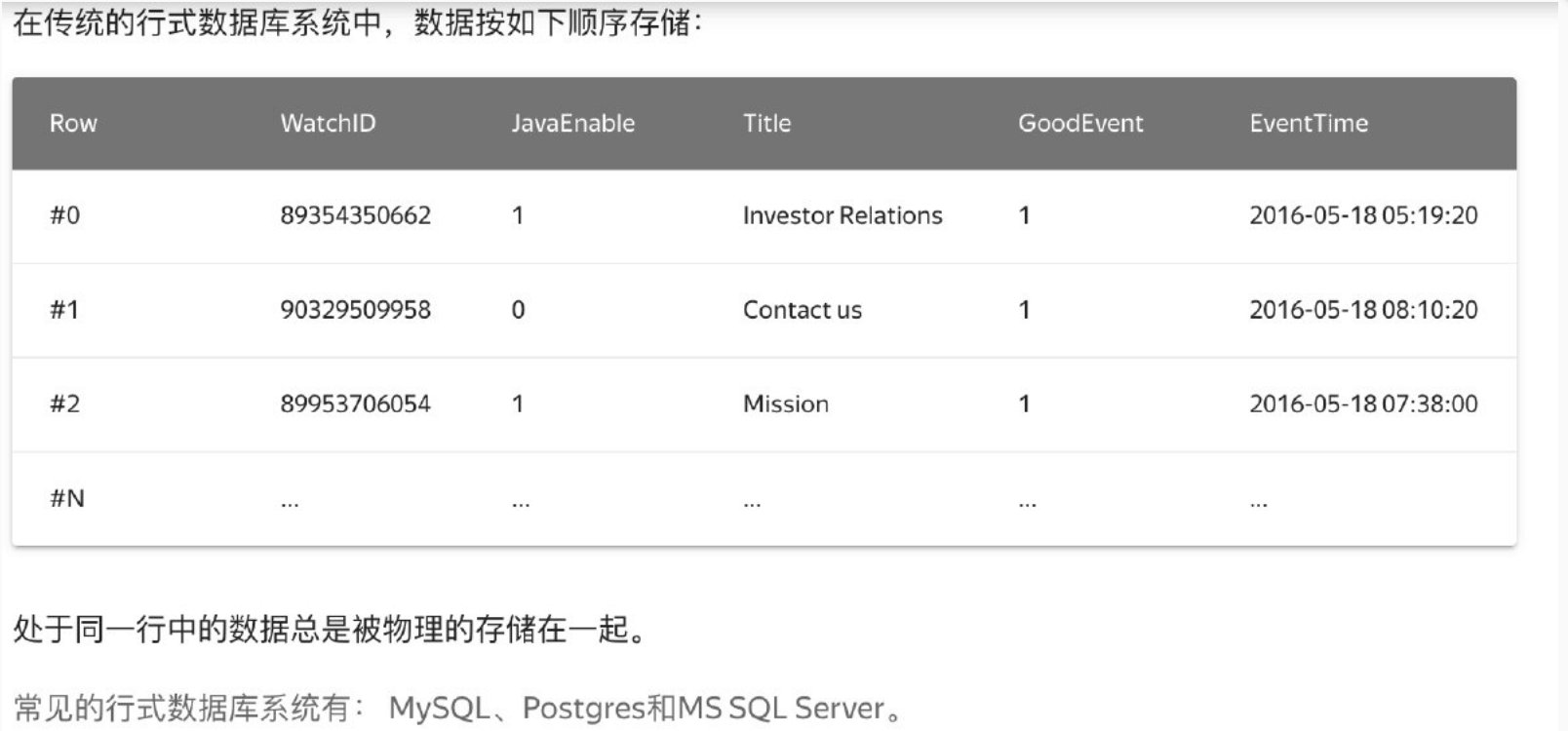

对于存储而言,列式数据库总是将同一列的数据存储在一起,不同列的数据也总是分开存储。
优点
- 每秒几亿行的吞吐能力
- 数据可以持续不断高效的写入到表中,并且写入的过程中不会存在任何加锁的行为。
- 为了高效的使用CPU,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理。
- 支持SQL
- 多核心并行处理 多服务器分布式处理 异步的多主复制技术。当数据被写入任何一个可用副本后,系统会在后台将数据分发给其他副本,以保证系统在不同副本上保持相同的数据
缺点
- 仅能用于批量删除或修改数据 每次写入不少于1000行的批量写入,或每秒不超过一个写入请求
- 没有完整的事务支持
- 稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。
IO
- 针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中你可以只读取你需要的数据。例如,如果只需要读取100列中的5列,这将帮助你最少减少20倍的I/O消耗。
- 由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储这也更容易压缩。这进一步降低了I/O的体积。
- 由于I/O的降低,这将帮助更多的数据被系统缓存。
解压缩的速度主要取决于未压缩数据的大小。
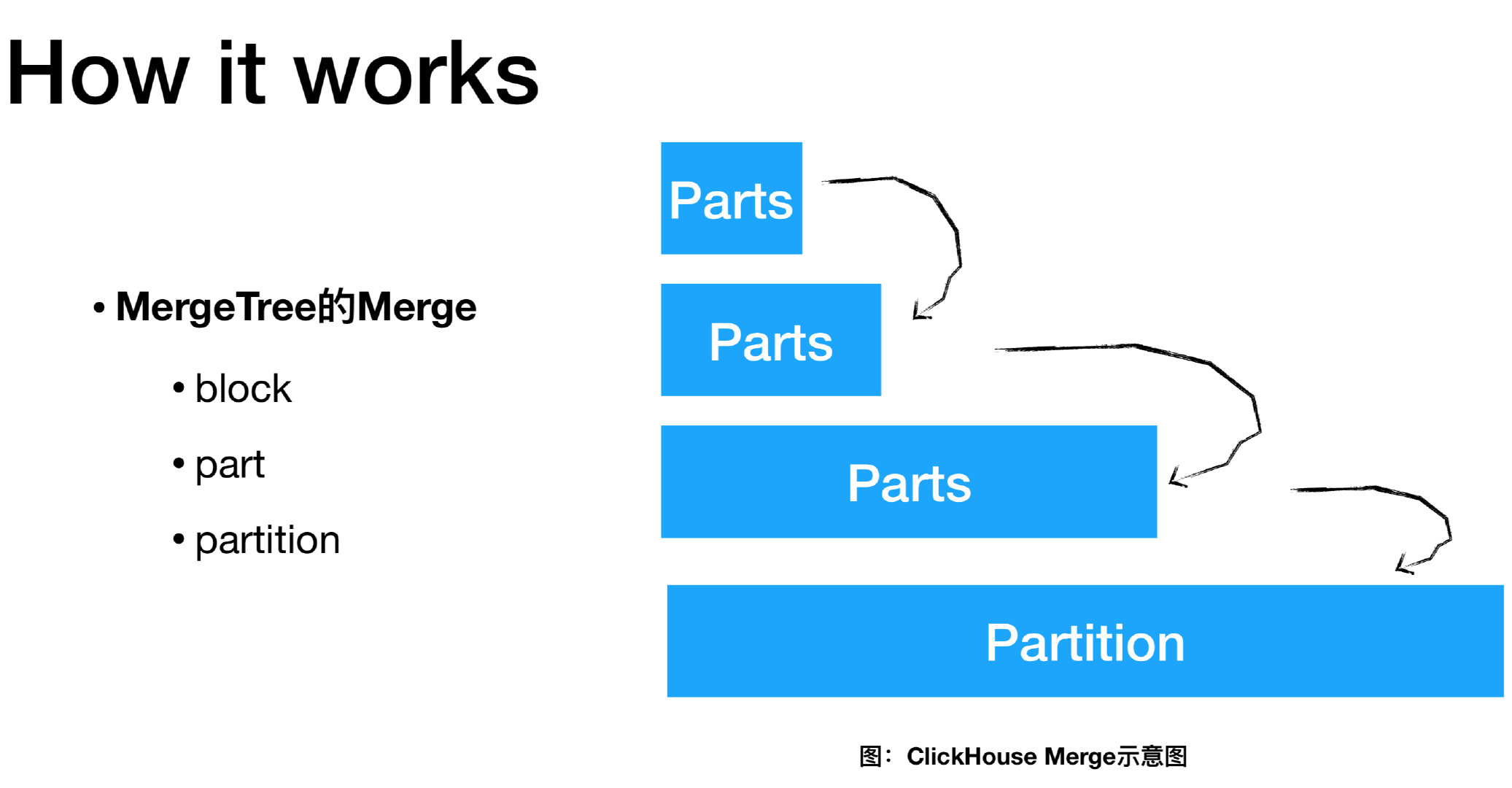
MergeTree
表由按主键排序的数据片段 组成。
当数据被插入到表中时,会分成数据片段并按主键的字典序排序。
例如,主键是 (CounterID, Date) 时,片段中数据按 CounterID 排序,具有相同 CounterID 的部分按 Date 排序。 不同分区的数据会被分成不同的片段,ClickHouse 在后台合并数据片段以便更高效存储。 不会合并来自不同分区的数据片段。这个合并机制并不保证相同主键的所有行都会合并到同一个数据片段中。
ClickHouse 会为每个数据片段创建一个索引文件,索引文件包含每个索引行(标记)的主键值。 索引行号定义为 n * index_granularity 。最大的 n 等于总行数除以 index_granularity 的值的整数部分。 对于每列,跟主键相同的索引行处也会写入标记。这些标记让你可以直接找到数据所在的列。
你可以只用一单一大表并不断地一块块往里面加入数据 – MergeTree 引擎的就是为了这样的场景。
ClickHouse 不要求主键唯一。所以,你可以插入多条具有相同主键的行。



视图
普通视图与物化视图
1 | |
-
普通视图不存储任何数据,只是执行从另一个表中的读取。换句话说,普通视图只是保存了视图的查询,当从视图中查询时,此查询被作为子查询用于替换FROM子句。
-
物化视图存储的数据是由相应的SELECT查询转换得来的。
Kafka 引擎
1 | |
- 使用引擎创建一个 Kafka 消费者并作为一条数据流。
- 创建一个结构表。
- 创建物化视图,改视图会在后台转换引擎中的数据并将其放入之前创建的表中。
当 MATERIALIZED VIEW 添加至引擎,它将会在后台收集数据。可以持续不断地从 Kafka 收集数据并通过 SELECT 将数据转换为所需要的格式。
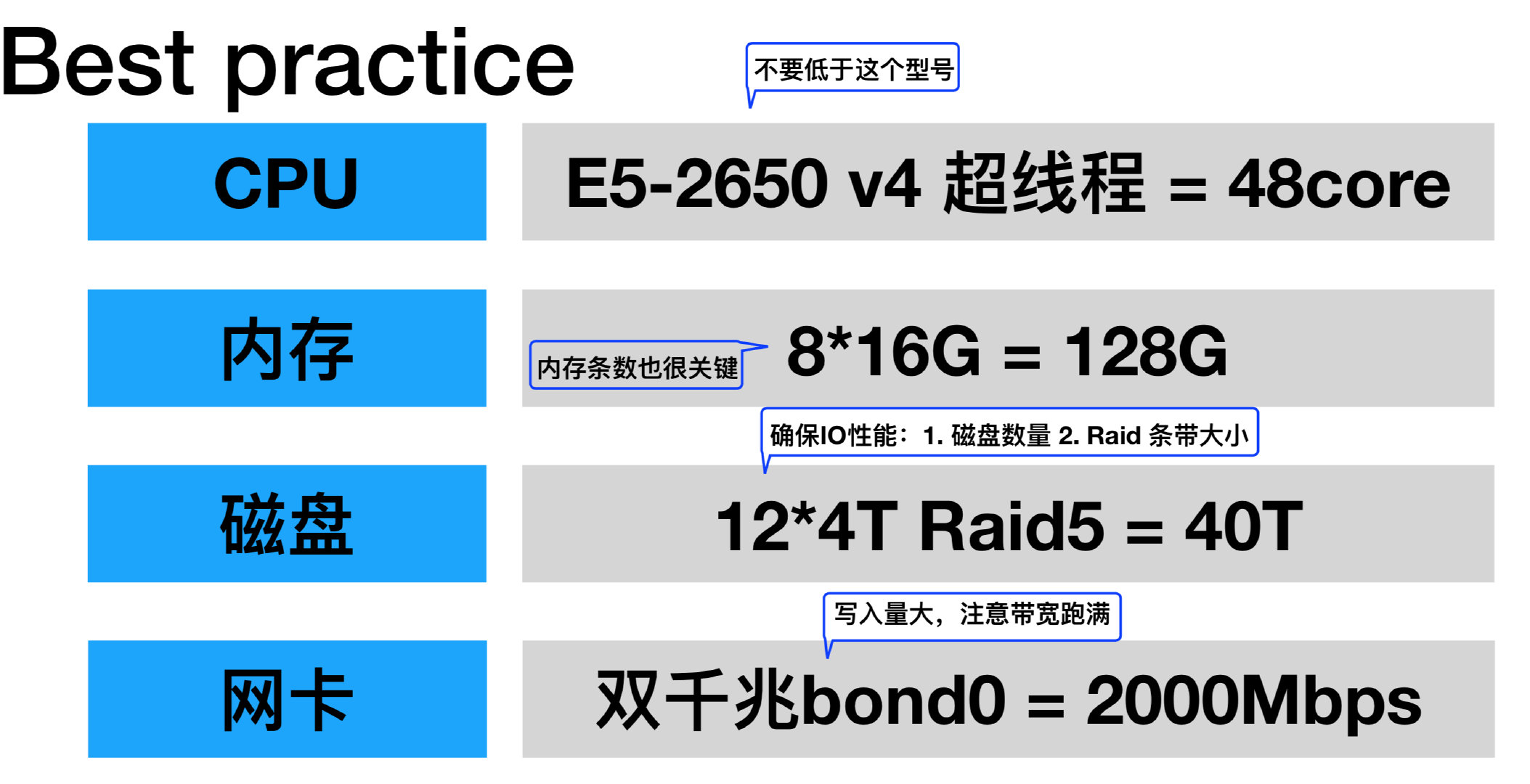
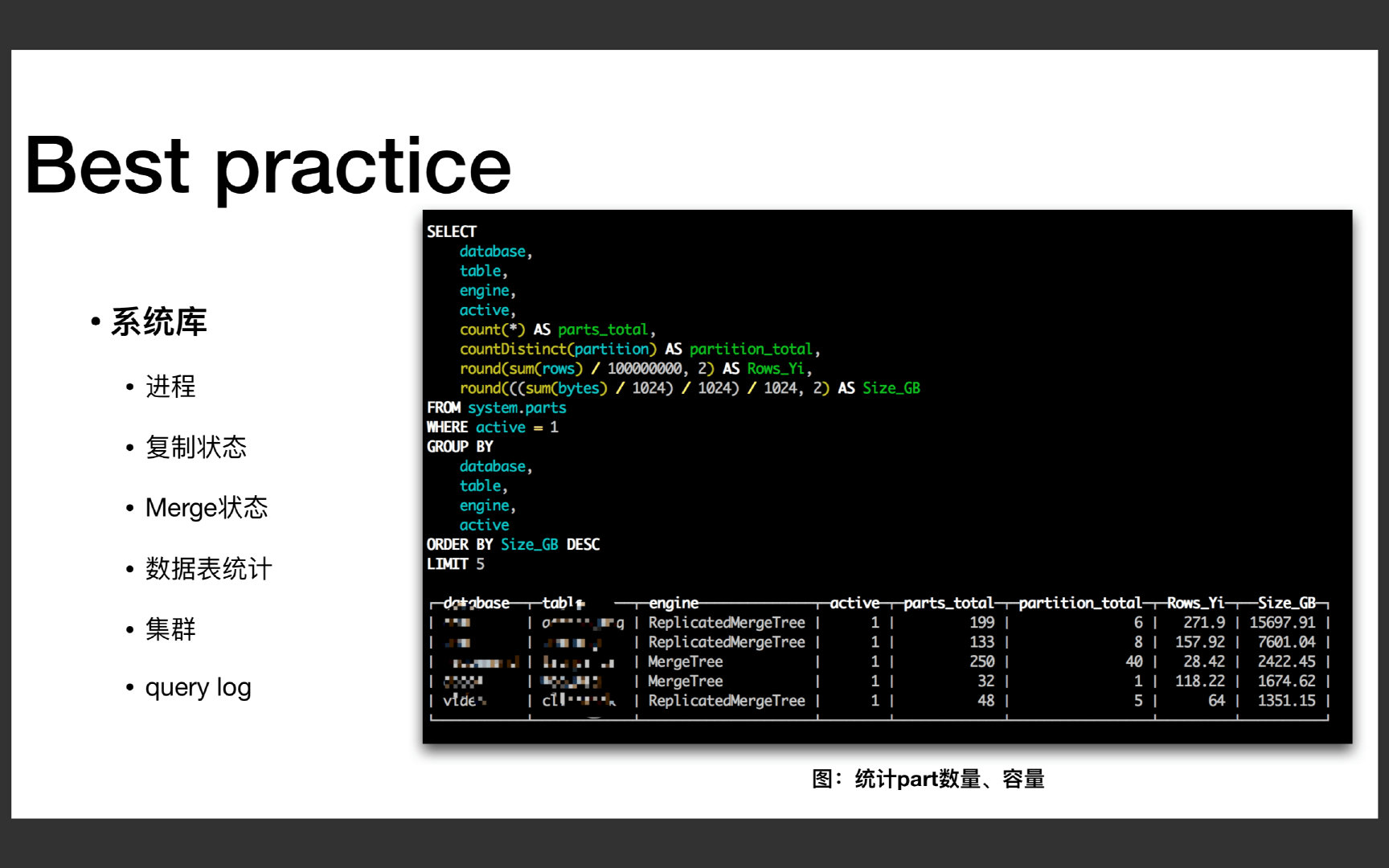
BestPractice 配置