ClickHouse内核分析-MergeTree的存储结构和查询加速
ClickHouse内核分析-MergeTree的Merge和Mutation机制
MergeTree 好处
The MergeTree storage structure requires sorting and storing user-written data in an ordered manner. The ordered storage of data brings two key advantages
MergeTree存储结构需要对用户写入的数据做排序然后进行有序存储,数据有序存储带来两大核心优势:
-
列存文件在按块做压缩时,排序键中的列值是连续或者重复的,使得列存块的数据压缩可以获得极致的压缩比。When compressing columnar files in blocks, the sorted values in the sorting key are often continuous or repeated, allowing for optimal compression ratios in columnar blocks.
-
存储有序性本身就是一种可以加速查询的索引结构,根据排序键中列的等值条件或者range条件我们可以快速找到目标行所在的近似位置区间,而且这种索引结构是不会产生额外存储开销的。
The inherent ordering of the storage itself acts as an index structure that can accelerate queries.By using equality or range conditions on the sorting key columns, we can quickly locate the approximate position interval of the target rows. Furthermore, this index structure does not incur any additional storage overhead.
一系列的MergeTree表引擎
包括基础的MergeTree,
拥有数据去重能力的ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree,
拥有数据聚合能力的SummingMergeTree、AggregatingMergeTree等。
但这些拥有“特殊能力”的MergeTree表引擎在存储上和基础的MergeTree其实没有任何差异,它们都是在数据Merge的过程中加入了额外的合并逻辑
存储结构
1 | |
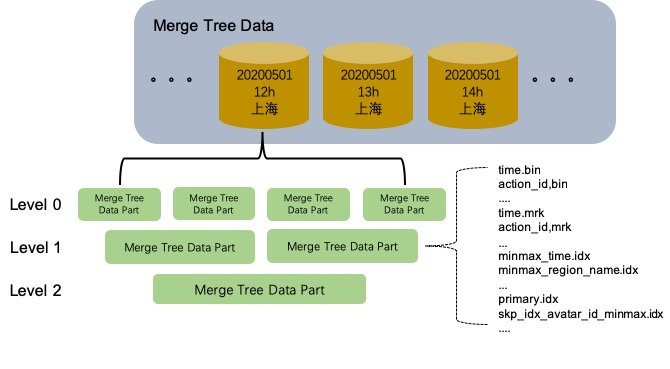
MergeTree表的存储结构中,每个数据分区相互独立,逻辑上没有关联。单个数据分区内部存在着多个MergeTree Data Part。这些Data Part一旦生成就是Immutable的状态,Data Part的生成和销毁主要与写入和异步Merge有关。MergeTree表的写入链路是一个极端的batch load过程,Data Part不支持单条的append insert。每次batch insert都会生成一个新的MergeTree Data Part。如果用户单次insert一条记录,那就会为那一条记录生成一个独立的Data Part,这必然是无法接受的。一般我们使用MergeTree表引擎的时候,需要在客户端做聚合进行batch写入或者在MergeTree表的基础上创建Distributed表来代理MergeTree表的写入和查询,Distributed表默认会缓存用户的写入数据,超过一定时间或者数据量再异步转发给MergeTree表。MergeTree存储引擎对数据实时可见要求非常高的场景是不太友好的。
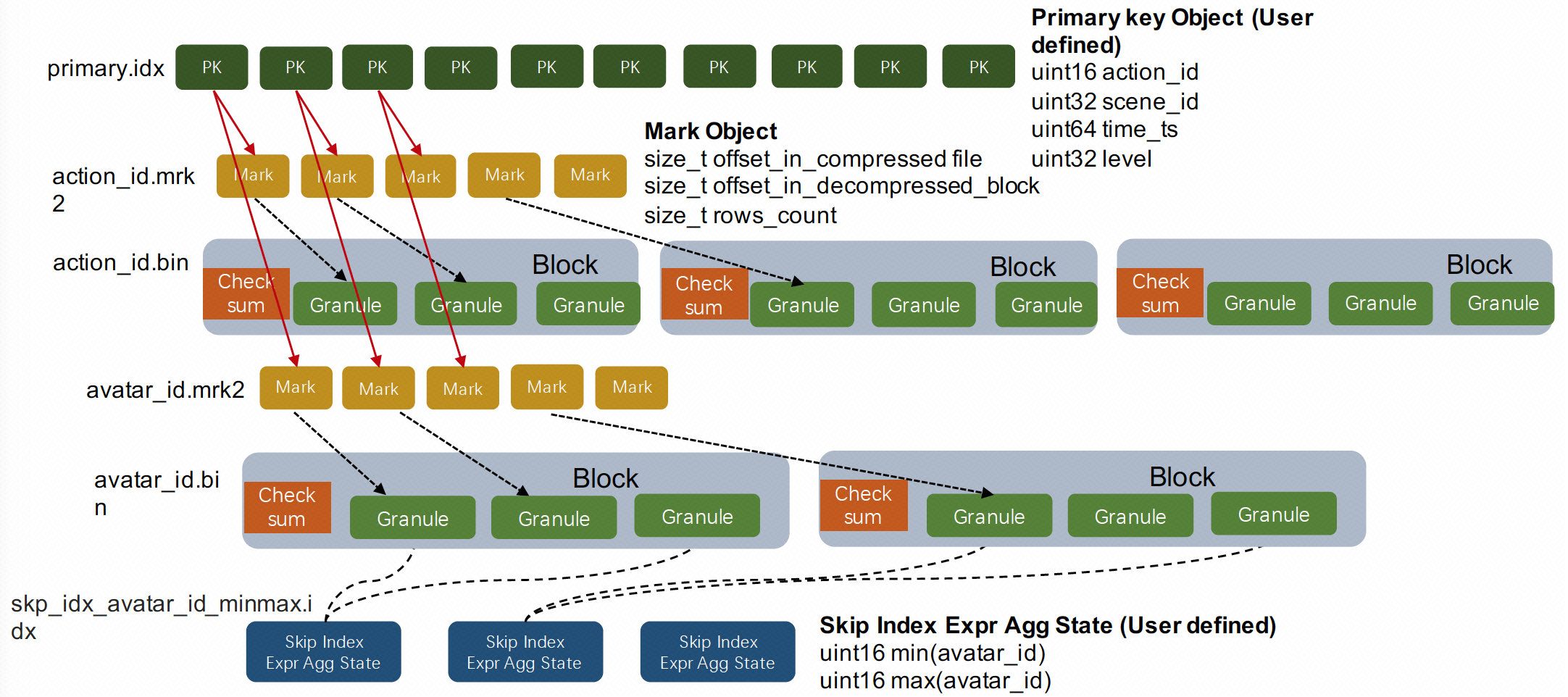
- 数据文件:action_id.bin、avatar_id.bin等都是单个列按块压缩后的列存文件。
- Mark标识文件:action_id.mrk2、avatar_id.mrk2等都是列存文件中的Mark标记
- Granule是数据按行划分时用到的逻辑概念。每隔确定行就是一个Granule。index_granularity_bytes会影响Granule的行数,它的意义是让每个Granule中所有列的sum size尽量不要超过设定值。
- Block是列存文件中的压缩单元。每个列存文件的Block都会包含若干个Granule,具体多少个Granule是由参数min_compress_block_size控制,每次列的Block中写完一个Granule的数据时,它会检查当前Block Size有没有达到设定值,如果达到则会把当前Block进行压缩然后写磁盘。
- 主键索引:primary.idx是表的主键索引。ClickHouse的主键索引存储的是每一个Granule中起始行的主键值,而MergeTree存储中的数据是按照主键严格排序的。所以当查询给定主键条件时,我们可以根据主键索引确定数据可能存在的Granule Range,再结合上面介绍的Mark标识,我们可以进一步确定数据在列存文件中的位置区间。ClickHoue的主键索引是一种在索引构建成本和索引效率上相对平衡的粗糙索引。
- 分区键索引:minmax_time.idx、minmax_region_name.idx是表的分区键索引。MergeTree存储会把统计每个Data Part中分区键的最大值和最小值,当用户查询中包含分区键条件时,就可以直接排除掉不相关的Data Part,这是一种OLAP场景下常用的分区裁剪技术。
- Skipping索引:skp_idx_avatar_id_minmax.idx是用户在avatar_id列上定义的MinMax索引。Merge Tree中 的Skipping Index是一类局部聚合的粗糙索引。用户在定义skipping index的时候需要设定granularity参数,这里的granularity参数指定的是在多少个Granule的数据上做聚合生成索引信息。用户还需要设定索引对应的聚合函数,常用的有minmax、set、bloom_filter、ngrambf_v1等,聚合函数会统计连续若干个Granule中的列值生成索引信息。Skipping索引的思想和主键索引是类似的,因为数据是按主键排序的,主键索引统计的其实就是每个Granule粒度的主键序列MinMax值,而Skipping索引提供的聚合函数种类更加丰富,是主键索引的一种补充能力。另外这两种索引都是需要用户在理解索引原理的基础上贴合自己的业务场景来进行设计的。
查询
数据查询过程,我大致把这个过程分为两块:索引检索和数据扫描。 index lookup and data scanning.
- 索引检索部分对每个MergeTree Data Part是串行执行,但Data Part之间的检索没有任何关联。The index lookup part is performed serially for each MergeTree Data Part, but there is no correlation between the lookups across different Data Parts.
- 数据扫描部分中最底层的列存扫描是多所有Data Part并行执行,各Data Part的列存扫描之间也没有任何关联。In the data scanning part, the columnar scans at the lowest level are executed in parallel across all Data Parts, and there is also no correlation between the columnar scans of different Data Parts.
索引检索
列存数据是以Granule为粒度被Mark标识数组索引起来的,Mark Range就表示Mark标识数组里满足查询条件的下标区间。
索引检索的过程
-
一个select查询时会先抽取出查询中的分区键和主键条件的KeyCondition
For a SELECT query, the KeyCondition for the partition key and primary key conditions in the query is first extracted.
-
首先会用分区键KeyCondition裁剪掉不相关的数据分区
Firstly, the KeyCondition for the partition key is used to prune irrelevant data partitions.
-
主键索引挑选出粗糙的Mark Range
The primary key index is used to select a rough Mark Range.
-
再用Skipping Index过滤主键索引产生的Mark Range
the Mark Range generated by the primary key index is filtered using the Skipping Index.
-
使用Skipping Index过滤主键索引返回的Mark Range之前,需要构造出每个Skipping Index的IndexCondition,不同的Skipping Index聚合函数有不同的IndexCondition实现,但判断Mark Range是否满足条件的接口和KeyCondition是类似的。
Before using the Skipping Index to filter the Mark Range returned by the primary key index, an IndexCondition needs to be constructed for each Skipping Index. Different Skipping Index aggregation functions may have different implementations of IndexCondition, but the interface for determining whether a Mark Range satisfies the condition is similar to the KeyCondition.
用主键索引挑选出粗糙的Mark Range的算法:一个不断分裂Mark Range的过程,返回结果是一个Mark Range的集合。
- 起始的Mark Range是覆盖整个MergeTree Data Part区间的
- 每次分裂都会把上次分裂后的Mark Range取出来按一定粒度步长分裂成更细粒度的Mark Range
- 然后排除掉分裂结果中一定不满足条件的Mark Range
- 最后Mark Range到一定粒度时停止分裂
数据扫描
-
Final模式
对CollapsingMergeTree、SummingMergeTree等表引擎提供一个最终Merge后的数据视图。前文已经提到过MergeTree基础上的高级MergeTree表引擎都是对MergeTree Data Part采用了特定的Merge逻辑。它带来的问题是由于MergeTree Data Part是异步Merge的过程,在没有最终Merge成一个Data Part的情况下,用户无法看到最终的数据结果。所以ClickHouse在查询是提供了一个final模式,这样用户就可以提前看到“最终”的数据结果了。
它会在各个Data Part的多条BlockInputStream基础上套上一些高级的Merge Stream,例如DistinctSortedBlockInputStream、SummingSortedBlockInputStream等,这部分逻辑和异步Merge时的逻辑保持一致。
-
Sorted模式
sort模式可以认为是一种order by下推存储的查询加速优化手段。因为每个MergeTree Data Part内部的数据是有序的。
所以当用户查询中包括排序键order by条件时只需要在各个Data Part的BlockInputStream上套一个做数据有序归并的InputStream就可以实现全局有序的能力。
-
Normal模式
这是基础MergeTree表最常用的数据扫描模式,多个Data Part之间进行并行数据扫描,对于单查询可以达到非常高吞吐的数据读取。
Normal模式中几个关键的性能优化点
-
并行扫描
MergeTree的存储结构要求数据不断mege,最终合并成一个Data Part,这样对索引和数据压缩才是最高效的。所以ClickHouse在MergeTree Data Part并行的基础上还增加了Mark Range并行。用户可以任意设定数据扫描过程中的并行度,每个扫描线程分配到的是Mark Range In Data Part粒度的任务,同时多个扫描线程之间还共享了Mark Range Task Pool,这样可以避免在存储扫描中的长尾问题。
-
数据Cache
MergeTree的查询链路中涉及到的数据有不同级别的缓存设计。主键索引和分区键索引在load Data Part的过程中被加载到内存,Mark文件和列存文件有对应的MarkCache和UncompressedCache,MarkCache直接缓存了Mark文件中的binary内容,而UncompressedCache中缓存的是解压后的Block数据。
-
SIMD反序列化
部分列类型的反序列化过程中采用了手写的sse指令加速,在数据命中UncompressedCache的情况下会有一些效果。
-
PreWhere过滤
ClickHouse的语法支持了额外的PreWhere过滤条件,它会先于Where条件进行判断。当用户在sql的filter条件中加上PreWhere过滤条件时,存储扫描会分两阶段进行,先读取PreWhere条件中依赖的列值,然后计算每一行是否符合条件。相当于在Mark Range的基础上进一步缩小扫描范围,PreWhere列扫描计算过后,ClickHouse会调整每个Mark对应的Granule中具体要扫描的行数,相当于可以丢弃Granule头尾的一部分行。
Mutation
MergeTree存储一旦生成一个Data Part,这个Data Part就不可再更改了。所以从MergeTree存储内核层面,ClickHouse就不擅长做数据更新删除操作。ClickHouse为用户设计了一套离线异步机制来支持低频的Mutation(改、删)操作。
执行过程
-
检查Mutation操作是否合法
MutationsInterpreter::validate函数dry run一个异步Mutation执行的全过程,其中涉及到检查Mutation是否合法的判断原则是列值更新后记录的分区键和排序键不能有变化。因为分区键和排序键一旦发生变化,就会导致多个Data Part之间之间Merge逻辑的复杂化。
-
保存Mutation命令到存储文件中,唤醒一个异步处理merge和mutation的工作线程
MergeTree会把整条Alter命令保存到存储文件夹下,然后创建一个MergeTreeMutationEntry对象保存到表的待修改状态中,最后唤醒一个异步处理merge和 mutation的工作线程。
因为Mutation的实际操作是异步发生的,在用户的Alter命令返回之后仍然会有数据写入,系统如何在异步订正的过程中排除掉Alter命令之后写入的数据呢?MergeTree中Data Part的Version机制,它可以在Data Part级别解决上面的问题。但是因为ClickHouse写入链路的异步性,ClickHouse仍然无法保证Alter命令前Insert的每条纪录都被更新,只能确保Alter命令前已经存在的Data Part都会被订正,推荐用户只用来订正T+1场景的离线数据。
异步Merge&Mutation
每个Data Part都有一个MergeTreePartInfo对象来保存它的meta信息
1 | |
- partition_id:表示所属的数据分区id。
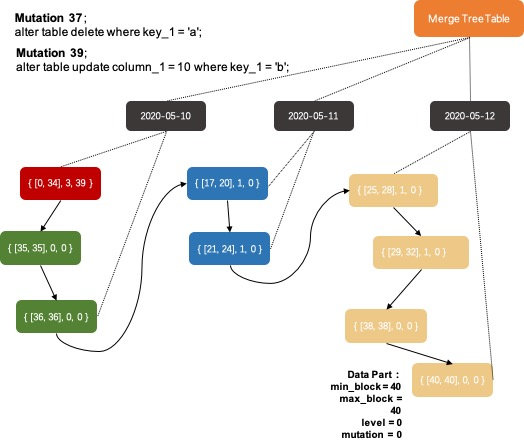
- min_block、max_block:blockNumber是数据写入的一个版本信息,在上一篇系列文章中讲过,用户每次批量写入的数据都会生成一个Data Part。同一批写入的数据会被assign一个唯一的blockNumber,而这个blockNumber是在MergeTree表级别自增的。以及MergeTree在merge多个Data Part的时候会准守一个原则:在同一个数据分区下选择blockNumber区间相邻的若干个Data Parts进行合并,不会出现在同一个数据分区下Data Parts之间的blockNumber区间出现重合。所以Data Part中的min_block和max_block可以表示当前Data Part中数据的版本范围。
- level:表示Data Part所在的层级,新写入的Data Part都属于level 0。异步merge多个Data Part的过程中,系统会选择其中最大的level + 1作为新Data Part的level。这个信息可以一定程度反映出当前的Data Part是经历了多少次merge,但是不能准确表示,核心原因是MergeTree允许多个Data Part跨level进行merge的,为了最终一个数据分区内的数据merge成一个Data Part。
- mutation:和批量写入数据的版本号机制类似,MergeTree表的mutation命令也会被assign一个唯一的blockNumber作为版本号,这个版本号信息会保存在MergeTreeMutationEntry中,所以通过版本号信息我们可以看出数据写入和mutation命令之间的先后关系。Data Part中的这个mutation表示的则是当前这个Data Part已经完成的mutation操作,对每个Data Part来说它是按照mutation的blockNumber顺序依次完成所有的mutation。
异步Mutation如何选择哪些Data Parts需要订正的问题。系统可以通过MergeTreePartInfo::getDataVersion() { return mutation ? mutation : min_block }函数来判断当前Data Part是否需要进行某个mutation订正,比较两者version即可。
Merge&Mutation工作任务
ClickHouse内核中异步merge、mutation工作由统一的工作线程池来完成,
这个线程池的大小用户可以通过参数background_pool_size进行设置。线程池中的线程Task总体逻辑如下,
可以看出这个异步Task主要做三块工作:
清理残留文件
过期的Data Part,临时文件夹,过期的Mutation命令文件
merge Data Parts
StorageMergeTree::merge函数是MergeTree异步Merge的核心逻辑,Data Part Merge的工作除了通过后台工作线程自动完成,用户还可以通过Optimize命令来手动触发。自动触发的场景中,系统会根据后台空闲线程的数据来启发式地决定本次Merge最大可以处理的数据量大小,max_bytes_to_merge_at_min_space_in_pool和max_bytes_to_merge_at_max_space_in_pool参数分别决定当空闲线程数最大时可处理的数据量上限以及只剩下一个空闲线程时可处理的数据量上限。当用户的写入量非常大的时候,应该适当调整工作线程池的大小和这两个参数。当用户手动触发merge时,系统则是根据disk剩余容量来决定可处理的最大数据量。
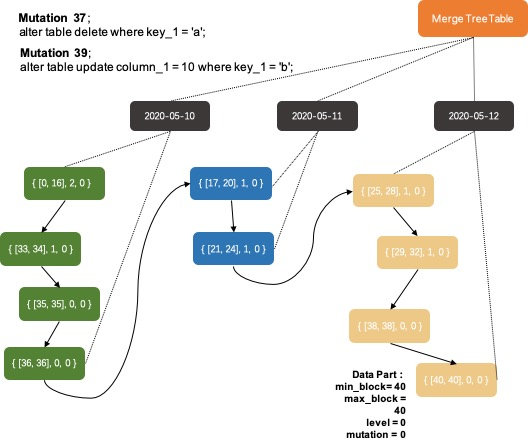
MergeTreeDataMergerMutator::selectPartsToMerge函数筛选出本次merge要合并的Data Parts,这个筛选过程需要准守三个原则:
- 跨数据分区的Data Part之间不能合并;
- 合并的Data Parts之间必须是相邻(在上图的有序组织关系中相邻),只能在排序链表中按段合并,不能跳跃;
- 合并的Data Parts之间的mutation状态必须是一致的,如果Data Part A 后续还需要完成mutation-23而Data Part B后续不需要完成mutation-23(数据全部是在mutation命令之后写入或者已经完成mutation-23),则A和B不能进行合并;
对于如何从这些序列中挑选出最佳的一段区间,ClickHouse抽象出了IMergeSelector类来实现不同的逻辑。当前主要有两种不同的merge策略:TTL数据淘汰策略和常规策略。
-
TTL数据淘汰策略:TTL数据淘汰策略启用的条件比较苛刻,只有当某个Data Part中存在数据生命周期超时需要淘汰,并且距离上次使用TTL策略达到一定时间间隔(默认1小时)。TTL策略也非常简单,首先挑选出TTL超时最严重Data Part,把这个Data Part所在的数据分区作为要进行数据合并的分区,最后会把这个TTL超时最严重的Data Part前后连续的所有存在TTL过期的Data Part都纳入到merge的范围中。这个策略简单直接,每次保证优先合并掉最老的存在过期数据的Data Part。
-
常规策略:这里的选举策略就比较复杂,基本逻辑是枚举每个可能合并的Data Parts区间,通过启发式规则判断是否满足合并条件,再有启发式规则进行算分,选取分数最好的区间。启发式判断是否满足合并条件的算法在SimpleMergeSelector.cpp::allow函数中,其中的主要思想分为以下几点:系统默认对合并的区间有一个Data Parts数量的限制要求(每5个Data Parts才能合并);如果当前数据分区中的Data Parts出现了膨胀,则适量放宽合并数量限制要求(最低可以两两merge);如果参与合并的Data Parts中有很久之前写入的Data Part,也适量放宽合并数量限制要求,放宽的程度还取决于要合并的数据量。第一条规则是为了提升写入性能,避免在高速写入时两两merge这种低效的合并方式。最后一条规则则是为了保证随着数据分区中的Data Part老化,老龄化的数据分区内数据全部合并到一个Data Part。中间的规则更多是一种保护手段,防止因为写入和频繁mutation的极端情况下,Data Parts出现膨胀。启发式算法的策略则是优先选择IO开销最小的Data Parts区间完成合并,尽快合并掉小数据量的Data Parts是对在线查询最有利的方式,数据量很大的Data Parts已经有了很较好的数据压缩和索引效率,合并操作对查询带来的性价比较低。
mutate Data Part
StorageMergeTree::tryMutatePart函数是MergeTree异步mutation的核心逻辑,主体逻辑如下。系统每次都只会订正一个Data Part,但是会聚合多个mutation任务批量完成,这点实现非常的棒。因为在用户真实业务场景中一次数据订正逻辑中可能会包含多个Mutation命令,把这多个mutation操作聚合到一起订正效率上就非常高。系统每次选择一个排序键最小的并且需要订正Data Part进行操作,本意上就是把数据从前往后进行依次订正。
- mutation没有实时可见能力。我这里的实时可见并不是指在存储上立即原地更新,而是给用户提供一种途径可以立即看到数据订正后的最终视图确保订正无误。类比在使用CollapsingMergeTree、SummingMergeTree等高级MergeTree引擎时,数据还没有完全merge到一个Data Part之前,存储层并没有一个数据的最终视图。但是用户可以通过Final查询模式,在计算引擎层实时聚合出数据的最终视图。这个原理对mutation实时可见也同样适用,在实时查询中通过FilterBlockInputStream和ExpressionBlockInputStream完成用户的mutation操作,给用户提供一个最终视图。
- mutation和merge相互独立执行。看完本文前面的分析,大家应该也注意到了目前Data Part的merge和mutation是相互独立执行的,Data Part在同一时刻只能是在merge或者mutation操作中。对于MergeTree这种存储彻底Immutable的设计,数据频繁merge、mutation会引入巨大的IO负载。实时上merge和mutation操作是可以合并到一起去考虑的,这样可以省去数据一次读写盘的开销。对数据写入压力很大又有频繁mutation的场景,会有很大帮助。