集群中多台服务的配置是不一致的。这就导致资源分配并不是均匀的,比如我们需要有些服务节点用来运行计算密集型的服务,而有些服务节点来运行需要大量内存的服务。而在 k8s 中当然也配置了相关服务来处理上述的问题,那就是 Scheduler。
Scheduler 是 kubernetes 的调度器,主要的任务是把定义的 Pod 分配到集群的节点上。听起来非常简单,但有很多要考虑的问题:
-
公平
- 如何保证每个节点都能被分配资源
-
资源高效利用
- 集群所有资源最大化被使用
-
效率
- 调度的性能要好,能够尽快地对大批量的 Pod 完成调度工作
-
灵活
- 允许用户根据自己的需求控制调度的逻辑
Scheduler 是作为单独的程序运行的,启动之后会一直坚挺 API Server,获取 PodSpec.NodeName 为空的 Pod,对每个 Pod 都会创建一个 binding,表明该 Pod 应该放到哪个节点上。
调度过程
调度分为几个部分
对每一个新创建的 Pod 或者是未被调度的 Pod,kube-scheduler 会选择一个最优的 Node 去运行这个 Pod。然而,Pod 内的每一个容器对资源都有不同的需求,而且 Pod 本身也有不同的资源需求。因此,Pod 在被调度到 Node 上之前, 根据这些特定的资源调度需求,需要对集群中的 Node 进行一次过滤。
首先是过滤掉不满足条件的节点,这个过程称为 predicate;First, the Nodes that do not meet the conditions are filtered out, which is called predicate。然后对通过的节点按照优先级排序Then, the filtered Nodes are sorted based on priority,这个是 priority;最后从中选择优先级最高的节点。Finally, the Node with the highest priority is selected如果中间任何一步骤有错误,就直接返回错误。Predicate 有一系列的算法可以使用:
PodFitsResources- 节点上剩余的资源是否大于
pod请求的资源 Checks if the remaining resources on the Node are greater than the resource requests of the Pod.
- 节点上剩余的资源是否大于
PodFitsHost- 如果
pod指定了NodeName,检查节点名称是否和NodeName匹配If the Pod specifies aNodeName, checks if the Node name matches theNodeName.
- 如果
PodFitsHostPorts- 节点上已经使用的
port是否和pod申请的port冲突Checks if the ports already used on the Node conflict with the ports requested by the Pod.
- 节点上已经使用的
PodSelectorMatches- 过滤掉和
pod指定的label不匹配的节点Filters out Nodes that do not match the labels specified by the Pod.
- 过滤掉和
NoDiskConflict- 已经
mount的volume和pod指定的volume不冲突,除非它们都是只读
- 已经
If there are no suitable Nodes during the predicate process, the Pod remains in the pending state and continues to retry scheduling until a Node meets the requirements. After this step, if multiple Nodes meet the requirements, the priorities process continues: sorting the Nodes based on priority.
如果在 predicate 过程中没有合适的节点,pod 会一直在 pending 状态,不断重试调度,直到有节点满足条件。经过这个步骤,如果有多个节点满足条件,就继续 priorities 过程:按照优先级大小对节点排序。优先级由一系列键值对组成,键是该优先级项的名称,值是它的权重(该项的重要性)。这些优先级选项包括:
LeastRequestedPriority- 通过计算 CPU 和 Memory 的使用率来决定权重,使用率越低权重越高。换句话说,这个优先级指标倾向于资源使用比例更低的节点。Determines the weight by calculating the CPU and memory utilization, with a higher weight for lower utilization. In other words, this priority metric favors Nodes with lower resource utilization ratios.
BalancedResourceAllocation- 节点上 CPU 和 Memory 使用率越接近,权重越高。这个应该和上面的一起使用,不应该单独使用。The closer the CPU and memory utilization on the Node, the higher the weight. This should be used together with the previous priority, not separately.
ImageLocalityPriority- 倾向于已经有要使用镜像的节点,镜像总大小值越大,权重越高。Favors Nodes that already have the image to be used, with a higher weight for larger total image sizes.
调度器先在集群中找到一个 Pod 的所有可调度节点,然后根据一系列函数对这些可调度节点打分, 选出其中得分最高的 Node 来运行 Pod。之后,调度器将这个调度决定通知给 kube-apiserver,这个过程叫做 绑定。The scheduler first finds all the schedulable Nodes for a Pod in the cluster, and then scores these schedulable Nodes based on a series of functions to select the Node with the highest score to run the Pod. Afterwards, the scheduler notifies the kube-apiserver of this scheduling decision, which is called binding
自定义调度器
除了 kubernetes 自带的调度器,你也可以编写自己的调度器。通过 spec:schedulername 参数指定调度器的名字,可以为 pod 选择某个调度器进行调度。比如下面的 pod 选择 my-scheduler 进行调度,而不是默认的 default-scheduler。
1 | |
亲和性
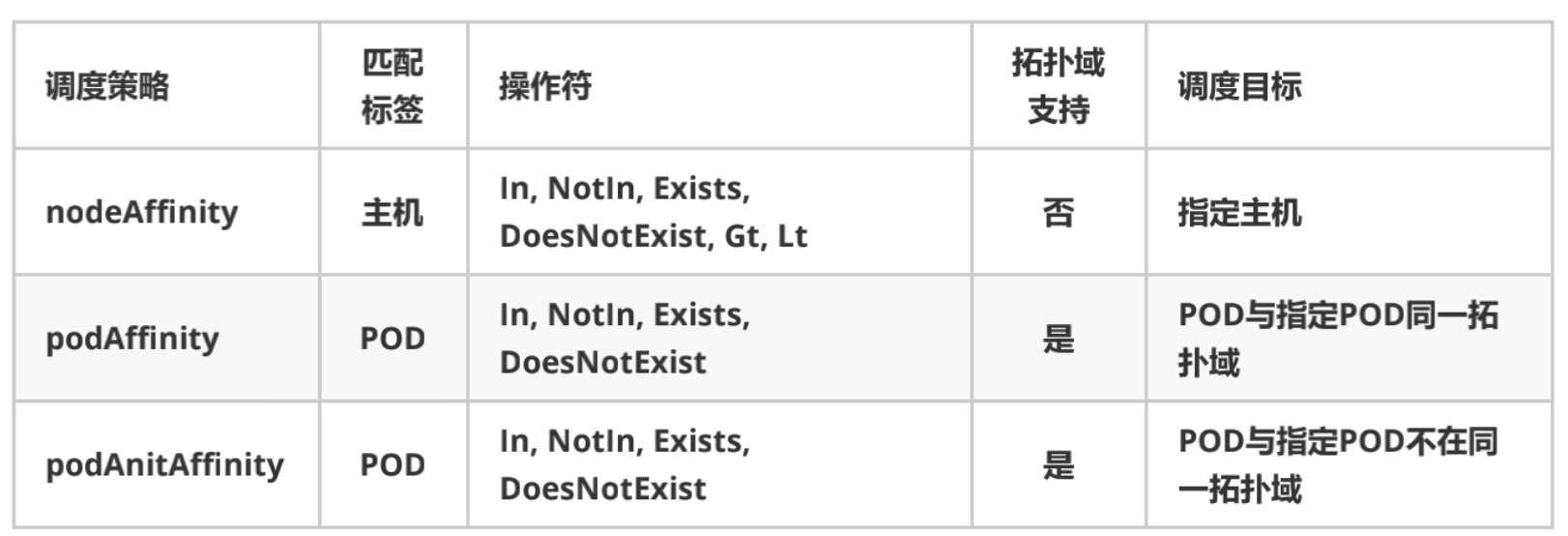
亲和性包括:节点亲和 Pod 亲和性
亲和性简而言之就是,表示我们部署的服务更加趋向于运行那些节点上面,增加了服务的部署可控性。
节点亲和性
pod.spec.nodeAffinity
- 键值运算关系
| 编号 | 运算关系 | 对应说明解释 |
|---|---|---|
| 1 | In |
label 的值在某个列表中 |
| 2 | NotIn |
label 的值不在某个列表中 |
| 3 | Gt |
label 的值大于某个值 |
| 4 | Lt |
label 的值小于某个值 |
| 5 | Exists |
某个 label 存在 |
| 6 | DoesNotExist |
某个 label 不存在 |
1 | |
-
硬策略 - requiredDuringSchedulingIgnoredDuringExecution 只
必须满足指定的规则才可以调度 Pod 到 Node 上
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19apiVersion: v1 kind: Pod metadata: name: affinity labels: app: node-affinity-pod spec: containers: - name: with-node-affinity image: hub.escape.com/library/myapp:v1 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: NotIn values: - k8s-node -
软策略 - preferredDuringSchedulingIgnoredDuringExecution 尽量
强调优先满足指定规则,调度 器会尝试调度 Pod 到 Node 上,但并不强求
1 | |
lgnoredDuringExecution 的意思是 :如果 一个 Pod 所在的节点在 Pod 运行期间标签发 生了变更 , 不再符合该 Pod 的节点 亲和性需求 ,则系 统将忽略 Node 上 Label 的 变化,该 Pod 能继续在该节点上运行。
- 硬软策略合体
1 | |
NodeAffinity 规则设登的注意事项如下。
- 如果同时定义了 nodeSelector 和 nodeAffinity, 那么必 须两个条件都得到满足, Pod 才能最终运行在指定的 Node 上 。
- 如果 nodeAffinity 指定了多个 nodeSelectorTerms, 那么其中一个能匹配成功即可 。
- 如果在 nodeSelectorTerms 中有多个 matchExpressioos, 则一个节点必须满足所有matchExpressions 才能运行该 Pod。
Pod 亲和性
pod.spec.affinity.podAffinity/podAntiAffinity
- 硬策略 - requiredDuringSchedulingIgnoredDuringExecution
- 软策略 - preferredDuringSchedulingIgnoredDuringExecution
1 | |
-
亲和性/反亲和性调度策略比较
topologyKey
拓扑域
一个拓扑域由一些Node节点组成,这些Node节点通常有相同的地理空间坐标,比如在同一个机架、机房或地区.我们一般用region表示机架、机房等的拓扑区域,用Zone表示地区这样跨度更大的拓扑区域。在极端情况下,我们也可以认为一个Node就是一个拓扑区域。
为此,Kubernetes内置了如下一些常用的默认拓扑域:
- kubernetes.io/hostname
- topology.kubernetes.io/region
- topology.kubernetes.io/zone
以上拓扑域是由Kubernetes自己维护的,在Node节点初始化时,controller-manager会为Node打上许多标签,比如kubernetes.io/hostname这个标签的值就会被设置为Node节点的hostname。
另外,公有云厂商提供的Kubernetes服务或者使用cloud-controller-manager创建的集群,还会给Node打上topology.kubernetes.io/region和topology.kubernetes.io/zone标签,以确定各个节点所属的拓扑域。
Pod亲和与互斥的调度具体做法,就是通过在Pod的定义上增加topologyKey属性,来声明对应的目标拓扑区域内几种相关联的Pod要“在一起或不在一起”。与节点亲和相同,Pod亲和与互斥的条件设置也是requiredDuringSchedulingignoredDuringExecution和preferredDuringSchedulingignoredDuringExecution。Pod的亲和性被定义于PodSpec的affinity字段的podAffinity子字段中;Pod间的互斥性则被定义于同一层次的podAntiAffinity子字段中。
原则上,topologyKey可以使用任意合法的标签Key赋值,但是出于性能和安全方面的考虑,对topologyKey有如下限制。
- 在Pod亲和性和RequiredDuringScheduling的Pod互斥性的定义中,不允许使用空的topologyKey。
- 如果Admission controller包含了LinlitPodHardAntiAffimtyTopology,那么针对RequiredDuringScheduling的Pod互斥性定义就被限制为kubernetes.io/hostname,要使用自定义的topologyKey,就要改写或禁用该控制器。
- 在PreferredDuringSchedu血g类型的Pod互斥性定义中,空的topologyKey会被解释为kubernetes.io/bostname、failure-domain.beta.kubemetes.io/zone及failure-domain.beta.kubernetes.io/region的组合。
- 如果不是上述情况,就可以采用任意合法的topologyKey了。
污点和容忍
节点亲和性,是 pod 的一种属性(偏好或硬性要求),它使 pod 被吸引到一类特定的节点。Taint 则相反,它使节点能够排斥一类特定的 pod。
Taint 和 toleration 相互配合,可以用来避免 pod 被分配到不合适的节点上。每个节点上都可以应用一个或多个 taint,这表示对于那些不能容忍这些 taint 的 pod,是不会被该节点接受的。如果将 toleration 应用于 pod 上,则表示这些 pod 可以(但不要求)被调度到具有匹配 taint 的节点上。
污点Taint
污点的组成 使用 kubectl taint 命令可以给某个 Node 节点设置污点,Node 被设置上污点之后就和 Pod 之间存在了一种相斥的关系,可以让 Node 拒绝 Pod 的调度执行,甚至将 Node 已经存在的 Pod 驱逐出去。每个污点的组成如下:
1 | |
每个污点有一个 key 和 value 作为污点的标签,其中 value 可以为空,effect 描述污点的作用。当前 taint effect 支持如下三个选项:
- PreferNoSchedule 表示 k8s 将尽量避免将 Pod 调度到具有该污点的 Node 上
- NoSchedule 表示 k8s 将不会将 Pod 调度到具有该污点的 Node 上
- NoExecute 表示 k8s 将不会将 Pod 调度到具有该污点的 Node 上,同时会将 Node 上已经存在的 Pod 驱逐出去
1 | |
-
污点的设置、查看和去除
1
2
3
4
5
6
7
8
9# 设置污点 $ kubectl taint nodes k8s-node1 key1=value1:NoSchedule $ kubectl taint nodes k8s-node1 type=master:NoExecute # 节点说明中查找Taints字段 $ kubectl describe pod pod-name # 去除污点 $ kubectl taint nodes k8s-node1 key1:NoSchedule-
1 | |
Pod 的 Toleration 声明 中的 key 和 effect 需要与 Taint 的设 置保待一致,并且满足以下条件之一 。
- operator 的值是 Exists (无须指定 value)。
- operator 的值是 Equal 并且 value 相等 。
如果不指定 operator, 则默认值为 Equal。
另外,有如下两个特例 。
- 空的key配合Exists操作符能够匹配所有键和值。
- 空的 effect 匹配所有 effect。
容忍 Tolerations
设置了污点的 Node 将根据 taint 的 effect:NoSchedule、PreferNoSchedule、NoExecute 和 Pod 之间产生互斥的关系,Pod 将在一定程度上不会被调度到 Node 上。但我们可以在 Pod 上设置容忍,意思是设置了容忍的 Pod 将可以容忍污点的存在,可以被调度到存在污点的 Node 上。
- PreferNoSchedule 表示 k8s 将尽量避免将 Pod 调度到具有该污点的 Node 上
- NoSchedule 表示 k8s 将不会将 Pod 调度到具有该污点的 Node 上
- NoExecute 表示 k8s 将不会将 Pod 调度到具有该污点的 Node 上,同时会将 Node 上已经存在的 Pod 驱逐出去
前面提到的 NoExecute 这个 Taint 效果对节点上正在运行的 Pod 有以下影响
-
没有设置 Toleration 的 Pod 会被立刻驱逐。
-
配置了对应 Toleration 的 Pod, 如果没有为 tolerationSeconds 赋值,则会一直留在这一节点 中 。
-
配置了对应 Toleration 的 Pod 且指定了 tolerationSeconds 值,则会在指定的时间后
驱逐 。 注意 , 在节点发生故障的情况下,系统将会以限速 ( rate-limiting) 模式逐 步给 Node设置 Taint, 这样就能避免在一些特定情况下( 比如 Master暂时失联) 有大量的 Pod被驱逐。
Kubernetes 调度器处理多个 Taint和 Toleration 的逻辑顺序为:
首先列出节点中所有的 Taint, 然后忽略 Pod 的 Toleration 能够匹配的部分,剩下的没被忽略的 Taint 就是对 Pod 的效果了 。
下面是几种特殊情况 。
- 如果在剩余的 Taint 中存在 effect=NoSchedule,则调度器不会把该 Pod 调度到这一节点上 。
- 如果在剩余的 Taint 中 没有 NoSchedule 效果,但是有 PreferNoSchedule 效果,则 调度器会尝试不把这个 Pod 指派给这个节点 。
-
如果在剩余的 Taint 中有 NoExecute 效果,并且这个 Pod 已经在该节点上运行,则会被驱逐;如果没有在该节点上运行,则也不会再被调度到该节点上 。
-
pod.spec.tolerations
- 其中 operator 的值为 Exists 将会忽略 value 值
- 其中 key, value, effect 要与 Node 上设置的 taint 保持一致
- 其中 tolerationSeconds 用于描述当 Pod 需要被驱逐时可以在 Pod 上继续保留运行的时间
1 | |
当不指定 key 值时,表示容忍所有的污点 key
1 | |
当不指定 effect 值时,表示容忍所有的污点作用
1 | |
有多个 Master 存在时,防止资源浪费,可以如下设置
1 | |
自动驱逐pod
TaintNodesByCondition 及 TaintBasedEvictions, 用来改善异常情况下的 Pod 调度与 驱逐问题,比如在节点内存吃 紧、节点磁盘空 间已 满、节点失联等情况下,是否自动驱逐某些 Pod 或者 暂时保留这些 Pod 等待节点恢复正常 。
-
不断地检查所有 Node 状态, 设置对应的 Condition。
-
不断地根据 Node Condition 设置对应的 Taint。
-
不断地根据 Taint 驱逐 Node 上的 Pod
其中 , 检查 Node 的状态并设置 Node 的 Taint 就是 TaintNodesByCondition 特性,即在 Node满足某些特定的条件时, 自动为 Node节点添加 Taint。
-
node.kubernetes.io/not-ready: 节点未就绪 。 对应 NodeCondition Ready 为 False 的
情况 。
-
node.kubemetes.io/unreachable : 节点不 可 触达 。 对应 NodeCondition Ready 为Unknown的情况。
-
node.kubemetes.io/out-of-disk: 节点磁盘空间已满。
-
node.kubernetes.io/network-unavailable: 节点 网络不可用 。
-
node.kubernetes.io/unschedulable: 节点不可调度 。
-
node.cloudprovider.kubernetes.io/uninitialized: 如果 kubelet是由“外部“云服务商
启动的, 则 该污点用来标识某个节点当前为不 可用 状态 。 在云控制器 ( cloud controller-manager) 初始化这个节点以后, kubelet 会将此污点移除 。
上述两个特性被默认启用 。 TaintNodesByCondition 这个特性 只会为节点添加 NoSchedule 效果的污点, TaintBasedEviction 则 为节点添加 NoExecute 效 果的污点。在 TaintBasedEvictions 特 性被开启之后 , kubelet 会在有资源压力时对相应的Node 节点自动加上对应的 NoExecute 效果的 Taint , 例如 node.kubernetes. io/rnernory- pressure、 node.kubernetes.io/disk-pressure。如果 Pod 没有设置对应的 Toleration, 则这部分 Pod 将被驱逐,以确保节点不会崩溃 。
指定调度节点
-
Pod.spec.nodeName
- 将 Pod 直接调度到指定的 Node 节点上,会跳过 Scheduler 的调度策略,该匹配规则是强制匹配。
1 | |
-
Pod.spec.nodeSelector
-
kubectl label nodes <node-name> <label-key>=<label-value> -
通过
kubernetes的label-selector机制选择节点,由调度器调度策略匹配label,而后调度Pod到目标节点,该匹配规则属于强制约束。
-
1 | |
1 | |
调度优先级
抢占Preemption
Preemption 则是 Scheduler 执行的行为,当一个新的 Pod 因为资源无法满足而不能被调度时, Scheduler 可能(有权决定)选择驱逐部分低优先级的 Pod 实例来满足此 Pod 的调度目标,这就是 Preemption 机制 。
-
Pod 被创建后会进入队列等待调度。 调度器从队列中挑选一个 Pod 并尝试将它调度到某个节点上。
-
如果没有找到满足 Pod 的所指定的所有要求的节点,则触发对悬决 Pod 的抢占逻辑。 让我们将悬决 Pod 称为 P。
-
抢占逻辑试图找到一个节点, 在该节点中删除一个或多个优先级低于 P 的 Pod,则可以将 P 调度到该节点上。
-
如果找到这样的节点,一个或多个优先级较低的 Pod 会被从节点中驱逐。 被驱逐的 Pod 消失后,P 可以被调度到该节点上。
如何使用优先级和抢占
-
新增一个或多个 PriorityClass。
-
创建 Pod,并将其
priorityClassName设置为新增的 PriorityClass。 当然你不需要直接创建 Pod;通常,你将会添加priorityClassName到集合对象(如 Deployment) 的 Pod 模板中。
PriorityClass
PriorityClass 是一个无名称空间对象,它定义了从优先级类名称到优先级整数值的映射。 名称在 PriorityClass 对象元数据的 name 字段中指定。 值在必填的 value 字段中指定。值越大,优先级越高。 PriorityClass 对象的名称必须是有效的 DNS 子域名, 并且它不能以 system- 为前缀。
PriorityClass 对象可以设置任何小于或等于 10 亿的 32 位整数值。 较大的数字是为通常不应被抢占或驱逐的关键的系统 Pod 所保留的。 集群管理员应该为这类映射分别创建独立的 PriorityClass 对象。
PriorityClass 还有两个可选字段:globalDefault 和 description。 globalDefault 字段表示这个 PriorityClass 的值应该用于没有 priorityClassName 的 Pod。 系统中只能存在一个 globalDefault 设置为 true 的 PriorityClass。 如果不存在设置了 globalDefault 的 PriorityClass, 则没有 priorityClassName 的 Pod 的优先级为零。
description 字段是一个任意字符串。 它用来告诉集群用户何时应该使用此 PriorityClass。
1 | |
- 如果你升级一个已经存在的但尚未使用此特性的集群,该集群中已经存在的 Pod 的优先级等效于零。
- 添加一个将
globalDefault设置为true的 PriorityClass 不会改变现有 Pod 的优先级。 此类 PriorityClass 的值仅用于添加 PriorityClass 后创建的 Pod。 - 如果你删除了某个 PriorityClass 对象,则使用被删除的 PriorityClass 名称的现有 Pod 保持不变, 但是你不能再创建使用已删除的 PriorityClass 名称的 Pod。
非抢占式 PriorityClass
1 | |
配置了 PreemptionPolicy: Never 的 Pod 将被放置在调度队列中较低优先级 Pod 之前, 但它们不能抢占其他 Pod。等待调度的非抢占式 Pod 将留在调度队列中,直到有足够的可用资源, 它才可以被调度。非抢占式 Pod,像其他 Pod 一样,受调度程序回退的影响。 这意味着如果调度程序尝试这些 Pod 并且无法调度它们,它们将以更低的频率被重试, 从而允许其他优先级较低的 Pod 排在它们之前。
非抢占式 Pod 仍可能被其他高优先级 Pod 抢占。
pod实例
1 | |
在你拥有一个或多个 PriorityClass 对象之后, 你可以创建在其规约中指定这些 PriorityClass 名称之一的 Pod。 优先级准入控制器使用 priorityClassName 字段并填充优先级的整数值。 如果未找到所指定的优先级类,则拒绝 Pod。
使用优先 级抢占的调度策略可能会导致某些 Pod 永远无法被成功调 度 。 因此优先级调度不但增加了系统的复杂性,还可能带来额外不稳定的因素 。 因此,一 旦发生资源紧张的局面,首先要考虑的是集群扩容,如果无法扩容,则再考虑有监管的优 先级调度特性,比如结合基于命名空间的资源配额限制来约束任意优先级抢占行为 。
支持 PodDisruptionBudget,但不保证
PodDisruptionBudget (PDB) 允许多副本应用程序的所有者限制因自愿性质的干扰而同时终止的 Pod 数量。 Kubernetes 在抢占 Pod 时支持 PDB,但对 PDB 的支持是基于尽力而为原则的。 调度器会尝试寻找不会因被抢占而违反 PDB 的牺牲者,但如果没有找到这样的牺牲者, 抢占仍然会发生,并且即使违反了 PDB 约束也会删除优先级较低的 Pod。
PodDisruptionBudget
控制器可以设置应用Pod集群处于运行状态最低个数,也可以设置应用POD集群处于运行状态的最低百分比,这样可以保证在主动销毁应用Pod的时候,不会一次性销毁太多的应用Pod。目的是对自愿中断的保护措施。
非自愿性中断(PodDisruptionBudget 机制完全无效 )
Pod 不会消失,直到有人(人类或控制器)将其销毁,或者当出现不可避免的硬件或系统软件错误。
- 后端节点物理机的硬件故障
- 集群管理员错误地删除虚拟机(实例)
- 云提供商或管理程序故障使虚拟机消失
- 内核恐慌(kernel panic)
- 节点由于集群网络分区而从集群中消失
- 由于节点资源不足而将容器逐出
自愿中断
由应用程序所有者发起的操作和由集群管理员发起的操作
- 删除管理该 pod 的 Deployment 或其他控制器
- 更新了 Deployment 的 pod 模板导致 pod 重启
- 直接删除 pod(意外删除)
集群管理员操作包括:
- 排空(drain)节点进行修复或升级。
- 从集群中排空节点以缩小集群(了解集群自动调节)。
- 从节点中移除一个 pod,以允许其他 pod 使用该节点。
1 | |
1 | |
.spec.minAvailable:表示发生自愿中断的过程中,要保证至少可用的Pods数或者比例.spec.maxUnavailable:表示发生自愿中断的过程中,要保证最大不可用的Pods数或者比例
上面配置只能用来对应 Deployment,RS,RC,StatefulSet的Pods,推荐优先使用 .spec.maxUnavailable。
注意:
- 同一个 PDB Object 中不能同时定义
.spec.minAvailable和.spec.maxUnavailable。 - 前面提到,应用滚动更新时Pod的
delete和unavailable虽然也属于自愿中断,但是实际上滚动更新有自己的策略控制(marSurge和maxUnavailable),因此PDB不会干预这个过程。 - PDB 只能保证
自愿中断时的副本数,比如evict pod过程中刚好满足.spec.minAvailable或.spec.maxUnavailable,这时某个本来正常的Pod突然因为Node Down(非自愿中断)挂了,那么这个时候实际Pods数就比PDB中要求的少了,因此PDB不是万能的!
使用上,如果设置 .spec.minAvailable 为 100% 或者 .spec.maxUnavailable 为 0%,意味着会完全阻止 evict pods 的过程( Deployment和StatefulSet的滚动更新除外 )。
Eviction 驱逐
1 | |
Eviction 是 kubelet 进程的行为,即当一个 Node 资源 不足 (underresourcepressure) 时,该节点上的 kubelet进程会执行驱逐动作,此时 kubelet 会综合考虑 Pod 的优先级、资源申请益与实际使用益等信息来计莽哪些 Pod 需要被驱逐; 当同样优先级的 Pod 需要被驱逐时,实际使用的资源世超过申请量最大倍数的高耗能 Pod 会被首 先驱逐 。
节点压力驱逐是 kubelet 主动终止 Pod 以回收节点上资源的过程。
kubelet 监控集群节点的 CPU、内存、磁盘空间和文件系统的 inode 等资源。 当这些资源中的一个或者多个达到特定的消耗水平, kubelet 可以主动地使节点上一个或者多个 Pod 失效,以回收资源防止饥饿。
在节点压力驱逐期间,kubelet 将所选 Pod 的 PodPhase 设置为 Failed。这将终止 Pod。
kubelet 并不理会你配置的 PodDisruptionBudget 或者是 Pod 的 terminationGracePeriodSeconds。
kubelet 使用各种参数来做出驱逐决定
驱逐信号
| 驱逐信号 | 描述 |
|---|---|
memory.available |
memory.available := node.status.capacity[memory] - node.stats.memory.workingSet |
nodefs.available |
nodefs.available := node.stats.fs.available |
nodefs.inodesFree |
nodefs.inodesFree := node.stats.fs.inodesFree |
imagefs.available |
imagefs.available := node.stats.runtime.imagefs.available |
imagefs.inodesFree |
imagefs.inodesFree := node.stats.runtime.imagefs.inodesFree |
pid.available |
pid.available := node.stats.rlimit.maxpid - node.stats.rlimit.curproc |
memory.available 的值来自 cgroupfs,而不是像 free -m 这样的工具。 这很重要,因为 free -m 在容器中不起作用
驱逐条件
驱逐条件的形式为 [eviction-signal][operator][quantity],其中:
eviction-signal是要使用的驱逐信号。operator是你想要的关系运算符, 比如<(小于)。quantity是驱逐条件数量,例如1Gi。quantity的值必须与 Kubernetes 使用的数量表示相匹配。 你可以使用文字值或百分比(%)。
例如,如果一个节点的总内存为 10Gi 并且你希望在可用内存低于 1Gi 时触发驱逐, 则可以将驱逐条件定义为 memory.available<10% 或 memory.available< 1G。 你不能同时使用二者。
软驱逐条件
软驱逐条件将驱逐条件与管理员所必须指定的宽限期配对。 在超过宽限期之前,kubelet 不会驱逐 Pod。 如果没有指定的宽限期,kubelet 会在启动时返回错误。
你可以既指定软驱逐条件宽限期,又指定 Pod 终止宽限期的上限,,给 kubelet 在驱逐期间使用。 如果你指定了宽限期的上限并且 Pod 满足软驱逐阈条件,则 kubelet 将使用两个宽限期中的较小者。 如果你没有指定宽限期上限,kubelet 会立即杀死被驱逐的 Pod,不允许其体面终止。
你可以使用以下标志来配置软驱逐条件:
eviction-soft:一组驱逐条件,如memory.available<1.5Gi, 如果驱逐条件持续时长超过指定的宽限期,可以触发 Pod 驱逐。eviction-soft-grace-period:一组驱逐宽限期, 如memory.available=1m30s,定义软驱逐条件在触发 Pod 驱逐之前必须保持多长时间。eviction-max-pod-grace-period:在满足软驱逐条件而终止 Pod 时使用的最大允许宽限期(以秒为单位)。
硬驱逐条件
硬驱逐条件没有宽限期。当达到硬驱逐条件时, kubelet 会立即杀死 pod,而不会正常终止以回收紧缺的资源。
你可以使用 eviction-hard 标志来配置一组硬驱逐条件, 例如 memory.available<1Gi。
kubelet 具有以下默认硬驱逐条件:
memory.available<100Minodefs.available<10%imagefs.available<15%nodefs.inodesFree<5%(Linux 节点)
驱逐监测间隔
kubelet 根据其配置的 housekeeping-interval(默认为 10s)评估驱逐条件
kubelet 驱逐时 Pod 的选择
如果 kubelet 回收节点级资源的尝试没有使驱逐信号低于条件, 则 kubelet 开始驱逐最终用户 Pod。
kubelet 使用以下参数来确定 Pod 驱逐顺序:
- Pod 的资源使用是否超过其请求
- Pod 优先级
- Pod 相对于请求的资源使用情况
因此,kubelet 按以下顺序排列和驱逐 Pod:
- 首先考虑资源使用量超过其请求的
BestEffort或BurstablePod。 这些 Pod 会根据它们的优先级以及它们的资源使用级别超过其请求的程度被逐出。 - 资源使用量少于请求量的
GuaranteedPod 和BurstablePod 根据其优先级被最后驱逐。
Pod 容灾调度
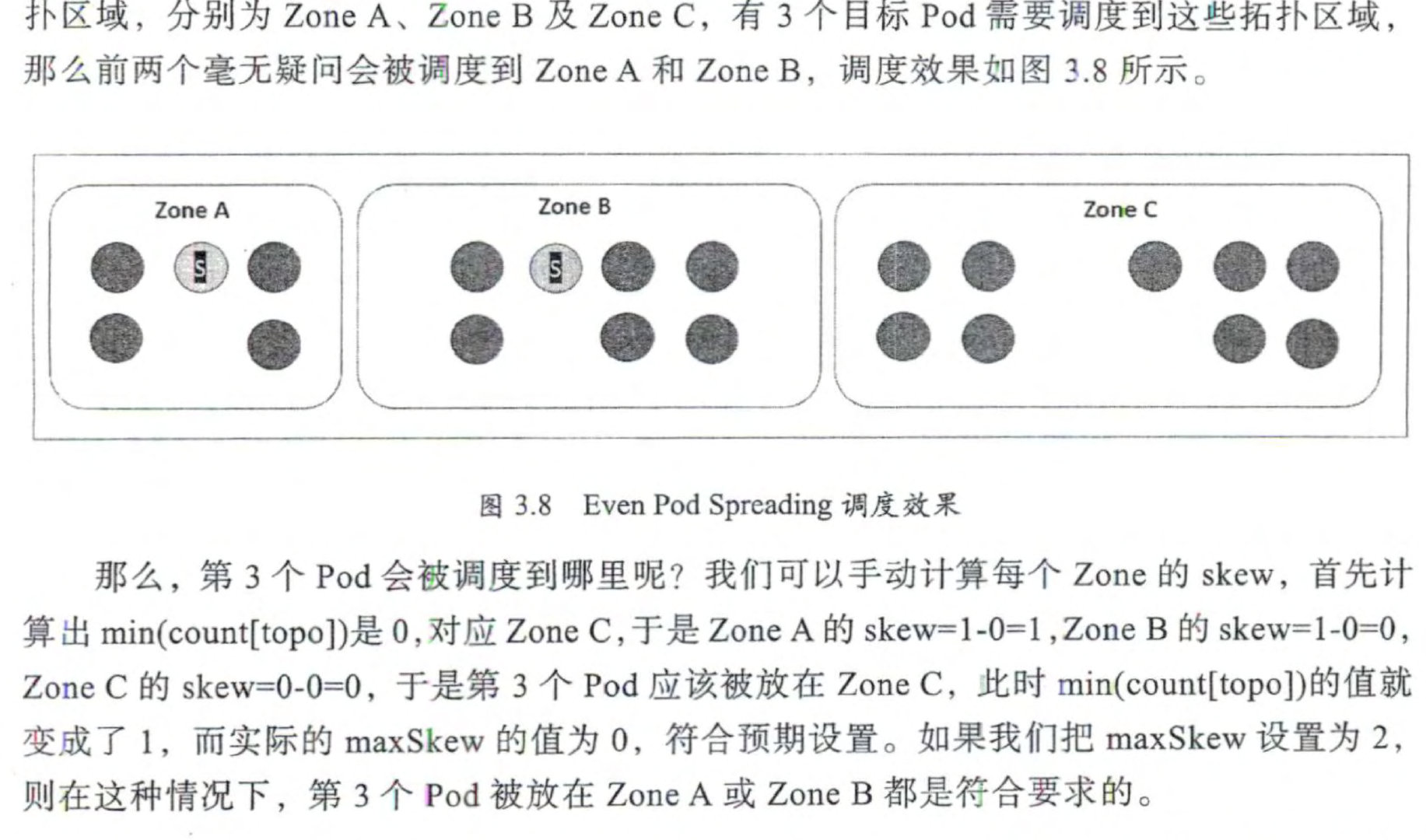
当我们的集群是为了容灾而建设的跨区域的多中心(多个 Zone) 集 群,即集群中的节点位于不同区域的机房时,此时最好的调度策略就是将需要容灾的应用 均匀调度到各个中心,当某个中心出现问题时,又自动调度到其他中心均匀分布。
Pod 的副本总数除以 Zone 的数蜇就是每个分区的 Pod 副本数量 。 但 这样做有个问题 : 如果某个 Zone 失效,那么这个 Zone 的 Pod 就无法迁移到其他 Zone。
在 Kubernetes 1. I6 版本中首次引入 Even Pod Spreading 特 性,用于通过 topologyKey 属性 识别 Zone, 并通过设置新的参数 topologySpreadCor.straints 来将 Pod 均匀调度到不同的 Zone。
假如我们的集群 被划分为多个 Zone, 我们有 一个应用(对应的 Pod 标签为 app=foo) 需要在每个 Zone 均 匀调度以实现容灾,则可以定义 YAML 文件如下 :
1 | |
在以上 YAML 定义中,关键的参数是 maxSkew。 max.Skew 用千指定 Pod 在各个 Zone 上调度时能容忍的最大不均衡数 :
- 值越大,表示能接受的不均衡调度越大;
- 值越小,表示 各个 Zone 的 Pod 数量分布越均匀 。
为了理解 maxSkew, 我们需要先理解 skew 参数的计算公式: skew[topo]=count[topo] - min(count[topo]),即每个拓扑区域的 skew 值都为该区域包括的目标 Pod 数量与整个拓扑 区域最少 Pod 数量的差,而 maxSkew 就是最大的 skew 值 。