NVIDIA准备
在每个工作节点上都安装 NVIDIA GPU 或 AMDGPU 驱动程序,如下所述 。 使用 NVIDIA GPU 的系统要求包括:
- NVIDIA 驱动程序的版本为 384.81 及以上;
- nvidia-docker 的版本为 2.0 及以上;
- kubelet 配置的容器运行时 (Container Runtime) 必须为 Docker;
- Docker 配置的默认运行时 (Default Runtime) 必须为 nvidia-container-runtime, 而不能用runc;
-
Kubernetes 版本为 1.11 及以上 。
- 检查系统要求
1 | |
NVIDIA 12.1 安装有网版
1 | |
1 | |
卸载
1 | |
1 | |
其中$distro/$arch应替换为以下之一:
ubuntu1604/x86_64ubuntu1804/cross-linux-sbsaubuntu1804/ppc64elubuntu1804/sbsaubuntu1804/x86_64ubuntu2004/cross-linux-sbsaubuntu2004/sbsaubuntu2004/x86_64ubuntu2204/sbsaubuntu2204/x86_64
1 | |
或者
1 | |
1 | |
1 | |
/etc/docker/daemon.json,修改docker Runtime
1 | |
1 |
|
NVIDIA Drivers
dial unix /var/run/docker.sock: connect: permission denied
1 |
|
检查驱动
检查驱动是否存在
使用nvcc -V检查驱动和cuda。
1 | |
然后nvidia-smi 有报错参考重新安装驱动
查看型号
1 | |
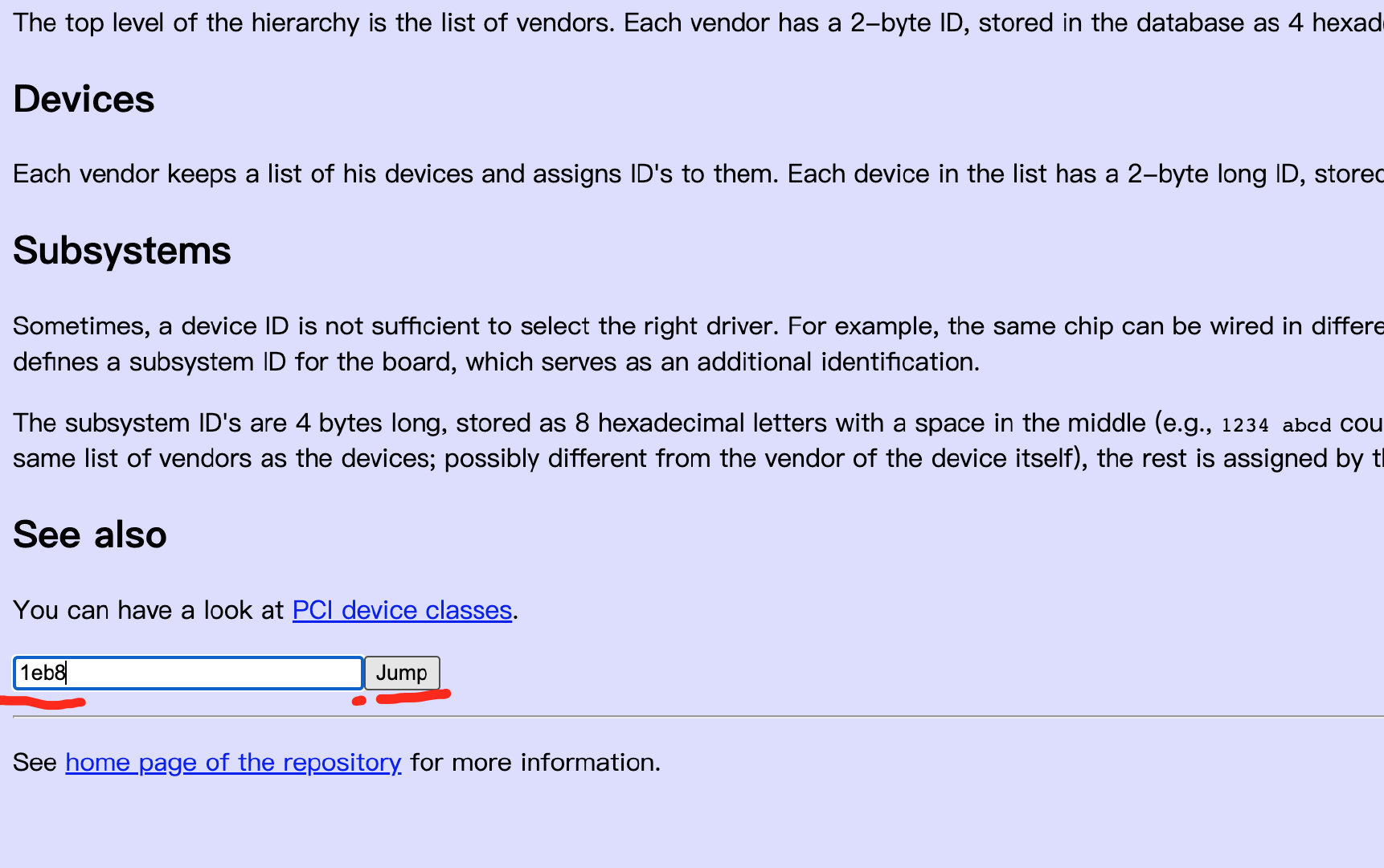
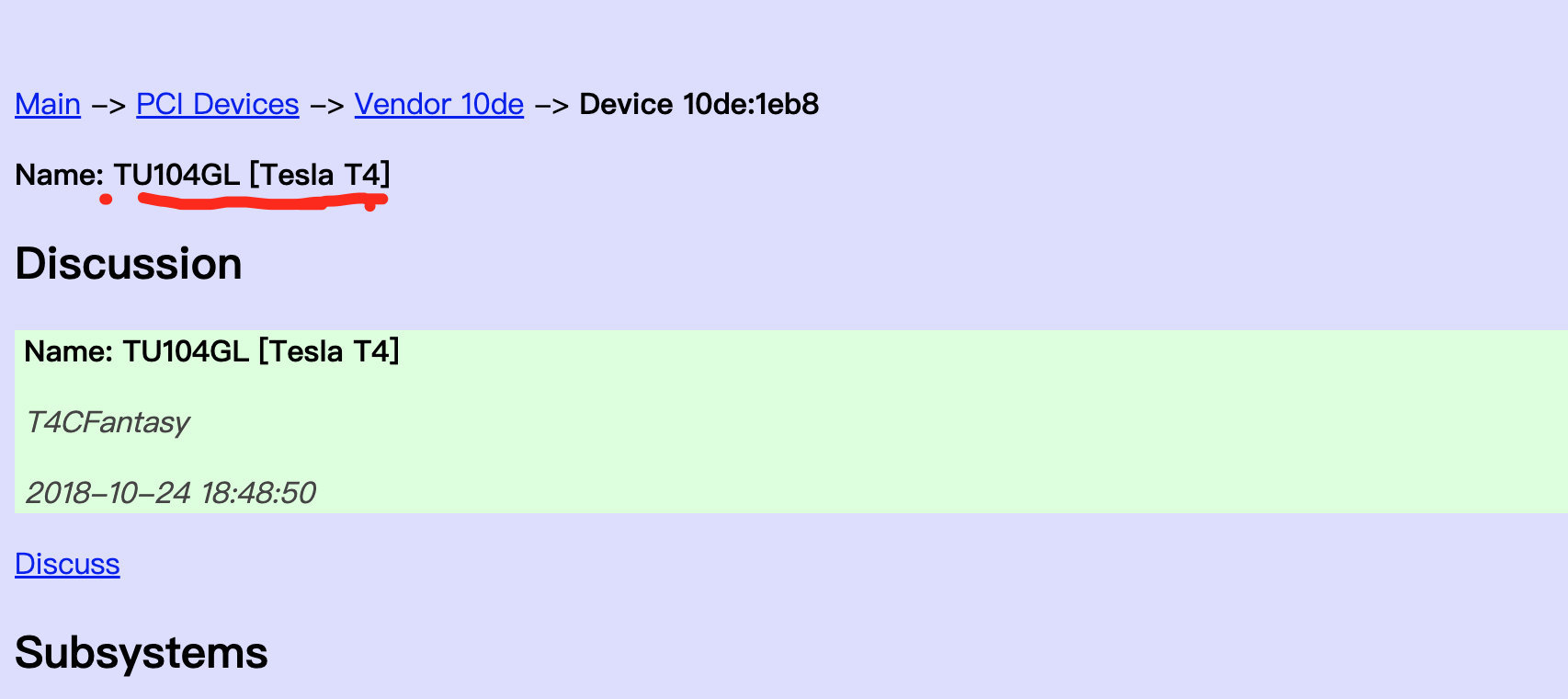
返回一个1eb8,可以通过PCI devices查询
也可以直接安装NVIDIA CUDA Toolkit
The CUDA Toolkit contains the CUDA driver and tools needed to create, build and run a CUDA application as well as libraries, header files, and other resources.
根据 https://github.com/NVIDIA/nvidia-docker CUDA Toolkit不是必须的,驱动是必须的
安装驱动
查看支持显卡的驱动最新版本及下载,下载之后是.run后缀 (可以直接下载驱动)

1 | |
代码注释:
-no-x-check #安装驱动时关闭X服务
-no-nouveau-check #安装驱动时禁用nouveau
-no-opengl-files #只安装驱动文件,不安装OpenGL文件
或者
1 | |
查看cuda版本
1 | |
查看显卡驱动版本
1 | |
验证驱动
1 | |
重新安装驱动
NVIDIA-SMI has failed because it couldn’t communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
运行nvidia-smi时,报错。
使用nvcc -V检查驱动和cuda。
1 | |
发现驱动是存在的,于是进行下一步
查看已安装驱动的版本信息
1 | |
重新安装
1 | |
等待安装完成后,再次输入nvidia-smi,查看GPU使用状态
nvidia-docker2
/etc/docker/daemon.json,修改docker Runtime
1 | |
根据Setting up Docker 安装nvidia-docker2
Setup the package repository and the GPG key:
1 | |
Install the nvidia-docker2 package (and dependencies) after updating the package listing:
1 | |
1 | |
Restart the Docker daemon to complete the installation after setting the default runtime:
1 | |
At this point, a working setup can be tested by running a base CUDA container:
1 | |
This should result in a console output shown below:
1 | |
注意事项
如果存在这种现象: “没有运行程序,nvidia-smi查看GPU-Util 达到100% GPU利用率很高” 需要把驱动模式设置为常驻内存才可以,设置命令:
nvidia-smi -pm 1
AliGPUShare
K8s + Nvidia-Device-Plugin的方式两个限制
- 每一块GPU同时最多只能被一个容器使用(会造成巨大的资源浪费)
- 没有考虑GPU卡之间的通道亲和性(因为不同的连接介质对卡与卡之间的数据传输速度影响非常大)
所以使用AliyunContainerService 提供Pod 之间共享 GPU解决方案
- https://blog.csdn.net/u012751272/article/details/120566202?spm=1001.2014.3001.5502
- https://github.com/AliyunContainerService/gpushare-scheduler-extender/blob/master/docs/install.md
配置调度器配置文件
从 Kubernetes v1.23 开始不再支持调度策略,而是应该使用调度程序配置。这意味着scheduler-policy-config.yaml需要包含在调度程序配置 ( /etc/kubernetes/manifests/kube-scheduler.yaml) 中。这是最终修改的kube-scheduler.yaml的示例
注意:如果您的 Kubernetes 默认调度程序部署为静态 pod,请不要编辑 /etc/kubernetes/manifest 中的 yaml 文件。您需要在
/etc/kubernetes/manifest目录外编辑 yaml 文件。并将您编辑的yaml文件复制到’/etc/kubernetes/manifest/’目录,然后kubernetes会自动使用yaml文件更新默认的静态pod。
1 | |
因为结合rke,需要修改kubeconfig路径
1 | |
使用rke配置cluster.yml scheduler config
1 | |
kube-scheduler容器启动,通过docker inspect kube-scheduler已经挂载了/etc/kubernetes,所以不用修改scheduler本身
1 | |
1 | |
部署GPU共享调度扩展器
1 | |
注意事项
-
单节点需要修改gpushare-schd-extender.yaml,不然会0/1 nodes are available: 1 node(s) didn’t match Pod’s node affinity/selector. 参考
1
2
3
4
5
6
7
8
9
10
11spec: hostNetwork: true tolerations: # - effect: NoSchedule # operator: Exists # key: node-role.kubernetes.io/master - effect: NoSchedule operator: Exists key: node.cloudprovider.kubernetes.io/uninitialized # nodeSelector: # node-role.kubernetes.io/master: ""
部署设备插件
1 | |
注意事项
- 默认情况下,GPU显存以GiB为单位,若需要使用MiB为单位,修改device-plugin-ds.yaml,将–memory-unit=GiB修改为–memory-unit=MiB
配置节点
1 | |
为要安装设备插件的所有节点添加标签“gpushare=true”,因为设备插件是 deamonset
1 | |
测试
1 | |
测试
部署官方测试demo
1 | |
1 | |
问题
和kubeflow结合,调度会失败,pod一直卡在pending
1 | |
- Enable GPU Memory as resource requirement for InferenceService
- 使用kubeflow1.6.1 使用自定义镜像有问题
- Custom GPU inference image cannot auto scale across multi GPUs. 根据这个可选的方案 volcano的gpushare功能 和 NVIDIA operator 分时GPU
NVIDIA GPU 方案
安装 nvidia-container-toolkit
安装nvidia-container-toolkit
1 | |
配置docker
使用 运行kubernetes时docker,编辑通常存在的配置文件/etc/docker/daemon.json以设置nvidia-container-runtime为默认的低级运行时:
1 | |
然后重新启动docker:
1 | |
NVIDIA device plugin
根据k8s官网安装NVIDIA device plugin,这个只能做到GPU被独占的效果,生产不使用
1 | |
安装成功
1 | |
NVIDIA operator
这个可以做到GPU share效果,使用的是Multi-Instance GPU (MIG)
MIG 允许您将 GPU 划分为多个较小的预定义实例,每个实例看起来都像一个迷你 GPU,在硬件层提供内存和故障隔离。您可以通过在这些预定义实例之一而不是完整的原生 GPU 上运行工作负载来共享对 GPU 的访问。
1 | |
1 | |
time-slicing-config.yaml,GPU 进行共享访问的配置,部署好后修改配置要重启nvidia-device-plugin-daemonset才会生效。
1 | |
1 | |
1 | |
安装
1 | |
operator运行情况
1 | |
1 | |
测试
1 | |
1 | |
1 | |
volcano
通过自定义scheduler,实现gpu-mem共享
Volcano是CNCF 下首个也是唯一的基于Kubernetes的容器批量计算平台,主要用于高性能计算场景。它提供了Kubernetes目前缺 少的一套机制,这些机制通常是机器学习大数据应用、科学计算、特效渲染等多种高性能工作负载所需的。作为一个通用批处理平台,Volcano与几乎所有的主流计算框 架无缝对接,如Spark 、TensorFlow 、PyTorch 、 Flink 、Argo 、MindSpore 、 PaddlePaddle 等。它还提供了包括基于各种主流架构的CPU、GPU在内的异构设备混合调度能力。Volcano的设计 理念建立在15年来多种系统和平台大规模运行各种高性能工作负载的使用经验之上,并结合来自开源社区的最佳思想和实践。
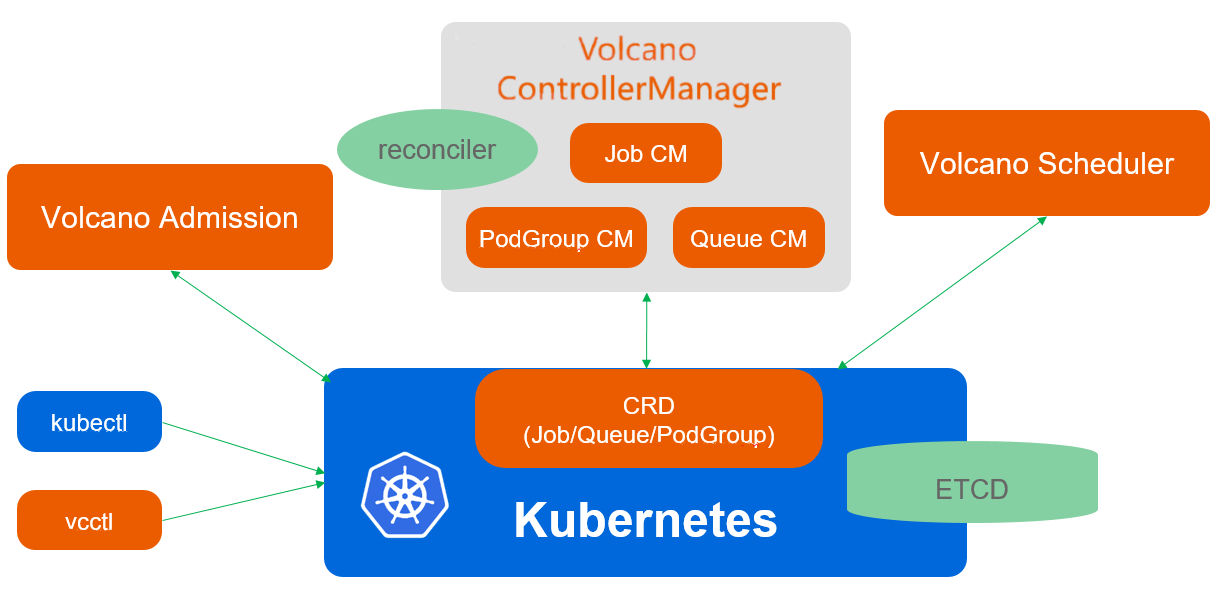
Volcano由scheduler、controllermanager、admission
- Scheduler Volcano scheduler通过一系列的action和plugin调度Job,并为它找到一个最适合的节点。与Kubernetes default-scheduler相比,Volcano与众不同的 地方是它支持针对Job的多种调度算法。
- Controllermanager Volcano controllermanager管理CRD资源的生命周期。它主要由Queue ControllerManager、 PodGroupControllerManager、 VCJob ControllerManager构成
- Admission Volcano admission负责对CRD API资源进行校验
podgroup是一组强关联pod的集合,主要用于批处理工作负载场景
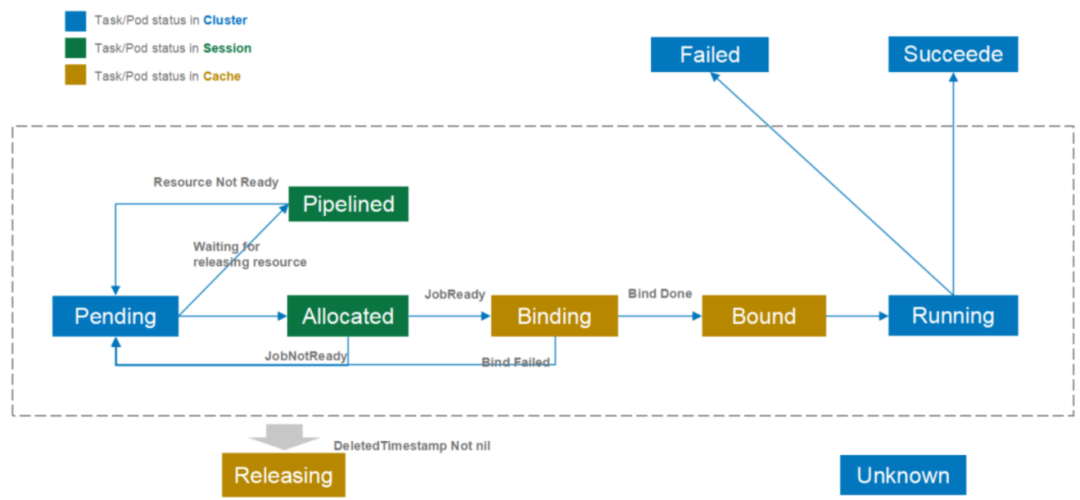
-
pending
pending表示该podgroup已经被volcano接纳,但是集群资源暂时不能满足它的需求。一旦资源满足,该podgroup将转变为running状态。
-
running
running表示该podgroup至少有minMember个pod或任务处于running状态。
-
unknown
unknown表示该podgroup中minMember数量的pod或任务分为2种状态,部分处于running状态,部分没有被调度。没有被调度的原因可能是资源不够等。调度 器将等待controller重新拉起这些pod或任务。
-
inqueue
inqueue表示该podgroup已经通过了调度器的校验并入队,即将为它分配资源。inqueue是一种处于pending和running之间的中间状态。
queue是容纳一组podgroup的队列,也是该组podgroup获取集群资源的划分依据
-
Open
该queue当前处于可用状态,可接收新的podgroup
-
Closed
该queue当前处于不可用状态,不可接收新的podgroup
-
Closing
该Queue正在转化为不可用状态,不可接收新的podgroup
-
Unknown
该queue当前处于不可知状态,可能是网络或其他原因导致queue的状态暂时无法感知
volcano启动后,会默认创建名为default的queue,weight为1。后续下发的job,若未指定queue,默认属于default queue
安装volcano
helm chart 下载https://github.com/volcano-sh/volcano/tree/release-1.7/installer/helm/chart
1 | |
命名空间必须是volcano-system,不然volcano-admission-service-pods-mutate起不来
1 | |
volcano_values.yaml
1 | |
打开GPU share 开关
1 | |
1 | |
安装Volcano device plugin
- NVIDIA drivers ~= 384.81
- nvidia-docker version > 2.0 (see how to install and it’s prerequisites)
- docker configured with nvidia as the default runtime.
- Kubernetes version >= 1.10
下载volcano-device-plugin.yaml,使用最新的不然有权限问题
运行情况
1 | |
测试
普通pod
1 | |
使用volcano调度,nvidia-smi 看不到任何进程,可以通过describe查看已分配资源
1 | |
kubeflow
1 | |
打开schedulerName feature,不然会报错
1 | |
1 | |