Service的后端是一组Endpoint列表,为客户端应用提供了极大的便利。但是随着集群规模的扩大及Service数量的增加,特别是Service后端Endpoint数量的增加,kube-proxy需要维护的负载分发规则(例如iptables规则或)pvs规则)的数噩也会急剧增加,导致后续对Service后端Endpoint的添加、删除等更新操作的成本急剧上升。
举例来说,假设在Kubernetes集群中有10000个Endpoint运行在大约5000个Node上,则对单个Pod的更新将需要总计约5GB的数据传输,这不仅对集群内的网络带宽浪费巨大,而且对Master的冲击非常大,会影响Kubernetes集群的整体性能,在Deployment不断进行滚动升级操作的情况下尤为突出。
Kubernetes从1.16版本开始引入端点分片(EndpointSlices)机制,包括一个新的EndpointSlice资源对象和一个新的EndpointSlice控制器,在1.17版本时达到Beta阶段。
EndpointSlice通过对Endpoint进行分片管理来实现降低Master和各Node之间的网络传输数据堡及提高整体性能的目标。对于Deployment的滚动升级,可以实现仅更新部分Node上的Endpoint信息,Master与Node之间的数据传输量可以减少100倍左右,能够大大提高管理效率。
EndpointSlice根据Endpoint所在Node的拓扑信息进行分片管理
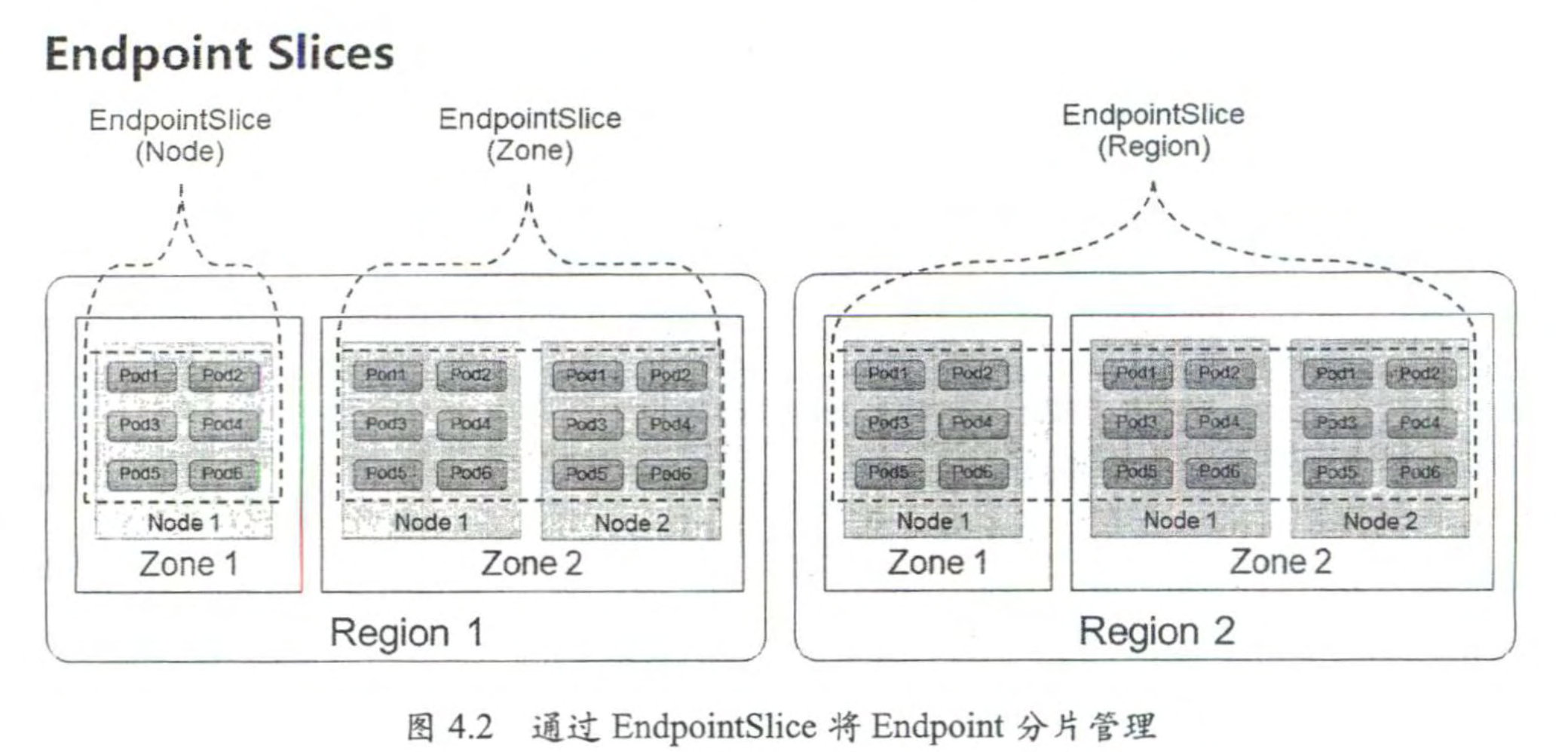
Endpoint Slices 要 实现的第 2 个目标是为基千 Node 拓扑的服务路由提供支持,这 需要 与服务拓扑 ( Service Topology ) 机制共同实现。
端点分片 (EndpointSlices)


EndpointSlice 的复制功能和数据分布管理机制进行说明

Kubernetes 控制平面对千 EndpointSlice 中数据的管理机制是尽可能填满,但不 会在多 个 EndpointSlice 数据不均衡的情况下主动执行重新平衡 (rebalance) 操作,其背后的逻辑 也很简单,步骤如下 。

Service Topology服务拓扑
默认情况下,发送到一个 Service 的流品会被均匀转发到每个后端 Endpoint, 但无 法根据更复杂的拓扑信息设置复杂的路由策略。服务拓扑机制的引入就是为了实现基于Node 拓扑的服务路由,允许 Service 创建者根据来源 Node 和目标 Node 的标签来定义流量路由策略 。
通过对来源 (source) Node 和目标 (destination) Node 标签的匹配,用户可以根据业 务需求对 Node 进行分组,设置有意义的指标值来标识”较近”或者”较远”的属性。例 如,对于公有云环境来说,通常有区域 (Zone 或 Region) 的划分,云平台倾向于把服务 流量限制在同 一 个区域内,这通常是因为跨区域网络流噩会收取额外的费用 。 另一个例子 是把流量路由到由 DaemonSet 管理的当前 Node 的 Pod 上 。 又如希望把流量保持在相同机 架内的 Node 上,以获得更低的网络延时 。
服务拓扑机制需要通过设置 kube-apiserver 和 kube-proxy 服务的启动参数
–feature-gates=”ServiceTopology=true,EndpointSlice=true” 进行启用(需要同时启用 EndpointS!ice 功能),然后就可以在 Service 资源对象上通过定义 topologyKeys 字段来控制 到 Service 的流益路由了 。
topologyKeys 字段设置的是一组 Node 标签列表,按顺序匹配 Node 完成流量的路由转 发,流量会被转发到标签匹配成功的 Node 上 。 如果按第 1 个标签找不到匹配的 Node, 就 尝试匹配第 2 个标签,以此类推 。 如果全部标签都没有匹配的 Node, 则请求将被拒绝, 就像 Service 没有后端 Endpoint 一样 。
将 topologyKeys 配置为“*”表示任意拓扑,它只能作为配置列表中的最后一个才有 效 。 如果完全不设置 topologyKeys 字段,或者将其值设置为空,就相当千没有启用服务拓 扑功能 。
对千需要使用服务拓扑机制的集群,管理员需要为 Node 设置相应的拓扑标签,包括 kubernetes.io/hostname、 topology.kubernetes.io/zone 和 topology.kubemetes.io/region。
然后为 Service 设置 topologyKeys 的值,就可以实现如下流呈路由策略 。
Service 和endpoint 流量流转过程
在 K8S 中,每个 Pod 都有其自己唯一的 ip 地址,而 Service 可以为多个 Pod(一组)提供相同的 DNS 名,并且可以在他们直接进行负载均衡。Service 是将运行在一组 Pods 上的应用程序公开为网络服务的抽象方法。
In Kubernetes (K8S), each Pod has its own unique IP address, while a Service can provide the same DNS name for multiple Pods (a group) and perform load balancing among them. Services are an abstract way of exposing applications running on a group of Pods as network services.
Service和pod不是直接连接,而是通过Endpoint资源进行连通。endpoint资源是暴露一个服务的ip地址和port的列表。 选择器用于构建ip和port列表,然后存储在endpoint资源中。当客户端连接到服务时,服务代理选择这些列表中的ip和port对中的一个,并将传入连接重定向到在该位置监听的服务器。 endpoint是一个单独的资源并不是服务的属性,endpoint的名称必须和服务的名称相匹配。
Services and Pods are not directly connected, but they are linked through the use of Endpoint resources. Endpoint resources expose a list of IP addresses and ports for a service. Selectors are used to build the list of IPs and ports, which are then stored in the Endpoint resource. When a client connects to the service, the service proxy selects one of the IP and port pairs from these lists and redirects the incoming connection to the server listening at that location. Endpoints are separate resources and not properties of the service. The name of the Endpoint must match the name of the Service.
每台机器上都运行一个 kube-proxy 服务,它监听 API server 中 service 和 endpoint 的变化情况,并通过 iptables 等来为服务配置负载均衡(仅支持 TCP 和 UDP)。
On each machine, a kube-proxy service runs, which monitors changes in services and endpoints in the API server and configures load balancing for the services using iptables and other mechanisms (only supports TCP and UDP).
iptabls流量
集群内发起调用,通过cluster ip访问到service。making calls within the cluster, you can access a Service using the Cluster IP 集群外发起调用,通过nodeport访问到service。making calls from outside the cluster, you can access a Service using NodePort
1 | |
iptables 分析 cluster IP
1 | |
Nodeport 多了KUBE-NODEPORTS,其他一样。
1 | |
kube-proxy iptables模式只在nat表和filter表增加了iptables规则
- NAT转发:在nat表中,kube-proxy会创建一些规则,将外部访问集群的流量转发到相应的Service或Pod。这些规则通常使用DNAT(目标网络地址转换)来修改流量的目标IP和端口。
- 应用访问控制:在filter表中,kube-proxy会创建一些规则,用于控制流量的进出。这些规则通常使用SNAT(源网络地址转换)和DNAT来修改流量的源IP和目标IP,以及允许或拒绝特定端口的访问。
IPVS
当网络数据包从pod的network namespace中通过linux veth pair设备进入到host宿主中的network namespace时,When network packets from the network namespace of the pod enter the network namespace of the host through the Linux veth pair device,
经过iptable一系列的NAT转换,把service的cluster ip和端口DNAT成pod的ip和端口。they go through a series of NAT transformations via iptables, which translates the cluster IP and port of the service to the IP and port of the pod.
同时leverage linux iptable的random模块,实现了对pod的负载均衡,然后再交由host对目标pod的路由策略来实现将数据包发往pod。
当然,这一切都是在linux内核空间实现的,和应用程序的用户空间没有关系。the random module of Linux iptables, load balancing is achieved for the pods, and then the host’s routing strategy for the target pod is used to send the packets to the pod.All of this is implemented in the Linux kernel space and has no relation to the user space .
- Linux内核高于2.4.x
- 在kube-proxy网络组件的启动参数中加入–proxy-mode=ipvs
- 安装ipvsadm工具
yum install ipvsadm,本质是ipvsadm是用户空间的程序,用来操作和管理ipvs
数据包会从pod的network namespace通过linux veth pair设备进入host的network namespace。host开启了路由转发功能,数据先进入到了iptable的PREROUTING chain中,我们查看这个chain
根据KUBE-SERVICES target,数据包匹配ipset KUBE-CLUSTER-IP。ipset是linux的内核数据结构,可以存储一些ip和端口的信息,ipvs模式的集群通过在iptable中匹配ipset,这样减少了iptable中的entry数量。在这里匹配了这个ipset之后进入了KUBE-MARK-MASQ这个target。ipset is a kernel data structure in Linux that can store information about IP addresses and ports. In an IPVS mode cluster, the IP set is matched in iptables, which helps reduce the number of entries in iptables.
1 | |
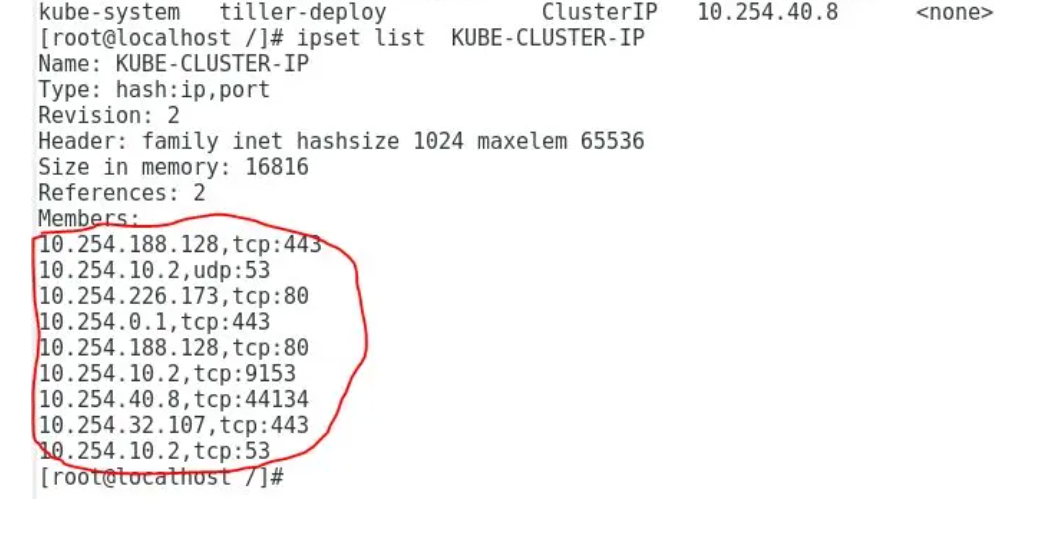
KUBE-CLUSTER-IP这个ipset里一共有9个entry,而且也匹配了集群中cluster ip类型service的ip和端口。
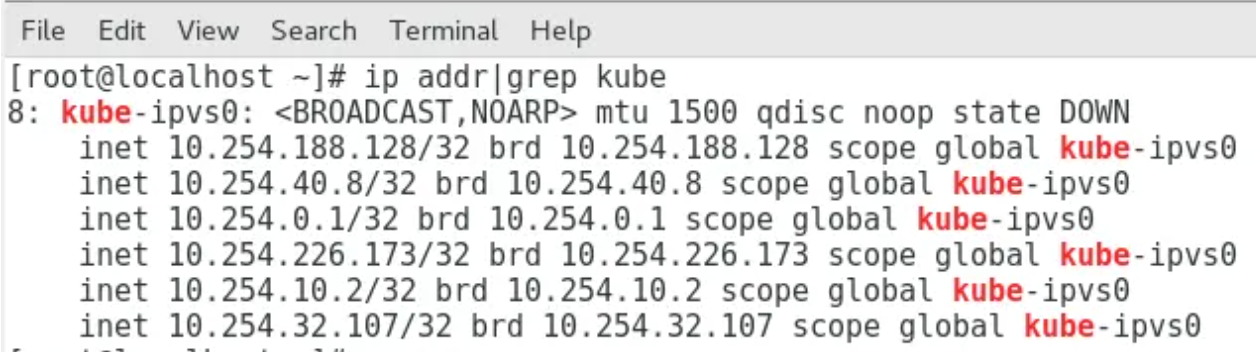
经过了PREROUTING chain以及相关的target之后数据会来到INPUT chain,这是因为对于ipvs模式,会在host的network namespace里创建kube-ipvs0网络设备,并且绑定了所有的cluster ip,这样数据就可以进入到INPUT chain。
1 | |
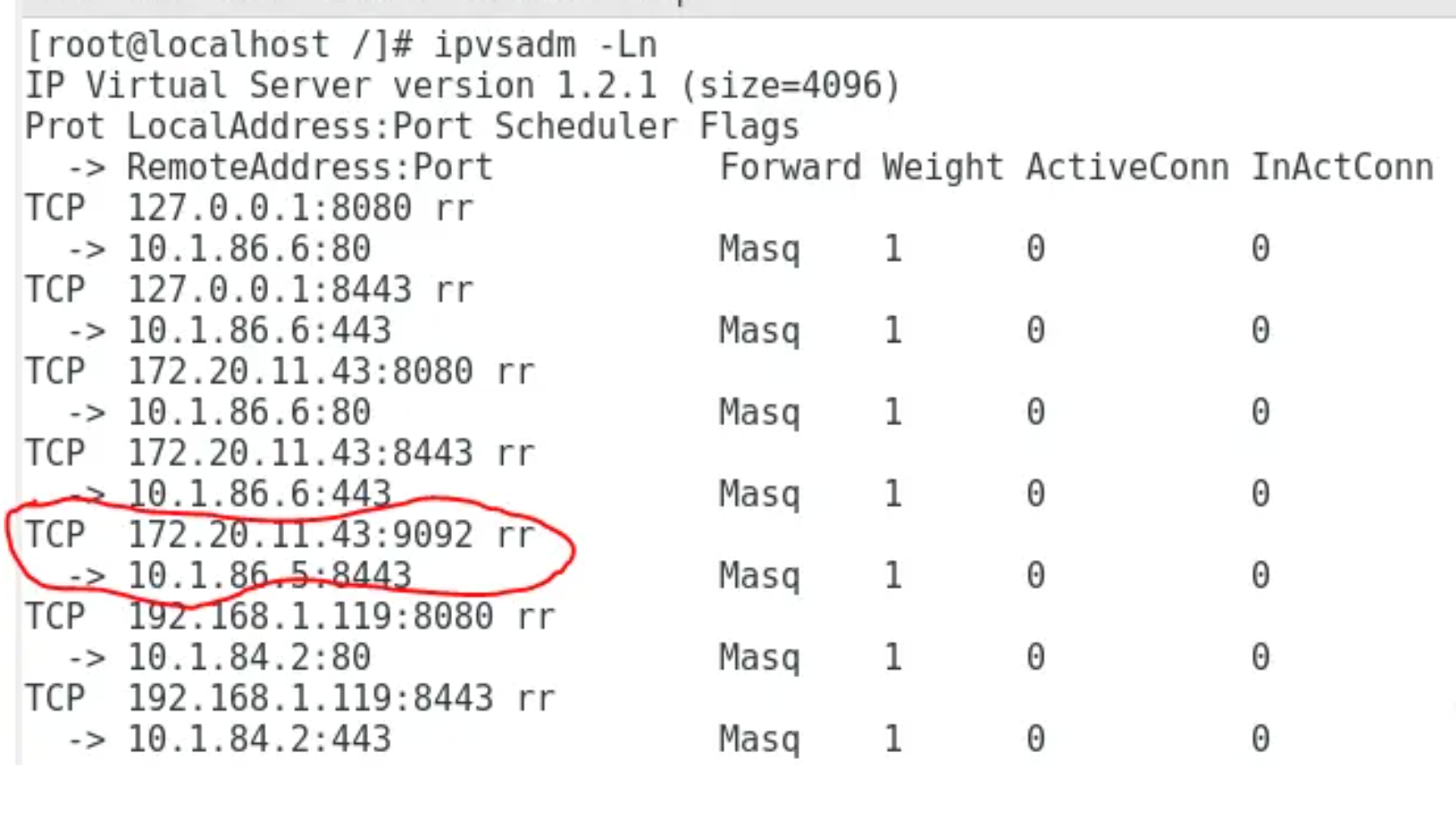
我们看到service service-nginx-app cluster ip为10.254.226.173:80,对应两个endpoint为10.1.86.6:80和10.1.86.7:80。然后通过ipvsadm工具查看确实是ipvs将其映射成两个endpoints,并且使用round robin的分配方式,分配权重为1和1,也就是均匀的实现负载均衡。
总结对于ipvs下的cluster ip的通讯方式为:
- 数据包从pod network namespace发出,进入host的network namespace,源ip为pod ip,源端口为随机端口,目标ip为cluster ip,目标port为指定port。
- 数据包在host network namespace中进入PREROUTING chain。
- 在PREROUTING chain中经过匹配ipset KUBE-CLUSTER-IP做mask标记操作。
- 在host network namespace中创建网络设备kube-ipvs0,并且绑定所有cluster ip,这样从pod发出的数据包目标ip为cluster ip,有kube-ipvs0网络设备对应,数据进入INPUT chain中。In the host network namespace, a network device called kube-ipvs0 is created and all cluster IPs are bound to it. This allows packets sent from pods with a destination IP of the cluster IP to be associated with the kube-ipvs0 network device and enter the INPUT chain.
- 在INPUT chain中ipvs利用映射规则(可由ipvsadm查看该规则)完成对cluster ip的DNAT和目标pod endpoints选择的负载均衡,然后直接把数据送入POSTROUTING chain。这时源ip为cluster ip,源端口为随机端口,目标ip为映射选择的pod ip,目标port为映射选择的port。In the INPUT chain, IPVS mapping rules (which can be viewed using the ipvsadm command) to perform Destination Network Address Translation (DNAT) for the cluster IP and load balancing by selecting target Pod endpoints. The data packets are then directly sent to the POSTROUTING chain. At this stage, the source IP is the Pod’s IP address, the source port is a random port, the destination IP is the IP address of the selected Pod from the mapping, and the destination port is the selected port from the mapping.
- 数据在POSTROUTING chain中,经过KUBE-POSTROUTING target完成MASQUERADE SNAT。这时源ip为下一跳路由所使用网路设备的ip,源端口为随机端口,目标ip为映射选择的pod ip,目标port为映射选择的port。The data, in the POSTROUTING chain, goes through the KUBE-POSTROUTING target to complete MASQUERADE SNAT. At this point, the source IP is the IP address of the next-hop router’s network device, the source port is a random port, the destination IP is the selected pod IP, and the destination port is the selected port.
- 数据包根据host network namespace的路由表做下一跳路由选择。
IPVS node port
node port数据包不会匹配ipset KUBE-CLUSTER-IP。因为node port是host的ip地址和目标port,并不在ipset KUBE-CLUSTER-IP中,那么这样数据就进入了KUBE-NODE-PORT。
发现KUBE-NODE-PORT target来匹配KUBE-NODE-PORT-TCP这个ipset
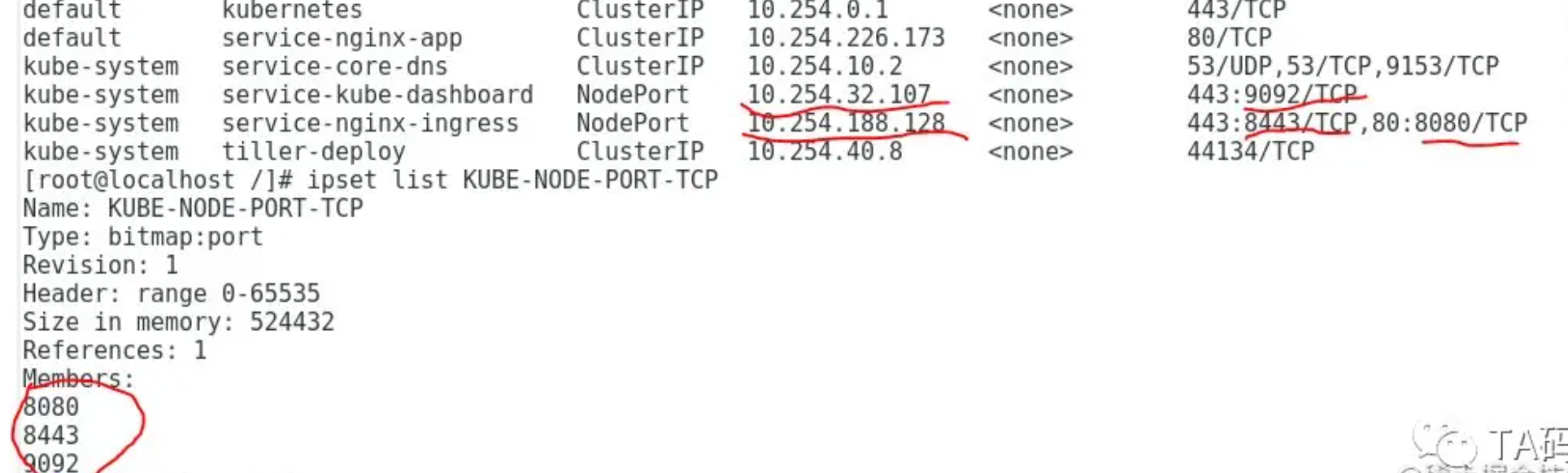
这里我们看到KUBE-NODE-PORT-TCP这个ipset里一共有3个entry,而且也匹配了集群中node port类型service的端口。
总结对于ipvs下的node port的通讯方式为:
- 数据包从host外部访问node port service的host端口,进入host的network namespace,源ip为外部 ip,源端口为随机端口,目标ip为host ip,目标port为node port。
- 数据包在host network namespace中进入PREROUTING chain。
- 在PREROUTING chain中经过匹配ipset KUBE-NODE-PORT-TCP做mask标记操作。
- 因为数据包的目标ip是host的ip地址,所以进入host network namespace的INPUT chain中。
- 数据在INPUT chain中被ipvs的内核规则修改(可由ipvsadm查看规则),完成负载均衡和DNAT,然后将数据直接送入POSTROUTING chain。这时源ip为外部ip,源端口为随机端口,目标ip为映射选择的pod ip,目标port为映射选择的port。The data is modified by the kernel rules of ipvs in the INPUT chain (which can be viewed using ipvsadm), to achieve load balancing and DNAT. Then, the data is directly sent to the POSTROUTING chain. At this point, the source IP is the external IP, the source port is a random port, the destination IP is the selected pod IP, and the destination port is the selected port.
- 数据在POSTROUTING chain中,经过KUBE-POSTROUTING target完成MASQUERADE SNAT。这时源ip为下一跳路由所使用网路设备的ip,源端口为随机端口,目标ip为映射选择的pod ip,目标port为映射选择的port。The data, in the POSTROUTING chain, goes through the KUBE-POSTROUTING target to complete MASQUERADE SNAT. At this point, the source IP is the IP address of the next-hop router’s network device, the source port is a random port, the destination IP is the selected pod IP, and the destination port is the selected port.
- 数据包根据host network namespace的路由表做下一跳路由选择。