概要
指标
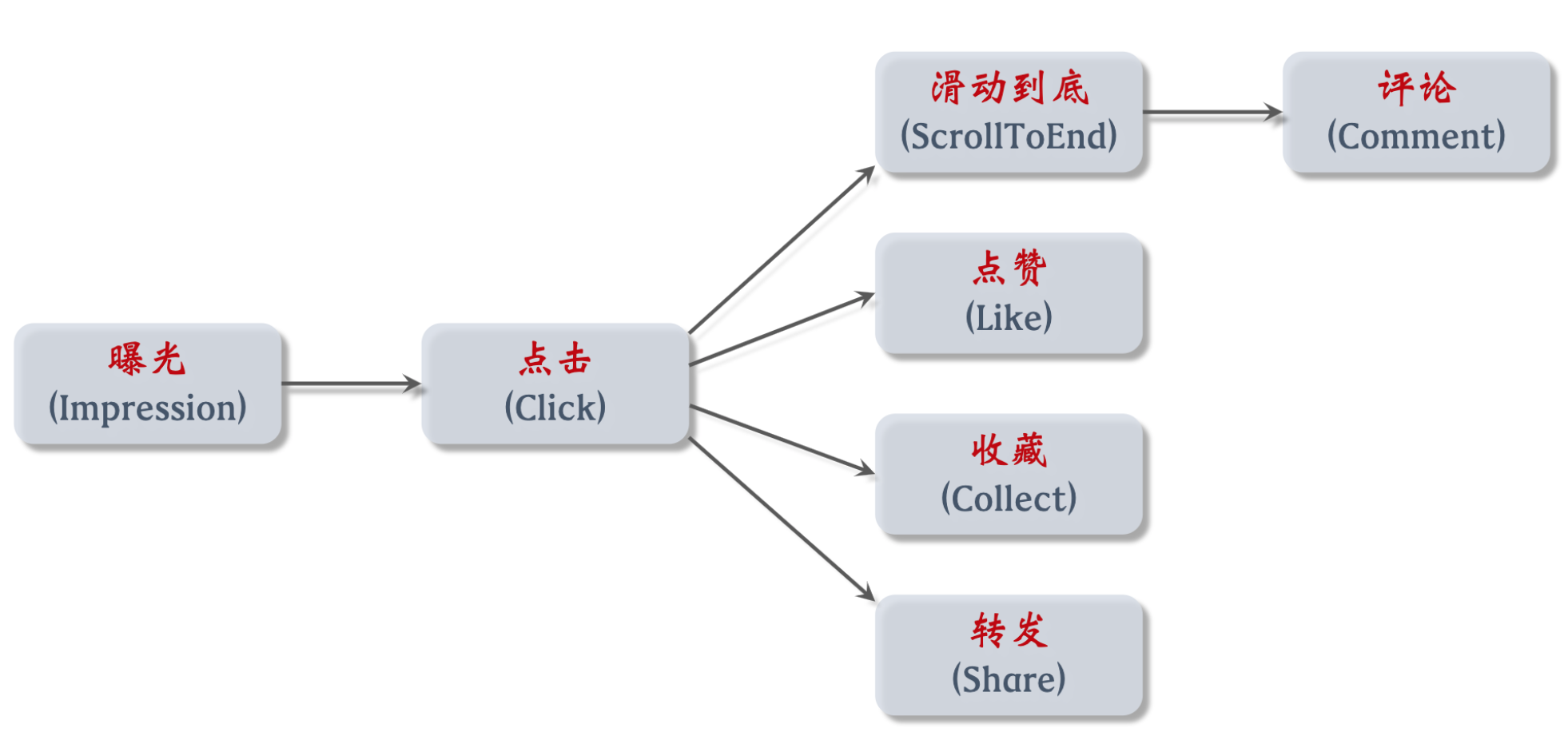
要熟悉产品转化流程,特征对建模有用,形成推荐信号
消费指标:反映用户对推荐是否满意
- 点击率 = 点击次数 / 曝光次数 —— 越高,证明推荐越精准 —— 不能仅追求它,不然都是标题党了
- 点赞率 = 点赞次数 / 点击次数
- 收藏率 = 收藏次数 / 点击次数
- 转发率 = 转发次数 / 点击次数
- 阅读完成率 = 滑动到底次数 / 点击次数 × f(笔记长度) —— f 用于归一化函数,让长笔记公平
这些都是短期消费指标,不能一味追求
因为重复推荐相似内容可以提高消费指标,但容易让用户腻歪,进而降低用户活跃度
而尝试提供多样性的内容,可以让用户发现自己新的兴趣点,提高用户粘性(但在这个过程中,消费指标可能下降)
北极星指标 —— 衡量推荐系统好坏 ,都是线上指标,只能上线了才能获得
- 用户规模:
- 日活用户数(DAU每天使用 1 次以上 +1)
- 月活用户数(MAU 每月使用 1 次以上 +1)
- 消费:
- 人均使用推荐的时长、人均阅读笔记的数量(最能反应推荐系统好坏)
- 发布:
- 发布渗透率、人均发布量 (核心竞争力,扩大内容池,由冷启动负责)
推荐链路
召回
- 快速从海量数据中取回几千个用户可能感兴趣的物品
- 从十几个召回通道选top百,几千个输出。将所有召回通道的内容融合后,会去重,并过滤(例如去掉用户不喜欢的作者的笔记,不喜欢的话题)
- 常见召回通道:协同过滤、双塔模型、等等
排序
- 粗排 (直接精排会非常耗时)
- 用小规模的模型的神经网络给召回的物品打分,然后做截断,选出分数最高的几百个物品。
- 粗排模型小,速度快;精排用的模型大,计算量大,打分更可靠
- 用粗排做筛选,再用精排 平衡计算量和准确性
- 用小规模的模型的神经网络给召回的物品打分,然后做截断,选出分数最高的几百个物品。
- 精排
- 用大规模神经网络给粗排选中的几百个物品打分,可以做截断,也可以不做截断。
重排
- 重排主要是考虑多样性,对精排结果做多样性抽样(MMR,DDP),得到几十个物品。
- 为什么不直接推荐精排结果:结果缺乏多样性
- 抽样依据:精排分数、多样性
- 还要用规则将相似的笔记打散
- 不能把内容过于相似的笔记,排在相邻的位置上 ,减少一个页面中的同质化内容
- 还得把广告插进去,根据生态要求调整排序
提升系统指标A/B test
对模型特征策略系统做改进步骤
- 离线实验 : 收集历史数据,在历史数据上做训练、测试。算法没有部署到产品中,没有跟用户交互。
- 小流量A/B test: 把算法部署到实际产品中,用户实际跟算法做交互。新旧策略对比指标 ,调整模型参数等
- 全流量上线
总结
- 分层实验:同层互斥(不允许两个实验同时影响一位用户)、不同层正交(实验有重叠的用户)
- 把容易相互增强(或抵消)的实验放在同一层,让它们的用户互斥
- Holdout:保留 10% 的用户,完全不受实验影响,可以考察整个部门对业务指标的贡献
- 实验推全:新建一个推全层,与其他层正交
- 反转实验:在新的推全层上,保留一个小的反转桶,使用旧策略。长期观测新旧策略的 diff
随机分桶
-
分 b = 10 个桶,每个桶中有 10% 的用户
-
首先用哈希函数把用户 ID 映射成某个区间内的整数,然后把这些整数均匀随机分成 b 个桶
-
全部 n 位用户,分成 b 个桶,每个桶中有 $\frac{n}{b}$ 位用户

- 计算每个桶的业务指标,比如 DAU、人均使用推荐的时长、点击率、等等
- 如果某个实验组指标显著优于对照组,则说明对应的策略有效,值得推全。
分层实验
流量不够:业务多,每个部门团队都需要做A/B test,实验组位置有限。
- 分层实验:召回、粗排、精排、重排、用户界面、广告(例如 GNN 召回通道属于召回层)
- 同层互斥(互斥可以避免同类策略相互干扰):example GNN 实验占了召回层的 4 个桶,其他召回实验只能用剩余的 6 个桶
- 不同层正交(不同类型的策略,通常不会相互干扰):每一层独立随机对用户做分桶。每一层都可以独立用 100% 的用户做实验
即 1 个用户虽然不能同时受 2 个召回实验的影响,但他可以受 1 个召回实验 + 1 个精排实验的影响,互斥可以避免同类策略相互干扰。
Holdout 机制
取 10% 的用户作为 holdout 桶,推荐系统使用剩余 90% 的用户做实验,两者互斥。
10% holdout 桶 vs 90% 实验桶的 diff(需要归一化)为整个部门的业务指标收益
holdout 桶里面不加任何新的实验,保持干净以便对照
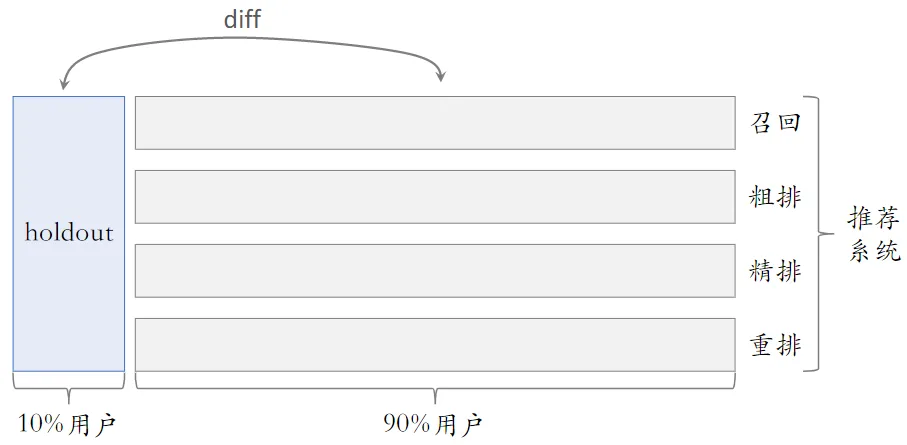
每个考核周期结束之后,清除 holdout 桶,让推全实验从 90% 用户扩大到 100% 用户
重新随机划分用户,得到 holdout 桶和实验桶,开始下一轮考核周期
新的 holdout 桶与实验桶各种业务指标的 diff 接近 0
随着召回、粗排、精排、重排实验上线和推全,diff 会逐渐扩大
反转实验
- 小流量实验观测到显著收益后尽快推全新策略。目的是腾出桶供其他实验使用,或需要基于新策略做后续的开发
- 有的指标(点击、交互)立刻受到新策略影响,有的指标(留存)有滞后性,需要长期观测
- 用反转实验解决上述矛盾,既可以尽快推全,也可以长期观测实验指标
- 新建一个推全层,与其他层正交(实验推全),在推全的新层中开一个旧策略的桶,长期观测实验指标
召回
基于物品协同过滤ItemCF
ItemCF原理:
- 如果用户喜欢物品 $item_1$ ,而且物品 $item_1$ 与 $item_2$ 相似
- 那么用户很可能喜欢物品 $item_2$
ItemCF实现
-
预估用户对候选物品的兴趣
$\sum_{j}\,l i ke\bigl(u s e r,\,i t e m_{j}\bigr)\times s i m\bigl(i t e m_{j},i t e m\bigr)$
-
从用户历史行为记录中,我们知道用户对 $item_j$ 的兴趣,还知道 $item_j$ 与候选物品的相似度
-
计算两个物品的相似度:
- 两个物品的受众重合度越高,两个物品越相似
- 计算物品相似度sim
- 把每个物品表示为一个稀疏向量,向量每个元素对应一个用户 对物品的兴趣分数,
- 相似度 sim 就是两个向量夹角的余弦
完整流程
- 事先做离线计算
- 建立“用户 → 物品”的索引
- 记录每个用户最近点击、交互过的物品 ID
- 给定任意用户 ID,可以找到他近期感兴趣的物品列表
- 建立“物品 → 物品”的索引
- 计算物品之间两两相似度
- 给定任意物品 ID,可以快速找到它最相似的 k 个物品
- 建立“用户 → 物品”的索引
- 线上做召回(索引的意义在于避免枚举所有的物品。用索引,离线计算量大,线上计算量小)
- 给定用户 ID,通过“用户 → 物品”索引,找到用户近期感兴趣的物品列表(last-n)
- 对于 last-n 列表中每个物品,通过“物品 → 物品”的索引,找到 top-k 相似物品
- 对于取回的相似物品(最多有 𝑛𝑘 个),用公式预估用户对物品的兴趣分数
- 返回分数最高的 100 个物品,作为推荐结果(如果取回的 item 中有重复的,就去重,并把分数加起来)
Swing
Swing (工业界很常用)和 ItemCF 很像,唯一区别在于如何定义相似度
ItemCF 的不足之处:重合用户是小圈子的话,可能造成不相关的物品,相似度很高。
- 降低小圈子用户的权重
- 大量不相关的用户同时交互两个物品,则说明两个物品的受众真的相同
计算
- 用户 u_1 喜欢的物品记作集合 $\mathcal{J}_1$
- 用户 u_2 喜欢的物品记作集合 $\mathcal{J}_2$
- 定义两个用户的重合度: $overlap(u_1,u_2)=|\mathcal{J}_1\cap\mathcal{J}_2|$
- 用户 $u_1$ 和 $u_2$ 的重合度高,则他们可能来自一个小圈子,要降低他们的权重
- 喜欢物品 $i_1$ 的用户记作集合 $\mathcal{W}_1$
- 喜欢物品 $i_2$ 的用户记作集合 $\mathcal{W}_2$
- 定义交集 $\mathcal{V}=\mathcal{W}_1\cap\mathcal{W}_2$
-
两个物品的相似度:$sim(i_1,i_2)=\sum_{u_1\in \mathcal{V}}\sum_{u_2\in \mathcal{V}}\frac{1}{α+overlap(u_1,u_2)}$
- $α$ 是超参数
- $overlap(u_1,u_2)$ 表示两个用户的重合度
- 重合度高,说明两人是一个小圈子的,那么他两对物品相似度的贡献就比较小
- 重合度小,两人不是一个小圈子的,他两对物品相似度的贡献就比较大
基于用户的协同过滤(UserCF)
UserCF原理:
-
如果用户 $user_1$ 跟用户 $user_2$ 相似,而且 $user_2$ 喜欢某物品
-
那么用户 $user_1$ 也很可能喜欢该物品
其他和itemCF 差不多
-
用户 $u_1$ 喜欢的物品记作集合 $\mathcal{J}_1$
-
用户 $u_2$ 喜欢的物品记作集合 $\mathcal{J}_2$
-
定义交集 $I=\mathcal{J}_1\cap\mathcal{J}_2$
-
两个用户的相似度: $sim(u_1,u_2)=\frac{|I|}{\sqrt{|\mathcal{J}_1|·|\mathcal{J}_2|}}$
越热门的物品,越无法反映用户独特的兴趣,对计算用户相似度越没有价值
-
降低热门物品权重后:$sim(u_1,u_2)=\frac \frac{1}{\log{(1+n_l)}}}}{\sqrt{ \mathcal{J}_1 · \mathcal{J}_2 }}$ - $n_l$:喜欢物品 $l$ 的用户数量,反映物品的热门程度
- 物品越热门,$\frac{1}{\log{(1+n_l)}}$ 越小,对相似度的贡献就越小
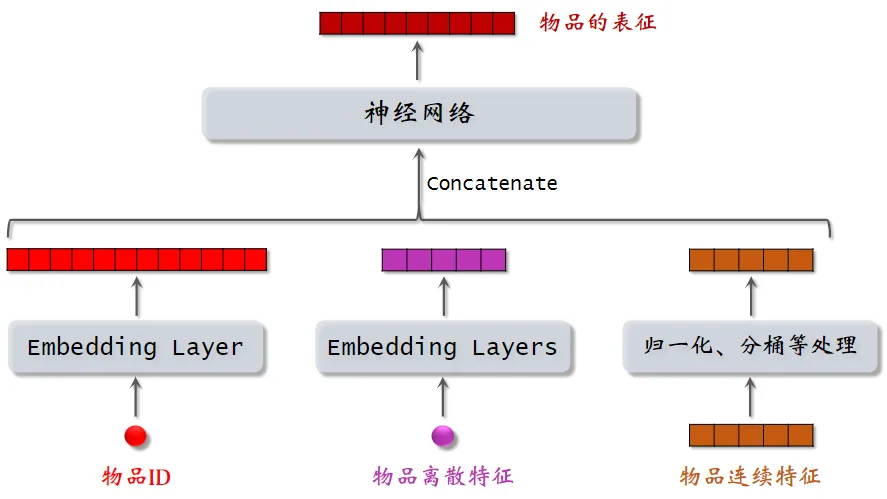
离散特征处理
离散特征处理的步骤
向量化:把序号映射成向量
- One-hot 编码:把序号映射成高维稀疏向量(向量中只有 0,1)类别数量太大时,通常不用 one-hot 编码
- Embedding:把序号映射成低维稠密向量(向量中有小数)
knn
衡量最近邻的标准:
-
欧式距离最小(L2 距离)
- 向量内积最大(内积相似度)
- 矩阵补充用的就是内积相似度
- 向量夹角余弦最大(cosine 相似度)
- 最常用
- 对于不支持的系统:把所有向量作归一化(让它们的二范数等于 1),此时内积就等于余弦相似度
数据预处理
- 所有物品embeding化,把数据据划分为多个区域
- 划分后,每个区域用一个向量表示,这些向量的长度都是 1
- 直至每个区域都用一个单位向量来表示,这些单位向量又称为 索引向量 (一般情况是几亿个物品被几万个索引向量划分,于是一个区域中就只有几万个物品)
实际推荐时
- 先把用户向量 $\bold{a}$与所有的索引向量做对比
- 计算相似度,找到最相似的索引向量
- 通过索引向量,我们找到索引对应区域中的所有物品,然后再计算该区域中所有物品与 $\bold{a}$ 的相似度
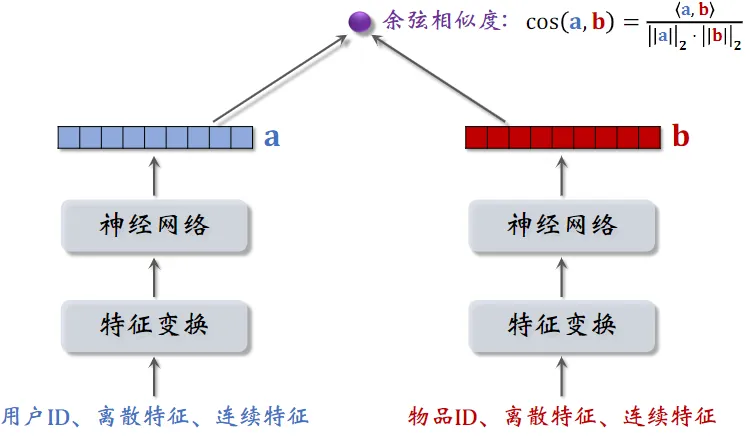
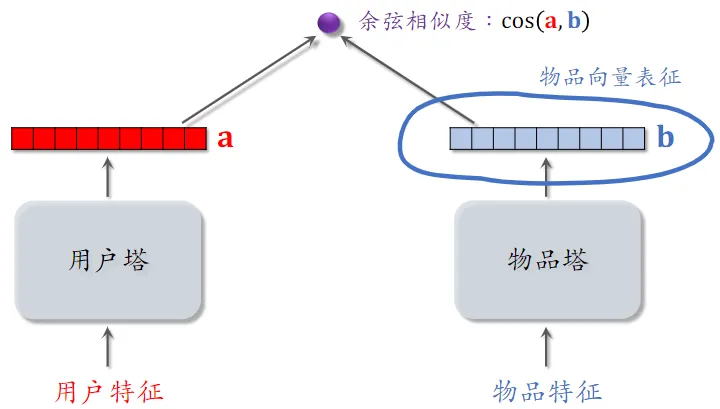
双塔模型
双塔模型:预估用户对物品兴趣
左塔提取用户特征,右塔提取物品特征
与矩阵补充的区别在于,使用了除 ID 外的多种特征作为双塔的输入
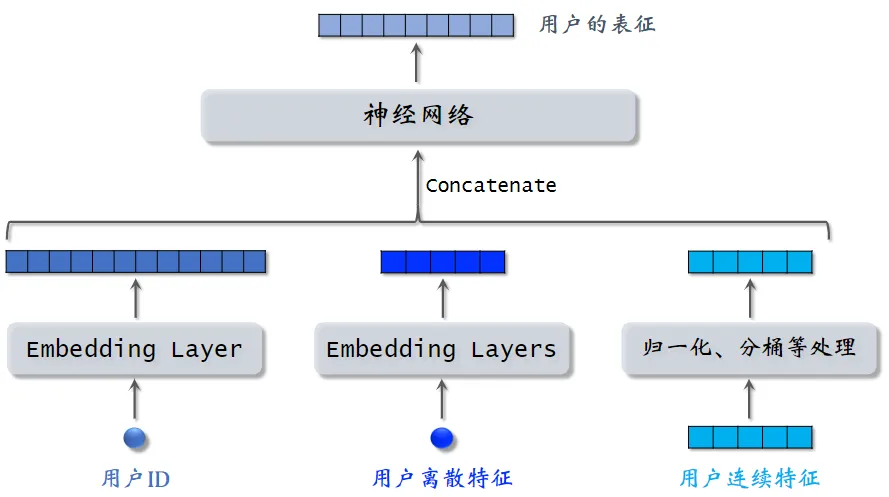
用户离散特征:例如所在城市、感兴趣的话题等
-
对每个离散特征,单独使用一个 Embedding 层得到一个向量
-
对于性别这种类别很少的离散特征,直接用 one-hot 编码
用户连续特征:年龄、活跃程度、消费金额等,不同特征不同处理常用归一化(均值为0、方差1),长尾(log,分桶),各指标处于同一数量级,适合进行综合对比评价。
正负样本选择
参考
- Embedding-based Retrieval in Facebook Search
- Sampling-bias-corrected neural modeling for large corpus item recommendations
正样本:曝光而且有点击的
用户—物品 二元组(用户对物品感兴趣)
- 少部分物品占据大部分点击,导致正样本大多是热门物品
- 解决方案:过采样冷门物品,或降采样热门物品
- 过采样(up-sampling):一个样本出现多次
- 降采样(down-sampling):一些样本被抛弃 (以一定概率抛弃热门物品,抛弃的概率与样本的点击次数正相关)

负样本
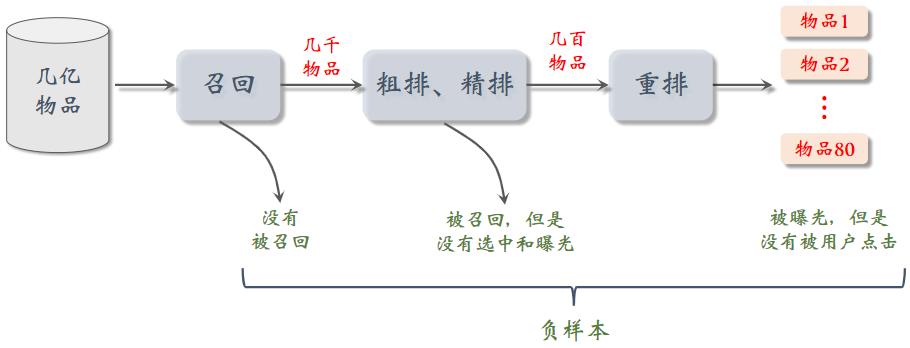
简单负样本 未被召回的物品
抽样
大概率是用户不感兴趣的,几亿物品只有几千个召回≈ 全体物品
从全体物品中做抽样,作为负样本就可以了
- 均匀抽样 or 非均匀抽样
均匀抽样,对冷门物品不公平
- 热门冷门二八分,均匀抽样产生的负样本中,大多是冷门物品。只会是冷门更冷,热门更热。
非均抽采样:目的是打压热门物品
-
抽样概率与热门程度(点击次数)正相关
-
$抽样概率 ∝ (点击次数)^{0.75}$,热门物品被抽到的概率降低
batch 内负样本
- 一个 batch 内有 n 个正样本
- 一个用户和 n-1 个物品组成负样本
- 这个 batch 内一共有 n(n-1) 个负样本
- 都是简单负样本。(因为第一个用户不喜欢第二个物品)
存在的问题
- 一个物品出现在 batch 内的$概率 ∝ 点击次数$,而不是 $∝ (点击次数)^{0.75}$,热门物品成为负样本的概率过大
修正偏差:
-
物品 i 被抽样到的概率:$p_i ∝ 点击次数$
- 预估用户对物品 i 的兴趣:$\cos{(\bold{a},\bold{b}_i)}$
- 做训练的时候,将兴趣调整为:$\cos{(\bold{a},\bold{b}_i)}-\log{p_i}$
- 这样纠偏,避免过度打压热门物品 ($p_i$越小,$-\log{p_i}$越大)
- 训练结束后,在线上做召回时,还是用 $\cos{(\bold{a},\bold{b}_i)}$ 作为兴趣
困难负样本 召回但是被粗排、精排淘汰的
困难指的是容易被分成正的。
被粗排淘汰的物品(比较困难)
- 这些物品被召回,说明和用户兴趣有关;又被粗排淘汰,说明用户对物品兴趣不大
- 而在对正负样本做二元分类时,这些困难样本容易被分错(被错误判定为正样本)
精排分数靠后的物品(非常困难)
- 能够进入精排,说明物品比较符合用户兴趣,但不是用户最感兴趣的
对正负样本做二元分类:
-
全体物品(简单)分类准确率高
- 被粗排淘汰的物品(比较困难)容易分错
- 精排分数靠后的物品(非常困难)更容易分错
训练数据
-
混合几种负样本
- 50% 的负样本是全体物品(简单负样本)
- 50% 的负样本是没通过排序的物品(困难负样本)
- 即在粗排、精排淘汰的物品
曝光但是未点击的, 不能作为负样本
训练召回模型不能用这种样本作为负样本,排序模型可以。
召回的目标:快速找到用户可能感兴趣的物品:重点是快速,不需要分太细,召回是尽可能把有兴趣的挑出来。
- 即区分用户 不感兴趣 和 可能感兴趣 的物品
- 而不是区分 比较感兴趣 和 非常感兴趣 的物品
使用有曝光没点击,作为负样本,召回效果会变差。
- 全体物品(easy ):绝大多数是用户根本不感兴趣的
- 被排序淘汰(hard ):用户可能感兴趣,但是不够感兴趣
- 有曝光没点击(没用):用户感兴趣,可能碰巧没有点击
- 曝光没点击的物品已经非常符合用户兴趣了,甚至可以拿来做召回的正样本
- 可以作为排序的负样本,不能作为召回的负样本
双塔训练
Pointwise:独立看待每个正样本、负样本,做简单的二元分类 (常用)
Pairwise:每次取一个正样本、一个负样本
Listwise:每次取一个正样本、多个负样
Pointwise训练
- 把召回看做二元分类任务
- 对于正样本,鼓励 $\cos{(\bold{a},\bold{b})}$ 接近 +1
- 对于负样本,鼓励 $\cos{(\bold{a},\bold{b})}$ 接近 −1
- 控制正负样本数量为 1: 2 或者 1: 3
Pairwise训练
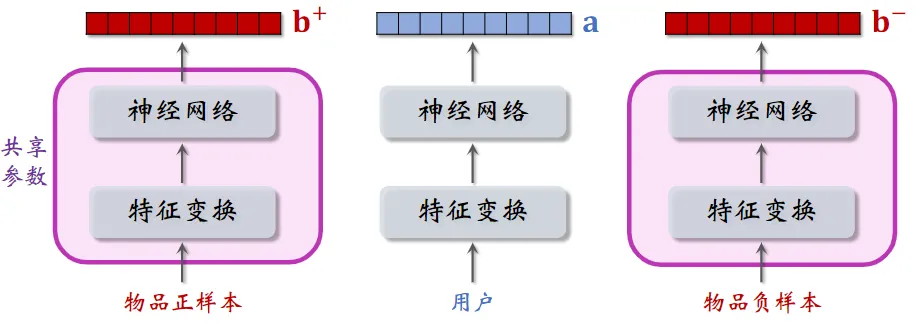
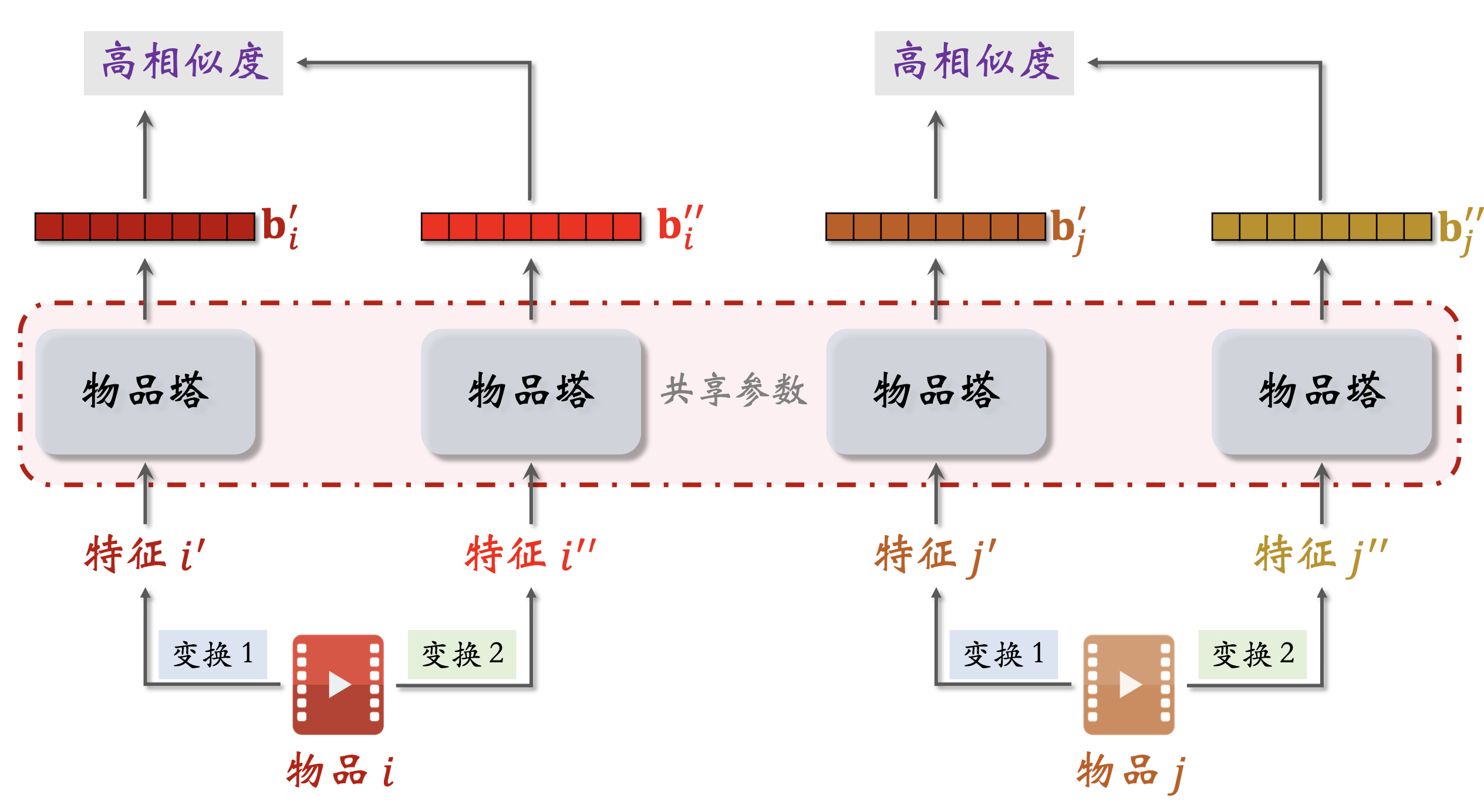
两个物品塔是相同的,它们共享参数
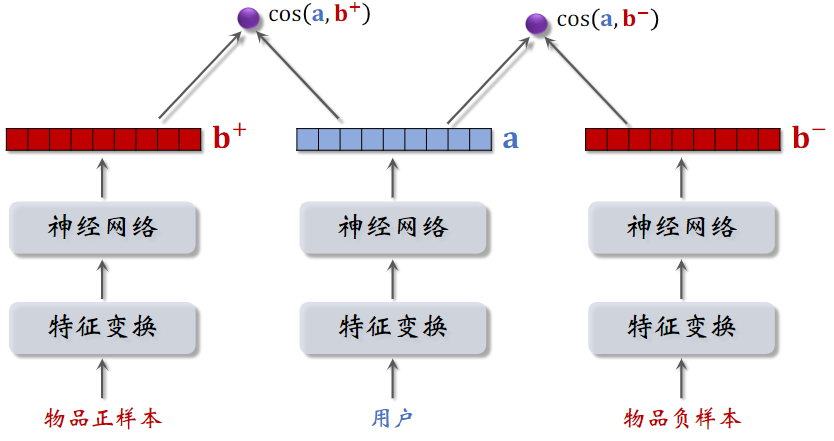
- 基本想法:鼓励 $\cos{(\bold{a},\bold{b}^+)}$ 大于 $\cos{(\bold{a},\bold{b}^-)}$, 两者相差大
- 如果 $\cos{(\bold{a},\bold{b}^+)} 大于 \cos{(\bold{a},\bold{b}^-)}+m$,则没有损失
- m 是超参数,需要调
- 否则,损失等于 $\cos{(\bold{a},\bold{b}^-)}+m-\cos{(\bold{a},\bold{b}^+)}$
- 如果 $\cos{(\bold{a},\bold{b}^+)} 大于 \cos{(\bold{a},\bold{b}^-)}+m$,则没有损失
- Triplet hinge loss: $L(\bold{a},\bold{b}^+,\bold{b}^-)=\max{{ 0,\cos{(\bold{a},\bold{b}^-)}+m-\cos{(\bold{a},\bold{b}^+)}}}$
- Triplet logistic loss:
-
$L(\bold{a},\bold{b}^+,\bold{b}^-)=\log{( 1+\exp{[\sigma·(\cos{(\bold{a},\bold{b}^-)}-\cos{(\bold{a},\bold{b}^+))}])}}$
-
$\sigma$ 是大于 0 的超参数,控制损失函数的形状,需手动设置
-
Listwise训练
-
一条数据包含:
- 一个用户,特征向量记作 $\bold{a}$
- 一个正样本,特征向量记作 $\bold{b}^+$
- 多个负样本,特征向量记作 $\bold{b}^-_1,…,\bold{b}^-_n$
- 鼓励 $\cos{(\bold{a},\bold{b}^+)}$ 尽量大,接近1
- 鼓励 $\cos{(\bold{a},\bold{b}^-_1)},…,\cos{(\bold{a},\bold{b}^-_n)}$ 尽量小,接近-1
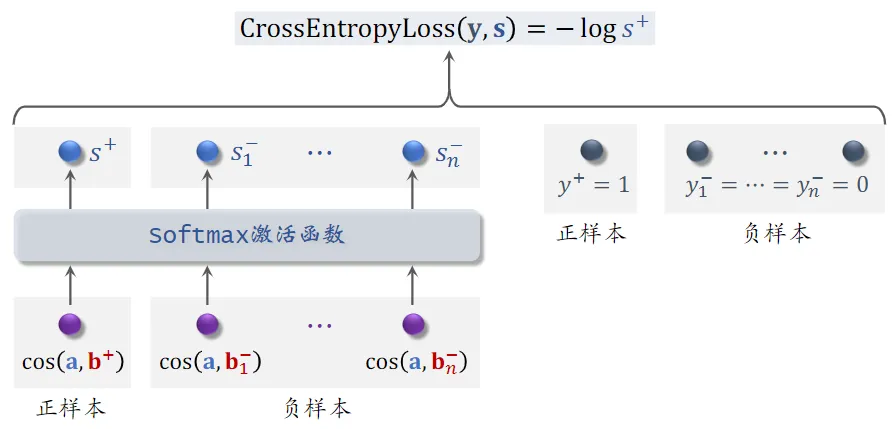
- 正样本 $y^+=1$,即鼓励 $s^+$ 趋于 1
- 负样本 $y^-_1=…=y^-_n=0$,即鼓励 $s^-_1…s^-_n$ 趋于 0
- 用 $y$ 和 $s$ 的交叉熵作为损失函数,意思是鼓励 $\rm Softmax$ 的输出 $s$ 接近标签 $y$
双塔总结
用户塔、物品塔各输出一个向量
两个向量的余弦相似度作为兴趣的预估值
三种训练方式:
- Pointwise:每次用一个用户、一个物品(可正可负)
- Pairwise:每次用一个用户、一个正样本、一个负样本
- Listwise:每次用一个用户、一个正样本、多个负样本
不适用于召回的模型
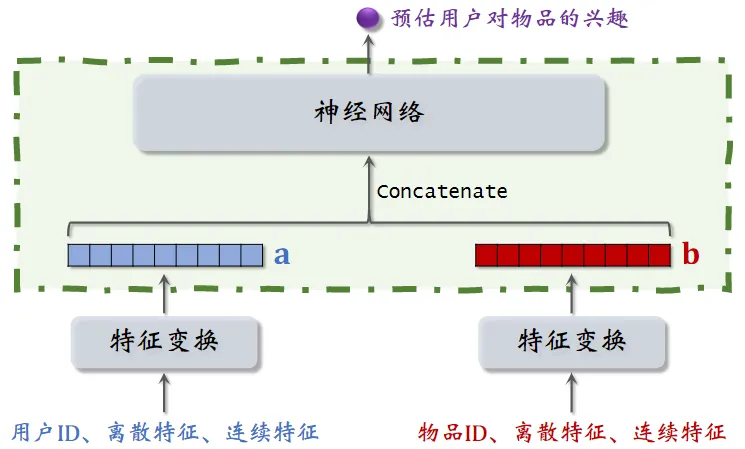
用户和物品的向量在进入神经网络前就拼接起来了,和双塔模型有很大区别
-
双塔模型是在后期输出相似度时才进行融合
-
用户(或物品)自身特征的拼接没有影响,依然保持了用户(或物品)的独立性
- 而一旦用户和物品进行拼接,此时的输出就特定于该 用户(或物品)了
这种前期融合的模型,不适用于召回
- 因为得在召回前,把每个用户向量对应的所有物品向量挨个拼接了送入神经网络
- 假设有一亿个物品,每给用户做一次召回,就得跑一亿遍
这种模型通常用于排序,在几千个候选物品中选出几百个,这样计算量不大。 以后看到这种模型就要意识到 —— 这是排序模型,不是召回模型
线上召回
双塔模型的召回
离线存储
- 完成训练之后,用物品塔计算每个物品的特征向量 $\bold{b}$,
- 然后存入向量数据库, 向量数据库建索引,以便加速最近邻查找
- 为什么离线计算
- 几亿物品向量 $\bold{b}$(线上算物品向量的代价过大)
线上召回:查找用户最感兴趣的 k 个物品
-
给定用户 ID 和画像,线上用神经网络现算(实时计算)用户向量 $\bold{a}$
-
把向量 $\bold{a}$ 作为 query,调用向量数据库做最近邻查找
-
返回余弦相似度最大的 k 个物品,作为召回结果
-
为什么线上计算
- 用户兴趣动态变化,而物品特征相对稳定
模型更新
全量更新:今天凌晨,用昨天全天的数据训练模型
- 在昨天模型参数的基础上做训练(不是重新随机初始化),
- 用昨天的数据random shuffle,训练 1 epoch,即每天数据只用一遍(因为数据量够大 多个epoch还会有过拟合风险)
- 发布新的 用户塔神经网络 和 物品向量,供线上召回使用
- 全量更新对数据流、系统的要求比较低
增量更新:做 online learning 更新模型参数,基于最新的全量更新做min级别的增量更新。
- 用户兴趣会随时发生变化
- 实时收集线上数据,做流式处理,生成 TFRecord 文件
- 对模型做 online learning,增量更新 ID Embedding 参数(不更新神经网络其他部分的参数)
- 即锁住全连接层的参数,只更新 Embedding 层的参数,这是出于工程实现的考量
- 发布用户 ID Embedding,供用户塔在线上计算用户向量
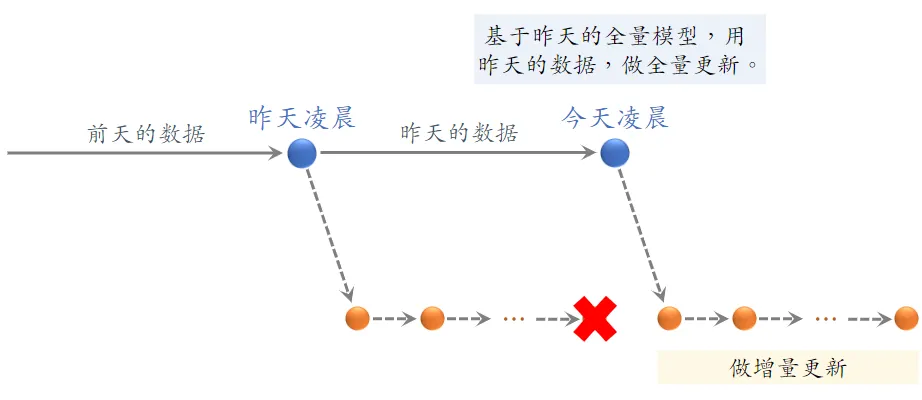
why 全量,增量都要,不能只要增量。
在不同时间段,用户行为不一样,这和全体数据的统计值差别很大
-
小时级数据有偏,分钟级数据偏差更大:在不同时间段,用户行为不一样,这和全体数据的统计值差别很大
- 全量更新:random shuffle,消除了不同时间段的差别
- 增量更新:按照数据从早到晚的顺序,做 1 epoch 训练
- 随机打乱优于按顺序排列数据,全量训练优于增量训练
更新模型
-
全量更新:今天凌晨,用昨天的数据训练整个神经网络,做 1 epoch 的随机梯度下降
-
增量更新:用实时数据训练神经网络,只更新 ID Embedding,锁住全连接层
实际的系统:
- 全量更新 & 增量更新 相结合
- 每隔几十分钟,发布最新的用户 ID Embedding,供用户塔在线上计算用户向量
改进双塔模型 针对物品塔优化
推荐系统的头部效应严重:
- 少部分物品占据大部分点击。
- 大部分物品的点击次数不高
- 高点击物品的表征学得好,长尾物品的表征学得不好。
自监督学习:做 data augmentation,更好地学习长尾物品的向量表征。
同一个物品的不同特征使用同一个物品塔相似度大,不同物品的相似度小。

特征变化
- Random Mask
- 随机选一些离散特征(比如类目),把它们遮住。
- 某物品的类目特征是 𝒰 = 数码, 摄影
- Mask 后的类目特征是 𝒰 = default 。
- Dropout(仅对多值离散特征生效)
- 一个物品有多个类目,类目是一个多值离散特征,Dropout:随机丢弃特征中 50% 的值
- 某物品的类目特征是 𝒰 = 美妆, 摄影 。
- Dropout 后的类目特征是 𝒰= 美妆 。
- 互补特征(complementary)
- 物品一共有 4 种特征 ID,类目,关键词,城市
- 随机分成两组 {ID,关键词} 和 {类目,城市}
- { default,类目,default,城市 }, { ID,default,关键词,default } 鼓励两个向量相似
实验效果:低曝光物品、新物品的推荐变得更准
Deep Retrieval
经典的双塔模型把用户、物品表示为向量,线上做最近邻 查找
Deep Retrieval 把物品表征为路径(path),线上查找 用户最匹配的路径
其他召回通道
这 6 条召回通道都是工业界在用的,只是它们的重要性比不上 ItemCF、Swing、双塔那些通道。
地理位置召回
GeoHash 召回,同城召回
-
用户可能对附近发生的事感兴趣
- GeoHash:对经纬度的编码,大致表示地图上一个长方形区域
- 索引:GeoHash → 优质笔记列表(按时间倒排)
- 根据用户定位的 GeoHash,取回该地点最新的 k 篇优质笔记
- 这条召回通道没有个性化
作者召回
关注作者召回
-
用户对关注的作者发布的笔记感兴趣
- 索引:
- 用户 → 关注的作者
- 作者 → 发布的笔记
- 召回:
- 用户 → 关注的作者 → 最新的笔记
有交互的作者召回
-
如果用户对某笔记感兴趣(点赞、收藏、转发),那么用户可能对该作者的其他笔记感兴趣
-
索引: 用户 → 有交互的作者
- 作者列表需要定期更新,加入最新交互的作者,删除长期未交互的作者
-
召回: 用户 → 有交互的作者 → 最新的笔记
相似作者召回
-
如果用户喜欢某作者,那么用户喜欢相似的作者
- 索引:作者 → 相似作者(k 个作者)
- 作者相似度的计算类似于 ItemCF 中判断两个物品的相似度
- 例如两个作者的粉丝有很大重合,则认定两个作者相似
- 召回:用户 → 感兴趣的作者 → 相似作者 → 最新的笔记 (n 个作者) (nk 个作者)(nk 篇笔记)
缓存召回
缓存召回
-
想法:复用前 n 次推荐精排的结果
- 背景:
- 精排输出几百篇笔记,送入重排
- 重排做多样性抽样,选出几十篇
- 精排结果一大半没有曝光,被浪费
- 精排前 50,但是没有曝光的,缓存起来,作为一条召回通道
缓存大小固定,需要退场机制
- 一旦笔记成功曝光,就从缓存退场
- 如果超出缓存大小,就FIFO笔记
- 笔记最多被召回 10 次,达到 10 次就退场
- 每篇笔记最多保存 3 天,达到 3 天就退场
曝光过滤
在召回阶段做,不一定所有推荐都会有这个
如果用户看过某个物品,则不再把该物品曝光给该用户
对于每个用户,记录已经曝光给他的物品。
对于每个召回的物品,判断它是否已经给该用户曝光过, 排除掉曾经曝光过的物品
一位用户看过 𝑛 个物品,本次召回 𝑟 个物品,如果暴力对 比,需要 𝑂(nr) 的时间,需要bloom
- Bloom filter 判断一个物品 ID 是否在已曝光的物品集合中
- no,那么该物品一定不在集合中
- yes,那么该物品很可能在集合中(可能误伤, 错误判断未曝光物品为已曝光,将其过滤掉。)
-
Bloom filter 把物品集合表征为一个 𝑚 维二进制向量。
-
每个用户有一个曝光物品的集合,表征为一个向量,需要 𝑚 bit 的存储。
- Bloom filter 有 𝑘 个哈希函数,每个哈希函数把物品 ID 映射成介于 0 和 𝑚 − 1 之间的整数。
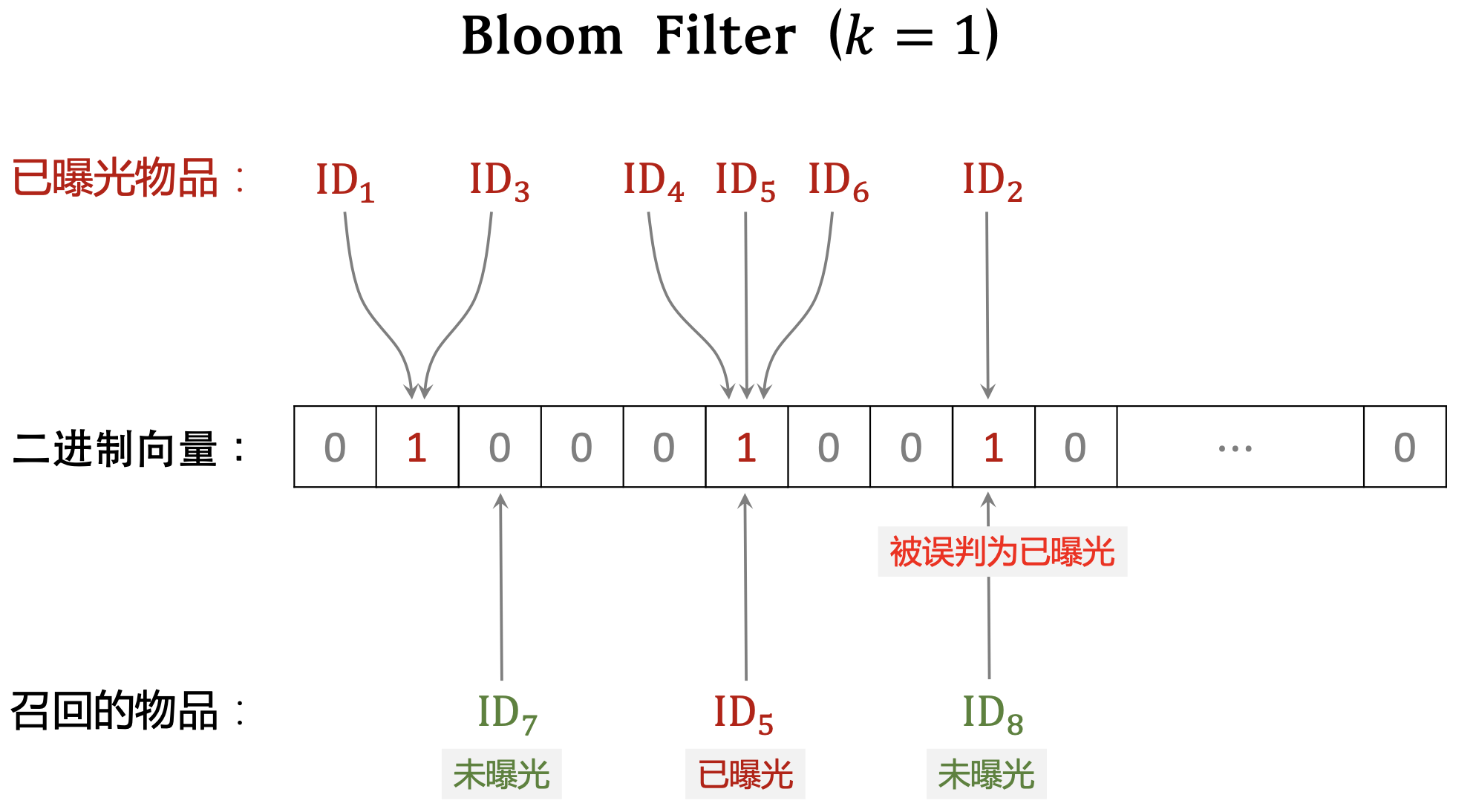
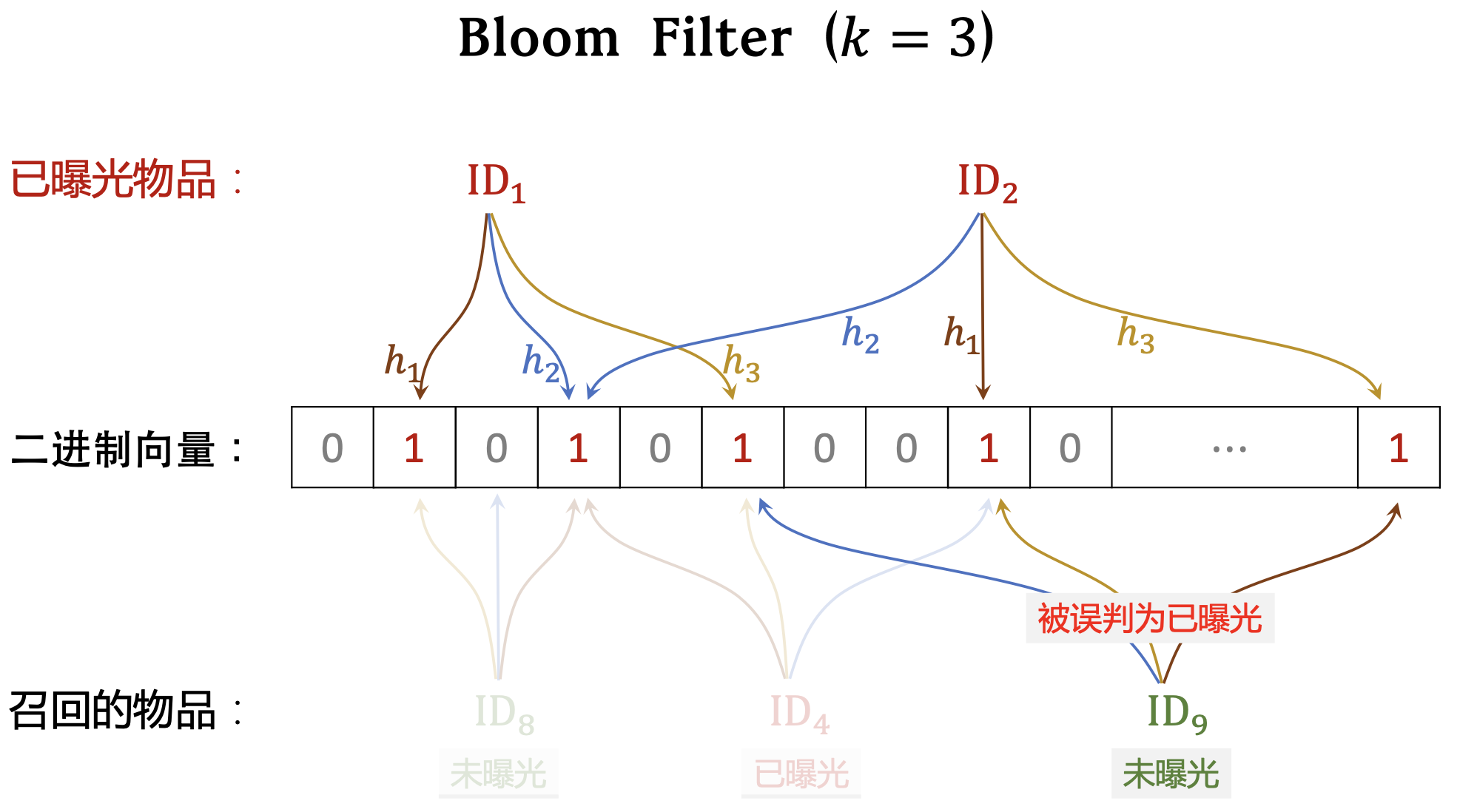
曝光物品集合大小为 𝑛,二进制向量维度为 𝑚,使用 𝑘 个哈 希函数。
- 𝑛 越大,向量中的 1 越多,误伤概率越大。(未曝光物品的 𝑘 个位置恰好都是 1 的概率大。)
- 𝑚 越大,向量越长,越不容易发生哈希碰撞。
- 𝑘 太大、太小都不好, 𝑘 有最优取值。

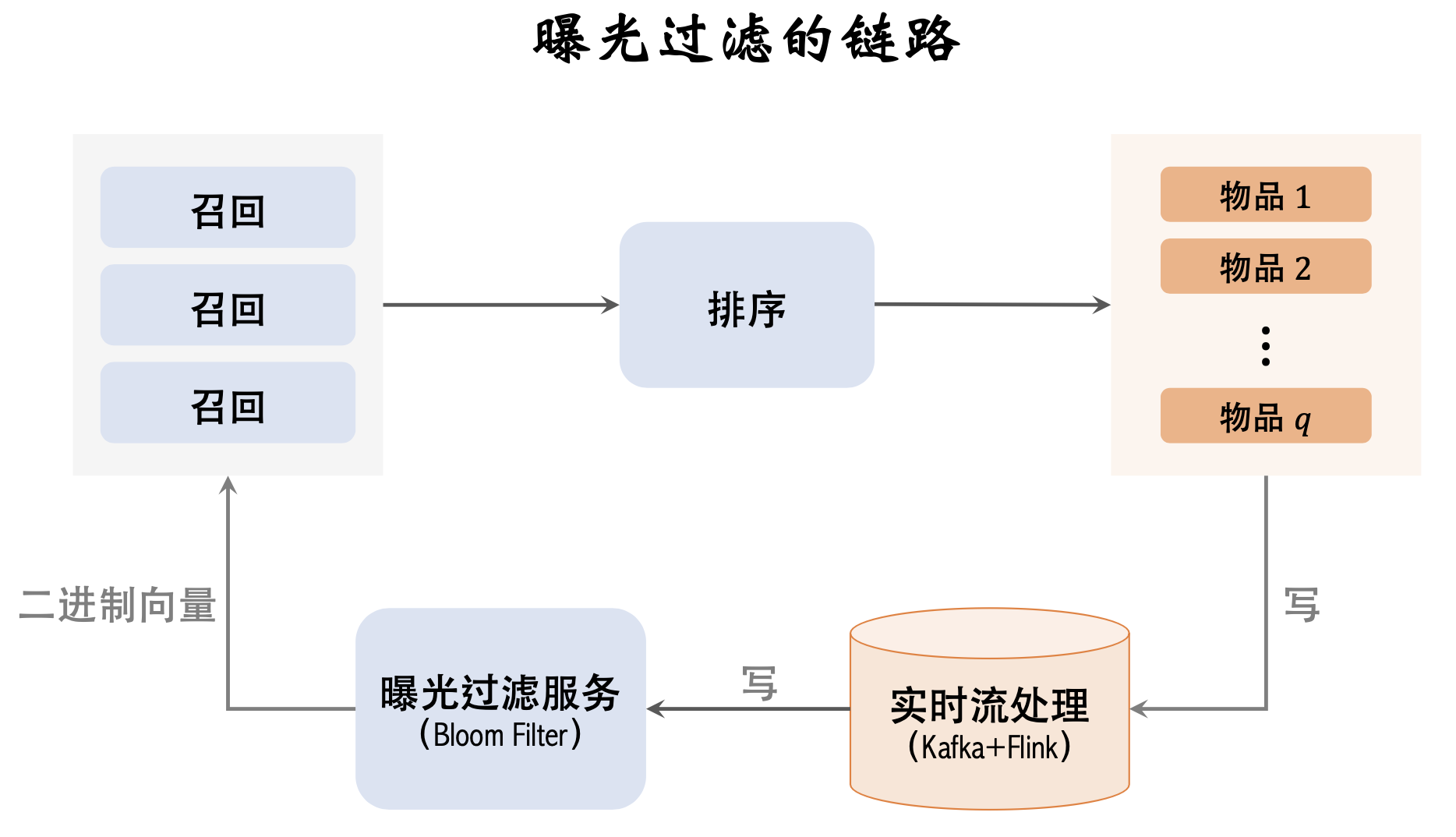
下面部分是曝光链路
记录曝光物品 ,更新bloom filter, 用于曝光过滤
- 记录曝光物品,必须要快(用户推荐页刷新快,要赶在下一刷前更新到bloom filter,所以做实时流处理)
- flink计算hash,更新到bloom filter
- 召回服务器计算物品hash,和bloom filter对比
缺点
- Bloom filter 只支持添加物品,不支持删除物品。想要删除得重新计算整个向量。
- 不能直接把物品对应的k个元素直接从1改成0,会影响其他物品。因为向量元素是所有物品共享的,改动会相当于移除其他物品
- 每天都需要从物品集合中移除年龄太大的物品(降低n,减少误伤)
排序
集中在粗排和精排,它们的原理基本相同。
排序的主要依据是用户对笔记的兴趣,而兴趣都反映在 用户—笔记 的交互中
对于每篇笔记,系统记录:
-
曝光次数(number of impressions)
-
点击次数(number of clicks)
-
点赞次数(number of likes)
-
收藏次数(number of collects)
-
转发次数(number of shares)
点击率 = 点击次数 / 曝光次数
点赞率 = 点赞次数 / 点击次数
收藏率 = 收藏次数 / 点击次数
转发率 = 转发次数 / 点击次数
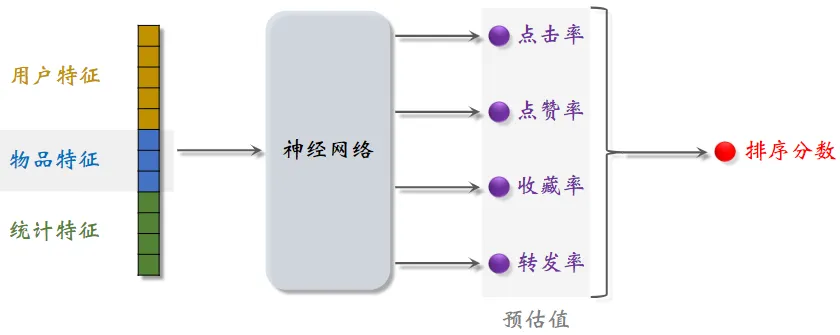
排序的依据
-
排序模型预估点击率、点赞率、收藏率、转发率等多种分数
-
融合这些预估分数(比如加权和)
-
根据融合的分数做排序、截断
多目标排序模型
sigmoid输出的值介于0~1之间,表示点击率
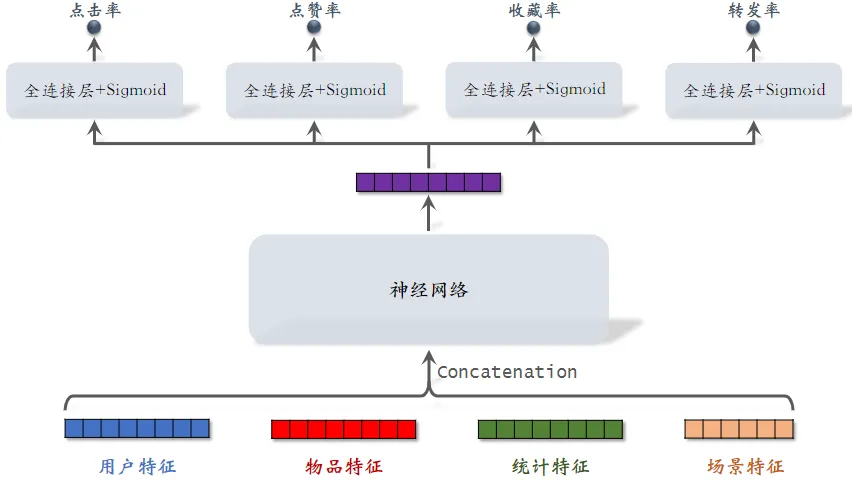
-
统计特征包括”用户统计特征”和”物品统计特征”
-
“场景特征” 是随着用户请求传过来的

训练:让预估值接近真实目标值
- 总的损失函数:
- 对损失函数求梯度,做梯度下降更新参数
困难:类别不平衡,即正样本数量显著少于负样本
- 每 100 次曝光,约有 10 次点击、90 次无点击
- 每 100 次点击,约有 10 次收藏、90 次无收藏
解决方案:负样本降采样(down-sampling)
- 保留一小部分负样本
- 让正负样本数量平衡,节约计算量
预估值校准
做完校准,才用来排序
- 如果单目标,降采样后的各个物品点击率相对顺序是不变的,不做校准也可以
- 在多任务目标下需要一个统一的量纲所以要校准
做了降采样后训练出的预估点击率会大于真实点击率。
-
正样本、负样本数量为
和
-
对负样本做降采样,抛弃一部分负样本
-
使用
个负样本,
是采样率
-
由于负样本变少,预估点击率大于真实点击率 (a越少,负样本越小,模型越高估点击率)
-
校准公式:
-
真实点击率:
(期望)
-
预估点击率:
(期望)
-
由上面两个等式可得校准公式:
Multi-gate Mixture-of-Experts (MMoE) 专家神经网络
Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
并不一定用上 MMoE 就一定有提升。造成的原因可能是实现不够好或不适用于特定业务。
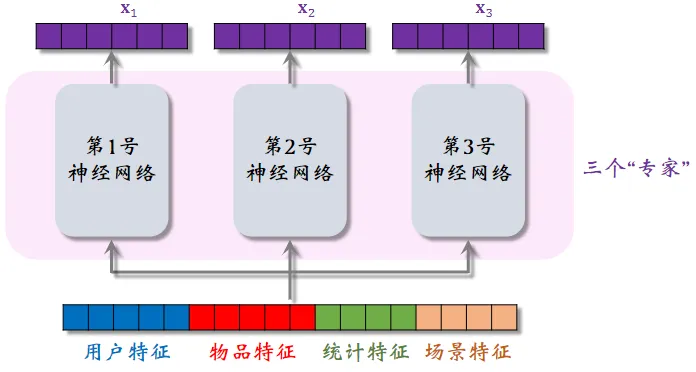
若干个神经网络结构相同,但是不共享参数。专家神经网络的数量是超参数,实践中通常用 4 个或 8 个
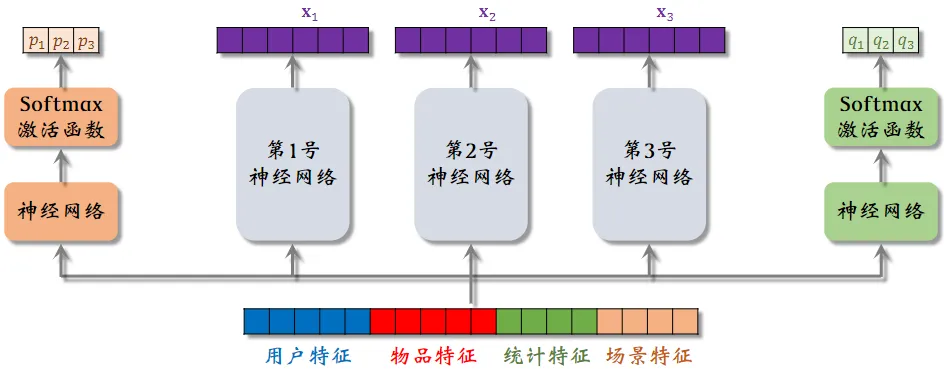
把特征向量输入左侧的神经网络,再通过 Softmax 输出 分别对应 3 个专家神经网络 (Softmax 结果相加等于1)
用 作为权重,对 3 个专家神经网络的输出
进行加权平均 (一组神经网络就是一个目标)
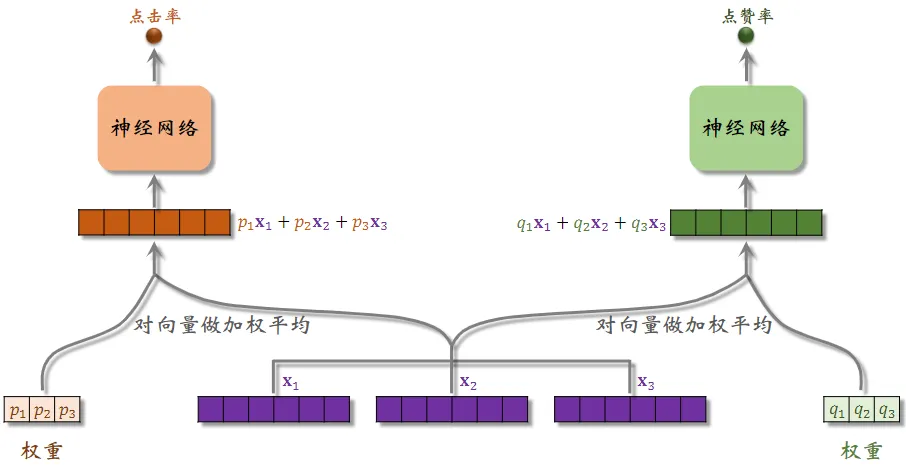
极化现象(Polarization)
专家神经网络在实践中的问题。
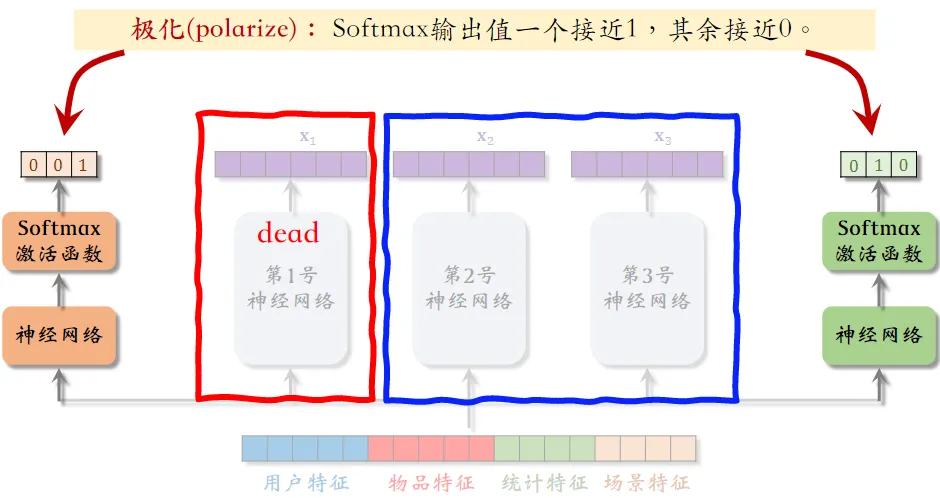
- 如果有
个“专家”,那么每个 softmax 的输入和输出都是
- 在训练时,对 softmax 的输出使用 dropout
- Softmax 输出的
- 每个“专家”被随机丢弃的概率都是 10% , 由于每个“专家”都可能被丢弃,神经网络就会尽量避免极化的发生
- Softmax 输出的
预估分数的融合
简单的加权和
- $p_{click}+w_1·p_{like}+w_2·p_{collect}+…$
点击率乘以其他项的加权和
- $p_{click}·(1+w_1·p_{like}+w_2·p_{collect}+…)$
-
$p_{click}=\frac{#点击}{#曝光}$,$p_{like}=\frac{#点赞}{#点击}$
- 所以 $p_{click}·p_{like}=\frac{#点赞}{#曝光}$
海外某短视频 APP 的融分公式
- $(1+w_{1}\cdot p_{time})^{\alpha_{1}}\ \cdot\ \ (1+w_{2}\cdot p_{like})^{\alpha_{2}}\ \cdots$
- $p_{time}$ 预估短视频观看时长
国内某短视频 APP (老铁)的融分公式
- 根据预估时长 $p_{time}$,对 $n$ 篇候选视频做排序
- 如果某视频排名第 $r_{time}$,则它得分 $\frac{1}{r^\alpha _{time} +\beta}$
- 对点击、点赞、转发、评论等预估分数做类似处理
- 最终融合分数: $\frac{w_{1}}{r_{\mathrm{time}}^{\alpha_{1}}+\beta_{1}}\ +\ \frac{w_{2}}{r_{\mathrm{click}}^{\alpha_{2}}+\beta_{2}}\ +\ \frac{w_{3}}{r_{\mathrm{like}}^{\alpha_{3}}+\beta_{3}}\ +\ \cdots$
- 公式特点在于 —— 使用预估的排名
某电商的融分公式
- 电商的转化流程:曝光 → 点击 → 加购物车 → 付款
- 模型预估:$p_{click}$、$p_{cart}$、$p_{pay}$
- 最终融合分数: $p_{\mathrm{cilck}}^{\alpha_{1}}\ \times\ \ p_{\mathrm{cart}}^{\alpha_{2}}\ \times\ \ p_{\mathrm{pay}}^{\alpha_{3}}\ \times\ \mathrm{price}^{\alpha_{4}}$
- 假如 $\alpha_{1}=\alpha_{2}=\alpha_{3}=\alpha_{4}=1$ 那该公式就是电商的营收,有明确的物理意义
视频排序
视频排序依据
图文 vs. 视频
-
图文笔记排序的主要依据:点击、点赞、收藏、转发、评论
-
视频排序的依据还有播放时长和完播
- 对于视频来说,播放时长与完播的重要性大于点击
直接用回归拟合播放时长效果不好。建议用 YouTube 的时长建模
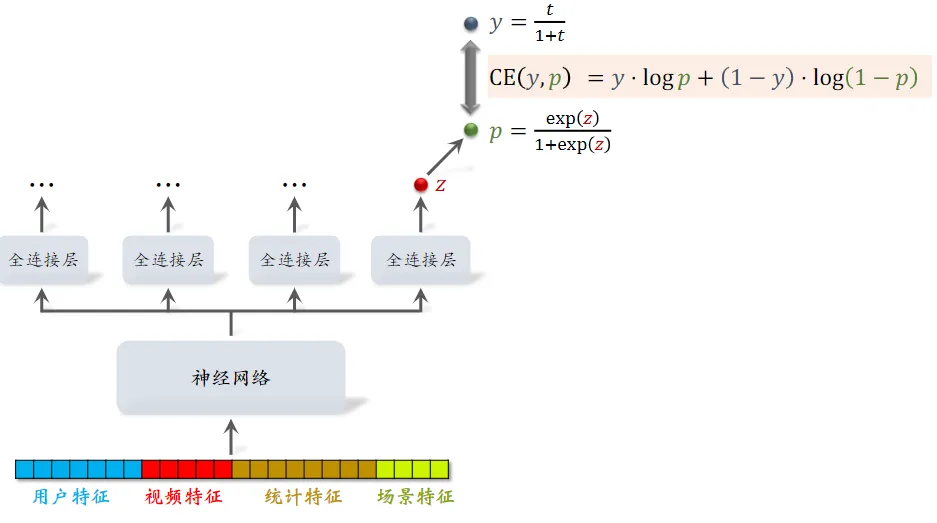
- 每个全连接层对应一个目标,假设最右边的输出对应播放时长 $z$
- 对 $z$ 做 Sigmoid 变换得到 $p$,然后让 $p$ 拟合 $y$,它们的交叉熵作为损失函数
- $y$ 是我们定义的,其中的 $t$ 是用户实际观看时长,$t$ 越大则 $y$ 越大
- 观察公式发现,如果 $p=y$,那么 $\exp{(z)}=t$ , 即 $\exp{(z)}$ 就是播放时长的预估值
- 即
就是播放时长的预估值
总结视频播放时长建模
-
把最后一个全连接层的输出记作 $z$。设 $p=sigmoid(z)$
-
实际观测的播放时长记作 $t$。(如果没有点击,则 $t = 0$)
- 做训练:最小化交叉熵损失 $-\left({\frac{t}{1+t}}\cdot\log p+{\frac{1}{1+t}}\cdot\log(1-p)\right)$
- 实践中可以去掉分母 $1+t$,就等于给损失函数做加权,权重是播放时长
- 做推理:把 $exp(z)$ 作为播放时长的预估
- 最终把 $exp(z)$ 作为融分公式中的一项
视频完播
- 回归方法
- 例:视频长度 10 分钟,实际播放 4 分钟,则实际播放率为 𝑦 = 0.4
- 让预估播放率 $p$ 拟合 $y$:$\textstyle{loss}=y\cdot\log p+(1-y)\cdot\log(1-p)$
- 线上预估完播率,模型输出 $p$ = 0.73,意思是预计播放 73%
- 二元分类方法
- 自定义完播指标,比如完播 80%
- 例:视频长度 10 分钟,播放 > 8 分钟作为正样本,播放 < 8 分钟作为负样本
- 做二元分类训练模型:播放 > 80% vs 播放 < 80%
- 线上预估完播率,模型输出 $p$ = 0.73,意思是 $\mathbb{P}(播放>80\%)=0.73$
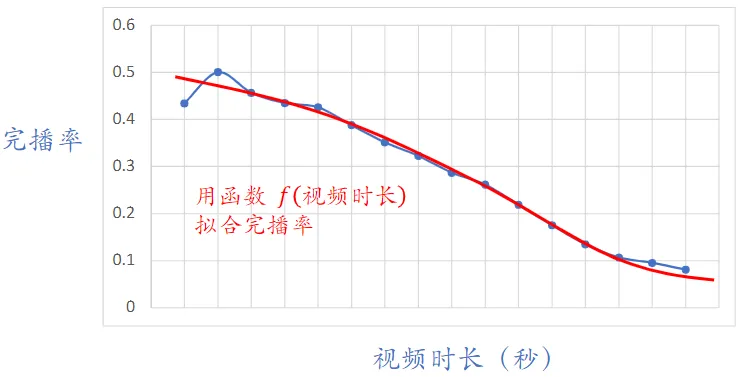
- 实际中不能直接把预估的完播率用到融分公式(why?)
- 因为视频越长,完播率越低
- 所以直接使用预估完播率,会有利于短视频,而对长视频不公平
- 线上预估完播率,然后做调整:$p_{finish}=\frac{预估完播率}{f(视频长度)}$
- $f$ 就是上图中的拟合曲线
- 把 $p_{finish}$ 作为融分公式中的一项
排序模型的特征
用户画像(User Profile)
- 用户 ID(在召回、排序中做 embedding)
- 用户 ID 本身不携带任何信息,但模型学到的 ID embedding 对召回和排序有很重要的影响
- 人口统计学属性:性别、年龄
- 账号信息:新老、活跃度……
- 模型需要专门针对 新用户 和 低活跃 用户做优化
- 感兴趣的类目、关键词、品牌
物品画像(Item Profile)
- 物品 ID(在召回、排序中做 embedding)
- 发布时间(或者年龄)
- GeoHash(经纬度编码)、所在城市
- 标题、类目、关键词、品牌……
- 字数、图片数、视频清晰度、标签数……
- 反映笔记的质量
- 内容信息量、图片美学……
- 事先用人工标注的数据训练 NLP 和 CV 模型,然后用模型打分
用户统计特征
- 用户最近 30 天(7 天、1 天、1 小时)的曝光数、点击数、点赞数、收藏数……
- 划分各种时间粒度,可以反映用户的 实时、短期、中长期 兴趣
- 按照笔记图文/视频分桶。(比如最近 7 天,该用户对图文笔记的点击率、对视频笔记的点击率)
- 反映用户对两类笔记的偏好
- 按照笔记类目分桶。(比如最近 30 天,用户对美妆笔记的点击率、对美食笔记的点击率、对科技数码笔记的点击率)
- 反映用户对哪个类目更感兴趣
笔记统计特征
- 笔记最近 30 天(7 天、1 天、1 小时)的曝光数、点击数、点赞数、收藏数……
- 划分时间粒度,可以提前发现哪些笔记过时了
-
按照用户性别分桶、按照用户年龄分桶……
- 作者特征:
- 发布笔记数
- 粉丝数
- 消费指标(曝光数、点击数、点赞数、收藏数)
场景特征(Context)
-
用户定位 GeoHash(经纬度编码)、城市
- 当前时刻(分段,做 embedding)
- 一个人在同一天不同时刻的兴趣是变化的
- 而且可以反推用户是在上班路上、公司、家里
-
是否是周末、是否是节假日
- 手机品牌、手机型号、操作系统
- 安卓用户和苹果用户的 点击率、点赞率 等数据差异很大
特征处理
- 离散特征:做 embedding
- 用户 ID、笔记 ID、作者 ID
- 类目、关键词、城市、手机品牌
- 连续特征:
- 做分桶,变成离散特征
- 年龄、笔记字数、视频长度
- 其他变换
- 曝光数、点击数、点赞数等数值做 $\log{(1+x)}$,解决数据异常值问题
- 转化为点击率、点赞率等值,并做平滑
特征覆盖率
-
很多特征无法覆盖 100% 样本
-
例:很多用户不填年龄,因此用户年龄特征的覆盖率远小于 100%
-
例:很多用户设置隐私权限,APP 不能获得用户地理定位,因此场景特征有缺失
-
提高特征覆盖率,可以让精排模型更准
- 想各种办法提高特征覆盖率,并考虑特征缺失时默认值如何设置
特征数据服务
用户画像(User Profile)
物品画像(Item Profile)
统计数据
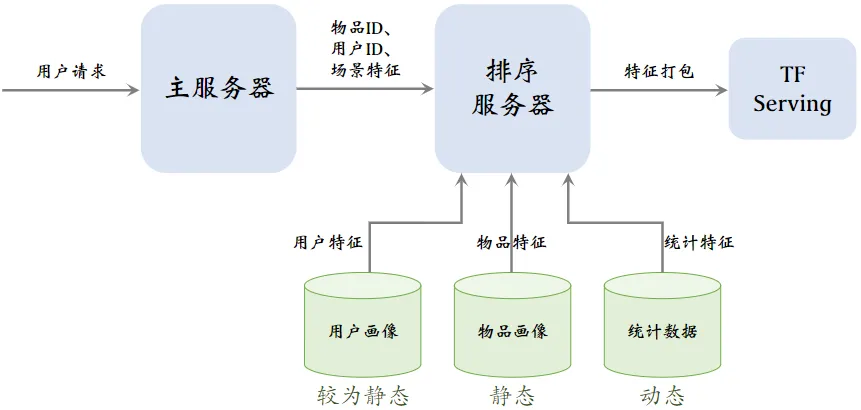
-
用户画像数据库压力小(每次只读 1 个用户),物品画像数据库压力非常大(每次读几千个物品)
-
工程实现时,用户画像中的特征可以很多很大,但尽量不往物品画像中塞很大的向量
-
由于用户和物品画像较为静态(考虑读取速度),甚至可以把用户和物品画像缓存在排序服务器本地,加速读取
-
收集了排序所需特征后,将特征打包发给 TF Serving,Tensorflow 给笔记打分并把分数返回排序服务器
-
排序服务器依据融合的分数、多样性分数、业务规则等给笔记排序,并把排名最高的几十篇返回主服务器
粗排
前面介绍的模型主要用于精排,本节介绍怎么做粗排。
精排
-
给几百篇笔记打分
-
单次推理代价很大
-
预估的准确性更高
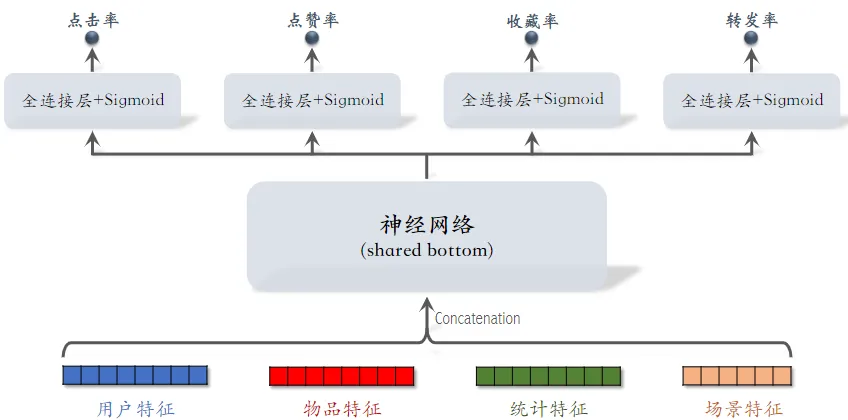
- 前期融合:先对所有特征做 concatenation,再输入神经网络
- 这个网络叫 shared bottom,意思是它被多个任务共享
- 线上推理代价大:如果有 $n$ 篇候选笔记,整个大模型要做 $n$ 次推理
粗排
-
给几千篇笔记打分
-
单次推理代价必须小
-
预估的准确性不高
双塔模型(一种粗排模型)
-
后期融合:把用户、物品特征分别输入不同的神经网络,不对用户、物品特征做融合
- 线上计算量小:
- 用户塔只需要做一次线上推理,计算用户表征 $\bold{a}$
- 物品表征 $\bold{b}$ 事先储存在向量数据库中,物品塔在线上不做推理
- 后期融合模型不如前期融合模型准确
- 预估准确性不如精排模型
- 后期融合模型用于召回,前期融合模型用于精排
小红书粗排用的三塔模型,效果介于双塔和精排之间。
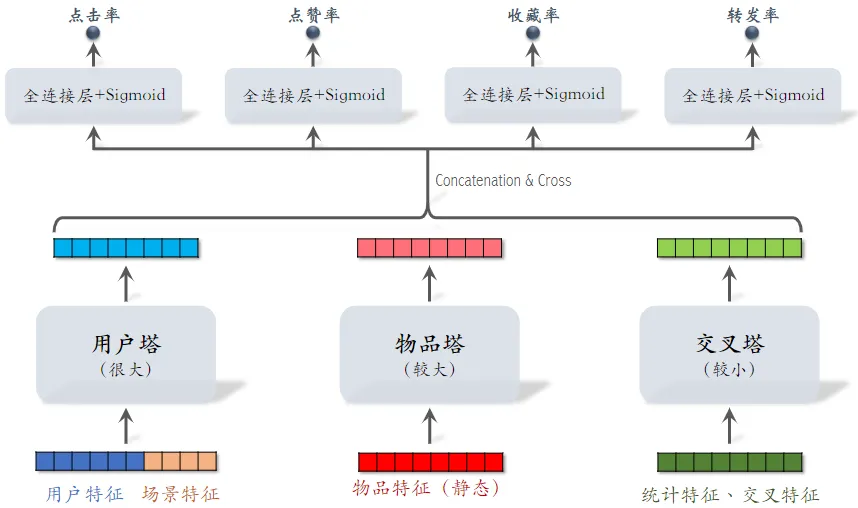
-
交叉特征:用户特征与物品特征做交叉
-
对 3 个塔输出的向量做 Concatenation 和 Cross(交叉)得到 1 个向量
-
与前期融合在最开始对各类特征做融合不同,三塔模型在塔输出的位置做融合
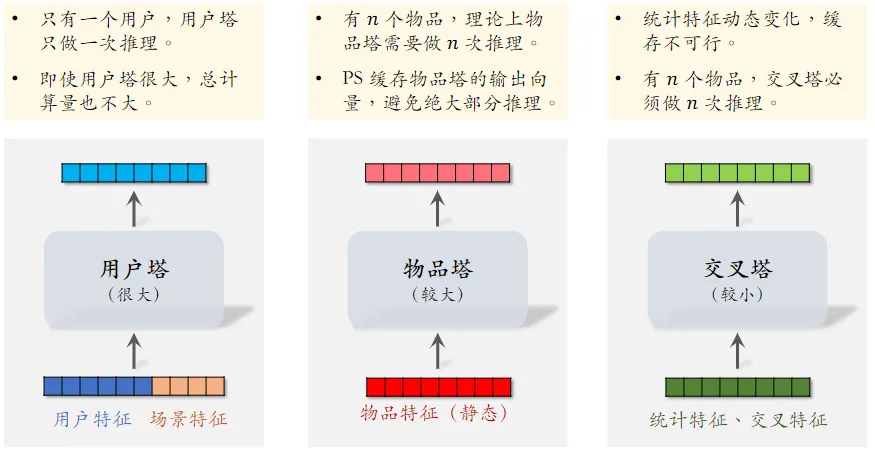
-
有 $n$ 个物品,模型上层需要做 $n$ 次推理
- 粗排推理的大部分计算量在模型上层
- 这个环节无法利用缓存节省计算量
- 三塔模型节省的是对物品推理的计算量
三塔模型的推理
- 从多个数据源取特征: - 1 个用户的画像、统计特征 - $n$ 个物品的画像、统计特征
- 用户塔:只做 1 次推理
- 物品塔:未命中缓存时需要做推理
- 交叉塔:必须做 $n$ 次推理
-
上层网络做 $n$ 次推理,给 $n$ 个物品打分
- 粗排模型的设计理念就是尽量减少推理的计算量,使得模型可以线上对几千篇笔记打分
特征交叉
在召回排序都会用到,特征值相乘,提升模型表达能力
深度交叉网络(DCN)
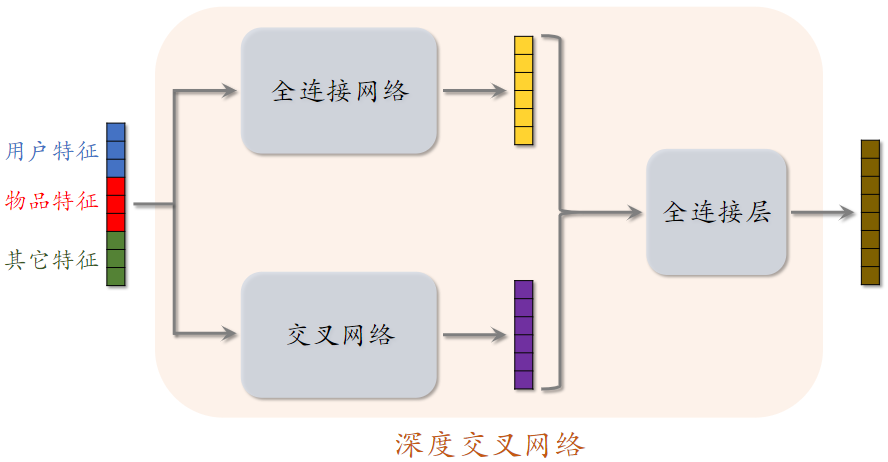
- 把 全连接网络、交叉网络、全连接层 拼到一起,就是 深度交叉网络 DCN
- 召回、排序模型中的各种 塔、神经网络、专家网络 都可以是 DCN
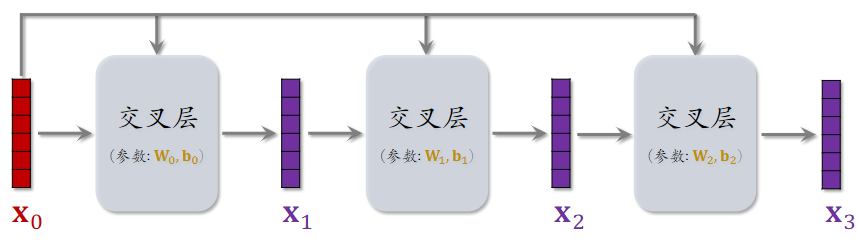
交叉层(Cross Layer)
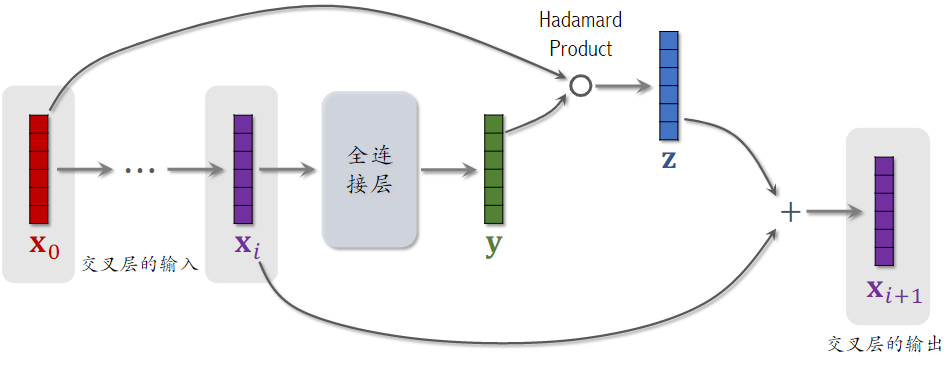
- Hadamard Product:逐元素相乘
- 这个操作类似于 ResNet 中的 跳跃链接 Skip Connection
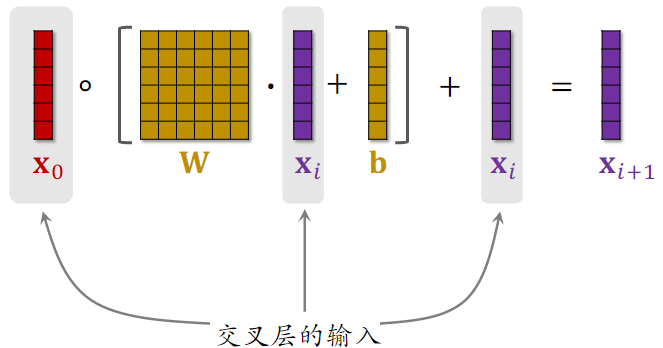
- 矩阵 $\bold{W}$ 和 $\bold{b}$ 是该交叉层的全部输入
- 交叉层的输出与输入形状相同
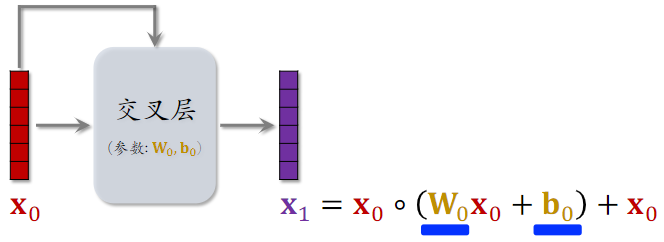
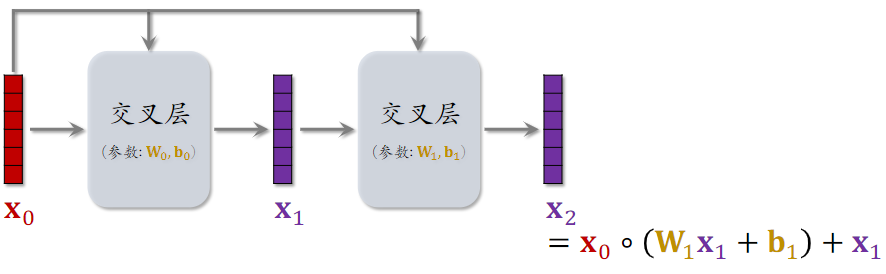
交叉网络(Cross Network)
SENet & Bilinear Cross
https://www.yuque.com/yuejiangliu/recommended-system-in-the-industry/feature-cross#EHRPS
用户LastN行为序列
用在用户塔里面
取平均
用户行为序列简称为 LastN,即用户最后交互的 个物品,LastN 可以反映用户对什么样的物品感兴趣
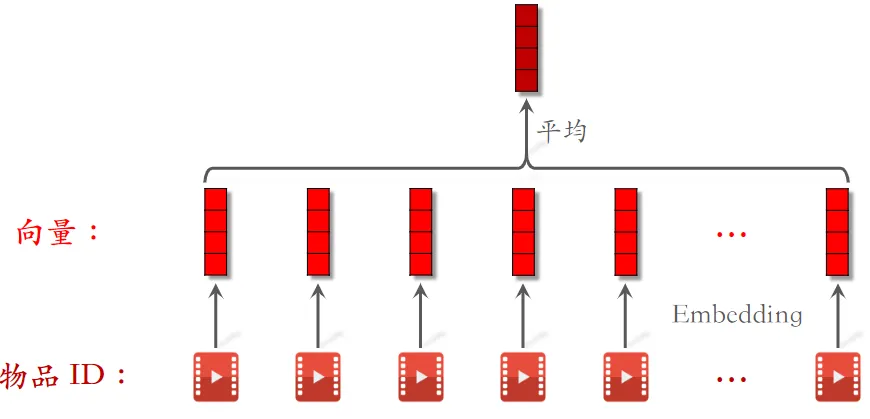
LastN 特征
- LastN:用户最近的 $n$ 次交互(点击、点赞等)的物品 ID
- 对 LastN 物品 ID 做 embedding,得到 $n$ 个向量,把 $n$ 个向量取平均,作为用户的一种特征
- 适用于召回双塔模型、粗排三塔模型、精排模型
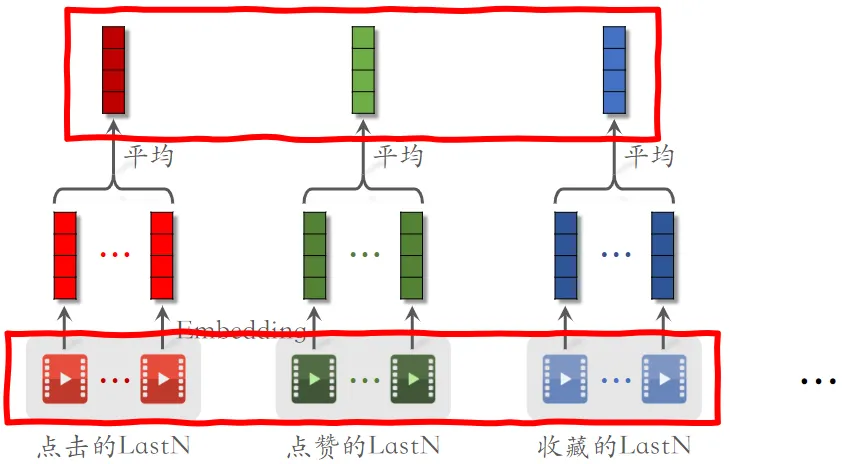
-
取平均是早期的用法,效果不错
-
现在更多的是用 Attention,但是计算量大
- 上面得到的多个向量拼接起来,作为一种用户特征,传到召回或排序模型中
- Embedding 不只有物品 ID,还会有物品类别等特征
DIN 模型
DIN 用加权平均代替平均,即注意力机制(attention)
权重:候选物品与用户 LastN 物品的相似度
候选物品:例如粗排选出了 500 个物品,那这 500 个就是精排的候选物品
- 计算相似度的方法很多,如 内积 和 余弦相似度 等
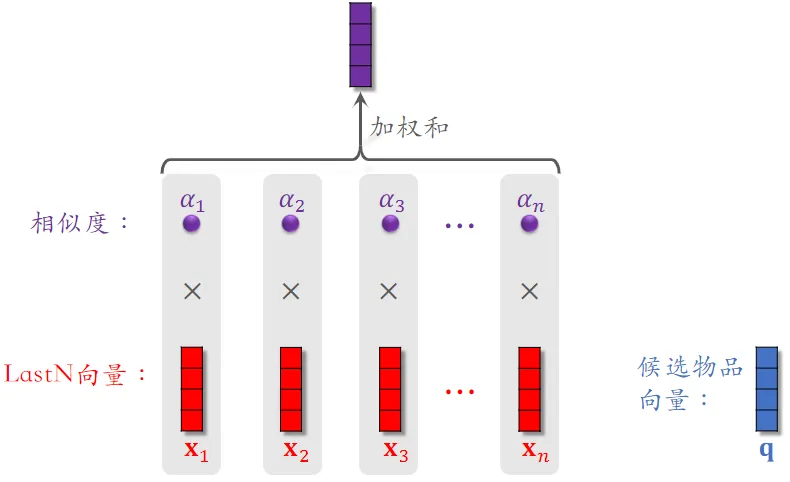
DIN 模型总结 :对于某候选物品,计算它与用户 LastN 物品的相似度
- 以相似度为权重,求用户 LastN 物品向量的加权和,结果是一个向量
- 把得到的向量作为一种用户特征,输入排序模型,预估(用户,候选物品)的点击率、点赞率等指标
- 本质是单头注意力机制(attention)
简单平均 vs. 注意力机制
简单平均 和 注意力机制 都适用于精排模型
- 简单平均适用于双塔模型、三塔模型
-
简单平均只需要用到 LastN,属于用户自身的特征,与候选物品无关
-
把 LastN 向量的平均作为用户塔的输入
-
- 注意力机制不适用于双塔模型、三塔模型
- 注意力机制 需要用到 LastN + 候选物品
- 用户塔看不到候选物品,不能把 注意力机制 用在用户塔
缺点
- 注意力层的计算量 ∝ $n$(用户行为序列的长度)
- 只能记录最近几百个物品,否则计算量太大
- 缺点:关注短期兴趣,遗忘长期兴趣 (不能随意增长用户行为序列长度,可以显著提升推荐系统的所有指标,但增加的计算量太大)
SIM 模型
SIM 模型的主要目的是保留用户的长期兴趣。
- 保留用户长期行为记录,$n$ 的大小可以是几千
- 对于每个候选物品,在用户 LastN 记录中做快速查找,找到 $k$ 个相似物品
- 把 LastN 变成 TopK,然后输入到注意力层
- SIM 模型减小计算量(从 $n$ 降到 $k$)
第一步:快速查找
方法一:Hard Search —— 根据规则做筛选
- 根据候选物品的类目,保留 LastN 物品中类目相同的
- 简单,快速,无需训练
方法二:Soft Search,embedding+knn
- 把物品做 embedding,变成向量
- 把候选物品向量作为 query,做 $k$ 近邻查找,保留 LastN 物品中最接近的 $k$ 个
- 效果更好,编程实现更复杂
第二步:注意力机制
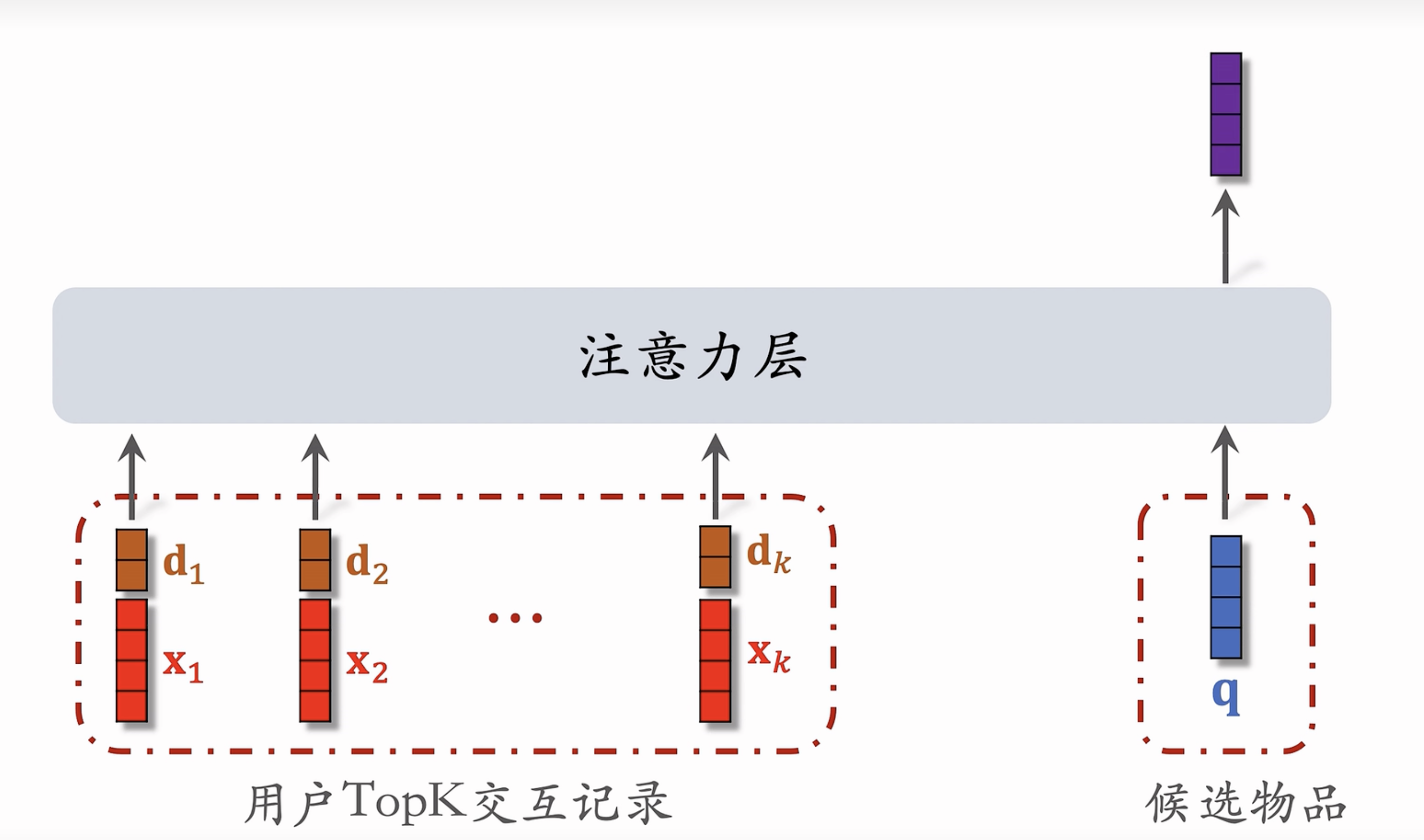
Trick:使用时间信息
- 用户与某个 LastN 物品的交互时刻距今为 $\delta$
- 对 $\delta$ 做离散化,再做 embedding,变成向量 $\bold{d}$
- 例如把时间离散为 1 天内、7 天内、30 天内、一年、一年以上
- 把两个向量做 concatenation,表征一个 LastN 物品
- 向量 $\bold{x}$ 是物品 embedding
- 向量 $\bold{d}$ 是时间的 embedding
为什么 SIM 使用时间信息,DIN不用?
- DIN 的序列短,记录用户近期行为,SIM 的序列长,记录用户长期行为
- 时间越久远,重要性越低,模型更加有效
行为序列总结
- 长序列(长期兴趣)优于短序列(近期兴趣)
- 注意力机制优于简单平均
- Soft search 还是 hard search?取决于工程基建
- 使用时间信息有提升
重排
为了保证推荐多样性,推荐给用户的物品两两间不相识,则说明推荐有多样性。
物品相似性的度量
相似性的度量
- 基于物品属性标签 ,重叠越多,越相似
- 类目、品牌、关键词……
- 基于物品向量表征
- 用召回的双塔模型学到的物品向量(不好)
- 基于内容的向量表征(好)
基于物品属性标签
- 物品属性标签:类目、品牌、关键词……
- 标签通常是通过 CV 或 NLP 算法通过图文推算的,不一定准确
- 根据 一级类目、二级类目、品牌 计算相似度
- 物品 $i$:美妆、彩妆、香奈儿
- 物品 $j$:美妆、香水、香奈儿
- 相似度:$\rm sim_1(i,j)=1,\rm sim_2(i,j)=0,\rm sim_3(i,j)=1$
为什么不能用召回的双塔模型学到的物品向量,计算相似度
- 推荐系统的头部效应明显,新物品 和 长尾物品 的曝光少
- 双塔模型学不好 新物品 和 长尾物品 的向量表征
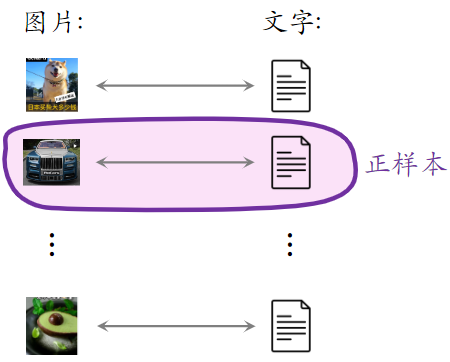
基于图文内容的物品表征
- CLIP 是当前公认最有效的预训练方法
- 思想: 对于 图片—文本 二元组,预测图文是否匹配
- 优势:无需人工标注。小红书的笔记天然包含图片 + 文字,大部分笔记图文相关
- 做预训练时:同一篇笔记的 图文 作为正样本,它们的向量应该高度相似;来自不同笔记的图文作为负样本
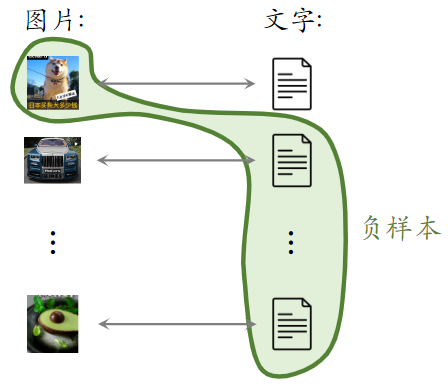
基于图文内容的物品表征
- 一个 batch 内有 $m$ 对正样本
- 一张图片和 $m-1$ 条文本组成负样本
- 这个 batch 内一共有 $m(m-1)$ 对负样本
提升多样性的方法

- 粗排和精排用多目标模型对物品做 pointwise 打分
- 对于物品 $i$,模型输出点击率、交互率的预估,融合成分数 $reward_i$
- $reward_i$ 表示用户对物品 $i$ 的兴趣,即物品本身价值
- 给定 $n$ 个候选物品,排序模型打分 ${\rm{reward}} _i,…,{\rm{reward}} _n$
- 后处理:从 $n$ 个候选物品中选出 $k$ 个,既要它们的总分高,也需要它们有多样性
- 精排的后处理通常被称为 —— 重排
- 增加多样性可以显著提升推荐系统指标(尤其是时长、留存率)
MMR Maximal Marginal Relevance
多样性
- 精排给 $n$ 个候选物品打分,融合之后的分数为 $\rm{reward} _i,…,\rm{reward} _n$
- 把第 $i$ 和 $j$ 个物品的相似度记作 $\rm sim(i,j)$
- 重排:从 $n$ 个物品中选出 $k$ 个,既要有高精排分数,也要有多样性

- 计算集合 ${\mathcal{R}}$ 中每个物品 $i$ 的 Marginal Relevance 分数: $MR_i={\theta\cdot{\mathrm{reward}}i-(1-\theta)\cdot max{j\in S}\mathrm s\mathrm i\mathrm m(i,\;j)}$
- $\rm{reward} _i$:物品 $i$ 的精排分数
- $\max_{j\in \mathcal{S}}\rm sim(i,j)$:物品 $i$ 的多样性分数
- 此处物品 $i$ 尚未选中,而物品 $j\in \mathcal{S}$ 都是已选中物品
- 若物品 $i$ 与已选中的某个物品 $j$ 相似度比较大,则起到抑制作用
- Maximal Marginal Relevance (MMR): ${\rm argmax}_{i\in {\mathcal{R}}} {\rm MR}_i$
- 每一轮从集合 $\mathcal{R}$ 中选择 $ {\rm MR}$ 分数最高的物品 $i$,然后将其移入集合 $\mathcal{S}$
概括 MMR 算法流程:
- 初始化:已选中的物品 ${\mathcal{S}}$ 初始化为空集,未选中的物品 ${\mathcal{R}}$ 初始化为全集 ${ 1,…,n}$
- 选择精排分数 $\rm{reward} _i$ 最高的物品,从集合 ${\mathcal{R}}$ 移到 ${\mathcal{S}}$
- 做 $k-1$ 轮循环:
- 计算集合 ${\mathcal{R}}$ 中所有物品的分数 ${MR_i}_{i\in\mathcal R}$
- 选出分数最高的物品,将其从 ${\mathcal{R}}$ 移到 ${\mathcal{S}}$
MMR滑动窗口
MMR缺点
- 已选中的物品越多(即集合 ${\mathcal{S}}$ 越大),越难找出物品 $i\in{\mathcal{R}}$,使得 $i$ 与 ${\mathcal{S}}$ 中的物品都不相似
解决方案:设置一个滑动窗口 ${\mathcal{W}}$,比如最近选中的 10 个物品,用 ${\mathcal{W}}$ 代替 MMR 公式中的 ${\mathcal{S}}$
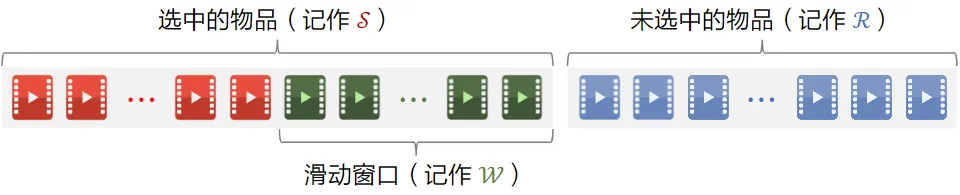
用滑动窗口:$argmax_{i\in\mathcal R}{\theta\cdot reward_i-\left(1-\theta\right)\cdot max_{j\in\mathcal W}sim\left(i,j\right)}$
用滑动窗口的可解释性:给用户曝光的连续物品应该不相似,但没必要隔得比较远的物品还不相似,用户大概率忘了
MMR总结
- MMR 使用在精排的后处理(重排)阶段
- 根据精排分数和多样性分数给候选物品排序
- MMR 决定了物品的最终曝光顺序
- 实际应用中通常带滑动窗口,这样比标准 MMR 效果更好
重排的规则
- 工业界的推荐系统一般有很多业务规则,这些规则通常是为了保护用户体验,做重排时这些规则必须被满足
- 下面举例重排中的部分规则,以及这些规则与 MMR 相结合
- 规则的优先级高于多样性算法
重排的规则
- 规则:最多连续出现 $k$ 篇某种笔记
- 小红书推荐系统的物品分为图文笔记、视频笔记
- 最多连续出现 $k=5$ 篇图文笔记,最多连续出现 $k=5$ 篇视频笔记
- 如果排 $i$ 到 $i+4$ 的全都是图文笔记,那么排在 $i+5$ 的必须是视频笔记
- 规则:每 $k$ 篇笔记最多出现 1 篇某种笔记
- 运营推广笔记的精排分会乘以大于 1 的系数(boost),帮助笔记获得更多曝光
- 为了防止 boost 影响体验,限制每 $k=9$ 篇笔记最多出现 1 篇运营推广笔记
- 如果排第 $i$ 位的是运营推广笔记,那么排 $i+1$ 到 $i+8$ 的不能是运营推广笔记
- 规则:前 $t$ 篇笔记最多出现 $k$ 篇某种笔记
- 排名前 $t$ 篇笔记最容易被看到,对用户体验最重要(小红书的 top 4 为首屏)
- 小红书推荐系统有带电商卡片的笔记,过多可能会影响体验
- 前 $t=1$ 篇笔记最多出现 $k=0$ 篇带电商卡片的笔记 - 即排名第一的笔记,不能是电商推广
- 前 $t=4$ 篇笔记最多出现 $k=1$ 篇带电商卡片的笔记
每一轮先用规则排除掉 ${\mathcal{R}}$ 中的部分物品,得到子集 ${\mathcal{R}}’$ , MMR 公式中的 ${\mathcal{R}}$ 替换成子集 ${\mathcal{R}}’$,选中的物品符合规则
DDP
DPP 的目标是从一个集合中选出尽量多样化的物品,契合重排的目标
DPP:行列式点过程, 目前推荐系统领域公认的最好多样性算法.
- 精排给 $n$ 个物品打分:$\rm{reward} _i,…,\rm{reward} _n$
- $n$ 个物品的向量表征:$v_{1},\cdots,v_{k}\in\mathbb{R}^{d}$
- 从 $n$ 个物品中选出 $k$ 个物品,组成集合 $\mathcal{S}$ - 价值大:分数之和 $\sum_{j\in\mathcal{S}} {\rm{reward}}_j$ 越大越好 - 多样性好:$\mathcal{S}$ 中 $k$ 个向量组成的超平形体 $\mathcal{P}(\mathcal{S})$ 的体积越大越好
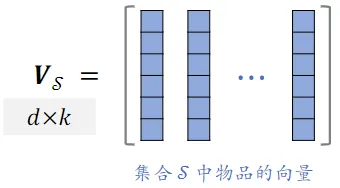
- 集合 $\mathcal{ S}$ 中的 $k$ 个物品的向量作为列,组成矩阵 $V_{ \mathcal{S}}\in\mathbb{R}^{d\times k}$
- 以这 $k$ 个向量作为边,组成超平形体 $\mathcal{ P}(\mathcal{ S})$
- 体积 $\operatorname{vol}\left({\mathcal{P}}(S)\right)$ 可以衡量 $\mathcal{ S}$ 中物品的多样性
- 设 $k\leq d$,行列式与体积满足:$\operatorname*{det}(V_{\mathcal{ S}}^{T}\,V_{\mathcal{ S}}):=:\mathrm{vol}({\mathcal P}(\mathcal{ S}))^{2}$
| Hulu 的论文将 DPP 应用在推荐系统: $argmax_{\mathrm S:\left | \mathrm S\right | =\mathrm k}\;\theta\cdot\left({\textstyle\sum_{j\in S}}reward_j\right)+(1-\theta)\cdot\log\;det\left(V_S^TV_S\right)$ |
- 前半部分计算集合中物品的价值
- 后半部分是行列式的对数,物品多样性越好,这部分越大
- Hulu 论文的主要贡献不是提出该公式,而是快速求解该公式
物品冷启动
UGC(用户产生的内容)比PGC(平台生产的内容)难,UGC内容良莠不齐,量大,难以人工评判和调控
为什么需要冷启动
- 新笔记缺少与用户的交互,导致推荐的难度大、效果差
- 扶持新发布、低曝光的笔记,可以增强作者发布意愿
优化冷启的目标
- 精准推荐:克服冷启的困难,把新笔记推荐给合适的用户,不引起用户反感
- 激励发布:流量向低曝光新笔记倾斜,激励作者发布
- 挖掘高潜:通过初期小流量的试探,找到高质量的笔记,给与流量倾斜
冷启动指标
评价指标
- 作者侧指标:反映用户的发布意愿
- 发布渗透率、人均发布量
- 用户侧指标:反映推荐是否精准,是否会引起用户反感
- 新笔记指标:新笔记的点击率、交互率
- 大盘指标:消费时长、日活、月活
- 内容侧指标:反映冷启是否能挖掘优秀笔记
- 高热笔记占比
作者侧指标
发布渗透率(penetration rate)
-
发布渗透率 = 当日发布人数 / 日活人数
-
发布一篇或以上,就算一个发布人数
-
例:
- 当日发布人数 = 100 万
- 日活人数 = 2000 万
- 发布渗透率 = 100 / 2000 = 5%
人均发布量
- 人均发布量 = 当日发布笔记数 / 日活人数
-
例:
- 每日发布笔记数 = 200 万
- 日活人数 = 2000 万
- 人均发布量 = 200 / 2000 = 0.1
发布渗透率、人均发布量反映出作者的发布积极性 冷启的重要优化目标是促进发布,增大内容池 新笔记获得的曝光越多,首次曝光和交互出现得越早,作者发布积极性越高
用户侧指标
新笔记的消费指标
-
新笔记的点击率、交互率
-
问题:曝光的基尼系数很大
- 即少量头部新笔记推送准确,但大部分新笔记的推送不准,综合下来点击率、交互率也很高
-
少数头部新笔记占据了大部分的曝光
-
-
分别考察高曝光、低曝光新笔记
- 高曝光:比如 >1000 次曝光
- 低曝光:比如 <1000 次曝光
大盘消费指标(不区分新老笔记)
- 优化冷启时,不是为了提升大盘指标,而是确保新策略不显著伤害大盘指标
- 大盘的消费时长、日活、月活
-
大力扶持低曝光新笔记会发生什么?
- 作者侧发布指标变好
- 用户侧大盘消费指标变差(损害用户体验)
内容侧指标
新内容的高热笔记占比
- 高热笔记:前 30 天获得 1000+ 次点击
- 高热笔记占比越高,说明冷启阶段挖掘优质笔记的能力越强
冷启动指标总结
- 作者侧指标:发布渗透率、人均发布量
- 用户侧指标:新笔记消费指标、大盘消费指标
- 内容侧指标:高热笔记占比
冷启动的优化点
- 优化全链路(包括召回和排序)
- 流量调控(流量怎么在新物品、老物品中分配)
召回的难点
召回的依据
- ✔ 自带图片、文字、地点
- ✔ 算法或人工标注的标签
-
❌ 没有用户点击、点赞等信息
- 这些信息可以反映笔记的质量,以及哪类用户喜欢该笔记
-
❌ 没有笔记 ID embedding
- ID embedding 是从用户和笔记的交互中学习出来的
冷启召回的困难
- 缺少用户交互,还没学好笔记 ID embedding,导致双塔模型效果不好
- 双塔模型是推荐系统中最重要的召回通道,没有之一
- 缺少用户交互,导致 ItemCF 不适用
召回通道
- ❌ ItemCF 召回(不适用)
- ❔ 双塔模型(改造后适用)
- ✔ 类目、关键词召回(适用)
- ✔ 聚类召回(适用)
- ✔ Look-Alike 召回(适用)
双塔模型
ID Embedding
-
改进方案 1:新笔记使用 default embedding
- 物品塔做 ID embedding 时,让所有新笔记共享一个 ID,而不是用自己真正的 ID
-
Default embedding:共享的 ID 对应的 embedding 向量
- 学出来的 Default embedding 比随机初始化一个 ID embedding 要好
- 到下次模型训练的时候,新笔记才有自己的 ID embedding 向量
-
改进方案 2:利用相似topk笔记 embedding 向量取平均
- 查找 top k 内容最相似的高曝笔记
-
把 k 个高曝笔记的 embedding 向量取平均,作为新笔记的 embedding
- 之所以用 高爆笔记,是因为它们的 embedding 通常学得比较好
多个向量召回池
- 多个召回池,让新笔记有更多曝光机会
- 1 小时新笔记
- 6 小时新笔记
- 24 小时新笔记
- 30 天笔记
- 所有召回池共享同一个双塔模型,那么多个召回池不增加训练的代价
类目召回
用户画像
-
感兴趣的类目:美食、科技数码、电影……
-
感兴趣的关键词:纽约、职场、搞笑、程序员、大学……
基于类目的召回
- 系统维护类目索引:
- 类目 → 笔记列表(按时间倒排)
- 用类目索引做召回:
- 用户画像 → 类目 → 笔记列表
- 取回笔记列表上前 k 篇笔记(即最新的 k 篇)
基于关键词的召回
-
系统维护关键词索引:
- 关键词 → 笔记列表(按时间倒排)
-
根据用户画像上的关键词做召回
缺点
缺点 1:只对刚刚发布的新笔记有效
- 取回某 类目/关键词 下最新的 k 篇笔记
- 发布几小时之后,就再没有机会被召回
- 所以应该在用户高频使用软件的时间段发布内容
缺点 2:弱个性化,不够精准
聚类召回
基本思想
- 如果用户喜欢一篇笔记,那么他会喜欢内容相似的笔记
- 事先训练一个神经网络,基于笔记的类目和图文内容,把笔记映射到向量
- 对笔记向量做聚类,划分为 1000 cluster,记录每个 cluster 的中心方向(k-means 聚类,用余弦相似度)
聚类索引
- 一篇新笔记发布之后,用神经网络把它映射到一个特征向量
- 从 1000 个向量(对应 1000 个 cluster)中找到最相似的向量,作为新笔记的 cluster
- 索引:cluster → 笔记 ID 列表(按时间倒排)
线上召回
- 给定用户 ID,找到他的 last-n 交互的笔记列表,把这些笔记作为种子笔记
- 把每篇种子笔记映射到向量,寻找最相似的 cluster(知道了用户对哪些 cluster 感兴趣)
- 从每个 cluster 的笔记列表中,取回最新的 $m$ 篇笔记
- 最多取回 $mn$ 篇新笔记
聚类召回与类目召回的缺点相同:只对刚发布的新笔记有效
内容相似度模型
聚类召回通过内容相似度模型来把笔记映射到向量。
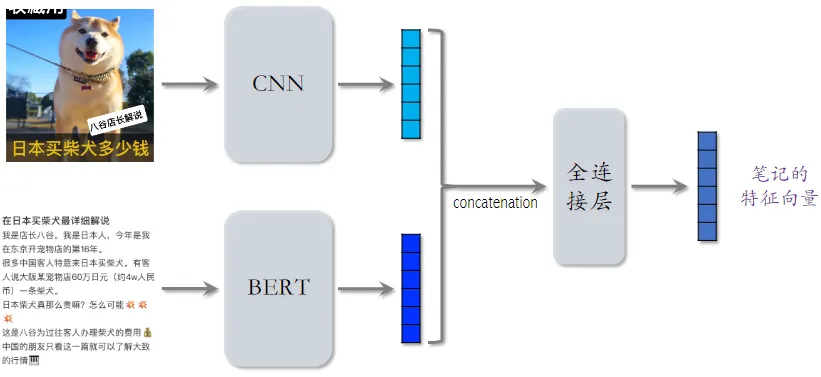
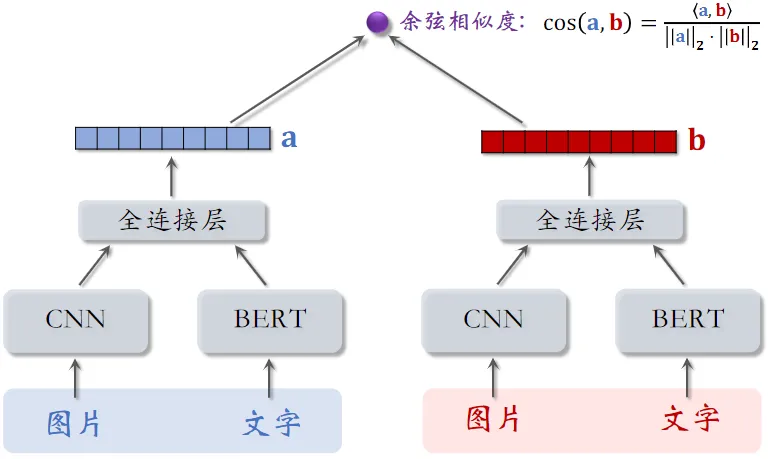
- 左右两个用的神经网络的参数是相同的
- CNN 和 BERT 可以用预训练模型,全连接层是随机初始化后训练出来的
训练内容相似度模型
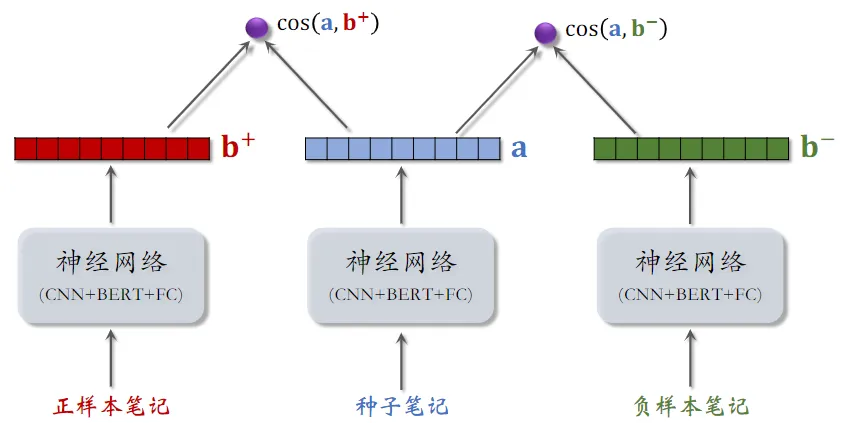 给定用户 ID,找到他的 last-n 交互的笔记列表,把这些笔记作为种子笔记, 此处的公式与 召回 - 双塔模型 - Pairwise 训练 中相似
给定用户 ID,找到他的 last-n 交互的笔记列表,把这些笔记作为种子笔记, 此处的公式与 召回 - 双塔模型 - Pairwise 训练 中相似
- 基本想法:鼓励 $\cos{(\bold{a},\bold{b}^+)}$ 大于 $\cos{(\bold{a},\bold{b}^-)}$
- Triplet hinge loss: $L(\bold{a},\bold{b}^+,\bold{b}^-)=\max{{ 0,\cos{(\bold{a},\bold{b}^-)}+m-\cos{(\bold{a},\bold{b}^+)}}}$
- Triplet logistic loss: $L(\bold{a},\bold{b}^+,\bold{b}^-)=\log{( 1+\exp{·(\cos{(\bold{a},\bold{b}^-)}-\cos{(\bold{a},\bold{b}^+))})}}$
< 种子笔记,正样本 >
- 方法一:人工标注二元组的相似度
- 方法二:算法自动选正样本
- 筛选条件:
- 只用高曝光笔记作为二元组(因为有充足的用户交互信息)
- 两篇笔记有相同的二级类目,比如都是“菜谱教程”
- 用 ItemCF 的物品相似度选正样本
- 筛选条件:
< 种子笔记,负样本 >
- 从全体笔记中随机选出满足条件的:
- 字数较多(神经网络提取的文本信息有效)
- 笔记质量高,避免图文无关
聚类召回总结
- 基本思想:根据用户的点赞、收藏、转发记录,推荐内容相似的笔记
- 线下训练:多模态神经网络把图文内容映射到向量
- 线上服务:
- 用户历史喜欢的笔记 → 特征向量 → 最近的 Cluster → 每个 Cluster 上的新笔记
Look-Alike人群扩散
广告适用广泛
Tesla Model 3 典型用户:
- 年龄 25~35
- 本科学历以上
- 关注科技数码
- 喜欢苹果电子产品
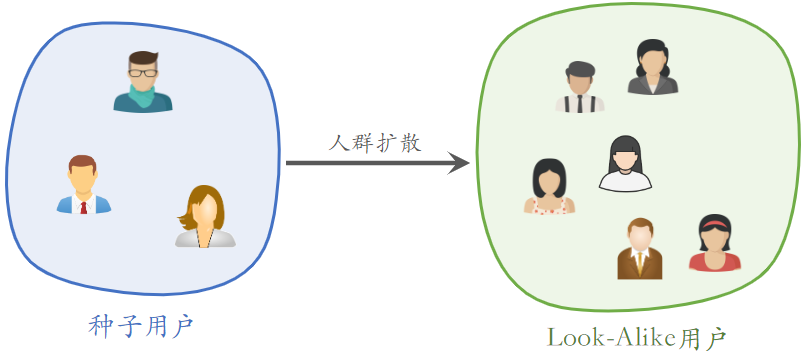
如何计算两个用户的相似度?
- UserCF:两个用户有共同的兴趣点
- Embedding:两个用户向量的 cosine 较大
Look-Alike 用于新笔记召回
- 点击、点赞、收藏、转发——用户对笔记可能感兴趣
- 把有交互的用户作为新笔记的种子用户,将种子用户的特征向量作为新笔记的特征向量
- 用 look-alike 在相似用户中扩散
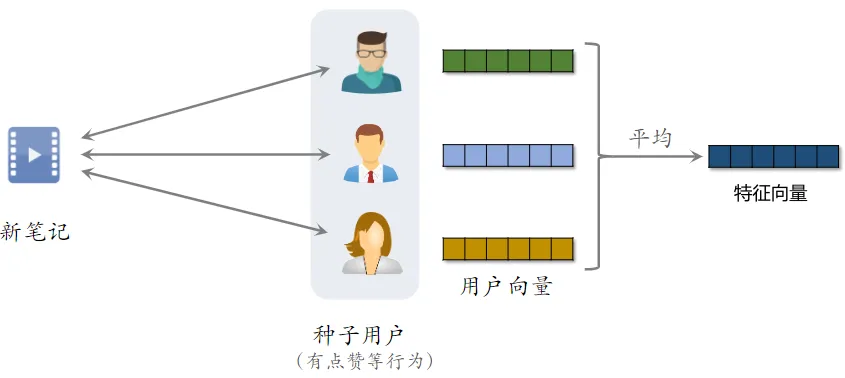
召回
- 系统把新笔记推荐给了许多用户,由于是新笔记,所以受众不太精准
- 而跟新笔记进行了交互用户,就成了种子用户
- 用双塔模型学习种子用户的向量,然后取均值,把得到的向量作为 新笔记 的表征
-
近线更新特征向量
-
近线:不用实时更新,做到分钟级更新即可
- 此处是做到每当有新交互发生后,几分钟内更新特征向量
-
- 特征向量是有交互的用户的向量的平均,将种子用户的特征向量作为新笔记的特征向量
- 每当有用户交互该物品,更新笔记的特征向量
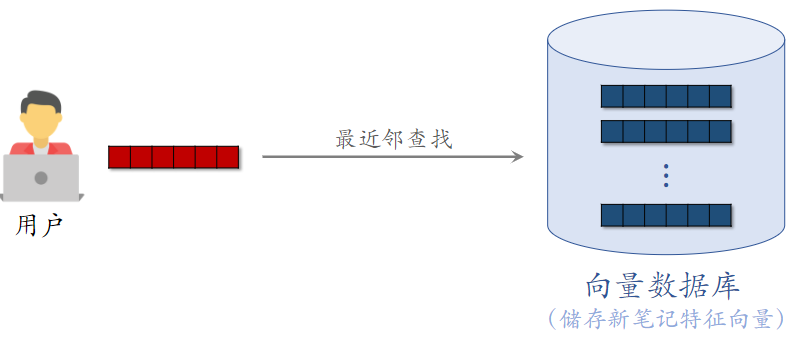
- 双塔模型计算用户特征向量
- 拿用户的特征向量,在向量数据库中做最近邻查找,取回几十篇笔记
- 这个召回通道就叫 Look-Alike
流量调控
工业界的通常做法是扶持新笔记
目的 1:促进发布,增大内容池
- 新笔记获得的曝光越多,作者创作积极性越高
- 反映在发布渗透率、人均发布量
目的 2:挖掘优质笔记
- 做探索,让每篇新笔记都能获得足够曝光
- 挖掘的能力反映在高热笔记占比
工业界的规则
- 假设推荐系统只分发年龄 <30 天的笔记。
- 假设采用自然分发,新笔记(年龄 <24 小时)的曝光占比为 1/30
- 扶持新笔记,让新笔记的曝光占比远大于 1/30
流量调控技术的发展
- 在推荐结果中强插新笔记
- 对新笔记的排序分数做提权(boost)(很划算的做法,实现不难,抖音、小红书前期都这么做)
- 通过提权,对新笔记做保量
- 差异化保量
新笔记提权
干涉粗排、重排环节,给新笔记提权
- 优点:容易实现,投入产出比好
-
缺点:
- 曝光量对提权系数很敏感
- 很难精确控制曝光量,容易过度曝光和不充分曝光
新笔记保量
新笔记保量
-
保量:不论笔记质量高低,都保证 24 小时获得 100 次曝光
-
在原有提权系数的基础上,乘以额外的提权的系数,比如:
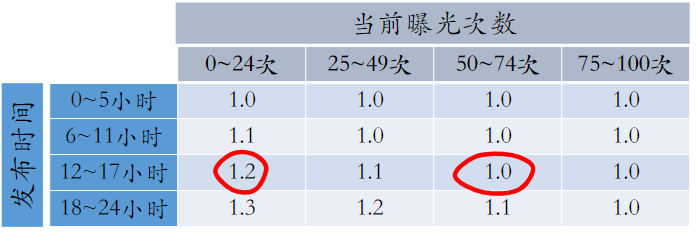
动态提权保量:用下面四个值计算提权系数
- 目标时间:比如 24 小时
- 目标曝光:比如 100 次
- 发布时间:比如笔记已经发布 12 小时
- 已有曝光:比如笔记已经获得 20 次曝光
提权系数 =$f(\frac{发布时间}{目标时间},\frac{已有曝光}{目标曝光})=f(0.5,0.2)$
保量的难点
- 保量成功率远低于 100%
- 很多笔记在 24 小时达不到 100 次曝光
- 召回、排序存在不足
- 提权系数调得不好
- 线上环境变化会导致保量失败
- 线上环境变化:新增召回通道、升级排序模型、改变重排打散规则……
- 线上环境变化后,需要调整提权系数
为什么不给新笔记一个很大的提权系数,保证曝光。
- 好处:分数提升越多,曝光次数越多
- 坏处:把笔记推荐给不太合适的受众
- 点击率、点赞率等指标会偏低
- 笔记长期会受推荐系统打压,难以成长为热门笔记
- 即这个笔记如果推荐给合适用户,那它是不错的,但强行提高曝光次数,导致它被经常推给不适合的用户,进而交互指标偏低
差异化保量
根据内容质量区分
普通保量:不论新笔记质量高低,都做扶持,在前 24 小时给 100 次曝光 差异化保量:不同笔记有不同保量目标,普通笔记保 100 次曝光,内容优质的笔记保 100~500 次曝光
- 基础保量:24 小时 100 次曝光
- 内容质量:用模型评价内容质量高低,给予额外保量目标,上限是加 200 次曝光
- 作者质量:根据作者历史上的笔记质量,给予额外保量目标,上限是加 200 次曝光
- 一篇笔记最少有 100 次保量,最多有 500 次保量
冷启动AB测试
作者侧(发布)指标:
- 发布渗透率、人均发布量
用户侧(消费)指标:
- 对新笔记的点击率、交互率
- 大盘指标:消费时长、日活、月活
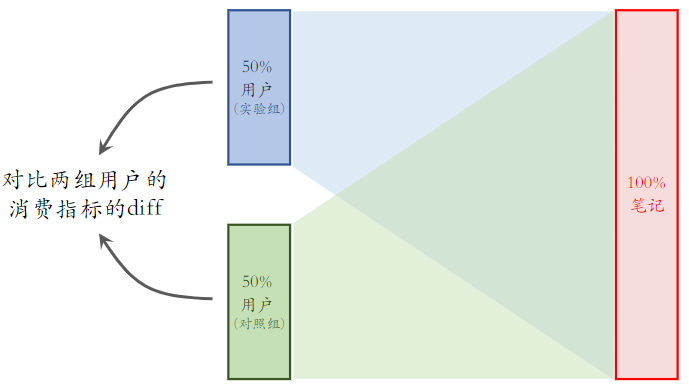
- 标准的 AB 测试只测大盘指标,而冷启动 AB 测试还要测上面提到的指标
用全量笔记测试,实验组用新策略
推荐系统标准的 AB 测试
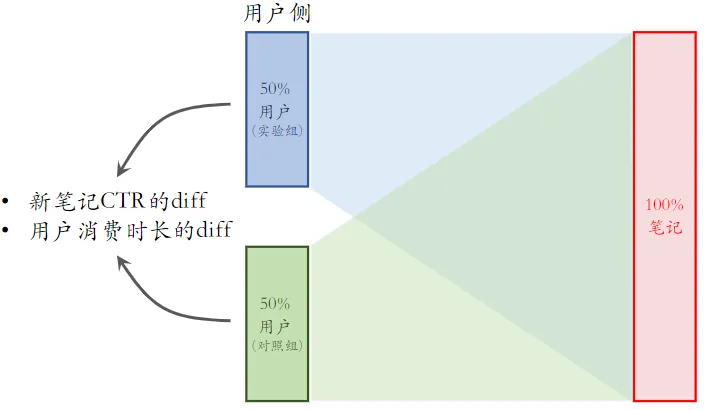
用户侧实验
用户侧实验
- 限定:保量 100 次曝光
- 假设:新笔记曝光越多,用户使用 APP 时长越低
- 这个假设很合理,因为新笔记推送不准确,过多会影响体验
- 新策略:把新笔记排序时的权重增大两倍
- 结果(只看消费指标):
- AB 测试的 diff 是负数(策略组不如对照组)
- 如果推全,diff 会缩小(比如 −2% → −1%)
有缺点,但影响不大(推全,diff 会缩小)
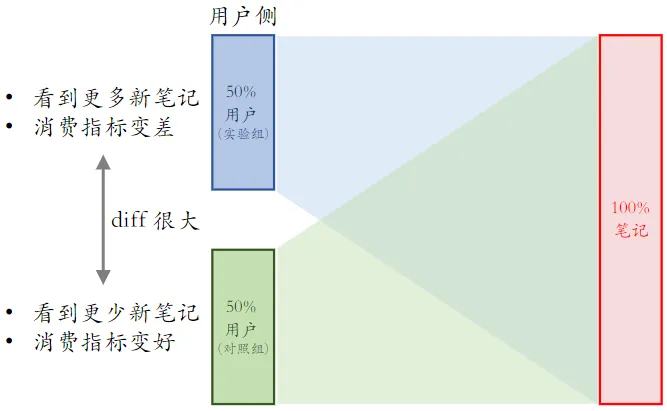
- 使用新策略后,实验组看到的新笔记会增多,又因为有着保量 100 次的目标,所以对照组看到的新笔记数量会减少
- 实验组看多了新笔记,消费指标变差;对照组看少了新笔记,消费指标变好
- 但推全后,这 100 次的保量目标会均匀的分配给所有用户,消费指标依然会下降,但不会有 实验组 那么差
作者侧实验
方案一

设定:
- 新老笔记走各自队列,没有竞争
- 重排分给新笔记 1/3 流量,分给老笔记 2/3 流量
新策略:把新笔记的权重增大两倍
- 这对新笔记来说依然是公平竞争,而新笔记在重排中还是 1/3 流量
- 所以新策略不会激励发布,不会改变发布侧指标
结果(只看发布指标):不合理
- AB 测试的 diff 是正数(实验组优于对照组)
- 如果推全,diff 会消失(比如 2% → 0)
缺点一:新笔记之间会抢流量
- 给实验组新笔记提权后,同是新笔记,实验组中的能获得更多曝光,而对照组中的曝光就少了
- 而一旦推全后,就不存在新笔记间强流量的情况,diff 就消失了
缺点二:新笔记和老笔记抢流量
-
举例说明
- 设定:新老笔记自由竞争
- 新策略:把新笔记排序时的权重增大两倍
- AB 测试时,50% 新笔记(带策略)跟 100% 老笔记抢流量
- 推全后,100% 新笔记(带策略)跟 100% 老笔记抢流量
- 作者侧 AB 测试结果与推全结果有些差异
新老笔记抢流量不是问题,问题是 AB 测试与推全后的 设定 不一致,导致 AB 测试的结果不准确
方案二
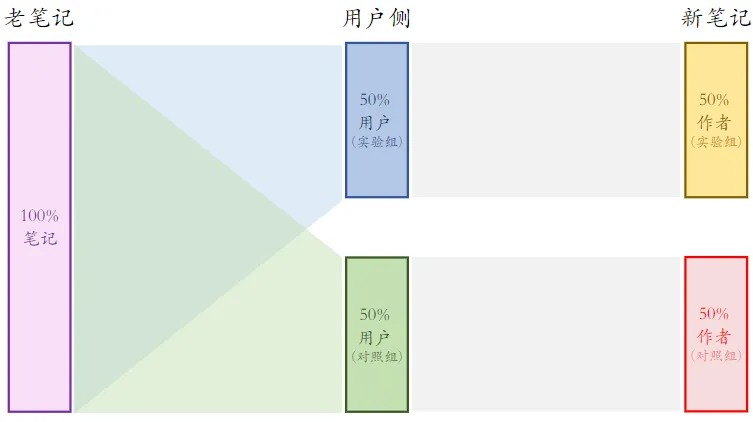
- 实验组用户只能看到实验组新笔记,对照组用户同理
- 这样就避免了两组新笔记抢流量
方案二比方案一的优缺点
- 优点:新笔记的两个桶不抢流量,作者侧实验结果更可信
-
相同:新笔记和老笔记抢流量,作者侧 AB 测试结果与推全结果有些差异
- 依然是 AB 测试时 50% 新笔记跟 100% 老笔记抢流量,推全后 100% 新笔记跟 100% 老笔记抢流量
- 缺点:新笔记池减小一半,对用户体验造成负面影响
方案三

- 相当于把小红书切成了 2 个 APP
- 这样做的实验结果是最精准的
- 不太可行,太损害用户体验了 (数据少了一半,但是跨国 APP 可以用这个方案呀)
AB测试总结
-
冷启的 AB 测试需要观测作者发布指标和用户消费指标
-
各种 AB 测试的方案都有缺陷(小红书有更好的方案,但也不完美)
-
设计方案的时候,问自己几个问题:
-
实验组、对照组新笔记会不会抢流量?
-
新笔记、老笔记怎么抢流量?
- AB 测试时怎么抢?推全后怎么抢?
-
同时隔离笔记、用户,会不会让内容池变小?
-
如果对新笔记做保量,会发生什么?实验准确性是否受影响
-
优化指标
日活用户数(DAU)和留存是最核心的指标
- 对于 UGC 平台,发布量和发布渗透率也是核心指标
目前工业界最常用 LT7 和 LT30 衡量留存
- 某用户今天登录 APP,未来 7 天中有4天 登录 APP,那么该用户今天的 LT7 等于 4。
- 显然有1≤LT7≤7和1≤LT30≤30
- LT 增长通常意味着用户体验提升。(除非 LT 增长且 DAU下降。)
其他核心指标: (这些指标的重要性低于 DAU 和留存)
- 用户使用时长
- 时长增长,LT 通常会增长
- 时长增长,阅读数、曝光数可能会下降 (用户时间有限)
- 总阅读数(即总点击数)、
- 总曝光数。
非核心指标:点击率、交互率、等等
召回模型&通道
推荐系统有几十条召回通道,它们的召回总量是固定的。 总量越大,指标越好,粗排计算量越大
- 双塔模型(two-tower)和 item-to-item(I2I)是最重要的 两类召回模型,占据召回的大部分配额。
- 有很多小众的模型,占据的配额很少。在召回总量不变的 前提下,添加某些召回模型可以提升核心指标。
- 有很多内容池,比如30天物品、1天物品、6小时物品、新 用户优质内容池、分人群内容池。
- 同一个模型可以用于多个内容池,得到多条召回通道
改进双塔模型
优化正样本、负样本
- 简单正样本:有点击的(用户,物品)二元组。
- 简单负样本:随机抽取组合的(用户,物品)二元组。
- 困难负样本:排序阶段排名靠后的(用户,物品)二元组
改进神经网络结构
Baseline:用户塔、物品塔分别是全连接网络,各输出一 个向量,分别作为用户、物品的表征
- 改进:用户塔、物品塔分别用 DCN 代替全连接网络。
- 改进:在用户塔中使用用户行为序列(last-n)
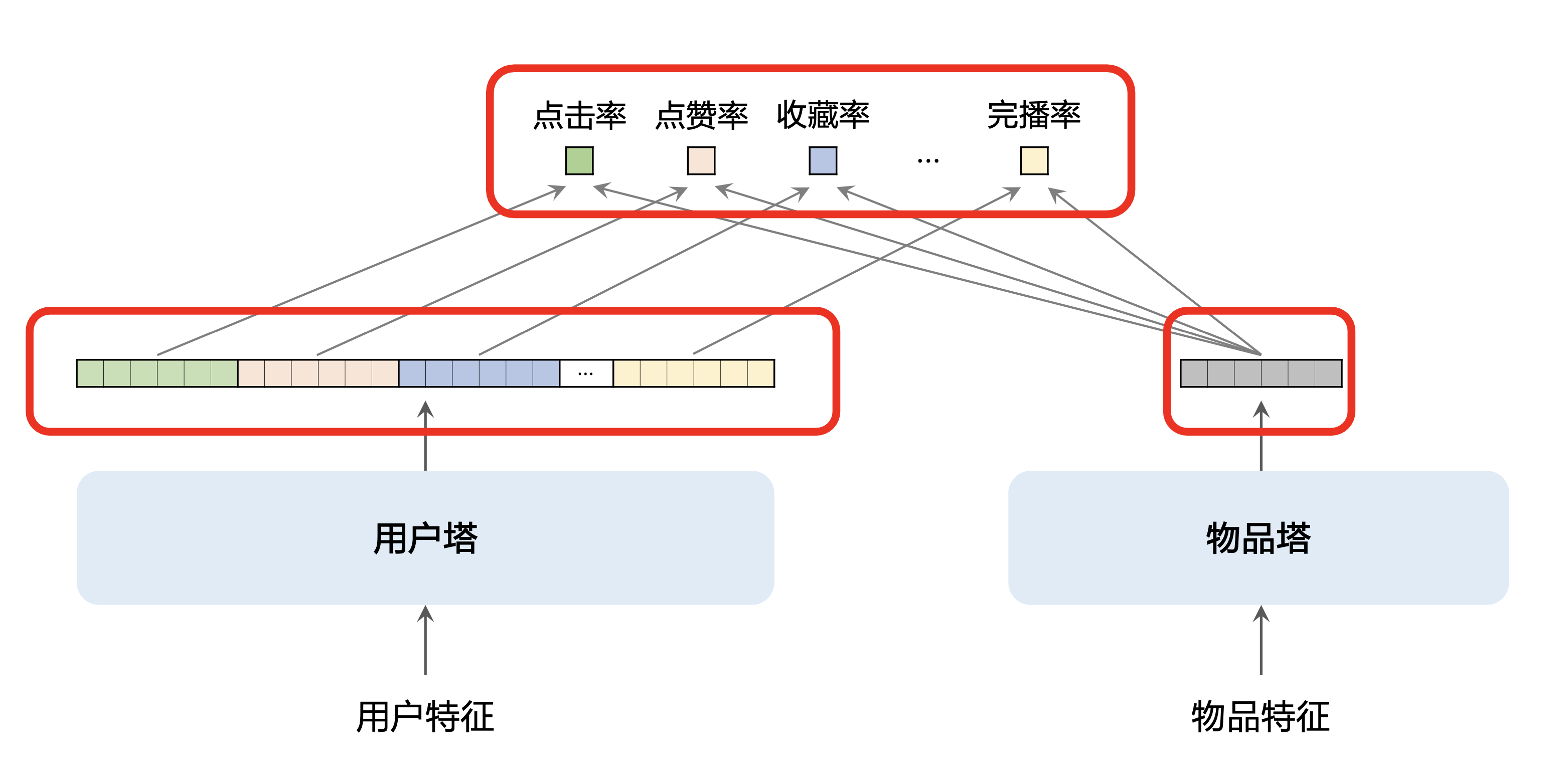
- 改进:使用多向量模型代替单向量模型。(标准的双塔模 型也叫单向量模型。)
- 多向量模型有点类似排序模型预估多个目标,而不是简单二分类区分正负样本。
改进模型的训练方法
Baseline:做二分类,让模型学会区分正样本和负样本
- 改进:结合二分类、batch 内负采样。(对于 batch 内负采样,需要做纠偏。)
- 改进:使用自监督学习方法,让冷门物品的 embedding 学 得更好。(特征增强)
Item-to-Item
I2I 是一大类模型,基于相似物品做召回。
最常见的用法是 U2I2I (user → item → item)
- 用户u喜欢物品 i1(用户历史上交互过的物品)
- 寻找 i1 的相似物品 i2
- 将i2推荐给u
如何计算物品相似度
- ItemCF 及其变体:
- ItemCF 、Online ItemCF、Swing、Online Swing 都是基于 相同的思想。
- 线上同时使用上述 4 种 I2I 模型,各分配一定配额
- 基于物品向量表征,计算向量相似度(内积,cos)。(双塔模 型、图神经网络均可计算物品向量表征。)
- 其他小模型 : 比如 PDN、Deep Retrieval、SINE、 M2GRL 等模型。
- U2U2I (user → user → item):已知用户 𝑢! 与 𝑢” 相似,且 𝑢” 喜欢物品 𝑖,那么给用户 𝑢! 推荐物品 𝑖。
- U2A2I (user → author → item):已知用户 𝑢 喜欢作者 𝑎, 且 𝑎 发布物品 𝑖,那么给用户 𝑢 推荐物品 𝑖。
- U2A2A2I (user → author → author → item):已知用户 𝑢 喜欢作者 𝑎!,且 𝑎! 与 𝑎” 相似,𝑎” 发布物品 𝑖,那么给 用户 𝑢 推荐物品 𝑖。
- 在召回总量不变的前提下,调整各召回通道的配额。(可 以让各用户群体用不同的配额。)
排序模型
精排
精排基座
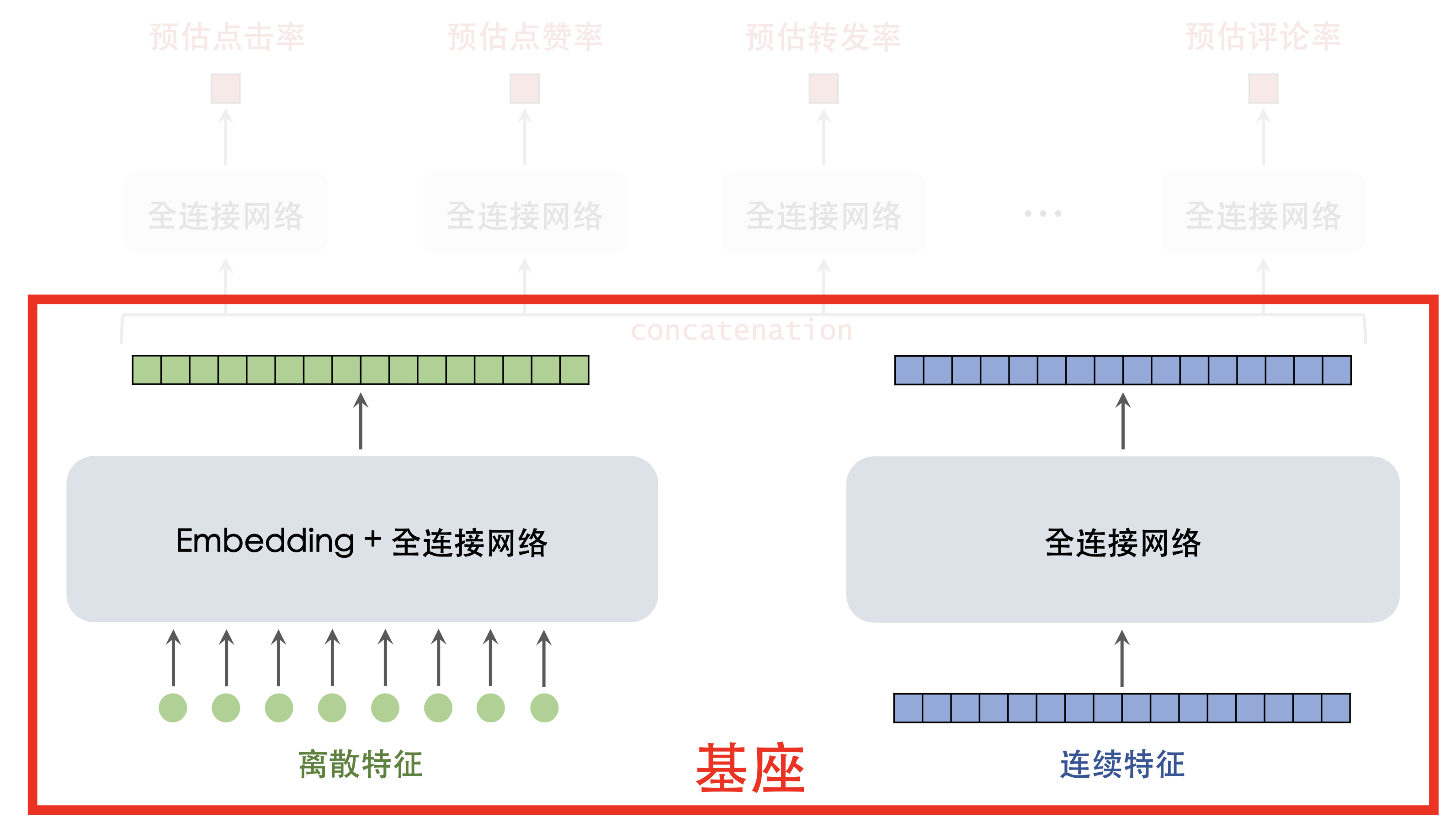
基座的输入包括离散特征和连续特征,输出一个向量,作为 多目标预估的输入
多目标预估
基于基座输出的向量,同时预估点击率等多个目标
- 改进 1:增加新的预估目标,并把预估结果加入融合公式。
- 最标准的目标包括点击率、点赞率、收藏率、转发率、评论率、 关注率、完播率
- 寻找更多目标,比如进入评论区、给他人写的评论点赞
- 改进 2:MMoE 、PLE 等结构可能有效,但往往无效。
- 改进 3:纠正 position bias 可能有效,也可能无效。
粗排
粗排的打分量比精排大 10 倍,因此粗排模型必须够快。
- 简单模型:多向量双塔模型,同时预估点击率等多个目标。
- 复杂模型:三塔模型 效果好,但工程实现难度较大。
蒸馏精排训练粗排,让粗排与精排更一致
- 方法1:pointwise 蒸馏。
- 设 𝑦 是用户真实行为,设 𝑝 是精排的预估。
- 用 (y+p)/2作为粗排拟合的目标。
- 例:
- 对于点击率目标,用户有点击(𝑦 = 1),精排预估 𝑝 = 0.6。
- 用 (y+p)/2= 0.8 作为粗排拟合的点击率目标。
- 方法2:pairwise 或 listwise 蒸馏。
- 给定 𝑘 个候选物品,按照精排预估做排序。
- 做 learning to rank (LTR),让粗排拟合物品的序(而非值)。
- 例:
- 对于物品 𝑖 和 𝑗,精排预估点击率为Pi > Pj。
- LTR 鼓励粗排预估点击率满足Pi > Pj,否则有惩罚。
- LTR 通常使用 pairwise logistic loss。
- 优点:粗精排一致性建模可以提升核心指标。
- 缺点:如果精排出bug,精排预估值 𝑝 有偏,会污染粗排训练 数据,不容易察觉。
用户行为序列建模
- 最简单的方法是对物品向量取平均,作为一种用户特征。
- DIN 使用注意力机制,对物品向量做加权平均。
- 工业界目前沿着 SIM 的方向发展。先用类目等属性筛选物 品,然后用 DIN 对物品向量做加权平均。
改进1:增加序列长度,让预测更准确,但是会增加计算成本 和推理时间
改进2:筛选的方法,比如用类目、物品向量表征聚类
- 离线用多模态神经网络提取物品内容特征,将物品表征为向量。
- 离线将物品向量聚为 1000 类,每个物品有一个聚类序号。
- 线上排序时,用户行为序列中有 𝑛 = 1,000,000 个物品。某候 选物品的聚类序号是 70,对 𝑛 个物品做筛选,只保留聚类序号 为 70 的物品。𝑛 个物品中只有数千个被保留下来。
- 同时有好几种筛选方法,取筛选结果的并集。
改进3:对用户行为序列中的物品,使用 ID 以外的一些特征。
概括:沿着 SIM 的方向发展,让原始的序列尽量长,然后做 筛选降低序列长度,最后将筛选结果输入 DIN。
在线学习
既需要在凌晨做全量更新,也需要全天不间断做增量更新。 设在线学习需要 10,000 CPU core 的算力增量更新一个精排模 型。推荐系统一共需要多少额外的算力给在线学习?
- 为了做 AB 测试,线上同时运行多个不同的模型。
- 如果线上有 𝑚 个模型,则需要 𝑚 套在线学习的机器。
- 线上有 𝑚 个模型,其中 1 个是 holdout,1 个是推全的模型, 𝑚 − 2 个测试的新模型。
每套在线学习的机器成本都很大,因此 𝑚 数量很小,制 约模型开发迭代的效率。 在线学习对指标的提升巨大,但是会制约模型开发迭代 的效率。最好在模型成熟后才开始在线学习
老汤模型
用每天新产生的数据对模型做 1 epoch 的训练。 久而久之,老模型训练得非常好,很难被超过。 对模型做改进,重新训练,很难追上老模型
如何快速判断新模型结构是否优于老模型,判断是否继续训练新模型
- 对于新、老模型结构,都随机初始化模型全连接层。
- Embedding 层可以是随机初始化,也可以是复用老模型训练好的参数。
- 用 𝑛 天的数据训练新老模型。(从旧到新,训练 1 epoch)
- 如果新模型显著优于老模型,新模型很可能更优。
- 只是比较新老模型结构谁更好,而非真正追平老模型。
如何更快追平、超过线上的老模型
- 已经得出初步结论,认为新模型很可能优于老模型。用几十 天的数据训练新模型,早日追平老模型。
- 方法 1:尽可能多地复用老模型训练好的 embedding 层,避免 随机初始化 embedding 层。(Embedding 层是对用户、物品 特点的“记忆”,比全连接层学得慢。)
- 方法 2:用老模型做 teacher,蒸馏新模型。(用户真实行为是 𝑦,老模型的预测是 𝑝,用 (y+p)/2作为训练新模型的目标。)
提升多样性
S:兴趣分数,即融合点击率等多个预估目标。
D:多样性分数,即物品 𝑖 与已经选中的物品的差异。
精排多样性
精排阶段,结合兴趣分数和多样性分数对物品 𝑖 排序
- 用 Si + Di 对物品做排序。
常用 MMR、DPP 等方法计算多样性分数,精排使用滑动 窗口,粗排不使用滑动窗口。
-
精排决定最终的曝光,曝光页面上邻近的物品相似度应该小。 所以计算精排多样性要使用滑动窗口。
-
粗排要考虑整体的多样性,而非一个滑动窗口中的多样性
除了多样性分数,精排还使用打散策略增加多样性。
- 类目:当前选中物品 𝑖,之后 5 个位置不允许跟 𝑖 的二级类目 相同。
- 多模态:事先计算物品多模态内容向量表征,将全库物品聚 为 1000 类;
- 在精排阶段,如果当前选中物品 𝑖,之后 10 个位 置不允许跟 𝑖 同属一个聚类。
粗排多样性
粗排给 5000 个物品打分,选出 500 个物品送入精排。提升粗排和精排多样性都可以提升推荐系统核心指标。
- 根据 Si 对 5000 个物品排序,分数最高的 200 个物品送入 精排。
- 对于剩余的 4800 个物品,对每个物品 𝑖 计算兴趣分数 Si 和多样性分数 Di。
- 根据 Si + Di 对剩余 4800 个物品排序,分数最高的 300 个 物品送入精排。
召回的多样性
添加噪声
用户塔将用户特征作为输入,输出用户的向量表征 , 然后 做 ANN 检索,召回向量相似度高的物品。
- 线上做召回时(在计算出用户向量之后,在做 ANN 检索之 前),往用户向量中添加随机噪声。
- 用户的兴趣越窄(比如用户最近交互的 𝑛 个物品只覆盖少 数几个类目),则添加的噪声越强。
- 添加噪声使得召回的物品更多样,可以提升推荐系统核心 指标。
抽样用户行为序列
用户最近交互的 𝑛 个物品(用户行为序列)是用户塔的输入
- 保留最近的 𝑟 个物品(𝑟 ≪ 𝑛)
- 从剩余的 𝑛 − 𝑟 个物品中随机抽样 𝑡 个物品(𝑡 ≪ 𝑛)。(可以 是均匀抽样,也可以用非均匀抽样让类目平衡。)
- 将得到的 𝑟 + 𝑡 个物品作为用户行为序列,而不是用全部 𝑛 个物 品。
抽样用户行为序列为什么能涨指标
- 注入随机性,召回结果更多样化
- 𝑛 可以非常大,可以利用到用户很久之前的兴趣
探索流量
每个用户曝光的物品中有 2%是非个性化的,用作兴趣探索
- 维护一个精选内容池,其中物品均为交互率指标高的优质物品。(内容池可以分人群,比如30~40岁男性内容池。)
- 从精选内容池中随机抽样几个物品,跳过排序,直接插入最终排序结果。
- 兴趣探索在短期内负向影响核心指标,但长期会产生正向 影响。
特殊对待新用户、低活用户等特殊人群
- 新用户、低活用户的行为很少,个性化推荐不准确。
- 新用户、低活用户容易流失,要想办法促使他们留存。
- 特殊用户的行为(比如点击率、交互率)不同于主流 用户,基于全体用户行为训练出的模型在特殊用户人 群上有偏。
涨指标的方法
- 构造特殊内容池,用于特殊用户人群的召回。
- 使用特殊排序策略,保护特殊用户。
- 使用特殊的排序模型,消除模型预估的偏差。
特殊内容池
新用户、低活用户的行为很少,个性化召回不准确。(既然个性化不好,那么就保证内容质量好。)
针对特定人群的特点构造特殊内容池,提升用户满意度。 (例如,对于喜欢留评论的中年女性,构造促评论内容池, 满足这些用户的互动需求。)
根据物品获得的交互次数、交互率选择优质物品。
- 圈定人群:只考虑特定人群,例如18~25岁一二线城市男性。
- 构造内容池:用该人群对物品的交互次数、交互率给物品打 分,选出分数最高的物品进入内容池。
- 内容池有弱个性化的效果。
- 内容池定期更新,加入新物品,排除交互率低和失去时效性的老物品。
- 该内容池只对该人群生效。
做因果推断,判断物品对人群留存率的贡献,根据 贡献值选物品。
通常使用双塔模型从特殊内容池中做召回。
- 双塔模型是个性化的。(个性化效果,取决于历史行为是否丰富)
- 对于新用户,双塔模型的个性化做不准。
- 靠高质量内容、弱个性化做弥补
额外的训练代价?
- 对于正常用户,不论有多少内容池,只训练一个双塔模型。
- 对于新用户,由于历史交互记录很少,需要单独训练模型。
额外的推理代价?
- 内容池定期更新,然后要更新 ANN 索引。
- 线上做召回时,需要做 ANN 检索。
- 特殊内容池都很小(比全量内容池小10~100倍),所以需要 的额外算力不大。
特殊排序策略
排除低质量物品
对于新用户、低活用户这样的特殊人群,业务上只关注留 存,不在乎消费(总曝光量、广告收入、电商收入)
对于新用户、低活用户,少出广告、甚至不出广告
新发布的物品不在新用户、低活用户上做探索
-
物品新发布时,推荐做得不准,会损害用户体验。
- 只在活跃的老用户上做探索,对新物品提权(boost)。
- 不在新用户、低活用户上做探索,避免伤害用户体验。
差异化的融分公式
新用户、低活用户的点击、交互行为不同于正常用户。
- 低活用户的人均点击量很小;没有点击就不会有进一步的交互。
- 低活用户的融分公式中,提高预估点击率的权重(相较于普通 用户)。
保留几个曝光坑位给预估点击率最高的几个物品。
- 例:精排从 500 个物品中选 50 个作为推荐结果,其中 3 个坑位给点击率最高的物品,剩余 47 个坑位由融分公式决定。
- 甚至可以把点击率最高的物品排在第一,确保用户一定能看到。
特殊的排序模型
特殊用户人群的行为不同于普通用户。新用户、低活用户的点 击率、交互率偏高或偏低。
排序模型被主流用户主导,对特殊用户做不准预估。
用全体用户数据训练出的模型,给新用户做的预估有严重偏差。
- 如果一个 APP 的用 90%是女性,用全体用户数据训练出的模型, 对男性用户做的预估有偏差。
方法 1:大模型 + 小模型。
- 用全体用户行为训练大模型,大模型的预估 𝑝 拟合用户行为 𝑦。
- 用特殊用户的行为训练小模型,小模型的预估 𝑞 拟合大模型的残差 𝑦 − 𝑝 (大模型的错误)。
- 对主流用户只用大模型做预估 𝑝。
- 对特殊用户,结合大模型和小模型的预估 𝑝 + 𝑞。
方法 2:融合多个 experts,类似 MMoE。
- 只用一个模型,模型有多个 experts,各输出一个向量。
- 对 experts 的输出做加权平均。
- 根据用户特征计算权重。
- 以新用户为例,模型将用户的新老、活跃度等特征作为输 入,输出权重,用于对 experts 做加权平均。
**方法 3:大模型预估之后,用小模型做校准。 **
-
用大模型预估点击率、交互率。
-
将用户特征、大模型预估点击率和交互率作为小模型(例 如 GBDT)的输入。
-
在特殊用户人群的数据上训练小模型,小模型的输出拟合 用户真实行为。
错误的做法
每个用户人群使用一个排序模型,推荐系统同时维护多个 大模型。
- 系统有一个主模型;每个用户人群有自己的一个模型。
- 每天凌晨,用全体用户数据更新主模型。
- 基于训练好的主模型,在某特殊用户人群的数据上再训练 1 epoch,作为该用户人群的模型。
短期可以提升指标;维护代价大,长期有害。
交互行为
推荐系统如何利用交互行为:将模型预估的交互率用于排序
- 模型将交互行为当做预估的目标
- 将预估的点击率、交互率做融合,作为排序的依据
关注量对留存的价值
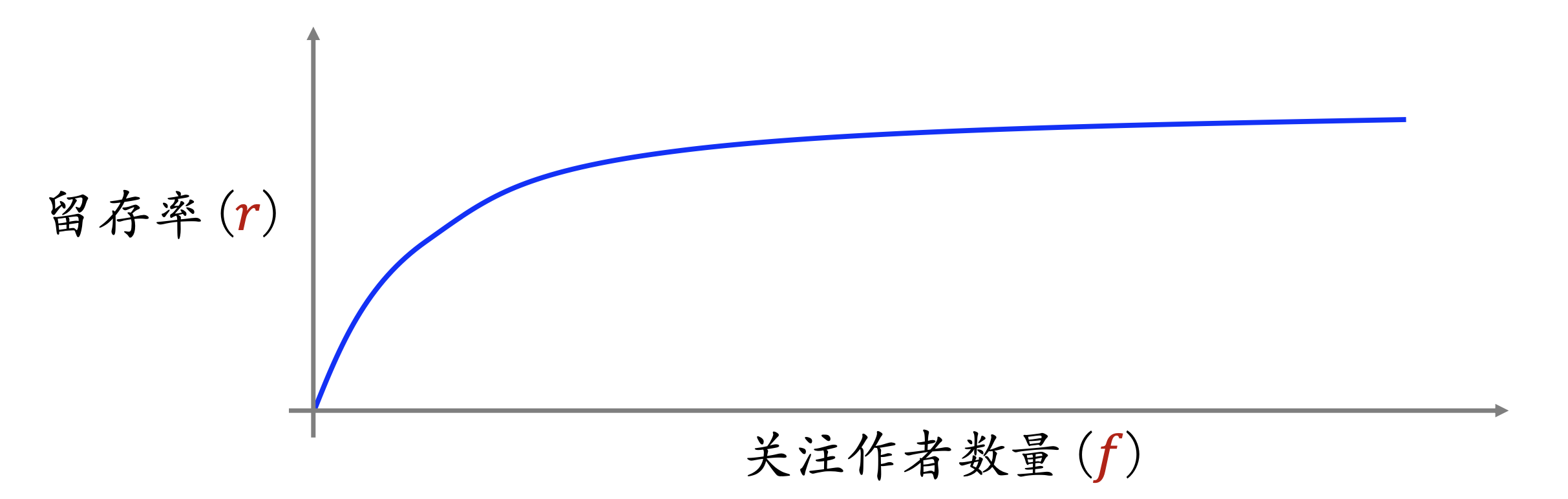
对于一位用户,他关注的作者越多,则平台对他的吸引力越强。
用户留存率( 𝑟)与他关注的作者数量(𝑓)正相关,如果某用户的 𝑓 较小,则推荐系统要促使该用户关注更多作者。
利用关注关系提升用户留存
方法 1:用排序策略提升关注量。
- 对于用户 𝑢,模型预估候选物品 𝑖 的关注率为 P。
- 设用户 𝑢 已经关注了 𝑓 个作者。
- 我们定义单调递减函数w(f) ,用户已经关注的作者越多, 则w(f) 越小。
- 在排序融分公式中添加 w(f) *P,用于促关注。(如果 f小,w(f) 大且P大,则w(f) *P给物品𝑖 带来很大加分。)
方法 2:构造促关注内容池和召回通道。
- 这个内容池中物品的关注率高,可以促关注。
- 如果用户关注的作者数 𝑓 较小,则对该用户使用该内容池。
- 召回配额可以固定,也可以与 𝑓 负相关。
粉丝数对促发布的价值
- UGC 平台将作者发布量、发布率作为核心指标,希望作者 多发布。
- 作者发布的物品被平台推送给用户,会产生点赞、评论、关 注等交互。
- 交互(尤其是关注、评论)可以提升作者发布积极性。
- 作者的粉丝数越少,则每增加一个粉丝对发布积极性的提升 越大。粉丝多的话,粉丝数提高,对作者影响不大。
用排序策略帮助低粉新作者涨粉。
- 某作者 𝑎 的粉丝数(被关注数)为 𝑓。
- 作者 𝑎 发布的物品 𝑖 可能被推荐给用户 𝑢,模型预估关注率 为 Pui。
- 我们定义单调递减函数 w(f) 作为权重;作者 𝑎 的粉丝越多, 则w(f) 越小。
- 在排序融分公式中添加 w(f) *Pui,帮助低粉作者涨粉。
隐式关注关系
隐式关注关系:用户 𝑢 喜欢看作者 𝑎 发布的物品,但是 𝑢没有关注 𝑎
隐式关注的作者数量远大于显式关注。挖掘隐式关注关系, 构造 U2A2I (user → author → item 已知用户 𝑢 喜欢作者 𝑎, 且 𝑎 发布物品 𝑖,那么给用户 𝑢 推荐物品 𝑖)召回通道,可以提升推荐系统核心指标
促转发(分享回流)
A 平台用户将物品转发到 B 平台,可以为 A 吸引站外流量
推荐系统做促转发(也叫分享回流)可以提升 DAU 和消费指 标。
简单提升转发次数是否有效呢?
-
模型预估转发率为 𝑝,融分公式中有一项 𝑤 ⋅ 𝑝,让转发率大的 物品更容易获得曝光机会。
-
增大权重 𝑤 可以促转发,吸引站外流量,但是会负面影响点击 率和其他交互率。指标是此消彼长的
在不损害点击和其他交互的前提下,尽量多吸引站外 流量。
-
其他平台的 Key Opinion Leader (KOL) ,不是本平台的
-
用户 𝑢 是我们站内的 KOL,但他不是其他平台的 KOL,他的 转发价值不大
-
用户 𝑣 在我们站内没有粉丝,但他是其他平台的 KOL,他的转 发价值大
-
如何判断本平台的用户是不是其他平台的 KOL
- 该用户历史上的转发能带来多少站外流量。
识别出的站外 KOL 之后,该如何用于排序和召回
方法 1: 排序融分公式中添加额外的一项ku*pui。
- ku :如果用户 𝑢 是站外 KOL,则 ku大。
- pui :为用户 𝑢 推荐物品 𝑖,模型预估的转发率。
- 如果 𝑢 是站外 KOL,则多给他曝光他可能转发的物品。
方法 2:构造促转发内容池和召回通道,对站外 KOL 生效(和促关注留存一样)
评论促发布
UGC 平台将作者发布量、发布率作为核心指标,希望作者多 发布。
关注、评论等交互可以提升作者发布积极性。
如果新发布物品尚未获得很多评论,则给预估评论率提权,让物品尽快获得评论。
排序融分公式中添加额外一项 wi * Pi。
-
wi: 权重,与物品 𝑖 已有的评论数量负相关。
-
Pi :为用户推荐物品 𝑖,模型预估的评论率。
有的用户喜欢留评论,喜欢跟作者、评论区用户互动。
- 给这样的用户添加促评论的内容池,让他们更多机会参与讨论。
- 有利于提升这些用户的留存。
有的用户常留高质量评论(评论的点赞量高)
- 高质量评论对作者、其他用户的留存有贡献。(作者、其他用户觉得这样的评论有趣或有帮助。)
- 用排序和召回策略鼓励这些用户多留评论。