背景
有个类似comfyUI的推理框架。根据推理任务参数,切换对应底模+lora。 而且换了服务器厂商,服务器硬软件很多参数不一样。切换模型非常耗时,会计算在用户等待时间里面。
现象
原来是A卡 ,新的是B卡, 底模大概20G+,lora 几十M
| 加载时间 | A(原) | B(新) | 本地 |
|---|---|---|---|
| 底模 | 180+s | 4~500s+ | 原 5s内, 新10s+ |
| lora | 30s | 30s+ | 几百ms |
排查
整个推理流程非常复杂,使用opentelemetry对推理过程进行路径追踪,时间埋点。 同时在本地还原。
- 底模路径 模型解密 + model
load_state_dict+ modelto cuda - lora路径 模型解密 + 按照attention processor 动态加载、加权、并合入已有模型的 attention 层(model
load_state_dict+ modelto cuda)
模型加载涉及:cpu(解密) 、磁盘(NFS,ssd等)、PCIE(单卡推理)、cuda驱动、k8s NUMA等
** 相同环境不同型号机器表现不一样,线下线上同个型号也不一样 **
-
B cpu表现 更差,更新解密算法,更加高效。
-
集群上面用的都是NFS服务,和磁盘相比相差很远。特别是B的NFS服务异常糟糕。直接在本地挂NFS盘,初见端倪 (马上直接上几百秒)
-
B卡服务器NUMA也非常糟糕 。 A卡服务的NUMA Affinity (NUMA Affinity 能告知该 GPU 对应的 NUMA 节点)只有0,1,B卡完全不一样的。而且卡之间都是最慢的连接方式(SYS < bridge connect PIX或PHB < NVLink)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25nvidia-smi topo -m GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity NUMA Affinity GPU NUMA ID GPU0 X SYS SYS SYS SYS SYS SYS SYS 24-31,88-95 3 N/A GPU1 SYS X SYS SYS SYS SYS SYS SYS 16-23,80-87 2 N/A GPU2 SYS SYS X SYS SYS SYS SYS SYS 8-15,72-79 1 N/A GPU3 SYS SYS SYS X SYS SYS SYS SYS 0-7,64-71 0 N/A GPU4 SYS SYS SYS SYS X SYS SYS SYS 56-63,120-127 7 N/A GPU5 SYS SYS SYS SYS SYS X SYS SYS 48-55,112-119 6 N/A GPU6 SYS SYS SYS SYS SYS SYS X SYS 40-47,104-111 5 N/A GPU7 SYS SYS SYS SYS SYS SYS SYS X 32-39,96-103 4 N/A Legend: X = Self SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI) NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU) PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge) PIX = Connection traversing at most a single PCIe bridge NV# = Connection traversing a bonded set of # NVLinksNUMA 的优势在于能够提供更高的内存带宽和更低的访问延迟。当 CPU 与 GPU 处在同一 NUMA 节点时,内存和 I/O 带宽利用率大大提高,有助于提升数据预处理和模型推理的速度,减少由于数据传输产生的瓶颈。
-
PCIE 测试,就像抽奖一样。
肉眼可见: PCIe链路状态目前处于降级状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
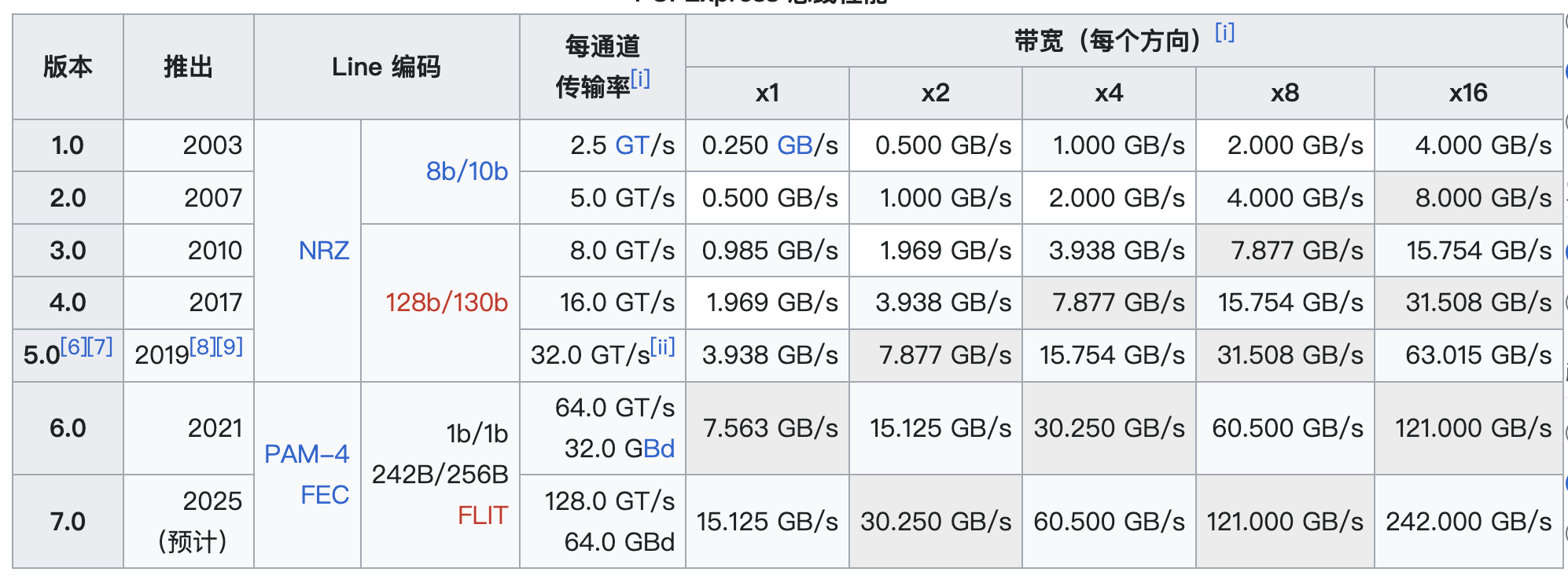
43# 按照测试工具 apt-get -y install pciutils # 查看某卡的PCIE性能 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 4090 Off | 00000000:61:00.0 Off | Off | | 46% 25C P8 22W / 450W | 8058MiB / 49140MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ lspci -vvv -s <Bus-Id> | grep LnkSta LnkSta: Speed 2.5GT/s (downgraded), Width x8 (downgraded) # 注意这个地方 速率和带宽完全被降频 LnkSta2: Current De-emphasis Level: -3.5dB, EqualizationComplete+, EqualizationPhase1+ # 查看卡所有信息,卡号对应的bus_id, pcie (可支持最高/目前)版本号,带宽(可支持最高/目前) nvidia-smi --query-gpu=index,name,pci.bus_id,pcie.link.gen.max,pcie.link.gen.current,pcie.link.width.max,pcie.link.width.current --format=csv index, name, pci.bus_id, pcie.link.gen.max, pcie.link.gen.current, pcie.link.width.max, pcie.link.width.current 0, NVIDIA GeForce RTX 4090, xxxx, 4, 4, 16, 16 1, NVIDIA GeForce RTX 4090, xxx, 4, 1, 16, 16 2, NVIDIA GeForce RTX 4090, xxxx, 4, 1, 16, 16 3, NVIDIA GeForce RTX 4090, xxxx, 4, 1, 16, 8 4, NVIDIA GeForce RTX 4090, xxxx, 4, 1, 16, 16 5, NVIDIA GeForce RTX 4090, 00000000:A1:00.0, 4, 1, 16, 16 6, NVIDIA GeForce RTX 4090, xxxxx, 4, 1, 16, 16 7, NVIDIA GeForce RTX 4090, xxxx, 4, 1, 16, 8 # 明显是供应商的问题 有可能是主版,BIOS配置等问题 # 真实测试 使用官方工具 路径 /usr/local/cuda-11.8/extras/demo_suite/bandwidthTest # 带宽减半基本速度减半官方标准PCIEPCI Express 总线性能
解决
尽量减少落盘或者读盘,才能大幅加速,甚至保存编译好 warnup 好的模型
- compiler cache not work ,暂时行不通
- 共享内存(multiprocessing.shared_memory.SharedMemory)
- 利用mmap 存放模型文件,加快读取,cache住
load_state_dict的参数 - 内存占用大(内部实现类似LRU cache淘汰机制,分别对应底模和lora分开管理,时间长且大的先删除)
- 利用mmap 存放模型文件,加快读取,cache住
to device最好一次过,不然很慢- lora 调用
load_state_dict可以多线程加快速度。
最终结果
| 加载时间 命中cache后 | B卡 | ||
|---|---|---|---|
| 底模 | 不到6s | ||
| lora | 不到2s | ||