MCP整体架构
整个MCP采用的是一个CS的架构。client和server端,一对一的配比。中间通过一个transport layer(传输层)。进行一个互相的交互。
多个client结合起来,变成一个应用(Host)。
client之间可以通过多个transport layer,来去调取对应的服务。
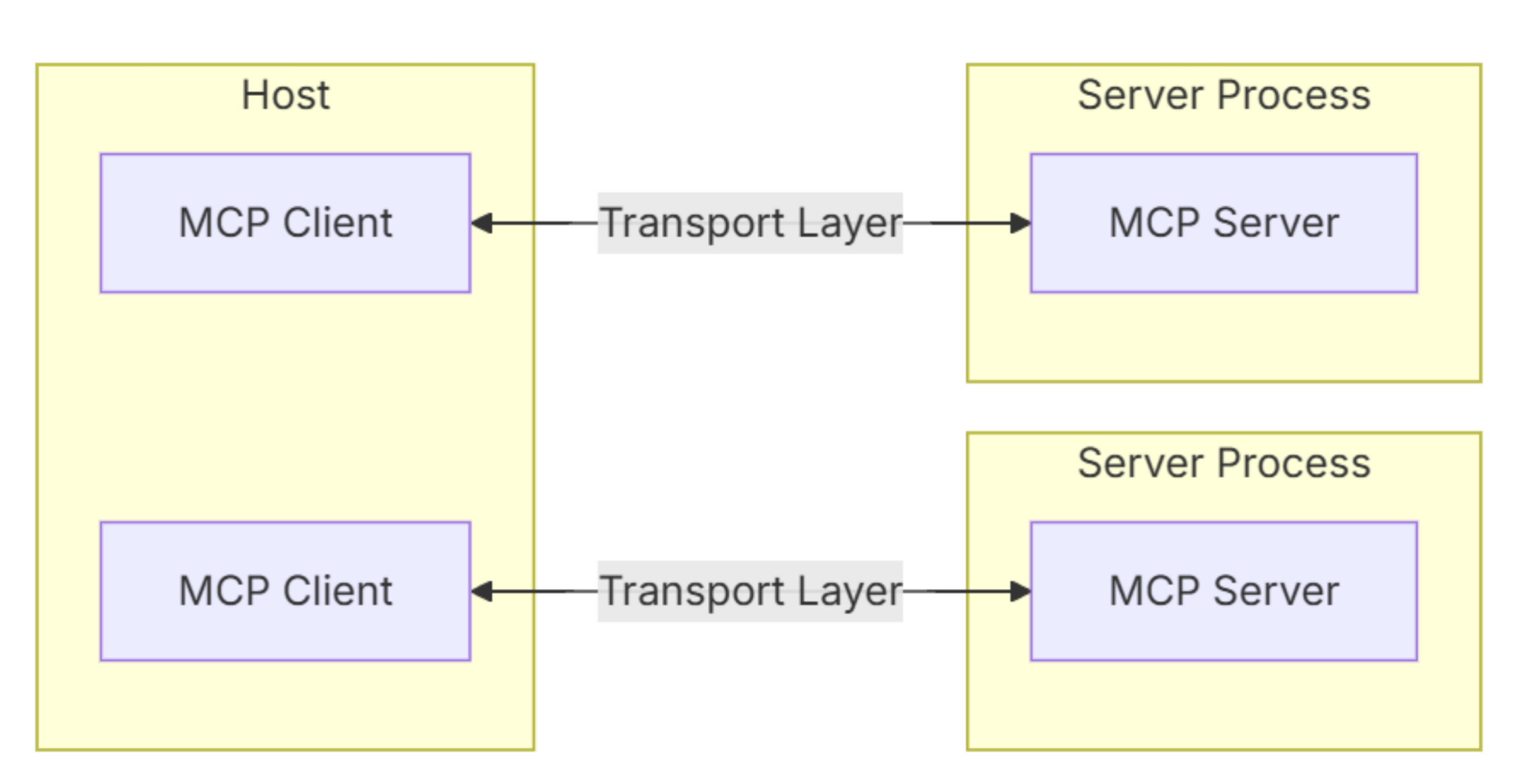
- Host(宿主):承载交互的应用程序。
- Transport Layer(传输层):负责在客户端和服务器之间建立通信。
- MCP Client(MCP 客户端):与 MCP 服务器进行通信的实体。
- MCP Server(MCP 服务器):管理工具和上下文,并处理来自 MCP 客户端的请求。
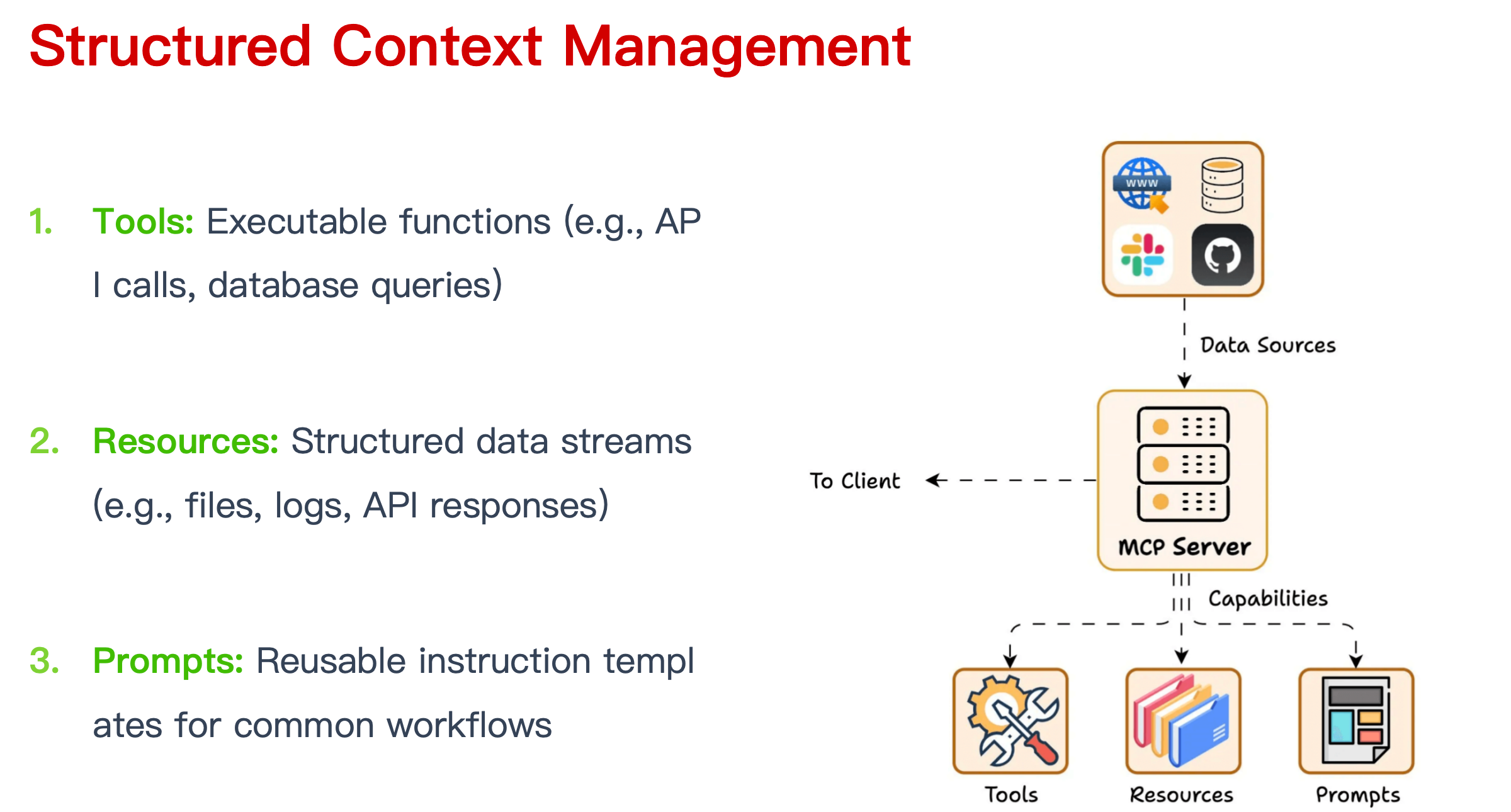
Structured Context Management
mcp 主要是提供了非常标准化结构化上下管理。
交互组织为三种标准化的原语(primitives):
- 工具(Tools):可执行的函数(例如 API 调用、数据库查询)
- 资源(Resources):结构化的数据流(例如文件、日志、API 响应)
- 提示模板(Prompts):可复用的指令模板,用于常见的工作流
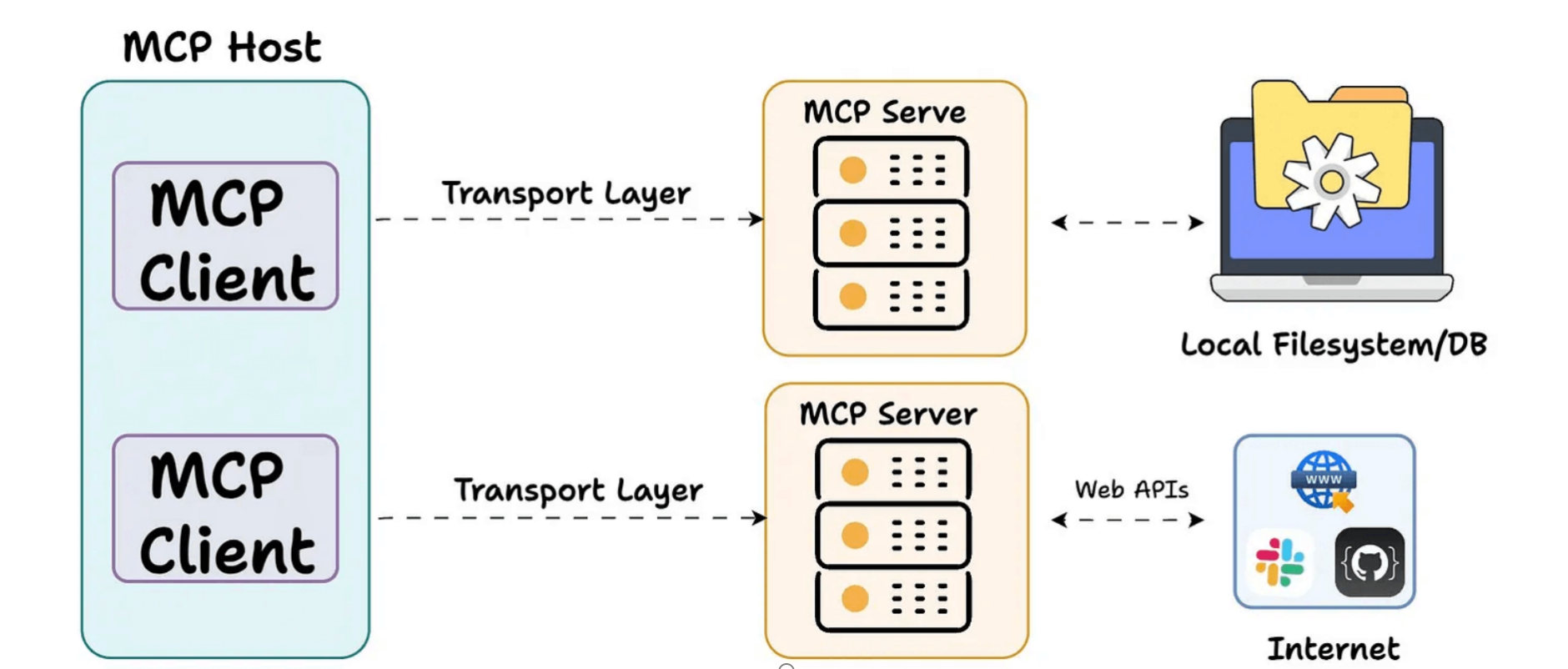
MCP 默认优先保障隐私。这意味着每次访问工具或资源时,都需要用户明确授权。服务器默认在本地运行,除非用户明确允许远程使用,因此敏感数据在未经同意的情况下不会离开受控环境。
MCP 提供了 STDIO 和 SSE 两种传输协议,当前很多实验性的工具都是使用 STDIO 传输。如果提供服务的话,则是使用 SSE(Server-Sent Events)
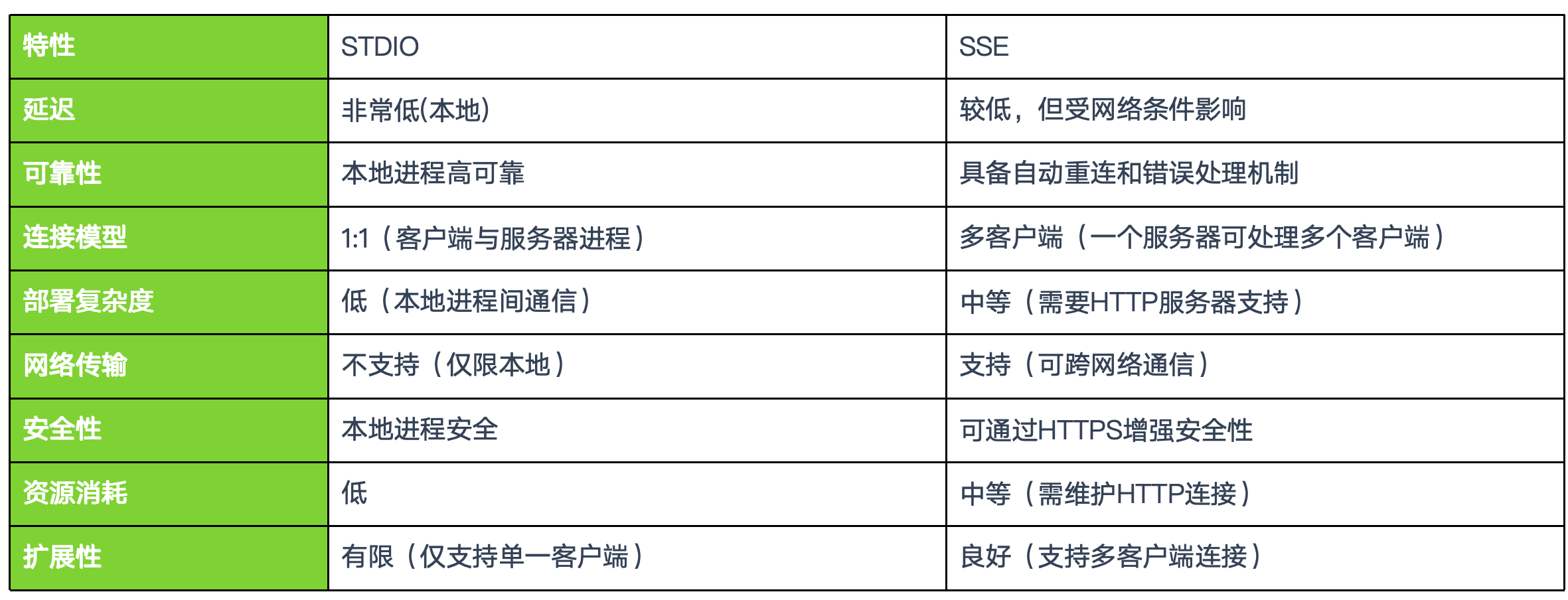
状态会话:维护会话状态,客户端和服务器之间建立长期连接,会话具有明确的生命周期。
双向RPC通信:客户端可以调用服务器(传统RPC模式),服务器可以调用客户端(反向RPC)。
标准化接口:定义了一组标准操作,使用JSON Schema定义参数和返回值,促进互操作性。
能力协商:初始化阶段进行能力协商,动态发现可用功能,适应不同实现和版本。
事件通知:支持单向通知,资源变更订阅模式,异步事件处理。
MCP 局限
-
工具文档至关重要, LLM 通过工具的文本描述来理解和选择工具,因此需要精心编写工具的名称、docstring 和参数说明。
-
工具的使用和理解严重依赖于 LLM 基础模型能力,工具的数量严重依赖于 LLM 的长上下文的记忆能力。
-
每一次模型调用只能选择有限的工具,不能做到真正智能,随着大模型基础能力的提升可能被逐步替换。
MCP 的选择基于 prompt,理论任意 LLM 都适配 MCP,只要能提供对应的工具描述。但是要做得更好,肯定进行了专门的后训练或者微调,才能更智能使用 MCP 提供的能力。
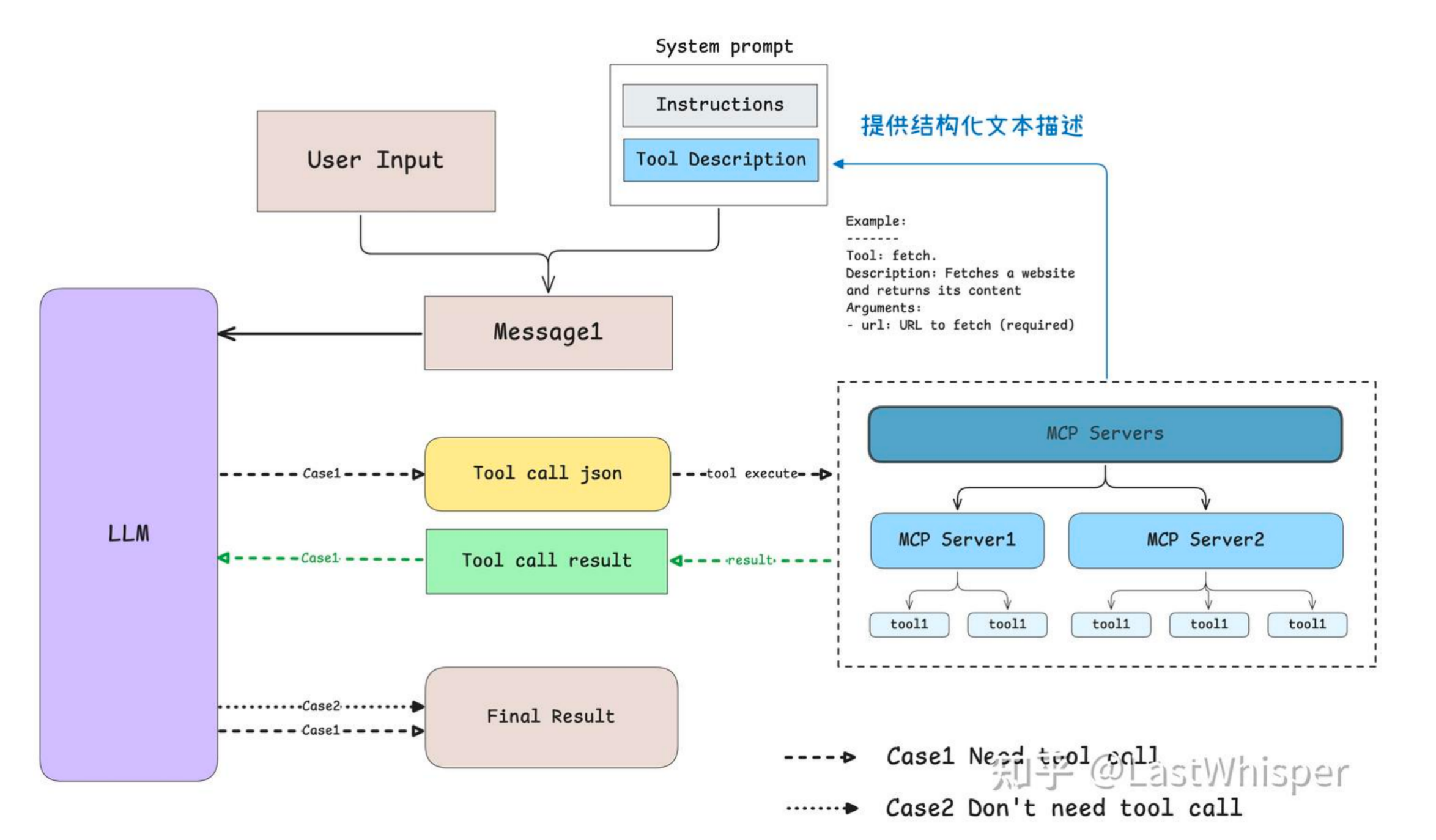
大模型如何通过MCP识别和调用工具
- LLM 大模型通过 prompt 来确定当前工具;
- 通过将工具具体使用描述以文本的形式传递给模型,供模型了解有哪些工具进行选择。
- 大模型通过 prompt,即提供所有工具的结构化描述和 few-shot 的 example 作为输入,来确定该使用哪些工具。
- 由 LLM 大模型的输出确定使用哪些 MCP Server;
- 当大模型分析用户请求后,会决定是否需要调用工具:
- 无需工具时:模型直接生成自然语言回复。
- 需要工具时:模型输出结构化 JSON 格式的工具调用请求。
- 当大模型分析用户请求后,会决定是否需要调用工具:
- MCP Client 执行对应 MCP Server,并对执行结果返回给 LLM 大模型。
1 | |
核心函数
1 | |
明确只支持单一工具调用结构,这是一个人为的限制,不是模型能力限制,而是出于以下几个设计权衡
- 简化逻辑,避免歧义。 不需要并行调用多个 MCP server。不需要合并多个工具返回结果再反馈给 LLM。工具框架来说,这是最小闭环单位的推理调用
- 有些工具调用之间存在依赖关系,调用工具 A 的返回值是工具 B 的输入 or 某些工具是“条件工具”,只有满足某条件才执行。
- 配合 REACT / Chain-of-Thought(CoT)风格推理, 符合逐步外部调用 + 反馈的交互系统。