在 Kubernetes 中,HorizontalPodAutoscaler 自动更新工作负载资源 (例如 Deployment 或者 StatefulSet), 目的是自动扩缩工作负载以满足需求。
HorizontalPodAutoscaler 管理 Deployment 的 replicas 字段。 Deployment Controller 负责设置下层 ReplicaSet 的 replicas 字段,对一个副本个数被自动扩缩的 StatefulSet 执行滚动更新,该 StatefulSet 会直接管理它的 Pod 集合 (不存在类似 ReplicaSet 这样的中间资源)
水平扩缩意味着对增加的负载的响应是部署更多的 Pod。 这与 “垂直(Vertical)” 扩缩不同,对于 Kubernetes, 垂直扩缩意味着将更多资源(例如:内存或 CPU)分配给已经为工作负载运行的 Pod。
如果负载减少,并且 Pod 的数量高于配置的最小值, HorizontalPodAutoscaler 会指示工作负载资源(Deployment、StatefulSet 或其他类似资源)缩减。
水平 Pod 自动扩缩不适用于无法扩缩的对象(例如:DaemonSet。)
HorizontalPodAutoscaler 被实现为 Kubernetes API resource和controller。
资源决定了控制器的行为。 在 Kubernetes 控制平面内运行的水平 Pod 自动扩缩控制器会定期调整其目标(例如:Deployment)的所需规模,以匹配观察到的指标。
控制原理
Kubernetes 将水平 Pod 自动扩缩实现为一个间歇运行的控制回路(它不是一个连续的过程)。间隔由 kube-controller-manager 的 --horizontal-pod-autoscaler-sync-period 参数设置(默认间隔为 15 秒)。
在每个时间段内,控制器管理器都会根据每个 HorizontalPodAutoscaler 定义中指定的指标查询资源利用率。 控制器管理器找到由 scaleTargetRef 定义的目标资源,然后根据目标资源的 .spec.selector 标签选择 Pod, 并从资源指标 API(针对每个 Pod 的资源指标)或自定义指标获取指标 API(适用于所有其他指标)。
- 使用资源指标 API,设置了目标使用率(例如CPU使用率),控制器获取每个 Pod 中的容器资源使用情况, 并计算资源使用率。如果设置了 target 值(例如接受请求数),将直接使用原始数据(不再计算百分比)。 接下来,控制器根据平均的资源使用率或原始值计算出扩缩的比例,进而计算出目标副本数。
- 使用自定义指示,只使用原始值,而不是使用率。
HorizontalPodAutoscaler 的常见用途是将其配置为从聚合 API (metrics.k8s.io、custom.metrics.k8s.io 或 external.metrics.k8s.io)获取指标。 metrics.k8s.io API 通常由名为 Metrics Server 的插件提供,需要单独启动。
默认情况下,HorizontalPodAutoscaler 控制器会从一系列的 API 中检索度量值。 集群管理员需要确保下述条件,以保证 HPA 控制器能够访问这些 API:
- 启用了 API 聚合层
- 相应的 API 已注册:
- 对于资源指标,将使用
metrics.k8s.ioAPI,一般由 metrics-server 提供。 它可以作为集群插件启动。 - 对于自定义指标,将使用
custom.metrics.k8s.ioAPI。 它由其他度量指标方案厂商的“适配器(Adapter)” API 服务器提供。 检查你的指标管道以查看是否有可用的 Kubernetes 指标适配器。 - 对于外部指标,将使用
external.metrics.k8s.ioAPI。可能由上面的自定义指标适配器提供。
- 对于资源指标,将使用
算法
Pod 水平自动扩缩控制器根据当前指标和期望指标来计算扩缩比例
\[期望副本数 = 向上取整ceil[当前副本数 * (当前指标currentMetricValue / 期望指标desiredMetricValue)]\]例如,如果当前指标值为 200m,而期望值为 100m,则副本数将加倍, 因为 200.0 / 100.0 == 2.0 如果当前值为 50m,则副本数将减半, 因为 50.0 / 100.0 == 0.5。如果比率足够接近 1.0(在全局可配置的容差范围内,默认为 0.1), 则控制平面会跳过扩缩操作。
在检查容差并决定最终值之前,控制平面还会考虑是否缺少任何指标, 以及有多少 Pod Ready。
在排除掉被搁置的 Pod 后,扩缩比例就会根据 currentMetricValue/desiredMetricValue 计算出来。
搁置条件
- 所有设置了删除时间戳的 Pod(带有删除时间戳的对象正在关闭/移除的过程中)都会被忽略, 所有失败的 Pod 都会被丢弃。
- 某个 Pod 缺失度量值,它将会被搁置,只在最终确定扩缩数量时再考虑。如果缺失某些度量值,控制平面会更保守地重新计算平均值,在需要缩小时假设这些 Pod 消耗了目标值的 100%, 在需要放大时假设这些 Pod 消耗了 0% 目标值。这可以在一定程度上抑制扩缩的幅度。
- 当使用 CPU 指标来扩缩时,任何还未就绪(还在初始化,或者可能是不健康的)状态的 Pod 或 最近的指标度量值采集于就绪状态前的 Pod,该 Pod 也会被搁置。工作负载会在不考虑遗漏指标或尚未就绪的 Pod 的情况下进行扩缩, 控制器保守地假设尚未就绪的 Pod 消耗了期望指标的 0%,从而进一步降低了扩缩的幅度。
考虑到尚未准备好的 Pod 和缺失的指标后,控制器会重新计算使用率。 如果新的比率与扩缩方向相反,或者在容差范围内,则控制器不会执行任何扩缩操作。 在其他情况下,新比率用于决定对 Pod 数量的任何更改。
指定了多个指标, 那么会按照每个指标分别计算扩缩副本数,取最大值进行扩缩。 如果任何一个指标无法顺利地计算出扩缩副本数(比如,通过 API 获取指标时出错), 并且可获取的指标建议缩容,那么本次扩缩会被跳过。 这表示,如果一个或多个指标给出的 desiredReplicas 值大于当前值,HPA 仍然能实现扩容。
由于在确定是否保留某些 CPU 指标时无法准确确定 Pod 首次就绪的时间,Pod 未准备好并在其启动后的一个可配置的短时间窗口内转换为准备好,它会认为 Pod “尚未准备好”。使用 --horizontal-pod-autoscaler-initial-readiness-delay 标志配置,默认值为 30 秒。一旦 Pod 准备就绪,过一段时间才开始保留,该值由 -horizontal-pod-autoscaler-cpu-initialization-period 标志配置,默认为 5 分钟。
最后,在 HPA 控制器执行扩缩操作之前,会记录扩缩建议信息。 控制器会在操作时间窗口中考虑所有的建议信息,并从中选择得分最高的建议。 这个值可通过 kube-controller-manager 服务的启动参数 --horizontal-pod-autoscaler-downscale-stabilization 进行配置, 默认值为 5 分钟。 用于指定在当前操作完成后,HPA 必须等待多长时间才能执行另一次缩放操作,这个配置可以让系统更为平滑地进行缩容操作,从而消除短时间内指标值快速波动产生的影响。
由于所有的容器的资源用量都会被累加起来,Pod 的总体资源用量值可能不会精确体现各个容器的资源用量。 这一现象也会导致一些问题,例如某个容器运行时的资源用量非常高,但因为 Pod 层面的资源用量总值让人在可接受的约束范围内,HPA 不会执行扩大目标对象规模的操作。
Metrics Server
HPA v2需要安装 Metrcis Server 了,Metrics Server 可以通过标准的 Kubernetes API 把监控数据暴露出来,有了 Metrics Server 之后,我们就完全可以通过标准的 Kubernetes API 来访问我们想要获取的监控数据了
1 | |
当我们访问上面的 API 的时候,我们就可以获取到该 Pod 的资源数据,这些数据其实是来自于 kubelet 的 Summary API 采集而来的。不过需要说明的是我们这里可以通过标准的 API 来获取资源监控数据,并不是因为 Metrics Server 就是 APIServer 的一部分,而是通过 Kubernetes 提供的 Aggregator 汇聚插件来实现的,是独立于 APIServer 之外运行的。
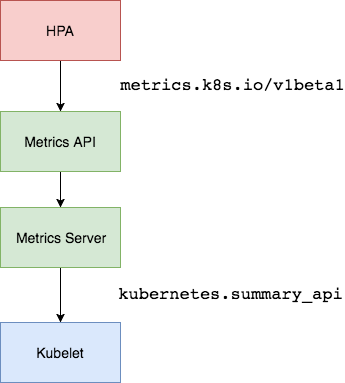
Aggregator 允许开发人员编写一个自己的服务,把这个服务注册到 Kubernetes 的 APIServer 里面去,这样我们就可以像原生的 APIServer 提供的 API 使用自己的 API 了,我们把自己的服务运行在 Kubernetes 集群里面,然后 Kubernetes 的 Aggregator 通过 Service 名称就可以转发到我们自己写的 Service 里面去了。
Metrics Server的相关错误
xxx: no such host,我们看到这个错误信息一般就可以确定是 DNS 解析不了造成的,我们可以看到 Metrics Server 会通过 kubelet 的 10250 端口获取信息,使用的是 hostname,我们部署集群的时候在节点的 /etc/hosts 里面添加了节点的 hostname 和 ip 的映射,但是是我们的 Metrics Server 的 Pod 内部并没有这个 hosts 信息,当然也就不识别 hostname 了
- 修改coredns
- 修改启动参数
--kubelet-preferred-address-types=InternalIP
HPA参考
HorizontalPodAutoscaler v2参考 1.23+,低于的可以用autoscaling/v2beta2 具体参考kubectl api-versions|grep auto
1 | |
用于缩小稳定窗口的时间为 300 秒(或是 --horizontal-pod-autoscaler-downscale-stabilization 参数设定值)。 只有一种缩容的策略,允许 100% 删除当前运行的副本,这意味着扩缩目标可以缩小到允许的最小副本数。 对于扩容,没有稳定窗口。当指标显示目标应该扩容时,目标会立即扩容。 这里有两种策略,每 15 秒添加 4 个 Pod 或 100% 当前运行的副本数,直到 HPA 达到稳定状态。
1 | |
- 当启用 HPA 时,删除 Deployment 和/或 StatefulSet 的
spec.replicas的值。 - 监控CPU,内存时候需要添加 request 资源声明,不然
failed to get cpu utilization: missing request for cpu
测试
资源指标
测试yaml
1 | |
1 | |
随着负载上去,REPLICAS增加,由于每个 Pod 通过 kubectl run 请求 200 milli-cores,这意味着平均 CPU 使用率为 100 milli-cores。
1 | |
多指标例子,依次考量各个指标。 HorizontalPodAutoscaler 将会计算每一个指标所提议的副本数量,然后最终选择一个最高值
1 | |
尝试确保每个 Pod 的 CPU 利用率在 50% 以内
自定义指标
这个我们就需要使用 Prometheus Adapter,Prometheus 用于监控应用的负载和集群本身的各种指标,Prometheus Adapter 可以帮我们使用 Prometheus 收集的指标并使用它们来制定扩展策略,这些指标都是通过 APIServer 暴露的,而且 HPA 资源对象也可以很轻易的直接使用。
prometheus采集到的metrics并不能直接给k8s用,因为两者数据格式不兼容,prometheus-adapter可以将prometheus的metrics 数据格式转换成k8s API接口能识别的格式
1 | |
rancher 安装了商店里面的Prometheus监控,里面已经有内置的rancher-monitoring-prometheus-adapter,不需要额外安装prometheus-adapter,修改对应的configmap
1 | |
1 | |
然后重启rancher-monitoring-prometheus-adapter,查看是否生效
1 | |
创建对应HPA
1 | |
测试
1 | |
rule 格式解析 可以参考Prometheus-adapter配置写法
将 Prometheus 查询语句nginx_vts_server_requests_total返回的指标,转换成以 namespace 和 pod 为维度的 nginx_vts_server_requests_per_second 指标,使用函数聚合
1 | |
-
seriesQuery:查询 Prometheus 的语句,通过这个查询语句查询到的所有指标都可以用于 HPA -
seriesFilters:查询到的指标可能会存在不需要的,可以通过它过滤掉。通过 seriesQuery 挑选需要处理的 metrics 集合,可以通过 seriesFilters 精确过滤 metrics。
1
2
3seriesQuery: '{__name__=~"^container_.*_total",container_name!="POD",namespace!="",pod_name!=""}' seriesFilters: - isNot: "^container_.*_seconds_total"seriesFilters
1
2is: <regex>, 匹配包含该正则表达式的metrics. isNot: <regex>, 匹配不包含该正则表达式的metrics. -
resources:通过seriesQuery查询到的只是指标,如果需要查询某个 Pod 的指标,肯定要将它的名称和所在的命名空间作为指标的标签进行查询,resources就是将指标的标签和 k8s 的资源类型关联起来,最常用的就是 pod 和 namespace。有两种添加标签的方式,一种是overrides,另一种是template。overrides:它会将指标中的标签和 k8s 资源关联起来。上面示例中就是将指标中的 pod 和 namespace 标签和 k8s 中的 pod 和 namespace 关联起来,因为 pod 和 namespace 都属于核心 api 组,所以不需要指定 api 组。当我们查询某个 pod 的指标时,它会自动将 pod 的名称和名称空间作为标签加入到查询条件中。比如nginx: {group: "apps", resource: "deployment"}这么写表示的就是将指标中 nginx 这个标签和 apps 这个 api 组中的deployment资源关联起来;- template:通过 go 模板的形式。比如
template: "kube_<<.Group>>_<<.Resource>>"这么写表示,假如<<.Group>>为 apps,<<.Resource>>为 deployment,那么它就是将指标中kube_apps_deployment标签和 deployment 资源关联起来。
-
name:用来给指标重命名的,之所以要给指标重命名是因为有些指标是只增的,比如以 total 结尾的指标。这些指标拿来做 HPA 是没有意义的,我们一般计算它的速率,以速率作为值,那么此时的名称就不能以 total 结尾了,所以要进行重命名。matches:通过正则表达式来匹配指标名,可以进行分组as:默认值为$1,也就是第一个分组。as为空就是使用默认值的意思。
-
metricsQuery:这就是 Prometheus 的查询语句的聚合,前面的seriesQuery查询是获得 HPA 指标。当我们要查某个指标的值时就要通过它指定的查询语句进行了。可以看到查询语句使用了速率和分组,这就是解决上面提到的只增指标的问题。对于每个
namespace和pod的组合,使用rate函数计算原始指标在 2 分钟内的变化率,然后使用sum函数对所有结果求和,得到每秒请求数的平均值。Series:表示指标名称,原始的 Prometheus 查询语句LabelMatchers:表示原始的 Prometheus 查询语句中的标签匹配条件,目前只有pod和namespace两种,因此我们要在之前使用resources进行关联GroupBy:表示自定义指标的维度,例如namespace和pod