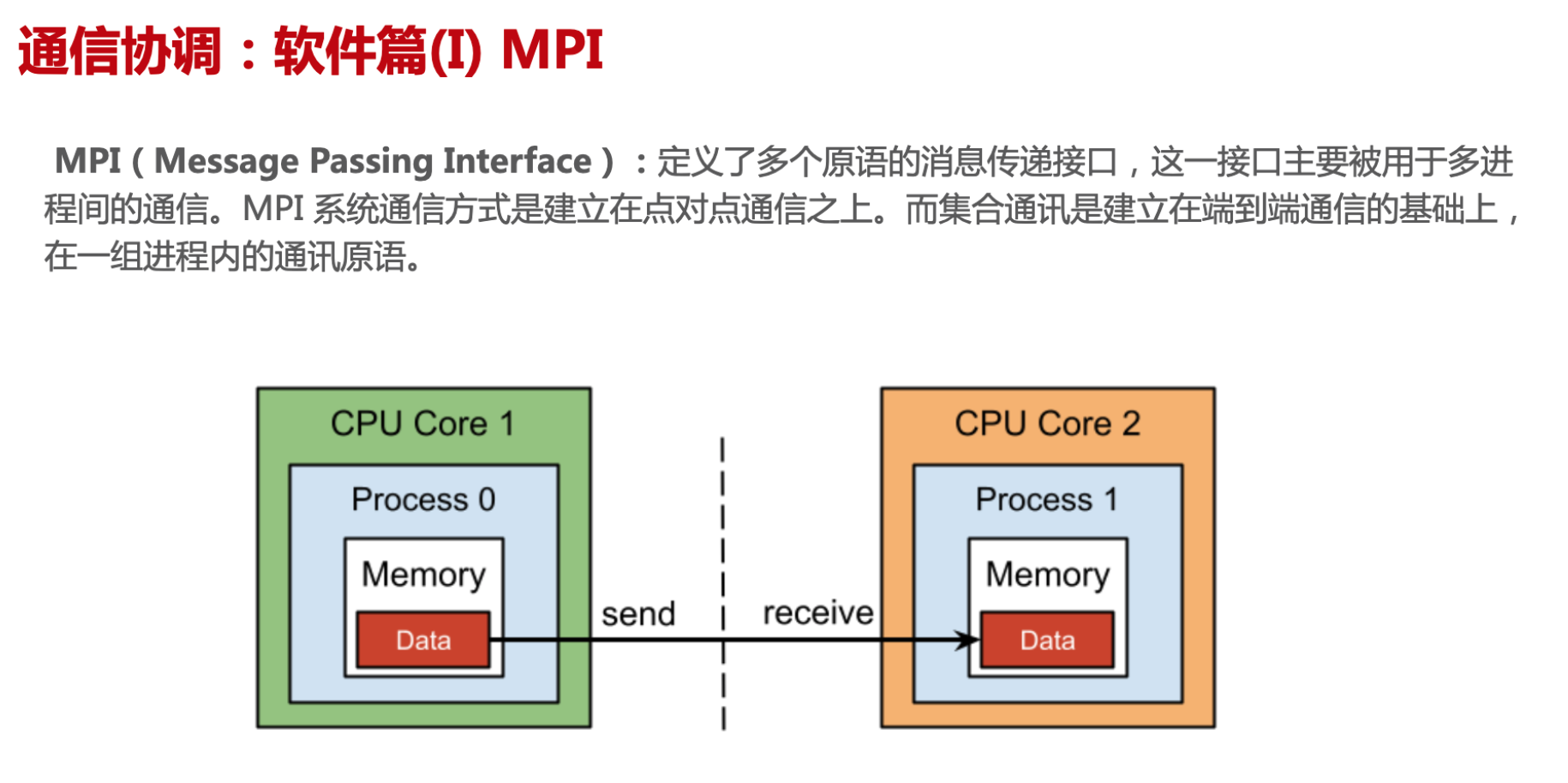
分布式训练集群
why
训练数据规模和单步计算量和模型相关相对固定,
- \[\mathrm{训练耗时}\;=\;\mathrm{训练数据规模}\;\ast\;\mathrm{单步计算量}/\mathrm{计算速率}\]
- \[\mathrm{计算速率}\;=\;\mathrm{单设备计算速率}(\mathrm{摩尔定律或者算法优化})\ast\mathrm{设备数}\;\ast\;\mathrm{多设备并行效率}(\mathrm{加速比})\]
但是可以提高计算速率
- 混合精度,算子融合,梯度累加
- 服务器架构,通信拓扑优化
- 数据并行 模型并行 流水并行
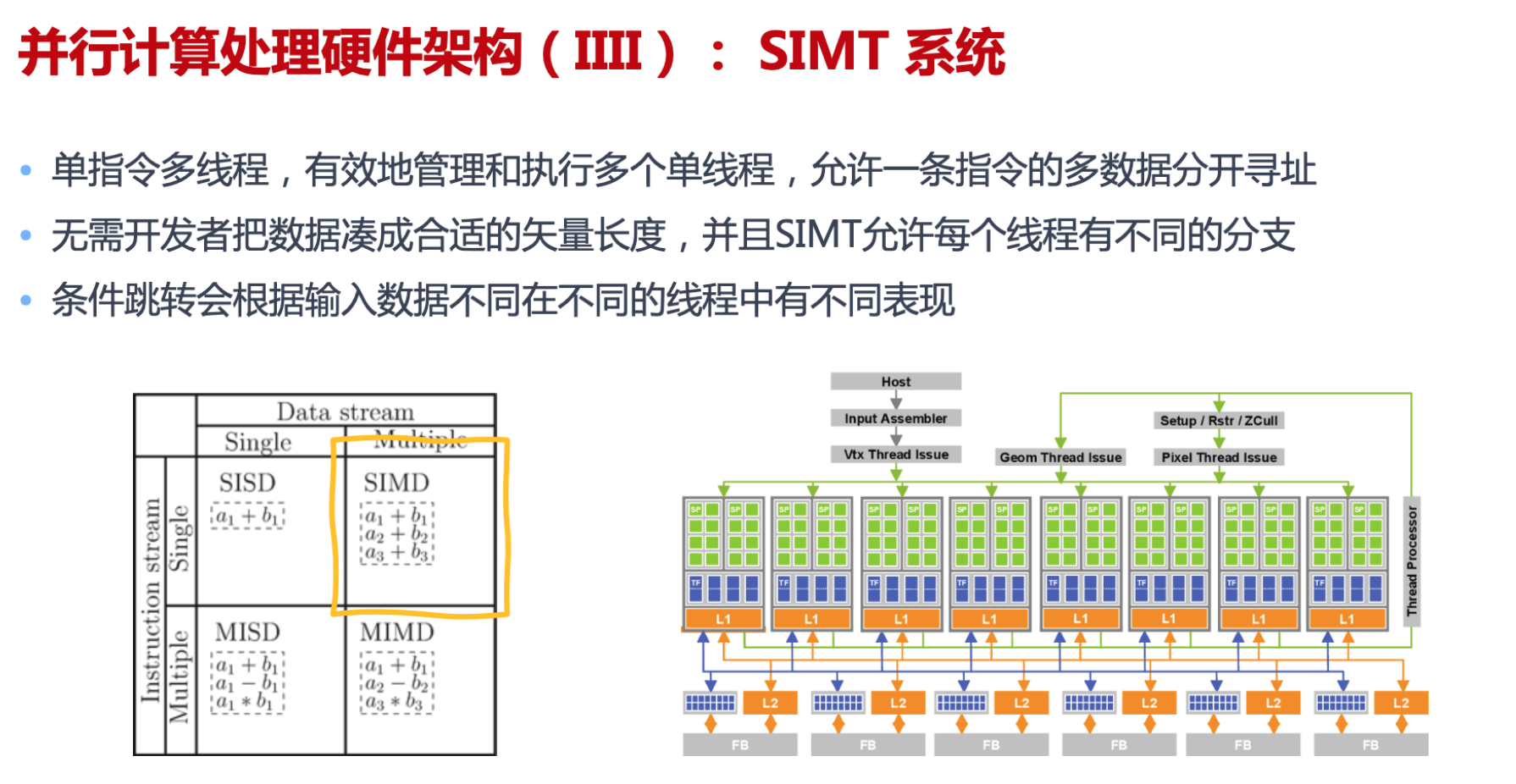
服务器架构
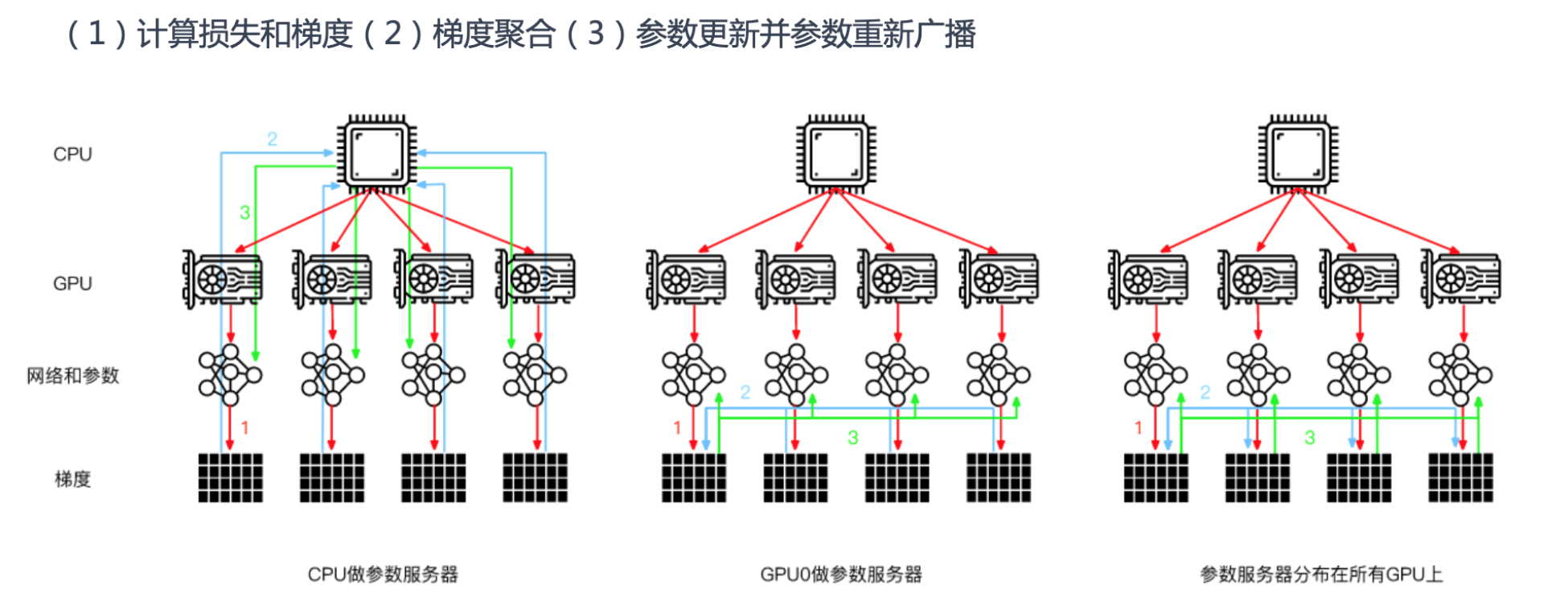
参数服务器
都是这三步:计算损失和梯度,梯度聚合, 参数更新并参数重新广播
- CPU作为参数服务器,CPU下发网络模型和参数给GPU卡计算损失和梯度,在CPU做梯度聚合,把所有参数更新到GPU卡
- GPU0作为参数服务器,CPU下发指令让每个GPU计算损失和梯度,在GPU0上梯度聚合,把所有参数更新到GPU卡
- 常用是第三种,CPU下发指令让每个GPU计算损失和梯度,通过通讯分布式并行梯度聚合,把所有参数更新到GPU卡
信息同步
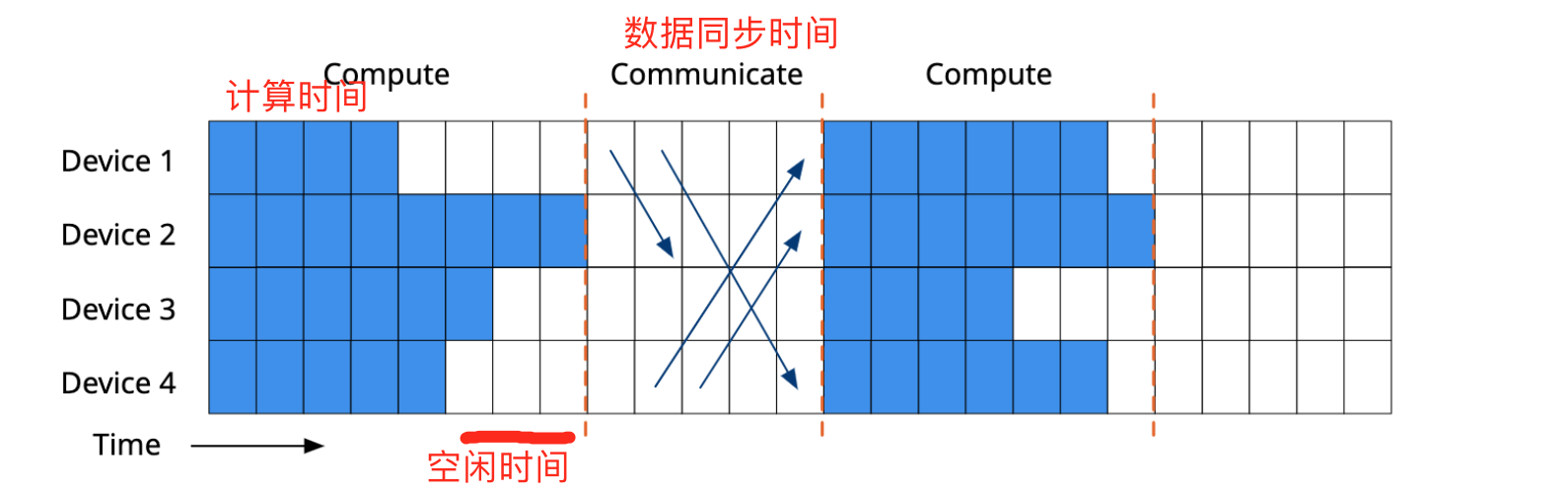
分布式 同步并行
- 必须等全部工作节点完成了本次通信之后才能继续下一轮本地计算
- 本地计算和通信同步严格顺序化,能够容易地保证并行的执行逻辑和串行相同
- 本地计算更早的工作节点需要等待其它工作节点处理,造成了计算硬件的浪费
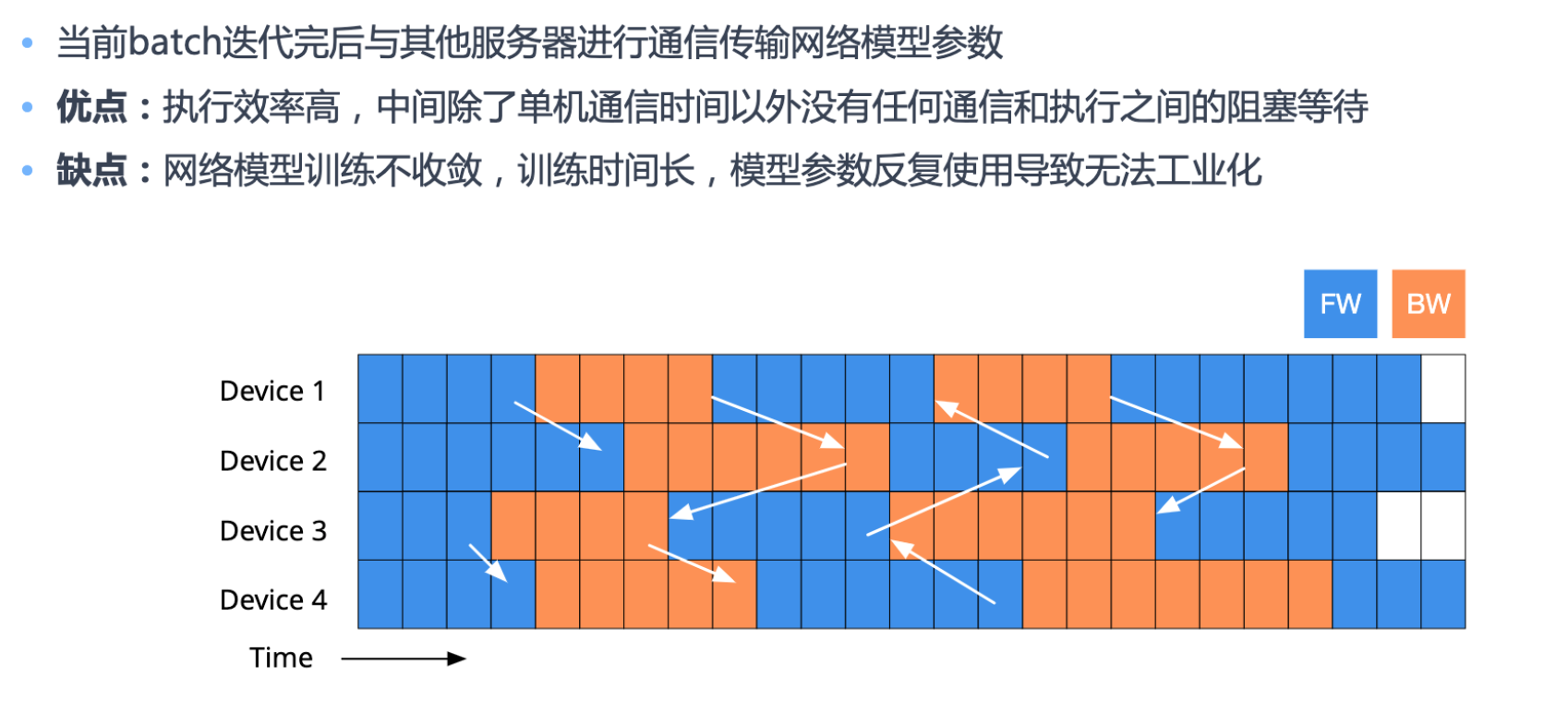
分布式 异步并行
半同步
- 通过动态限制进度推进范围,有限定的宽松同步障的通信协调并行
- 跟踪节点进度并维护最慢节点,保证计算最快和最慢节点差距在一个预定的范围内
不等太慢的,以多数worker可以接受的时间完成同步
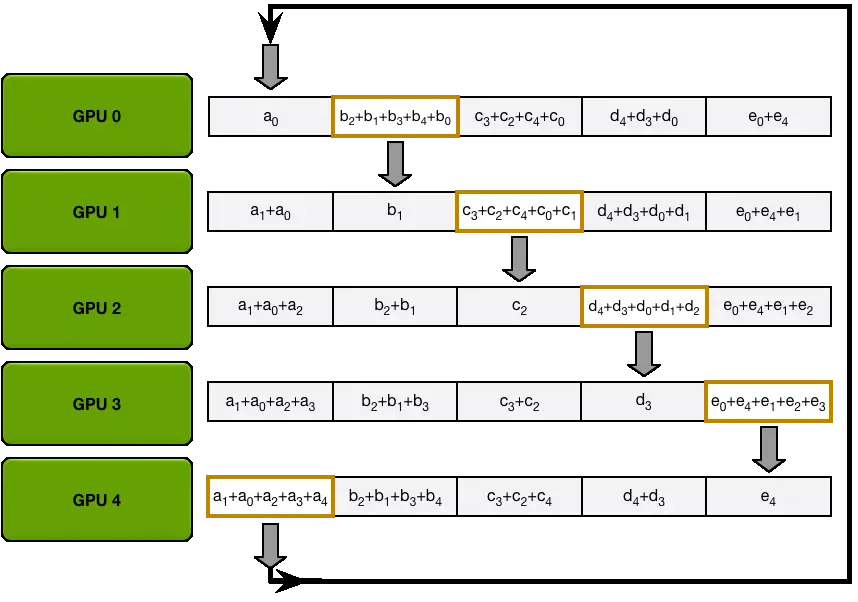
环同步 Ring Synchronization
GPU之间使用NVLink连接,每个GPU之间可以互相访问到,环有不同形状
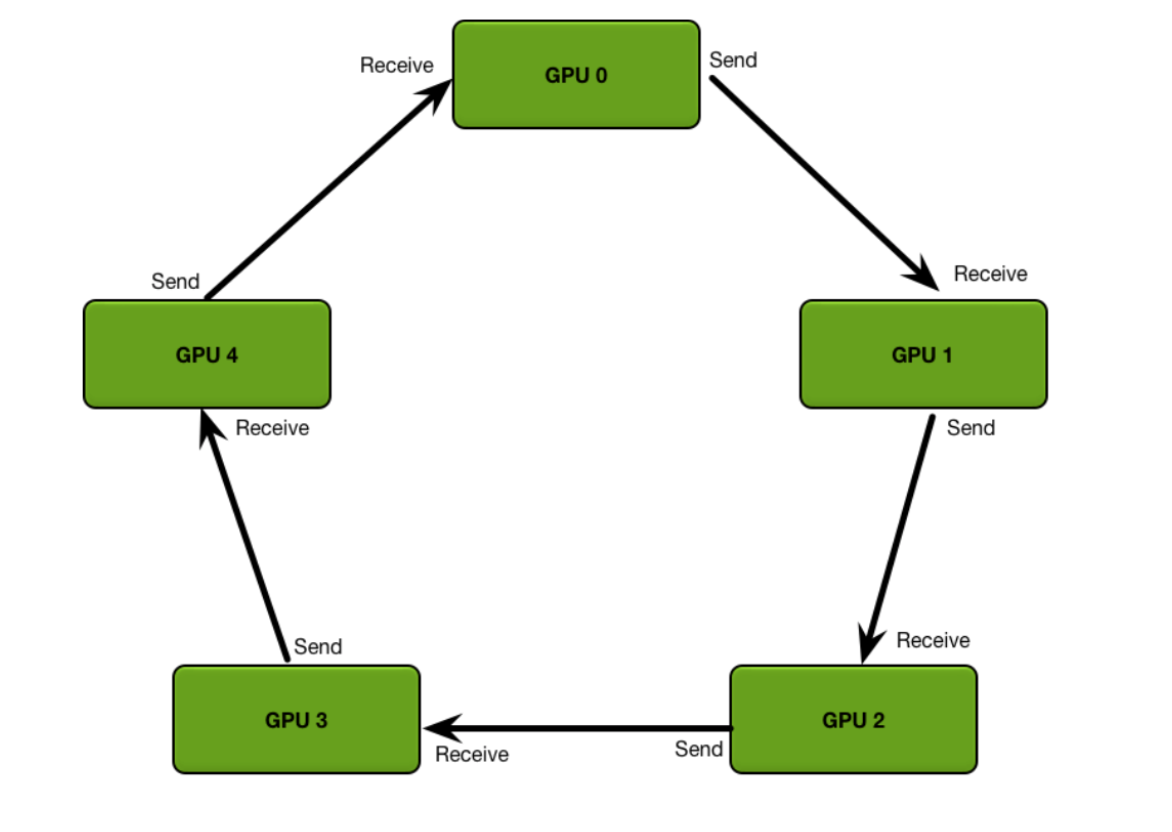
ring all reduce 算法 ,遍历两次所有GPU完成一次通信
-
Scatter-reduce,遍历完一个环每个GPU都有全数据的一个备份

-
all-gather 广播数据,遍历一次所有GPU都拥有所有数据的备份
通讯实现
https://github.com/chenzomi12/DeepLearningSystem/blob/main/061FW_AICluster/03.communication.pdf
通信实现方式
计算机网络通信中最重要两个衡量指标主要是 带宽和 延迟,分布式训练中需要传输大量的网络模型参数
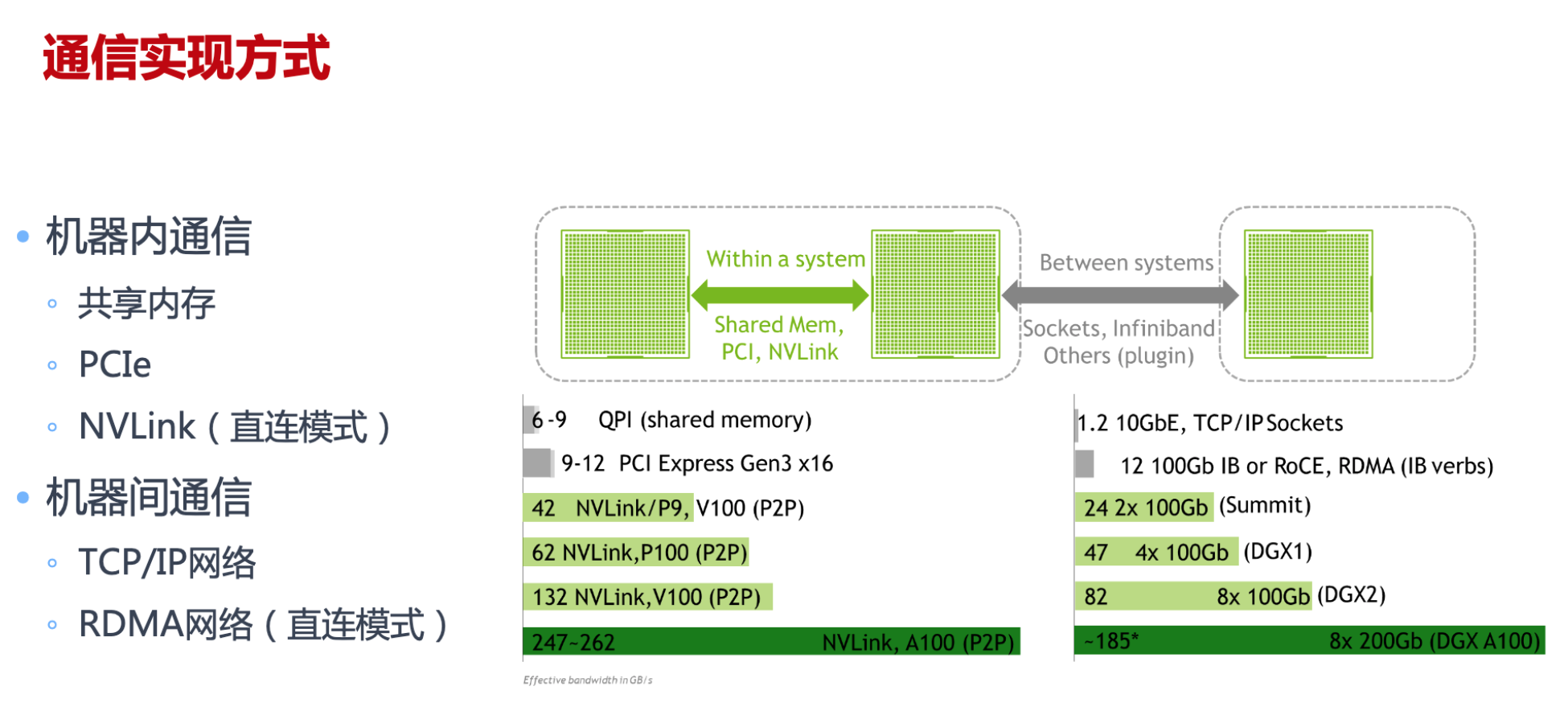
CPU共享内存,PCIe插槽(CPU GPU之间),NVLink(GPU之间)
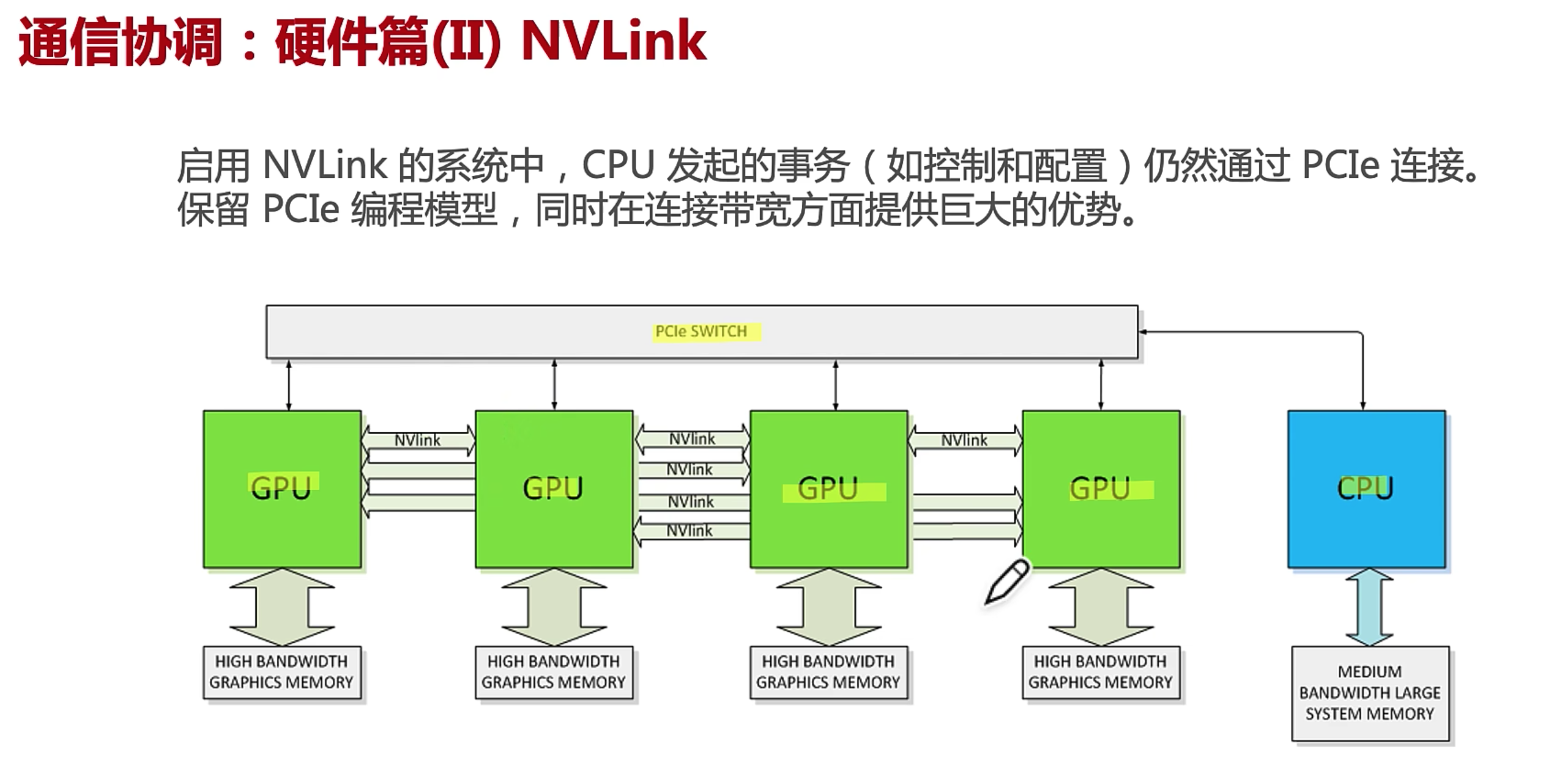

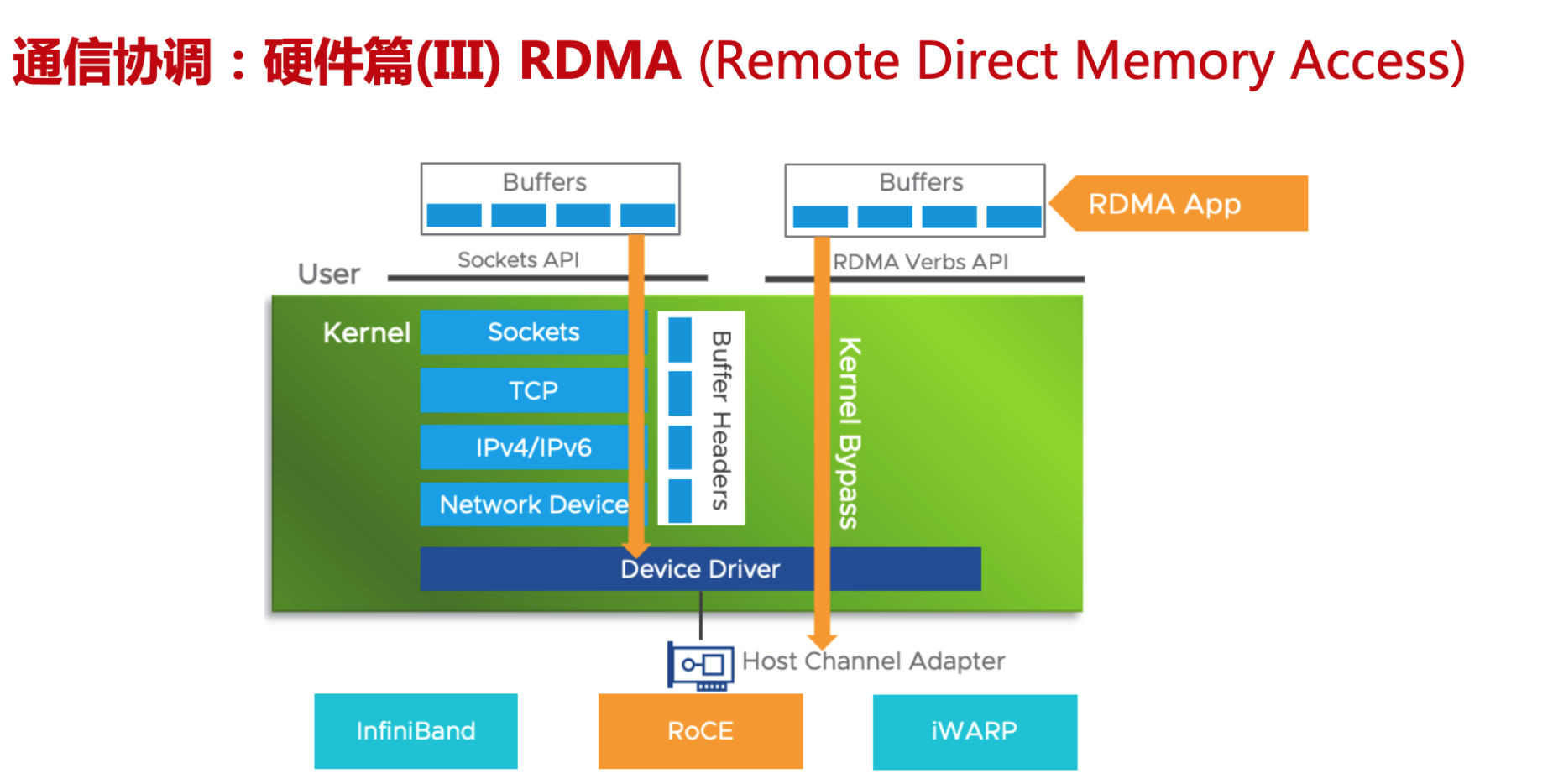
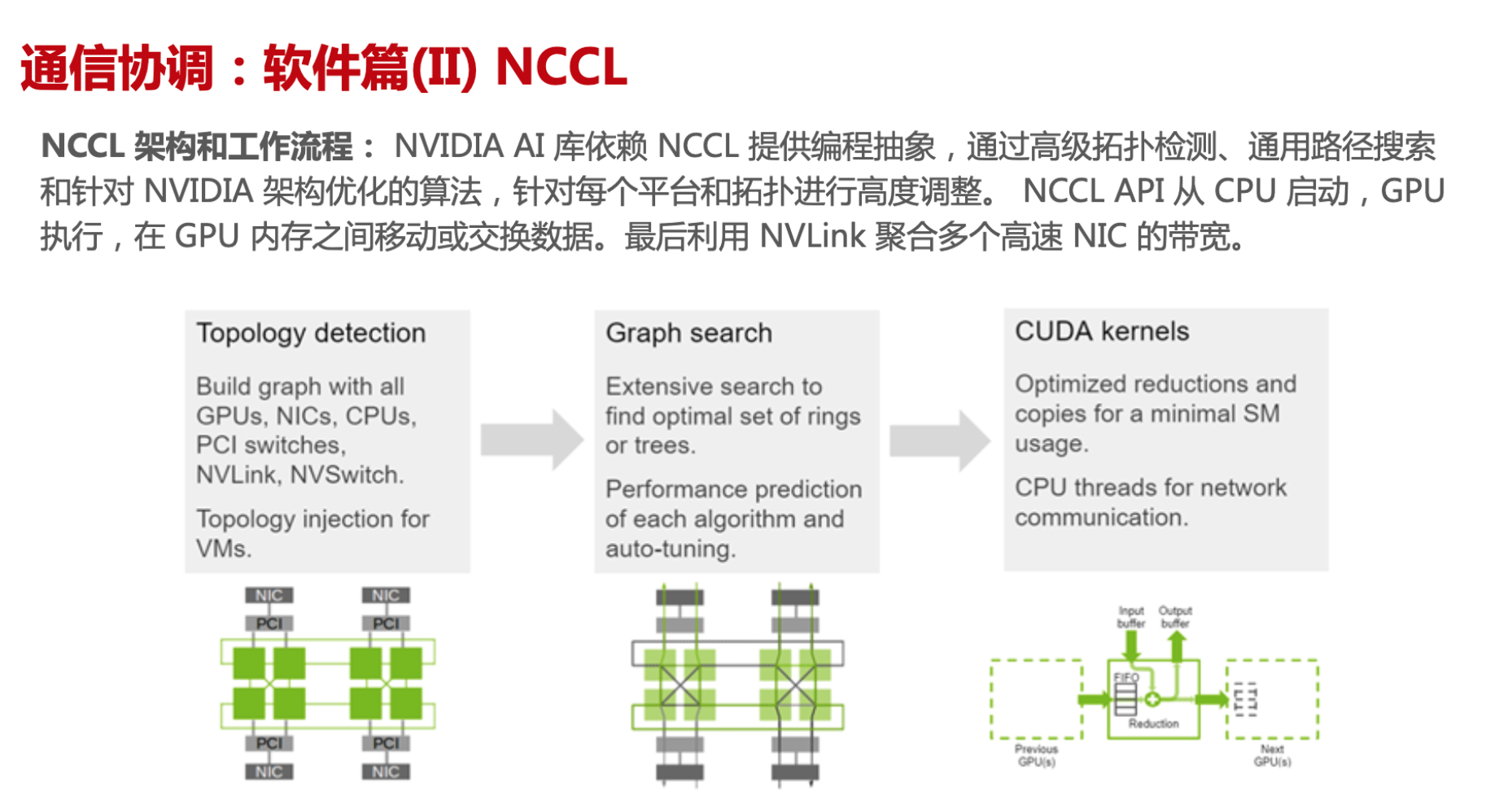
通信实现方式
点对点通信 Send/Recv
-
TCP/IP
-
RDMA
集合式通信 AII-Reduce
- TCP/IP
- NCCL
集合式通信原语
一对多 Scatter/ Broadcast
-
Broadcast
某个节点想把自身的数据发送到集群中的其他节点,那么就可以使用广播Broadcast的操作。
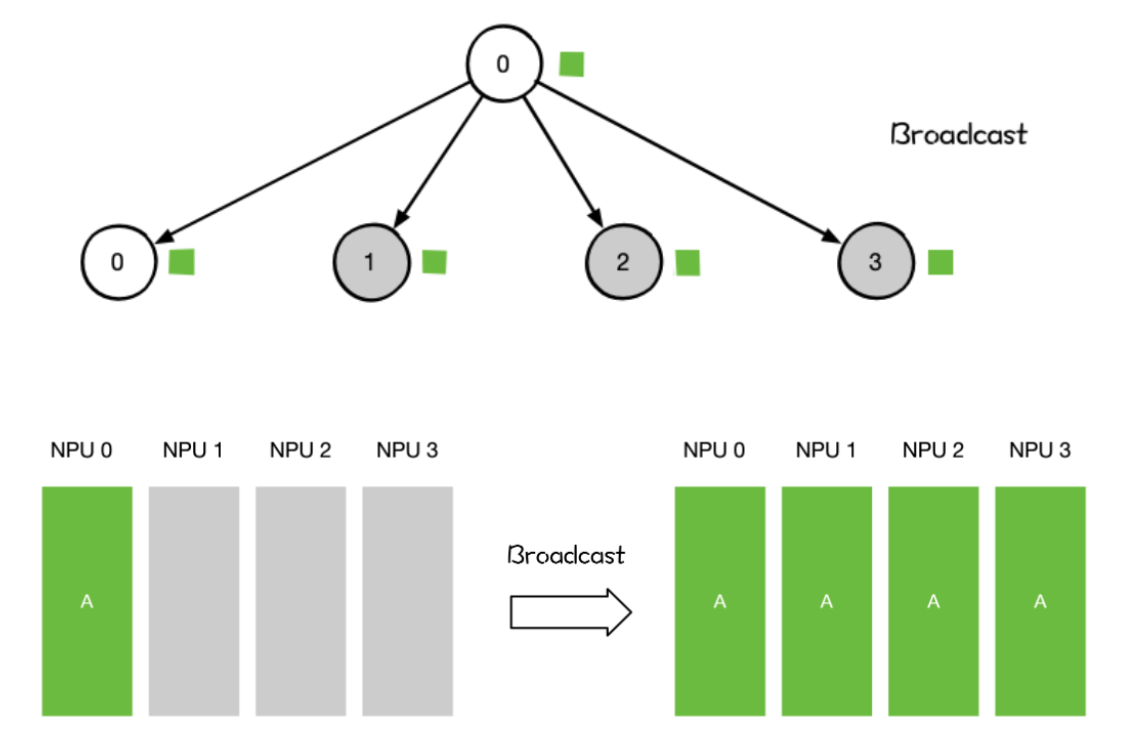
分布式机器学习中常用于网络参数的初始化。
-
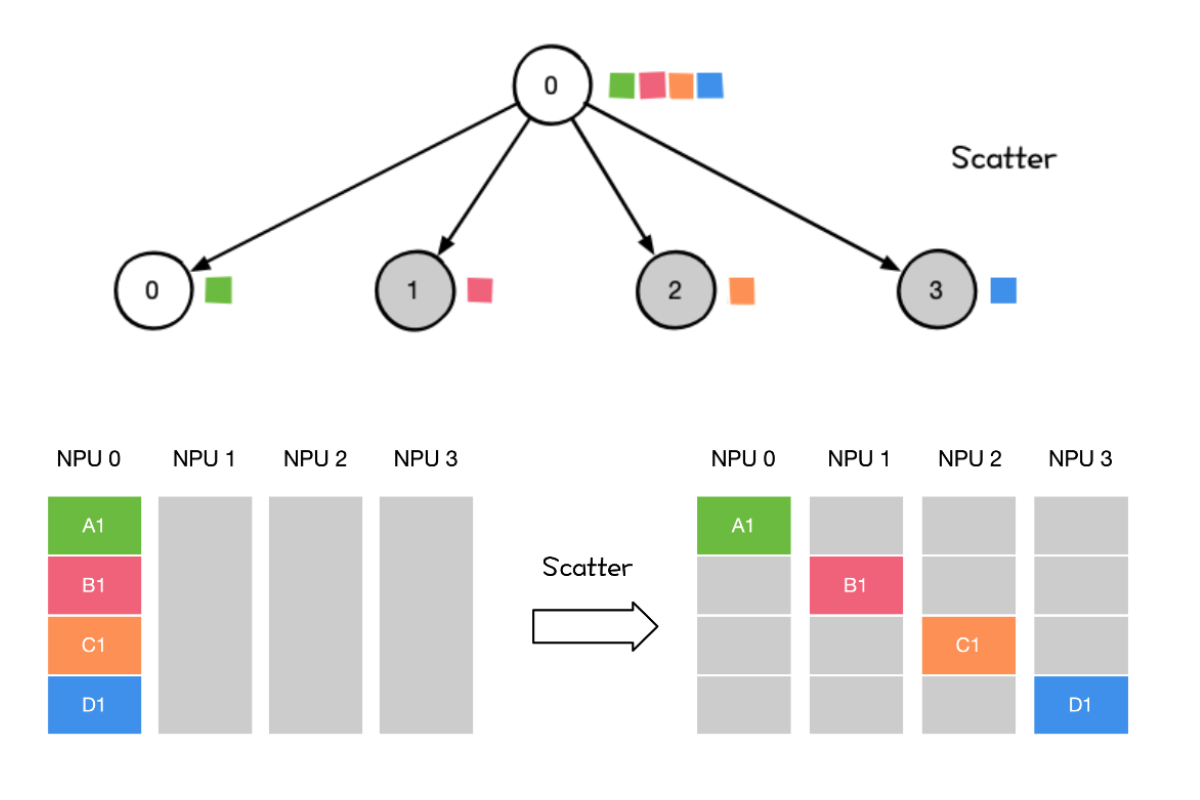
Scatter
将主节点的数据进行划分并散布至其他指定的节点。
多对一 Reduce/Gather
-
Reduce Reduce 称为规约运算,是一系列简单运算操作的统称。细分可以包括:SUM、MIN、MAX、PROD、LOR等类型的规约操作。
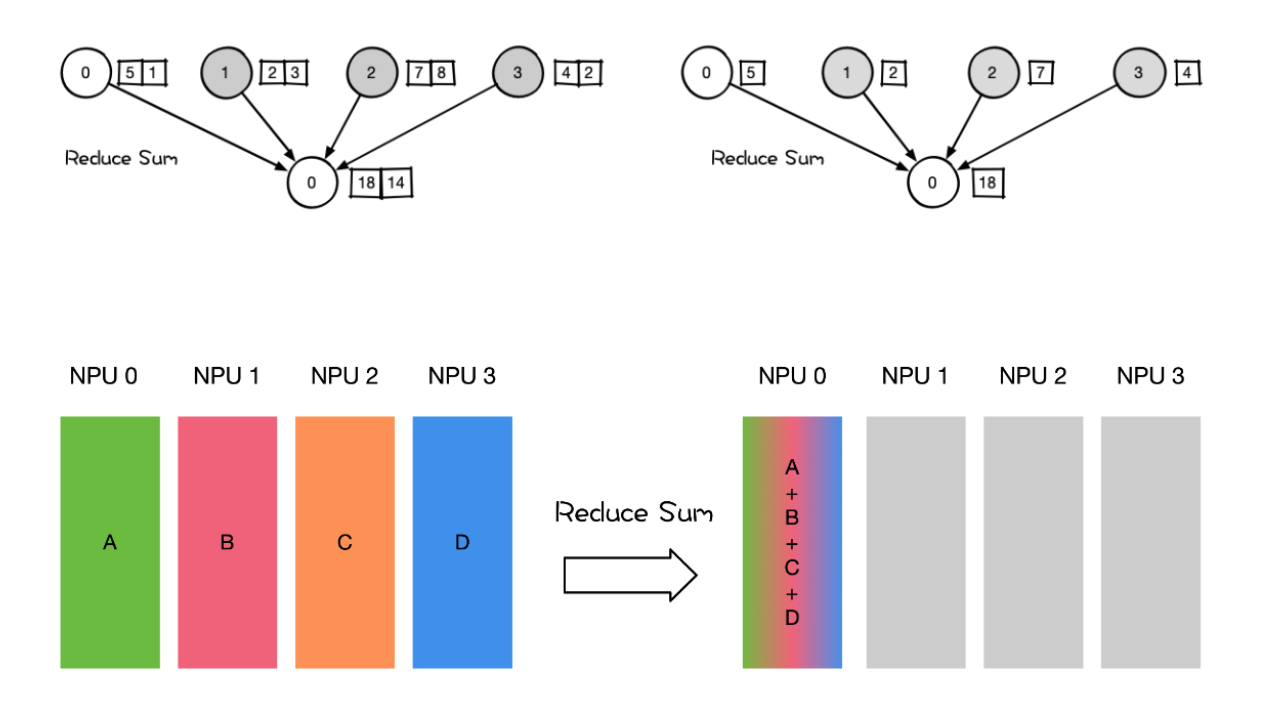
-
Gather
将多个 Sender 上的数据收集到单个节点上,Gather 可以理解为反向的 Scatter。
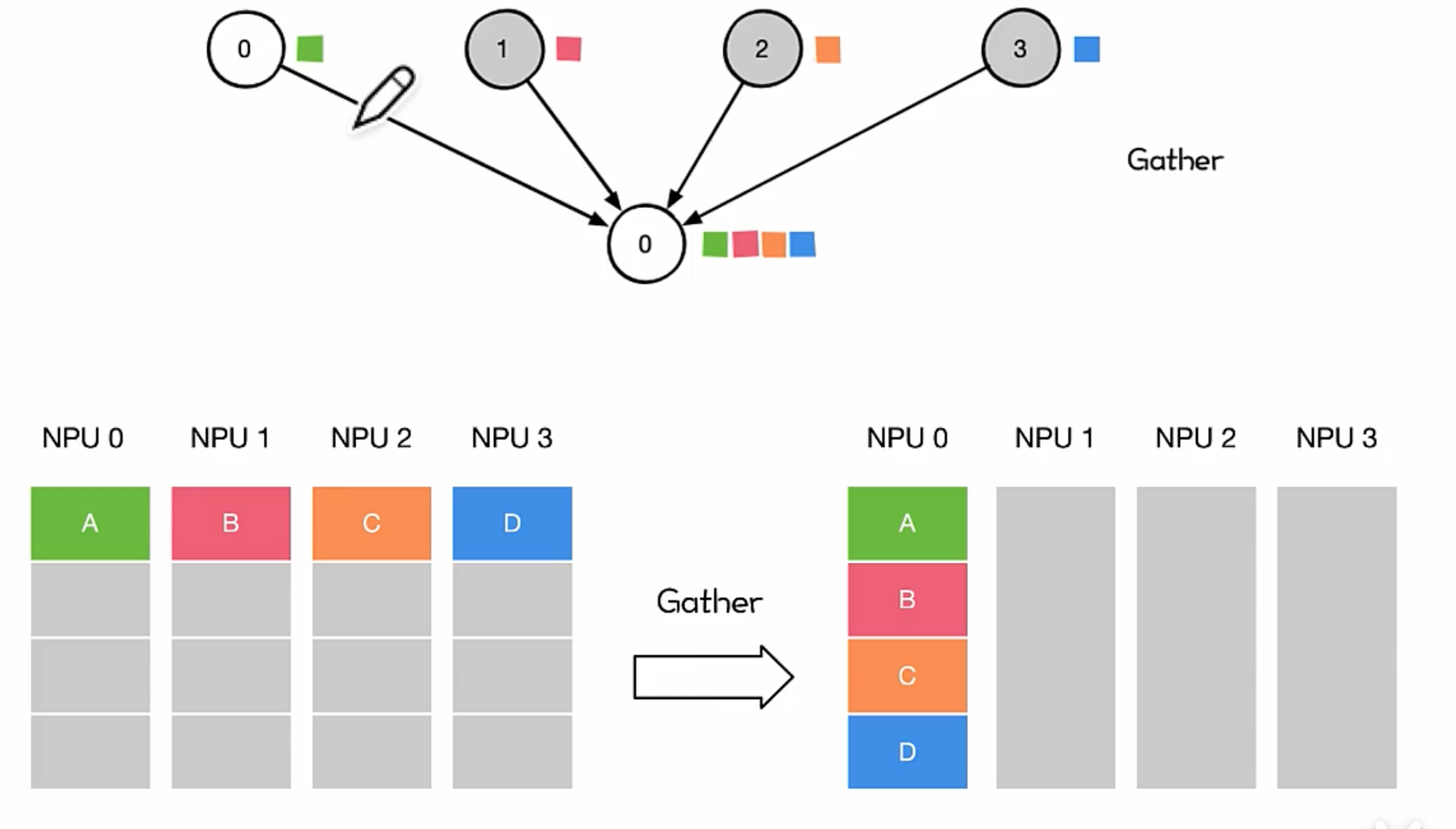
对很多并行算法很有用,比如并行的排序和搜索
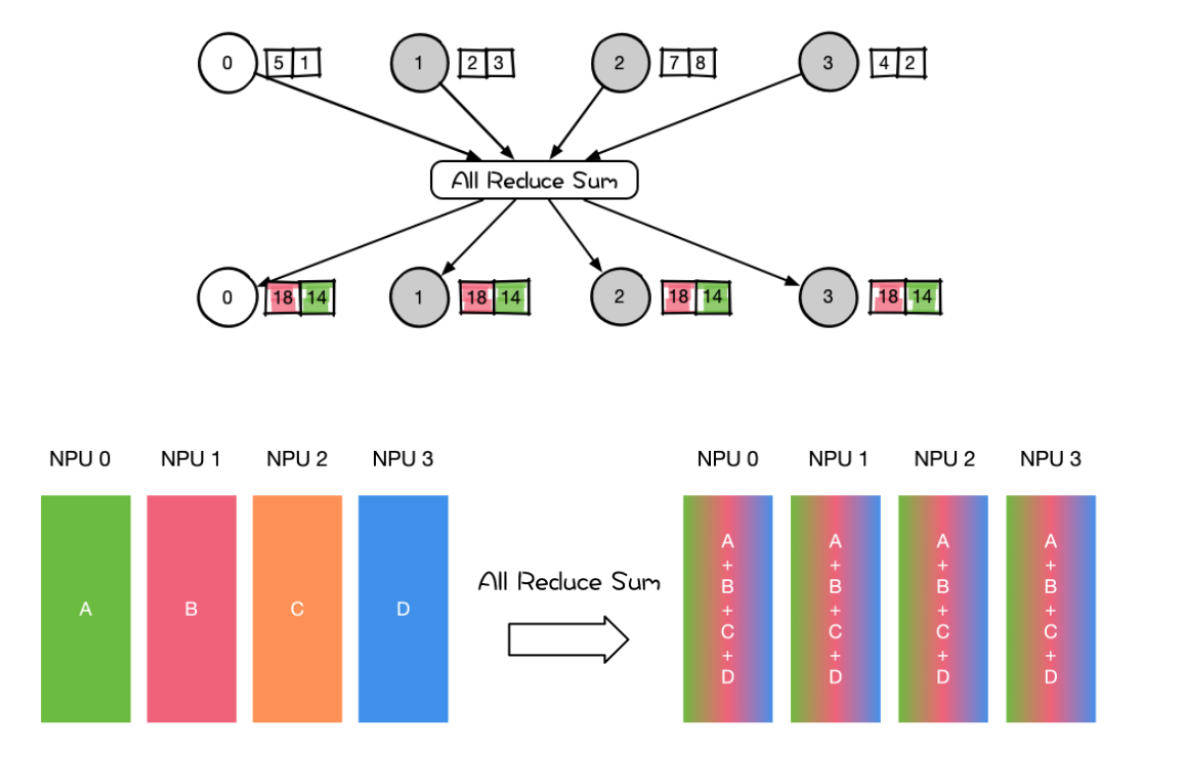
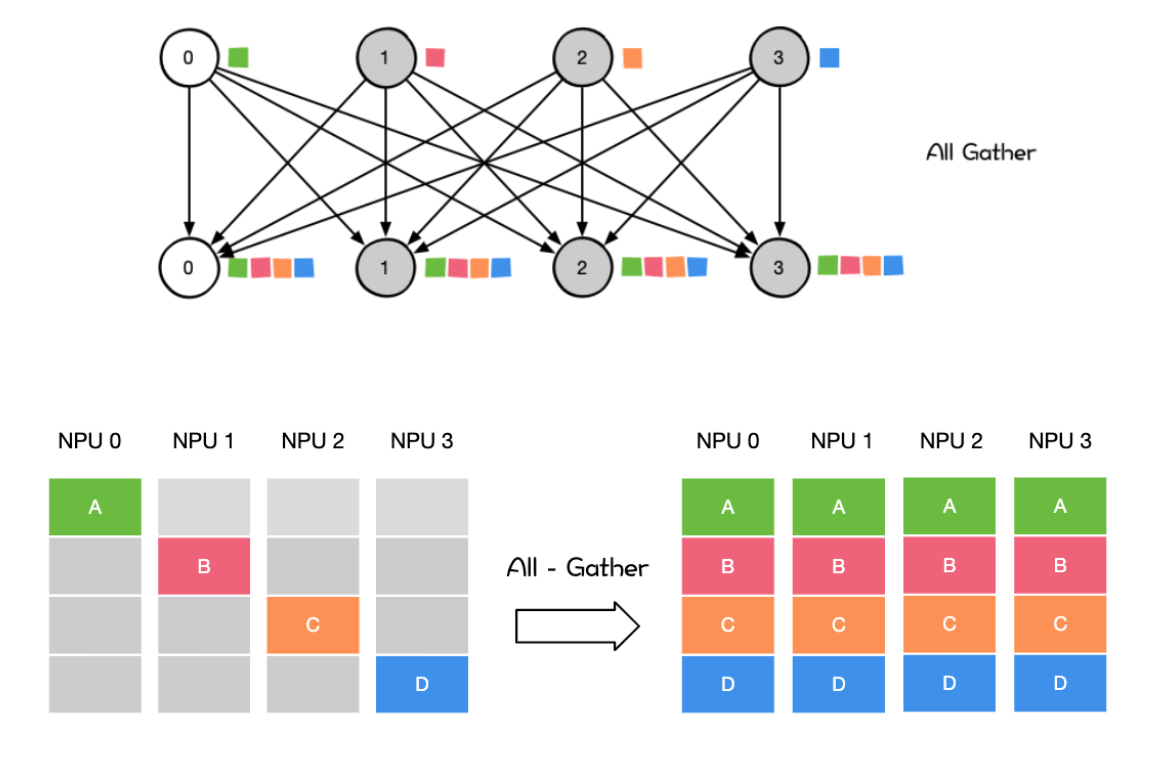
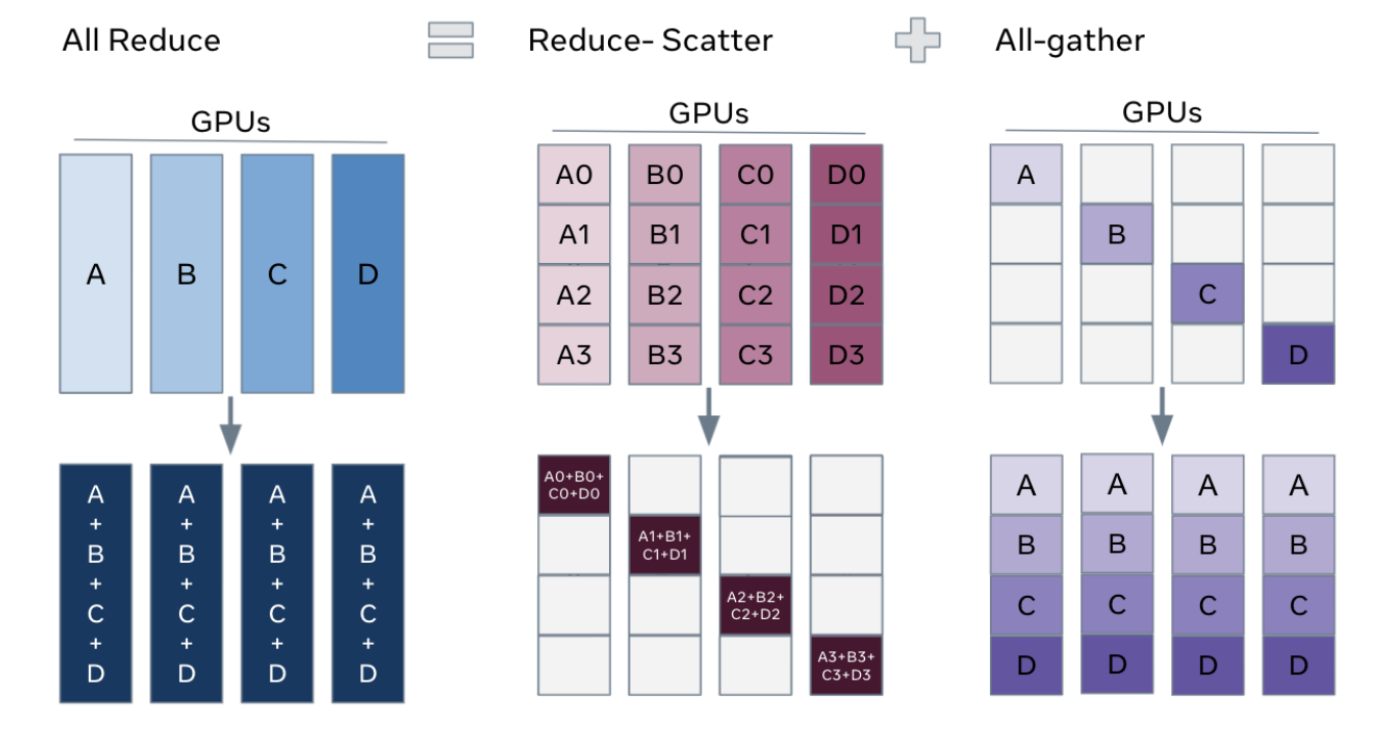
多对多 All Reduce/ All Gather
AII Reduce则是在所有的节点上都应用同样的Reduce操作。AIl Reduce操作可通过Reduce + Broadcast 或者 Reduce-Scatter +AlI-Gather 操作作完成
All Gather会收集所有数据到所有节点上。All Gather = Gather + Broadcast。发送多个元素到多个节点很有用即在多对多通信模式的场景
Reduce Scatter操作会将个节点的输入先进行求和,然后在第0维度按卡数切分,将数据分发到对应的卡上。
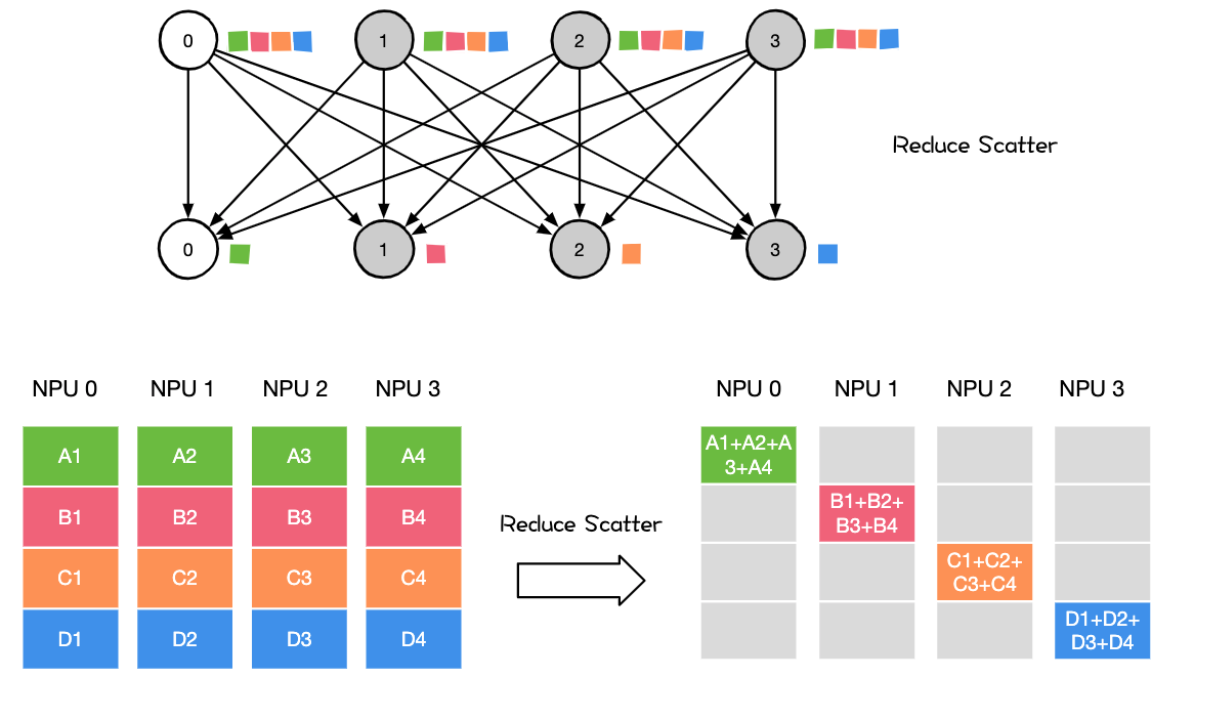
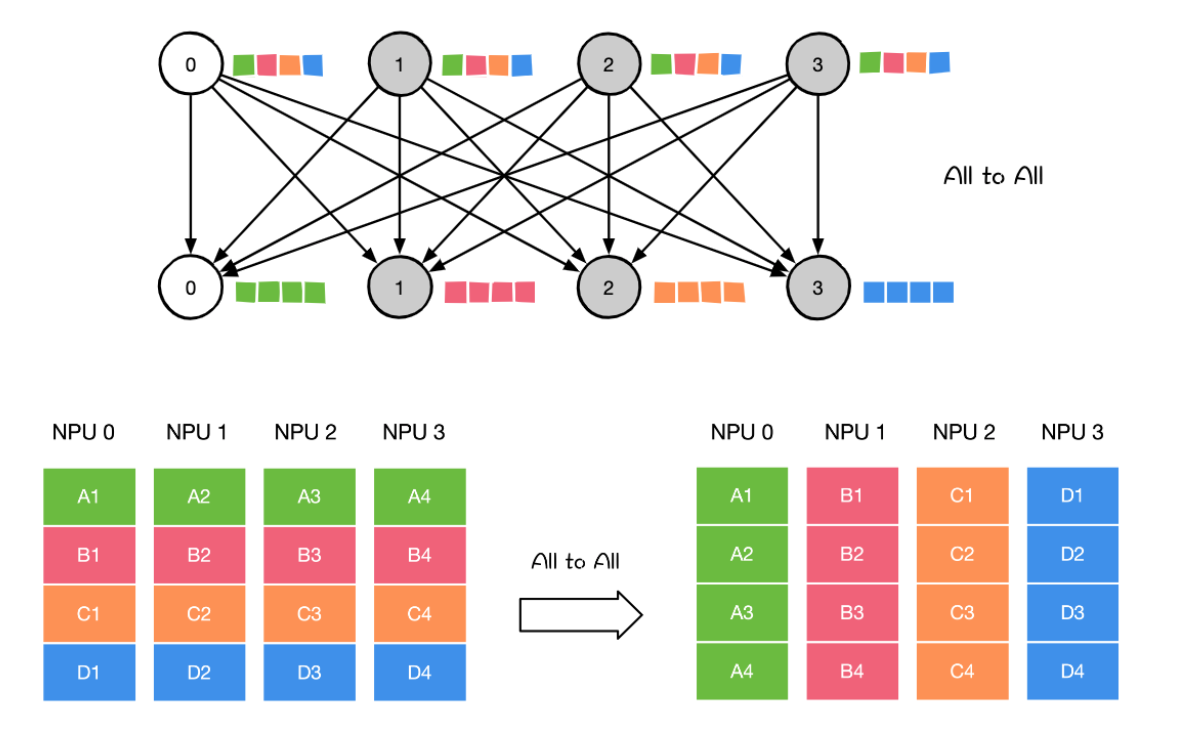
ALL to all 将节点i的发送缓冲区中的第j块数据发送给节点j,节点j将接收到的来自节点的数据块放在自身接收缓冲区的第i块位置
分布式训练系统
https://github.com/chenzomi12/DeepLearningSystem/blob/main/061FW_AICluster/05.system.pdf
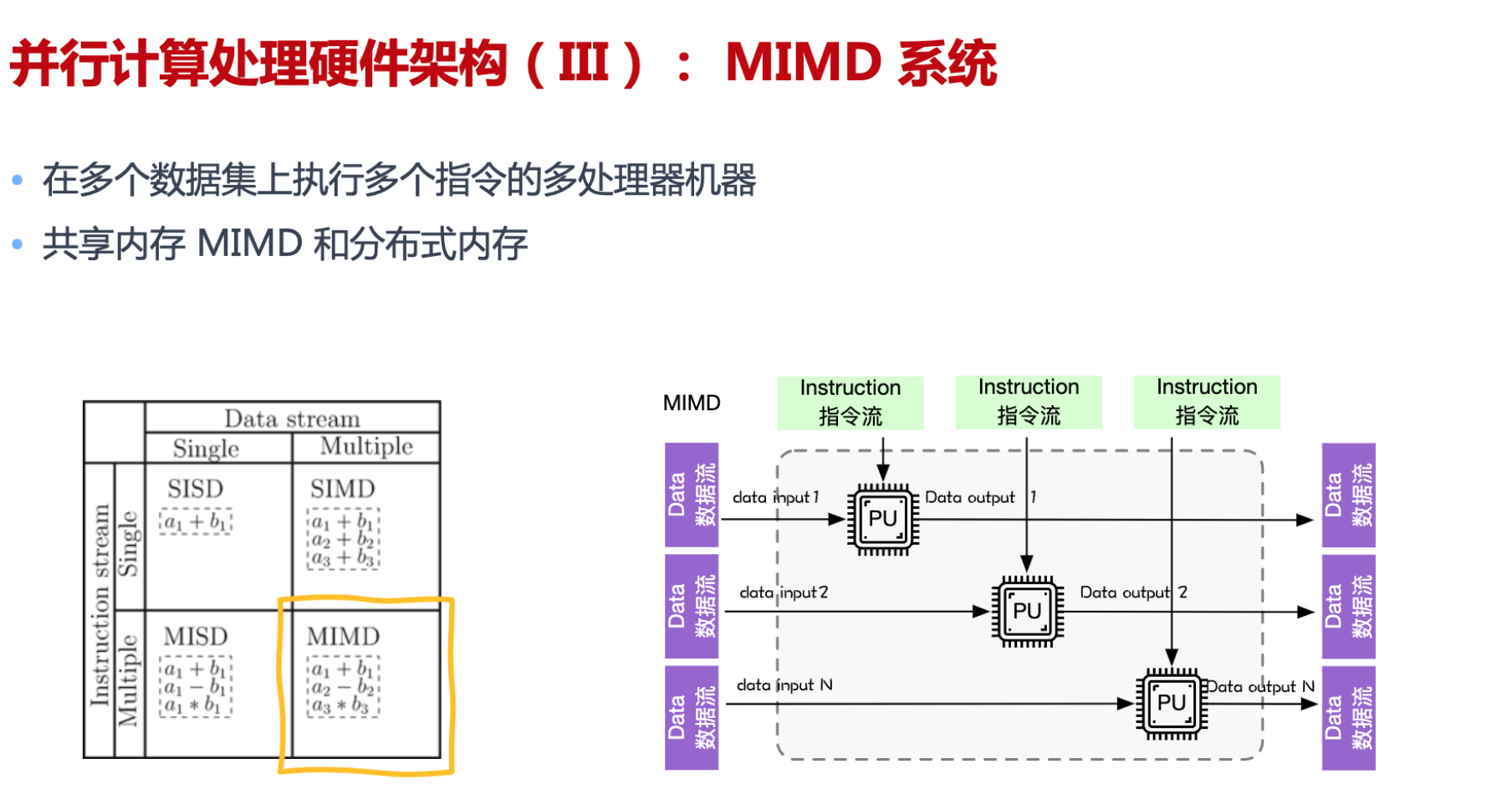
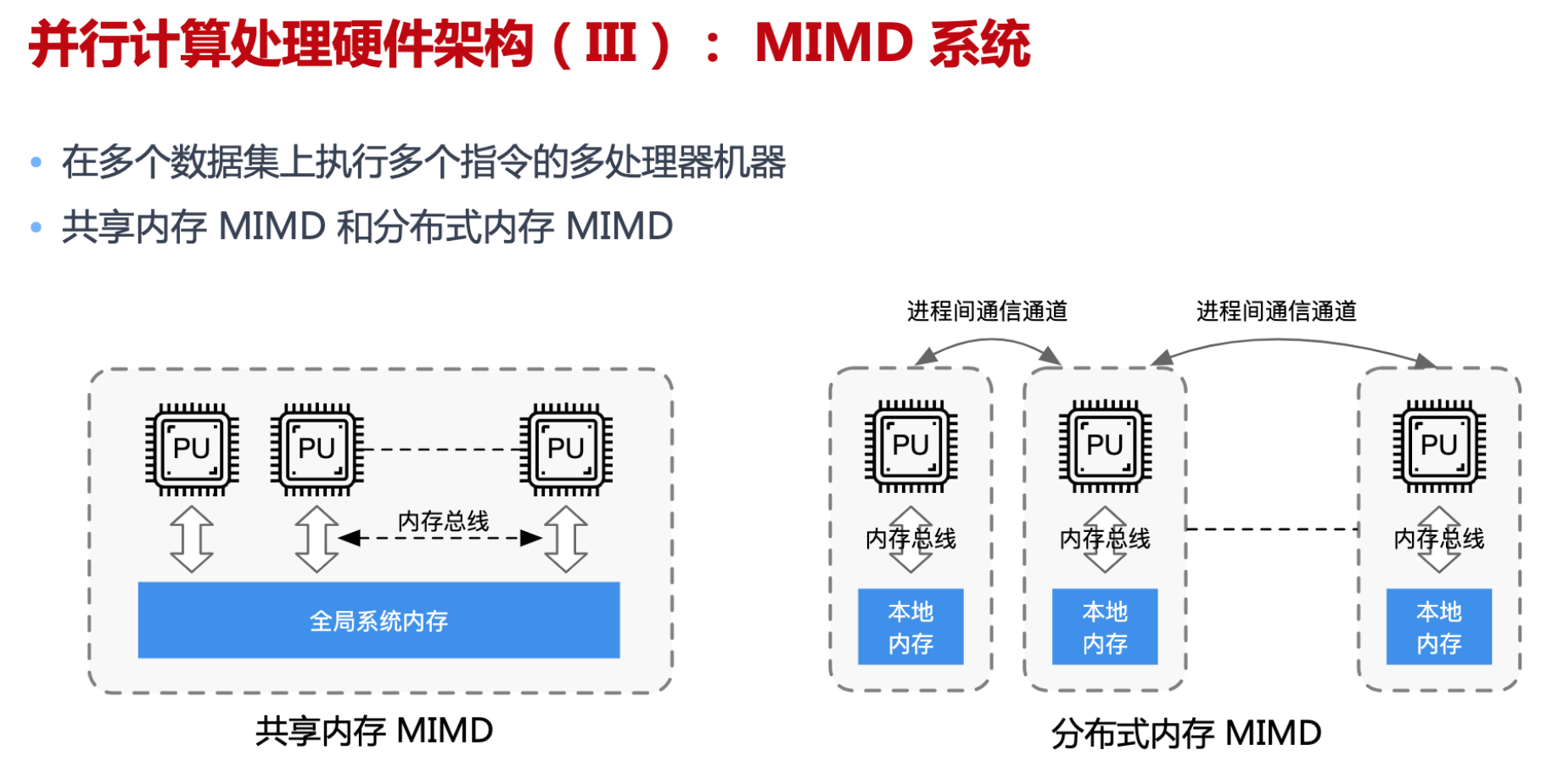
硬件
软件
-
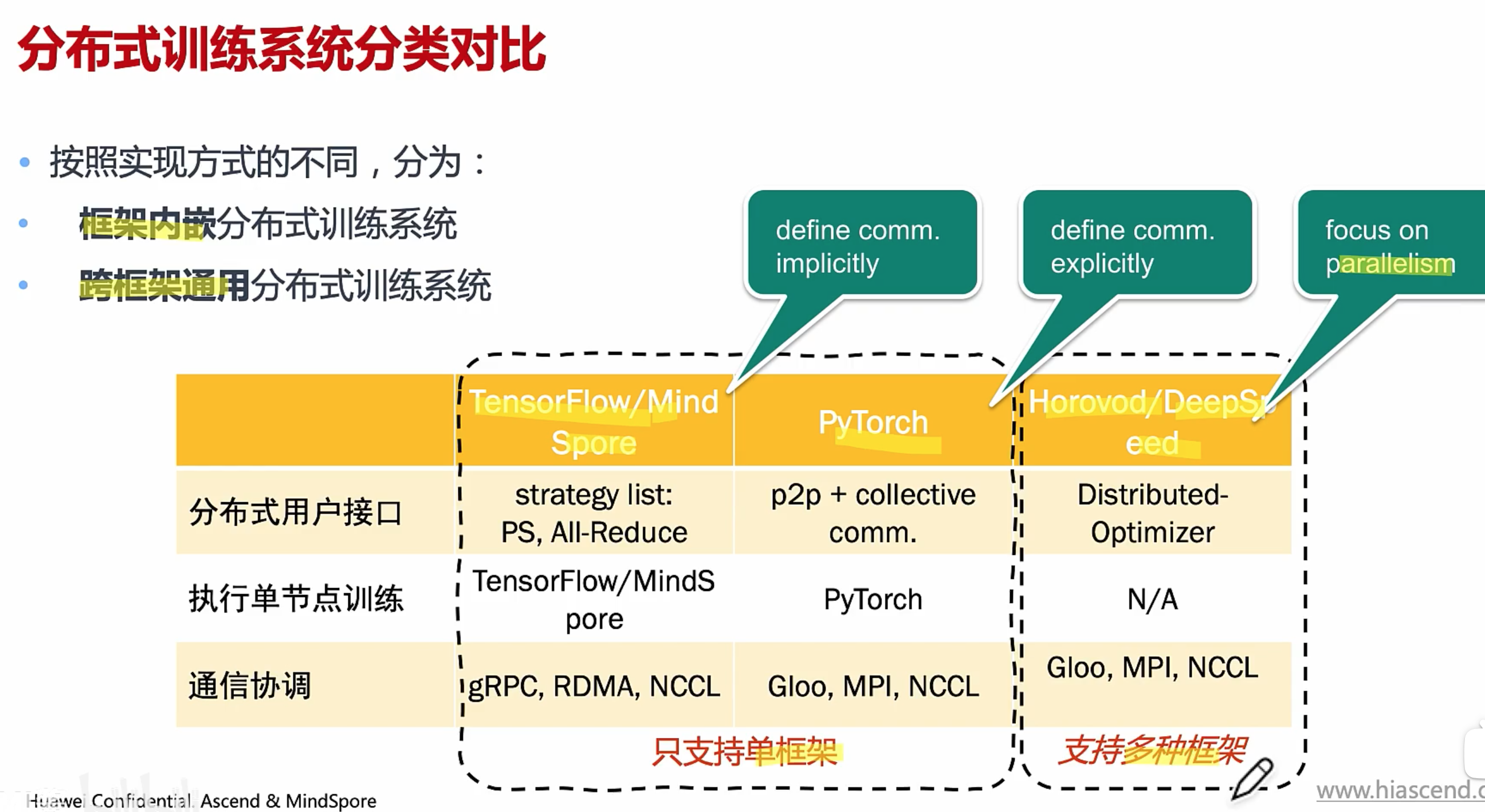
分布式用户接口
用户通过接口,实现模型的分布化
-
执行单节点训练
产生本地执行的逻辑
-
通信协调
实现多节点之间的通信协调
意义:提供易于使用,高效率的分布式训练
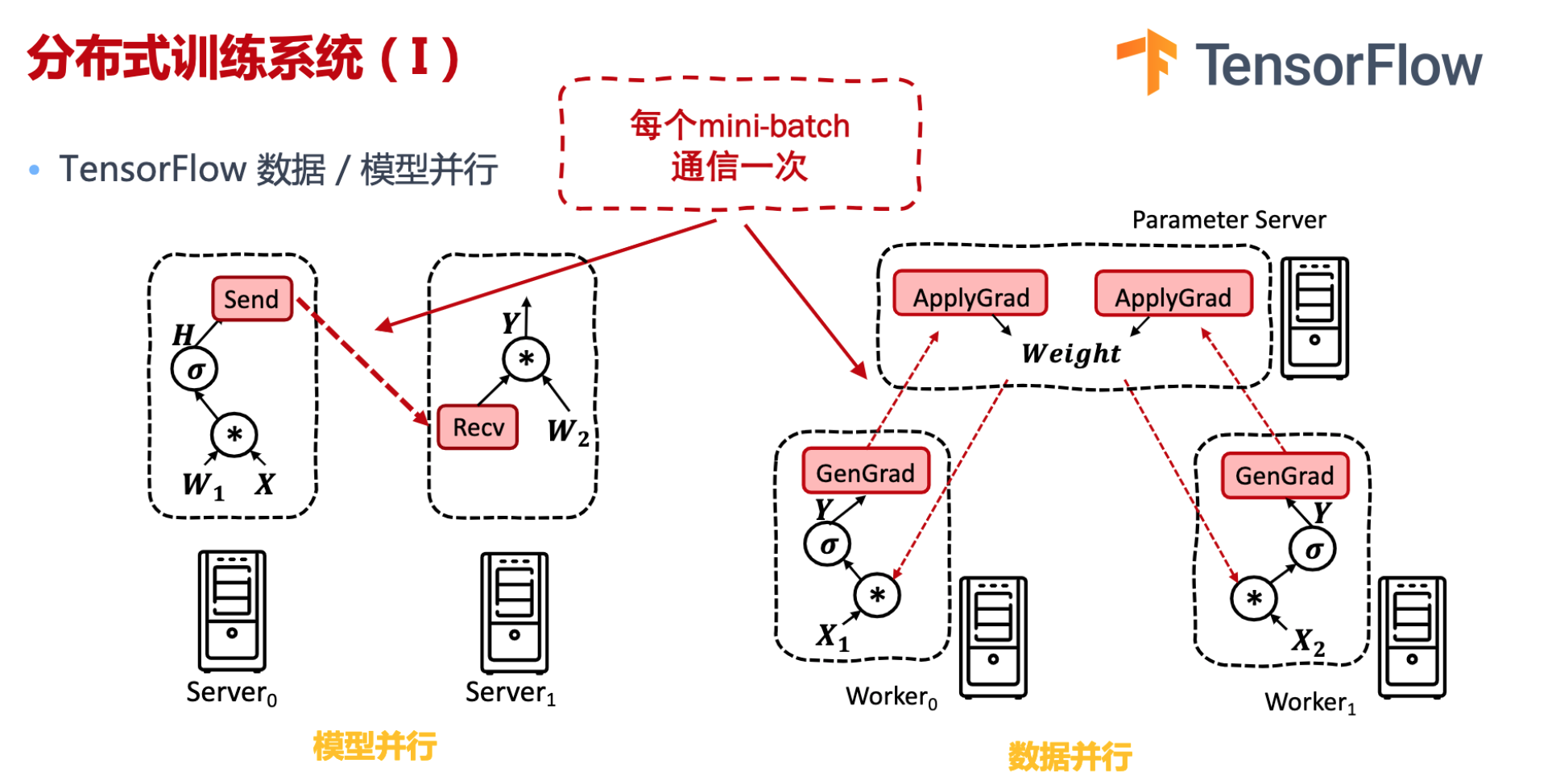
Tensorflow:模型并行主要是计算图分布式切分,算子通信。数据并行的数据包括(模型的参数、梯度等)
Pytorch: 支持点对点(同步异步通信),集合通信 ,非常灵活。
大模型训练挑战

内存
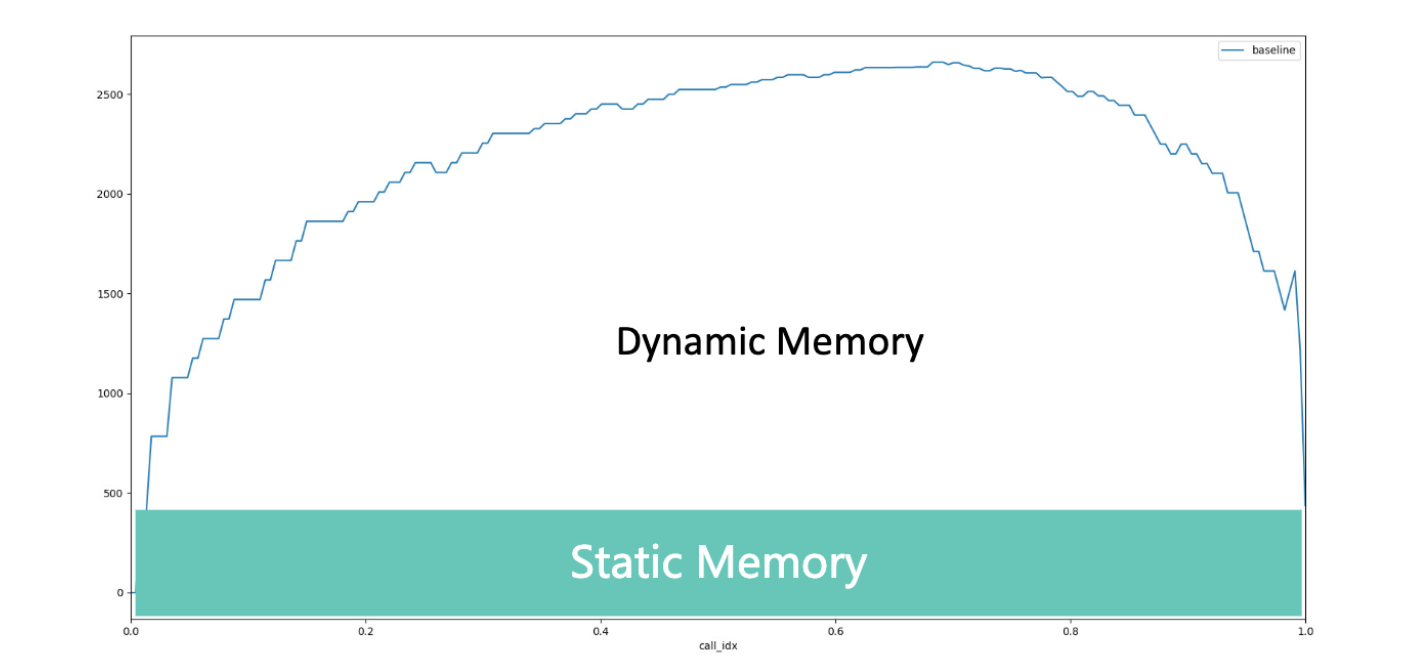
静态内存:模型自身的权重参数、优化器状态信息,由于是比较固定的所以称为静态参数
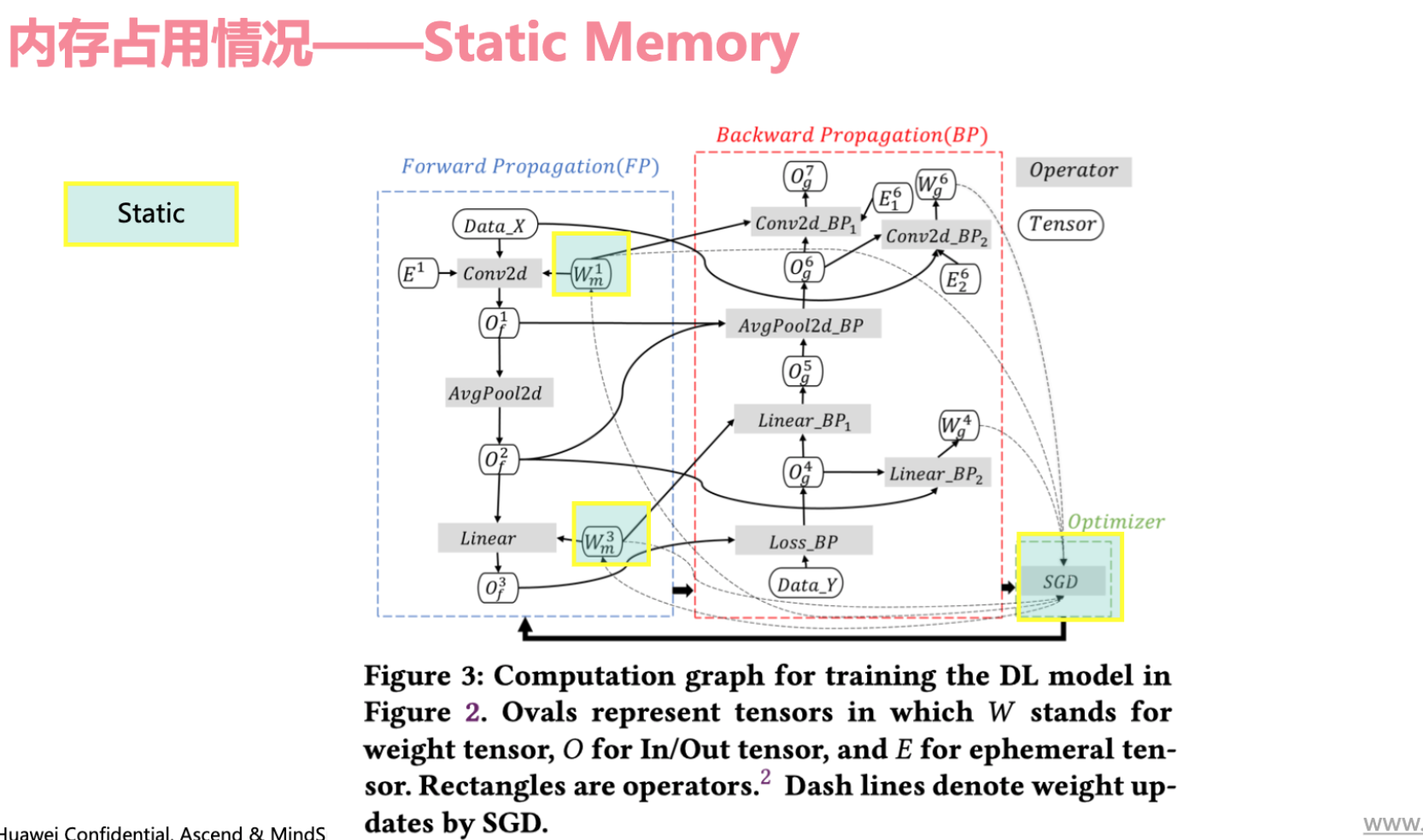
动态内存:训练过程产生前向/梯度输出、算子计算临时变量,会在反向传播时逐渐释放的内存。
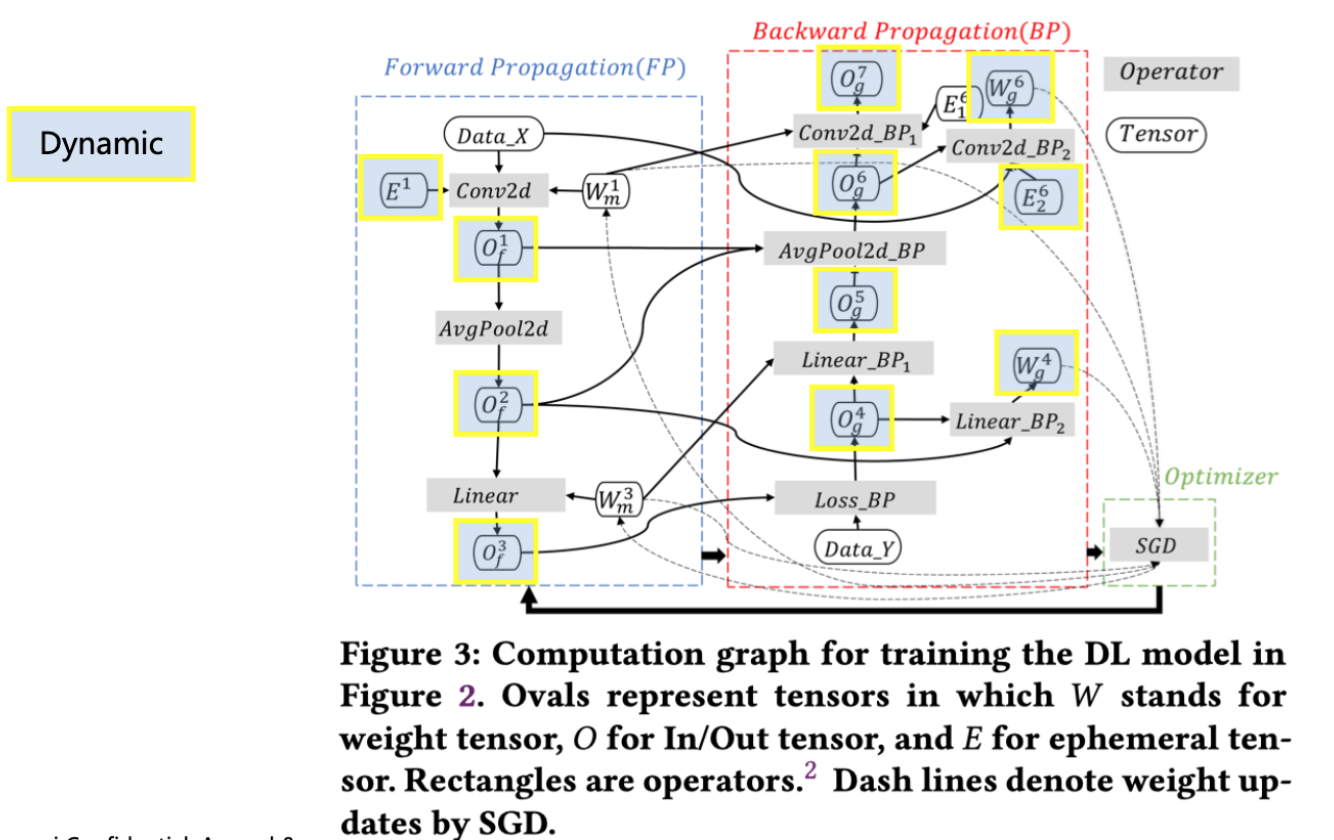
并行策略
除了训练数据,主要占据显存的地方
- 模型状态量(参数、梯度和优化器状态量)
- 激活函数也需要占据额外的显存,其随批量大小(batch size)而增加

计算效率随着计算时间对通信时间的比例的增加而增加。该比例与 batch size成正比。但是,模型可以训练的 batch size有一个上限,如果超过这个上限,则收敛情况会迅速恶化。
数据并行
Data parallelism
-
Data parallelism, DP
-
Distribution Data Parallel, DDP
-
Fully Sharded Data Parallel, FSDP
Data parallelism DP 对数据并行
-
Data Parallel自动分割训练数据并将model jobs发送到多个GPU。独立计算梯度,数据同步(集合通信)进行梯度累积,更新权重,完成一次训练
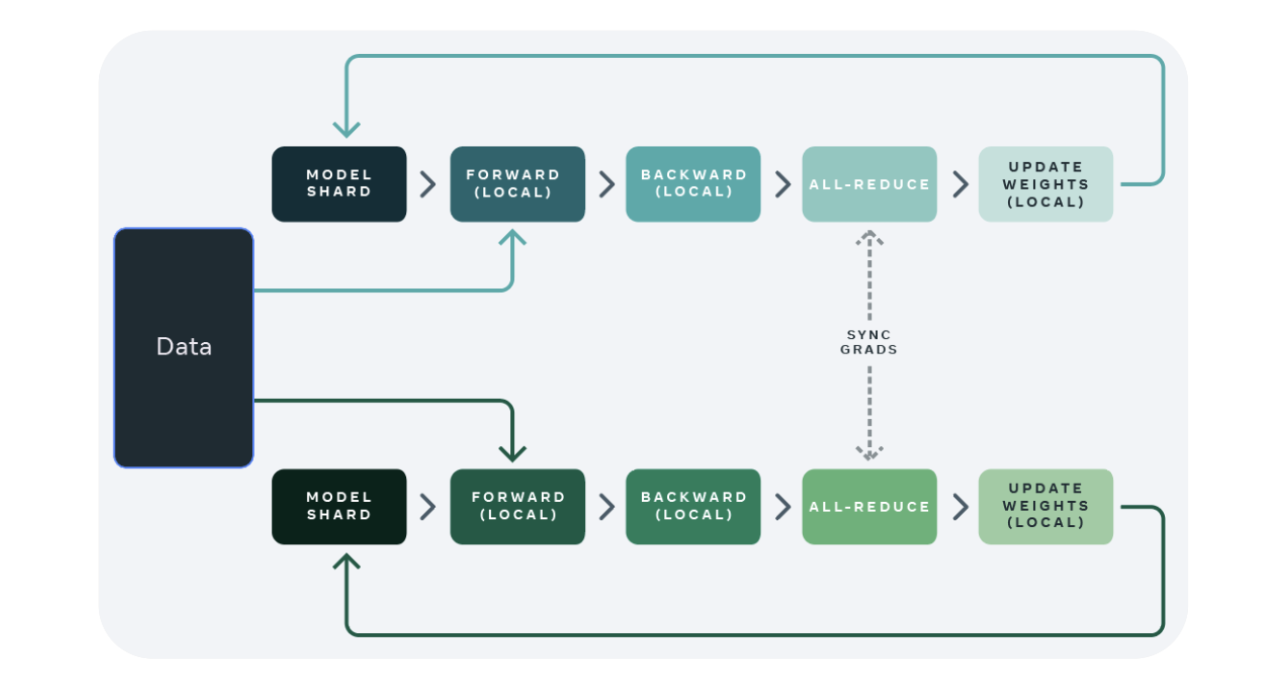
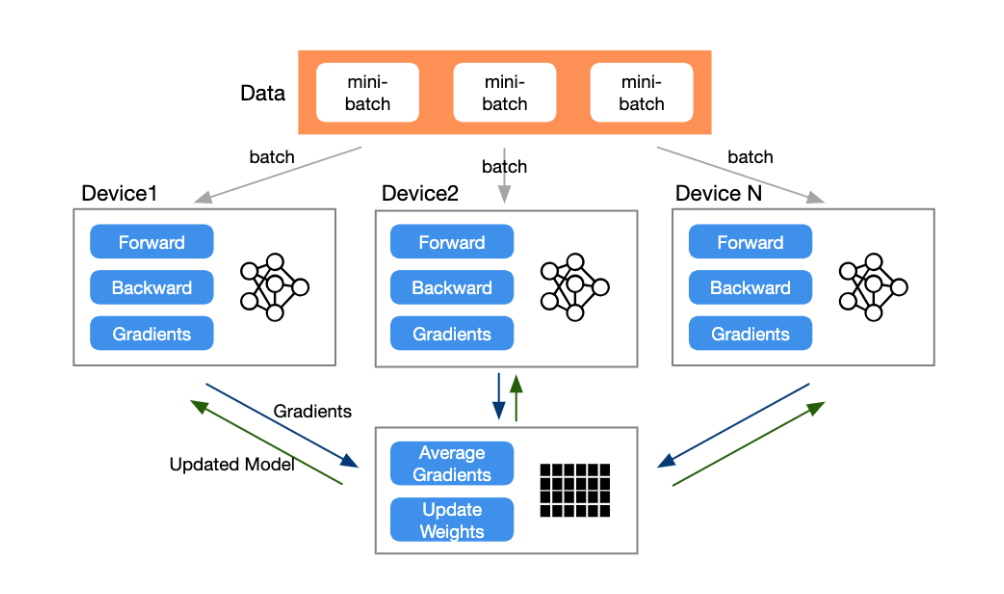
限制点
- 多线程执行,python有GIL约束
- GPU独立计算梯度,如何高效完成梯度累积(不同梯度进行求和汇总)
- 使用同步更新:把梯度汇总到参数服务器(Parameter Server),模型容易收敛,异步更新,很难收敛。
- GPU0作为参数服务器。0号节点负载很重,通讯成本是随着gpu数量的上升而线性上升的

Distribution Data Parallel DDP 对梯度并行
- 多进程执行
- DP 的通信成本随着 GPU 数量线性增长,而 DDP 支持 Ring AllReduce,其通信成本是恒定的,与 GPU 数量无关。
- 同步梯度差(不是算完才更新)
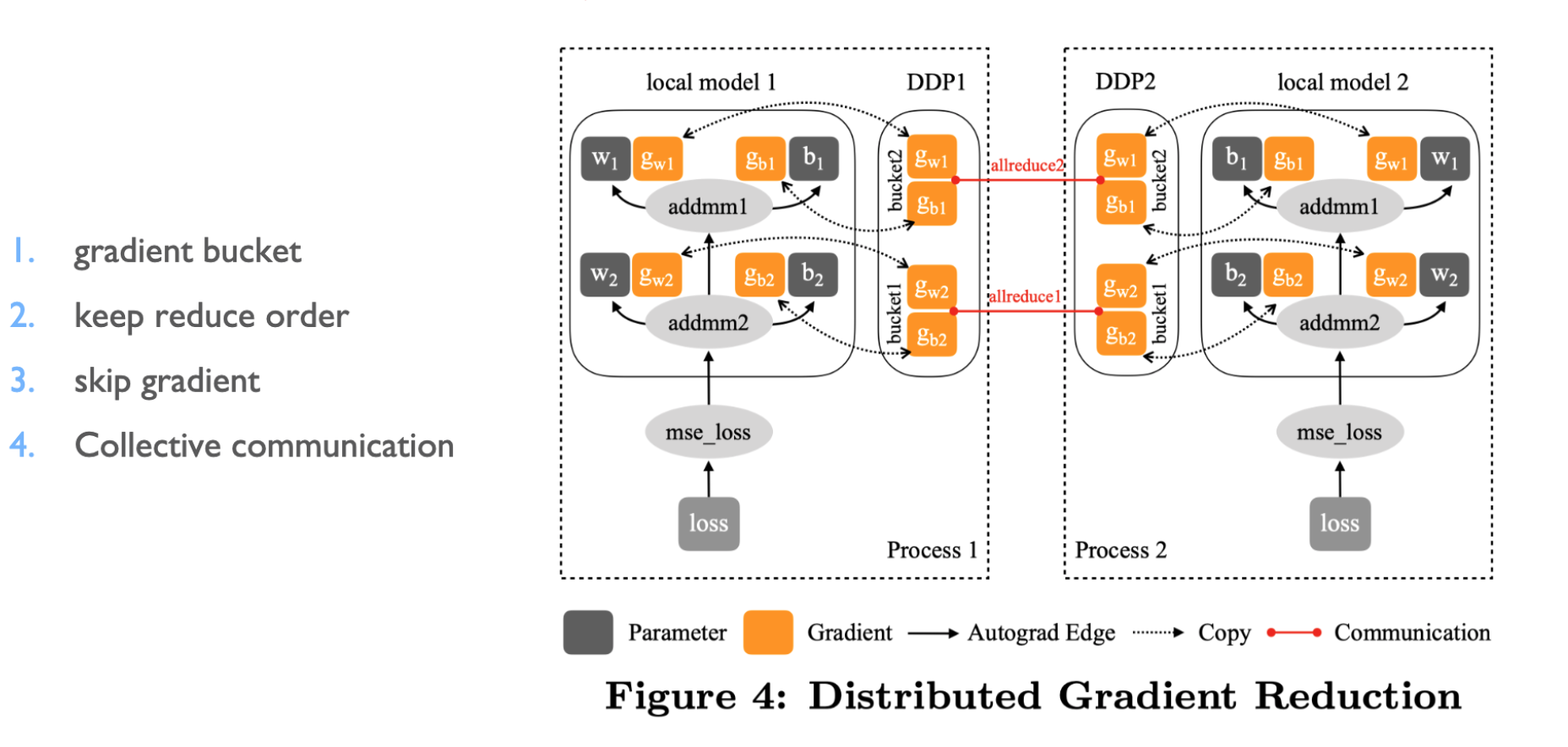
- 对每层梯度进行分桶,梯度逆向排序看哪个先更新,跳过很久没更新的,进行集合通信
- 边计算边通信梯度
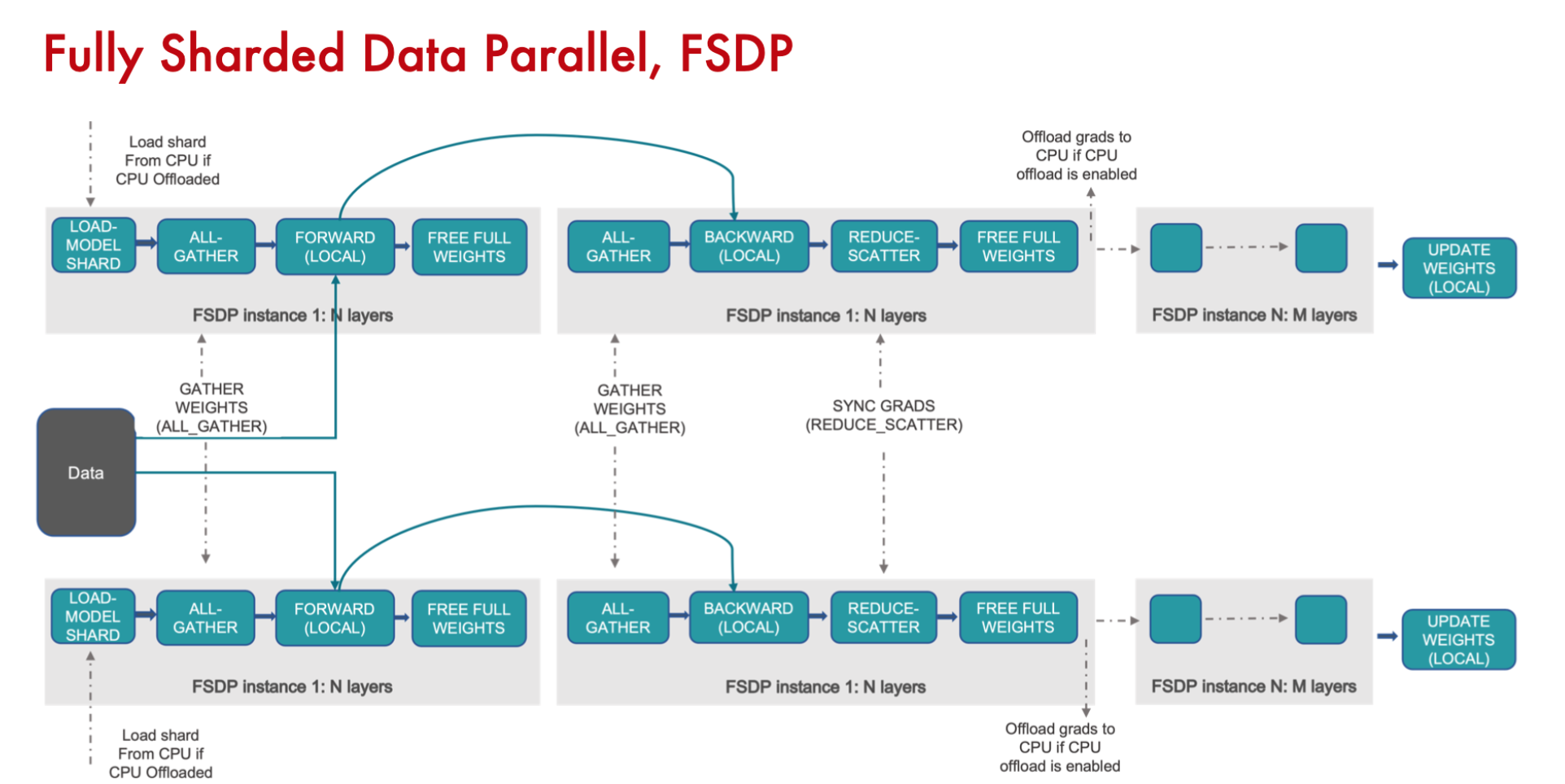
Fully Sharded Data Parallel FSDP
- 对参数、梯度和优化器状态量进行并行
- 可以将参数、梯度和优化器状态卸载到 CPU (可选)
将DDP中的All-Reduce拆成reduce-scatter + all-gather
数据拆分后,进行前向和反向计算,reduce-scatter,把不需要的权重参数offload到CPU,需要再load到GPU进行all-gather
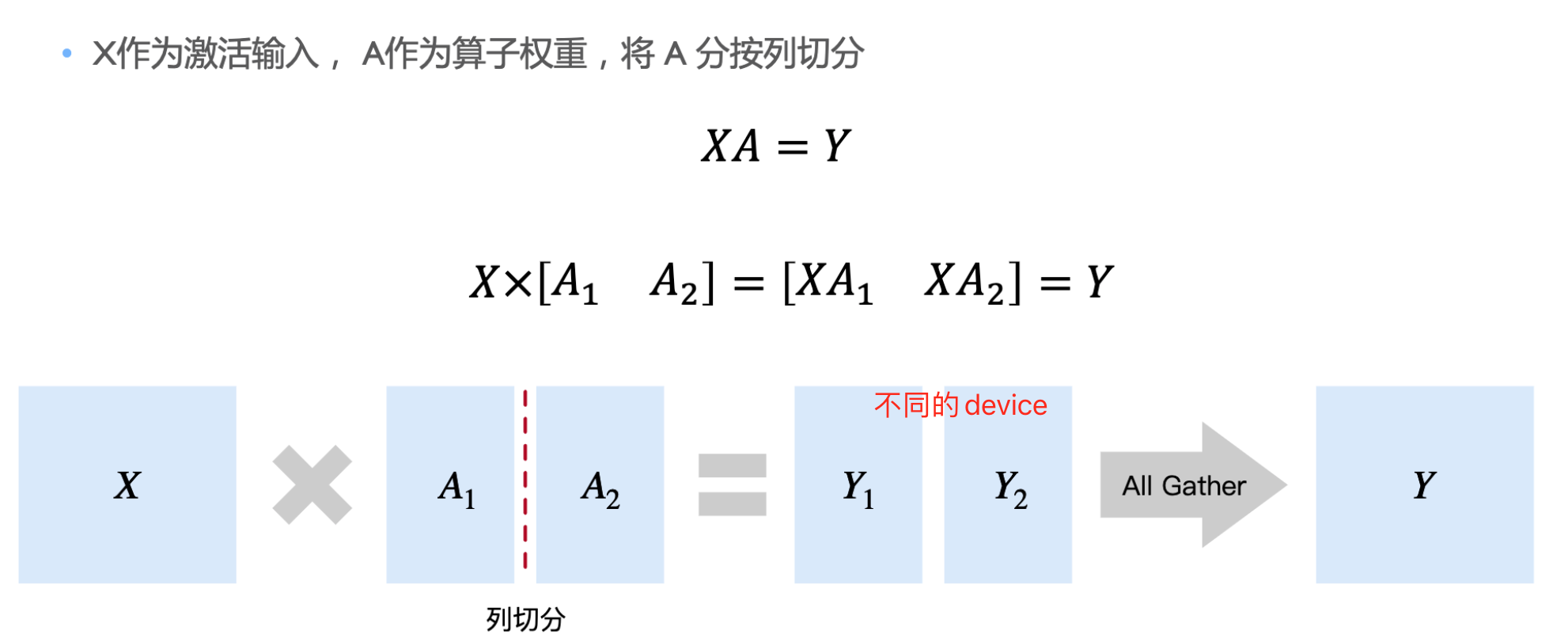
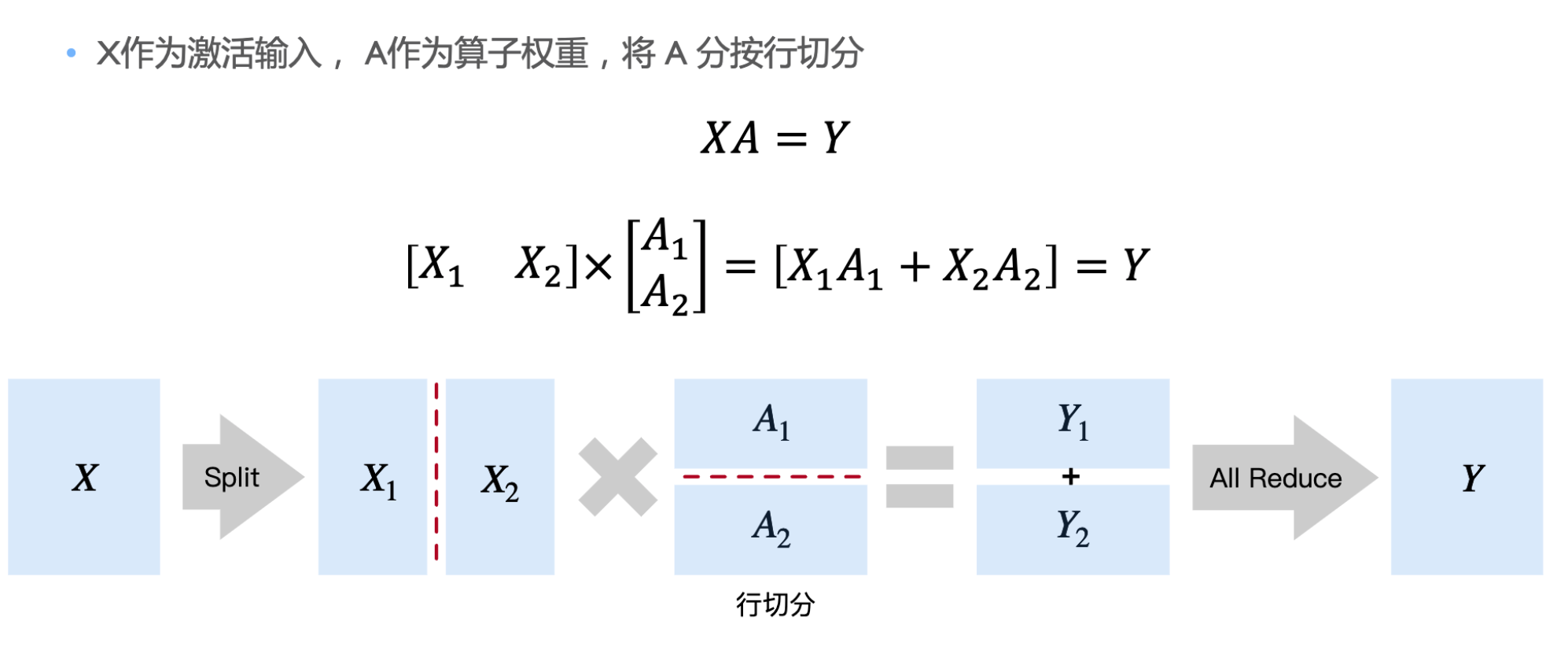
Model 并行 MP
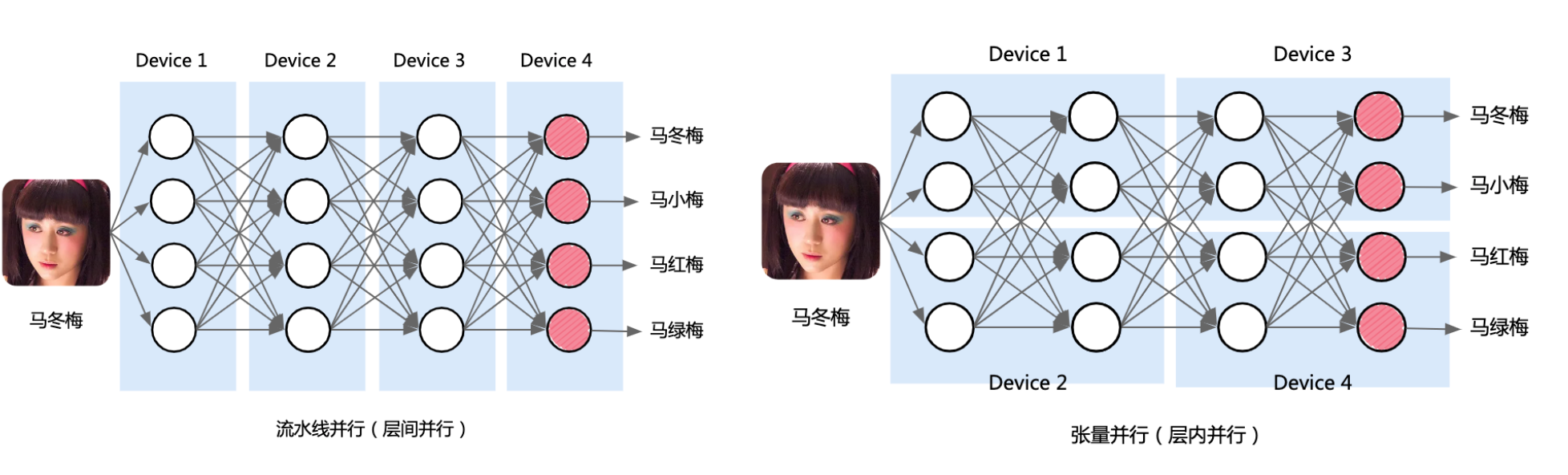
流水线并行: 按模型layer层切分到不同设备,即层间并行
张量并行: 将计算图中的层内的参数切分到不同设备,即层内并行
张量并行
如何正确切分,通讯成本比计算成本高
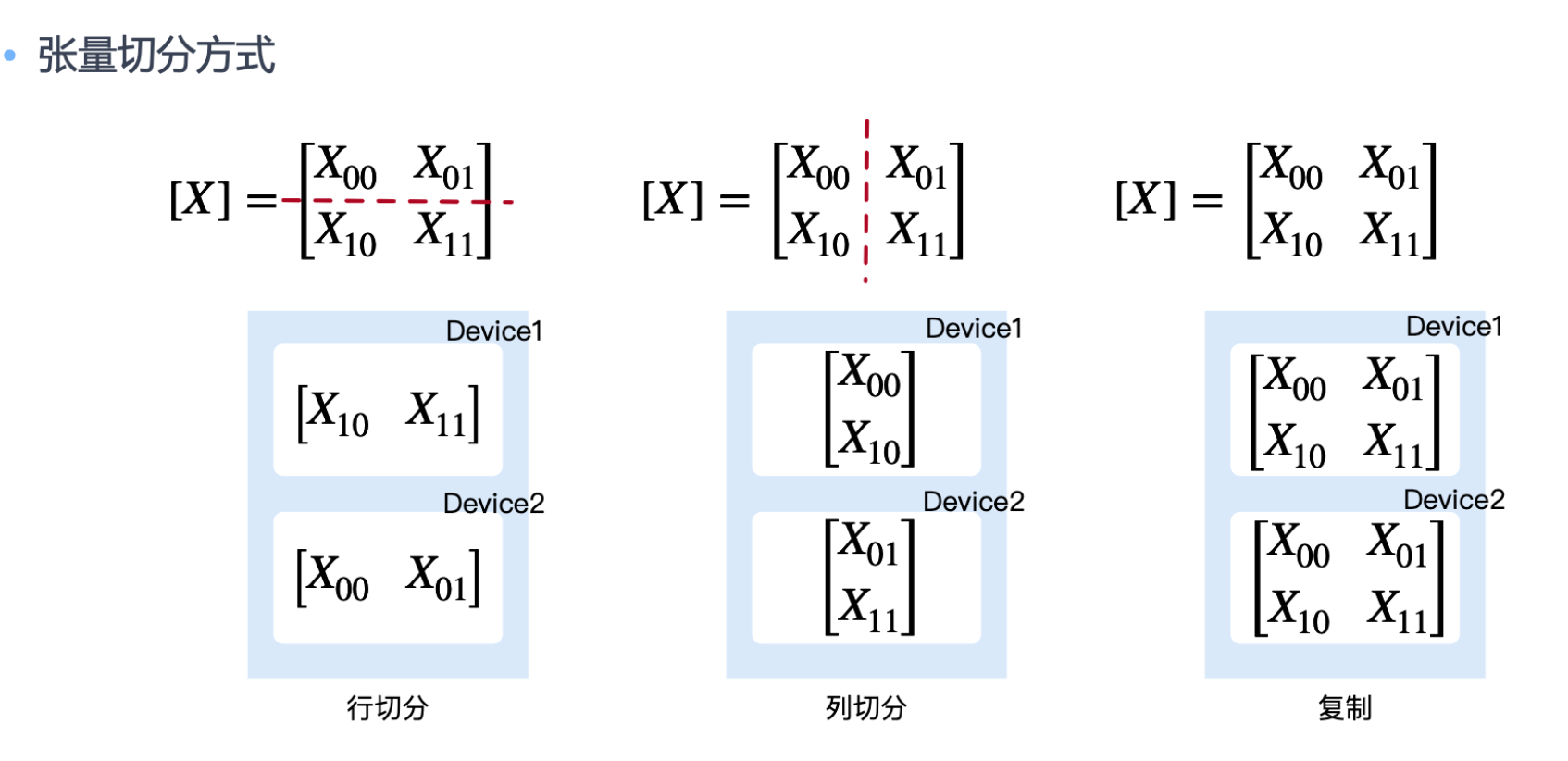
按列切分
按行切分
流水线并行
由于按模型layer层切分到不同设备,会后layer之间先后顺序的问题。
-
朴素流水线并行:同一时刻只有一个设备进行计算,其余设备处于空闲状态,计算设备利用率常较低
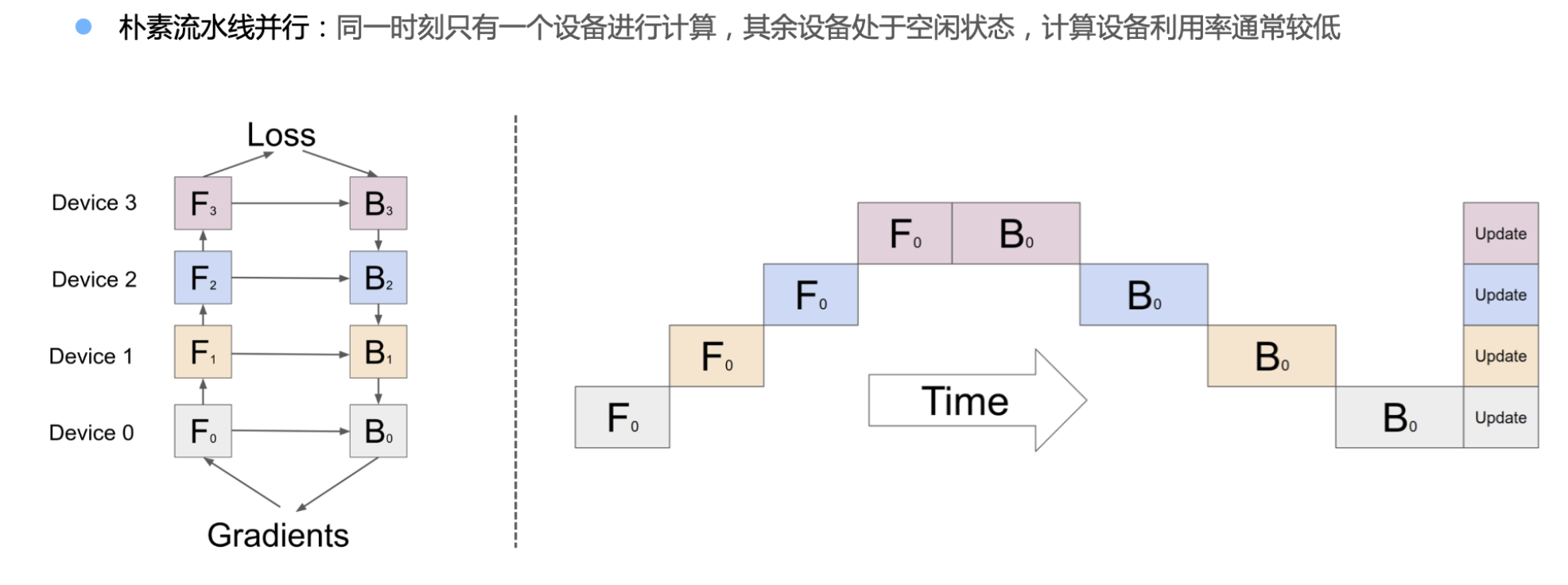
Forward Backward 计算过程
-
小批次流水线并行:将朴素流水线并行的 batch 再进行切分,减小设备间空闲状态的时间,可以显著提升流水线并行设备利用率。
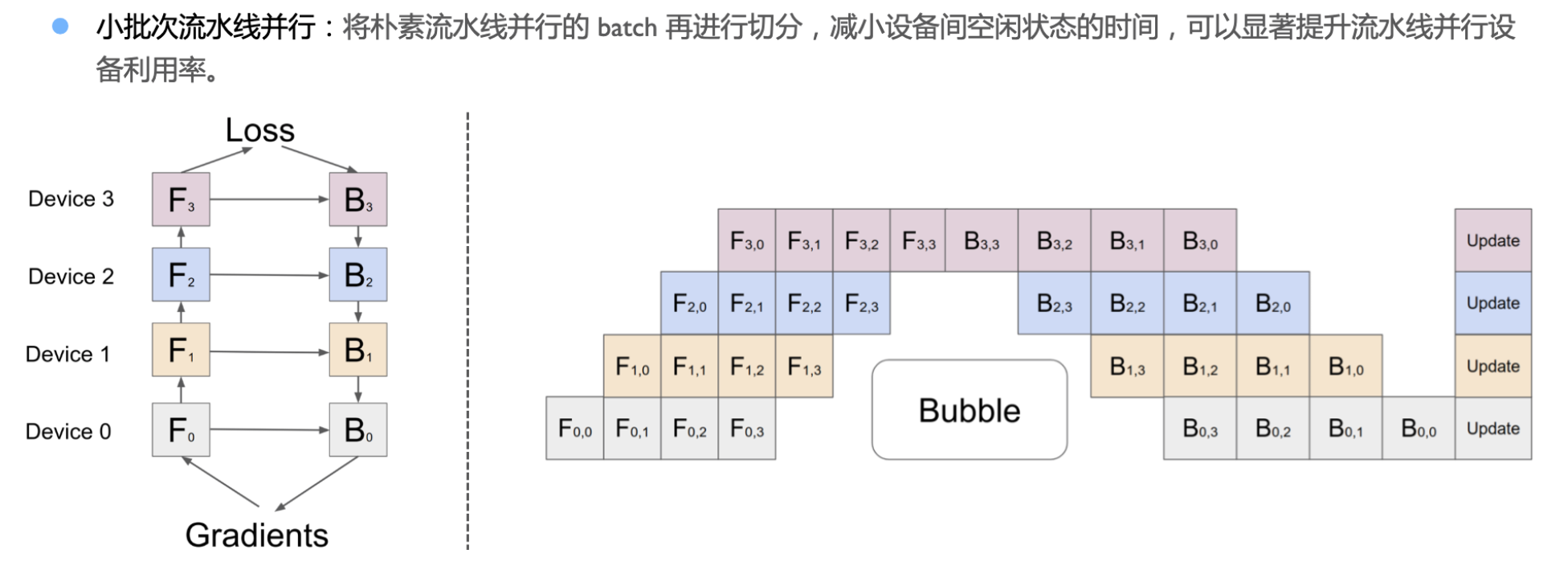
Gpipe
- 把模型切分成不同的stage(每个stage 包含若干层)
- 引入小批次micro-batch,越小 idle越小
- 使用重计算(反向不用正向结果,而是重新计算Forwad结果),计算成本远比内存消耗的成本要低。
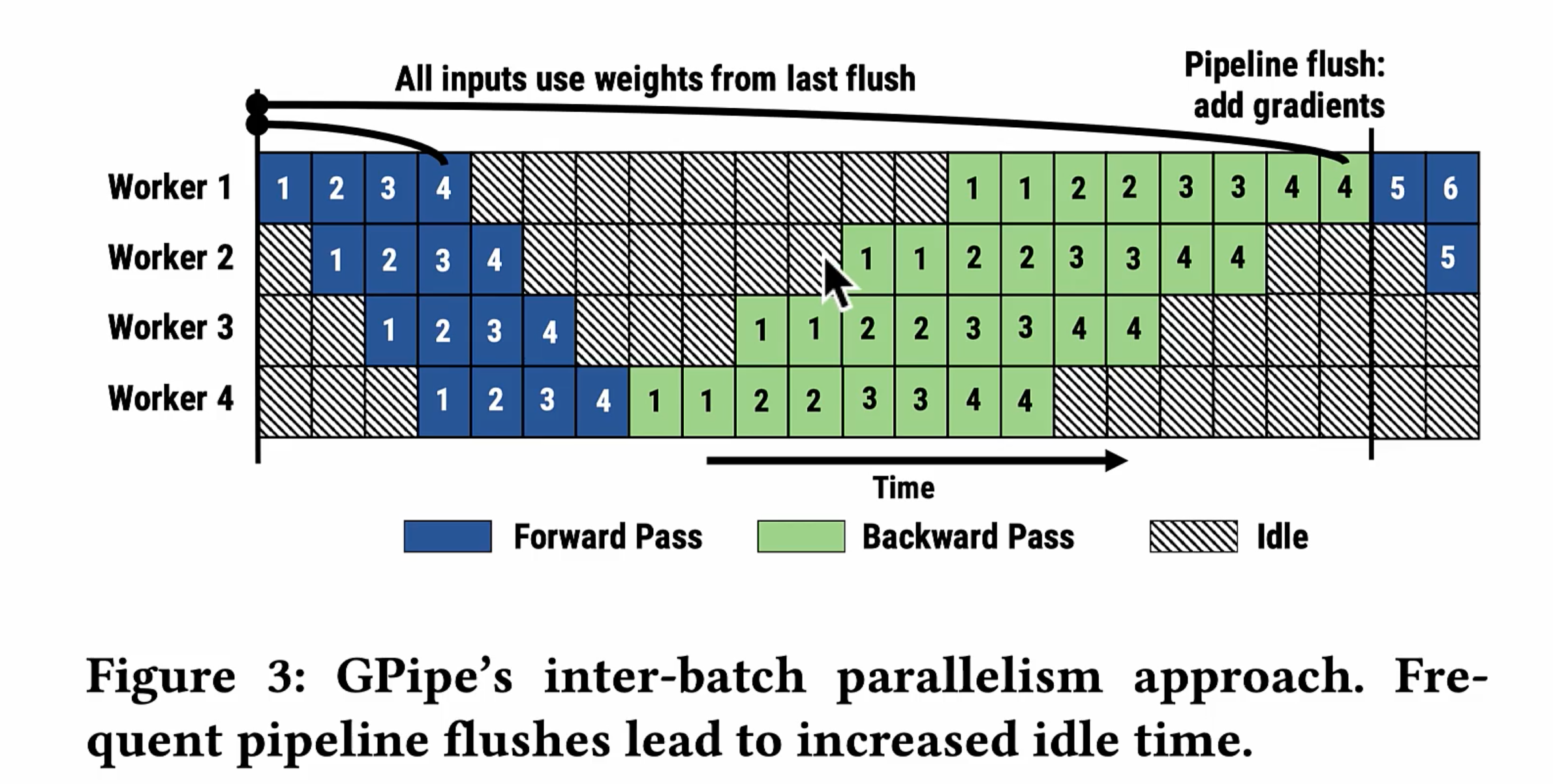
缺点:
- 批次越小,会有大量的forward计算,频繁流水线交互。训练的总体时间拉长。
- 大量的重计算,导致模型的权重,激活的中间变量变得更多,消耗动态内存
PipeDream
前面都是所有的forward做完再做backword,现在是一个forward做完马上做backword,可以及时释放不必要的中间变量。
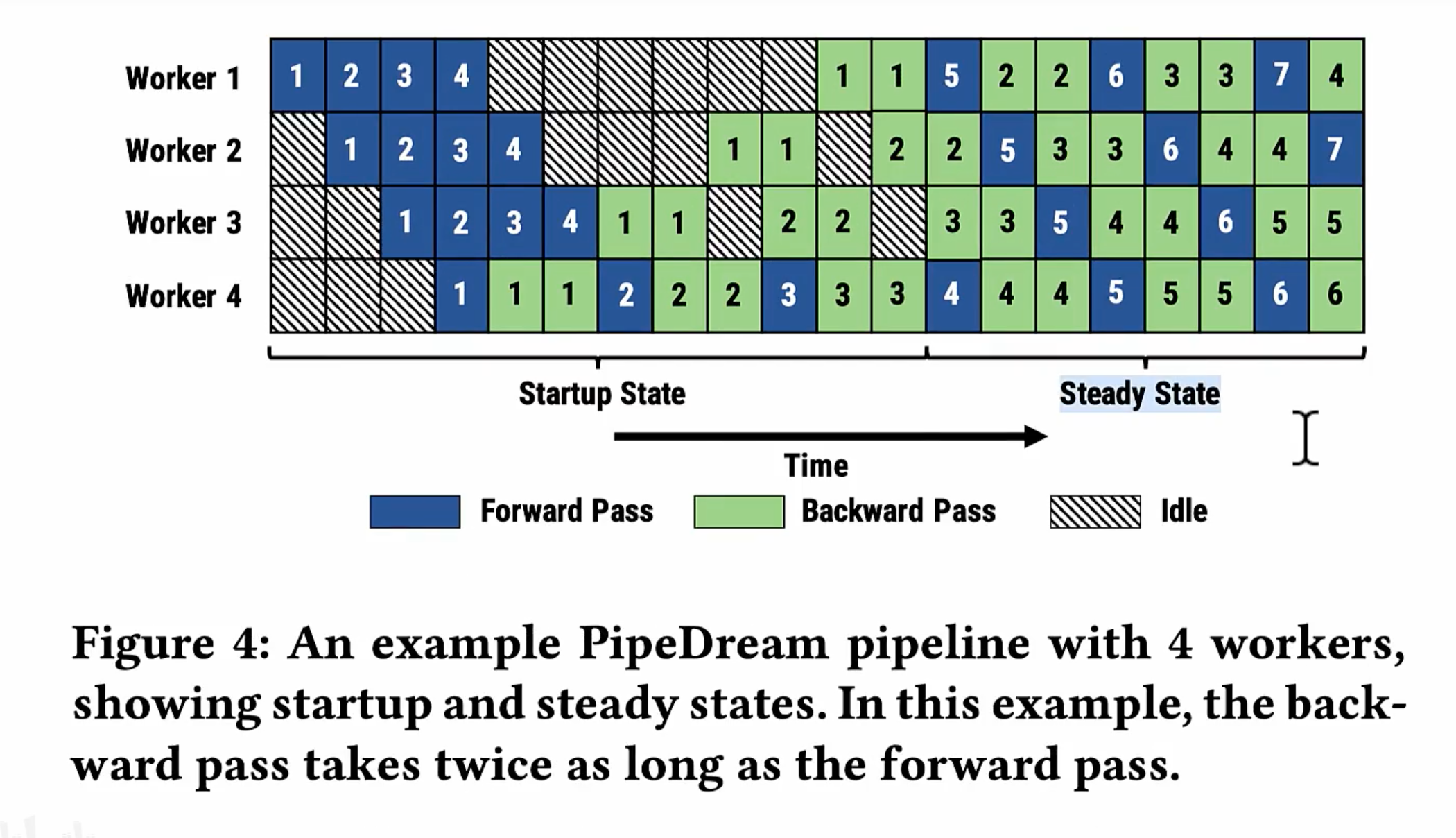
steady state 就没有idle。但是权重何时更新,梯度何时同步
为解决这两个问题,PipeDream 分别采用了 Weight stashing 和 Vertical Sync 两种技术
- Weight stashing: 为每个active minibatch都保存一份参数。前向计算时,每个stage 都是用最新的参数处理输入的minibatch,然后将这份参数保存下来用于同一个minibatch的后向计算,保证前向计算和后向计算的参数是关联的。
- Vertical Sync: 每个minibatch进入pipeline时都使用输入stage最新版本的参数,并且参数的版本号会伴随该minibatch数据整个生命周期,在各个阶段都是用同一个版本的参数(而不是前文所说的都使用最新版本的参数),从而实现了stage间的参数一致性。
ZeRO MP DP 优化显存和计算效率
参考 分布式训练 Parameter sharding 之 ZeRO
显存和计算
主要占据显存的地方
- 模型状态量(参数、梯度和优化器状态量)
- 激活函数也需要占据额外的显存,其随批量大小(batch size)而增加
计算效率随着计算时间对通信时间的比例的增加而增加。该比例与 batch size成正比。但是,模型可以训练的 batch size有一个上限,如果超过这个上限,则收敛情况会迅速恶化。
对比DP MP
数据并行data parallell
数据并行中,每批输入的训练数据都在数据并行的 worker 之间进行平分。反向传播之后,我们需要进行通信来规约梯度,以保证优化器在各个 worker 上可以得到相同的更新。数据并行性具有几个明显的优势,包括计算效率高和工作量小。但是,数据并行的 batch size 会随 worker 数量提高,而我们难以在不影响收敛性的情况下无限增加 batch szie。
显存效率:数据并行会在所有 worker 之间复制模型和优化器,因此显存效率不高。
计算效率:随着并行度的提高,每个 worker 执行的计算量是恒定的。数据并行可以在小规模上实现近乎线性扩展。但是,因为在 worker 之间规约梯度的通信成本跟模型大小成正相关,所以当模型很大或通信带宽很低时,计算效率会受到限制。梯度累积是一种常见的用来均摊通信成本的策略,它可以增加batch size,在本地使用 micro-batch 进行多次正向和反向传播,在进行优化器更新之前再规约梯度,从而分摊通信成本。
模型并行 model parallell
它可以在多个 worker 之间划分模型的各个层。DeepSpeed 利用了英伟达的 Megatron-LM 来构建基于 Transformer 的大规模模型并行语言模型。模型并行会根据 worker 数量成比例地减少显存使用,这是这三种并行模式中显存效率最高的。但是其代价是计算效率最低。
显存效率:模型并行的显存使用量可以根据 worker 数量成比例地减少。至关重要的是,这是减少单个网络层的激活显存的唯一方法。DeepSpeed 通过在模型并行 worker 之间划分激活显存来进一步提高显存效率。
计算效率:因为每次前向和反向传播中都需要额外通信来传递激活,模型并行的计算效率很低。模型并行需要高通信带宽,并且不能很好地扩展到通信带宽受限的单个节点之外。此外,每个模型并行worker 都会减少每个通信阶段之间执行的计算量,从而影响计算效率。模型并行性通常与数据并行性结合使用,以便在内存和计算效率之间进行权衡。
总结
模型状态通常在训练过程中消耗最大的内存量,但是现有的方法,如DP和MP并不能提供令人满意的解决方案。DP具有良好的计算/通信效率,但内存效率较差,而MP的计算/通信效率较差。
更具体地说,
- DP在所有数据并行进程中复制整个模型状态,导致冗余内存消耗
-
虽然MP对这些状态进行分区以获得较高的内存效率,但往往会导致过于细粒度的计算和昂贵的通信,从而降低了扩展效率。
- 这些方法静态地维护整个训练过程中所需的所有模型状态,即使在训练过程中并非始终需要所有模型状态。
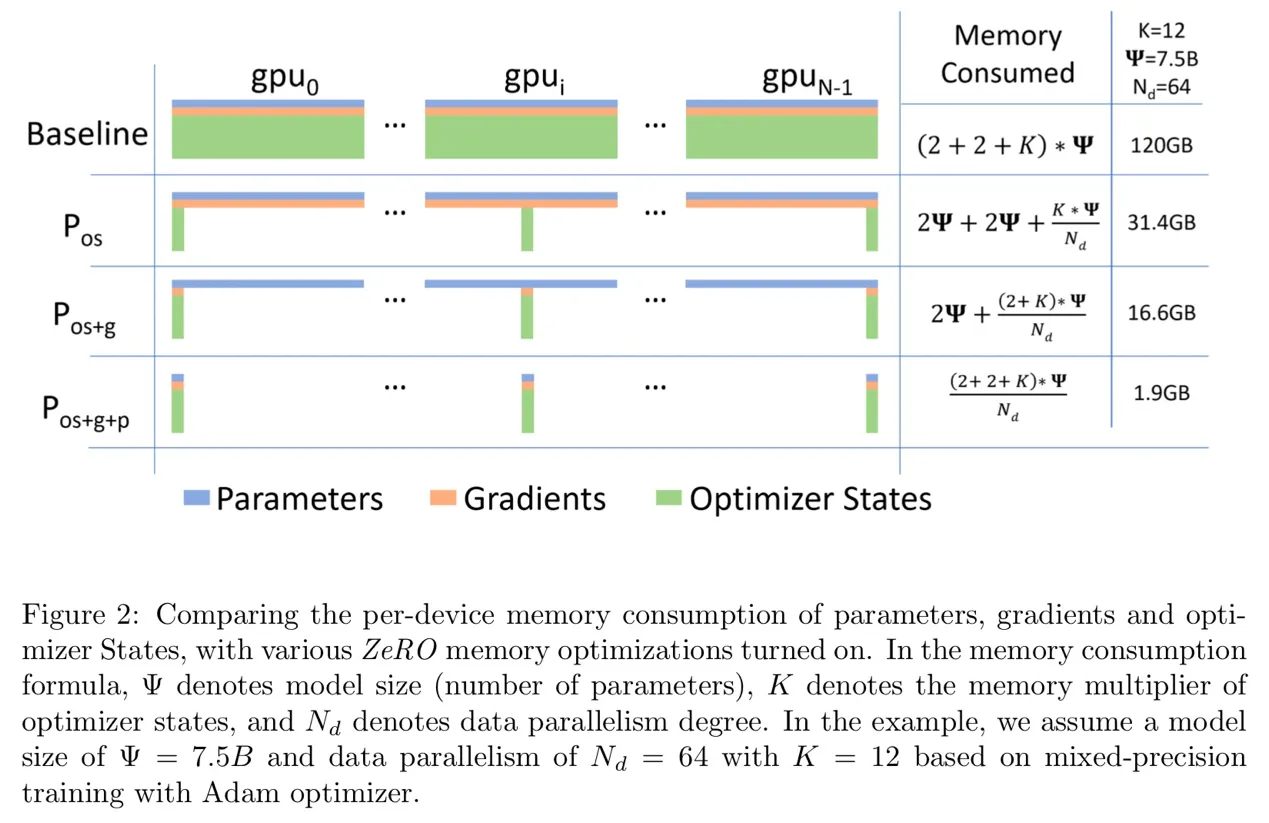
ZeRO提出的内存优化
数据并行具有较好的通信和计算效率,但内存冗余严重。因此,ZeRO通过对参数(包括优化器状态、梯度和参数)进行分区来消除这种内存冗余,每个GPU仅保存部分参数及相关状态。
ZeRo stages
学习类型
在 迁移学习 中,由于传统深度学习的 学习能力弱,往往需要 海量数据 和 反复训练 才能 泛化
-
Zero-shot learning 就是希望我们的模型能够对其从没见过的类别进行分类,让机器具有推理能力,实现真正的智能。其中零次(Zero-shot)是指对于要分类的类别对象,一次也不学习。
-
One-shot learning 指的是我们在训练样本很少,甚至只有一个的情况下,依旧能做预测。
-
如果训练集中,不同类别的样本只有少量,则成为Few-shot learning。就是给模型待预测类别的少量样本,然后让模型通过查看该类别的其他样本来预测该类别。