决策树
不同的表达式 path view / 递归view
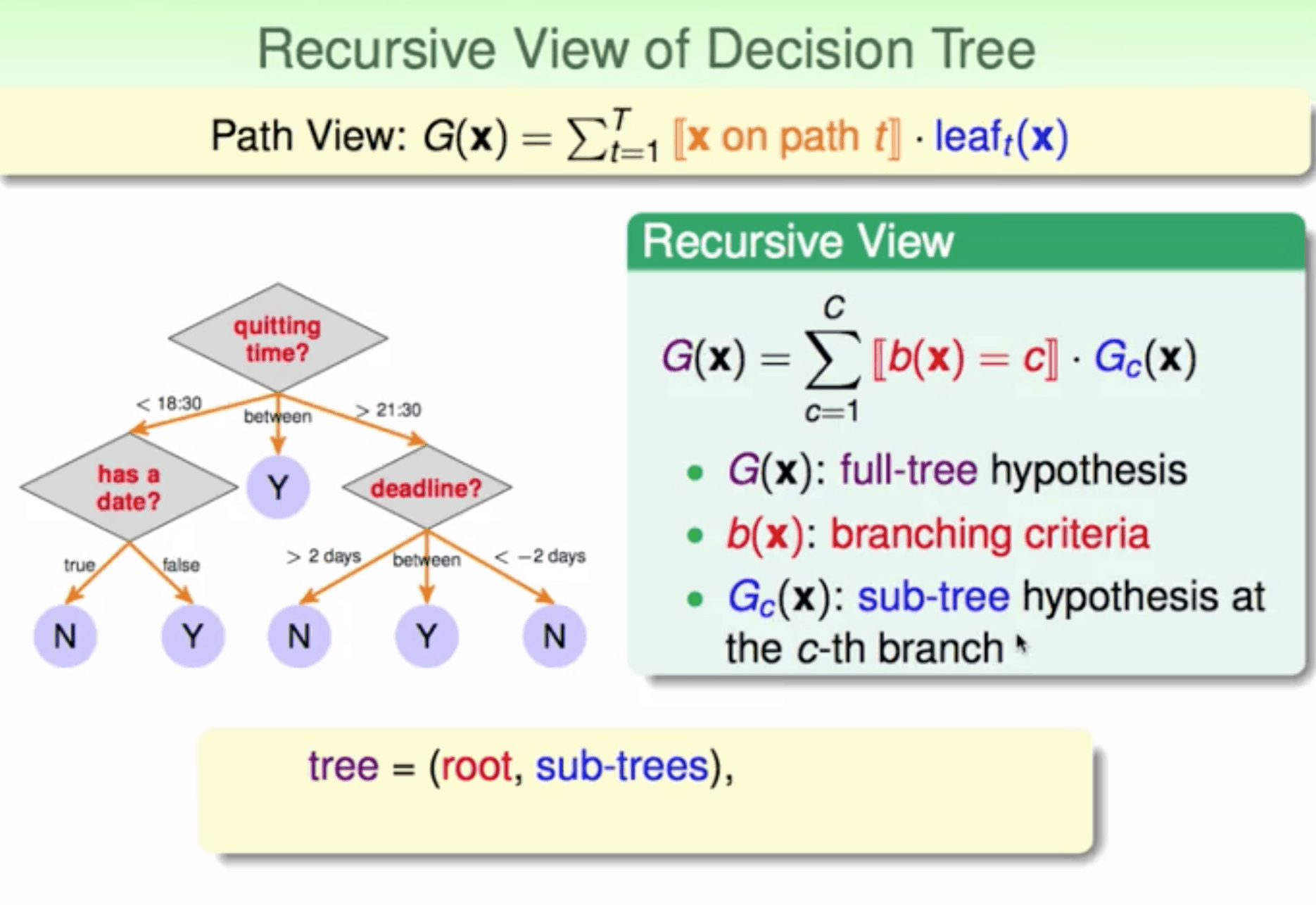
- 分支个数(number of branches)
- 分支条件(branching criteria)
- 终止条件(termination criteria)
- 基本算法(base hypothesis)
C&RT
可处理 回归 二元 多元分类

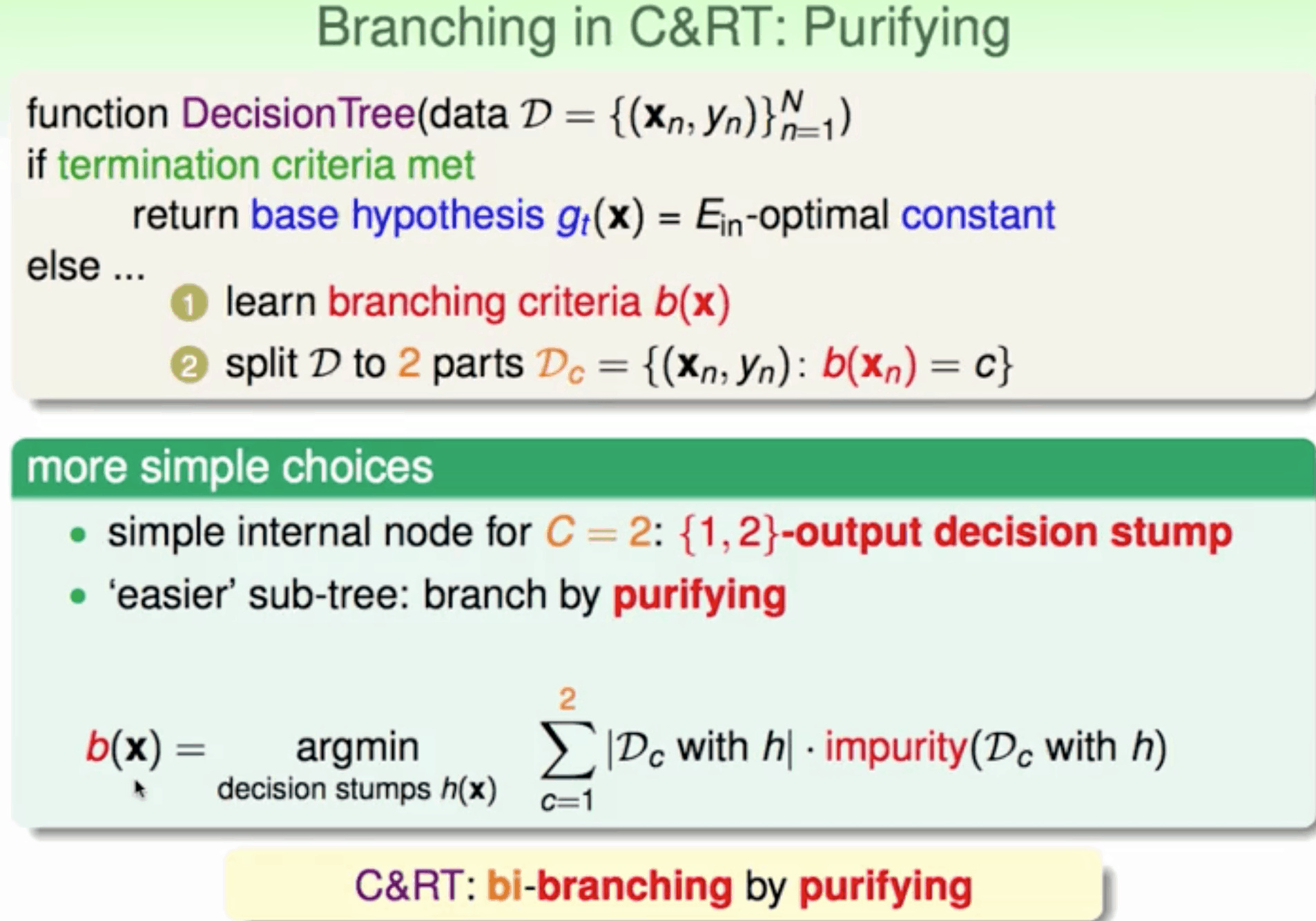
不纯度计算

 分类
分类
1 | |
 回归
回归
1 | |
停止条件
 不纯度impurity为0,表示该分支已经达到了最佳分类程度
所有的xn相同,无法对其进行区分
不纯度impurity为0,表示该分支已经达到了最佳分类程度
所有的xn相同,无法对其进行区分
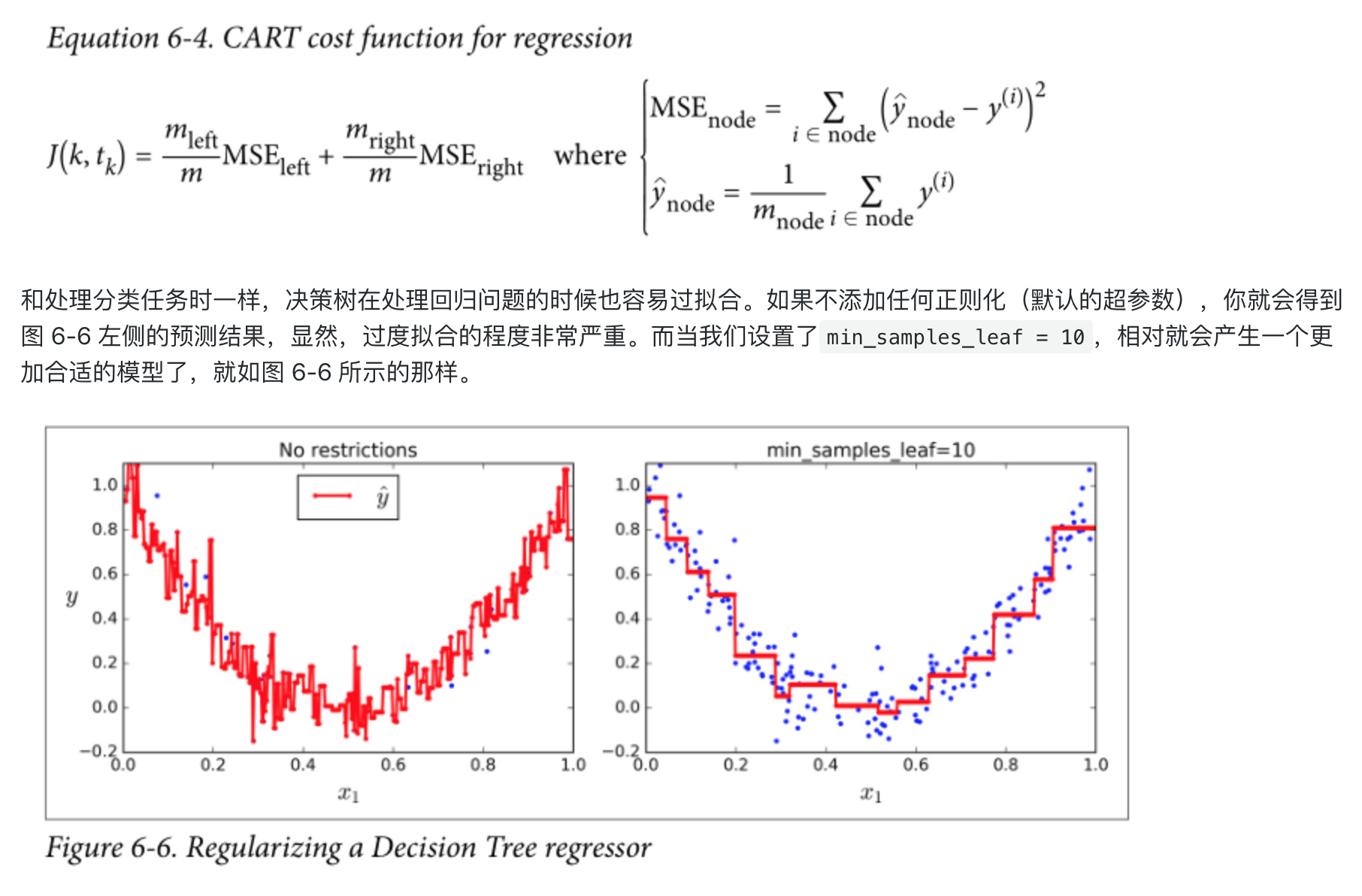
容易overfit
prune 剪枝
叶子数衡量正则化 $\lambda$ 用validation决定
 剪枝过程
want N 片叶子
剪枝过程
want N 片叶子
- 剪去one-leaf remove 剩下的树有N-1情况
- argmin(Ein(G)) in N-1 直到得到不同叶子min Ein model
- 计算model误差最小
surrogate 替代品
缺失关键特征导致无法判断,寻找与该特征相似的替代feature

随机森林
bagging + C&RT bagging 制造data-set 训练 C&RT
- 不同决策树可以由不同主机并行训练生成,效率很高;
- 随机森林算法继承了C&RT的优点;
- 将所有的决策树通过bagging的形式结合起来,避免了单个决策树造成过拟合的问题
1
2
3
4>>>from sklearn.ensemble import RandomForestClassifier >>>rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, n_jobs=-1) >>>rnd_clf.fit(X_train, y_train) >>>y_pred_rf = rnd_clf.predict(X_test)增强决策树多样性
- 选择子特征 而不是 sub_data-set
- 选择子特征做线性组合成一个特征
特征选择
对于某个特征,如果用另外一个随机值替代它之后的表现比之前更差,则表明该特征比较重要,所占的权重应该较大,不能用一个随机值替代。
通过比较某特征被随机值替代前后的表现,就能推断出该特征的权重和重要性
permutation bootstrap 选出 打乱所有样本某个特征值 => 求出特征重要性

为了避免重新训练,应该permutation OOB的值 训练时使用原数据,进行OOB验证时,将所有的OOB样本的某特征重新洗牌,验证G的表
1 | |
adaboost rf
权重u实际上表示该样本在bootstrap中出现的次数,反映了它出现的概率。那么可以根据u值, 对原样本集D进行一次重新的随机sampling,也就是带权重的随机抽样。sampling之后,会得到一个新的D’, D’中每个样本出现的几率与它权重u所占的比例应该是差不多接近的
G的权重a容易无限大 是有prune 限制树高
