sklearn xgboot
Ensemble 好处 feature transform和regularization 单一模型通常只能倾向于feature transform和regularization之一,但是Ensemble却能将feature transform和regularization各自的优势结合起来
常见的 Ensemble 方法有这么几种:
Blending
用不相交的数据训练不同的 Base Model,将它们的输出取(加权)平均。实现简单,但对训练数据利用少了。
vote 分类
 avg 回归
avg 回归

加权Linear blending
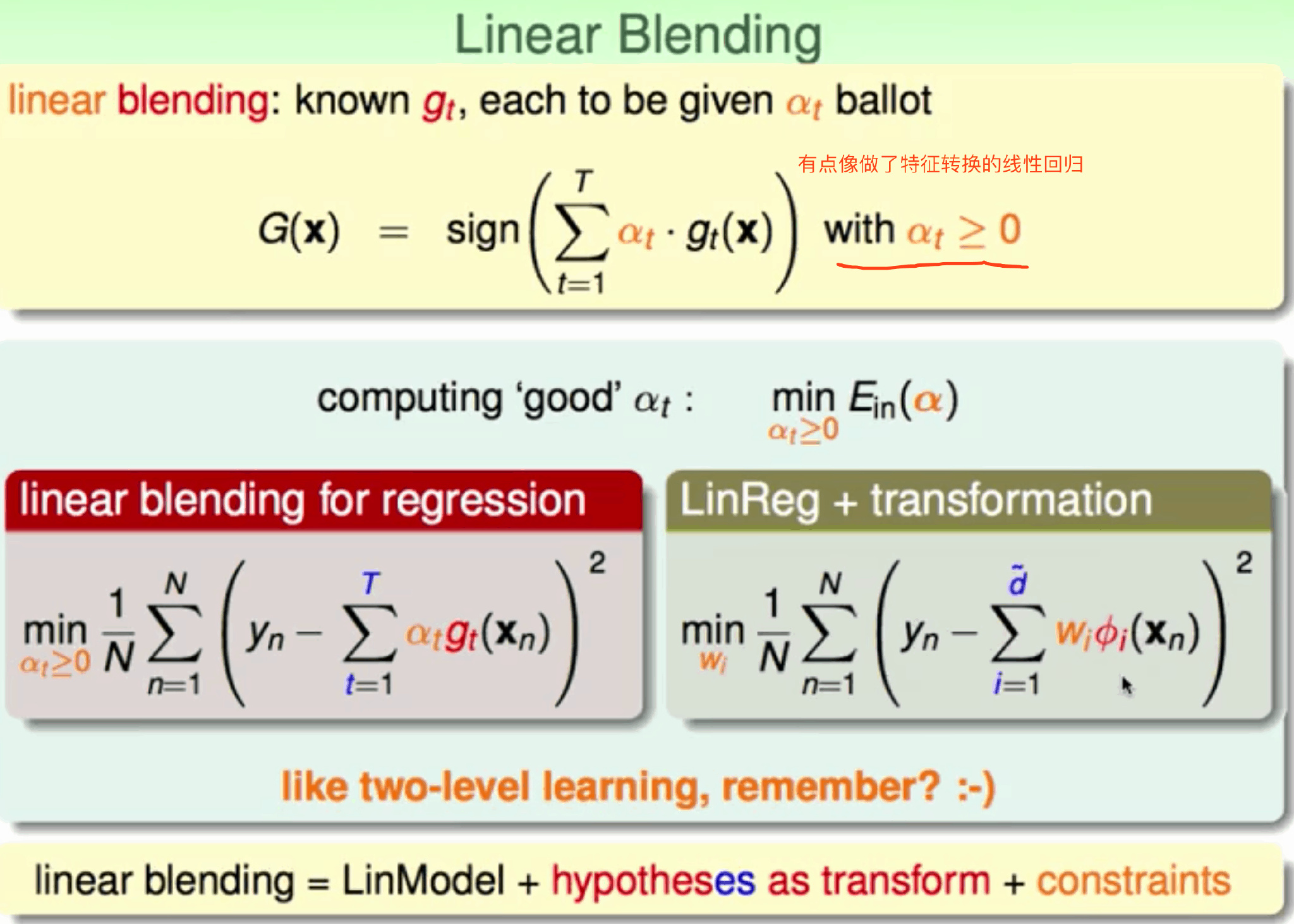
训练过程
用validation 训练不同的base model, 得到的值代入 Linear blending 获取对应的权重a。 使用完整的data set 训练不同的base model得到更好的model + 之前的权重 => 目标函数
获取base model
- select different base model
- different params

投票分类器
1 | |
voting="soft"有更好的效果,使用交叉验证去预测类别概率,其降低了训练速度
If ‘hard’, uses predicted class labels for majority rule voting. Else if ‘soft’, predicts the class label based on the argmax of the sums of the predicted probabilities, which is recommended for an ensemble of well-calibrated classifiers.
1 | |
测试集准确率
1 | |
Stacking
在blending的基础上 => 多层blending
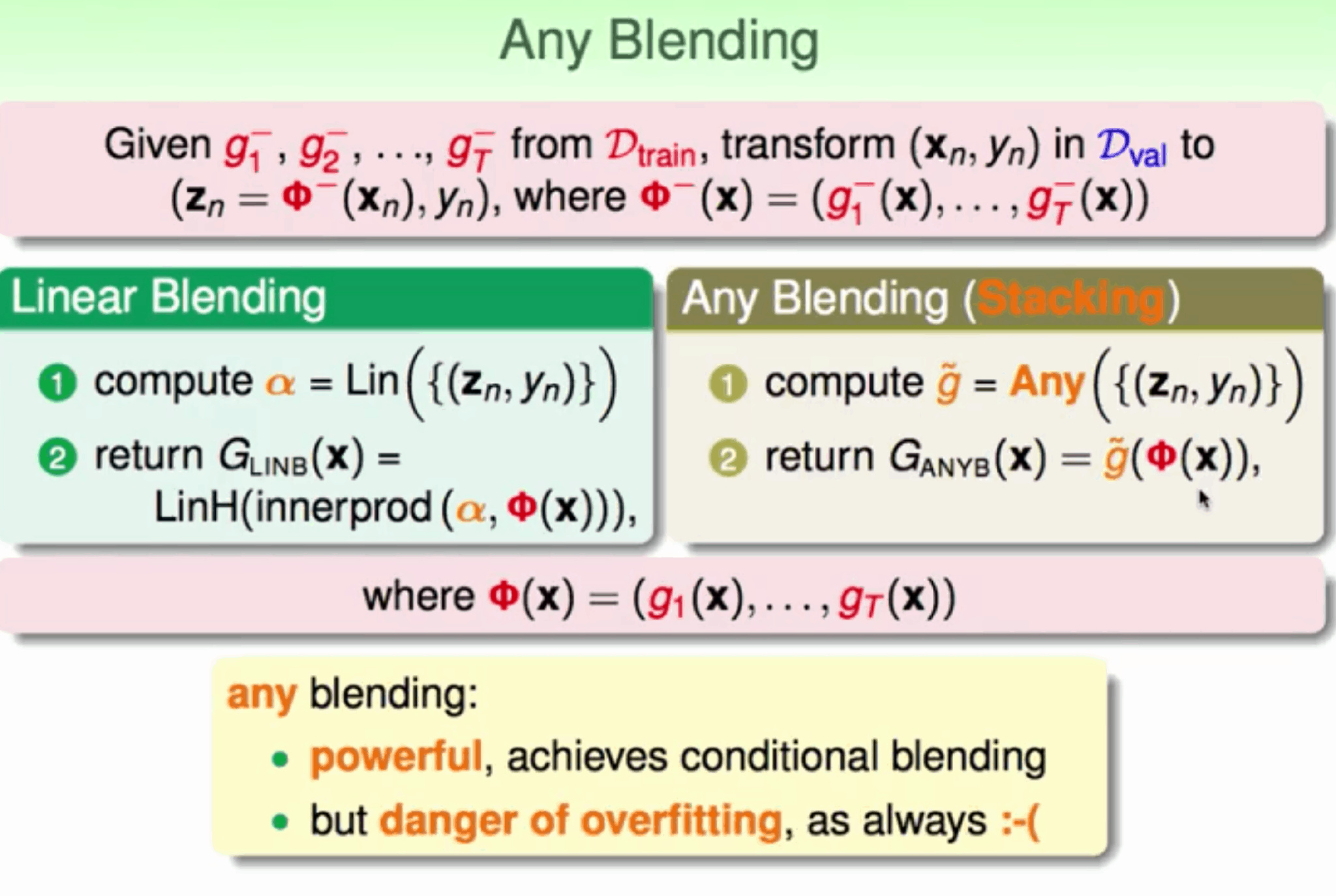 Blending只有一层,而Stacking有多层 使用前一层的输出(预测结果)作为本层的训练集(有点像多层神经网络) ,不使用琐碎的函数(如硬投票)来聚合集合中所有分类器的预测,训练一个模型来执行这个聚合
模型复杂度过高,容易造成过拟合
Blending只有一层,而Stacking有多层 使用前一层的输出(预测结果)作为本层的训练集(有点像多层神经网络) ,不使用琐碎的函数(如硬投票)来聚合集合中所有分类器的预测,训练一个模型来执行这个聚合
模型复杂度过高,容易造成过拟合
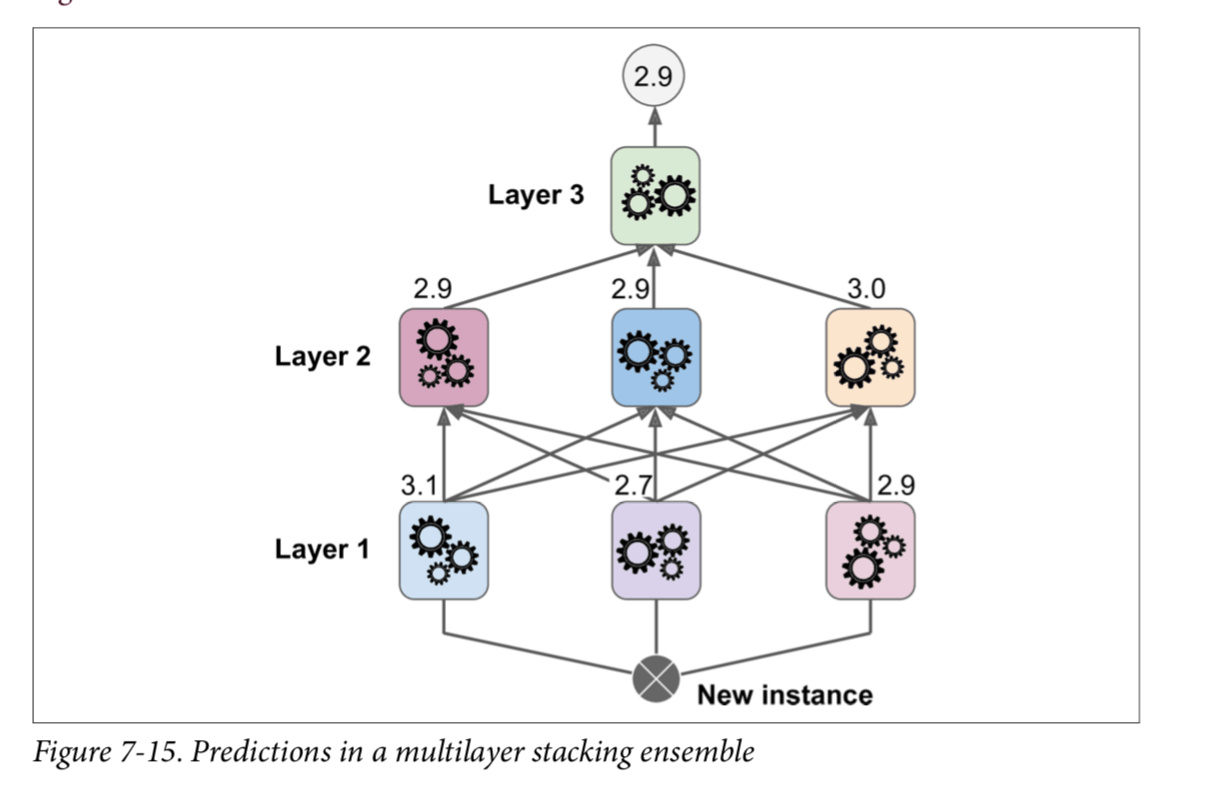
例子:
诀窍是将训练集分成三个子集:第一个子集用来训练第一层,第二个子集用来创建训练第二层的训练集(使用第一层分类器的预测值),
第三个子集被用来创建训练第三层的训练集(使用第二层分类器的预测值)。以上步骤做完了,我们可以通过逐个遍历每个层来预测一个新的实例。
 你也可以使用开源的项目例如 brew (网址为 https://github.com/viisar/brew)
你也可以使用开源的项目例如 brew (网址为 https://github.com/viisar/brew)
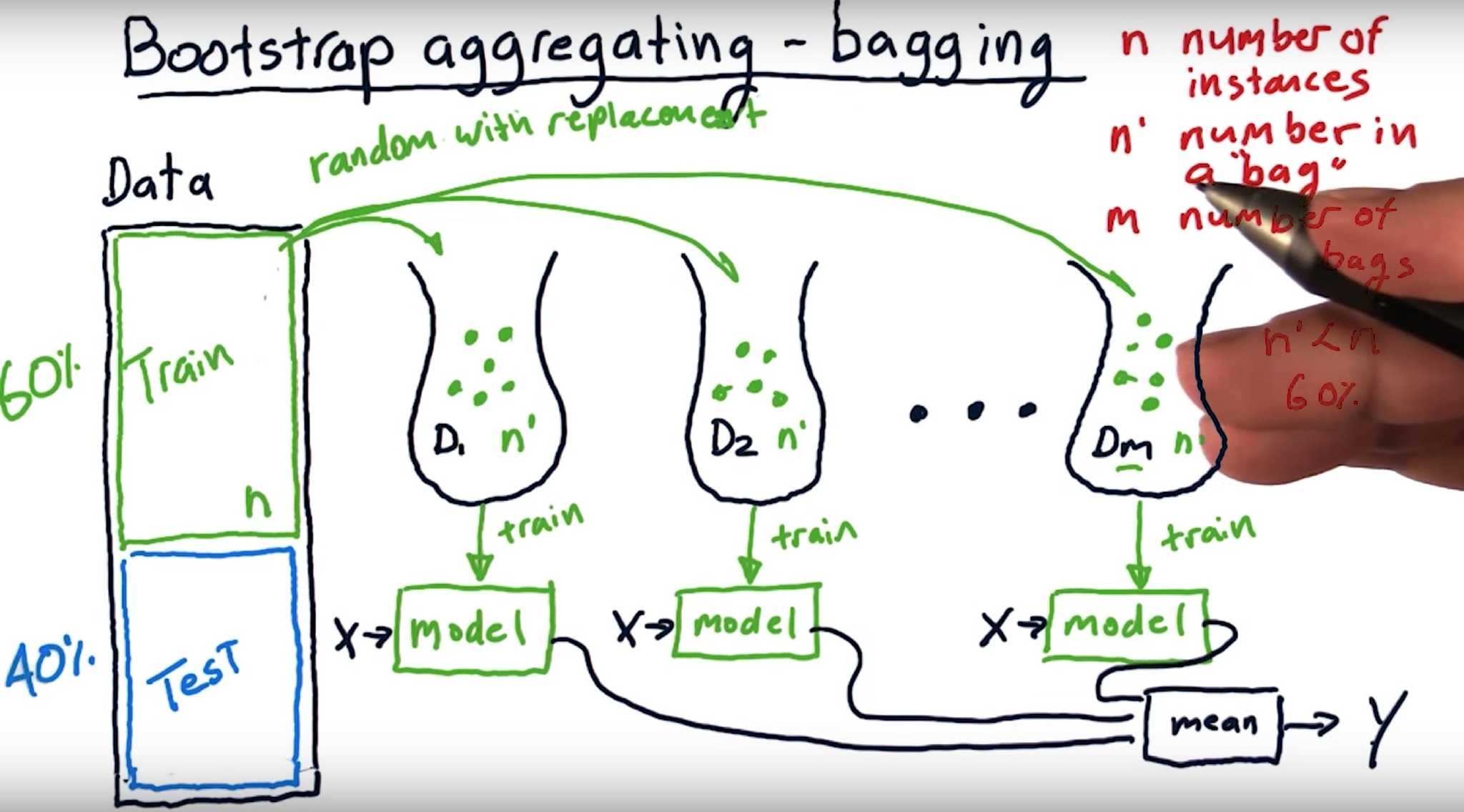
Bagging
使用训练数据的不同随机子集来,有放回随机抽取m次每次n个样本作为子集训练相同Base Model,由于不同data-set子集得到不同的model
最后进行每个 Base Model 权重相同的 Vote。也即 Random Forest 的原理。Pasting 是无放回
Blending & Bagging 都是可并行训练base model 再aggregation
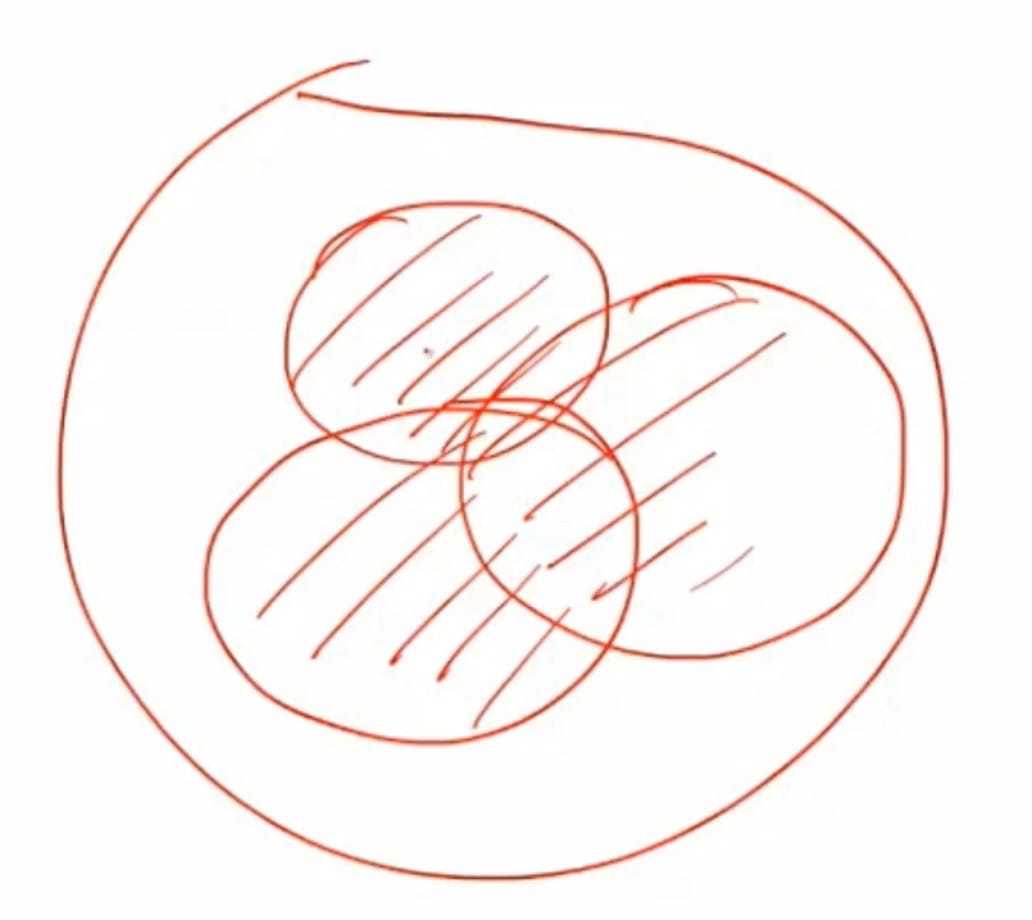
以上算法不能解决下图 阴影是三个model都出错部分
BaggingClassifier类或者对于回归可以是BaggingRegressor。尝试Pasting,就设置bootstrap=False
如果基分类器可以预测类别概率(例如它拥有predict_proba()方法),那么BaggingClassifier会自动的运行软投票,这是决策树分类器的情况。
1 | |
OOB
out-of-bag bagging 没有被选上的数据 用来验证G- 直接验证G 加快效率
 BaggingClassifier来自动评估时设置oob_score=True来自动评估
BaggingClassifier来自动评估时设置oob_score=True来自动评估
1 | |
测试集
1 | |
Boosting
迭代地训练 Base Model,每次根据上一个迭代中预测错误的情况修改训练样本的权重。也即 Gradient Boosting,Adaboost 的原理。比 Bagging 效果好,但更容易 Overfit。
前一个base model 预测错误的的样本会增权,正确的会减少权重,权值更新过后的样本训练下一个新的base model 直到目标错误率或最大迭代次数
aggregation时 表现好的model 权重就大
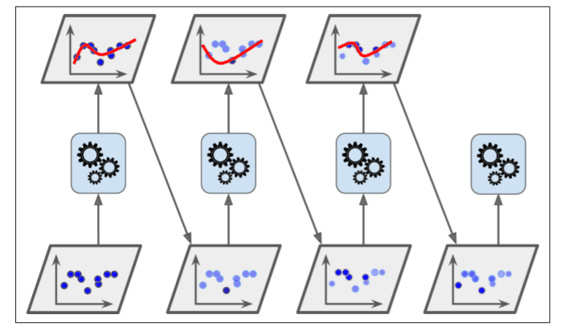
AdaBoost
错误因子犯错放大,正确缩小
 通常学习比乱猜要好所以犯错率ϵt <= 0.5
通常学习比乱猜要好所以犯错率ϵt <= 0.5
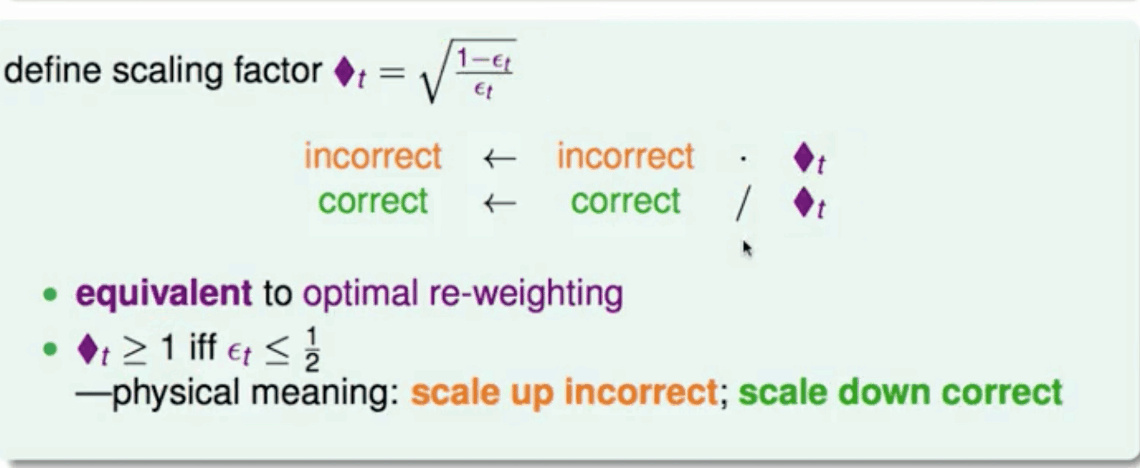
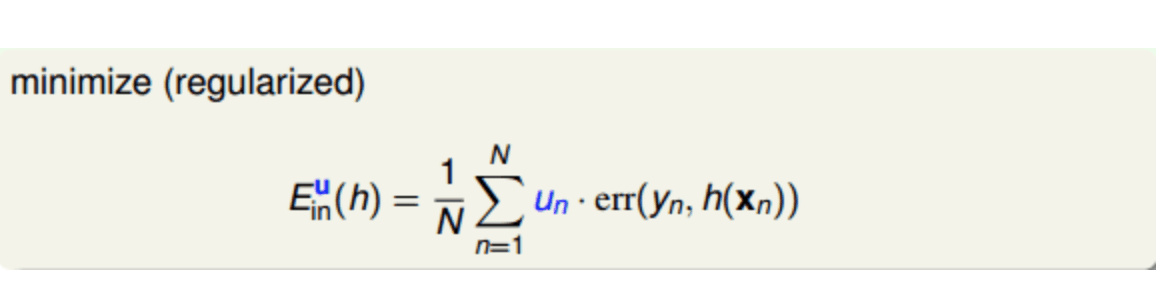
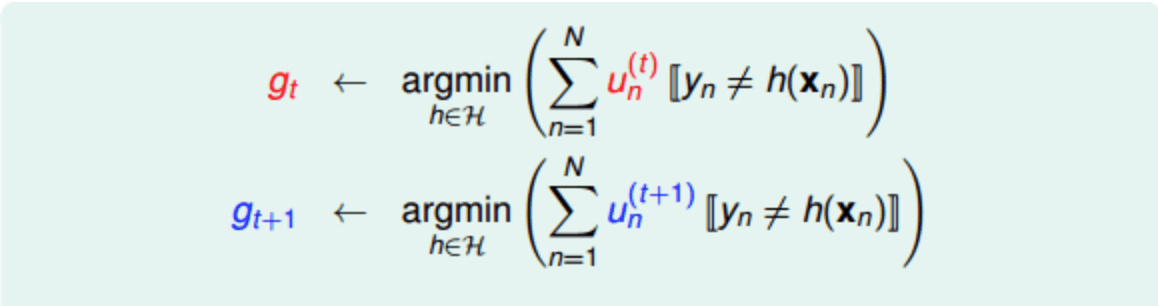 u 表示重要性初始化
u 表示重要性初始化
 aggregation时 表现好的 权重就大 $\alpha\;=\;\frac12\ln\left(\frac{1-\varepsilon_t}{\varepsilon_t}\right)$
aggregation时 表现好的 权重就大 $\alpha\;=\;\frac12\ln\left(\frac{1-\varepsilon_t}{\varepsilon_t}\right)$
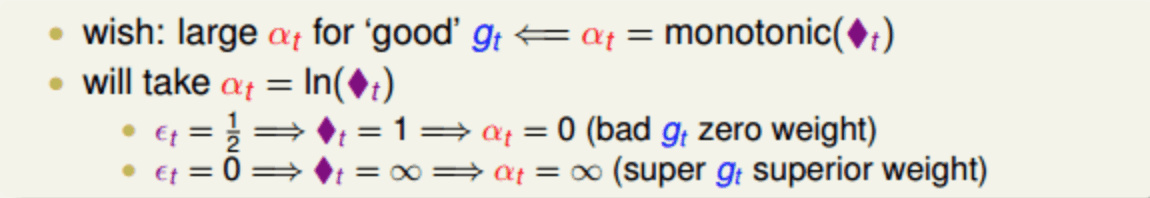
1 | |
Gradient Boosting
也是通过向集成中逐步增加分类器运行的,每一个分类器都修正之前的分类结果,不像Adaboost那样每一次迭代都更改实例的权重, 这个方法是去使用新的分类器去拟合前面分类器预测的残差
GBRT Gradient Boosted Regression Trees
1 | |
1 | |
找到树的最佳数量 staged_predict
1 | |
早停法 设置warm_start=True来实现 ,这使得当fit()方法被调用时 sklearn 保留现有树,并允许增量训练
1 | |