引用计数法Reference Counting
1 | |
在Python中每一个对象的核心就是一个结构体PyObject,它的内部有一个引用计数器(ob_refcnt)。程序在运行的过程中会实时的更新ob_refcnt的值,来反映引用当前对象的名称数量。当某对象的引用计数值为0,那么它的内存就会被立即释放掉。
一旦对象的引用计数为0,该对象立即被回收,对象占用的内存空间将被释放。
它的缺点是
- 需要额外的空间维护引用计数
-
在一些场景下,可能会比较慢。正常来说垃圾回收会比较平稳运行,但是当需要释放一个大的对象时,比如字典,需要对引用的所有对象循环嵌套调用,从而可能会花费比较长的时间
- 不过最主要的问题是它不能解决对象的“循环引用”
循环引用

因此如果是使用引用计数法来管理这两对象的话,他们并不会被回收,它会一直驻留在内存中,就会造成了内存泄漏(内存空间在使用完毕后未释放)。为了解决对象的循环引用问题,Python引入了标记-清除和分代回收两种GC机制。
标记清除解决循环引用问题
- GC会把所有的活动对象打上标记
-
没有标记的对象非活动对象进行回收
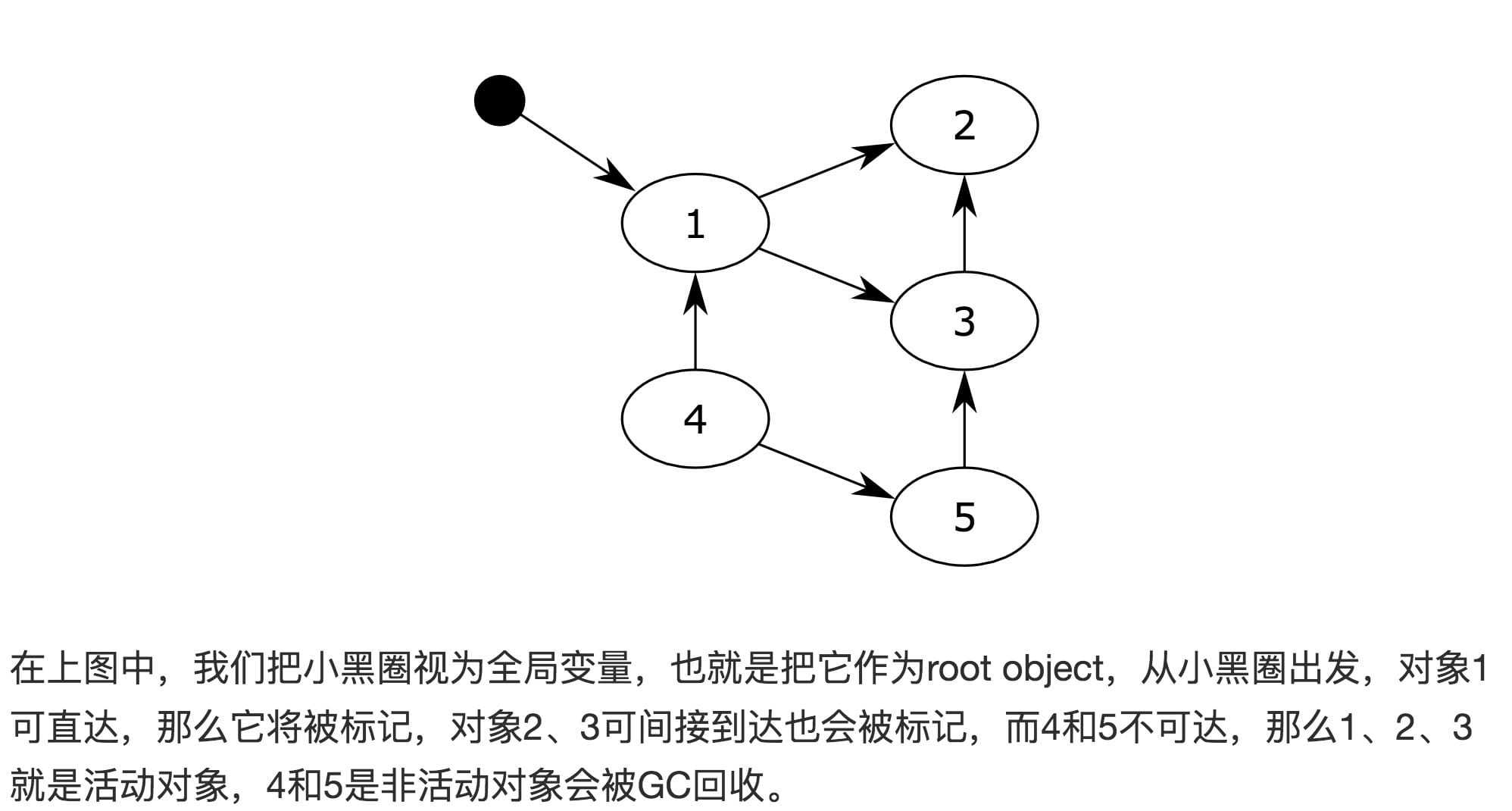
-
标记阶段,遍历所有的对象,如果是可达的(reachable),也就是还有对象引用它,那么就标记该对象为可达
In the marking phase, all objects are traversed. If an object is reachable, which means it is still referenced by other objects, it is marked as reachable.
-
清除阶段,再次遍历对象,如果发现某个对象没有标记为可达,则就将其回收。
In the sweeping phase, objects are traversed again. If an object is found to be unmarked, it is then collected.
标记清除算法作为Python的辅助垃圾收集技术主要处理的是一些容器对象, 比如list、dict、tuple,instance等,因为对于字符串、数值对象是不可能造成循环引用问题。 Python使用一个双向链表将这些容器对象组织起来。不过,这种简单粗暴的标记清除算法也有明显的缺点:清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
分代回收
在循环引用对象的回收中,整个应用程序会被暂停,为了减少应用程序暂停的时间
对象存在时间越长,越可能不是垃圾,应该越少去收集。这样在执行标记-清除算法时可以有效减小遍历的对象数,从而提高垃圾回收的速度。
The longer an object exists, the less likely it is to be garbage and thus should be collected less frequently. This approach reduces the number of objects to be traversed during the mark and sweep algorithm, resulting in improved garbage collection speed.
以空间换时间 Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。同时,分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象