文本嵌入
文本嵌入模型主要用于计算文本的向量表示,这里的向量指的就是数学向量,也叫特征向量
通过文本嵌入模型,可以计算文本的特征向量,然后通过向量的相似度计算,可以找出特征相似的文本内容。
向量搜索&基于关键词搜索的区别
- 向量搜索是基于词向量的语义相似性进行的,它可以找到与查询语义上相关的结果,即使查询词和结果中的词不完全匹配。向量搜索会把词映射到一个高维向量空间,计算向量之间的相似性。这样即使词本身不匹配,只要语义上相似,也能找到相关的结果。
- 基于关键词的搜索是简单的字符串匹配。它只会返回包含完全匹配查询词的结果。如果文档使用了不同的词语,即使语义相似,也不会被匹配到。
架构
https://milvus.io/docs/architecture_overview.md
Milvus 建立在 Faiss、Annoy、HNSW 等流行的矢量搜索库之上,旨在对包含数百万、数十亿甚至数万亿矢量的密集矢量数据集进行相似性搜索。
Milvus 还支持数据分片、数据持久化、流式数据摄取、向量和标量数据之间的混合搜索、时间旅行等许多高级功能。该平台提供按需性能,并且可以进行优化以适应任何嵌入检索场景。我们建议使用 Kubernetes 部署 Milvus,以获得最佳可用性和弹性。
Milvus 采用共享存储架构,存储和计算分离,计算节点可水平扩展。Milvus 遵循数据平面和控制平面分解的原则,包括四层:接入层、协调器服务、工作节点和存储。在扩展或灾难恢复方面,这些层是相互独立的。
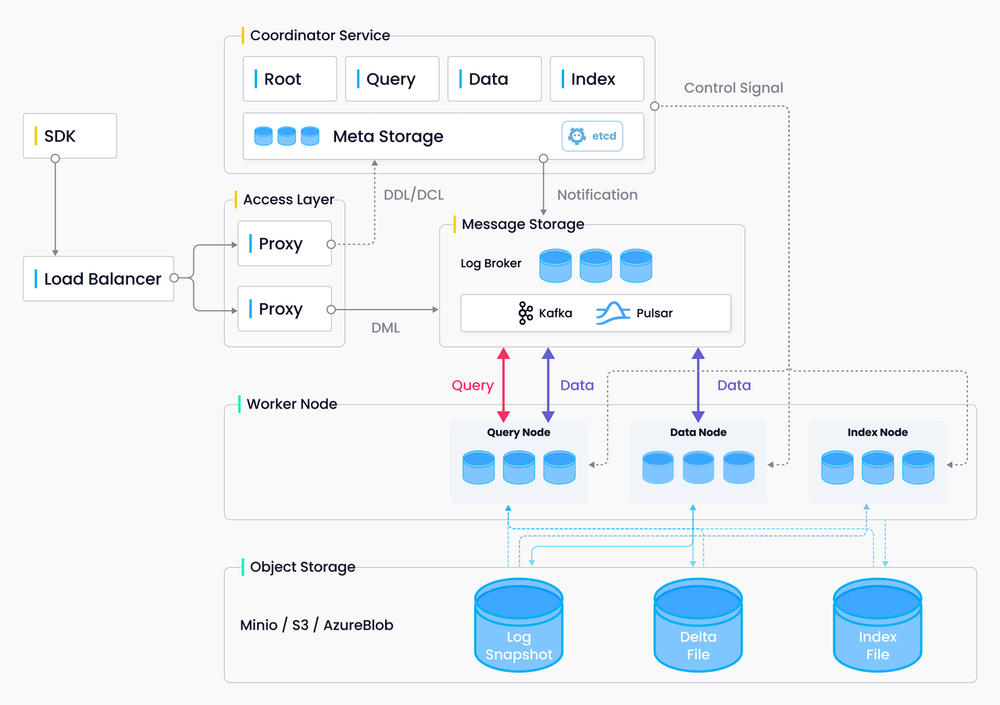
接入层
访问层由一组无状态代理组成,是系统的前端层和用户的端点。它验证客户端请求并减少返回结果
协调员服务
协调器服务将任务分配给工作节点并充当系统的大脑。它承担的任务包括集群拓扑管理、负载均衡、时间戳生成、数据声明和数据管理。
协调器类型有四种:根协调器(root coord)、数据协调器(data coord)、查询协调器(query coord)和索引协调器(index coord)。
- 根协调器:根坐标处理数据定义语言 (DDL) 和数据控制语言 (DCL) 请求,例如创建或删除集合、分区或索引,以及管理 TSO(时间戳 Oracle)和时间自动收录器发布。
- 查询协调器: 查询坐标管理查询节点的拓扑和负载平衡,以及从增长段到密封段的切换。
- 数据协调员:数据协调管理数据节点的拓扑,维护元数据,并触发刷新、压缩等后台数据操作。
- 索引协调器:索引坐标管理索引节点的拓扑、构建索引并维护索引元数据。
工作节点
它们遵循协调器服务的指令并执行来自代理的数据操作语言 (DML) 命令。由于存储和计算分离,工作节点是无状态的,部署在 Kubenetes 上可以促进系统横向扩展和灾难恢复。工作节点分为三种类型
- 查询节点:查询节点检索增量日志数据,并通过订阅日志代理将其转换为不断增长的段,从对象存储加载历史数据,并在向量和标量数据之间运行混合搜索。
- 数据节点:数据节点通过订阅日志代理来获取增量日志数据,处理变异请求,并将日志数据打包成日志快照并存储在对象存储中。
- 索引节点:索引节点构建索引。索引节点不需要常驻内存,可以通过Serverless框架来实现。
贮存
存储是系统的骨骼,负责数据的持久化。它包括元存储、日志代理和对象存储。
-
元存储:
元存储存储元数据的快照,例如集合架构、节点状态和消息消费检查点。存储元数据需要极高的可用性、强一致性和事务支持,因此 Milvus 选择了 etcd 进行元存储。Milvus 还使用 etcd 进行服务注册和健康检查。
-
对象存储
对象存储存储日志的快照文件、标量和向量数据的索引文件以及中间查询结果。Milvus 使用 MinIO 作为对象存储,可以轻松部署在 AWS S3 和 Azure Blob 这两种全球最受欢迎、最具成本效益的存储服务上。但对象存储的访问延迟较高,且按查询次数收费。为了提高性能并降低成本,Milvus 计划在基于内存或 SSD 的缓存池上实现冷热数据分离。
-
日志经纪人
日志代理是一个支持回放的发布-订阅系统。它负责流数据持久化、执行可靠的异步查询、事件通知以及查询结果的返回。当工作节点从系统故障中恢复时,它还能确保增量数据的完整性。Milvus 集群使用 Pulsar 作为日志代理;Milvus 独立版使用 RocksDB 作为日志代理。此外,日志代理可以很容易地替换为Kafka和Pravega等流数据存储平台。
数据插入
Milvus 中的每个集合指定多个分片,每个分片对应一个虚拟通道(vchannel)。如下图所示,Milvus 为日志代理中的每个 vchannel 分配一个物理通道(pchannel)。任何传入的插入/删除请求都会根据主键的哈希值路由到分片。
由于 Milvus 没有复杂的事务,DML 请求的验证被前移到代理。代理将从 TSO(时间戳 Oracle)请求每个插入/删除请求的时间戳,TSO 是与根协调器并置的计时模块。随着旧时间戳被新时间戳覆盖,时间戳用于确定正在处理的数据请求的顺序。代理从数据坐标中批量检索信息,包括实体的段和主键,以提高整体吞吐量并避免中央节点负担过重。
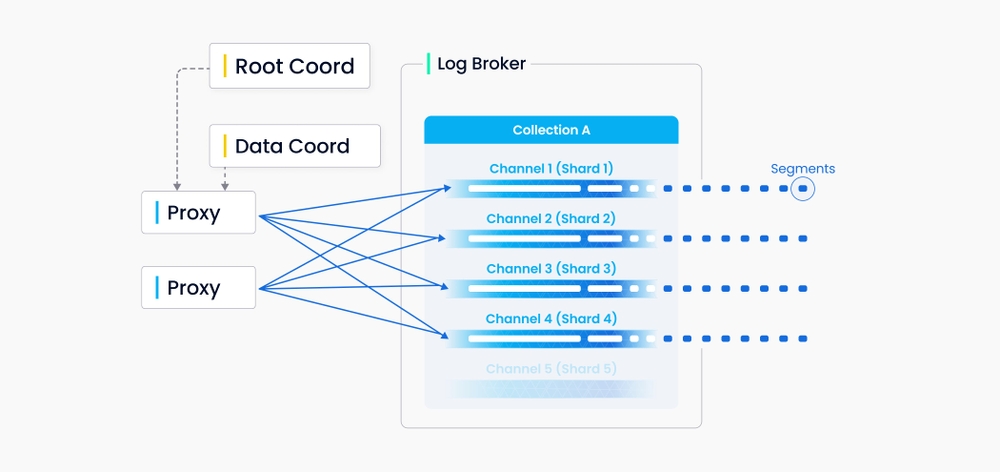
DML(数据操作语言)操作和DDL(数据定义语言)操作都会写入日志序列,但DDL操作由于出现频率较低,只分配一个通道。
Vchannels在底层日志代理节点中维护。每个通道在物理上都是不可分割的,并且可供任何节点使用,但只能用于一个节点。当数据摄取速率达到瓶颈时,需要考虑两件事:日志代理节点是否过载并需要扩展,以及是否有足够的分片来保证每个节点的负载平衡。
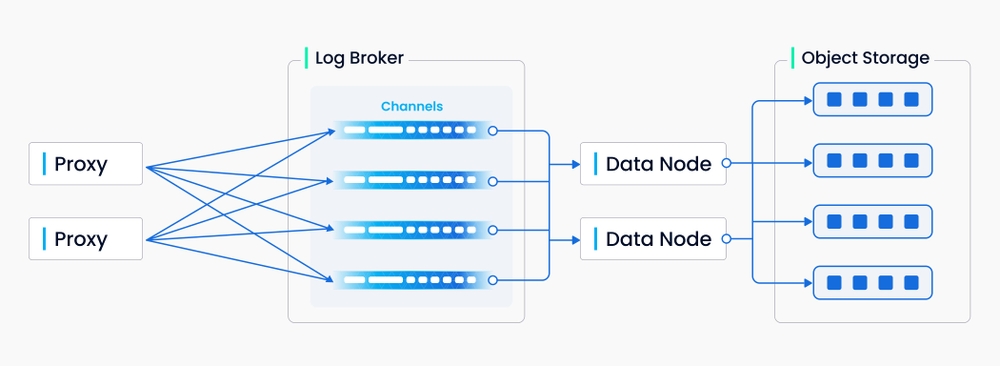
上图封装了日志序列写入过程中涉及的四个组件:代理、日志代理、数据节点和对象存储。该过程涉及四个任务:DML请求的验证、日志序列的发布订阅、流式日志到日志快照的转换以及日志快照的持久化。这四个任务彼此解耦,以确保每个任务都由其相应的节点类型处理。同一类型的节点是平等的,可以独立弹性伸缩,以适应各种数据负载,特别是海量且高波动的流数据。
对比其他
Pinecone
https://www.pinecone.io/
完全托管,不能私有化部署,不考虑
Vespa
https://python.langchain.com/docs/integrations/providers/vespa
https://vespa.ai/