self attention自注意力机制
可以考虑整个向量序列信息来计算,计算量大 Attention Is All You Need 论文
算法
https://www.youtube.com/watch?v=hYdO9CscNes&list=PLJV_el3uVTsMhtt7_Y6sgTHGHp1Vb2P2J&index=12&ab_channel=Hung-yiLee
-
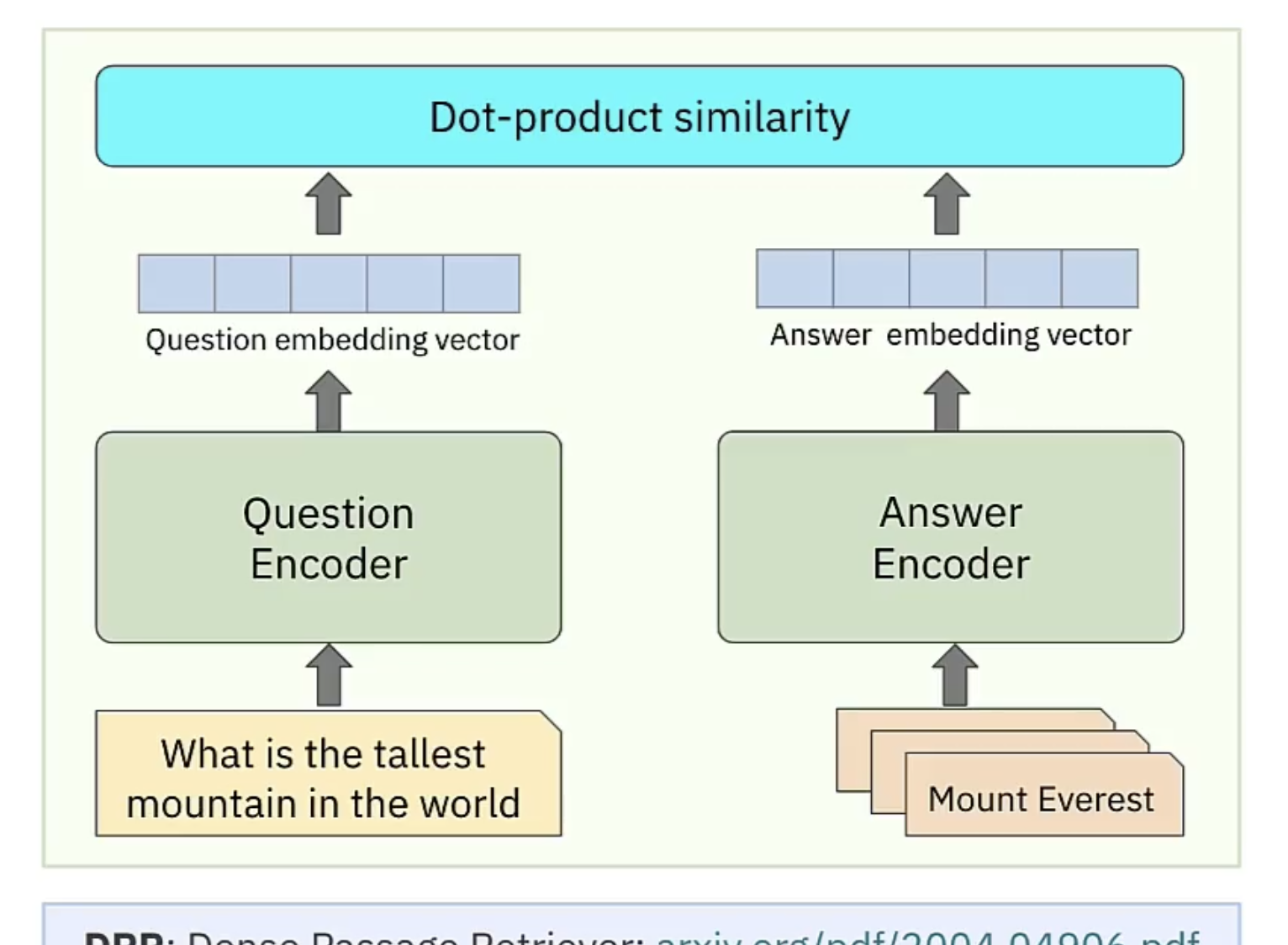
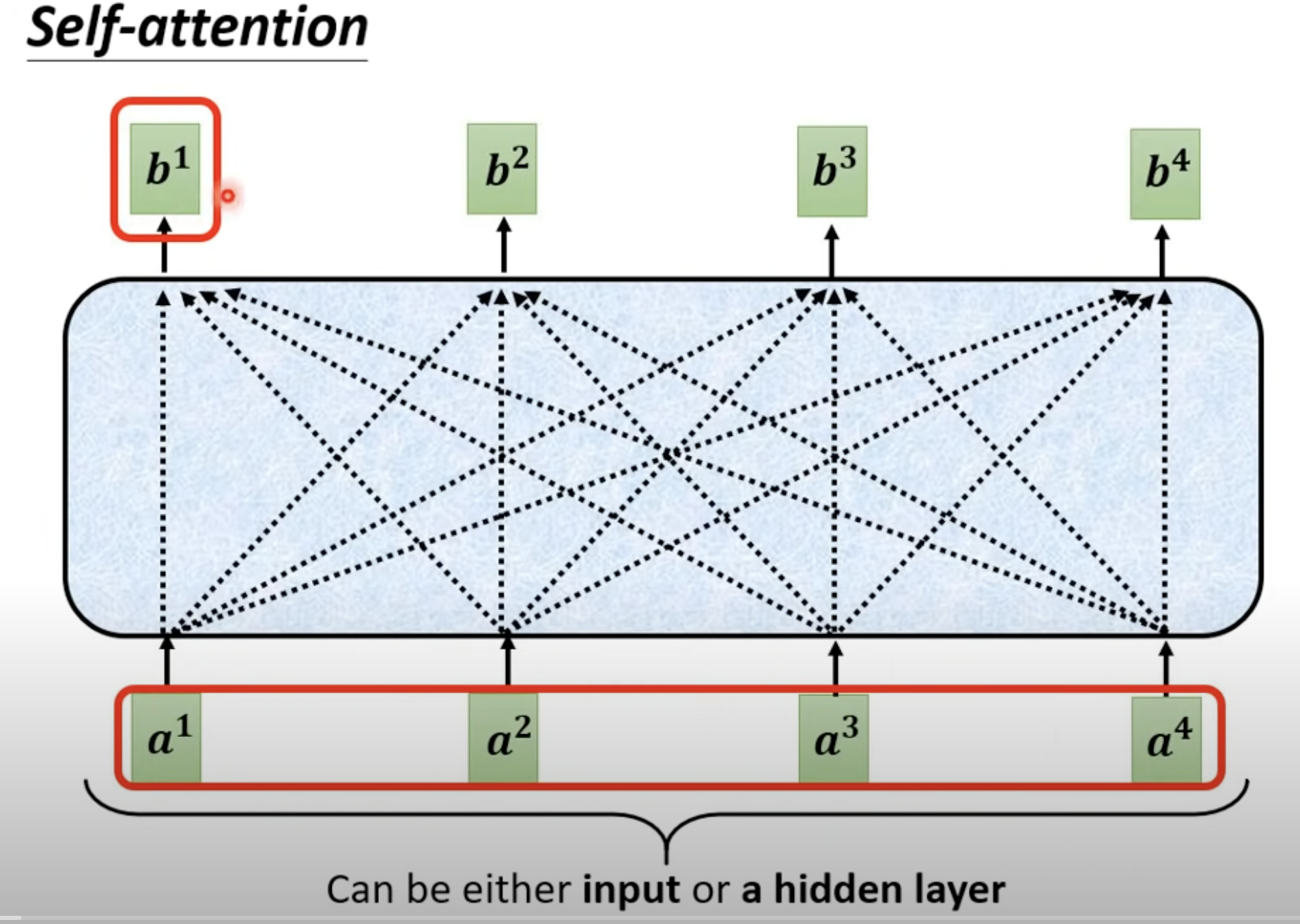
每一个output b,都是考虑所有的a 生成的,计算输入序列中每个位置与其他位置之间的关联程度,从而为每个位置生成一个上下文向量。它能够对序列中的不同位置进行全局关联性建模,无论位置的距离远近。 This approach allows for global modeling of the correlation between different positions in the sequence, regardless of their distance. Generate a context vector for each position
-
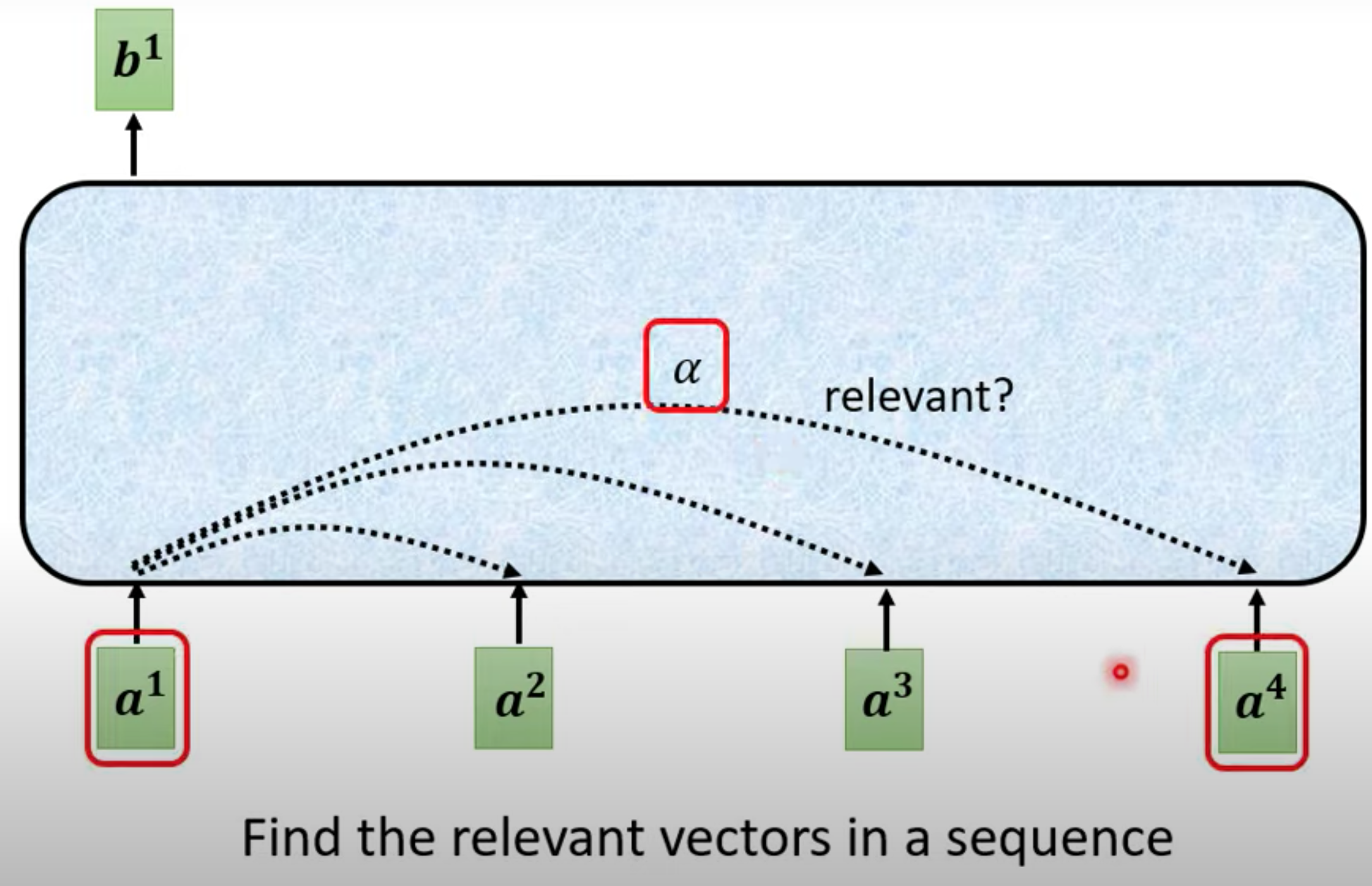
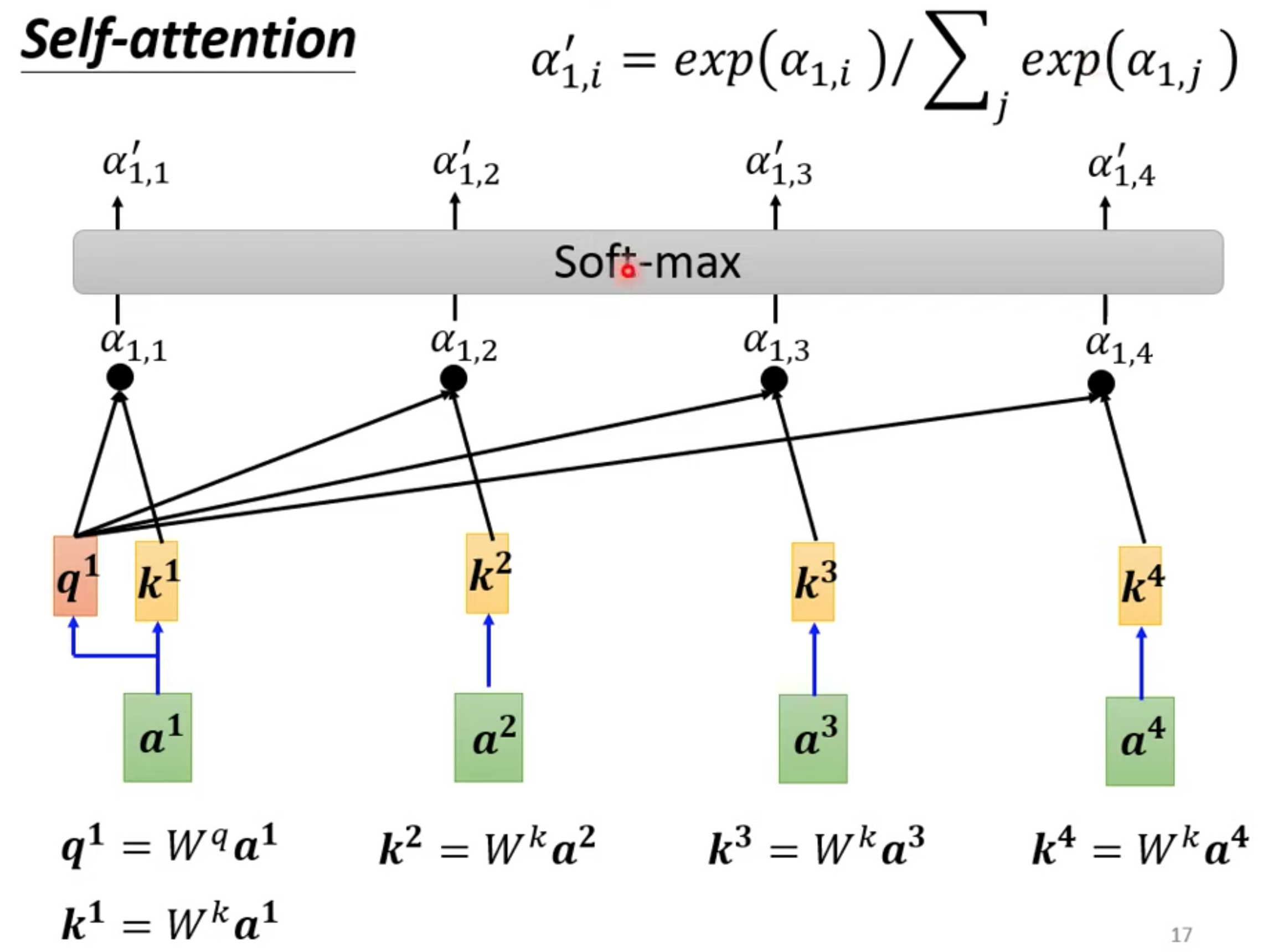
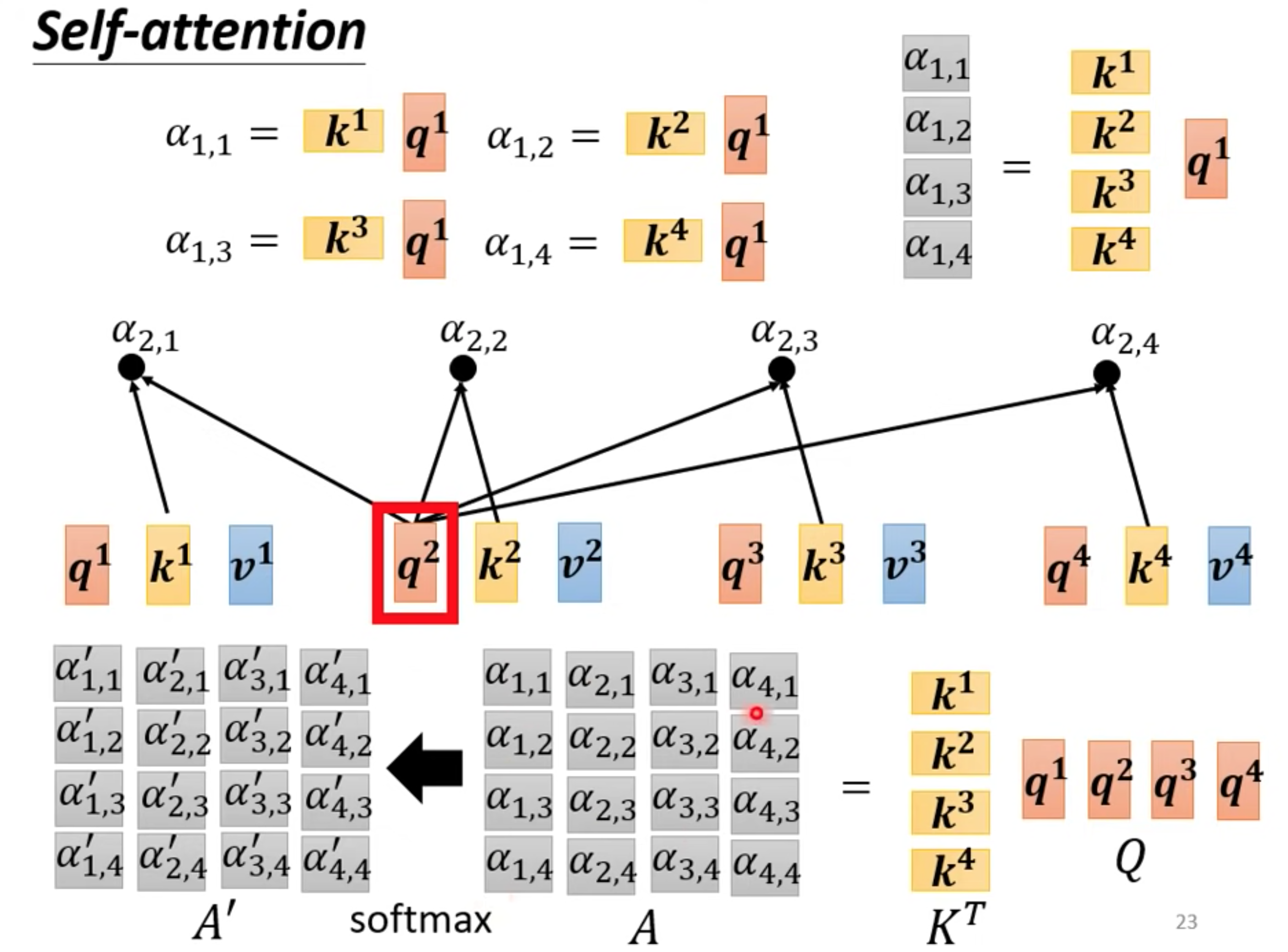
计算和a1最相关的向量,相关度由alpha表示,计算alpha的方法有很多
向量$\vec{a}=[a_{1},a_{2},\cdot\cdot\cdot,a_{n}]$和向量${\vec{b}}=[b_{1},b_{2},\cdot\cdot,b_{n}]$ 內積定義
$\vec{a}\cdot\vec{b}=\sum_{i=1}^{n}a_{i}b_{i}=a_{1}b_{1}+a_{2}b_{2}+\cdot\cdot\cdot+a_{n}b_{n}$
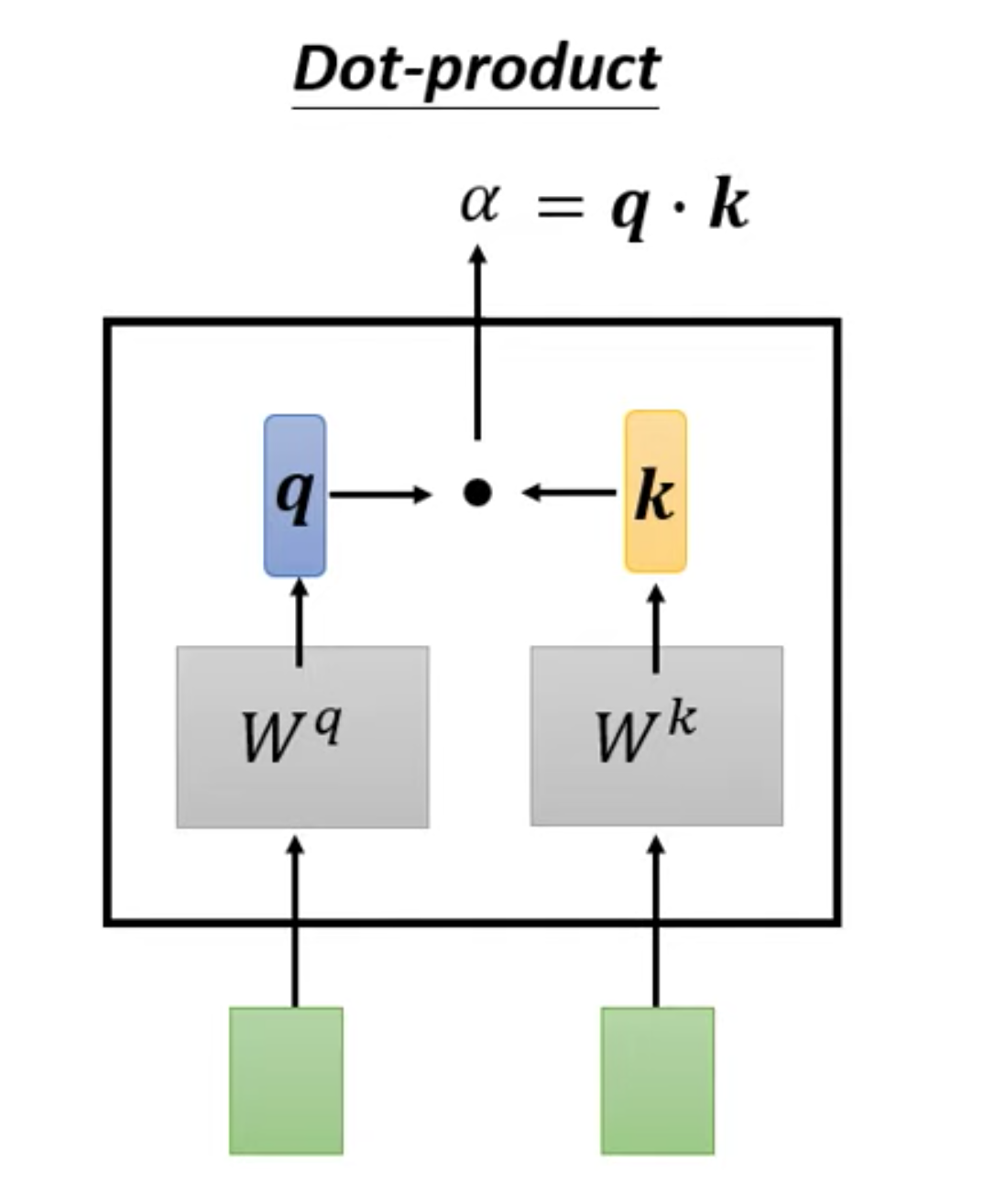
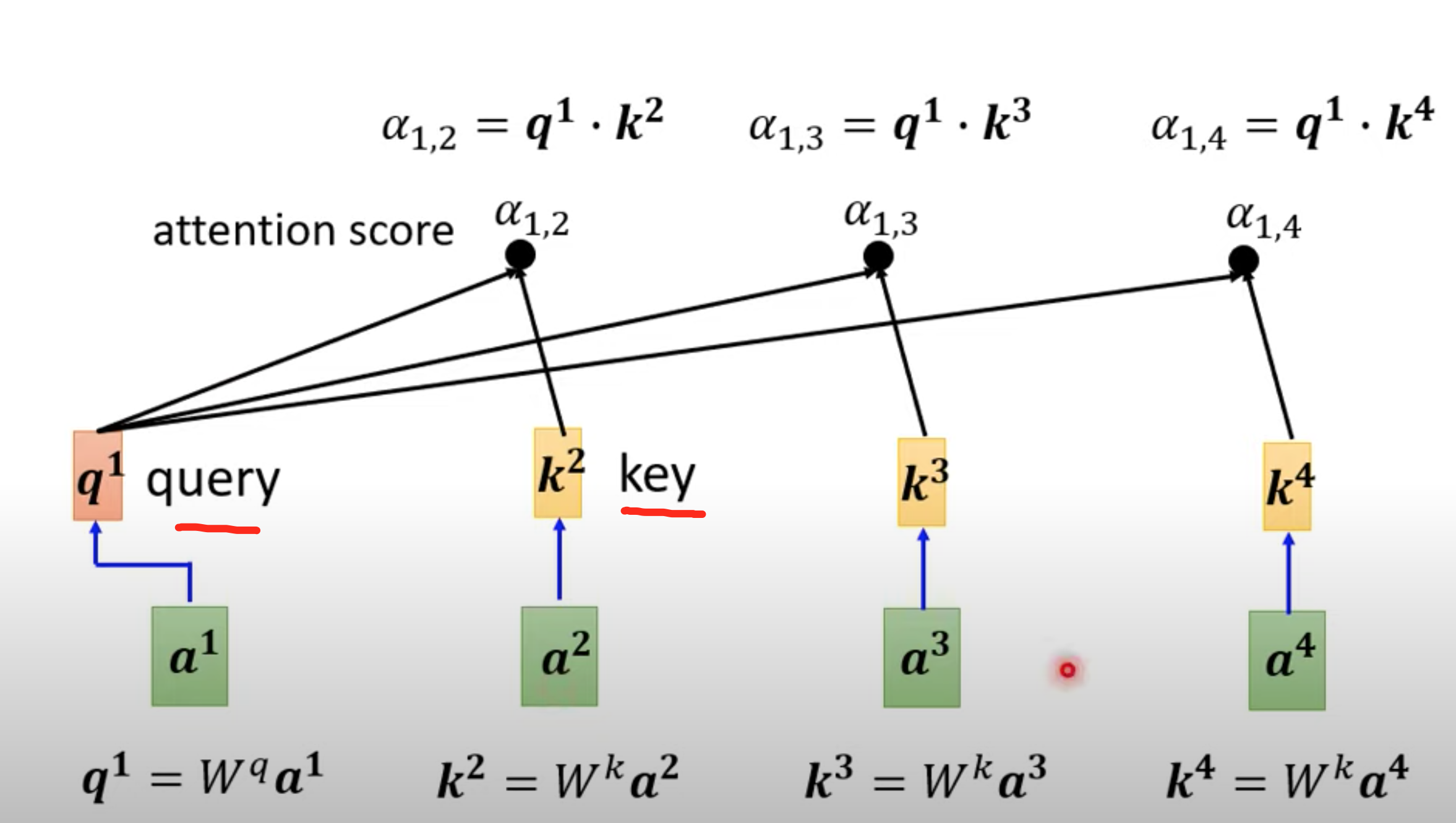
向量分别乘以对应不同的矩阵,得到q,k向量,再内积
-
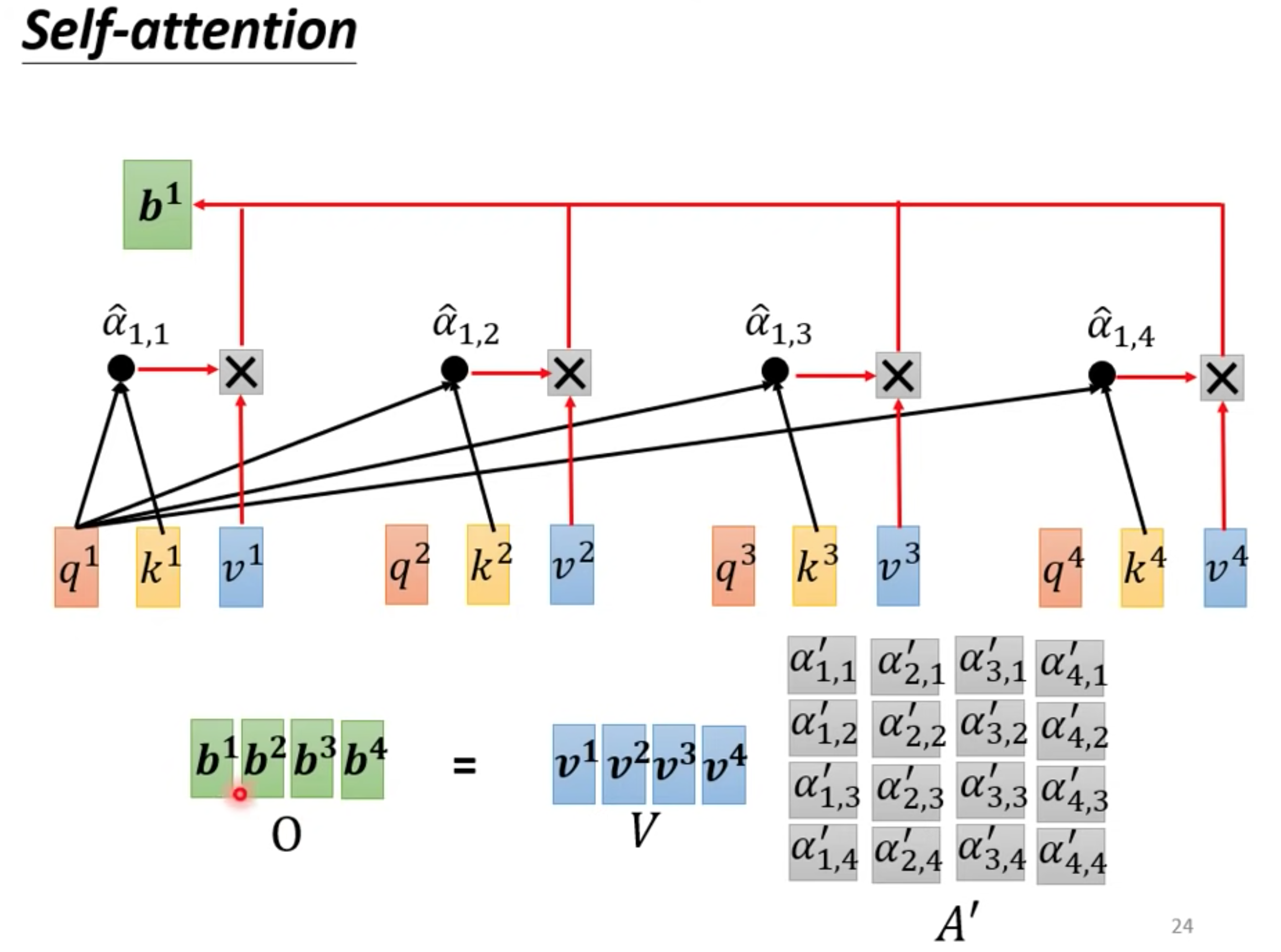
通过关联性计算output b
不一定是soft-max,做一个归一化处理。输出范围在 (0, 1) 之间,但所有输出的和为 1。
提取信息:
Q(查询)和K(键)用于计算注意力权重,而V(值)则携带实际的信息。注意力机制的目的是将Q和K的关系转化为对V的加权求和。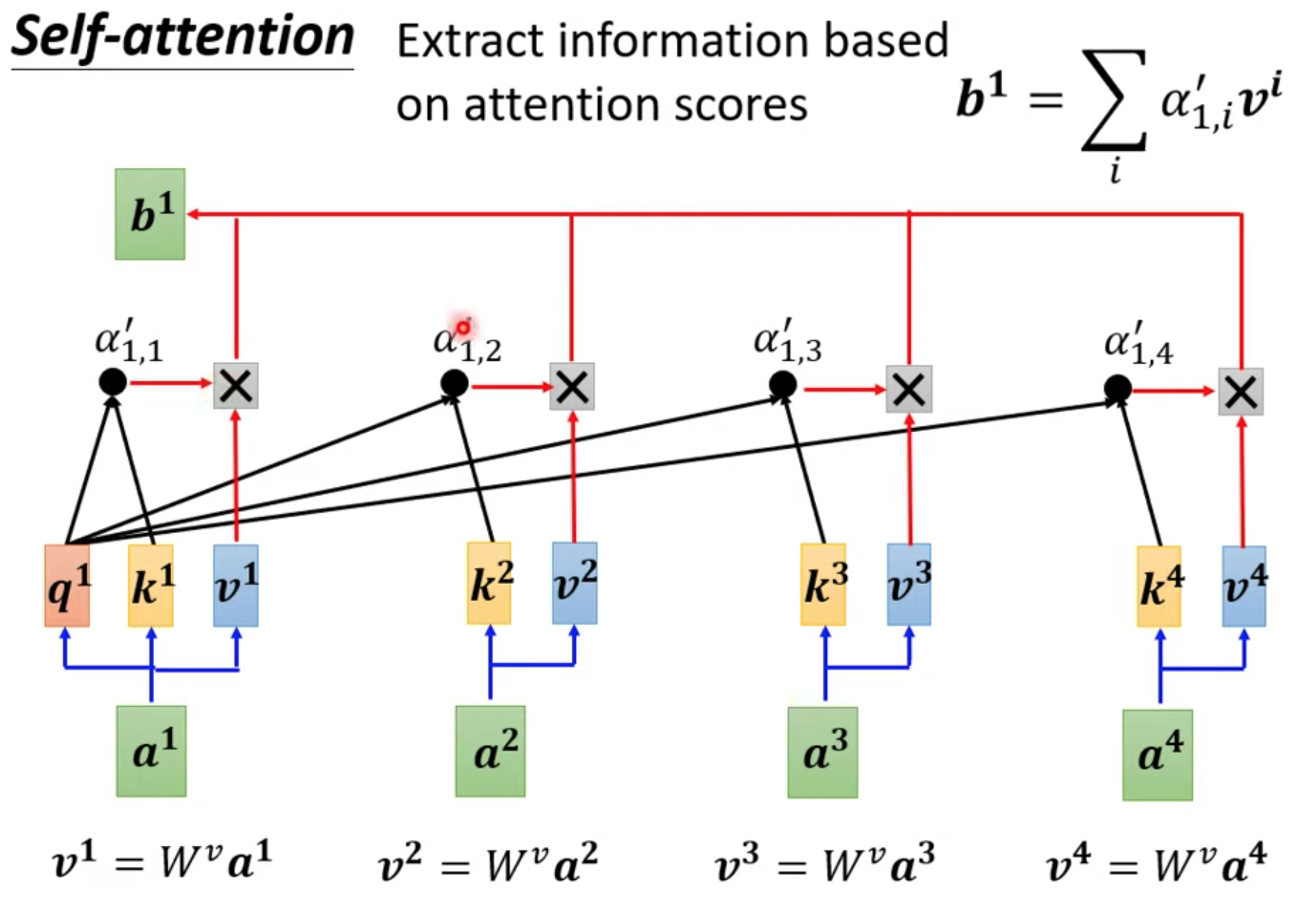
b1 到b4是并行产生的
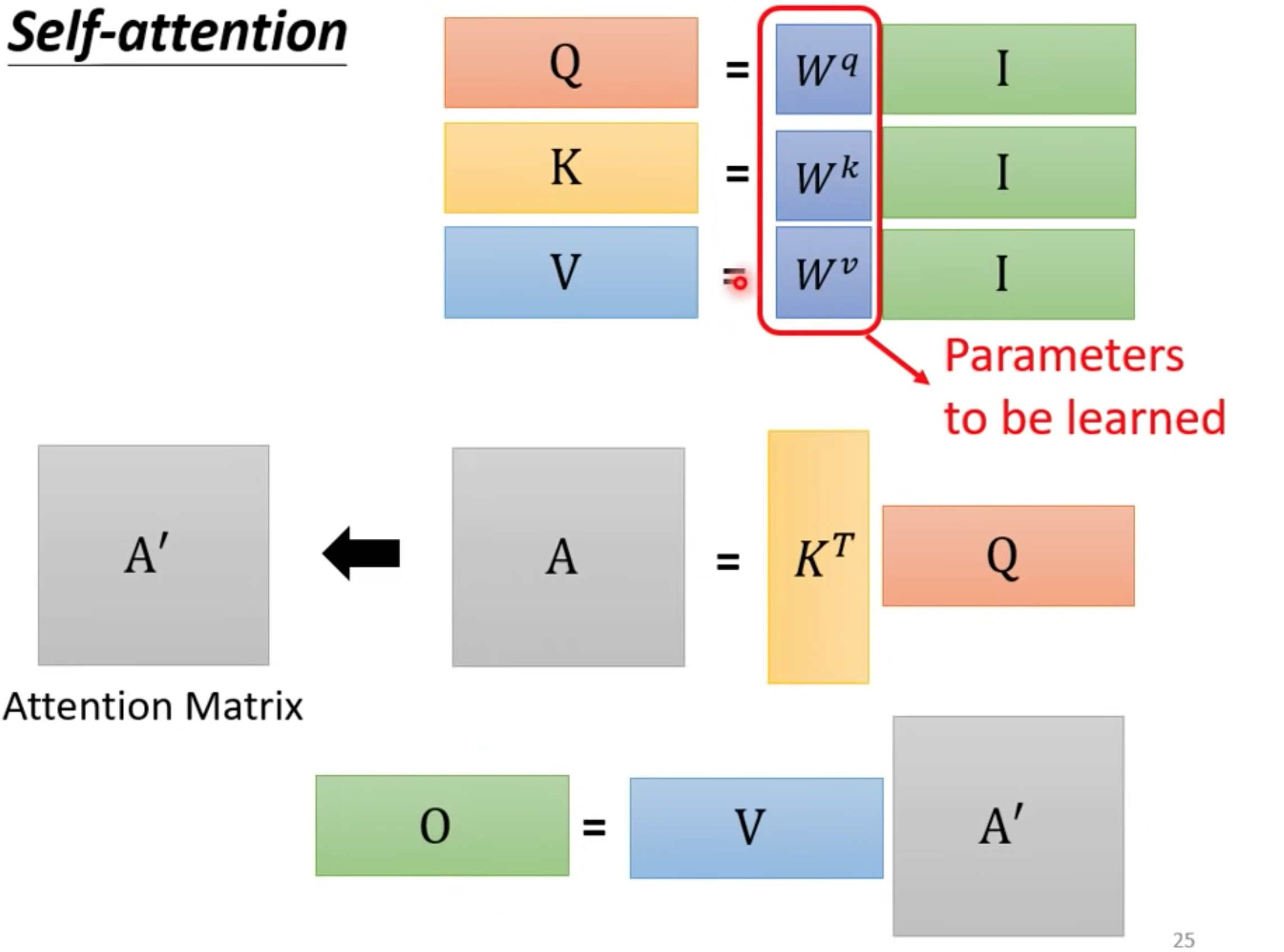
矩阵算法
可以把所有向量a 看成是一个矩阵I,得到QKV矩阵
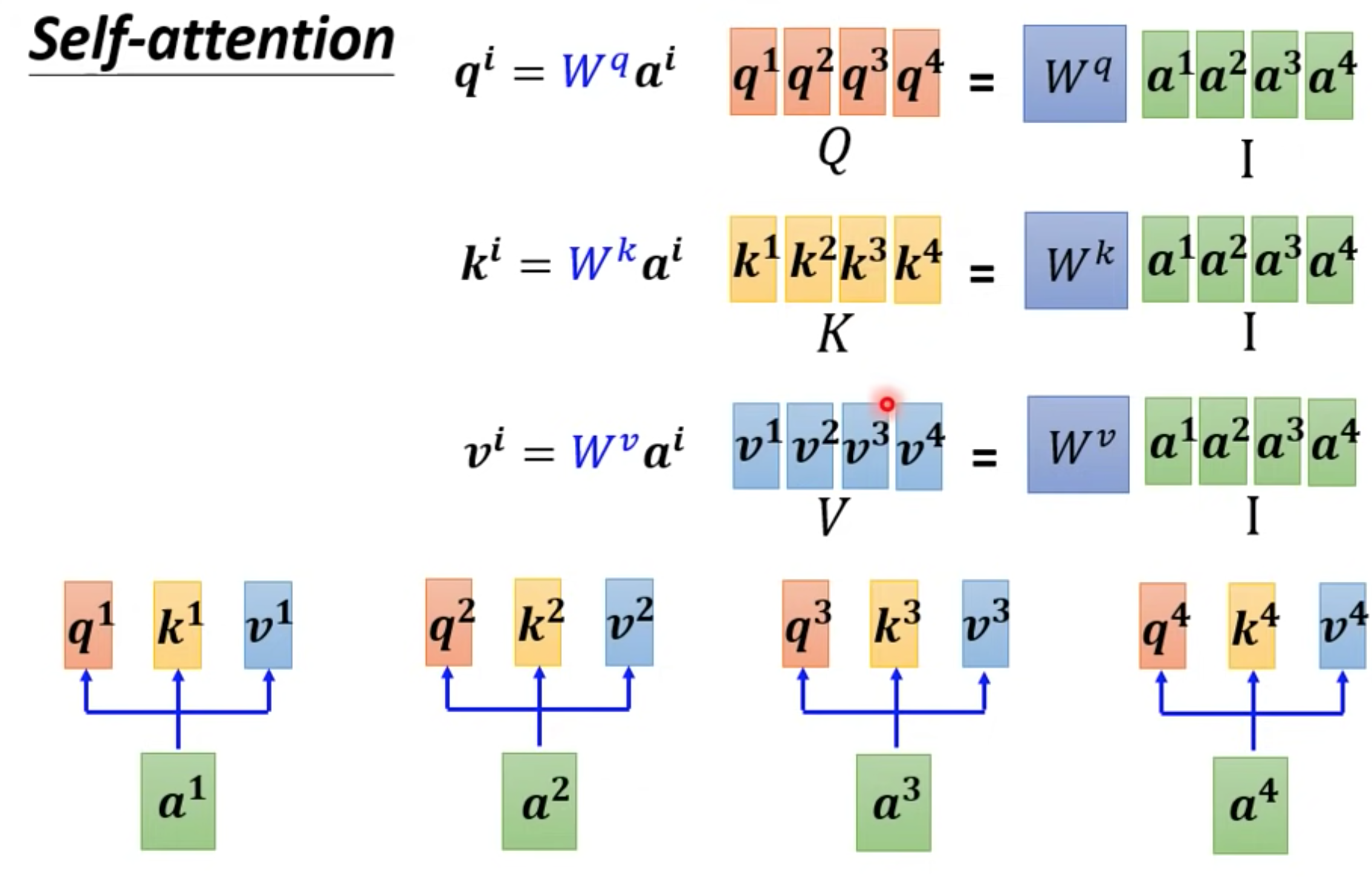
获取alpha
获取ouput
模型需要训练QKV
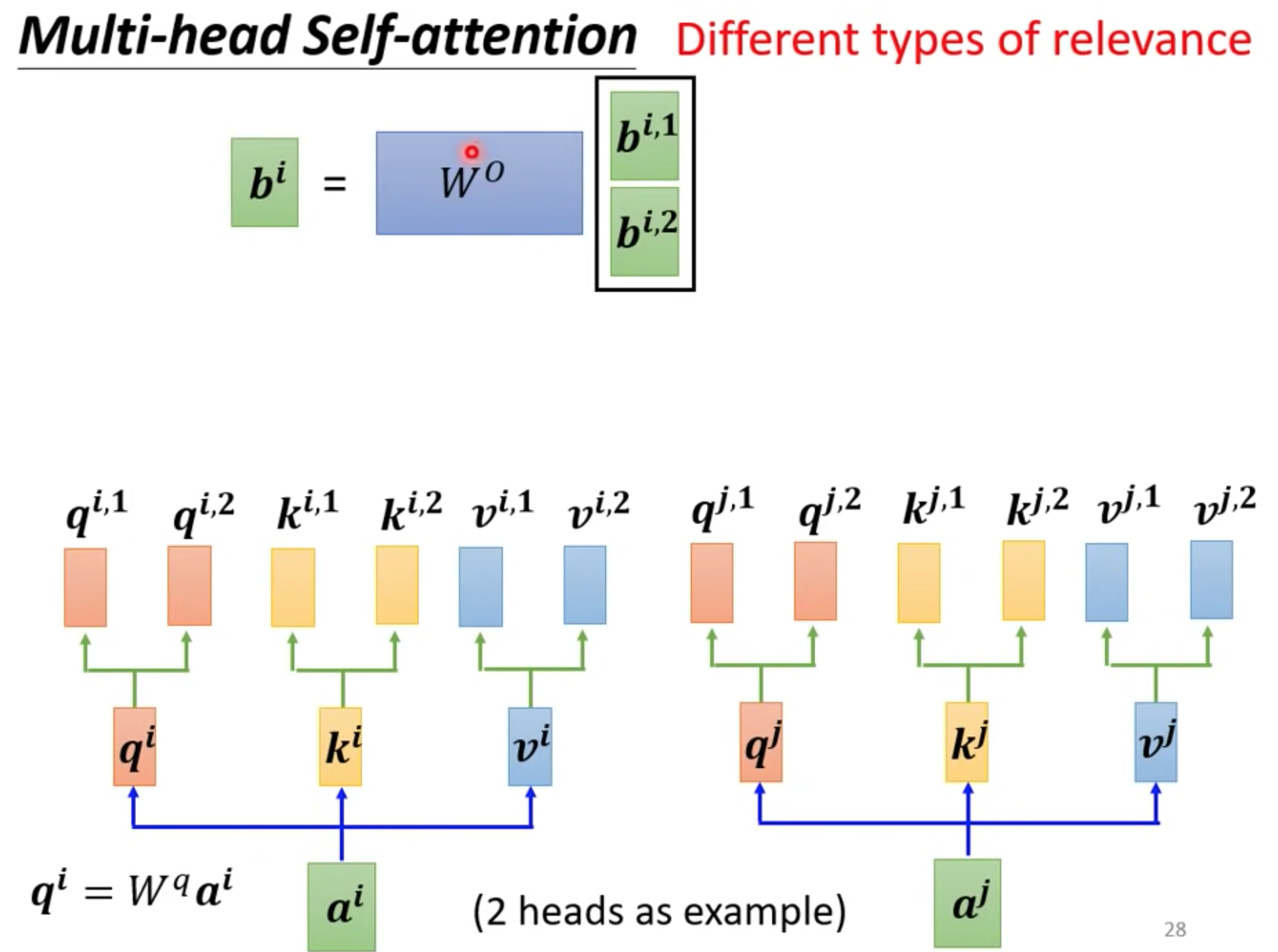
multi-head
一个q代表一种相关性,需要多种就要多个q,超参数 ,模型就能够从不同的角度对输入序列进行多重关注,从而更好地捕捉序列中的信息。
q represents a query vector used to calculate the attention scores between the input elements. The multiple relationships multiple query vectors can be used
q 分别乘以不同矩阵得到不同的q,独立计算就行和one head一样
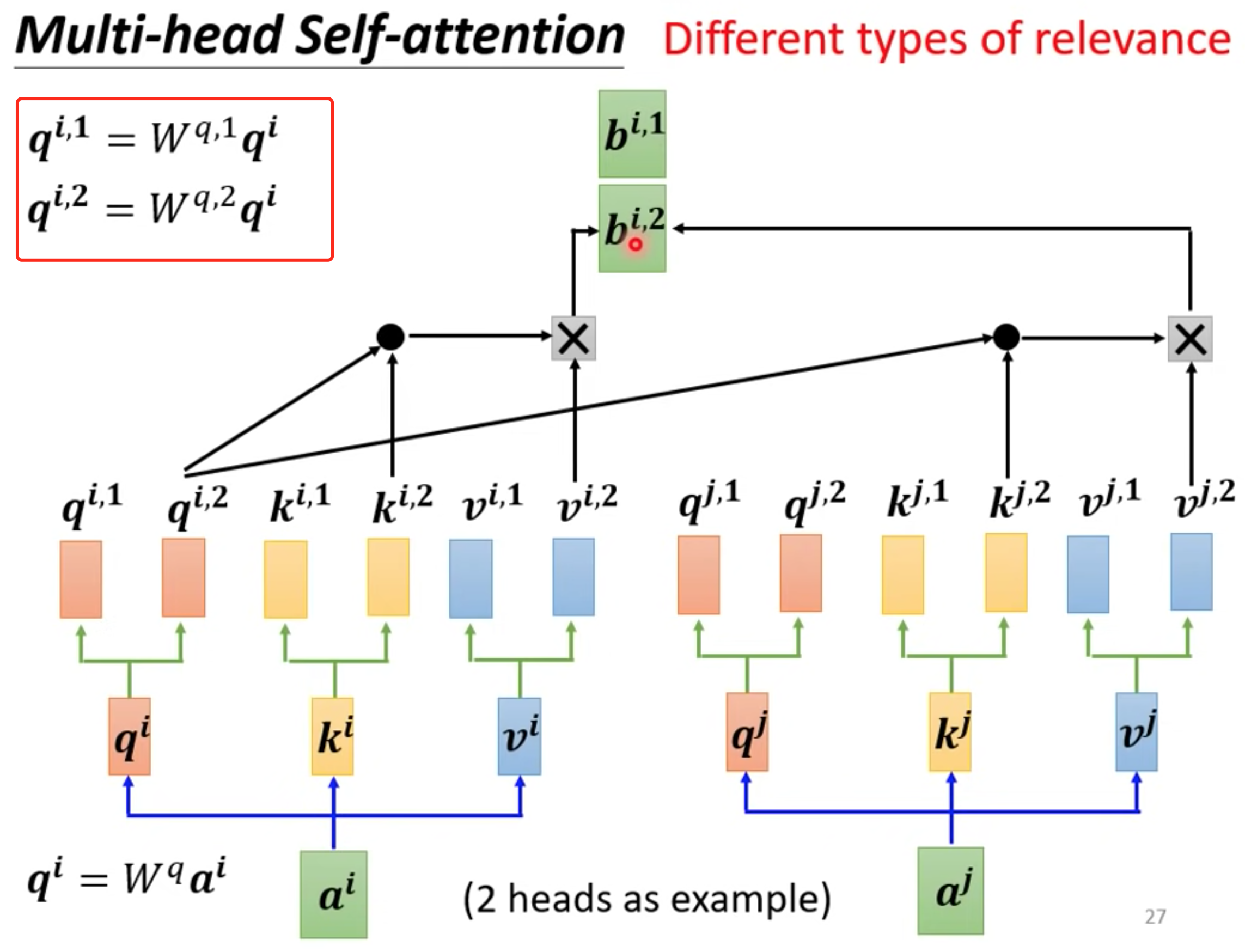
等到output
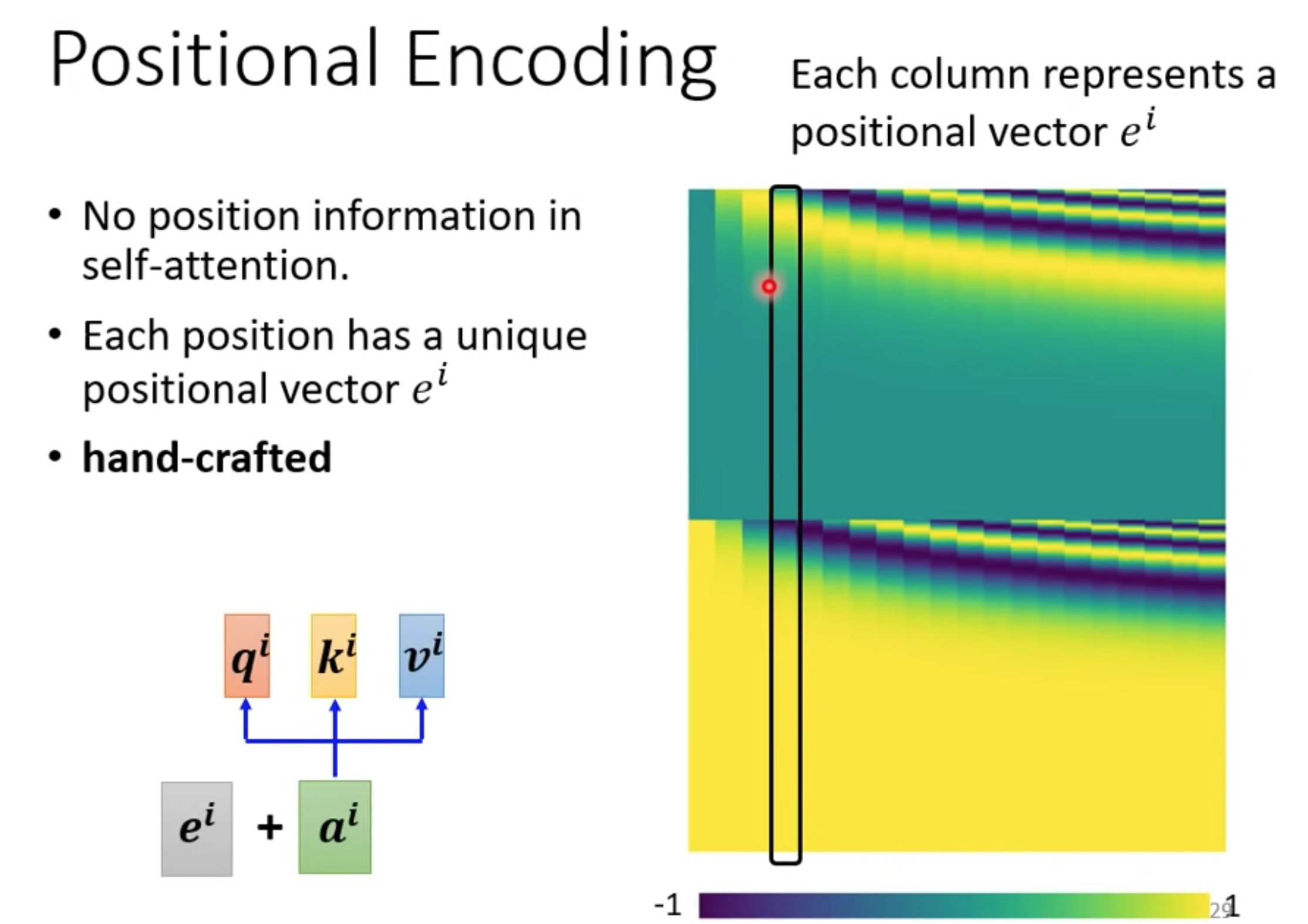
位置信息
在Transformer模型中,Positional Encoding(位置编码)用于为输入序列中的每个位置添加独特的位置信息。由于Transformer没有像循环神经网络(RNN)那样的显式顺序处理机制,它无法捕捉到序列中元素的相对位置信息。为了解决这个问题,Transformer引入了位置编码。
In the Transformer model, Positional Encoding is used to add unique positional information to each position in the input sequence. Since the Transformer does not have an explicit sequential processing mechanism like recurrent neural networks (RNNs), it cannot capture the relative positional information of elements in the sequence. To address this issue, the Transformer introduces positional encoding.
Positional Encoding是通过将位置信息编码为一个向量序列,并将其与输入向量相加来实现的。这样,每个位置的输入向量将包含来自位置编码的信息和原始输入的信息。位置编码的目的是为了在Transformer模型中引入关于输入序列中元素顺序的信息,以便更好地处理序列数据。
Positional Encoding is achieved by encoding the position information into a sequence of vectors and adding them to the input vectors. This way, the input vector for each position will contain information from both the positional encoding and the original input. The purpose of positional encoding is to introduce information about the order of elements in the input sequence in the Transformer model, in order to better process sequential data.
self-attention没有位置信息,可以用
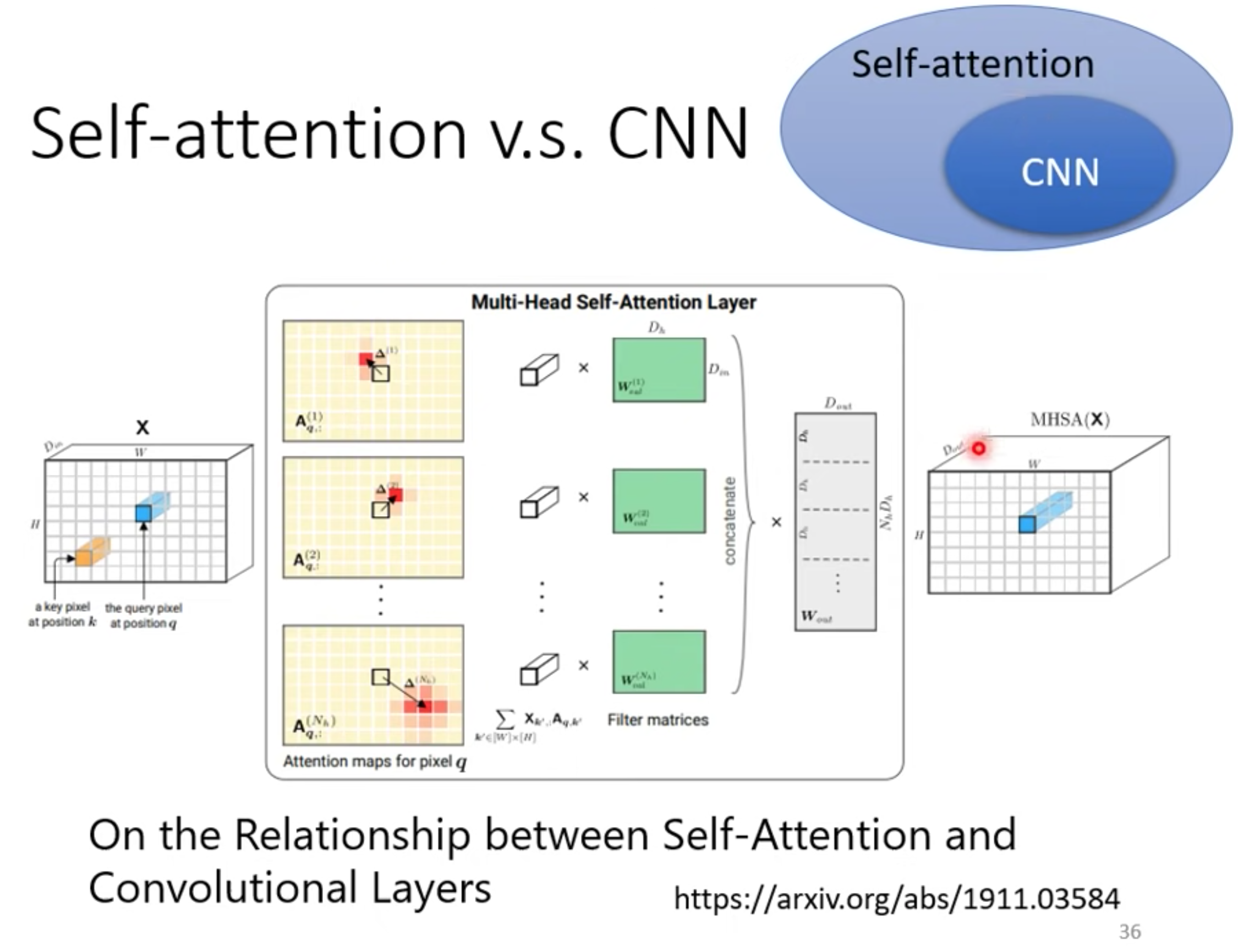
与CNN RNN对比
CNN
self-attention是更复杂的CNN

Self-attention通过计算输入序列中每个位置与其他位置之间的关联程度,从而为每个位置生成一个上下文向量。它能够对序列中的不同位置进行全局关联性建模,无论位置的距离远近。
CNN通过滑动窗口的卷积操作来提取局部特征,然后通过池化操作进行降采样。CNN在局部区域内共享权重,因此能够捕捉到输入数据的局部模式。
意味着自注意力在CNN中的应用是有限制的,它只能在一个可学习的感受野内进行注意力计算,从而更加灵活地捕捉到不同位置之间的关系,而无需依赖固定大小的卷积核。
RNN
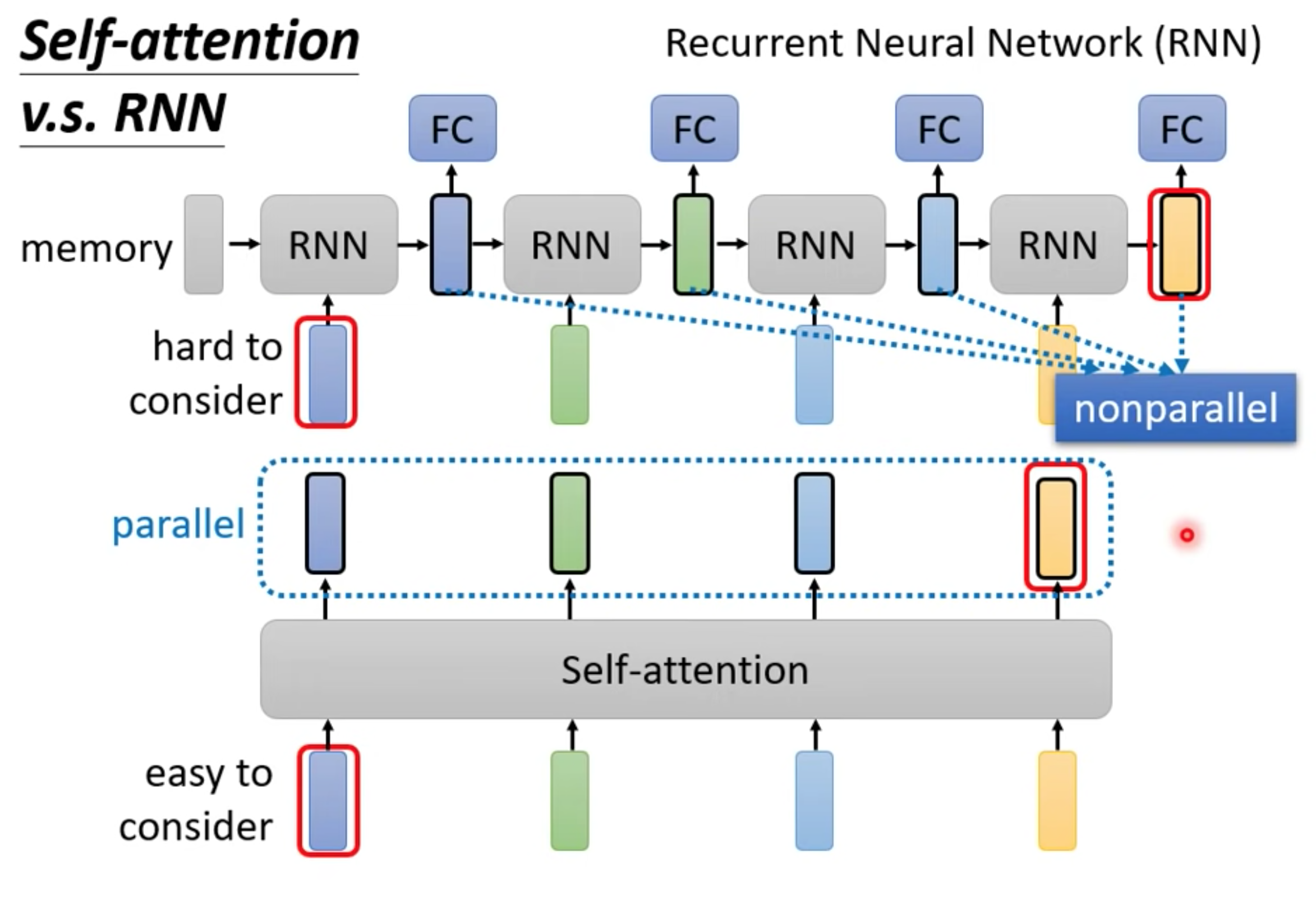
主要两个不同
- 单向RNN只能考虑最先输入的向量,而不是整个句子。双向RNN,最右边的黄色output,很容易忘记最左边的蓝色input。但是self-attention可以通过QK联系起来。
- self-attention可以并行计算,RNN只能等上一个向量处理完后的输出才作为下一个的输入,不能并行计算。
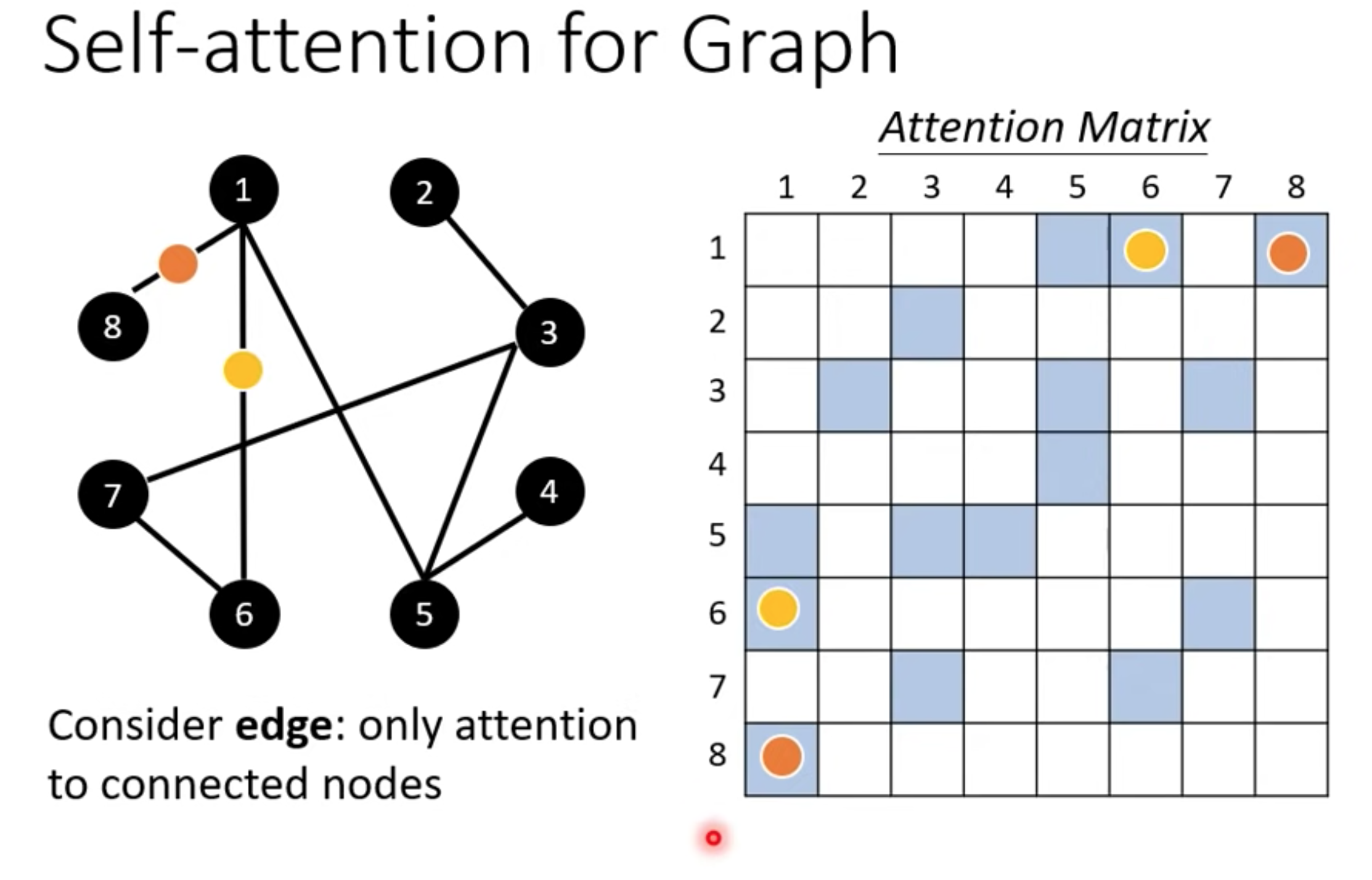
图GNN
图的节点也可以当成向量,计算alpha矩阵时候可以只计算有边连接的节点
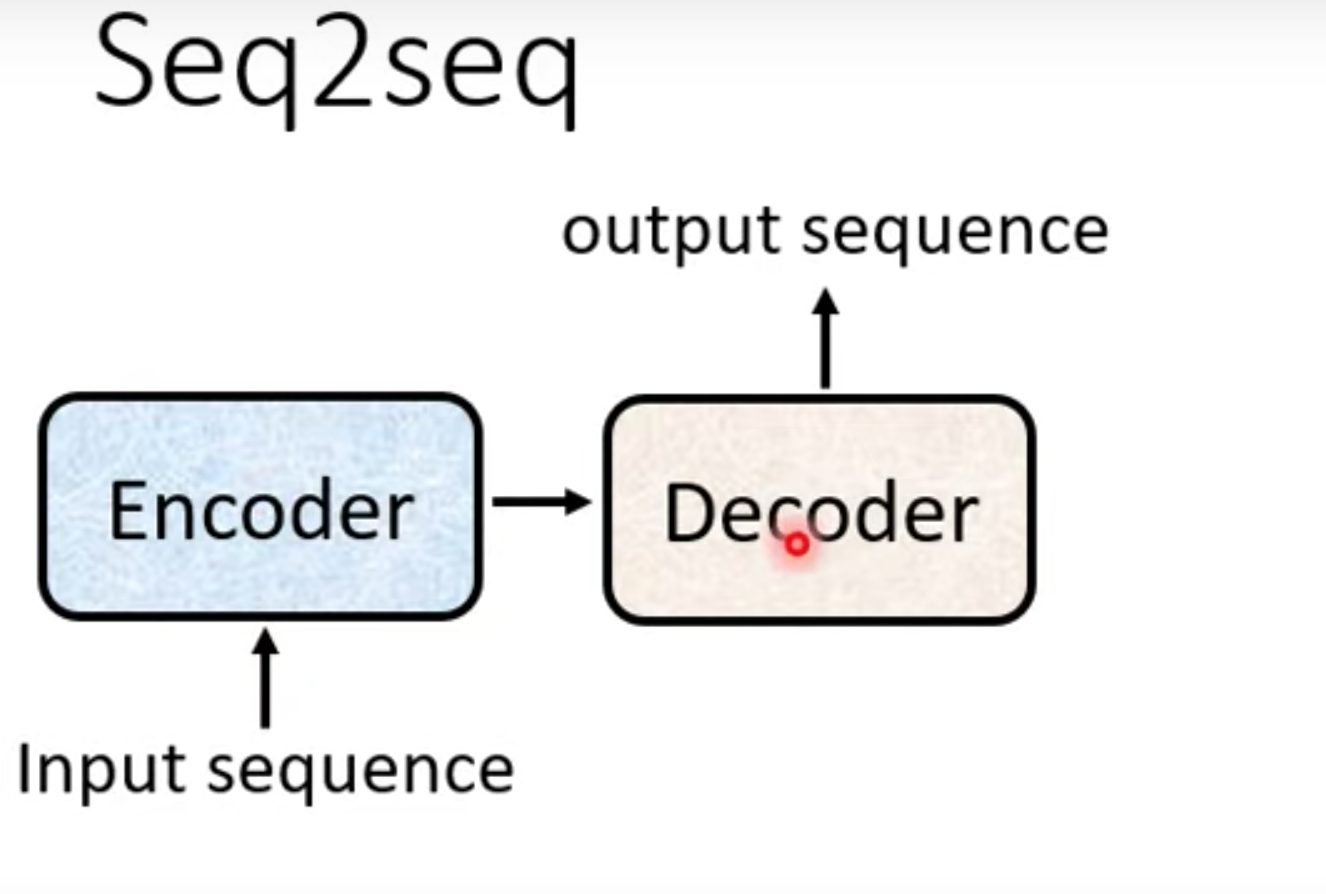
Transformer
seq2seq,output的长度由model决定。通常有两步份组成。 encoder , decoder
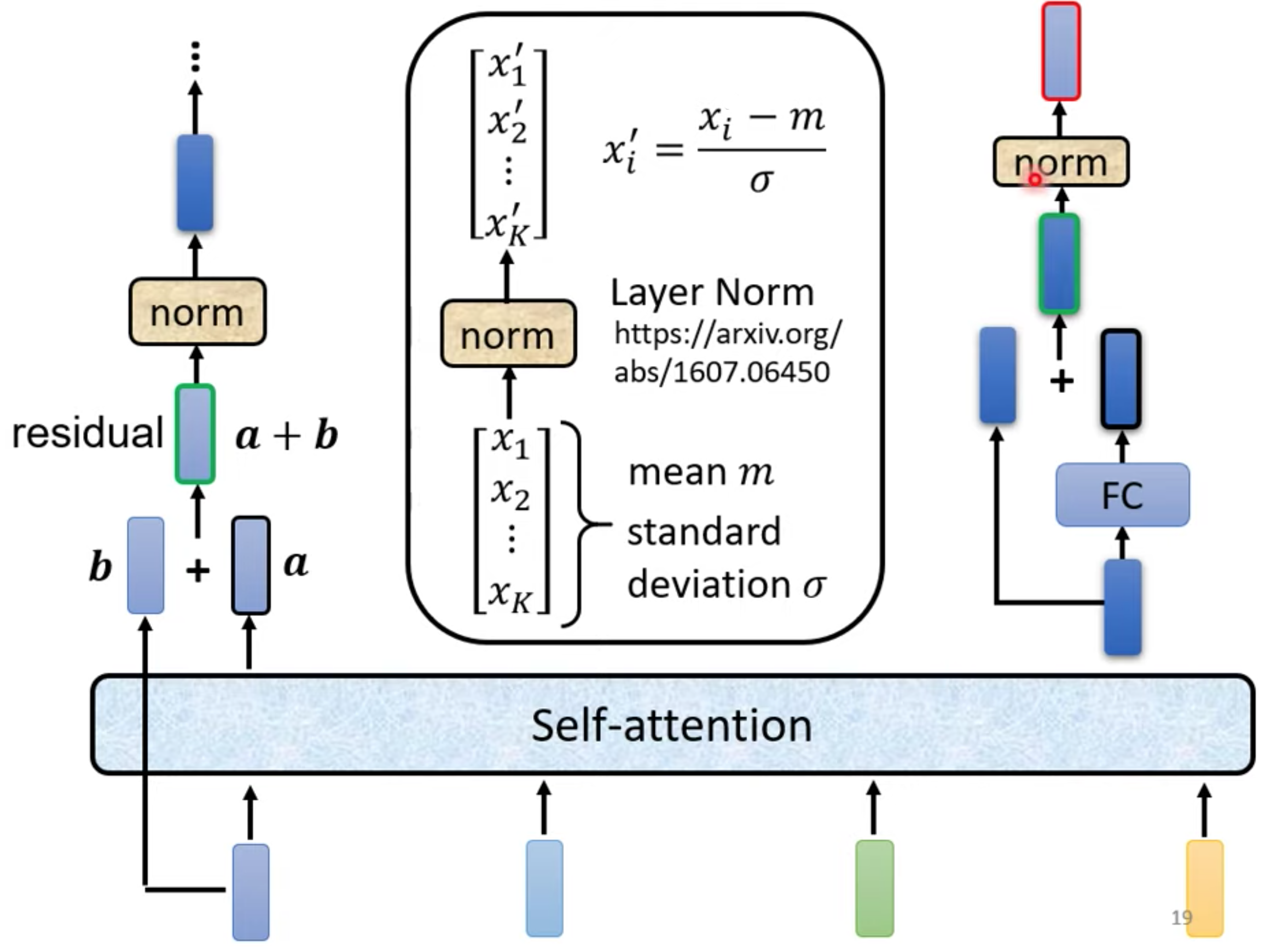
Encoder 原始结构
x是输入,h是输出,每个block,由不同layer构成。
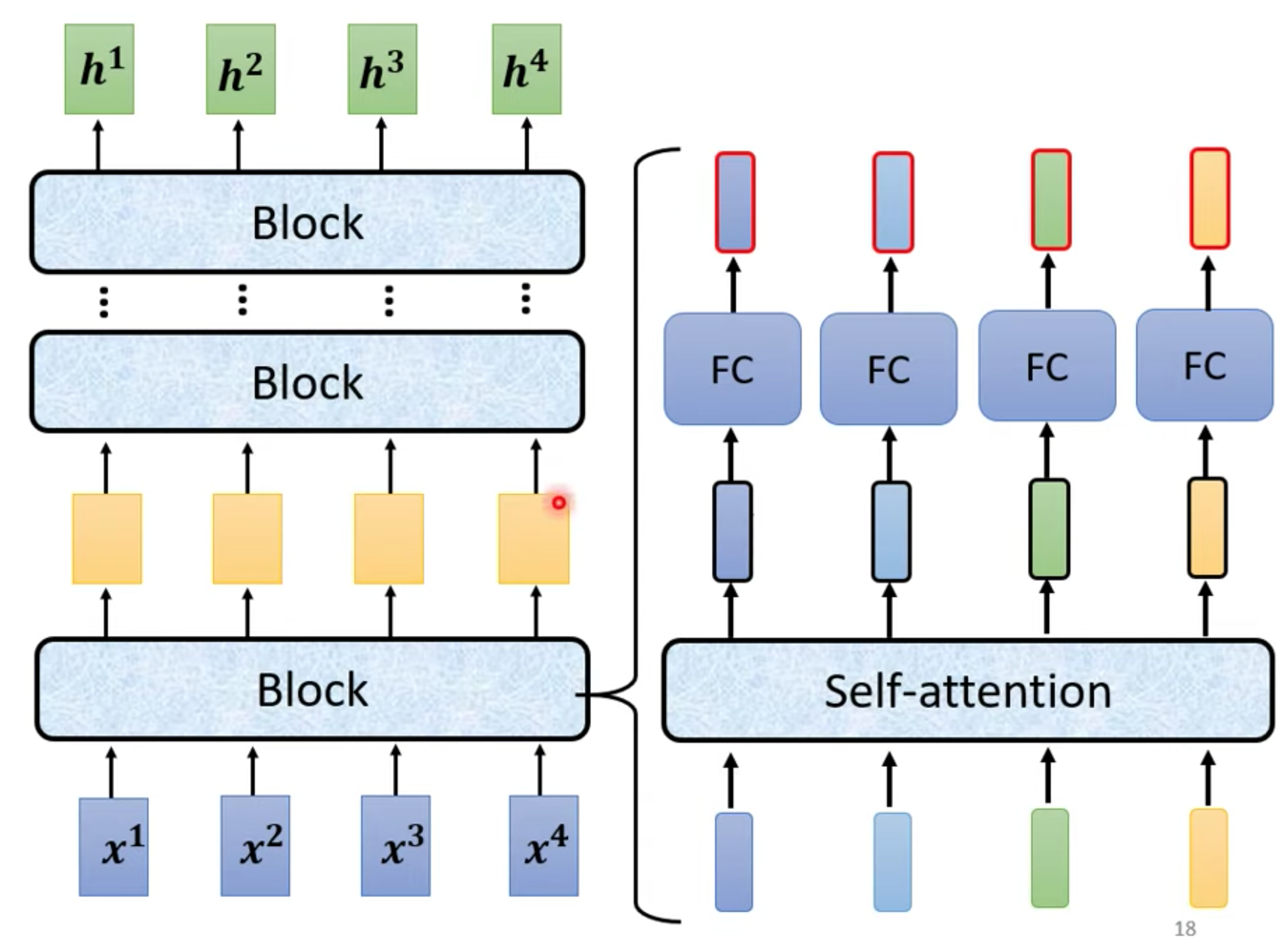
Transformer使用不同的方法,block详解。使用residual(input + output 作为下一层input) + layer norm
- 残差网络可以避免在深度网络层中出现梯度消失或梯度爆炸的问题。
- 小批量训练中表现良好,并且具有良好的收敛性, 在注意力架构中,层归一化比批归一化更常用,因为注意力机制经常应用于序列数据。
MLP FC是Fully Connected Neural Network 全连接神经网络 也叫前馈神经网络(Feedforward Neural Network,FFN)
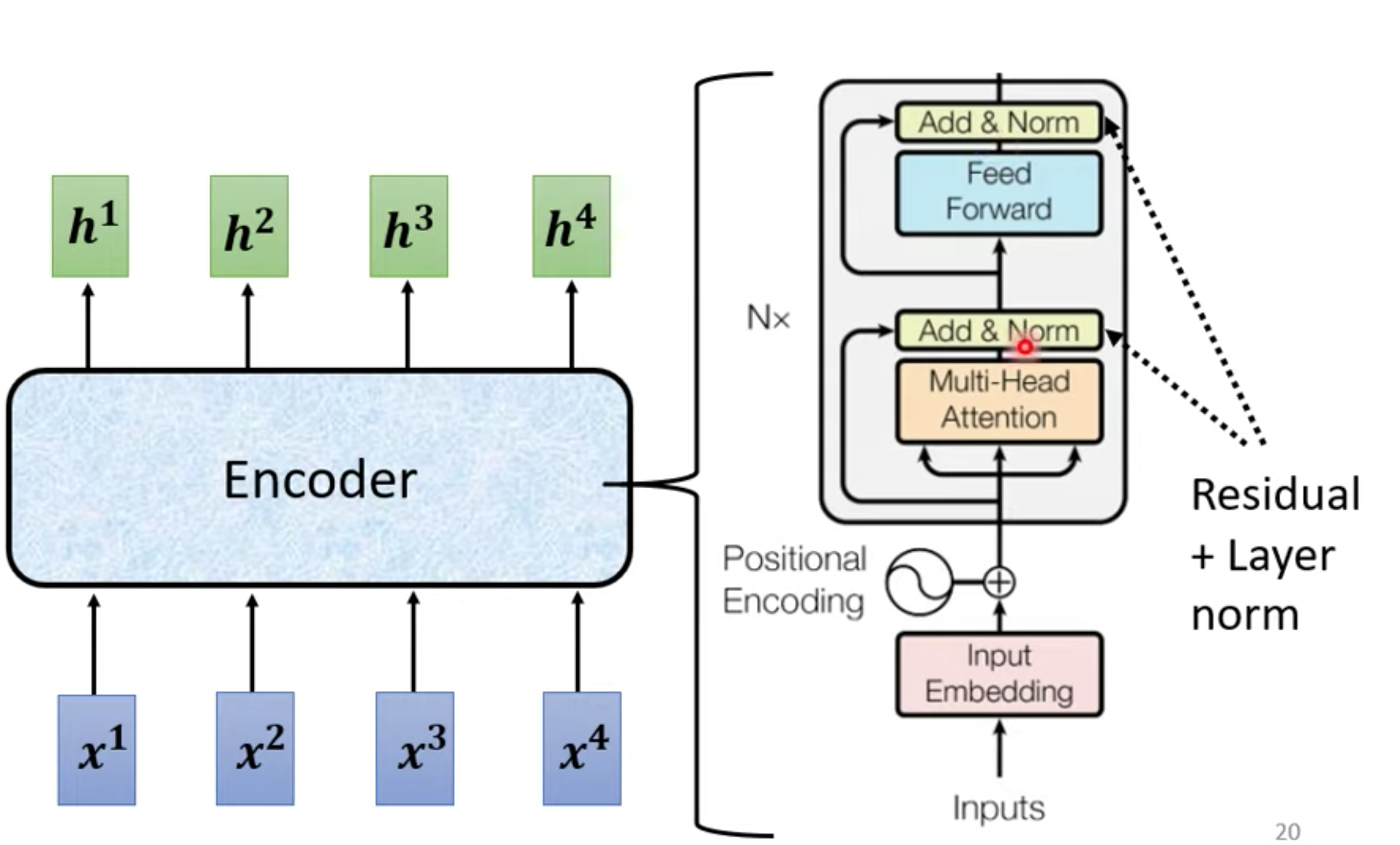
完整Transformer encode, 使用 block 会重复N遍
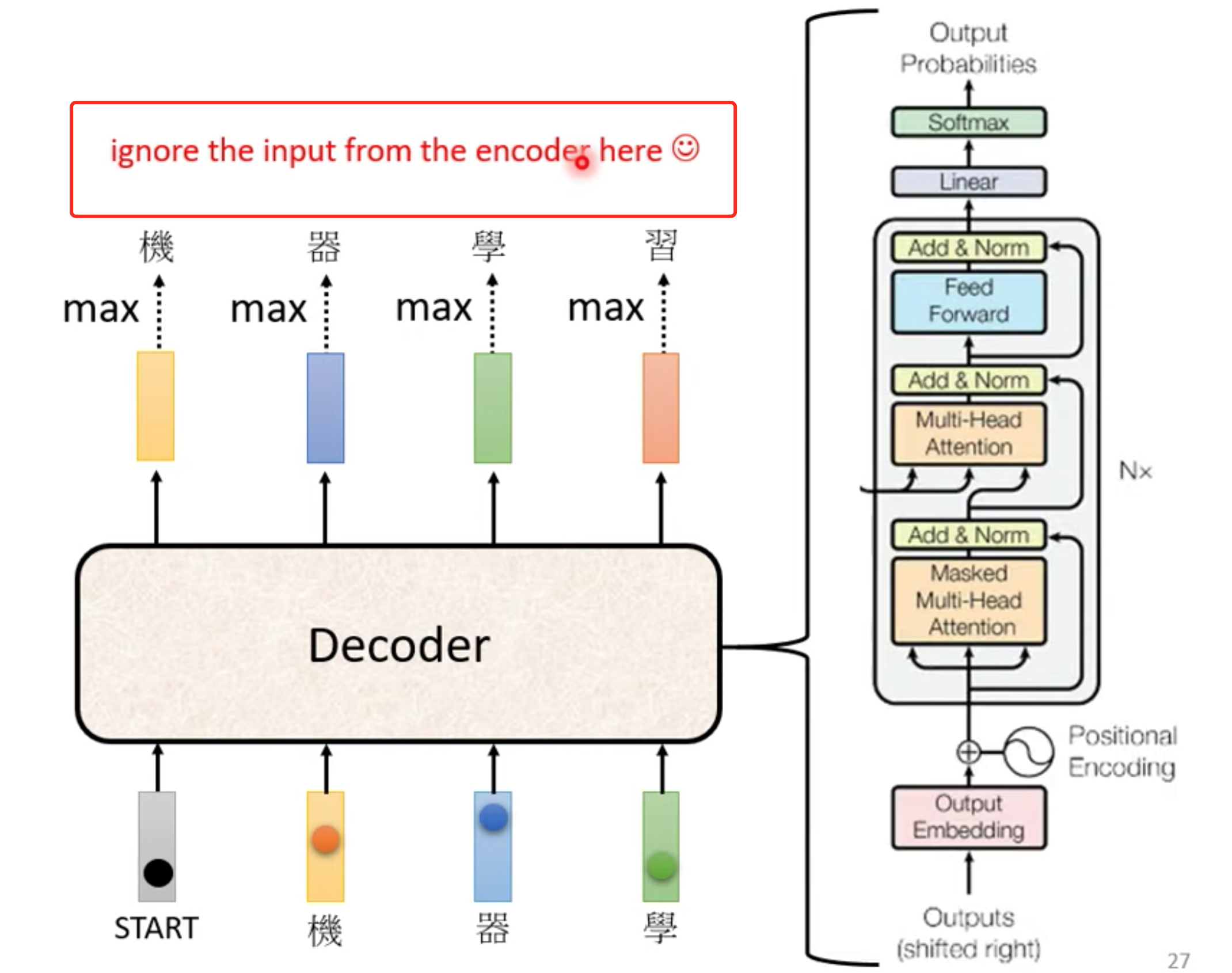
Decoder
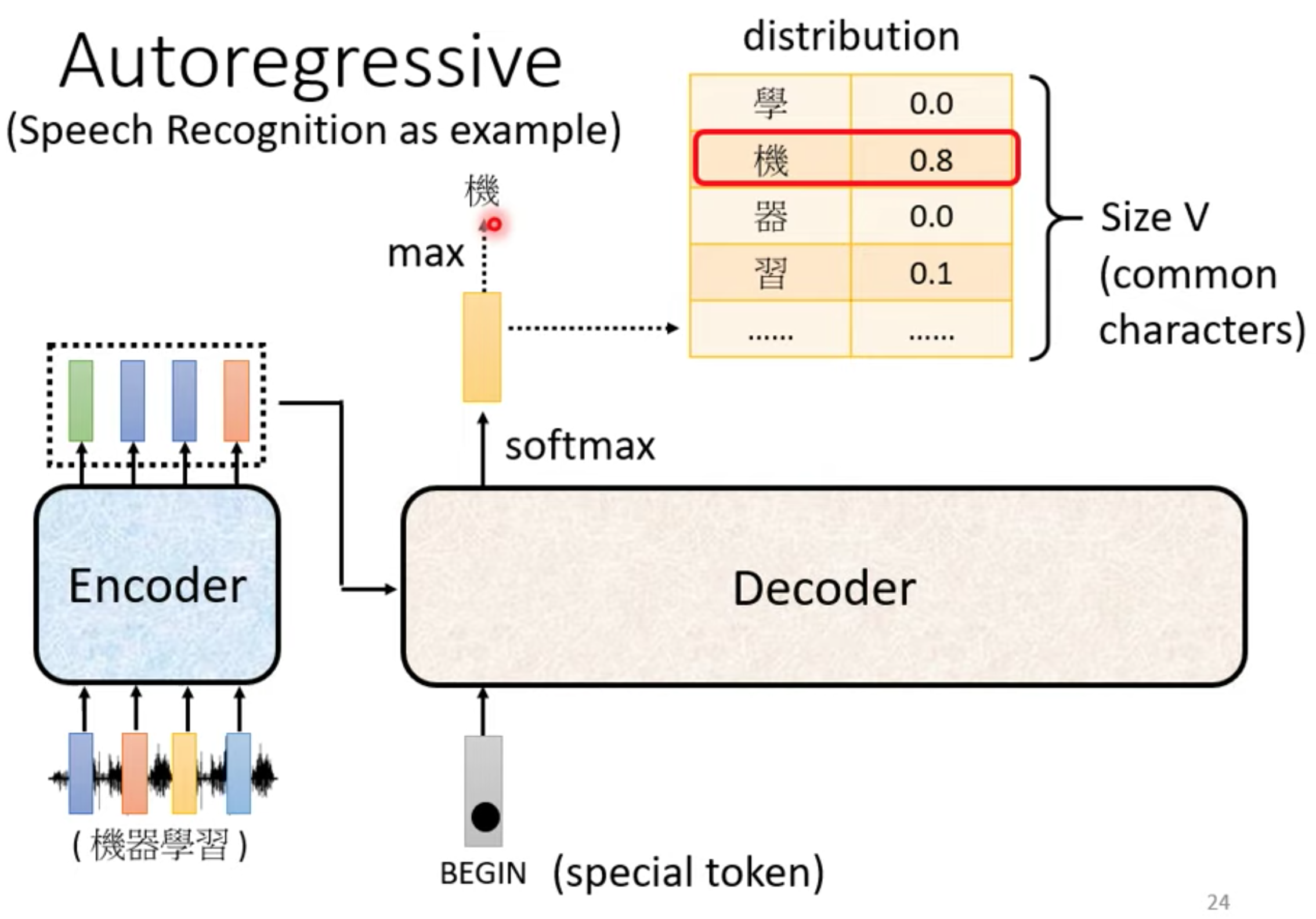
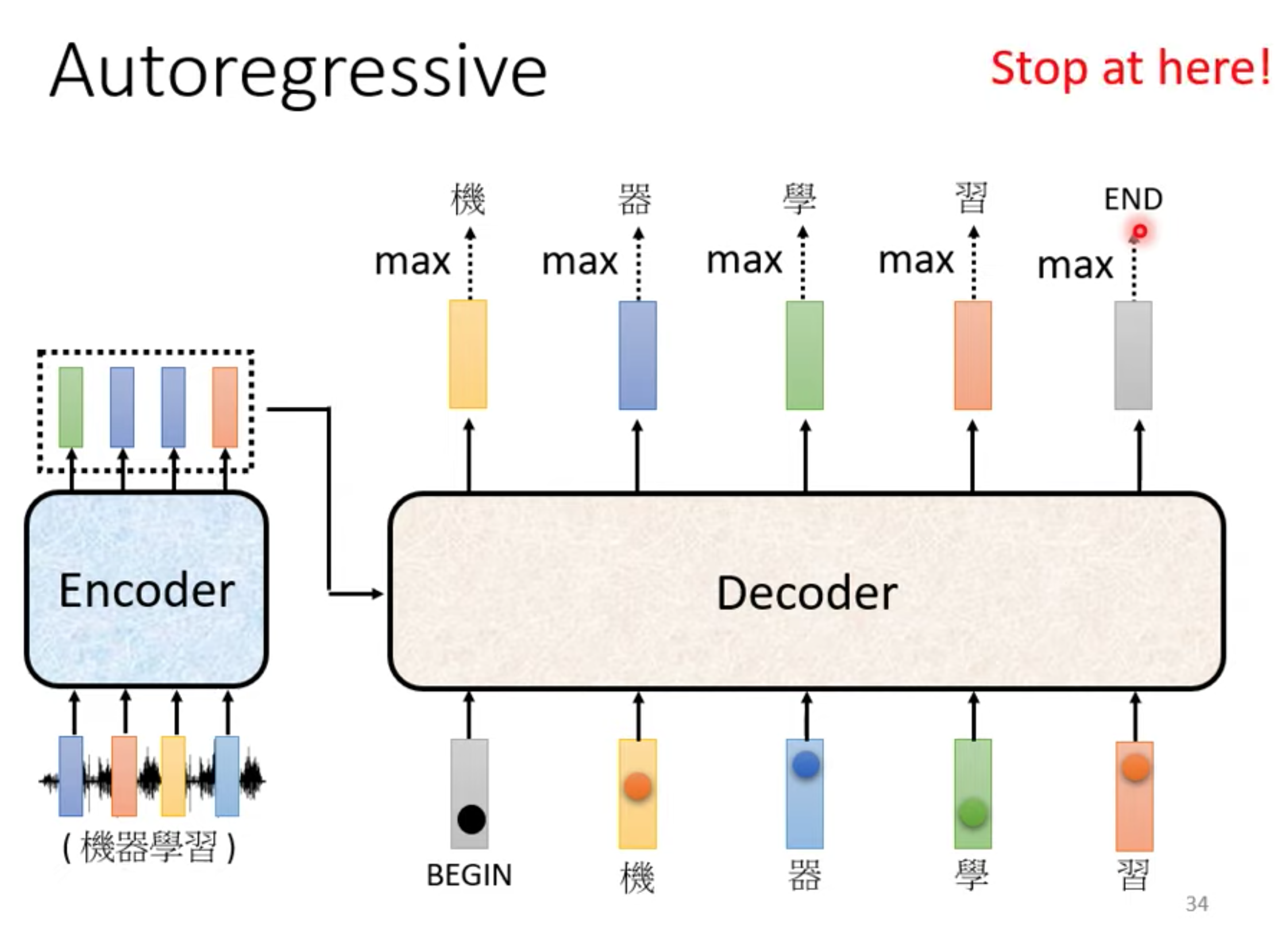
autoregressive
先忽略encoder input
在encoder输出里面加一个BOS(begin special token) , 输出常见字表,取softamx后的最大值的那个字。
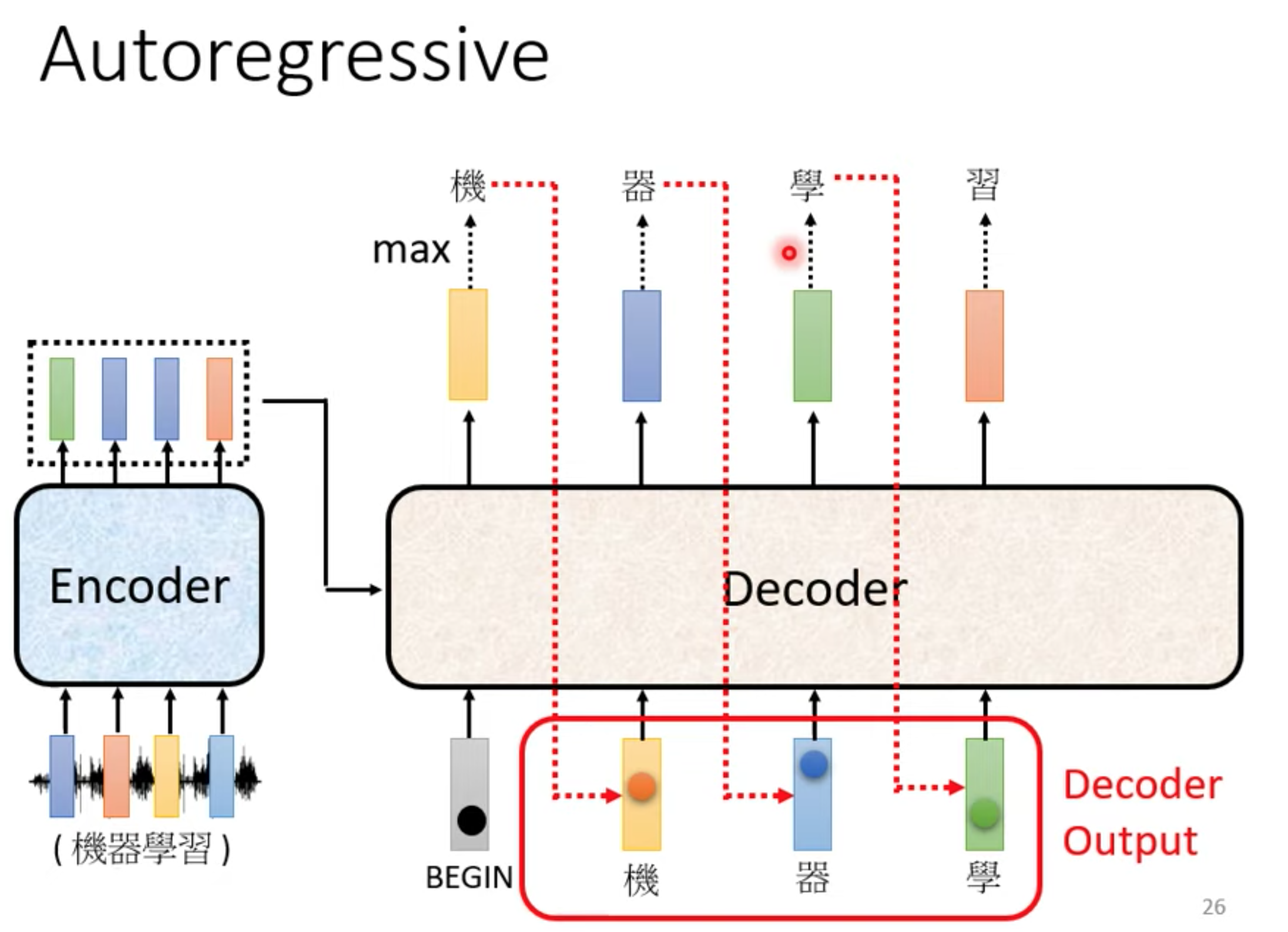
这个字作为下一个输入
decoder大概结构,与encoder非常相似,但是decoder 多了一个Masked multi-head self-attention
Masked multi-head self-attention
一般的self-attention生成b,要考虑整个seq的信息。
但是masked 只考虑比它前的向量信息(生成b3,只考虑a1~a3)
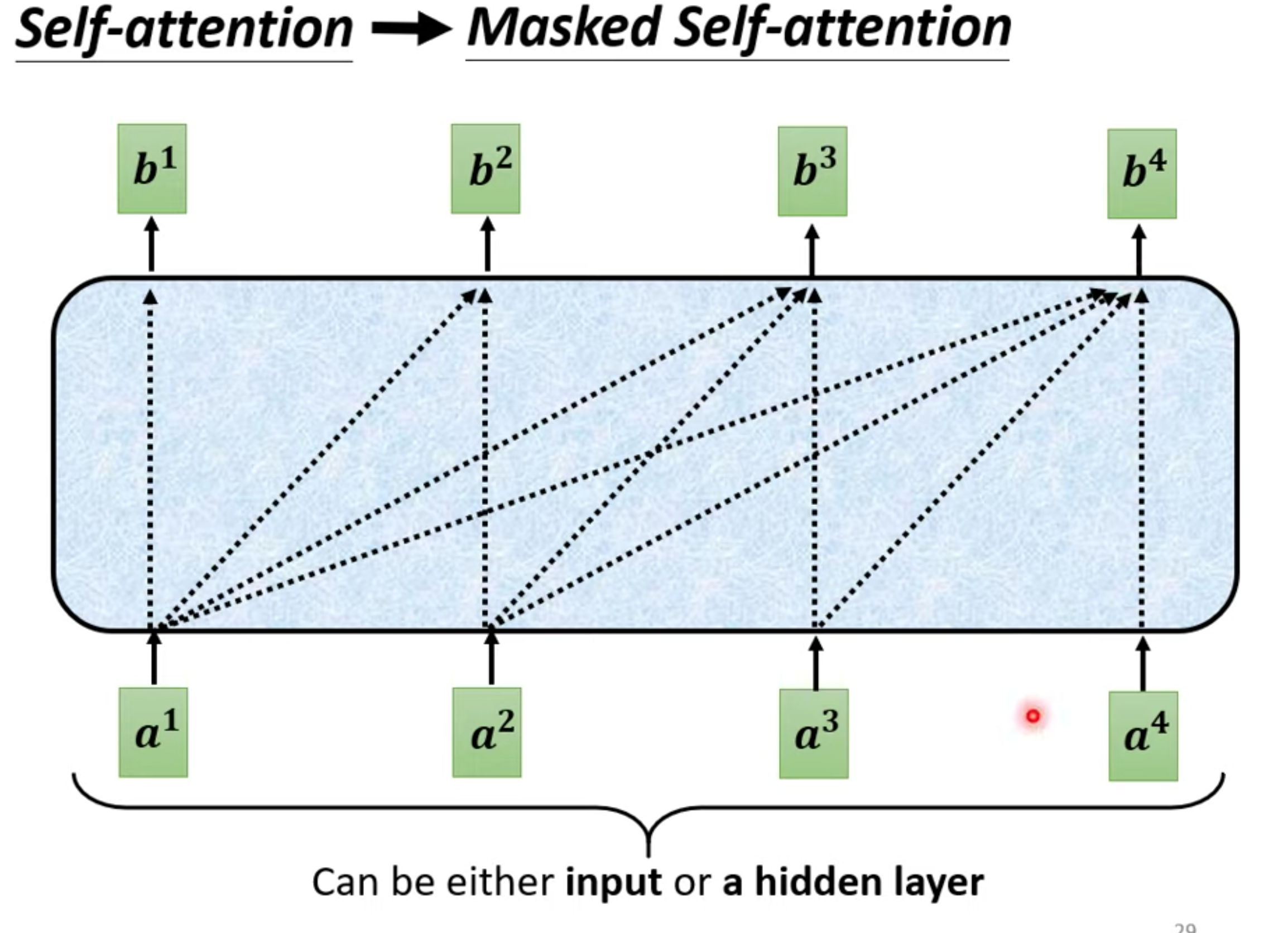
Why Masked : 因为decoder的input决定这样,输入也是一个个进来,不可能考虑到后面的向量。
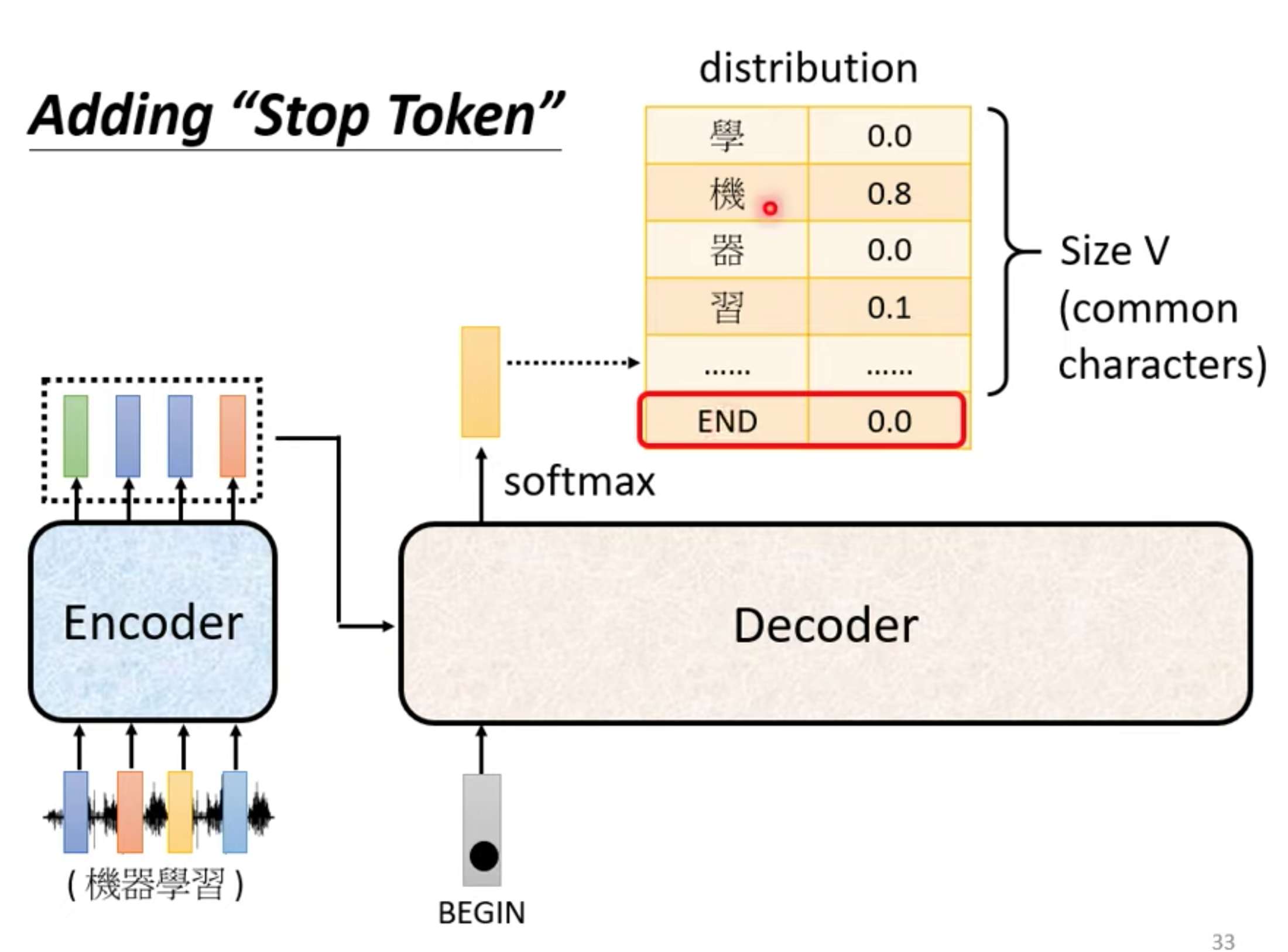
decoder 什么时候停
output seq 长度由model自己决定。 在vocabulary 加入stop token , 和begin token一样不一样都可以。
Non autoregressive
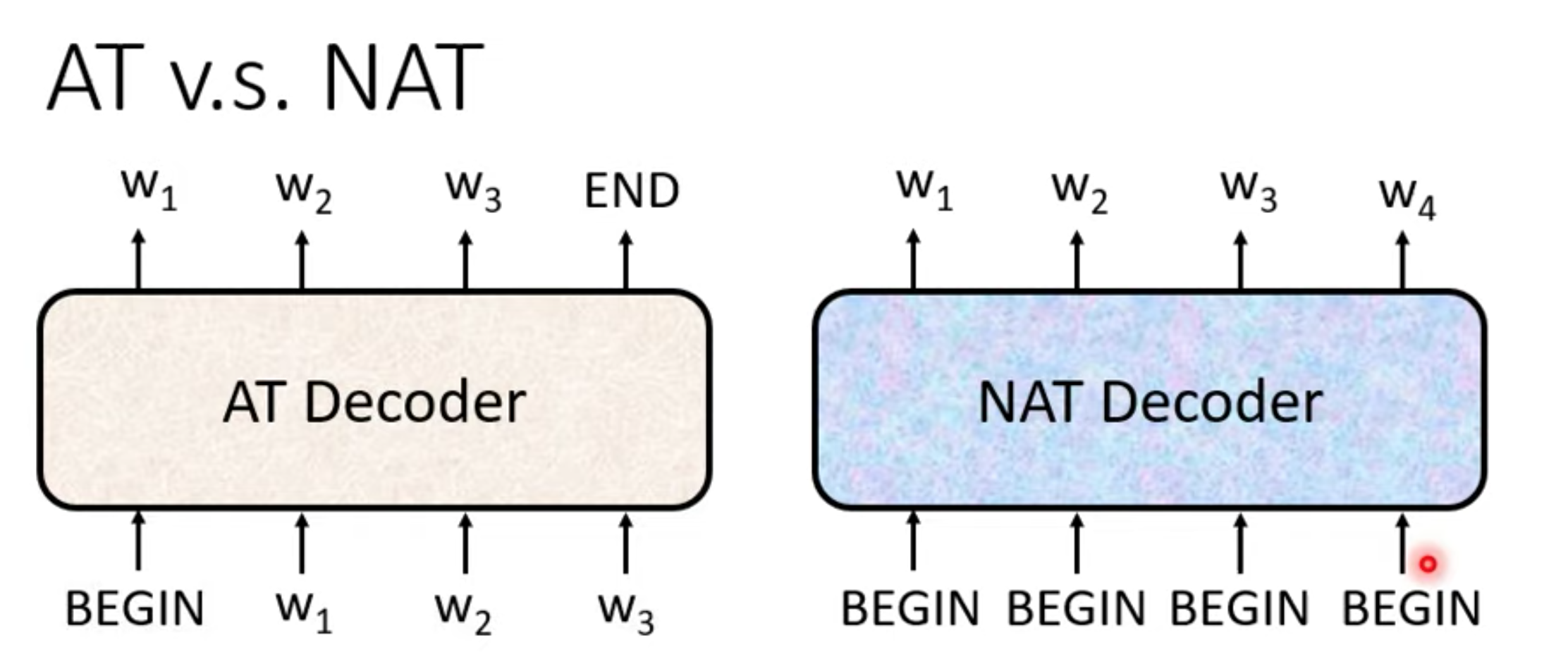
NAT input一堆begin,output整句输出。
when stop,(output 长度)
- 需要另外一个predictor预测
- 直接输出一个很长的output,出现stop token就忽略的output token
优点:
- 生成速度快比AT,可以output可以并行生成
- 可以很好控制输出长度
缺点
- 没有AT的表现好(why multi-modality)
Transformer的endcoder和decoder结合 cross attention
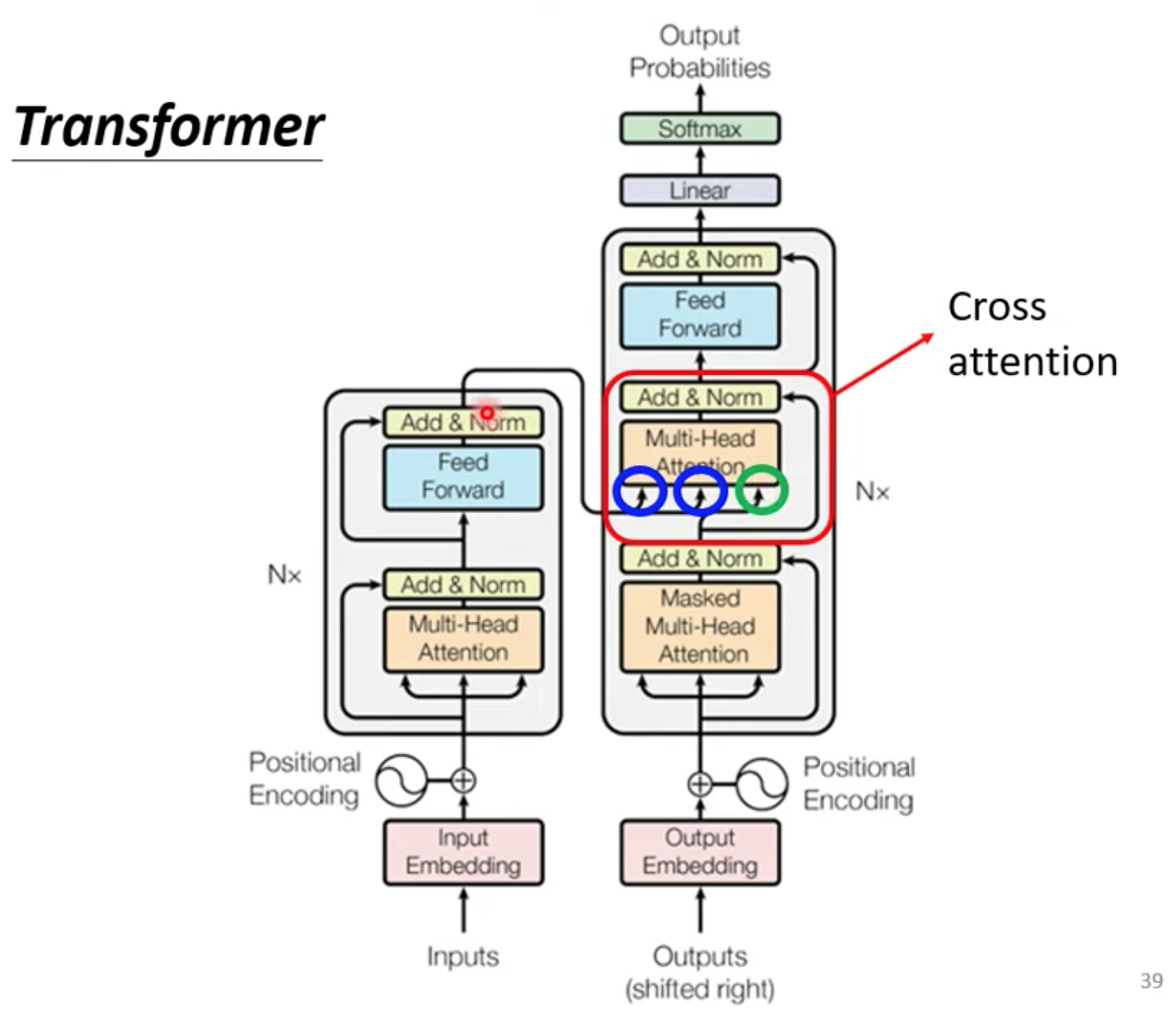
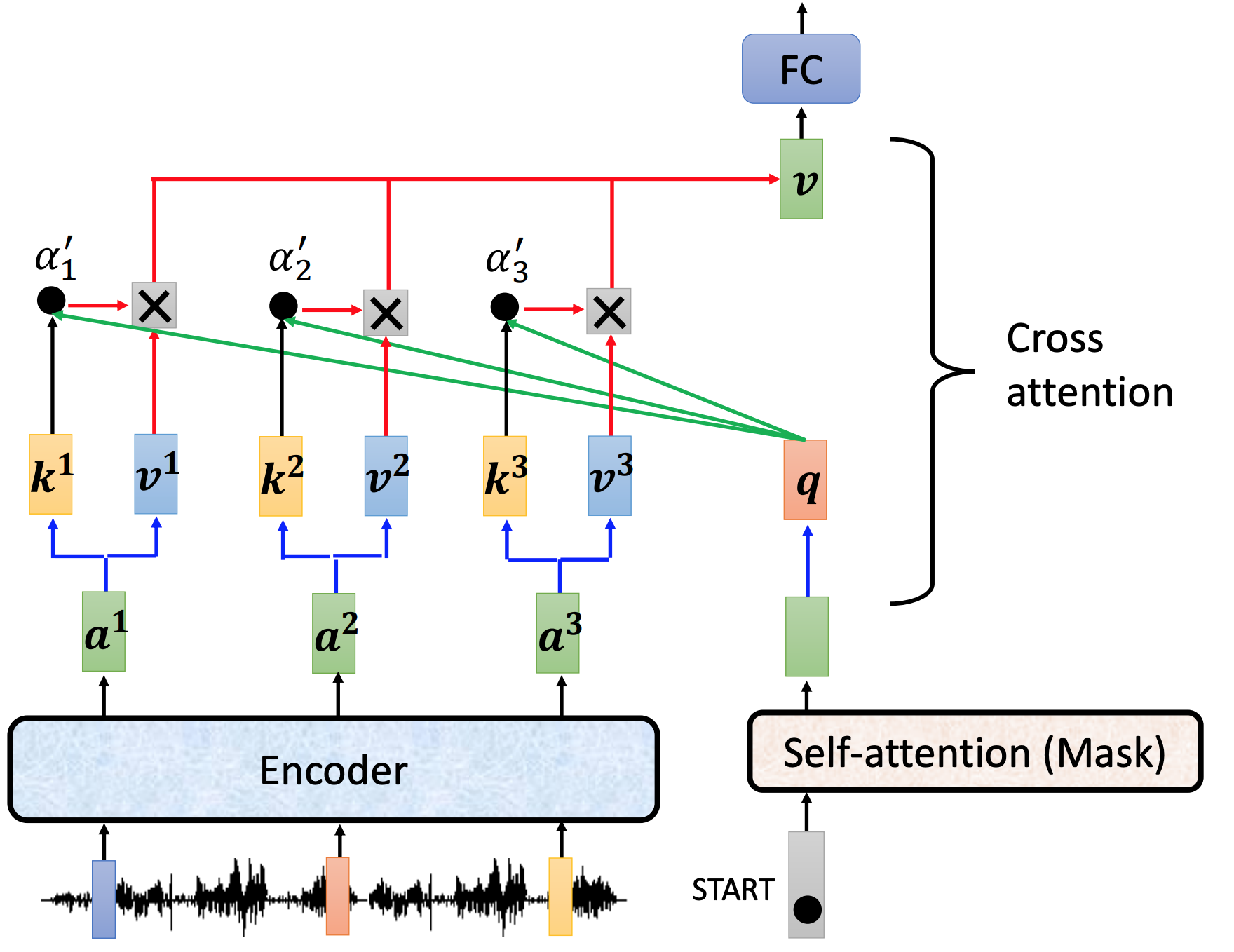
cross attention 做了什么。用endoder的output和mask的output,计算出来的V作为下一层(FC层)的input
train loss
每次decoder的output,都是对vocabulary(词汇表)的一次分类问题
每一个output,都要和其正确答案(vocabulary one-hot vector)进行cross entropy ,所有的cross entropy总和最小。
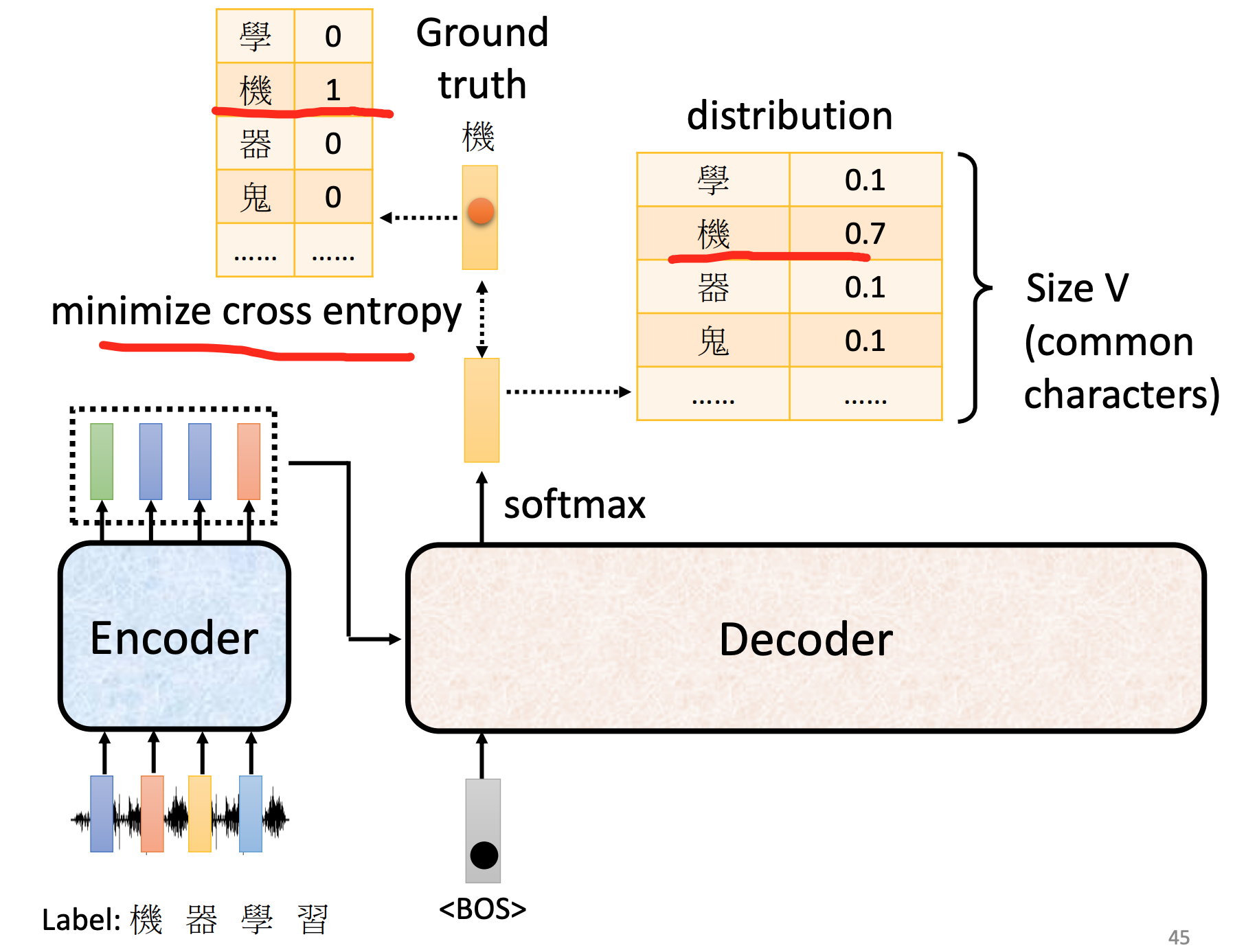
训练时候,decoder给正确答案。
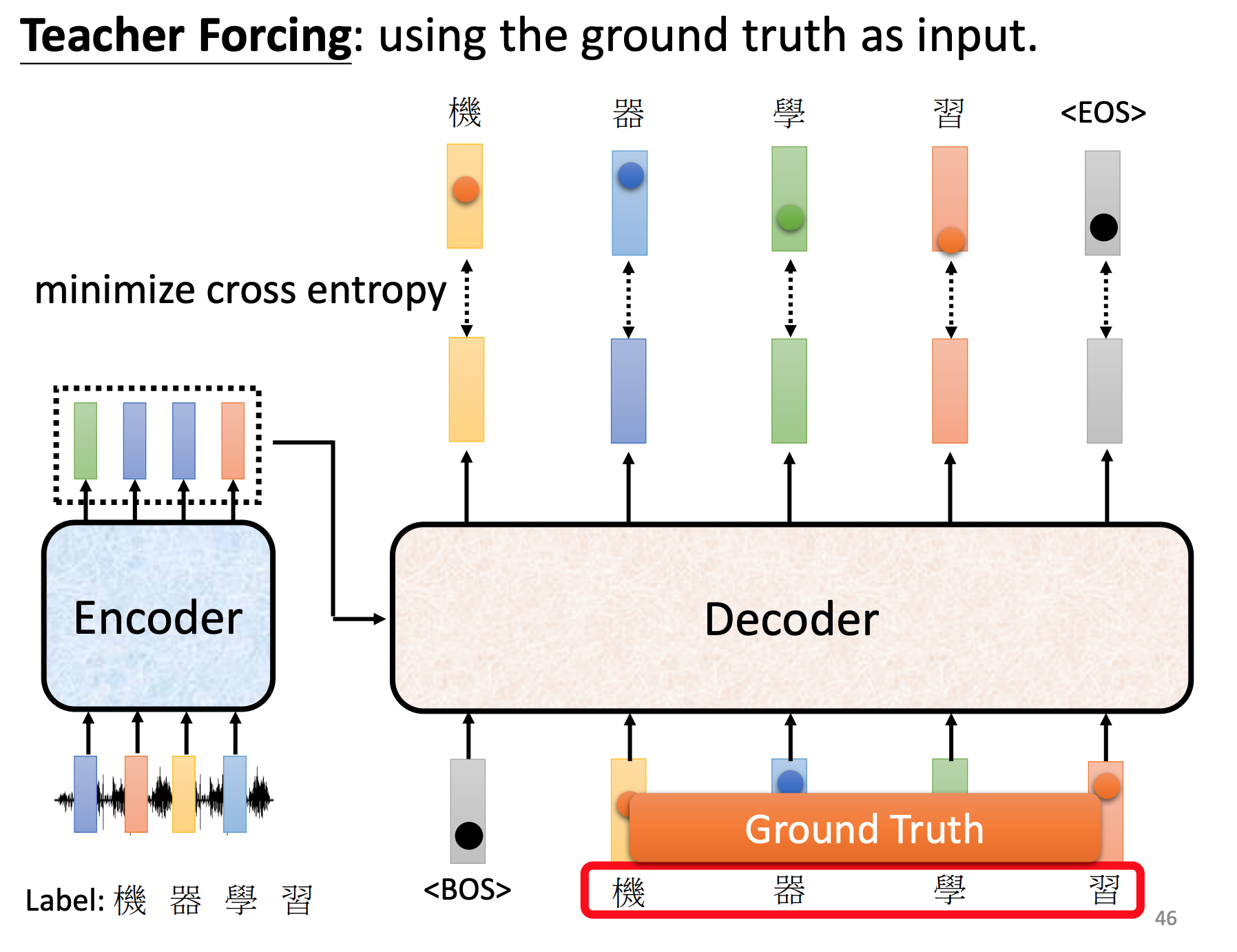
tips
-
Copy Mechanism 从input复制某些词汇到output 场景: 翻译,chat,summary
-
Guided Attention 强迫Attention有固定模式,Attention不能漏,语序不能错 场景:语音识别、TTS Monotonic Attention ,Location-aware attention
-
Beam Search decoder的output,不一定选最大可能那个,帮助寻找较好路径 (对需要创造性的任务效果不好,有确切答案的任务效果好)
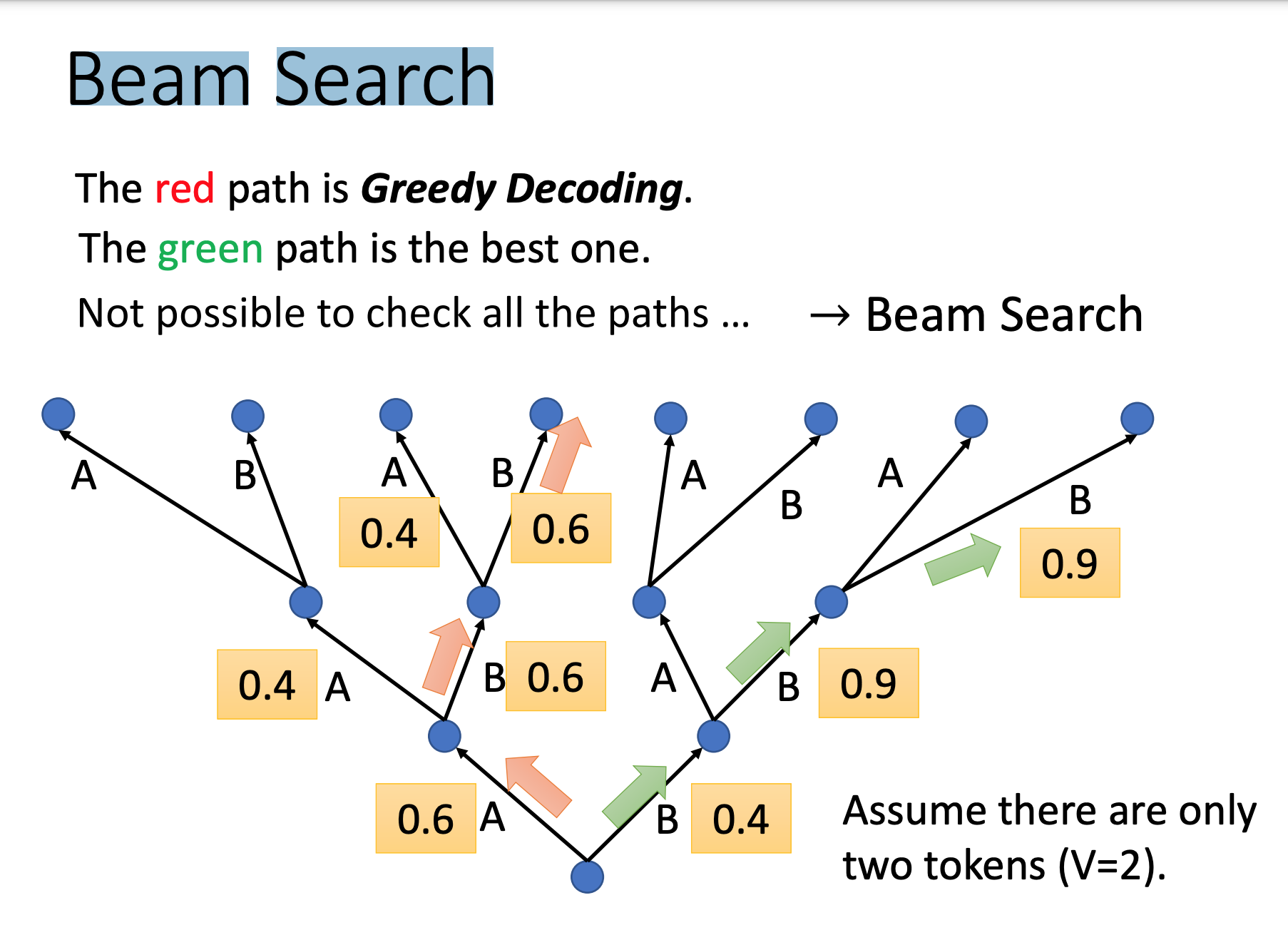
-
Scheduled Sampling 训练测试要加入一些错误的列子,效果会更好
MOE
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
稀疏门控专家混合模型 ( Sparsely-Gated MoE):旨在实现条件计算,即神经网络的某些部分以每个样本为基础进行激活,作为一种显著增加模型容量和能力而不必成比例增加计算量的方法。
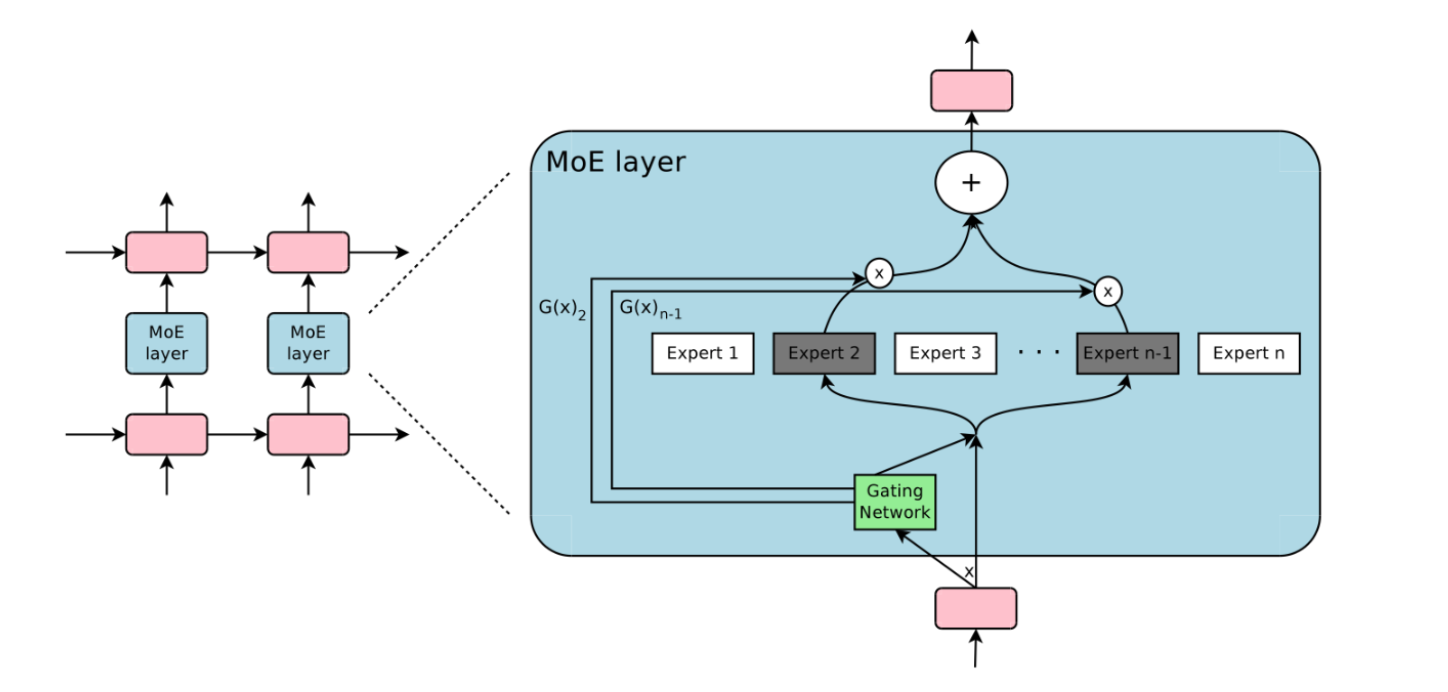
为了保证稀疏性和均衡性(为了不让某个expert专家权重特别大),对softmax做了如下处理 :
- 引入KeepTopk,这是个离散函数,将top-k之外的值强制设为负无穷大,从而softmax后的值为0。(合理听取某些专家建议,其他就不学习)
- 加noise,这个的目的是为了做均衡,这里引入了一个Wnoise的参数,后面还会在损失函数层面进行改动。

将大模型拆分成多个小模型(每个小模型就是一个专家),对于一个样本来说,无需经过所有的小模型去计算,而只是激活一部分小模型进行计算这样就节省了计算资源。稀疏门控 MOE,实现了模型容量超过1000倍的改进,并目在现代 GPU 集群的计算效率损失很小
Flash Attention 加速训练
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
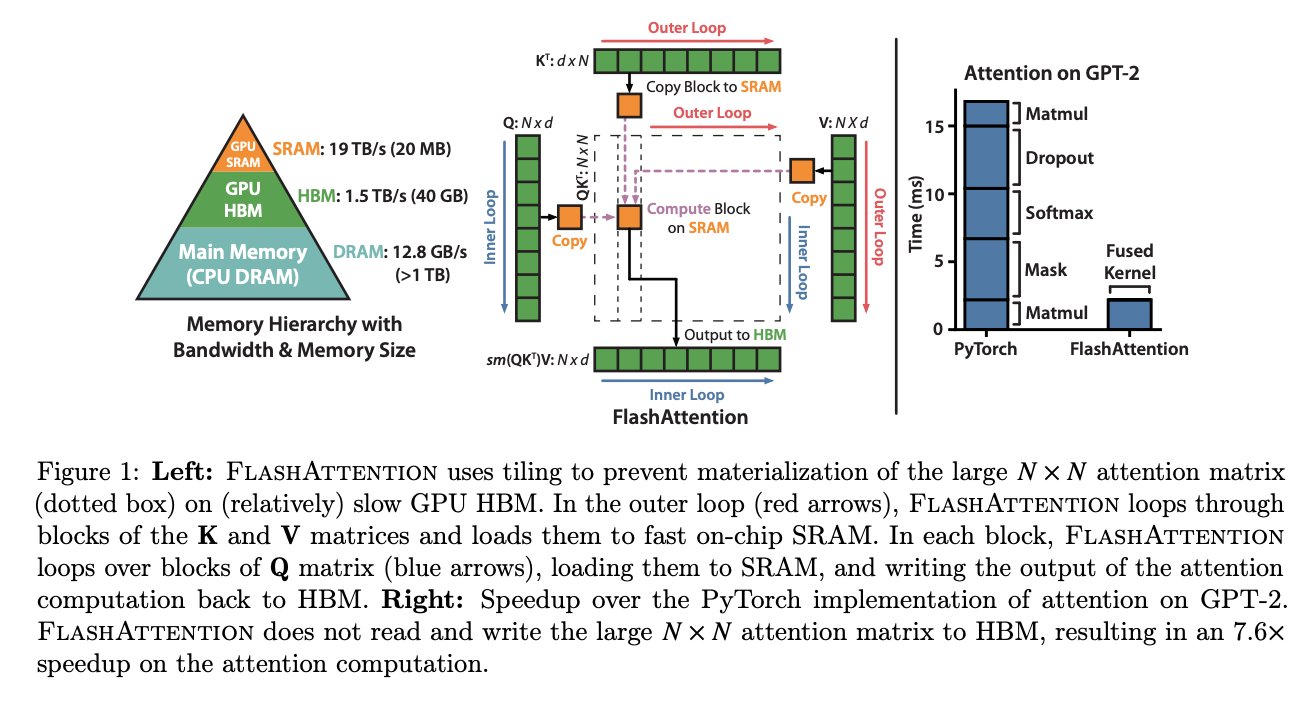
在外循环(红色箭头)中,FLASHATTENTION 循环遍历 K 和 V 矩阵块并将它们加载到快速片上 SRAM。在每个块中,FLASHATTENTION 循环遍历Q 矩阵块(蓝色箭头),将它们加载到 SRAM,并将attention计算的输出写回 HBM。
- SRAM的IO速度远大于GPU HBM的IO速度,在SRAM做运算搬运结果更快
- 将长度为N的句子的Q和{K,V}对分成诸多小块,外循环和内循环在长度轴N上进行,循环计算
materialization “材料化”指的是将 N x N 的注意力矩阵存储或表示在内存中,特别是存储在GPU的高带宽内存(HBM)上的过程。通过平铺注意力矩阵并将其加载到片上SRAM(快速的片上内存)中,避免了在相对较慢的GPU HBM上完全材料化整个注意力矩阵。这种方法有助于提高FLASHATTENTION实现中注意力计算的效率和速度。
KV cache 加速推理

空间换时间,提升算力利用率。
Transformers 结构里的 keys 和values通常被称为 KV,这些tensors 会存在 NPU 显存中,用于生成下一个 token 。这些 KV 中间值占用很大的内存,而且大小动态变化,导致有接近60%-80% 预留显存浪费。因此 Transformers 结构的推理加速常用的优化手段使用 KV Cache 算法。LLMs 大模型生成式推理包含两个阶段
-
预填充 Cache
输入一个 prompt 序列,计算第一个输出token过程中,这时 Cache 是空的,为每个 transformer 层生成 key cache 和 value cache , 即 KY cache ,在输出 token 时第一次KV Cache完成境充。

-
使用 KVCache 阶段 计算第二个输出 token 至最后一个 token,此时 Cache 有值,接下来是使用并更新KV cache,每轮推理读取缓存中的 KV Cache,一个接一个地生成词,当前生成的词依赖于之前已经生成的词,同时将当前轮输出的新 Key、Value 追加写入至缓存 Cache 中
将矩阵相乘转换成矩阵和向量相乘,推理速度比较快。

1 | |
KV Cache 的目标是缓存可重复利用的计算结果,避免不必要的计算,以加快token生成速度的技术,供后续的生成步骤使用。
1 | |
- Q 矩阵是依赖于输入的,每次都不同,无法进行缓存。因此,通常不会缓存 Q 矩阵。
- 缓存 Q 矩阵可能需要大量内存,而且通常不太实际。因此,平衡计算和内存的使用,只缓存 K 和 V 矩阵是更合理的选择。
其他加速方法
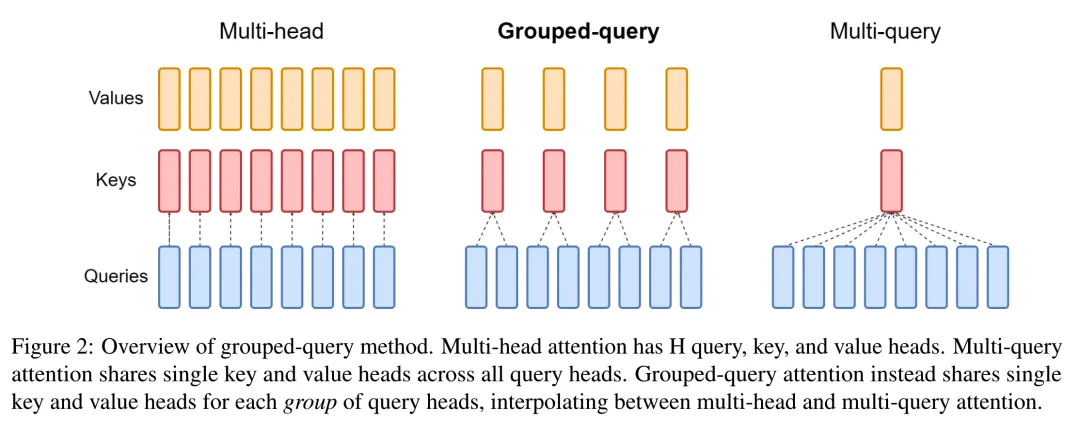
MQA (Multi-Query Attention)
MQA是MHA的一个变体,它旨在减少解码过程中的计算和存储需求,特别是在自回归生成任务中
MHA中,每个注意力头的 、 是不一样的,而MQA这里,每个注意力头的 Key 和 Value 矩阵是一样的,值是共享的。而其他步骤都和MHA一样
尽管MQA在减少计算资源方面有效,但它可能会限制模型的表达能力,因为它强制所有头共享相同的键和值。
GQA(Grouped-Query Attention)
就提出了一个折中的办法,既能减少MQA效果的损失,又相比MHA需要更少的缓存。
在GQA中,查询被分成几个组,每组内的查询共享相同的键和值,但不同组之间保持独立。
Vision Transformer(VIT)
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
图像任务直接作用Transformer上面
把图片所有像素拉成一维数组放到Transformer,图片尺寸(224*224=507776),远远超过大模型可接受的序列长度。
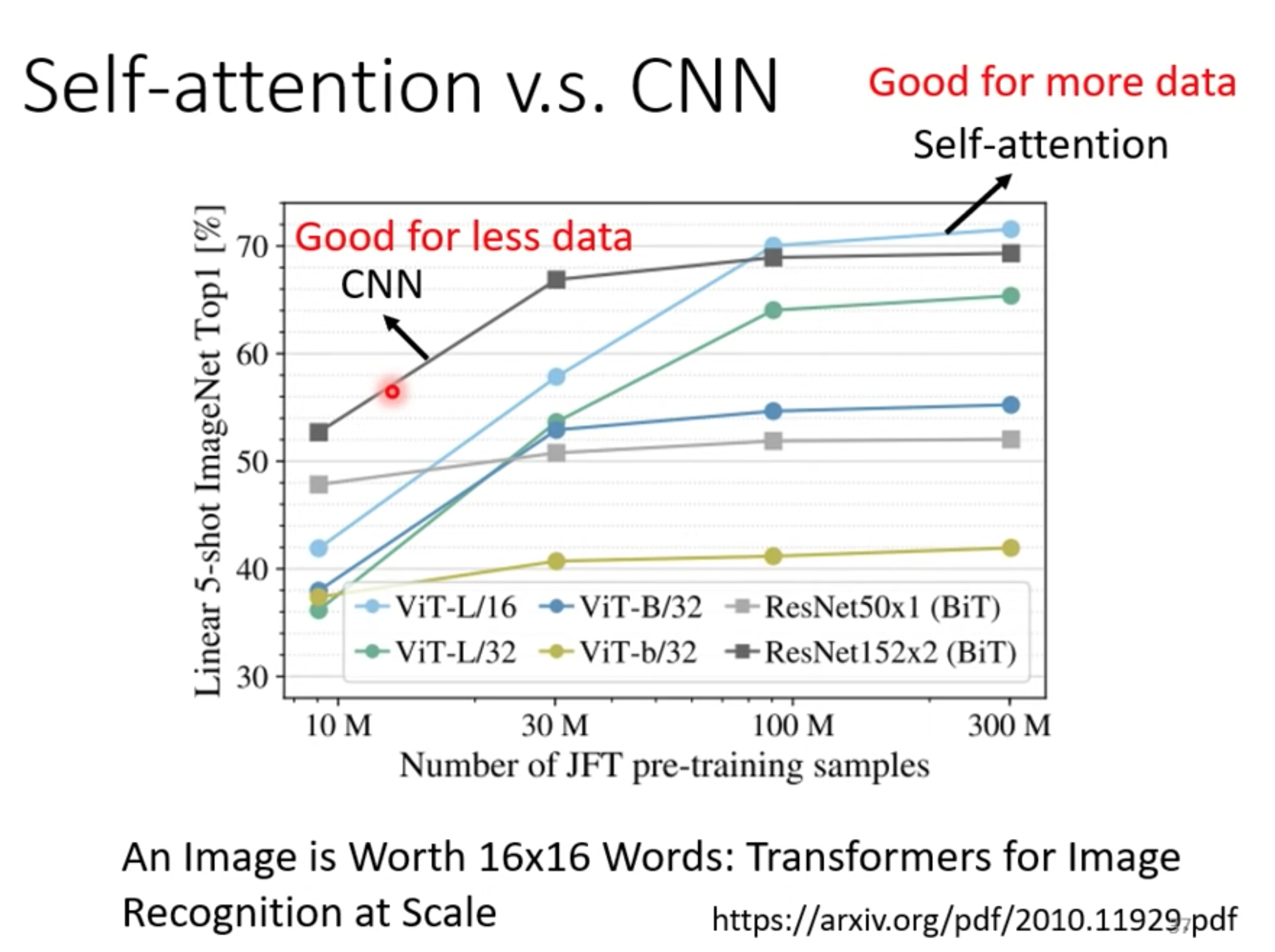
VIT有足够规模的数据预训练效果比现有的残差网络效果接近甚至更好。除了抽取图像块和位置编码用了一些图像特有的这个归纳偏置,然后就可以使用和NLP一样的Transformer。
和CNN相比,要少很多这种图像特有的归纳偏置。在中小数据集上的表现不如CNN。
patch+位置信息
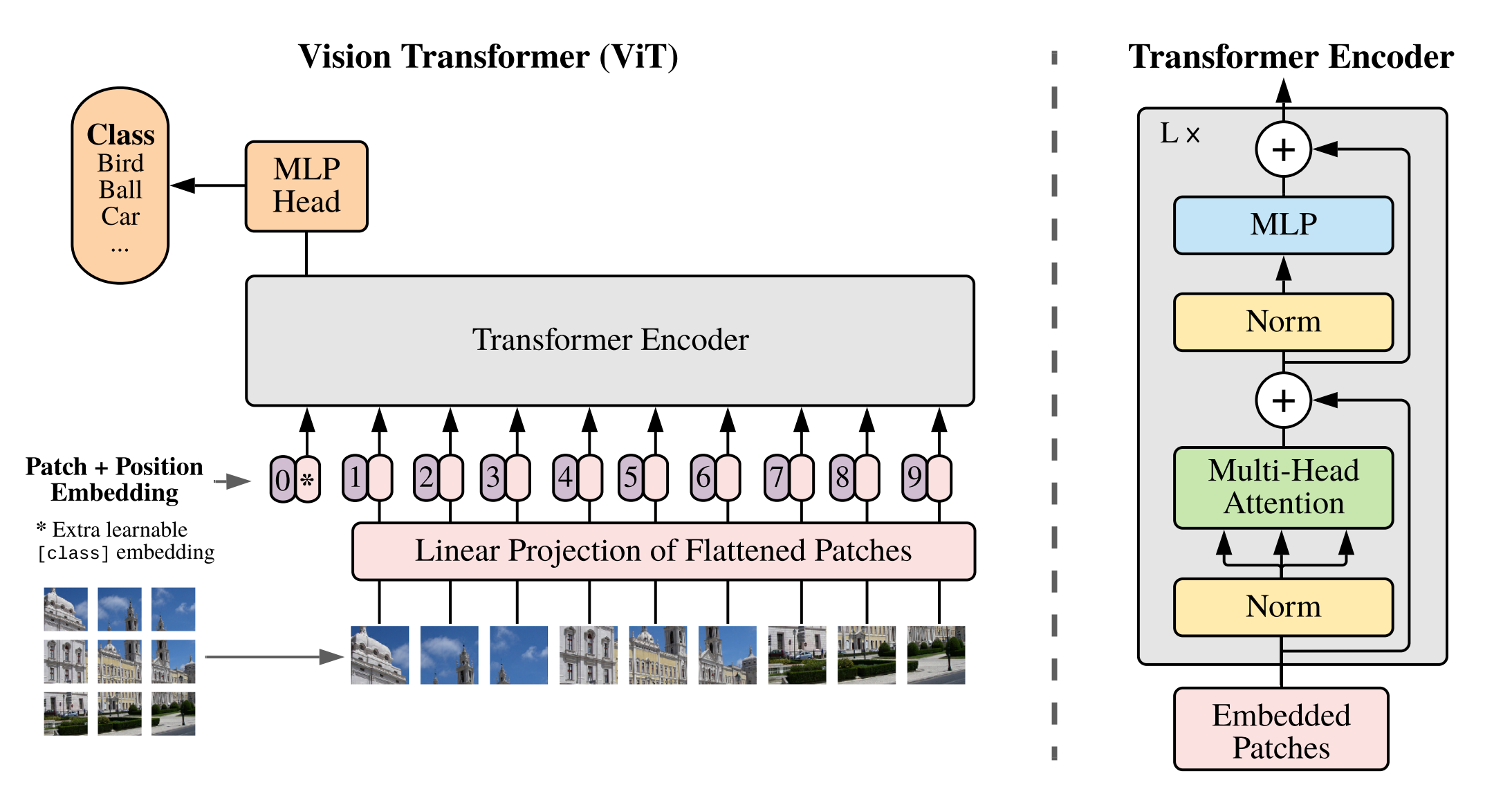
ViT的首要任务是将图转换成词的结构,将图片分割成小块,每个小块就相当于句子里的一个词。这里把每个小块称作Patch。
假设:patch 16x16,224/16 = 14 序列长度=14x14=196
而Patch Embedding就是把每个Patch再经过一个全连接网络压缩成一定维度的向量。
假设:原图224x224x3(RGB channel) 转换成一个patch 的维度(16x16x3=768) 总共196个,通过一个全连接层(768x768),最终向量Patch(196x768) x 全连接层(768x768)= 向量(196x768) + cls_token(1x768) = embedding(197x168)
加入cls_token永远放在位置0,由于所有token之间都交换信息,其他的embedding表达的都是不同的patch的特征,而cls_token是要综合所有patch的信息,产生一个新的embedding,来表达整个图的信息。
位置信息
和向量维度都是一样的,直接和embedding(197x168)相加 = Embedded Patches(197x168)
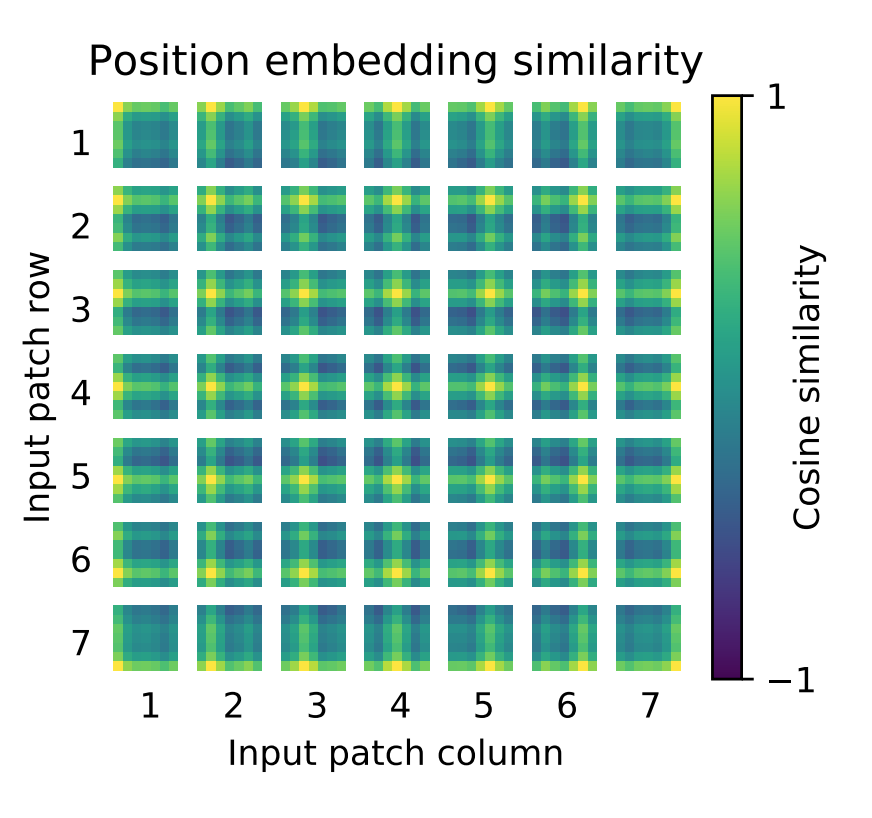
图片尺寸改变会影响,patch size 和位置编码,使用更大尺寸图片微调有局限性。位置编码可以学习到2d信息。
CLIP Contrastive Language-Image Pre-training
Learning Transferable Visual Models From Natural Language Supervision
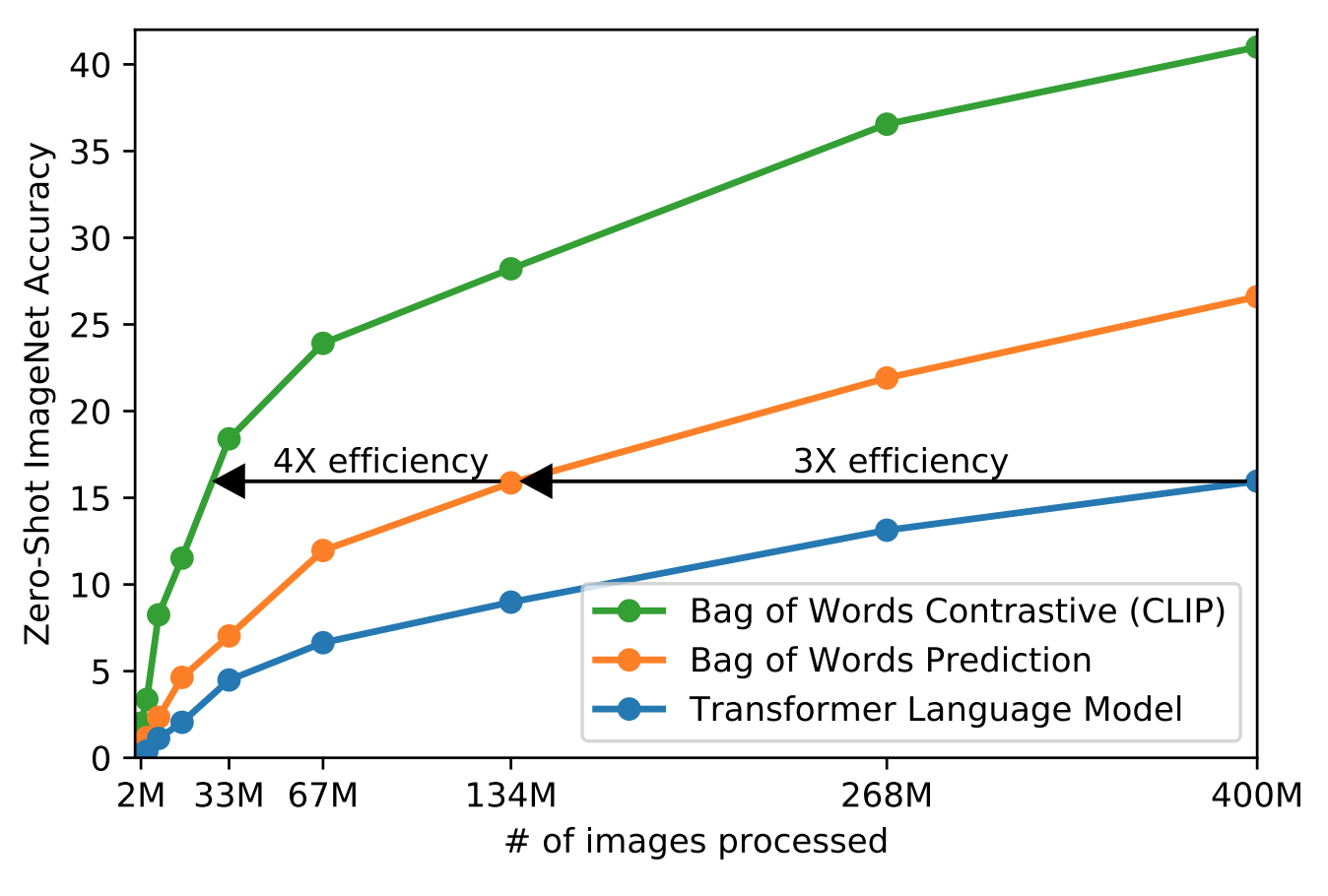
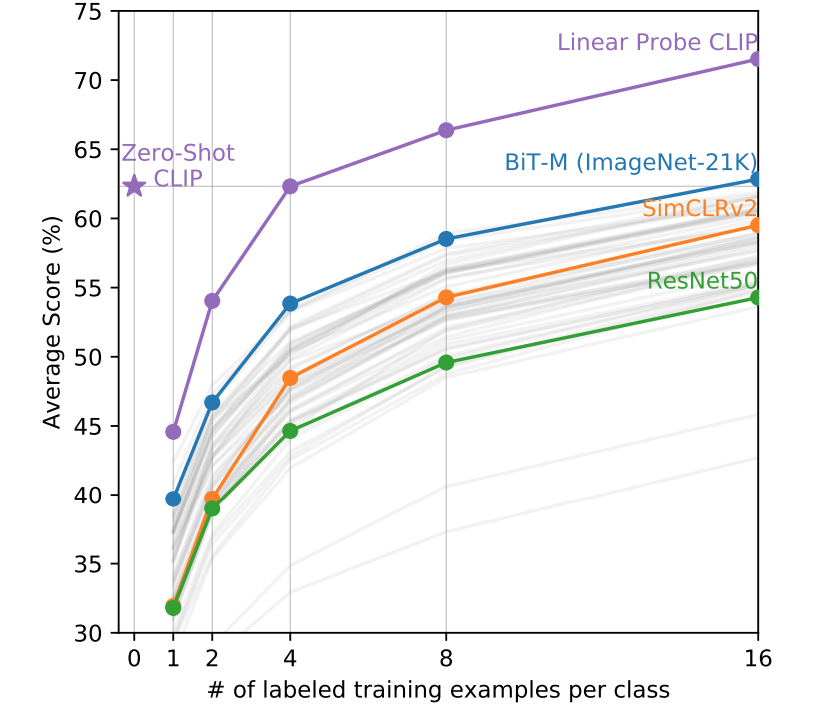
真正把视觉和文字上语义联系到一起,做到zero shot推理,泛化性能远比有监督训练出来的模型厉害
-
利用文本监督信号,而不是N选一这样的标签,训练集必须够大(WebImageText WIT)
-
给定图片去逐字逐句预测文本,而且对同一张图描述会很多,所以简化成衡量文字信息和图片是否配对,可以提高训练效率
-
传统模型主要研究特征学习的能力,学习泛化性较好的特征,应用到下游任务时还需要微调,所以需要zero shot 迁移
预训练
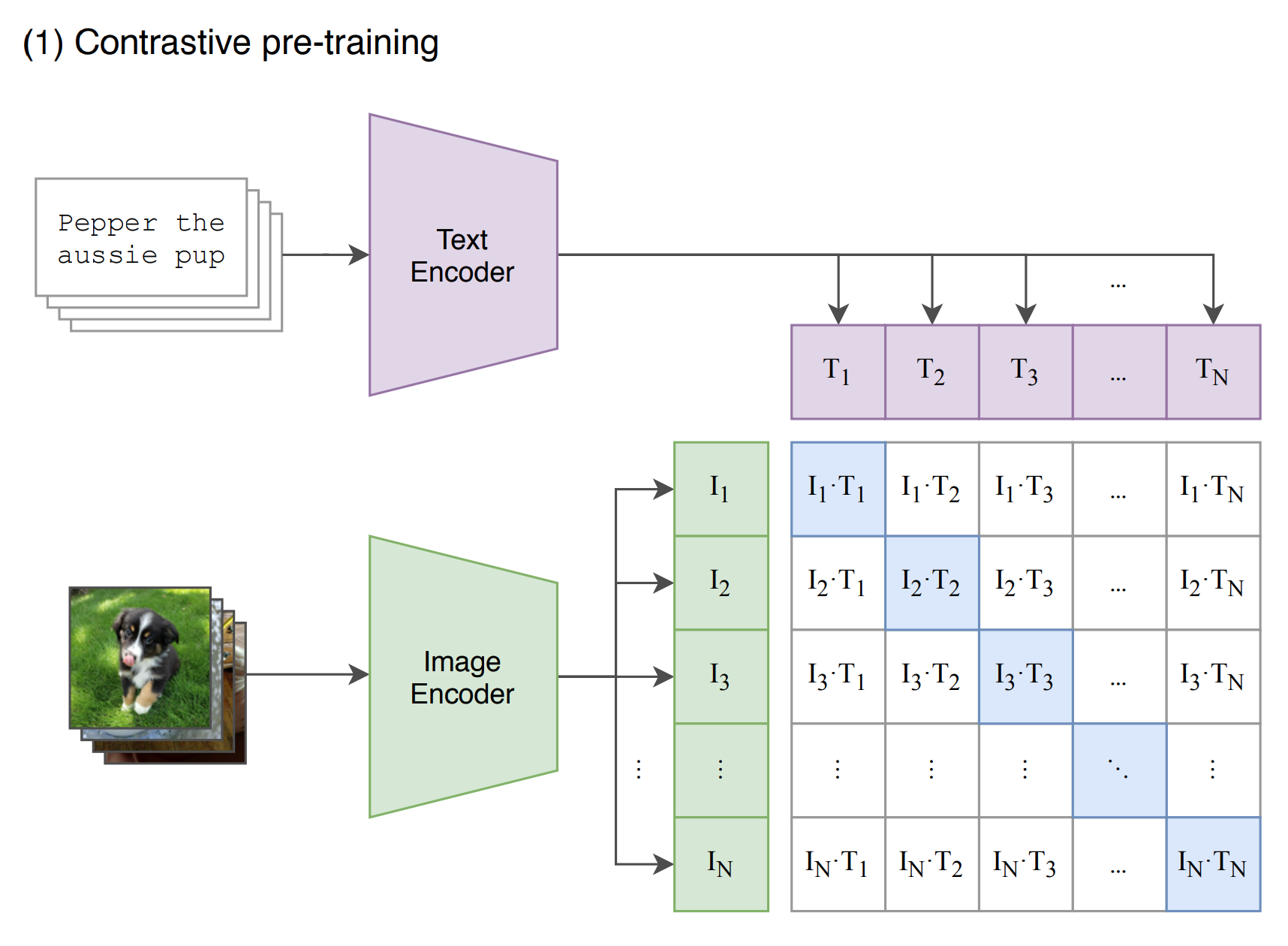
通过各自的Encoder得到N个特征,CLIP通过这些特征进行对比学习(对角线是正样本,白色底是负样本)
1 | |
学习的目标是学习这样一个嵌入空间,其中相似的样本对彼此靠近,而不相似的样本对相距很远。对比学习可以应用于有监督和无监督的环境。在处理无监督数据时,对比学习是自监督学习中最强大的方法之一。
在对比学习的损失函数的早期版本中,仅涉及一个正样本和一个负样本。最近训练目标的趋势是在一批中包含多个正负对。
CLIP 接受上亿对 text-img 数据训练,学习到给定文本与图像的关系
- 图像及文本通过各自编码器,映射到 m 维空间
- 计算每个 <图像,文本>对的 cos 值相似度
- 训练使正确编码 <图像,文本> 间cos值相似度最大化
推理
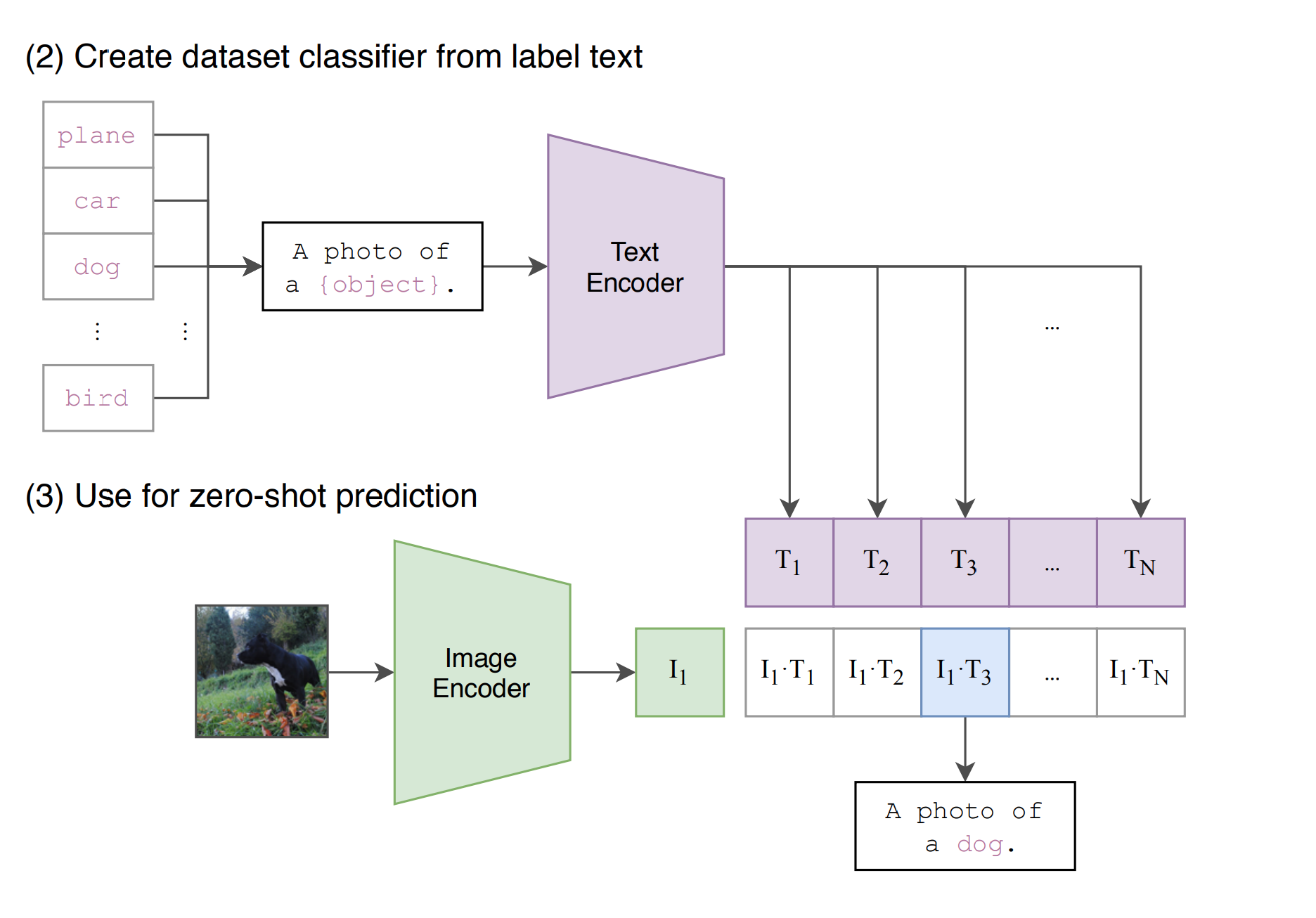
怎样推理分类
- 把所有的分类套入到prompt template,变成一个句子,然后和训练好的编码器进行encoder,得到N个文本特征。
- 将图片和训练好的编码器进行encoder,得到图片特征。和所有的文本特征,计算相似度
- 根据相似度可以得到分类
真正使用的时候,object可以换成其他从来没有训练的单词,图片也可以随便,CLIP可以做到zeor shot,普通的分类模型固定类别N选一
局限性
-
扩大CLIP规模无法扩大性能
-
不擅长细分类,抽象概念
-
图片和训练图集差得远一样表现差
-
只能从给定的类比判断是否类似,不能好像生成式那样生成新输出
-
数据利用率不高,需要太多数据
-
数据没有太多清洗,有数据偏见
-
few shot效果反而不好
ViLT
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
图像相关的模态,以前的模型通过区域特征的抽取,相当于目标检测任务,输出一些离散序列看出单词,输入到transformer和NLP模型做模态融合。
但是模型在运行时间方面浪费好多。去掉卷积特征(预训练好的一个分类模型抽出来的特征图)和区域特征(根据特征图做的目标检测的那些框所带来的特征)带来的监督信号,加快运行时间。但是性能没有使用特征的强 先预训练,再微调。
使用特征带来的坏处
- 运行效率不行。(抽出特征的时间比模态融合的时间长)
- 模型表达能力受限,因为预训练好的目标检测器,规模不大,用的数据集也小类别数不多,因为文本是没有限制的。
为什么用目标检测
- 需要语义强离散的特征表现形式,每个区域可以看出单词。
- 和下游任务有关(某个物体是否存在,物体在哪),和物体有强关联性
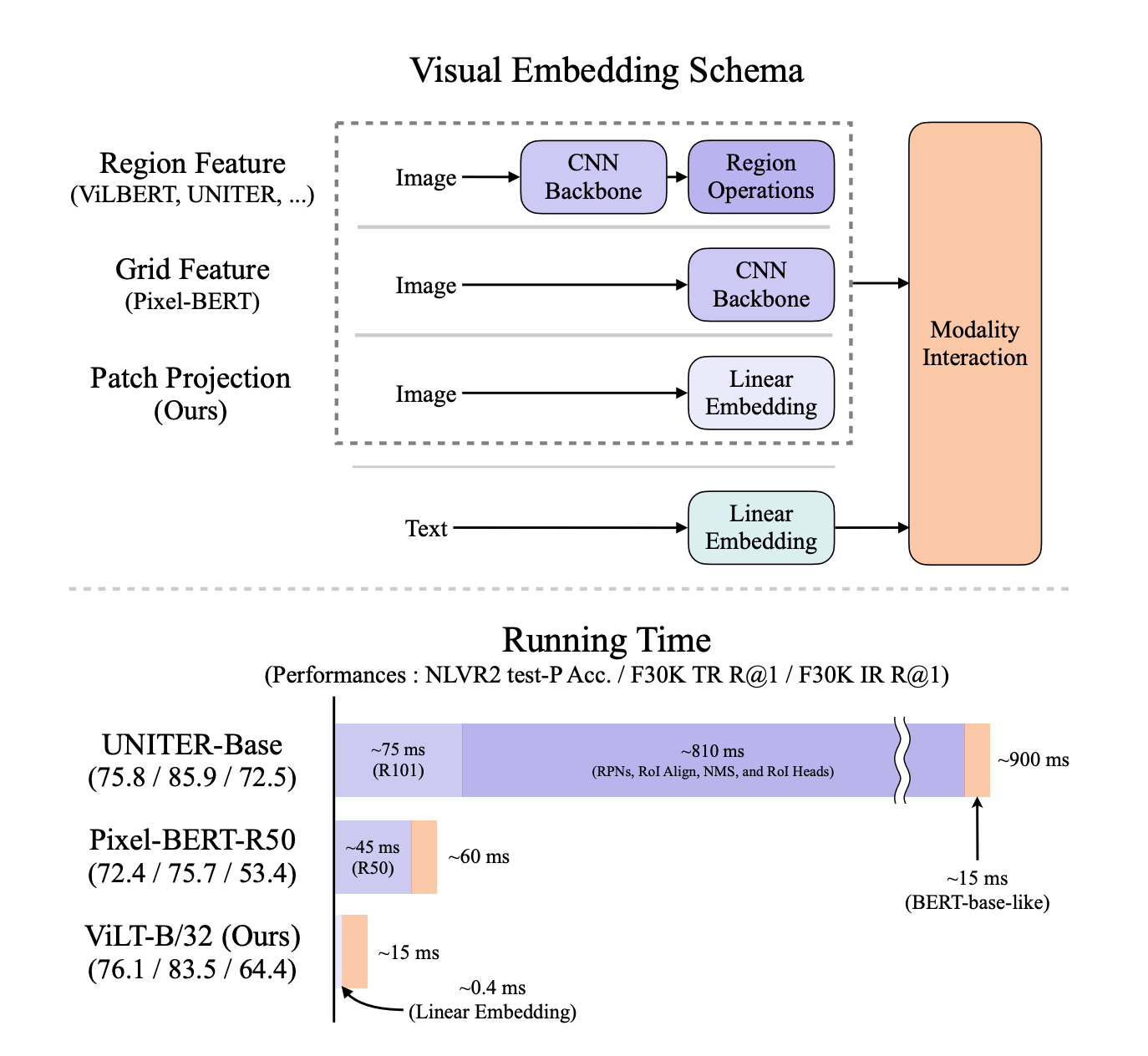
改进
受到VIT启发。
- 使用patch emedding简化计算复杂度,保持性能
- 使用数据增强(image-text pair 对应的语义),尽量保证可以对应上
- NLP整个词mask调,(当时CV的完形填空的方法还没正式有)
衡量模型
- 图像和文本表达能力是否平衡(之前图像训练贵很多),参数量
- 模态的融合(做得不好,影响下游任务)
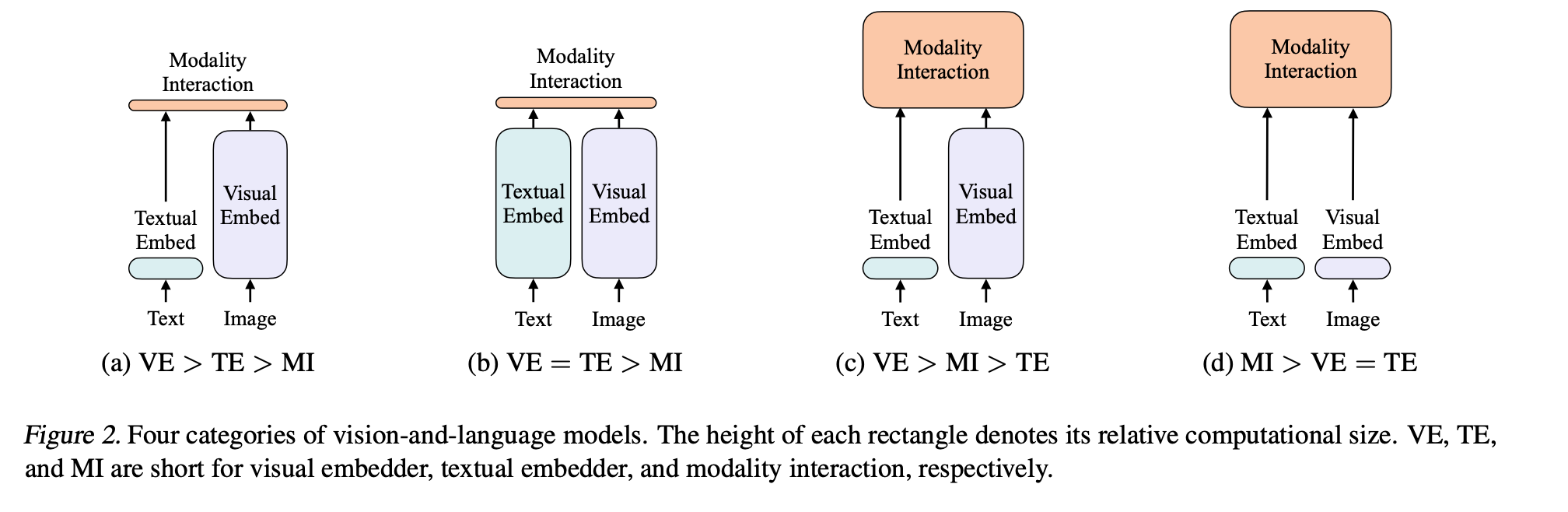
对现有领域的信息,进行分类。加深对领域的理解。
模态融合
效果各有千秋
-
single-stream approaches
只用一个模型处理两个输入(图像和文本),直接向量串联,让transformer自己去学 (使用了这个)
-
dual-stream approaches
使用两个模型,对各自的输入,充分去挖掘单独模态里包含的信息,在某个时间点用transformer融合。引入更多参数,成本贵。
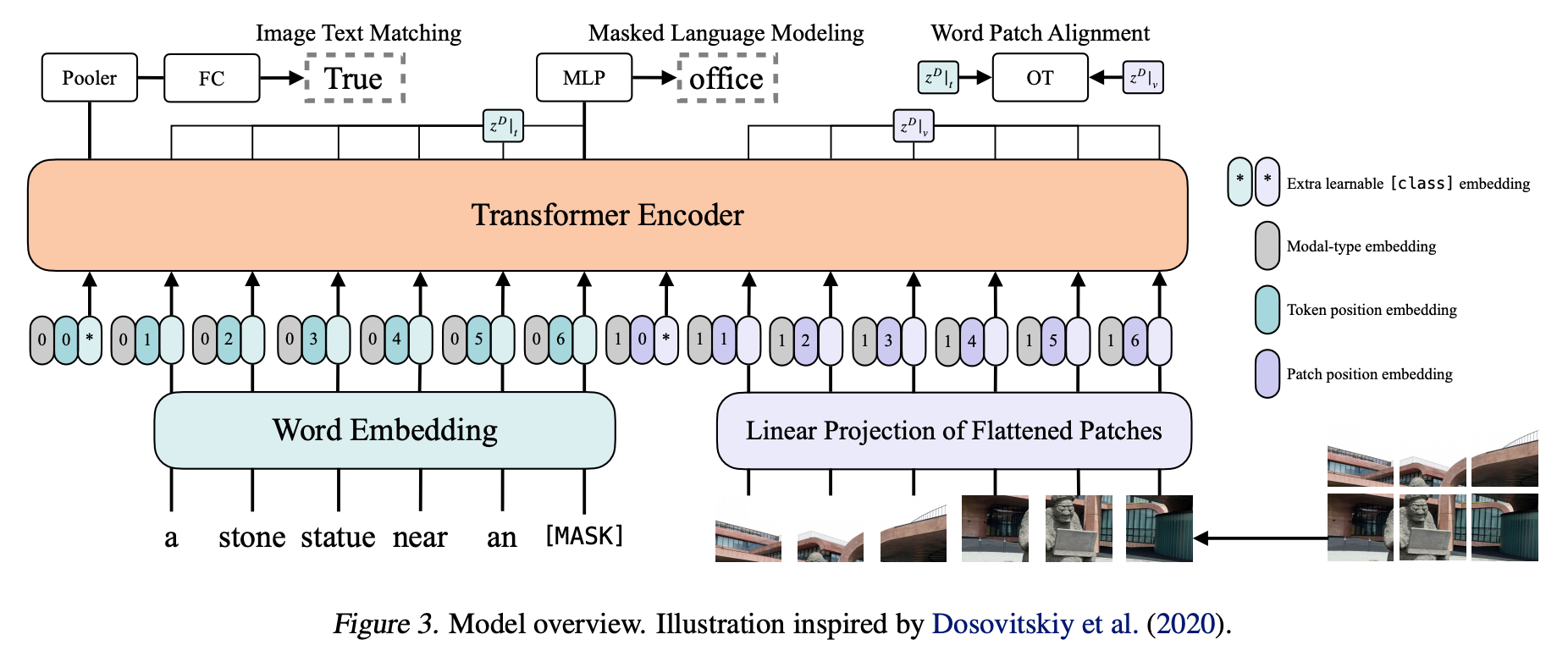
1 | |
Diffusion Model
Denoising Diffusion Probabilistic Models (DDPM)
Reverse Process
生成带噪音的特定尺寸的图片,然后一步步过滤噪音(Denoise), 到生成清晰图片。靠近最后一步的是1
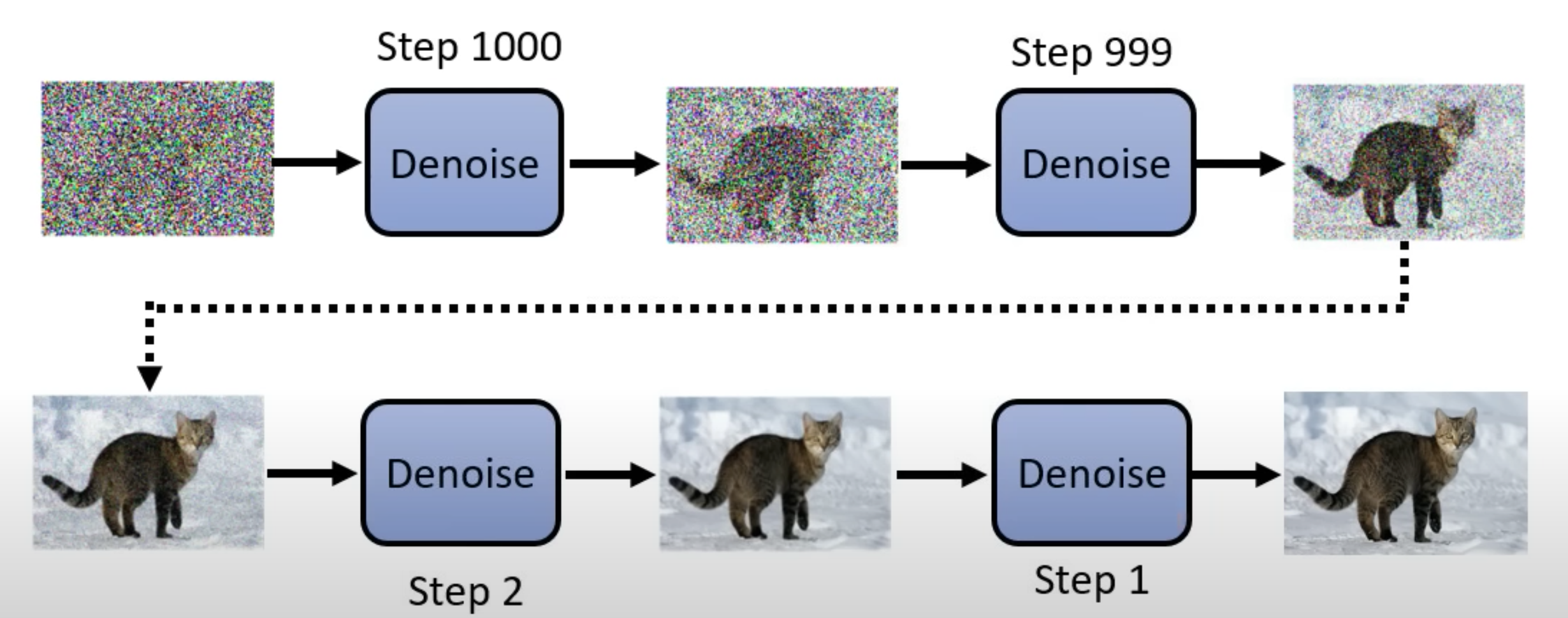
本来图片就已经在噪音的图里面,现在只是需要过滤掉噪音。
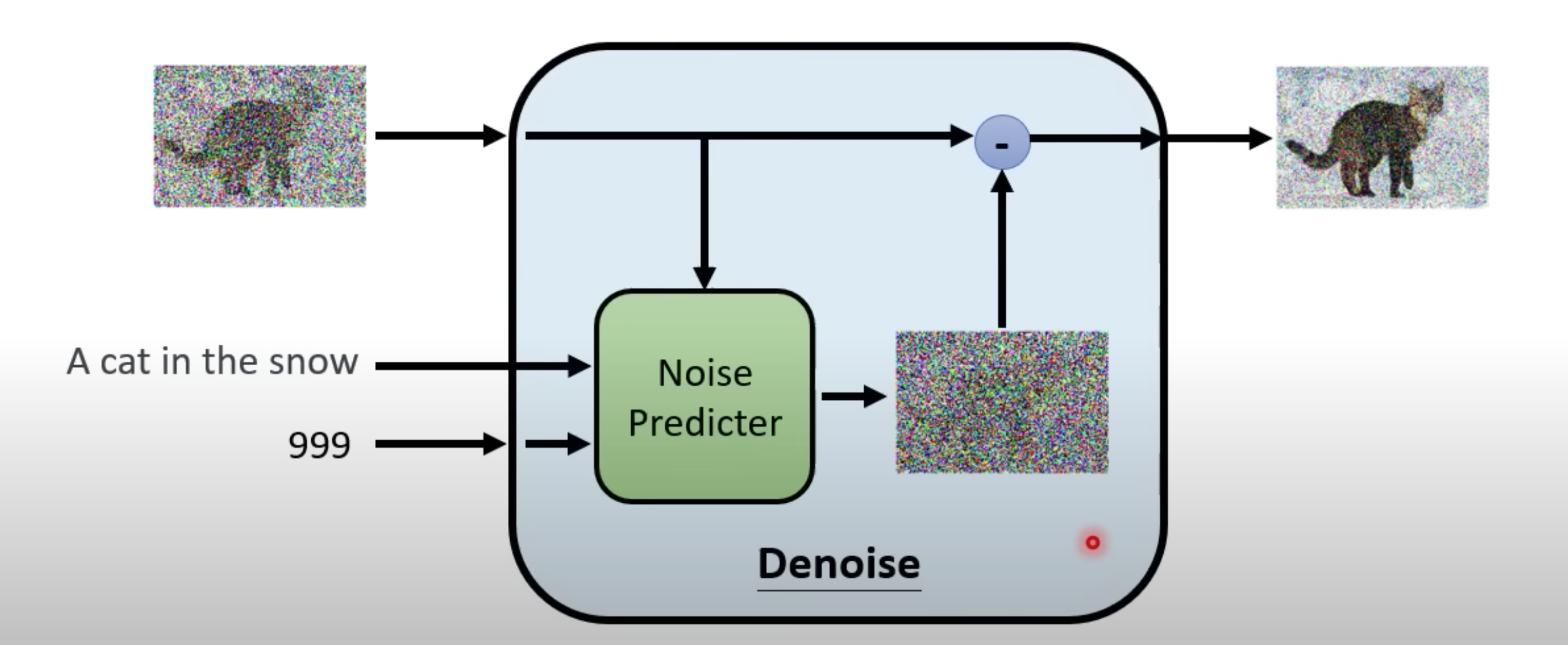
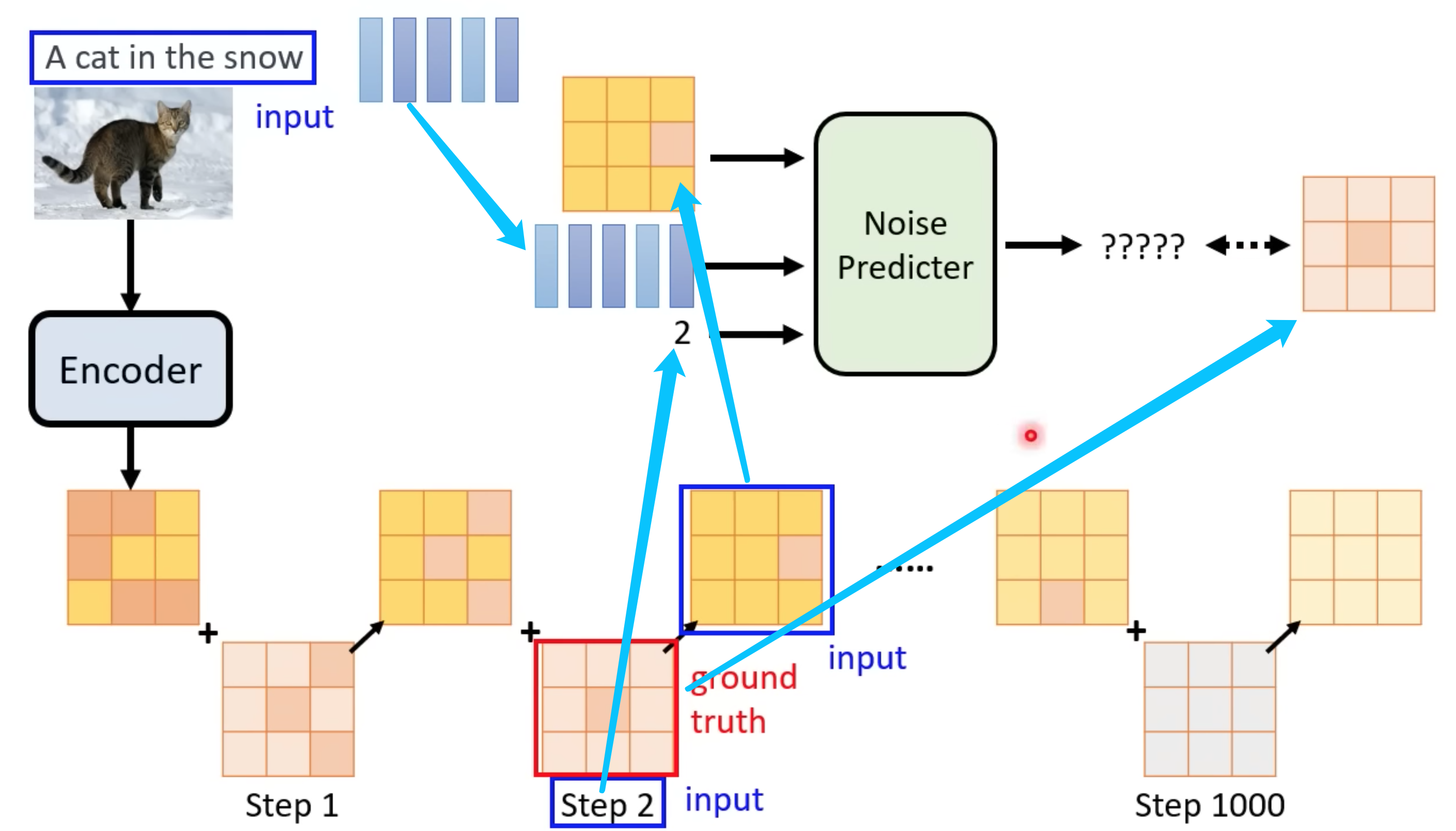
Denoise Model 的input (图片和现在噪音的程度),使用同一个model进行过滤。

Noise Predicter
它就是预测这张图片里面噪音应该长什么样子,再把它输出的噪音去减去这个要被Denoise的图片,然后就产生Denoise以后的结果
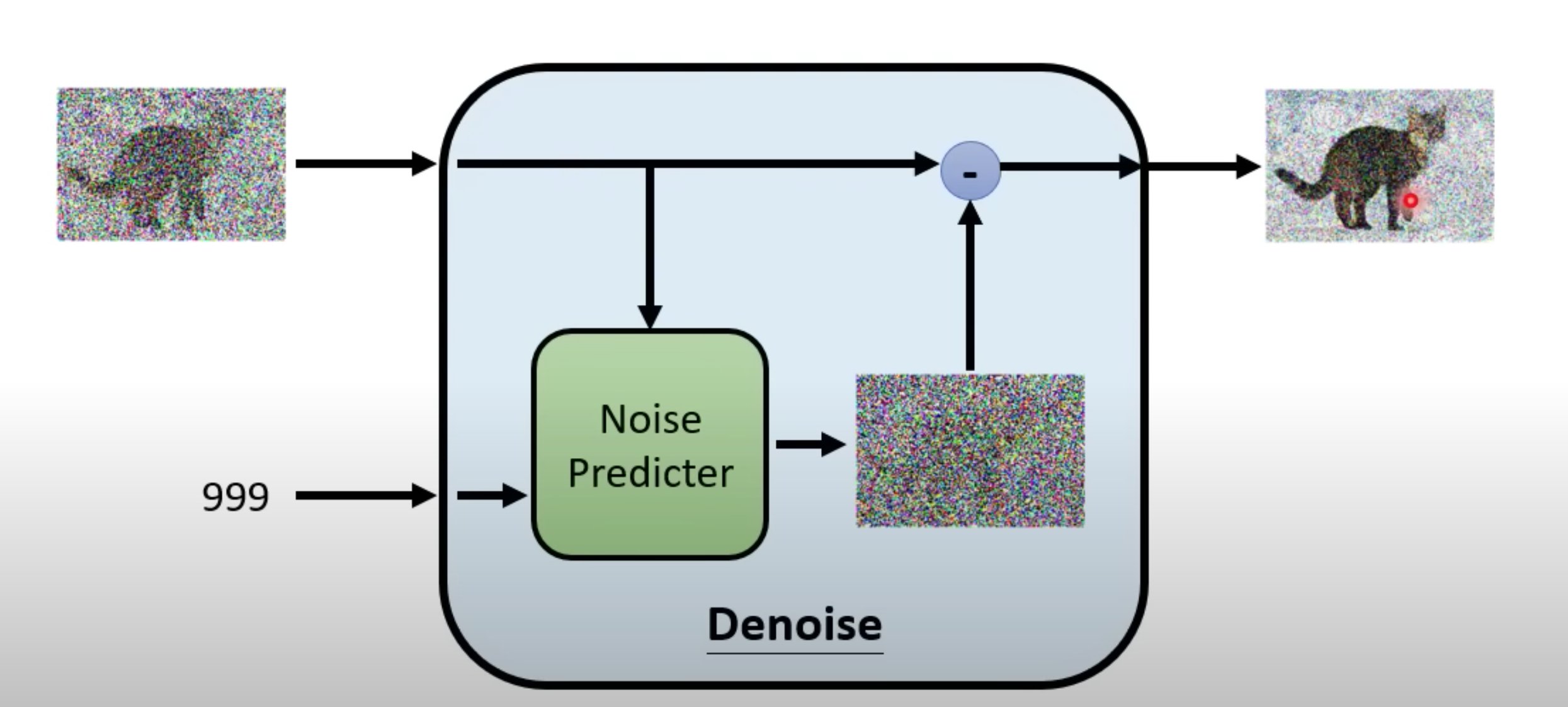
为什么不输入是要被Denoise的图片输出就直接是Denoise的结果?
- 如果你今天你的Denoise Model可以产生一只带噪音的猫,那为什么不直接画猫
- 产生一个带噪音的猫 和 产生一张图片里面的噪音难度不一样,直接产生前者比较难
训练Noise Predicter过程,使用Forward Process(Diffusion Process)。
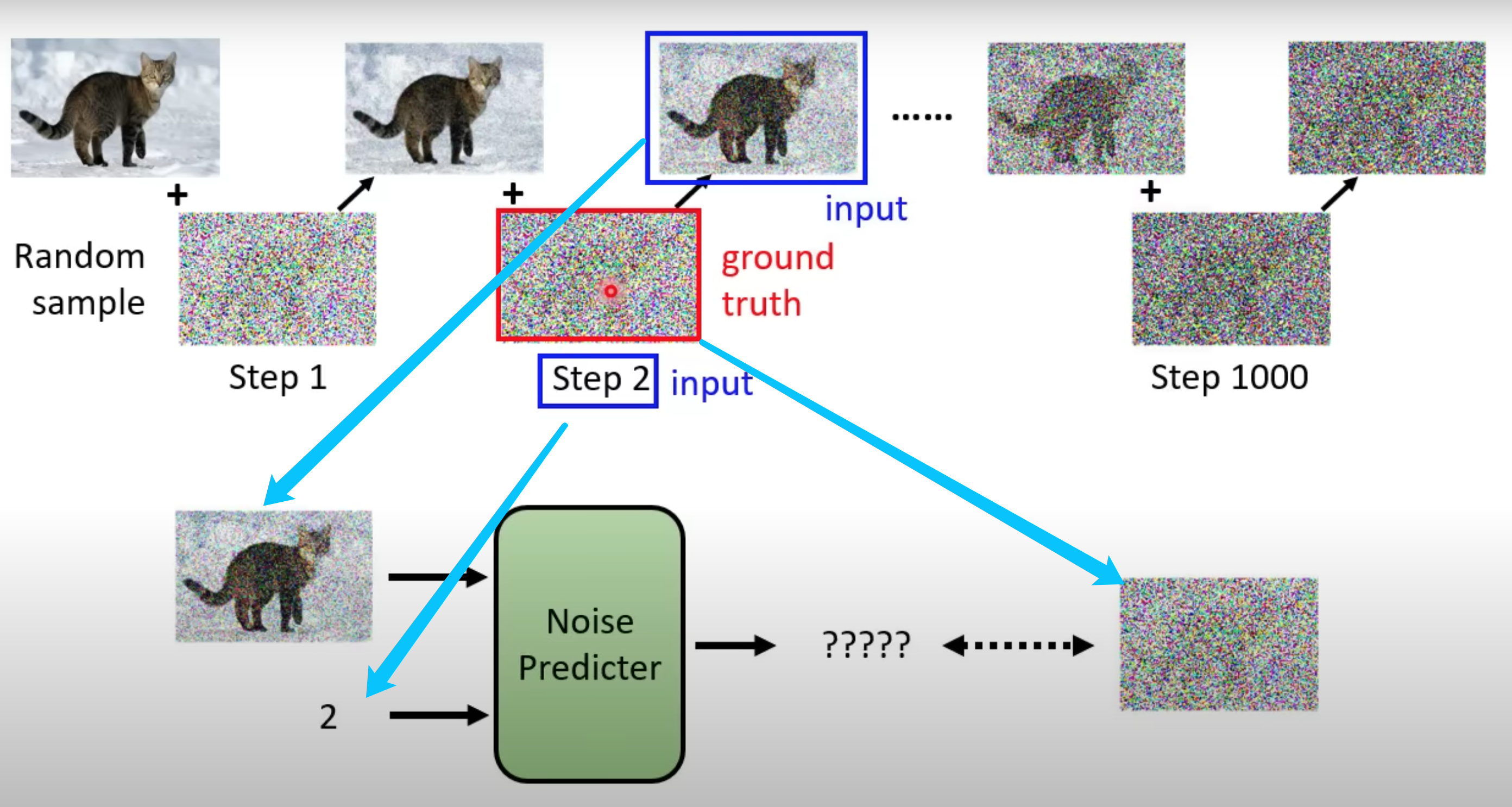
主动加随机噪音往前推导,生成训练集。
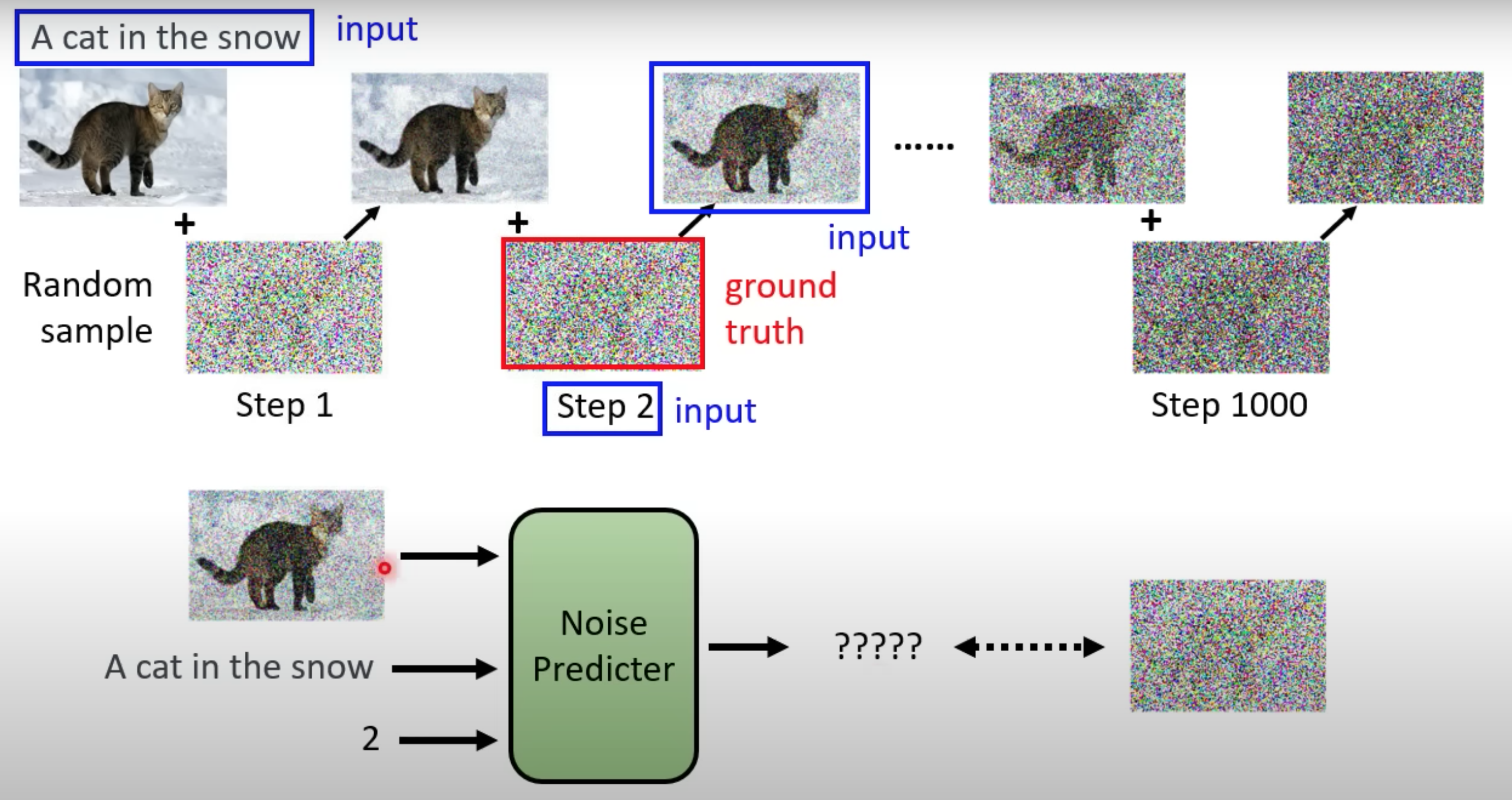
Text to image
训练时候Noise Predicter加上文字说明,Laion 比较大的一个训练集
Stable Diffusion
一般由三部分组成,encoder,图片生成model,decoder,分开三块训练。
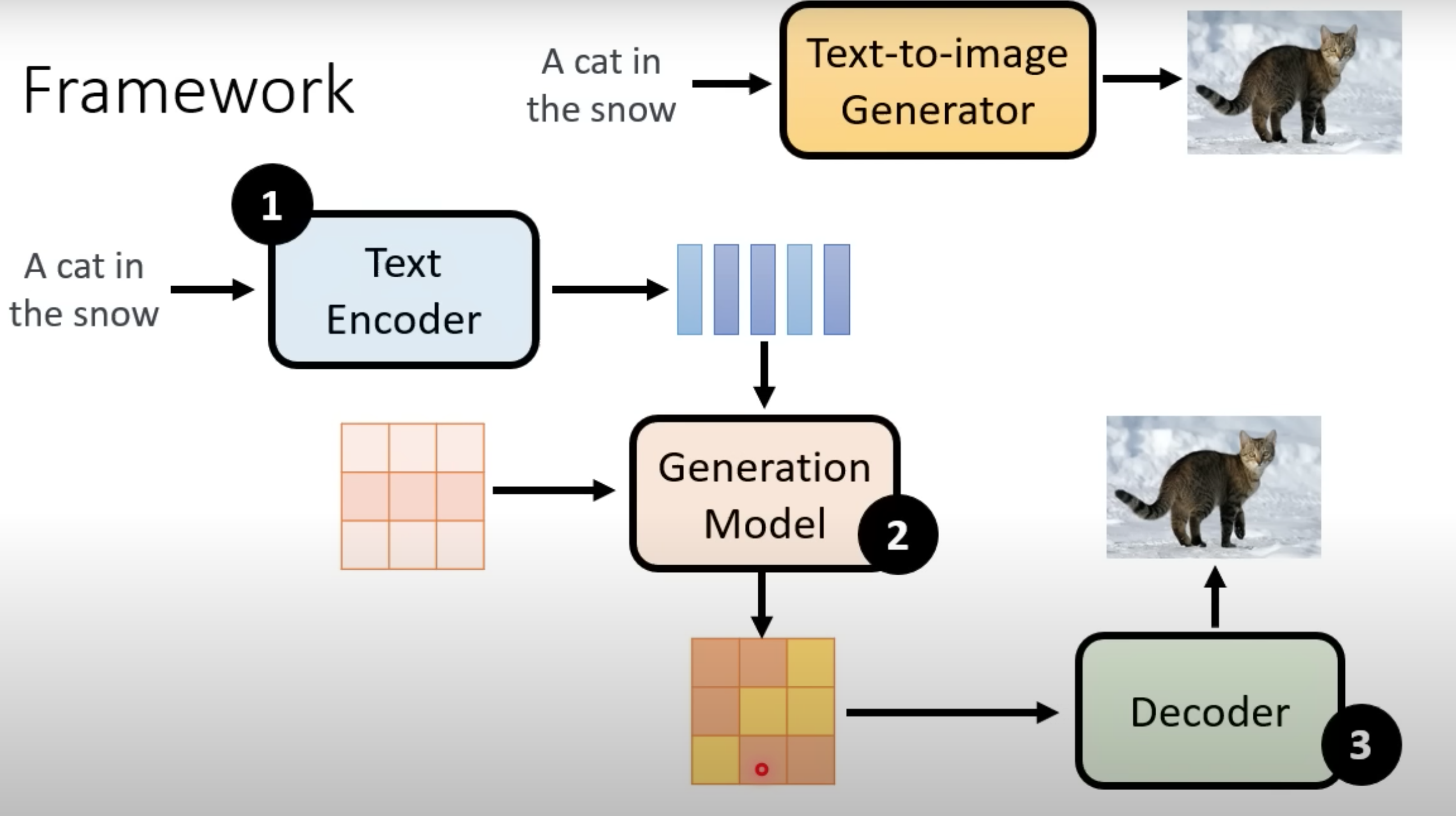
encoder对结果影响大,图片生成model的规模影响小, 偏向右下效果好
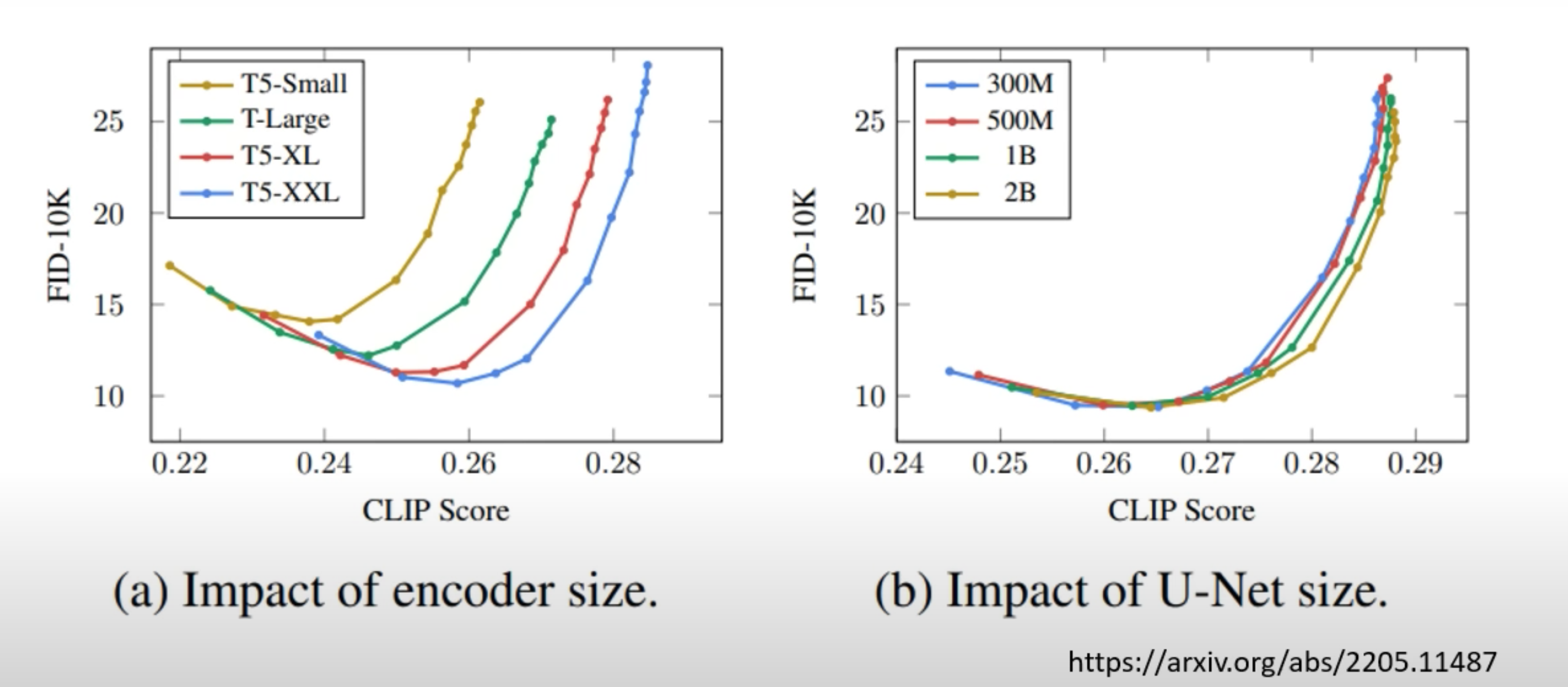
FID 对比图片相似程度
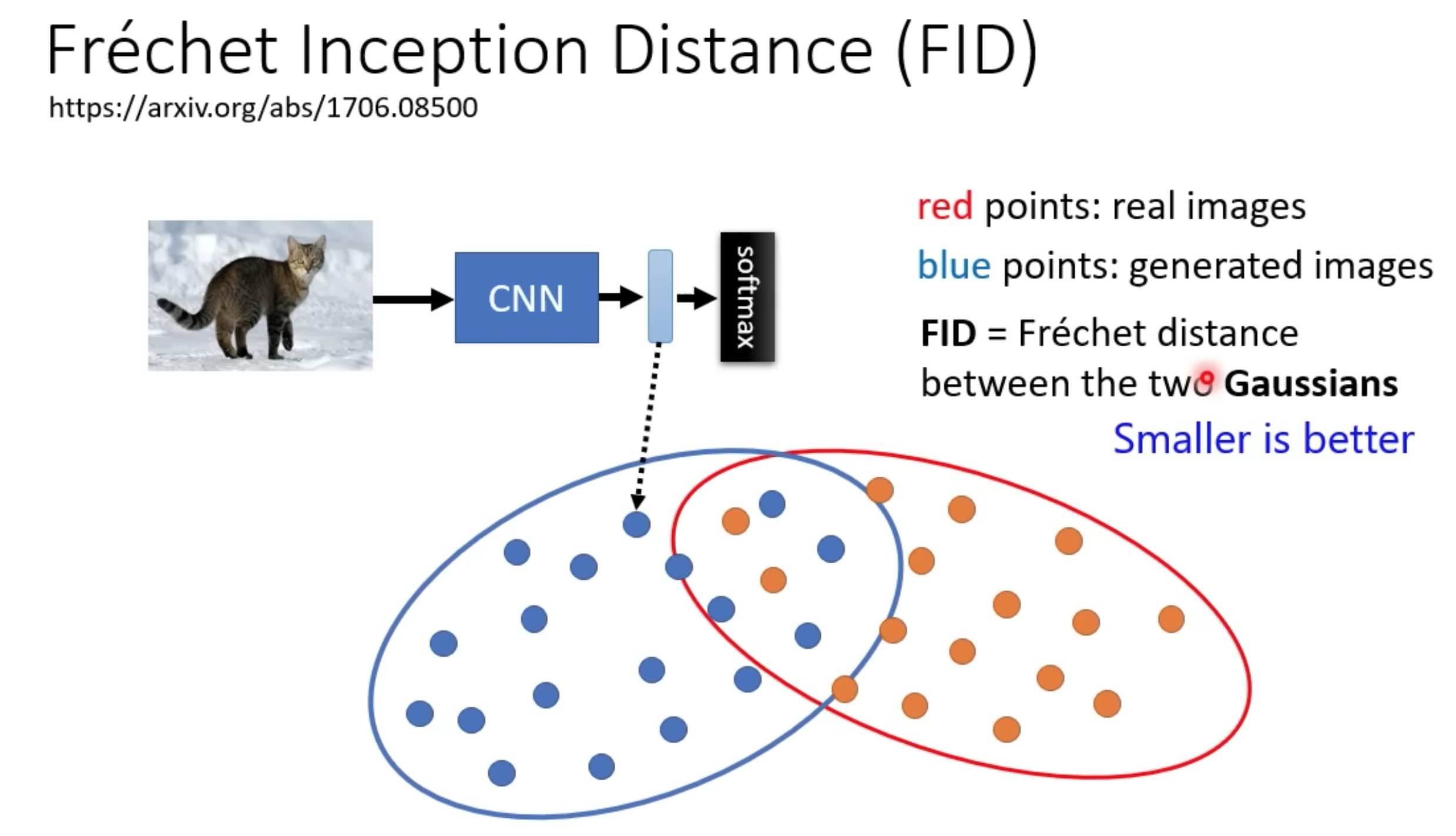
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
训练一个图片分类model(CNN+softmax),计算原图和生产的图的高斯分布距离,FID越小,越相近。
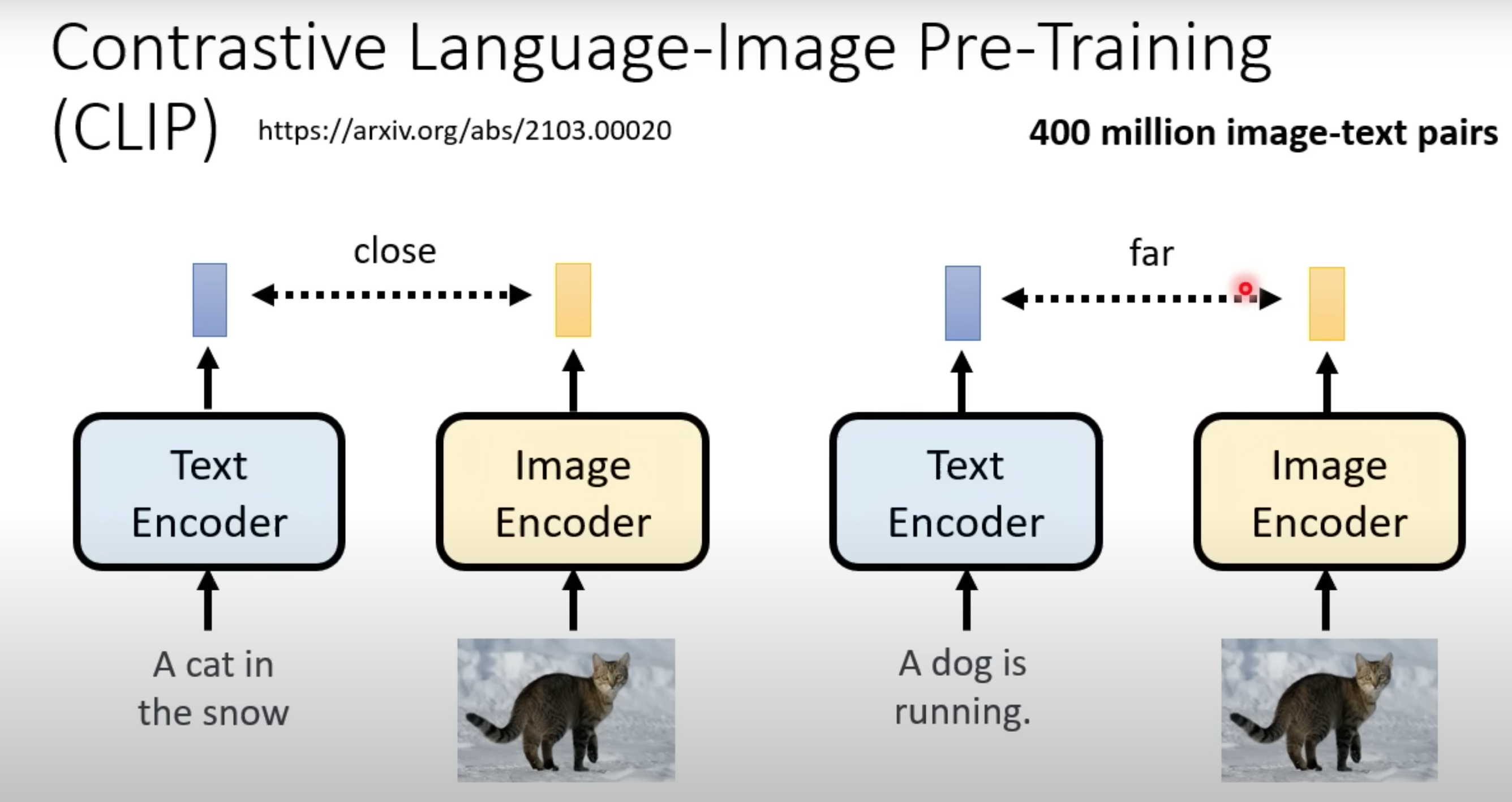
CLIP
Learning Transferable Visual Models From Natural Language Supervision
通过image-text对的训练集,衡量文字和图片是否真的有对应关系。
Decoder 训练
图片生成model 的output分成两种
-
最终目标的小图 (用大图缩小,生成小-大图训练集)
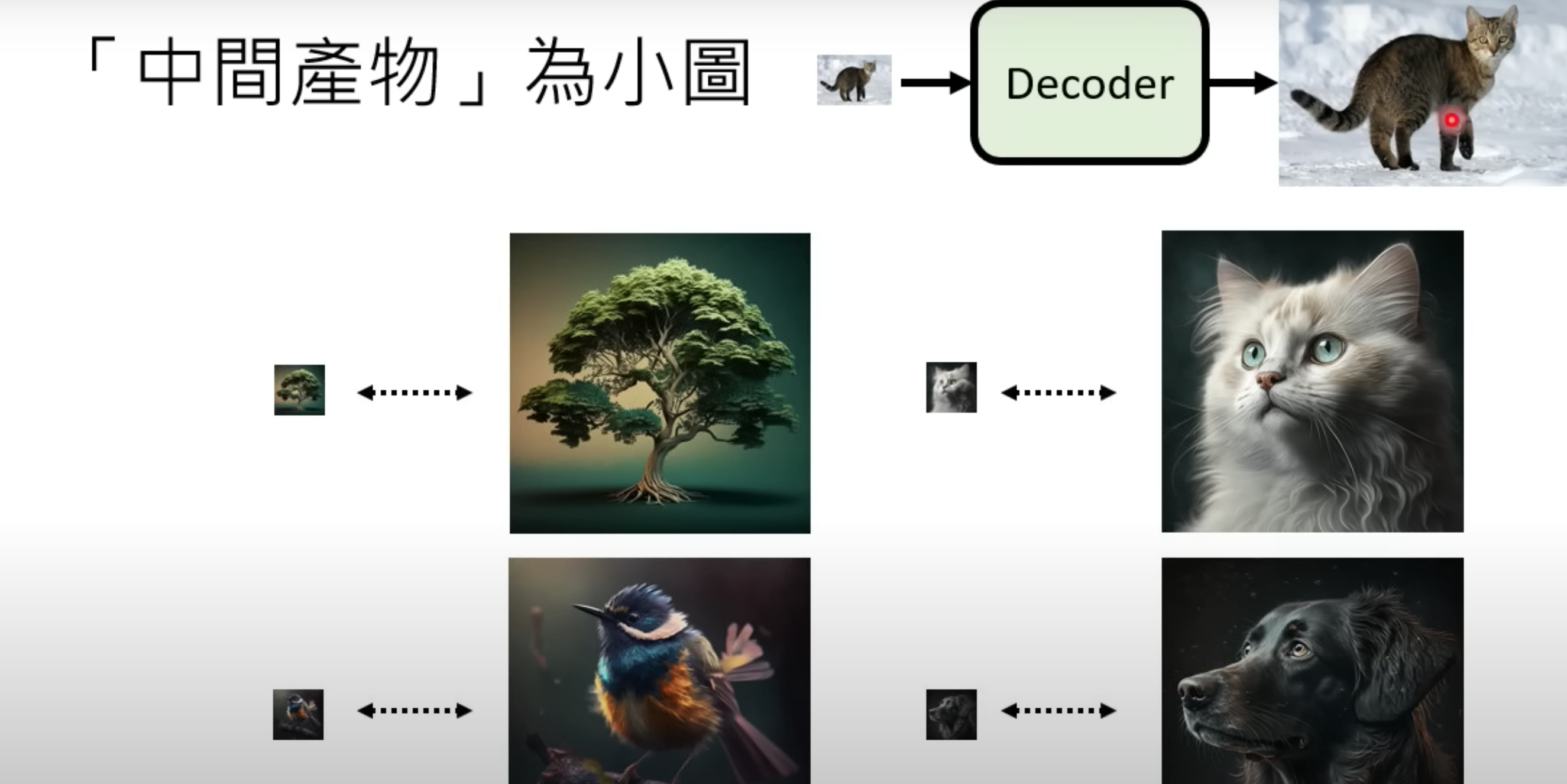
-
和最终目标相关的非人类识别的中间产物Latent,拿最终的输入和输出图片对比,训练出Auto encoder后,直接拿decoder用
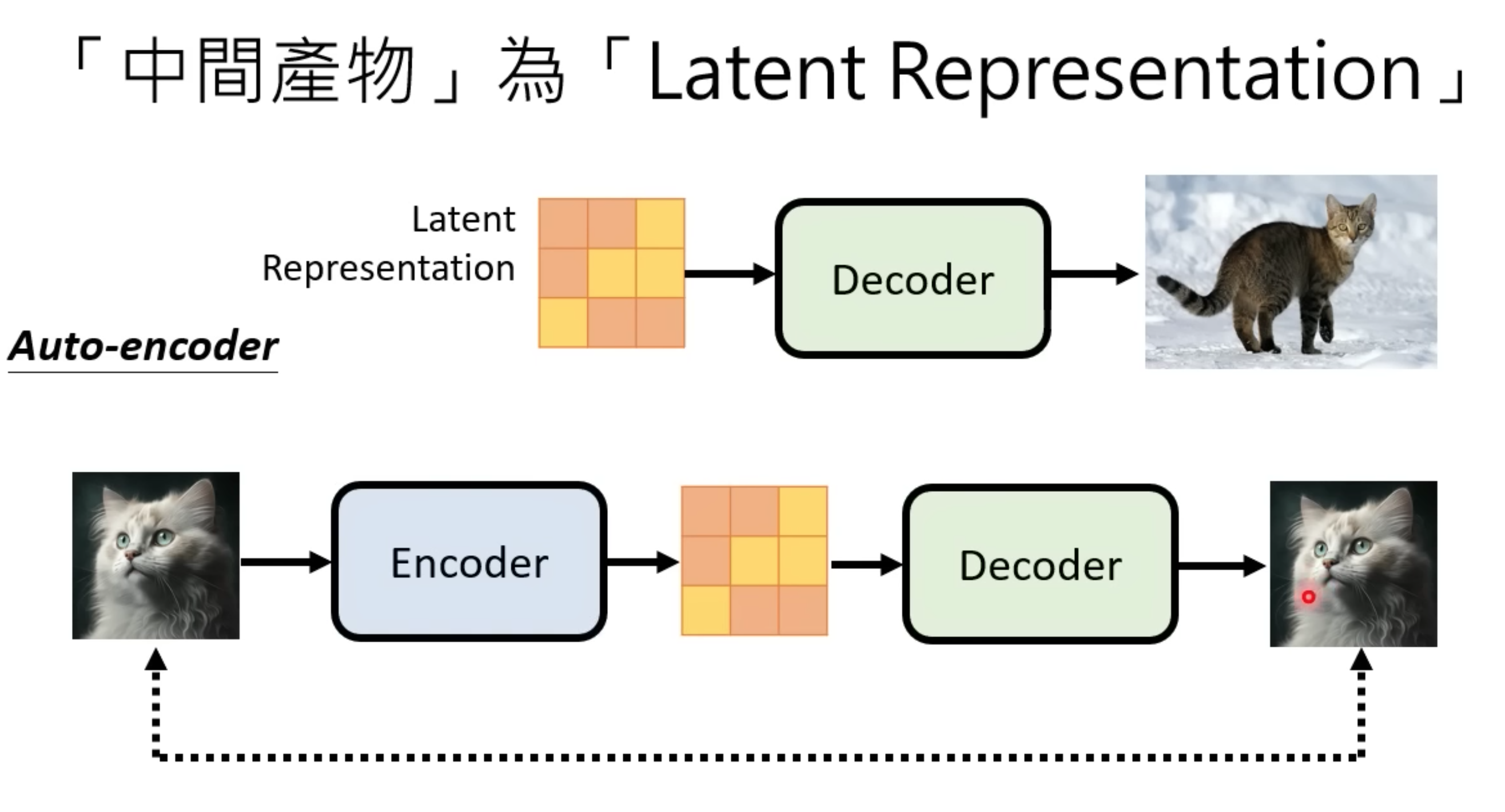
-
Latent space 是一个低维空间,可以捕捉输入数据的基本特征。这种降维是通过各种技术实现的,例如自动编码器和变分自动编码器 (VAE)
-
图像生成: 将高维数据(例如图像)映射到低维Latent space,模型可以通过在Latent space中采样点来生成新的、逼真的图像。
-
数据压缩: 是一种有效的数据压缩手段,通过主成分分析(PCA)等技术,可以保留相关信息,同时丢弃冗余细节,从而实现更高效的存储和处理。
-
异常检测: 用于异常检测,通过识别与学习模式有显著偏差的数据点。
-
图片生成model 训练
模仿DDPM
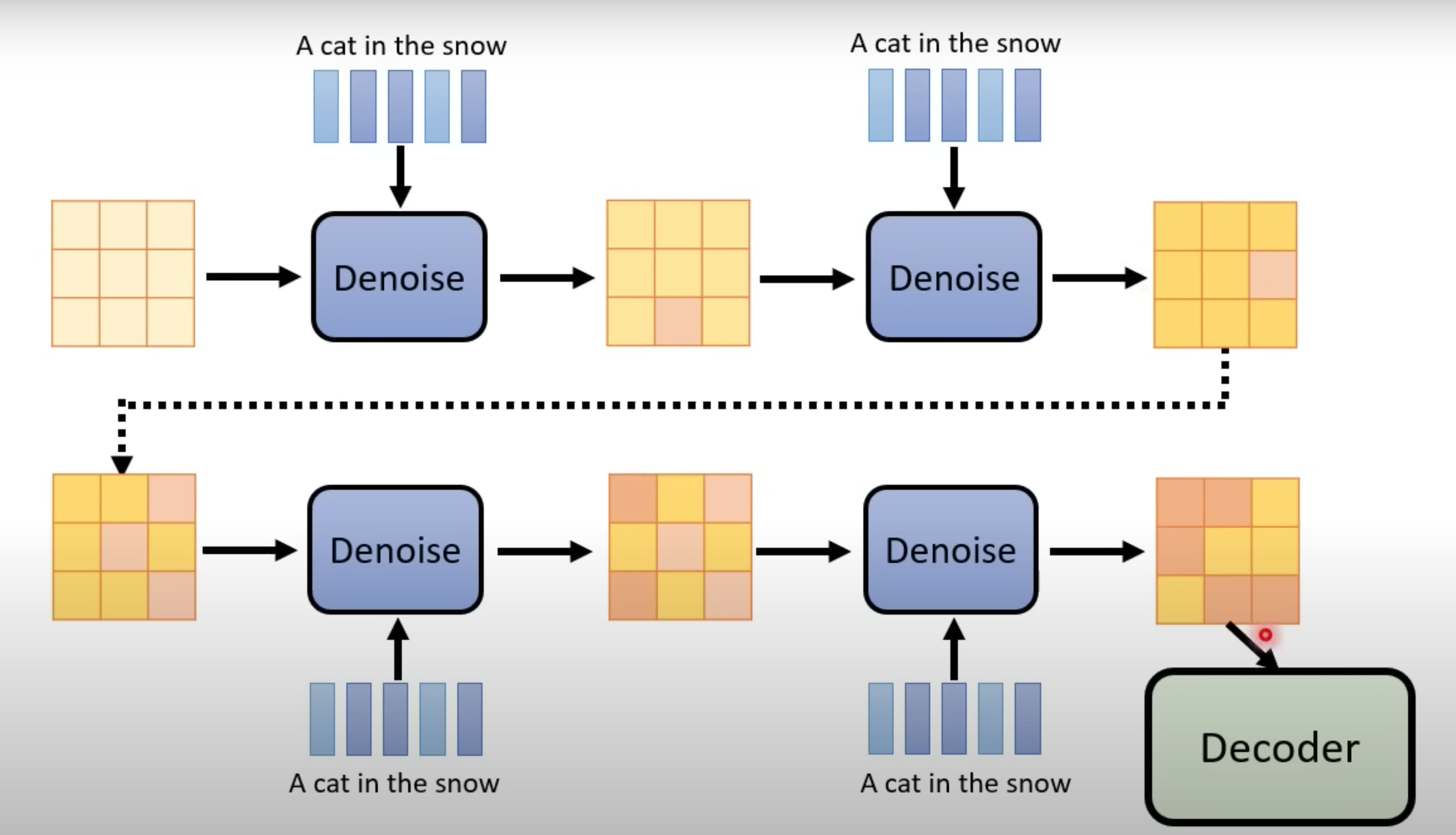
最终效果
随机生成噪音+ 文字encoder , 多次Denoise降噪,然后Decoder。生图过程:中间产物每次Decode
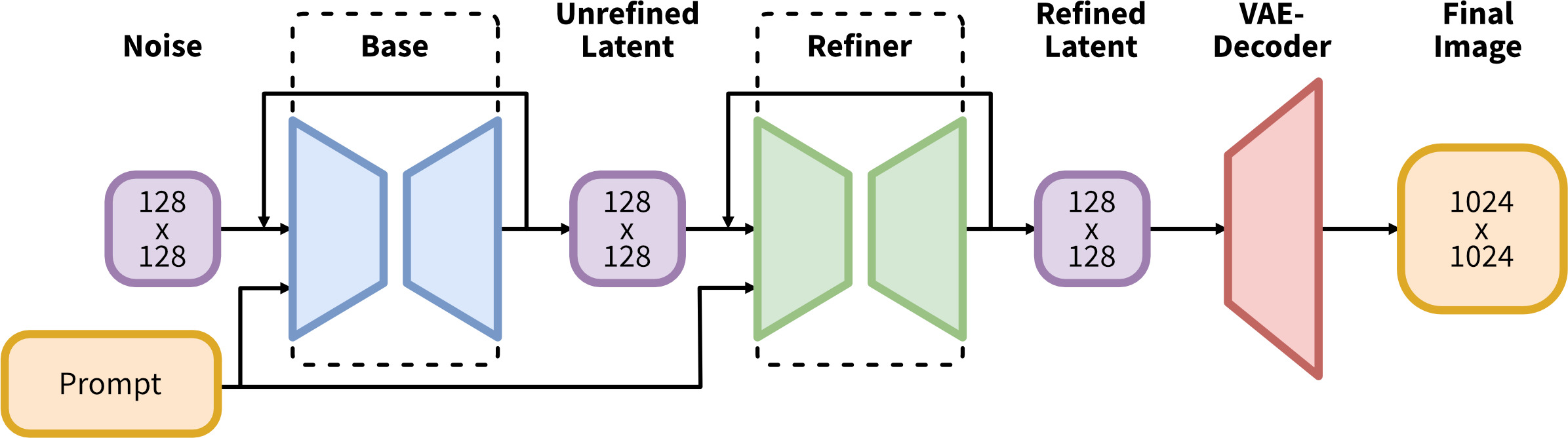
SDXL
Stable Diffusion XL是一个二阶段的级联扩散模型(Latent Diffusion Model),包括Base模型和Refiner模型。其中Base模型的主要工作和SD差不多,具备文生图(txt2img)、图生图(img2img)、图像inpainting等能力。在Base模型之后,级联了Refiner模型,对Base模型生成的图像Latent特征进行进行小噪声去除和细节质量提升,其本质上是在做图生图的工作。
- SDXL Base模型由U-Net、VAE以及CLIP Text Encoder(两个)三个模块组成
- SDXL Refiner模型同样由U-Net、VAE和CLIP Text Encoder(一个)三个模块组成
当输入是图片时,Stable Diffusion XL和Stable Diffusion一样,首先会使用VAE的Encoder结构将输入图像转换为Latent特征,然后U-Net不断对Latent特征进行优化,最后使用VAE的Decoder结构将Latent特征重建出像素级图像。除了提取Latent特征和图像的像素级重建外,VAE还可以改进生成图像中的高频细节,小物体特征和整体图像色彩。
当Stable Diffusion XL的输入是文字时,这时我们不需要VAE的Encoder结构,只需要Decoder进行图像重建。
Unet
SDXL相比之前的版本,Unet的变化主要有如下两点:
- 采用了更大的UNet,之前版本的SD Unet 参数量为860M,而SDXL参数量达到了2.6B,大约是其的3倍。
- Unet 结构发生了改变,从之前的4stage变成了3stage
在第一个stage中不使用SDXL_Spatial Transformer_X模块,可以明显减少显存占用和计算量。然后在第二和第三个stage这两个维度较小的feature map上使用数量较多的SDXL_Spatial Transformer_X模块,能在大幅提升模型整体性能(学习能力和表达能力)的同时,优化了计算成本。 U-Net设计思想也让SDXL的Base出图分辨率提升至1024x1024。在出图参数保持一致的情况下,Stable Diffusion XL生成图片的耗时只比Stable Diffusion多了20%-30%之间
SDXL Unet 结构
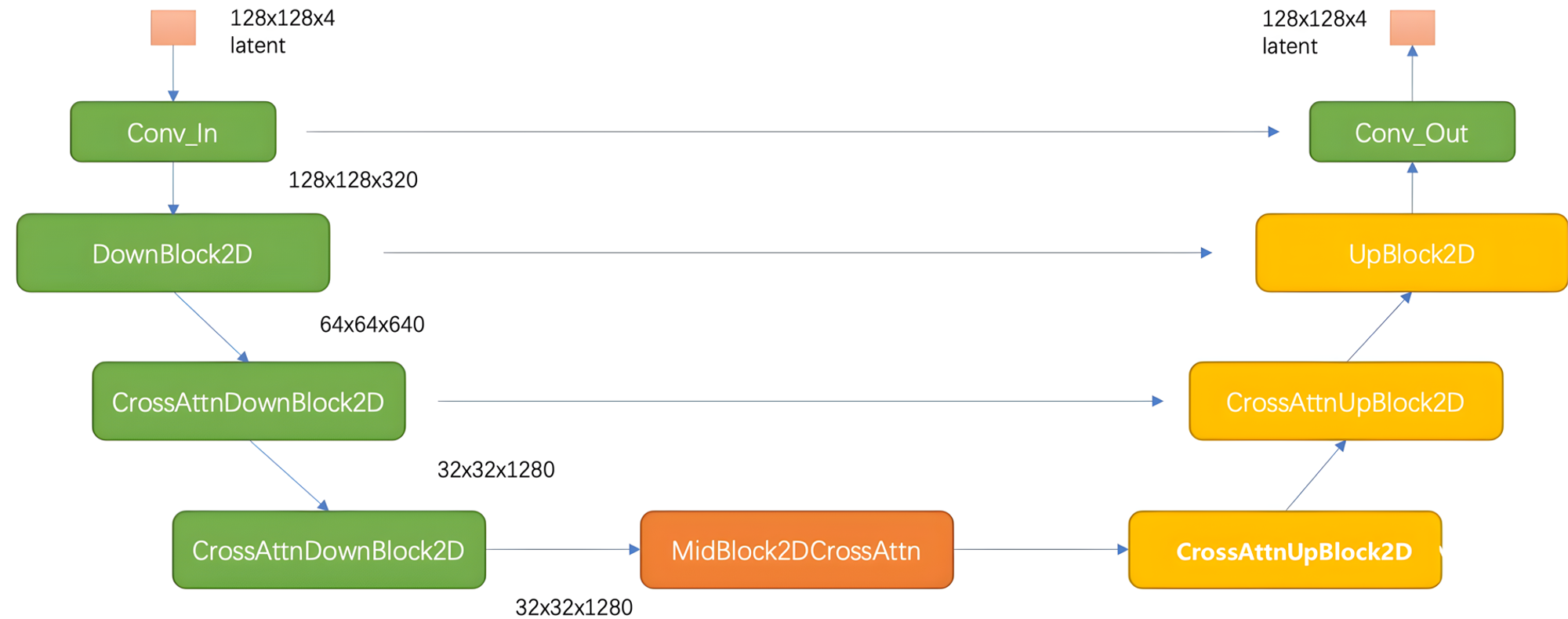
SD1.x Unet 结构
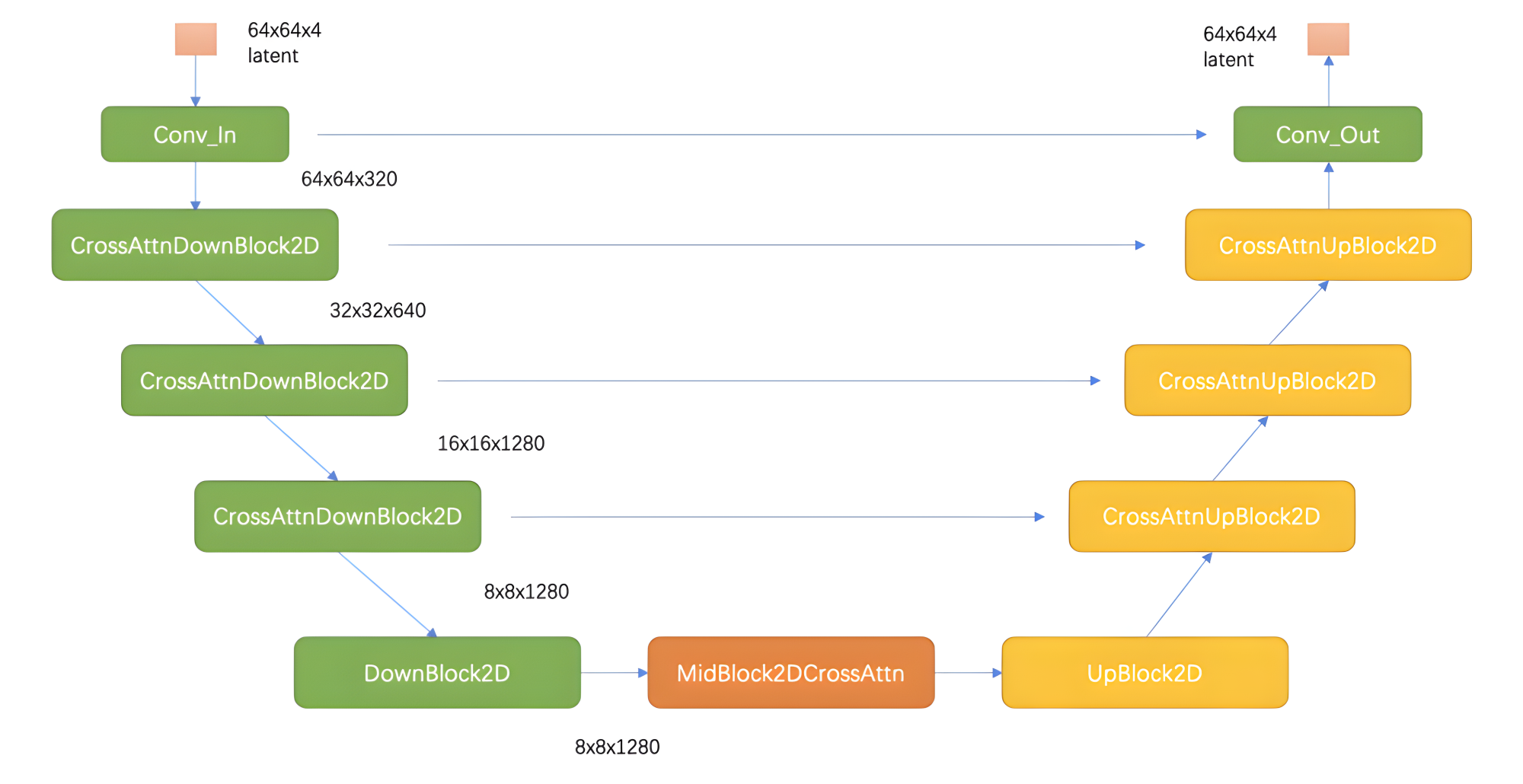
VAE
VAE的Encoder结构将输入图像转换为Latent特征
VAE的Decoder结构将Latent特征重建出像素级图像
除了能进行图像压缩和图像重建的工作外,通过切换不同微调训练版本的VAE模型,能够改变生成图片的细节与整体颜色(更改生成图像的颜色表现,类似于色彩滤镜)。
Sora
Scaling Law:模型规模的增大对视频生成质量的提升具有明确意义,从而很好地解决视频一致性、连续性等问题
DataEngine:数据工程很重要,如何设计视频的输入(e.g. 是否截断、长宽比、像素优化等)、patches 的输入方式、文本描述和文本图像对质量
SORA = [VAE encoder + DiT (DDPM) + VAE decoder +CLIP]
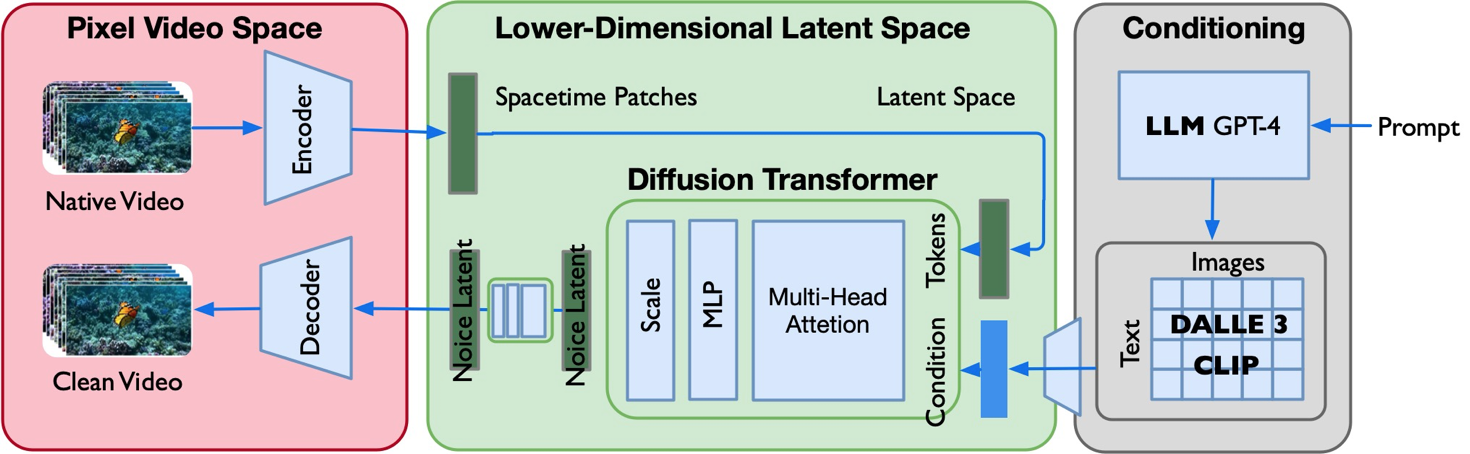
-
使用 DALLE 3(CLIP ) 把文本和图像对 <text,image> 联系起来;
-
视频数据切分为 Patches 通过 VAE 编码器压缩成低维空间表示;
-
基于 Diffusion Transformer 从图像语义生成,完成从文本语义到图像语义进行映射;
-
DiT 生成的低维空间表示,通过 VAE 解码器恢复成像素级的视频数据;
因为基于 Diffusion Transformer替换UNet,所以模型大小、数据集大小和用于训练的计算浮点数的增加,模型的性能会提高。
-
基于扩散模型 SD/SDXL,都是U-Net 网络模型结构把模型规模限定,SD/SDXL 作为经典网络只公布了推理和微调, 市场上都是基于 SD/SDXL 进行二次创作
-
DiT 利用 transformer 结构探索新的扩散模型,成功用 transformer 替换 U-Net 主干
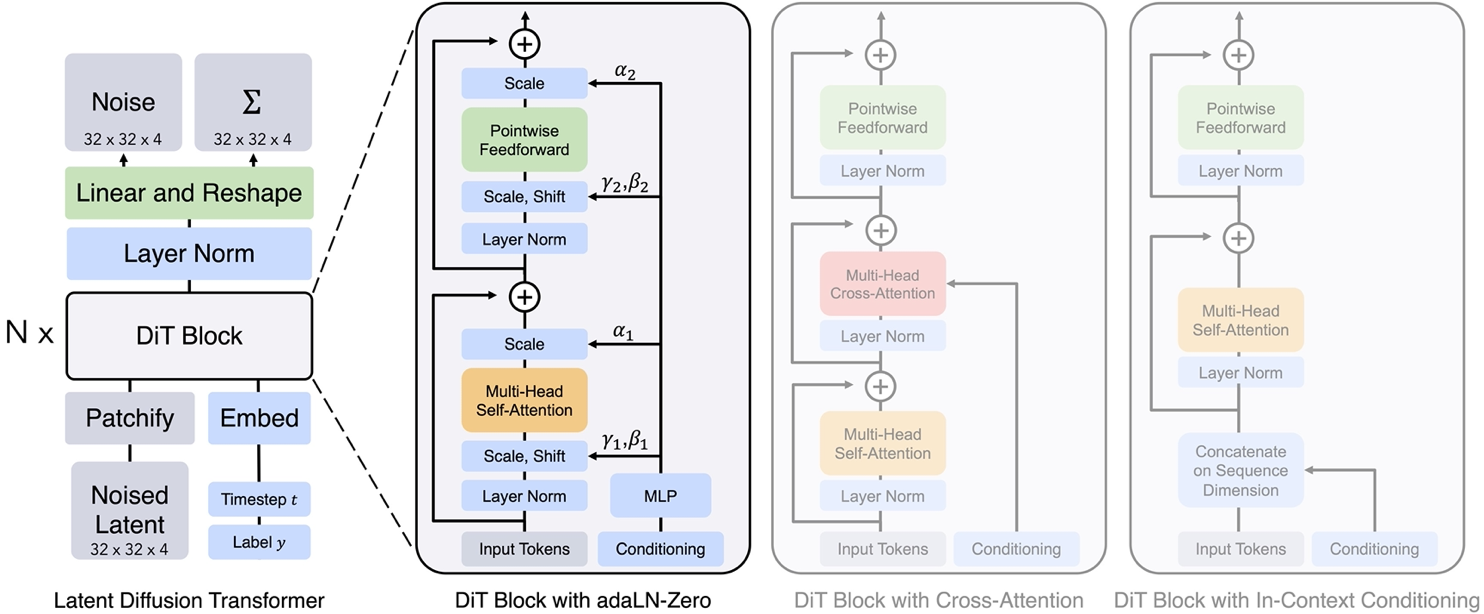
- DiT 首先将将每个 patch 空间表示 Latent 输入到第一层网络,以此将空间输入转换为 tokens 序列。
- 将标准基于 ViT 的 Patch 和 Position Embedding 应用于所有输入 token,最后将输入 token 由 Transformer 处理。
- DiT 还会处理额外信息,e.g. 时间步长、类别标签、文本语义等。
Grop
大模型性能指标
- 延迟 Latency 输入文本à获取结果时间(以每词元每秒 Tokens/s )
- 确保流畅用户体验,LLM 输出速度 >10-15 Tokens/s,即单 Token 延迟 <100ms,H100 ~50 Tokens/s
- 吞吐指 LLM 单位时间内能处理数据量(每秒查询数 Query/second )
- 吞吐量越大越好,但是因为在有限的硬件资源下,吞吐量大可以支持更多并发的用户访问
大模型推理阶段
-
Prefill:提示词 Prompt 处理被称为预填充(prefill),一次性将大量 Tokens 预先进行计算输入到模型中 去生成 KV-Cache,通过一次 Forward 就可以完成。
Prefill 时延对应第一个 Token 的时延,与输入序列中 Token 数量有关
-
Decoding:从生成第一个 Token 后开始,采用自回归方式一次生成一个 Token,直到生成一个特殊的 Stop Token 为止,常规的大模型推理阶段。
Decoding 阶段时延决定整体时延,由输出序列的 Token 数决定 Groq 性能提升的重点
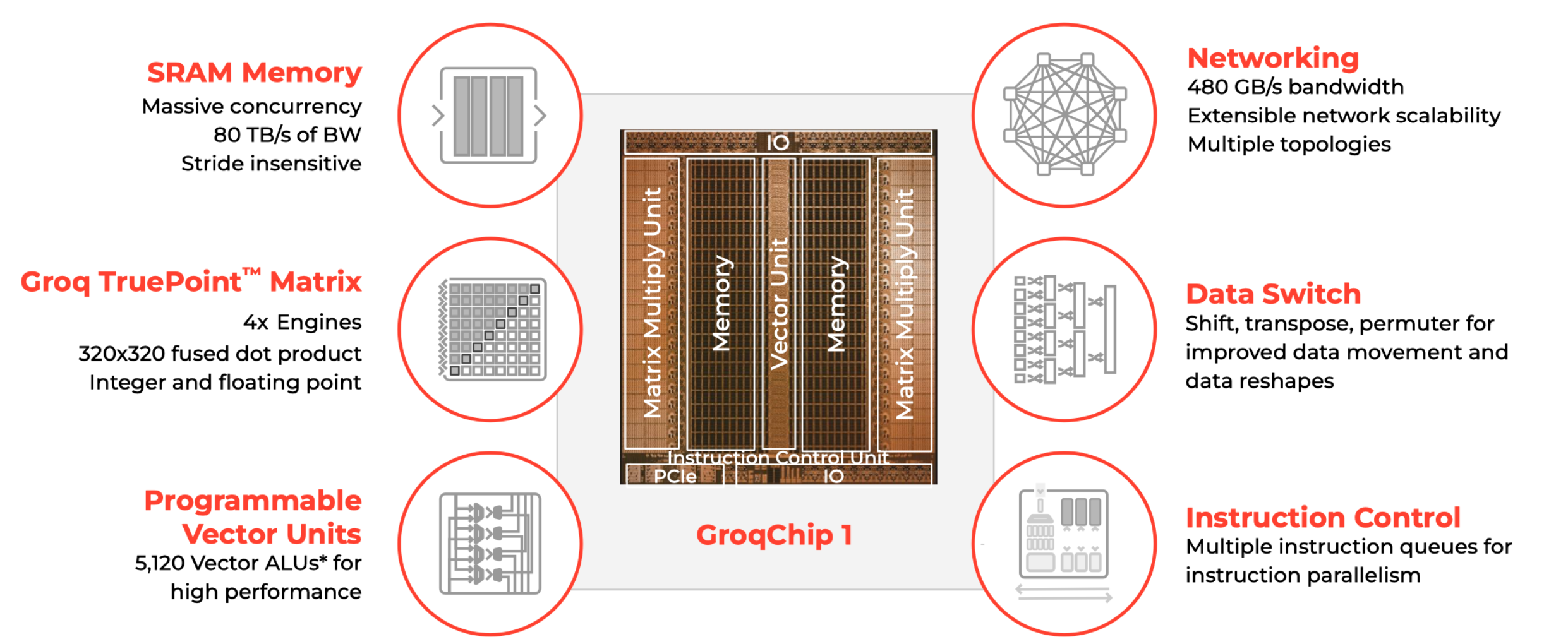
Groq思路:
-
硬件极致简化
-
调度交给编译器
-
硬件根据指令执行
Groq 软件定义硬件
编译器提前规划好所有计算逻辑,芯片 chip 上执行一切指令都有确定延迟,即保证确定性的计算,确定性的访存和确定性的通信。
- 确定性计算需要明确所有执行指令的执行序和执行时间
- 确定性访存要求避免使用DRAM作为存储单元(DRAM 访问延迟不固定)
- 确定性通信要求通信的逻辑和时序严格同步。
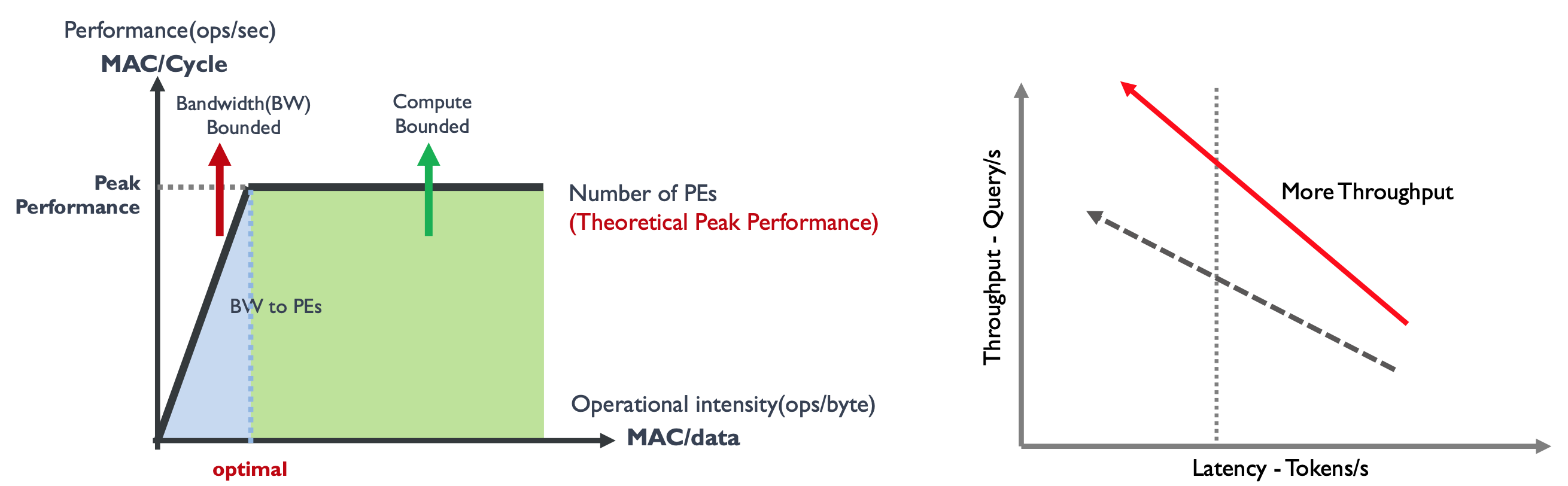
固定硬件 & 固定时延:随着 Batch Size 增加,系统从带宽受限区域 Bandwidth Bound 转变为计算受限区域Compute Bound。需要增加峰值算力,吞吐-时延曲线会向左上方移动。
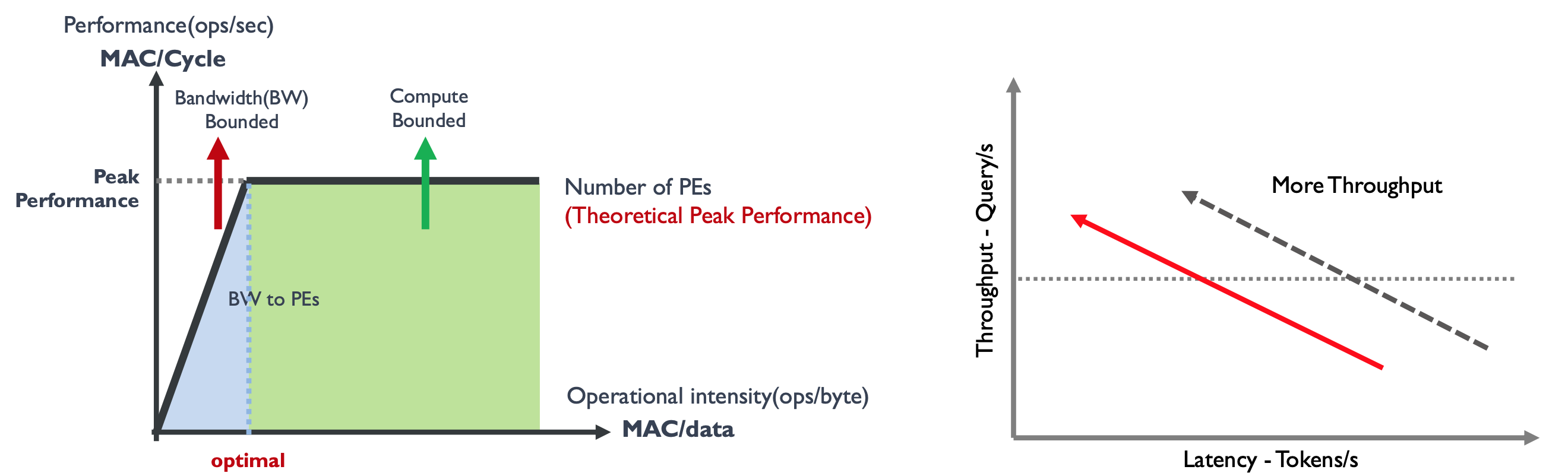
固定硬件 & 固定吞吐:模型 Batch Size 不变(1/2/4 较小的值),因为 LLM 推理过程采用自回归方式一次 生成一个,循环输入到模型中,因此对带宽要求极高,推理服务处于带宽受限区域 Bandwidth Bound。需要 增加片内带宽,吞吐-时延曲线会向左平移。
Grop取消 L3/L2/L1 Cache所有数据放 SRAM, 提高带宽
| Grop | H100 | |
|---|---|---|
| 制造工艺 | 14nm | 4nm |
| 单芯片算力 FP16 TFLOPs | 188 | 989 |
| 节点内带宽 GB/s | RealScale:800 | N VLinks:900 |
| 单节点内存 吞吐 | 1. 76GB | 640GB |
| 80GB 推理所需节点数 | 45 | 0. 125 |
| 80GB 推理所需卡数 | 347 需要大规模集群 | 1 |
| 访存带宽 时延 | 80TB/s | 3.35TB/s |
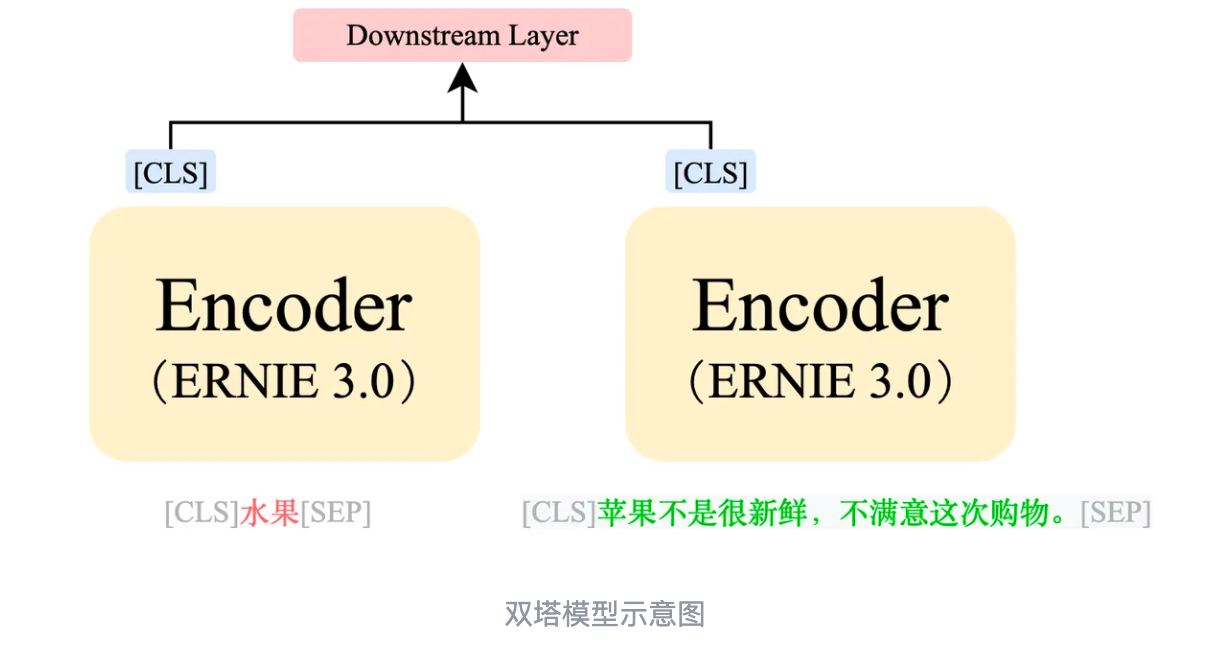
NLP 单塔 双塔
文本匹配(Text Matching)是NLP下的一个分支,单塔模型和双塔模型是文本匹配领域中的两种常见结构,用于计算文本之间的相似度。
-
单塔模型:
- 在单塔模型中,整个过程只进行一次模型计算。
- 我们将两句文本通过 [SEP] 进行拼接,然后将拼接好的数据输入模型。
- 模型通过输出中的 [CLS] token 进行二分类任务,判断两句文本是否相似。
- 单塔模型的优势在于准确率较高,但缺点是计算速度较慢。

-
双塔模型:
- 双塔模型的思想是将类别信息和评论信息分别计算,以适应不同类别的变化。
- 首先,我们对类别和评论文本分别进行编码,得到各自的语义特征。(两个模型可以不一样)
- 然后,通过余弦相似度等度量方式计算两段文本的相似度。
- 双塔模型的优势在于计算速度较快,但准确率相对较低。
Emebedding