大模型训练挑战

内存
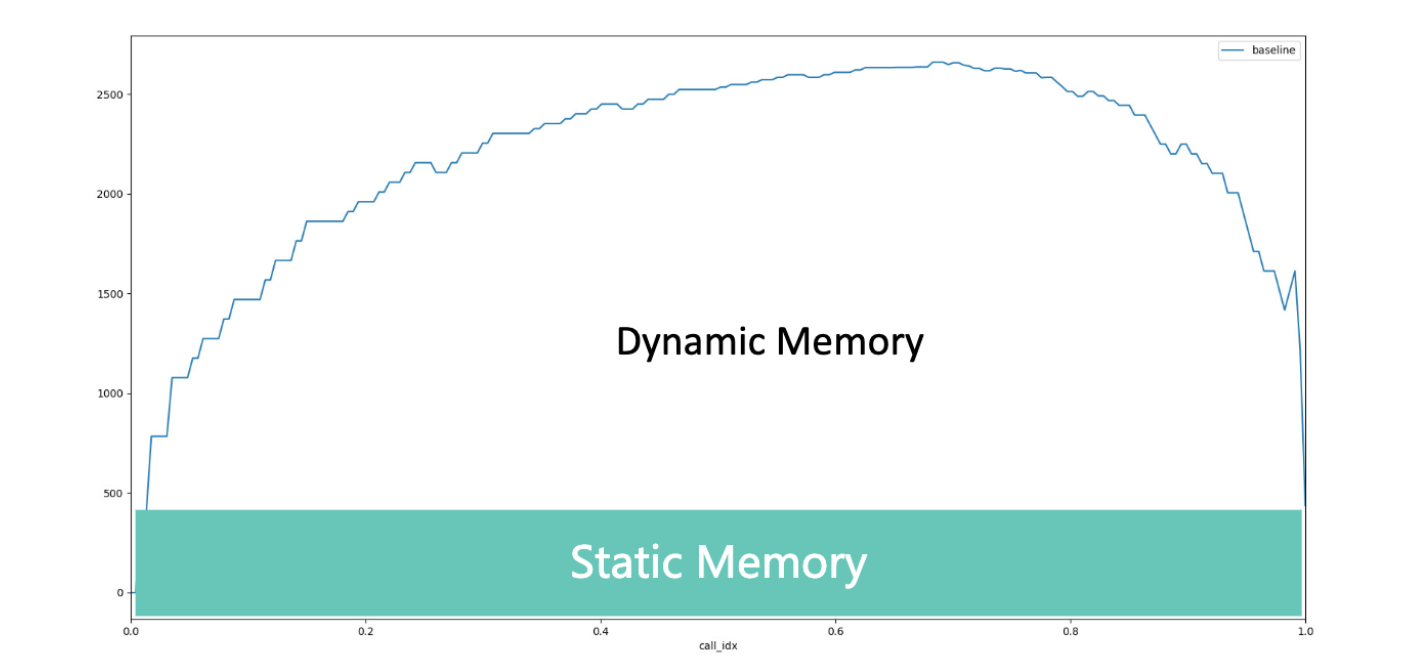
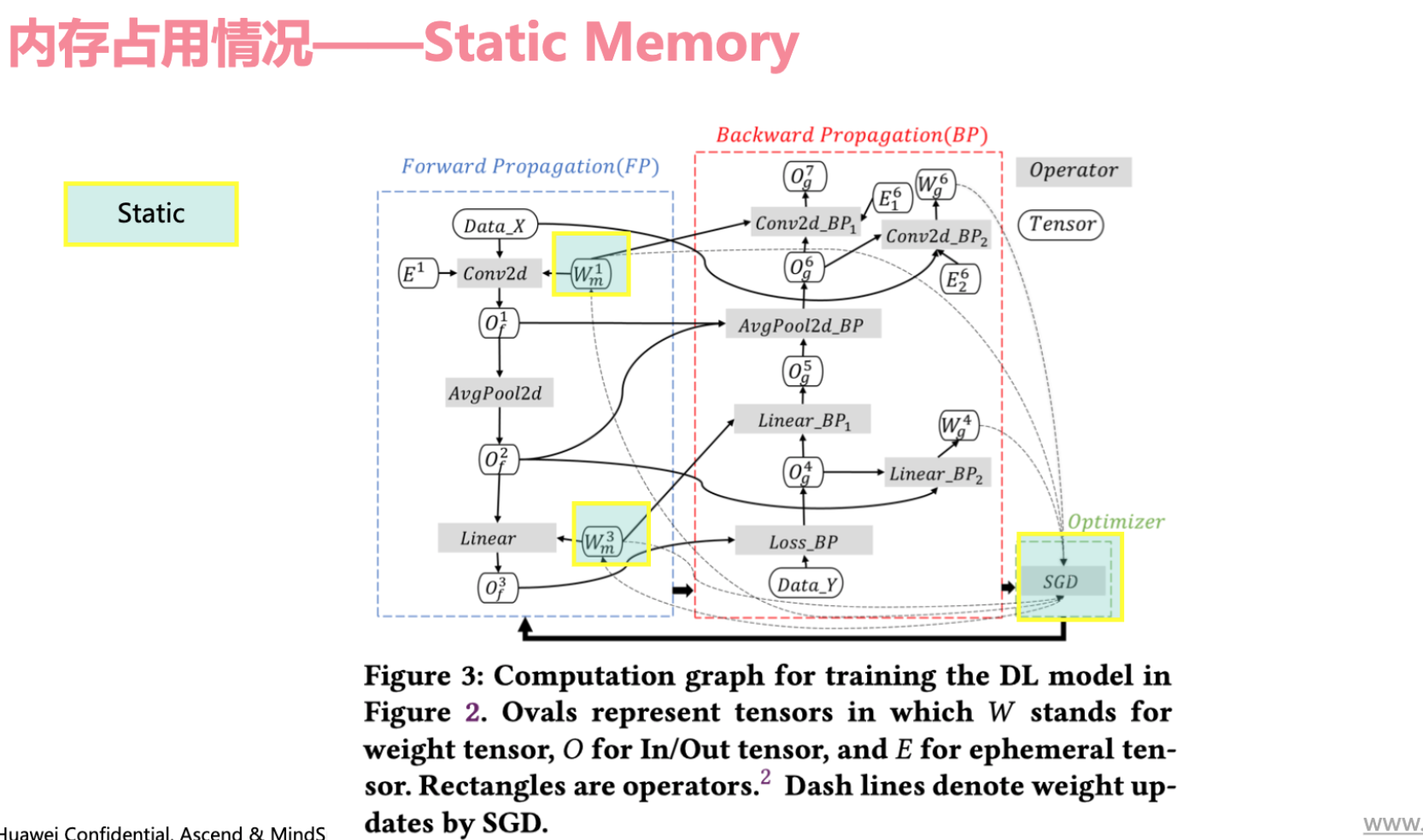
静态内存:模型自身的权重参数、优化器状态信息,由于是比较固定的所以称为静态参数
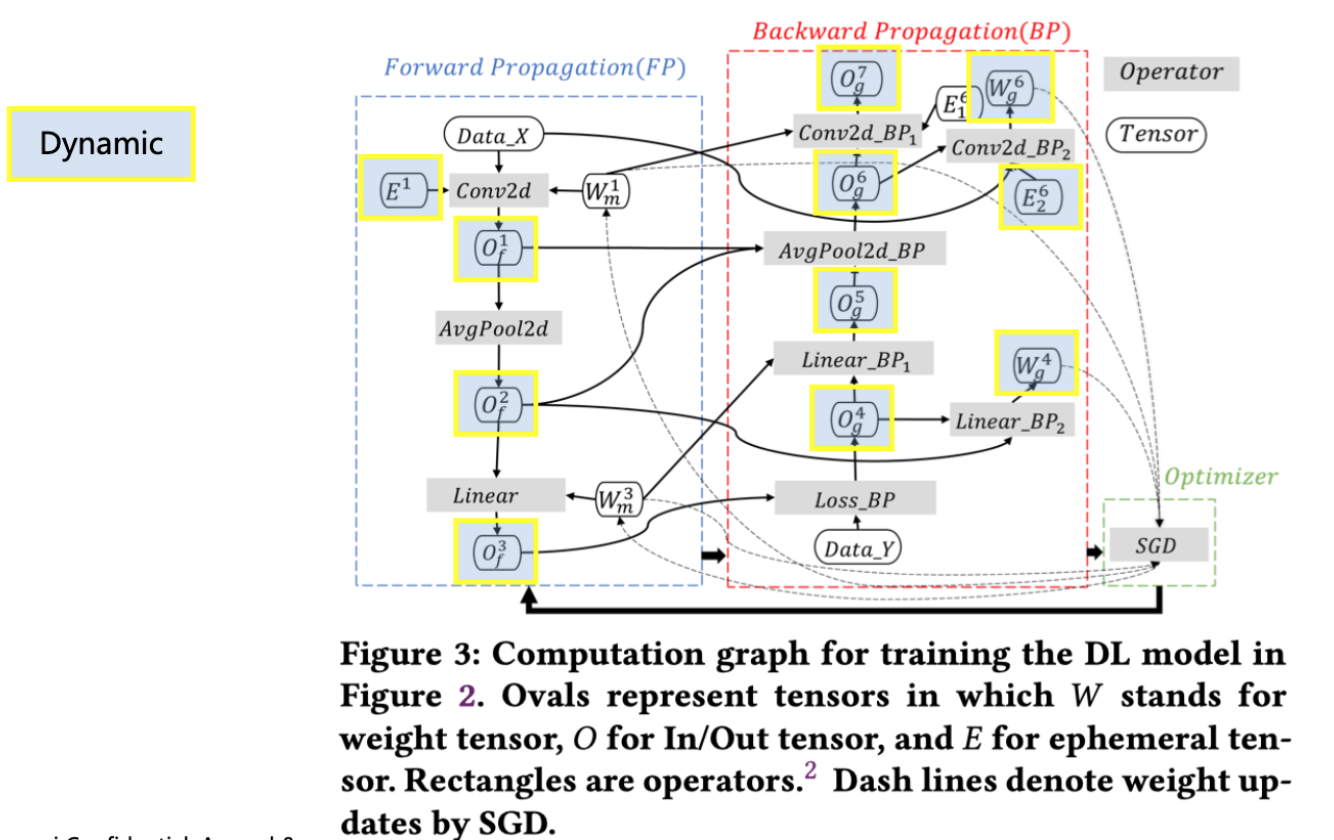
动态内存:训练过程产生前向/梯度输出、算子计算临时变量,会在反向传播时逐渐释放的内存。
并行策略
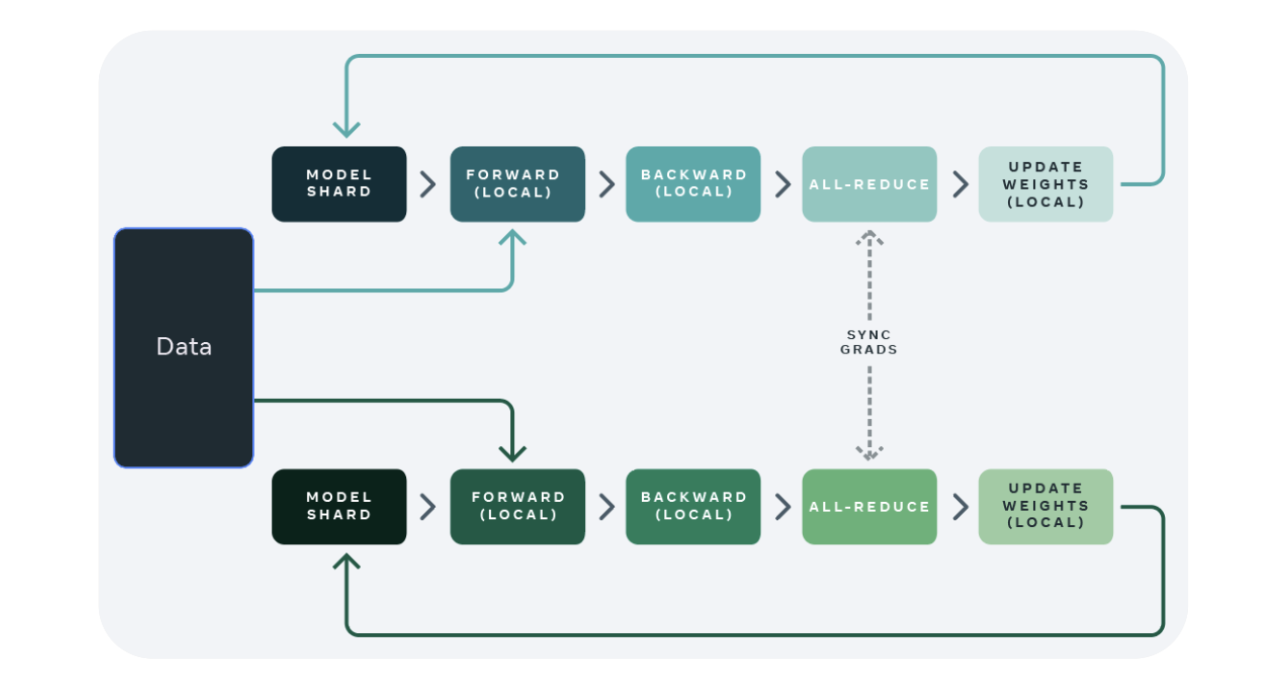
数据并行 DP
Data parallelism
-
Data parallelism, DP
-
Distribution Data Parallel, DDP
-
Fully Sharded Data Parallel, FSDP
Data parallelism DP 对数据并行
-
Data Parallel自动分割训练数据并将model jobs发送到多个GPU。独立计算梯度,数据同步(集合通信)进行梯度累积,更新权重,完成一次训练 (单卡完成整个训练)Data Parallel automatically splits the training data and sends model jobs to multiple GPUs. Each GPU independently computes gradients, and data synchronization (collective communication) is used for gradient accumulation, weight updates, and completing one training iteration (with a single GPU handling the entire training process).
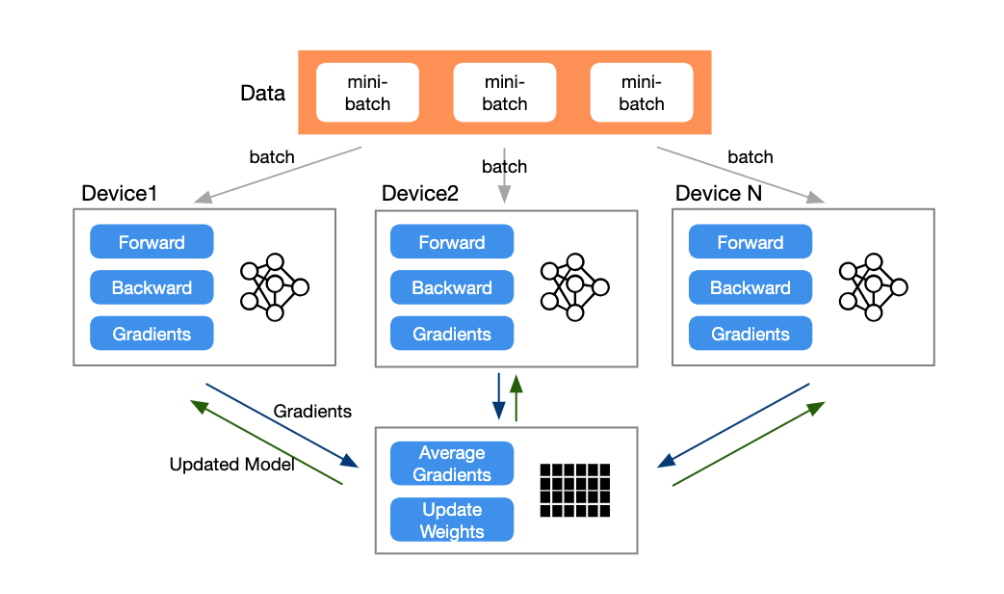
限制点
-
单进程多线程执行,python有GIL约束,不能充分发挥多卡优势
Single-process multi-threading execution in Python is constrained by the Global Interpreter Lock (GIL), which prevents the full utilization of multiple cores.
-
GPU独立计算梯度,如何高效完成梯度累积(不同梯度进行求和汇总)When it comes to efficient gradient accumulation (summing up different gradients), there are a few approaches
-
使用同步更新,时间长:把梯度汇总到参数服务器(Parameter Server),模型容易收敛,异步更新,很难收敛。
Synchronous updates, time-consuming: Accumulate the gradients on a parameter server. This approach can lead to better model convergence. However, asynchronous updates are difficult to converge.
-
GPU0作为参数服务器。0号节点负载很重,通讯成本是随着gpu数量的上升而线性上升的,占据的资源也多
Assign GPU0 as the parameter server. This approach can lead to heavy load on GPU0, increased communication costs as the number of GPUs increases, and a higher resource consumption.
-
nn.DataParallel 只适合单机多卡训练,不支持多节点(但是适合推理),要适当加大batch_size, 会更节省时间
1 | |
1 | |
Distribution Data Parallel DDP 对梯度并行
- 多进程执行 Multi-process execution
- DP 的通信成本随着 GPU 数量线性增长,而 DDP 支持 Ring AllReduce,其通信成本是恒定的,与 GPU 数量无关。DistributedDataParallel (DDP) supports Ring AllReduce, which has a constant communication cost regardless of the number of GPUs. On the other hand, the communication cost of DataParallel (DP) increases linearly with the number of GPUs.
- 同步梯度差(不是算完才更新)synchronize gradient differences
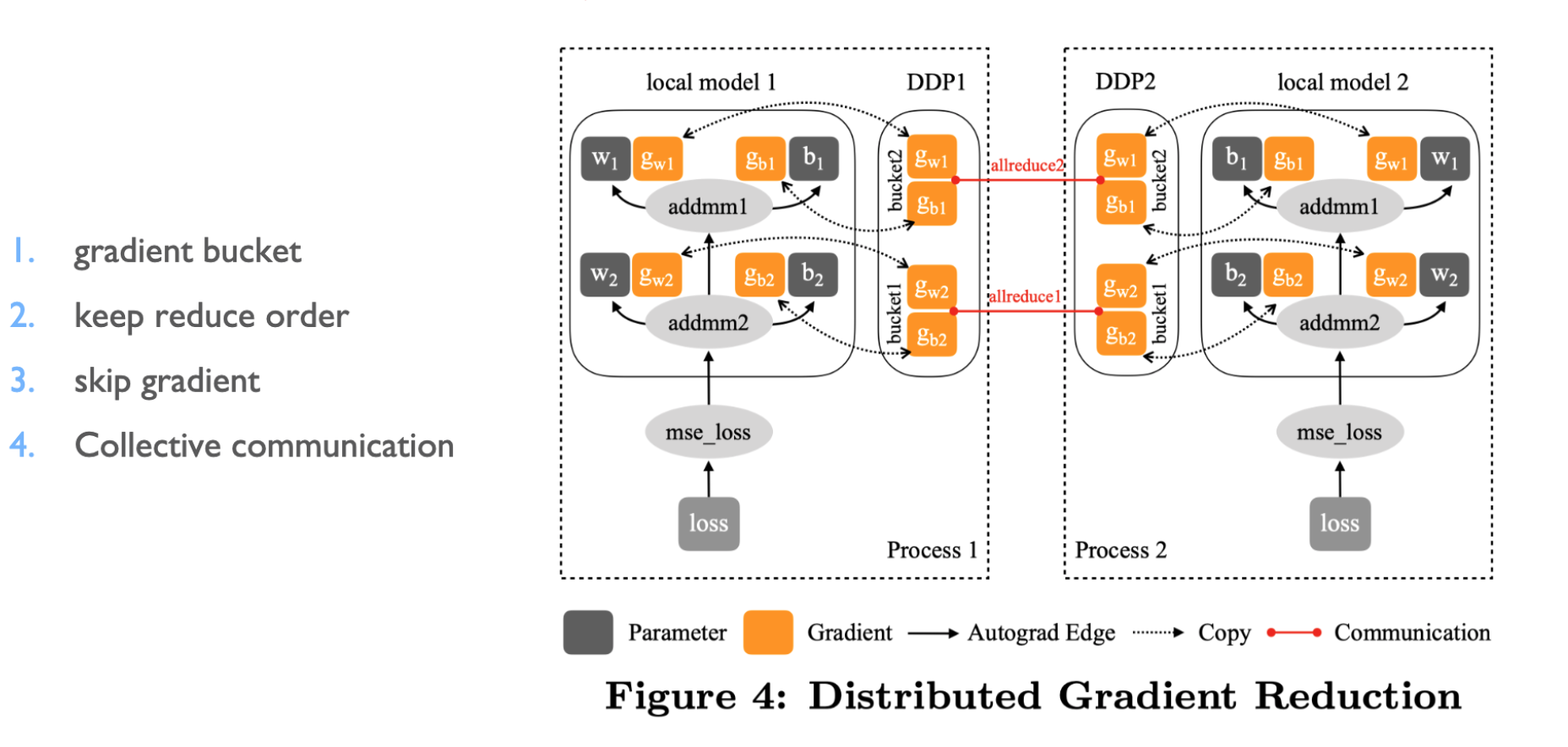
- 对每层梯度进行分桶,梯度逆向排序看哪个先更新,跳过很久没更新的,进行集合通信 To optimize training speed, DistributedDataParallel (DDP) overlaps gradient communication with backward propagation calculations. This allows for concurrent execution of workloads on different resources, speeding up the training process.
- 边计算边通信梯度,为了加快训练速度,DDP将梯度通信与后向传播计算重叠,促进在不同资源上并发执行工作负载。Additionally, you can partition the gradients for each layer into buckets and prioritize the updates based on the reverse order of gradients. This way, you can skip updating gradients that haven’t been updated for a long time and perform collective communication to synchronize the updates.
ZeRo Zero Redundancy Optimizer
参考
占用计算 1B(十亿参数)的模型 , float 4字节
参数量 = 1B * 4Bytes = 4GB
梯度 = 1B * 4Bytes = 4GB
优化器= 1B * 8Bytes(AdamW) = 8GB
还有其他等等(激活函数也需要占据额外的显存,其随批量大小(batch size)而增加)
显存和计算
主要占据显存的地方
- 模型状态量(参数、梯度和优化器状态量)模型本身相关且必须存储的参数
非模型必须,训练过程中产生的参数
- 激活函数也需要占据额外的显存,其随批量大小(batch size)而增加
- Temporary Buffers:临时存储
- Unusable Fragmented Memory:碎片化存储空间

计算效率随着计算时间对通信时间的比例的增加而增加。该比例与 batch size成正比。但是,模型可以训练的 batch size有一个上限,如果超过这个上限,则收敛情况会迅速恶化。
ZeRO提出的内存优化
数据并行具有较好的通信和计算效率,但内存冗余严重。因此,ZeRO通过对参数(包括优化器状态、梯度和参数)进行分区来消除这种内存冗余,每个GPU仅保存部分参数及相关状态。
Data parallelism offers good communication and computational efficiency but suffers from significant memory redundancy. Therefore, ZeRO addresses this issue by partitioning the parameters, including optimizer states, gradients, and parameters, to eliminate memory redundancy. Each GPU only stores a portion of the parameters and their associated states.
ZeRo stages
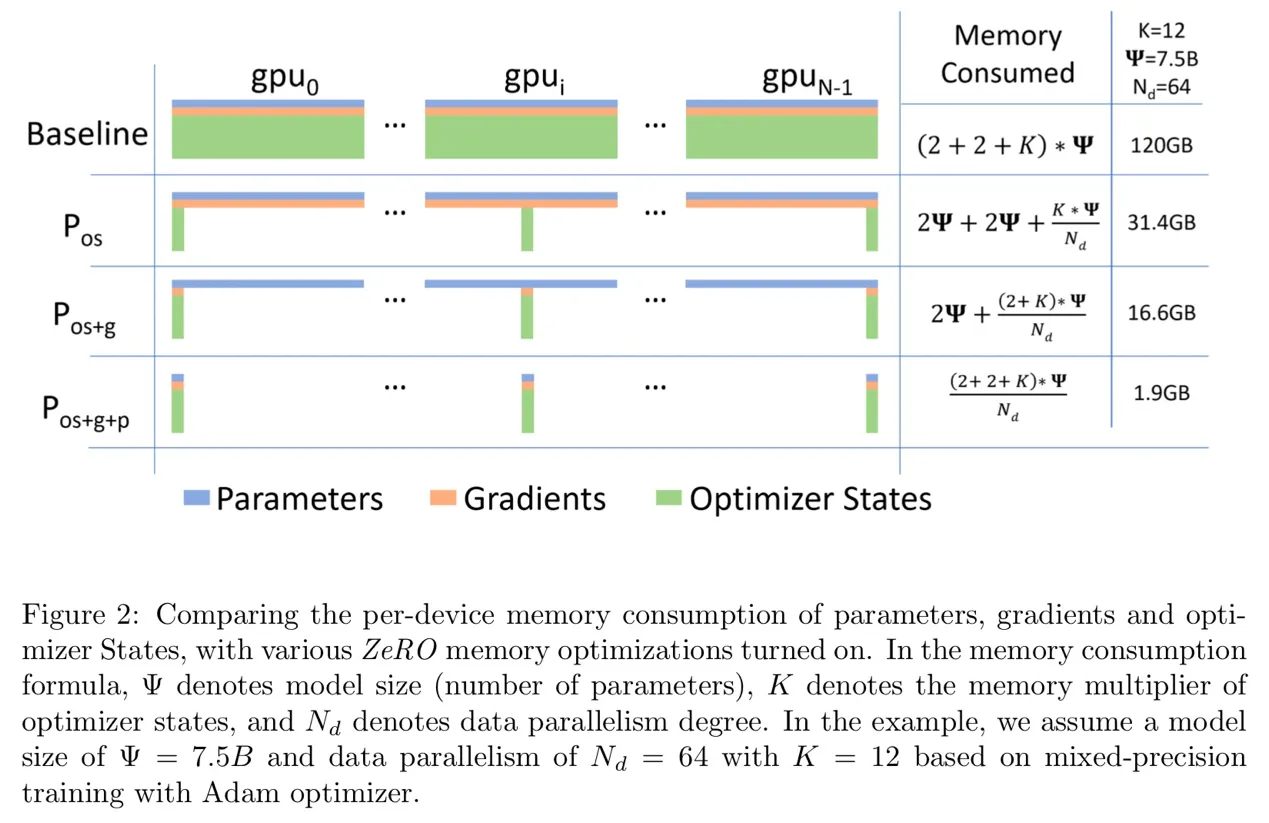
- 假设模型参数量 Ψ ,使用Adam优化器混合精度训练:
- 模型参数和梯度 float16,显存消耗为 2Ψ + 2Ψ;
- Adam 维护 float32 模型副本,消耗 4Ψ;
- Adam 辅助变量 fp32 momentum + fp32 variance,显存消耗 4Ψ+4Ψ;
- 模型消耗 2Ψ+2Ψ=4Ψ ,Adam 消耗 4Ψ+4Ψ+4Ψ=12Ψ,总消耗 4Ψ+12Ψ= 16Ψ
- 优化器显存占用表示 KΨ(不同的优化器不同),则、混合精 度训练显存占用 4Ψ+KΨ
ZeRO-DP
Optimizer->ZeRO1
只对 optimizer 状态进行切分,占用内存原始1/4;
- 将optimizer state,batch数据分成N份,每块GPU上各自维护一份
- 每块GPU上存一份完整的参数W,做完一轮foward和backward后,各得一份梯度$G_n$
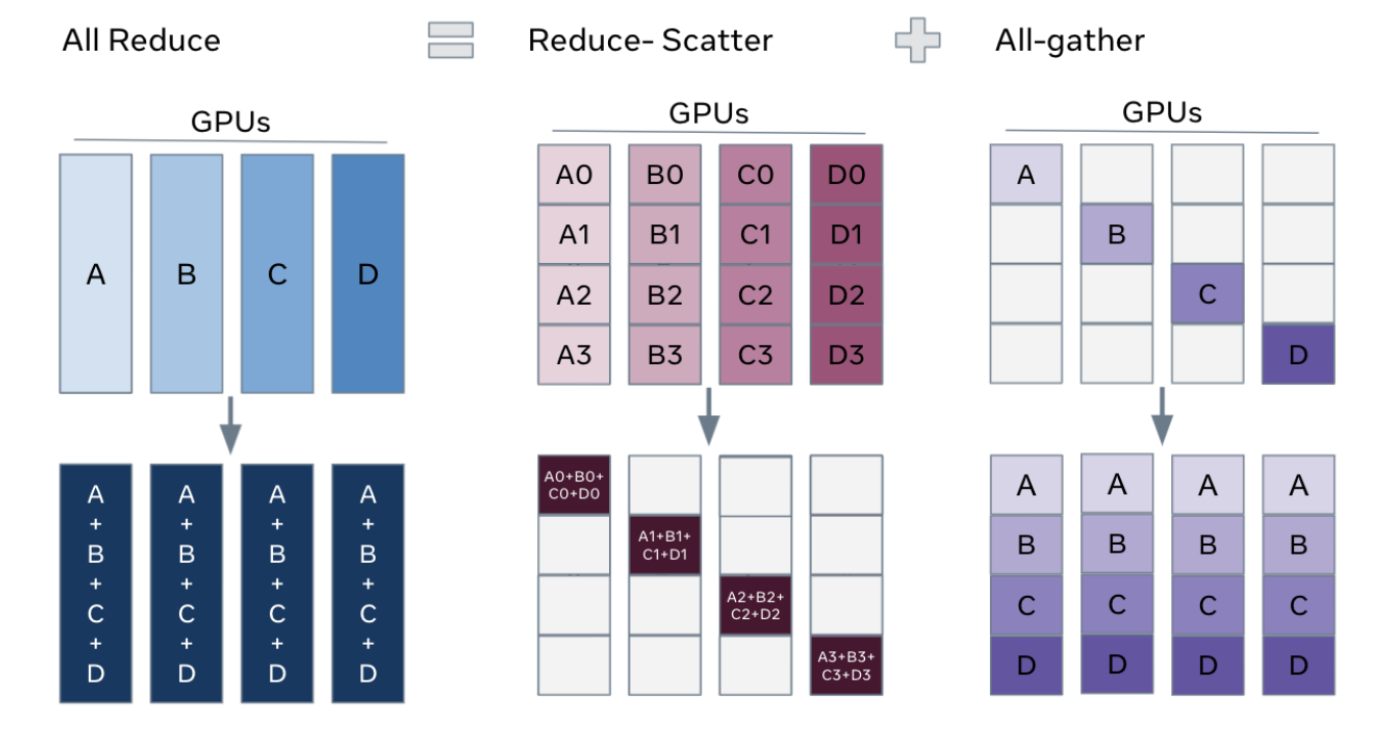
- 对梯度$G_n$做一次AllReduce(reduce-scatter + all-gather),得到完整的梯度G
- 单 GPU 通讯量 $2Φ$
- 得到完整梯度 G,对权重 W 更新。由于每块GPU上只保管部分optimizer states,权重 W 更新由 optimizer states 和 grad 共同决定,因此只能将相应的W进行更新,对W做一次All-Gather,使得每 GPU 都有更新后完整 W
- 单 GPU 通讯量 $Φ$
在Pos阶段优化器状态划分
-
根据 DP 维度将 Adam 优化器状态划分为N等份;
-
每GPU 需要存储和更新总优化器状态的1/N,并更新1/N参数;
-
每训练 Step 末尾,使用 all-gather 获得整个参数的更新完整的权重w
显存分析
-
显存从4Ψ+KΨ降低到4Ψ+KΨ/N
-
当N很大时,显存占用接近于 4Ψ,带来 4 倍显存节约。
Gradient+Optimzer->ZeRO2
对 optimizer 和 grad 进行切分,占用内存原始1/8;
-
梯度 Grad 也进行切分,每个GPU各自维护一块梯度,每块GPU上存一份完整的参数W
-
做完一轮foward和backward后,算得一份梯度$G_n$
-
对梯度$G_n$做一次Reduce-Scatter,保证每个GPU上所维持的那块梯度$G_n$是聚合梯度
-
每块GPU用自己对应的O和G去更新相应的W。更新完毕后,每块GPU维持了一块更新完毕的W。
-
同理,对W做一次All-Gather,将别的GPU算好的W同步到自己这来,单 GPU 通讯量 $Φ$
在Pos+g阶段优化器状态 + 梯度划分
- 梯度跟优化器强相关,因此优化器可以更新其独立的梯度参数
- 重点是更新梯度参数时候使用Reduce-Scatter,梯度参数更新后马上释放,显存从2Ψ->2Ψ/N
- 实现过程中使用分桶Bucket,将梯度分到Bucket中并在桶上进行Reduce-Scatter
显存分析
- 移除梯度和优化器状态冗余,将显存从4Ψ+KΨ降低到2Ψ+KΨ/N
- 当N很大时,显存占用接近于 2Ψ,带来 8 倍显存节约。
Parameter+Gradient+Optimizer->ZeRO3
对 optimizer、grad 和模型参数进行切分,内存减少与数据并行度和复杂度成线性关系,同时通信容量是数据并行性的 1.5 倍
- 每个GPU维护一块模型状态,每块GPU上只保存部分参数$W_n$,
- 做forward时,对$W_n$做一次All-Gather,取回分布在别的GPU上的$W_n$,得到一份完整的W。forward做完,立刻把不是自己维护的$W_others$抛弃。 单 GPU 通讯量 $Φ$
- 做backward时,对$W_n$做一次All-Gather,取回完整的W,backward做完,立刻把不是自己维护的$W_others$抛弃。 单 GPU 通讯量 $Φ$
- backward 后得到各自梯度$G_n$,对 $G_n$执行 Reduce-Scatter,从其他 GPU 聚合自身维护的梯度$G_n$。聚合操作结束后,立刻把不是自己维护的G抛弃。 单 GPU 通讯量 $Φ$
- 用自己维护的O和G,更新$W_n$。由于只维护部分$W_n$,因此无需再对$W_n$做任何AllReduce操作
在Pos+g+p阶段优化器状态 + 梯度 + 权重划分
- 拆分到forward&backward过程,通过broadcast从其他GPU中获取参数
- 通过增加通信开销,减少每张GPU中的显存占用,以通信换显存,使得显存占用与N成正比
显存分析
- 移除梯度、优化器状态、权重冗余,将显存从4Ψ+KΨ降低到(4Ψ+KΨ)/N
- 带来DP增加1.5X单卡通讯量
ZeRO-R
其他减少内存消耗优化
- Partitioned Activation Checkpointing
每块GPU上只维护部分的activation,需要时再从别的地方聚合过来就行。需要注意的是,activation对显存的占用一般会远高于模型本身,通讯量也是巨大的。激活值存储,用于反向传播计算。这部分消耗通常占显存很大一部分。Partitioned Activation Checkpoint 会 offload 到CPU 降低激活值对显存消耗,几乎到0,但会增加通信成本。
-
Constant Size Buffers
训练过程中的暂存空间,用于缓存中间结果。选择了临时数据缓冲区的大小,以平衡内存和计算效率。
- 提升带宽利用率。当GPU数量上升,GPU间的通讯次数也上升,每次的通讯量可能下降(但总通讯量不会变)。数据切片小了,就不能很好利用带宽了。如果等数据积攒到一定大小,再进行通讯,可以提高带宽的利用率。
- 使得存储大小可控。在每次通讯前,积攒的存储大小是常量,是已知可控的,更方便使用者对训练中的存储消耗和通讯时间进行预估。
-
Memory fragmentation
对碎片化的存储空间进行重新整合,整出连续的存储空间。防止出现总存储足够,但连续存储不够而引起的存储请求失败。
由于ZeRO消除了DP中的内存效率问题,自然而然地会问:我们是否仍然需要MP,以及何时需要?
-
当与ZeRO-R一起使用时,MP可以减少非常大模型的激活值内存占用
When used in conjunction with ZeRO-R, MP (Model Parallelism) can reduce the memory footprint of extremely large models by optimizing the storage of activation values. By partitioning the model across multiple GPUs, each GPU only needs to store a portion of the activation values, leading to reduced memory usage.
-
对于激活值内存不是问题的较小模型,当仅使用DP时聚合批量大小过大以至于无法获得良好收敛性时,MP也可能有益处。
For smaller models where memory usage of activation values is not a concern, MP can still be beneficial when using only DP (Data Parallelism) and encountering challenges with large aggregated batch sizes that hinder good convergence. By distributing different parts of the model across multiple GPUs, the per-GPU batch size is reduced, potentially improving convergence.
在这些情况下,可以将ZeRO与MP结合起来,以使用可接受的聚合批量大小来适应模型。
ZeRO vs TP
ZeRO 形式上模型并行,实质上数据并行
- 张量并行:相同输入 X,每 GPU 上各算模型一部分,最后通过通信来进行聚合àforward 和 backward 过程中,GPU 只需要维护其独立W来计算即可
- ZeRO 并行:forward 和 backward 过程中,把GPU 上维护W进行聚合,本质上用完整W进行计算。它是不同输入 X,完整参数 W,最终再进行聚合。
实际并行时候,只能使用 ZeRO Stage 1 + PTD 多维混合并行
ZeRO-Offload
把占用显存多的部分卸载 offload 到CPU上,计算和激活值部分放到 GPU 上 ,比起跨机, 更能节省内存,也能减少跨机跨通信域通讯压力。
要注意的地方
- CPU和GPU之前通信增加
- 避免 CPU 参与过多计算,计算负载尽可能在 GPU
按计算量进行区分
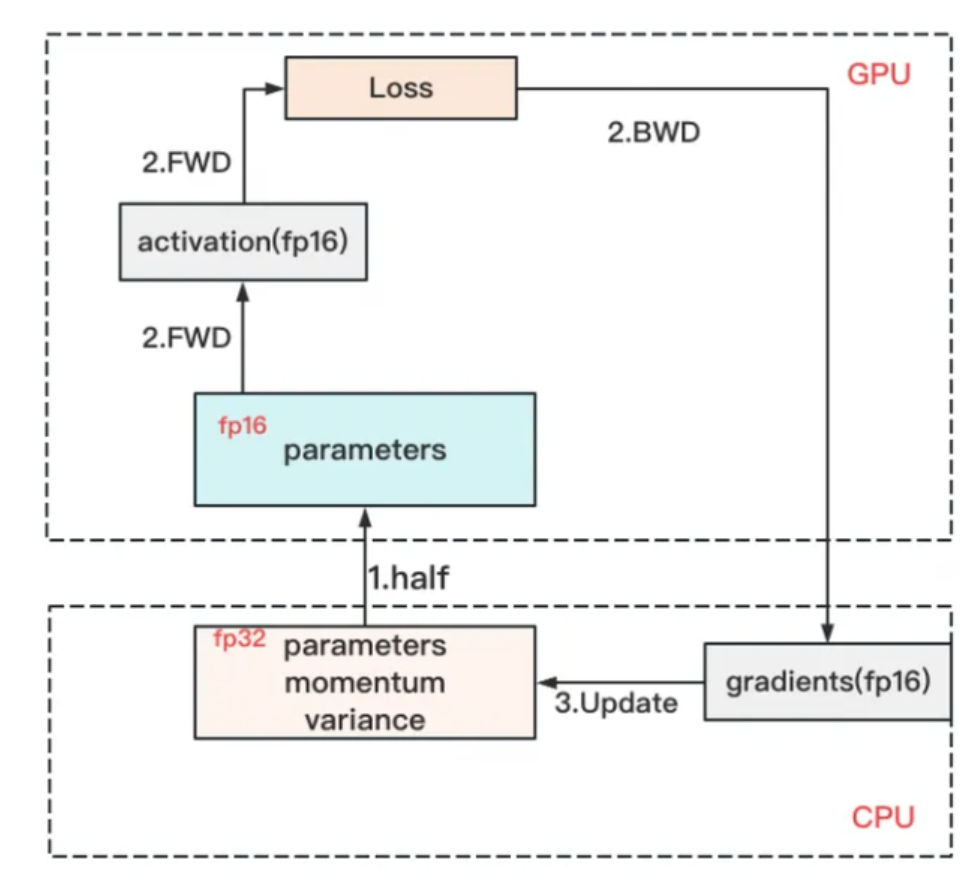
-
forward&&backward计算量高, 相关的权重参数计算 & 激活值计算仍然 在 GPU
-
update部分计算量低以通信为 主,且需要的显存较大,放入 CPU & D DR。相关部分 Optimizer States(fp32) Update 和 Gradients (fp16) Update 等
Fully Sharded Data Parallel FSDP
- 对参数、梯度和优化器状态量进行并行
- ZeRO-Offload : 可以将参数、梯度和优化器状态卸载到 CPU (可选)
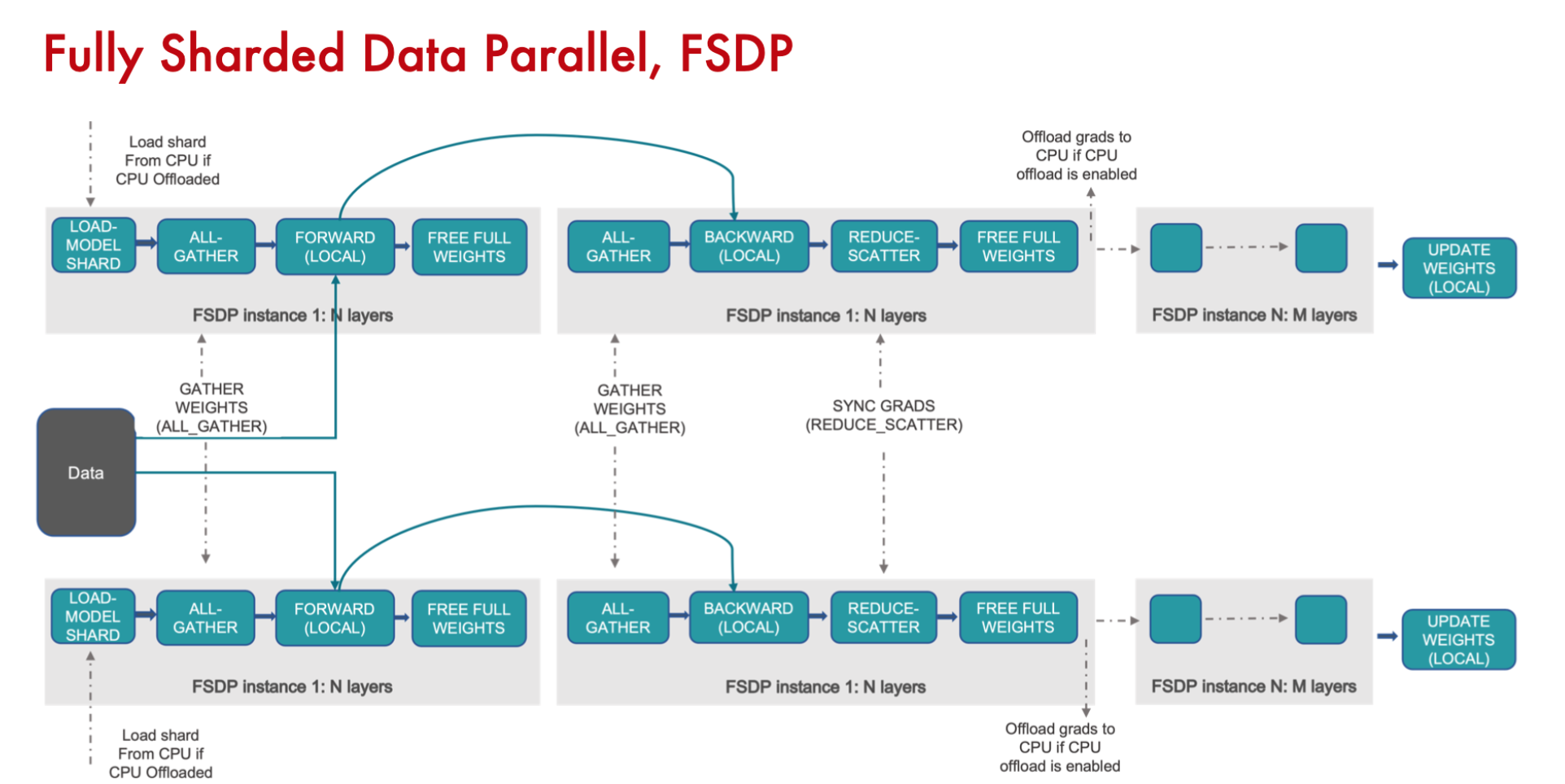
将DDP中的All-Reduce拆成reduce-scatter + all-gather
数据拆分后,进行前向和反向计算,reduce-scatter,把不需要的权重参数offload到CPU,需要再load到GPU进行all-gather
Model 并行 MP
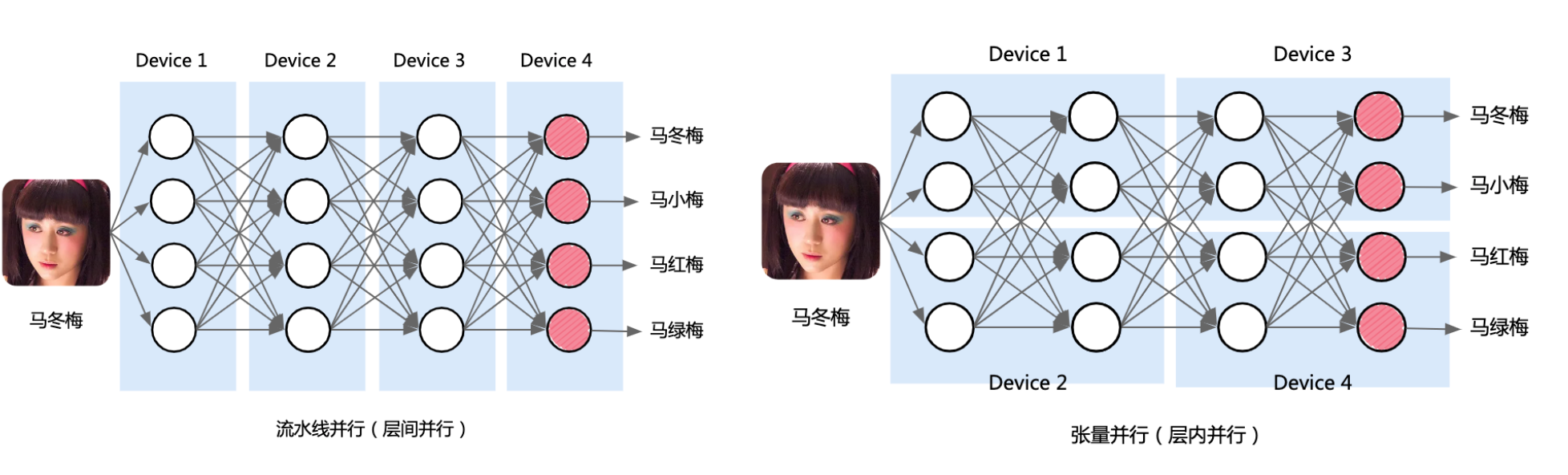
流水线并行: 按模型layer层切分到不同设备,即层间并行
“Pipeline parallelism” refers to splitting the computational tasks of a model across different devices at the layer level, enabling parallel processing between layers.
张量并行: 将计算图中的层内的参数切分到不同设备,即层内并行
“Tensor parallelism” involves splitting the parameters within each layer of the computational graph across different devices, enabling parallel processing within layers.
张量并行
如何正确切分,通讯成本比计算成本高
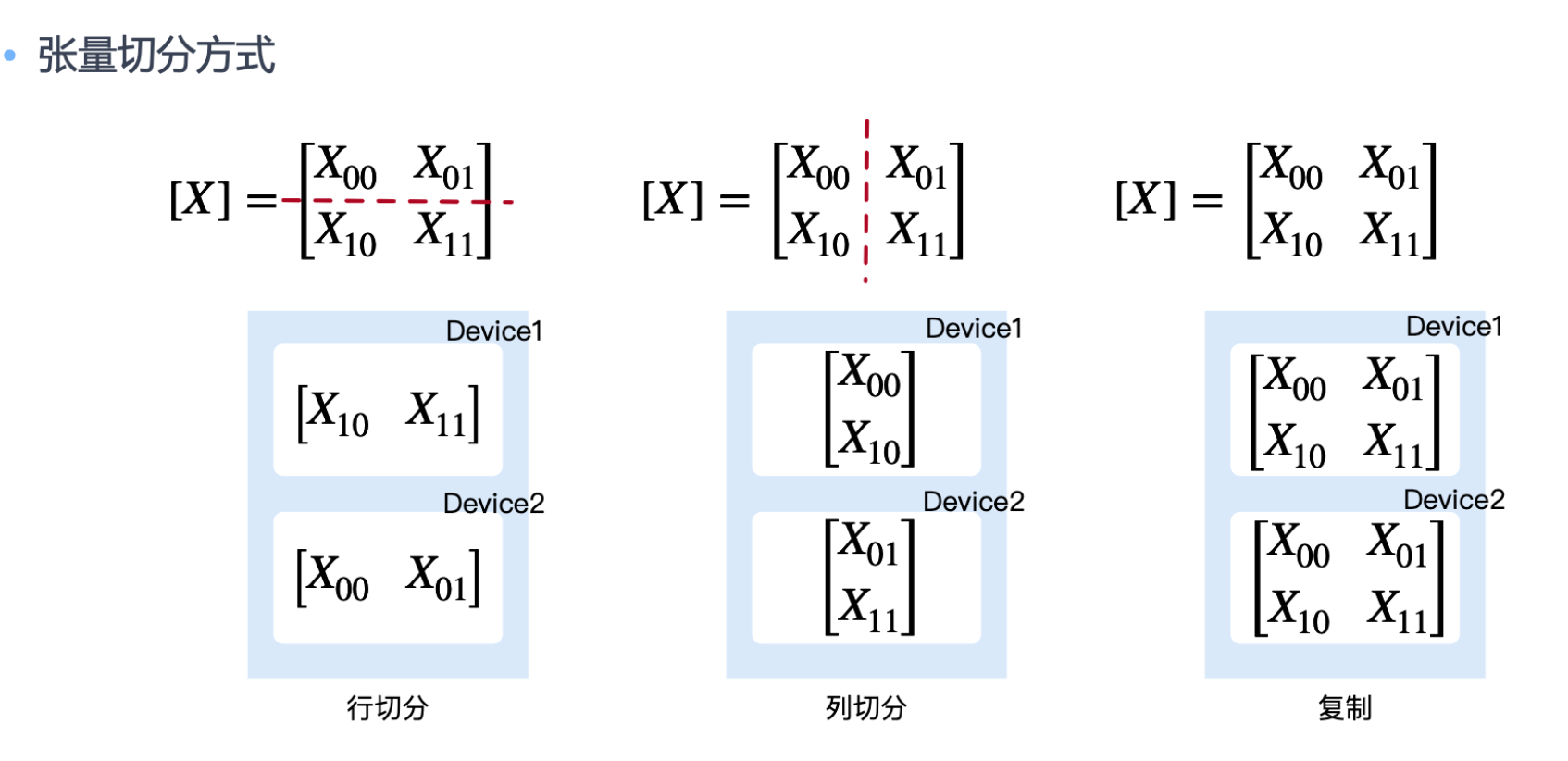
按列切分 把结果按照列拼接起来,与不使用并行数学计算等价结果
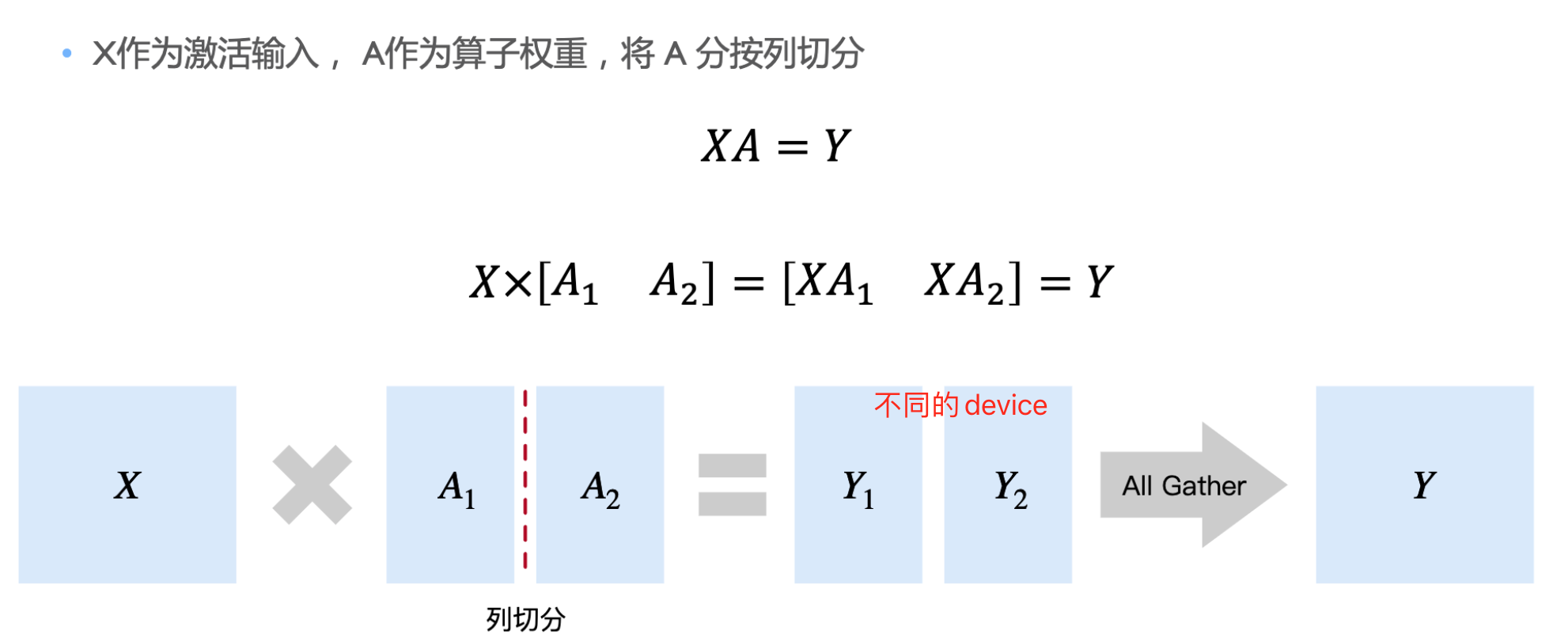
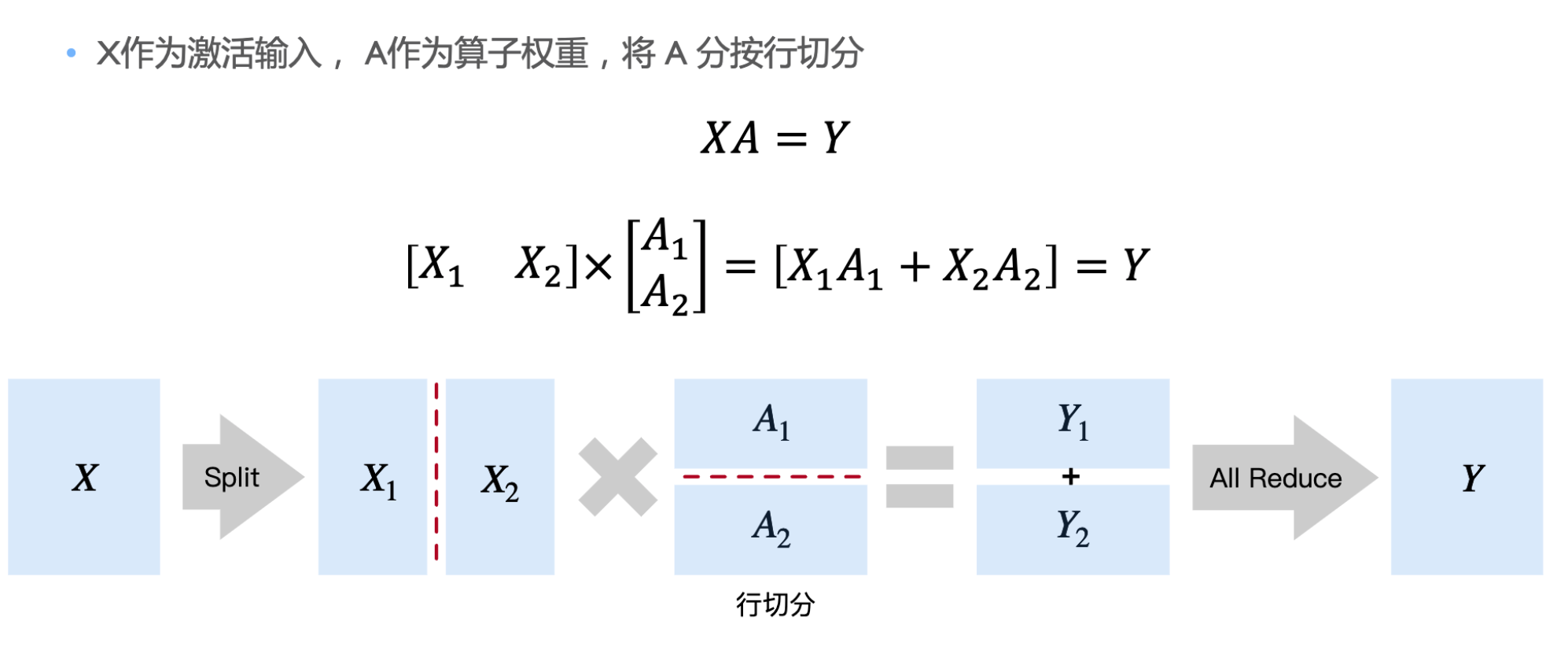
按行切分 每次 Split 引起两次额外通信(前向传播和后向传播各一次)
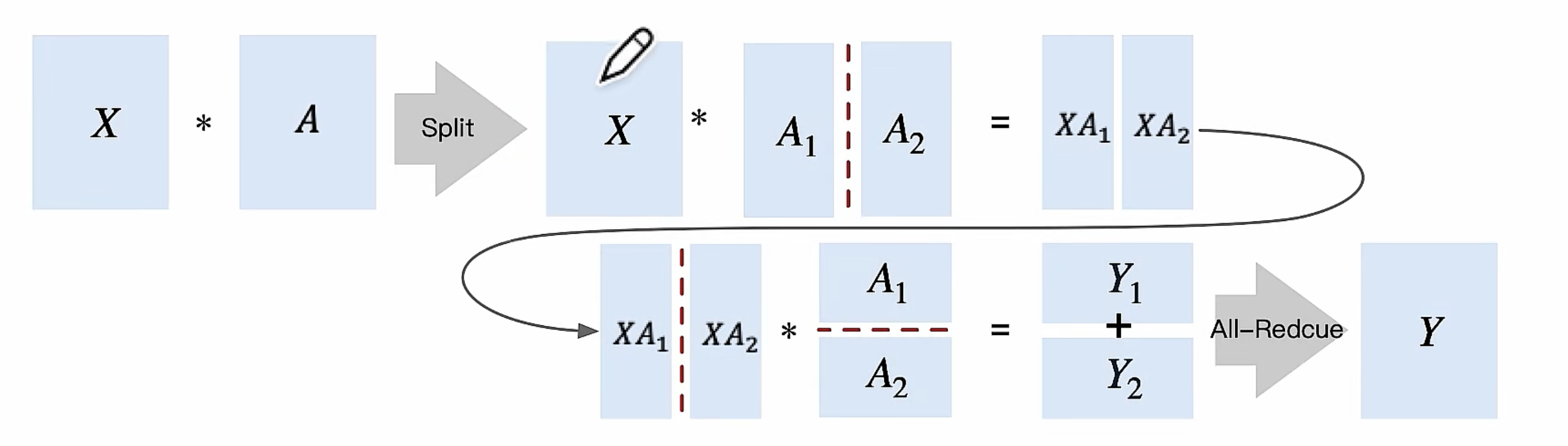
如果多次连续矩阵乘,利用数学上的传递性和结合律。可以把数据通信延后到后续计算步骤,即把参数进行列切 ALLGather 和 Split 省略掉,从而降低通信量。
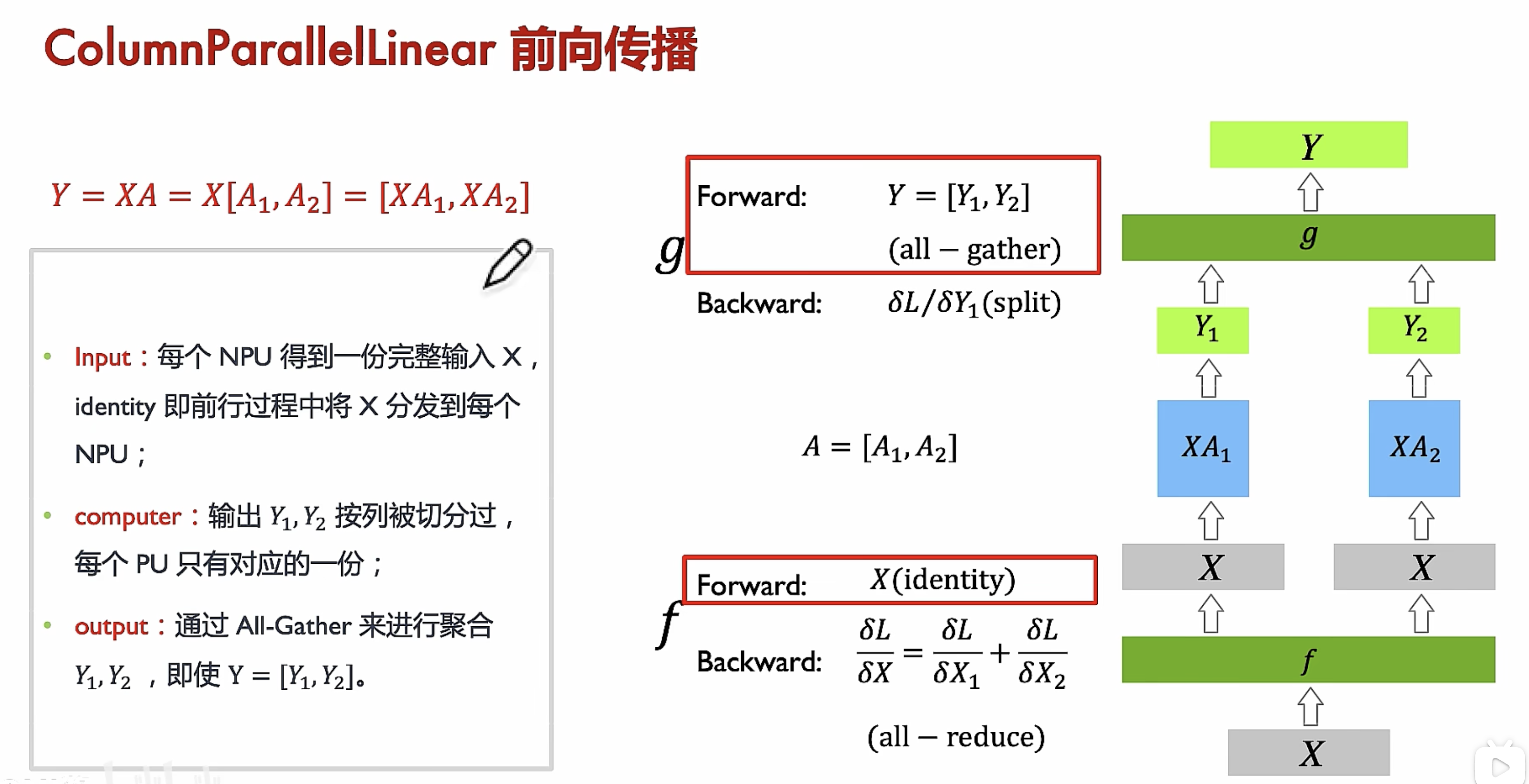
列切分前后传播
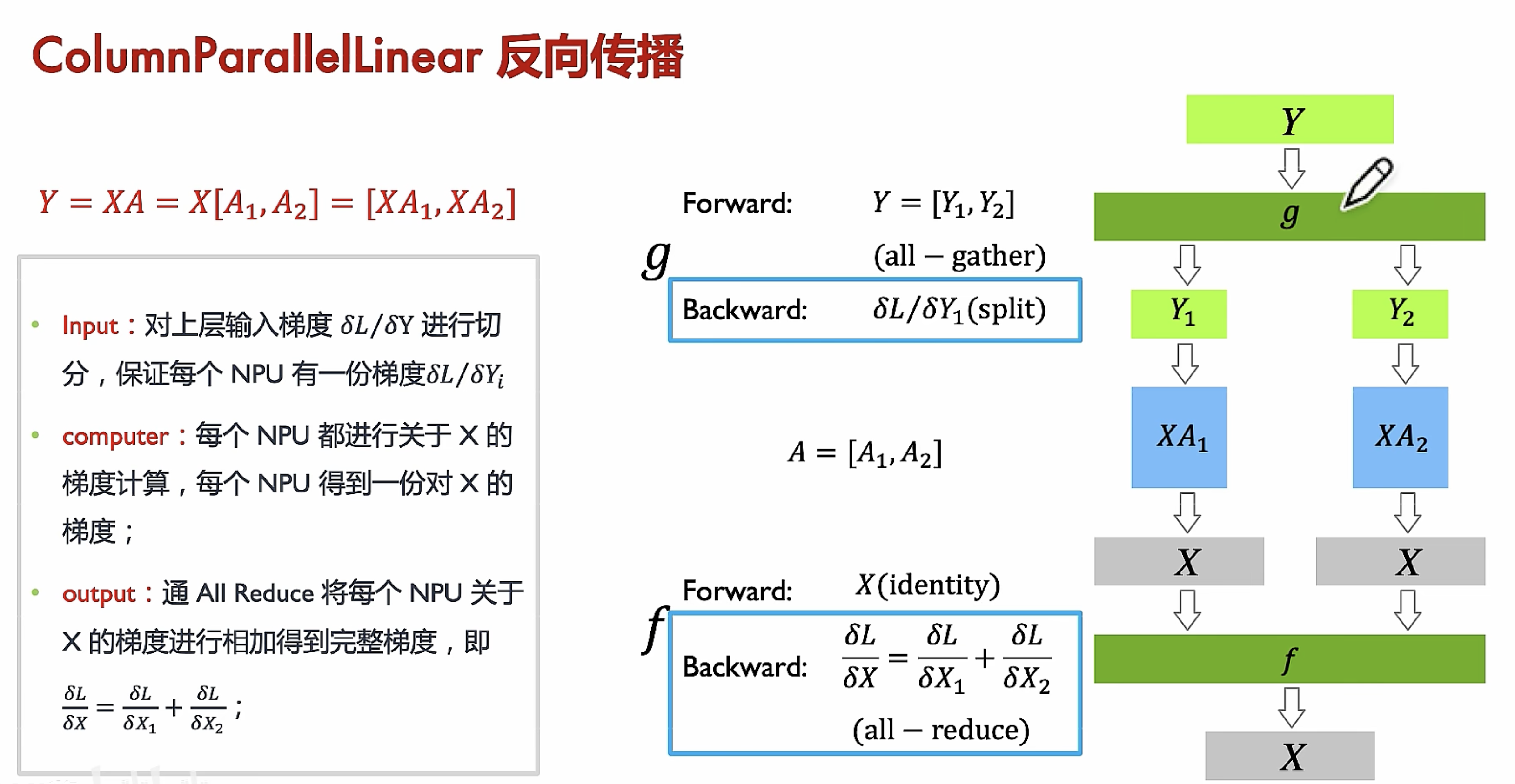


行切分前后传播
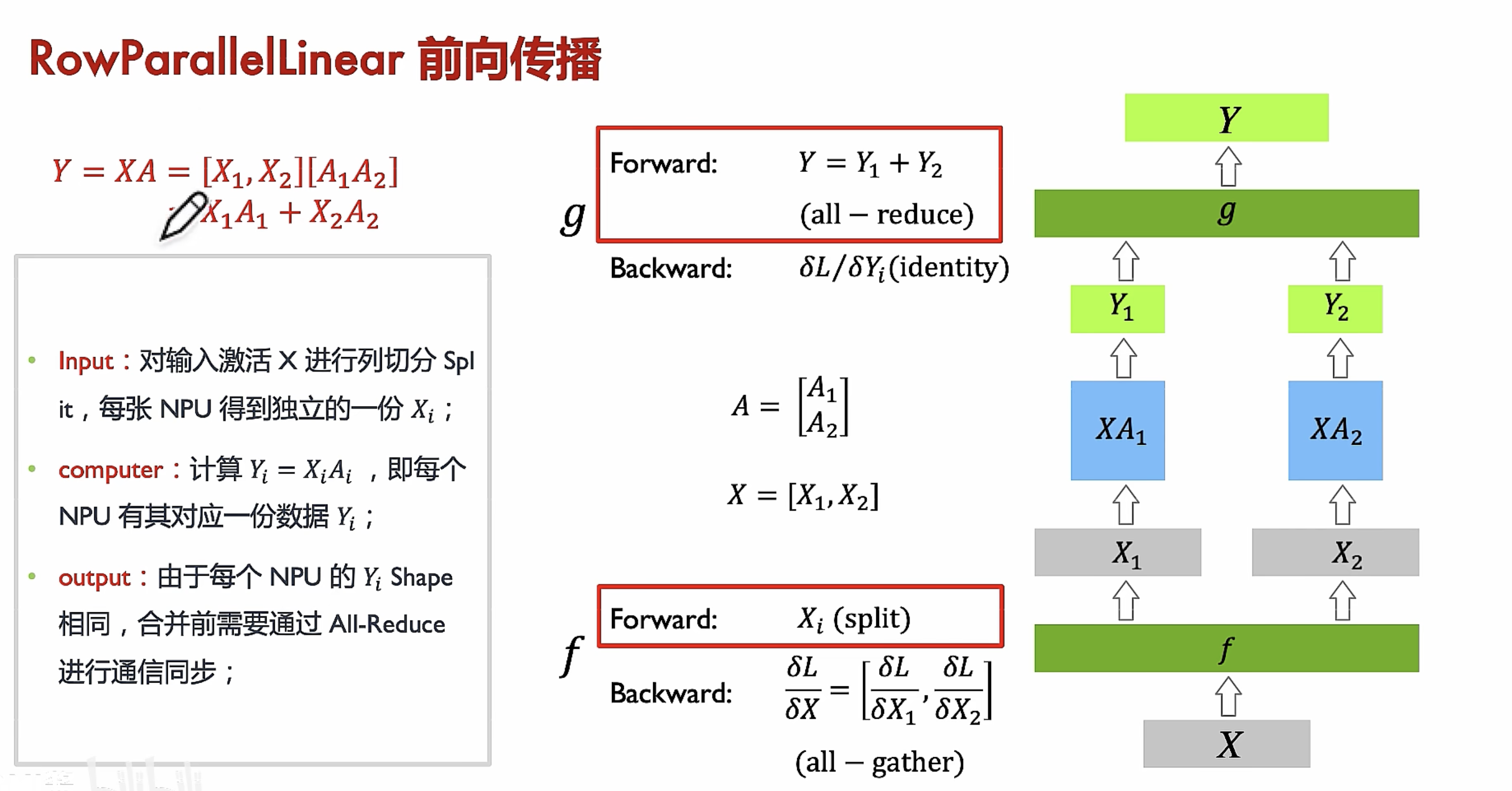
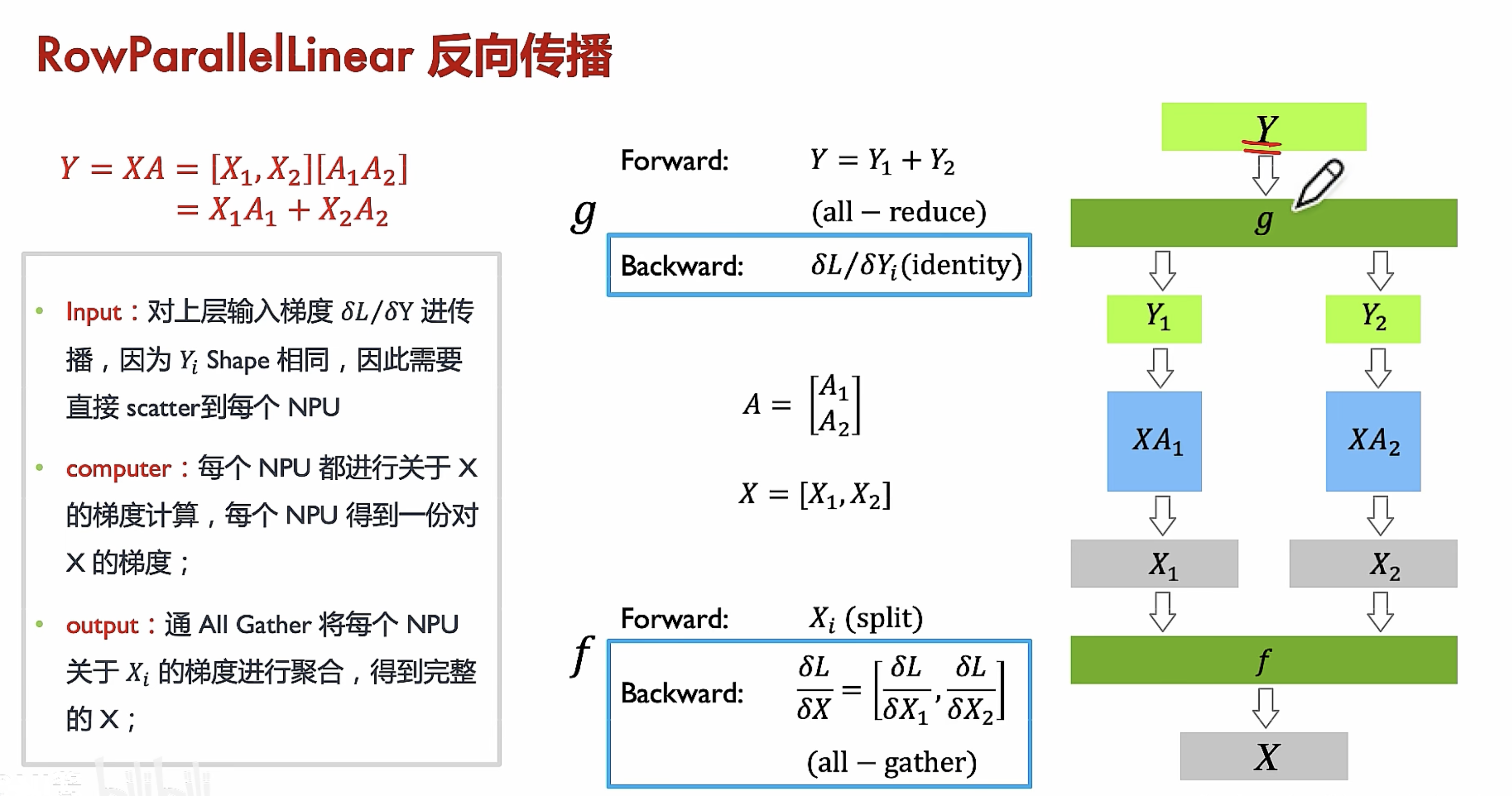


流水线并行
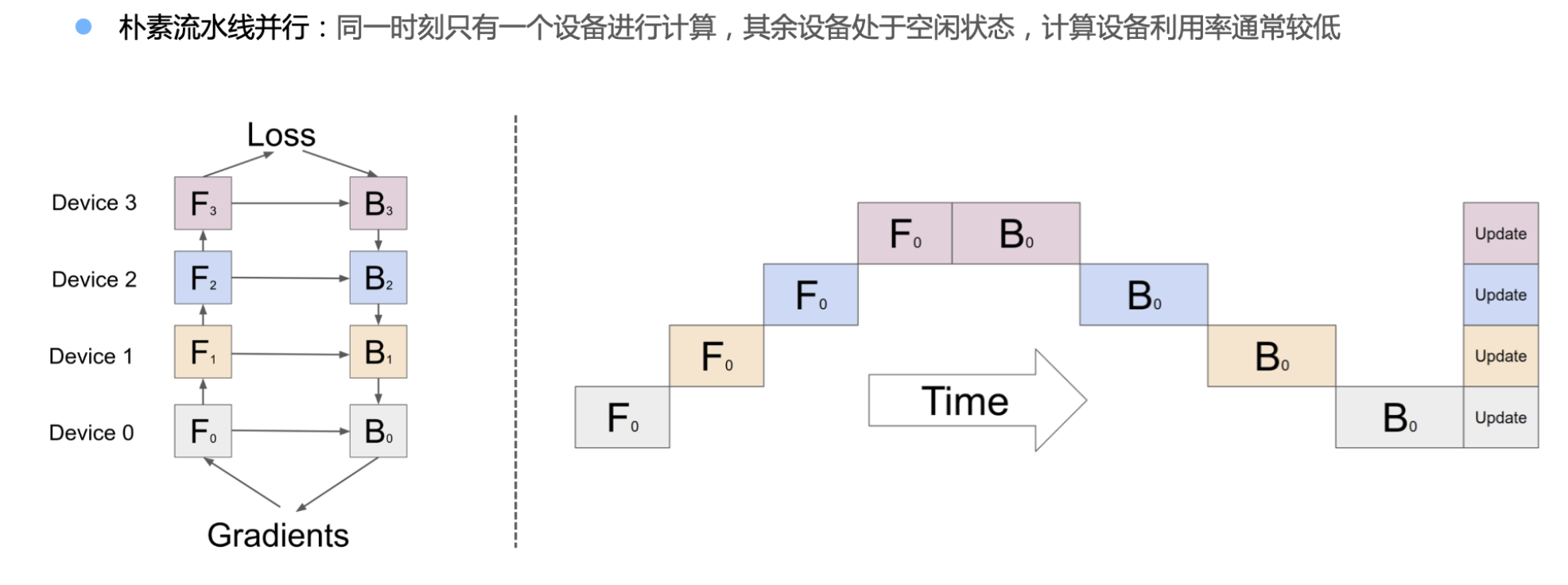
由于按模型layer层切分到不同设备,会后layer之间先后顺序的问题。
-
朴素流水线并行:同一时刻只有一个设备进行计算,其余设备处于空闲状态,计算设备利用率常较低
-
K 为 NPU 数量,朴素流水线 Bubble 时间为 O(K−1∕K)
-
NPU 数量越多时,空置比例接近 1,浪费计算资源;
-
通信和计算缺乏重叠 overlap,网络传输中间输出 (FWD) 和梯度 (BWD) 时,没有 NPU 执行计算;
-
消耗大量内存,先执行 Forward 的 NPU 将保留整个 batch 的缓存激活,直到优化器更新 Update
Forward Backward 计算过程
-
-
小批次流水线并行:将朴素流水线并行的 batch 再进行切分,减小设备间空闲状态的时间,可以显著提升流水线并行设备利用率。
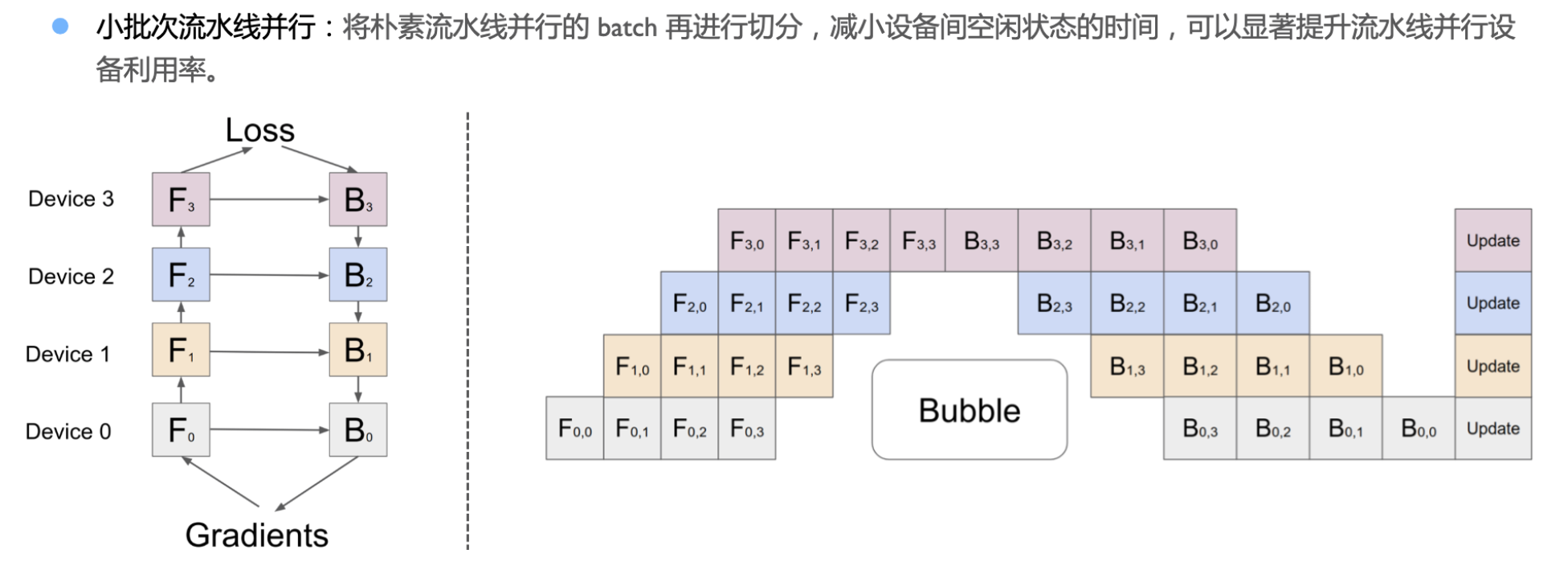
Gpipe
- 把模型切分成不同的stage(每个stage 包含若干层)
- 引入小批次micro-batch,越小 idle越小
- 使用激活重计算(反向不用正向结果,而是重新计算Forwad结果),计算成本远比内存消耗的成本要低。
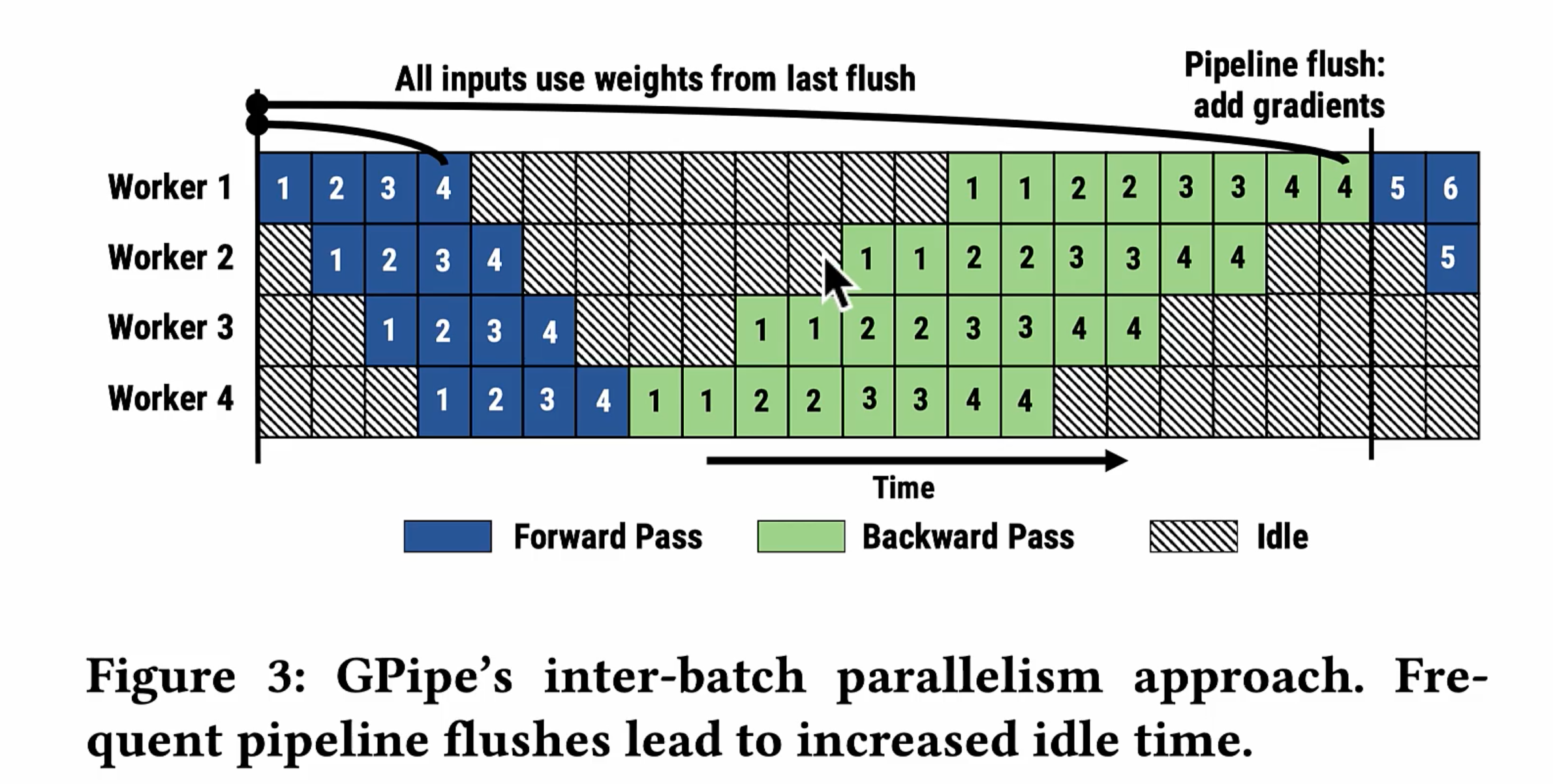
缺点:
- 批次越小,会有大量的forward计算,频繁流水线交互。训练的总体时间拉长。
- 大量的重计算,导致模型的权重,激活的中间变量变得更多,消耗动态内存
空泡率:$t_pb$ 为 bubble 耗时,$m$为 micro-batch, $p$ 为 pipeline stages, $t_id$ 为理想的迭代时间,$ t_f$ 表示前向时间, $ t_b$ 表示反向时间,pipeline bubble 占据共有$ (p−1) $个前向和反向,$ t_pb=(p−1)(t_f+t_b) $,理想时间$ t_id=m(t_f+t_b)$:
\[bubble time fraction =t_pb/t_id=p−1/m\]目标:降低空泡比率,需要$ m≫p$ ,but 动态内存峰值占用高。 每个 micro-batch 反向算梯度计算,都需要前向激活值,m 个 micro-batch 前向结束时(CoolDown),达到内存占用的峰值。
PipeDream
前面都是所有的forward做完再做backword,现在是一个forward做完马上做backword,可以及时释放不必要的中间变量。
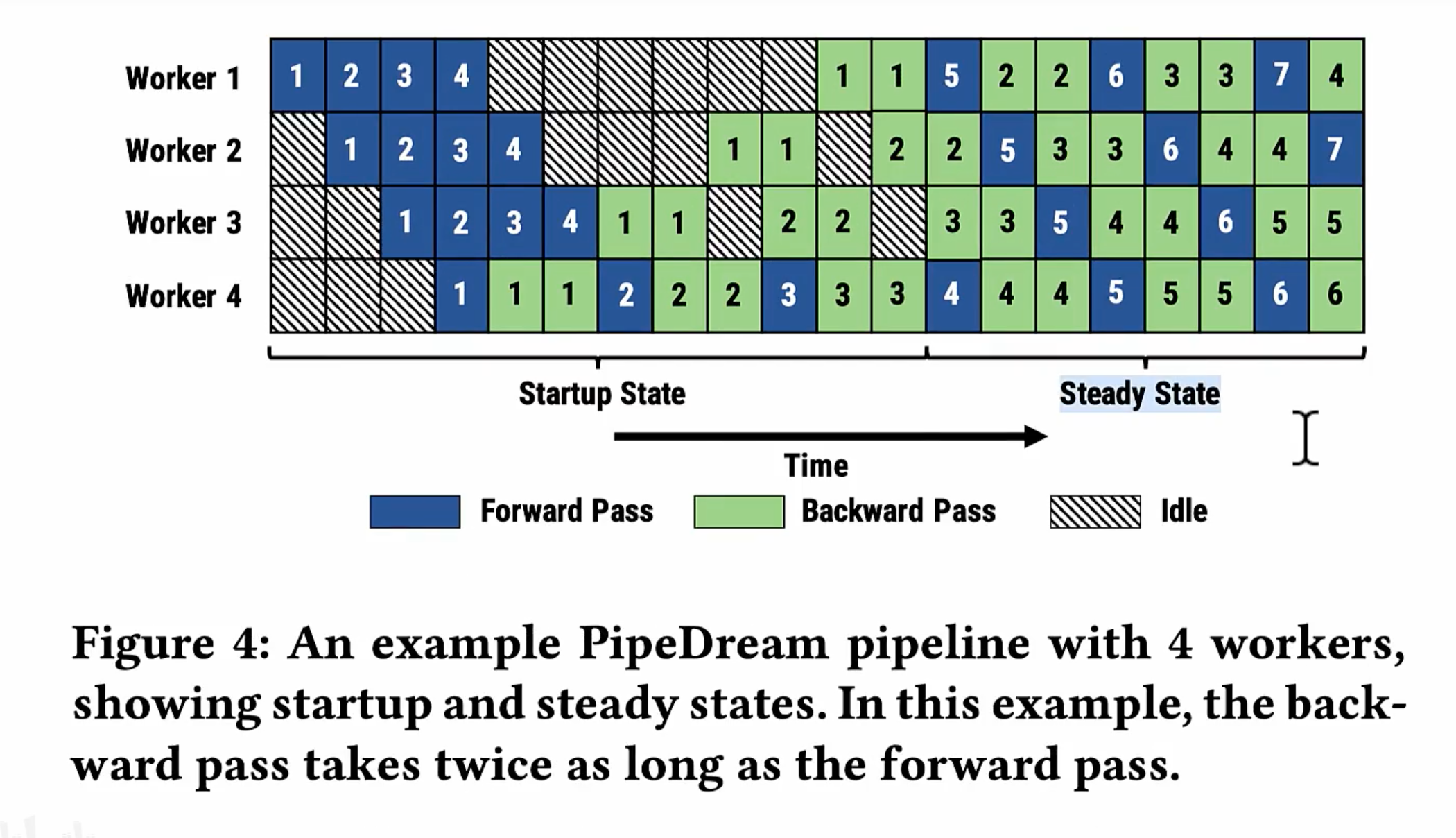
steady state 就没有idle。但是权重何时更新,梯度何时同步
为解决这两个问题,PipeDream 分别采用了 Weight stashing 和 Vertical Sync 两种技术
- Weight stashing: 为每个active minibatch都保存一份参数。前向计算时,每个stage 都是用最新的参数处理输入的minibatch,然后将这份参数保存下来用于同一个minibatch的后向计算,保证前向计算和后向计算的参数是关联的。
- Vertical Sync: 每个minibatch进入pipeline时都使用输入stage最新版本的参数,并且参数的版本号会伴随该minibatch数据整个生命周期,在各个阶段都是用同一个版本的参数(而不是前文所说的都使用最新版本的参数),从而实现了stage间的参数一致性。
对比DP MP
数据并行data parallell
数据并行中,每批输入的训练数据都在数据并行的 worker 之间进行平分。反向传播之后,我们需要进行通信来规约梯度,以保证优化器在各个 worker 上可以得到相同的更新。数据并行性具有几个明显的优势,包括计算效率高和工作量小。但是,数据并行的 batch size 会随 worker 数量提高,而我们难以在不影响收敛性的情况下无限增加 batch szie。
显存效率:数据并行会在所有 worker 之间复制模型和优化器,因此显存效率不高。 inefficient memory usage
计算效率:随着并行度的提高,每个 worker 执行的计算量是恒定的。数据并行可以在小规模上实现近乎线性扩展。但是,因为在 worker 之间规约梯度的通信成本跟模型大小成正相关,所以当模型很大或通信带宽很低时,计算效率会受到限制。梯度累积是一种常见的用来均摊通信成本的策略,它可以增加batch size,在本地使用 micro-batch 进行多次正向和反向传播,在进行优化器更新之前再规约梯度,从而分摊通信成本。
模型并行 model parallell
它可以在多个 worker 之间划分模型的各个层。DeepSpeed 利用了英伟达的 Megatron-LM 来构建基于 Transformer 的大规模模型并行语言模型。模型并行会根据 worker 数量成比例地减少显存使用,这是这三种并行模式中显存效率最高的。但是其代价是计算效率最低。
显存效率:模型并行的显存使用量可以根据 worker 数量成比例地减少。至关重要的是,这是减少单个网络层的激活显存的唯一方法。DeepSpeed 通过在模型并行 worker 之间划分激活显存来进一步提高显存效率。
计算效率:因为每次前向和反向传播中都需要额外通信来传递激活,模型并行的计算效率很低。模型并行需要高通信带宽,并且不能很好地扩展到通信带宽受限的单个节点之外。此外,每个模型并行worker 都会减少每个通信阶段之间执行的计算量,从而影响计算效率。模型并行性通常与数据并行性结合使用,以便在内存和计算效率之间进行权衡。
总结
模型状态通常在训练过程中消耗最大的内存量,但是现有的方法,如DP和MP并不能提供令人满意的解决方案。DP具有良好的计算/通信效率,但内存效率较差,而MP的计算/通信效率较差。
更具体地说,
- DP在所有数据并行进程中复制整个模型状态,导致冗余内存消耗
-
虽然MP对这些状态进行分区以获得较高的内存效率,但往往会导致过于细粒度的计算和昂贵的通信,从而降低了扩展效率。
- 这些方法静态地维护整个训练过程中所需的所有模型状态,即使在训练过程中并非始终需要所有模型状态。
学习类型
在 迁移学习 中,由于传统深度学习的 学习能力弱,往往需要 海量数据 和 反复训练 才能 泛化
-
Zero-shot learning 就是希望我们的模型能够对其从没见过的类别进行分类,让机器具有推理能力,实现真正的智能。其中零次(Zero-shot)是指对于要分类的类别对象,一次也不学习。
-
One-shot learning 指的是我们在训练样本很少,甚至只有一个的情况下,依旧能做预测。
-
如果训练集中,不同类别的样本只有少量,则成为Few-shot learning。就是给模型待预测类别的少量样本,然后让模型通过查看该类别的其他样本来预测该类别。