https://github.com/chenzomi12/DeepLearningSystem/tree/main/06Foundation/03Storage

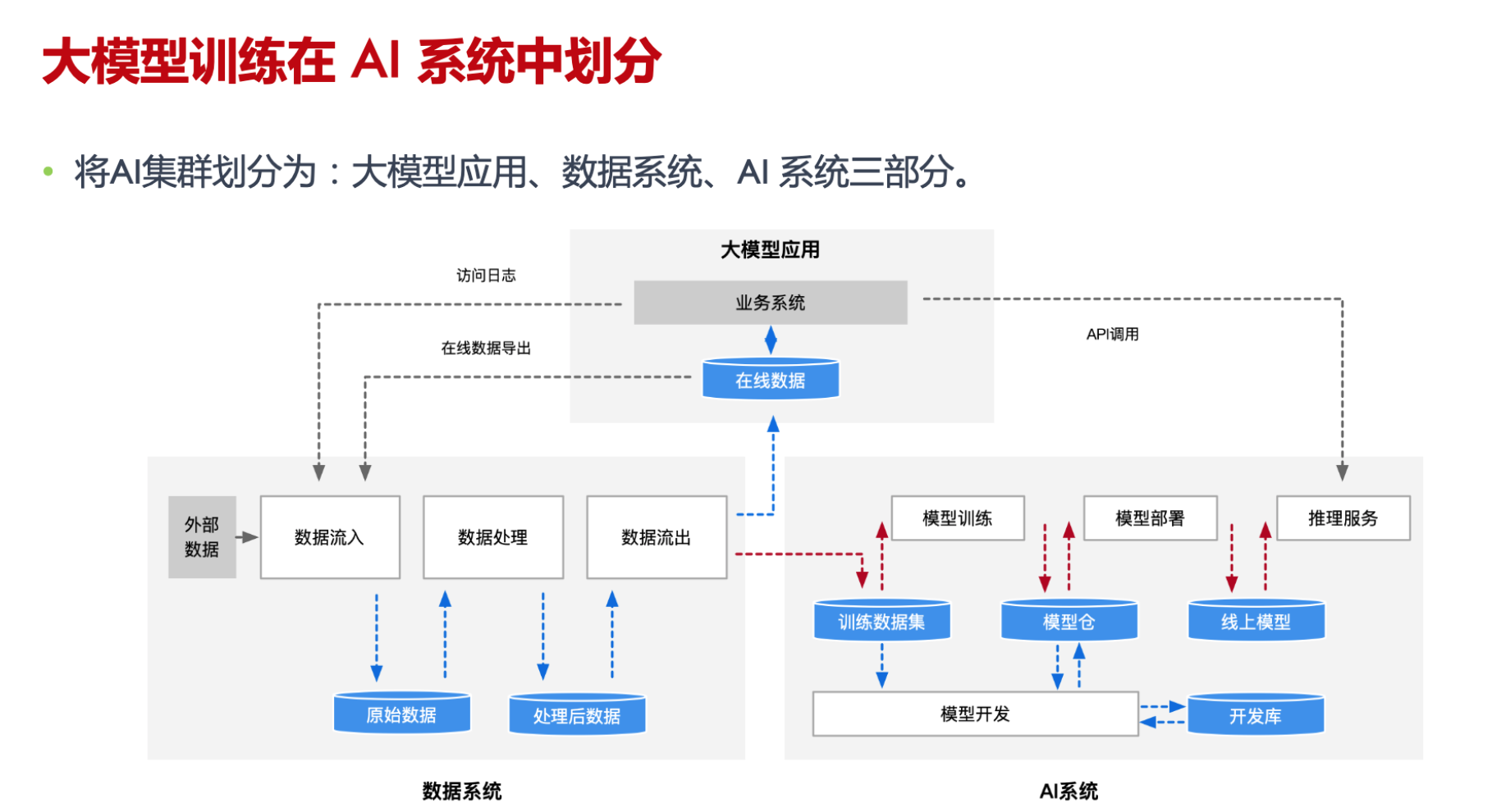
挑战
-
海量小文件的高并发、低延迟读写
海量多模态、异构小文件的高并发、低延迟读写。
LLMs 以文本语料为主,同时存在pdf、 doc、excel 等各种格式,甚至存在医疗、气象等专用格式。大部分为半结构化的数据,其大小从 10KB 到 100 KB 不等小文本文件,存在数亿级的文件数量.。大模型训练过程中,频繁从数据集取 Token,每 Token 4 Byte,实时高并发小IO性能需要极低延迟。存储性能瓶颈在于对小文件 OPS,而非带宽
-
异构多模态数据,需分布式并行读写 (NLP不在其中)
多模态数据快速训练加载,高度依赖分布式并行能力。
- 异构多模态文件数据间存在关联、嵌套关系,如图-文对应、文-视频对应等
- 异构数据需被高速加载到 LLMs 进行分布式训练,高并发、低延迟成为巨大挑战
-
超大规模非结构化数据,需海量存储空间 AI 大模型需要高质量、大规模、多样性的数据集 随着数据和模型规模的增长,数据量会呈现指数级增长,独立存储无法满足应用需求。海量存储空间和可以横向扩展的存储系统尤为重要,分布式存储解决方案势在必行
-
模型训练存储稳定性
模型训练过程中,需要提供稳定的训练断点保存和回复的存储能力为了减少 TTA,高吞吐和低延时为 NPU 计算提供数据支撑,减少 NPU 计算等待模型训练 Checkpoint 必不可少,优化 Checkpoint 并缩短其耗时,减少训练中断时间存储模型 Checkpoint 时间,为 Checkpoint 数据可快速写入,需要高带宽提升存储稳定性,避免每次故障元数据同步,需要停止服务重新拉起
问题主要集中在训练和预处理流程。
指标
-
IOPS(Input / Output Operations per Second)
每秒钟可以处理 I/O 数, 表示块存储处理读写。(输出/输入)的能力,单位为次,衡量存储系统 I/O 处理能力。
指标 描述 数据访问方式 总IOPS 每秒执行的I/O操作总次数 对硬盘存储位置的不连续访问和连续访问 随机读IOPS 每秒执行的随机读I/O操作的平均次数 对硬盘存储位置的不连续访问 随机写IOPS 每秒执行的随机写I/O操作的平均次数 顺序读IOPS 每秒执行的顺序读I/O操作的平均次数 对硬盘存储位置的连续访问 顺序写IOPS 每秒执行的顺序写I/O操作的平均次数 -
吞吐量 Throughput
- 吞吐量 = IOPS * I/O大小,单位时间内可以成功传输的数据数量,单位为MB/s,存储介质的 I/O越大,IOPS 越高,那么每秒 I/O 吞吐量就越高。
- 当应用 I/O 大小较大,例如离线分析、数据仓库等应用,可以选择吞吐量更大的存储产品。如果部署大量顺序读写的应用,需要关注吞吐量。当应用 I/O 对时延较为敏感,比较随机且 I/O 大小相对较小,例如OLTP事务型数据库、企业级等应用,可以选择 IOPS 更高的ESSD云盘、SSD云盘。
-
访问时延 Latency
时延指块存储处理一个 I/O 所需时间,即发起 I/O 请求到 I/O 处理完成的时间间隔,单位为 s、ms 或者 μs。过高的时延会导致应用性能下降或报错。
完成一个 IO 所花费时间(lat_io),对分布式存储系统来说,延时通常和如下几个因素有关:
- lat_send:发送请求的延时
- lat_recv:接收回复的延时
- lat_srv_process:服务器处理请求的延时
- lat_client_process: 客户端处理请求的延时
- n: 一次 IO 需要请求的数量
- 𝑙𝑎𝑡_𝑖𝑜 = (𝑙𝑎𝑡_𝑠𝑒𝑛𝑑 + 𝑙𝑎𝑡_𝑟𝑒𝑐𝑣 + 𝑙𝑎𝑡_𝑠𝑟𝑣_𝑝𝑟𝑜𝑐𝑒𝑠𝑠 + 𝑙𝑎𝑡_𝑐𝑙𝑖𝑒𝑛𝑡_𝑝𝑟𝑜𝑐𝑒𝑠𝑠) ∗ 𝑛
此外,延迟还和如下因素有关:
- 缓存及命中率:若IO请求缓存命中可以大幅减少IO延时。
- IOsize:IO越大时延越大,但也不是绝对的,还和块对齐以及具体实现相关。
- IOwait:IO等待时间,无论是网络IO还是磁盘IO或是存储实现,多采用队列保存请求,当队列长度 比较长时,就会有一部分时间是在队列中等待,进而影响 IO 延时。
-
带宽 bandwidth
以字节为单位衡量每秒钟的IO速率(bandwidth),即每秒钟可以处理的数据量,常以 MB/s 或GB/s 为单位,用于衡量存储系统的吞吐量。其通常与如下因素有关:
- IO Size:每次IO的字节数量(io_size)
- 并发数量:同时有多少并发请求(con_num)
- IOPS:每秒钟完成的IO数量。iops = con_num * lat_io
- 𝑏𝑎𝑛𝑑𝑤𝑖𝑑𝑡h = 𝑖𝑜_𝑠𝑖𝑧𝑒 ∗ 𝑖𝑜𝑝𝑠 = 𝑖𝑜_𝑠𝑖𝑧𝑒 ∗ 𝑐𝑜𝑛_𝑛𝑢𝑚 ∗ 𝑙𝑎𝑡_𝑖𝑜
- io_size 越大,带宽越大,但实践中通常4k、8k、16k当IO较少时满足这种正比关系,当io_size达 到1M、4M、8M时系统吞吐量并不会继续增加。因为太大 IO实现也会分解为若干小的IO执行, 此外io_size增加可能导致lat_io增加,可能会互相抵消。
优化
训练数据存储
-
大模型训练过程语料数据持续更新
-
训练数据在不同数据预处理流程中频繁流动。有必 要针对非结构化和半结构化数据提供专用存储系统,例如数据湖
数据湖存储类型: 文件系统 对象存储对比
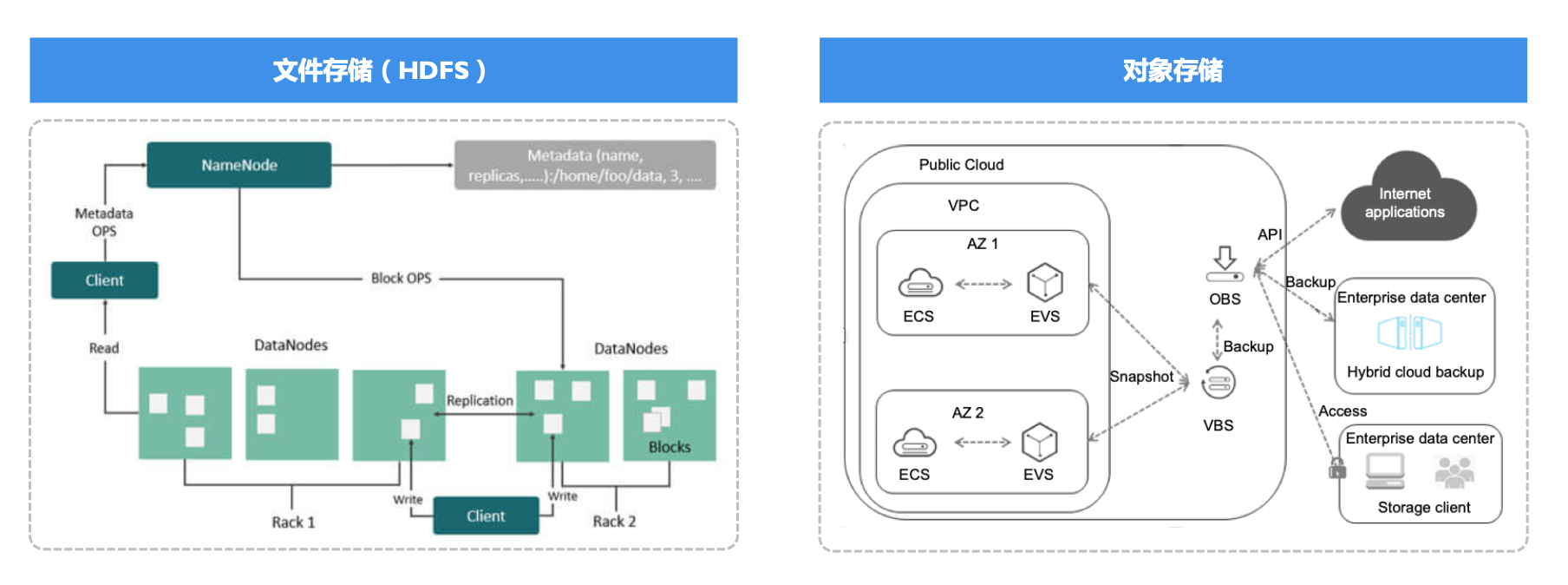
- 扩展能力:HDFS 采用集中式数据,规模受限。对象存储采用分布式数据可水平扩展,单集群可支持万亿文件、EB 级规模。
- 存储成本:HDFS 诞生于存算一体的时代。对象存储天然面向存算分离设计,结合 EC 编码、分级存储等丰富的能力,可以实现大规模数据长期保存的更优成本。
| 文件系统 | 对象存储 | |
|---|---|---|
| 扩展性 | NameNode 单点,层级命名空间 限制单集群上限10亿文件,PB级别容量 | 无架构扩展瓶颈 单集群可支持万亿规模文件,EB级别容量 |
| 成本 | 3X副本,存算一体架构,存储成本和计算成本同步增 长 | EC 编码,1.5X 副本容灾 存算分离架构,存储成本个存储容量相关 |
| 可用性 | 可容忍2个副本损坏 | 取决于EC校验块数量,18+6可容忍6个块故障 |
| 吞吐 | 集群规模相关 | 和集群规模强相关 |
| 生态 | 传统大数据领域接受度高 | 存算分离架构流行,AI 领域接受度高 |
总结:
将公开数据集、训练数据、模型结果统一存储到对象存储中(数据湖),实现不同形态的数据 统一存储和高效流转。
训练流程
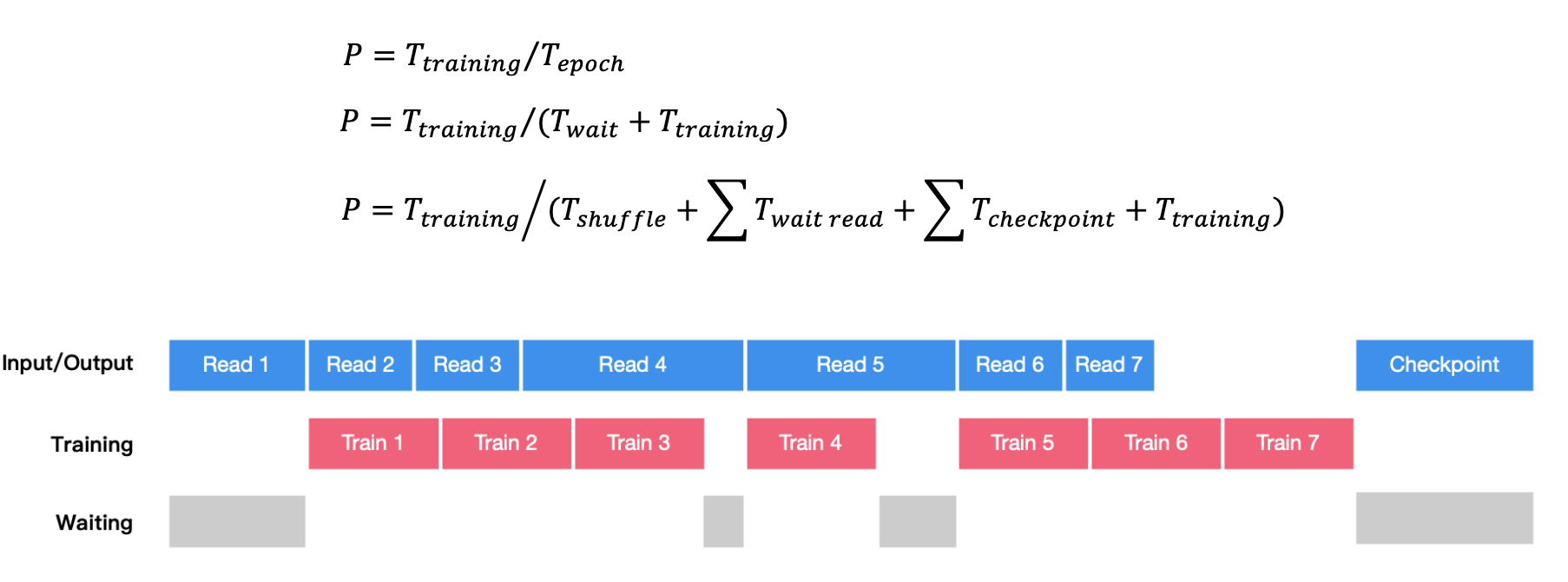
每轮 epoch 需要对数据集进行 Shuffle,然后将数据划分为 N batch,每次读取 1 batch 进行一次 训练迭代。周期性保存 Checkpoint 用于故障快速恢复。
分析
数据清洗过程
Shuffle 和Read数据读取对存储的操作:
-
Shuffle:元数据操作,主要是针对数据List
-
Read:元数据操作&数据本身的操作
1
2
3
4
5
6
7
8
9
10# trainging Epoch for each in epoch: # List files in the datasets # pre-processing of datasets for mbs in batch: # Read files of the batch # Training pass checkpoint.save()
对于大量小文件,延时和吞吐是性能关键
- 文件越小,元数据操作耗时占比越大
- 延时、吞吐是降低数据清洗过程关键
小文件对象存储
元数据性能影响:对象存储采用 key-value 方式维护元数据,很好解决 小文件规模扩展问题
操作 & 协议路径的影响:数据清洗 Shuffle 用到的 List 操作性能延时偏高,对象存储协议访问路径长,小文件频繁读取延时大
存储数据加载
训练执行与 IO 时序关系:每轮 Epoch 耗时由数据 Shuffle 时间、计算执行时间、数据读取等待。
优化方案
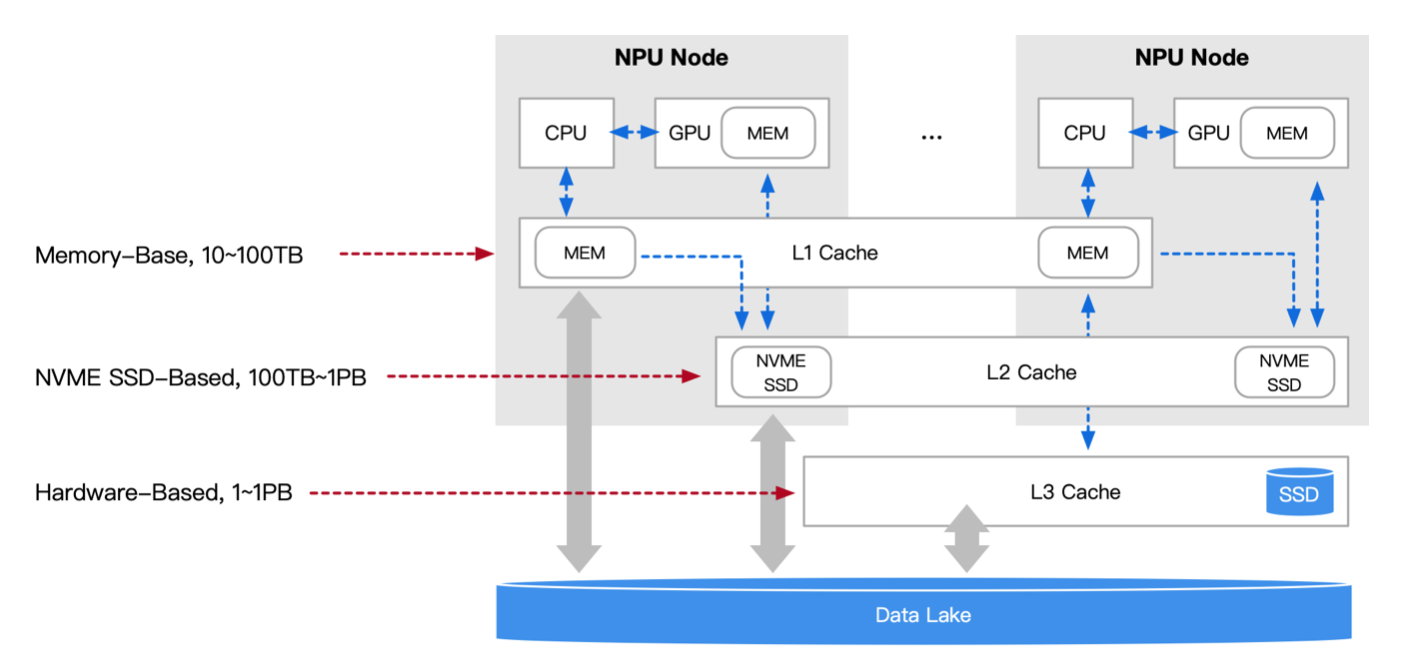
多层数据缓存
提供多层缓存加速,分层次提供远端、近端的数据读取性能。即按需将热数据缓存到 GPU 内 存和 Local 本地盘中,利用数据本地性提供高性能访问。e.g.,训练先将 Checkpoint 写到性能相 对容易保证的本地存储,再向远端对象存储服务器(数据湖)上传。
训练数据加载
尽量提高训练效率 and/or 利用率,减少 NPU 空闲,主要优化集中在
- 优化数据清洗过程,数据搬运和处理与计算重叠;
- 优化读取过程,让每 Epoch 读取数据耗时小于计算耗时,使得 I/O 时间被计算时间隐藏;
- 优化 Checkpoint 保存和加载过程,缩短 Checkpoint 耗时,减少训练中断时间;

调度优化减少数据等待
将数据集作为抽象实体统一管理,让非竞争性算力资源流水线化,提升计算利用率

同步的存储加速
与训练数据以小文件为主不同,大模型单个节点 checkpoint > 100GB。多个训练节点同时写, 需要恢复时又同时读,对存储提出了很高的吞吐要求。Checkpoint 保存和加载期间整个训练是中断的,因此提高吞吐,将 Checkpoint 耗时控制在尽量 小的占比,对于减少训练等待、提高计算资源利用率非常重要。
Checkpoint 直接写入 CPU 内存或 NVME SSD, 并采用流式 & 分块上传的方式,无需等 Checkp oint 全部写完就开始向数据湖上传。
- 异步写来突破上传对象存储的带宽限制。训练程序不用等待数据上传完成,即可恢复训练。其耗时取决于 NVME SS D 写入能力,极大缩短 Checkpoint 写入时间。
- 对于 Latest Checkpoint 采用异步写的同时,让其驻留在 CPU 内存,当训练需要恢复时直接读取,解决 Checkpoint 快速加载问题。
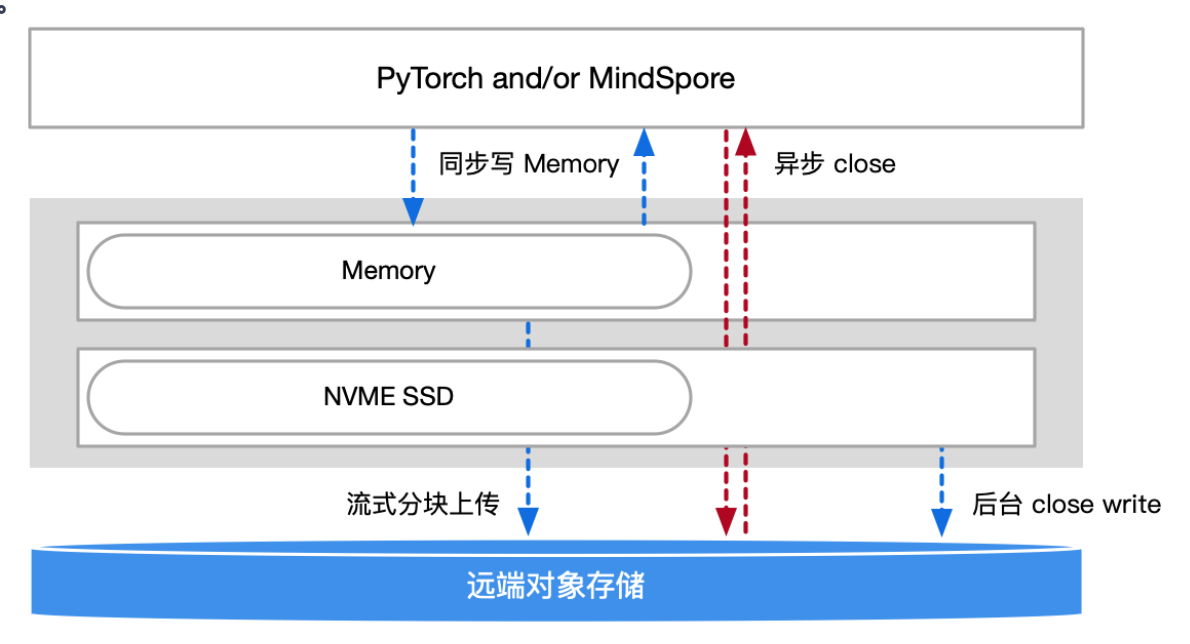
CKPT 保存流程
LLMs 中训练数据加载开销远小于整个训练过程开销,该优化收益有限(而且可 能影响用户使用习惯和降低易用性),因此很多存储优化方案专门针对Checkpoint。
频繁保存CKPT原因
大模型在训练过程中,可能会遇到硬件故障、系统问题、网络错误、液冷供给等问题。千卡AI 集群 2~3天,频繁中断会导致大模型训练难以丝滑持续进行,因此需要通过 Checkpoint(保存 模型权重参数) 来保存和恢复进度。
对于百/千亿参数 LLMs 大模型,Checkpoint 时间开销从分钟级到小时级不等(Checkpoint 存储 read/write 耗时与模型大小成正比) 。Save Checkpoint 时大模型训练任务需要暂停。
一旦大模型训练过程出现中断,之前迭代的 Epoch 次数在恢复时需要重新计算,通常会花费数 小时的时间。大模型训练过程一般使用 千卡规模 AI 集群,因此总体损失数千个 NPU 卡时间。
保存加载流程
- 大模型训练过程频繁保存和加载 Checkpoint(CKPT)都是个灾难
- Checkpoint 配置的频率,决定了 AI 集群中故障恢复后的重训成本
大模型因为模型参数量太大,需要切分到不同 NPU,每个 NPU 有独立的模型权重参数。
- Save :保存一次完整Checkpoint需要聚合所有NPU的权重信息,然后再回传对象存储服务器。
- Write:加载一次 Checkpoint 需要把聚合后的模型权重按照 AI 集群分布进行切分,逐个 NPU 加载。
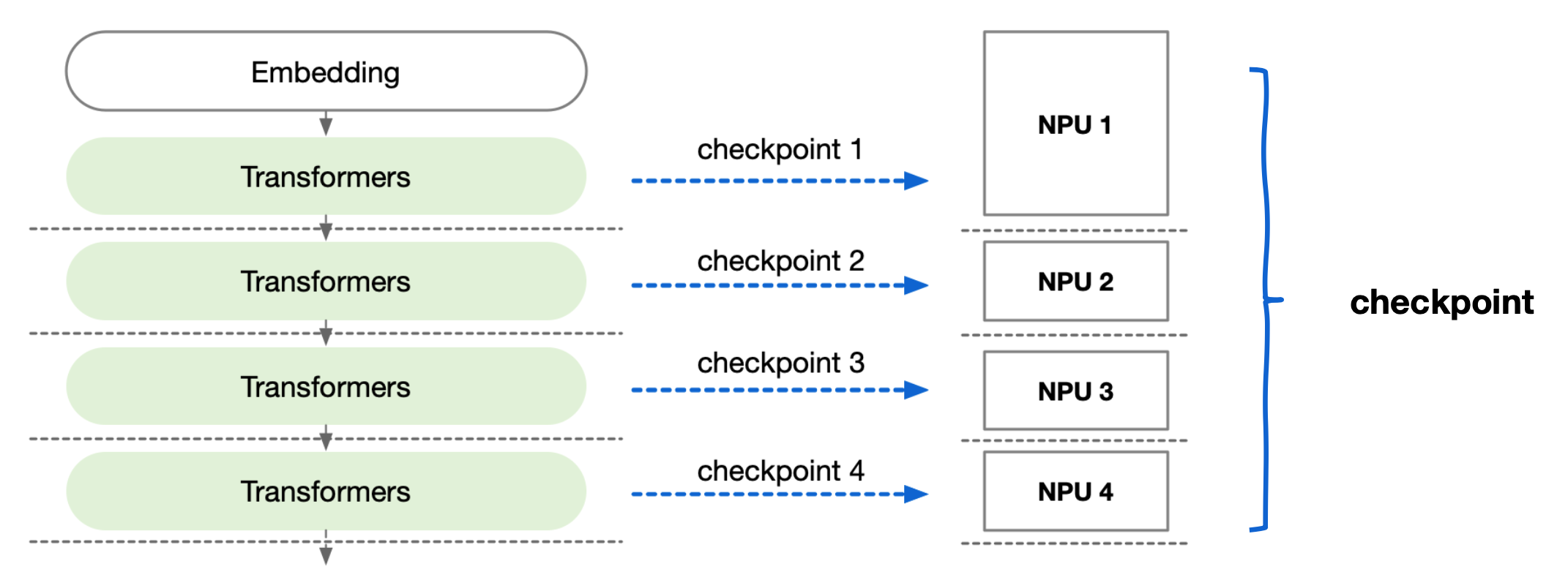
保存加载策略
什么时候应该完整保存 Checkpoint、什么时候直接保存单个 NPU Checkpoint
- 数据湖保存分片的 CKPT 和完整的 CKPT
- 程序定期保存分片 CKPT,定期汇聚分片 CKPT
加载时什么时候对完整 Checkpoint 进行切分后加载,什么时候直接加载
- 如果没有节点坏掉,中断恢复直接拉起分片存储 的 CKPT,便于加载
- 如果节点坏掉,使用完整的 CKPT 根据新的分布 式策略进行切分后重新拉起
文件成分分析
Checkpoint 主要存储是网络模型状态的元数据
- 网络模型权重参数Modelparameters
- 网络模型梯度参数Modelgradients
- 优化器状态信息OptimizerStatus
- 训练状态信息 T raining Status
- 配置信息Configuredata
Checkpoint 用途:故障快速恢复、二次训练、模型微调
Checkpoint 保存加载:torch.save() and torch.load()
-
torch.save()
网络模型在训练过程中会间隔一定时间保存一次 Checkpoint,用来记录当前训练的状态信息。
save() 数据序列化过程主要步骤
- pickler元数据序列化 data.pkl
- 网络模型结构信息
- 数据类型
- 序列化后模型层的key
- save存储数据 data.id_N
- 实际存储的张量 Tensor 数据
- pickler元数据序列化 data.pkl
-
torch.load()
save() 的逆操作过程,数据根据 I/O 顺序读,不做过度的分析
load() 数据反序列化过程主要步骤:
- pickler元数据反序列化
- read读取key对应的value数据
优化方案对比
优化 Checkpoint 保存和加载过程,缩短 Checkpoint 耗时,减少训练中断时间。
| 成熟度 | ||
|---|---|---|
| 将CKP T模型数据存放在数据湖 | save() and/or load() | 5 |
| CKP T的save过程从同步到异步 | save() | 2 |
| CKP T流式分块存储 | save() | 2 |
| 多文件加速聚合 | save() and/or load() | 4 |
| 本地内存缓存,同步写内存 | save() and/or load() | 4 |
| 数据拷贝过程使用零拷贝 | save() and/or load() |
将CKPT模型数据存放在数据湖
-
单节点:每个训练节点使用更快的NVME SSD代替HDD进行存储,再分层回传数据湖;
- 多节点:一个节点挂了,其CKPT被其他节点代替继续进行训练;
- 优点:大容量、高吞吐、数据可共享
save() 过程由同步到异步
- 将 save() 过程与下一轮的训练迭代并行,计算掩盖存储耗时。(系统崩溃、节点挂掉时需要处理数据部分写入逻辑。CKPT 添加 success 标记位便于恢复)
CKPT流式分块存储
采用流式 & 分块上传的方式,无需等 Checkpoint 全部写完到 Memory/SSD 就开始向数据湖上传。
系统崩溃、节点挂掉时需要处理数据部分写入逻辑。CKPT 添加 success 标记位便于恢复。
多文件加速聚合
torch.save() 将多个 tensor 分别写入各自文件 idx,对meta data要求高,写入开销大。
重写 torch.save()/load() 方法定义数据存储流程,聚合多个 tensor 数据文件;为了 load 过程中数据读取,保留每份数据的索引 index。
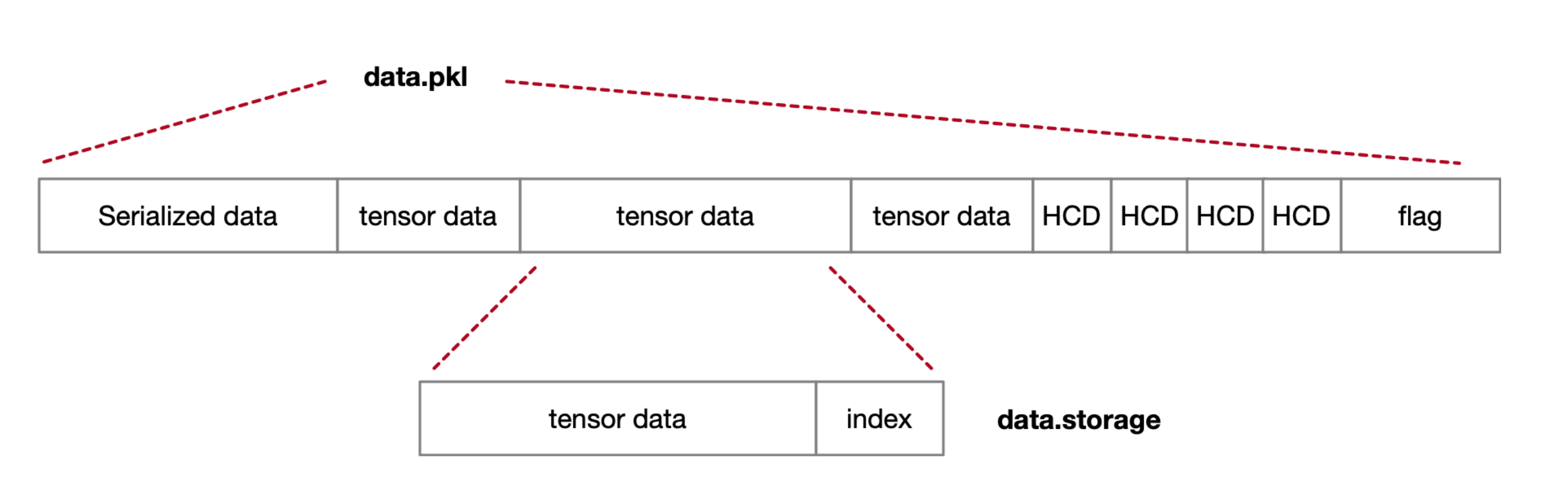
把多个tensor文件聚合传输,避免系统对小文件快速读写,减少IO开销。
本地内存缓存,同步写内存
对于 Latest Checkpoint 采用异步写的同时,CKPT save() 时驻留在 CPU 内存,当训练需要恢复 时 load() 直接读取,再从数据湖中读取备份到内存,解决 Checkpoint 快速加载问题。
数据拷贝过程使用零拷贝
通过操作系统的内核技术,实现用户 buffer 间的数据传递,达到数据零拷贝、内存节省的目的。 此时 CKPT 数据要求存放在节点内存中。
存算
近存计算的好处
- 减少数据在片内和片外的流动搬运,所带来的性能开销,减少时延
- 降低能耗,是系统架构发展的本质要求所驱动。
存算分离的好处
- 计算算力和存储能力能够根据自身业务动态 Scale,更容易扩展
- 计算、存储和网络关键指标不同,计算重吞吐,存储重稳定性,网络重时延
- 系统复杂度不同,存储对于系统复杂度容错率低,高可用度要求严苛
- NVIDIA H100 本质上属于存算分离架构,逻辑上把节点的内存和显存结合一 起,通过 NVLink 高速访问。