搜索引擎基础
搜索引擎指标
北极星指标:
-
用户规模、留存率。
-
单个策略不容易提升规模和留存
-
规模和留存指标更适合作为大盘长期指标观察。
- 评估整个团队长期的表现(所有策略叠加)。
- 长期优化搜索体验,规模和留存会稳定提升, 反映在 A/B 测试的 holdout 上。
中间指标:
- 用户的点击等行为,反映搜索质量的好坏。
- 与规模和留存强关联,做 A/B 测试,中间指标很容易显著。
人工体验评估:
- 人工评估搜索体验,考察 GSB、DCG 等指标。
- Side by side 评估,以 GSB 作为评价指标,对比新旧两种策 略,决策新策略是否可以推全(争议比较大!)
- 评估过于主观,评估标准未必与普通用户体验一致。
- 结果噪声大,稳定性不如 A/B 测试。
- 速度慢于 A/B 测试,影响开发迭代效率。
- 人工成本比较贵。
- 个性化较难处理,仅凭用户画像难以判断用户真实需求
- 月度评估:以平均 DCG 作为评价指标,与自己往期做对比、 与竞对做对比,判断搜索团队整体水平。
- Side by side 和月度评估的区别:
- 目的不同:前者决策新策略是否推全,后者判断搜索团队整体水平。
- 指标不同:前者的指标是GSB,后者的指标是 DCG。
- 有无争议:前者充满争议,后者没有缺点和争议。
北极星指标
用户规模
- 日活用户数(Daily Active User,DAU)
- 搜索日活(Search DAU),推荐日活(Feed DAU) 分情况
- 搜索渗透率 = Search DAU / DAU。搜索体验越好,用户 越喜欢用搜索功能,则搜索渗透率越高。
- 提升搜索日活、搜索渗透率的方法:
- 搜索的体验优化,可以提升搜索留存,从而提升搜索日活。
- 产品设计的改动,从推荐等渠道向搜索导流,提升搜索渗 透率,从而提升搜索日活。
留存率
APP 的次 7 日内留存(次 7 留)
- Feb 1有 1 亿用户使用 APP。
- 这 1 亿人中,有 8 千万在 Feb 2~8 使用 APP 至少一次。
- Feb1的次7留=8千万/1亿= 80%。
常用的留存指标:次 1 留、次 7 留、次 30 留
-
次 𝑛 留随 𝑛 单调递增:
-
次1留 ≤ 次7留 ≤ 次30留
-
APP 次 𝑛 留、搜索次 𝑛 留、推荐次 𝑛 留。
现在更流行 LT7 和 LT30 留存指标。
- 某用户今天登录 APP,未来 7 天中有4天 登录 APP,那么该用户今天的 LT7 等于 4。
- 显然有1≤LT7≤7和1≤LT30≤30
- LT 增长通常意味着用户体验提升。(除非 LT 增长且 DAU下降。)
中间指标
体验优化的策略往往同时改善多种中间指标:有点比、首屏有点比、平均首点位置、主动换词率、交互指标。
单个体验优化的策略很难在短期内显著提升留存指标。 (通常微弱上涨,不具有统计显著性。)
上述中间指标与留存有很强的关联。长期持续改善中间指 标,留存指标会稳定上涨。
点击率 & 有点比
优化搜索排序,通常会同时改善有点比、首屏有点比、平均 首点位置。三者与留存指标强相关。
文档点击率
- 曝光:用户在搜索结果页上看到文档,就算 曝光。
- 文档点击:在曝光之后,用户点击文档,进 入文档的详情页。
- 文档点击率:文档点击总次数 / 文档曝光总 次数。
有点比(查询词点击率)
- 查询词点击:用户点击搜索结果页上任意一 篇文档,就算“查询词点击”。
- 查询词点击率(有点比): 查询词点击总次 数 / 搜索总次数。
首屏有点比
- 查询词首屏点击:用户点击搜索结果页首屏 的任意一篇文档,就算“查询词首屏点击”。
- 查询词首屏点击率(首屏有点比):查询词 首屏点击总次数 / 搜索总次数。
- 首屏有点比 ≤ 有点比。
对比
- 文档点击率:10% 左右。
- 查询词点击率 (有点比):70% 左右。
- 查询词首屏点击率 (首屏有点比):60% 左右。
- 有点比重要性高于文档点击率
首点位置
平均首点位置:
- 一次搜索之后,记录第一次点击发生的位置。
- 如果没有点击,或者首点位置大于阈值 𝑥,则首点位置取 𝑥。
- 对所有搜索的首点位置取平均。
平均首点位置小,说明符合用户需求的文档排名靠前,用户 体验好。
主动换词率
-
如果用户搜到需要的文档,通常不会换查询词。
-
例:女性用户搜“机械键盘”,结果大多是黑色的,不符合用户喜好(个性化差)。用户会换词为“机械键盘 女性”。
-
例:搜“权利的游戏”,搜索引擎没能自动纠错,搜到的文 档很少、质量不好。用户会换词为“权力的游戏”
-
-
一定时间间隔内,搜的两个查询词相似(比如编辑距离小),则被认定为换词
主动换词 vs 被动换词 要区分
- 被动换词,比如搜索建议“您是不是想搜 权力的游戏”,用户 点击建议。
- 主动换词,原因是没有找到满意的结果,说明搜索结果不好。
交互指标
用户点击文档进入详情页,可能会点赞、收藏、转发、关 注、评论
- 交互通常表明用户对文档非常感兴趣(强度大于点击), 因此可以作为中间指标(类似于有点比、首点位置、换词 率)。
- 交互行为稀疏(每百次点击,只有 10 次点赞、2 次收藏), 单个交互率波动很大,而且在 A/B 测试中不容易显著。
- 取各种交互率的加权和作为总体交互指标(解决波动大的问题),权重取决于交 互率与留存的关联强弱
人工体验评估
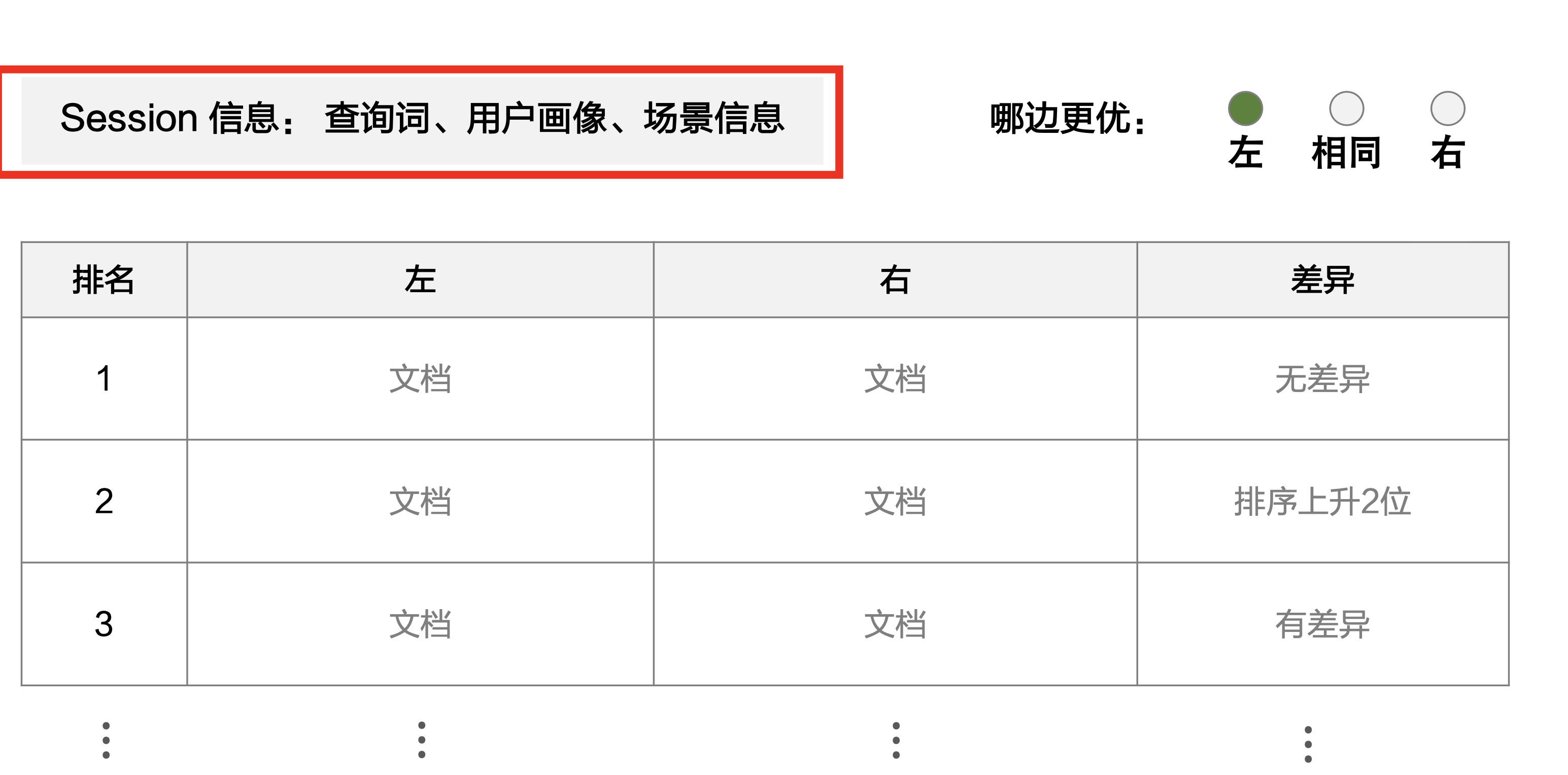
Side by Side 评估
随机抽一批搜索日志,取其中查询词、用户画像、场景。运行新旧两种策略,得到两个搜索结果页(文档列表)
- 固定查询词、用户、场景,搜索结果的差异只来自于策略。
- 随机抽样搜索日志时,需要覆盖高频、中频、低频查询词。
对于一条查询词,人工评估两个列表,分别对应新旧两种策略。
- 基于查询词、用户画像、搜索场景,判断左右两个列表谁更好。
- 盲评,即新策略出现在左、右的概率都是 50%。
- 不是判断具体哪篇文档更好,而是判断哪个列表整体更好
使用 GSB 作为评价指标。
- 如果新策略更优,记作 Good (G)。
- 如果两者持平,记作 Same (S)。
- 如果旧策略更优,记作 Bad (B)。
- 例:评 300 条查询词,GSB 为 50: 220: 30。
月度评估
每个月随机抽取一批搜索日志,每条搜索日志包含查询词 𝑞、 用户 𝑢、场景 𝑐、排名前 𝑘 的文档 𝑑1。。。dk
- 随机抽样搜索日志时,需要覆盖高频、中频、低频查询词。
- 文档数量 𝑘 取决于平均下滑深度,比如 𝑘 = 20
标注员评估每一篇文档i,打分 score( 𝑞, 𝑢, 𝑐, 𝑑i)
- 可以单独给相关性、内容质量、或时效性打分。
- 可以只打一个综合满意度分数。
用 DCG 评价一次搜索 𝑞,𝑢,𝑐,𝑑1。。。dk 结果的好坏
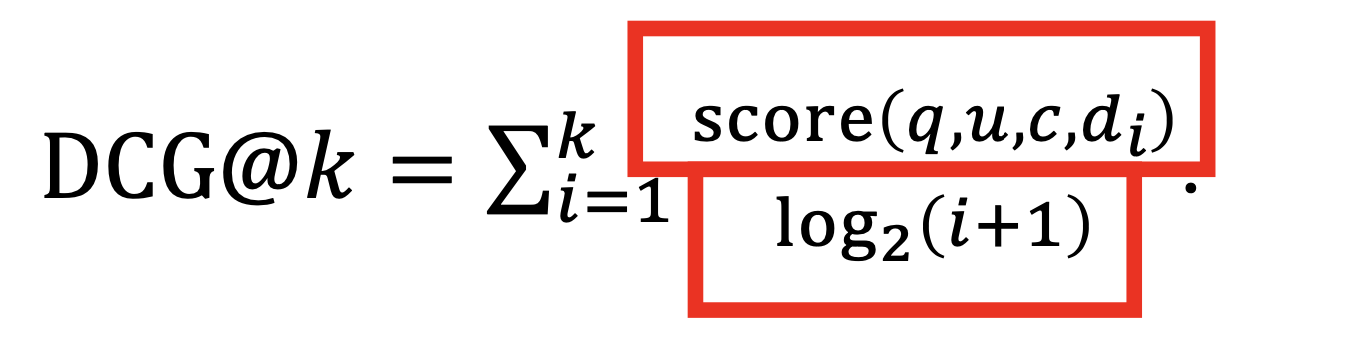
对所有搜索日志,取 DCG 的均值,作为月度评估的结果。
- 可以是自我对比,是否优于往期的 DCG。
- 可以与竞对对比,是否优于竞对的 DCG
垂搜 通搜
垂直搜索
针对某一个行业的搜索引擎 (电商,酒店机票,招聘)
-
垂搜的文档普遍是结构化的,容易根据文档属性标签做 检索筛选
- 电商:可以限定品牌、卖家、价格、颜色。
- 学术:可以限定关键词、作者、期刊、年份。
- 本地生活:可以限定类目、商圈、距离。
-
垂搜用户的意图明确
- 大众点评用户搜索“寿司”,目的是找寿司餐厅。
- 淘宝用户搜索“拳击”,目的是找拳击相关的商品。
通用搜索
覆盖面广,不限于一个领域(谷歌、百度、必应)
- 文档来源广,覆盖面大
- 没有结构化,检索的难度大
- 用户使用通搜的目的各不相同,较难判断用户意图
用户满意度
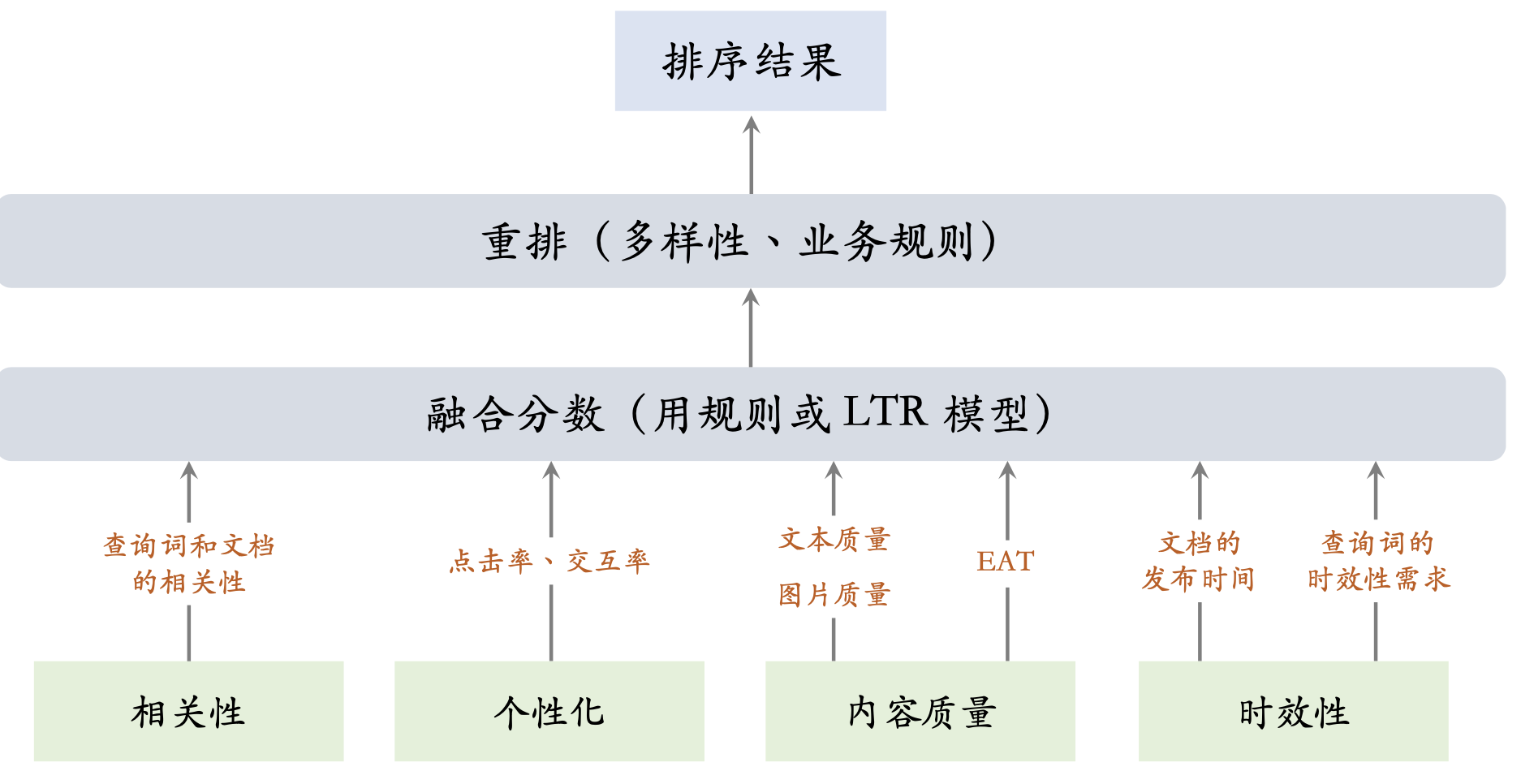
相关性、内容质量、时效性是影响用户满意度的三大因素。
移动互联网时代,个性化、地域性也会影响用户满意度。
通用搜索引擎迭代优化的目标是让用户更满意。
- 如何让用户更满意?提升相关性、内容质量、时效性、个性化。
- 如何评价用户体验?留存、有点比等客观指标;人工评估的主 观指标。
相关性
相关性是查询词q与文档d两者的关系
- 相关性是客观标准,不取决于用户u。(如果大多数有背景知识的人认为 (q,d)相关,则判定为相关。)
- 相关性是语义上的,不是字面上的。(相关是指d能满足q的需求或回答 q提出的问题。)
- 查询词 q可能有多重意图。只要 d命中 q 的一种主要 意图,则 (q,d)相关
内容质量
EAT 是谷歌提出的内容质量评价标准,针对作者、网站。
- 专业性(Expertise): 作者有专业资质,比如医生、记者等。
- 权威性(Authoritativeness): 作者、网站在领域内有影响力, 不会被用户质疑。
- 可信赖(Trustworthiness): 作者、网站的名声好坏。
对于 your money (财税,购物等) or your life (医疗,法律,就业等)方面的查询词,EAT 是排序的重要因子
文本质量:文章写得好不好?
- 文章的价值:文章是否清晰、全面,事实是否准确,信息是否有用。
- 作者的态度和水平:写作是否认真、写作的专业程度、写作的技巧。
- 宠物饲养:解释清楚、事实正确,对读者有价值。
- 笑话:好笑。
- 影评:清晰、全面、公正、深刻。
- 文章的意图:有益、有害
- 有益:分享有用的知识、攻略、亲身经历。
- 有害:虚假信息、软广、散布仇恨、男女对立、发泄情绪。
-
标题党、图文不一致、虚假引流标签、堆砌关键词
- 图片质量(或视频质量):分辨率、有无水印、是不是 截图、图片是否清晰、图片的美学
文本质量不是一个分数,而是很多个分数,在搜索排序 中起作用
- 对于每个文本质量分数,都有一个专门训练的模型。
- 模型:BERT 等 NLP 模型、CLIP 等多模态模型
- 数据:制定分档规则,然后人工标注
- 在文档发布、或被检索时,用模型打分,分数存入文档 画像。
时效性
优化搜索时效性的关键是识别查询词的时效性意图 (即查询词对“新”的需求)。
- 分类:突发时效性、一般时效性(强/中/弱/无)、 周期时效性。
- 识别方法:数据挖掘、语义模型
突发时效性
-
查询词涉及突发的新闻、热点事件
-
如果查询词带有突发时效性,那么用户想看最近发布的文档
- 识别方法:以数据挖掘为主。
- 挖掘站内搜索量激增的查询词。
- 挖掘站内发布量激增的关键词。
- 爬取其他网站的热词。
- 为什么不能用 BERT 等自然语言模型
- 人擅长什么,深度学习就擅长什么,人擅长判断文字质量、相关性,BERT 也擅长
- 如果不借助新闻媒体,人无法判断突发时效性
一般时效性
只看查询词字面就可以判断时效性意图的强弱。(无需知 道近期是否有大新闻。)
- 按需求强度分为 4 档:强、中、弱、无。
- 识别方法:BERT 等语义模型
周期时效性
- 在每年特定时间表现为突发时效性,在其 他时间表现为无时效性
- 双十一、春晚小品、高考作文、奥斯卡
- 可以不做任何处理。(当查询词表现出突发时效性时,会被算法挖掘到。)
- 可以通过人工标注、数据挖掘识别周期时效性查询词
个性化
考虑到不同用户有不同偏好,搜索引擎可以根据用户特征 做排序(类似推荐系统)
- 用预估点击率、交互率来衡量用户对文档的偏好。
- 结合相关性、内容质量、时效性、个性化(预估点击率和 交互率)等因子对候选文档排序。
为什么需要个性化和点击率模型
- 查询词越宽泛(例如“头像”),就越需要个性化排序
- 宽泛的查询词(例如“头像” )相关的文档数量巨大,其中小部分是用户感兴趣的。
- 精准的查询词(例如“权力的游戏龙妈头像” )不需要个性化。
- 预估点击率和交互率有利于提升相关性和内容质量
- 相关且高质量的文档更容易被点击、点赞、收藏、转发
- 与 BERT 等语义模型互补,解决 bad case。
- 即便是非个性化排序,也会用模型预估点击率和交互率,有助于 提升排序效果。
搜索引擎链路
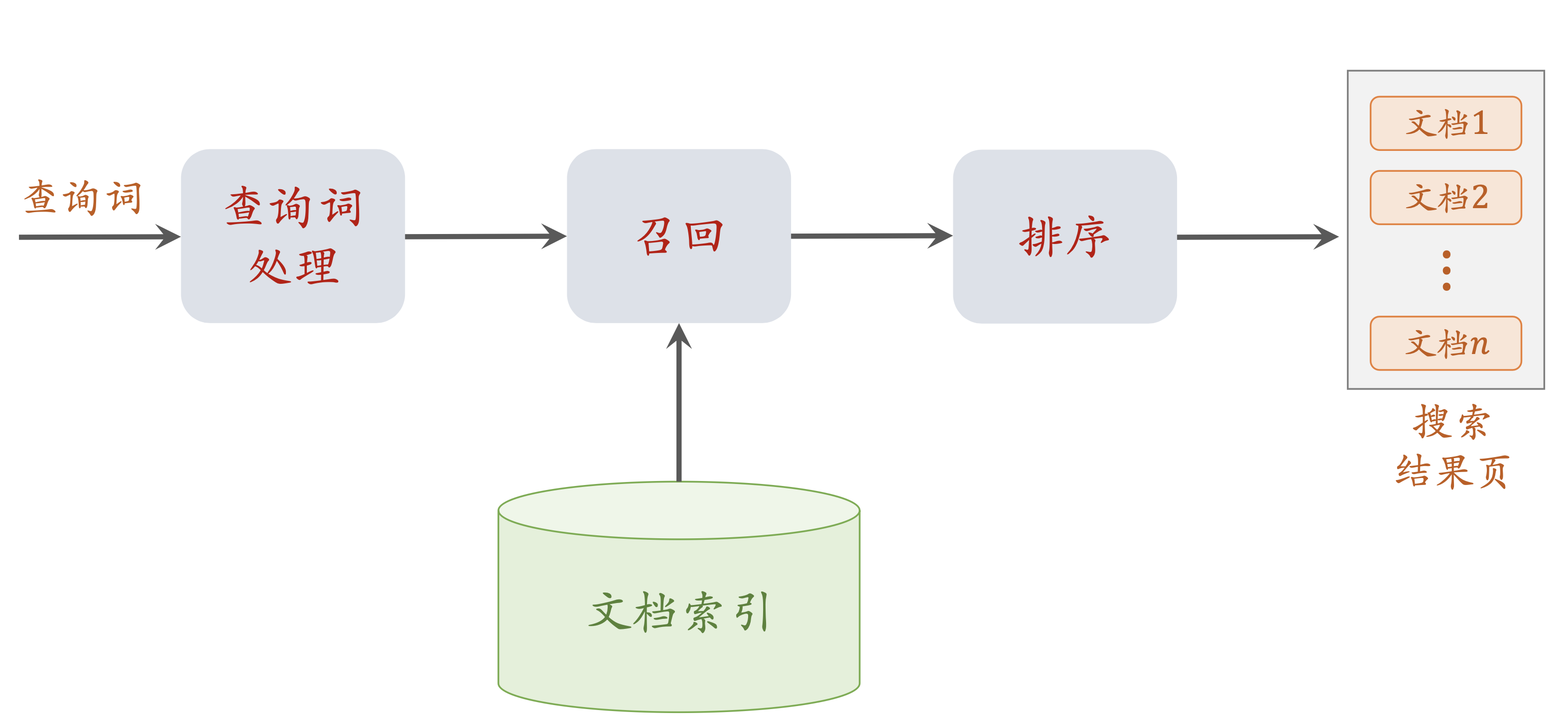
查询词处理
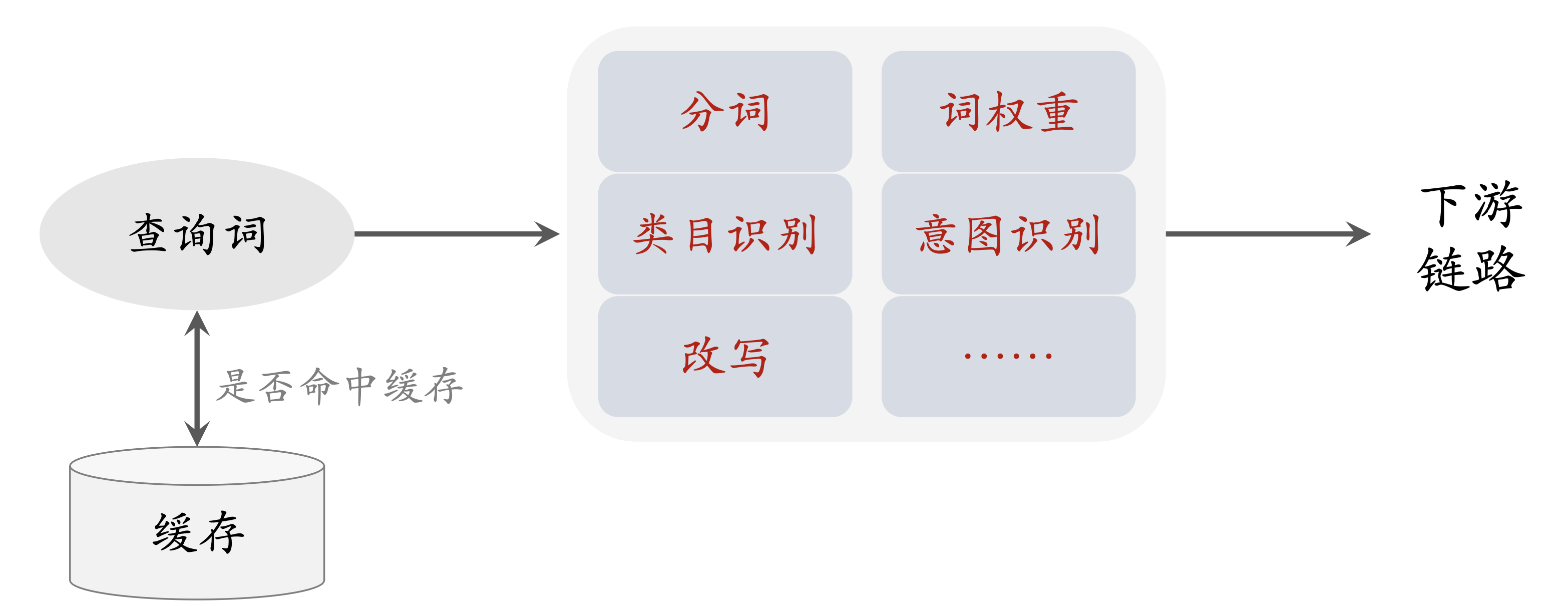
分词(Tokenization)
为什么需要做分词(向量召回可以不需要)
- 文本召回根据词 (term) 在倒排索引中检索文档。
- 倒排索引的 key 大多是“冬季”、“卫衣”、“推荐”这样的常 用词,数量不大
- 假如倒排索引的 key 是“冬季卫衣推荐”这样的词,倒排 索引会过于巨大
词权重(Term Weight)
冬季卫衣推荐 -> 冬季 / 卫衣 / 推荐
三个词同等重要吗?丢弃一两个词可以吗?
词权重: 卫衣 > 冬季 > 推荐
为什么要计算词权重
- 如果查询词太长,没有文档可以同时包含其中所有词,需要丢弃不重要的词(方便召回)
- 计算查询词与文档的相关性时,可以用词权重做加权(召回根据相关性)
类目识别
每个平台都有各自的多级类目体系
用NLP技术识别文档、查询词的类目
- 在文档发布(或被爬虫获取到)时,离线识别文档类目
- 在用户做搜索时,在线识别查询词的类目
召回模型、排序模型将文档、查询词类目作为特征
查询词意图识别
时效性意图:查询词对文档“新”的需求,召回和排序均需要 考虑文档的年龄。
地域性意图:召回和排序不止需要文本相关性,还需要结合 用户定位地点、查询词提及的地点、文档定位的地点。
用户名意图:用户想要找平台中的某位用户,应当检索用户 名库,而非检索文档库。
求购意图:用户可能想要买商品,同时在文档库、商品库中 做检索。
查询词改写(可以大幅提升体验)
用户输入查询词 𝑞,算法将其改写成多个查询词q1…..qk (独立用𝑞,q1…..qk 做召回,对召回的文档取并集。)
查询词改写有什么用
- 解决语义匹配、但文本不匹配的问题 (代词,缩略词等)
- 𝑞 = “LV包” ,𝑑 = “推荐几款LOUIS VUITTON包包”
- 𝑞 和 𝑑 语义相关,但文本召回无法用 𝑞 检索到 𝑑。
- 解决召回文档数量过少的问题 (𝑞 不规范表达、或 𝑞 过长,导致召回结果很少)
召回
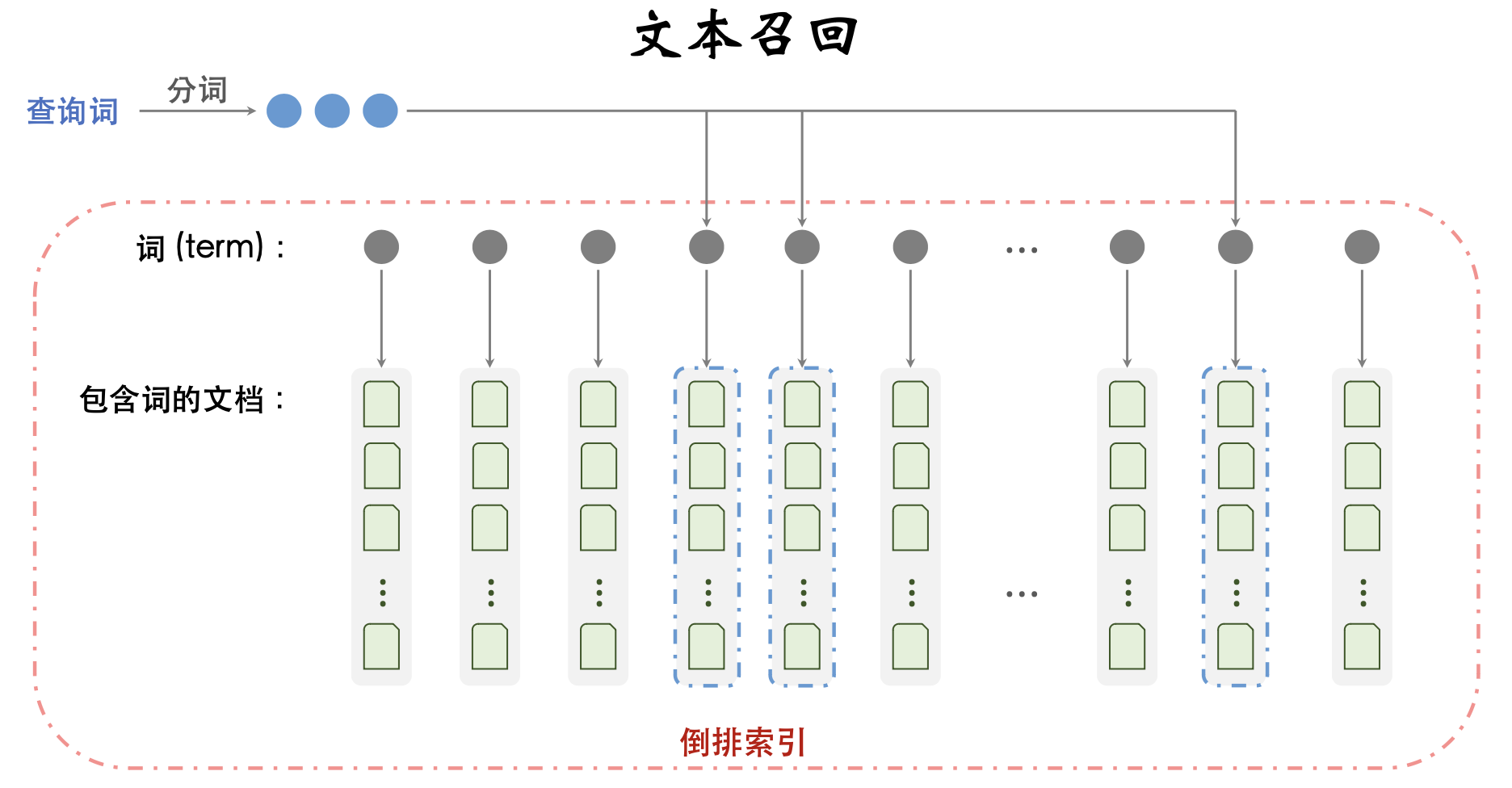
文本召回:借助倒排索引,匹配 𝑞 中的词和 𝑑 中的词。
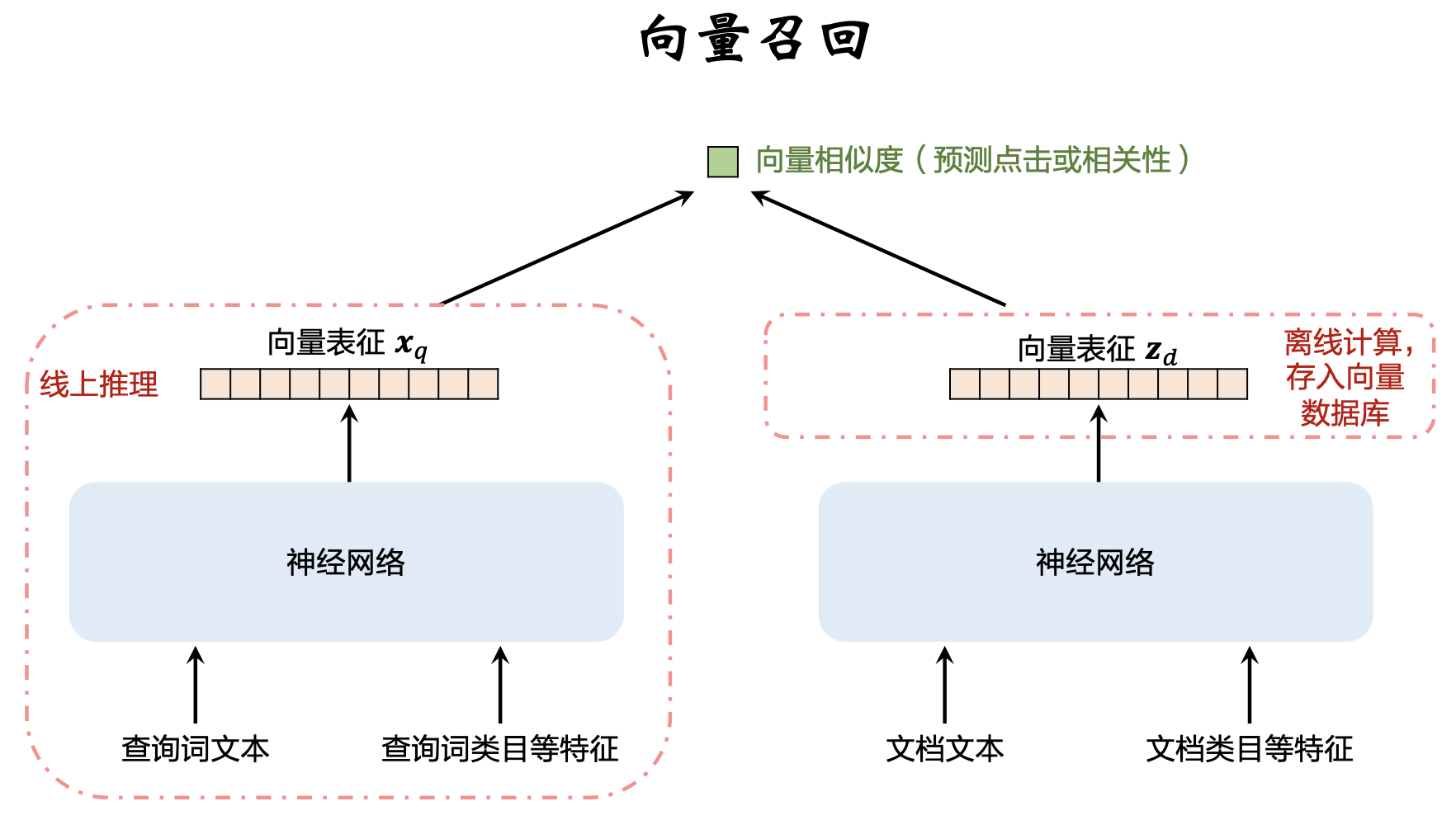
向量召回:将 𝑞 和 𝑑 分别表征为向量 𝒙’和 𝒛。给定 𝒙’,查找相似度高的 𝒛。
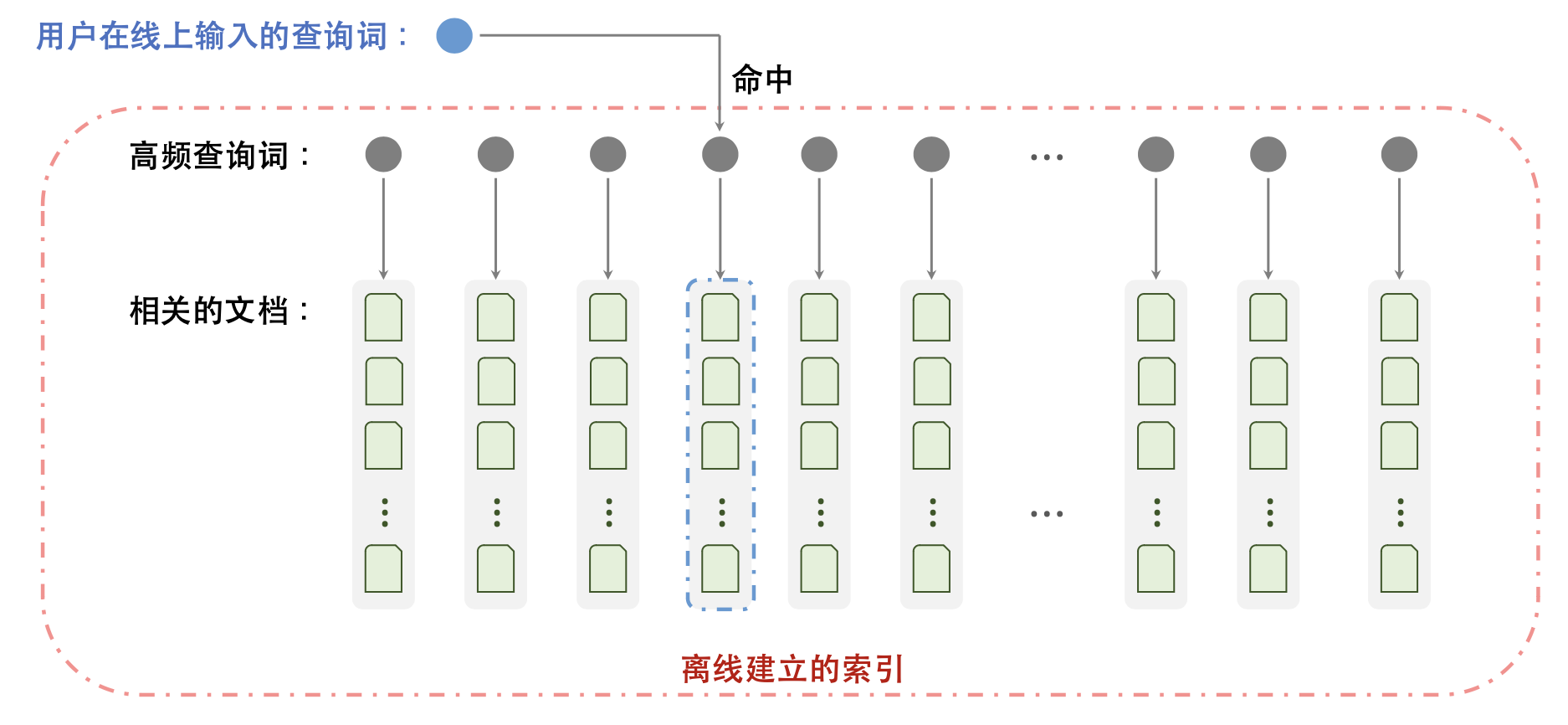
KV召回:对于高频查询 𝑞,离线建立 𝑞 → List⟨𝑑⟩ 这样的 key-value 索引。线上直接读取索引,获取 𝑞 相关的文档
文本召回
- 离线处理文档,建立倒排索引。(给定词 𝑡,可以快速找到 所有包含 𝑡 的文档。)
- 给定查询词 𝑞,做分词得到多个词 𝑡1,⋯,𝑡k。
- 对于每个词 𝑡,检索倒排索引,得到文档的集合 𝒟。
- 求 𝑘 个集合的交集 𝒟1 ∩ ⋯ ∩ 𝒟k ,作为文本召回的结果。
- 交集可能很小、甚至为空。因此需要对 𝑞 做丢词、改写
向量召回
KV召回
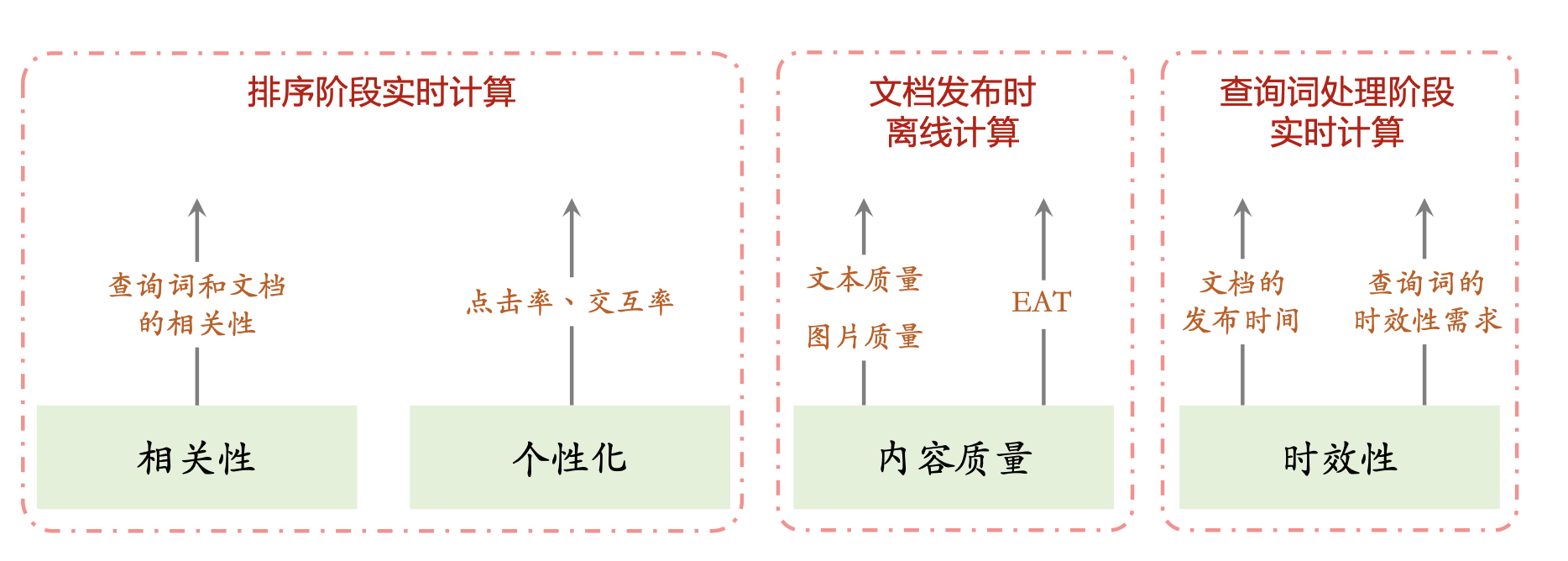
排序
相关性:重要性最高,在线上用 BERT 模型实时计算查询词和文 档的相关性。
内容质量:指文档的文本和图片质量、以及作者或网站的 EAT。 算法离线分析文档的内容质量,把多个分数写到文档画像中。
时效性:主要指查询词对“新”的需求。查询词处理分析时效性, 把结果传递给排序服务器。
个性化:在不同的搜索引擎中,个性化的重要性各不相同。在线 上用多目标模型预估点击率和交互率(与推荐系统几乎相同)。
相关性
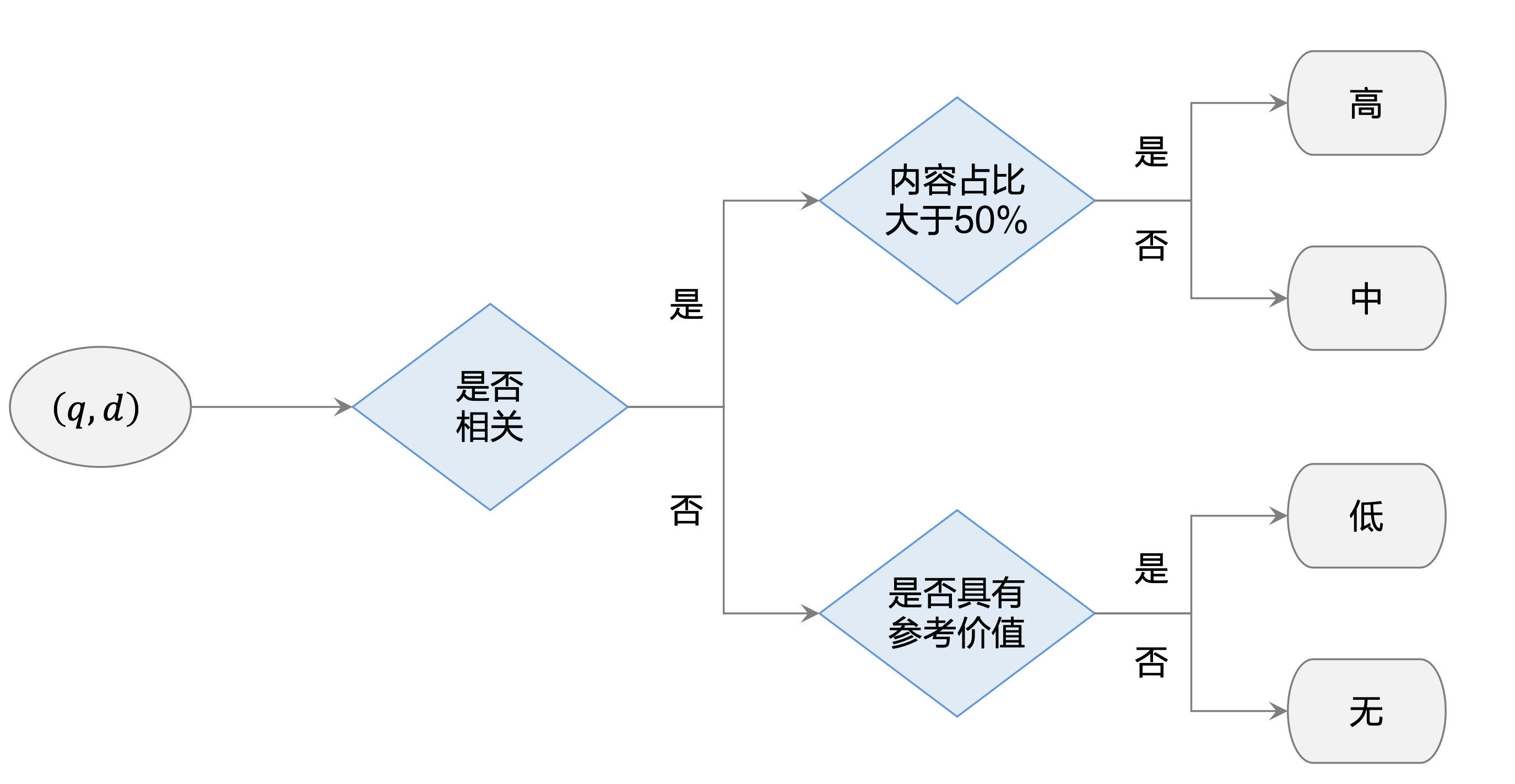
制定标注规则和 标注数据
-
人为将 𝑞, 𝑑 的相关性划分为 4 个(或 5 个)档位。
- 相关性分档规则非常重要!假如日后有大幅变动,需要重 新标注数据,丢弃积累的数据。
- 产品和算法团队监督指导标注团队的工作,累积数十万
- 算法团队用人工标注的数据训练相关性模型
相关性是指 𝑑 能满足 𝑞 的需求或回答 𝑞 提出的问题
-
𝑞, 𝑑 满足需求匹配,不是纯粹字面匹配,哪怕 𝑞 和 𝑑 字面上完全不匹配,两者也可以被判定为相关,即便 𝑞 和 𝑑 字面匹配,两者也可能不相关
- 匹配 q: 谁掌握芯片制造的尖端技术 d: 全球最先进的光刻机都由荷兰 ASML 公司制造
- 不匹配 q: 巴伦西亚旅游 d: 我去巴伦西亚旅游, 吃到了最好最正宗的西班牙海鲜饭,回 来研究了一番,这个视频给大家介绍西班牙海鲜饭的做法
-
相关性标注只考虑相关性,不考虑内容质量、时效性等因素
- 内容质量的问题,不是相关性的问题:𝑞 = 什么药物可以治愈新冠? 𝑑 = 一则虚假广告,声称某种草药可以治愈新冠,并用阴阳调 和原理解释该草药克制新冠病毒。
- 满足相关性,但是时效性低:𝑞 = 上海落户政策,𝑑 = 一篇过时的文章,介绍2015年的上海落户政策。
-
查询词 𝑞 可能有多种意图,文档 𝑑 只需命中一种意图就算 相关。(只是个性化,用户画像的问题)
-
搜上位词,出下位词,判定为相关,搜下位词,出上位词,判定为不相关
- 搜 𝑞 = “红色口红”,出 𝑑 = “玫红色口红” 相关
- 搜 𝑞 = “潮汕美食”,出 𝑑 = “经典广东菜”。 不相关
-
丢核心词、重要限定词,判定为不相关;丢不重要的限定词,判 定为相关
-
搜 𝑞 = “情人节餐厅”,出 𝑑 = “情人节礼物”。
- 搜 𝑞 = “黄石公园春季旅游”,出 𝑑 = “黄石公园秋季旅游” 。 (判定困难)
- 具体要看 𝑑 能否满足 𝑞 的主要需求或回答 𝑞 提出的问题。
- 搜 𝑞 = “精彩的好莱坞动作片”,𝑑 = “好莱坞动作片 top 10” 可以满足 𝑞 的需求,所以相关。
- 搜 𝑞 = “精彩的好莱坞动作片”,𝑑 = “精彩的宝莱坞动作片” 无法满足 𝑞 的需求,所以不相关。
-
标注的流程
由算法团队抽取待标注样本
- 从搜索日志中随机抽取 𝑛 条查询词。既有高频查询词,也有中、低频查询词
- 给定 𝑞,从搜索结果中抽取 𝑘 篇文档,组成二元组$( 𝑞, 𝑑_1)$ , ⋯,$(𝑞,𝑑_k)$ 。4个相关性档位的样本数量尽可能平衡
- 不能直接取搜索结果页排名 top 𝑘 的文档,否则高档位文档 过多,低档位文档过少, 不利于训练
由产品团队和算法团队监督标注过程和验收结果
- 遇到难以界定档位的 𝑞, 𝑑 ,由产品和算法团队做界定和解 释。
- 一条样本由至少两人标注,两人标注的结果需要有一致性。
- 一致率大于某个阈值(例如 80%)才会被接受。
- 产品团队抽查标注结果,要求准确率高于某个阈值。
- 可以事先往数据中“埋雷”(产品团队自己标注的样本),考 察埋雷样本的标注准确率。
相关性的评价指标
- Pointwise 评价指标:Area Under the Curve (AUC)。
- 单独评价每一个 (q,d)二元组,判断预测的相关性分数与真实标签的相似度。
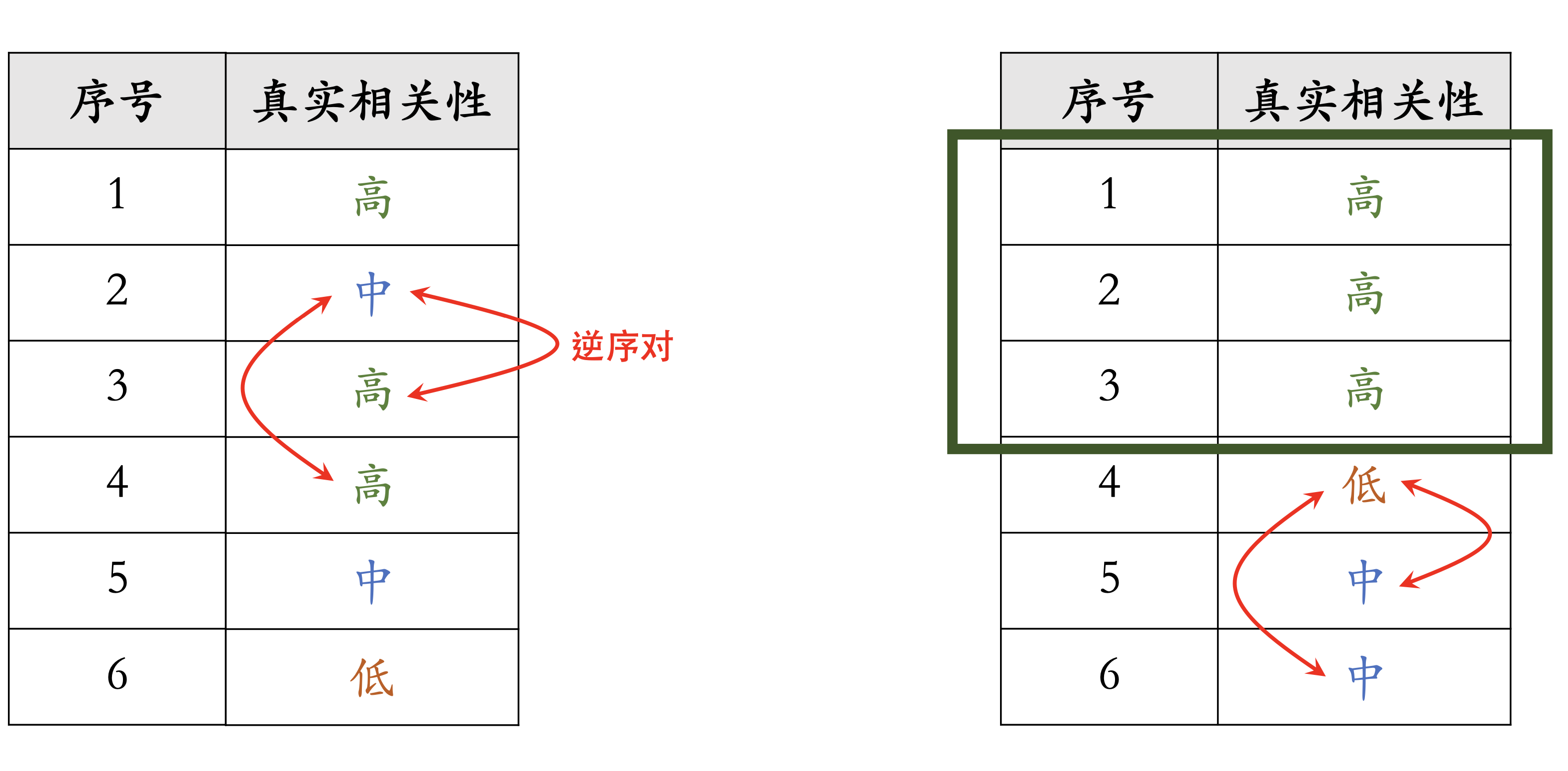
- Pairwise 评价指标:正逆序比 (Positive to Negative Ratio,PNR)。
- 对比 $(q,d_1)$和$(q,d_2)$,判断两者的序是否正确(正序对或逆序对)
- Listwise 评价指标: Discounted Cumulative Gain (DCG)。
- 对比 $(q,d_1)$…….$(q,d_n)$,判断整体的序 关系的正确程度。
用 AUC 和 PNR 作为离线评价指标,用 DCG 评价模型在 线上排序的效果。
Pointwise 评价指标
二分类评价指标
- 把测试集相关性档位转化为 0/1。
- 高、中两档合并,作为标签 y= 1。
- 低、无两档合并,作为标签 y = 0。
- 相关性模型输出预测值y∈ 0,1。
用 AUC (ROC线下面积)评价模型的预测是否准确。
Pairwise 评价指标
正逆序比(PNR)
- 根据模型估计的相关性分数 p对文 档做排序。(不知道真实相关性分 数。)
- 它们的分 数满足p1>…..> p6。
- 有k篇文档,则 $\begin{pmatrix}k\2\end{pmatrix}=\frac{k!}{2!\times(k-2)!}$种方式将文档两两组合
- $\mathrm{例中}k=6,有\begin{pmatrix}6\2\end{pmatrix}\;={15\mathrm{种组合}}$,有 2 个逆序对,13 个正序对
- PNR = 13/2
缺点只考虑了文档之间的序,而没有考虑整体的序,PNR一样,但明显右边比较好效果,listwise指标可以区分
Listwise 评价指标
逆序对出现的位置不影响 pairwise 指标。
逆序对越靠前,对 listwise 指标造成的损失越大。
CG@k
- $有n\mathrm{篇候选文档},\mathrm{根据模型打分做降序排列}\mathrm{它们的真实}\;\mathrm{相关性分数为}y_1…..y_n$
- $\mathrm{只关注排在前}\;k(k\;\ll\;n,)\;\mathrm{的文档},\mathrm{它们最可能获得曝光},\;\mathrm{对用户体验的影响最大}。$
- $Cumulative\;Gain:\;CG@k\;={\;{\textstyle\sum_{i=1}^k}\;}y_i$
- CG@k 最大化
- 真实相关性分数 y最高的k 篇文档被模型排在前k
- 缺点:前k篇文档的序不重要, 它们之间可以存在逆序对,不影响指标
Discounted Cumulative Gain: $DCG@k\;={\;{\textstyle\sum_{i=1}^k}\;}\frac{y_i}{\log_2\left(i+1\right)}$ 排名越靠前,i越小,分母越小,DCG越大。
DCG@$ 何时最大化
- 真实相关性分数 y最高的k 篇文档被模型排在前k
- 前k篇文档不存在逆序对
怎样使用相关性评价指标
离线评价指标
- 事先准备人工标注的数据,划分为训练集和测试集
- 完成训练之后,计算测试集上的 AUC 和 PNR,如果有提升证明有效
- 相关性有 4 个档位,为什么不用多分类的评价指标(Macro F1 和 Micro F1)
- 相关性的标签存在序关系:高 > 中 > 低 > 无
- 多分类把 4 种标签看做 4 个类别,忽略其中的序关系
- 把“高”错判为“中”、或错判为“无”,错误严重程度不同。但被 多分类视为同等的分类错误。
线上评价指标 每月一次
- 一个搜索 session用户搜索 q,搜索结果页上按顺序展示文 档$d_1 …. d_n$
- 从搜索日志中抽取一批 session,覆盖高、中、低频查询词
- 对于每个 session,取排序最高的 k 篇文档$d_1 …. d_k$
- k的设定取决于用户浏览深度,比如k = 20
- 高频查询词前 20 篇文档几乎都是高相关,指标过高,所以得设置k大点
- 高频查询词的 k 设置得较大(比如 k= 40),低频查询词的 k设置得较小(比如 k= 20)
- 人工标注相关性分数,记作$y_1 …. y_n$
- 计算DGC@k,作为该 session 的评价指标
- 对 DCG@k 关于所有 session 取平均,评价线上相关性模型
文本匹配
传统的搜索引擎使⽤⼏⼗种⼈⼯设计的⽂本匹配分数,
作为线性模型或树模型的特征,模型预测相关性分数。
- 词匹配分数(TF-IDF、BM25)、词距分数(OkaTP、BM25TP)。
- 其他分数:类⽬匹配、核⼼词匹配等。
- ⽬前搜索排序普遍放弃⽂本匹配,改⽤ BERT 模型;仅剩⽂本召回使⽤⽂本匹配做海选
词匹配分数
中⽂分词:将查询词、⽂档切成多个字符串(term)
- 查询词: q = “好莱坞电影推荐
- 𝒬 = {好莱坞, 电影, 推荐}
𝒬 中的词在文档 𝑑 中出现次数越多,则 𝑞 与 𝑑 越可能相关。TF-IDF 和 BM25 都是基于上述想法
Term Frequency (TF) 词频
分词结果记作集合 $\vartheta$,例如 $\vartheta$ = 好莱坞, 电影, 推荐
- $t\in\vartheta$ 是一个词 (term),例如 𝑡 = “电影”。
- 词 𝑡 在文档 𝑑 中出现次数叫做词频,记作 $tf_{t,d}$
- $tf_{t,d}$越大,说明 𝑡 与 𝑑 越可能相关。
- ${\textstyle\sum_{t\in\vartheta}}tf_{t,d}$越大,则 𝑞 与 𝑑 越可能相关
用$tf_{t,d}$衡量相关性有个缺陷: 文档 𝑑 越长,则$tf_{t,d}$越大
-
把文档 𝑑 重复两遍,得到 $d’=d\;+d\;$
- TF 变成的原先两倍
- 文档 $d’$和 𝑑 的信息量相同,算出的相关性分数应当相等,实际情况是不相等
解决方法: 用文档 𝑑 的长度(记作 $l_d$)对词频做归一化, 使用$\textstyle\sum_{t\in\vartheta}{\displaystyle\frac{tf_{t,d}}{l_d}}$消除文档长度影响
还有缺陷:加和同等对待所有 𝑡 ,词的重要性各不相同,不该同等对待。
语义重要性 (term weight):电影 > 好莱坞 > 推荐
- 𝑡 = “电影” 是核心词。
- 𝑡 = “好莱坞” 是重要的限定词。
- 𝑡 = “推荐” 是不重要的词。
Document Frequency (DF) 衡量词的语义重要性
- $df_t$:词 𝑡 在多少文档中出现过。 (数据集一共有 𝑁 篇文档)
- $df_t$:介于0和𝑁之间。
- $df_t$大,说明词 𝑡 判别能力弱,应当设置较小权重。
- “你”、“的”、“是” 这样的停用词(stop word)的 DF 接近 𝑁,对判断相关性几乎不起作用。
- “好莱坞”、“强化学习”、“王者荣耀” 的 DF 都很小,判别能力强。
Inverse Document Frequency (IDF) = $idf_t\;=\;\log\frac N{df_t}$
IDF 只取决于文档的数据集
- $idf_t$可以衡量词 𝑡 的判别能力; $idf_t$越大,词 𝑡 越重要。
- 改成加权和 $\textstyle\sum_{t\in\vartheta}{\displaystyle\frac{tf_{t,d}}{l_d}}\times idf_t$衡量
查询词 𝑞 的分词结果记作$\vartheta$,它与文档 𝑑 的相关性可以
用 TF-IDF 衡量 $\textstyle TFIDF(\vartheta,d)\;=\;\sum_{t\in\vartheta}{\displaystyle\frac{tf_{t,d}}{l_d}}\times idf_t$
BM25(Okapi Best Match 25)
BM25 可以看做 TF-IDF 的一种变体, 是所有词匹配分数里面最强
归一化的词频 * IDF相似
\[\begin{array}{cccc}\sum_{t\in\vartheta}&\frac_{t,d}\cdot(k+1)}_{t,d}+k\cdot\left(1-b+b\cdot{\displaystyle\frac{l_d}{mean(l_d)}})\right)}&.\;\left(1+\frac{N-{\mathrm{df}}_t+0.5}_t+0.5}\right)&\end{array}\]$ 𝑘和𝑏是参数,通常设置𝑘∈ [1.2,2] 和𝑏=0.75。$
词袋模型(bag of words)
TF-IDF 和 BM25 隐含了词袋模型假设:只考虑词频,不考虑 词的顺序和上下文
词袋模型忽略词序和上下文,不利于准确计算相关性。
RNN、BERT、GPT 都不是词袋模型
词距分数
查询词 $\vartheta$= 亚马逊,雨林
-
文档 𝑑 = 我在亚马逊上网购了一本书,介绍东南亚热带雨林的植物群落
- 虽然 $\vartheta$与 𝑑 的文本匹配,但是两者不相关(需求不匹配)
- 如果用 TF-IDF 或 BM25 计算相关性,会得出错误结论
- 想要避免这类错误,需要用到词距
- 词距:$\vartheta$ 中的两个词出现在文档 𝑑 中,两者间隔多少词 , 词距越小,$\vartheta$ 与 𝑑 越可能相关。
OkaTP
词𝑡在文档𝑑中出现的位置记作集合$O(𝑡,𝑑 )$
- 𝑡 出现在文档 𝑑 中第 27、84、98 位置上
- 那么$O(𝑡,𝑑 )$ = {27,84,98}。
𝑡 和 $t’$ 是查询词 $\vartheta$ 中的两个词,它们的词距分数
\[\mathrm{tp}(t,t',d)={\textstyle\sum_{o\in O(t,d)}}\,{\textstyle\sum_{o'\in O(t',d)}}\,\frac1{\left(o-o'\right)^2}\]𝑡 和 $t’$ 是查询词 $\vartheta$ 中的两个词,在文档 𝑑 中出现次数越多、距离越近, $\mathrm{tp}(t,t’,d)$越大
OkaTP定义
$\begin{array}{cccc}\sum_{t,t’\in\vartheta,t\neq t’}&\frac{tp(t,t’,d)\cdot(k+1)}{tp(t,t’,d)+k\cdot\left(1-b+b\cdot{\displaystyle\frac{l_d}{mean(l_d)}})\right)}&.\;&min(idf_t,idf_{t’})\end{array}$
文本匹配总结
词匹配分数包括 TF-IDF、BM25 等
- TF:词在文档中出现次数越多越好
- IDF:词在较少的文档中出现,则给词较高的权重。
- 基于词袋模型,只考虑词频,不考虑词序和上下文。
词距分数包括 OkaTP 等
- 查询词 Q中的词在文档中出现次数越多越好
- 查询词 Q中任意两个词在文档中越近越好
将词匹配、词距等分数作为特征,用线性模型或树模型 预测相关性。
基于文本匹配的传统方法效果远不如深度学习
BERT模型及其推理
现代搜索引擎普遍使⽤ BERT 模型计算 q和 d的相关性
- 交叉 BERT 模型(单塔)准确性好,但是推理代价⼤,通常⽤于链路下游(精排、粗排)。
- 双塔 BERT 模型不够准确,但是推理代价⼩,常⽤于链路上游(粗排、召回海选)
训练相关性 BERT 模型的 4 个步骤:预训练、后预训练、微调、蒸馏
交叉 BERT 模型
交叉:自注意力层对查询词和文档做了交叉
模型输入一般是query, title, content。 也可能有更多摘要和achor query
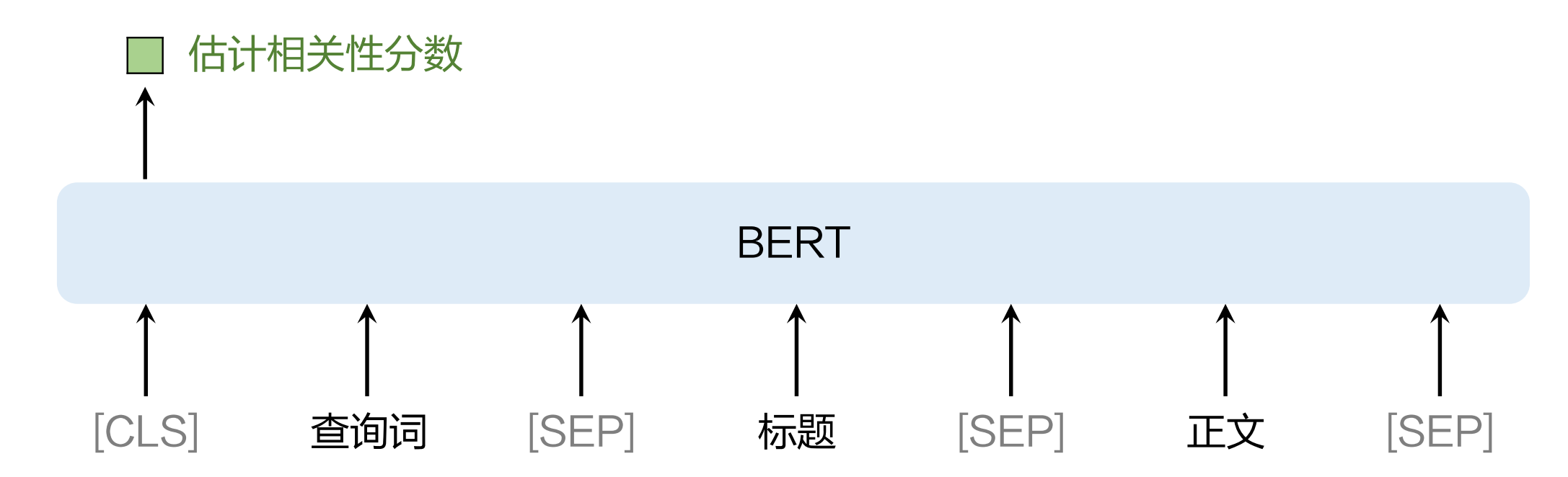
输入会切分成token, token被embedding层表征为向量, 具体分成3种embedding
-
token embedding:表征 token 本⾝
-
position embedding:位置编码,表征token的序
-
segment embedding:⽤于区分查询词、标题、正⽂ (不一定要用,模型可以通过sep标志区分)
每个token被表征为 3个向量,取加和作为token 的表征
交叉 BERT分词 字粒度 vs 字词混合粒度
分词对相关性预测有很大影响
字粒度:将每个汉字/字符作为⼀个 token。
- 词表较⼩(⼏千),只包含汉字、字母、常⽤字符。
- 实现简单,无需做分词
字词混合粒度:做分词,将分词结果作为 tokens。
- 词表较⼤(⼏万、⼗⼏万),包含汉字、字母、常⽤符号、常⽤中⽂词语、常⽤英⽂单词。
- 与字粒度相⽐,字词混合粒度得到的序列长度更短(即 token 数量更少)
序列更短(token 数量更少)有什么好处
- BERT 的计算量是 token 数量的超线性函数(介于线性(全连接层 )和平方(自注意力)时间复杂度之间,序列越长,推理成本越大)
- 为了控制推理成本,会限定 token 数量,例如 128 或 256
- 如果⽂档超出 token 数量上限,会被截断,或者做抽取式摘要。(但是都会降低准确性)
- 使⽤字词混合粒度,token 数量更少,推理成本降低。(字粒度需要 256 token,字词混合粒度只需要 128 token。)
交叉BERT模型的推理降本
对每个(q,d)⼆元组计算相关性分数 score,代价很⼤
⽤ Redis 这样的 KV 数据库缓存 (q,d,score)
- (q,d)作为 key, 相关性分数 (score) 作为 value。
- 如果命中缓存,则避免计算, 如果超出内存上限,按照 least recently used (LRU) 清理缓存
模型量化技术,例如将 float32 转化成 int8
- 训练后量化 (post-training quantization,PTQ)
- 训练中量化 (quantization-aware training,QAT)
- 训练时候做前向和反向传播 : 前向使用量化后的低精度计算,反向使用原来浮点数权重和梯度
使⽤⽂本摘要降低 token 数量
- 如果⽂档长度超出上限,则⽤摘要替换⽂档
- 在⽂档发布时计算摘要。可以是抽取式,也可以是⽣成式
- 如果摘要效果好,可以将 token 数量上限降低,⽐如从 128 降低到 96
双塔 BERT 模型
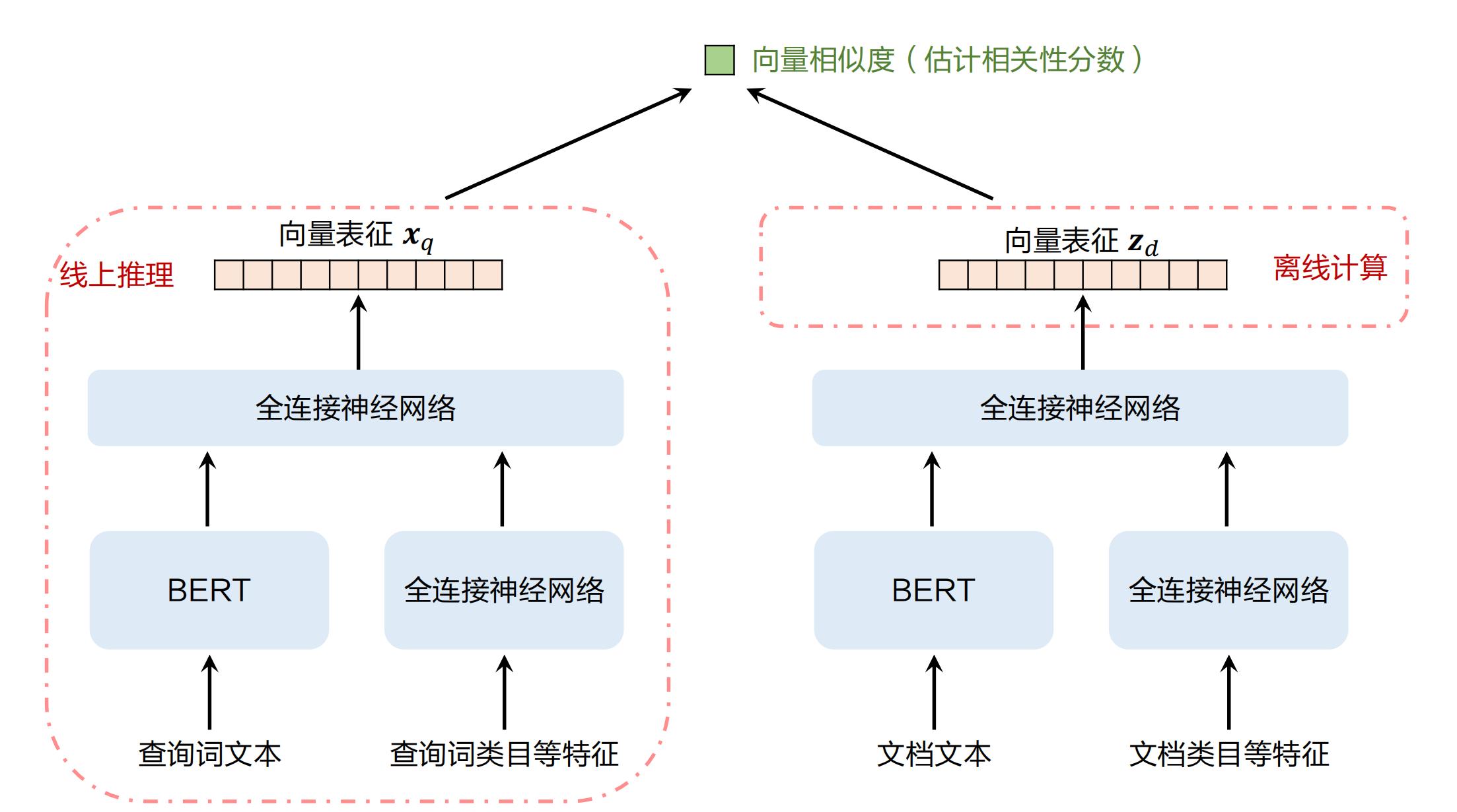
- 事先离线计算每篇⽂档 $d$ 的向量表征$Z_d$ ,将 $(d, Z_d)$存⼊哈希表
- 线上计算$(q,d)$的相关性时,给定候选⽂档 $d$,从哈希表中读取它的向量表征$Z_d$。
- 线上计算查询词$q$的向量表征$X_q$,然后计算內积$<X_q,Z_d>$作为 $(q,d)$相关性分数
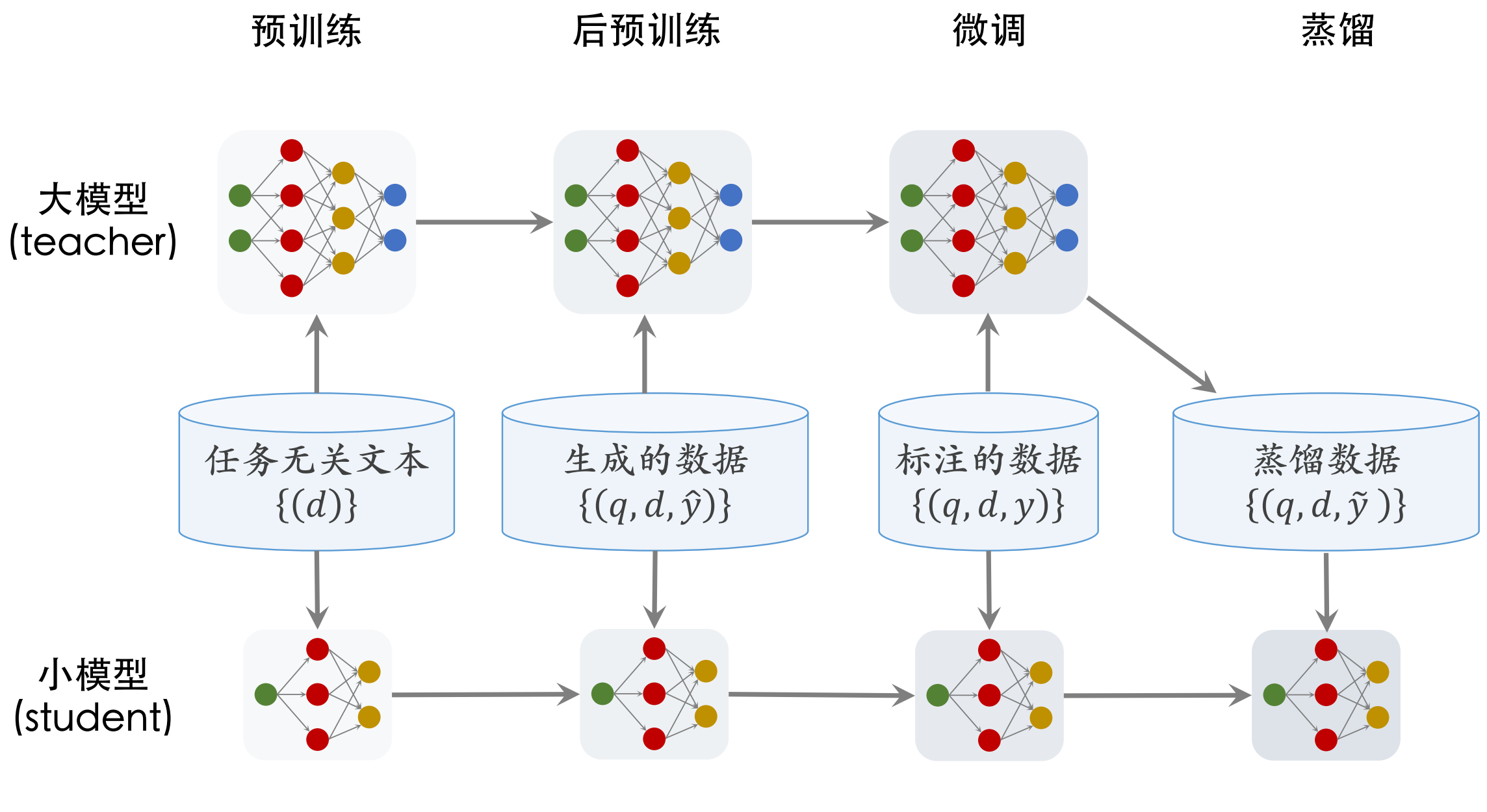
训练相关性BERT模型
训练分 4 个步骤:预训练 (pretrain)、后预训练 (post pretrain)、微调 (fine tuning) 、蒸馏 (distillation)
- 预训练:⽤ MLM (Mask language Model)等任务预训练模型。
- 后预训练:利⽤⽤户的点击、交互数据训练模型。(效果更好)
- 微调:⽤⼈⼯标注的相关性数据训练模型。
- 蒸馏:得到更⼩的模型,加速线上的推理
Bert微调 (fine tuning)
微调⽤监督学习训练模型,模型估计 q 和 d 的相关性。 ⼈⼯标注数⼗万、数百万条样本,每条样本为(q,d,y) 。
可以把估计相关性看作回归任务,也可以看作排序任务。
- 回归任务让预测的值 p 拟合 y,起到“保值”的作⽤
- 给定 (q,d),模型估计相关性为 p
- p 越接近真实标签 y 越好
- 排序任务让 p 的序拟合 ?y的序,起到“保序”的作⽤
- 给定两条样本$ (q,d_1,y_1)$ 和 $ (q,d_2,y_2)$,满⾜ $y_1> y_2$
- 模型预测的相关性分数 $p_1 , p_2$ 应当满⾜ $p_1> p_2$
回归任务

排序任务
数据:⼀条样本包含⼀条查询词 q 和 k 篇⽂档$ d_1….d_k$
对于 $(q,d_i)$ ,真实相关性分数记作 $y_i$,模型预测的相关性记作$p_i$
- 两种排序⽅式:按照$y_i$ 排序、按照 $p_i$排序。
- 排序任务不在乎按照$y_i$ 和 $p_i$排序的值是否接近,只在乎两种排序是否接近
设$y_i > y_j$,损失函数应当⿎励 $p_i - p_j$尽量⼤。
- 如果 $p_i >= p_j$(模型预测正确),则称 $(i,j)$为正序对。
- 如果$p_i < p_j$(模型预测错误),则称 $(i,j)$为逆序对。
- 损失函数应当惩罚逆序对,⿎励正序对 ->应当⿎励 $p_i - p_j$尽量⼤。
- Pairwise logistic 损失函数 $\textstyle\sum_{(i,j):y_i>y_j}\;\ln\left(1+\exp\left(-\gamma\cdot\left(p_i-p_j\right)\right)\right)!$
微调:小结
- 可以把估计相关性看作回归任务,也可以看作排序任务。
- 看作回归任务,使⽤均⽅差损失 (MSE) 或交叉熵损失(CE),有利于提升 AUC 指标。
- 看作排序任务,使⽤ pairwise logistic 损失,有利于提升正逆序⽐指标。
-
不要把估计相关性看作多分类任务
- 如果同时⽤ AUC 和正逆序⽐作为离线评价指标,则同时使⽤ CE 和 pairwise logistic 损失
Bert后预训练 (post pretrain)
Pre-trained Language Model based Ranking in Baidu Search
Pre-trained Language Model-based Retrieval and Ranking for Web Search
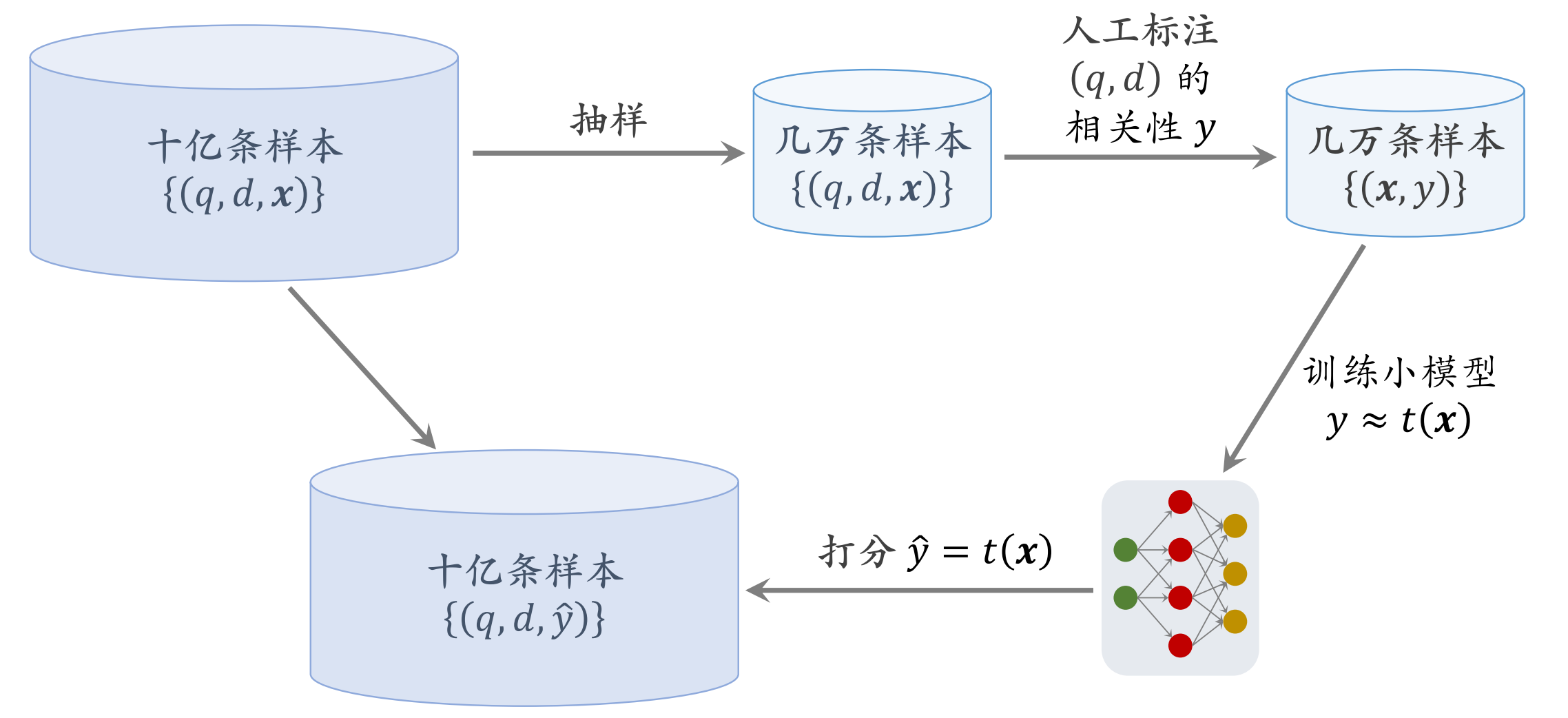
从搜索⽇志中挑选⼗亿对 (q,d)。
- 搜索⽇志记录⽤户每次搜索的查询词 q 和搜索引擎返回的⽂档。
- 根据搜索⽇志抽取查询词 q,需要覆盖⾼、中、低频的q。
- 给定 q,搜索⽇志记录搜到的⽂档 $ d_1….d_n$、以及模型评估的相关性分数(不是⼈⼯标注的) 。
- 根据相关性分数,选取 n 篇⽂档的⼀个⼦集,均匀覆盖各相关性档位。
⾃动⽣成标签:将⽤户⾏为 x 映射到相关性分数 $\widehat y$
-
对搜索⽇志做统计,得出 (q,d) 的点击率和多种交互率,记作向量 x , 一定程度反映q,d相关性
-
已经得到⼗亿条样本 (q,d,x) ,其中向量 x是⽤户⾏为
-
相关性 y 与 x存在某种函数关系。(相关性越⾼,则⽤户越有可能点击和交互。)
-
找出 y 与 x的函数关系: $\widehat y = t(x)$
- 选取⼏万对(q,d) ,⼈⼯标注相关性分数 y。
- 搜索⽇志记录了(q,d)的⽤户⾏为 x。
- 得到⼏万条样本 (x,y ),训练⼀个⼩模型 t(x)拟合 y , x维度不高,样本量不大没必要用大模型。
-
⼩模型 t(x) 只能使⽤点击率、交互率作为输⼊
-
尽量不使⽤⽂本特征作为输⼊。
-
绝对不能⽤相关性 BERT 模型打分作为输⼊,否则会产⽣反馈回路。(BERT 模型打分 –> 训练⼩模型 –> ⼩模型⽣
成数据 –> 训练 BERT 模型)
-
-
对于所有⼗亿条样本 (q,d,x) ,⽤训练好的⼩模型打分得到⼗亿条样本 $(q,d,\widehat y) $
用$(q,d,\widehat{y)}$ 训练模型(⽅法与微调类似,额外加上预训练的 MLM 任务,避免灾难遗忘)
- 基于预训练的 BERT 模型,⽤ $(q,d,\widehat{y)}$ 做监督学习
- 监督学习同时⽤ 3 个任务,取 3 个损失函数的加权和。
- 回归任务,起到“保值”的作⽤(模型的输出尽量接近 $\widehat y$有利于 AUC 指标。)
- 排序任务,起到 “保序” 的作⽤(⿎励正序对、惩罚逆序对),有利于正逆序⽐指标。
- 预训练的 MLM 任务,避免清洗掉预训练的结果
为什么有效
⼤幅增加了有标签样本数量(百万 to ⼗亿)
- ⼈⼯标注的相关性数据只有⼏⼗万到⼏百万条(q,d,y) 。
- 后预训练使⽤⼗亿条 $(q,d,\widehat{y)}$
- 巨⼤的数据量使模型更准确。
⽤户⾏为 x 与相关性 y 有很强关联
- (q,d)的相关性越⾼,越有可能得到点击和交互。
- ⼩模型可以根据点击率和交互率 x 较为准确地推断 y
- ⼩模型⽣成的标签 y虽然有噪声,但也有很⼤的信息量
Bert蒸馏 (distillation)
为什么做蒸馏
- ⽤户每搜⼀个查询词,排序需要⽤相关性 BERT 模型给数百、数千对 $(q,d)$ 打分
- BERT 模型越⼤,计算量越⼤,给相关性的打分越准。
- 精排常⽤ 4~12 层交叉 BERT,粗排常⽤ 2~4 层交叉BERT(或双塔 BERT)。
- 两种⽅法谁更好?
- 直接训练训练⼩模型(2~12 层)。
- 先训练 48 层⼤模型,再蒸馏⼩模型。(效果更优)
- ⼯业界经验:
- 48 层对⽐ 12 层,AUC ⾼ 2% 以上。 (2%已经很高)
- 48 层蒸馏 12 层,AUC ⼏乎无损。
- 48 层蒸馏 4 层,AUC 损失 0.5%。
做预训练、后预训练、微调,训练好 48 层 BERT ⼤模型,作为 teacher
- Teacher 模型越⼤,它本⾝越准确,蒸馏出的 student 也越准确。
- 48 层 teacher,效果优于 24 层和 12 层 teacher
准备⼏亿对$(q,d)$(方法和后预训练一样) ,⽤ teacher 给$(q,d)$打分 $\widetilde y$
- 蒸馏的数据量越⼤越好。
- 数据量少于 1 亿,蒸馏会损失较⼤ AUC。
- 数据量超过 10 亿,边际效益很⼩
在$(q,d,\widetilde{y)}$ 上做监督学习训练⼩模型
- 只训练 1 epoch。(1 亿条样本上训练 2 epoch,效果不如 2亿条样本上训练 1 epoch。)
- 与微调相同,同时⽤回归任务、排序任务
蒸馏:一些有效的技巧
Student ⼩模型要先预热、再蒸馏 (比啥都不做,或者只做预训练强)
- 预热:先做预训练、后预训练、微调训练 student。(与训练 teacher 的步骤相同。)
- 基于预热的模型,⽤蒸馏数据 $(q,d,\widetilde{y)}$ 训练 student
不要做逐层蒸馏
- 逐层蒸馏:让 student 的中间层拟合 teacher 的中间层
- ⽤相同的算⼒,直接拟合 优于逐层蒸馏。(逐层蒸馏代价大,效果不好控制( 十万,百万),还不如直接增大数据量)
- 多级蒸馏和单级蒸馏谁更好
- 多级蒸馏: 48层 –> 12层 –> 4层
- 单级蒸馏: 48层–> 4层。(多数倾向,单级已经损失足够少)
- 有争议,可能是单级蒸馏更好