推理系统是一个专门用于部署人工智能模型,执行推理预测任务的人工智能系统。它类似于传统的 Web 服务或移动端应用系统,但专注于 AI 模型的部署与运行。通过推理系统,可以将神经网络模型部署到云端或者边缘端,并服务和处理用户的请求。因此,推理系统也需要应对模型部署和服务生命周期中遇到的挑战和问题。
- 提供可以被用户调用的接口
- 能够完成一定的数据处理将输入数据转为向量
- 能够在指定低延迟要求下返回用户响应
- 能够利用多样的加速器进行一定的加速
- 能够随着用户的增长保持高吞吐的服务响应和动态进行扩容
- 能够可靠的提供服务,应对软硬件的失效
- 能够支持算法工程师不断更新迭代模型,应对不断变化的新框架
推理系统思考点
在实际维护推理系统的过程中,需要全面考虑并解决以下问题:
首先,如何设计并生成用户友好、易于调用的 API 接口,以便用户能够便捷地与推理系统进行交互。其次,关于数据的生成,需要明确数据的来源、生成方式以及质量保障措施,确保推理系统能够依赖准确、可靠的数据进行运算。
再者,在网络环境的影响下,如何实现低延迟的用户反馈是一个关键挑战。需要优化网络传输机制,减少数据传输的延迟,确保用户能够及时获得推理结果。同时,充分利用手机上的各种加速器或 SoC 加速资源对于提升推理系统的性能至关重要。需要深入研究手机硬件的特性,合理利用加速资源,提高推理的运算速度和效率。
另外,当用户访问量增大时,如何确保服务的稳定性和流畅性是一个必须面对的问题。需要设计合理的负载均衡策略,优化系统架构,提高系统的并发处理能力。此外,为了应对潜在的风险和故障,需要制定冗灾措施和扩容方案,确保在突发情况下推理系统能够稳定运行。
最后,随着技术的不断发展,未来可能会有新的网络模型上线。需要考虑如何平滑地集成这些新模型,并制定 AB 测试策略,以评估新模型的性能和效果。
总之,维护推理系统需要综合考虑多个方面的问题,从 API 接口设计、数据生成、网络延迟优化、硬件加速资源利用、服务稳定性保障、冗灾与扩容措施,到新模型上线与测试等方面,都需要进行深入研究与精心规划。
AI 生命周期
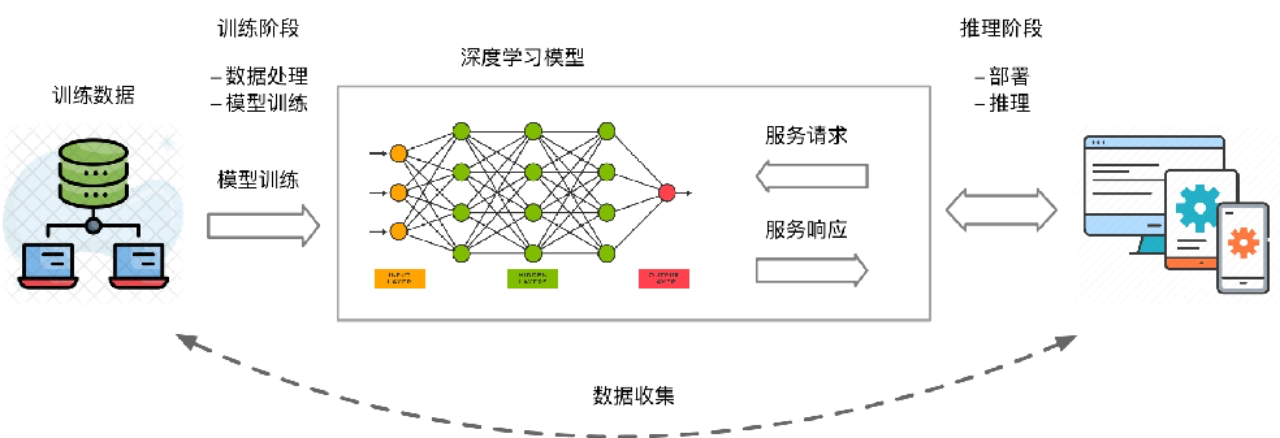
神经网络模型的生命周期(Life Cycle)最核心的主要由数据准备、模型训练推理以及模型部署三个阶段组成。
训练任务:
- 数据中心中更像是传统的批处理任务,需要执行数小时,数天才能完成,其一般配置较大的批尺寸追求较大的吞吐,将模型训练达到指定的准确度或错误率。
- 设计合适 AI 模型结构以及损失函数和优化算法,将数据集以 mini-batch 反复进行前向计算并计算损失,反向计算梯度利用优化函数来更新模型,使得损失函数最小。训练过程最重要是梯度计算和反向传播。
推理任务
- 执行 7 X 24 的服务,其常常受到响应延迟的约束,配置的批尺寸更小,模型已经稳定一般不再被训练
- 在训练好的模型结构和参数基础上,一次前向传播得到模型输出过程。相对于训练,推理不涉及梯度和损失优化。最终目标是将训练好的模型部署生产环境中。
推理相比训练的新特点与挑战
- 模型被部署为长期运行的服务
- 推理有更苛刻的资源约束
- 推理不需要反向传播梯度下降
- 部署的设备型号更加多样
推理系统的考量

- 模型训练后会保存在文件系统中,随着训练处的模型效果不断提升,可能会产生新版本的模型,并存储在文件系统中并由一定的模型版本管理协议进行管理。
- 之后模型会通过服务系统部署上线,推理系统首先会加载模型到内存,同时会对模型进行一定的版本管理,支持新版本上线和旧版本回滚,对输入数据进行批尺寸(Batch Size)动态优化,并提供服务接口(例如,HTTP,gRPC等),供客户端调用。
- 用户不断向推理服务系统发起请求并接受响应。除了被用户直接访问,推理系统也可以作为一个微服务,被数据中心中其他微服务所调用,完成整个请求处理中一个环节的功能与职责。
- 推理系统中,以数据中心的服务端推理系统为主,兼顾边缘侧移动端推理的场景,但是这些策略本身大部分是数据中心与边缘侧都适用
推理系统的优化目标
低延迟(Latency):满足服务等级协议的延迟
- 交互式APP 低延迟需求与训练 AI 框架目标不一致
- 大模型更准确,但浮点运算量更大
- Sub-second 级别延迟约束制数据 Batch Size
- 模型融合容易引起长尾延迟 Long Tail Latency
吞吐量(Throughputs):暴增负载的吞吐量需求
- 充分利用AI芯片能力1)批处理请求;2)指令级运算
- 支持动态 Shape 和自适应批尺寸 Batch Size
- 多模型装箱使用加速器容器
- 扩展副本部署
高效率(Efficiency):高效率,低功耗使用GPU, CPU
- 模型压缩
- 高效使用 AI 推理芯片
- 装箱(bin-packing)使用加速器
灵活性(Flexibility):支持多种框架, 提供构建不同应用的灵活性
- AI 服务的部署,优化和维护困难且容易出错
- 框架多样,硬件多样
- 大多数框架都是为训练设计和优化。开发人员需要将必要的软件组件拼凑在一起,跨多个不断发展的框架集成和推理需求
- 多种部署硬件的支持
- 服务系统需要灵活性
- 支持加载不同 AI 框架的模型
- AI 框架推陈出新和版本不断迭代
- 与不同语言接口和不同逻辑的应用结合
- 解决方法
- 深度学习模型开放协议:跨框架模型转换
- 接口抽象:提供不同框架的通用抽象
- 容器:运行时环境依赖与资源隔离
- RPC:跨语言,跨进程通信
扩展性(Scalability):扩展支持不断增长的用户或设备
- 随着请求负载增加自动部署更多的解决方案 ,进而才可以应对更大负载,提供更高的推理吞吐和让推理系统更加可靠。
- 通过底层 Kubernetes 部署平台,用户可以通过配置方便地自动部署多个推理服务的副本,并通过部署前端负载均衡服务,达到高扩展性提升吞吐量。更多副本也使得推理服务有了更高的可靠性。
推理流程全景
部署态
推理系统一般可以部署在云或者边缘。
- 云端部署的推理系统更像传统 Web 服务,
- 在边缘侧部署的模型更像手机应用和IOT应用系统
Cloud 云端
云端有更大的算力,内存,且电更加充足满足模型的功耗需求,同时与训练平台连接更加紧密,更容易使用最新版本模型,同时安全和隐私更容易保证。
相比边缘侧可以达到更高的推理吞吐量。但是用户的请求需要经过网络传输到数据中心并进行返回,同时使用的是服务提供商的软硬件资源。

好处
- 对功耗、温度、 Model Size 没有严格限制
- 有用于训练和推理的强大硬件支持
- 集中的数据管理有利于模型训练
- 模型更容易在云端得到保护
- 深度学习模型的执行平台和AI 框架统一
问题
- 云上提供所有人工智能服务成本高昂
- 推理服务对网络依赖度高
- 数据隐私问题
- 数据传输成本
- 很难定制化模型
Edge 端侧
边缘侧设备资源更紧张(例如,手机和 IOT 设备),且功耗受电池约束,需要更加在意资源的使用和执行的效率。用户的响应只需要在自身设备完成,且不需消耗服务提供商的资源。

问题
- 严格约束功耗、热量、模型尺寸小于设备内存
- 硬件算力对推理服务来说不足
- 数据分散且难以训练
- 模型在边缘更容易受到攻击
- 不同设备不同的平台多样,无通用解决方案
解决
- 应用层算法优化 : 考虑到移动端部署的苛刻资源约束条件下,提供针对移动端部署的 AI 模型
- 高效率模型设计: 通过模型压缩的量化、剪枝、蒸馏、神经网络结构搜索(NAS)等技术,减少模型尺寸
- 移动端框架——推理引擎: TensorFlow Lite,MNN、TensorRT,ONNX Runtime、MindSpore Lite等推理引擎推出
- 移动端芯片 提供高效低功耗芯片支持,如 Google Edge TPU,NVIDIA Jetson 、Huawei Ascend 310系列
云端系统推理
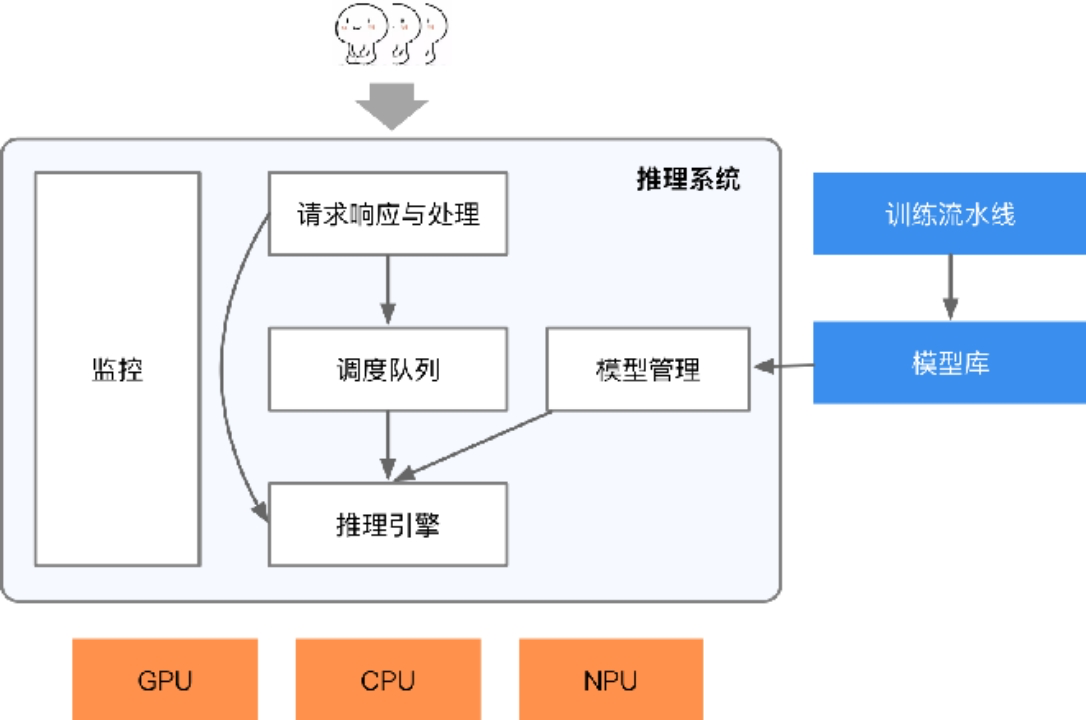
- 如何实现低延迟高吞吐
- 系统需要序列化与反序列化请求,并通过后端高效执行,满足一定的响应延迟。
- 相比传统的 Web 服务,推理系统常常需要接受图像,文本,音频等非结构化数据,单请求或响应数据量一般更大,这就需要对这类数据有高效的传输,序列化,压缩与解压缩机制。
- 如何分配调度请求?
- 系统可以根据后端资源利用率,动态调整批尺寸,模型的资源分配,进而提升资源利用率,吞吐量。
- 如果是通过加速器进行的加速推理,还要考虑主存与加速器内存之间的数据拷贝,通过调度或预取等策略在计算的间歇做好数据的准备。
- 如何管理AI生命周期
- 如何管理模型
- 算法工程师不断验证和开发新的版本模型,需要有一定的协议保证版本更新与回滚。
- 推理芯片如何加速
- 在边缘端等场景会面对更多样的硬件,驱动和开发库,需要通过编译器进行一定代码生成让模型可以跨设备高效运行,并通过编译器实现性能优化
- 云端推理引擎执行
- 推理引擎将请求映射到模型作为输入,并在运行时调度深度学习模型的内核进行多阶段的处理。
- 如果是部署在异构硬件或多样化的环境,还可以利用编译器进行代码生成与内核算子优化,让模型自动化转换为高效的特定平台的可执行的机器码。
- 健康监控
- 云端的服务系统应该是可观测的,才能让服务端工程师监控,报警和修复服务,保证服务的稳定性和 SLA。
- 例如,一段时间内响应变慢,通过可观测的日志,运维工程师能诊断是哪个环节成为瓶颈,进而可以快速定位,应用策略,防止整个服务突发性无法响应(例如,OOM 造成服务程序崩溃)。
边缘推理方式
**边缘设备计算 **将模型部署在设备端,聚焦如何优化模型执行降低延迟
- 端侧模型结构设计
- 通过模型量化、剪枝等压缩手段

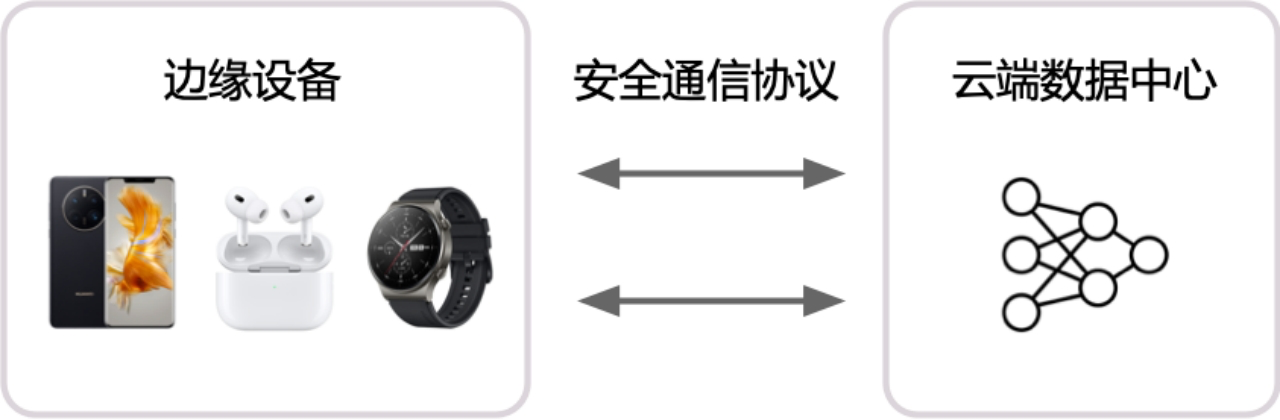
安全计算 + 卸载到云端:将模型部署于数据中心,边缘侧通过安全通信协议将请求发送到云端,云端推理返回结果,相当于将计算卸载到云端
- 利用云端运行提升模型安全性
- 适合部署端侧无法部署的大模型
- 完全卸载到云端有可能违背实时性的需求
边缘设备 + 云端服务器:
利用 AI 模型结构特点,将一部分层切(或者其 Student 模型)分放置在设备端进行计算,其他放置在云端。这种方式一定程度上能够比方式 2 降低延迟,由于其利用了边缘设备的算力,但是与云端通信和计算还是会带来额外开销。
因为有可能数据安全的问题,数据不能传输到云端
分布式计算 联邦学习
从分布式系统角度抽象问题,AI 计算在多个辅助边缘设备上切片
- 切片策略根据设备计算能力,内存约束
- 通过细粒度的切片策略,将模型切片部署其他边缘设备
- 运行对计算模型进行调度, 并通过输入数据通过负载均衡策略进行调度
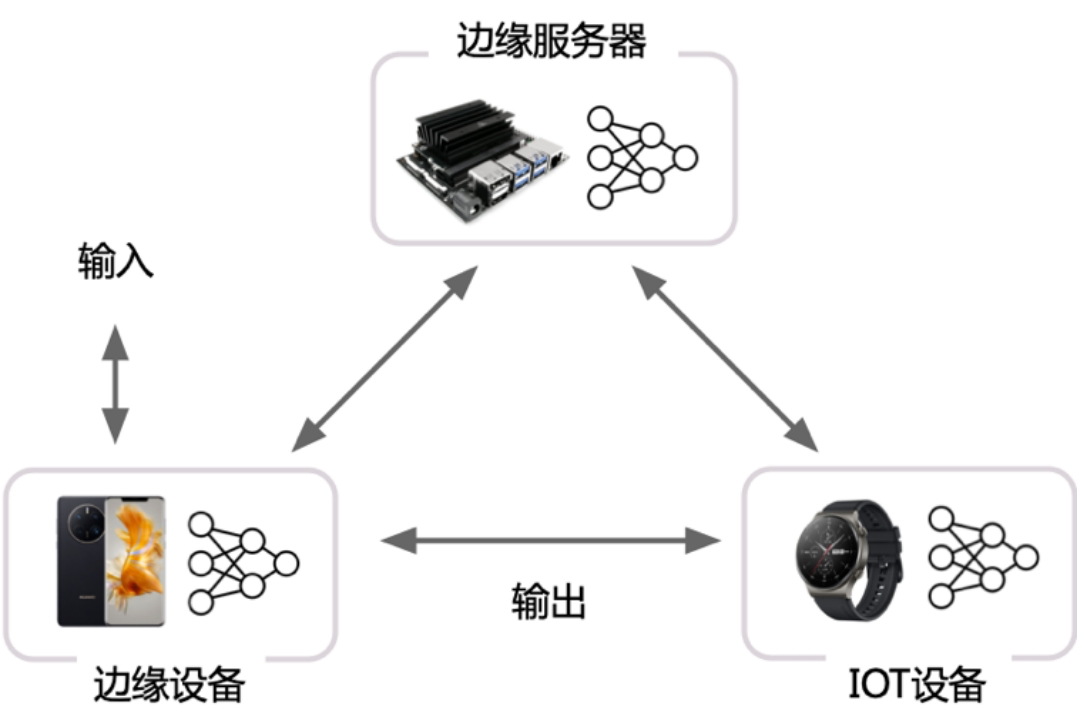
跨设备 Offloading
决策基于经验性的权衡功耗,准确度,延迟和输入尺寸等度量和参数,不同的模型可以从当前流行的模型中选择,或者通过知识蒸馏,或者通过混合和匹配的方式从多个模型中组合层。如较强的模型放在边缘服务器,较弱模型放置在设备。
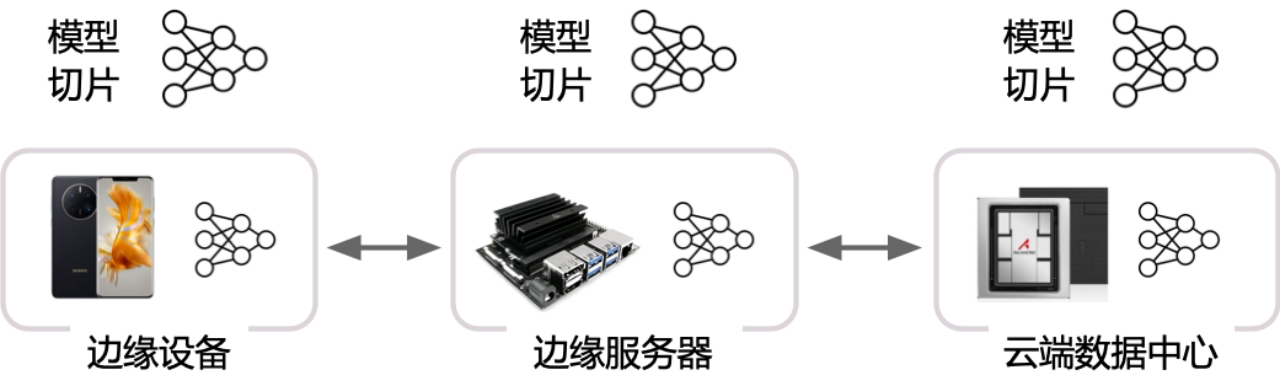
推理系统架构
接入层: 支持 HTTP/REST 和 GRPC 协议
模型仓库: 本地的持久化存储介质 S3等
模型编排 , 推理引擎,监控
推理、部署、服务化
推理(Inference)
对于训练(Training)而言的推理,即模型前向计算,也就是对于给出的输入数据计算得到模型的输出结果;相对预测(Prediction)的推理,是统计学领域的范畴。
部署(Deployment)
训练得到的模型主要目的还是为了更有效地解决实际中的问题,因此部署是一个非常重要的阶段。模型部署的课题也非常多,包括但不仅限于:移植、压缩、加速等。
服务化(Serving)
模型的部署方式是多样的:封装成一个SDK,集成到APP或者服务中;封装成一个web服务,对外暴露接口(HTTP(S),RPC等协议)。
常见的服务化框架
模型生命周期管理
需要模型版本管理的原因
- 每隔一段时间训练出的新版本模型替换线上模型,
- 但是可能存在缺陷,如果新版本模型发现缺陷需要回滚
模型生命周期管理
- 金丝雀(Canary)策略
- 当获得一个新模型版本,当前服务模型成为 second-newest,用户可以选择同时保持这两个版本
- 将所有推理请求流量发送到当前两个版本,比较它们的效果
- 一旦对最新版本达标,用户就可以切换到仅该版本
- 方法需要更多的高峰资源,避免将用户暴露于缺陷模型
- 回滚(Rollback)策略
- 如果在当前的主要服务版本上检测到缺陷,则用户可以请求切换到特定的较旧版本
- 卸载和装载的顺序应该是可配置的
- 当问题解决并且获取到新的安全版本模型时,从而结束回滚
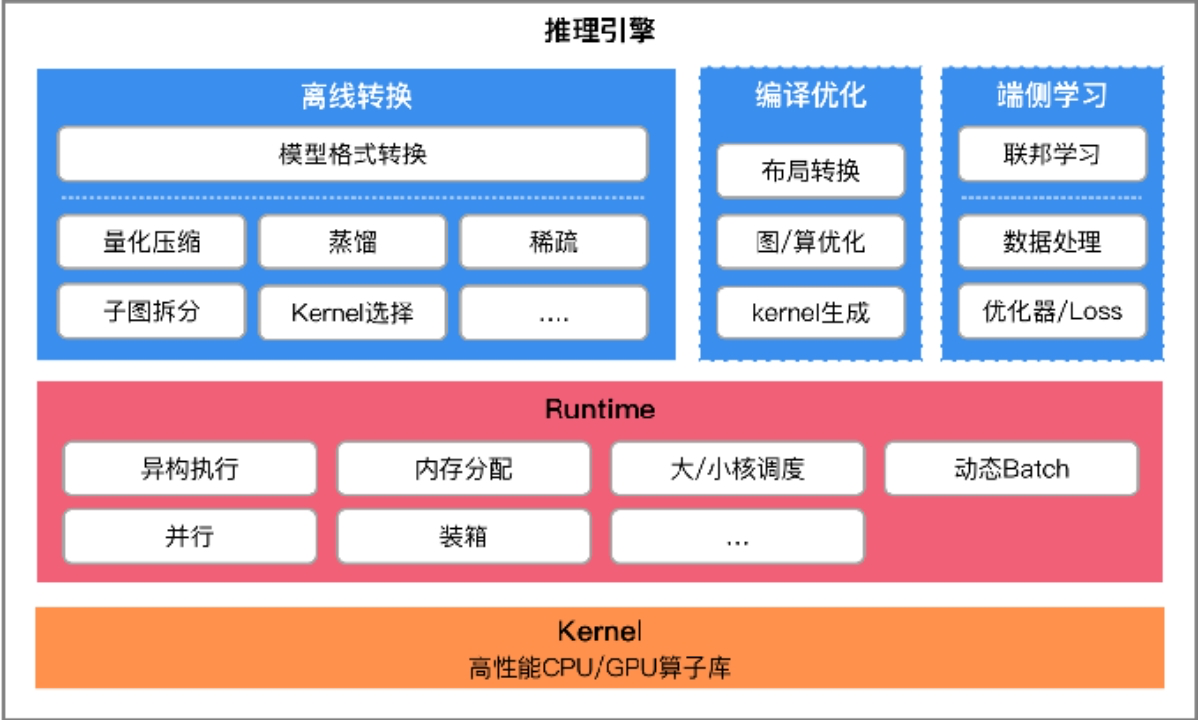
推理引擎架构
推理引擎特点
轻量、通用、易用、高效
高效
- 需要对 iOS / Android / PC 不同硬件架构和操作系统进行适配,单线程下运行深度学习模型达到设备算力峰值。
- 针对主流加速芯片进行深度调优,如 OpenCL 侧重于推理性能极致优化,Vulkan 方案注重较少初始化时间。
- 编写SIMD代码或手写汇编以实现核心运算,充分发挥芯片算力,针对不同kernel算法提升性能。
- 支持不同精度计算以提升推理性能,并对 ARMv8.2 和 AVX512 架构的相关指令进行了适配

轻量
- 主体功能无任何依赖,代码精简,可以方便地部署到移动设备和各种嵌入式设备中。
- 支持 Mini 编辑选项进一步降低包大小,大约能在原库体积基础上进一步降低体积。
- 支持模型更新精度 FP16/Int8 压缩与量化,可减少模型50% - 75% 的体积。
通用
- 支持 Tensorflow、PyTorch、MindSpore、ONNX 等主流模型文件格式。
- 支持 CNN / RNN / GAN / Transformer 等主流网络结构。
- 支持多输入多输出,任意维度输入输出,支持动态输入,支持带控制流的模型。
- 支持 服务器 / 个人电脑 / 手机 及具有POSIX接口的嵌入式设备。
- 支持 Windows / iOS 8.0+ / Android 4.3+ / Linux / ROS 等操作系统。
易用(针对开发者)
- 支持使用算子进行常用数值计算,覆盖 numpy 常用功能
- 提供 CV/NLP 等任务的常用模块
- 支持各平台下的模型训练
- 支持丰富的 API 接口
推理引擎挑战
需求复杂 vs 程序大小
- AI 模型本身包含众多算子,如 PyTorch有1200+ 算子、Tensorflow 接近 2000+ 算子,推理引擎需要用有限算子去实现不同框架训练出来 AI 模型所需要的算子。
- AI 应用除去模型推理之外,也包含数据前后处理所需要的数值计算与图像处理,不能引入大量的三方依赖库,因此需要进行有限支持。
算力需求 vs 资源碎片化
- AI 模型往往计算量很大,需要推理引擎对设备上的计算资源深入适配,持续进行性能优化,以充分发挥设备的算力。
- 计算资源包括 CPU , GPU , DSP 和 NPU ,其各自编程方式是碎片化,需要逐个适配,开发成本高,也会使程序体积膨胀。
执行效率 vs 模型精度
- 高效的执行效率需要网络模型变小,但是模型的精度希望尽可能的高;
- 云测训练的网络模型精度尽可能的高,转移到端侧期望模型变小但是保持相同的精度;
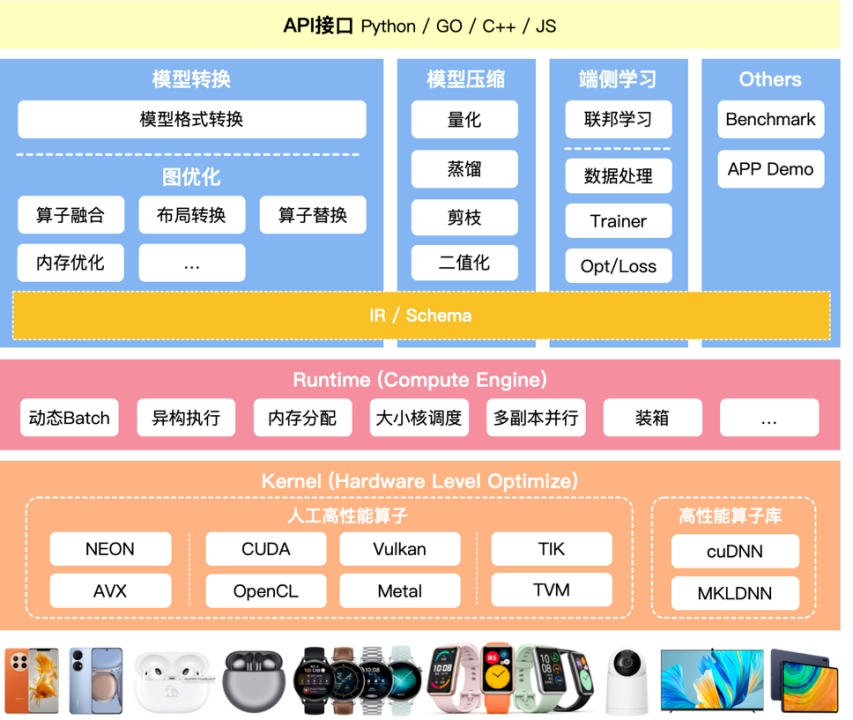
推理引擎整体架构
- 如何对不同 AI 框架结果转换?
- 如何保持精度下减少模型尺寸?
- 如何加快调度与执行?
- 如何提高算子性能?
- 如何利用边缘设备算力?
主要分成两大块
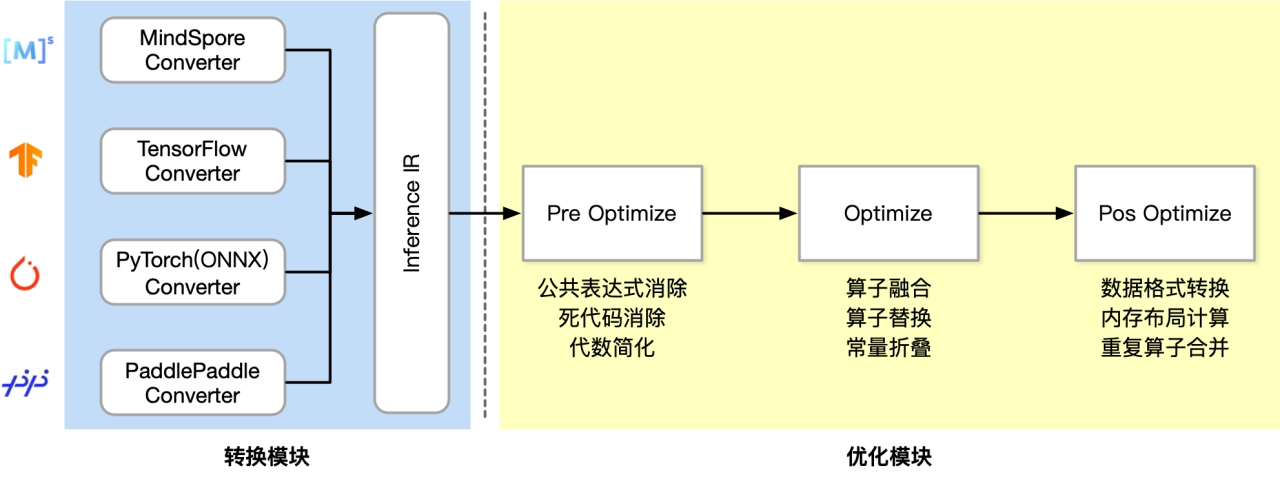
优化阶段
模型转换工具,由转换和图优化构成;模型压缩工具、端侧学习和其他组件组成。 (蓝色以上)
- 模型转换工具 : 模型格式转换,计算图优化,
- 模型进行压缩: 减少模型大小,加快训练速度,保持相同精度
- 端侧学习:增量学习 , 联邦学习
- 性能对比,集成模块 app demo
- 中间表达: Schema 为了 统一表达
运行阶段
即推理引擎,负责AI模型的加载与执行,可分为调度与执行两层。
- Runtime:模型加载,执行
- 高性能算子层:算子优化,算子执行,算子调度
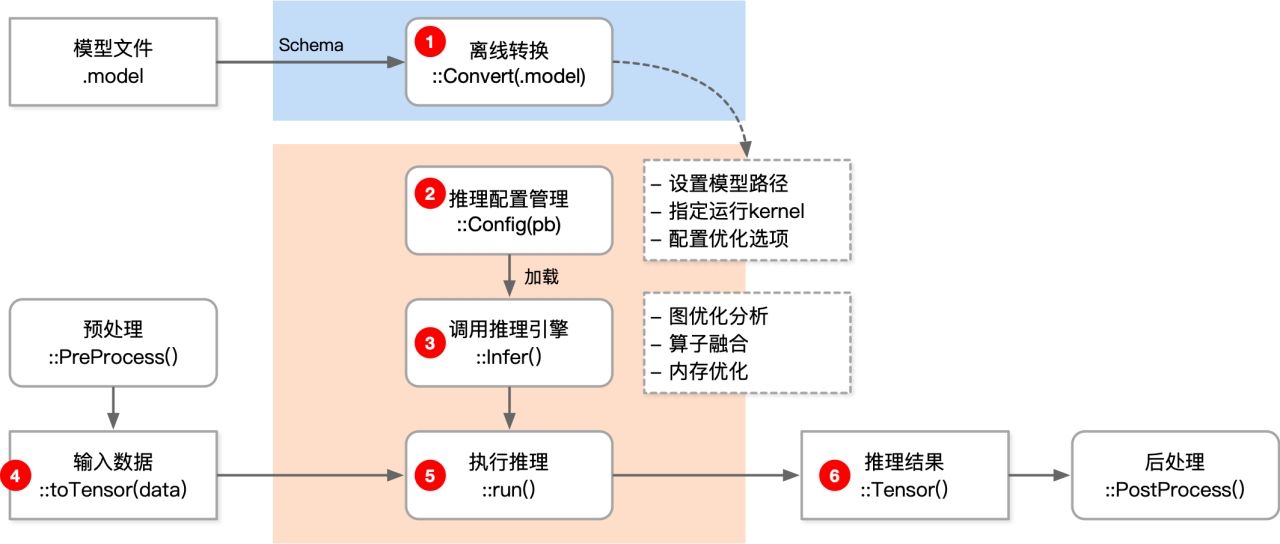
推理引擎工作流程
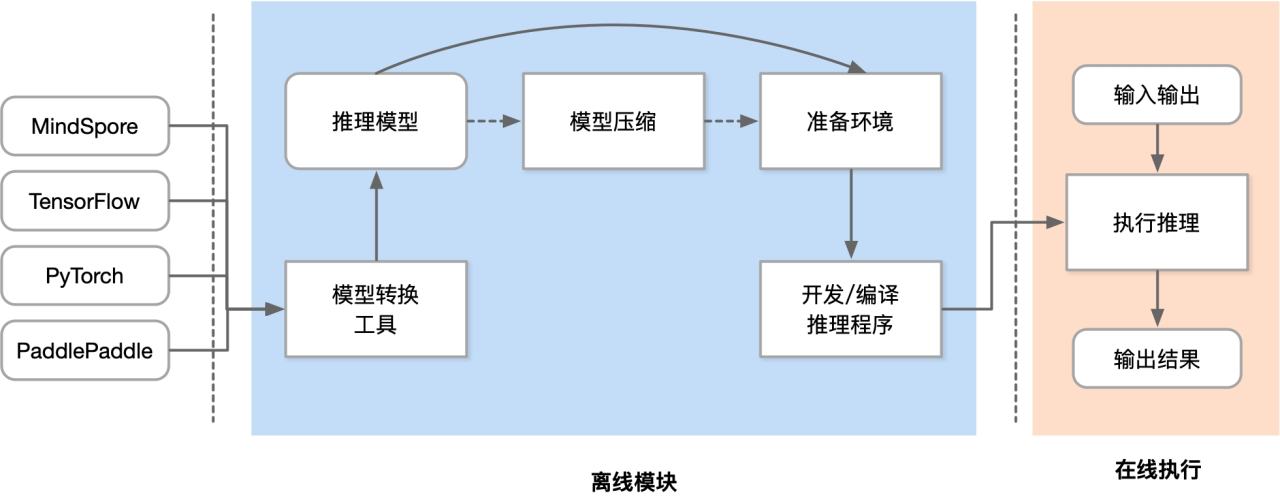
- 开发推理程序才是真正开始使用推理引擎,使用推理引擎的API去开发
- 执行时候是依靠推理引擎执行
开发推理程序
模型小型化
模型、卡参数
比较重要FLOPs/S,Params,MAC, 内存带宽
FLOPs
FLOPs 是 floating point operations 的缩写(s 表复数),指浮点运算次数,可以用来衡量算法/模型的复杂度,表示计算量。论文中常用的还有 GFLOPs 和 TFLOPs。
- 一个 GFLOPS(GigaFLOPS)等于每秒十亿($=10^{9}$)次浮点运算。
- 一个 TFLOPS(TeraFLOPS)等于每秒一万亿($=10^{12}$)次浮点运算。
FLOPS每秒所执行的浮点运算次数(Floating-point Operations Per Second )
理解为计算速度,是一个衡量硬件性能/模型速度的指标,即一个芯片的算力。
MACCs乘-加操作次数(Multiply-accumulate Operations)
MACCs 大约是 FLOPs 的一半,将 𝑤∗𝑥+𝑏 视为一个乘法累加或 1 个 MACC
Params
模型含有多少参数,直接决定模型的大小,也影响推断时对内存的占用量,单位通常为 M,通常参数用 float32 4bytes表示,所以模型大小是参数数量的 4 倍
MAC
内存访问代价(Memory Access Cost),指的是输入单个样本,模型/卷积层完成一次前向传播所发生的内存交换总量,即模型的空间复杂度,单位是 Byte。
**内存带宽 ** 300GB/s
- 内存带宽决定了它将数据从内存(vRAM) 移动到计算核心的速度,是比计算速度更具代表性的指标,
- 内存带宽值取决于内存和计算核心之间数据传输速度,以及这两个部分之间总线中单独并行链路数量。

典型结构对比
卷积核的尺寸 K,卷积核通道等于 $c_{in}$,卷积核个数等于 $c_{out}$。
标准卷积层Std Conv(主要贡献计算量)
-
Params
$𝑘_ℎ×𝑘_𝑤×𝑐_{in}×𝑐_{out}$
-
FLOPs H W 是图像长宽
$𝑘_ℎ×𝑘_𝑤×𝑐_{in}×𝑐_{out}×𝐻×𝑊$
其中$k_{h}$与$k_{w}$分别为卷积核的高宽,$c_{in}$与$c_{out}$分别是输入输出维度。
全连接层 FC(主要贡献参数量)
全连接层 FC
-
Params
$c_{in}\times c_{out}$
-
FLOPs
$ c_{in}\times c_{out} $
其中 $c_{in}$ 与 $c_{out}$ 分别是输入输出维度。
Group 卷积 主要贡献参数量
-
Params
$ (k_{h}\times k_{w}\times c_{in}/g\times c_{out}/g)\times g = k_{h}\times k_{w}\times c_{in}\times c_{out}/g $
-
FLOPs
$ k_{h}\times k_{w}\times c_{in}\times c_{out}\times H \times W /g $
Depth-wise 卷积 主要贡献参数量
-
Params
$ k_{h}\times k_{w}\times c_{in}\times c_{out}/c_{in} = k_{h}\times k_{w}\times c_{out} $
-
FLOPs
$ k_{h}\times k_{w}\times c_{out}\times H \times W $
CNN轻量化网络总结
SqueezeNet/ShuffleNet/MobileNet系列介绍
轻量级模型
SqueezeNet 系列(2016)ShuffleNet 系列(2017)MobileNet 系列(2017)ESPnet 系列(2018)FBNet系列(2018)EfficientNet 系列(2019)GhostNet 系列(2019)
卷积核方面:
- 大卷积核用多个小卷积核代替 (低秩分解)
- 单一尺寸卷积核用多尺寸卷积核代替
- 固定形状卷积核趋于使用可变形卷积核
- 使用1×1卷积核 - bottleneck结构
卷积层通道方面:
- 标准卷积用depthwise卷积代替
- 使用分组卷积
- 分组卷积前使用 channel shuffle
- 通道加权计算
卷积层连接方面:
- 使用skip connection,让模型更深
- densely connection,融合其它层特征输出
Transformer轻量化网络总结
MobileViT (2021)Mobile-Former(2021)EfficientFormer(2022)
如何选择轻量化网络:
-
不同网络架构,即使 FLOPs 相同,但其 MAC 也可能差异巨大
-
FLOPs 低不等于 latency 低,结合具硬件架构具体分析多数时候加速芯片算力的瓶颈在于访存带宽不同硬件平台部署轻量级模型需要根据具体业务选择对应指标
模型压缩
量化
剪枝
蒸馏
模型转化与图优化
模型转化与图优化的目标
转换模块
- AI 模型本身包含众多算子,推理引擎需要用有限算子实现不同框架 AI 模型所需要的算子。
- 不同 AI 训练框架的算子重合度高,但不完全一样
- 推理引擎需要用有限算子实现不同框架 AI 模型所需要的算子
- 解决:拥有自己的算子定义和格式对接不同AI框架的算子层
- 支持不同框架 Tensorflow、PyTorch、MindSpore、ONNX 等主流模型文件格式。
- AI 训练框架随版本变迁会有不同的导出格式
- AI 训练框架随版本变迁有大量的算子新增与修改
- 解决:自定义计算图IR对接不同AI框架及其版本
- 支持 CNN / RNN / GAN / Transformer 等主流网络结构。
- 丰富Demo和Benchmark提供主流模型性能和功能基准
- 支持多输入多输出,任意维度输入输出,支持动态输入,支持带控制流的模型。
- 支持可扩展性和AI特性对不同任务、大量集成测试验证
优化模块,消除用于
-
结构冗余:深度学习网络模型结构中的无效计算节点、重复的计算子图、相同的结构模块,可以在保留相同计算图语义情况下无损去除的冗余类型;(计算图优化算子融合、算子替换、常量折叠)
-
精度冗余:推理引擎数据单元是张量,一般为FP32浮点数,FP32表示的特征范围在某些场景存在冗余,可压缩到 FP16/INT8 甚至更低;数据中可能存大量0或者重复数据。 (模型压缩低比特量化、剪枝、蒸馏等)
-
算法冗余:算子或者Kernel层面的实现算法本身存在计算冗余,比如均值模糊的滑窗与拉普拉斯的滑窗实现方式相同。 (统一算子/计算图表达Kernel提升泛化性)
-
读写冗余:在一些计算场景重复读写内存,或者内存访问不连续导致不能充分利用硬件缓存,产生多余的内存传输。(数据排布优化,内存分配优化)
转换与优化模块架构与流程
Converter由Frontends和Graph Optimize构成。前者负责支持不同的AI 训练框架;后者通过算子融合、算子替代、布局调整等方式优化计算图
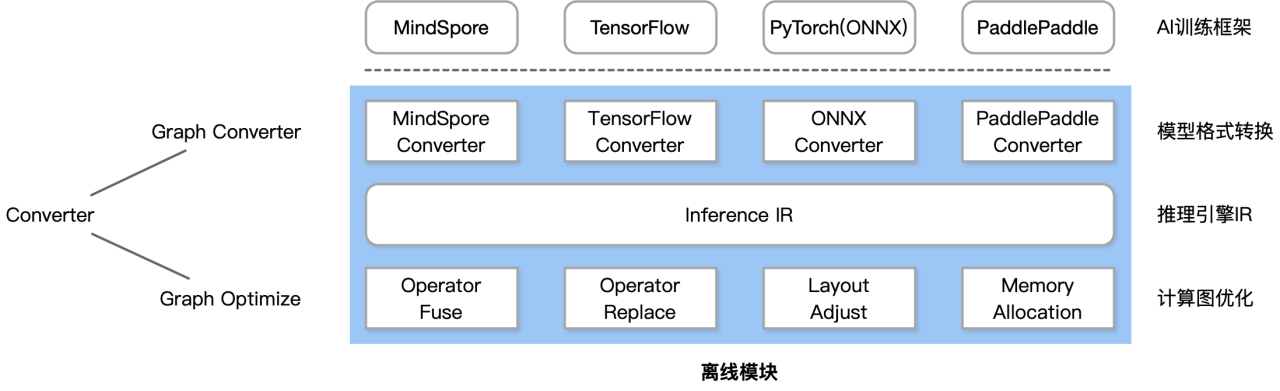
计算图优化类似AI编译器前端优化,很多时候推理引擎没必要做编译器,可以更多基于pattern或者规则优化,让离线模块尽可量简单和小,与训练框架不一样,不需要考虑自动微分,分布式并行,静态图和动态图的问题
工作流程
模型转化技术
Principle and architecture - 转换模块挑战与架构
Model serialization - 模型序列化/反序列化
protobuffer / flatbuffer 目标文件格式
IR define - 自定义计算图
IR/SchemaTechnical details -转换流程和技术细节
ONNX Introduction - ONNX 转换介绍
模型序列化和反序列化
模型序列化:模型序列化是模型部署的第一步,如何把训练好的模型存储起来,以供后续的模型预测使用,是模型部署的首先要考虑的问题。
- 序列化分类:跨平台跨语言通用序列化方法,主要优四种格式:XML,JSON,Protobuffer 和 flatbuffer。而使用最广泛为 Protobuffer,Protobuffer为一种是二进制格式。
模型反序列化:将硬盘当中的二进制数据反序列化的存储到内存中,得到网络模型对应的内存对象。无论是序列化与反序列的目的是将数据、模型长久的保存。
pytorch
PyTorch 内部格式只存储已训练模型的状态,主要是对网络模型的权重等信息加载。
PyTorch 内部格式类似于 Python 语言级通用序列化方法 pickle。(包括 weights、biases、Optimizer)
只是保存网络模型对应的参数,网络模型的结构、计算图等没有保存,而是通过代码承载
1 | |
ONNX:内部支持 torch.onnx.export
1 | |
目标文件格式
protocol buffers
protocol buffers 是一种语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于数据通信协议、数据存储等。特点为:语言无关、平台无关; 比 XML 更小更快更为简单;扩展性、兼容性好。
protocol buffers 中可以定义数据的结构,然后使用特殊生成的源代码轻松的在各种数据流中使用各种语言进行编写和读取结构数据。甚至可以更新数据结构,而不破坏由旧数据结构编译的已部署程序。
Protobuffer 编码模式
计算机里一般常用的是二进制编码,如int类型由32位组成,每位代表数值2的n次方,n的范围是0-31。Protobuffer 采用 TLV 编码模式,即把一个信息按照 tag-length-value 的模式进行编码。tag 和 value 部分类似于字典的 key 和 value,length 表示 value 的长度,此外 Protobuffer 用 message 来作为描述对象的结构体。
1 | |
Protobuffer 遍解码过程
- 根 message 由多个 TLV 形式的 field 组成,解析 message 的时候逐个去解析 field。
- 由于 field 是 TLV 形式,因此可以知道每个 field 的长度,然后通过偏移上一个 field 长度找到下一个 field 的起始地址。其中 field 的 value 也可以是一个嵌套 message。
- 对于 field 先解析 tag 得到 field_num 和 type。field_num 是属性 ID,type 帮助确定后面的 value 一种编码算法对数据进行解码。
FlatBuffers
FlatBuffers 主要针对部署和对性能有要求的应用。相对于 Protocol Buffers,FlatBuffers 不需要解析,只通过序列化后的二进制buffer即可完成数据访问。FlatBuffers 的主要特点有:
- 数据访问不需要解析
- 内存高效、速度快
- 生成的代码量小
- 可扩展性强
- 强类型检测
- 易于使用
| Protobuffer | Flatbuffers | |
|---|---|---|
| 支持语言 | C/C++, C#, Go, Java, Python, Ruby, Objective-C, Dart | C/C++, C#, Go, Java, JavaScript, TypeScript, Lua, PHP, Python, Rust, Lobster |
| 版本 | 2.x/3.x,不相互兼容 | 1.x |
| 协议文件 | .proto,需指定协议文件版本 | .fbs |
| 代码生成工具 | 有(生成代码量较多) | 有(生成代码量较少) |
| 协议字段类型 | bool, bytes, int32, int64, uint32, uint64, sint32, sint64, fixed32, fixed64, sfixed32, sfixed64, float, double, string | bool, int8, uint8, int16, uint16, int32, uint32, int64, uint64, float, double, string, vector |
自定义计算图IR
为什么推理引擎需要自定义计算图:把不同的计算图对接到同一个IR,方便后面图优化的处理
自定义计算图IR结构
基于计算图的AI框架:基本组成
-
基本数据结构:Tensor 张量Tensor形状: [2, 3, 4, 5]元素类型:int, float, string, etc
-
基本运算单元:Operator 算子由最基本的代数算子组成,根据深度学习结构组成复杂算子,N个输入Tensor,M个输出Tensor
AI 框架与推理引擎的计算图区别
| AI框架计算图 | 推理引擎计算图 | |
|---|---|---|
| 计算图组成 | 算子 + 张量 + 控制流 | 算子 + 张量 + 控制流 |
| 正反向 | Forward + Backward | Forward |
| 动静态 | 动态图 + 静态图部分 AI 框架实现动静统一可以互相转换 | 以静态图为主 |
| 分布式并行 | 依托 AI 集群计算中心,计算图支持数据并行、张量并行、流水线并行等并行切分策略 | 以单卡推理服务为主,很少考虑分布式推理 |
| 使用场景 | 训练场景,以支持科研创新,模型训练和微调,提升算法精度 | 推理场景,以支持模型工业级部署应用,对外提供服务 |
graph_tensor.fbs tensor
1 | |
graph_op.fbs 算子
1 | |
graph_net.fbs 图
1 | |
自定义计算图流程
构建计算图 IR:根据自身推理引擎的特殊性和竞争力点,构建自定义的计算图
解析训练模型:通过解析 AI 框架导出的模型文件,使用 Protobuffer / flatbuffer 提供的API定义对接到自定义 IR 的对象
生成自定义计算图:通过使用 Protobuffer / flatbuffer 的API导出自定义计算图
模型转换技术思路
直接转换:直接将网络模型从 AI 框架转换为适合目标框架使用的格式;
- 内容读取:读取 A 框架生成的模型文件,并识别模型网络中的张量数据的类型/格式、算子的类型和参数、计算图的结构和命名规范,以及它们之间的其他关联信息。
- 格式转换:将 step1 识别得到的模型结构、模型参数信息,直接代码层面翻译成推理引擎支持的格式。当然,算子较为复杂时,可在 Converter 中封装对应的算子转换函数来实现对推理引擎的算子转换。
- 模型保存:在推理引擎下保存模型,可得到推理引擎支持的模型文件,即对应的计算图的显示表示。
规范式转换:设计一种开放式的文件规范,使得主流 AI 框架都能实现对该规范标准的支持
- ONNX是一种针对机器学习所设计的开放式文件格式,用于存储训练好的网络模型。它使得不同的 AI 框架 (如Pytorch, MindSpore) 可以采用相同格式存储模型数据并交互。
- ONNX 定义了一种可扩展的计算图模型、一系列内置的运算单元(OP)和标准数据类型。每一个计算流图都定义为由节点组成的列表,并构建有向无环图。其中每一个节点都有一个或多个输入与输出,每一个节点称之为一个 OP
模型转换通用流程
- AI框架生成计算图(以静态图表示),常用基于源码 AST 转换和基于 Trace 的方式;
- 对接主流通用算子,并重点处理计算图中的自定义算子;
- 目标格式转换,将模型转换到一种中间格式,即推理引擎的自定义 IR;
- 根据推理引擎的中间格式 IR,导出并保存模型文件,用于后续真正推理执行使用。

图优化
什么是图优化
-
基于一系列预先写好的模板,减少转换模块生成的计算图中的冗余计算,比如 Convolution 与 Batch Normal / Scale 的合并,Dropout 去除等。
-
图优化能在特定场景下,带来相当大的计算收益,但相当依赖根据先验知识编写的模板,相比于模型本身的复杂度而言注定是稀疏的,无法完全去除结构冗余。
为什么AI框架或者AI编译器的图优化采用基于规则树或者特殊IR树的方式进行优化融合,而推理引擎的图优化采用 Hard Code 或者模板匹配呢?
- 采用 Hard Code 或者模板匹配只能覆盖常用有用的场景,通过编译的方式可以覆盖到很多常规的应用
- AI框架多数情况下用来创新,要考虑长尾问题,而且大部分是在计算中心或者强算力执行的,所以时间不是非常重要(编译耗时)。可以采取JIT的编译方式去提升性能
- 推理引擎一般针对的是常用的模型进行部署,图优化部分是离线的或者AOT方式。使用Hard Code 或者模板匹配更好覆盖常用有用的场景就行
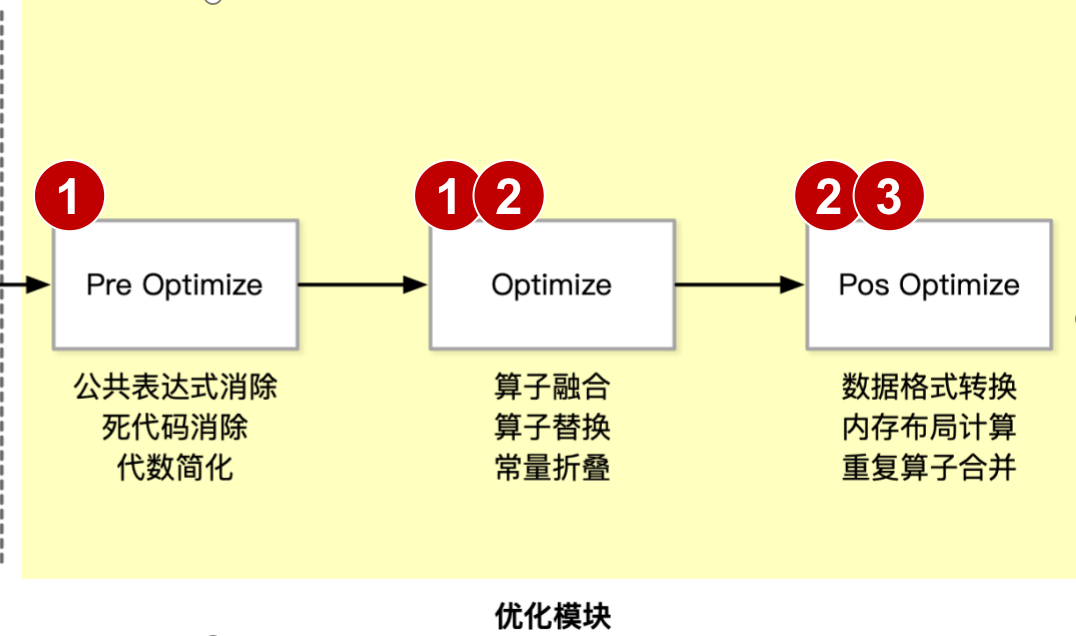
图优化方式
-
Basic: 基础优化涵盖了所有保留计算图语义的修改,如:O1常量折叠、O2冗余节点消除和O3有限数量的算子融合。
-
Extended: 扩展优化仅在运行特定后端,如 CPU、CUDA、NPU 后端执行提供程序时适用。其针对硬件进行特殊且复杂的 Kernel 融合策略和方法。
-
Layout & Memory: 布局转换优化,主要是不同 AI 框架,在不同的硬件后端训练又在不同的硬件后端执行,数据的存储和排布格式不同。
ONNX Runtime定义了GraphOptimizationLevel枚举,用于确定将启用哪个优化级别。选择一个级别会启用该级别的优化,以及所有前面级别的优化。例如,启用扩展优化也会启用基本优化。将这些级别映射到枚举的方式如下所示:
1 | |
Constant Folding 常量折叠
Constant folding,常量折叠,编译器优化技术之一,通过对编译时常量或常量表达式进行计算来简化代码。
Statically computes parts of the graph that rely only on constant initializers. This eliminates the need to compute them during runtime. 常量折叠是将计算图中可以预先可以确定输出值的节点替换成常量,并对计算图进行一些结构简化的操作。
Constant Folding 常量折叠:
如果一个 Op 所有输入都是常量 Const,可以先计算好结果Const 代替该 Op,而不用每次都在推理阶段都计算一遍。

ExpandDims 折叠:
ExpandDims Op 指定维度的输入是常量 Const,则把这个维度以参数的形式折叠到 ExpandDims 算子中。

Binary 折叠:
Binary Op 第二个输入是标量 Const ,把这个标量以参数的形式折叠到 Binary Op 的属性中。

Redundant eliminations 冗余节点消除
Remove all redundant nodes without changing the graph structure. 在不改变图形结构的情况下删除所有冗余节点 。
Op本身无意义:有些 Op 本身不参与计算,在推理阶段可以直接去掉对结果没有影响。
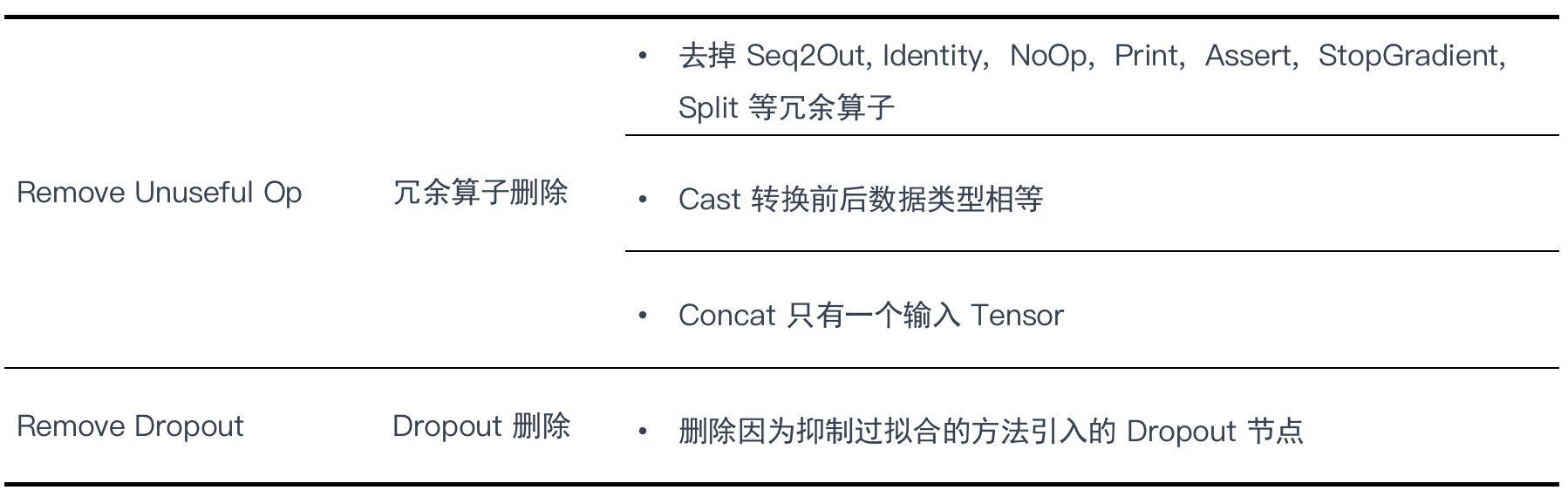
Op 参数无意义:有些 Op 本身是有意义,但是设置成某些参数后就变成了无意义了的 Op
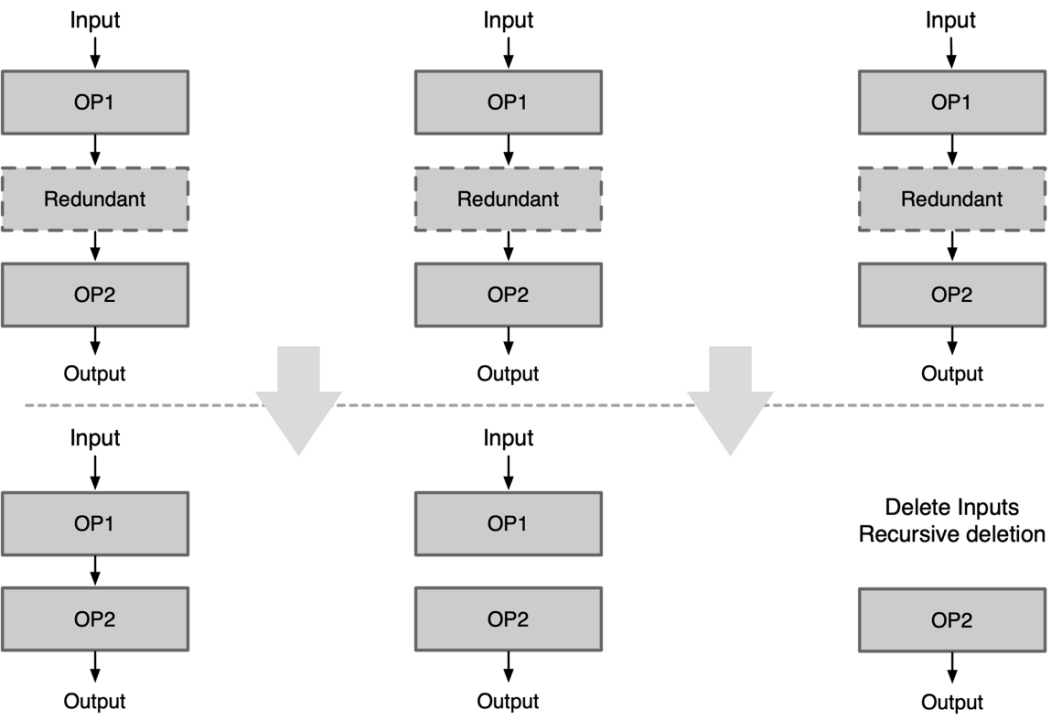
| Tensor Cast | Cast 消除 | Tensor 转换数据排布格式时当参数 Src 等于 Dst 时,该 Op 无意义可删除 |
|---|---|---|
| Slice Elimination | Slice 场景消除 | Slice Op 的 index_start 等于0或者 index_end 等于 c-1 时,该Op无意义可删除 |
| Expand Elimination | Expand 消除 | Expand Op 输出 shape 等于输入 shape 时,该 Op 无意义可删除 |
| pooling1x1 Elimination | pooling 消除 | Pooling Op 对滑窗 1x1 进行池化操作 |
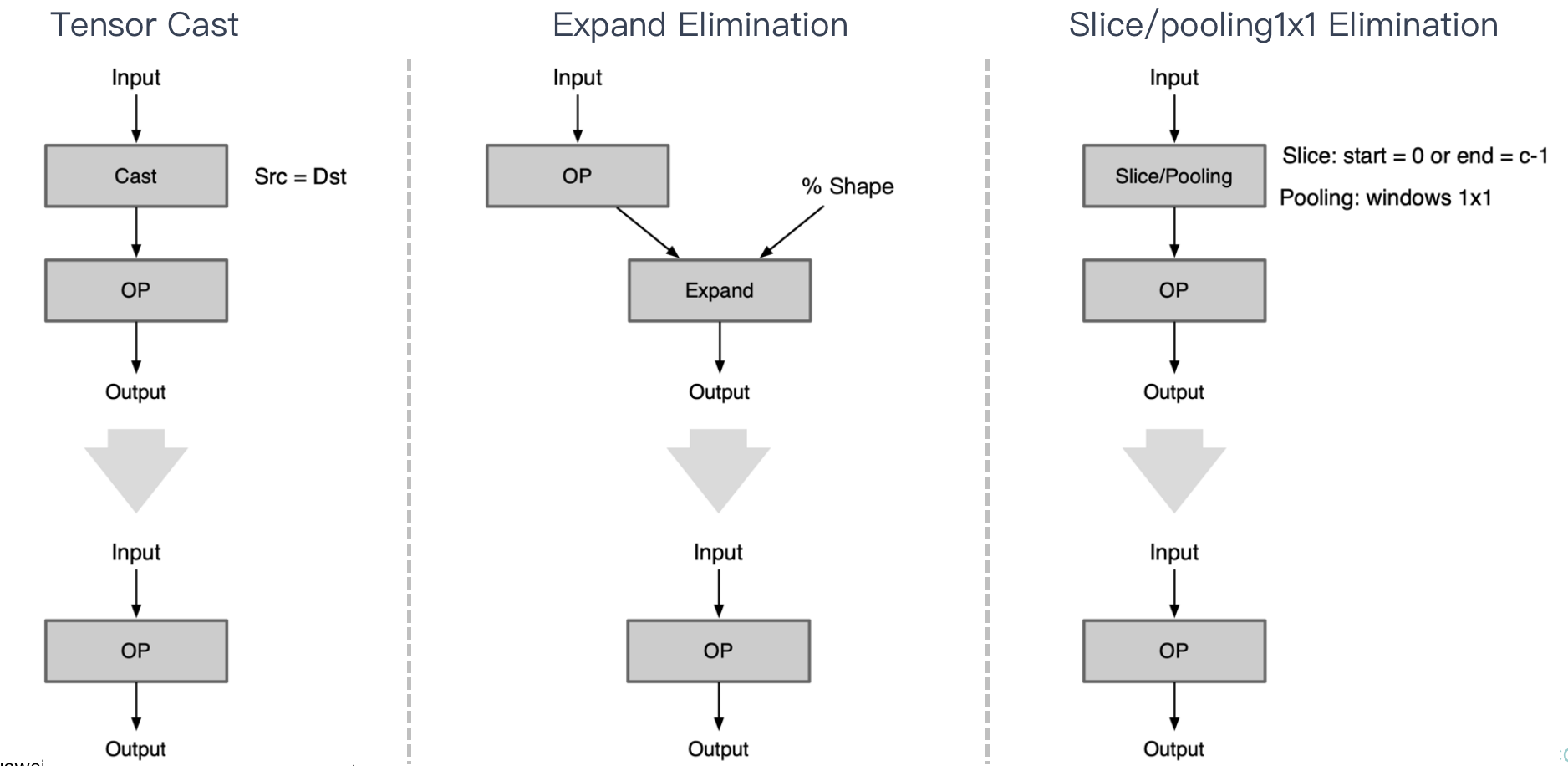
Op 位置无意义:一些 Op 在计算图中特殊位置会变得多余无意义;
| Remove Output Cast | 输出后消除 | 模型的输出不需要进行内存排布转换 |
|---|---|---|
| Unsqueeze Elimination | Unsqueeze 消除 | 当 Unsqueeze Op 输入是 Const 时,可以将 Const 执行 Unsqueeze 操作后直接删除 Unsqueeze |
| Orphaned Eliminate | 孤儿节点消除 | 网络模型中存在一些数据节点,当没有其他 Op 将该 Const Op 作为输入时可认为其为孤儿 orphaned 节点删除 |
| Reshape before binary Eliminate | Reshape 消除 | 在 Binary Op 前面有 Reshape 算子,则将其删除 |
| Reshape/Flatten after global pooling Eliminate | Reshape 消除 | Reshape 为 flatten 时(即期望 Reshape 后 Tensor w=1,h=1,c=c),而global pooling 输出 Tensor w=1,h=1,c=c,则将其删除 |
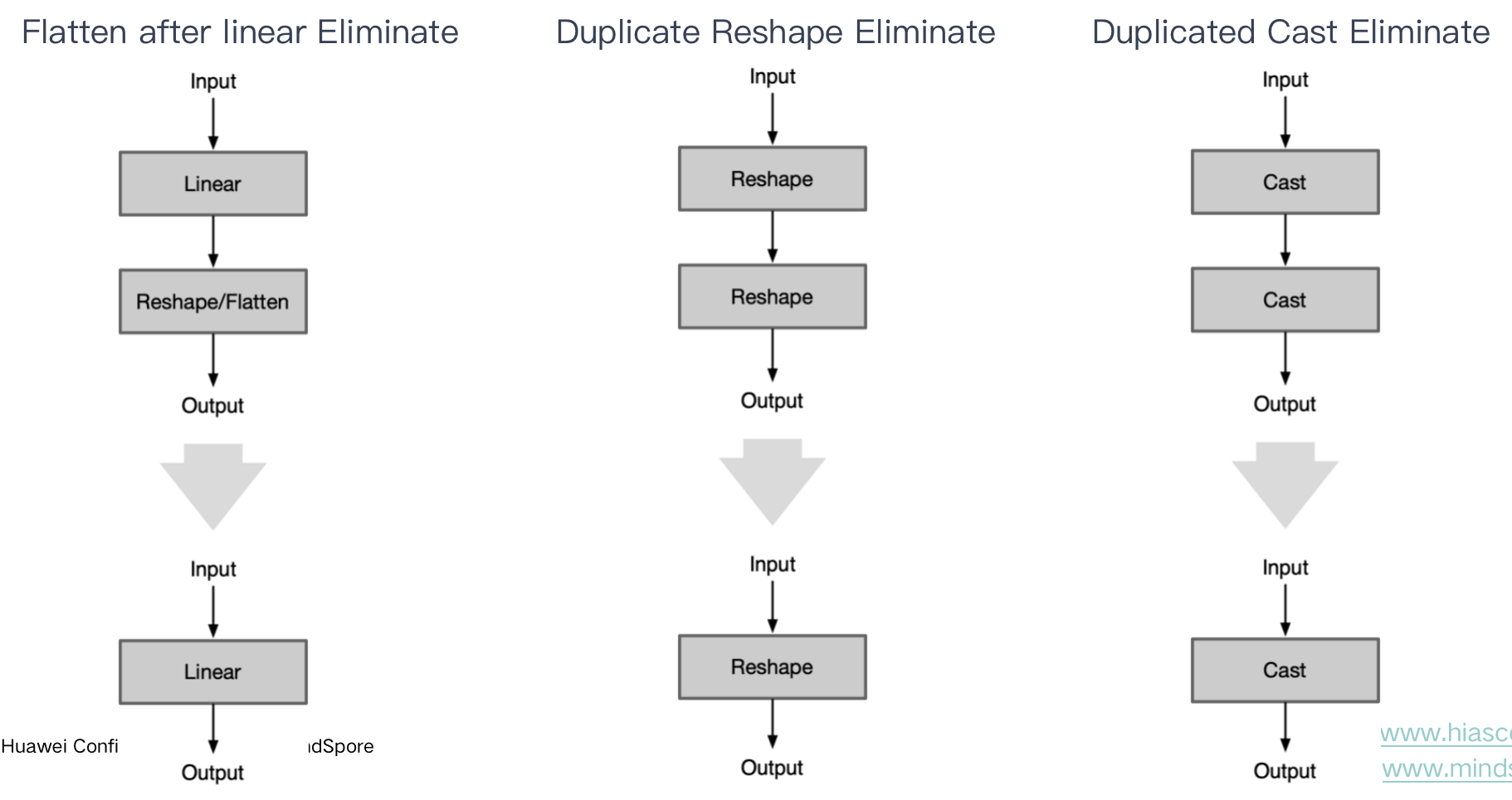
| Flatten after linear Eliminate | Flatten 消除 | linear 全连接层输出 tensor 为 w=1,h=1,c=c时,后续 Flatten Op 可删除 |
| Duplicate Reshape Eliminate | 重复消除 | 连续 Reshape 只需要保留最后一个 Reshape |
| Duplicated Cast Eliminate | 重复消除 | 连续的内存排布转换或者数据转换,只需要保留最后一个 |
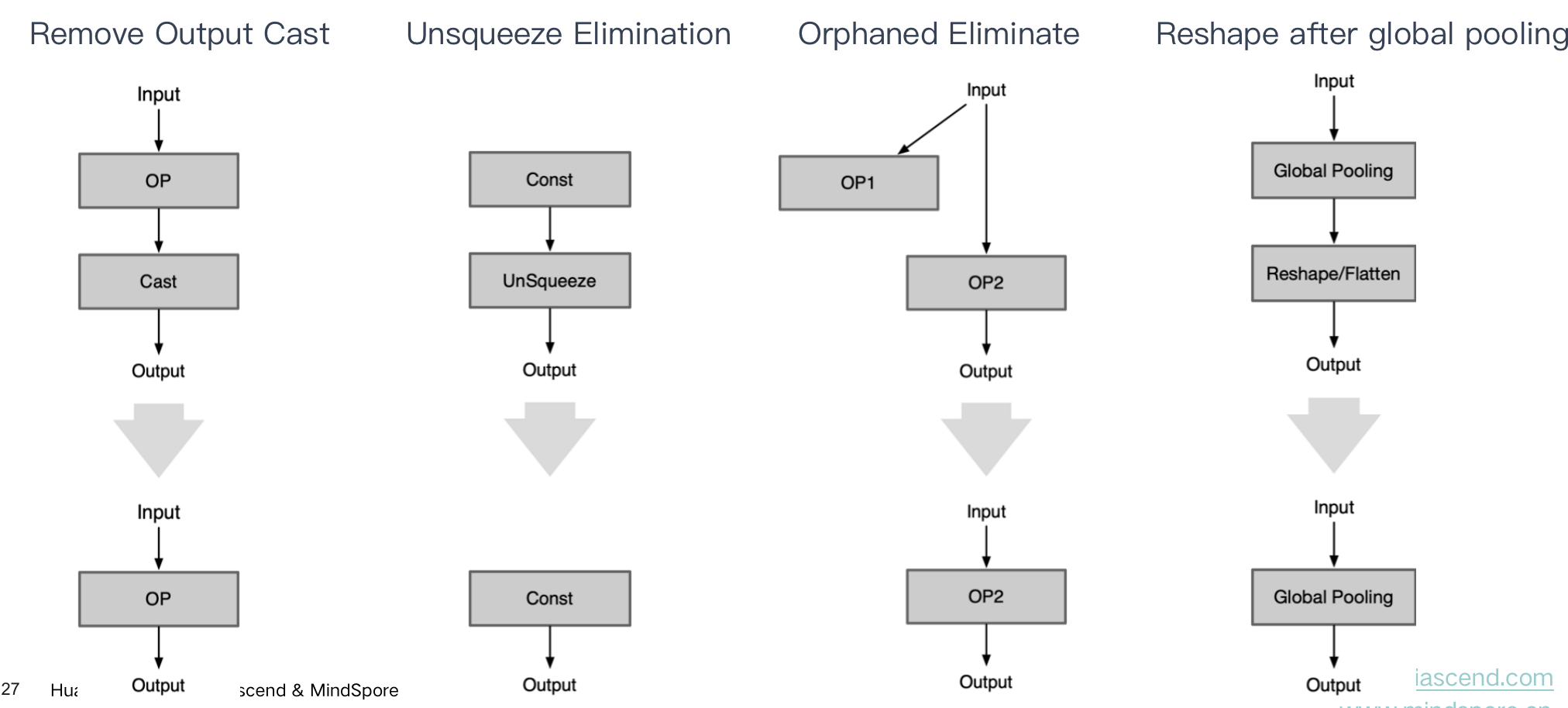
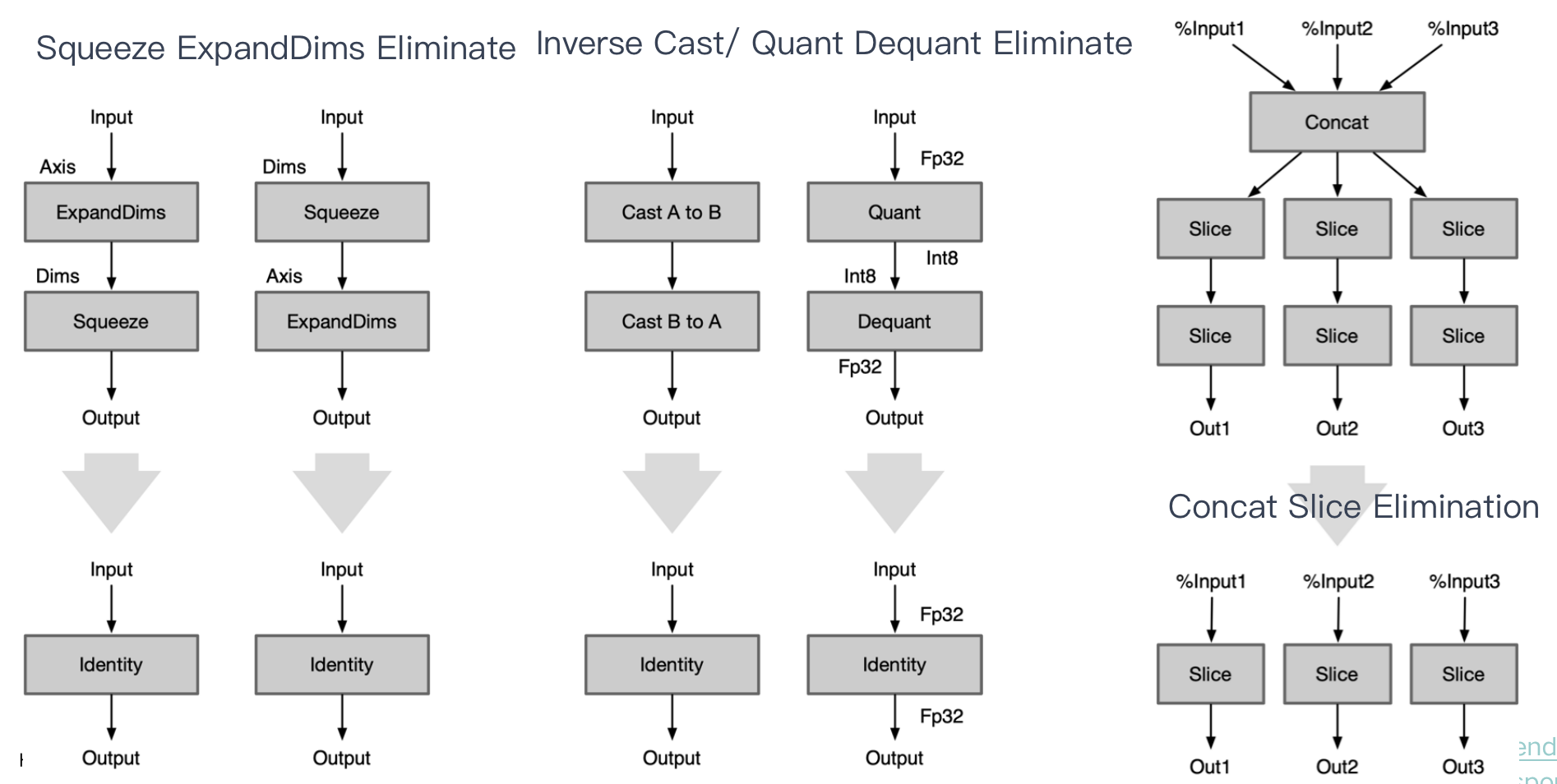
Op 前后反义:前后两个相邻 Op 进行操作时,语义相反的两个 Op 都可以删除
| Squeeze ExpandDims Eliminate | Squeeze和ExpandDims这两个Op是反义的,一个压缩维度,一个是拓展维度,当连续的这两个Op指定的axis相等时即可同时删除这两个Op | |
|---|---|---|
| Inverse Cast Eliminate | 当连续的两个内存排布转换Op的参数前后反义,即src1等于dst2,可同时删除这两个 Op | |
| Quant Dequant Eliminate | 连续进行量化和反量化,可同时删除这两个 Op | |
| Concat Slice Elimination | 合并后又进行同样的拆分,可同时删除这两个 Op |
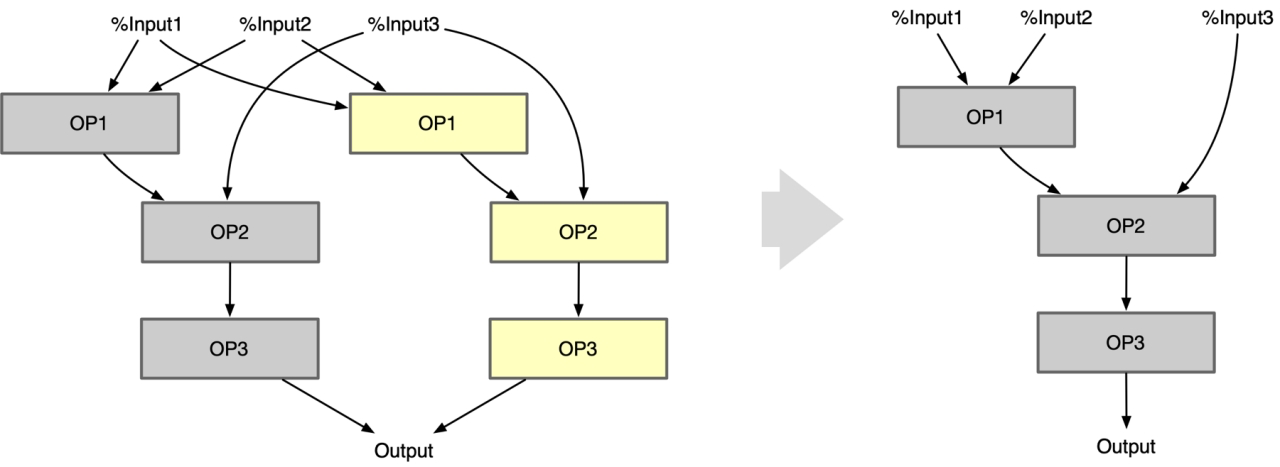
公共子图: 最大公共子图问题是给定两个图,要求去掉一些点后,两个图都得到一个节点数至少为b的子图,且两个子图完全相同。
| Common Subexpression Elimination | 当模型当中出现了公共子图,如一个输出是另外两个同类型同参数的Op的输入,则可进行删除其中一个Op。(同时这是一个经典的Leetcode算法题目,寻找公共子树,有兴趣可自行搜索) | |
|---|---|---|
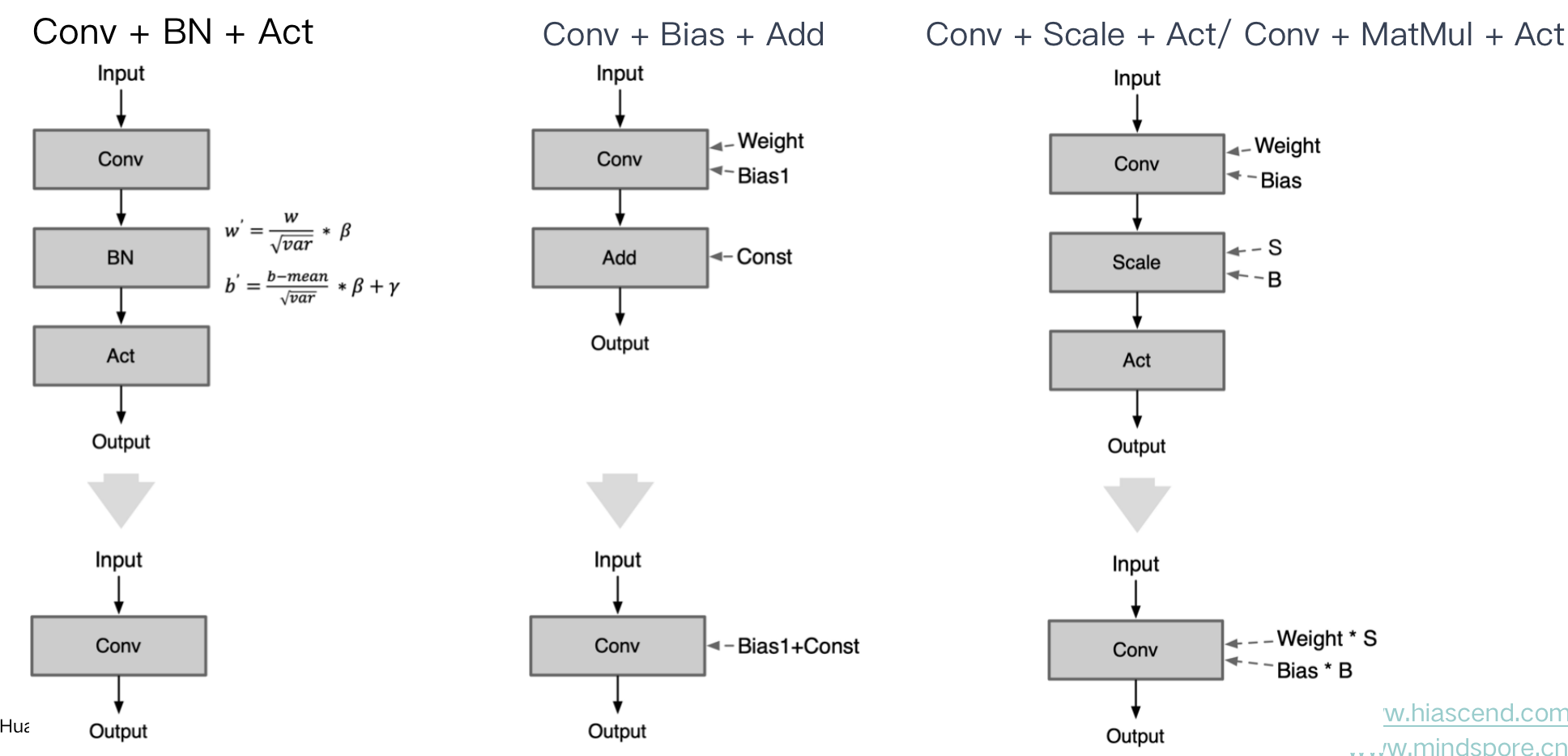
Operation fusion 算子融合
Op线性融合:相邻 Op 存在数学上线性可融合的关系;
| Conv + BN + Act | Conv Op 后跟着的 Batch Normal 的算子可以把 BN 的参数融合到Conv里面 |
|---|---|
| Conv + Bias + Add | Conv Op 后跟着的 Add 可以融合到 Conv 里的 Bias 参数里面 |
| Conv + Scale + Act | Conv Op 后跟着的 Scale 可以融合到 Conv 里的 Weight 里面 |
| Conv + MatMul + Act | Conv Op 后跟着的 MatMul 可以融合到 Conv 里的 Weight 里面 |
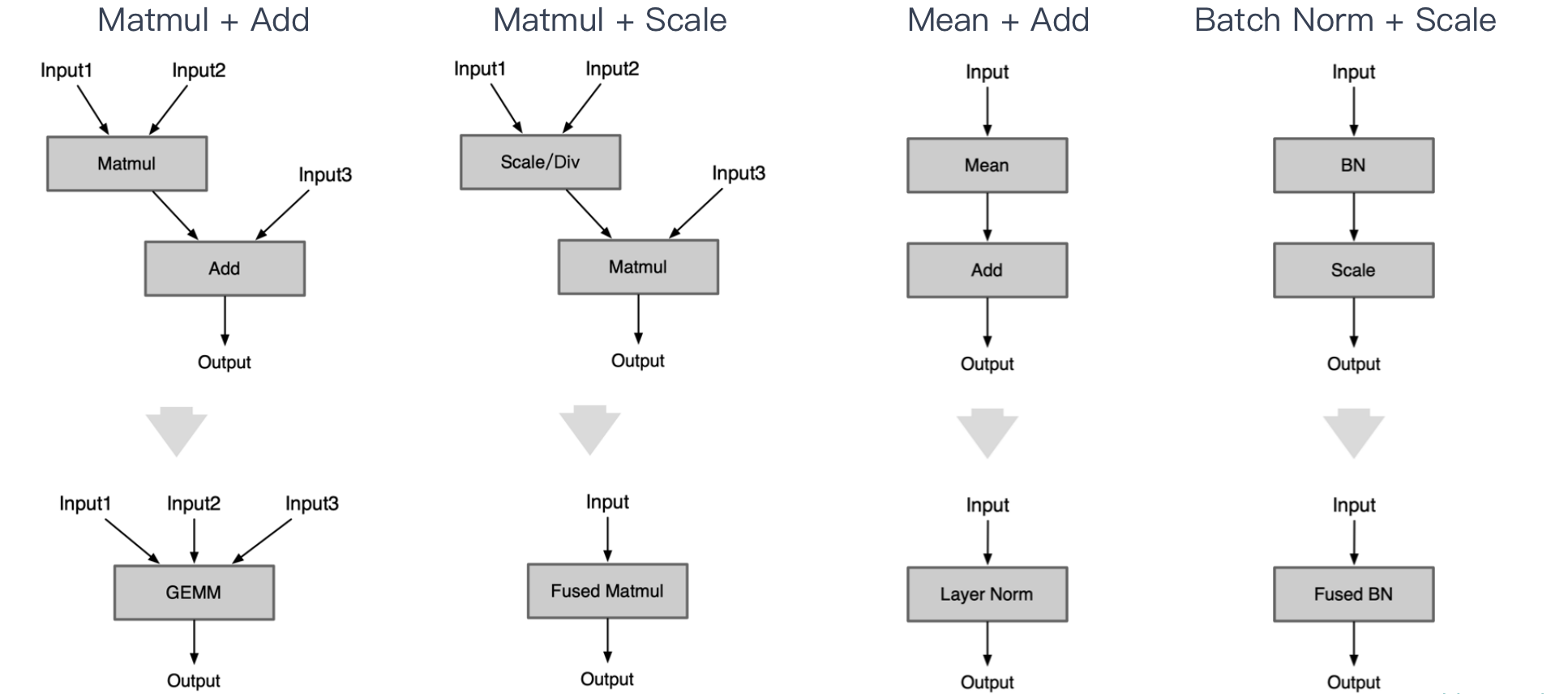
| Matmul + Add | 使用 GEMM 代替矩阵乘 Matmul + Add |
|---|---|
| Matmul + Scale | Matmul 前或者后接 Scale / Div 可以融合到 Matmul 的相乘系数 alpha 里 |
| Mean + Add | 使用 Mean 后面跟着 Add,使用 Layer Norm 代替 |
| Batch Norm + Scale | scale 的 s 和 b 可以直接融合到 BN Op 里 |
| Matmul + Batch Norm | 与 Conv + BN 相类似 |
| Matmul + Add | 全连接层后 Add 可以融合到全连接层的 bias 中 |
Op激活融合:算子与后续的激活相融合;

Operation Replace 算子替换
Replace node with another node. 算子替换,即将模型中某些算子替换计算逻辑一致但对于在线部署更友好的算子。
算子替换的原理是通过合并同类项、提取公因式等数学方法,将算子的计算公式加以简化,并将简化后的计算公式映射到某类算子上。算子替换可以达到降低计算量、降低模型大小的效果。
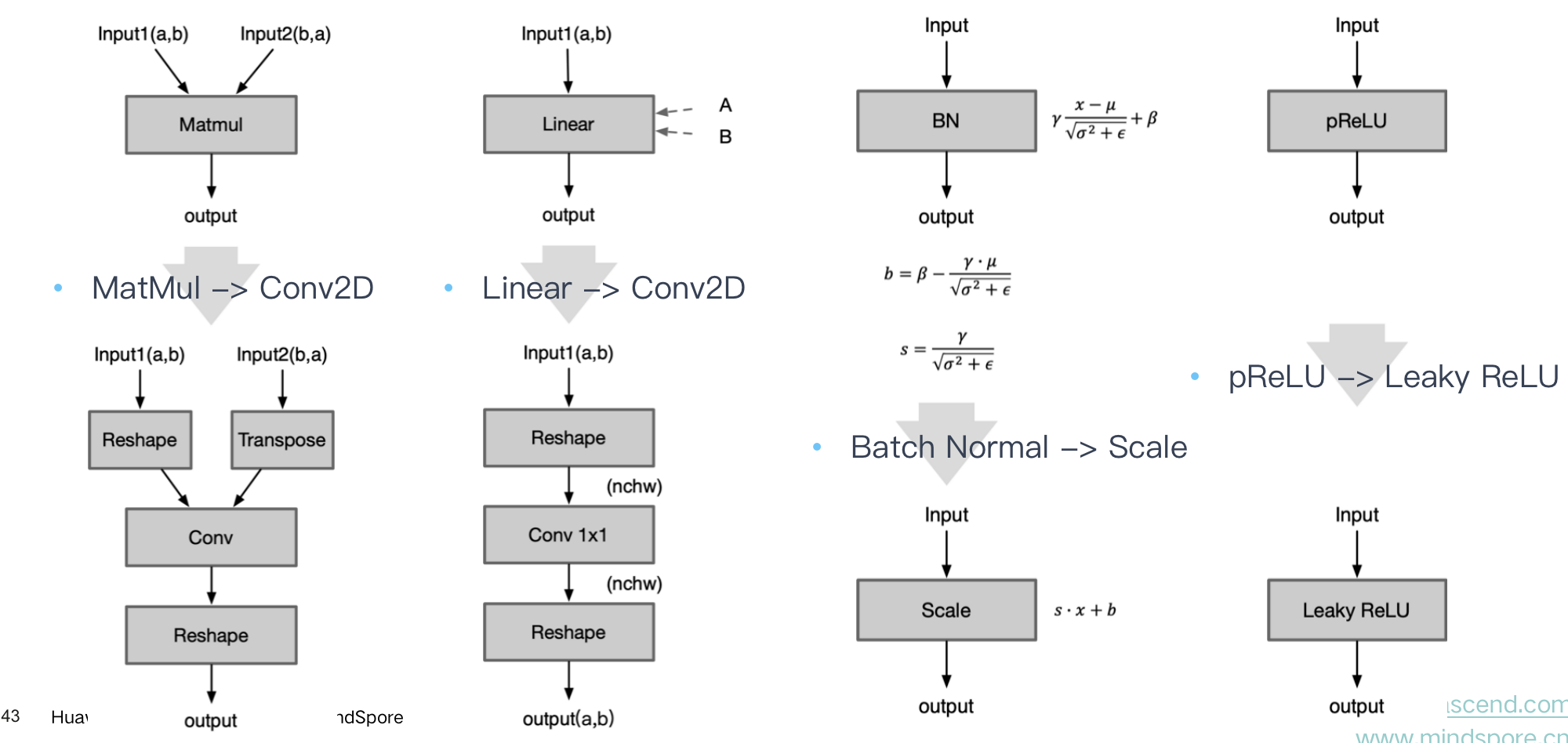
One to One:将某 Op 以另外 Op 代替,能减少推理引擎需要单独实现及支持的 OP
| MatMul -> Conv2D | 将矩阵乘变成Conv,因为一般框架对Conv是做了更多的优化 |
|---|---|
| Linear -> Conv2D | 将全连接层转变成1x1 Conv,因为对Conv做了更多的优化 |
| Batch Normal -> Scale | BN是等价于Scale Op的,转换成Scale计算量更少,速度更快 |
| pReLU -> Leaky ReLU | 将 pReLU 转变成 Leaky ReLU,不影响性能和精度的前提下,聚焦有限算法 |
| Conv -> Linear After global pooling | 在 Global Pooling 之后 Conv 算子转换成为全连接层 |
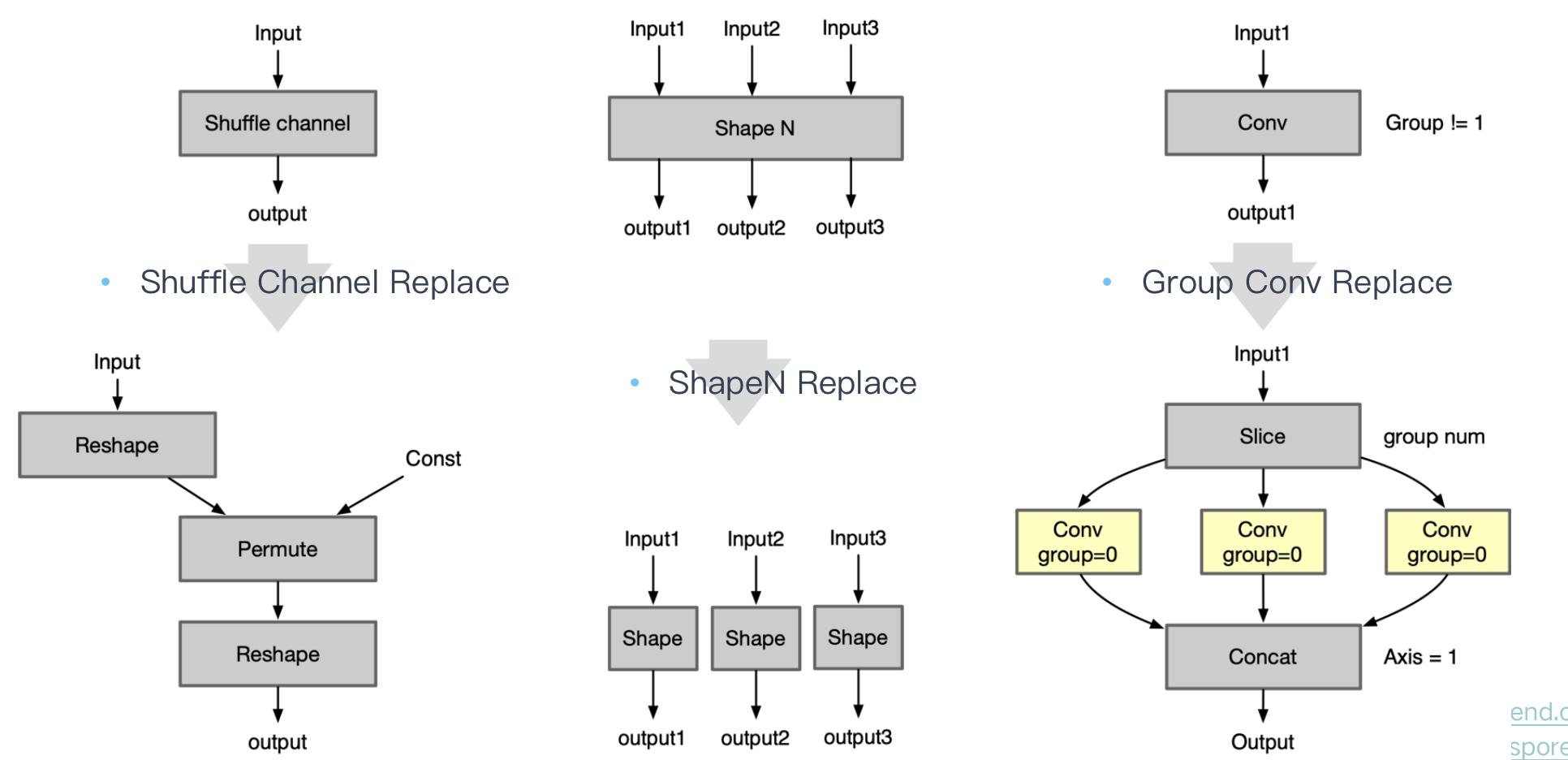
一换多:将某 Op 以其他 Op 组合形式代替,能减少推理引擎需要单独实现及支持 Op 数量
| Shuffle Channel Replace | Shuffle Channel Op 大部分框架缺乏单独实现,可以通过组合 Reshape + Permute实现 |
|---|---|
| Pad Replace | 将老版onnx的pad-2的pads从参数形式转成输入形式 |
| ShapeN Replace | 将 ShapeN Op 通过组合多个 Shape 的方式实现 |
| Group Conv Replace | 把Group 卷积通过组合 Slice、Conv 实现 |
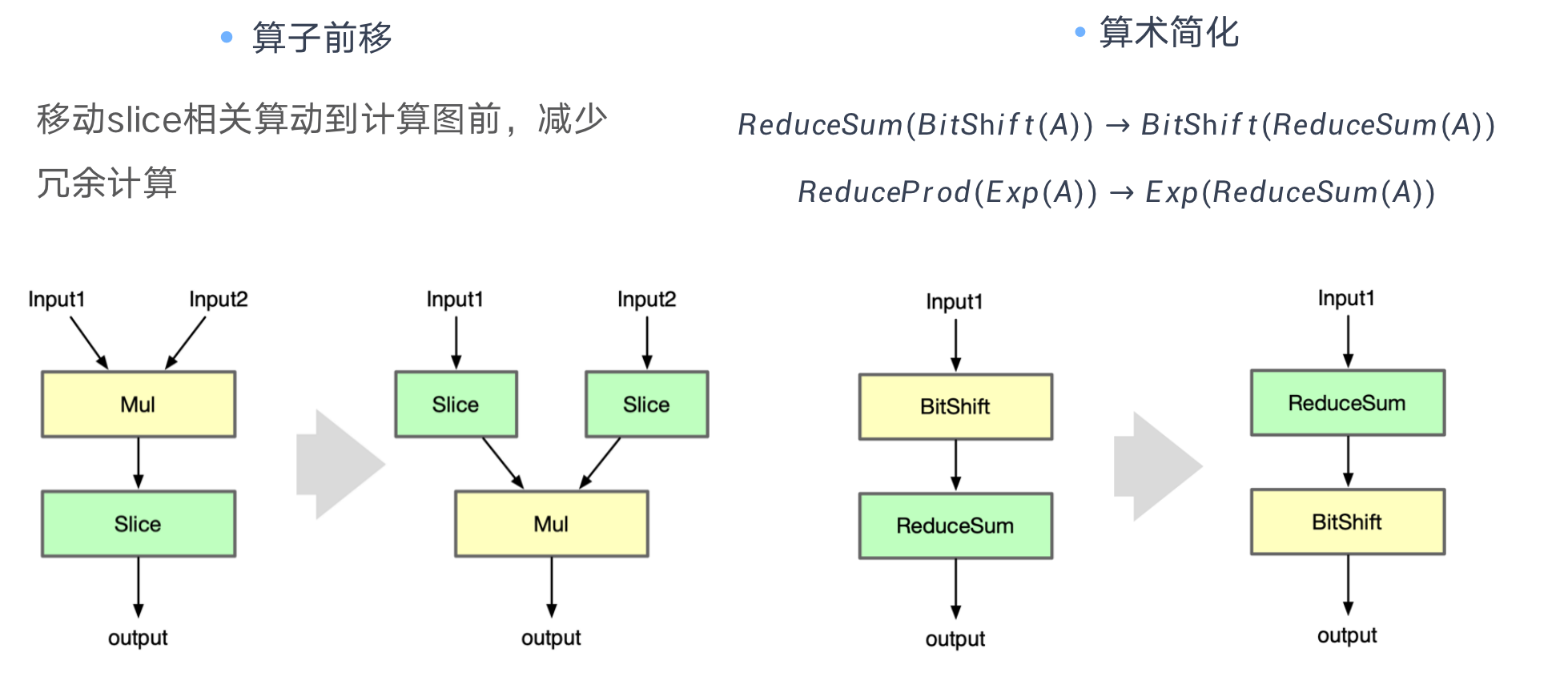
Operation Forward 算子前移
| Slice and Mul | Shuffle Channel Op 大部分框架缺乏单独实现,可以通过组合 Reshape + Permute实现 |
|---|---|
| Bit shift and Reduce Sum | 利用算术简化中的交换律,对计算的算子进行交换减少数据的传输和访存次数 |
Extended Graph Optimizations 其他图优化
扩展优化仅在运行特定后端,如 CPU、CUDA、NPU 后端执行提供程序时适用。其针对硬件进行特殊且复杂的 Kernel 融合策略和方法。
These optimizations include complex node fusions. They are run after graph partitioning and are only applied to the nodes assigned to the CPU or CUDA or ROCm execution provider.有些 Op 在一些框架上可能没有直接的实现,而是通过一些 Op 的组合,如果推理引擎实现了该 Op,就可以把这些组合转成这个 Op,能够使得网络图更加简明清晰。
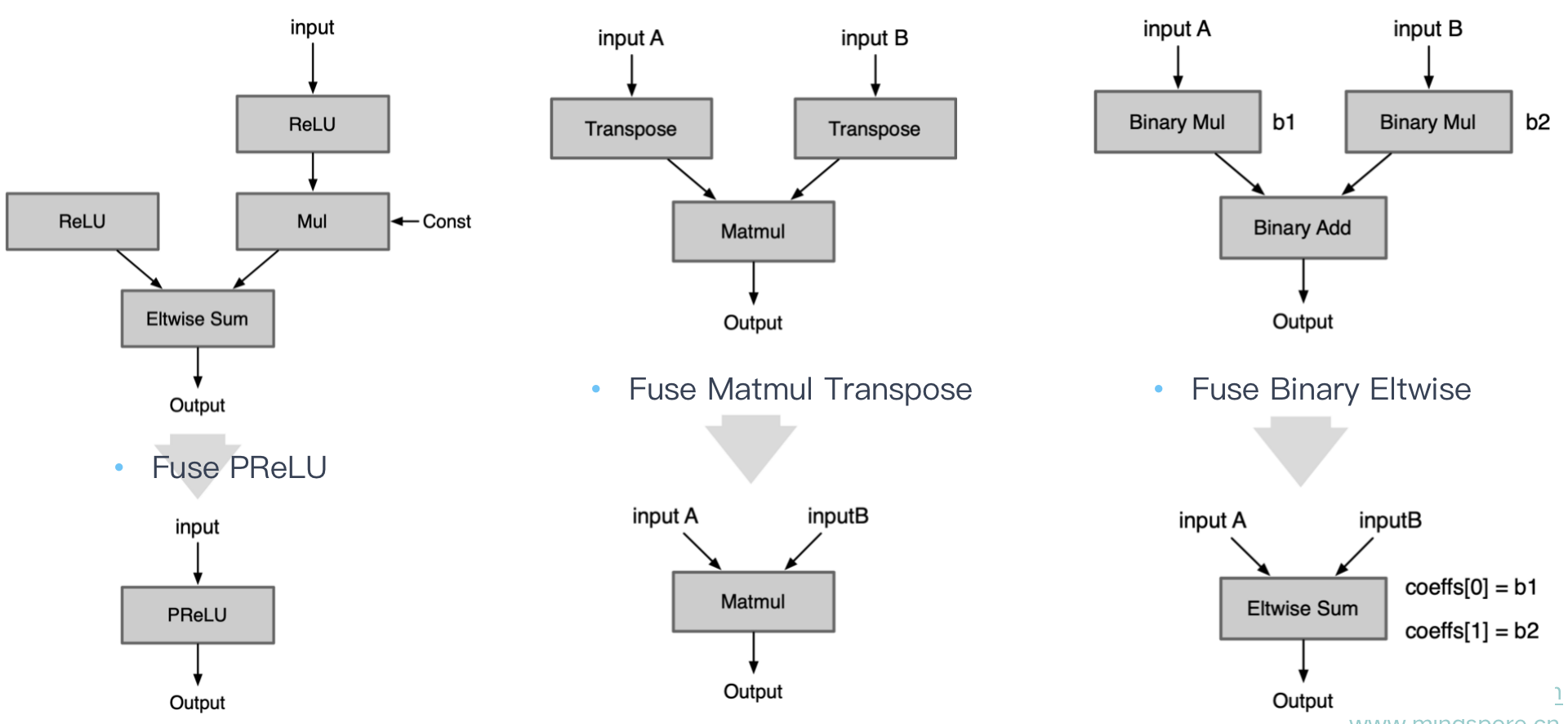
| Fuse Layer Norm | 组合实现的 Norm Op 直接转换成一个Op |
|---|---|
| Fuse PReLU | 组合实现的 PReLU Op 直接转换成一个Op |
| Fuse Matmul Transpose | 有些框架的矩阵乘法Matmul层自身是不带转置操作的,当需要转置的矩阵乘法时需要前面加一个transpose层。如 Onnx 的 Matmul 自身有是否转置的参数,因此可以将前面的transpose层转换为参数即可 |
| Fuse Binary Eltwise | x3 = x1 *b1+x2 *b2,把 BinaryOp Add 转换成 Eltwise Sum,而 Eltwise Sum是有参数 coeffs,可以完成上述乘法的效果,因此把两个 BinaryOp Mul 的系数融合到Eltwise Sum 的参数 coeffs |
| Fuse Reduction with Global Pooling | 对一个三维 tensor 先后两次分别进行w维度的 reduction mean 和h维度的reducetion mean,最终只剩下c这个维度,就等于进行了一次global_mean_pooling |
数据转换节点
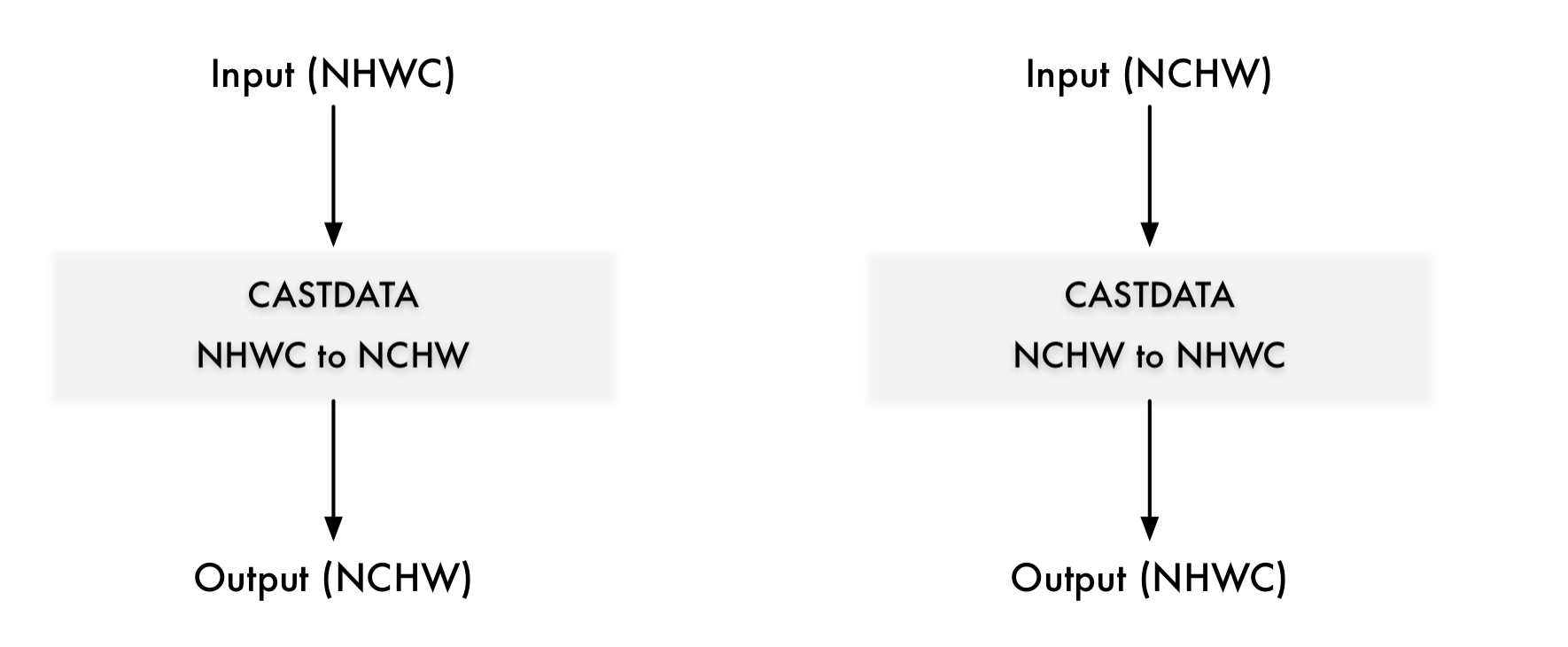
常见数据转换节点
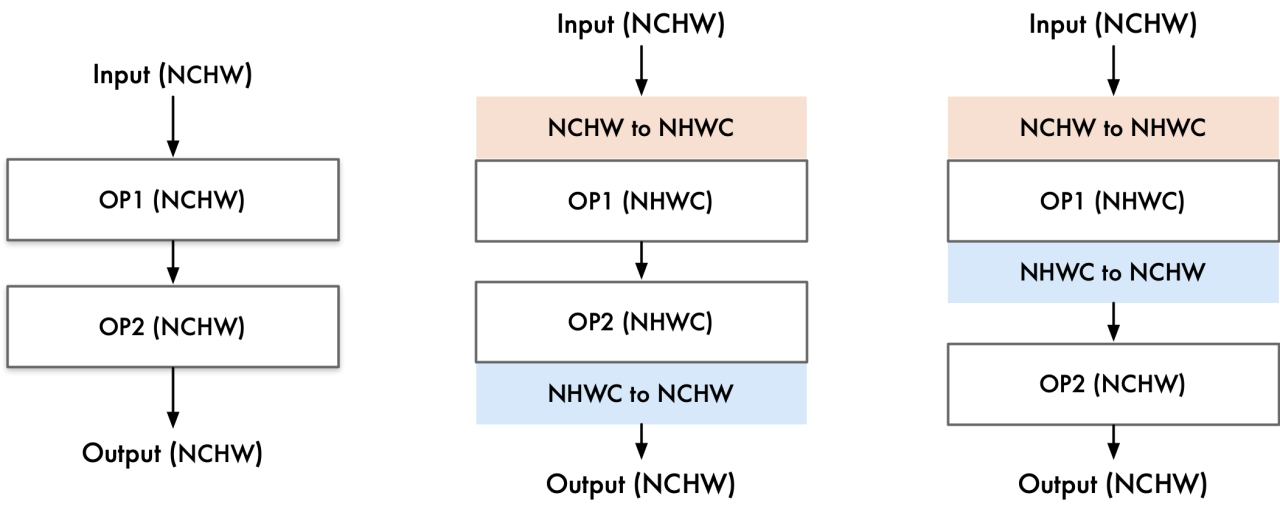
内存优化方法
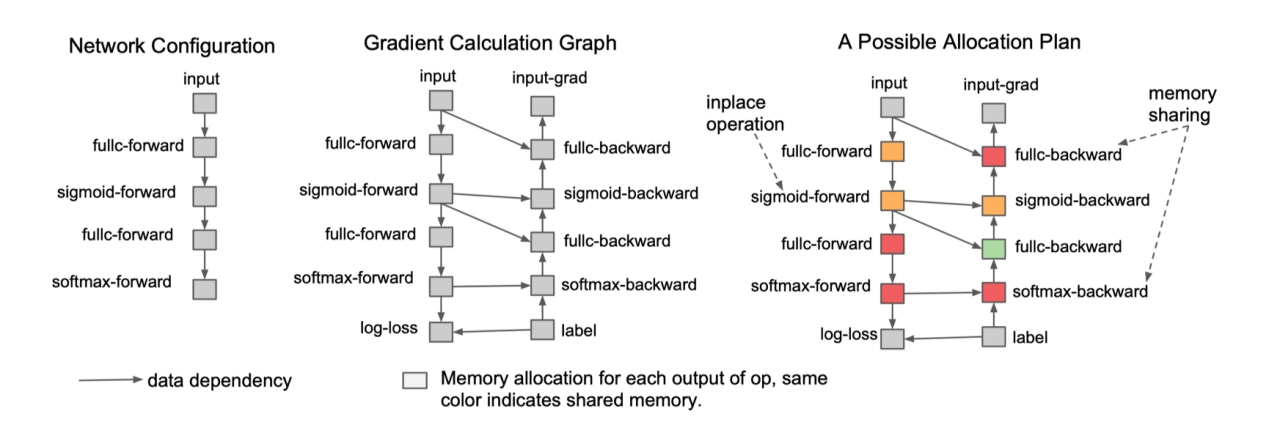
Inplace operation:如果一块内存不再需要,且下一个操作是element-wise,可以原地覆盖内存
Memory sharing:两个数据使用内存大小相同,且有一个数据参与计算后不再需要,后一个数据可以覆盖前一个数据