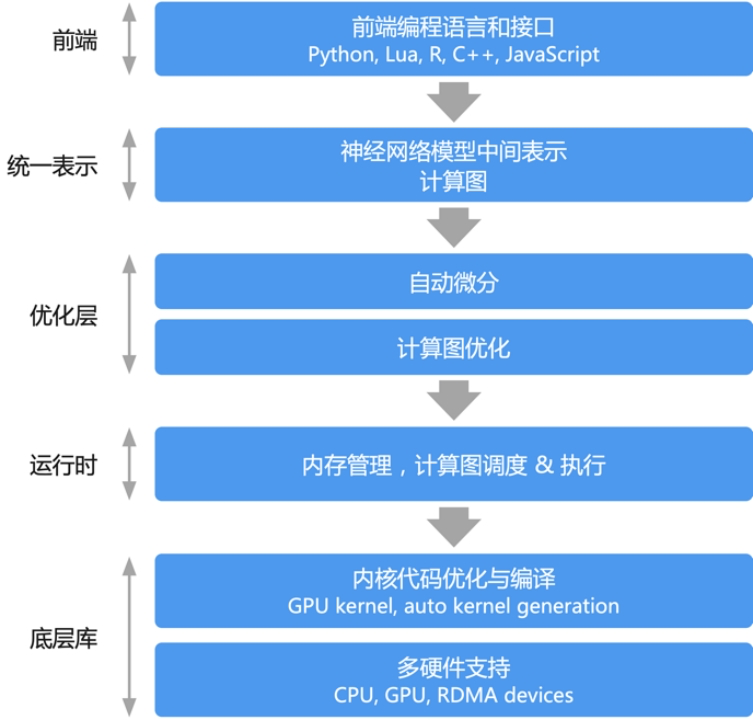
计算图基本结构
基本数据结构:
- Tensor 张量高维数组,对标量,向量,
- 矩阵的推广Tensor形状(Shape): [3, 2, 5]
- 元素基本数据类型(Data Type):int, float, string, etc.
优点:
- 后端自动推断并完成元素逻辑存储空间向物理存储空间的映射
- 基本运算类型作为整体数据进行批量操作,适合单指令多数据(SIMD)并行加速
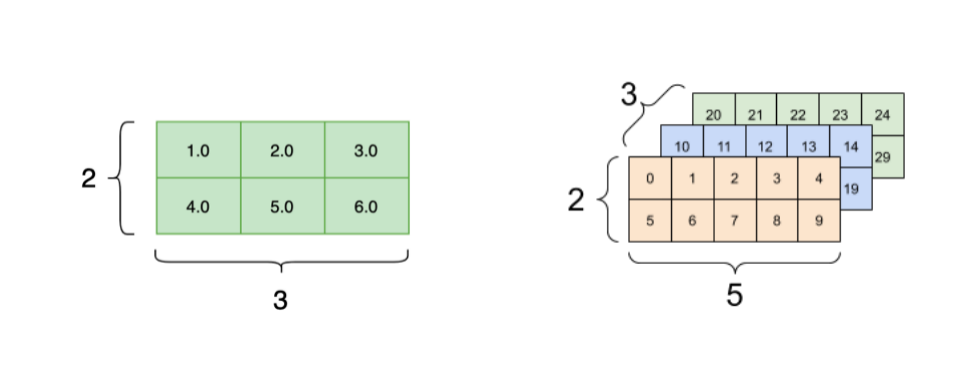
基本运算单元:Operator 算子
- 由最基本的代数算子组成
- 根据深度学习结构组成复杂算子
- N个输入Tensor,M个输出Tensor
| Add | Log | While |
|---|---|---|
| Sub | MatMul | Merge |
| Mul | Conv | BroadCast |
| Div | BatchNorm | Reduce |
| Relu | Loss | Map |
| Floor | Sigmoid | ….. |
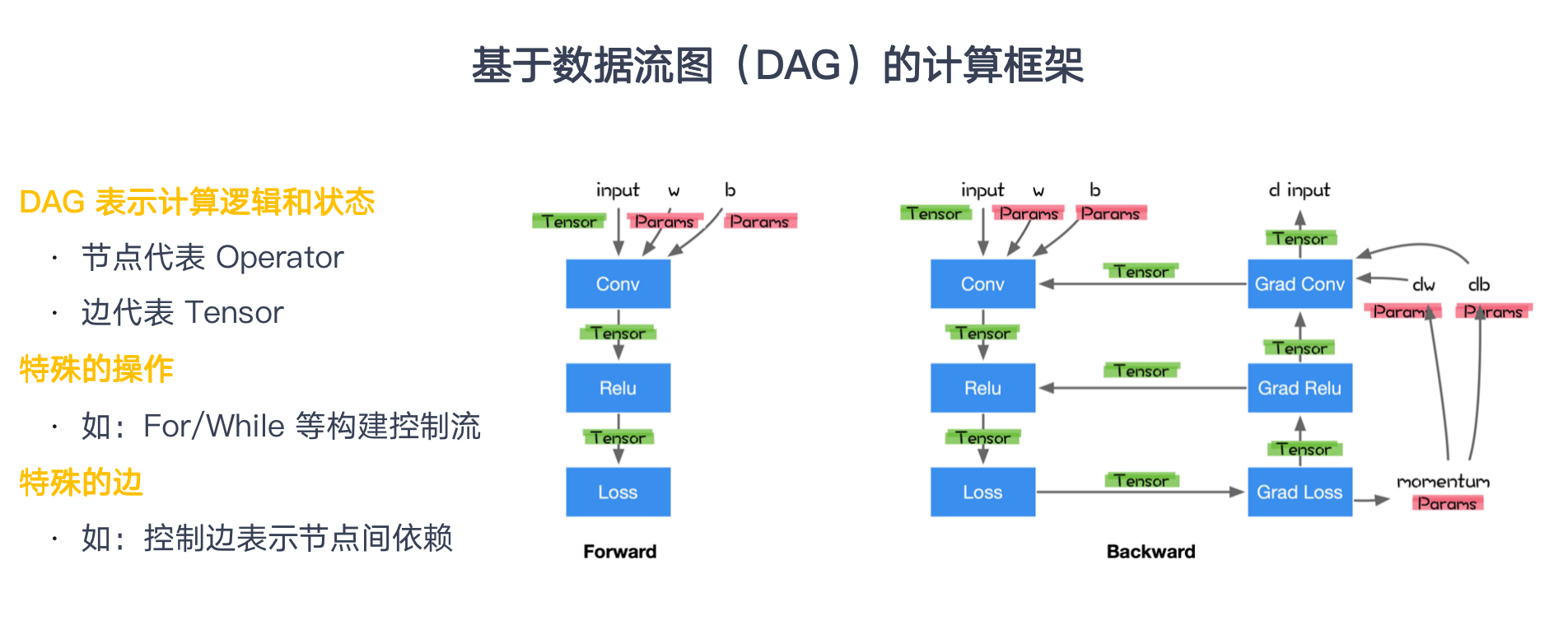
自动微分
原子操作构成的复杂前向计算程序,关注自动生成高效的反向计算程序
符号微分( Symbolic Differentiation)
符号微分:通过求导法则和导数变换公式,精确计算函数的导数
-
将原表达式转换为导数表达式
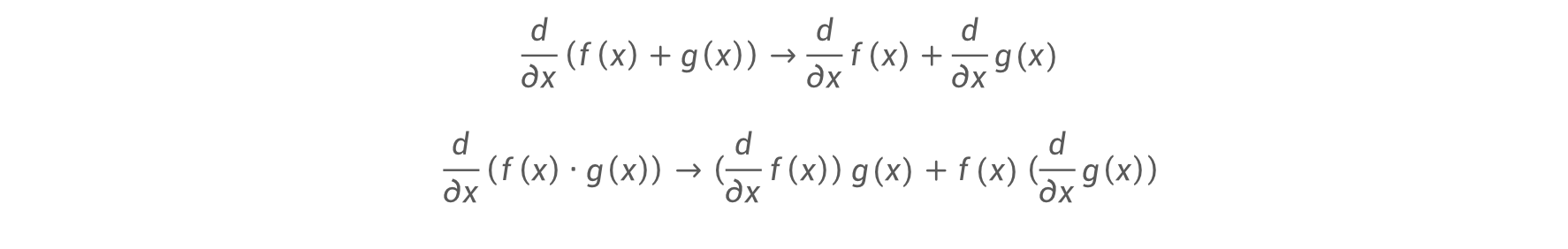
- 优势 精确数值结果
-
缺点 表达式膨胀
-
深度学习中的应用问题
-
深度学习网络非常大 -> 待求导函数复杂 -> 难以高效的求解
-
部分算子无法求导:如 Relu, Switch 等
-
数值微分(Numerical Differentiation)
数值微分:使用有限差分进行近似导数
-
可以使用有限差分来近似
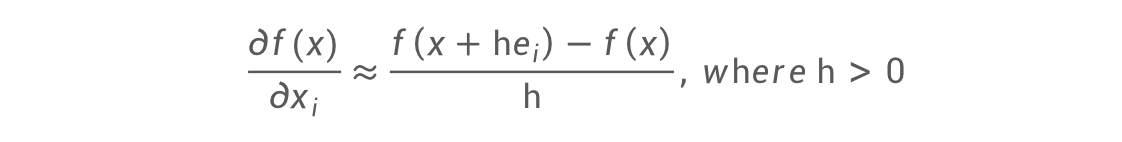
- 优势 容易实现
- 缺点
- 计算结果不精确
- 计算复杂度高
- 对 h 的要求高
- 深度学习中的应用问题
- 数值计算中的截断和近似问题导致无法得到精确导数
- 部分算子无法求导:如 Relu, Switch 等
自动微分(Auto Differentiation)
-
自动微分:
-
所有数值计算都由有限的基本运算组成
-
基本运算的导数表达式是已知的
-
通过链式法则将数值计算各部分组合成整体
-
-
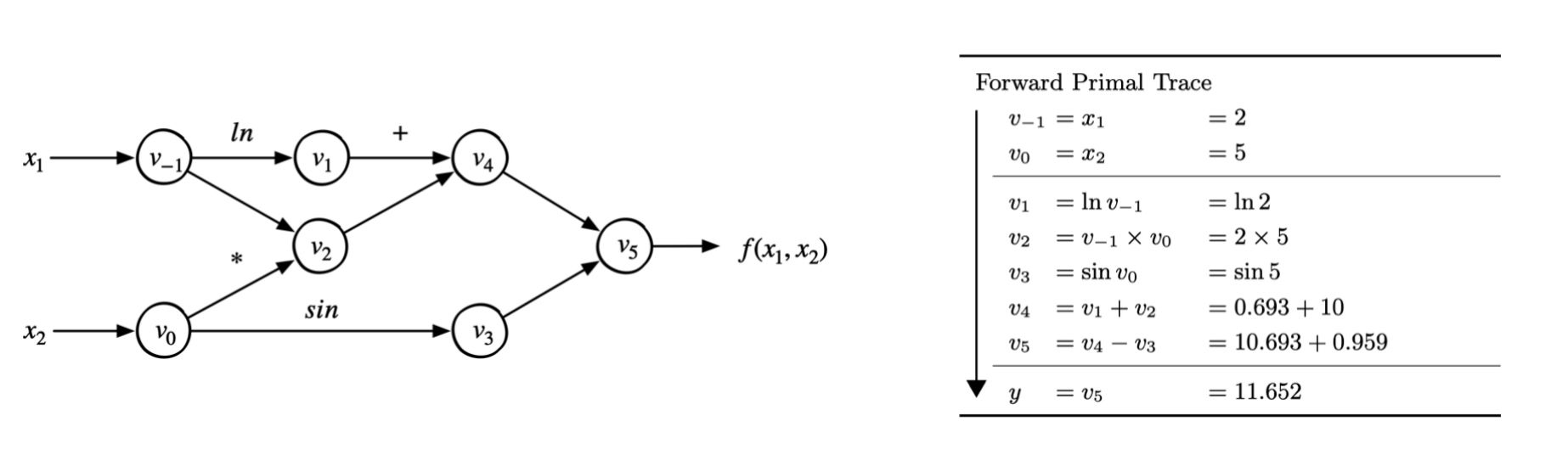
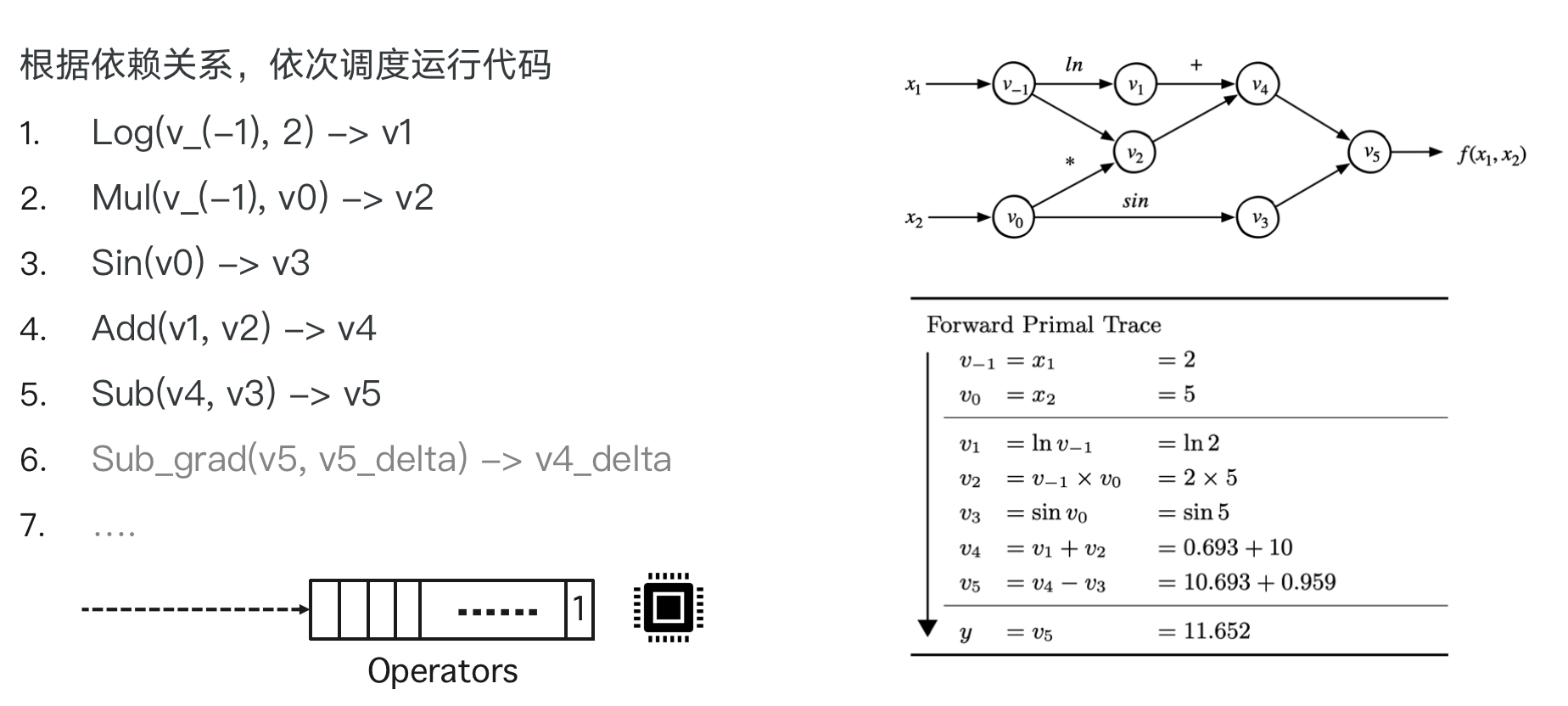
表达式追踪(Evaluation Trace):追踪数值计算过程的中间变量
- 引入中间变量将一个复杂的函数,分解成一系列基本函数
- 将这些基本函数构成一个计算流图 (DAG)
$f(x_1,x_2)=ln(x_1)+x_1x_2−sin(x_2)$
-
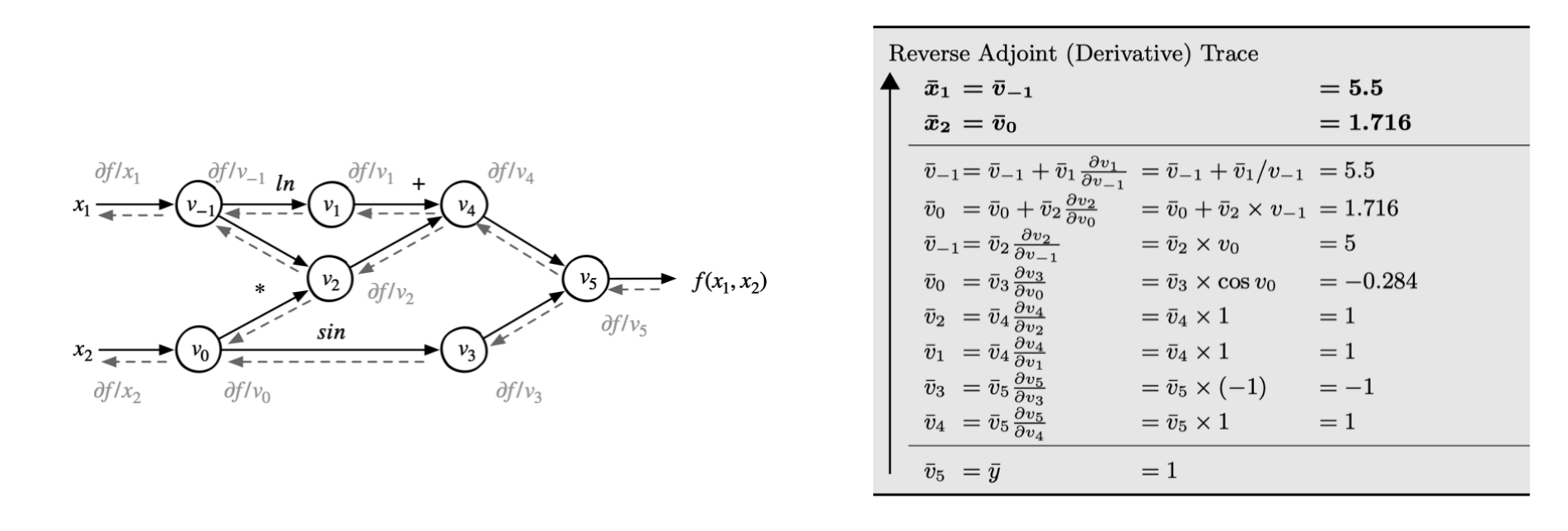
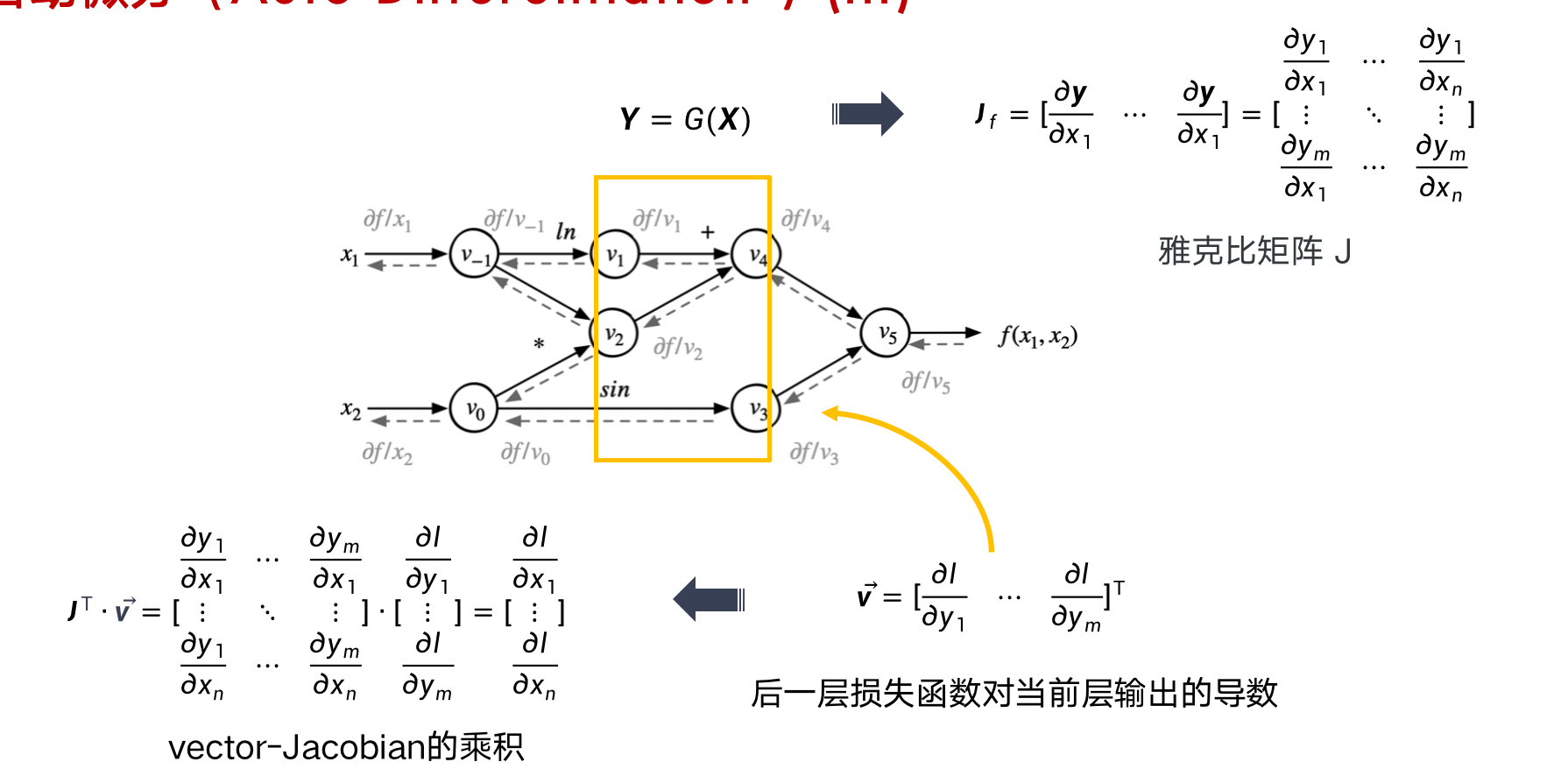
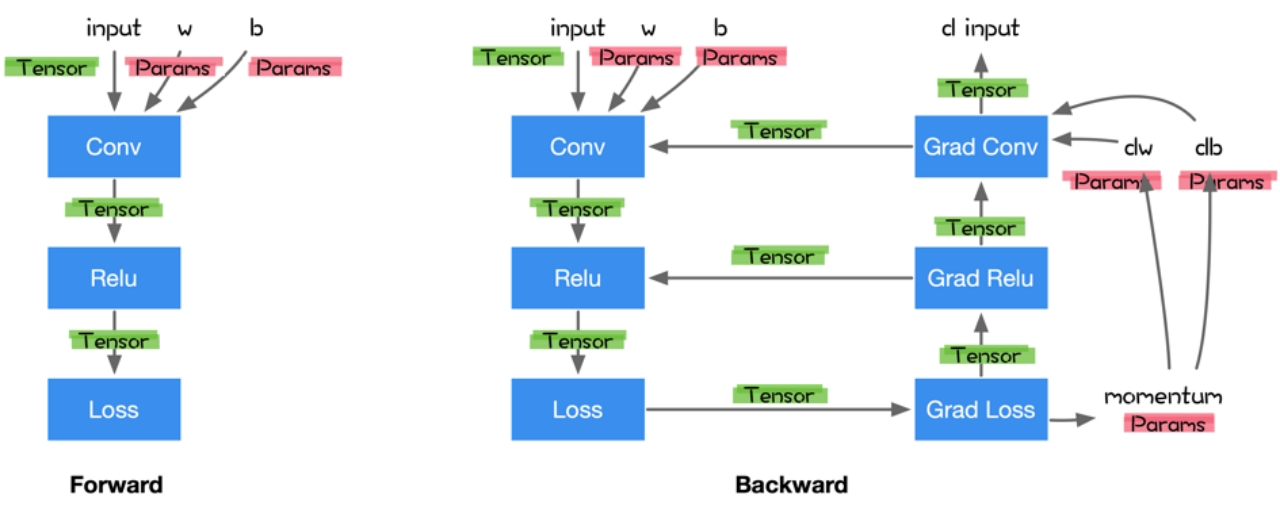
注册前向计算结点和反向计算结点 (计算反向的时候需要正向的结果)
- 前向结点接受输入计算输出
- 反向结点接受损失函数对当前张量操作输出的梯度 v
- 计算当前张量操作每个输入的vector-Jacobian乘积
在深度学习框架中实现自动微分的方式
(PyTorch)
-
前向计算并保留中间计算结果
-
根据反向模式的原理依次计算出中间导数
-
表达式追踪(Evaluation Trace):追踪数值计算过程的中间变量
问题
- 需要保存大量中间计算结果
- 方便跟踪计算过程
(Tensorflow, MindScope)
-
将导数的计算也表示成计算图
-
通过 Graph IR 来对计算图进行统一表示
主要特点:
- 不便于调试跟踪计算和数学表达过程
- 方便全局图优化
- 节省内存
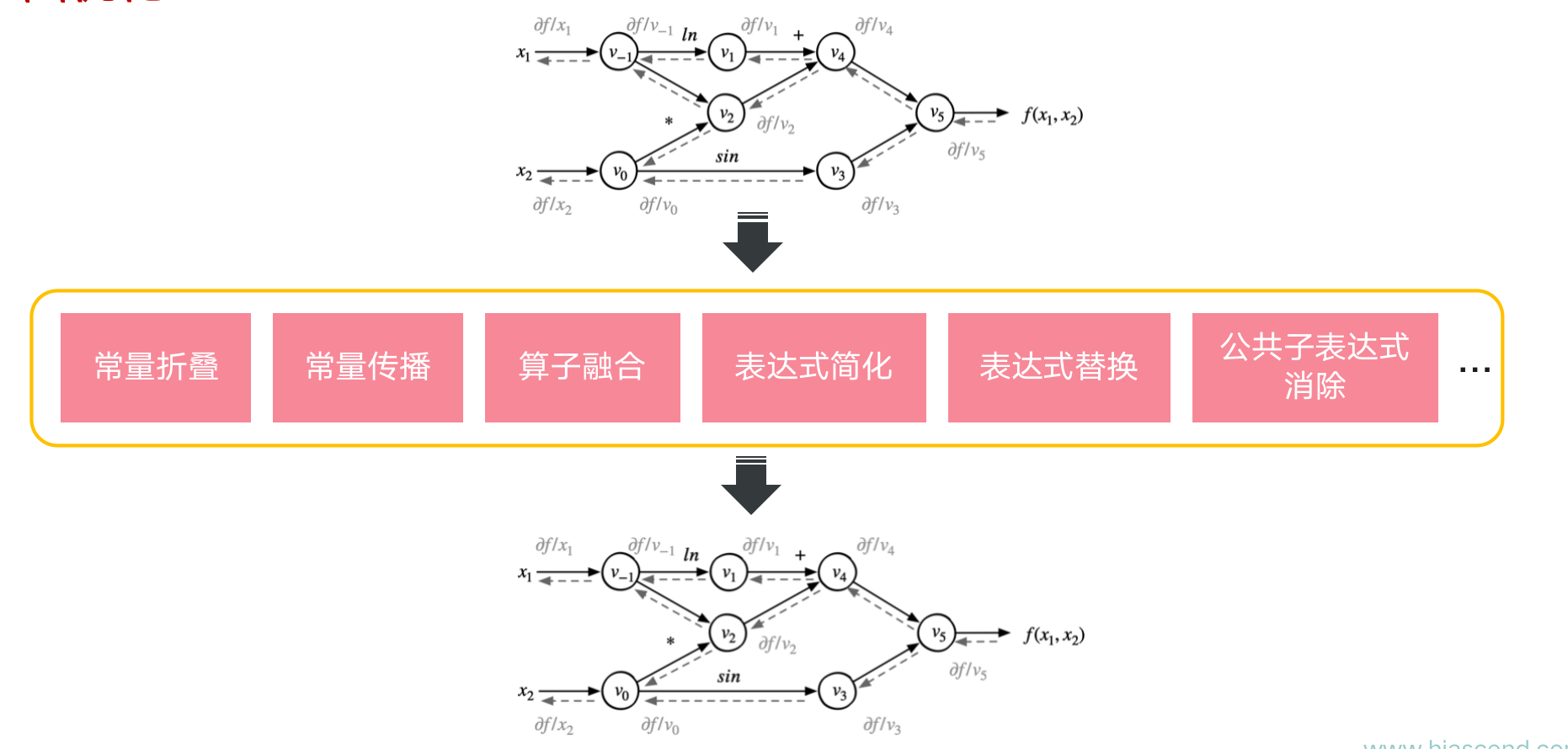
优化Pass
-
给定前向数据流图
- 以损失函数为根节点广度优先遍历前向数据流图
- 按照对偶结构自动生成出求导数据流图
模型表示:计算图
前端语言:用来构建计算图
自动微分:基于反向模式的原理,构建计算图
图优化 – 图调度与执行
图优化
计算图的出现允许 AI 框架在执行前看到深度学习模型定义全局信息
计算图作为 AI 框架中的高层中间表示,可以通过图优化 Pass 去化简计算图或提高执行效率
利用反向微分计算梯度通常实现为数据流图上的一个优化 Pass
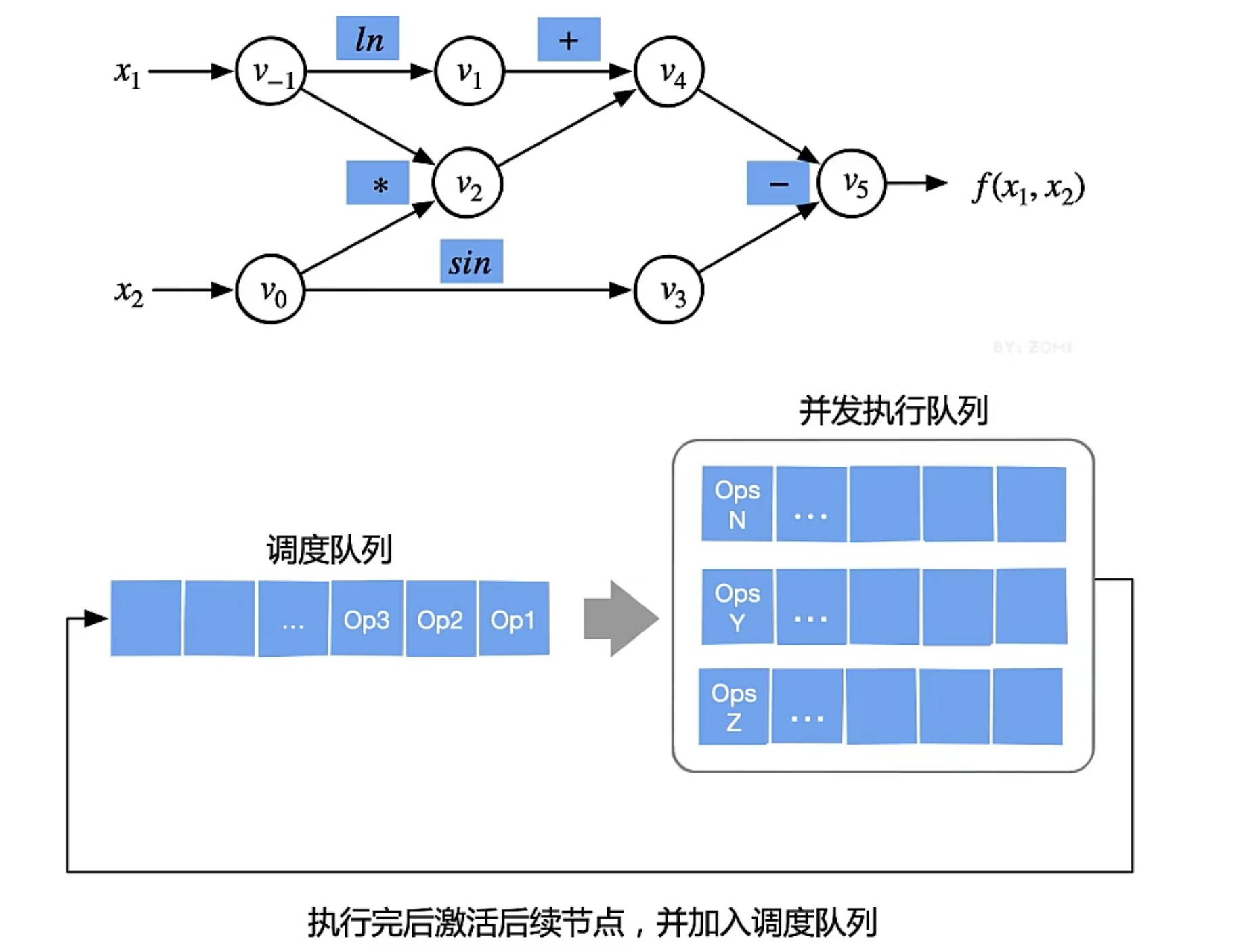
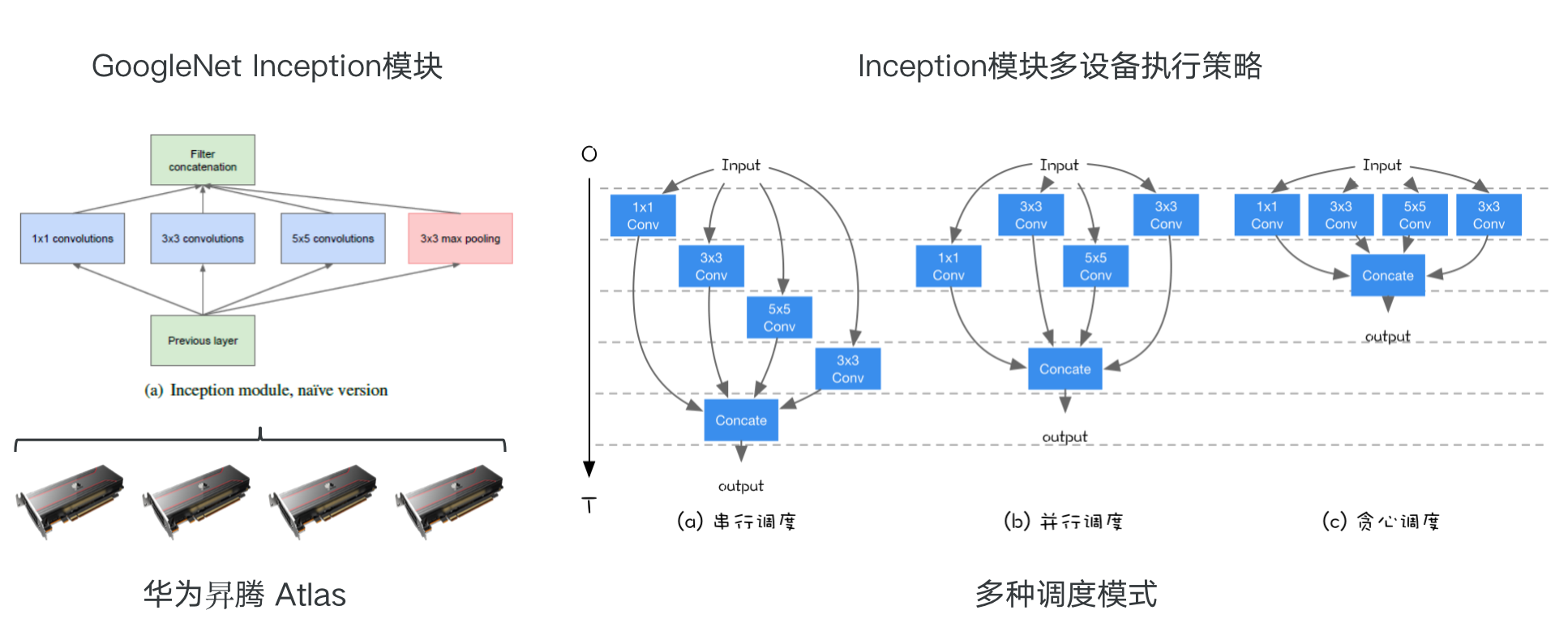
计算图的调度与执行
计算图的单设备算子间调度
- 计算图准确的描述了算子之间的依赖关系
- 根据计算图找到相互独立的算子进行并发调度,提高计算的并行性
计算图的切分与多设备执行
跨设备的边将被自动替换成 Send/Recv 算子或者是通过 通讯原语 进行数据传输
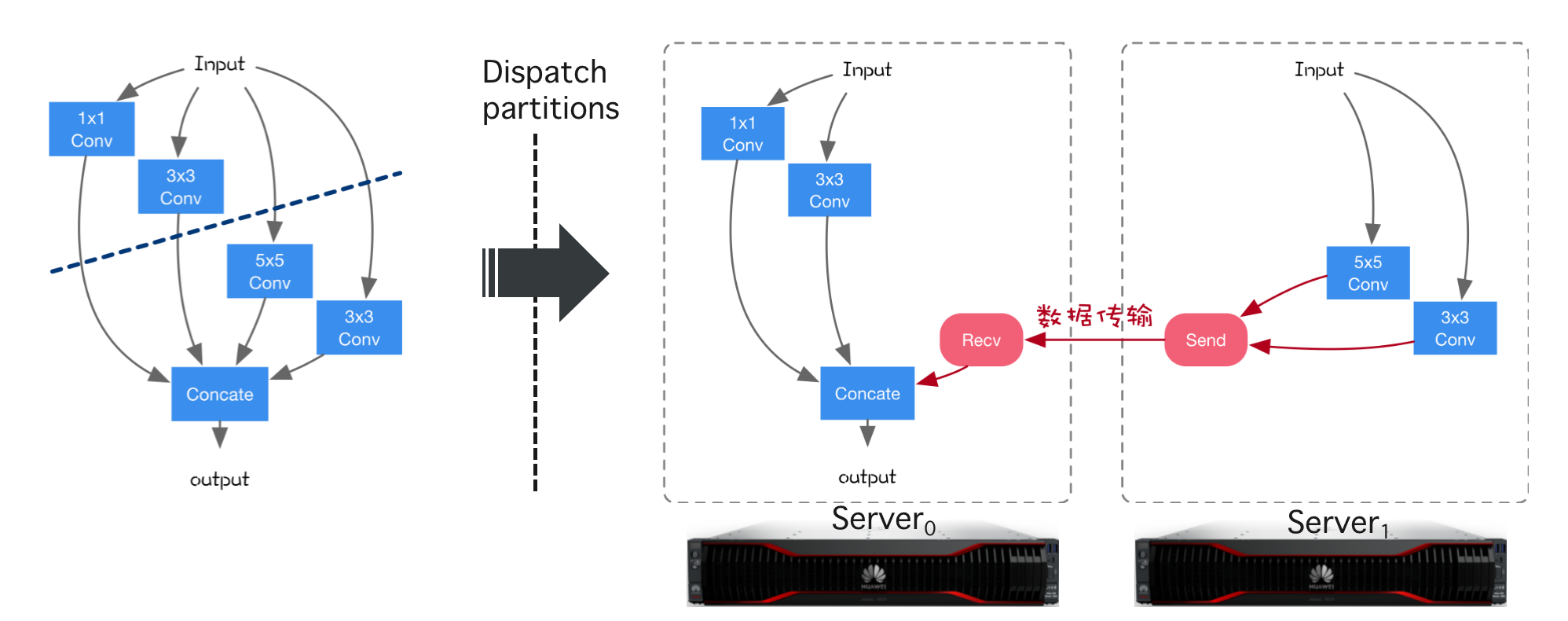
计算图切分:给定一个计算图,将计算图切分后(单算子/子图)放置到多设备上,每个设备拥有计算图的一部分。
插入跨设备通信:经过切分计算图会被分成若干子图,每个子图被放置在一个设备上,进行跨设备跨子图数据传输。
控制流
modeling_decision_transformer 其实是指里面的 if else for 等, AI 框架支持动态流语句
1 | |
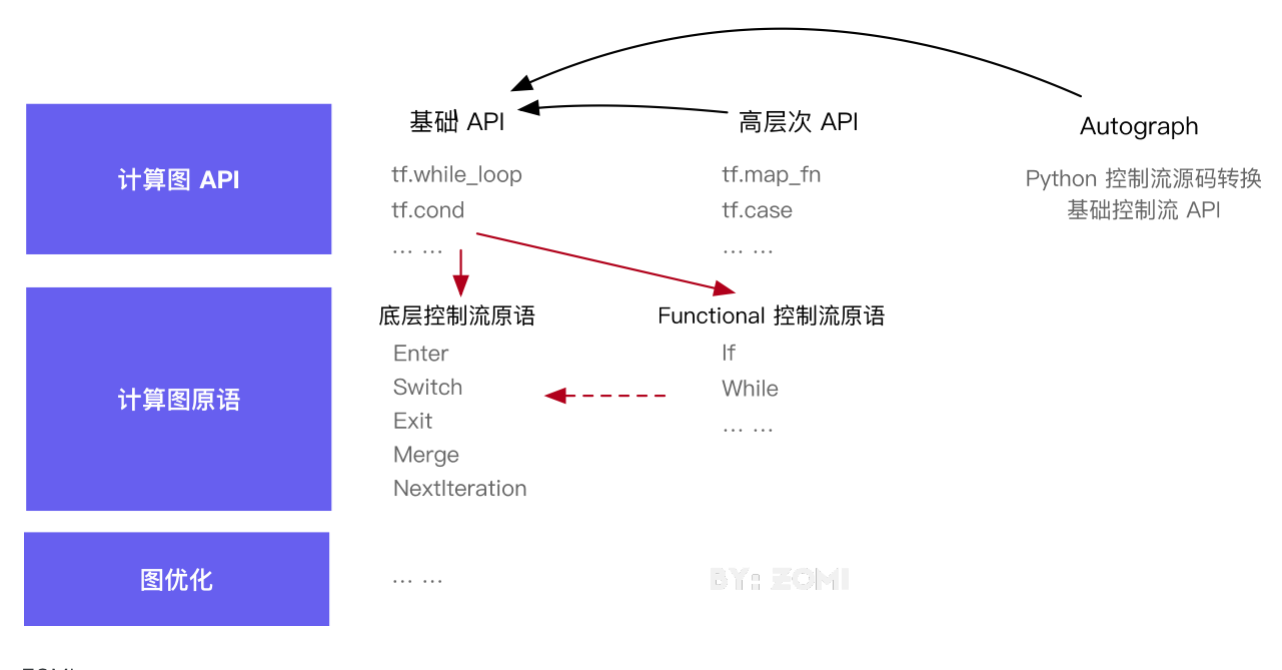
控制流解决方案
- 后端对控制流语言结构进行原生支持(支持控制流算子或者原语),计算图中允许数据流和控制流的混合; TensorFlow
- 复用前端语言的控制流语言结构,用前端语言中的控制逻辑驱动后端数据流图的执行; PyTorch
- 后端对控制流语言结构解析成子图,对计算图进行延伸; MindSpore
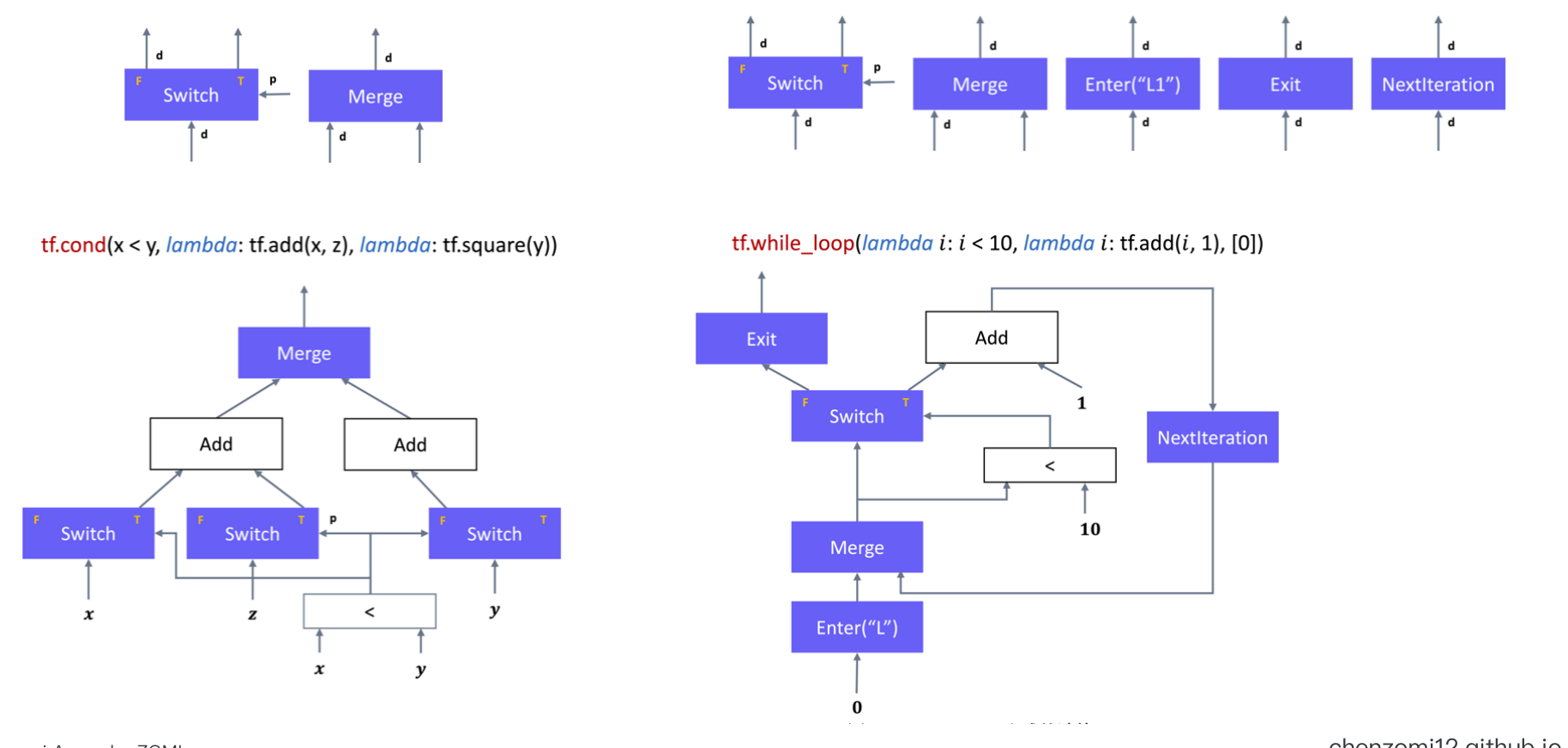
静态图:向数据流图中添加控制流原语
声明式编程计算前获得计算图的统一描述,使得编译期器能够全局优化
执行流无需在前端语言与运行时反复切换,可以有更高的执行效率
缺点
- 控制流原语语义设计首要服务于运行时系统的并发执行模型,与深度学习概念差异大;()
- 对控制流原语进行再次封装,以控制流API的方式供前端用户使用,导致计算图复杂;(简单的if else 已经很复杂,再多点嵌套就难以想象)
优点
- 向计算图中引入控制流原语利于编译期得到全计算过程描述,发掘运行时效率提升点;
- 解耦宿主语言与执行过程,加速运行时执行效率;
https://www.tensorflow.org/api_docs/python/tf/while_loop

动态图:复用宿主语言控制流语句
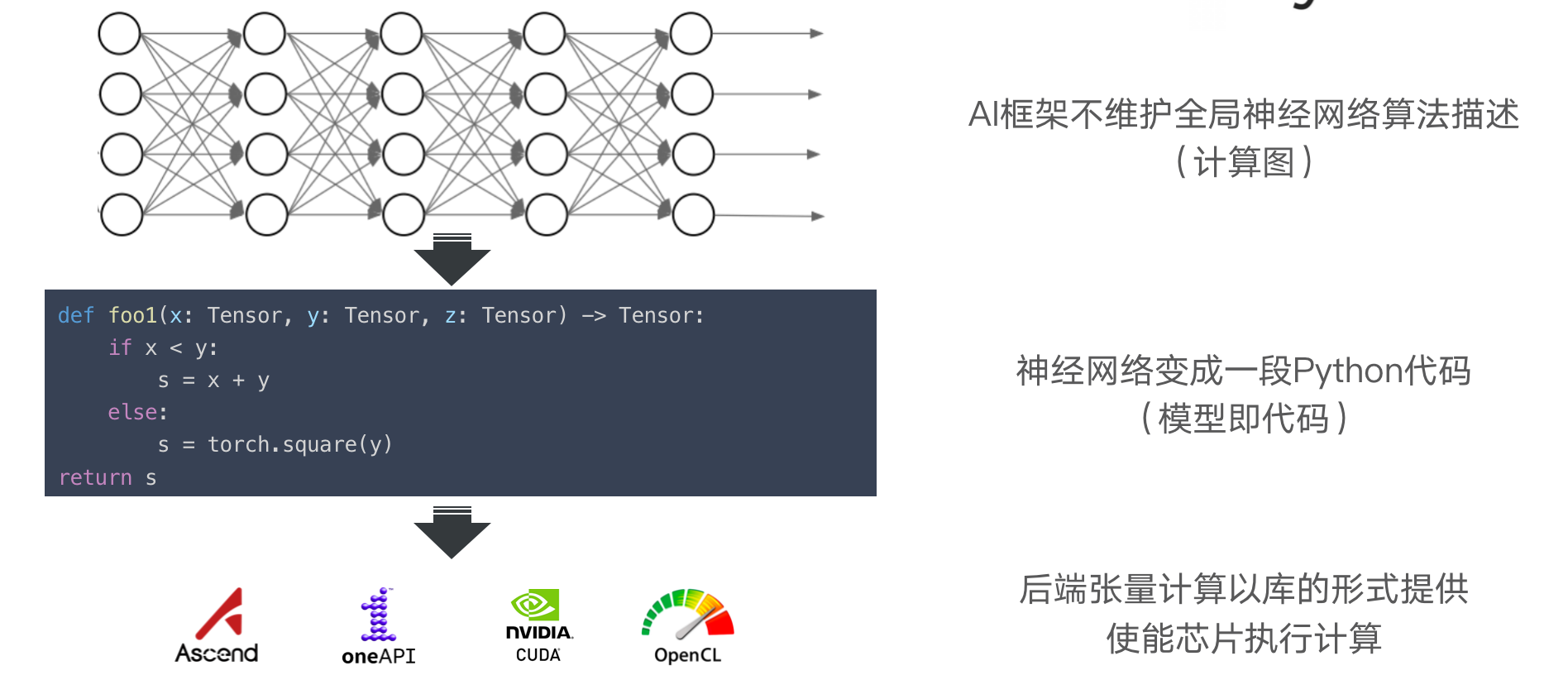
优点
- 用户能够自由地使用前端宿主的控制流语言,即时输出张量计算的求值结
- 定义神经网络计算就像是编写真正的程序
缺点
- 用户易于滥用前端语言特性,带来复杂的性能问题
- 执行流会在语言边界来回跳转,带来严重运行时开销 (有的在CPU执行,有的在GPU)
- 控制流和数据流被严格地隔离在前端语言和后端语言,跨语言优化困难
静态图:源码解析对计算图展开和转换子图
计算图能够表达的控制直接展开,如for(xxx)展开成带顺序的计算图;
通过创建子图进行表示,运行时时候动态选择子图执行,如 if else;
优点
- 用户能够一定程度自由地使用前端宿主的控制流语言;
- 解耦宿主语言与执行过程,加速运行时执行效率;
- 计算图在编译期得到全计算过程描述,发掘运行时效率提升点;
缺点
- 硬件不支持控制方式下,执行流会仍然会在语言边界跳转,带来运行时开销;
- 部分宿主的控制流语言不能表示,带有一定约束性
动态图转换为静态图
Tensorflow (auto-graph) PyTorch (JIT)
基于追踪Trace:直接执行用户代码,记录下算子调用序列,将算子调用序列保存为静态图,执行中脱离前端语言环境,由运行时按照静态图逻辑执行; (不可能所有代码遍历一遍生成静态图,业界比较少)
- 优点 : 能够更广泛地支持宿主语言中的各种动态控制流语句;
- 缺点: 执行场景受限,只能保留程序有限执行轨迹并线性化,静态图失去源程序完整控制结构
基于源代码解析:以宿主语言的抽象语法树(AST)为输入,转化为内部语法树,经过别名分析,SSA(static single value assignment),类型推断等Pass,转换为计算图表示;
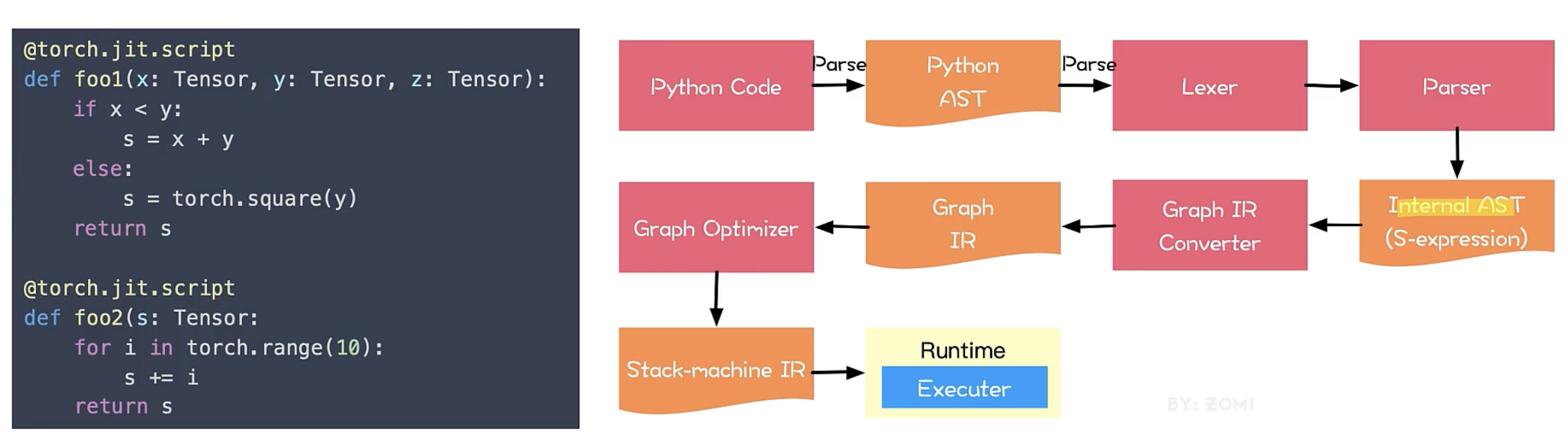
- 优点 能够更广泛地支持宿主语言中的各种动态控制流语句
- 缺点
- 后端实现和硬件实现会对静态图表示进行限制和约束,多硬件需要切分多后端执行逻辑
- 宿主语言的控制流语句并不总是能成功映射到后端运行时系统的静态图表示
- 遇到过度灵活的动态控制流语句,运行时会退回到由前端语言跨语言调用驱动后端执行