分布式基本概念
group: 进程组,一个分布式任务对应一个进程组,一般就是所有卡都在一个组里
world size:全局的并行数,一般情况下等于总的卡数 也有可能一个进程控制几张卡
node: 节点,可以是一台机器,或者一个容器,节点内包含多个GPU
rank(global rank): 整个分布式训练任务内的进程序号
local rank:每个node内部的相对进程序号
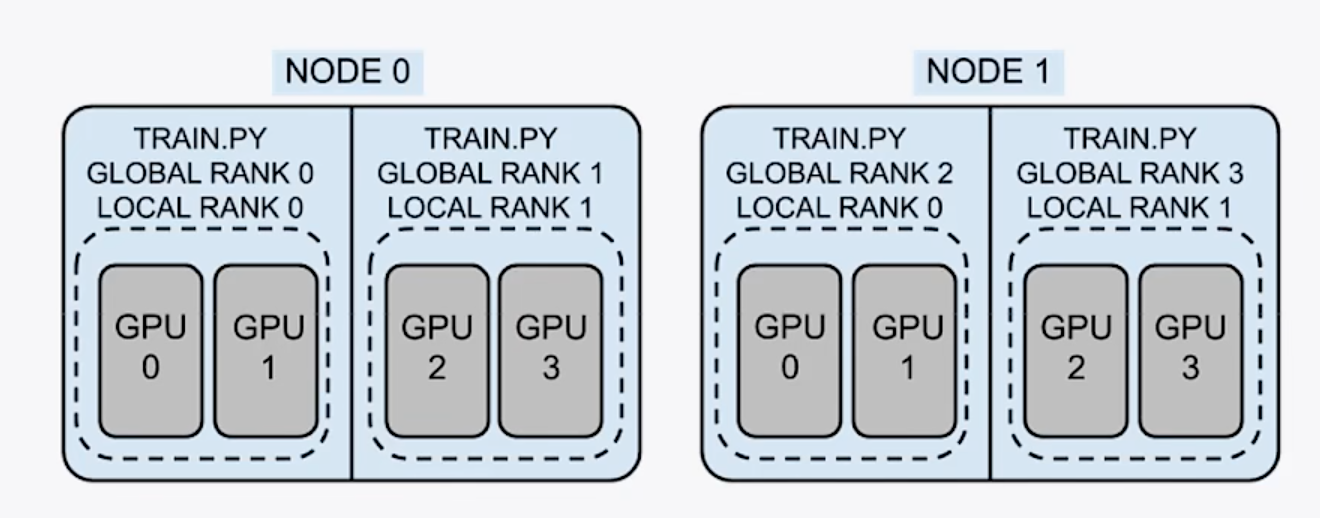
2机4卡分布式训练 node=2,world size=4,每个进程占用两个GPU
DDP代码
1 | |
1 | |
Accelerate
Accelerate简单介绍
Accelerate库本身不提供分布式训练的内容,但是其内部集成了多种分布式训练框架DDP、FSDP、Deepspeed等
1 | |
1 | |
Accelerate 进阶
混合精度训练
混合精度训练是一种提高神经网络训练效率的技术,它结合了32位的单精度(FP32)浮点数和16位的半精度(FP16/BF16)浮点数来进行模型的训练。混合精度训的方法可以减少GPU内存的使用,同时加速训练过程。
- 以FP32精度加载模型
- 在前向传播过程中,使用 FP16 计算激活输出
- 在反向传播过程中,使用 FP32 计算梯度更新。
- 将更新后的权重转换回 FP16 存储,循环

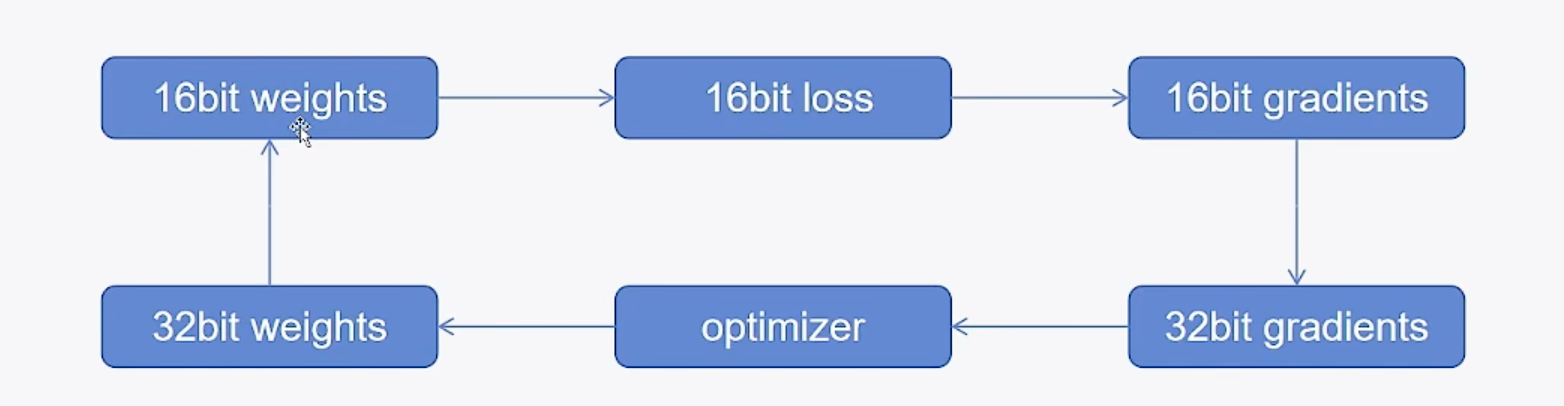
这种混合使用 FP16 和 FP32 的方式能够有效地平衡训练速度和模型精度:
- 使用 FP16 存储可以大幅减少内存占用和提高训练速度,因为 FP16 只需要 FP32 一半的存储空间。
- 但直接使用 FP16 进行梯度更新可能会导致数值精度问题,如梯度消失或爆炸。
- 所以采用 FP32 进行梯度计算,可以确保梯度更新的精度,从而保证最终模型的性能。
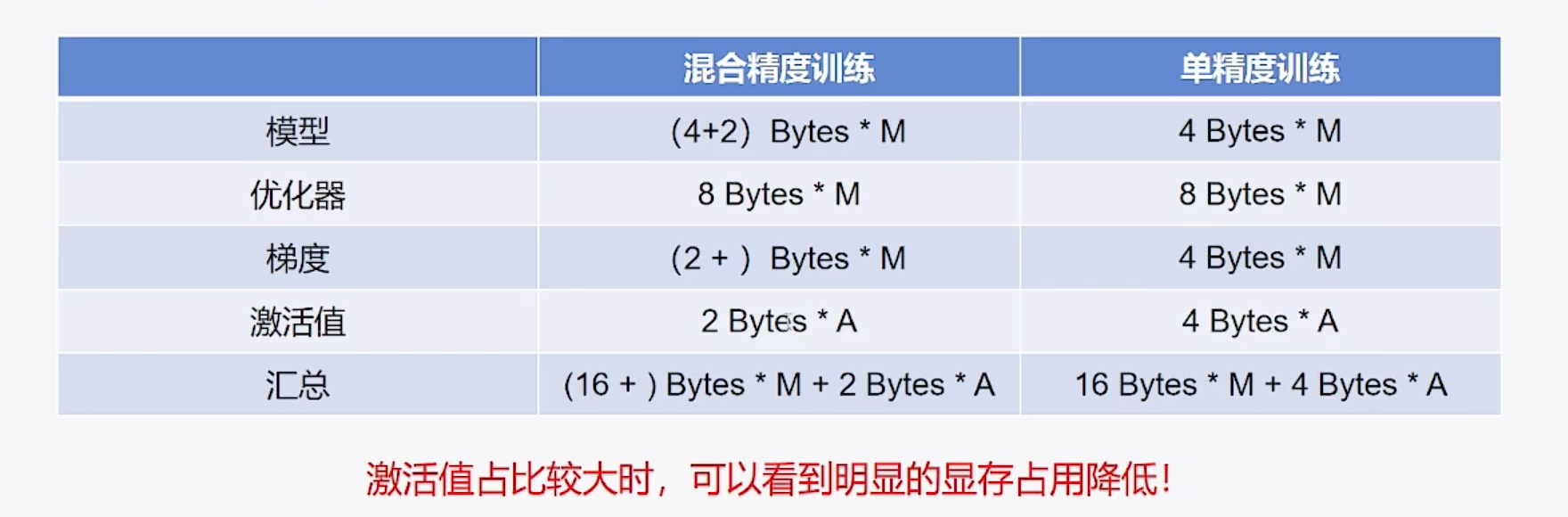
一定会减少显存占用吗
三种方法
accelerator = Accelerator(mixed_precision="bf16")acclerator config && choice bf16accelerator launch --mixed_precision bf16 {script.py}
梯度累积
gradient_accumulation_steps
梯度累积是一种深度学习训练技术,它允许模型在有限的硬件资源下模拟更大批量大小的训练效果。 梯度累积的具体做法
- 分割Batch:将大的训练数据Batch分割成多个小的Mini-Batch。
- 计算梯度:对每个Mini-Batch独立进行前向和反向传播,计算梯度。
- 累积梯度:不立即更新模型参数,而是将这些小Batch的梯度累积起来
- 更新参数:当累积到一定数量的梯度后,再统一使用这些累积的梯度来更新模型参数
方法
-
accelerator=Accelerator(gradient accumulation steps=xx) -
然后训练过程中,加入accelerator.accumulate(model)的上下文
with accelerator.accumulate(model):
日志记录
方法
accelerator = Accelerator(log_with="tensorboard", project dir="xx")- 初始化tracker
accelerator.init_trackers("runs") - 结束训练
accelerator.end_training()
模型保存
模型保存内容
- 模型权重,pytorch_model.bin/model.safetensors
- 模型配置文件,关于模型结构描述的信息,一般是config.json
- 其他文件,generation_config.json、adapter_model.safetensors(lora)
如何进行模型保存
-
单机训练的情况
- 调用model.save pretrained(save directory)即可
-
分布式训练情况
-
直接调用model.save_pretrained(save_directory)会报错,需要去包装
-
并非所有进程都需要存,主进程保存即可
-
accelerator.save_model(model,accelerator.project_dir + f"/step_{global_step}/model")- 模型训练不会保存config.json,不能直接加载
- lora模型训练,直接保存完整模型,不会保存lora模型
-
1
2
3
4
5
6accelerator.unwrap_model(model).save_pretrained( save_directory=accelerator.project_dir + f"/step_{global_step}/model", is_main_process=accelerator.is_main_process, state_dict=accelerator.get_state_dict(model), save_func=accelerator.save )
-
断点续训
什么是断点续训
- 当训练过程因为某些原因被中断时,断点续训允许我们从上次中断的地方恢复训练,而不是从头开始。这样可以节省量的时间和计算资源。
如何进行断点续训
- 保存检查点(checkpoint)。
- 加载检查点(模型权重、优化器状态、学习调度器、随机状态)
- 跳过已训练数据(epoch、batch)
方法
- 保存检查点
accelerator.save_state() - 加载检查点
accelerator.load_state() - 计算跳过的轮数和步数
resume_epoch、resume_step -
数据集跳过对应步数
accelerator.skip_first_batches(trainloader, resume_step)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74def train(model, optimizer, trainloader, validloader, accelerator: Accelerator, resume, epoch=3, log_step=10): global_step = 0 start_time = time.time() # 计算跳过的轮数 resume_step = 0 # 步数 resume_epoch = 0 if resume is not None: # 加载检查点 accelerator.load_state(resume) # 每轮步数 55 steps_per_epoch = math.ceil(len(trainloader) / accelerator.gradient_accumulation_steps) # 当前总步数 150 resume_step = global_step = int(resume.split("step_")[-1]) # 当前轮数 2 resume_epoch = resume_step // steps_per_epoch # 剩余步数 40 resume_step -= resume_epoch * steps_per_epoch accelerator.print(f"resume from checkpoint -> {resume}") # 从当前轮数开始 for ep in range(resume_epoch, epoch): model.train() if resume and ep == resume_epoch and resume_step != 0: # 数据集跳过对应步数 active_dataloader = accelerator.skip_first_batches(trainloader, resume_step * accelerator.gradient_accumulation_steps) else: active_dataloader = trainloader for batch in active_dataloader: with accelerator.accumulate(model): # 梯度累积上下文 optimizer.zero_grad() output = model(**batch) loss = output.loss accelerator.backward(loss) optimizer.step() # 是否进行梯度同步 if accelerator.sync_gradients: global_step += 1 if global_step % log_step == 0: loss = accelerator.reduce(loss, "mean") accelerator.print(f"ep: {ep}, global_step: {global_step}, loss: {loss.item()}") # 记录日志 accelerator.log({"loss": loss.item()}, global_step) if global_step % 50 == 0 and global_step != 0: accelerator.print(f"save checkpoint -> step_{global_step}") # 保存检查点 accelerator.save_state(accelerator.project_dir + f"/step_{global_step}") accelerator.unwrap_model(model).save_pretrained( save_directory=accelerator.project_dir + f"/step_{global_step}/model", is_main_process=accelerator.is_main_process, state_dict=accelerator.get_state_dict(model), save_func=accelerator.save ) acc = evaluate(model, validloader, accelerator) accelerator.print(f"ep: {ep}, acc: {acc}, time: {time.time() - start_time}") # 记录日志 accelerator.log({"acc": acc}, global_step) # 结束训练tracker accelerator.end_training() def main(): # 梯度累积 记录日志路径 accelerator = Accelerator(gradient_accumulation_steps=2, log_with="tensorboard", project_dir="ckpts") # 初始化tracker accelerator.init_trackers("runs") .... # train(model, optimizer, trainloader, validloader, accelerator, resume="/gemini/code/ckpts/step_150")
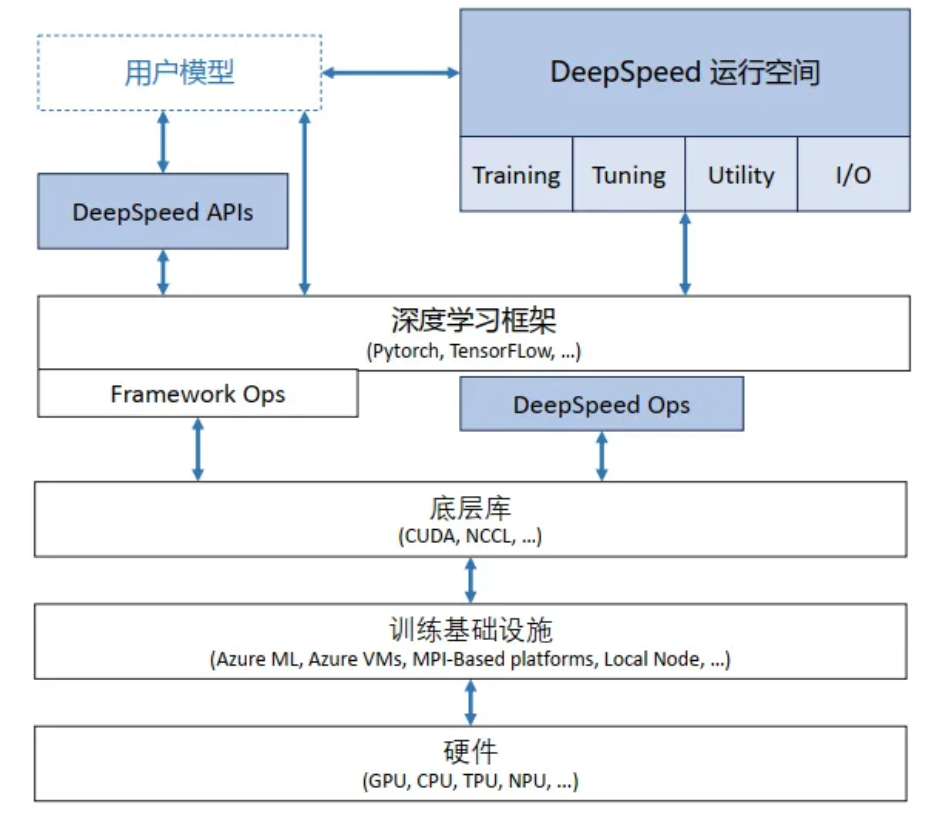
Deepspeed实战

-
Training为大模型训练供 ZeRO、3D-Parallelism、DeepSpeed-MoE、ZeRO-Infinity等特性
- Inference 用的比较少(已经用不少推理引擎框架) 提供Tensor、Pipeline、Expert等并行特性与推理内核、通信优化和异构内存特性结合
- **Compression ** 更多的是为Inference服务, 提供 ZeroQuant 和 XTC 等 SoTA 在压缩方面的创新
APIs:
- 配置参数在 ds_config.json 中,通过 API 接口可以调用 DeepSpeed 训练/推理模型;
RunTime:
- 核心运行时组件,负责管理、执行和优化性能。包括数据、模型、并行优化、微调、故障检测以及 CheckPoint 保存和加载等任务。
Ops:
- 底层内核组件,使用C++和CUDA实现。优 化计算和通信,提供底层操作;
ZeRo
1 | |
Megatron-LM实践
https://github.com/NVIDIA/Megatron-LM
Megatron-LM: 使用模型并行训练数十亿参数的语言模型 在GPU集群上高效大规模训练语言模型:Megatron-LM的应用 在大型Transformer模型中减少激活重计算
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
- Reducing Activation Recomputation in Large Transformer Models
从单节点到千卡都表现,有个稳定线性表现。
要实现在 AI 集群高吞吐量,需要在多个方面进行创新和精心设计:
- 高效计算核(kernel)实现,基于计算操作 compute-bound 而非内存绑定 memory-bound
- 对网络模型进行多维并行 PTD(pipeline、tensor、data),以减少网络发送的字节数,提升模型利用率 MFU
- 特定通信域优化和高速硬件互联
启动
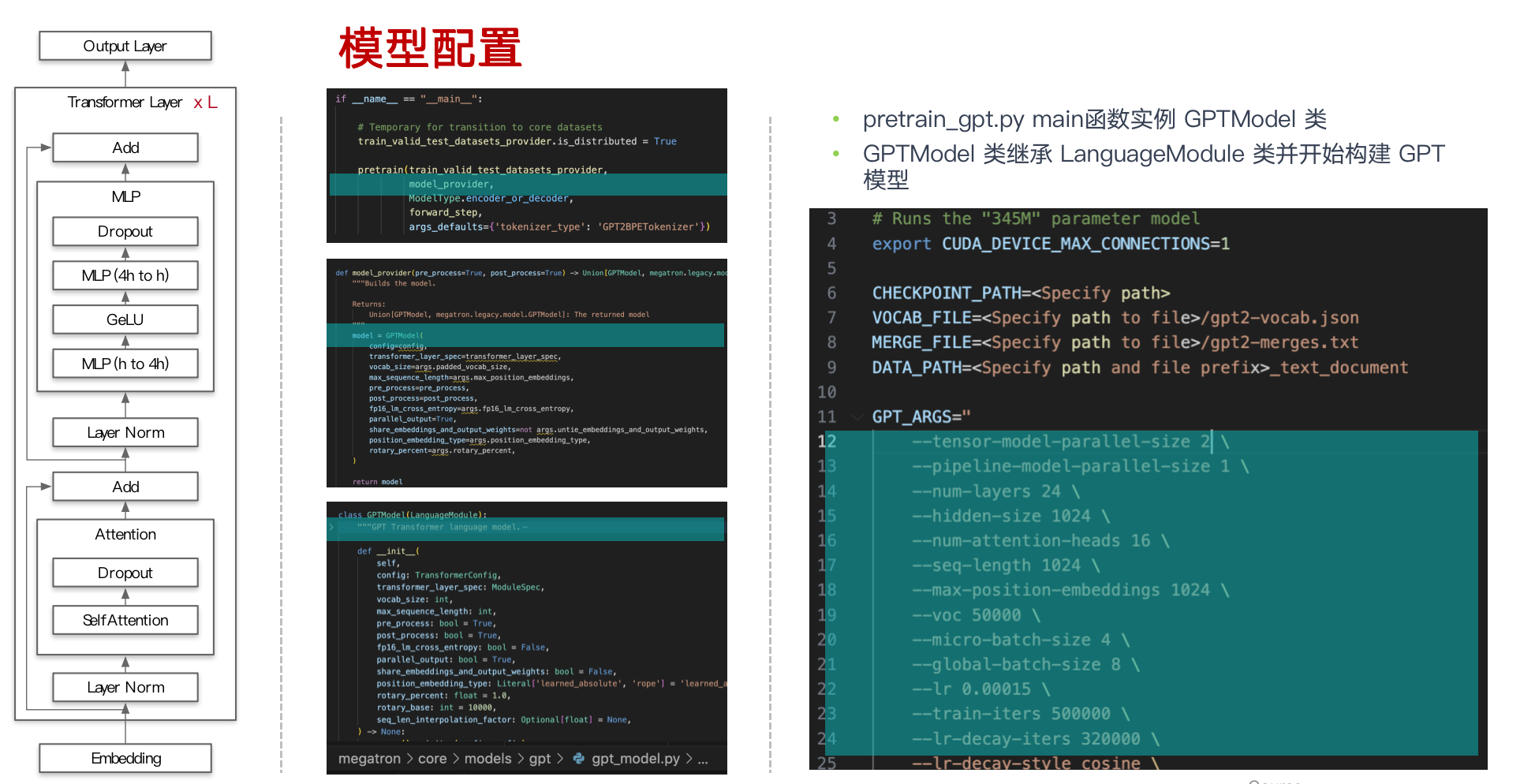
- 启动脚本在 examples/pretrain_bert_distributed.sh,其利用了 torch.distributed.launch 来启动多个进程。具体业务代码是 pretrain_bert.py
- 因为 GPUS_PER_NODE 是8,所以 nproc_per_node 是8,这样,在本机上就启动了8个进程,每个进程之中含有模型的一部分。进程的 rank 是被 torch.distributed.launch 调用 elastic 自动分配的
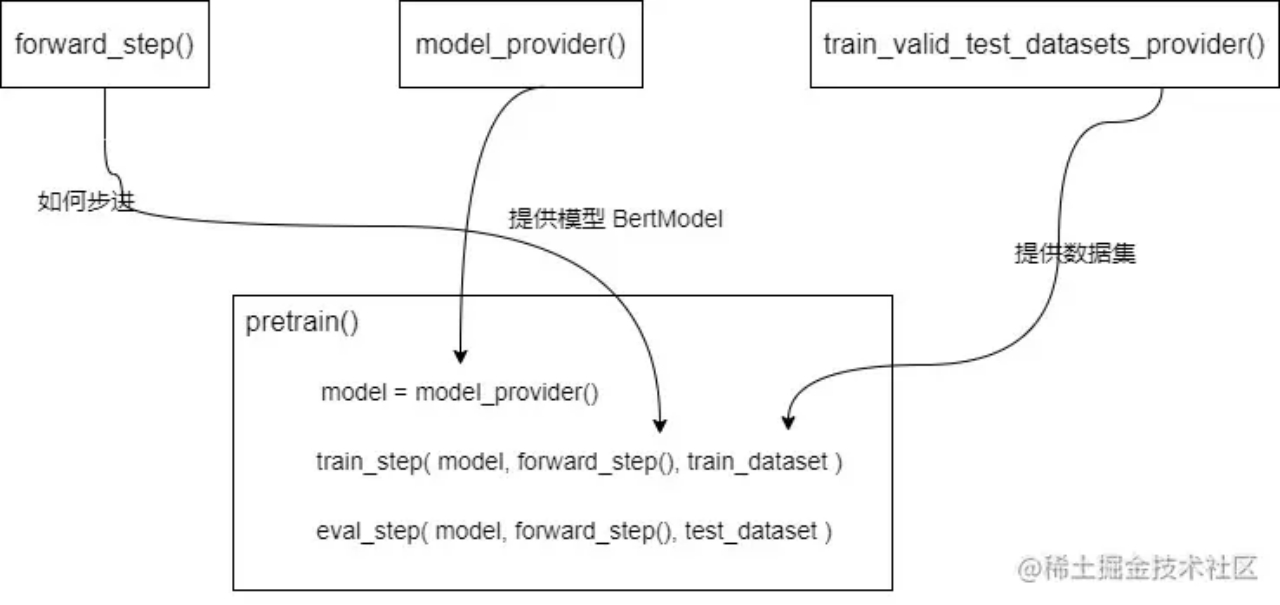
构造基础
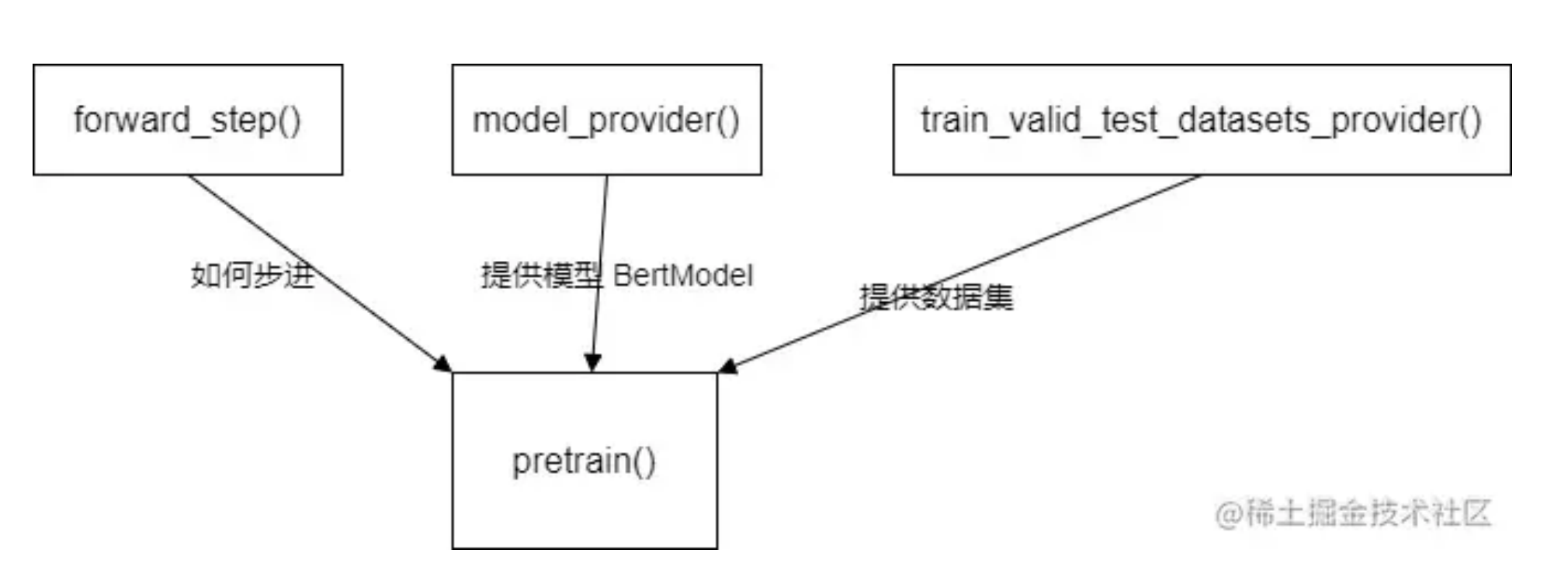
- 获取模型
- model_provider返回模型普通版本(vanilla version)。所谓vanilla,我们指的是一个简单的cpu模型,没有 fp16或 ddp,但是已经被 Megatron 改造为并行的版本。
- 获取数据集
- train_valid_test_datasets_provider 接受train/valid/test数据集的大小,返回 “train,valid,test” 数据集。
- 步进函数
- forward_step 接受“数据迭代器”和“模型”,并返回“loss”标量,该标量带有一个字典,其中key:value是希望在训练期间监视信息,例如“lm loss:value”
- forward_step 会调用 get_batch 获取batch 数据,其内部会从迭代器获取数据,然后使用broadcast_data函数把输入数据从 rank 0 广播到所有tensor-model-parallel 其他 ranks之上
三个不同的函数分别为预训练提供不同的功能输入,做到了解耦。
Pretrain 函数
初始化Megatron。
-
使用model_provider设置模型、优化器和lr计划。
-
调用train_val_test_data_provider以获取train/val/test数据集。
-
使用forward_step_func训练模型。
initialize_megatron 设置全局变量,初始化分布式环境等。(分布式网络模型,哪张卡跑什么 网络模型层数)
-
_initialize_distributed() 位于 megatron/initialize.py
- 调用 torch.distributed.init_process_group 初始化分布式环境
- 创建完worker进程之后,程序需要知道哪些进程在训练同一个模型,torch.distributed.init_process_group 就实现了这个功能。
- torch.distributed.init_process_group 会生成一个进程组,同组内进程训练同一个模型,也能确定用什么方式进行通信。
- 进程组会给组内每个进程一个序号,就是gloabl rank,如果是多机并行,每个机器创建的进程之间也有一个序号,就是 local rank。如果是单机多卡并行,local rank 和 global rank是一致的。
- 调用 mpu.initialize_model_parallel 来设置MP、DP等进程组,每个 rank 对应进程都有自己全局变量
- _TENSOR_MODEL_PARALLEL_GROUP :当前 rank 所属的 Intra-layer model parallel group,TP 进程组。
- _PIPELINE_MODEL_PARALLEL_GROUP :当前 rank 所属的Intra-layer model parallel group,PP进程组。
- _MODEL_PARALLEL_GROUP :当前 rank 所属于MP进程组,包括了 TP 和 PP。
- _ EMBEDDING_GROUP : Embedding 并行对应进程组。
- _DATA_PARALLEL_GROUP :当前 rank 所属的 DP 进程组。
- 调用 torch.distributed.init_process_group 初始化分布式环境
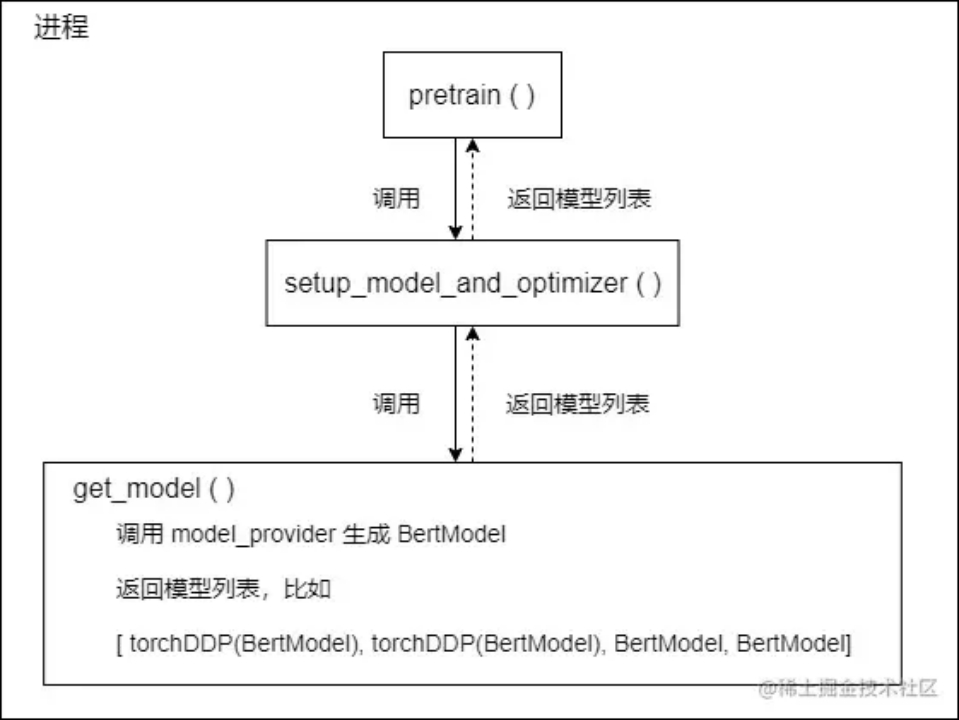
setup_model_and_optimizer 设置模型和优化器,其中重点是get_model
GPT 中含多层 transformer,直接按照层数切分,每层相同 Transformer layer。分布式并行启动了 N 个进程,每个进程里面有一个子模型,即原始 GPT 模型部分层。但怎么知道每个子模型包含了多少层?
通过 initialize_megatron() 建立的进程组,get_model() 会依据目前进程组情况进行处理。单个进程内模型获取如下
分布式并行启动了 N 个进程,每个进程里面有一个子模型,即原始 GPT 模型部分层。通过 initialize_megatron() 建立的进程组,get_model() 会依据目前进程组情况进行处理。
设置数据 build_train_valid_test_data_iterators: 对数据进行处理,提供 train()/valid()/test() 不同数据集
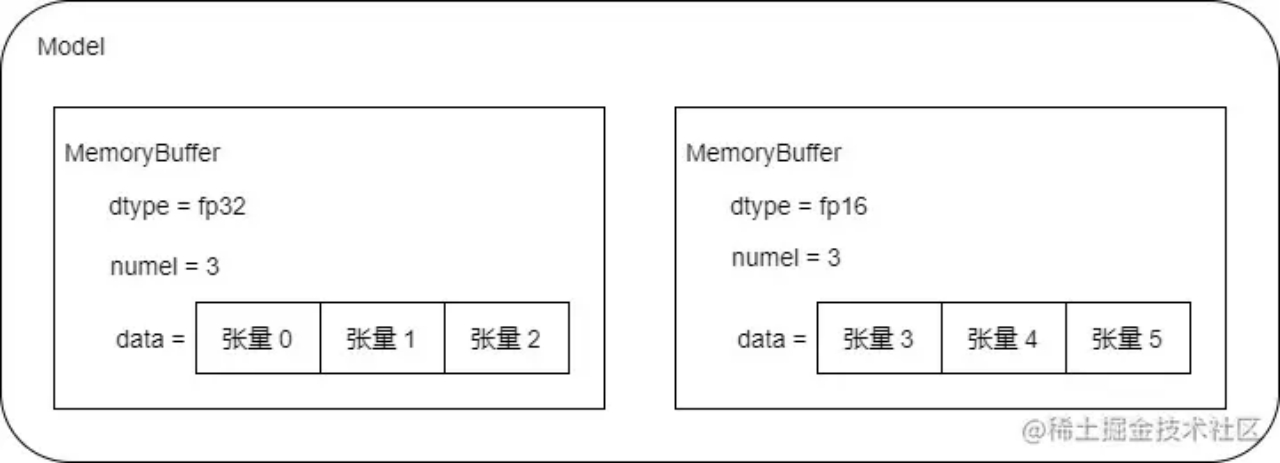
分布式数据DDP: Megatron-LM 中单独实现分布式数据并行 DistributedDataParallel()
- 使用连续内存来存储和累积梯度,每一种类型的张量属于一个统一的内存,可以统一执行 allreduce
- init() 初始化目的是把同类型梯度连续存储
- MemoryBuffer() 是内存抽象
- _make_param_hook() 用于拷贝梯度
- zero_grad_buffer() 用于将buffer清零
Megatron-LM 中单独实现分布式数据并行 DistributedDataParallel()
假设模型有6个参数,3个 fp32,3 个 fp16,被组合成两个连续内存 MemoryBuffer
训练step:train_step() 获取 get_forward_backward_func() 得到 schedule,因为是流水线并行,所以需要 schedule 如何具体训练
获取schedule: get_forward_backward_func 获取 pipeline 的schedule,这里分为 flush 和 interleaving 两种
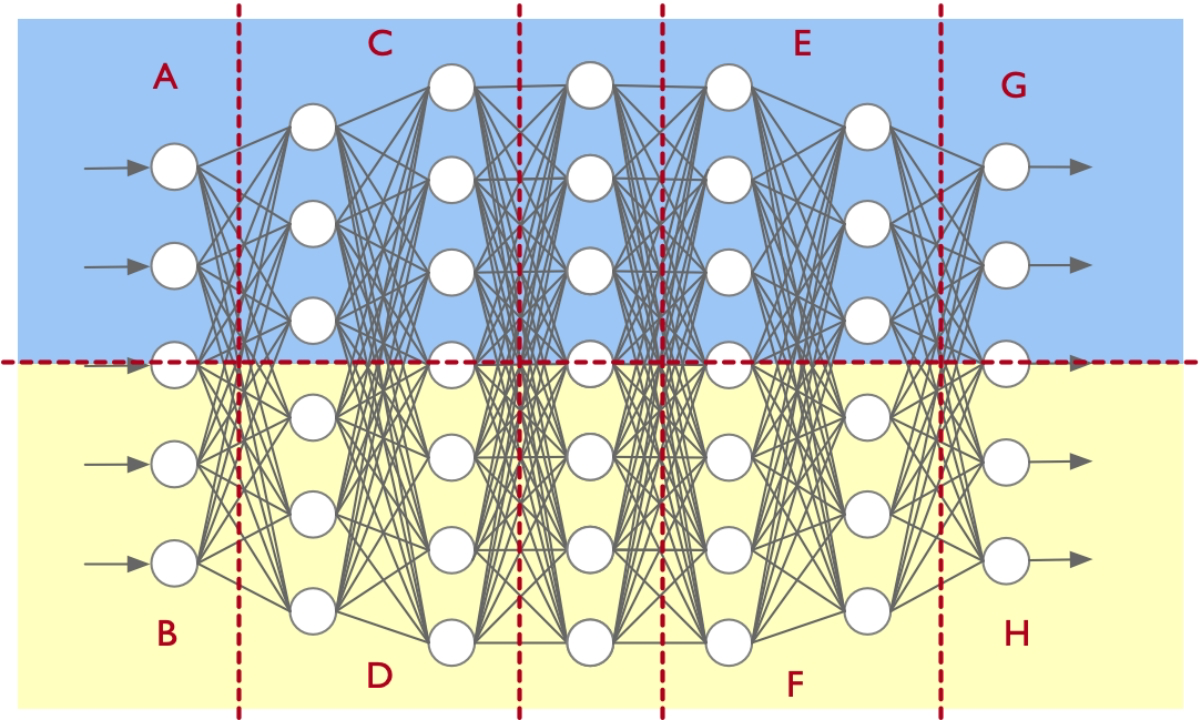
PTD(pipeline、tensor、data)
initialize_model_parallel 并行配置初始化
1 | |
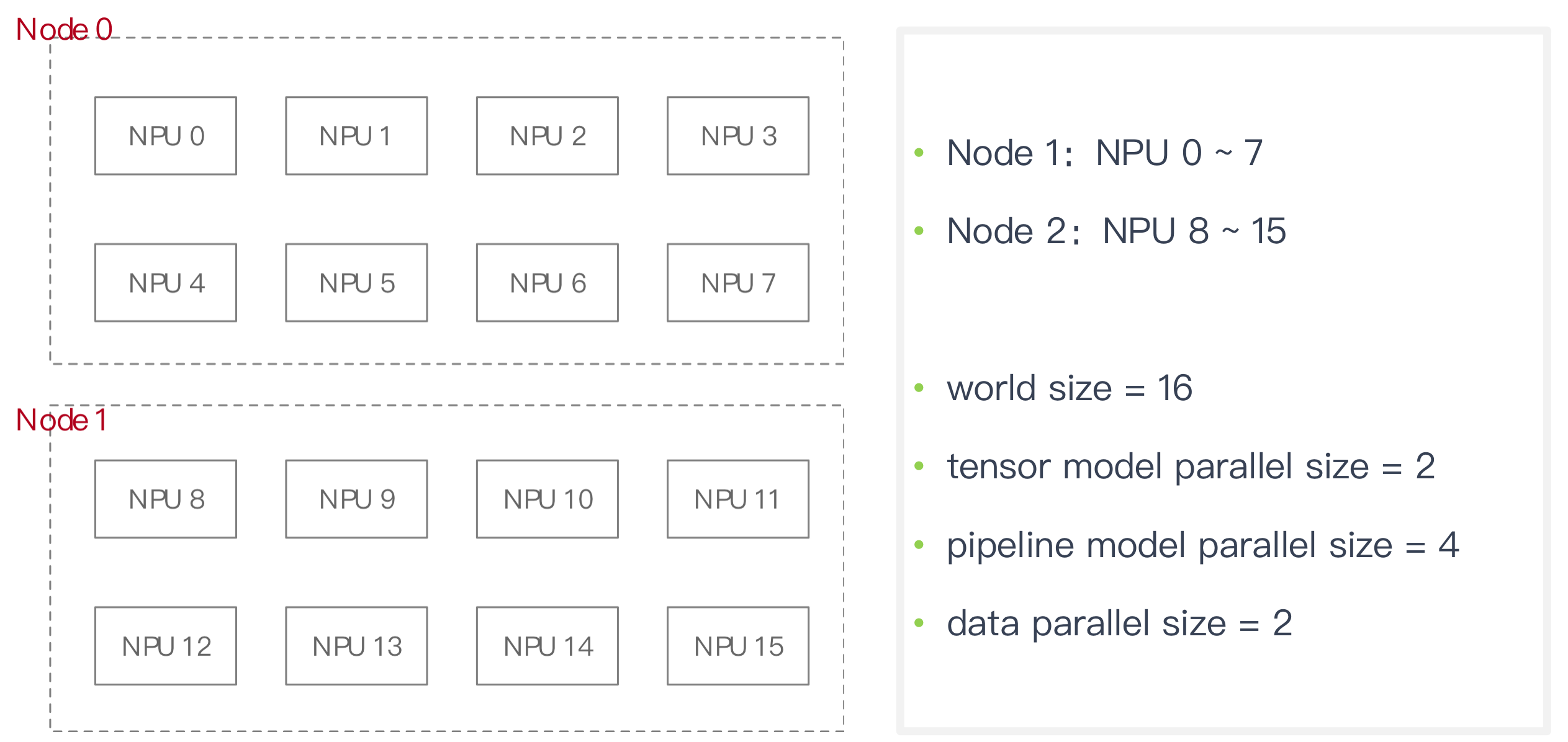
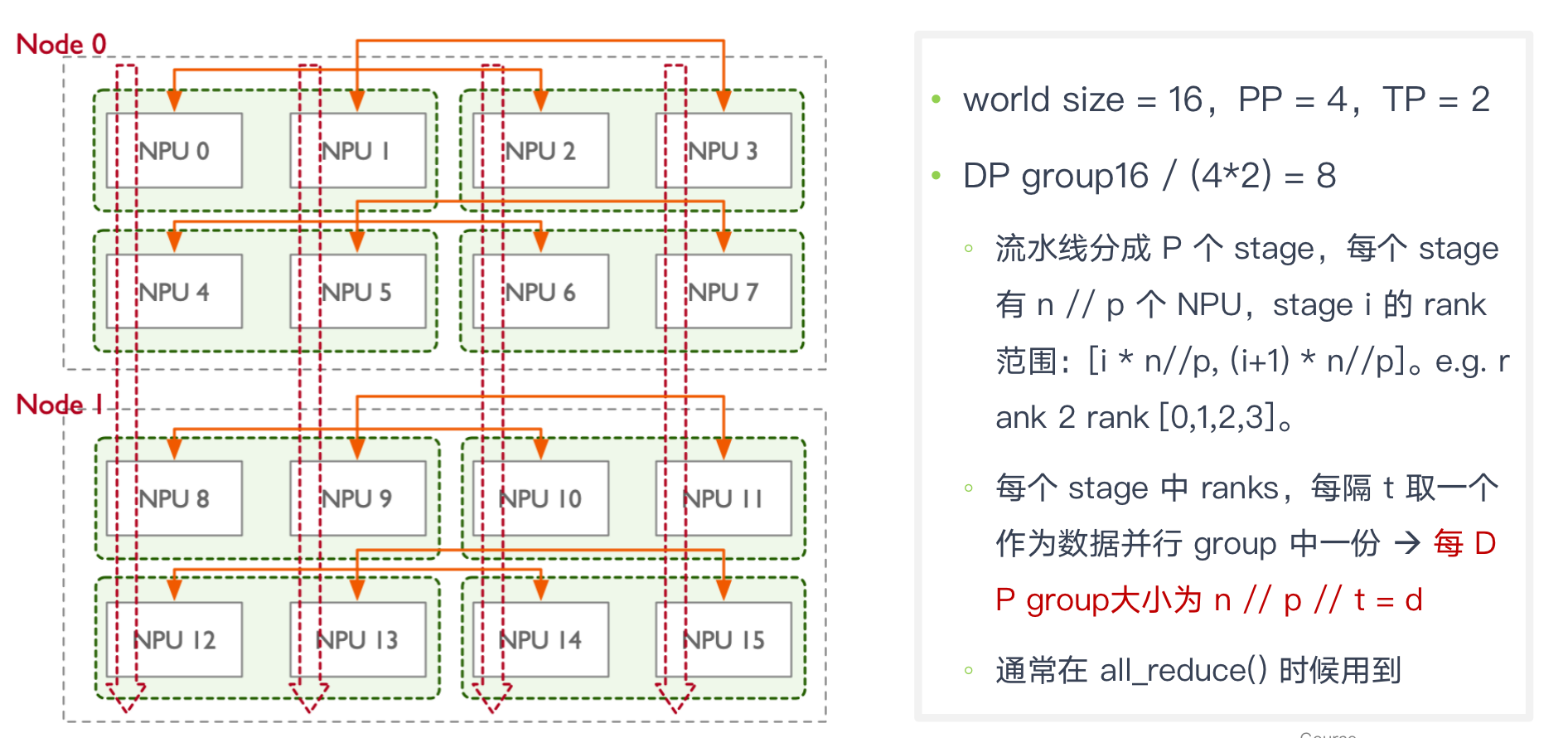
假定16 GPU,两个 node,rank 0~7 第一个节点,rank 8 ~15 属于第二个节点:
- TP 组大小 2,16 个 GPU 被分成 8 组: [g0, g1], [g2, g3], [g4, g5], [g6, g7], [g8, g9], [g10, g11], [g12, g13], [g14, g15]
- PP 组大小 4,16 个 GPU 被分成 4 组: [g0, g4, g8, g12], [g1, g5, g9, g13], [g2, g6, g10, g14], [g3, g7, g11, g15]
- DP 组大小 2,16 个 GPU 被分成 8 组:[g0, g2], [g1, g3], [g4, g6], [g5, g7], [g8, g10], [g9, g11], [g12, g14], [g13, g15]
每组个数最好偶数,不然可能造成通信变慢
模型并行切分配置(TP,PP)
PTD TP
megatron/core/parallel_state.py Build the tensor model-parallel groups.
1 | |
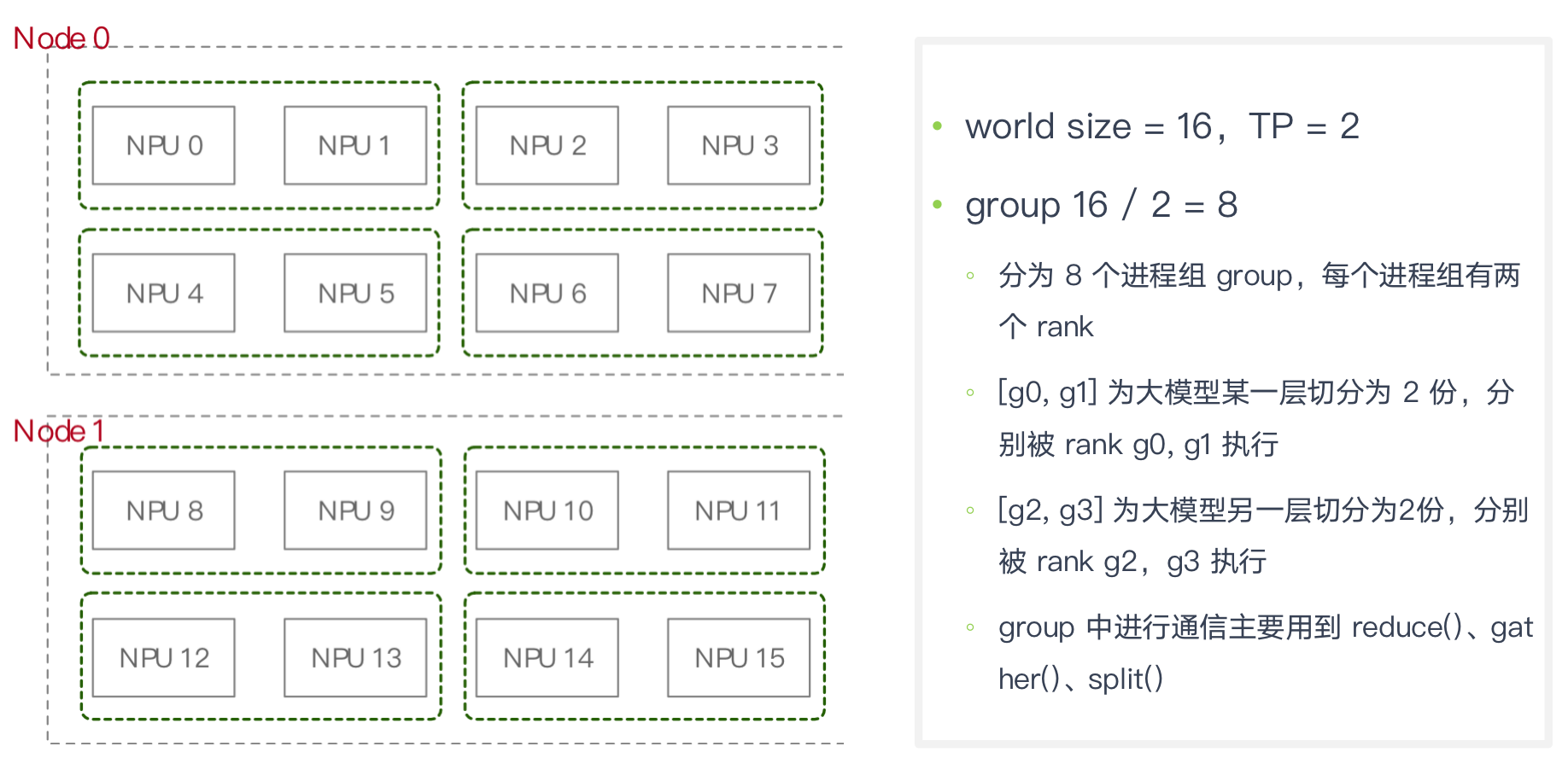
当 TP 反向传播时,利用 _TENSOR_MODEL_PARALLEL_GROUP group 组内进行集合通信,反向时候需要同一份的权重W和梯度G进行更新 (all-reduce)
PTD PP
PP 进程组 rank 分配
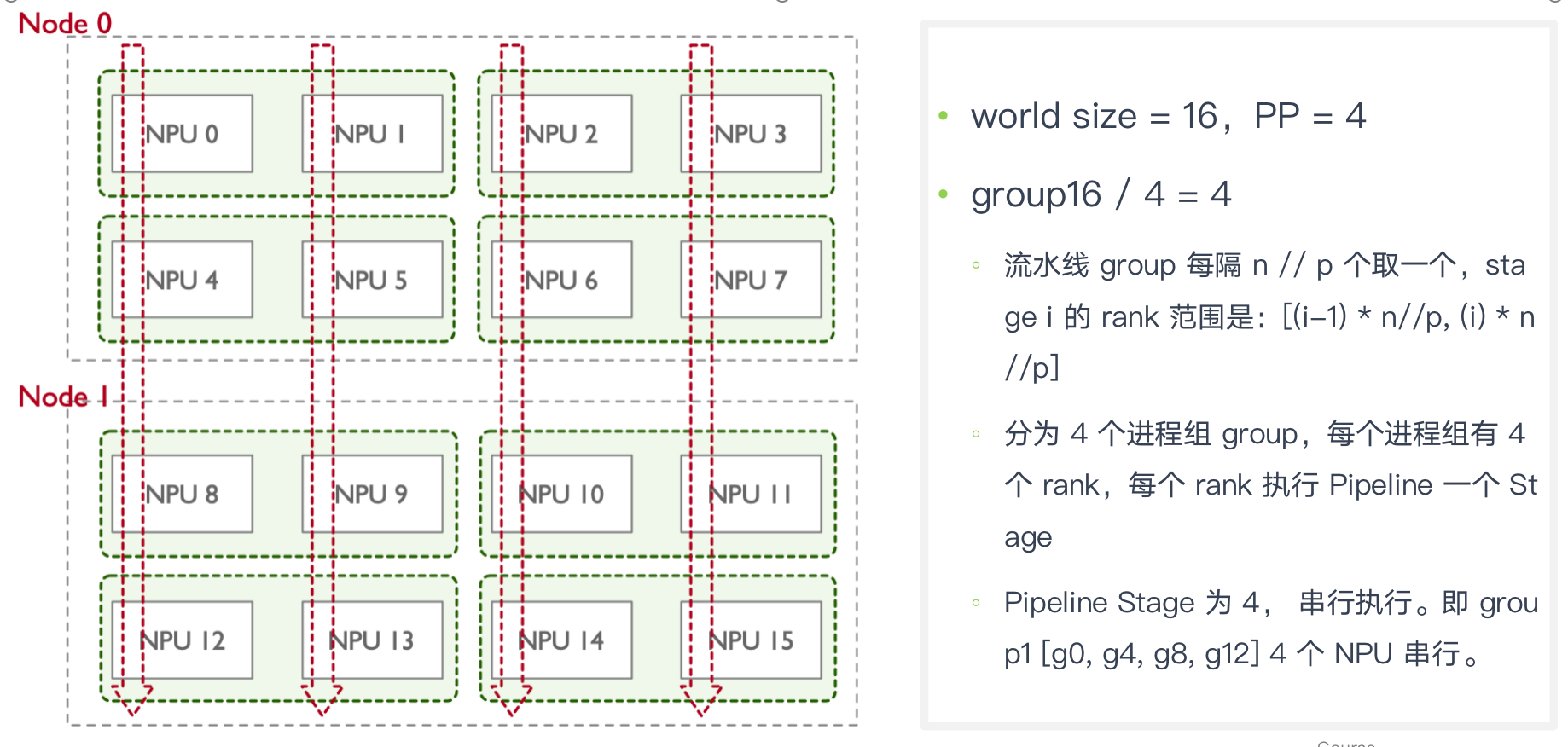
当 PP 进行通信时,使用 P2POp 点对点的通信方式,而不是集合通信方式
PTD DP
TxP 即放下一个大模型所需要 NPU 资源数:2 * 4
d = (总 NPU / 一个模型需要资源 ) = n / ( t * p) = 16/(2*4) = 2
n 个 NPU 可以同时训练 d 个大模型,可用 d 个 mini-batches 输入到 d 个大模型中进行训练
因此数据并行 DP 维度为 d
代码遍历DP深度,TP分组,计算group 对应的rank。
多维并行与配置关系
DP 组大小 2,16 个 GPU 被分成 8 组:[g0, g2], [g1, g3], [g4, g6], [g5, g7], [g8, g10], [g9, g11], [g12, g14], [g13, g15]
- 一组分到同一个batch数据
- 两个节点都跑模型的一部分(g0,g2)是不同模型的同一个部分
PP 组大小 4,16 个 GPU 被分成 4 组: [g0, g4, g8, g12], [g1, g5, g9, g13], [g2, g6, g10, g14], [g3, g7, g11, g15]
-
一组[g0, g4, g8, g12]一条流水线,纵向流水线串行,横向是同一个stage
- 一个模型一个stage有两张卡
- [g0, g4, g8, g12], [g1, g5, g9, g13] 是同一个模型
TP 组大小 2,16 个 GPU 被分成 8 组: [g0, g1], [g2, g3], [g4, g5], [g6, g7], [g8, g9], [g10, g11], [g12, g13], [g14, g15] 一组平分某一层模型网络
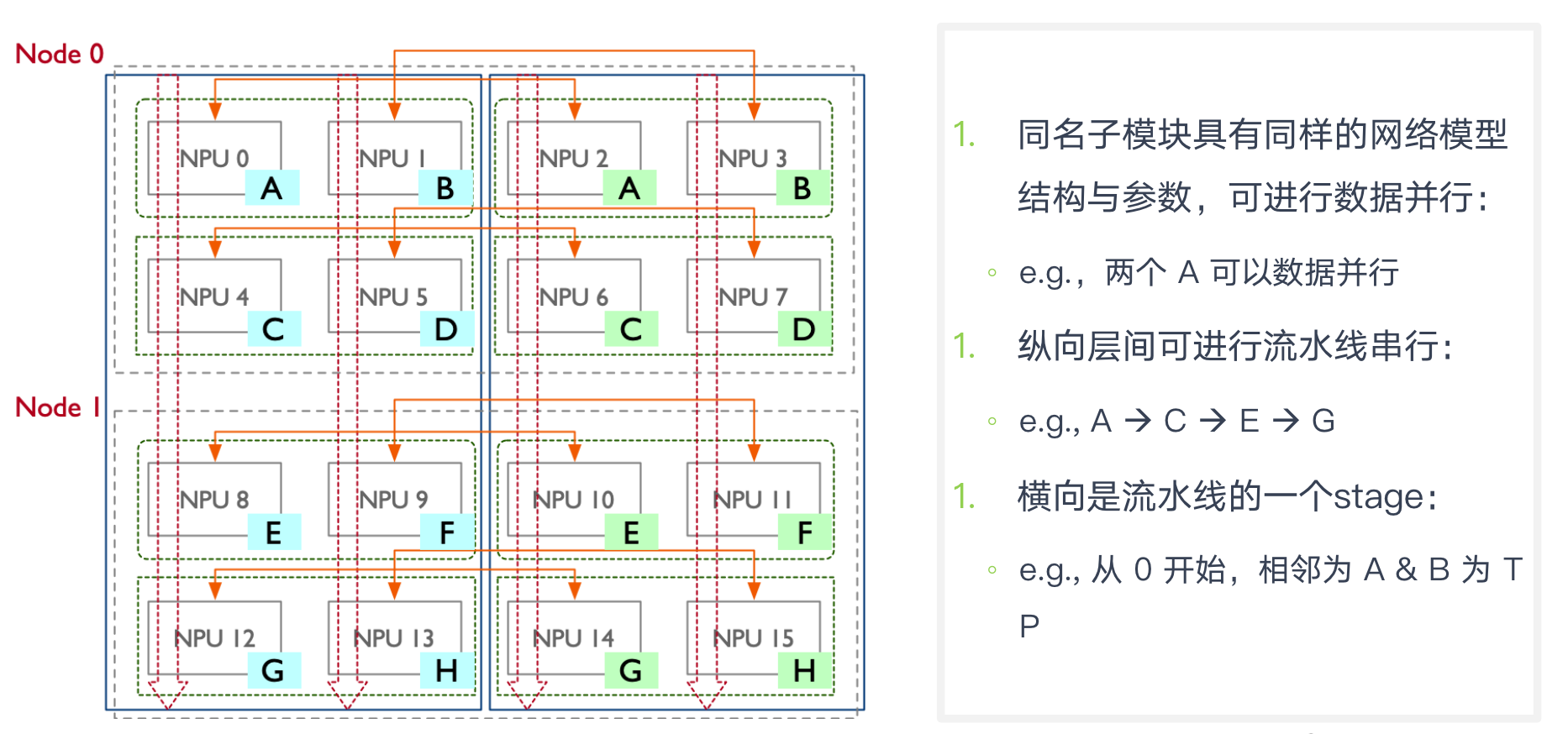
PTD 并行配置
TP 张量并行被用于节点内( intra-node transformer )层
- TP 张量并行计算密集且耗费大量带宽,节点内利用高带宽(nvlink)可以高效运行
PP 流水并行主要被用于节点间(inter-node transformer )层
- PP 通信(点对点)带宽占用少,其可以有效利用集群中多节点设计
DP 在 PP 和 TP 基础之上进行加持,使得训练可以扩展到更大规模和更快的速度
- 尽管 DP 可高效扩展,但不能单独使用 DP 来训练超大模型,应该在TP,PP上做扩展
- HBM 不足
- 数据并行扩展限制
仿真rank分配
1 | |
如何把大模型按照模型层数或者切分好的模块,分块放到对应的 NPU 上
- rank 根据 PTD 全局变量映射到 NPU
- 模型初始化通过 offset 根据 rank 生成对应层(ParallelTransformer)
- 模型参数根据 rank 拷贝到对应 NPU 上然后执行训练
配置规范
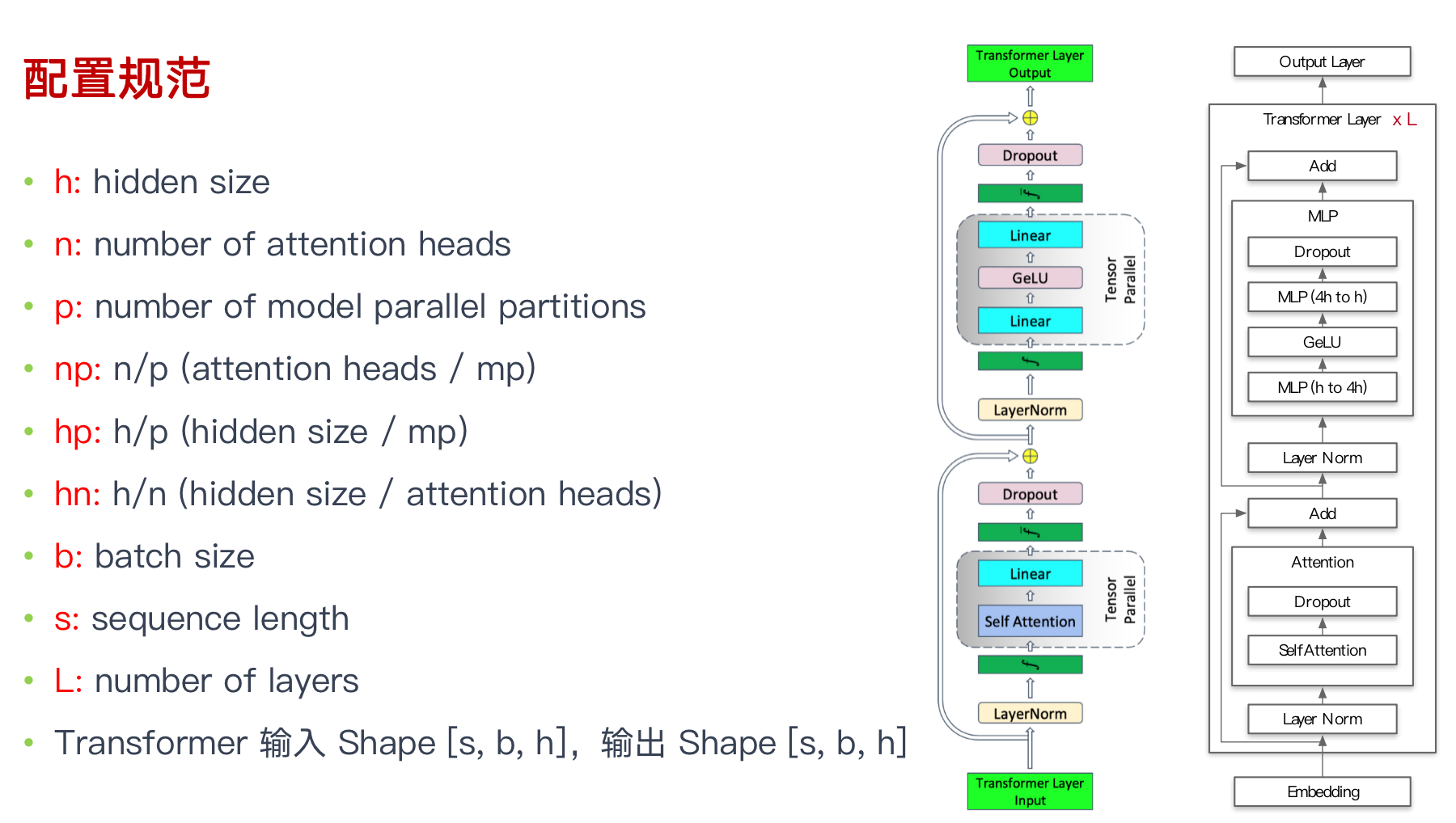
张量并行 TP 代码剖
序列并行 SP 代码剖析
实现上 ColossalAI 借鉴了 Ring-Allreduce 算法实现,通过 RingQK 和 RingAV 两种计算方式实现序列并行
核心是 通讯换内存,当处理的序列越来越长,DP一个device很难放得下。
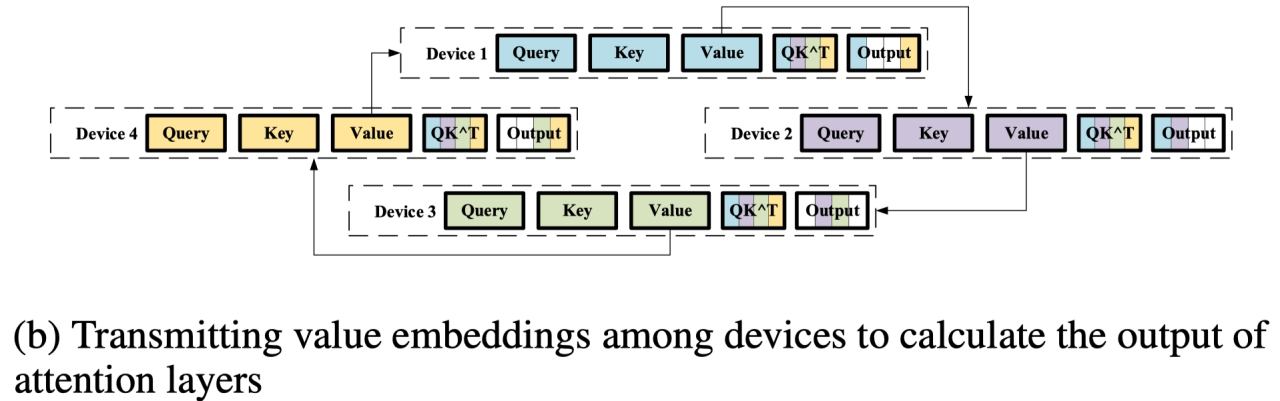
RingQK 过程
- 每 NPU 保存一份 sub Seq,但是 Q/K/V 的计算有需要和完整的 Seq 作为输入
- 利用Ring All-Reduce 在每次通信 iter 时,互相传输各 NPU 的子序列数据
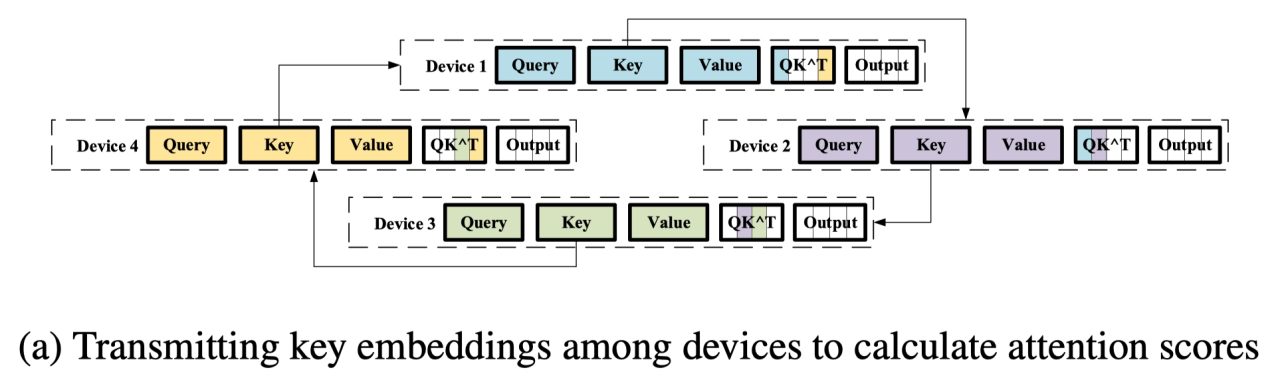
- NPU1 接收了 NPU4 的 Key,计算 NPU1 & NPU4 的$ QK^T_1$
- NPU2 接收了 NPU1 的 Key,计算 NPU2 & NPU1 的 $QK^T_2$
- ….N-1 个 iter 后,所有 NPU 都有完整 $QK^T$ 结果,完成一次 RingQK 过程
RingAV 过程
接下来计算 Attention Scores,通过 Ring All-Reduce 算法计算每 NPU 的$ Attention Prob * Value$
与 RingQK 相同的计算逻辑,每 NPU 都传输各自 Value,得到最终的输出