https://www.bilibili.com/video/BV1jz421h7CA/?spm_id_from=333.788&vd_source=d591262dc9ce1bba22682d1cba1ca930
| 通信特性 | NCCL | HCCL |
|---|---|---|
| 通信算法 | ring/mesh + ring/Hav-Doub/Pair-Wise, etc. | ring + Tree ring, etc. |
| 通信链路 | 灵渠总线/PCIE | NVLink / NVSwitch / GPU-Direct / PCIE |
| 通信操作 | allreduce、broadcast、reduce、reduce | scatter、allgather、all2all、send、recv |
| 通信域管理 | 全局通信域、子通信域、基于全局/子通信域配置算法 | 全局通信域、子通信域、自定义通信域配置算法 |
通信算法: XCCL 集合通信库实现流量统一规划,满足复杂物理拓扑中流量有序交换,最大化集群通信性能;
通信原语/操作:提供不同 NPU 硬件上进程间的通信方式或者通信 API,即建立在通信算法上层概念,通过不同的通信算法来实现;
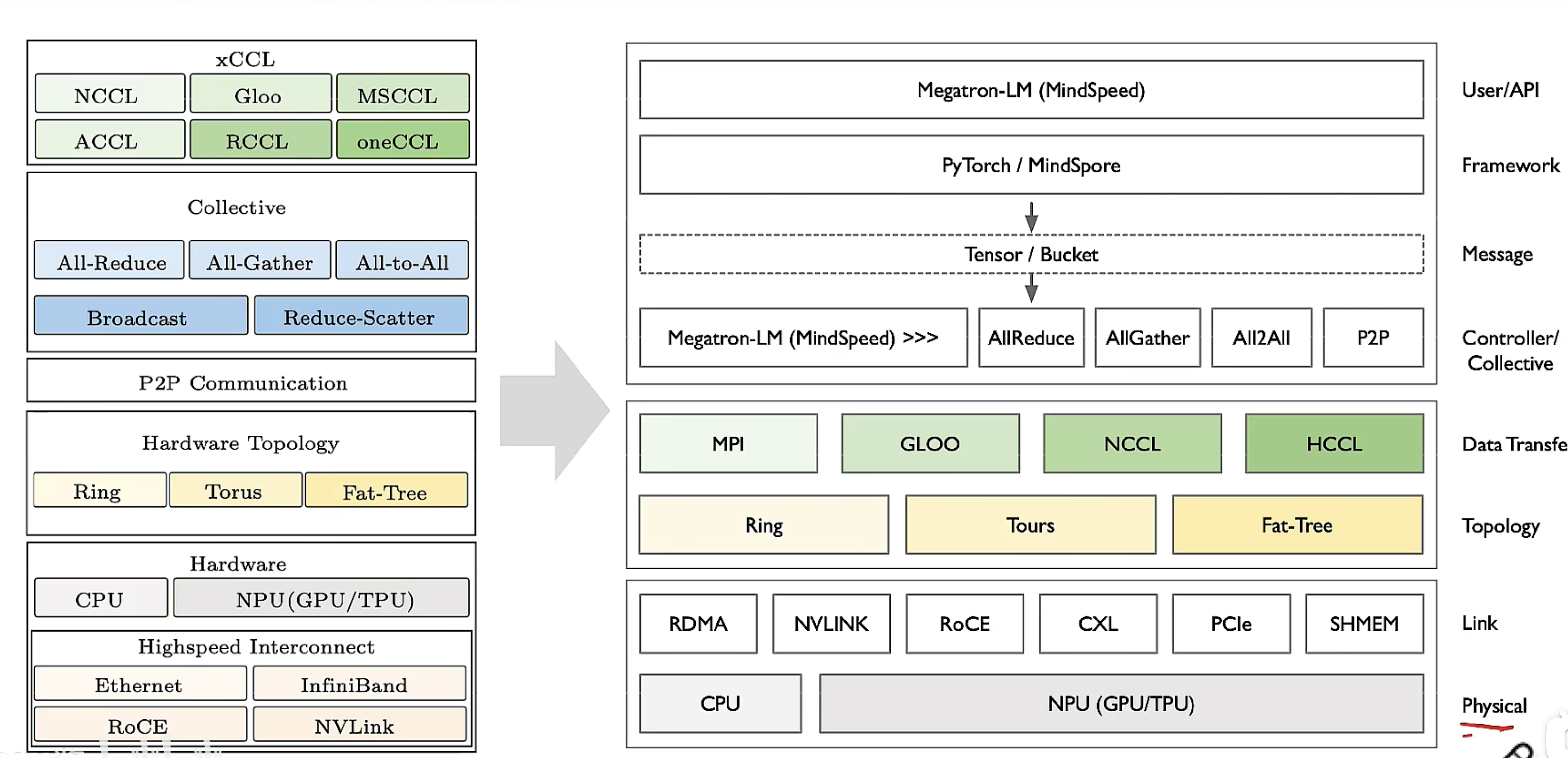
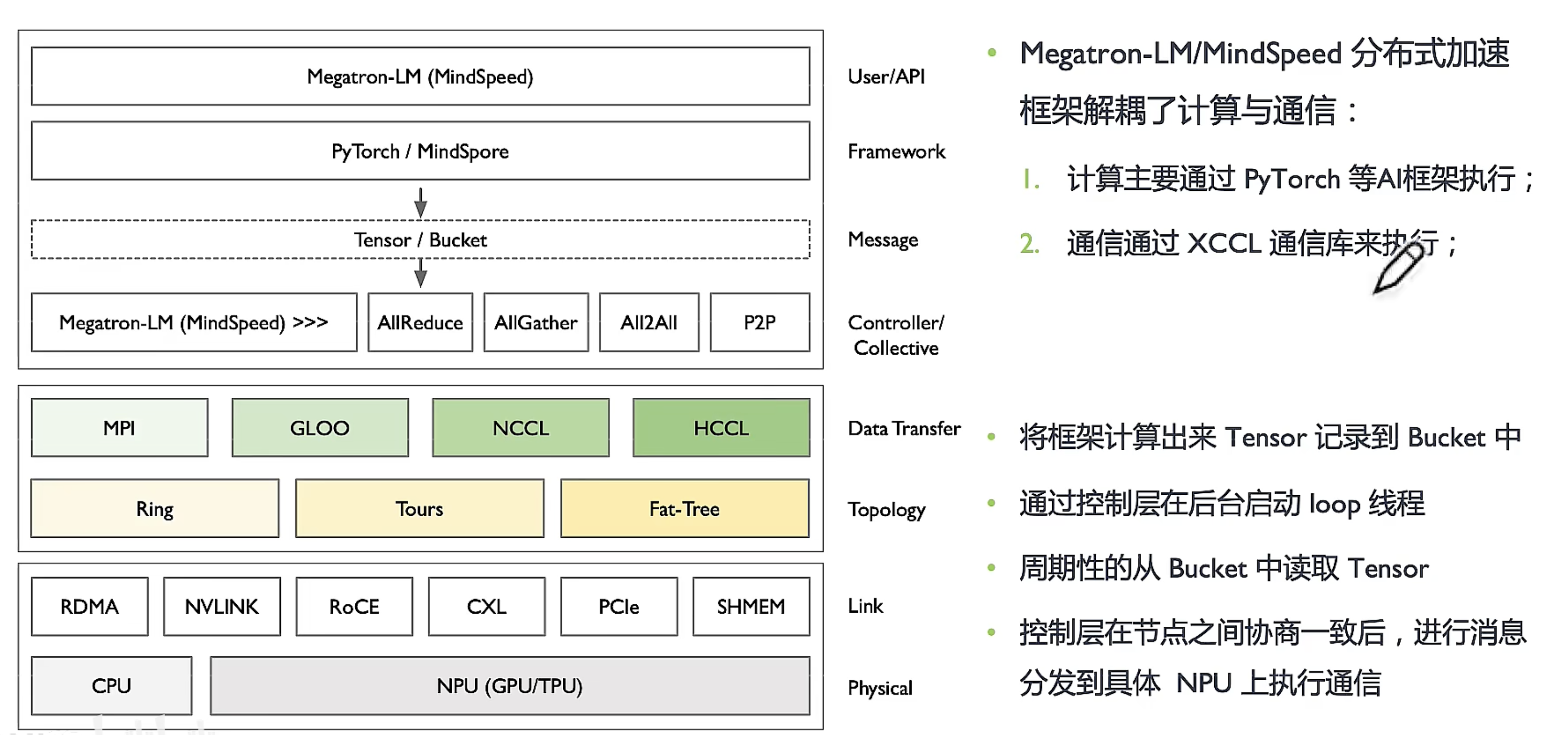
计算与通讯解耦
神经网络训练过程中,每一层神经网络都会计算出一个梯度Grad,如果反向传播得到一个梯度,马上调用集合通信AllReduce进行梯度规约,在集群中将计算与通信同步串行,那么集群利用率(MFU)性能就很差。
如GPT3 176B有96层Transformers对应Grad个数96×112,设计算梯度1ms,通信500ms,每次时间50Ims,总体需要501×96×12=577152ms,近5777s完成一次梯度迭代。
将计算与通信解耦,计算的归计算,通信的归通信,通过性能优化策略减少通信的次数 (分布式加速库:解耦计算和通信,分别提供计算、通信、内存、并行策略的优化方案。)
- 提升集群训练性能(模型利用率 MFU/算力利用率 MFU )
- 避免总信与计算假死锁(计算耗时长,通信长期等待)
xCCL在AI系统位置
通讯同步
AI对通讯的算法需求
传统服务器配备一张网卡用于节点间通信,为支持AI配置多个 GPU。Al 训练需要 GPU 间梯度同步多 GPU 并发访问网络,网卡成为系统瓶颈。PCle 链路带宽分配与路径长度密切相关,长路径获得带宽分配较低,跨 Socket 通信问题就变得严重。
网络架构主要解决 AI 训练中同步通信导致短板效应。
- 拥塞控制算法:对两个碰撞流进行限速,使其尽快达到均分物理带宽的目的,不能解决 AI训练集群通信效率。
- AI业务通信的同步性,每个通信最终性能决定于最慢的连接。均分带宽意味着事务完成时间的成倍提升,严重影响AI通信性能。
不同时期的需求
- 单一化业务,整个 AI系统只为大模型(LLM、LMM等)或者搜广推服务,几乎没有其他业务的复用性
- 用于超大规农的模型(百/千亿参数量)的训练、推理,L0 基础大模型算法研究的探索
- 训练大模型走极致性能优化路线 vs 虚拟化云服务和 AI 通用算力服务化走性价比路线;

大模型时代
-
大模型处于快速发展期,当前基于 Transformer 的模型结构固定,模型通信流量相对明确
-
面对超长序列、MOE 结构、低精度数据格式 FP8 等在通信流量仍然存在挑战和不确定性
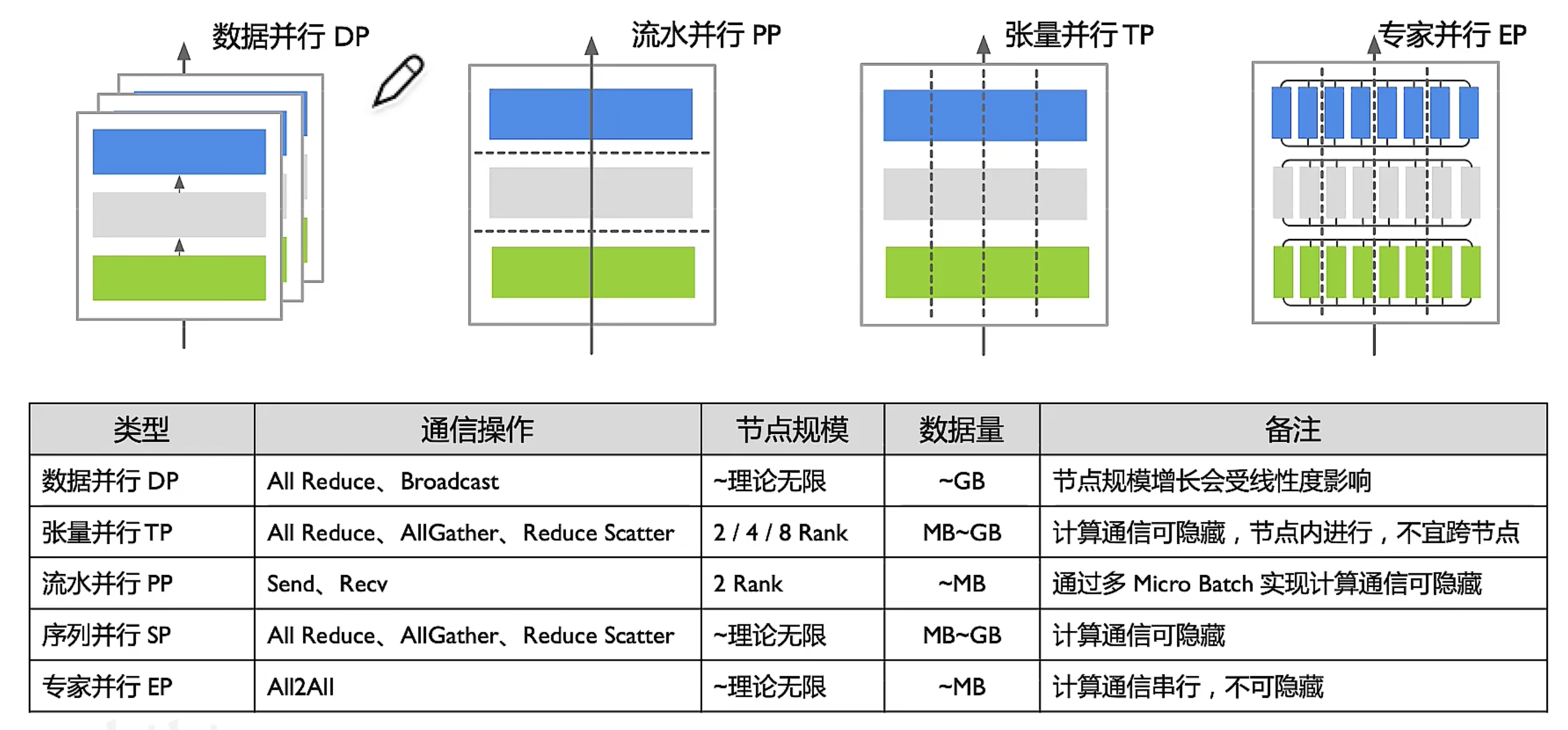
并行模式 通信产生原理 通信操作 数据并行(纯数据并行) 反向梯度更新时需要进行 all reduce 将梯度聚合 All reduce ZeRO1(优化器状态并行) 只能更新部分权重,需要多执行一次 all gather 将权重聚合 All reduce
All GatherZeRO2(梯度并行) 每张卡只需要 reduce 部分梯度,更新部分权重后一样需要 all gather 将权重聚合 Reduce Scatter
All GatherZeRO3(权重并行) 每张卡只需要 reduce 部分梯度,更新部分权重,但是前向和反向时同样需要 all gather 将权重聚合 Reduce Scatter
All GatherPipeline(层间并行) 前向和反向时需要各 rank 传递激活值 Send
Recv (点对点通讯)并行方式 通信操作 总通信量 单次通信量 算法 Rank 间关系 数据并行 张量并行 All Reduce GB 25MB, PyTorch 可配置参数缓存 Bucket 大小 Ring 同序号卡通信 HD 同序号卡通信 Tree 同序号卡通信 MoE 并行 All2All GB 按 Token 发送,KB 级别 Pair-wise 夸序号卡通信 分层通信 同序号卡通信 流水并行 Send/Recv MB 按 BSH 发送,MB 级别 P2P 夸序号卡通信
集合通信难点
-
需要在固定网络互联结构(网络拓扑 Topology)约束下进行高效通信;
- 集合通信算法与物理网络互联结构强相关,需要充分发挥网络通信效率;
- 在效率与成本、带宽与时延间进行合理取舍。
信息同步
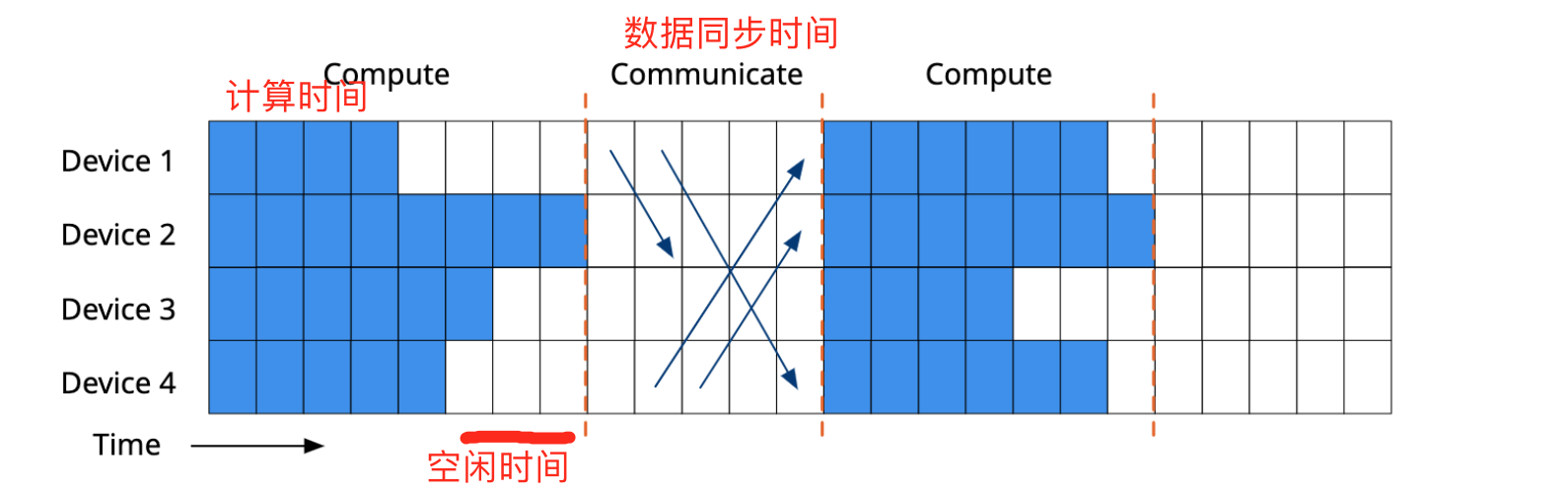
分布式 同步并行
- 必须等全部工作节点完成了本次通信之后才能继续下一轮本地计算
- 本地计算和通信同步严格顺序化,能够容易地保证并行的执行逻辑和串行相同
- 本地计算更早的工作节点需要等待其它工作节点处理,造成了计算硬件的浪费
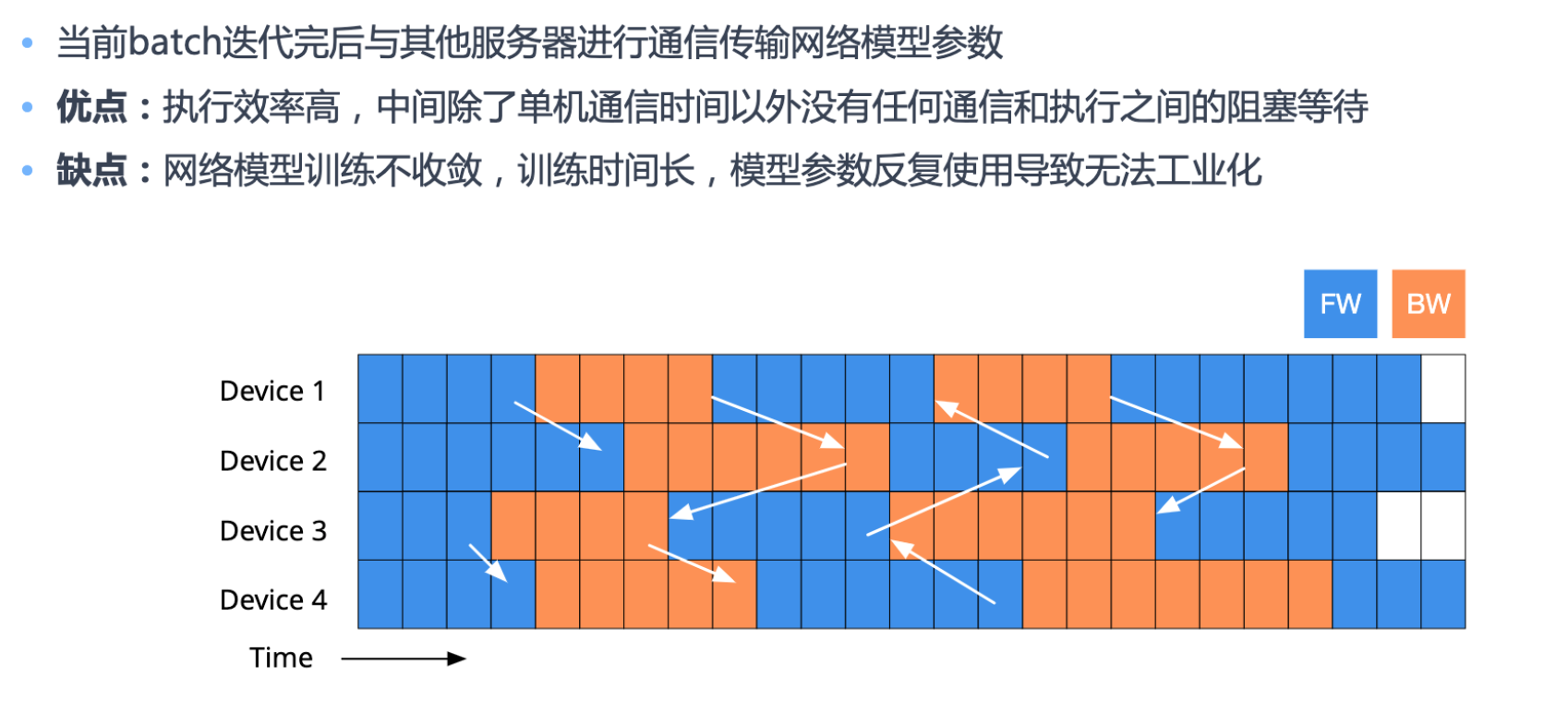
分布式 异步并行
半同步
- 通过动态限制进度推进范围,有限定的宽松同步障的通信协调并行
- 跟踪节点进度并维护最慢节点,保证计算最快和最慢节点差距在一个预定的范围内
不等太慢的,以多数worker可以接受的时间完成同步
环同步 Ring Synchronization
GPU之间使用NVLink连接,每个GPU之间可以互相访问到,环有不同形状
最常见实现算法基于 Ring All Reduce,NVIDIA NCCLv1.x通信库采用该算法,每次跟相邻的两个节点进行通信,每次通信数据总量的 I/N
适用拓扑
- Star、Tree等小规模集群; 通信步骤: 2×(N - 1) Step;
优点
- 实现简单, 能充分利用每个节点的上行和下行带宽;
缺点
- 通信延迟随着节点数线性增加, 特别是对于小包延迟比较明显; Ring 大, Ring All Reduce 效率也会变得很低。
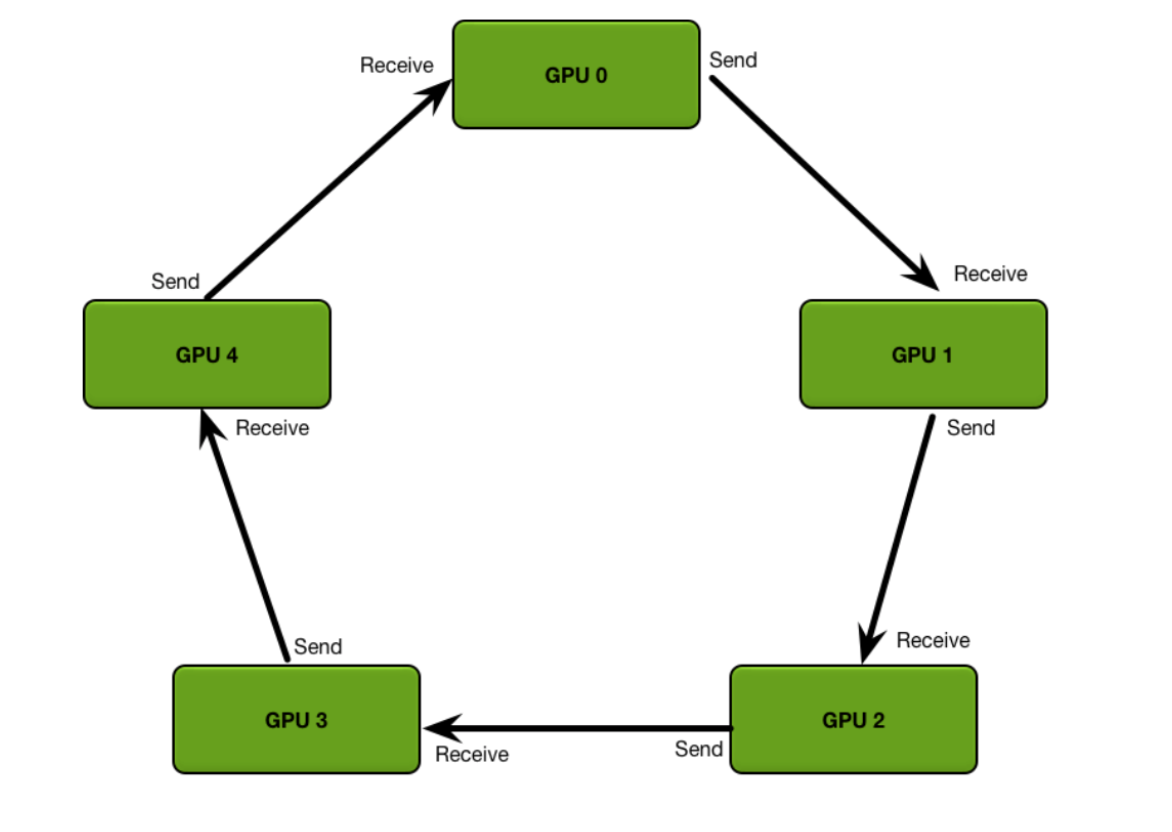
Ring 算法执行步骤
- Ring 算法将进程组织成一个逻辑环 (Ring),数据沿着环流动。该算法执行 2(N - 1) 步,每一步进程 r 向其邻居 (r + 1)%P 发送 P/N 的数据,并接收来自进程 (r - 1)%N 的数据,聚合接收到数据, 每个进程发送数据总量为 2P(N - 1)/N。
- 假设 N 为进程数, P 为需要聚合的总数据量,数据被分成 N 块, 一块为 P/N。
ring all reduce 算法 ,遍历两次所有GPU完成一次通信
-
Scatter-reduce,遍历完一个环每个GPU都有全数据的一个备份

-
all-gather 广播数据,遍历一次所有GPU都拥有所有数据的备份
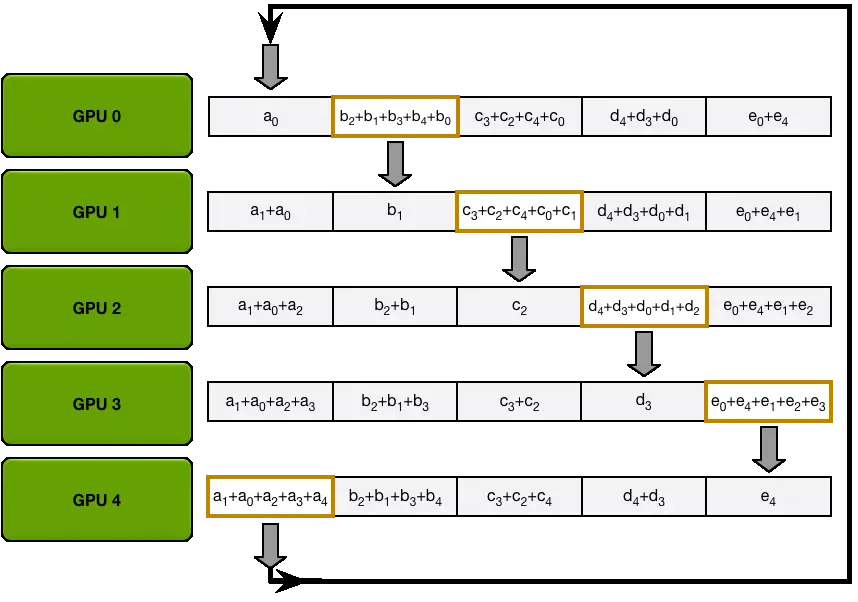
Halving-Doubling 算法
基本介绍
- 每次选择节点距离倍增的节点进行通信, 每次通信量倍减 (或倍增),访问步长按指数衰减
- 如异步HCCL, 阿里ACCL均采用该算法
适用拓扑
- Fat-Tree 等; 通信步骤: log2 N
优点
- 通信步骤较少, 只有 2×log2 N 次 (N 为参与通信 Rank 数), 通信即可完成, 有更低延迟,并且可以同时并发访问其他XPU
缺点
- 固定并行算法 (如 TP=8 存在并性能劣化严重), 每一个步骤相互通信 Rank 均不相同, 链接回切换会带来额外开销
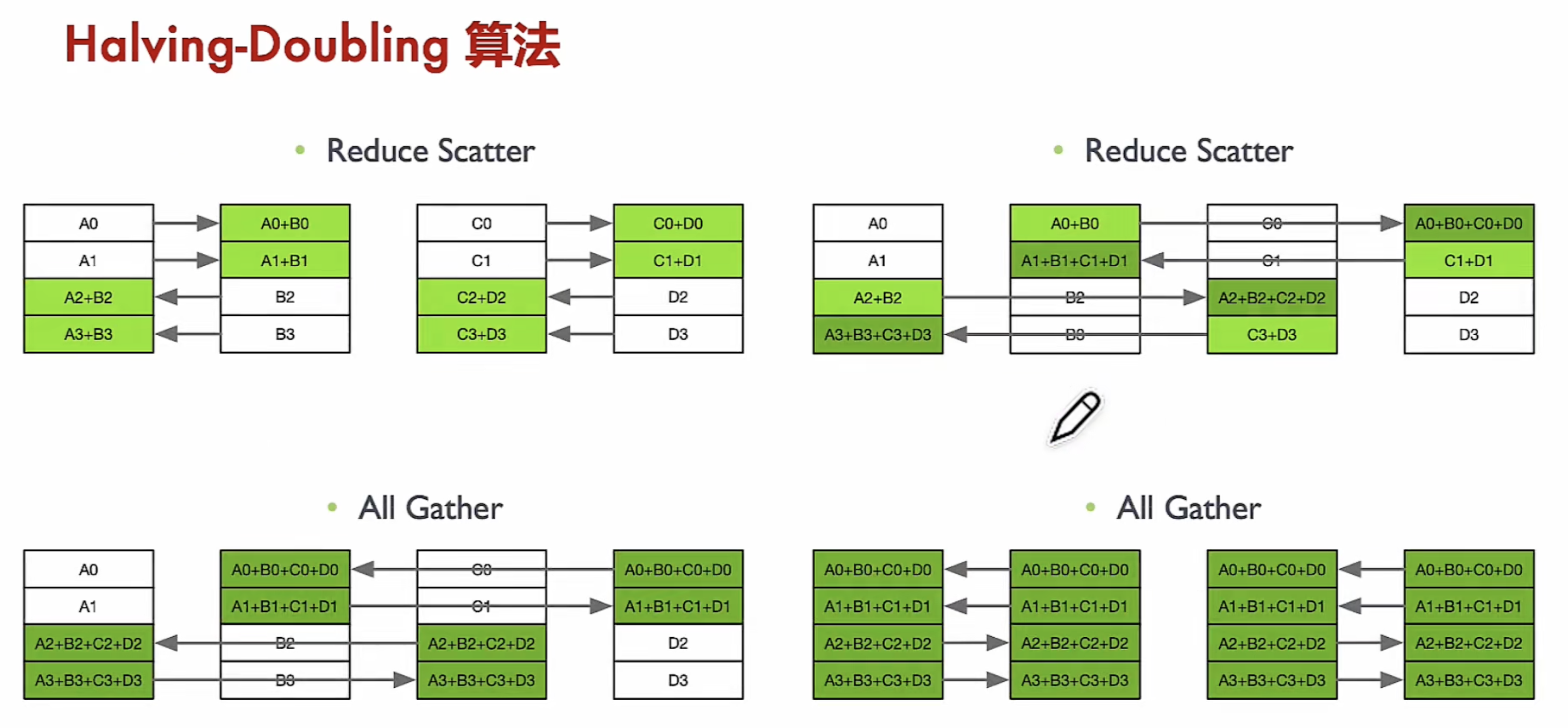
组网拓扑不同,并行配置不同,需要理解组网方式才能设置更好的并行策略。
| 算法 | 步骤数 | 发送数据量 | 优缺点对比 |
|---|---|---|---|
| Ring | 2×(N-1) | 2P(N-1)/N | 发送数据量少,聚合大数据性能好; 用于小规模节点数时优选; 每次通信域链接不用改变,较为固定; 连接方式更加稳定; |
| Halving-Doubling | 2×log2 N | 2P(N-1)/N | 步骤数和发送数据量少,聚合大数据性能好; 用于大规模节点数时较优; 固定网络拓扑上可以做到全局无拥; 通信链接在变化,网络拓扑未知下容易遇到拥塞; |
通讯实现
https://github.com/chenzomi12/DeepLearningSystem/blob/main/061FW_AICluster/03.communication.pdf
通信实现方式
计算机网络通信中最重要两个衡量指标主要是 带宽和 延迟,分布式训练中需要传输大量的网络模型参数
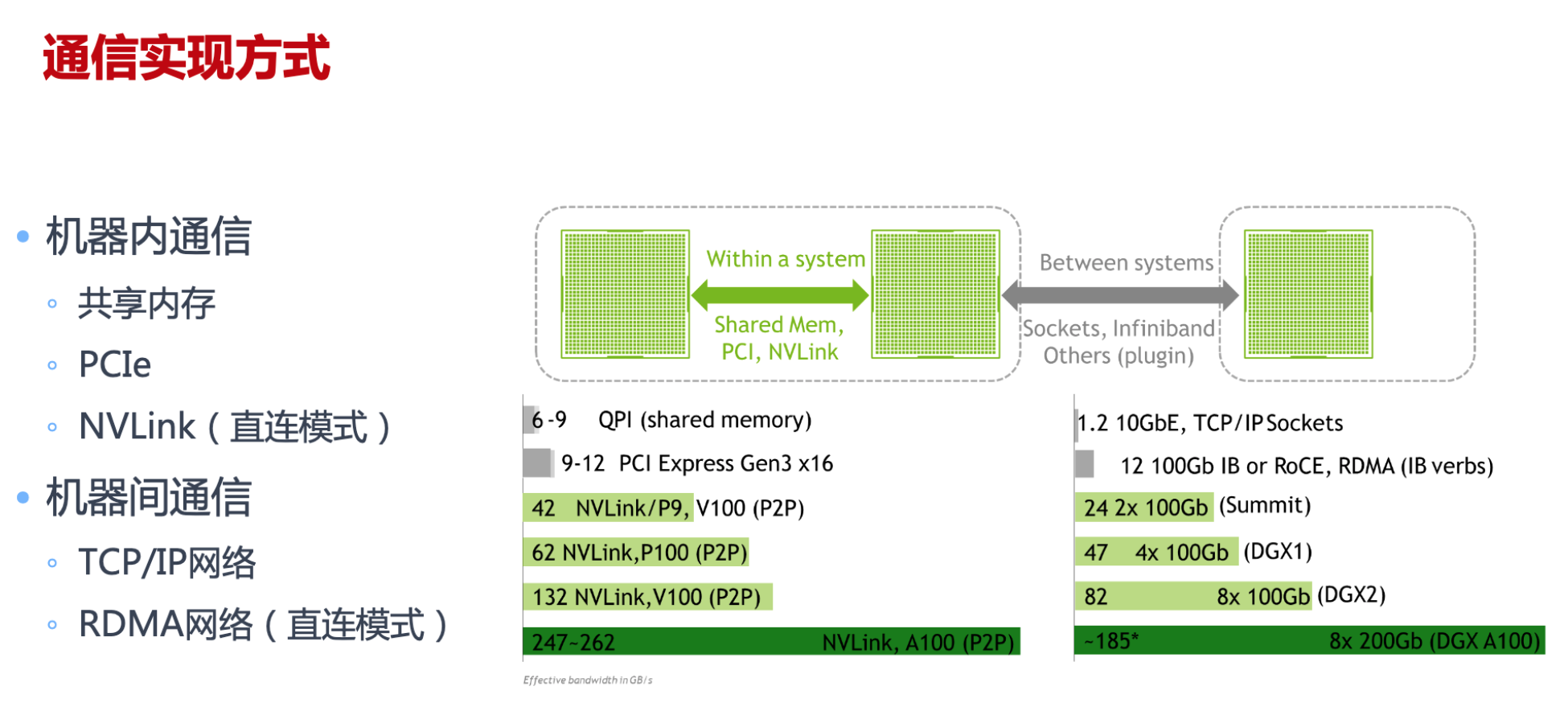
CPU共享内存,PCIe插槽(CPU GPU之间),NVLink(GPU之间)

通信实现方式
点对点通信 Send/Recv
-
TCP/IP
-
RDMA
集合式通信 AII-Reduce
- TCP/IP
- NCCL
集合式通信原语
一对多 Scatter/ Broadcast
-
Broadcast
某个节点想把自身的数据发送到集群中的其他节点,那么就可以使用广播Broadcast的操作。
单个 rank 把自身的数据发送到集群中的其他 rank
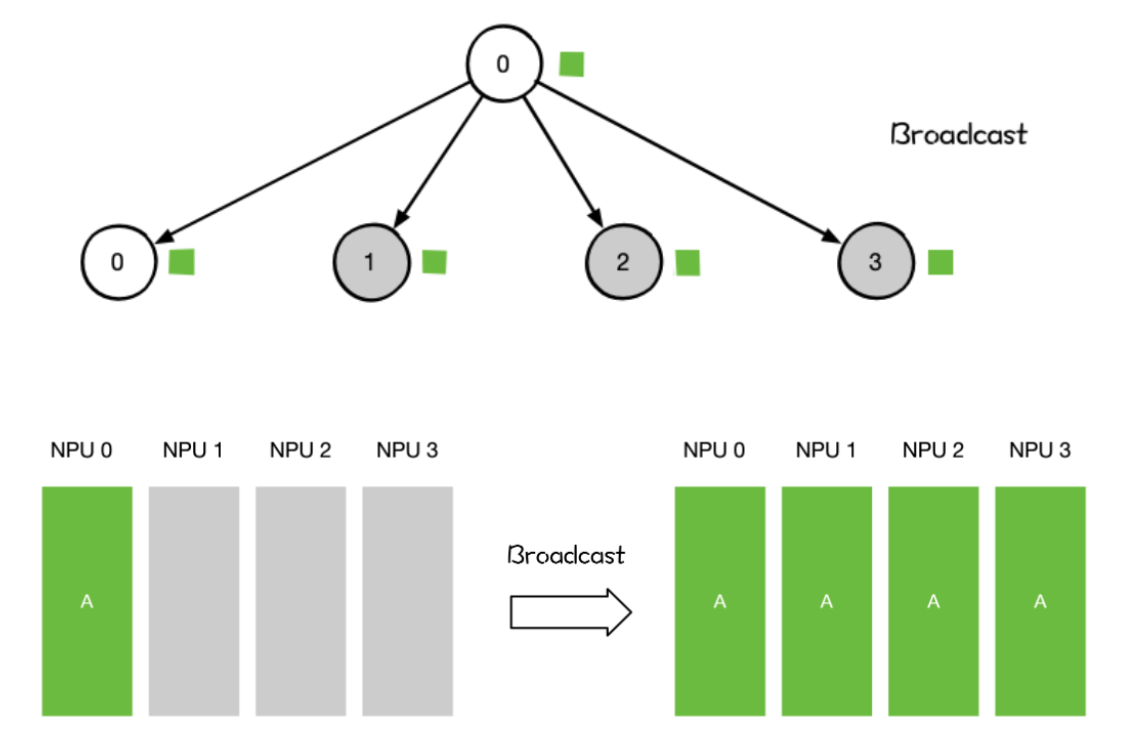
用法
- 网络参数 Init Weight 的初始化
- 数据并行 DP 对数据分发初始化
- AlIReduce里的 broadcast + reduce组合里的 broadcast 操作
-
Scatter
将主节点的数据进行划分并散布至其他指定的节点。
将主节点的数据进行划分并散布至其他指定的 Rank
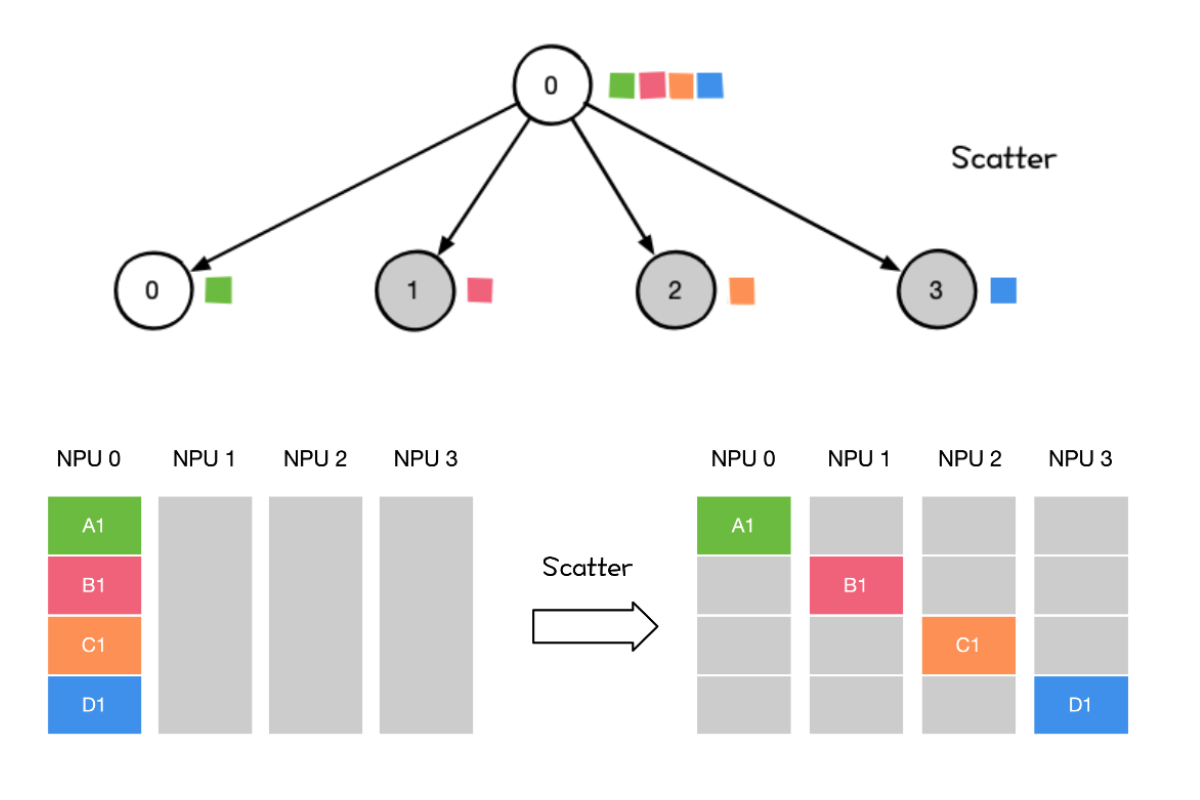 用法
用法- Reduce Scatter 组合里的 Scatter操作
- 流水并行里初始化时将模型 Scatter 到不同 Rank上
多对一 Reduce/Gather
-
Reduce
把多个 Rank 的数据规约运算到一个 Rank 上。 Reduce 称为规约运算,是一系列简单运算操作的统称。细分可以包括:SUM、MIN、MAX、PROD、LOR等类型的规约操作。
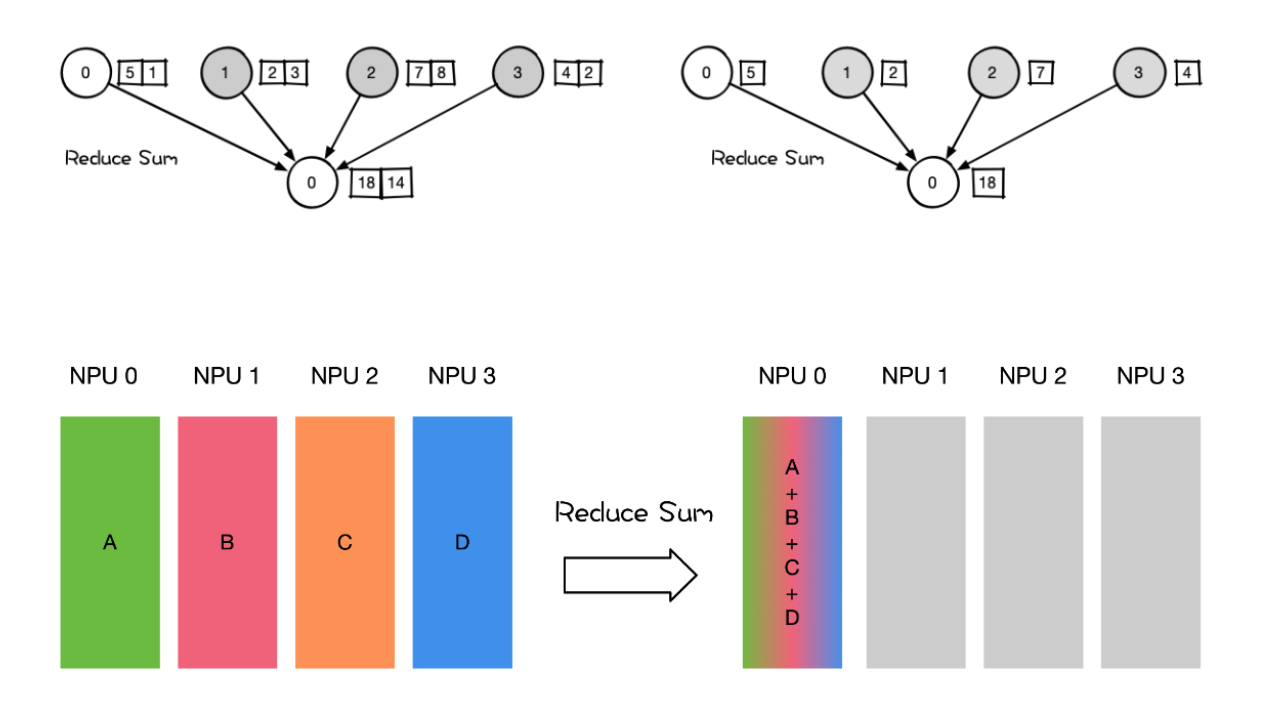
用法
-
AllReduce里的Broadcast,Reduce组合 Reduce操作
-
Reduce Scatter 组合里的 Reduce操作
-
大模型训练权重 CKPT 保存
-
-
Gather
将多个 Sender 上的数据收集到单个节点上,Gather 可以理解为反向的 Scatter。
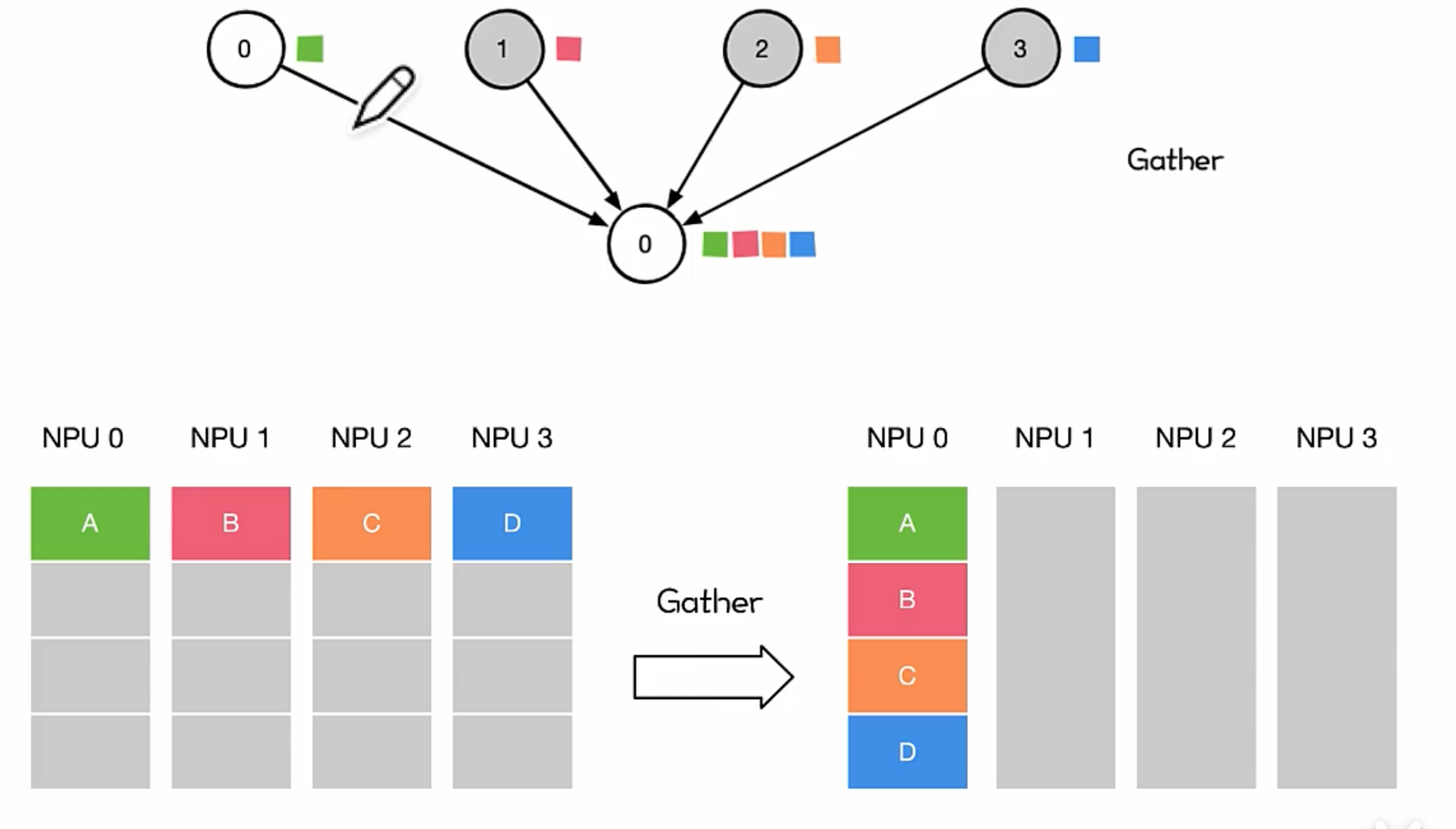
对很多并行算法很有用,比如并行的排序和搜索
用法
- Gather 相对用得比较少,AIl Gather会在张量并行 TP 用得较多
多对多 All Reduce/ All Gather
-
AII Reduce则是在所有的节点上都应用同样的Reduce操作。AIl Reduce操作可通过Reduce + Broadcast 或者 Reduce-Scatter +AlI-Gather 操作作完成
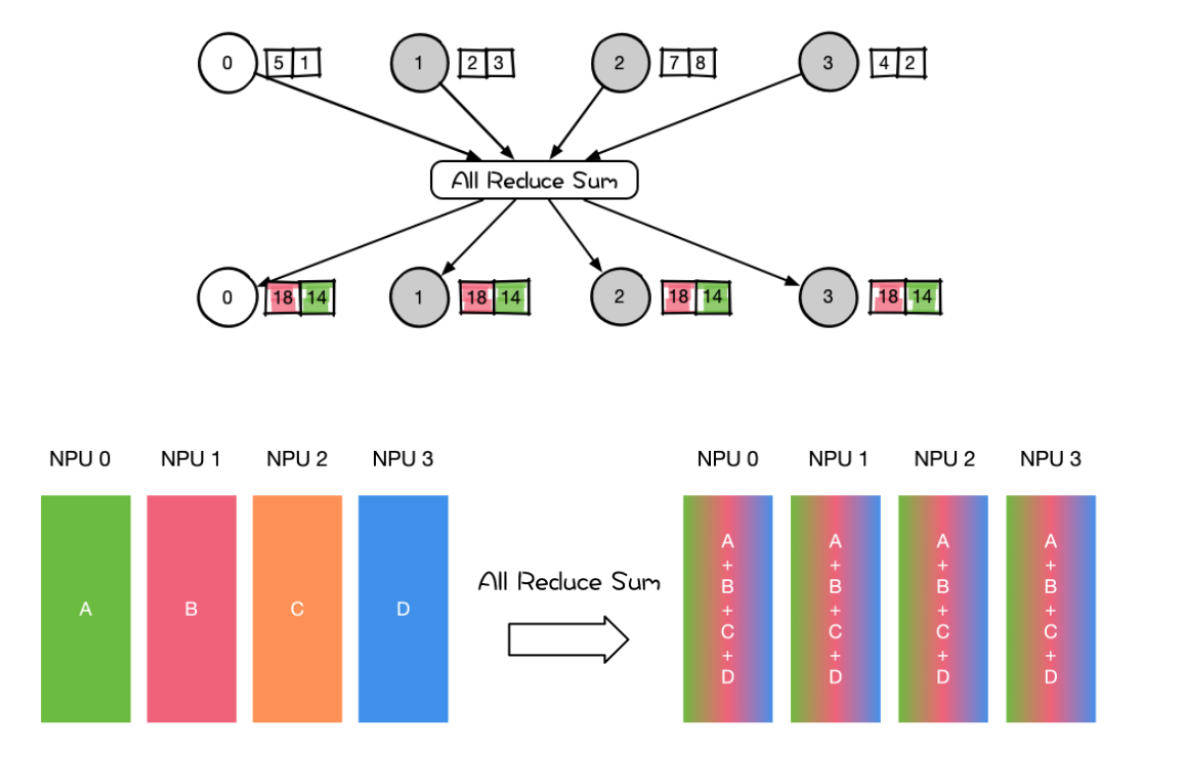 用法
用法- 在专家并行、张量并行、序列并行中大量地使用 AII Reduce 对权重和梯度参数进行聚合。
- 数据并行 DP 各种通信拓扑结构比如Ring AlReduce、Tree AlReduce里的 AllReduce 操作;
-
两种实现方式差异 使用Reduce-Scatter +AlI-Gather
- Reduce + Broadcast
- 在Reduce+broadcast里,Reduce先将N张NPU梯度reduce sum到 master RankNPU0 上再通过 broadcast 将 NPU0 中平均梯度复制到其他 NPU:
- 通信数据: N 个 Rank 数据 reduce sum 到一个 Rank.
- e.g. 假设为一个节点 8 个 Rank, 每个 Rank 携带 100MB, 8 个 Rank 800MB, 导致 XPU0 在频繁发收数据, 剩余 Rank 空闲, 集群效率低;
- 通信带宽: NPU0 网络带宽会成为瓶颈, 所有 Rank 数据只能通过 NPU0 进行 reduce 和 broadcast, 数据量 较大 则 NPU0 成为瓶颈.
- e.g. Tensor Parallelism;
- 互联拓扑: NPU 不一定两两全部互联, N 个 Rank 每次 Reduce 或 broadcast, 受限网络互联实现, 最终需要采用 ring/tree 策略进行 reduce 或 broadcast, 集群效率低.
- **Reduce-Scatter +AlI-Gather **每个 NPU 都会从前向接受数据,并发送数据给后向,算法主要分为
- Reduce Scatter: 先 scatter 拆分数据块再进行 reduce,每块 NPU 都会包括完整融合的同维特度。
- Gather: 进行全局 Gather 同步,最后所有 NPU 都会得到完整的权重。
- 充分考虑到 NPU 上梯度 tensor 的情况
- e.g. 一个梯度 400MB, reduce scatter 将其分成 NPU 个数份, 假设为 8个, 即每份 50MB, 从而减少单个 NPU 计算量及节约带宽
- Reduce Scatter 通过将数据拆分成小块,同时进行 Reduce Scatter, 从而提高计算效率并减少通信时间, 进而提高 All Reduce 效率。
- Reduce + Broadcast
-
All Gather会收集所有数据到所有节点上。All Gather = Gather + Broadcast。发送多个元素到多个节点很有用即在多对多通信模式的场景
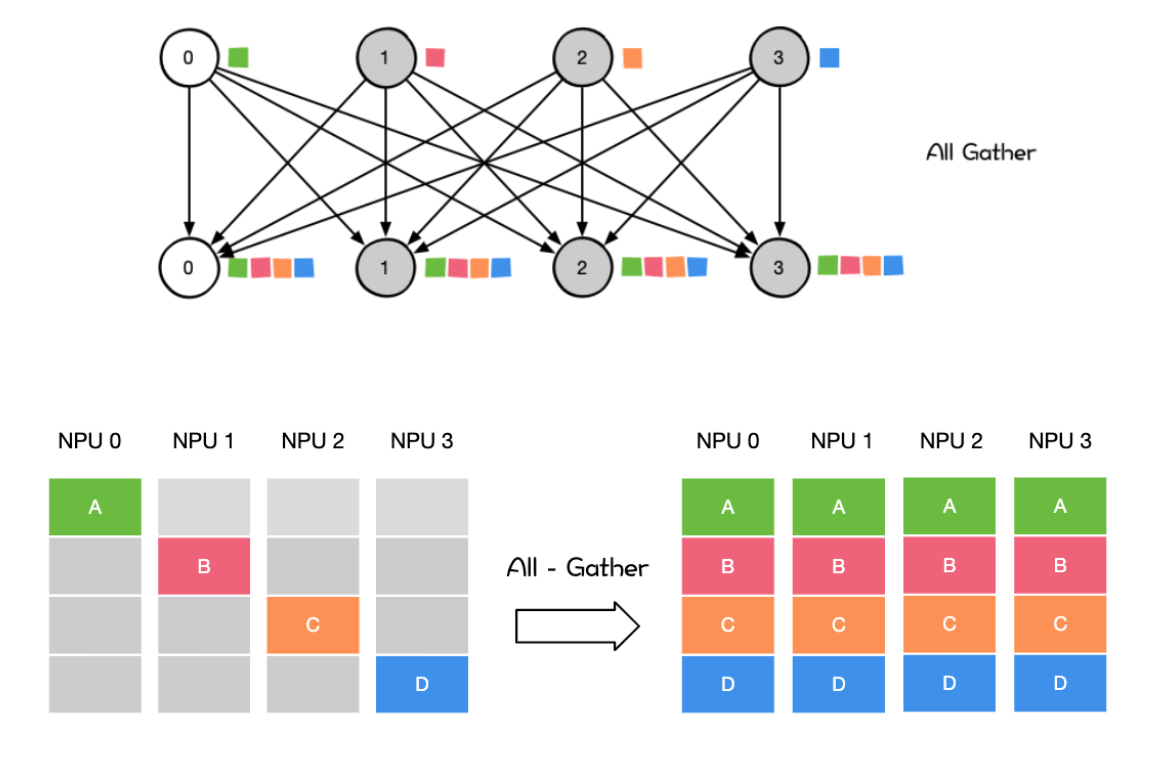
用法
- 在专家并行、张量并行、序列并行中大量地使用 AII Gather 对权重和梯度参数进行聚合。
- 模型并行里前向计算里的参数全同需要用 AIl Gather 把模型并行步,里将切分到不同的 GPU上的参数全同步到一张 GPU 上才能进行前向计算。
-
Reduce Scatter操作会将个节点的输入先进行求和,然后在第0维度按卡数切分,将数据分发到对应的卡上。
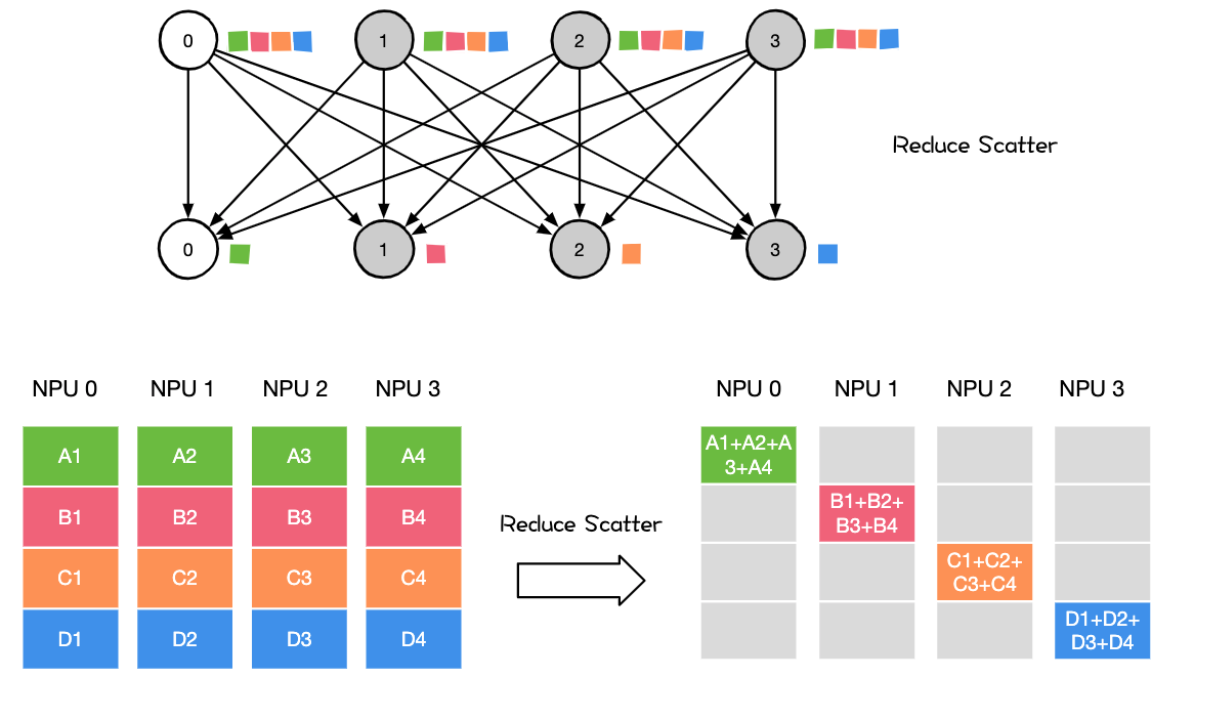
**用法 ** 可应用于数据并行 DP 和模型并行MP
- 数据并行 AlReduce 里的 Reduce Scatter,AlGather 组合里的 Reduce Scatter操作
- 模型并行前向 AIIGather 后的反向计算 Reduce Scatter
-
ALL to all 将节点i的发送缓冲区中的第j块数据发送给节点j,节点j将接收到的来自节点的数据块放在自身接收缓冲区的第i块位置
对All-Gather的扩展,但不同的节点向某一节点收集到的数据是不同的。
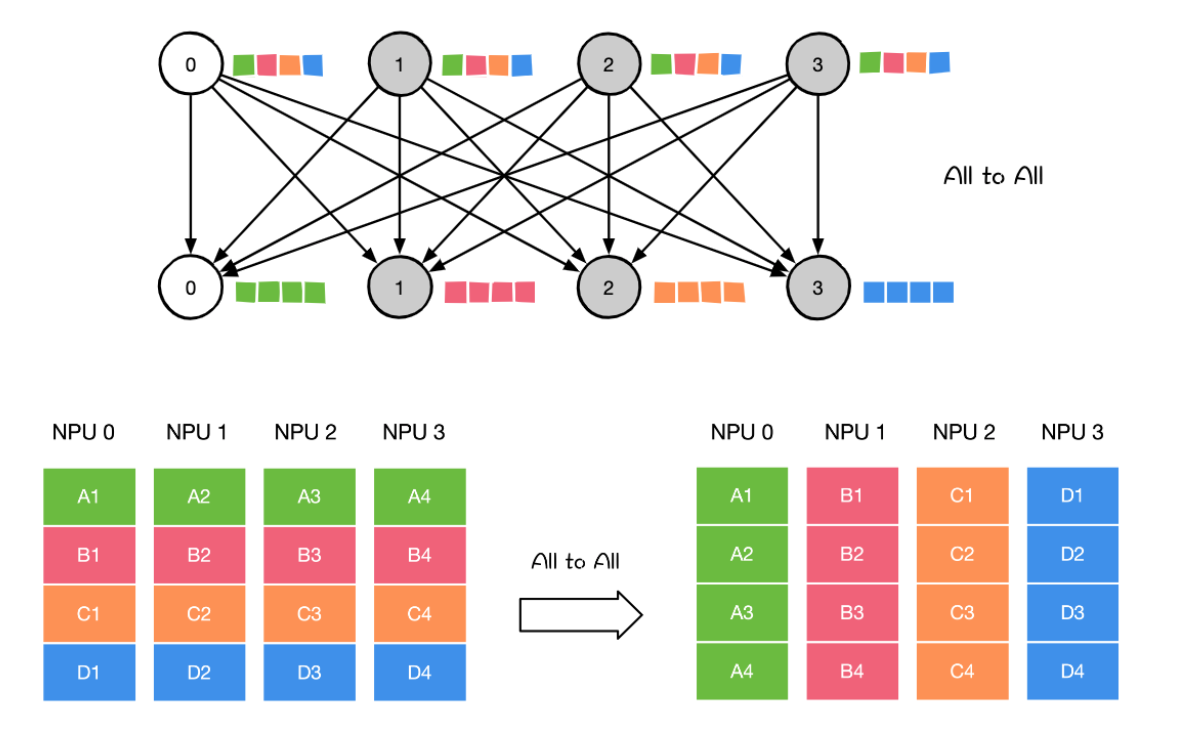
**用法 **
- 应用于模型并行中的 TP/SP/EP
- 模型并行里的矩阵转置
- DP 到模型并行的矩阵转置
通信域 Rank
MPI 通信在通信域控制和维护下进行,所有 MPI 通信任务都直接或间接用到通信域这一参数,对通信域的重组和划分可以方便实现任务的划分
通信域(communicator)
是一个综合的通信概念。其包括上下文(context),进程组(group),虚拟处理器拓扑(topology)。其中进程组是比较重要的概念,表示通信域中所有进程的集合。一个通信域对应一个进程组。
什么是进程与进程组
- 每个进程客观上唯一的(一个进程对应一个 Process lD)
- 同一个进程可以属于多个进程组(每个进程在不同进程组中有个各自 RankID)
- 同一个进程可以属于不同的进程组(PID),因此也可以属于不同的通信域
通信域与进程之间的关系
-
同一个进程,可以属于不同通信域
-
同一个进程,可以同时参与不同通信域的通信,互不干扰。
group: 进程组,一个分布式任务对应一个进程组,一般就是所有卡都在一个组里
world size:全局的并行数,一般情况下等于总的卡数 也有可能一个进程控制几张卡
node: 节点,可以是一台机器,或者一个容器,节点内包含多个GPU
rank(global rank): 整个分布式训练任务内的进程序号
local rank:每个node内部的相对进程序号
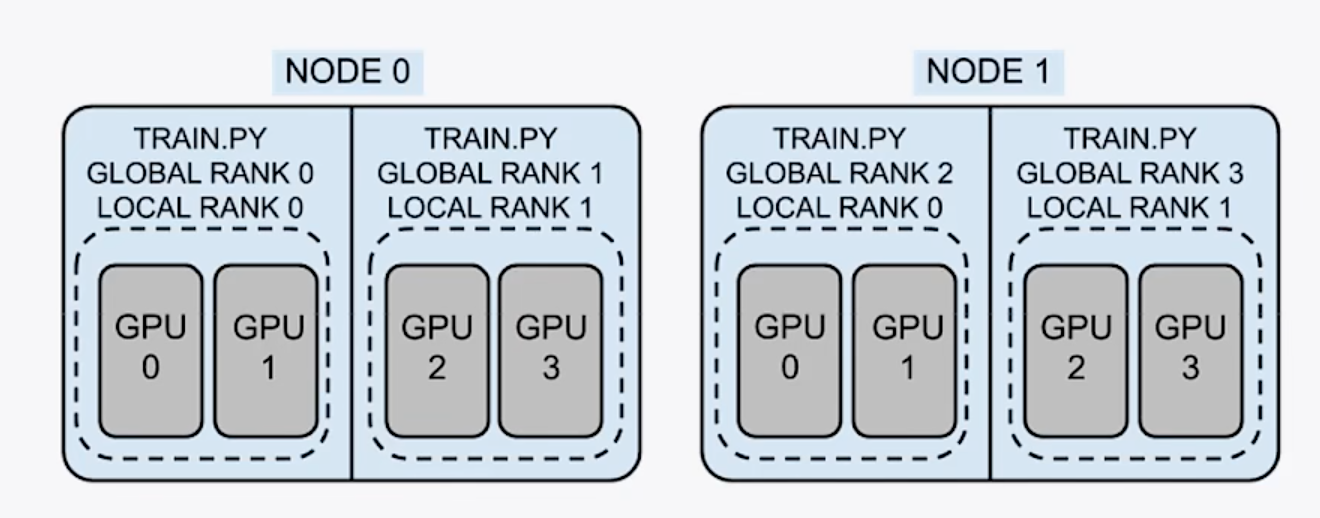
2机4卡分布式训练 node=2,world size=4,每个进程占用两个GPU
分布式训练集群
why
训练数据规模和单步计算量和模型相关相对固定,
- \[\mathrm{训练耗时}\;=\;\mathrm{训练数据规模}\;\ast\;\mathrm{单步计算量}/\mathrm{计算速率}\]
- \[\mathrm{计算速率}\;=\;\mathrm{单设备计算速率}(\mathrm{摩尔定律或者算法优化})\ast\mathrm{设备数}\;\ast\;\mathrm{多设备并行效率}(\mathrm{加速比})\]
但是可以提高计算速率
- 混合精度,算子融合,梯度累加 (单设备计算速率)
- 服务器架构,通信拓扑优化 (设备数)
- 数据并行 模型并行 流水并行 (加速比)
服务器架构
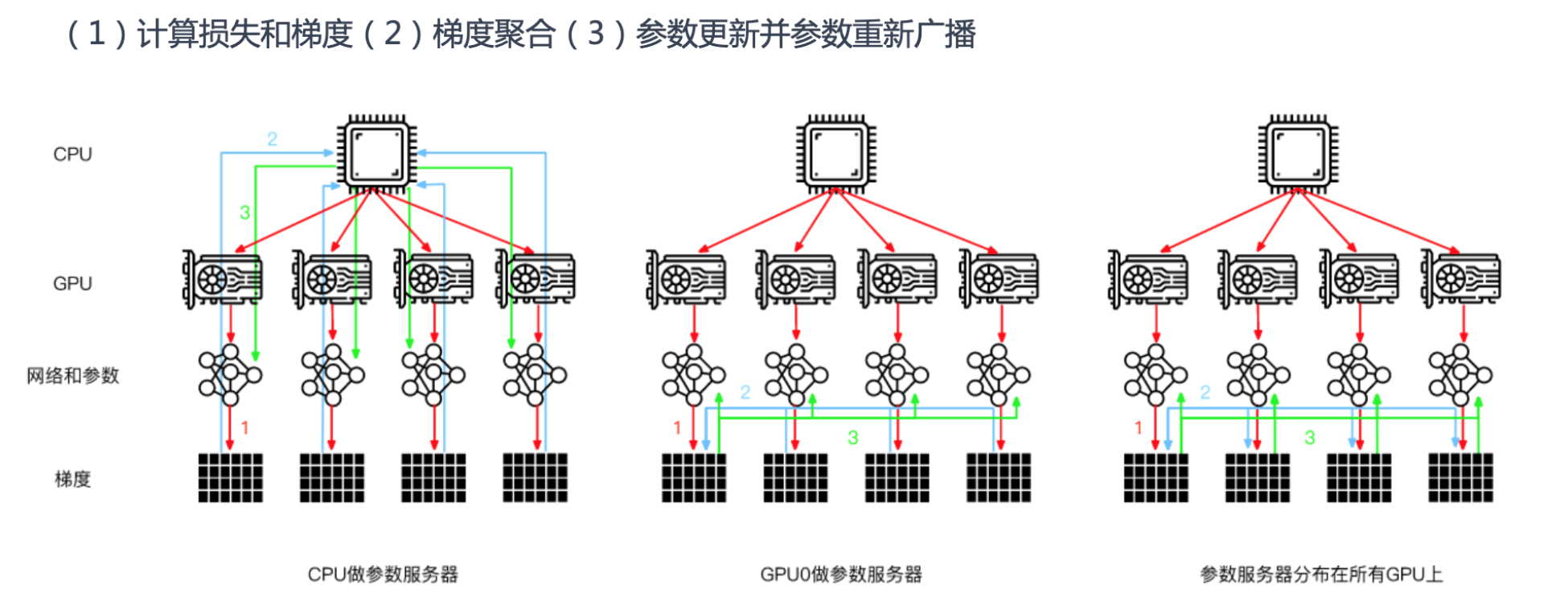
参数服务器
都是这三步:计算损失和梯度,梯度聚合, 参数更新并参数重新广播
- CPU作为参数服务器,CPU下发网络模型和参数给GPU卡计算损失和梯度,在CPU做梯度聚合,把所有参数更新到GPU卡
- GPU0作为参数服务器,CPU下发指令让每个GPU计算损失和梯度,在GPU0上梯度聚合,把所有参数更新到GPU卡
- 常用是第三种,CPU下发指令让每个GPU计算损失和梯度,通过通讯分布式并行梯度聚合,把所有参数更新到GPU卡
分布式训练系统
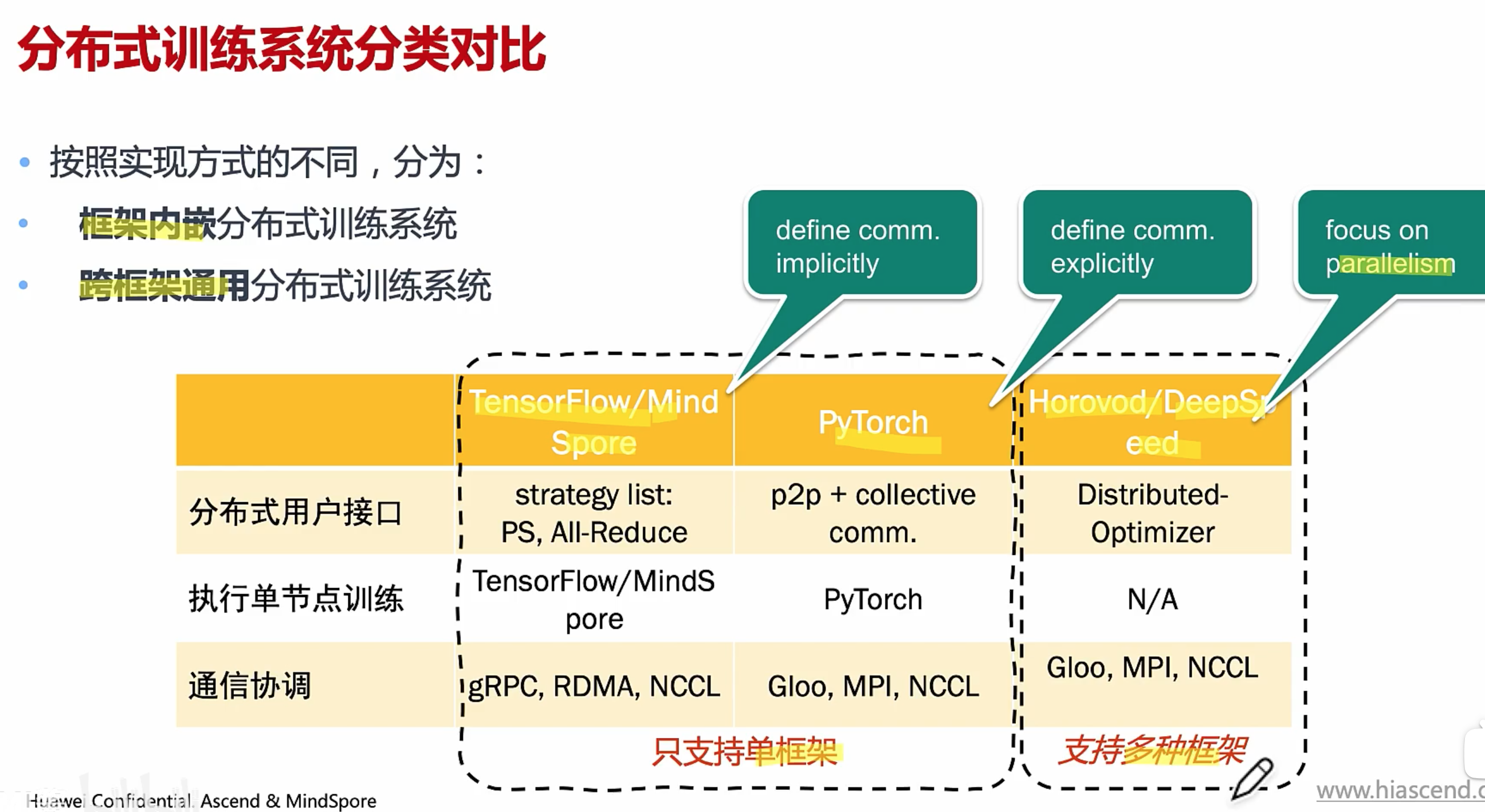
https://github.com/chenzomi12/DeepLearningSystem/blob/main/061FW_AICluster/05.system.pdf
硬件
软件
-
分布式用户接口
用户通过接口,实现模型的分布化
-
执行单节点训练
产生本地执行的逻辑
-
通信协调
实现多节点之间的通信协调
意义:提供易于使用,高效率的分布式训练
PyTorch 分布式训练通信依赖torch.distributed模块实现
- Point-2-Point 供send和recv 语义,用于任务间通信
- Collective Communication:提供scatter/broadcast/gather/reduce/all reduce/all gather 通信操作
不同 backend 在提供的通信语义上具有一定的差异性
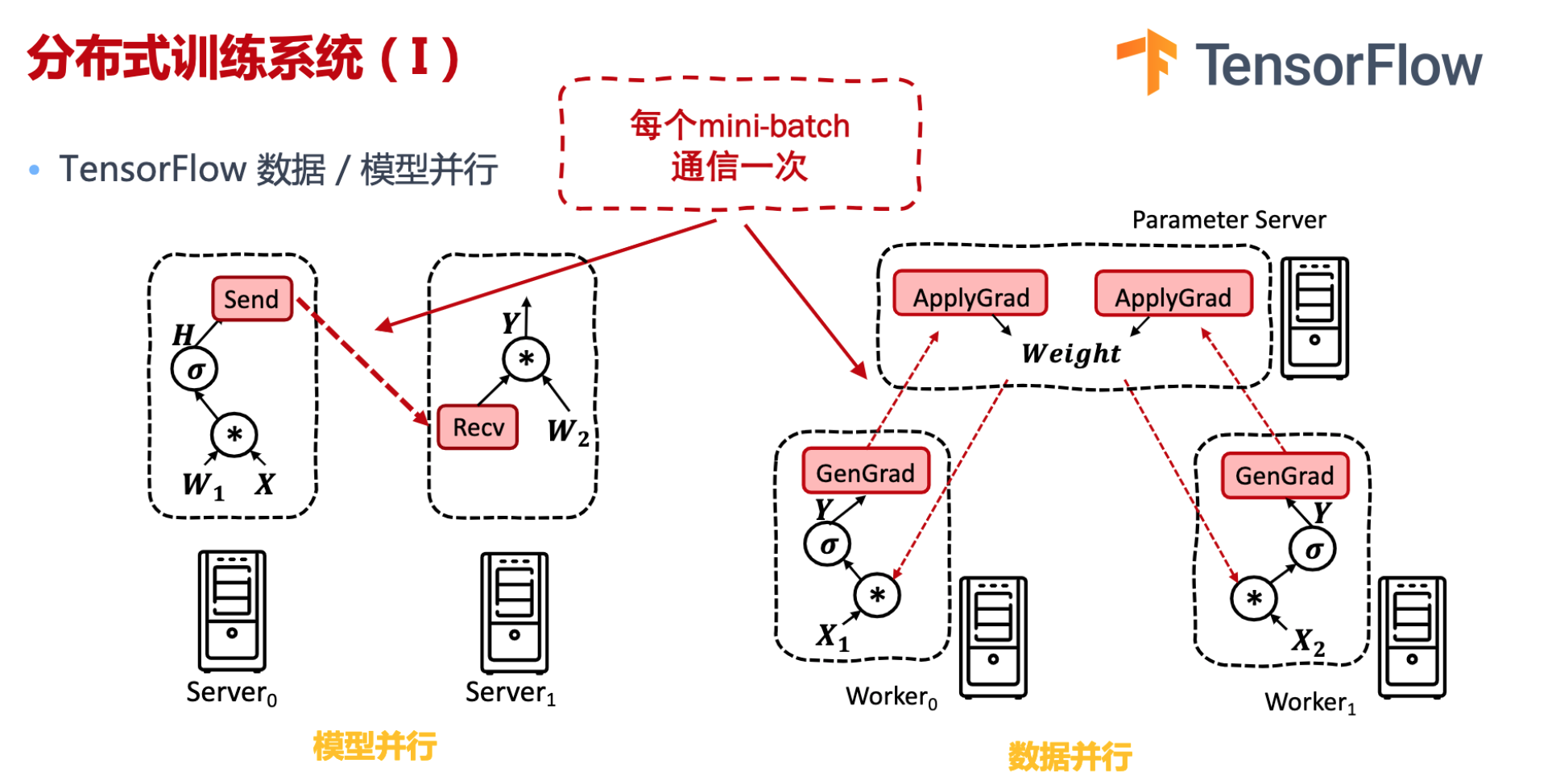
Tensorflow:模型并行主要是计算图分布式切分,算子通信。数据并行的数据包括(模型的参数、梯度等)
Pytorch: 支持点对点(同步异步通信),集合通信 ,非常灵活。
组网互联
- 传统组网 传统方案中(<2018),GPU 互联采用 PCle,服务器节点间互联采用以太网 Ethernet.
- 现在大模型数据、参数量极大。服务器不同计算节点间,对超高带宽、超低延迟和超高可靠性的互联技术要求高。
目前趋势
- Die间,多芯粒互联技术和合封技术正加速崛起。(XPU 内部)
- 片间,由 PCle 向多节点无损网络演进 (XPU 之间,节点之间)
- 集群间,互联方式从 TCP/IP 向 RDMA 架构转变
DIE间
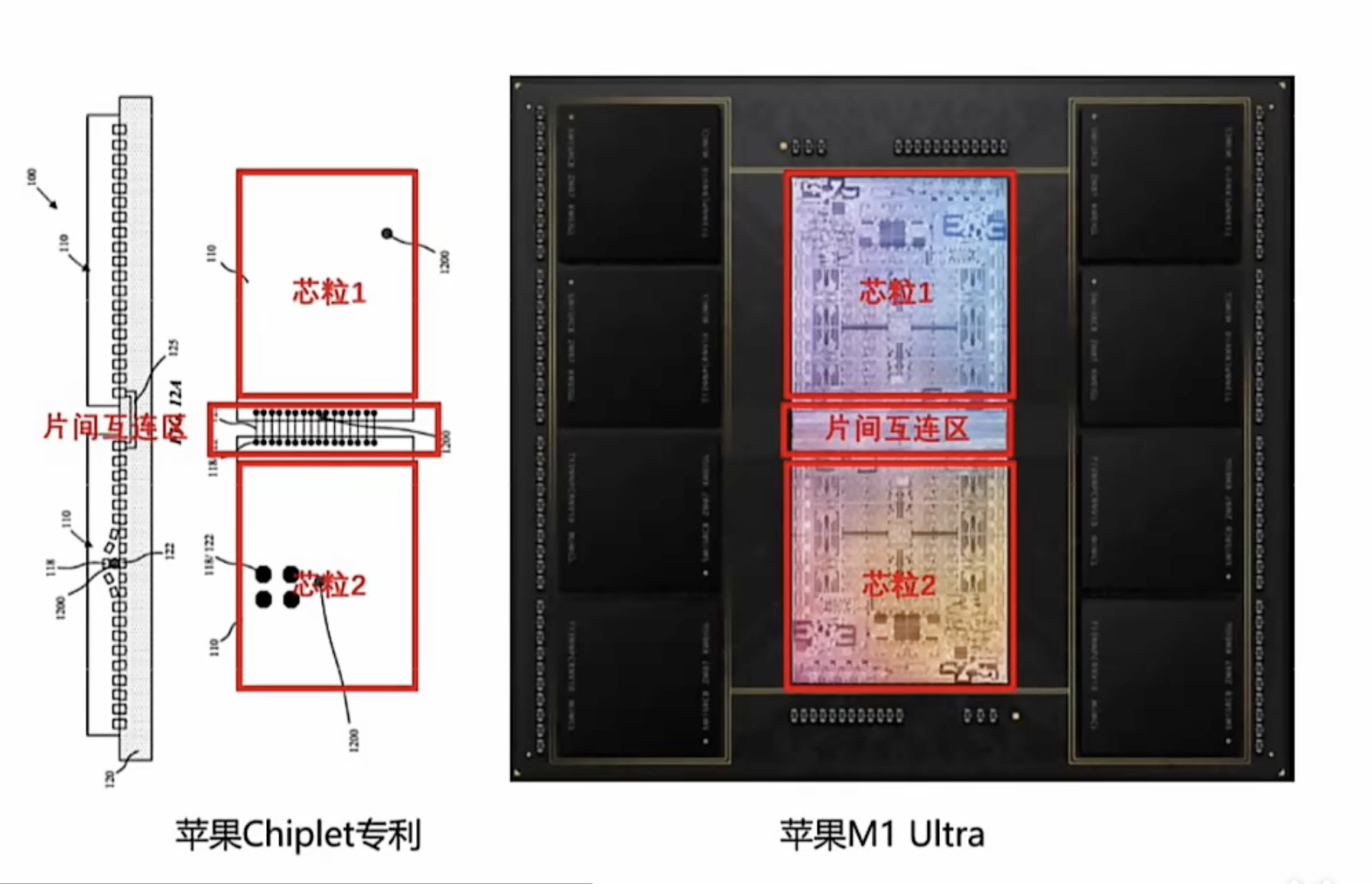
SoC 架构转向 Chilet 异构
大模型对算力需求持续增长,在工艺发展较慢情况下,继续提升算力,A芯片从传统 SoC 架构转向 Chiplet 异构。除了芯粒数量不断增加,为有效发挥片内算力,也引发芯粒间互联挑战。
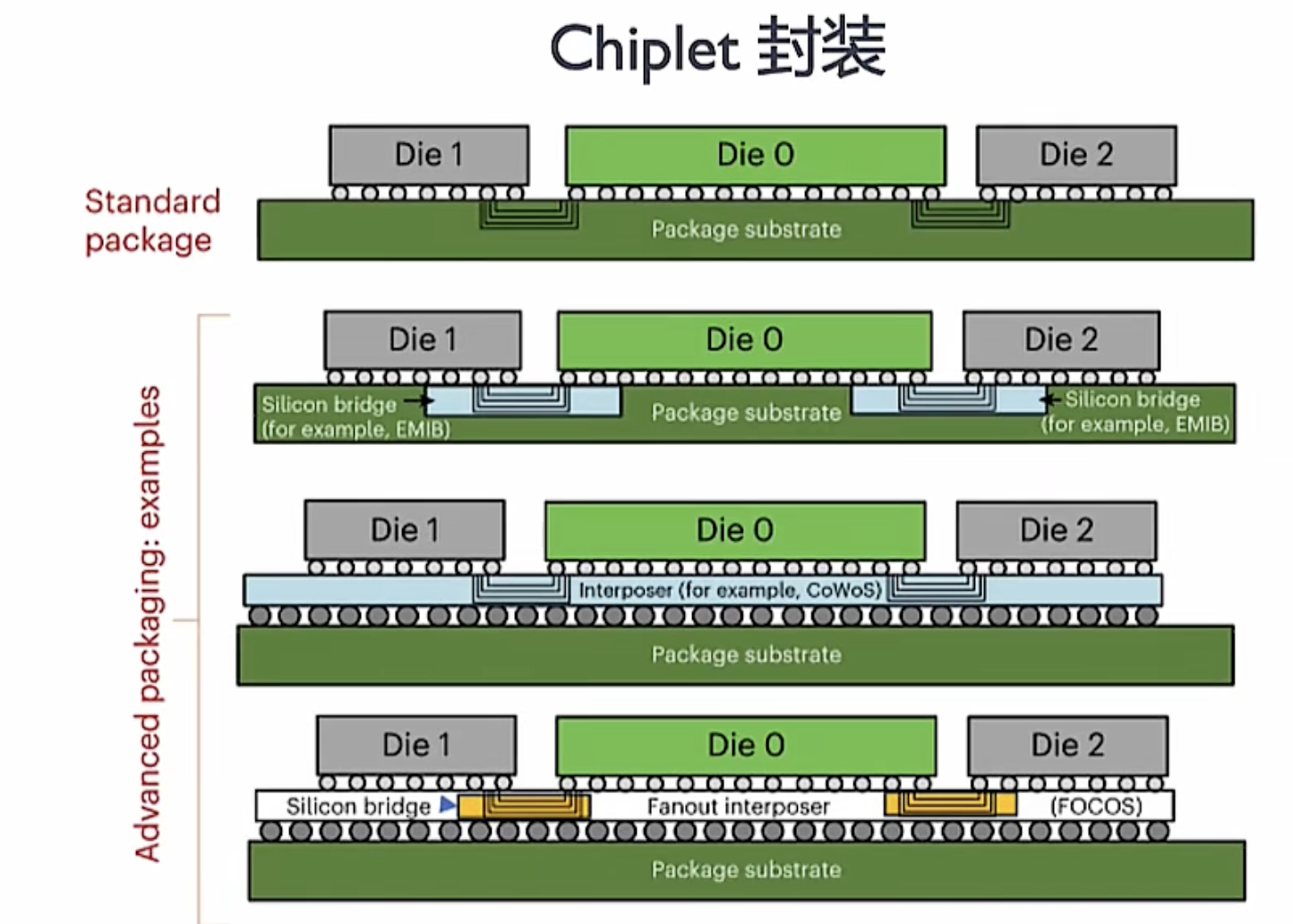
随芯片系统变得越来越复杂,不同功能单元(芯粒),产生大量数据流需要专用的互联接口来实现数据的传输和调度。这种专用互联接口简称为 Die2Die接口,负责在不同芯粒间传输数据,协调调度数据流,确保芯片系统高效运行。
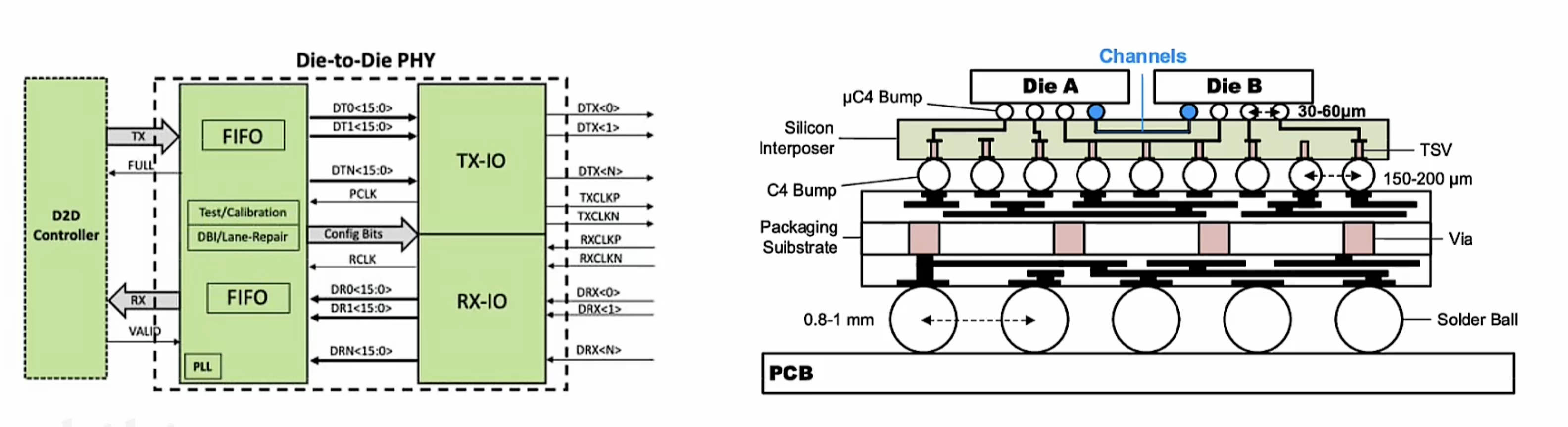
IO DIE
- 专用互联芯粒,作为数据传输和调度核心,整合存储单元。Die2Die 接口和多种高速接口,通过自定义算法实现数据流和信息流的分发调度IO Die
- 通常适用于 2.5D Chiplet 芯片架构。
Base Die
- 当芯片性能继续增高,平面维度也很难满足 Die间互次需求。于是,互联方式逐渐从 2D to 3D 垂直迭代。
- 芯片行业开始基于芯粒 3D 堆叠方式,进一步提升芯片算力密度
- 集成 die2die 3D 接口,Cache 等模块,实现更快垂直互联,减少片内存储延迟和功耗.
NPU之间互联
一般架构
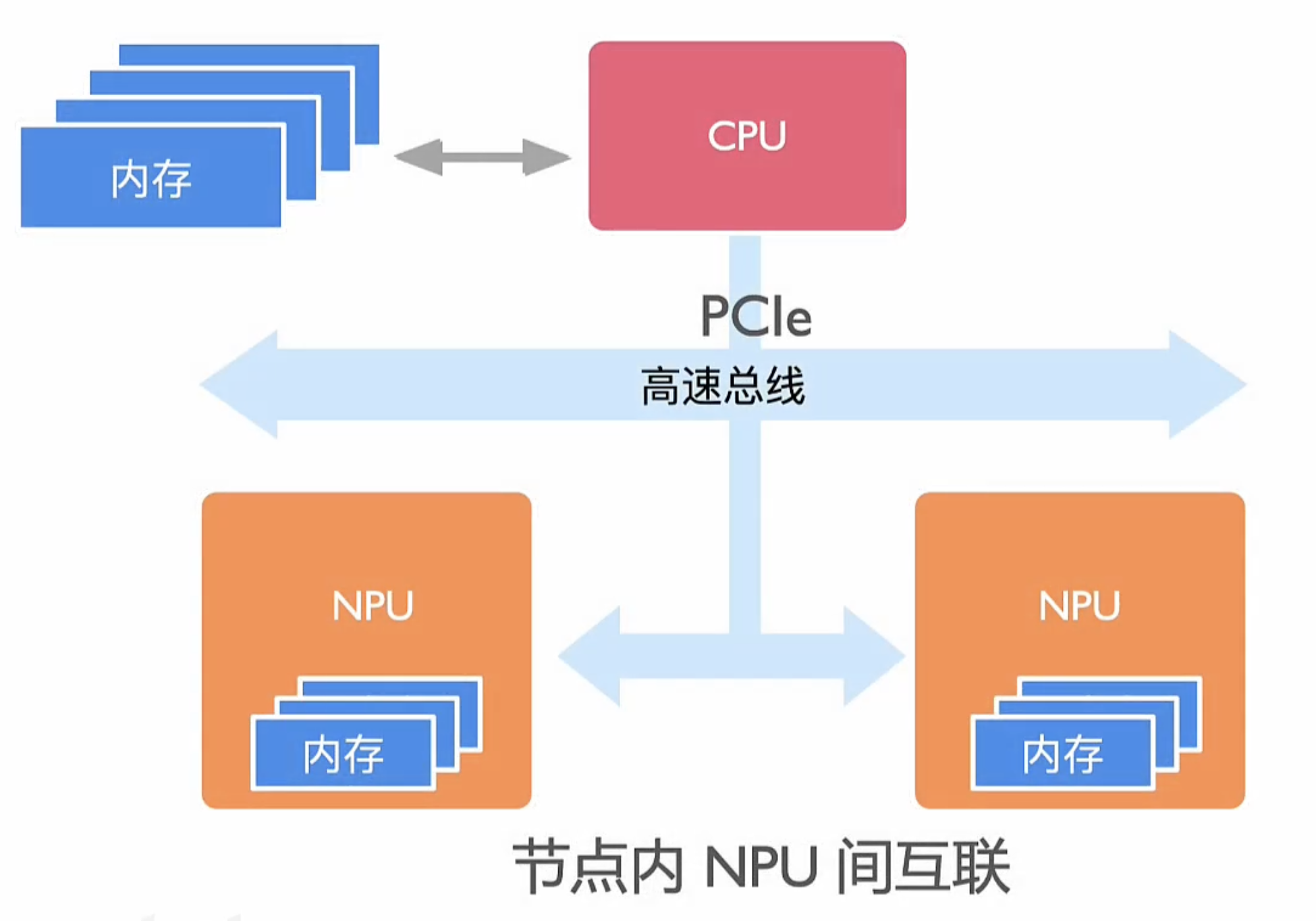
节点内 NPU 间互联
- PCle
- 共享内存
- 私有协议直连(NVlink 多节点无损网络协议)
发展趋势
-
CPU host (DDR),NPU Devices(HBM ),其各自有本地内存;
- 在 AI集群下,NPU 之间需要高速交换数据,为了保证通信性能NPU 之间设计专用高速互联通道
- AI计算的发展逐渐让 H-D 间由传统 PCle 向多节点无损网络演进;
NVLink
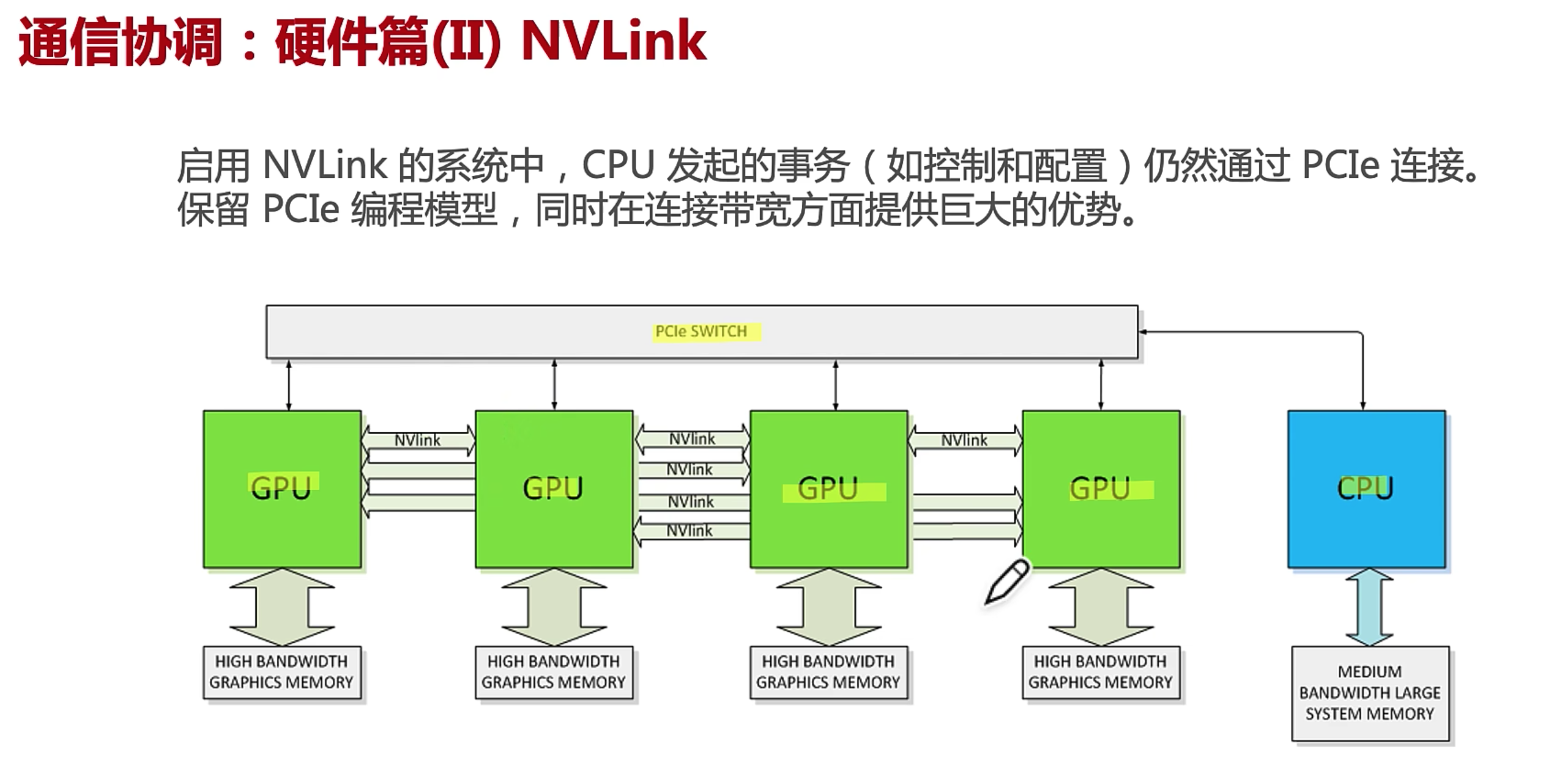
NVLink 设计目的,突破 PCle屏障,实现 GPU2GPU 及 CPU2GPU 片间高效数据交互。NVLink 由软件协议组成,通过 PC 板上多对导线实现,让 GPU2GPU 间高速度收发显存数据。
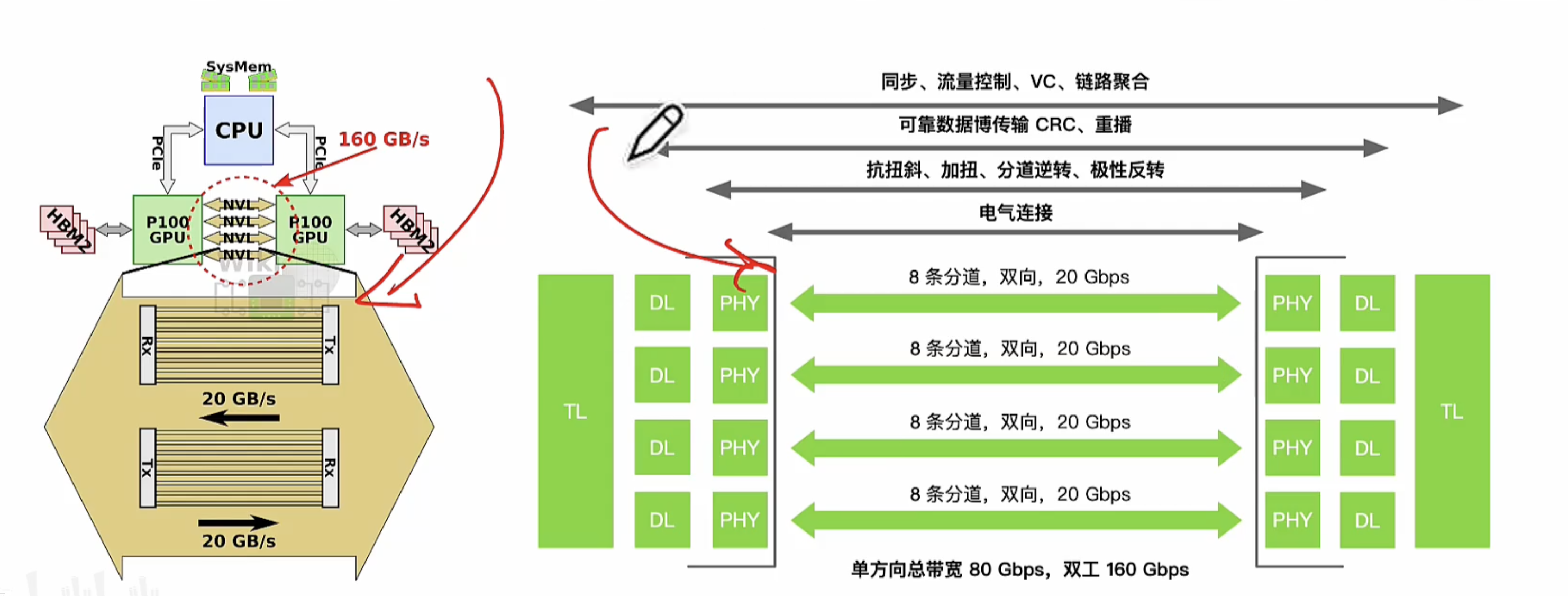
通过 NVLink GPU 间互联链路采用点对点私有互联协议,绕开 PCle 总线直连多个 GPU 并组建成 GPU 计算阵列。
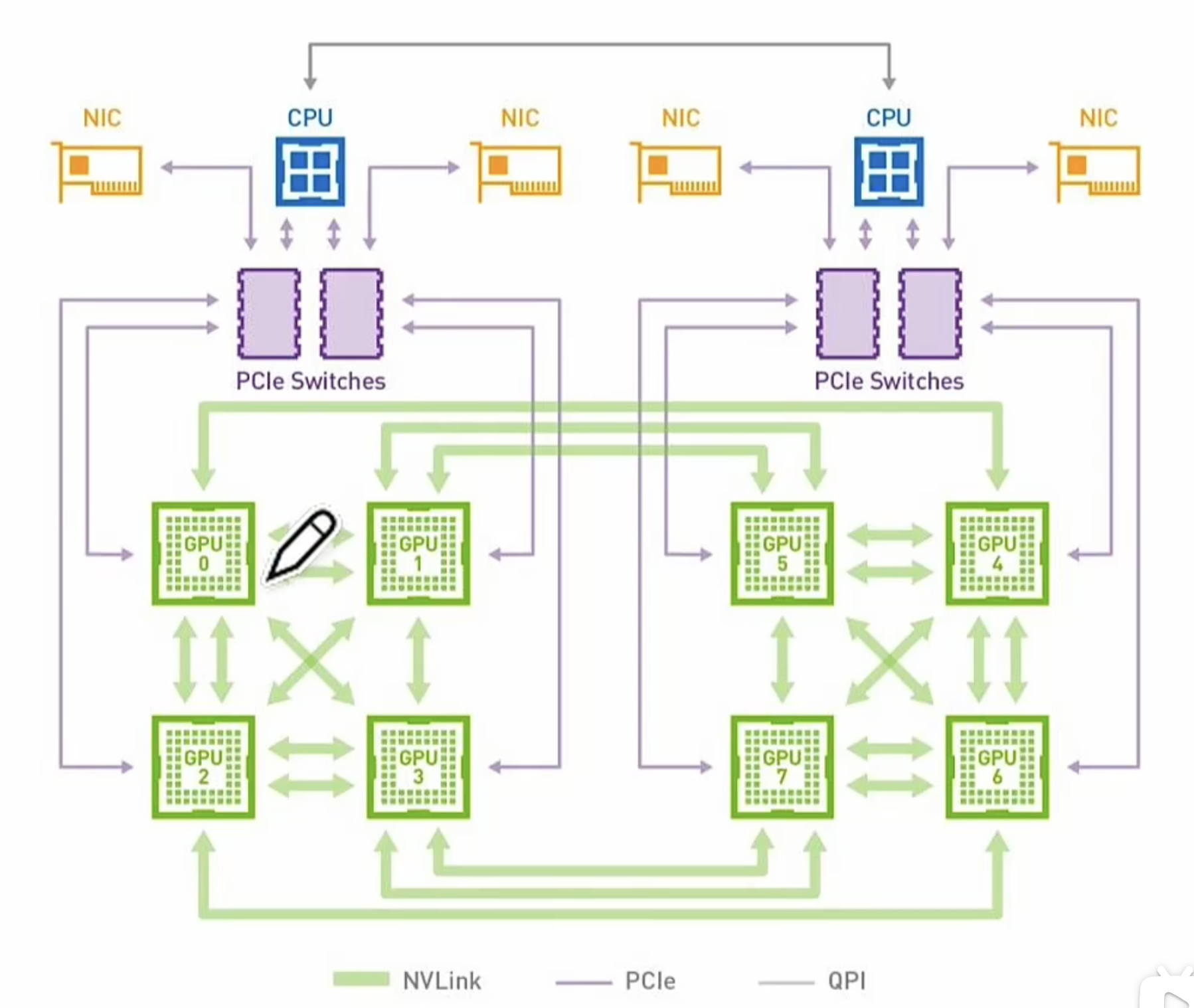
NVSwitch
NVSwitch 基于 NVLink 组成可实现多节点 GPU 直联。不但绕开服务器内 PCle 互联,还绕开服务器间以太网通讯,降低GPU 通讯延迟,增强 AI计算中数据同步效率。
NVSwitch 基于无损数据交间互联网络,并非一颗简单芯,而是一套复杂系统,需要系统的片间互联协议算法和匹配产品
NVIDIA DGX
NVIDIA DGX其系统中8个 GPU 上 NVLink 通过 NVSwitch 芯片共享快速、直接连接,共同组成了一个 NVLink 网络,使服务器中的每一个 GPU 都成为 AI 集群中一部分。
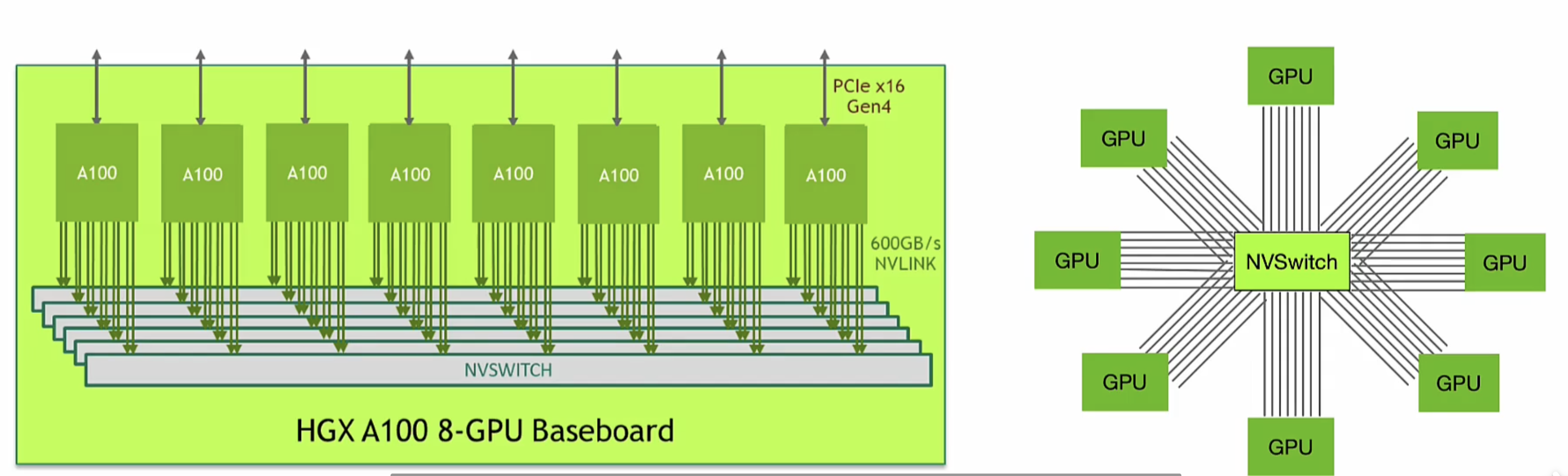
应该根据具体的服务器的形态和服务器的网络的拓扑去配置对应的分布式并行的策略或者去写对应的一个集合通讯的算法
片内互联挑战与技术壁垒
-
片间接口复杂性;
如何利用高速片间接口,使其满足芯片直连需求,又可完成设备交换功能
-
交换算法扩展性:
如何利用已有计算体系实现 AI集群内高速数据传输需求
-
网络协议适配性
如何构建覆盖 CPU、NPU、片内存储领域的网络协议,无缝适配已有硬件设备或上层软件系统。
节点间互联
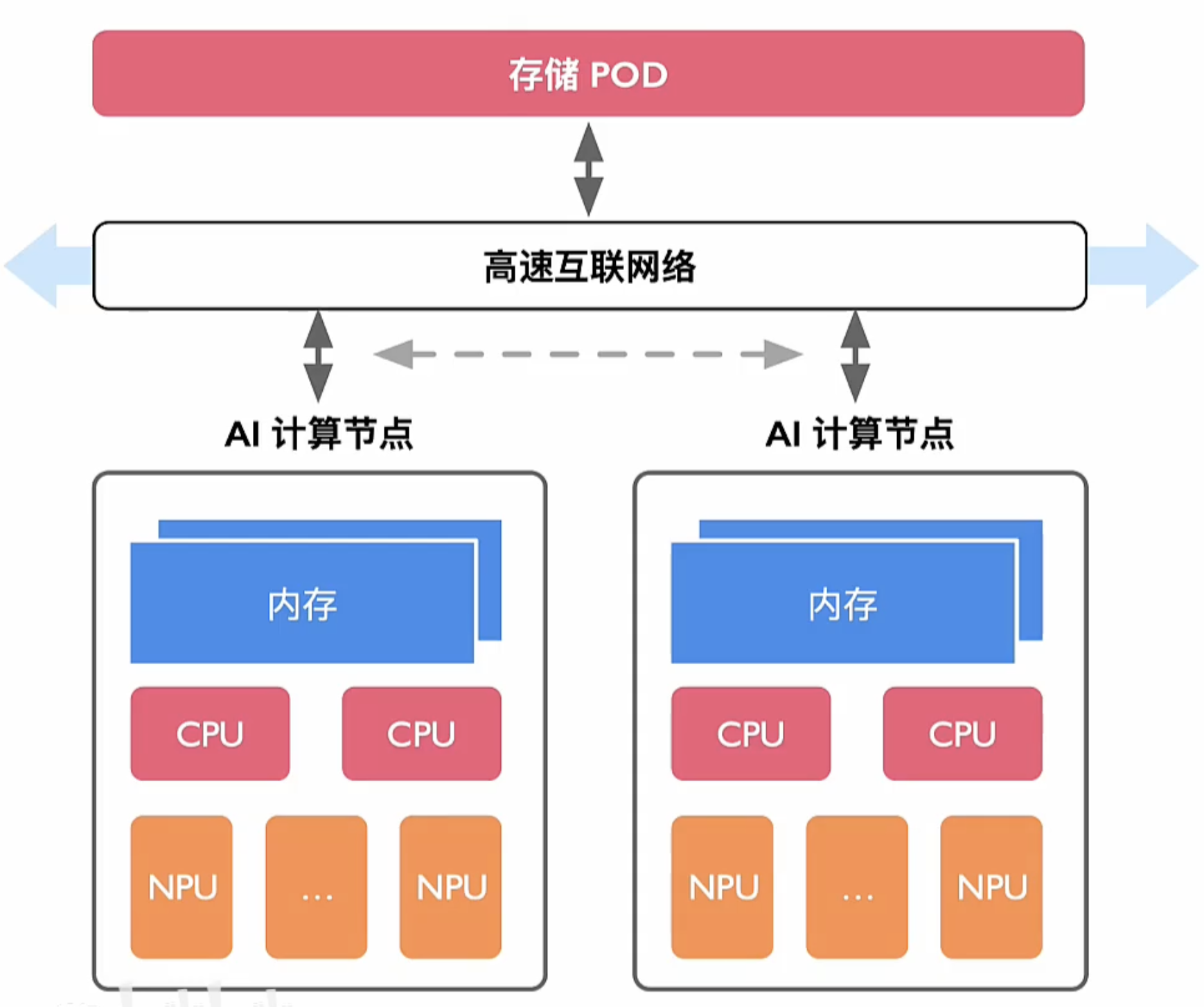
计算节点间
- 通信TCP/IP 网络
- RDMA 网络
- InfiniBand
- ROCEI
- iWARP
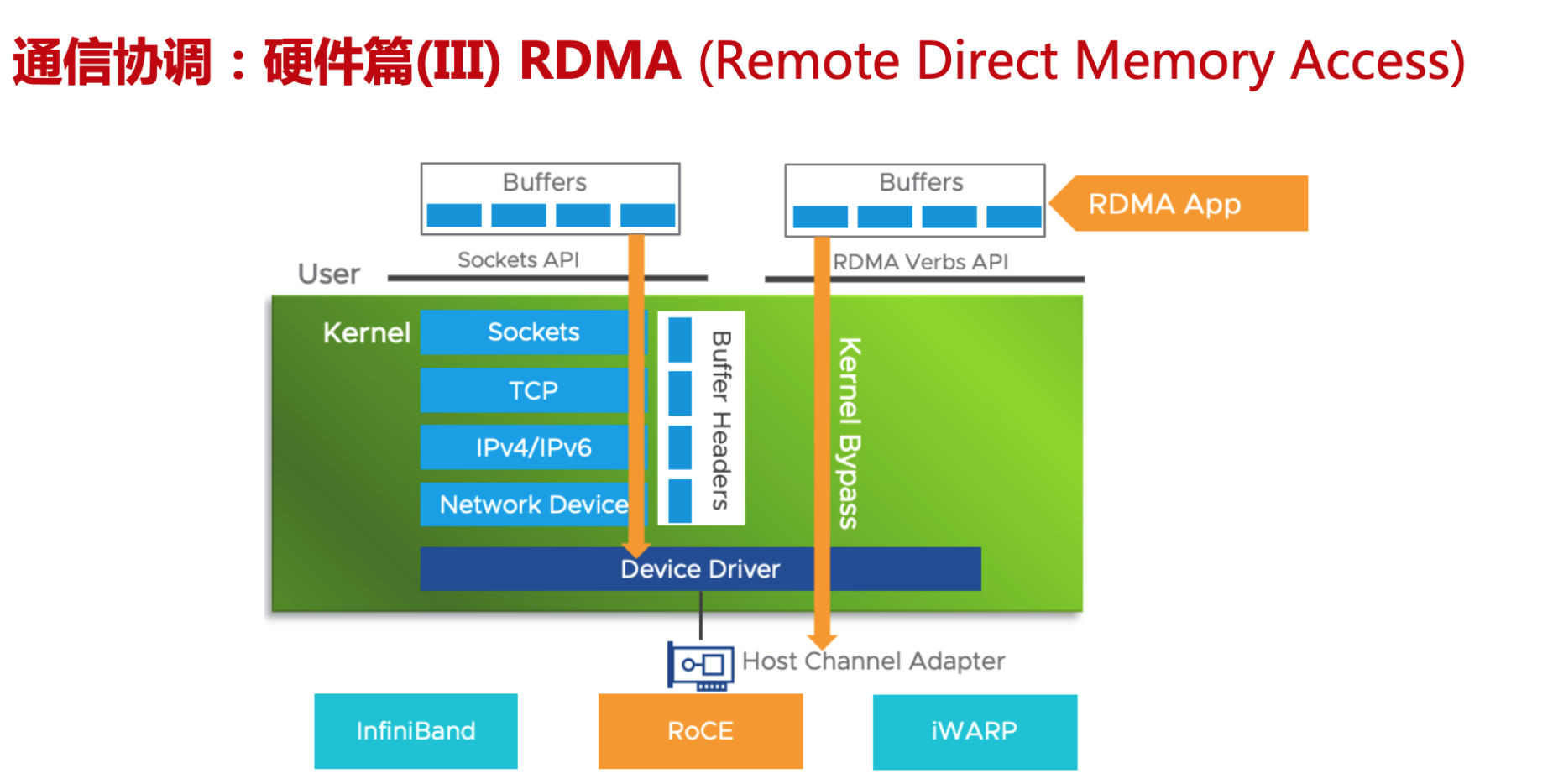
万卡集群已经成为大模型训练标配,面对大模型规模庞大的数据交互,传统TCP/P 协议逐渐被RDMA (Remote Direct Memory Access) 技术全称远程直接内存访问技术取代。解决网络传输中服务器端数据处理的延迟而产生的。
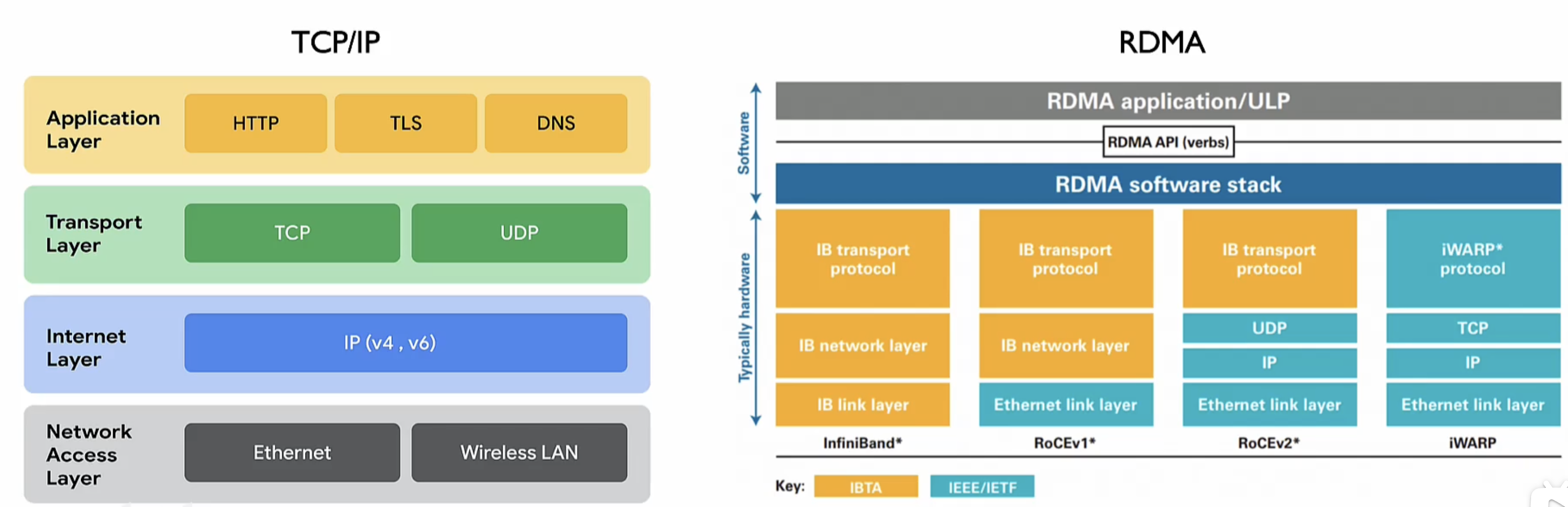
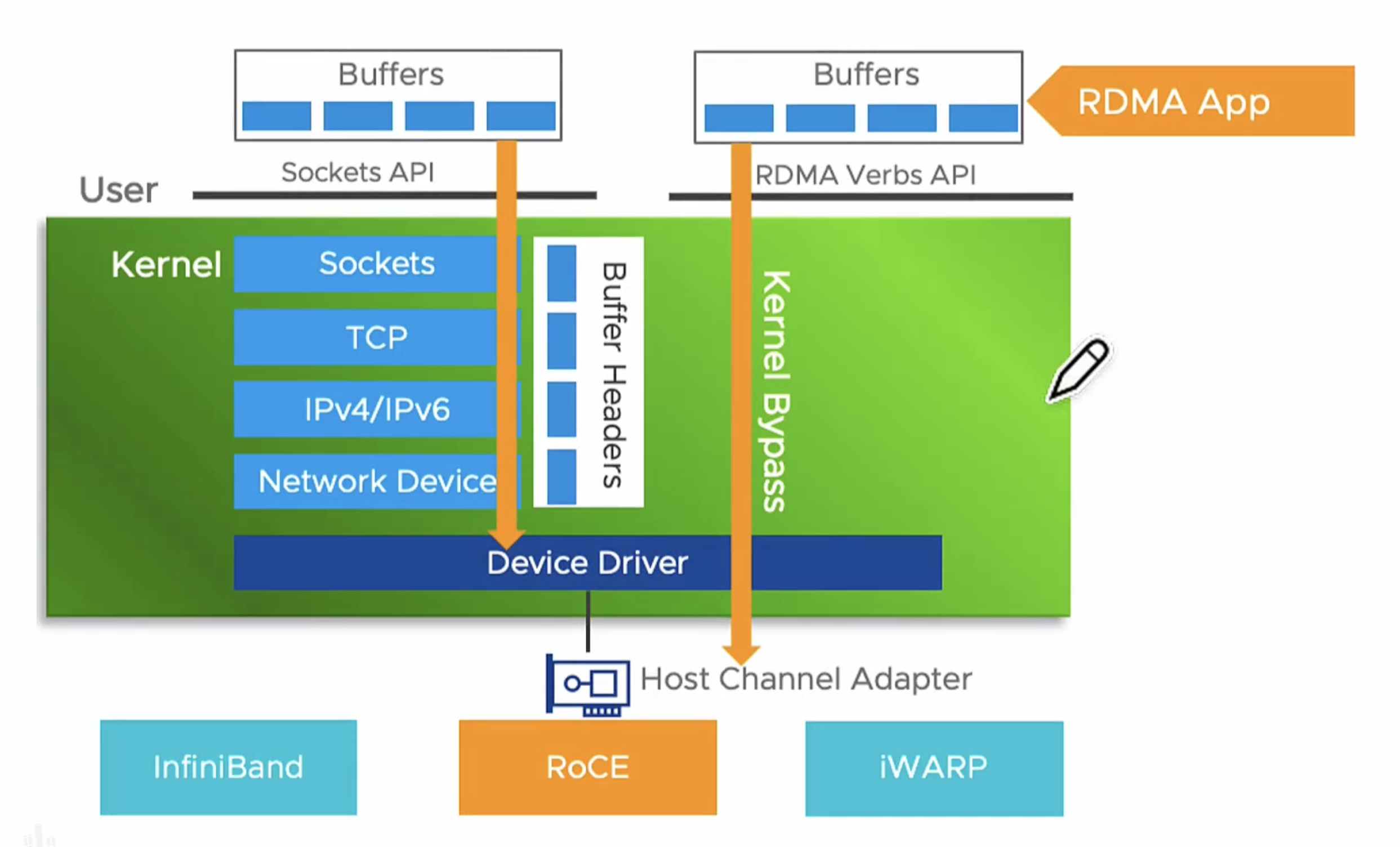
没有经过OS层,直接从总线去获取device 的一个具体内存,然后通过网络进行传输
| InfiniBand (NVIDIA 私有) | iWARP | RoCE 性价比 | |
|---|---|---|---|
| 性能 | 最好 | 稍差(受TCP影响) | 与 InfiniBand 相当 |
| 成本 | 高 | 中 | 低 |
| 稳定性 | 好 | 差 | 较好 |
| 交换机 | IB交换机 | 以太网交换机 | 以太网交换机(可利用现有的) |
RDMA通过网络将数据从一个系统快速移动到另一个系统中,而不需要消耗计算机的处理能力。它消除了内存拷贝和上下文切换的开销,因而能解放内存带宽和 CPU 周期用于提升系统的整体性能。阿里RDMA
先看看最常见的 Kernel TCP,其收数据的流程主要要经过以下阶段:
- 网卡驱动从内核分配 dma buffer,填入收队列
- 网卡收到数据包,发起 DMA,写入收队列中的 dma buffer
- 网卡产生中断
- 网卡驱动查看收队列,取出 dma buffer,交给协议栈
- 协议栈处理报文
- 操作系统通知用户态程序有可读事件
- 用户态程序准备 buffer,发起系统调用
- 内核拷贝数据至用户态程序的 buffer 中
- 系统调用结束
可以发现,上述流程有三次上下文切换(中断上下文切换、用户态与内核态上下文切换),有一次内存拷贝。虽然内核有一些优化手段,比如通过 NAPI 机制减少中断数量,但是在高性能场景下, Kernel TCP 的延迟和吞吐的表现依然不佳。
使用 RDMA 技术后,收数据的主要流程变为(以send/recv为例):
- 用户态程序分配 buffer,填入收队列
- 网卡收到数据包,发起 DMA,写入收队列中的 buffer
- 网卡产生完成事件(可以不产生中断)
- 用户态程序 polling 完成事件
- 用户态程序处理 buffer
上述流程没有上下文切换,没有数据拷贝,没有协议栈的处理逻辑(卸载到了RDMA网卡内),也没有内核的参与。CPU 可以专注处理数据和业务逻辑,不用花大量的 cycles 去处理协议栈和内存拷贝。
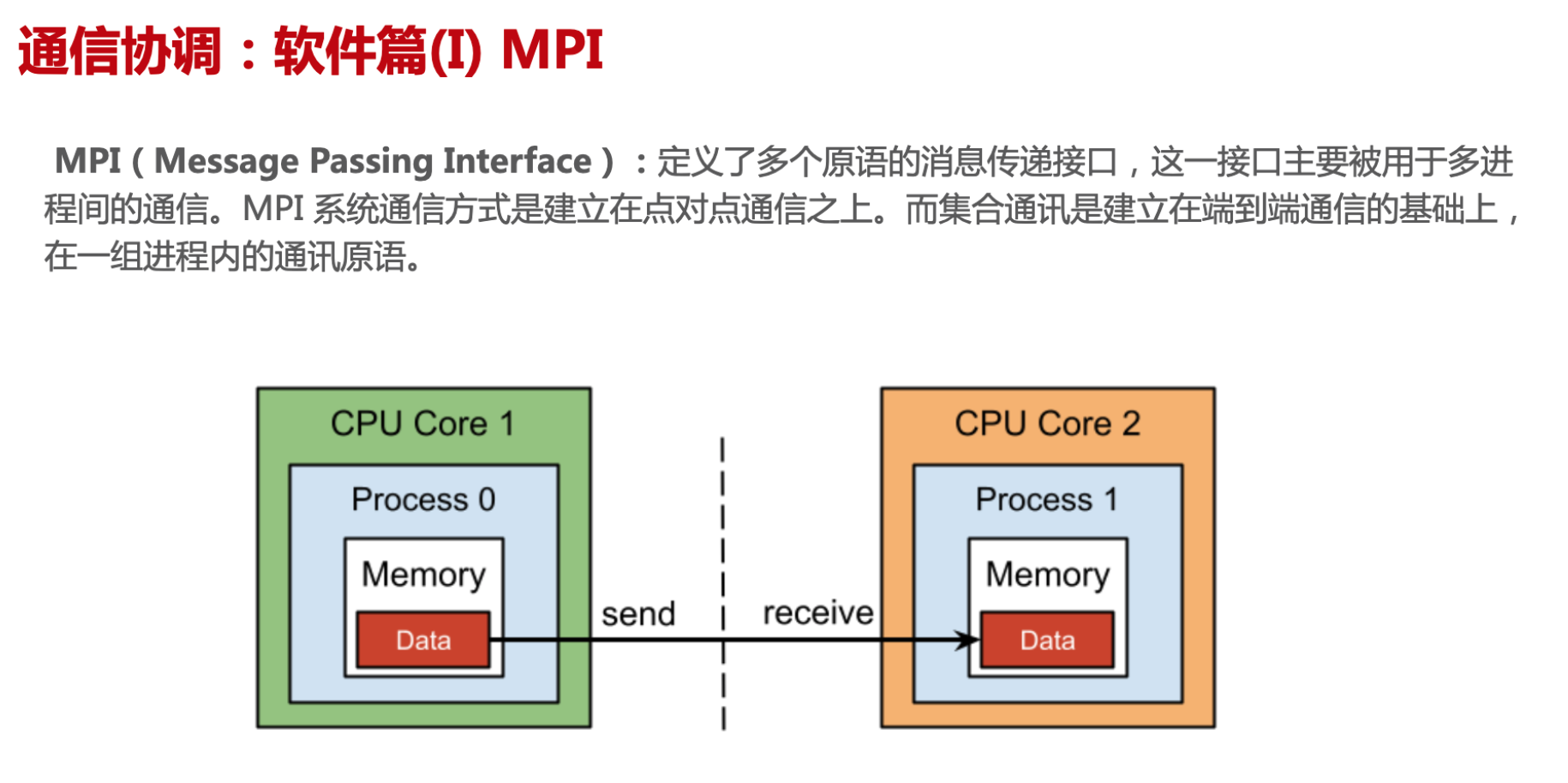
MPI
MPI P2P 概念
MPI
MPI 是集合通信库 XCCL 的基础,包含了很多基本概念和 基础 API 定义,是了解 NV NCCL 和 Huawei HCCL 的最好入门
MPI(message passing interface)跨语言的通讯协议 or 范式标准,提供了应用程序接口 API,包括协议和通信语义。支持语义丰富的消息通信机制,包括点对点、组播和多播模式。(基于TCP/IP之上去实现)
MPI标准规定了基于消息传递的并行编程 API的调用规范和语义,不同的实现(如 mpich / openmpi)采用不同优化策略。
P2P
点对点通信:两个进程间通信,用于控制同步或者数据传输,如 MPI_Send 和 MPI_Recv。
通信方式:两进程 Process 计算结束后,相互交换消息前需要请求访问,再进行下一阶段计算
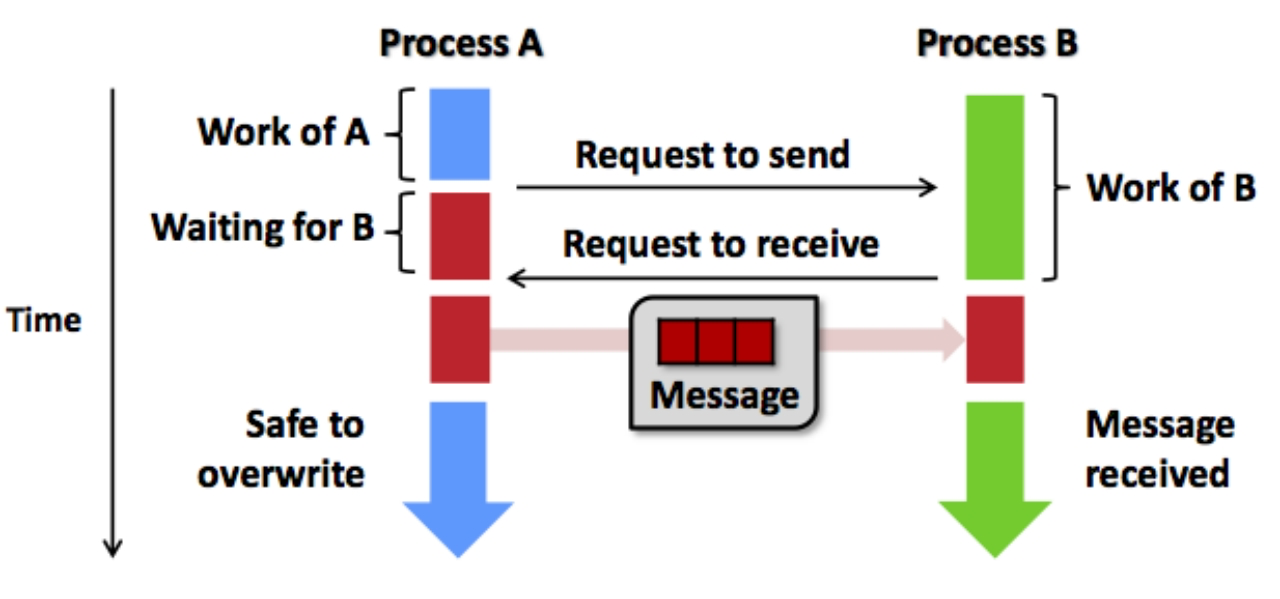
点对点通信分为同步(阻塞blocking)和异步(非阻塞non-blocking)。
同步阻塞:
- MPI_Send 返回意味进程发送数据结束,进程缓冲可以重用/覆盖,但不代表 Receiver 收到数据。
- MPI_Recv 返回意味着数据已经接收到进程的缓冲区,可以使用。
异步非阻塞:
- 意义在于进程 send / receive 操作马上返回,继续后续阶段的计算
- 当程序要求操作必须确认完成时,调用相应测试接口(e.g. MPI_Wait)阻塞等待操作完成
- 异步编程相对复杂,但使得计算和通信可以一定程度并行,降低数据同步带来的运行时开销
MPI原语
进程启动与收发数据顺序:
Broadcast
-
当 MPI 进程启动后,每个 Process 会分配唯一序号 Rank。集合通信需要指定一个协调者(e.g. Rank 0 Process,一般称为 ROOT),由其负责将数据发送给所有进程。
-
以接口 MPI_BCAST 为例,它将数据从根进程发送到所有其它进程。所有进程都调用 MPI_BCAST。虽然每个进程都调用 MPI_Bcast,但根进程负责广播数据,其它进程接收数据。
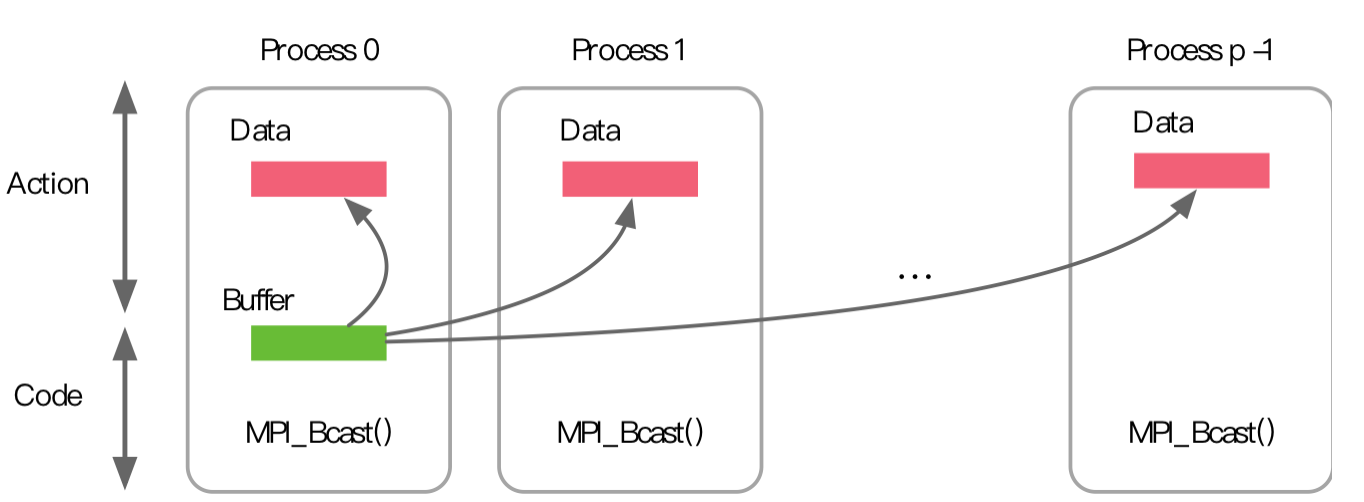
-
Gather
MPI_Gather 行为恰好相反,每个进程将数据发送给根进程
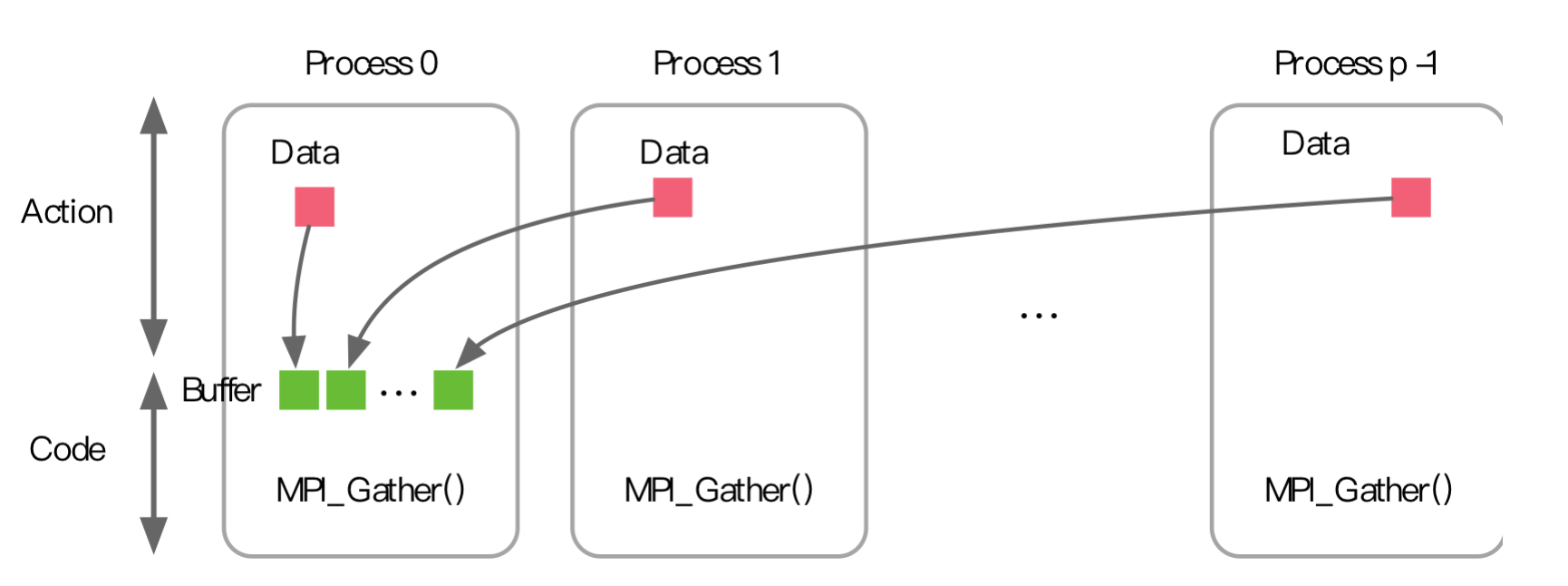
同步 Barrier
- 某些场景下,多个进程需要协调同步进入某个过程。MPI提供了同步原语例如MPI_Barrier。所有进程调用MPI_Barrier,阻塞程序直到所有进程都开始执行这个接口,然后返回。
- Barrier 作用就是让所有进程确保 MPI_Barrier 之前的工作都已完成,同步进入下一个阶段。
MPI 程序
MPI 程序编程模式为迭代式“计算 + 通信”,程序可以分为计算块和通信块
每个程序可以独立完成计算块,计算完成后进行交互(通信 or 同步)交互后后进入下一阶段计算,直到所有任务完成,程序退出。
每个程序独立完成计算后,到达交汇点,同时调用集合通信原语(Primitive)完成数据通信,然后根据结果进行后续计算。
当计算规模较大,集合通信性能非常关键,不同 MPI 实现框架有不同优化方案。实际工程应用中,往往采用更复杂拓扑结构来提升性能
任务分解
MPI框架只提供通信机制 —— 任务间同步和通信手段,与计算无关。
- 计算任务如何分解和实现,数据如何划分,任务如何合并等问题由程序开发者决定。
- MPI 框架在程序启动时为每个程序副本分配唯一 Rank ID。程序通过获取和根据 Rank 确定任务。
一个典型 MPI 程序由用户程序部分(MPI User)链接 MPI 库(MPI Interface)构成,计算任务本身的算法实现、任务分解和合并实现在用户程序部分,与MPI无关,也不受MPI限制。SO MPI 提供给开发者灵活性,实现了最小封装。
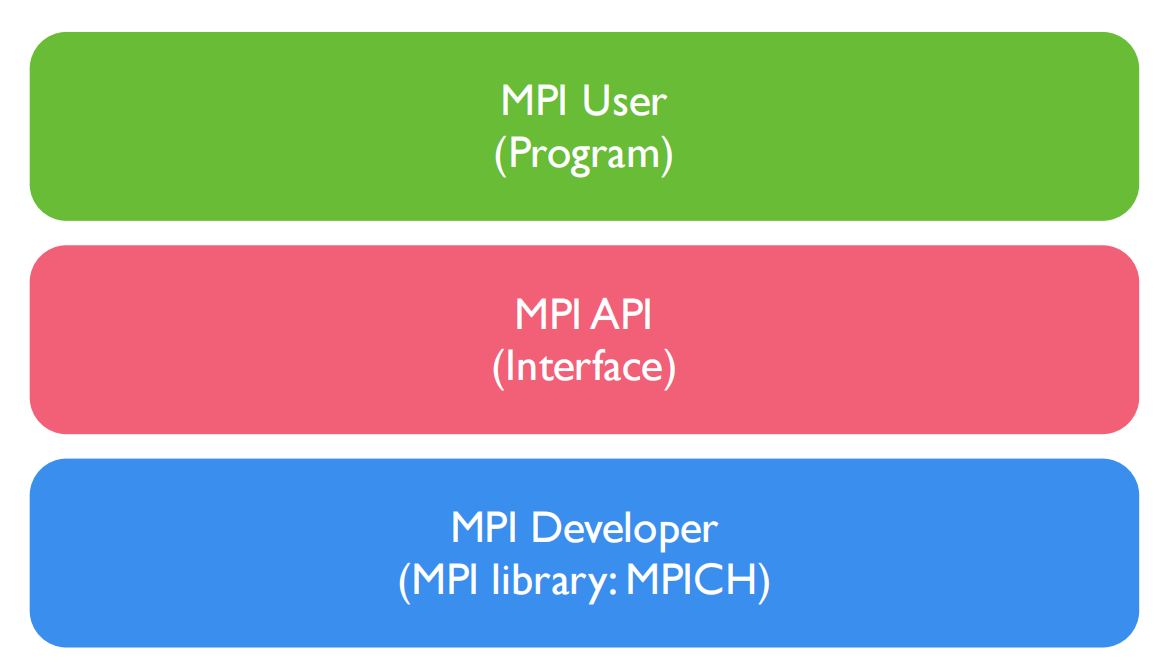
xCCL 通信库
xCCL(XXXX Collective Communication Library)集合通信库,大体上会遵照 MPI 提供 API 接口规定,实现了包括点对点通信(SEND,RECV 等),集合通信( REDUCE,BROADCAST,ALLREDUCE等)等相关接口;
主要区别
- 针对统一通信原语,在不同的网络拓扑实现不同的优化算法。
- 根据自己硬件或者是系统需要,在底层实现上进行相应改动,保证接口的稳定和性能。
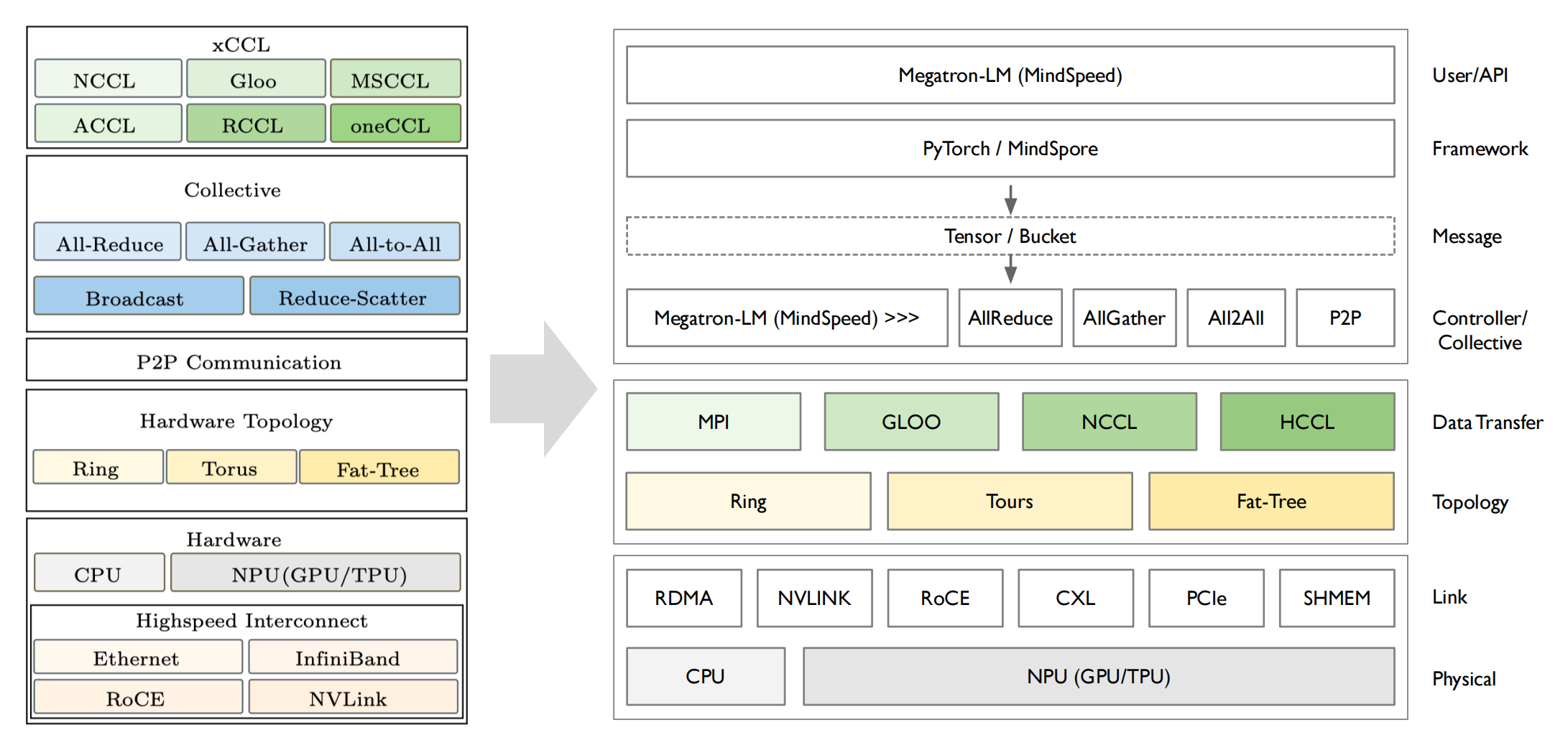
所有的xCCL库都是基于网络通讯的拓扑之上,进行构建。
对基础集合通信算法创新
- 对开源网络拓扑编排算法进行优化
- 对基础通信算子&集合通信算法进行优化
网络传输优化
- 对拥塞控制、路由控制进行优化
- 对传输协议层、路由协议层等进行细化操作
端网协同专用优化
- 端网协同自研协议栈,匹配自研交换机
- 适配自研的网络架构进行优化
NCCL
NVIDIA 集合通信库 (NCCL) 是一个类 MPI 通信库,可实现 GPU 的集合通信算法相关操作
- all-gather / all-reduce / broadcast / reduce / reduce-scatter / point-to-point send and receive
NVIDIA通信库
- 低延迟与高带宽:优化通信路径和数据传输策略,实现低延迟&高带宽;
- 并行性:支持多并发集合操作,可以在不同数据流上同时进行通信,进一步提高了计算效率。
- 容错性:GPU/网络连接出现故障,NCCL自动重新配置通信路径,确保系统的健壮性和可靠性。
优点
- 生态开源:
- 支持用户按需自定义新的集合通信算法(ACCL、TCCL 等);
- 内置基础通信算子,开箱即用;
- 灵活解耦:
- CUDA 等其他组件解耦单独商发,版本独立演进和发布;
- 暴漏不同层级 API,灵活兼顾自定义性能增强与开发易用性;
- 提供 NCCL Net Plugin API;
缺点
- 节点间拓扑识别能力、流量监控、信息获取能力有限;
- GPU + IB(InfiniBand) 效果更好,RDMA 等网络支持度一般;
- 缺乏对异构网络(clos/tours/RDMA)通信传输系统级优化,需要用户基于原子接口开发;
- CC算法编排不感知物理拓扑,当前内置ring、tree算法只适合ring、tree型物理拓扑;
- 容错管理粒度粗,任意执行过程出错,NCCL 重启;
InfiniBand
是一种高性能网络架构,广泛应用于数据中心和高性能计算(HPC)环境。它支持远程直接内存访问(RDMA),使得数据可以在不同计算机的内存之间直接传输,而无需经过 CPU,从而大幅提高了数据传输效率和减少了延迟。
RDMA(远程直接内存访问)
RDMA 允许一台计算机的应用程序直接访问另一台计算机的内存,而无需中介。这种机制的优点包括:
- 低延迟:通过绕过操作系统和 CPU,减少了数据传输的延迟。
- 高吞吐量:可以实现更高的数据传输速率,适合大规模并行计算。
- 降低 CPU 负载:CPU 不再需要处理每一个数据包的传输,释放计算资源用于其他任务。
Clos 结构
Clos 网络是一种多级交换网络结构,特别适用于高带宽和低延迟的需求。它由多个交换机组成,通常分为输入层、中间层和输出层。Clos 网络的优点包括:
- 扩展性:可以通过增加交换机和链接来扩展网络容量。
- 容错性:由于有多条路径,某些路径故障不会影响整体网络的连接性。
Torus 结构
Torus 网络是一种周期性拓扑结构,通常用于高性能计算集群。它的特点是:
- 对称性:所有节点的连接性相同,可以有效地平衡负载。
- 低延迟:通过多条路径连接节点,降低了节点之间的通信延迟。
MULTI-GPU TRAINING:Data parallel
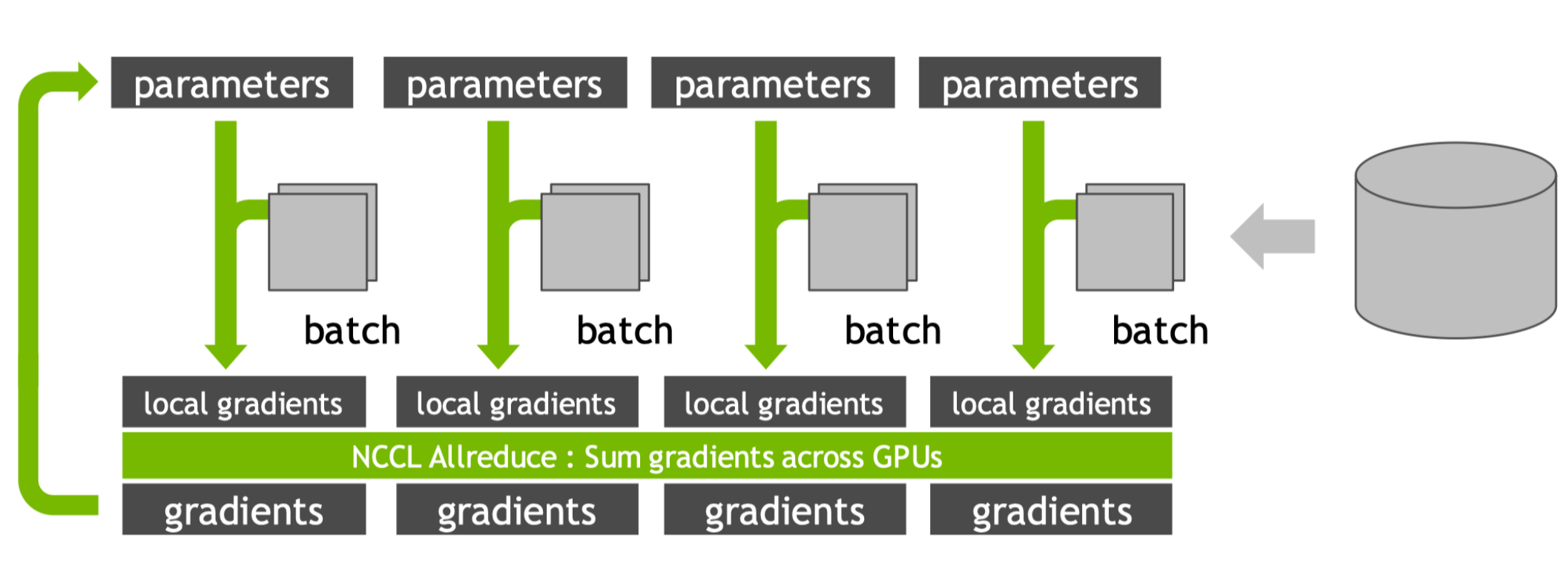
节点内 intra Node 通信更快,节点外 Inter node 通信慢
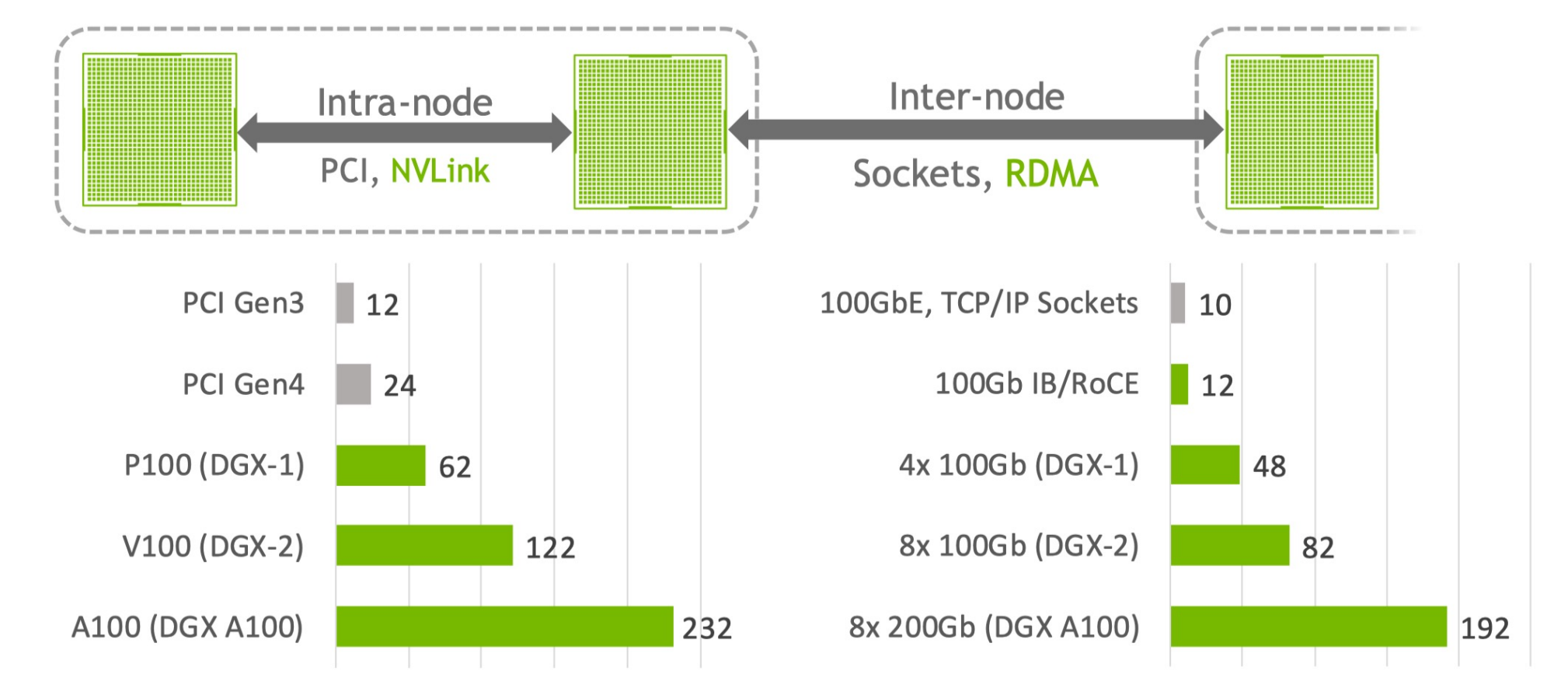
NCCL 初始化BOOTSTRAP : Principle
worker0 和其他 workers 的交互
worker0 生成一个id,声明自己是一个root thread,会通知所有的rank。
worker0作为主节点,负责发现集群中的其他workers。它会收集每个节点的网络地址和相关信息。- 在进行数据传输之前,
worker0会向所有其他workers发送同步信号,确保所有节点在同一时间准备好进行通信。可以使用 barrier 或其他同步原语来实现。 - 一旦所有
workers同步完成,就可以开始
NCCL Bootstrap 在同一个任务中使用 TCP/IP sockets 去连接不同的 Ranks,然后提供一个带外信道在 Ranks 间传输不同的数据。
Bootstrap 操作在 NCCL 整个生命周期内都是可用的,不过主要用于初始化(Init)阶段,当然也可以用于动态连接时 send/recv 操作
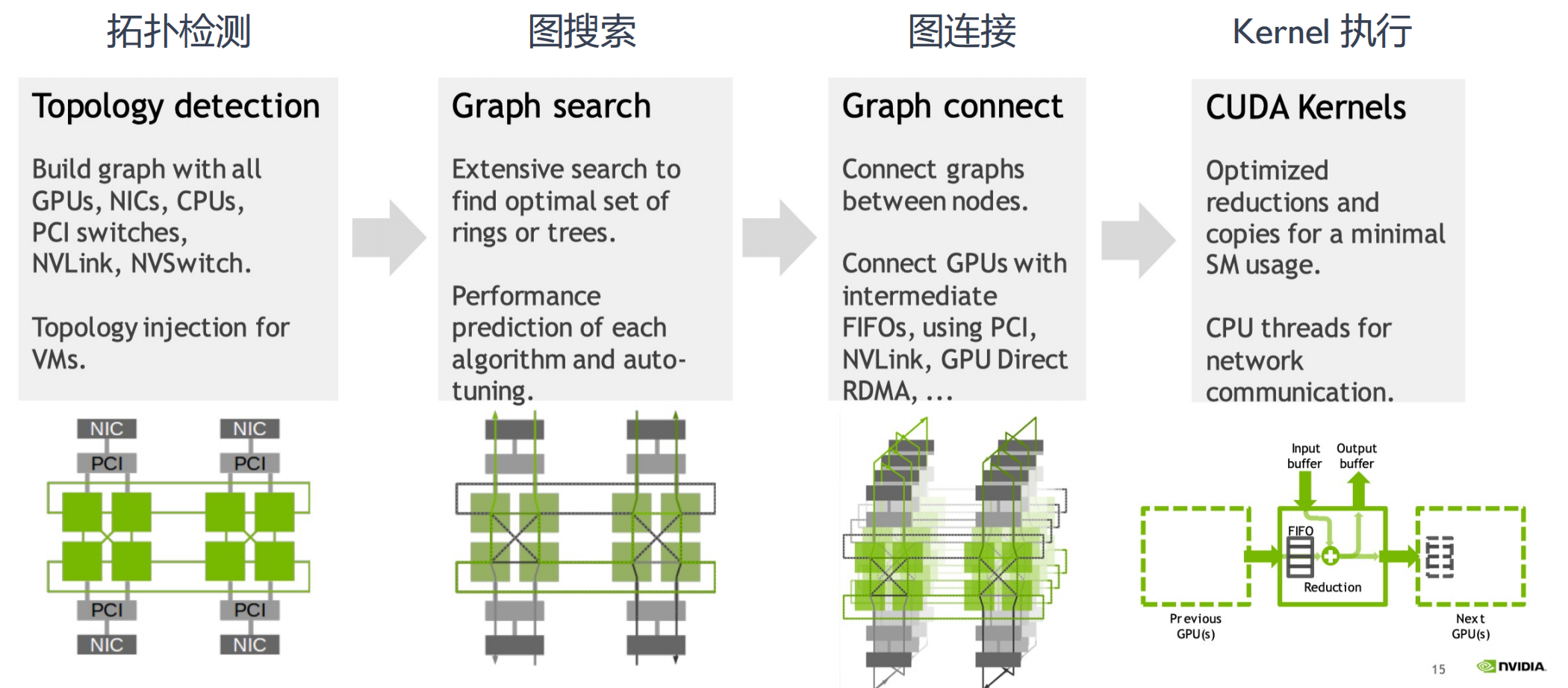
NCCL 架构 ARCHITECTURE: Optimized kernels for all platforms
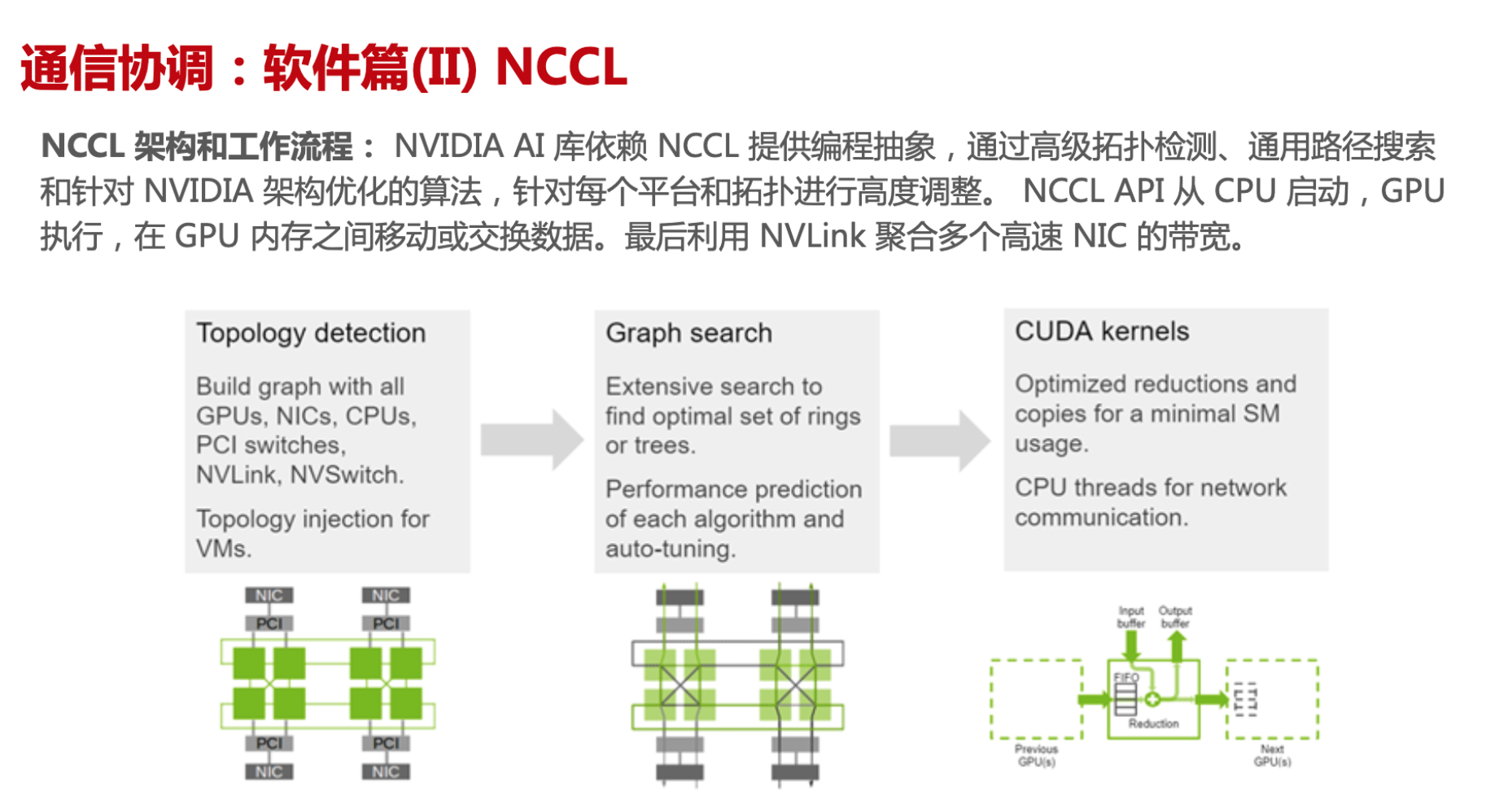
通讯整个流程分成4步
-
拓扑检测:
-
构建包含所有组件的图,包括GPU、NIC(网络接口卡)、CPU和交换机等。
- 提供虚拟机的拓扑注入功能。
- 感知整个物理拓扑:根据硬件信息去感知或者构建拓补图
- 节点内进行多路径搜索,最大限度地提高节点内和节点间带宽
- 根据 Channel 数和传输速率对每种算法和协议的延迟和带宽进行建模
-
-
图搜索:
-
进行广泛的搜索,以识别最佳配置(如环或树)。
-
涉及算法的性能预测和自动调优。
-
-
图连接:
-
连接节点之间的图。
-
通过各种接口(如PCI、NVLink)促进GPU之间的通信。
-
-
CUDA内核:
-
专注于优化操作(如归约和数据复制),以实现最小的资源使用。
-
利用CPU线程进行网络通信。
-
节点间通信 INTER-NODE COMMUNICATION
节点和交换机Connect rails together 多轨连接
- 对每个节点的 Rings 进行相互连接
- 前提假设:NIC(网口)可以在节点间进行高效通信
- 树通过节点之间进行连接,节点内通过多块 NIC 网卡聚合带宽
Dual binary tree 双二叉树
两棵互补二叉树,每一棵树处理一半的数据,充分利用网络带宽。
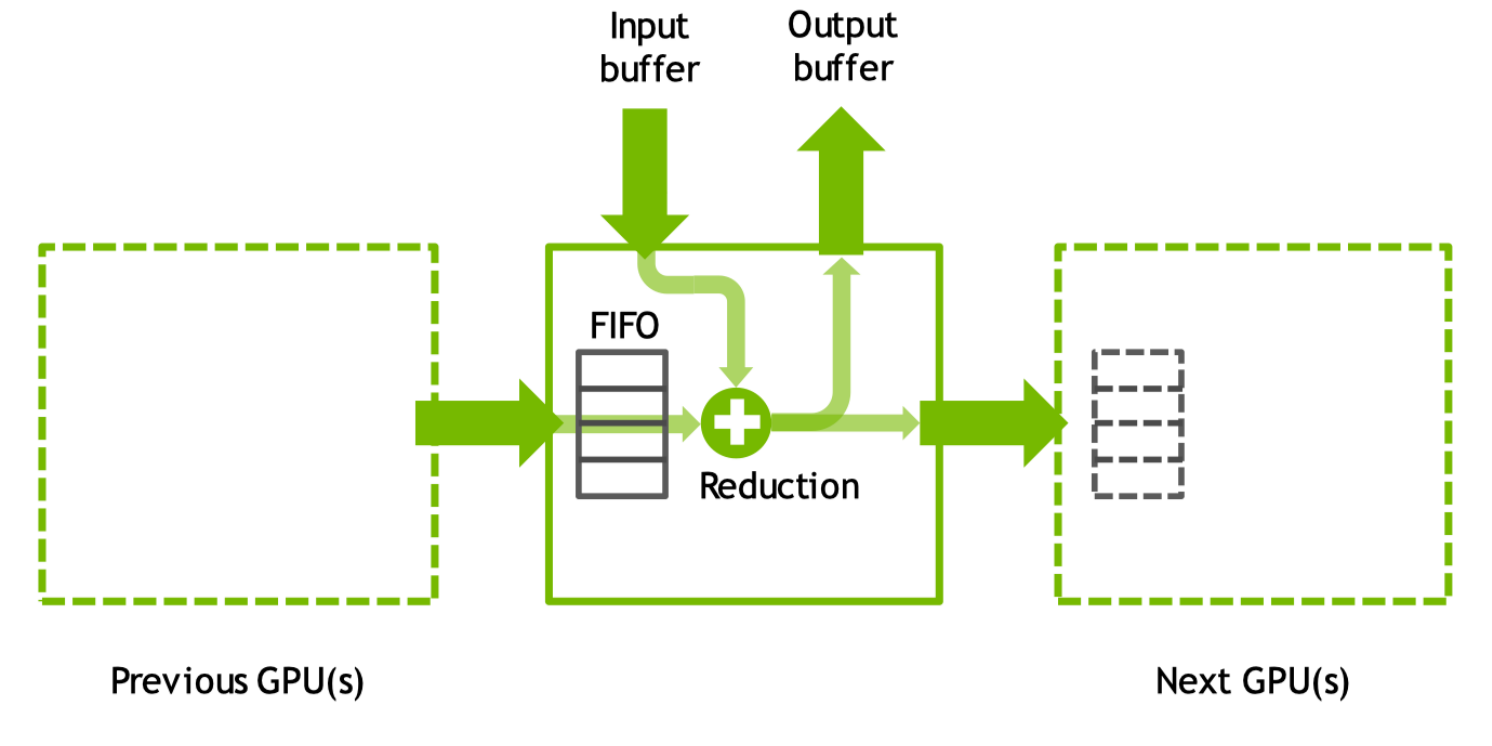
GPU通信核心
GPU 核心内
- 通过 GPU 内 FIFO 队列从其他 GPU 中接收和发送数据
- 使用本地和远程缓冲区执行 reductions 和 copy 操作
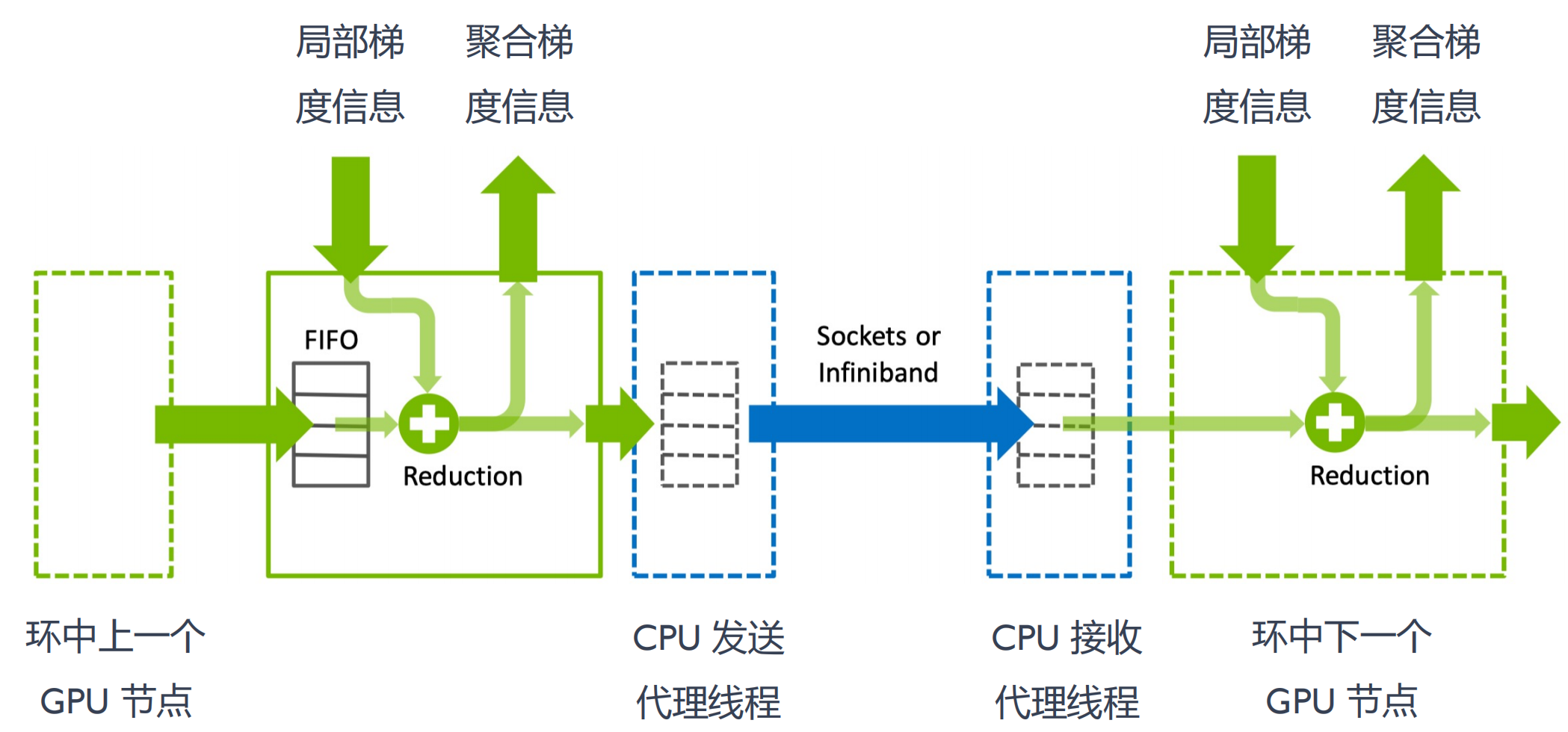
节点间通信
节点之间通过sockets
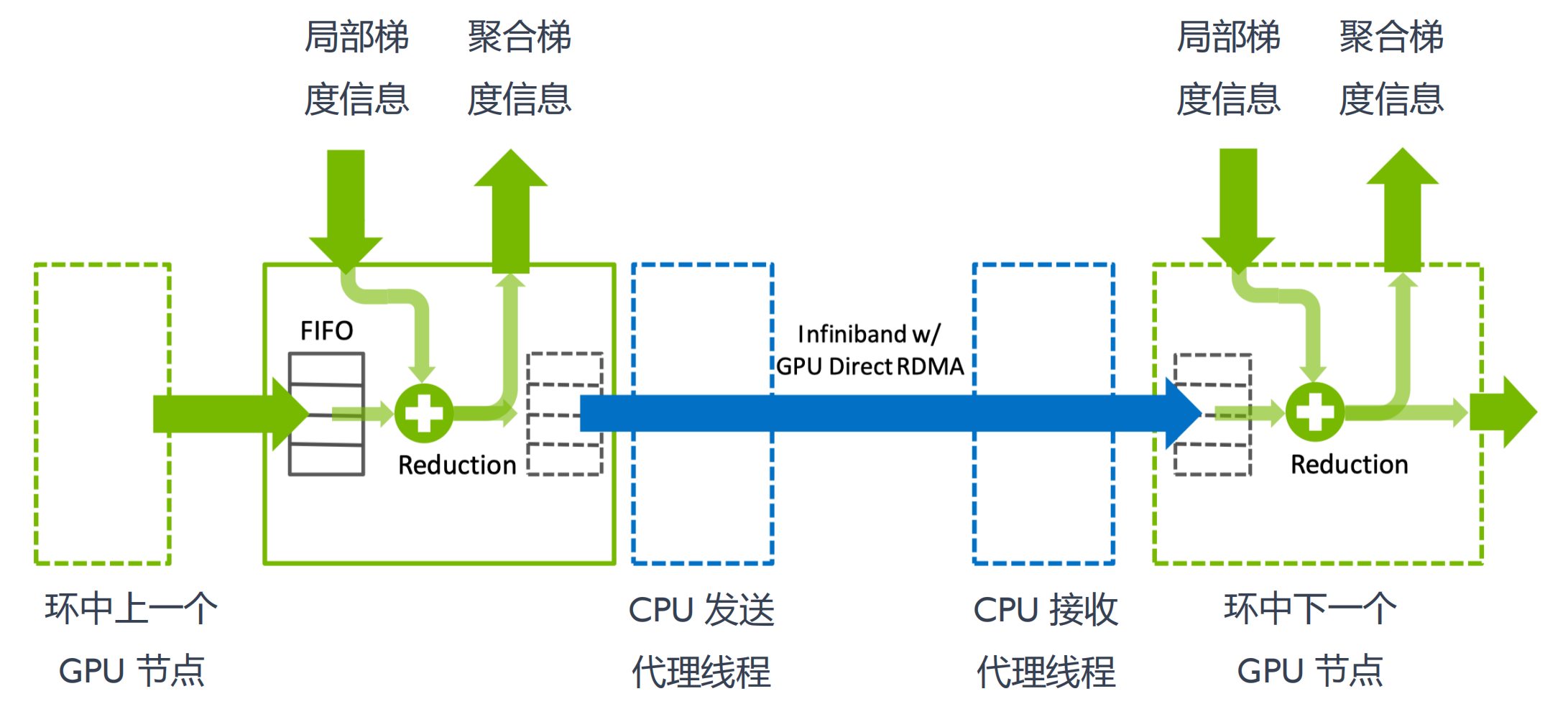
GPU Direct RDMA
跨节点直连,没有cpu代理线程
数据发送和接收
- 随节点数增加,网络时延也会增加
- 带宽理论值可以指引优化方向
- 不同节点通信拓扑结构,很大程度影响通信带宽
通信协议
NCCL 使用 3 种不同的协议 LL、LL128 和 Simple :
- 其分别具有不同延迟(
~1us、~2us 和 ~6us)- LL,Low Latency协议
- 优化小数据量传输:小数据量情况下,打不满传输带宽时,优化同步带来的延迟
- 提供低延迟:8 bit 原子存储操作,提供低延迟通信。
- LL128 Low Latency 128 协议依赖硬件NVLink 实现
- 默认协议:LL128 能够以较低延迟达到较大带宽率,NCCL 会在带有 NVLink 硬件上默认使用该协议
- 低延迟:128 字节原子存储
- LL,Low Latency协议
- 其分别具有不同带宽(50%、95% 和 100%)
- 以及其他影响其性能的差异。
集合通信基本概念
https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/index.html
Devices and Streams 设备和 Sreams 流:
- NCCL 可以在多个 GPU 间进行通信。同时 NCCL 支持与 CUDA 流(Streams)集成,实现异步通信和并行计算。
Synchronization 同步:
-
分布式计算中,同步是至关重要。
-
NCCL 提供各种同步原语,e.g. barrier 同步,以确保进程在执行集合通信时一致状态。
Performance Optimization 性能优化:
- 提供集体通信合并、数据传输批量处理、信道拆分、数据拆分、通信与计算并行等优化的方式。
Collective Operations 集合通信操作:
-
NCCL 支持多种集合通信操作,可以在多个 GPU 或节点间进行数据同步和合并。
-
e.g. 广播(Broadcast)、规约(Reduction)、聚合(Aggregation)、AllReduce、AllGather 等。
Processes and Groups 进程和组:
-
NCCL 中进程(Processes)表示参与通信的计算节点。
-
进程可以组织成组(Groups),以便在组内进行集合通信。
Communicators 通信者:
- 指定参与通信的进程组和具体的通信操作,其定义了一组能够互相发消息的进程。
- 进程中每个进程会被分配一个序号,称作 Rank,进程间显性地通过指定 Rank 来进行通信。
Communicators
1 | |
使用多个 Communicator
- 使用多个NCCL Communicator需要小心的进行同步,否则会造成死锁。NCCL kernel会因为等待数据到来而阻塞,在此期间任何CUDA操作都会导致设备同步,意味着需要等待所有的NCCL kernel完成。
- 即NCCL kernel在等待数据到来期间如果有任何CUDA operation进入了队列就会导致死锁,因为NCCL也会执行CUDA调用,而NCCL的CUDA调用会进入队列中等待前一个CUDA操作执行完毕。
Communicator 状态
- Finalizing
- ncclCommFinalize 会把一个communicator从ncclSuccess状态转变为ncclInProgress状态,开始完成background中的各种操作并与其他ranks之间进行同步。
- ncclCommFinalize会将所有未完成的操作以及与该communicaotr所属的网络相关的资源会被flushed并被释放掉。一旦所有的NCCL操作都完成了,communicator会将状态转换成ncclSuccess。可以通过ncclCommGetAsyncError来查询状态。
- Destroying
- 一个Communicator被Finalize之后,下一步就是释放掉它所拥有的全部资源,包括它自己也会被释放。ncclCommDestroy函数会释放掉一个Communicator的本地所属资源。
- 调用 ncclCommDestroy 时候如果对应的Communicator的状态是ncclSuccess,那么可以保证这个调用是非阻塞,否则这个调用可能会被阻塞。会释放掉一个Communicator的所有资源然后返回,对应的Communicator也不能再被使用。
Error handling错误处理
1 | |
- 所有的NCCL调用都会返回一个NCCL错误码(error code)。
- 如果某个NCCL调用返回的error code不是ncclSuccess或者ncclInternalError,并且NCCL_DEBUG设置为WARN,NCCL会打印出human-readable的信息来解释内部发生了什么导致该错误的发生。
- 如果NCCL_DEBUG设置为INFO,NCCL也会打印出导致该错误的调用栈,以便帮助用户定位和修复问题。
- 一些communicator 错误,尤其是网络错误,会通过ncclCommGetAsyncError函数报告。
- 发生异步错误的操作通常将难以继续进行下去并且该操作将永远不能完成。因此当异步错误发生的时候,对应的操作应该被丢弃且通信器应该被destroy,可以通过ncclCommAbort来进行上述操作。
- 如果是等待NCCL操作完成的时候发生了异步错误,我们的应用中应该调用ncclCommGetAsyncError函数来destroy对应的communicator。
Fault Tolerance容错
1 | |
- NCCL提供了许多feature来让我们的应用从严重的错误中恢复到正常,比如网络连接失败、节点宕机以及进程挂掉等。当这样的错误发生的时候,应用应该能够调用 ncclCommAbort 方法来释放相应的 communicator 的资源,然后创建一个新的 communicator 继续之前的任务。为了保证 ncclCommAbout 能够在任何时间点被调用,所有的NCCL调用都可以是非阻塞(异步)的操作。
- 为了正确的弃用,当一个communicator中任何一个rank出错了的时候,所有其他的rank都需要调用 ncclCommAbort 来启用它们自己的 NCCL communicator。用户可以实现方法来决定什么时候以及是否弃用这些 communicator 并重新开始当前的NCCL操作。
集合通信Collective Operations
- 集体操作(Collective Operation)需要被每个 rank 都调用,从而形成一次集体的操作。如果失败的话可能会导致其他rank陷入无尽的等待。
组调用Group Calls
- 组函数可以将多个调用合并成一个。有三种用法,它们也可以组合起来 :
- 使用一个线程管理多个GPU
- 聚合通信算子,从而提升性能
- 合并多个send/receive类型的点对点操作。
点对点通信Point-to-point
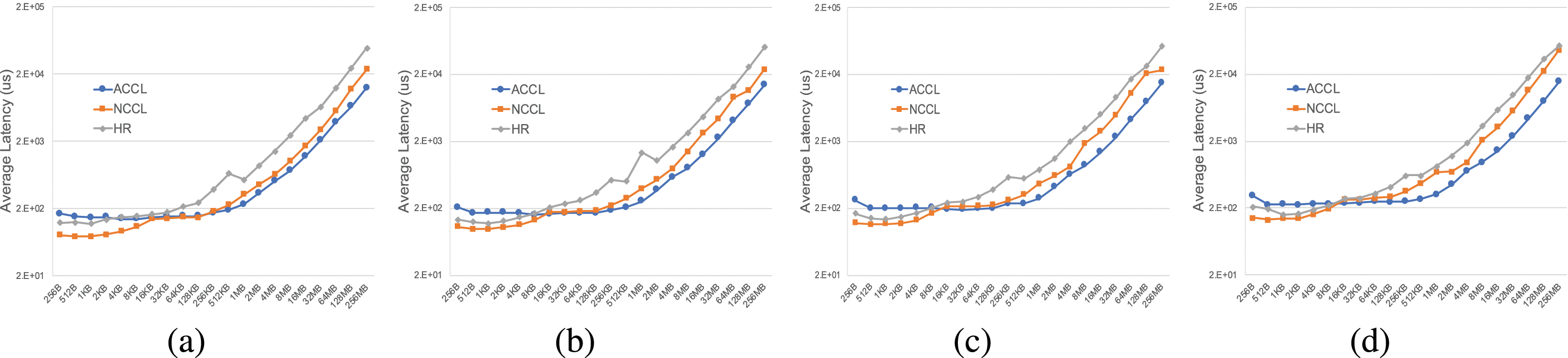
ACCL
EFLOPS: Algorithm and System Co-design for a High Performance Distributed Training Platform (2021)基于NCCL(Nvidia Collective Communication Library)开发的集合通信库
ACCL面向阿里云灵骏架构设计,通过算法与拓扑深入协同来收获更好的通信性能(BigGraph网络拓扑),ACCL的关键特性包括:
-
异构拓扑感知,如节点内PCIE与NVLink/NVSwitch、节点间多轨RDMA网络,分层混合充分利用不同互连带宽。
-
端网协同选路,算法与拓扑协同设计实现无拥塞通信,支撑训练性能上规模可扩展。
-
在网多流负载均衡,多任务并发、资源争抢时保障整体吞吐。
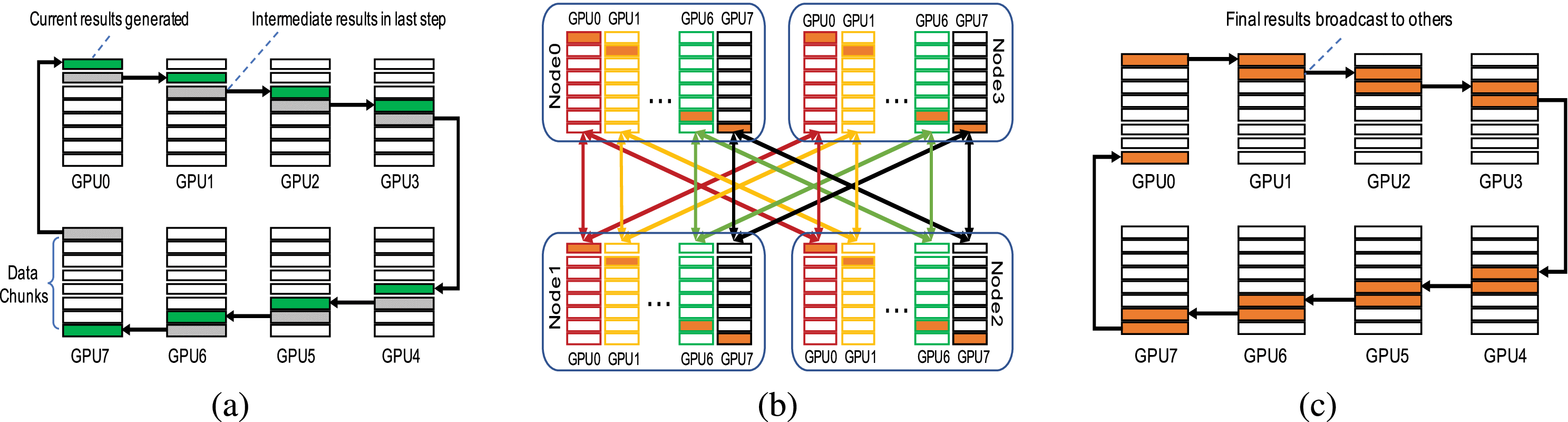
BigGraph网络拓扑
- 两层交换机分组互联,每层一个交换机和另一层交换机全互联。两层交换机间至少存在N/2个物理链路可用。
- 两层交换机间最短路径确认,接入不同层次任意两个device间最短路径具有唯一性并等长
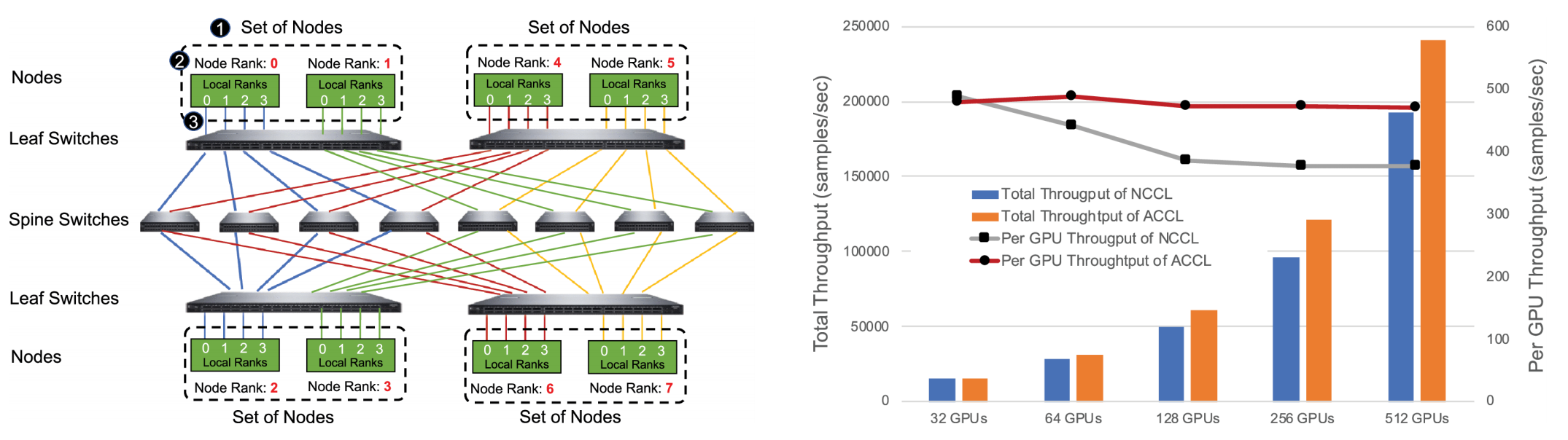
- HD 算法逻辑连接和 BigGraph 拓扑物理链路进行映射,避免链路争用,彻底解决网络拥塞。
- Halving-Doubling with rank-mapping(HDRM),从集合通信管理层面分配链路。
TCCL
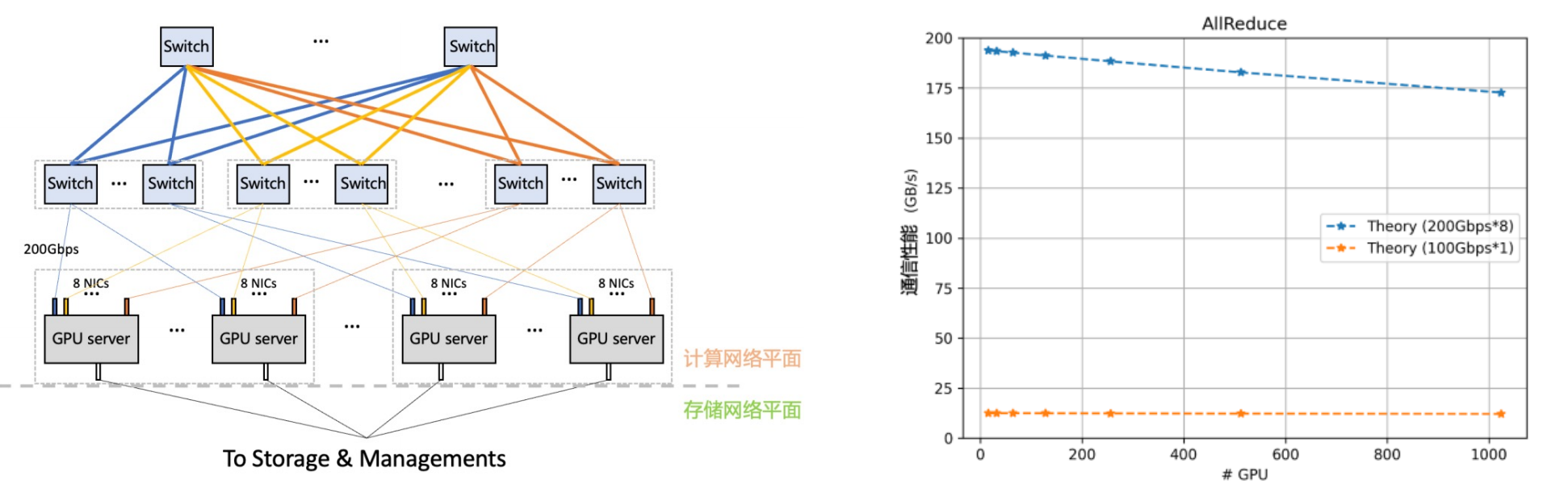
Tencent腾讯集合通信库
TCCL(Tencent Collective Communication Library)针对腾讯云星脉网络架构的通信库。依托星脉网络硬件架构,为 AI 大模型训练供更高效的网络通信性能,同时具备网络故障快速感知与自愈的智能运维能力
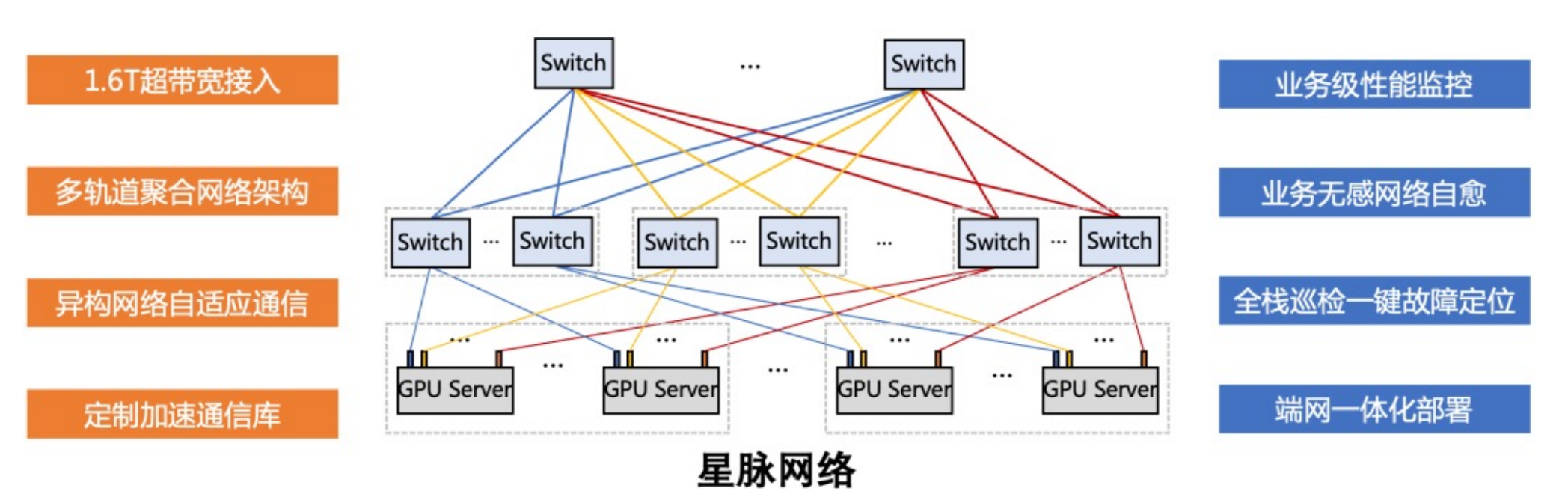
-
双网口动态聚合优化,端网协同自研协议栈,发挥 GPU 性能极限。
-
全局 Hash 路由(Global Hash Routing),负载均衡,避免拥塞。
-
拓扑亲和 fat-tree 组网,流量调度监控,最小化流量绕行。
-
自研交换机,可编程RDMA拥塞控制算法。
Intel oneCCL
oneAPI Collective Communications Library (oneCCL) https://github.com/intel/torch-ccl
https://oneapi-src.github.io/oneCCL/introduction/sample.html
oneCCL 是 Intel 开发的一个高效通信库,作为 oneAPI 生态系统的一部分
oneCCL 支持多种通信模式,包括点对点、广播、规约等:
-
oneCCL 支持 SYCL,可与 Level Zero 驱动层配合,充分利用 Intel 的 NPU 和 GPU 硬件资源。
-
提供自动线程亲和性设置功能,可以优化多核处理器上的并行性能。
-
对于低精度数据类型,e.g. BF16 提供专门的优化支持
AMD RCCL
AMD ROCm Communication Collectives Library(RCCL) https://github.com/ROCm/rccl
https://rocm.docs.amd.com/projects/rccl/en/latest/
-
RCCL (pronounced “Rickel”) ,AMD ROCm 生态的一部分。
-
RCCL替代NCCL,Infinity Fabric替代节点内的NVSwitch。
AMD RCCL主要特性
- GPU 到 GPU(P2P)直接通信操作
- 支持通过 PCIe 和 xGMI 互连在本地传输数据
- 支持通过 InfiniBand Verbs 和 TCP/IP 套接字在网络上传输数据。
- 对标 CUDA 使用NCCL相同 API,所以RCCL还支持通信器和拓扑等特性
- RCCL 中流特性与 NCCL 中流特性不同,它使用 HIP 流而不是 CUDA 流
Meta Gloo
Gloo is a collective communications library
Facebook GLOO
- Gloo 是 facebook出品的一个类似MPI的集合通信库
- Gloo 提供系列基于 CUDA-aware 的 All reduce 实现;
- Mate 开源机器学习集合通信库,对 all reduce 提供多种实现方案:
- allreduce_ring / allreduce_ring_chunked / allreduce_halving_doubling / allreducube_bcube
- 集成 GPU-Direct,实现多 GPU 内存缓冲区间数据传输,减少 Host – Device 内存复制;
- Gloo支持通过 PCIe 和 NVLink 等互连进行多 GPU 通信
- Gloo支持不同的数据传输方式进行节点间和节点内的数据通信
NCCL算法 通信算法与网络拓扑协同优化
PXN
2022 年 NCCL 2.12 引入新功能 PXN,即 PCI × NVLink,使 GPU 能够通过 NVLink 与节点上的NIC (网卡)进行通信。
不需要使用 QPI (快速通道互联(Intel QuickPath Interconnect,QPI),Intel 开发并使用的点对点处理器互联架构,用来实
现CPU之间的互联)或其他 CPU 协议。使得每个 GPU 仍然尝试尽可能多地使用本地 NIC 提升集合通信算法,当然也可以访问其他NIC
多轨通信
GPU 不是在本地内存上准备缓冲区供本地 NIC 发送,而在中间 GPU 上准备缓冲区,通过 NVLink 写入该缓冲区。接着通知管理该 NIC 的 CPU 代理数据已经准备好,而不是通知其自己 CPU代理
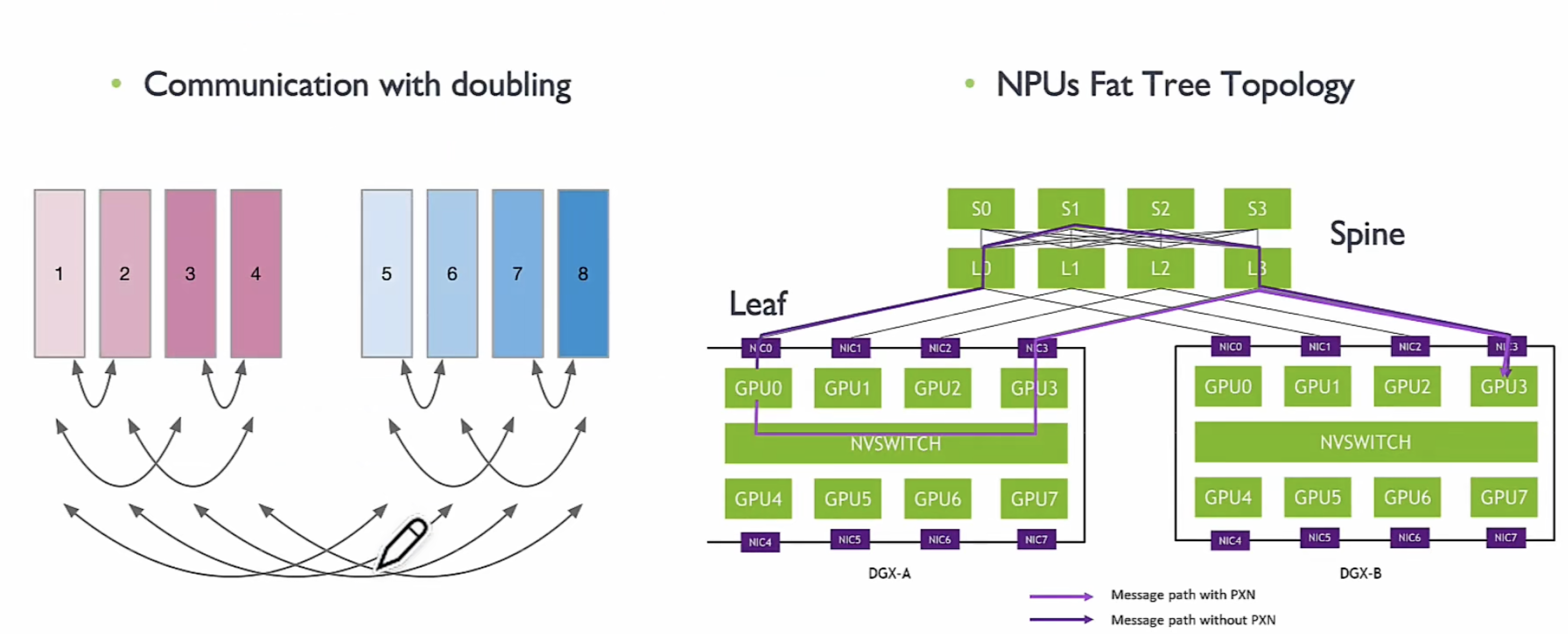
通常是**Spine-leaf两层交换架构 **
- 数据流动:当数据从服务器(连接至Leaf交换机)流向另一台服务器时,数据首先到达Leaf交换机,然后通过Spine交换机转发到目标Leaf交换机,最后送达目标服务器。
- 多路径传输:由于每个Leaf交换机与多个Spine交换机相连,数据可以通过不同的路径传输,从而提高冗余性和带宽利用率。
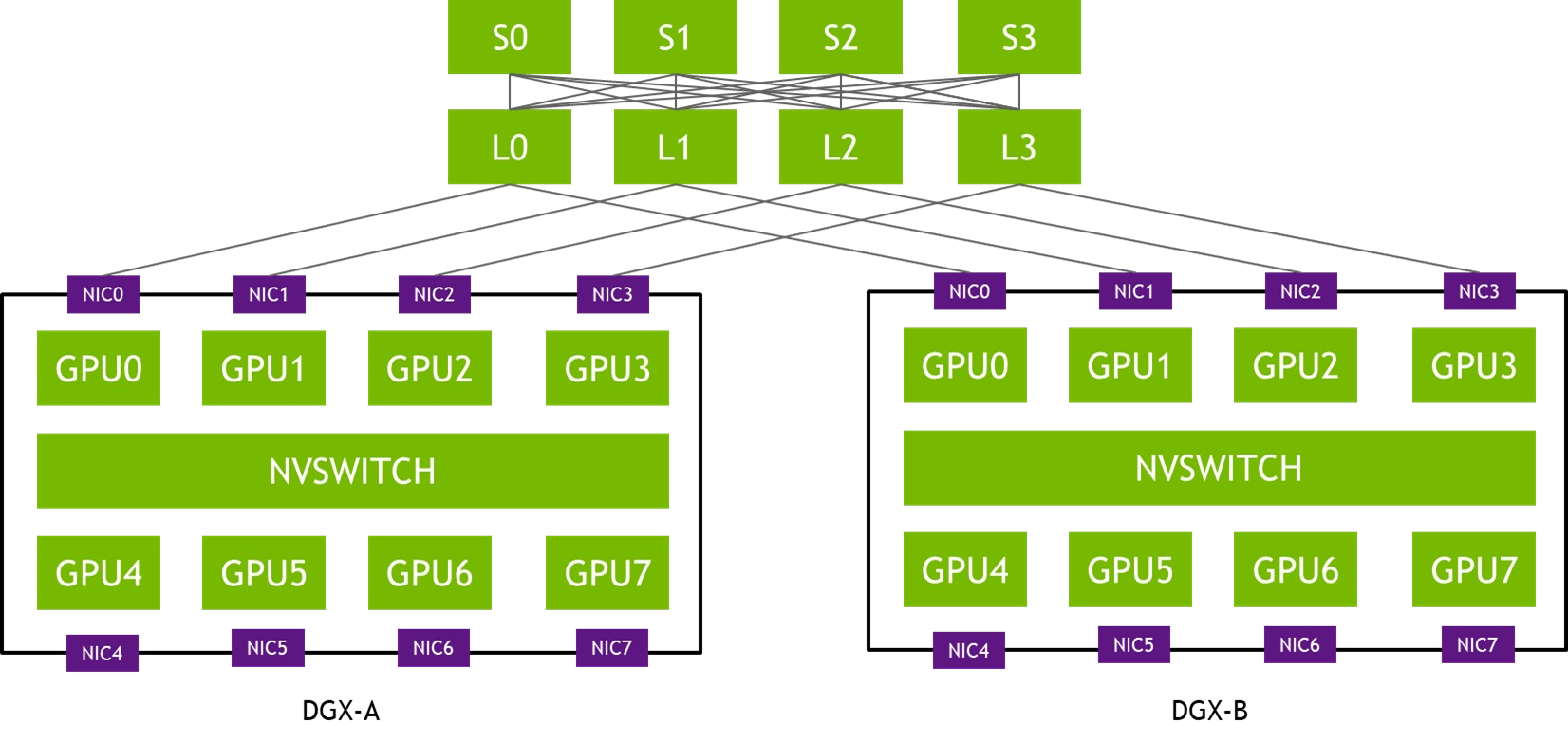
PXN 利用节点内 GPU 间 NVSwitch 连接,首先将数据移动到与目的地位于同一轨道上 GPU,然后将其发送到目的地而无需跨轨道。这可以实现消息聚合和网络流量优化。
example A(GPU0) -> B(GPU3) S L
- 正常 A(GPU0) , L0,S0,L3 ,B(GPU3) 4次网络通讯和转发
- PXN A(GPU0) , A(GPU3),L3 ,B(GPU3) 2次网络通讯和转发
在同一对 NIC 之间传递的数据被聚合,最大限度地提高有效数据传输速率和网络带宽。
DBT Double Binary Tree
ring VS DBT
-
NCCL 时延
-
tree: 节点规模越大,时延衰减不明显
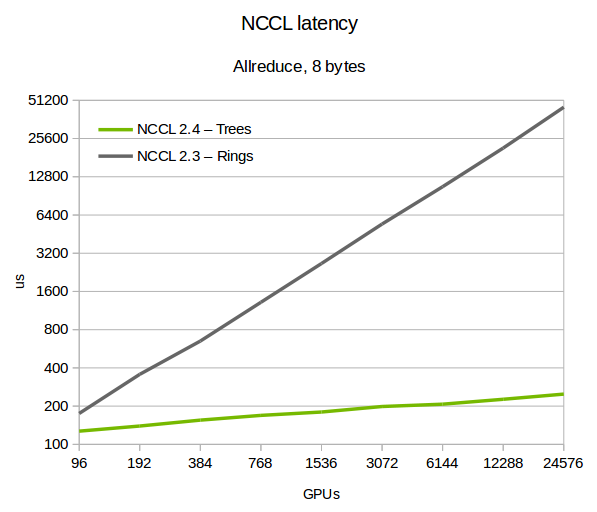
-
-
NCCL 带宽
- 拓扑感知的过程,就会选择算法,根据规模选择
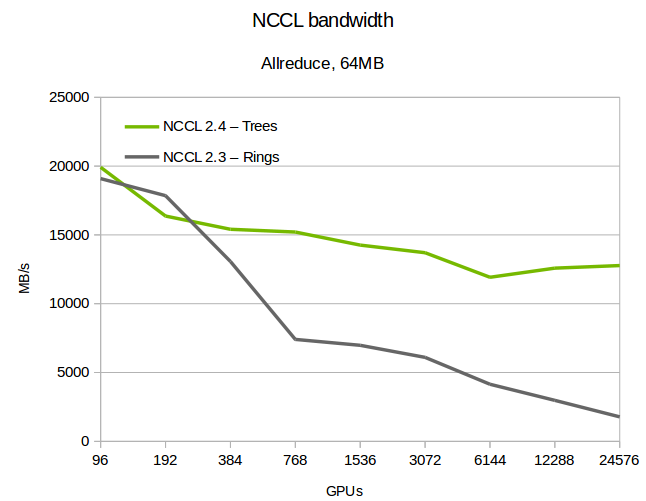
用户传入 n Bytes 长度数据,总耗时
$time\;=\;latency\;+\;nBytes\;/\;algo_bw$
- $algo_bw$为算法带宽,基础总线带宽为$bus_bw$(每个 channel 带宽乘channel数) ,然后根据实测的数据对带宽进行一些修正(Treex0.9,不可能全部打满)
- 计算$algo_bw$算法带宽,Tree 时除以 2,上行一次,下行一次相当于发送两倍数据量,Ring 除以$2x(n\;ranks-1)/n\;ranks$
- NCCL 最后将计算出的每种协议和算法的带宽延迟保存到bandwidths和latencies。当用户执行allreduce api的时候会通过getAlgoInfo计算出每种算法和协议组合的执行时间,选出最优的
ring all reduce
- Ring 方式 all reduce 算法提高大 Message 传输效率
- MPI-Send 和 MPI receive 点到点通信接口实现 all reduce 操作
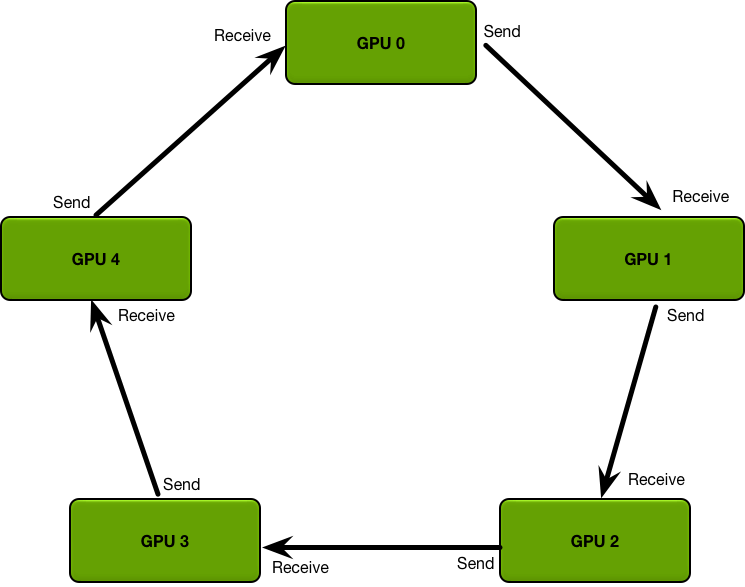
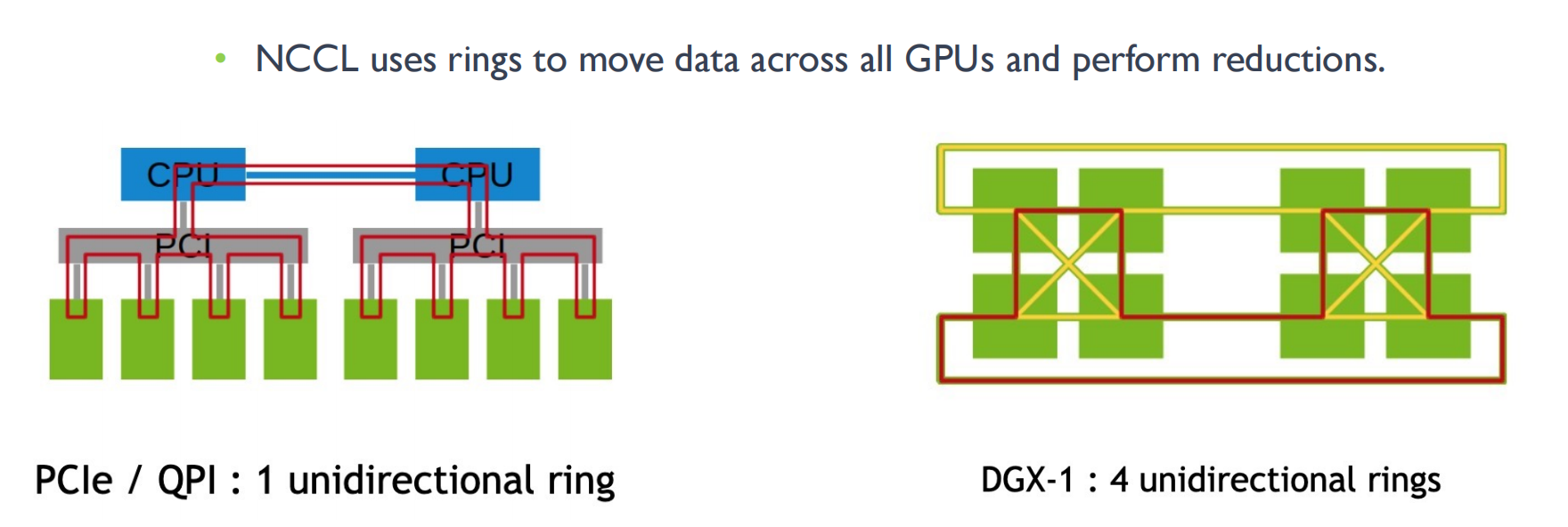
最常见实现算法基于 Ring All Reduce,NVIDIA NCCLv1.X通信库采用该算法,每次跟相邻的两个节点进行通信,每次通信数据总量的 1/N
适用拓扑:Star、Tree 等小规模集群;通信步骤:2×(N− 1) Step
优点
- 减少GPU间传输时间, OpenMPI 在多 GPU 下效率提升
- 实现简单,能充分利用每个节点的上行和下行带宽
缺点
- 通信延迟随着节点数线性增加,特别是对于小包延迟增加比较明显;Ring太大,Ring All Reduce 效率也会变得很低
引入Tree算法
- All reduce 操作用于对多个 GPU 上的梯度求和,通常使用环 Ring 来实现全带宽。环的随着训练任务中使用的 GPU 个数增加,ring all-reduce 延迟会线性增长
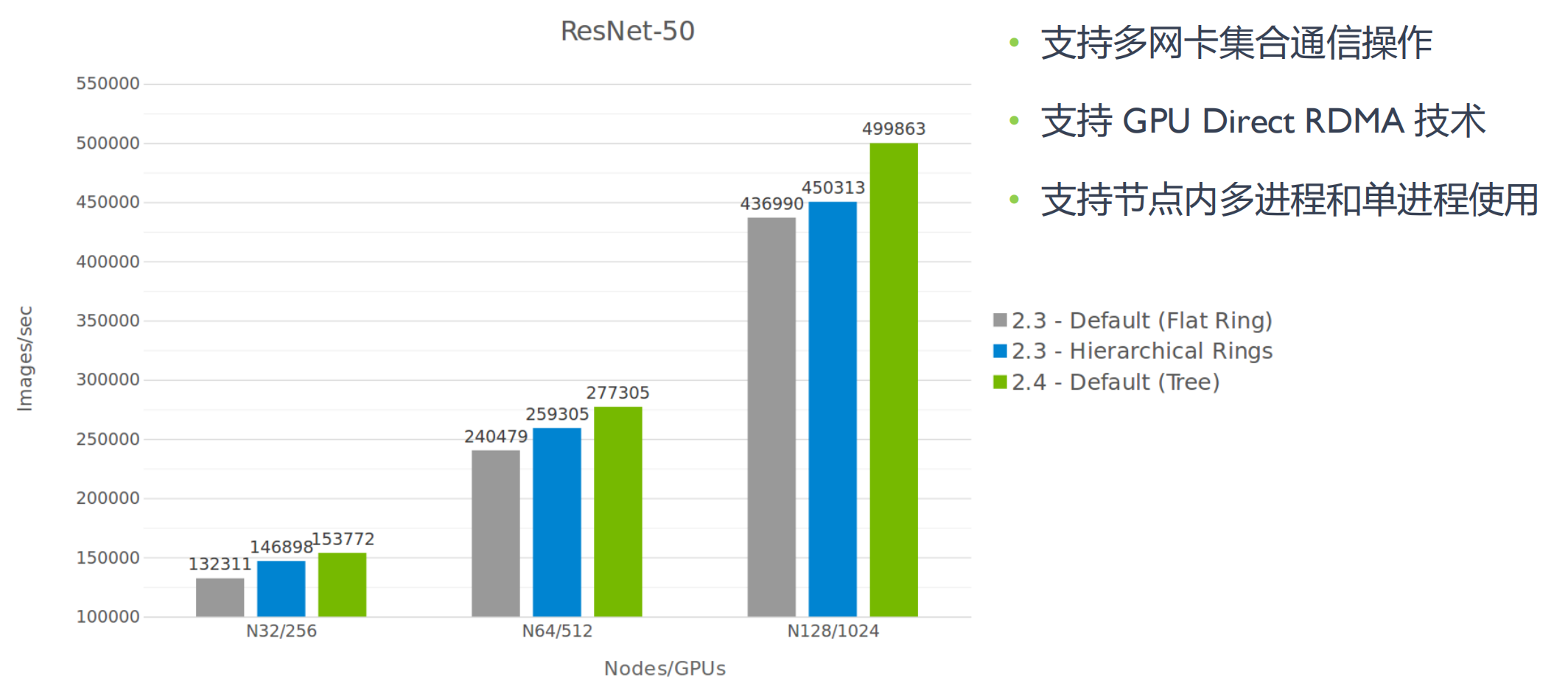
- 开始出现大规模分布式并行实验,采用分层的二维环算法(Hierarchical Rings)取代了扁平环(Flat Ring),以获得更好的带宽,同时降低延迟
- 分层环仍然为了解决这个问题,NCCL 2.4 版本引入了 tree 算法,即 double binary tree;2.4 版本后,NCCL 同时具备 Tree 和 Ring 算法
朴素二叉树 Native binary Tree
朴素二叉树(Native binary Tree)算法将所有 GPU 节点构造成一棵二叉树,支持 broadcast,reduce,前缀和,
父节点下发消息M到子节点,叶节点因为没有子节点,所以叶结点只会接收 M
并行
将 M 切分为 k 个 block,从而充分利用网络带宽(Stream 数),进行可以流水线并行起来
缺点
叶节点只接收但是不发送数据,因此只利用了带宽的一半
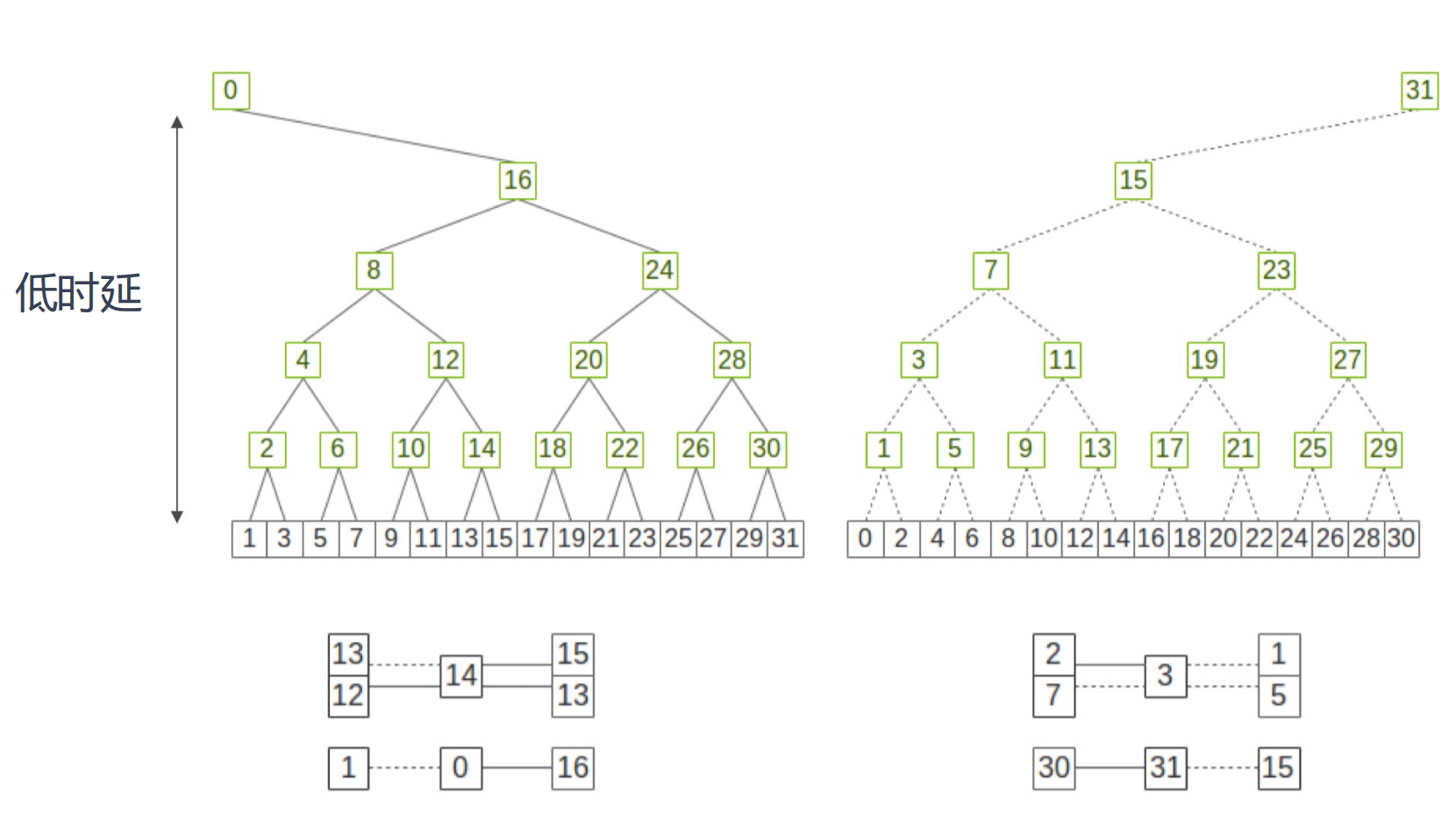
双二叉树 double Binary Tree
MPI 引入 double binary tree 算法,结合算法中广播和归约操作的全带宽(可以组合成一个 all reduce,先执行归约,然后执行广播)和对数延迟的优势。小型 or 中型集群的集合通信操作上性能更好。
假设一共有 N 个设备,MPI 构建两颗大小为 N 树 T1 和 T2,T1 中间节点在 T2 为叶节点,T1和 T2 同时通信,各自负责消息 M 的一半,这样每个节点的双向带宽可以都被利用到
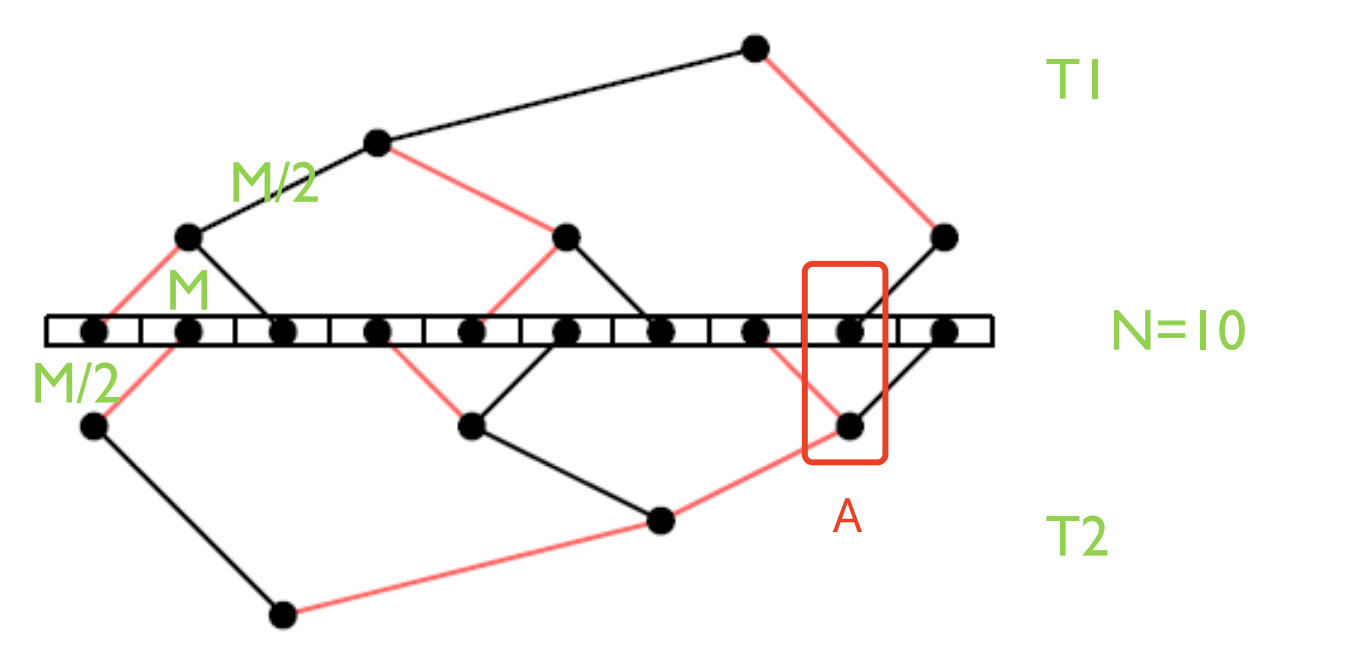
- A在T1,T2是同一个点,A在T2是中间节点,A在T1是叶子
- 不同的树,同一个节点(A)连接父节点的颜色不同
- 节点连接叶子的颜色不同
两棵树同时工作,在每一步中从父节点中收数据,并将上一步中收到的数据发送给子节点(叶子节点也可以发),如在偶数步骤中使用红色边,奇数步骤中使用黑色边,一个步骤中可以同时收发,从而利用了双向带宽
T2 构树两种方式:
-
shift 移位,将 rank 向左 shift 一位,如 rank10 变成 rank9,构树与 T1 保持一致,使得 T1 和 T2 树结构完全一致;
-
mirror,将 rank 镜像,如 rank0 镜像为 rank9,使得 T1 和 T2 树结构是镜像对称,不过 mirror 方式只能用于设备(NPU/GPU)数为偶数的场景,否则会存在节点在两棵树中都是叶节点
在NCCL中的双二叉树 double Binary Tree
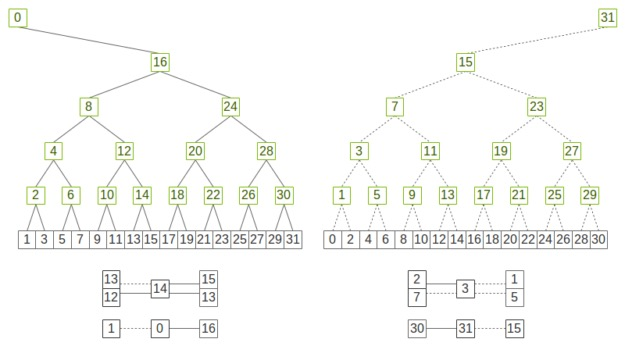
二叉树中一半或更少的等级是节点,一半(或更多)的等级是叶子。每一个节点是一个服务器,节点内的卡是一条链。
如果使用这两棵树中的每一棵树来处理一半的数据,则每个等级最多会接收一半的数据两次,发送一半的数据两次,在发送/接收数据方面与环一样优化。
基础通信模型
对集群通信成本进行建模是一个重要又具有挑战性的工作,了解通信性能模型的发展、作用,以及现有的各类集合通信模型分别做什么、为何这样设计、有哪些进一步的贡献、优缺点等等
集群的计算节点越来越复杂,以同一节点上的进程间通信为例,它们可以使用共享内存作为缓冲区通信(GPU Direct),也可以通过高性能网络(如 InfiniBand/RoCE v2)使用操作系统模块、操作系统旁路或远程内存访问(RDMA)进行消息的直接传输。
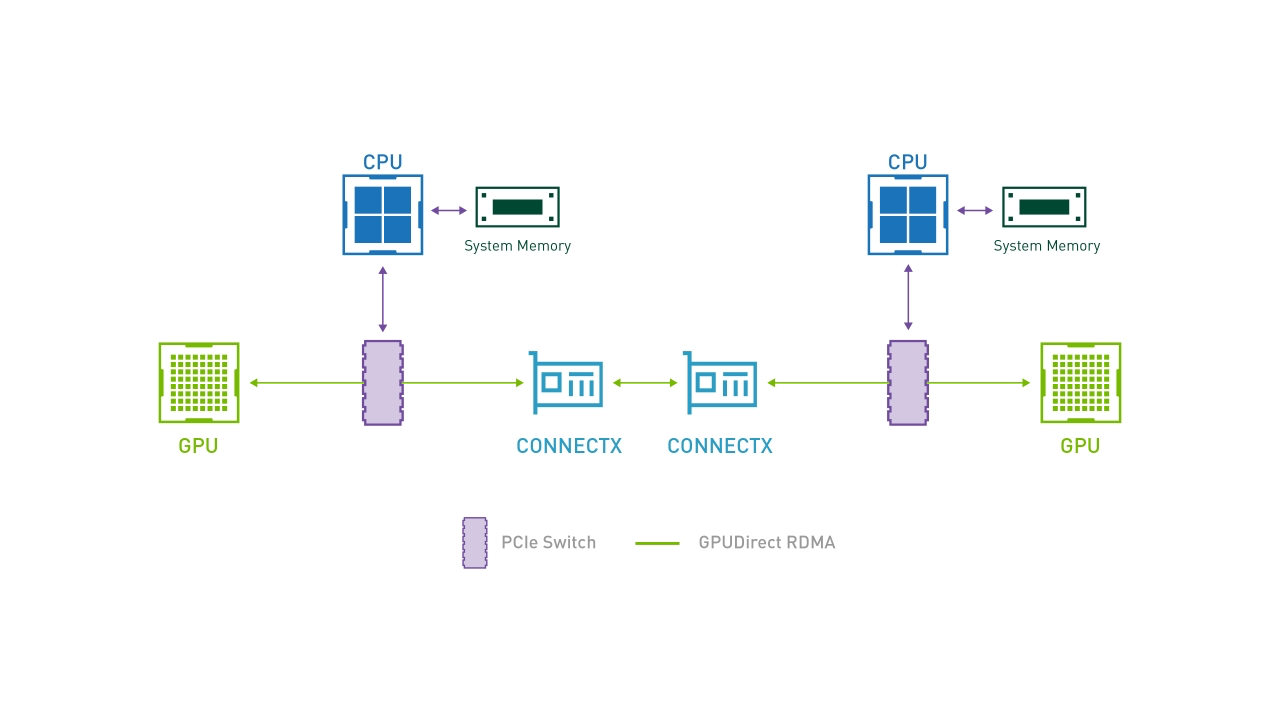
- 通信的性能模型使用一系列参数对一次点对点通信的时间消耗进行建模,因为点对点通信(P2P)的成本可以推广到集合通信当中
- 集合通信在大模型训练和推理过程中,占用了相当高的耗时,因此许多研究都致力于提高 XCCL 的集合通信性能
通信性能模型主要能从两点提供帮助:
- 为集合通信算法设计提供参考
- 主要是理论层面分析,分析集合通信算法底层的点对点通信顺序与步数,表示总体通信时间成本,从而评价通信算法的优劣,反过来指导通信优化算法的设计。
- 具体分析某一通信模式的性能
- 主要是实践层面,通过建立通信性能模型来估计集合通信优化算法的性能,能够基于当前网络拓扑和优化算法计算出一个具体通信耗时,更进一步让 XCCL 库可以自适应地选择具体的通信优化算法,从而优化集合通信操作效率。
Postal 模型
Postal 模型中,点对点通信的时间 $T_{p2p}(m)=\lambda$, Postal 模型假设同一时间一个设备(CPU)仅能发送或接收一个消息。
希望通过引入网络延迟对全连接网络的通信进行建模分析。
Hockney 模型
Hockney 模型也被称为 $α−β$ 模型,Postal 模型基础上引入了带宽,并限制每次传输数据量
Hockney 模型一次点对点通信成本 $T_{p2p}(n)=\alpha+n\ast\beta$。Hockney 模型假设一个设备节点(CPU)可以同时执行一个发送操作和一个接收操作。
其中
- α:节点间的固定时延
- β:每 byte 数据传输耗时
LogP 模型
LogP 模型名称中的四个字母代表了模型中四项参数:
- L(Latency):网络延迟,发送方发送完最后一个字节到接收方接收完最后一个字节的时间。
- o(Overhead):准备开销,处理器为发送/接收消息花费时间,包括准备消息、发送队列排队、向 NIC发送信号等。
- g(Gap per message):间隔。NIC 向链路注入相邻两个数据包之间所需要的最小时间,其倒数反应了网络带宽,处理器在网络中被阻塞之前能够发送 ⌈L/g⌉ 个消息。
- P(Process):进程总数。
LogP 模型发送一个短消息时间成本为 $T_{p2p}(m)=o_r+L+o_s$ ,区分发送方和接收方的开销,即 $o_s$ 与 $o_r$
LogP 模型主要进展是考虑到处理器对通信延迟影响,g 存在意味着处理器能够做一些非通信de 开销工作,因此可以存在计算与通信重叠。
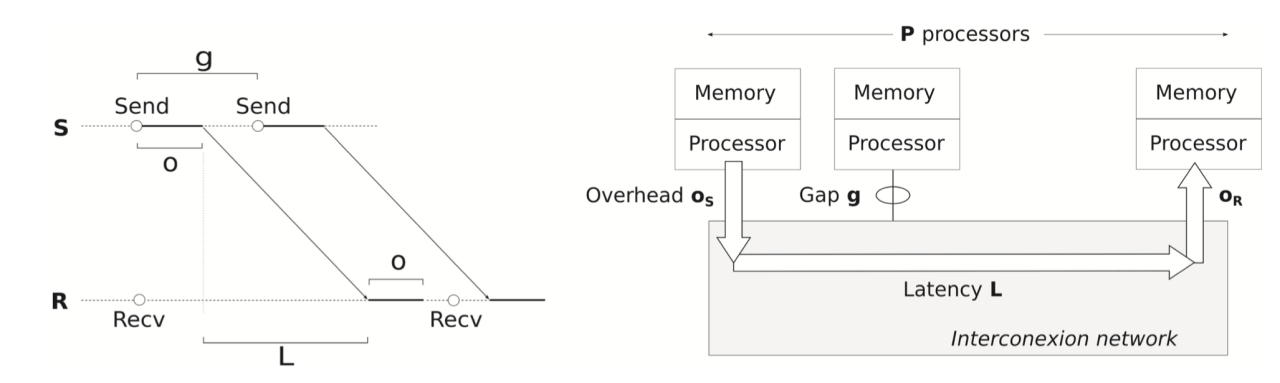
LogP 模型有着重要的地位,同时也是后续许多模型的基础,其限制是仅考虑短消息。
LogGP 模型多引入了一个参数 G(Gap per byte),用来向网络中注入两个字节最小间隔,对于长消息而言 1/G 代表网络带宽,对应于Hockney中 β(每 byte 数据传输耗时)
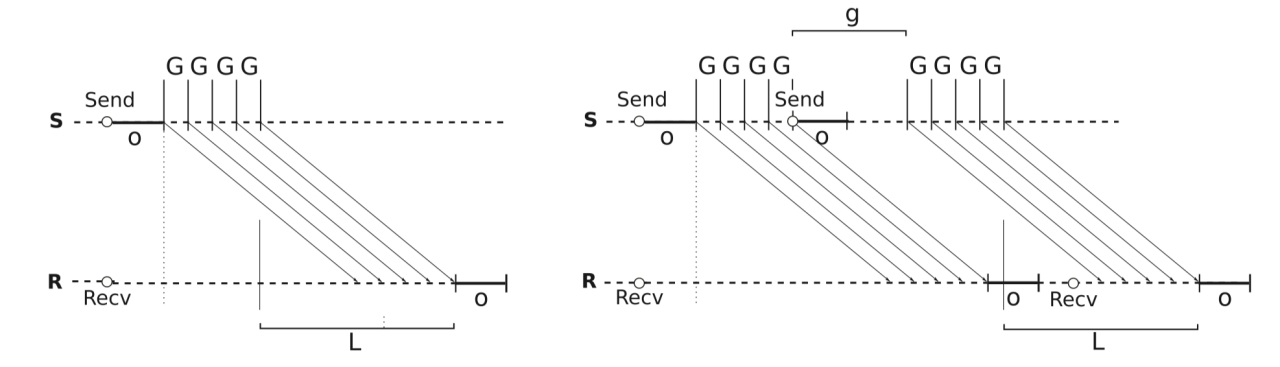
LogGP 模型对网络带宽建模无疑是更准确,发送单个消息是时间成本可表示为 $T_{p2p}=2o+L+(m-1)G$
发送 n 个消息为$T_{p2p}=2o+n\ast(L+(m-1)G)+(n-1)\ast g$
集合通信算法带宽影响因素
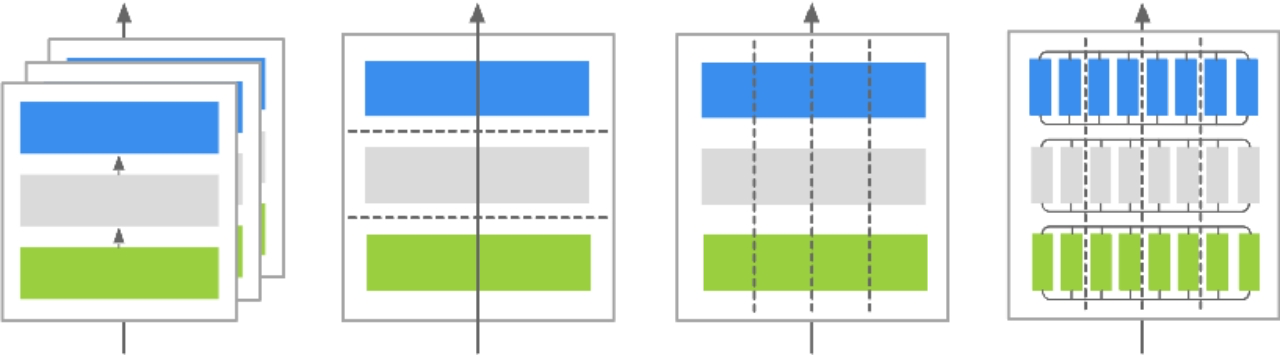
| 类型 | 操作 | 节点规模 | 数据量 | 备注 |
|---|---|---|---|---|
| TP | allreduce、allgather、reducescatter | 64chip | MB-GB | Matmul流水,隐藏部分通信 |
| PP | Send/Recv | 2chip | KB-MB | 可隐藏流水 |
| DP | allreduce | 1000+ chip | GB | 计算通信重叠,可隐藏流水 |
| EP | all2all | 256chip | KB-MB | 计算通信串行,不可隐藏 |
集合通信算法带宽
集合通信算法带宽 = $\frac{Data}{\sum_{k=1}^nargmax(X_{i,j},k)}$
$X_{i,j},k\;=\;\frac{Data}{\mathrm{物理带宽}\times\mathrm{带宽利用率}\times\mathrm{收敛比}\times\mathrm{拥塞比}}+T_{\mathrm{通信抖动}}+T_{\mathrm{通信启动}}+T_{\mathrm{静态时延}}$
其中:
- $X_{i,j},k$ 第 K 个数据切片在 rank i 跟rank j 之间数据传输完成时间
- argmax:集合通信性能受限于短板效应,所以取最大完成的时间
制约
-
互联拓扑:收敛比
- 硬件能力IO Die & 交换芯片:物理带宽
- 物理调度 & 网络拓扑& 通信算法 HCCL:Data 、通信抖动、静态时延
- 通信协议短距离 UBC & 长距离 RoCE:: 通信抖动、静态时延、带宽利用率