TVM
1 | |
1 | |
1 | |
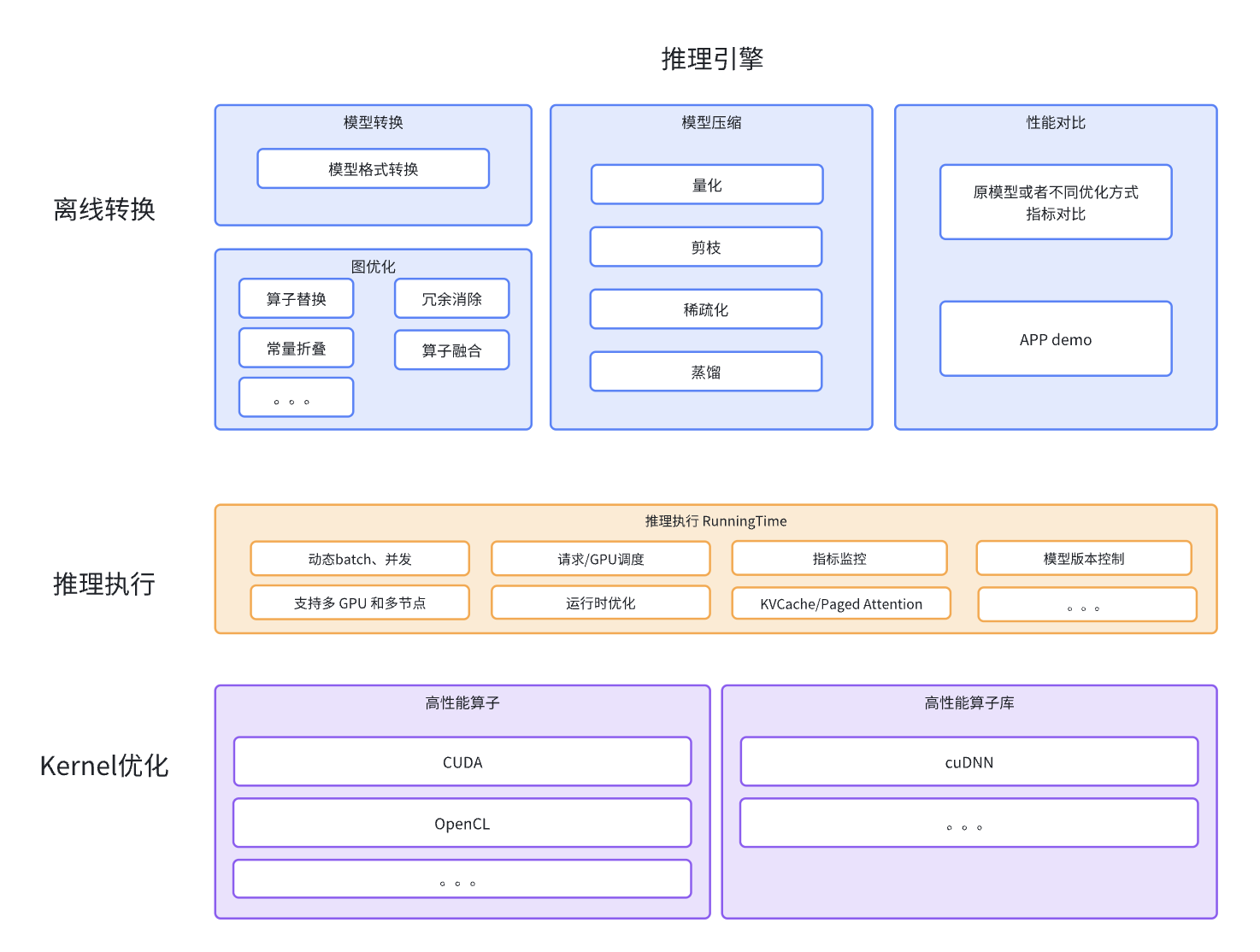
TensorRT相关总览
需要到的镜像
https://catalog.ngc.nvidia.com/containers 参考类似docker hub
-
nvcr.io/nvidia/tensorrt:24.05-py3
- 说明 https://docs.nvidia.com/deeplearning/tensorrt/container-release-notes/index.html
-
nvcr.io/nvidia/tritonserver:24.05-py3
-
nvcr.io/nvidia/tensorflow:24.05-tf2-py3
-
nvcr.io/nvidia/pytorch:24.05-py3
-
nvcr.io/nvidia/tritonserver:24.05-trtllm-python-py3
TensorRT
1 | |

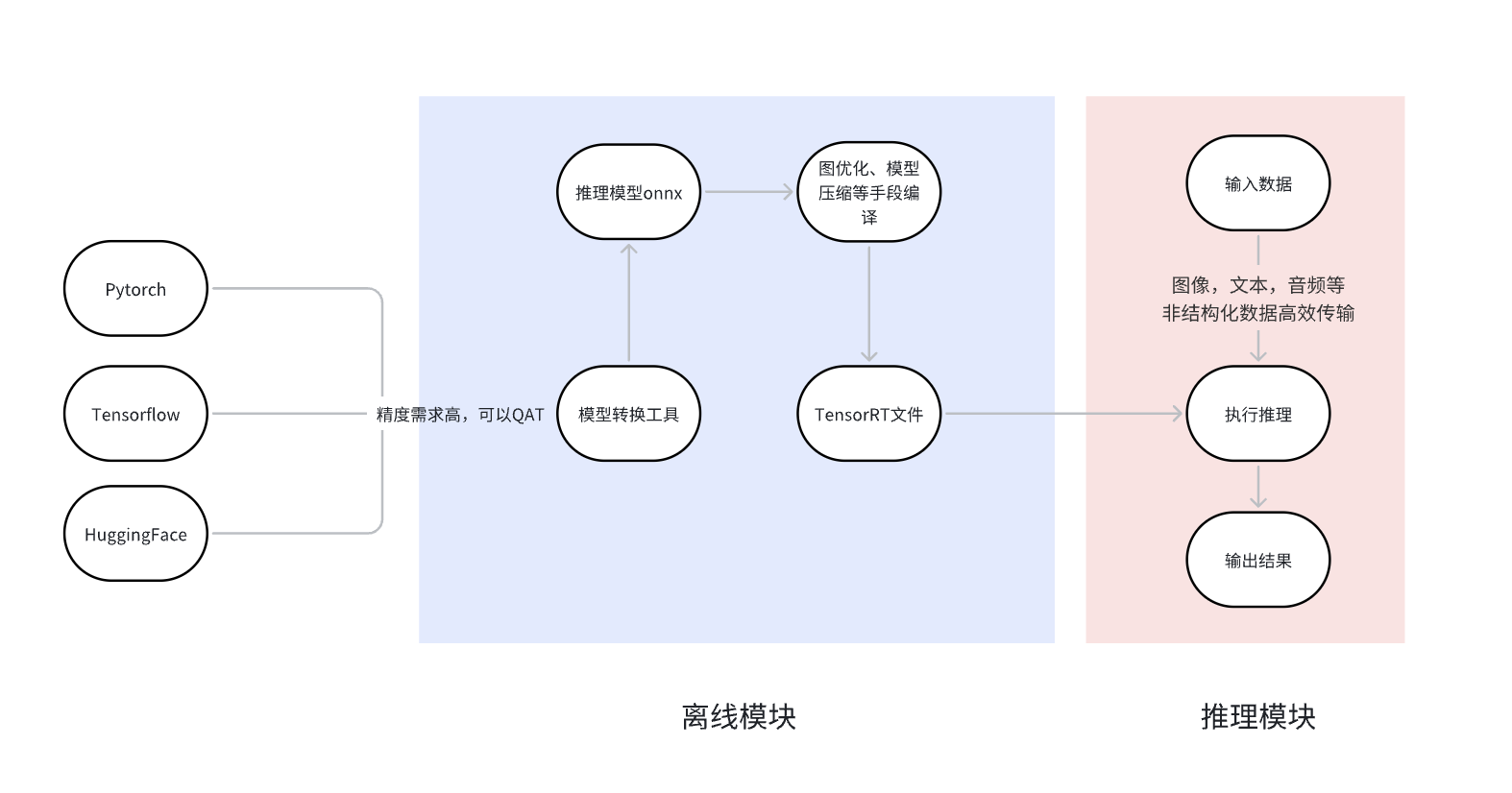
PyTorch 原生支持ONNX 导出。对于 TensorFlow,推荐的方法是tf2onnx。

- 对于计算密集型:矩阵乘法和卷积,使用高效算子
- 对于缓存密集型:使用算子融合,减少缓存和拷贝的数据量,提高访问效率。
- 使用低精度:精度损失可以允许的条件下,减少推理时间,和内存显存使用量
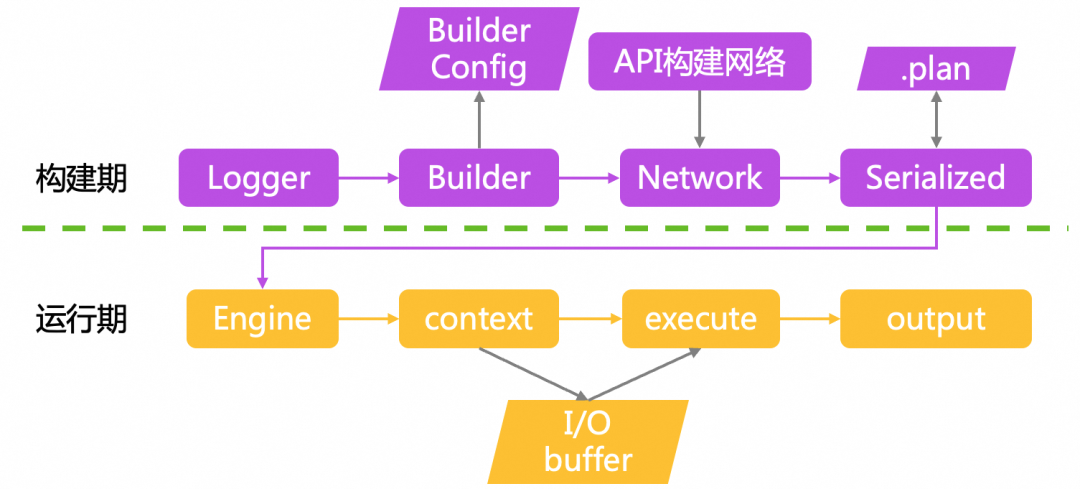
TensorRT 分为两个阶段运行。
-
第一阶段通常是离线执行的构建阶段您需要为 TensorRT 提供模型定义,TensorRT 会针对目标 GPU 对其进行优化。
-
创建网络定义。NetworkDefinition(C++, Python) 怎样从onnx转换到TensorRT,用到Layer (C++, Python) and Tensor (C++, Python) interfaces.
-
调用构建器来创建引擎。构建器会消除无效计算,折叠常数,并重新排序和组合操作,以便在GPU上更高效地运行。它可以选择降低浮点计算的精度,可以通过简单地在16位浮点数中运行它们,或者通过量化浮点值使计算可以使用8位整数进行。它还会用不同的数据格式计时每个层的多个实现,然后计算出一个最佳的执行计划,以最小化内核执行和格式转换的综合成本。
构建器以序列化的形式创建引擎,称为计划 plan,可以立即反序列化,或保存到磁盘以备将来使用。
-
-
第二阶段,您可以使用优化后的模型运行推理。 Runtime (C++, Python).
- 使用运行时时,通常会执行以下步骤:
- 反序列化一个计划来创建一个引擎。
- 从引擎创建执行上下文。
- 然后,重复以下步骤:
- 为推理填充输入缓冲区。
- 在执行上下文上调用enqueueV3()以运行推理
Engine interface (C++, Python) 表示一个经过优化的模型。您可以查询引擎以获取有关网络的输入和输出张量的信息 - 例如预期的维度、数据类型、数据格式等等。从引擎创建的执行
ExecutionContext interface (C++, Python)是调用推理的主要接口。执行上下文包含与特定调用相关联的所有状态 - 因此您可以将多个上下文与单个引擎关联,并在并行执行中运行它们。
在调用推理时,必须在适当的位置设置输入和输出缓冲区。根据数据的性质,这可以在CPU或GPU内存中。如果根据您的模型不明显,可以查询引擎以确定在哪个内存空间提供缓冲区。
缓冲区设置好后,可以将推理加入队列(enqueueV3)。所需的内核将排队在CUDA流上,并尽快将控制返回给应用程序。某些网络需要在CPU和GPU之间进行多次控制传输,因此控制可能不会立即返回。要等待异步执行完成,请在流上同步使用 cudaStreamSynchronize。
- 使用运行时时,通常会执行以下步骤:
- onnx-to-trt
- 直接构造network
- 使用 cuBLAS 实现 Hardmax 层,将实现包装在 TensorRT 插件,Python 中动态加载此库
- 权重剥离 sample_weight_stripping 重新调整后的完整引擎用于推理,保证不会损失性能和准确性
- 替换原始 ONNX 模型中不受支持的节点(HardMax / Compress)
- TensorRT 构建引擎时显示动画进度条
trtexec
https://github.com/NVIDIA/TensorRT/issues/3253 get sample data and trtexec
https://github.com/NVIDIA/TensorRT/blob/release/10.7/docker/ubuntu-22.04.Dockerfile
1 | |
1 | |
1 | |
如果您不知道输入张量的名称和形状,您可以通过使用Netron等工具可视化 ONNX 模型或在模型上 运行Polygraphy模型检查来获取信息。
1 | |
将解析您的 ONNX 文件,构建一个 TensorRT 计划文件,测量这个计划文件的性能,然后打印性能摘要,如下所示:
1 | |
它打印了很多性能指标,但最重要的两个指标是 吞吐量和中位延迟。在这种情况下,批处理大小为 4 的 ResNet-50 模型可以以每秒 507 次推理的吞吐量运行(由于批处理大小为 4,因此每秒 2028 张图像),中位延迟为1.969 毫秒。
1 | |
额外需要的依赖
1 | |
1 | |
Polygraphy
1 | |
Polygraphy 是一个工具包,旨在帮助运行和调试各种框架中的深度学习模型
除其他功能外,Polygraphy 还可以让您:
- 在多个后端(如 TensorRT 和 ONNX-Runtime)之间运行推理,并比较结果(例如:API、CLI)
- 将模型转换为各种格式,例如具有训练后量化的 TensorRT 引擎(例如:API、CLI)
- 查看各种模型的信息(例如:CLI)
- 在命令行上修改 ONNX 模型:
- 隔离 TensorRT 中的错误策略(例如:CLI)
NVIDIA DALI
NVIDIA 数据加载库 (DALI) 是一个 GPU 加速库,用于数据加载和预处理,以加速深度学习应用程序。它提供了一组高度优化的构建块,用于加载和处理图像、视频和音频数据。它可以用作流行深度学习框架中内置数据加载器和数据迭代器的便携式替代品。
深度学习应用需要复杂的多阶段数据处理管道,包括加载、解码、裁剪、调整大小和许多其他增强功能。这些数据处理管道目前在 CPU 上执行,已成为瓶颈,限制了训练和推理的性能和可扩展性。
DALI 通过将数据预处理转移至 GPU 来解决 CPU 瓶颈问题。此外,DALI 依靠自己的执行引擎,旨在最大限度地提高输入管道的吞吐量。预取、并行执行和批处理等功能对用户而言都是透明的。
Stable Diffusion
Stable-Diffusion-WebUI-TensorRT
1 | |
SDXL + A100 40G, 50 steps
| Time sec | Memory MiB | batch_size ,num_images_per_prompt = 1, step=50 | 优化 | 备注 |
|---|---|---|---|---|
| 6 | 8041 | 1 | baseline | |
| 29 | 10415 | 5 | baseline | |
| 29 | 10423 | 5 | vae | |
| 30 | 8537 | 5 | vae+cpu_offload | 内存节省多,会变慢 |
| 32 | 8583 | 5 | vae+cpu_offload + xformers | xformers 好像没什么用 |
| 11 | 10063 | 5 | vae+cpu_offload + xformers+DeepCache | DeepCache 加速明显 内存上升 |
| 8 | 9763 | 5 | vae+cpu_offload + xformers+DeepCache+ Tgate | 只用Tgate 不太明显 得配合DeepCache 用 |
| 19 | 8837 | 5 | vae+cpu_offload + xformers+ Tgate | |
| 19 | 28667 | 4 | tensorRT demo | 最大只能batch_size = 4 占用显存几乎翻倍,也不支持lora int8编译内存超过64G ,128G可以, |
| 16 | 26493 | 4 | tensorRT int8 demo | |
| https://github.com/huggingface/diffusion-fast torch编译 | 显卡A100 40G 显存爆 | |||
| 11 | 11353 | 5 | vae+cpu_offload + xformers+DeepCache+ fuse_qkv_projections | |
| 8 | 11055 | 5 | vae+cpu_offload + xformers+DeepCache+ Tgate+fuse_qkv_projections | |
| 3 | 7113 | 5,step=8 | sdxl-light + vae+cpu_offload + xformers | 推理显存 批量小的话可以,不用cache 对加速影响不大但提高显存占用 |
1 | |
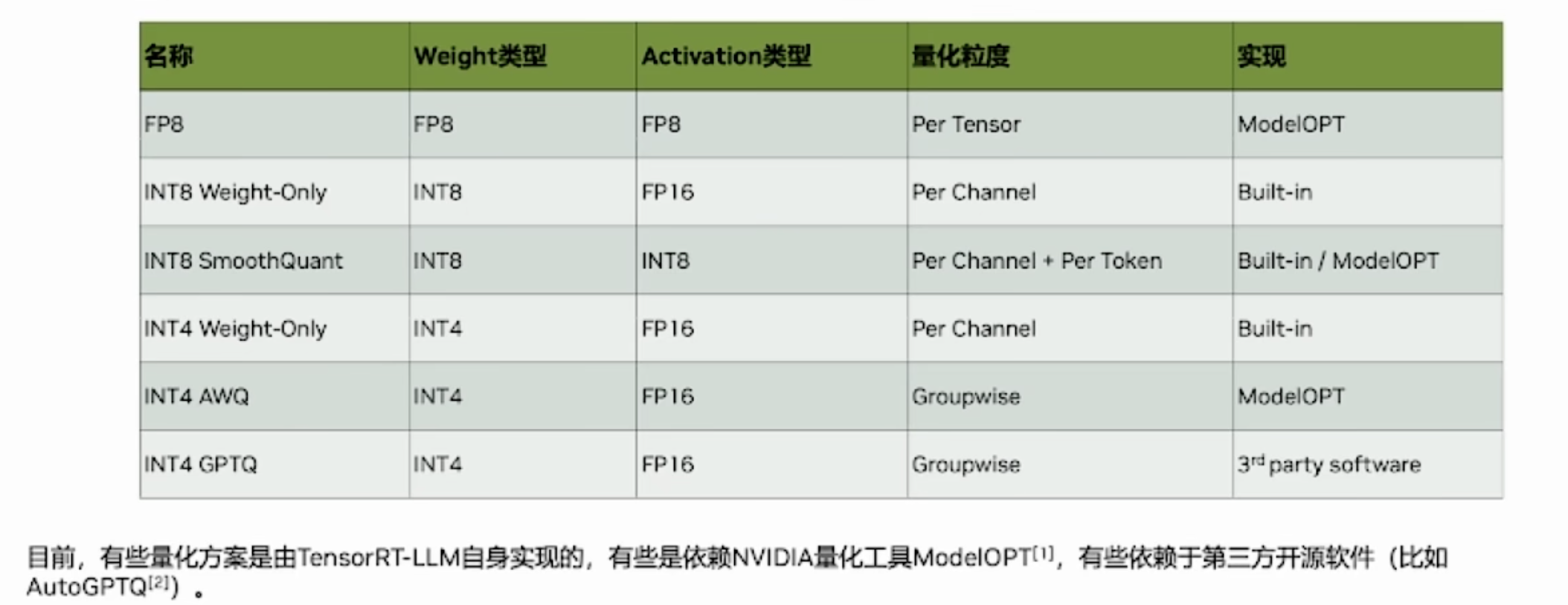
量化压缩
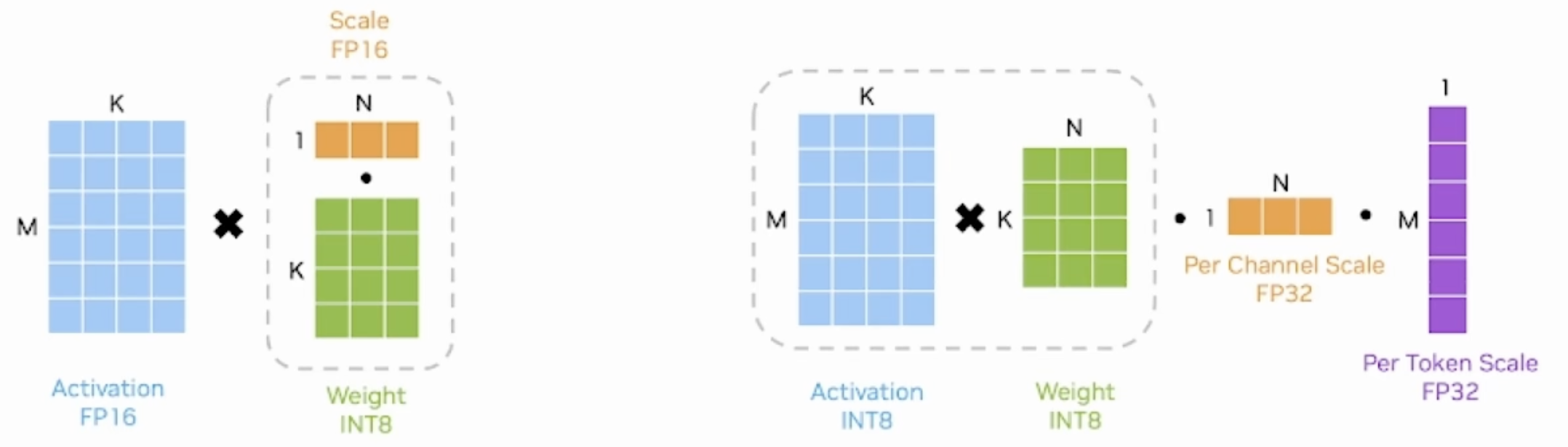
TensorRT 支持使用低精度类型来表示量化浮点值。量化方案是对称量化 - 量化值以有符号 INT8、FP8E4M3(简称 FP8)或有符号 INT4 表示,从量化值到非量化值的转换只是乘法。在相反方向上,反量化使用倒数比例,然后进行舍入和限制。
TensorRT 将激活和权重量化为 INT8 和 FP8。对于 INT4,仅支持权重量化。
量化网络可以通过两种(互斥的)方式处理:使用隐式量化或显式量化。
两种处理模式之间的主要区别在于您是否需要显式控制量化
- 隐式量化 : PTQ且各层精度不可控(哪个精度快用哪个)
- 显式量化 : PTQ(QDQ) 和 QAT(QDQ)
| 隐式量化 | 显式量化 | |
|---|---|---|
| Supported quantized data-types | INT8 | INT8, FP8, INT4 |
| User control over precision | Global builder flags and per-layer precision APIs. | Encoded directly in the model. |
| API | Model + Scales (dynamic range API)Model + Calibration data | Model with Q/DQ layers. |
| Quantization scales | Weights:Set by TensorRT (internal)Per-channel quantizationINT8 range [-127, 127] Activations:Set by calibration or specified by the userPer-tensor quantizationINT8 range [-128, 127] |
Weights and activations: Specified using Q/DQ ONNX operatorsINT8 range [-128, 127]FP8 range: [-448, 448]INT4 range: [-8, 7] Activations use per-tensor quantization. Weights use either per-tensor quantization, per-channel quantization or block quantization. |
隐式量化
隐式量化仅在量化 INT8 时受支持,并且不能与强类型一起使用(因为类型不是自动调整的,并且将激活转换为 INT8 和从 INT8 转换为激活的唯一方法是通过 Q/DQ 运算符)。
当网络具有 QuantizeLayer和DequantizeLayer。当没有QuantizeLayer或者 DequantizeLayer网络中的层数,并且在构建器配置中启用了 INT8。隐式量化模式仅支持 INT8。
在隐式量化网络中,每个作为量化候选的激活张量都有一个关联的尺度,该尺度由校准过程推导出来或由 API 函数指定setDynamicRange如果 TensorRT 决定量化张量,它将使用这个比例。
在处理隐式量化网络时,TensorRT 在应用图形优化时将模型视为浮点模型,并适时使用 INT8 来优化层执行时间。如果某个层在 INT8 中运行得更快,并且在其数据输入和输出上分配了量化尺度,则将为该层分配具有 INT8 精度的内核。否则,将分配高精度浮点(即 FP32、FP16 或 BF16)内核。如果需要以牺牲性能为代价来提高精度,可以使用 API 指定Layer::setOutputType andLayer::setPrecision.
1 | |
显式量化
在显式量化网络中,量化和反量化操作明确表示为QuantizeLayer(C++、Python)和DequantizeLayer (C++、Python)节点 - 今后这些节点将被称为 Q/DQ 节点。与隐式量化相比,显式形式精确指定了执行量化类型转换的位置,并且优化器将仅执行由模型语义决定的量化类型的转换,即使:
- 添加额外的转换可以提高层精度(例如,选择 FP16 内核实现而不是量化类型实现)。
- 添加或删除转换会导致引擎执行速度更快(例如,选择量化类型内核实现来执行指定为具有高精度的层,反之亦然)。
训练后量化(PTQ) 将已经训练好的浮点模型的权重(weight)和激活值(activation)进行处理, 将它们转换成精度更低的类型。这个过程会导致量化后的模型准确率下降,使用小批量数据进行校准(Calibration),也叫 Calibration 后量化
量化感知训练(QAT) 在训练期间计算比例因子,向浮点模型中插入一些伪量化(FakeQuantize)算子来模拟量化和量化过程。这允许训练过程补偿量化和反量化操作的影响。 TensorRT在QAT量化时会插入FQ算子,其作用是将输入先进行量化为INT8,再反量化为FP32,在逻辑上表现为QDQ节点。
example
- QAT PTQ for example demo
- trtexec 美团 example
- efficientdet 量化
- efficientnet 量化 TensorFlow
- tensorflow_object_detection_api 量化
- detectron2 cnn 量化
TensorFlow-Quantization
We provide an open-source TensorFlow-Quantization Toolkit to perform QAT in TensorFlow 2 Keras models following NVIDIA’s QAT recipe. This leads to optimal model acceleration with TensorRT on NVIDIA GPUs and hardware accelerators. More details can be found in the NVIDIA TensorFlow-Quantization Toolkit User Guide.
TensorFlow 1 does not support per-channel quantization (PCQ). PCQ is recommended for weights in order to preserve the accuracy of the model.
1 | |
PyTorch-Quantization
PyTorch 1.8.0 and forward support ONNX QuantizeLinear/DequantizeLinear support per channel scales. You can use pytorch-quantization to do INT8 calibration, run quantization aware fine-tuning, generate ONNX and finally use TensorRT to run inference on this ONNX model. More detail can be found in NVIDIA PyTorch-Quantization Toolkit User Guide.
1 | |
自动插入QDQ
1 | |
控制是否需要量化, 可以通过这个去逐个量化,检查精度损失。
1 | |
替代 quant_modules.initialize
1 | |
自定义量化层
1 | |
pytorch-quantization classification_flow
定义我们的模型
2. 对模型插入 QDQ
3. 统计 QDQ 节点的 range 和 scale –> 标定
4. 做敏感度的分析 –> 需要知道,哪个层对精度指标影响比较大?? 关闭掉对精度影响大的层
5. 导出一个带 QDQ 节点 PTQ 的模型
6. 对模型进行 finetune –> QAT
TransformerEngine
We provide TransformerEngine, an open-source library for accelerating training, inference and exporting of transformer models. It includes APIs for building a Transformer layer as well as a framework agnostic library in C++ including structs and kernels needed for FP8 support. Modules provided by TransformerEngine internally maintain scaling factors and other values needed for FP8 training. You can use TransformerEngine to train a mixed precision model, export an ONNX model, and finally use TensorRT to run inference on this ONNX model.
1 | |
TensorRT Model Optimizer
TensorRT Model Optimizer是一个库,包含最先进的模型优化技术,包括量化和稀疏性(减少深度学习模型内存占用并加速推理的技术)以压缩模型。目前 ModelOpt 支持 PyTorch 和 ONNX 框架中的量化。ModelOpt 基于原始精度的模拟量化来模拟、测试和优化,以在模型精度和不同的低精度格式之间找到最佳平衡。为了实现实际的加速和内存节省,可以将具有模拟量化的模型导出到部署框架,例如 TensorRT 或 TensorRT-LLM
1 | |
代码示列 https://github.com/NVIDIA/TensorRT-Model-Optimizer?tab=readme-ov-file#examples
推理服务
cuda-python
pycuda 推理代码 SemanticSegmentation example
sample onnx_resnet50 trt example
Triton Inference Server
Triton 推理服务器使团队能够从多个深度学习和机器学习框架部署任何 AI 模型,包括 TensorRT、TensorFlow、PyTorch、ONNX、OpenVINO、Python、RAPIDS FIL 等。Triton 支持在 NVIDIA GPU、x86 和 ARM CPU 或 AWS Inferentia 上跨云、数据中心、边缘和嵌入式设备进行推理。Triton 推理服务器为许多查询类型提供优化的性能,包括实时、批处理、集成和音频/视频流。
基于 NVIDIA Triton 推理服务器端到端部署 LLM serving
TensorRT-LLM
TensorRT-LLM可加速并优化 NVIDIA GPU 上最新大型语言模型 (LLM) 的推理性能
TensorRT-LLM 提供了一个全面的库,用于编译和优化 LLM 以进行推理。TensorRT-LLM 集成了所有优化(即内核融合和量化、运行时优化(如 C++ 实现)、KV cache、In-Flight Batching和Paged Attention)等,同时提供了直观的 Python API 来定义和构建新模型。
1 | |
矩阵量化
- per tensor(亦称layerwise)
- 整个矩阵看作集合S,矩阵中的所有元素共享一个缩放系数
- 优点在于简单,全局只有一个缩放系数
- 缺点也很明显,如果矩阵中数值尺度相差悬殊,那么大尺度的数值会导致一个很小的缩放系数,从而导致小尺度的数值趋于零甚至归零。而大语言模型常常具有这种数值分布特征,所以通常不使用per tensor,尤其是使用线形量化时。
- per channel(亦称channelwise)
- 如果集合S内的数值波动越小,那么缩放系数就能越大,量化精度就越高。另一方面,如果S内的个数越少,出现大幅波动的概率也就越小,于是自然想到,将矩阵分片量化能提高量化精度,且分片越小,精度就越高。
- 将矩阵每一列作为一个分片进行量化,每一列内的所有元素共亨一个缩放系数,而列之间相互独立,这便是per channel量化,能增加数值之间的区分度,保留更多的源分布信息。
- 当然,按行分片也是可行的。在矩阵乘法AxB中,我们通常将A按行量化,将B按列量化,即原则上是沿着内维度(inner dimension)量化。换言之,假设A为MxK矩阵,B为KxN矩阵,则沿K维度量化,A有M个行缩放系数,B有N个列缩放系数。
- 在LLM中,A通常为activation,其每一行是某一个token的embedding,因此我们把A的按行量化也称为per token量化
- groupwise
- 相对于分片,进一步提高精度。Groupwise是将G个元素看作集合S进行数值是化,G称为group size.
- 代价是缩放系数的个数膨胀,从per channel的N到 $\frac{M\times N}{group_size}$, 其中M为短阵行数,N为矩阵列数。
- 随着分片粒度变小,精度越来越高,而量化开销越大,这需要折衷,事实上,对于一个MxN的矩阵,per channel只是groupwise在group_size=M时的特例,per tensor则是group_size =MxN时的特例。
反量化
在构建模型时,各层的权重已经完成了量化。在推理过程中,根据activation是否使用量化数值类型,又可分为两大类weight-only,weiaht & activation。它们决定了短阵乘法过程中,反量化操作的执行时机
- 以典型的INT8 weight-only量化为例,其weight是per channel量化的INT8,而activation使用FP16类型。在推理时,需要先按列乘以scale将weight反量化为FP16,再与activation相乘
- SmoothQuant方法是weight&activation量化,其weight和activation都使用INT8类型,所以有两组缩放系数,一组是用于wcight的per-channel scale,一组是用于activation的per-token scale。先执行INT8的矩阵乘法,再分别按列、按行乘以两组缩放系数
- 是一种同时确保准确率且推理高效的训练后量化 (PTQ) 方法,可实现 8 比特权重、8 比特激活 (W8A8) 量化。由于权重很容易量化,而激活则较难量化,因此,SmoothQuant 引入平滑因子s来平滑激活异常值,通过数学上等效的变换将量化难度从激活转移到权重上
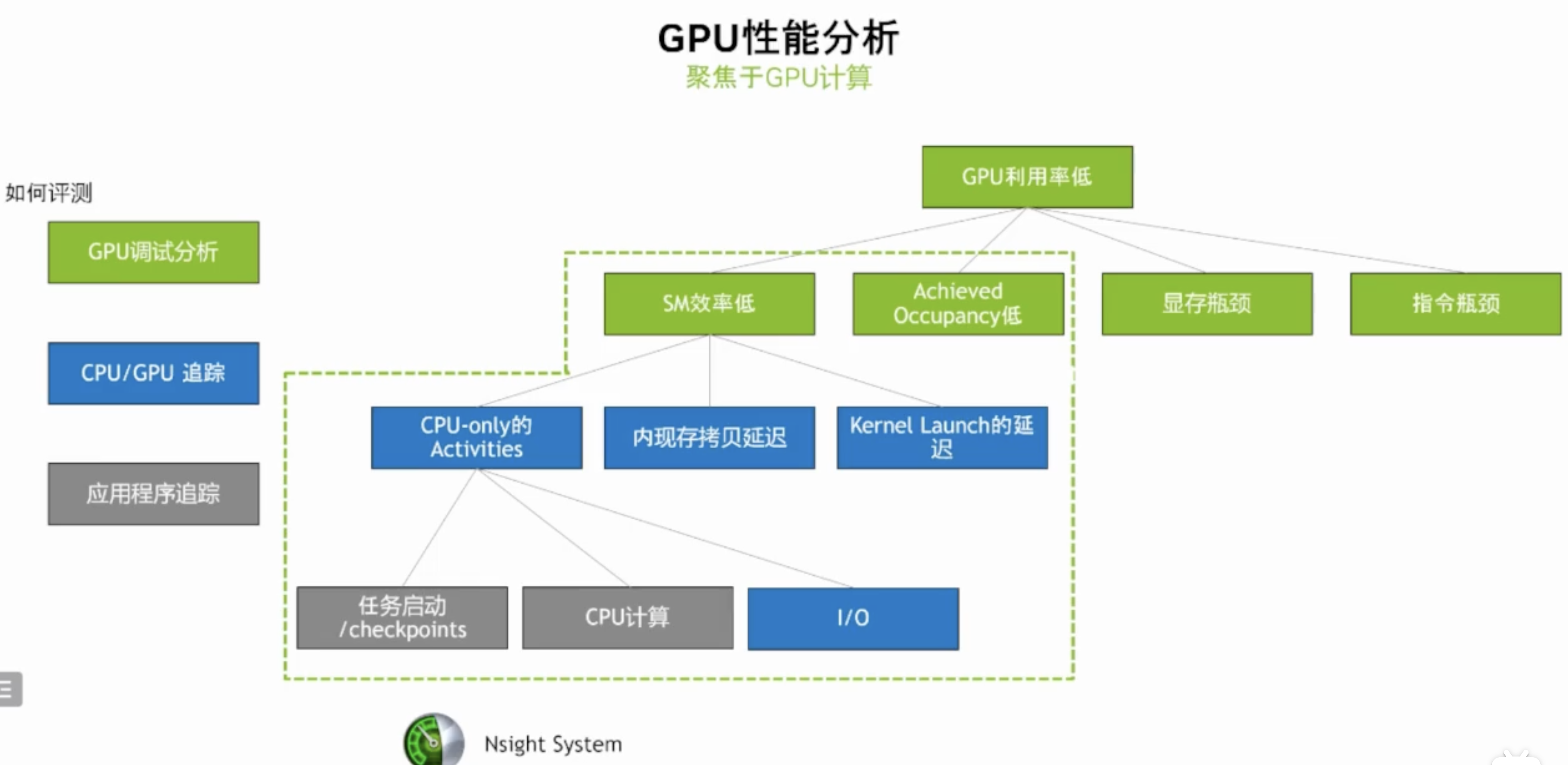
NVIDIA Nsight
使用 Nsight Systems可以了解应用程序的执行流程、确定性能瓶颈以及发现并行化的机会,针对单个程序,生产profile性能分析;而Nsight Compute与Nsight Systems不同,其是一款针对 CUDA 应用程序的内核(Kernel)级**性能分析和调试工具,它专注于 GPU 上的计算性能,提供了详细的性能指标、诊断和指导,帮助开发者优化 CUDA Kernel 的性能。DCGM用于管理和监控集群环境中的 NVIDIA 数据中心 GPU 的工具。它包括主动健康监控、全面诊断、系统警报和治理策略(包括电源和时钟管理)。它可以由基础设施团队独立使用,并可轻松集成到 NVIDIA 合作伙伴的集群管理工具、资源调度和监控产品中。
NVIDIA性能分析工具Nsight Systems/Compute 的使用介绍
【CUDA进阶】深入理解 Nsight System 和 Nsight Compute
Nsight Systems
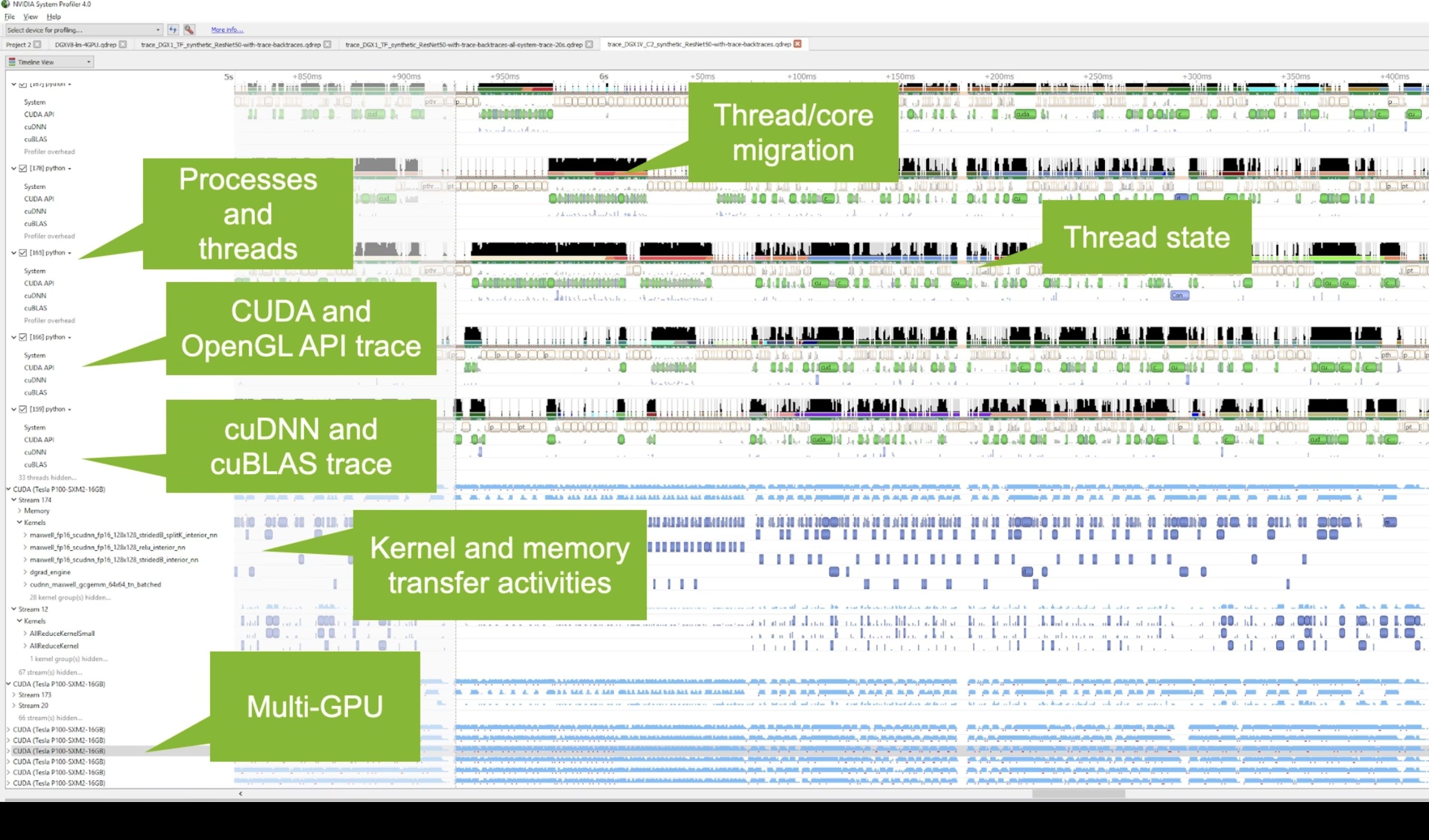
Get an overview of each theads activities
- Which core the thread isrunning and the utilization 线程正在运行的核心以及它的利用率
- CPU state and transition CPU的状态及其转换情况
- OS runtime libraries usage: pthread, file l/0, etc 操作系统运行时库的使用情况,比如pthread和文件I/O等
- API usage: CUDA, CUDNN,CuBLAS, TensorRT, .. API的使用情况,比如CUDA、CUDNN、CuBLAS和TensorRT等

CPU线程上的发生的CUDA runntime API调用
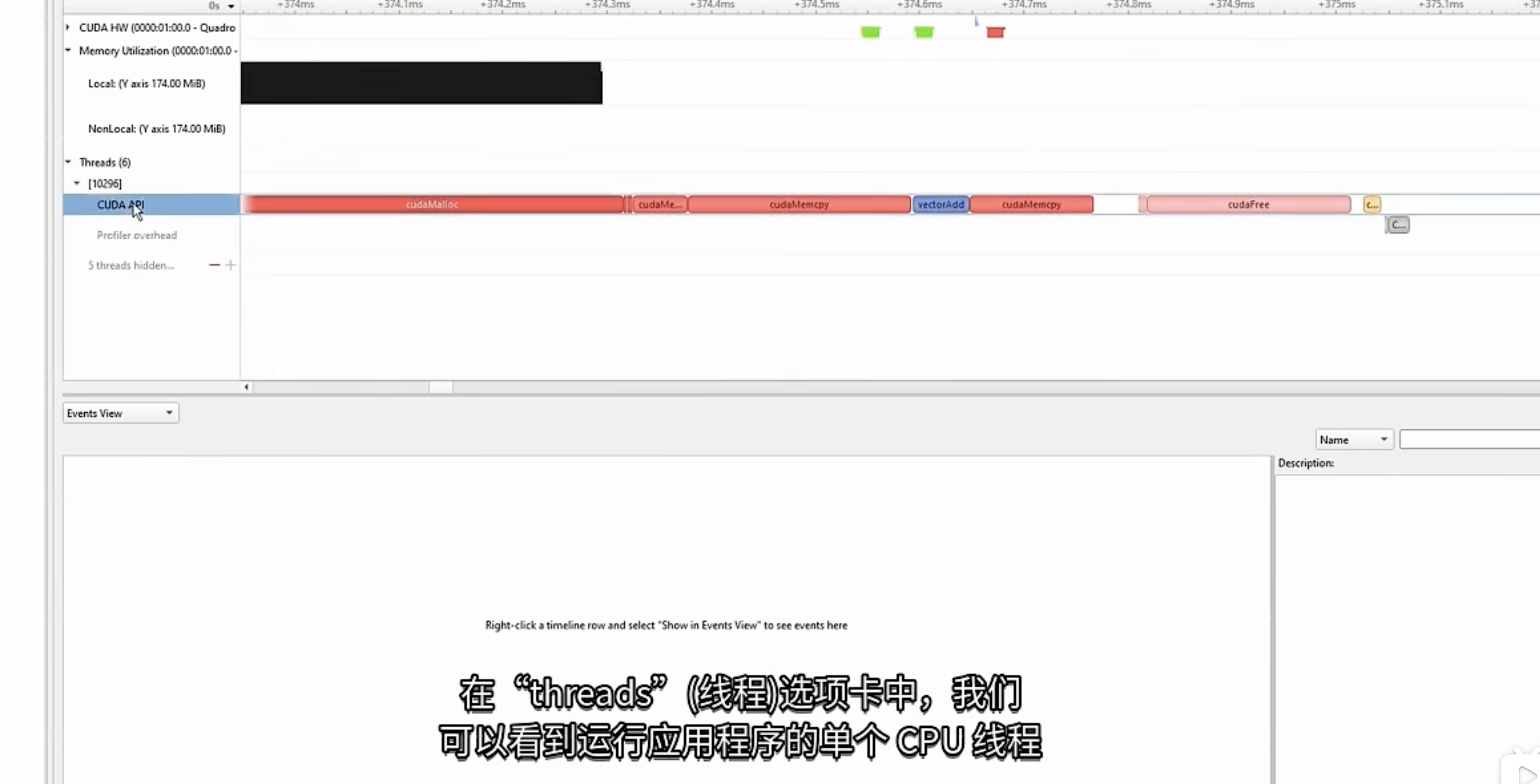
- cudaMalloc 为输入输出数据配GPU显存
- CUDAmemcpy 将输入数据从 CPU 复制到 GPU 显存 或者 显存到CPU
- cudaFree CUDA冻结调用,以清理之前分配的所有 GPU 资源
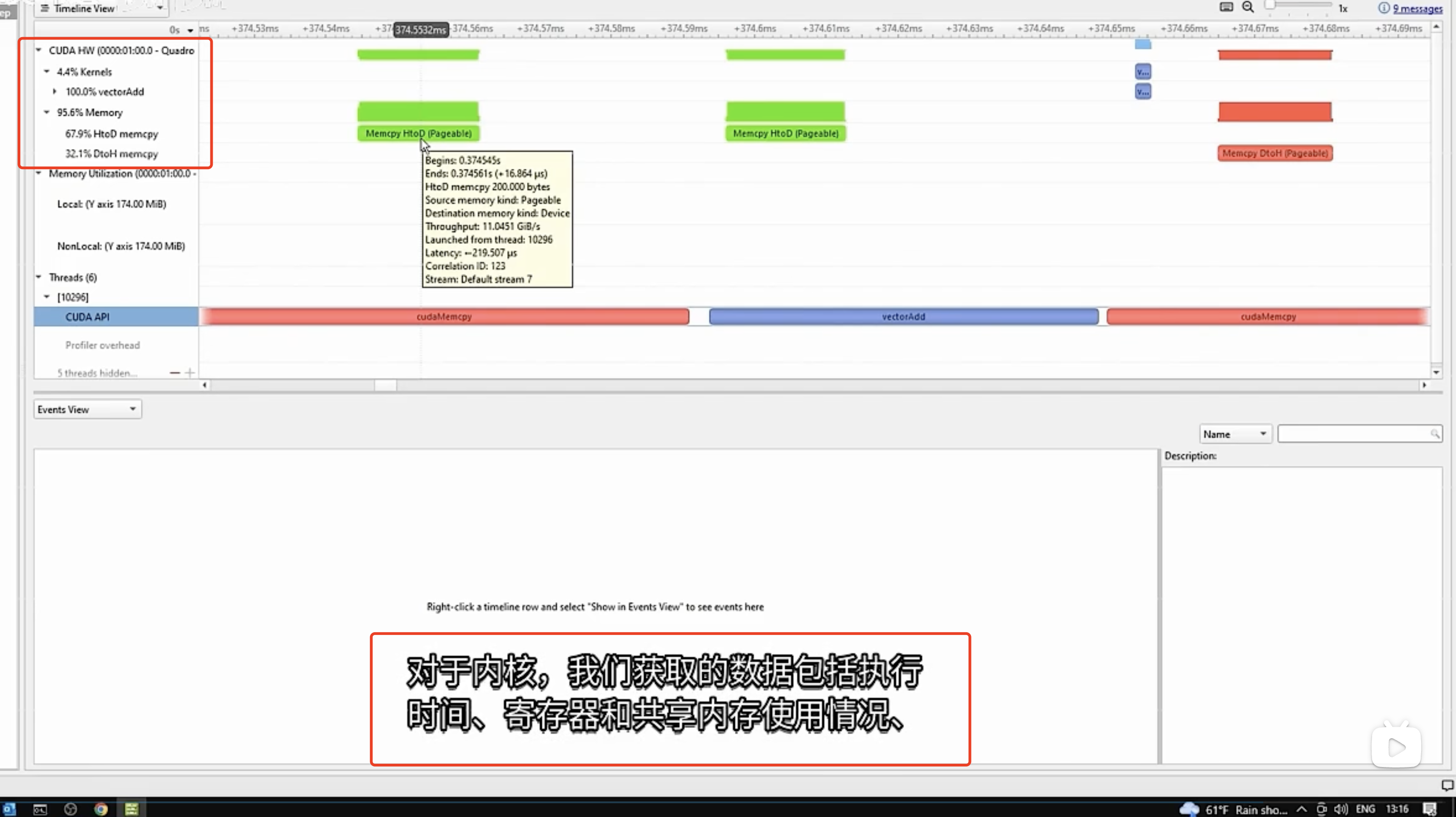
GPU运行的情况
1 | |

-
osrt OS runtime libraries
这会跟踪 C 运行时和 POSIX 线程 (pthread) 库公开的系统调用包装器和线程同步接口。这不会执行完整的运行时库 API 跟踪,而是专注于可能需要f很长时间才能执行的函数,或者在等待事件完成时可能导致线程从 CPU 中取消调度的函数。
-
允许用户手动检测其应用程序。然后,Nsight Systems 可以收集信息并将其显示在时间线上。
通常,即使应用程序不是为分析目的而构建的,对 NVTX 函数的调用也可以保留在源代码中,因为当未连接分析器时,开销非常低。
NVTX 不适用于注释非常频繁调用的非常小的代码片段。一个好的经验法则是:如果注释的代码通常需要不到 1 微秒的执行时间,则应谨慎地在此代码周围添加 NVTX 范围。
加入nvtx 注释



-
Nsight Systems 能够捕获有关分析过程中 CUDA 执行的信息。
可以收集以下信息并将其显示在报告的时间线上:
- CUDA API 跟踪 — 应用程序进行的 CUDA 运行时和 CUDA 驱动程序调用的跟踪。
- CUDA 运行时调用通常以
cuda前缀开头(例如cudaLaunch)。 - CUDA 驱动程序调用通常以
cu前缀开头(例如cuDeviceGetCount)。
- CUDA 运行时调用通常以
- CUDA 工作负载跟踪 — GPU 上发生的活动跟踪,包括内存操作(例如主机到设备的内存复制)和内核执行。在使用 CUDA API 的线程中,时间线树中会出现额外的子行。
- 在 Nsight Systems Workstation Edition 上,cuDNN 和 cuBLAS API 跟踪以及 OpenACC 跟踪
cudaMemcpyAsync是 CUDA 中用于在主机(Host)和设备(Device)之间异步复制数据的函数。HtoD和DtoH分别表示从主机到设备(Host to Device)和从设备到主机(Device to Host)的数据传输。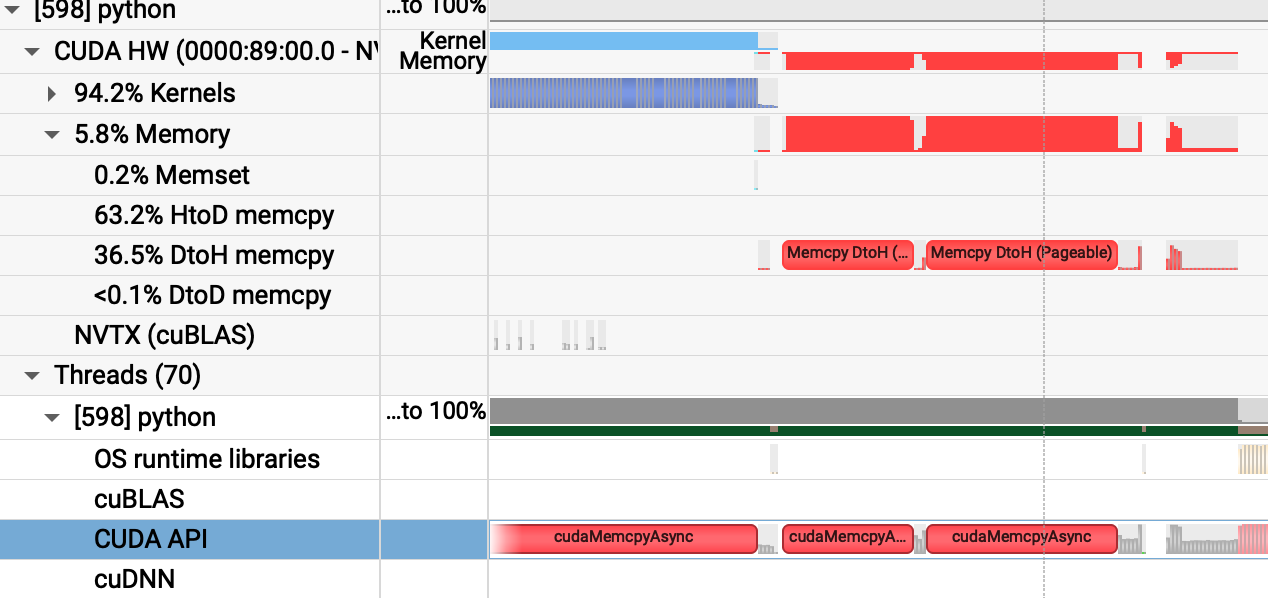
- CUDA API 跟踪 — 应用程序进行的 CUDA 运行时和 CUDA 驱动程序调用的跟踪。
-
GPU 上下文切换
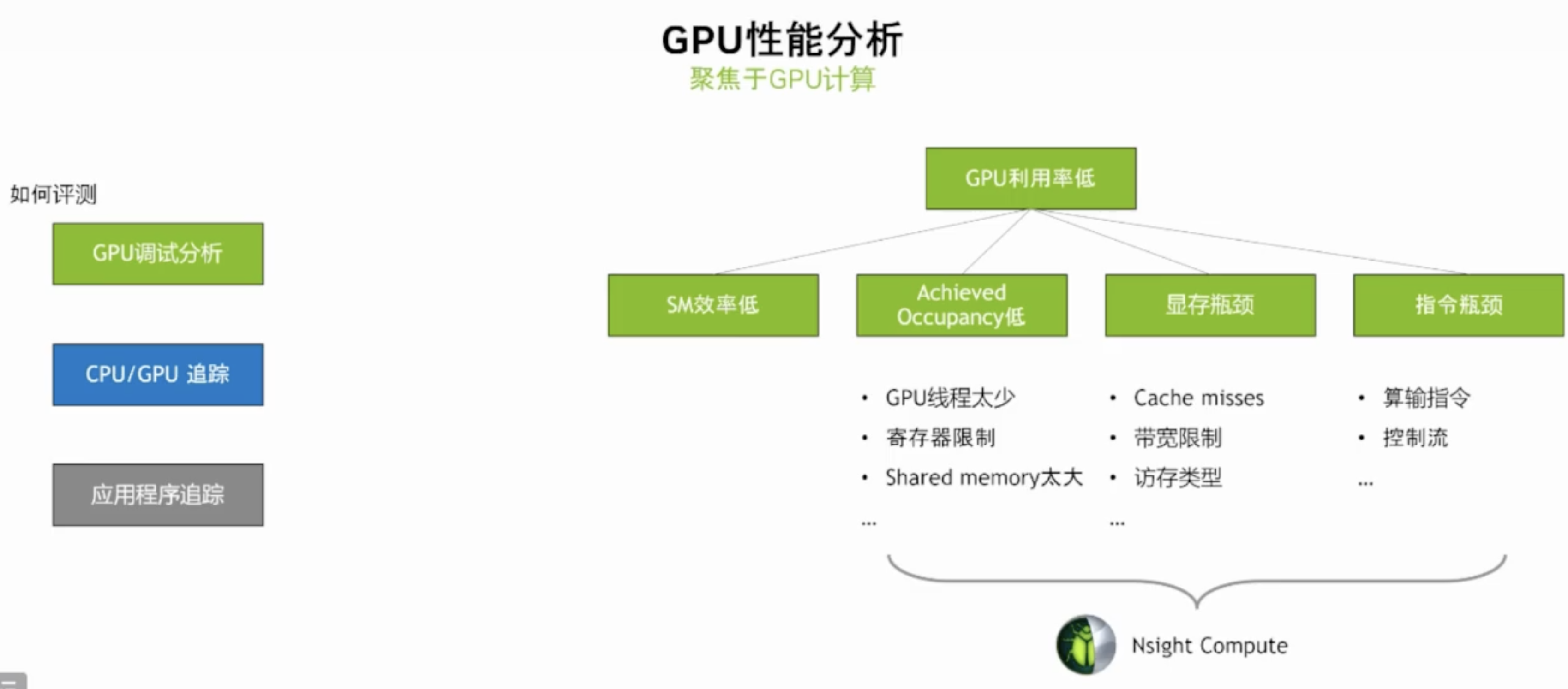
--gpuctxsw, 所有进程的上下文记录。这些记录具有有效的上下文 ID 和进程 ID,并具有全精度时间戳。GPU 指标功能
--gpu-metrics-device=[all, none, <index>]旨在识别使用 GPU 进行计算和图形处理的应用程序的性能限制因素。它使用定期采样来收集与不同 GPU 硬件单元相关的性能指标和详细时间统计信息,并利用专用硬件以最小的开销一次性捕获这些数据。这些指标概述了 GPU 在计算、图形和输入/输出 (IO) 活动中随时间变化的效率,例如:
- IO 吞吐量: PCIe、NVLink 和 GPU 内存带宽
- SM 利用率: SM 活动、张量核心活动、发出的指令、扭曲占用率和未分配的扭曲槽
它旨在帮助用户回答常见问题:
- 我的 GPU 空闲吗?
- 我的 GPU 满了吗?内核网格大小和流够用吗?我的 SM 和 warp 槽满了吗?
- 我正在使用 TensorCores 吗?
- 我的指导率高吗?
- 我可能被 I/O 或 Warp 数量等堵塞了吗?
大量内核操作
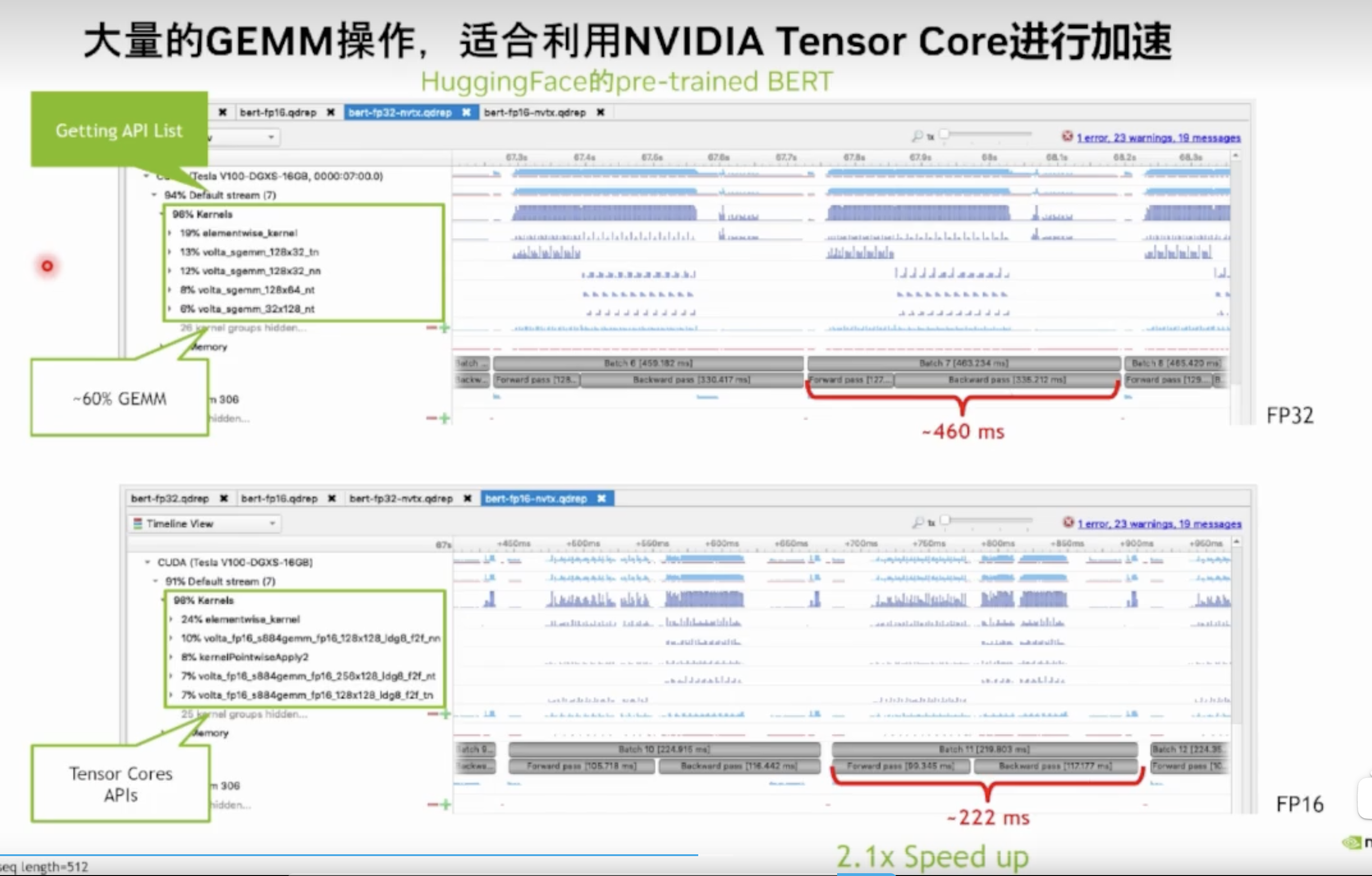
常用命令
1 | |
自定义监控点
只能生成.qdstrm,这个中间文件,生成.nsys-rep 失败
1 | |
Nsight Compute
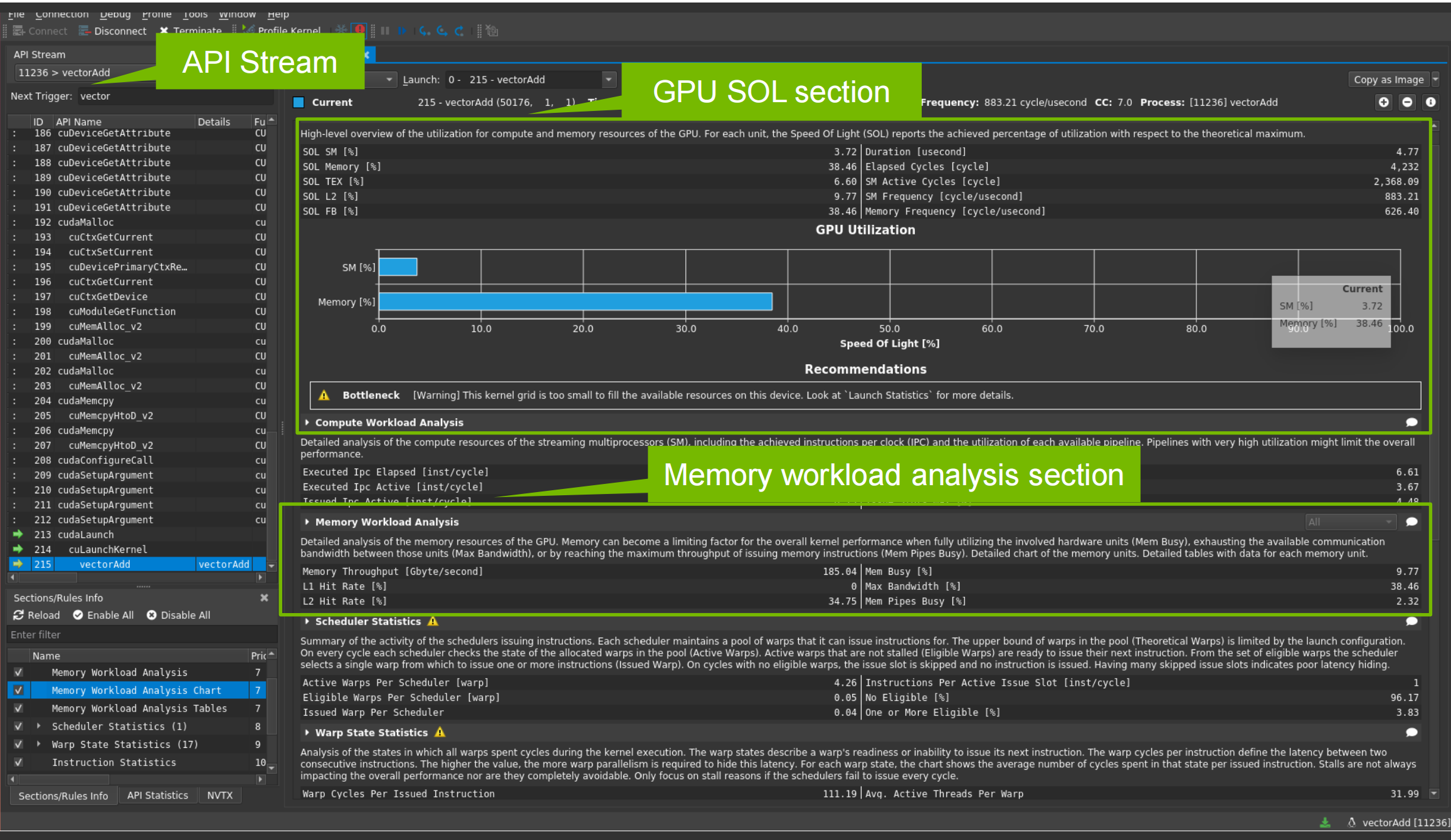
GPU speed of Light Throughput
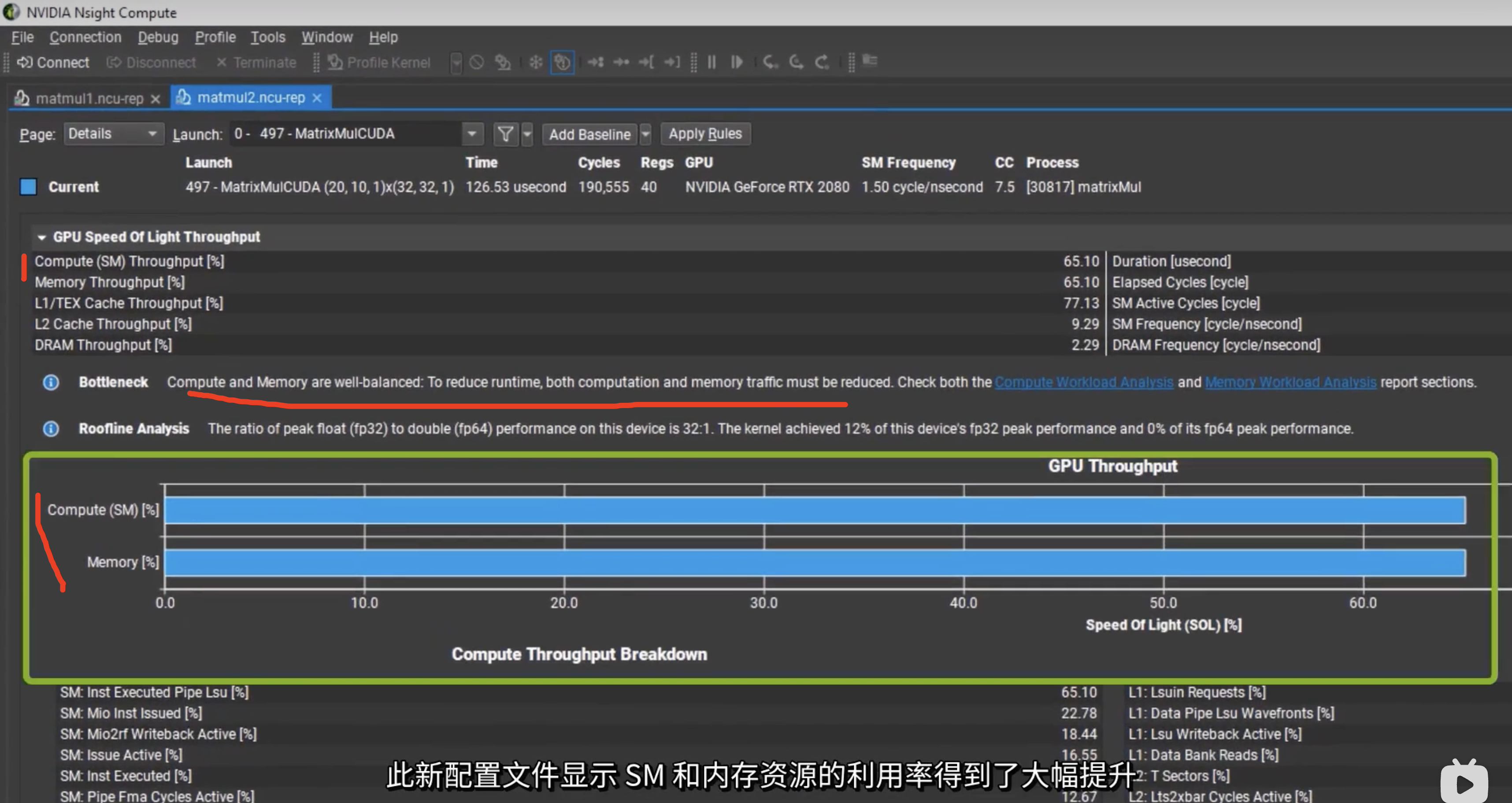
根据提示提高GPU利用率
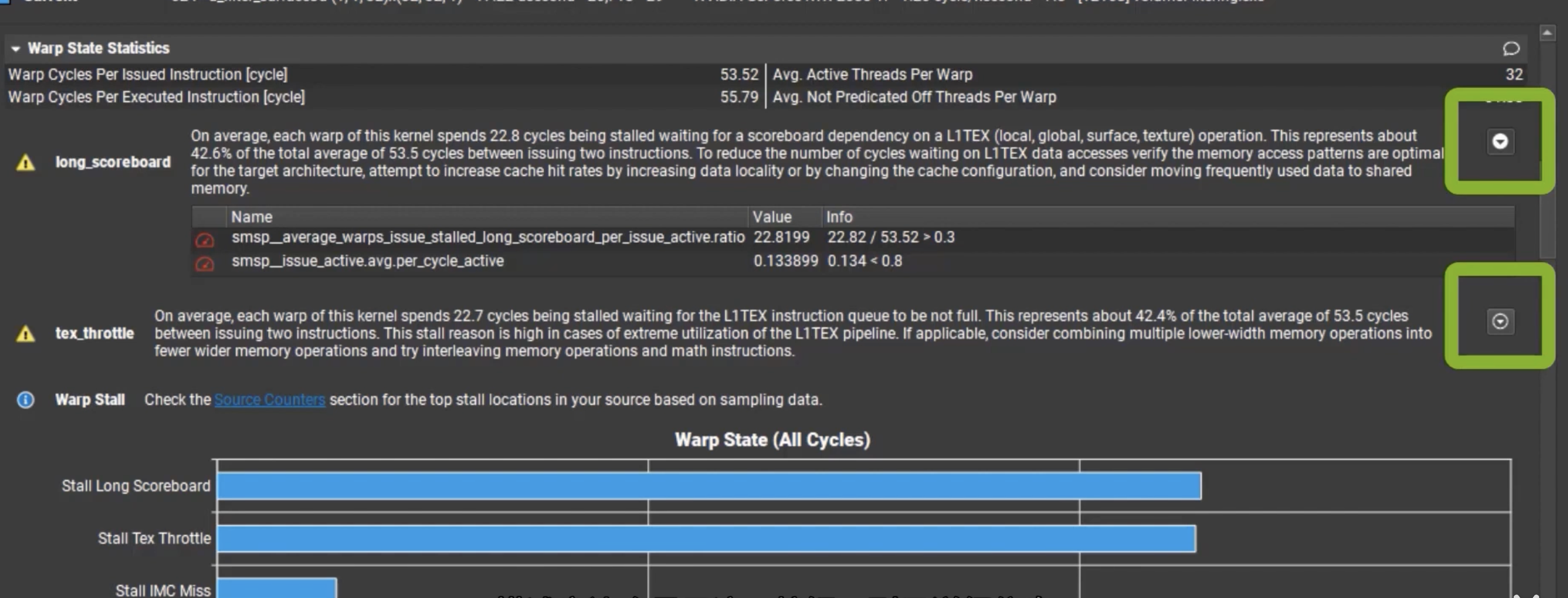
Warp State Statistics
线程束状态统计数据部分中查看具有多个问题的内核

本部分提供了在内核执行期间,线程束在各状态下消耗的周期,对于每种状态,图表都显示了每个发出指令。一般来说,在某种停滞状态中消耗的周期越多,影响性能的可能性就越大。
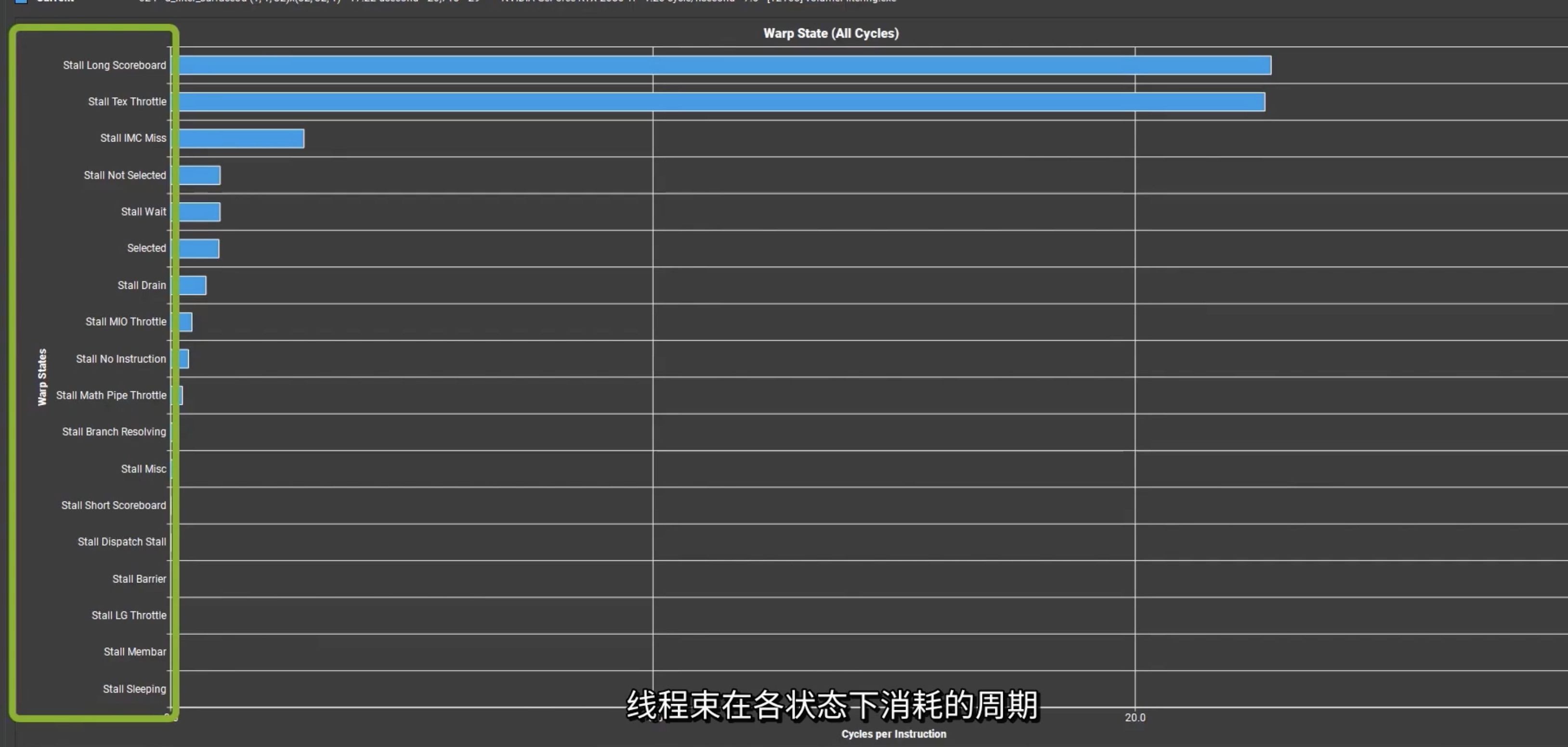
这里可以获取更详细信息
baseline
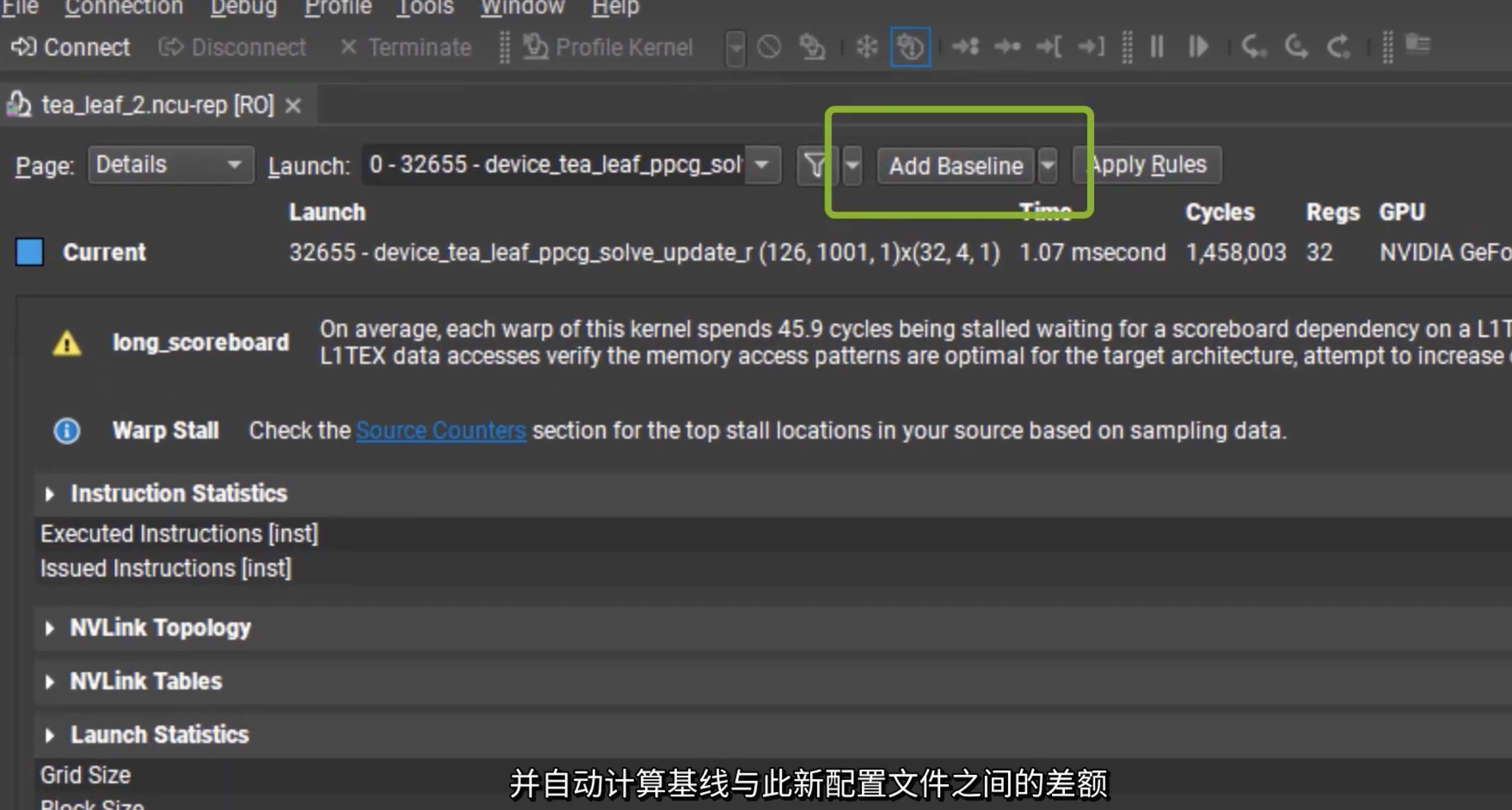
性能指南
-
最大化并行执行,实现最大利用率;
应用层
- Host的串行工作负载;Device的并行工作负载。需要线程间通信的计算尽可能在单个线程块内执行。
Device:
- 在较低层次上,应用程序应该最大化设备多处理器之间的并行执行。
- 多个内核可以在一个设备上同时执行,因此也可以通过使用流来使足够多的内核同时执行(如异步并发执行中所述),从而实现最大利用率。
多处理器级别
- GPU 多处理器主要依靠线程级并行来最大限度地提高其功能单元的利用率。因此,利用率与驻留 warp 的数量直接相关。每次发出指令时,warp 调度程序都会选择一条准备执行的指令。
-
优化内存使用情况,实现最大的内存吞吐量;
- 尽量减少低带宽的数据传输
- 尽量减少主机和设备之间的数据传输,因为它们的带宽比全局内存和设备之间的数据传输低得多。
- 一次大传输总是比单独进行每次传输效果更好
- 最大限度地利用片上内存来最大限度地减少全局内存和设备之间的数据传输:共享内存和缓存
- 尽量减少主机和设备之间的数据传输,因为它们的带宽比全局内存和设备之间的数据传输低得多。
- 尽量减少低带宽的数据传输
-
优化指令使用,实现最大的指令吞吐量;
- 尽量减少使用低吞吐量的算术指令;这包括在不影响最终结果的情况下用精度换取速度
- 尽量减少由控制流指令引起的Control Flow Instructions
- 减少指令数量
-
尽量减少内存抖动。
- 频繁分配和释放内存的应用程序可能会发现,分配调用会随着时间的推移而变慢,直至达到极限。
- 不要尝试使用
cudaMalloc/cudaMallocHost/cuMemCreate分配所有可用内存,因为这会强制内存立即驻留并阻止其他应用程序使用该内存。这可能会给操作系统调度程序带来更多压力,或者只是阻止使用相同 GPU 的其他应用程序完全运行。 - 尝试在应用程序早期分配适当大小的内存,并且仅在应用程序不需要时才进行分配。减少应用程序中的
cudaMalloc+cudaFree调用次数,尤其是在性能关键区域。 - 如果应用程序无法分配足够的设备内存,请考虑使用其他内存类型(如
cudaMallocHost或)cudaMallocManaged,虽然性能可能不高,但可以让应用程序取得进展。 - 对于支持该功能的平台,
cudaMallocManaged允许超额认购,并cudaMemAdvise启用正确的策略,将允许应用程序保留大部分(如果不是全部)性能cudaMalloc。cudaMallocManaged也不会强制分配驻留,直到需要或预取为止,从而减少操作系统调度程序的总体压力并更好地支持多原则用例。