模型量化是一种将浮点计算转成低比特定点计算的技术,可以有效的降低模型计算强度、参数大小和内存消耗,但往往带来巨大的精度损失。尤其是在极低比特(<4bit)、二值网络(Ibit)、甚至将梯度进行量化时,带来的精度挑战更大。
好处
- 减少内存,显存,存储占用:FP16的位宽是FP32的一半,因此权重等参数所占用的内存也是原来的一半,节省下来的内存可以放更大的网络模型或者使用更多的数据进行训练。
- 加快通讯效率:针对分布式训练,特别是在大模型训练的过程中,通讯的开销制约了网络模型训练的整体性能,通讯的位宽少了意味着可以提升通讯性能,减少等待时间,加快数据的流通。
- 计算效率更高:低比特的位数减少少计算性能也更高,INT8 相对比 FP32的加速比可达到3倍甚至更高
- 降低功耗
- 支持微处理器,有些微处理器属于8位的,低功耗运行浮点运算速度慢,需要进行8bit量化,让模型在边缘集群或终端机器运行。
坏处
- 精度损失,推理精度确实下降
- 硬件支持程度,不同硬件支持的低比特指令不相同。不同硬件提供不同的低比特指令计算方式不同( PFI6、HF32)。不同硬件体系结构Kernel优化方式不同
- 软件算法是否能加速,混合比特量化需要进行量化和反向量,插入 Cast 算子影响 kernel 执行性能。降低运行时内存占用,与降低模型参数量的差异。模型参数量小,压缩比高,不代表执行内存占用少。
要看显卡对精度(precision)的支持
当然也可以使用量化模型(Quantized model),或者更低精度(加载模型时候使用torch_dtype,一般加载用torch.float16或者torch.bfloat16)。通常用BF16 (精度低,范围大),因为FP16(half, 半精度,精度高) 会经常溢出,导致数值不稳定、模型不收敛(non-convergence) ,新卡支持BF16
It is common to use the BF16 (bfloat16) data type because it offers a larger range while maintaining a lower precision. This can be beneficial in avoiding frequent overflow issues that may arise with the FP16 (half precision) data type, which can lead to numerical instability and non-convergence of the model. It’s great to know that the new cards support BF16, as it provides a good balance between precision and range for improved model stability and convergence.
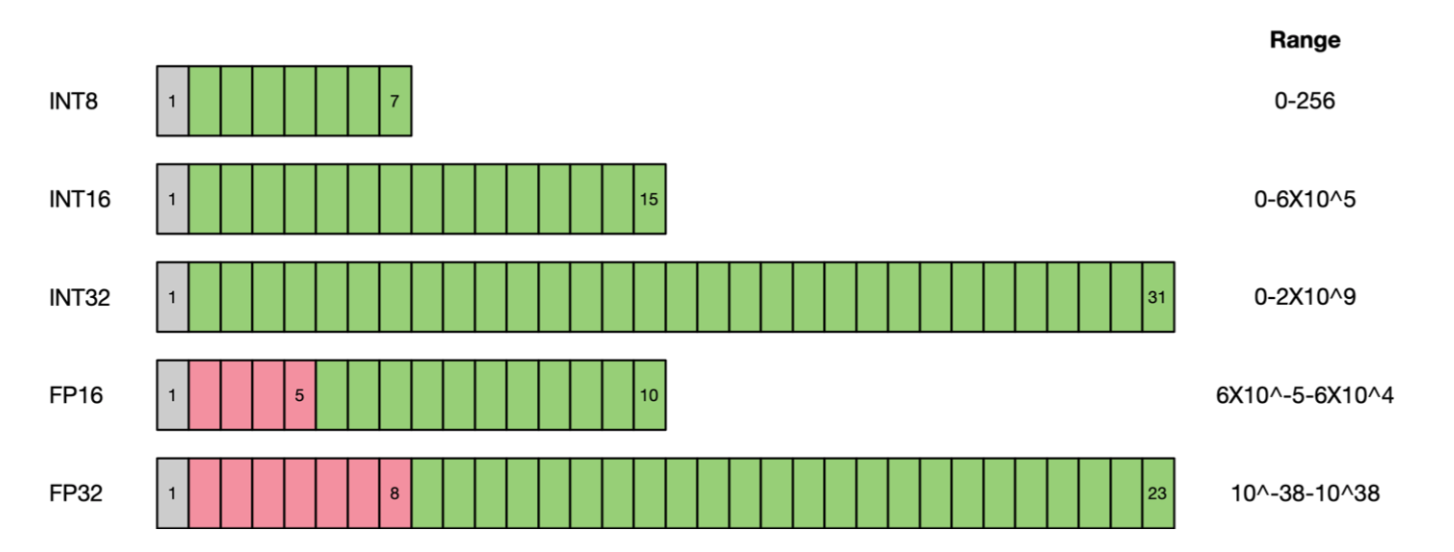
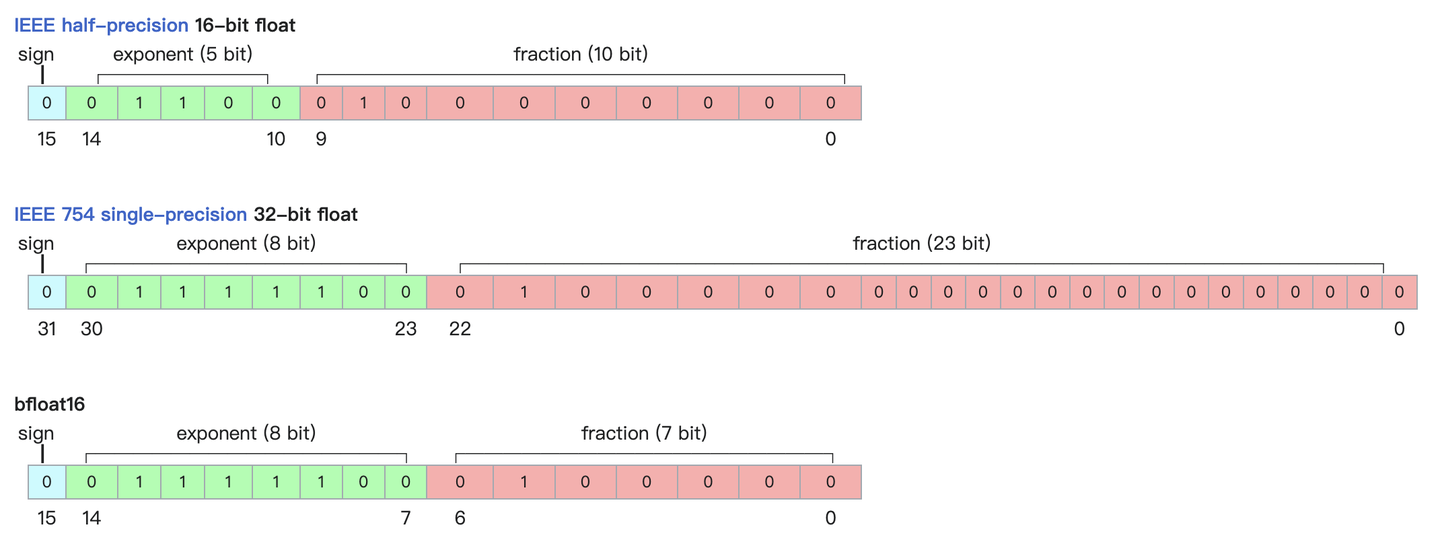
符号位,指数位(取值范围),尾数(精度)
精度对模型的影响
浮点数据类型主要分为双精度(FP64)、单精度(FP32 1 8 23)、半精度(FP16)BF16,int8 , fp4,nf4
深度学习模型训练好之后,其权重参数在一定程度上是冗余的,在很多任务上,我们可以采用低精度
量化原理
浮点数用整数,建立映射关系。
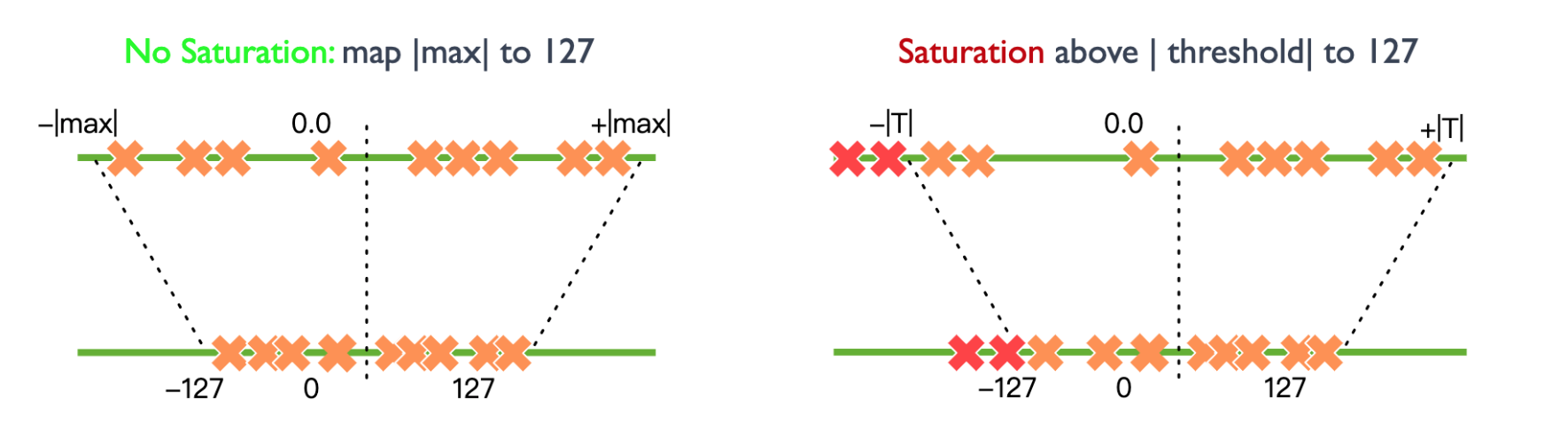
图例映射到int8,上面是浮点数最大最小值,浮点数范围可以截断,超过就不映射。
量化类型分对称和非对称,是否根据0轴是对称轴, int uint
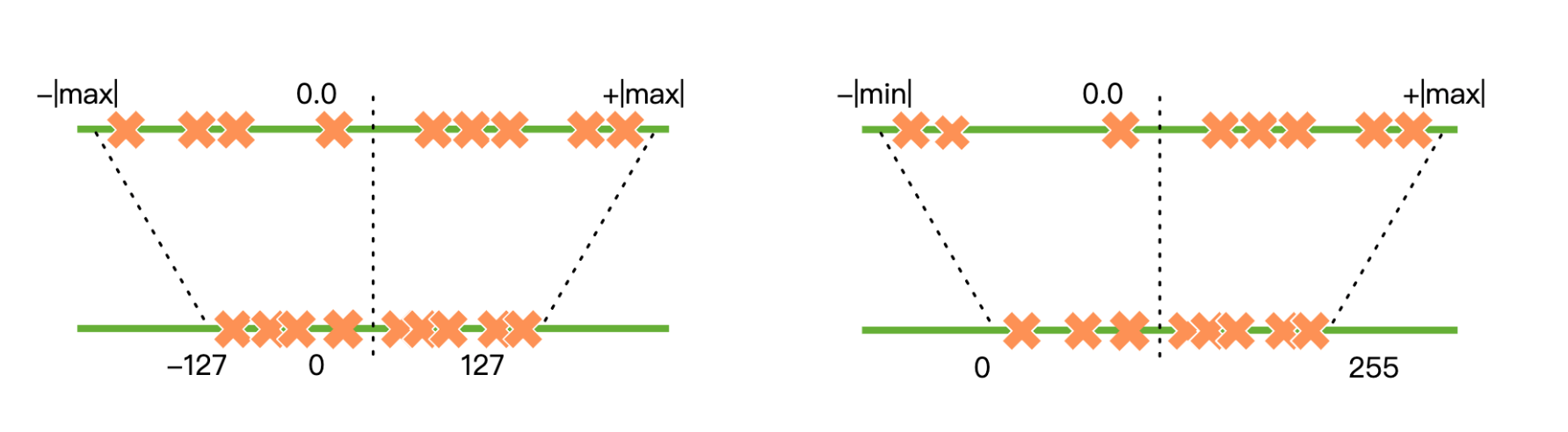
量化公式 int8作为实例


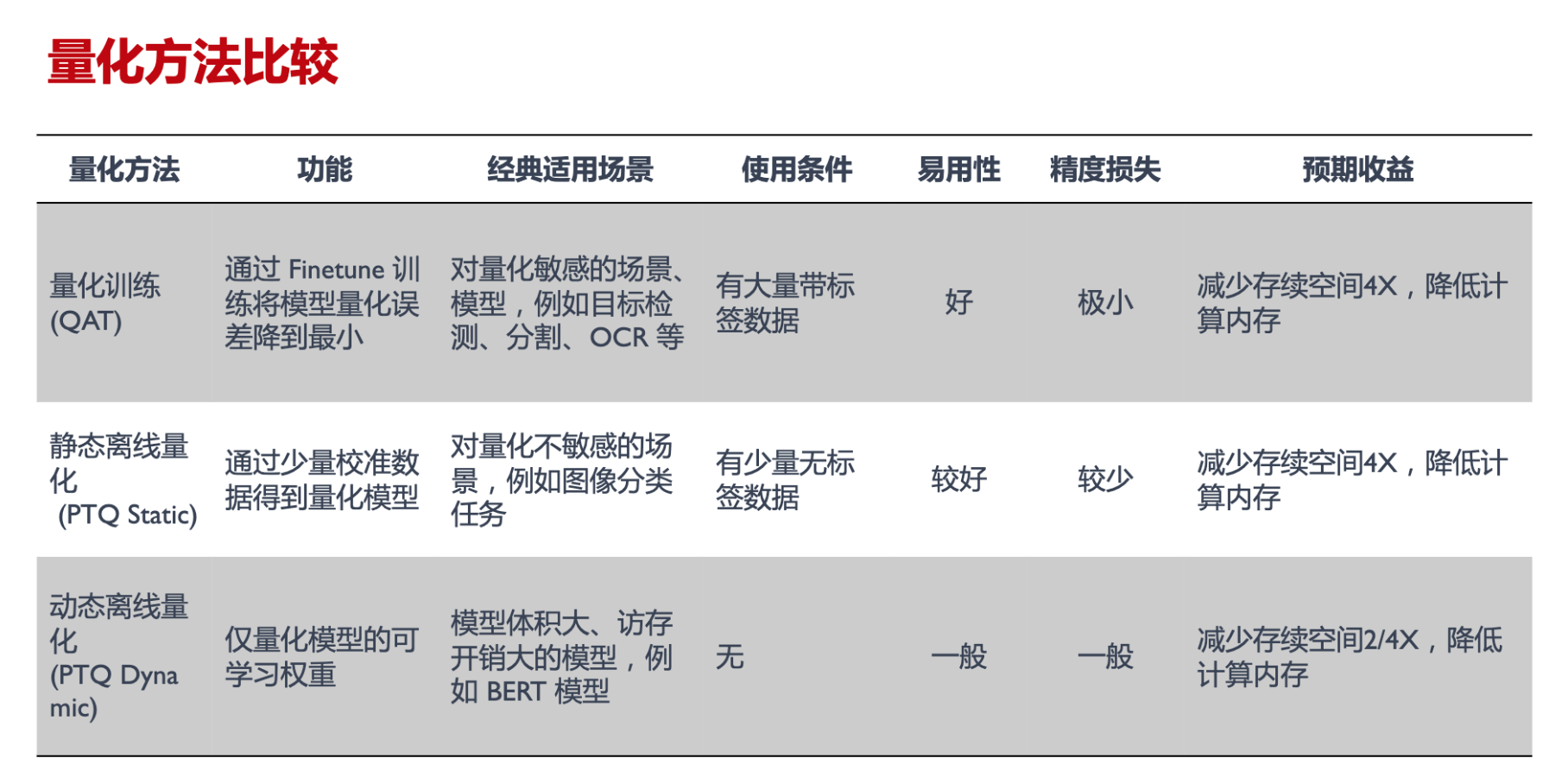
量化方法
- 训练后量化 (post-training quantization,PTQ)
- 静态离线量化(Post Training Quantization Static, PTQ Static)静态离线量化使用少量无标签校准数据,采用 KL 散度等方法计算量化比例因子
- 要保证数据集多样性和代表性
- 训练中量化 (quantization-aware training,QAT)
- 训练时候做前向和反向传播 : 前向使用量化后的低精度计算,反向使用原来浮点数权重和梯度
- QAT量化训练让模型感知量化运算对模型精度带来的影响,通过 finetune 训练降低量化误差
- 动态离线量化(Post Training Quantization Dynamic, PTQ Dynamic)动态离线量化仅将模型中特定算子的权重从FP32类型映射成 INT8/16 类型 (直接走量化,不管误差)
量化感知训练(QAT)由于训练成本较高并不实用,而训练后量化(PTQ)在低比特场景下面临较大的精度下降。
矩阵量化
- per tensor(亦称layerwise)
- 整个矩阵看作集合S,矩阵中的所有元素共享一个缩放系数
- 优点在于简单,全局只有一个缩放系数
- 缺点也很明显,如果矩阵中数值尺度相差悬殊,那么大尺度的数值会导致一个很小的缩放系数,从而导致小尺度的数值趋于零甚至归零。而大语言模型常常具有这种数值分布特征,所以通常不使用per tensor,尤其是使用线形量化时。
- per channel(亦称channelwise)
- 如果集合S内的数值波动越小,那么缩放系数就能越大,量化精度就越高。另一方面,如果S内的个数越少,出现大幅波动的概率也就越小,于是自然想到,将矩阵分片量化能提高量化精度,且分片越小,精度就越高。
- 将矩阵每一列作为一个分片进行量化,每一列内的所有元素共亨一个缩放系数,而列之间相互独立,这便是per channel量化,能增加数值之间的区分度,保留更多的源分布信息。
- 当然,按行分片也是可行的。在矩阵乘法AxB中,我们通常将A按行量化,将B按列量化,即原则上是沿着内维度(inner dimension)量化。换言之,假设A为MxK矩阵,B为KxN矩阵,则沿K维度量化,A有M个行缩放系数,B有N个列缩放系数。
- 在LLM中,A通常为activation,其每一行是某一个token的embedding,因此我们把A的按行量化也称为per token量化
- groupwise
- 相对于分片,进一步提高精度。Groupwise是将G个元素看作集合S进行数值是化,G称为group size.
- 代价是缩放系数的个数膨胀,从per channel的N到 $\frac{M\times N}{group_size}$, 其中M为短阵行数,N为矩阵列数。
- 随着分片粒度变小,精度越来越高,而量化开销越大,这需要折衷,事实上,对于一个MxN的矩阵,per channel只是groupwise在group_size=M时的特例,per tensor则是group_size =MxN时的特例。
反量化
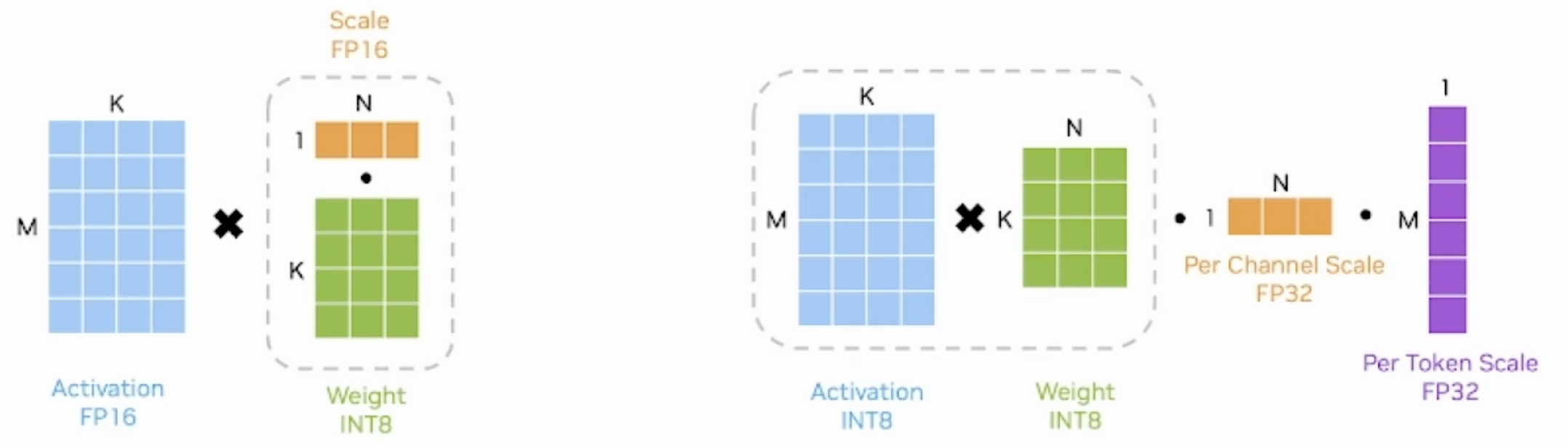
在构建模型时,各层的权重已经完成了量化。在推理过程中,根据activation是否使用量化数值类型,又可分为两大类weight-only,weiaht & activation。它们决定了短阵乘法过程中,反量化操作的执行时机
- 以典型的INT8 weight-only量化为例,其weight是per channel量化的INT8,而activation使用FP16类型。在推理时,需要先按列乘以scale将weight反量化为FP16,再与activation相乘
- SmoothQuant方法是weight&activation量化,其weight和activation都使用INT8类型,所以有两组缩放系数,一组是用于wcight的per-channel scale,一组是用于activation的per-token scale。先执行INT8的矩阵乘法,再分别按列、按行乘以两组缩放系数
- 是一种同时确保准确率且推理高效的训练后量化 (PTQ) 方法,可实现 8 比特权重、8 比特激活 (W8A8) 量化。由于权重很容易量化,而激活则较难量化,因此,SmoothQuant 引入平滑因子s来平滑激活异常值,通过数学上等效的变换将量化难度从激活转移到权重上
QAT
https://github.com/chenzomi12/DeepLearningSystem/blob/main/043INF_Slim/03.qat.pdf
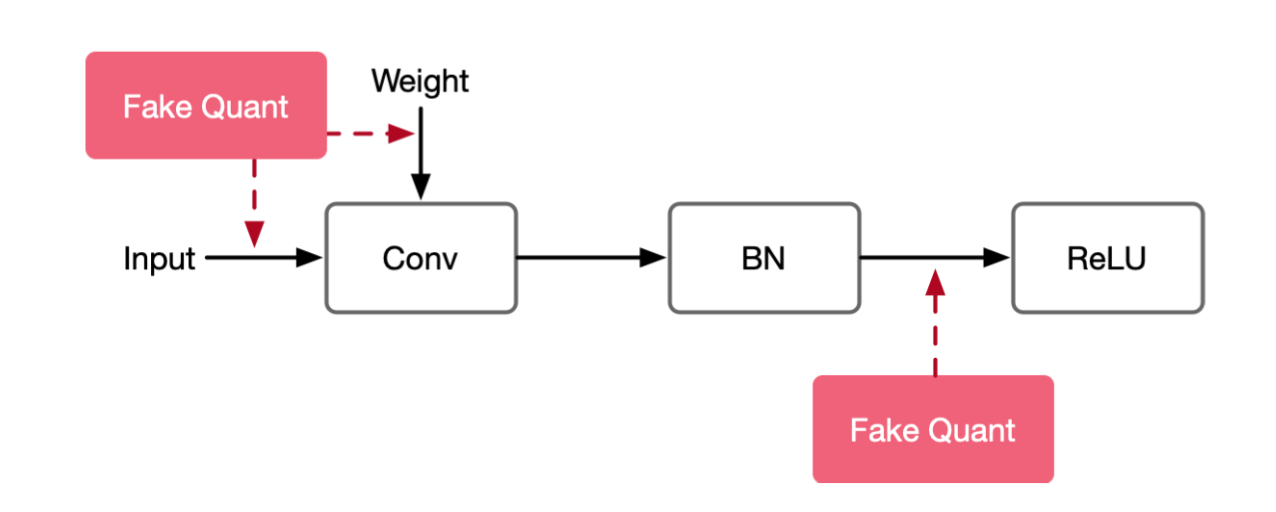
感知量化训练( Aware Quantization Training),通常在密集计算,激活函数,输入输出的地方插入fake quant
模型中插入伪量化节点fake quant来模拟量化引入的误差。端测推理的时候折叠fake quant节点中的属性到tensor中,在端测推理的过程中直接使用tensor中带有的量化属性参数。
算法流程
- 预训练模型改造网络模型,插入fake quant
- 用大量标签数据和改造后的模型,进行train/fine tuning
- 通过学习把量化误差降低
- 最后输出QAT model
- QAT model通过转换模块,去掉冗余fake quant,得到量化后模型
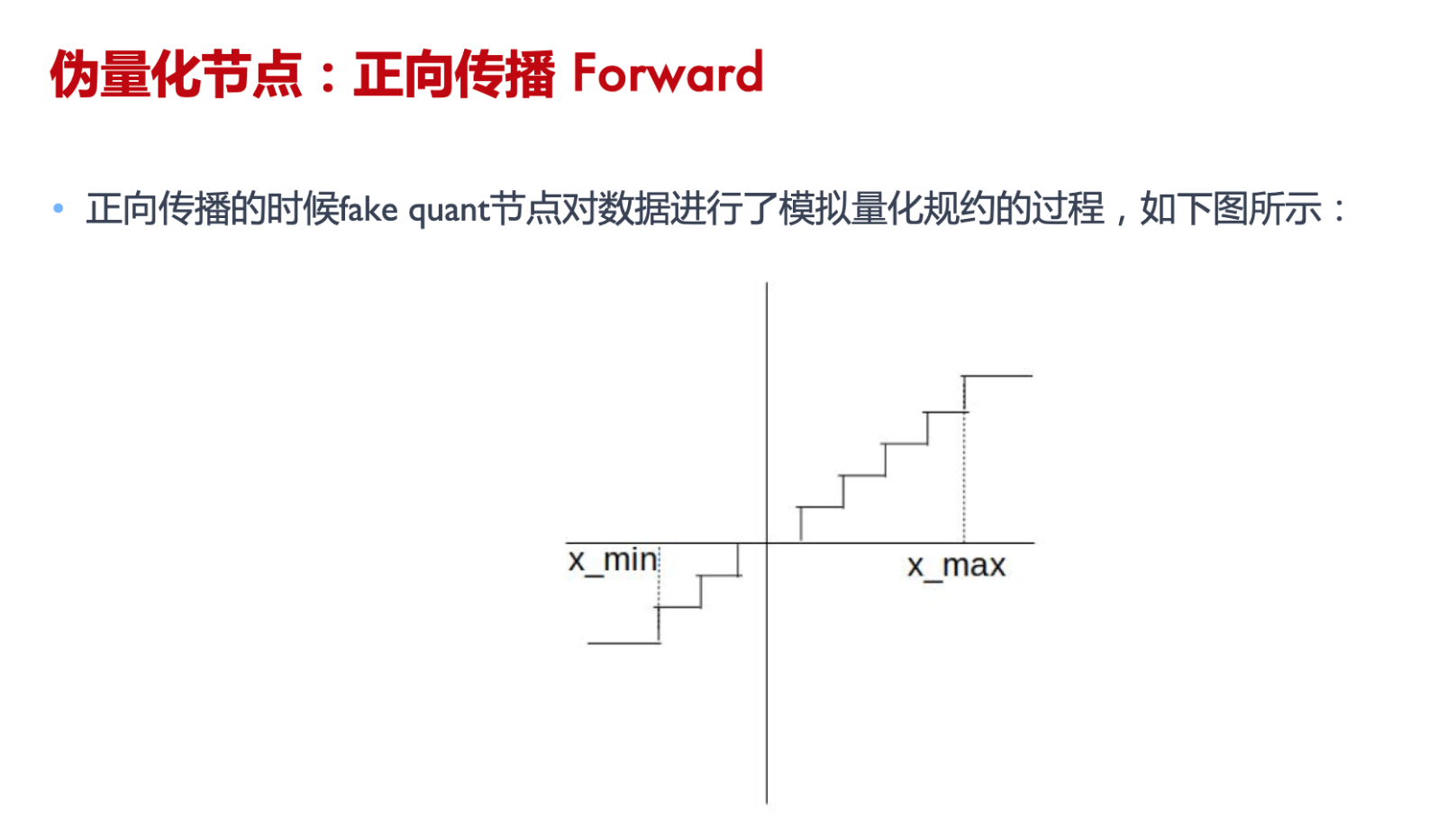
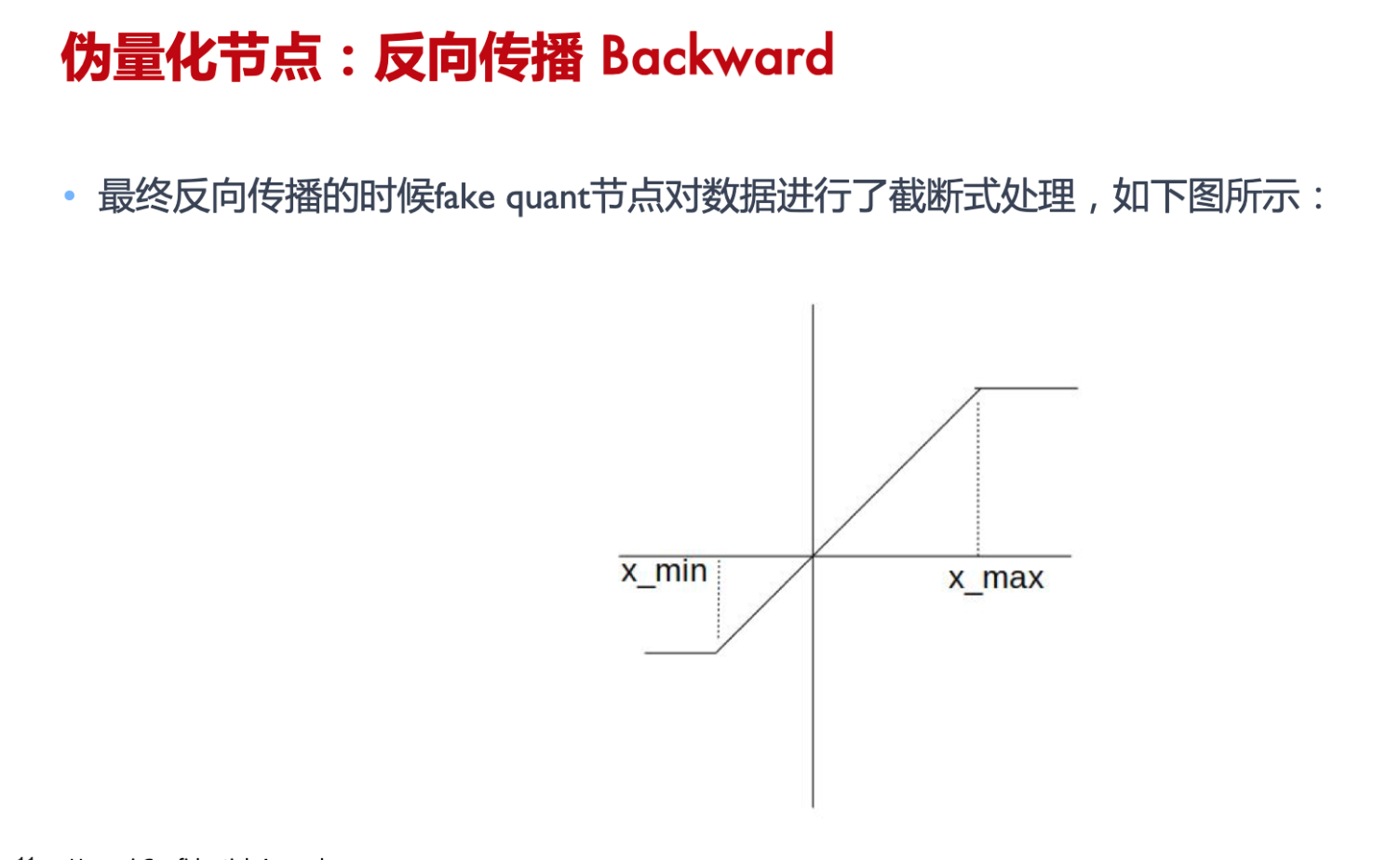
伪量化节点的作用
- 找到输入数据的分布,即找到 min 和 max 值 ;
- 模拟量化到低比特操作的时候的精度损失,把该损失作用到网络模型中,传递给损失函数。让优化器去在训练过程中对该损失值进行优化。


PTQ
PTQ Dynamic
动态离线量化 ( Post Training Quantization Dynamic, PTQ Dynamic)
- 仅将模型中特定算子的权重从FP32类型映射成 INT8/16 类型
- 主要可以减小模型大小,对特定加载权重费时的模型可以起到一定加速效果
- 但是对于不同输入值,其缩放因子是动态计算,因此动态量化是几种量化方法中性能最差的
权重量化成 INTI6 类型,模型精度不受影响,模型大小为原始的 1/2。 权重量化成 INT8 类型,模型精度会受到影响,模型大小为原始的 1/4.
算法流程
- 对预训练模型的FP32权重转换成int8,就可以得到量化模型
PTQ Static
静态离线量化( Post Training Quantization Static, PTQ Static)
-
同时也称为校正量化或者数据集量化。使用少量无标签校准数据,核心是计算量化比例因子使用静态量化后的模型进行预测,在此过程中量化模型的缩放因子会根据输入数据的分布进行调整。
-
静态离线量化的目标是求取量化比例因子,主要通过对称量化、非对称量化方式来求,而找最大值或者闯值的方法又有MinMax、KLD、ADMM、EQ等方法
算法流程
-
预训练模型改造网络模型,插入fake quant
-
用少量非标签数据和改造后的模型,进行校正
-
通过量化
-
最后输出PTQ model

1 | |


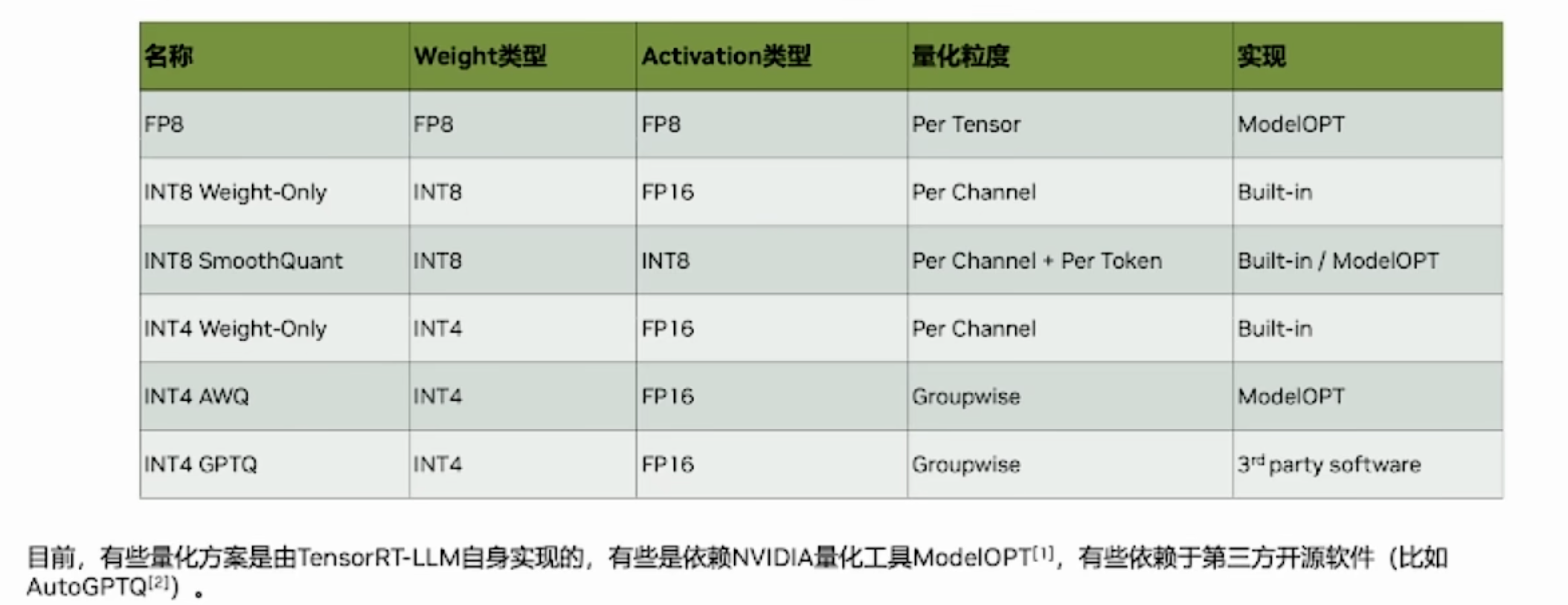
GPTQ
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
采用 int4/fp16 (W4A16) 的混合量化方案,其中模型权重被量化为 int4 数值类型,而激活值则保留在 float16,是一种仅权重量化方法。在推理阶段,模型权重被动态地反量化回 float16 并在该数值类型下进行实际的运算。
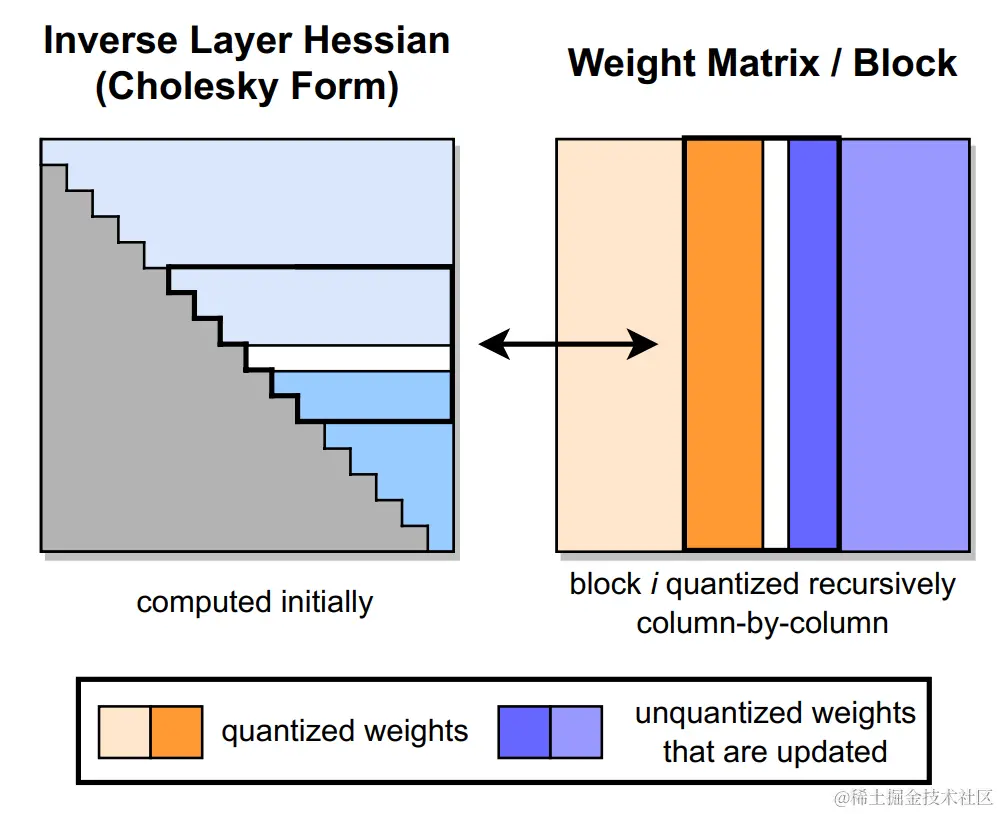
GPTQ 将权重分组(如:128列为一组)为多个子矩阵(block)。对某个 block 内的所有参数逐个量化,每个参数量化后,需要适当调整这个 block 内其他未量化的参数,以弥补量化造成的精度损失。因此,GPTQ 量化需要准备校准数据集。
GPTQ 量化过程如下图所示。首先,使用 Cholesky 分解中 Hessian 矩阵的逆,在给定的step中对连续列的块(粗体)进行量化,并在step结束时更新剩余的权重(蓝色)。量化过程在每个块内递归应用:白色中间列表示当前正在被量化。
GPTQ 的创新点如下:
- 取消贪心算法:OBS 采用贪心策略,先量化对目标影响最小的参数;但 GPTQ 发现直接按顺序做参数量化,对精度影响也不大。这项改进使得参数矩阵每一行的量化可以做并行的矩阵计算(这意味着我们可以独立地对每一行执行量化。即所谓的 per-channel quantization)。对于大模型场景,这项改进使得量化速度快了一个数量级;
- Lazy Batch-Updates:OBQ 对权重一个个进行单独更新,作者发现性能瓶颈实际在于GPU的内存带宽,而且同一个特征矩阵W不同列间的权重更新是不会互相影响的。因此作者提出了延迟批处理的方法,通过延迟一部分参数的更新,一次处理多个(如:128)列,来缓解带宽的压力,大幅提升了计算速度。
- Cholesky 分解:用 Cholesky 分解求海森矩阵的逆,提前计算好所有需要的信息,在增强数值稳定性的同时,后续更新的过程中再计算,进一步减少了计算量。
该方案有以下两方面的优点:
- int4 量化能够节省接近4倍的内存,这是因为反量化操作发生在算子的计算单元附近,而不是在 GPU 的全局内存中。
- 由于用于权重的位宽较低,因此可以节省数据通信的时间,从而潜在地提升了推理速度。
一般来说,GPTQ推荐使用8-bit量化及groupsize = 128。
AWQ
激活感知权重量化(Activation-aware Weight Quantization,AWQ),是一种对大模型仅权重量化方法。通过保护更“重要”的权重不进行量化,从而在不进行训练的情况下提高准确率。

- LLM 的权重并非同等重要,与其他权重相比,有一小部分显著权重对 LLM 的性能更为重要。因此,作者认为跳过这些显著权重不进行量化,可以在不进行任何训练的情况下,弥补量化损失造成的性能下降。
- 确定了权重重要性的一种广泛使用的方法是查看其大小(magnitude)或 L2-norm
- 根据激活幅度(magnitude)选择权重可以显著提高性能,通过只保留 0.1%-1% 的较大激活对应权重通道就能显著提高量化性能,甚至能与基于重构的 GPTQ 相媲美
- 因此,我们认为幅度较大的输入特征通常更为重要,通过保留相应的权重为 FP16 可以保留这些特征,从而提高模型性能。
- 但这种混合精度数据类型会给系统实现带来困难(硬件效率低下)。因此,我们需要想出一种方法来保护重要的权重,而不将其实际保留为 FP16。
- 通过激活感知缩放保护显著权重,按逐通道(per-channel)缩放来减少显著权重的量化误差,这种方法不存在硬件效率低下的问题。
- 该方法不依赖于任何回归或反向传播,而这是许多量化感知训练方法所必需的。 它对校准集的依赖最小,因为我们只测量每个通道的平均幅度(magnitude),从而防止过拟合。因此,该方法在量化过程中需要更少的数据,并且可以将LLM的知识保留在校准集分布之外。
尽管我们只做了权重量化,但要找到显著的权重通道,我们应该根据激活分布而不是权重分布。与较大激活幅度(activation magnitudes)相对应的权重通道更加突出,因为它们处理了更重要的特征。
为了避免硬件效率低下的混合精度实现,我们分析了权重量化产生的误差,并推导出放大显著通道(salient channels)可以减少其相对量化误差。然后我们设计了一种按通道缩放的方法,以自动搜索最优缩放(scaling),使全部权重下的量化误差最小。
AWQ 不依赖于任何反向传播或重构,因此可以很好地保持 LLM 在不同领域和模态上的泛化能力,而不会过拟合校准集
低精度训练FP16
半精度LLama训练
- LlaMA2模型分词器的padding_side要设置为right,否则可能不收敛
- LlaMA2模型的分词器词表的问题要适当调整数据的最大长度,保证数护内容的完整性
- LlaMA2模型加载时,torch_dtype为半精度,否则模型将按照fp32加载
- 当启用gradient_checkpoint训结时,需要一并调用model.enable_input_require_grads()方法
- 当完全采用fp16半精度进行训练且采用adam优化器时,需要调整优化器的adam_epsilon的值,否则模型无法收敛
LLM.int8 混合精度
量化是一种模型压缩的方法,使用低精度数据类型对模型权重或者激活值进行表示。简单来说,量化就是将高精度的数字通过某种手段将其转换为低精度的数据
LLM.int8() 的实现主要在 bitsandbytes 库
absmax量化的细节。要计算absmax量化中fp16数字与其对应的int8数字之间的映射,您必须首先除以张量的绝对最大值,然后乘以数据类型的总范围。
例如,假设您想要在包含 的向量中应用 absmax 量化[1.2, -0.5, -4.3, 1.2, -3.1, 0.8, 2.4, 5.4]。您提取它的绝对最大值,5.4在本例中就是如此。Int8 的范围为[-127, 127],因此我们将 127 除以5.4并获得23.5缩放因子。因此,将原始向量乘以它就得到量化向量[28, -12, -101, 28, -73, 19, 56, 127]。
优化方法
- 使用更多的量化参数 (scale factor) Use more quantitative parameters
- 矩阵乘法(Matrix multiplication)A*B可以看作是A的每一行乘上B的每一列(column),为A的每一行和B的每一列单独设置scale factor,这种方式被称之为Vector-wise量化 For each row of A and each column of B, set a separate scale factor. This approach is called Vector-wise quantization.
- 离群值(Outliers): 超出某个分布范围的值通常称为离群值。8 位精度的动态范围极其有限,因此量化具有多个大值的向量会产生严重误差。误差在一点点累积的过程中会导致模型的最终性能大幅度下降 Values that are outside a certain distribution range are usually referred to as outliers. With a limited dynamic range of 8-bit precision, quantizing vectors with multiple large values can result in significant errors. The accumulation of errors over time can greatly degrade the final performance of the model.
使用
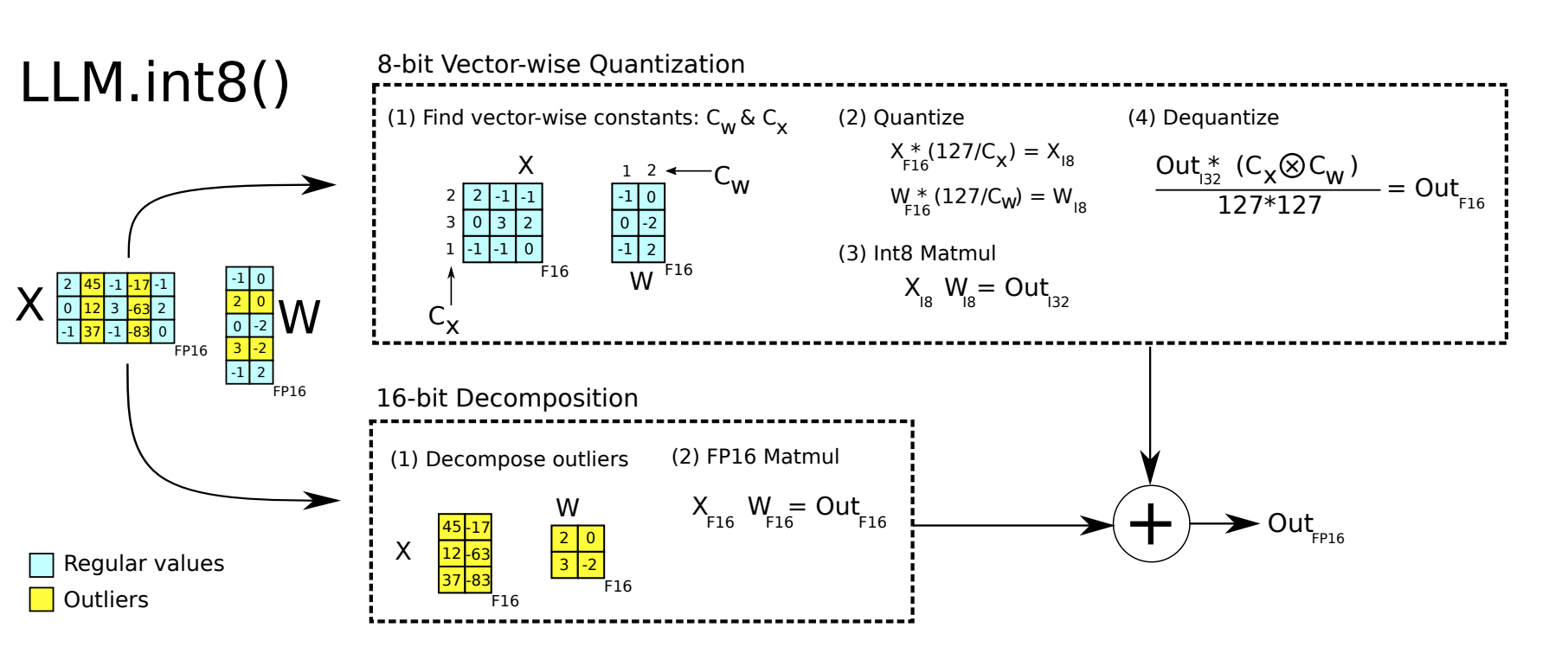
- 从输入隐藏状态中,按列提取异常值(即大于特定阈值的值) Extracting outliers (values greater than a specific threshold) from the input hidden state column-wise.
- 对 FP16 中的离群值矩阵和 int8 中的非离群值矩阵分别执行矩阵乘法 Performing matrix multiplication on the outlier matrix in FP16 and the non-outlier matrix in int8.
- 对非离群值矩阵结果进行反量化,并将离群值和非离群值结果相加,以获得 FP16 中的完整结果。 Dequantizing the result of the non-outlier matrix and adding it to the outlier matrix to obtain the complete result in FP16.

1 | |
虽然 LLM.in8() 带来的性能下降微乎其微,但是这种分离计算的方式拖慢了推理速度
int4 NF4
4bit 量化,不能继续使用线性量化,4 bit的表示范围比8bit更小,粒度更粗,不用非常大的离群值,就使得量化后的参数都集中在某数值上,量化误差会非常大
线性量化
数据归一化到[-1,1],把[-1,1]均匀切分成N区间 (N取决于量化bit),归一化的结果归属于第几个区间,量化结果便为几。
数据的分布对量化结果非常重要。如果待量化的数据为均匀分布,那么线性量化的结果即使是4bit也不会太差
但是一般模型权重数值分布,并不是均匀分布,而是正态分布。
1 | |
分位数量化
把顺序排列的一组数据分割为若干相等部分的分割点的数值即为相应的分位数。
四分位数则是将数据按照大小顺序排序后,把数据分割成四等分的三个分割点上的数值.
示例 {6, 7,15, 36, 39, 40, 41, 42, 43,47,49) 二分位数 (中位数): 40 四分位数:15,40,43

要存储的值非常多
NF4算法
- 根据标准正态分布得到16个量化值,并将量化值也缩放至[-1,1]
- Based on the standard normal distribution, I generated 16 quantized values and scaled them to the range of [-1, 1]

X_norm在NF4中找对应到对应量化值,q_x量化值对应index

双重量化,减少存储空间,针对absmax,进行int8 double quantization to reduce storage space, using int8 for absmax.

分页优化器 当显存不足时,将优化器的参数转移到CPU内存上,在需要时再将其取回,防止显存峰值时OOM
1 | |
量化部署
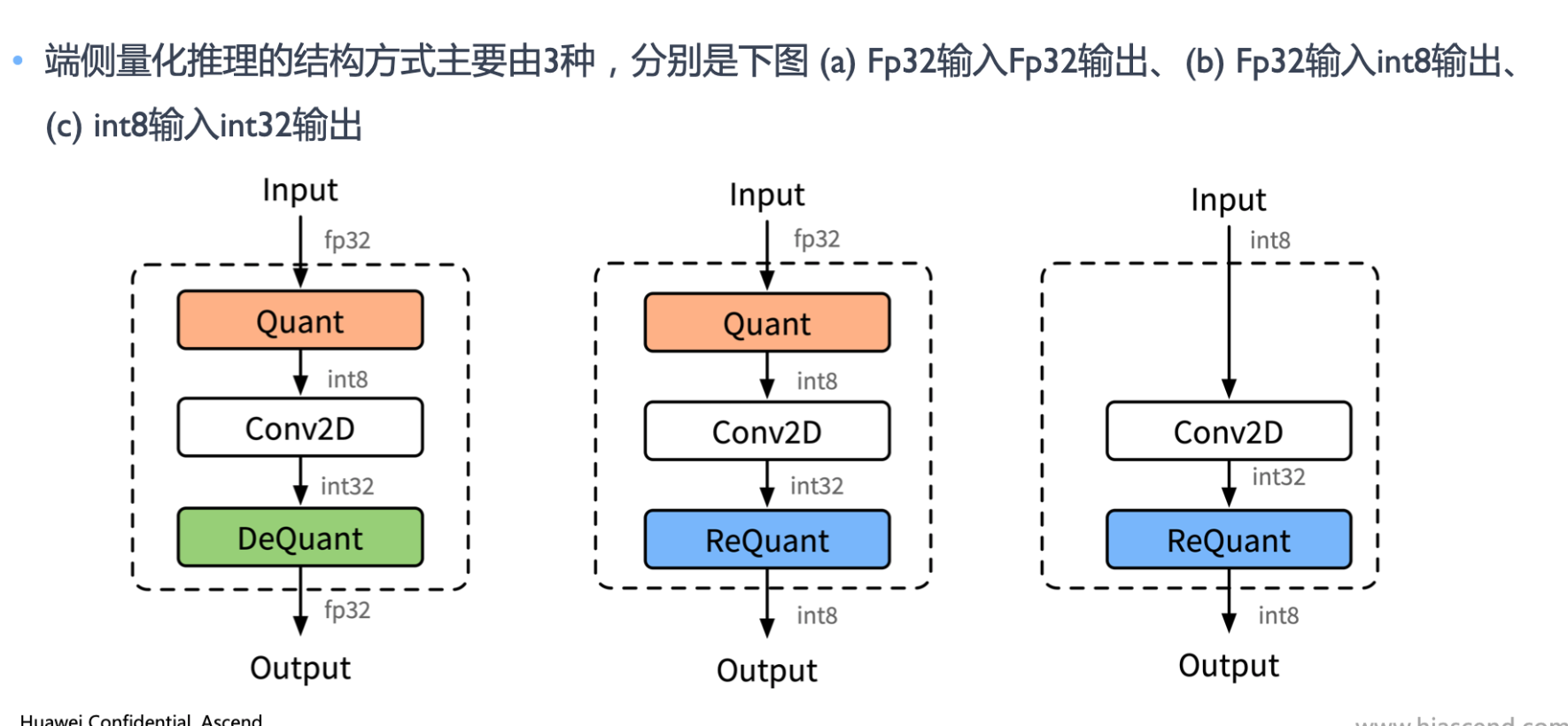
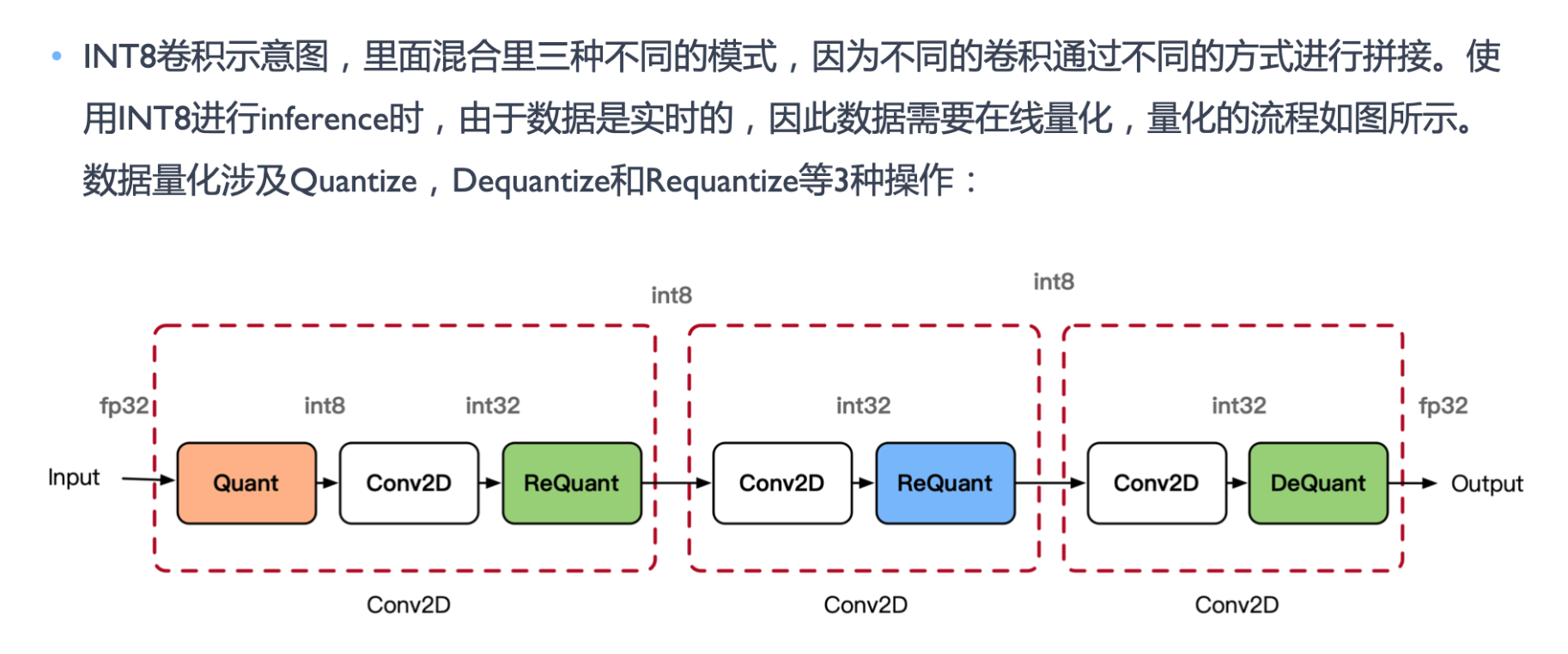
量化

反量化

重量化
