Material for cuda-mode lectures
CUDA Techniques to Maximize Compute and Instruction Throughput
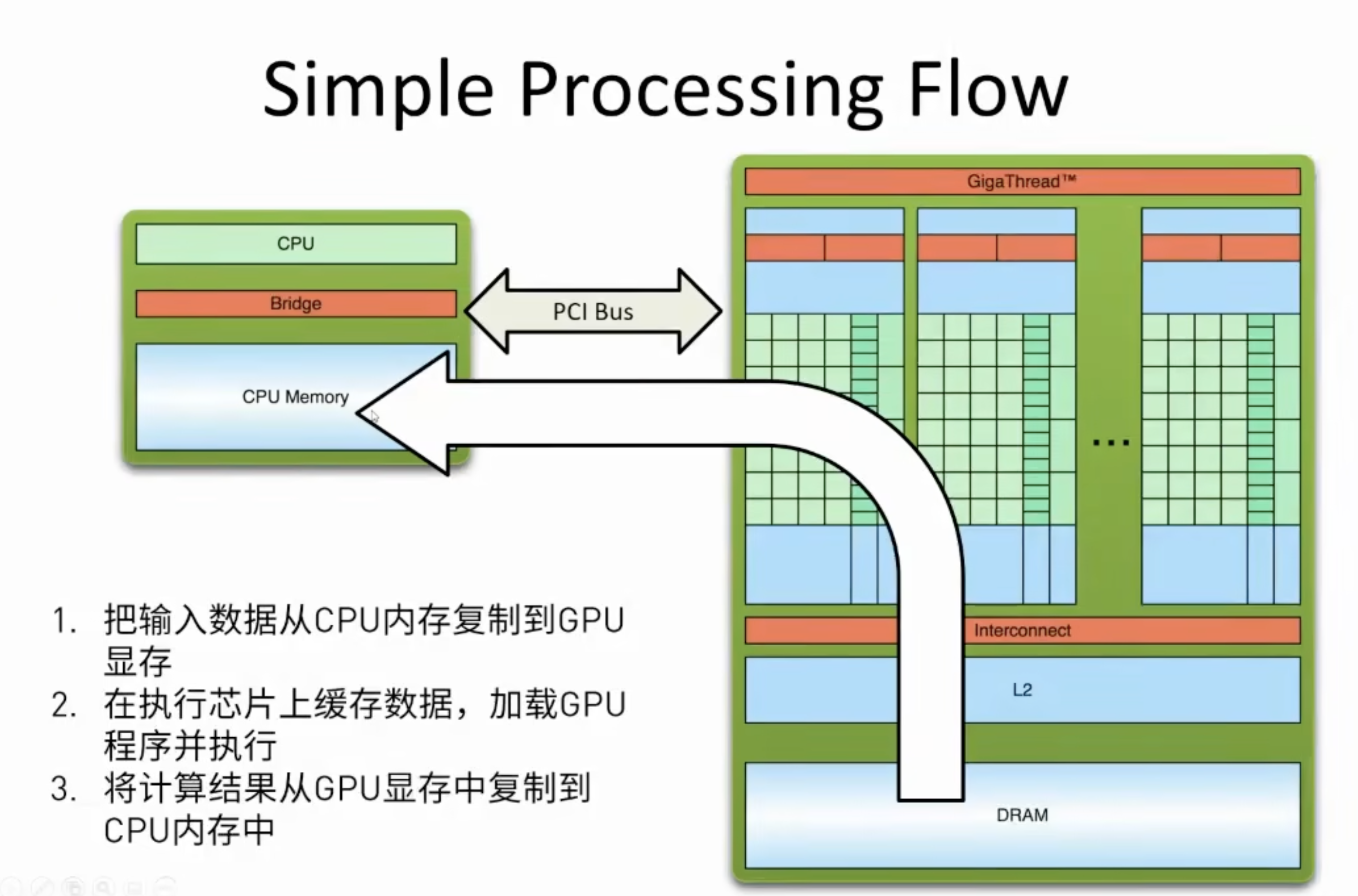
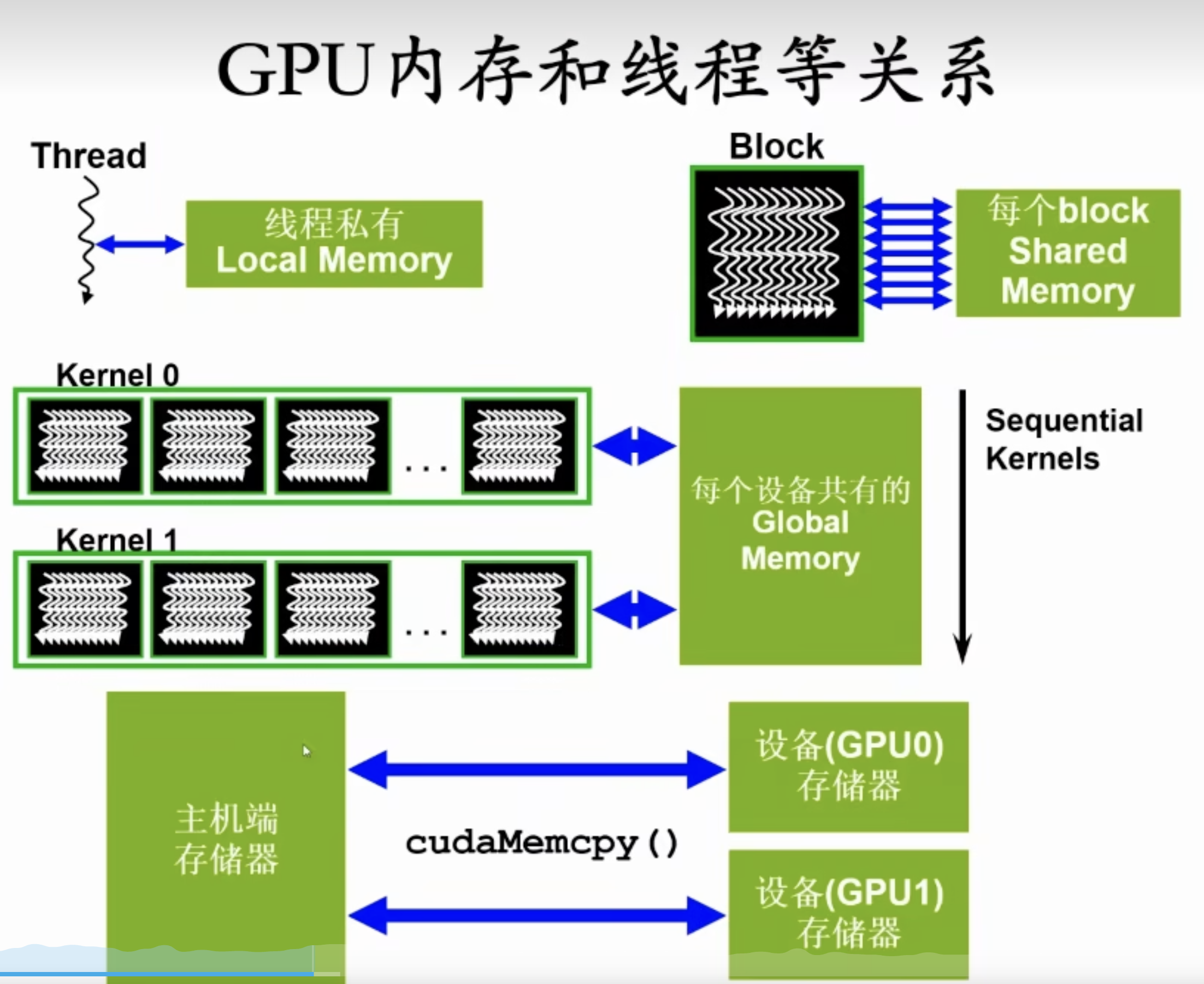
Host The CPU and its memory (host memory)
Device The GPU and its memory (device memory)
之间是PCIe或者NVLink
概念
内核
当调用函数时,它们会由 N 个不同的CUDA 线程并行执行 N 次,而不是像常规 C++ 函数那样只执行一次。
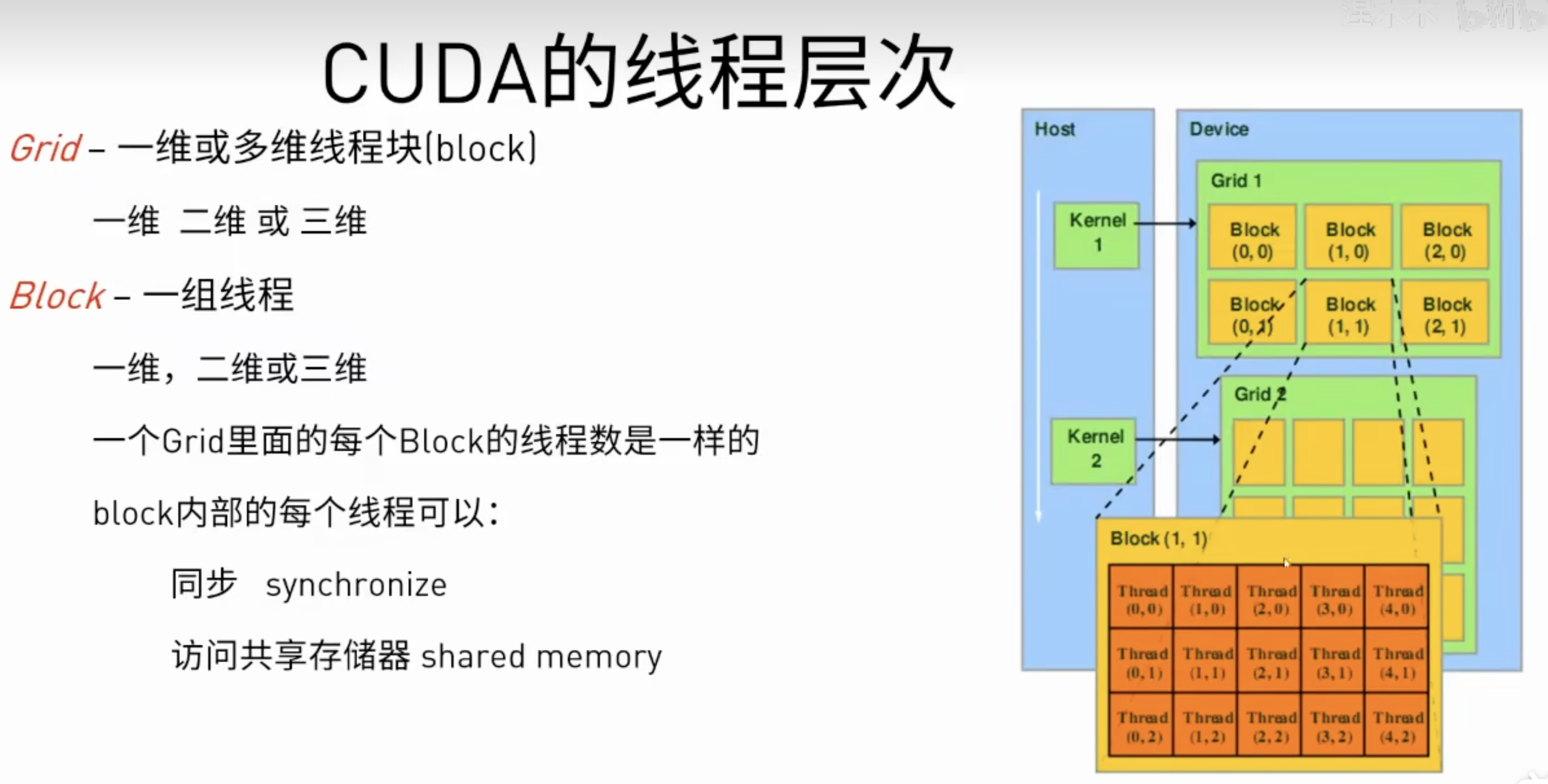
线程层级
线程层级

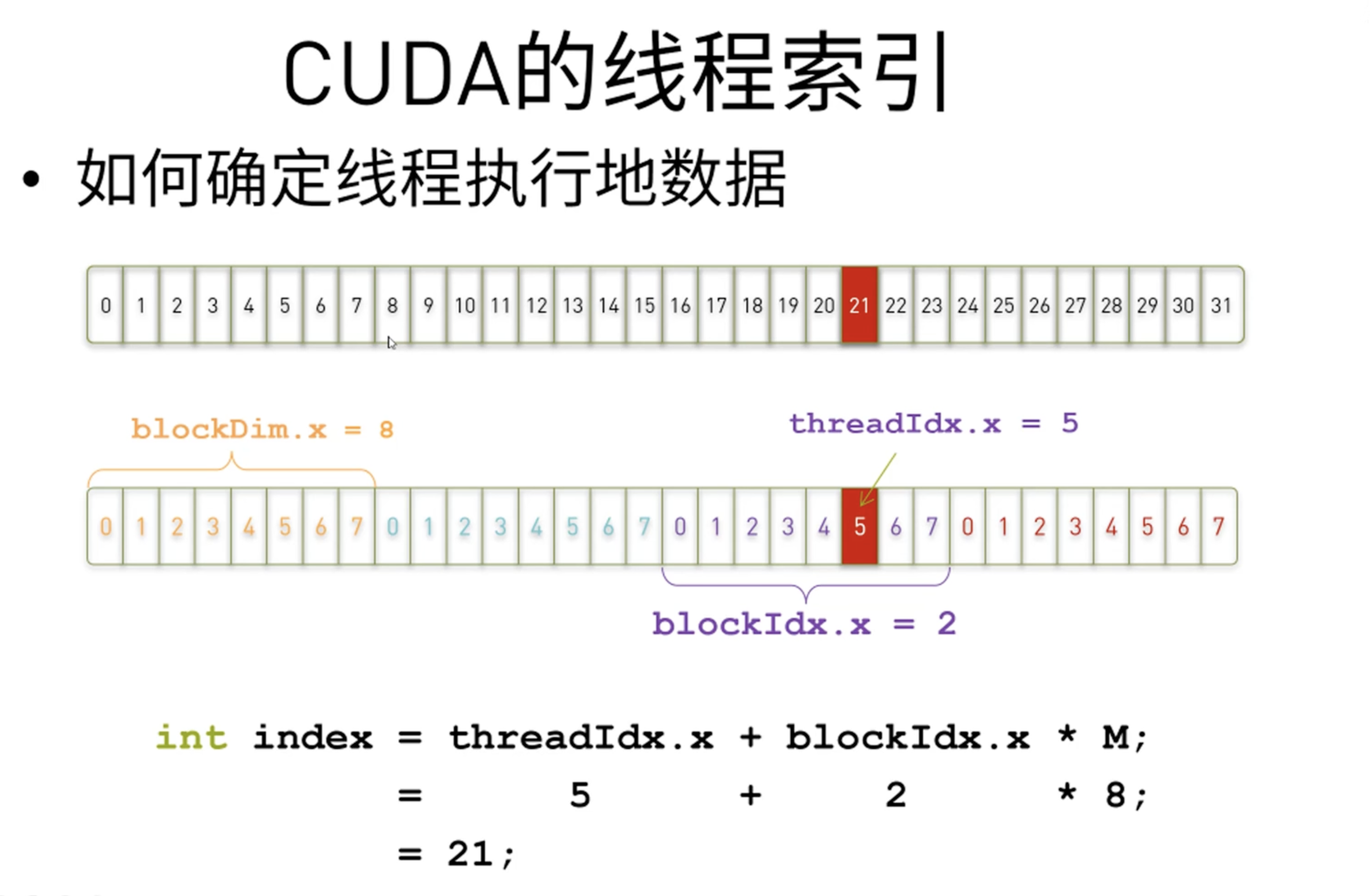
线程索引定位

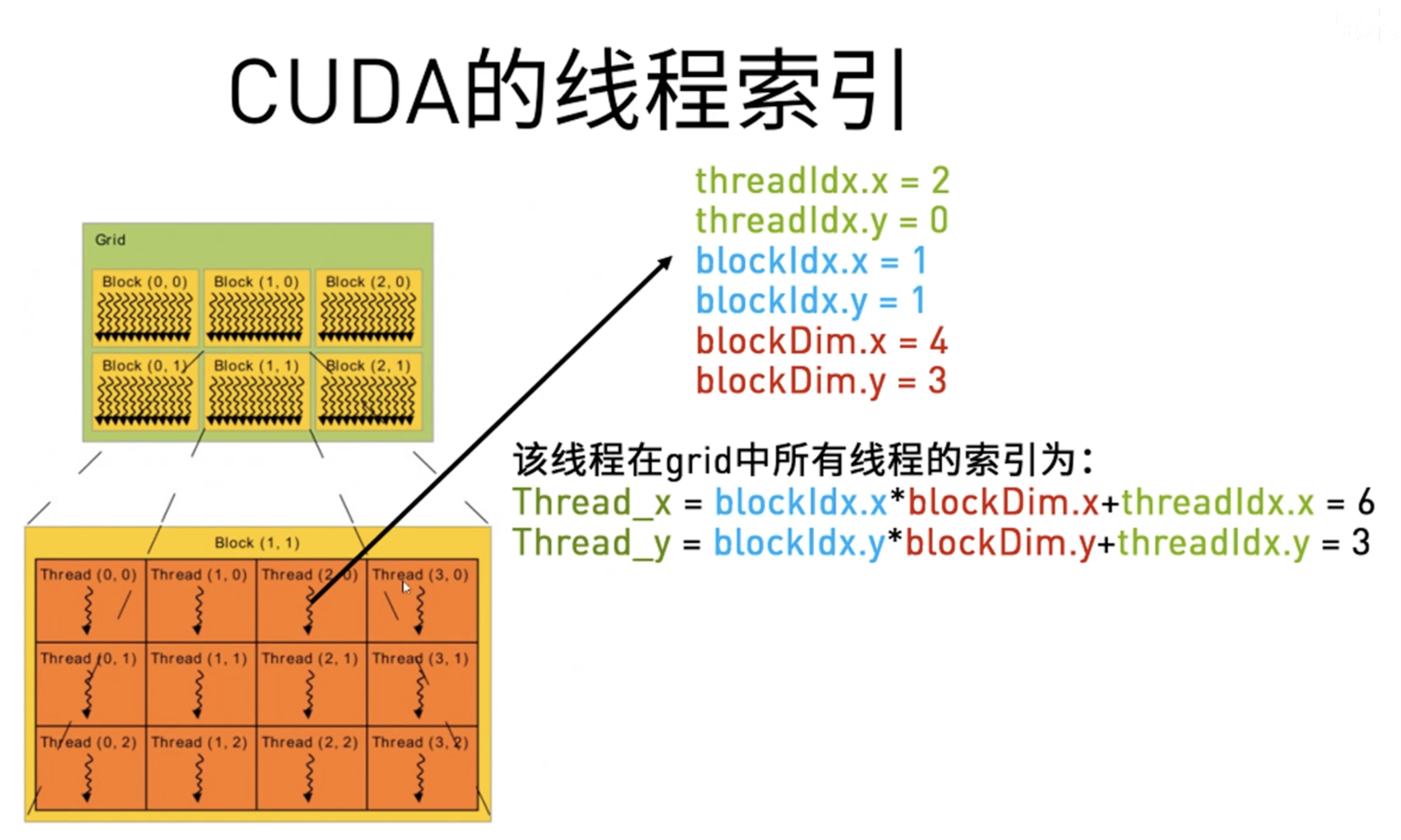
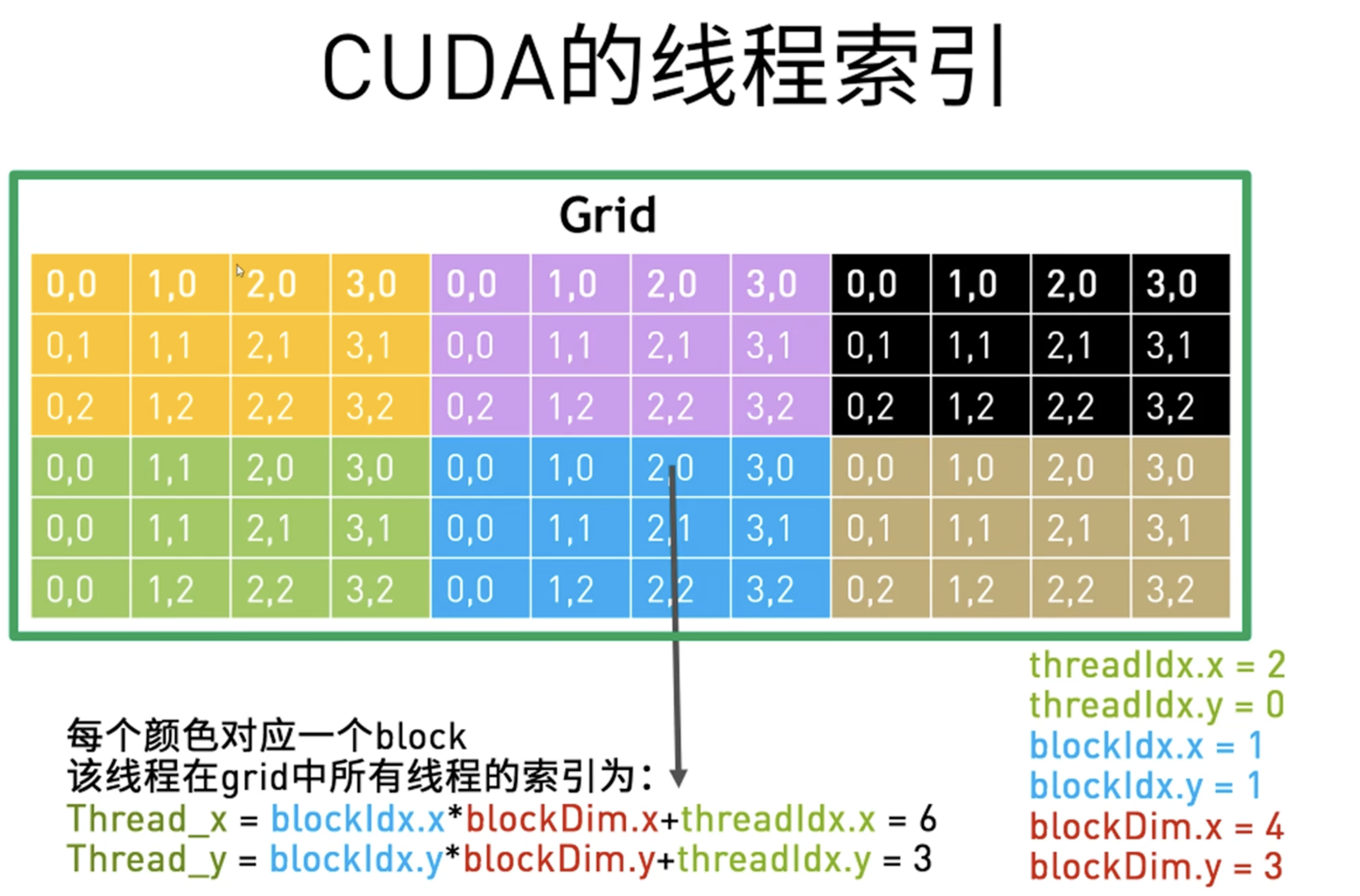
当要处理的数据大于线程总数时,我们利用grid-stride loop的方法处理,有点像CNN的做法步长,红框/绿框移动

二维
1 | |
一维 任意长度N , 每块线程数 M kernel <<< grid_size, block_size >>>(参数);

线程块(Block)
由多个线程组成的一个分组。线程块中的线程可以通过共享内存共享数据并同步执行以协调内存访问来进行协作。__syncthreads()充当屏障,块中的所有线程都必须等待该屏障,然后才允许任何线程继续执行。
- 线程块的大小和数量在调用kernel函数时指定。网格中的每个块都可以通过一维、二维或三维唯一索引来标识
- 一个线程块最多可包含 1024 个线程。
- 每个线程块在一个SM上执行,线程块之间相互独立。必须能够以任意顺序、并行或串行方式执行它们。这种独立性要求允许线程块以任意顺序在任意数量的内核上进行调度。从而使程序员能够编写随内核数量扩展的代码。
- CUDA编程模型中的线程网格(Grid)由多个线程块组成。

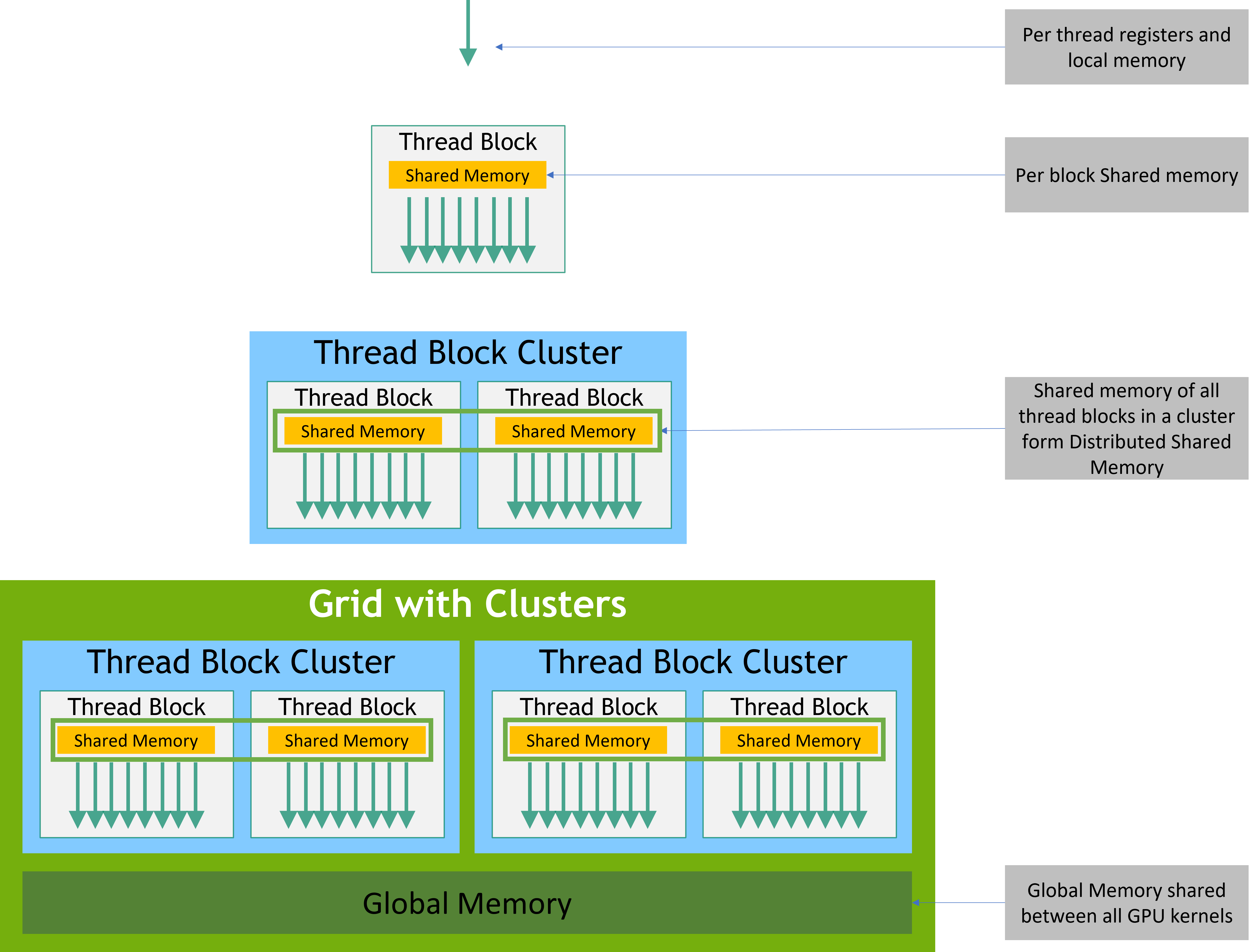
与线程块类似,集群也被组织成一维、二维或三维,如图所示。集群中的线程块数量可以由用户定义,CUDA 支持集群中最多 8 个线程块作为可移植集群大小。请注意,在 GPU 硬件或 MIG 配置太小而无法支持 8 个多处理器时,最大集群大小将相应减小。这些较小配置以及支持超过 8 个线程块集群大小的较大配置的识别是特定于架构的,可以使用 API 进行查询cudaOccupancyMaxPotentialClusterSize。
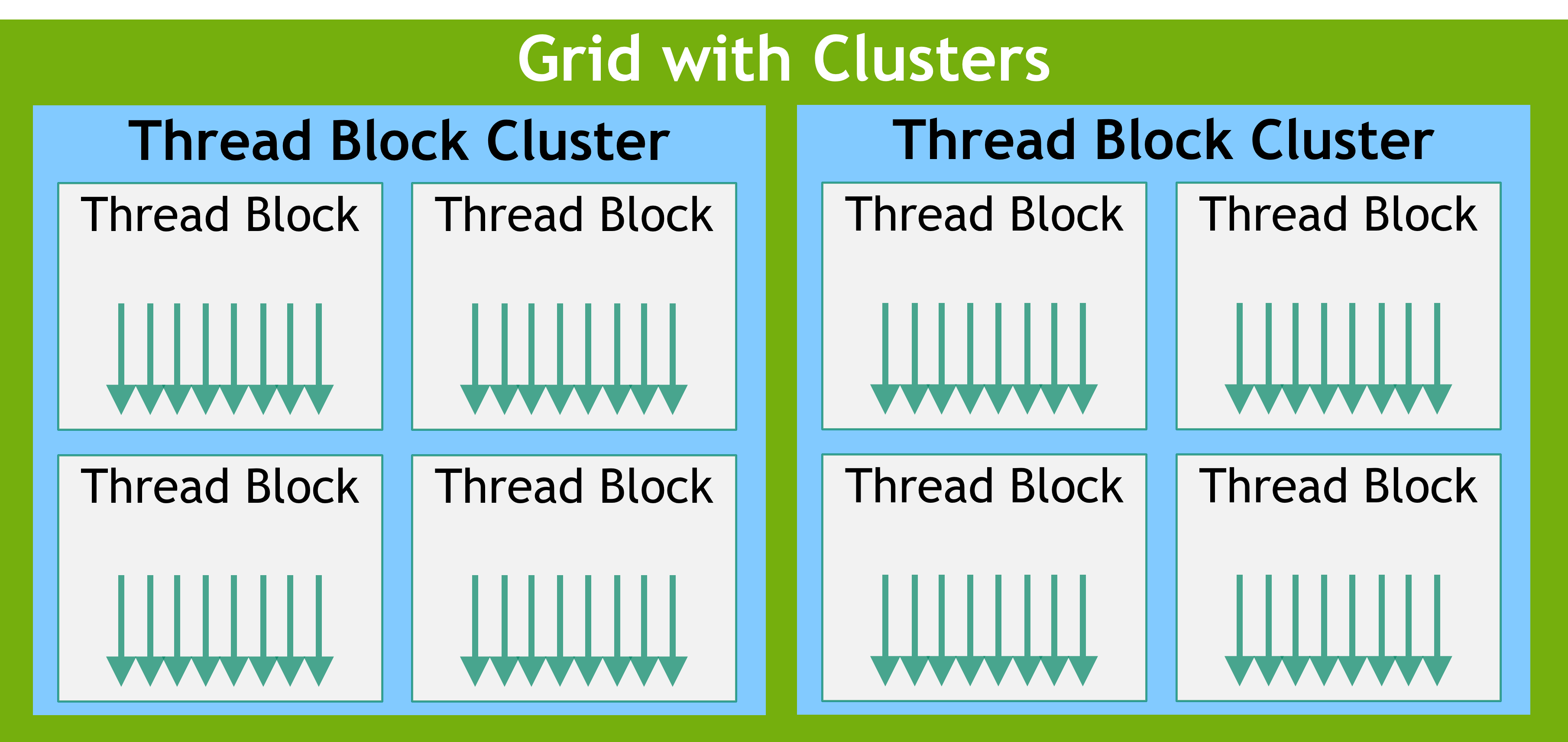
属于集群的线程块可以访问分布式共享内存。集群中的线程块能够读取、写入和对分布式共享内存中的任意地址执行原子操作。分布式共享内存给出了在分布式共享内存中执行直方图的示例。
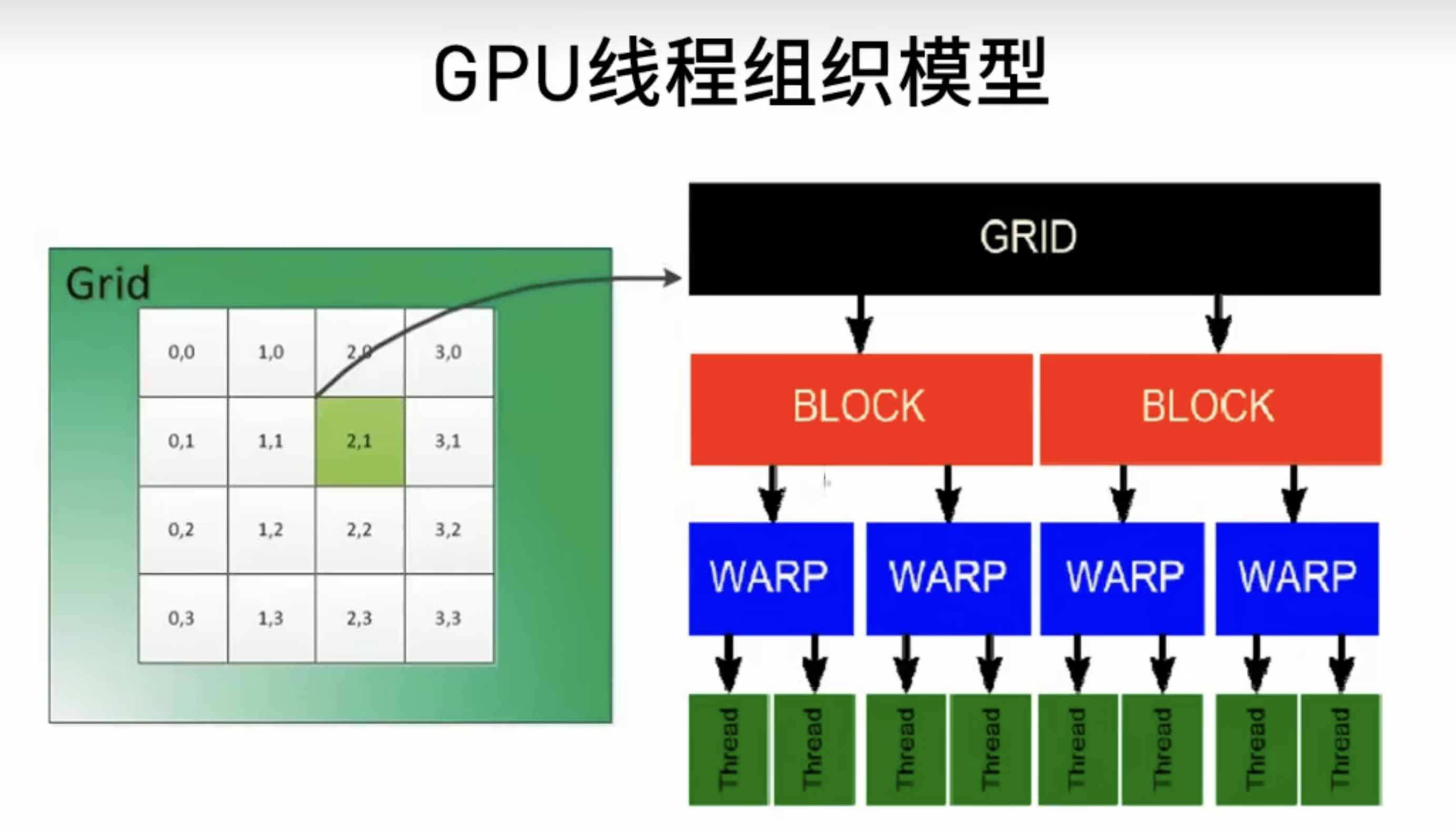
线程束 Warp
线程束(Warp)是GPU中的一个基本执行单元。在NVIDIA的CUDA架构中,一个线程束由32个并行执行的线程组成。这些线程同时开始执行相同的指令,但它们可以操作不同的数据。指令总是以 warp 为单位进行发布。线程束的设计目的是为了充分利用GPU的SIMD(单指令多线程)架构。
- 一个线程束包含32个线程。共享执行上下文,Shared Memory
- 线程束中的所有线程同时执行相同的指令,但可以操作不同的数据。
- 如果线程束中的线程分支执行不同的指令(即条件分支),会导致所谓的“线程发散”问题,这可能会降低性能,因为线程束中不同路径的执行会被串行化。
- 每个 Warp 的执行上下文(程序计数器、寄存器等)在 Warp 的整个生命周期内都在芯片上维护。因此,从一个执行上下文切换到另一个执行上下文没有任何成本,并且每次发出指令时,Warp 调度程序都会选择一个 Warp,该 Warp 中有线程准备执行其下一个指令( Warp 中的活动线程),并将指令发送给这些线程。
SM流多处理器
流多处理器(Streaming Multiprocessor, SM)SM负责管理和调度线程束的执行。线程束是SM中基本的执行单元。
-
每个SM可以同时执行多个线程束。当线程块终止时,将在空出的多处理器上启动新的块。
-
SM内部包含ALU(算术逻辑单元)、FPU(浮点运算单元)、共享内存、寄存器文件和线程调度器。
-
SM的数量和配置决定了GPU的并行计算能力。更多的SM意味着可以同时处理更多的线程束,从而提供更高的计算能力。
-
配备了 warp 调度器,是 SM 中的指令分发单元。warp调度器将决定何时以及哪些指令被执行
一个GPU由多个SM组成。
- 每个SM可以同时执行多个线程束。
- 线程束中的线程在SM内执行,利用SM的计算资源进行计算。
Kernel函数
是在GPU上执行的函数,是CUDA编程模型的核心。它是并行执行的代码,通常由大量线程同时运行。在调用kernel函数时,需要指定线程网格的配置,包括线程块的数量和每个线程块中的线程数量。当一个线程块的网格被启动后,网格中的线程块分布在SM中。一旦线程块被调度到一个SM上,线程块中的线程会被进一步划分为线程束。
- 在 device 上面运行
- 在host 端代码调用 (也可以用 device code调用)
- nvcc 会把源码分离成host,device代码两部分,不同编译器处理
- Device functions (e.g. mykernel()) processed by NVIDIA compiler
- Host functions (e.g. main()) processed by standard host compiler:
1 | |
内核参数空间的最大限制为 4
| Qualifier Keyword | Callable From | Executed On | Executed By |
|---|---|---|---|
| host (default) | Host | Host | Caller host thread |
| global | Host (or Device) | Device | New grid of device threads |
| device | Device | Device | Caller device thread |
1 | |
内存层级
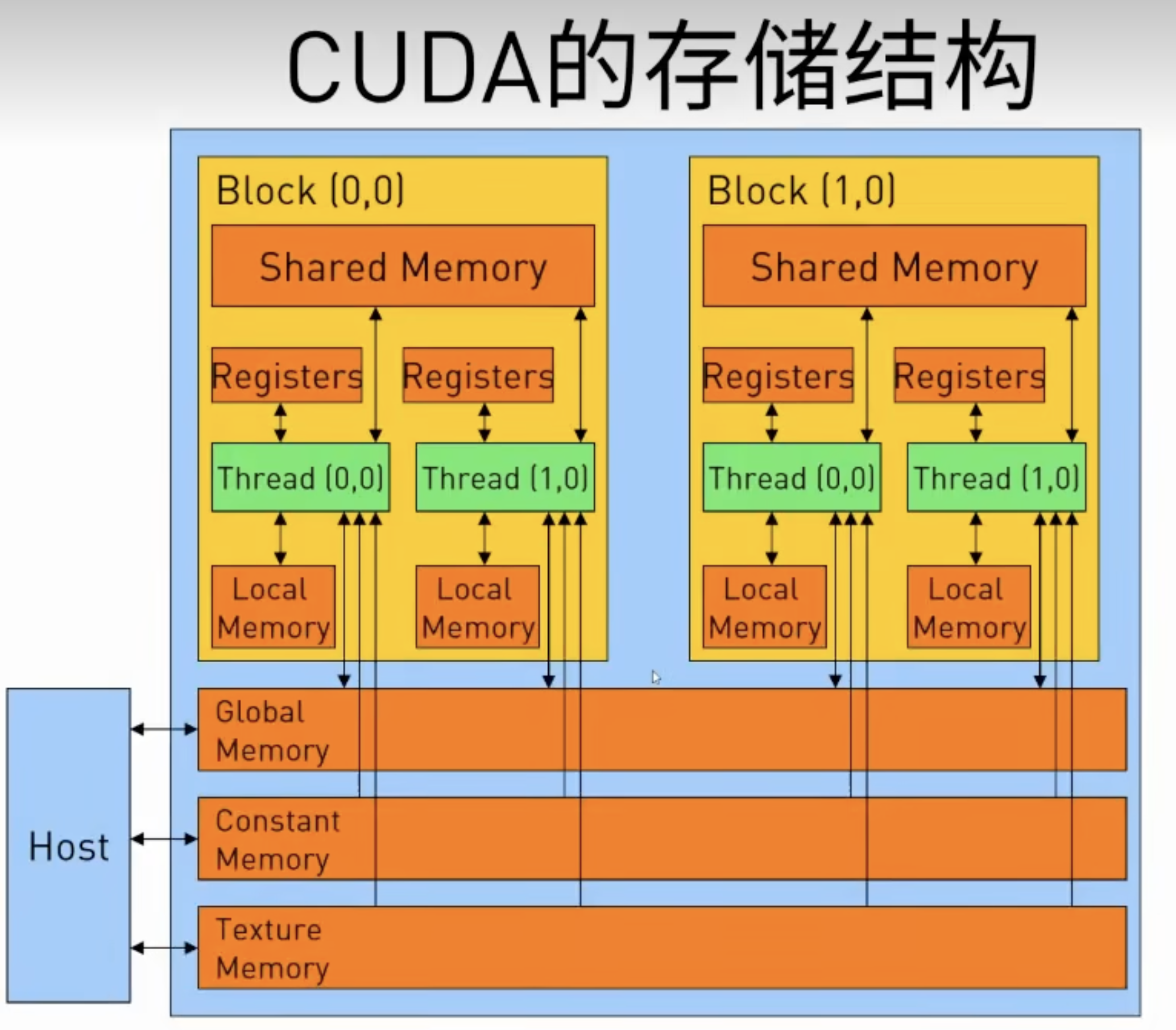
| 变量声明 | Memory | Scope | Lifetime |
|---|---|---|---|
| Automatic variables other than arrays | Register | Thread | Grid |
| Automatic array variables | Local | Thread | Grid |
| device shared int SharedVar; | Shared | Block | Grid |
| device int GlobalVar; | Global | Grid | Application |
| device constant int ConstVar; | Constant | Grid | Application |
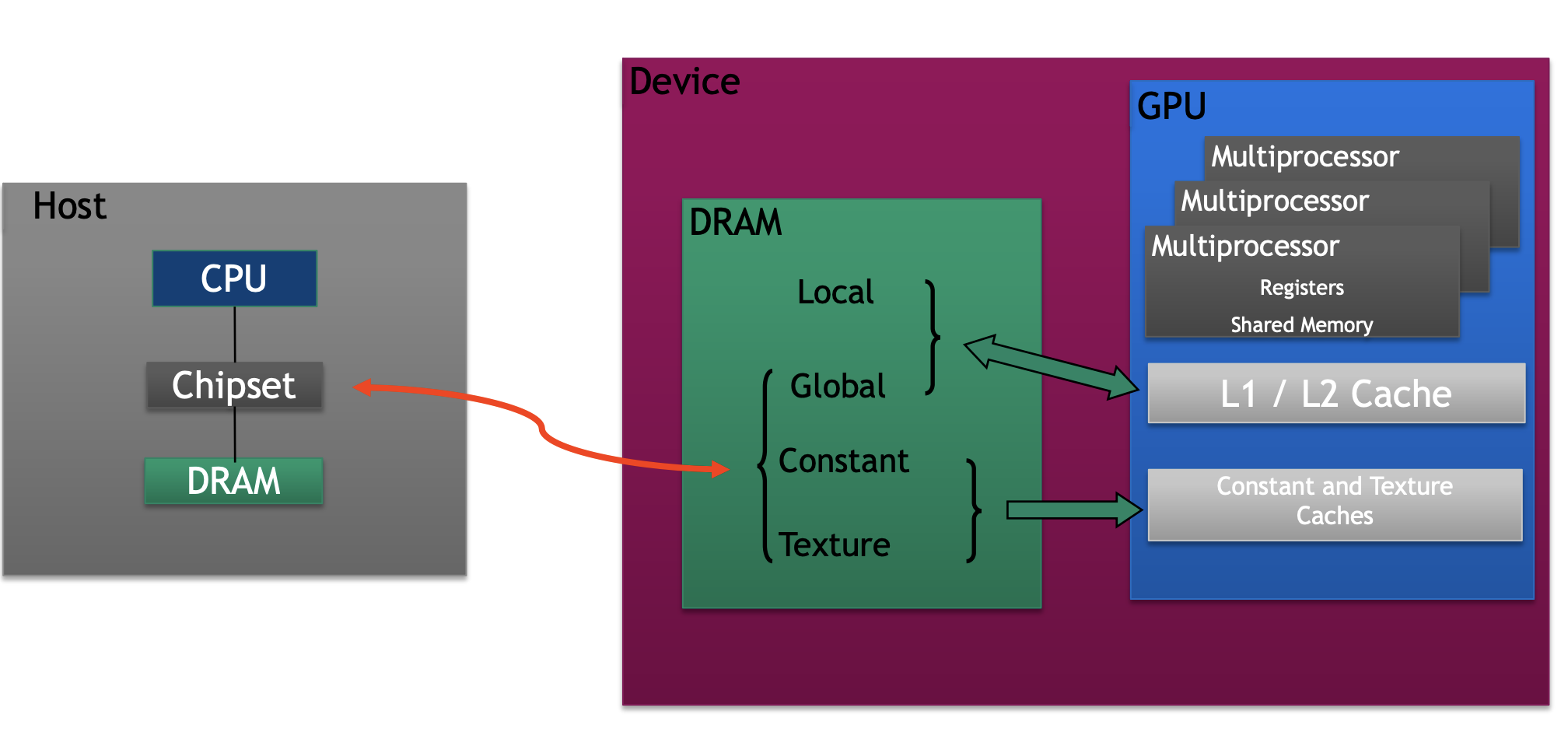
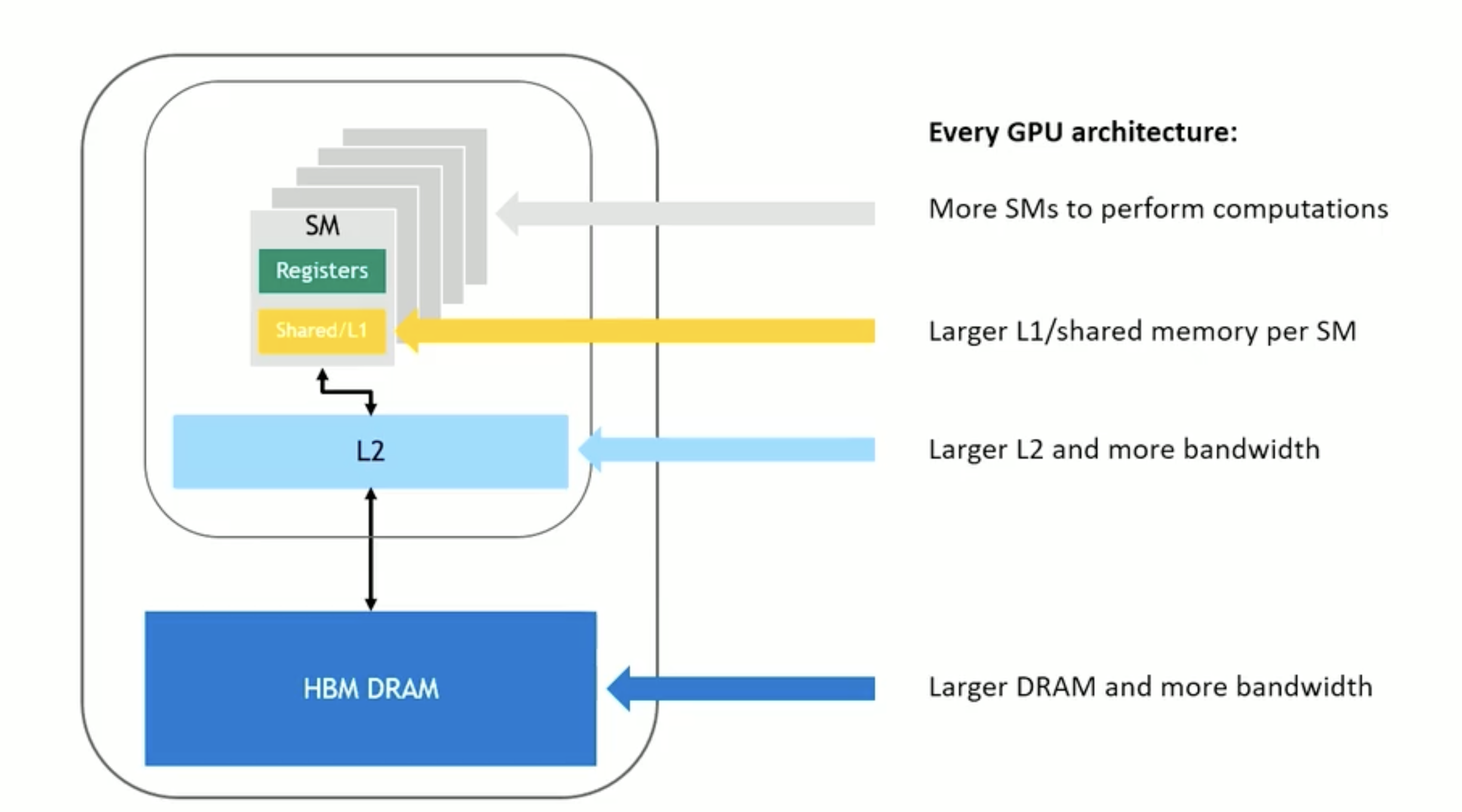
GPU内存概览
register , local memory 每个线程独享的 (快)
shared memory/L1 block线程共享 (快,小)共享内存实际上是在 GPU 芯片上实现的,因此我们可以称之为片上内存。由于它是片上的,其速度也比全局内存快得多。通常最多可达48KB共享(或64KB、96KB等)。延迟非常低。吞吐量非常高:>1 TB/s的总和。
1 | |
- 线程间的交流通道
- 可编程的 cache
- 通过缓存数据减少 glabal memory 访存次数。
cuda bank conflict memory padding
编程技巧
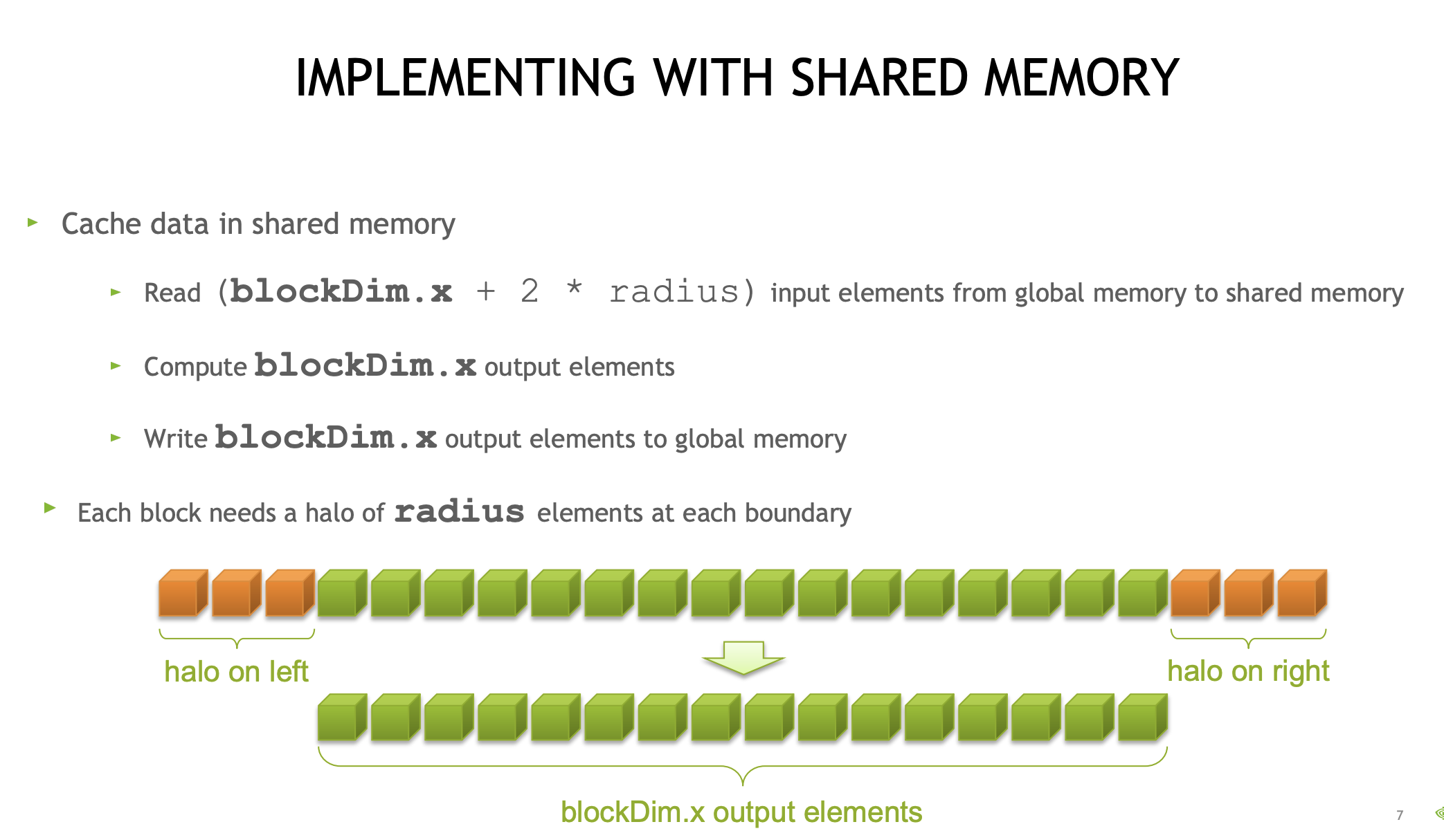

矩阵转置
1 | |
当您每个线程存储(或加载)超过 4 个字节时,即每个 warp 超过 128 个字节时,GPU 不会发出单个事务。最大事务大小为 128 个字节。每个事务的宽度为 128 个字节。bank conflicts是按事务进行的,而不是按请求、warp或指令进行的。
CPU只能访问到以下内存
-
global memory 所有线程共享 (慢,大) 物理实现,通常实现在 GPU 的动态随机荐取存储器(DRAM)中。这并非位于 GPU 芯片本身,而是由多个高速内存设备组成。这些设备与 GPU 相连。 延迟高(数百个周期)。吞吐量:高达约900 GB/s(Volta V100)。所有线程以及主机(CPU)都可以访问。
-
常量和纹理 memory (只读,相对global快)
CUDA 线程在执行期间可能会访问来自多个内存空间的数据。每个线程都有私有的本地内存。每个线程块都有共享内存,该共享内存对块的所有线程可见,并且具有与块相同的生命周期。线程块集群中的线程块可以对彼此的共享内存执行读取、写入和原子操作。所有线程都可以访问相同的全局内存。
CUDA 编程模型还假设主机和设备都在 DRAM 中维护各自的内存空间,分别称为Host内存和 Decice内存。因此,程序通过调用 CUDA 运行时来管理内核可见的全局、常量和纹理内存空间。这包括设备内存分配和释放以及主机和设备内存之间的数据传输。
Global 内存
这图有问题L1 cache
加载:
缓存
- 默认模式。
- 尝试在L1中命中,然后是L2,再然后是全局内存(GMEM)。
- 加载粒度为128字节行。
非缓存
- 使用
-Xptxas -dlcm=cg选项编译 nvcc。 - 尝试在L2中命中,然后是全局内存(GMEM)。
- 不要在L1中命中,如果已经在L1中,则使该行失效。
- 加载粒度为32字节。
存储:
- 使L1失效,写回L2。
内存操作是按warp(32个线程)发出的。 段是32字节
- 与所有其他指令一样。
操作:
-
warp中的线程提供内存地址。
-
确定所需的行/段。
-
请求所需的行/段。
访存优化
Warp请求32个不对齐的连续4字节的单元
int c = a[idx]; or int c = a[rand()%warpSize];(随机落到一个范围里)
没有任何额外请求未被swarp中的某个线程所使用, 总线利用率100%,每个请求的享节均得到利用。(pefect Coalescing 完美合并)
- 32个线程,提供32个地址,而内存控制器需要决定如何处理这种请求,它会讲这些地址根据其所在的行或者段进行合并或者分组(合并)。随后它不再请求32个地址单独地址,而是一组连续的行或者段。
- 如果实现了完全合并,则意味着我所描述的情况得以实现。所有地址均能通过最少量的线或段得到满足。


int c = a[idx-2];
- 地址位于两个缓存行之间。
- Warp需要128字节的数据。
- 在缺失时,总线传输256字节。
- 总线的使用效率为50%。
现在,这些数字,目即这些索引,都是相邻的。但它们相对于前一个示例有所偏移。实际上,它们会跨越一条线或线段的边界。
在这种情况下,它们跨越了边界,因此肉存控制器会将这些地址合并为两个独立的组,一组属于第一个边界区域,即内存地址从0 到 128 的部分,而太部分线程将归并到第二个区域,即内存地址从128到 256 的范围。因此,内存控制器需要请求两条行或多个段来处理此次请求。
如果我们请求两条缓存行,意味着内存控制器将需要检索 256字节。请记住,你不能要求少示最小量即一条缓存行或一段内存。若受限于从内存检索数据的能力,即内存瓶颈,性能将直接下降50%

全局内存优化指南
努力实现完美的合并(Coalescing):
- (对齐起始地址 - 可能需要填充)。
- 一个warp应在连续区域内进行访问。
确保有足够的并发访问以饱和总线:
- 每个线程处理多个元素。
- 多个加载可以被流水线处理。
- 索引计算通常可以被重用。
启动足够的线程以最大化吞吐量:
- 通过切换线程(warps)来隐藏延迟。
使用所有缓存!
Shared 内存
用途:
- 线程间在一个块内的通信。
- 缓存数据以减少冗余的全局内存访问。
- 用于改善全局内存访问模式。
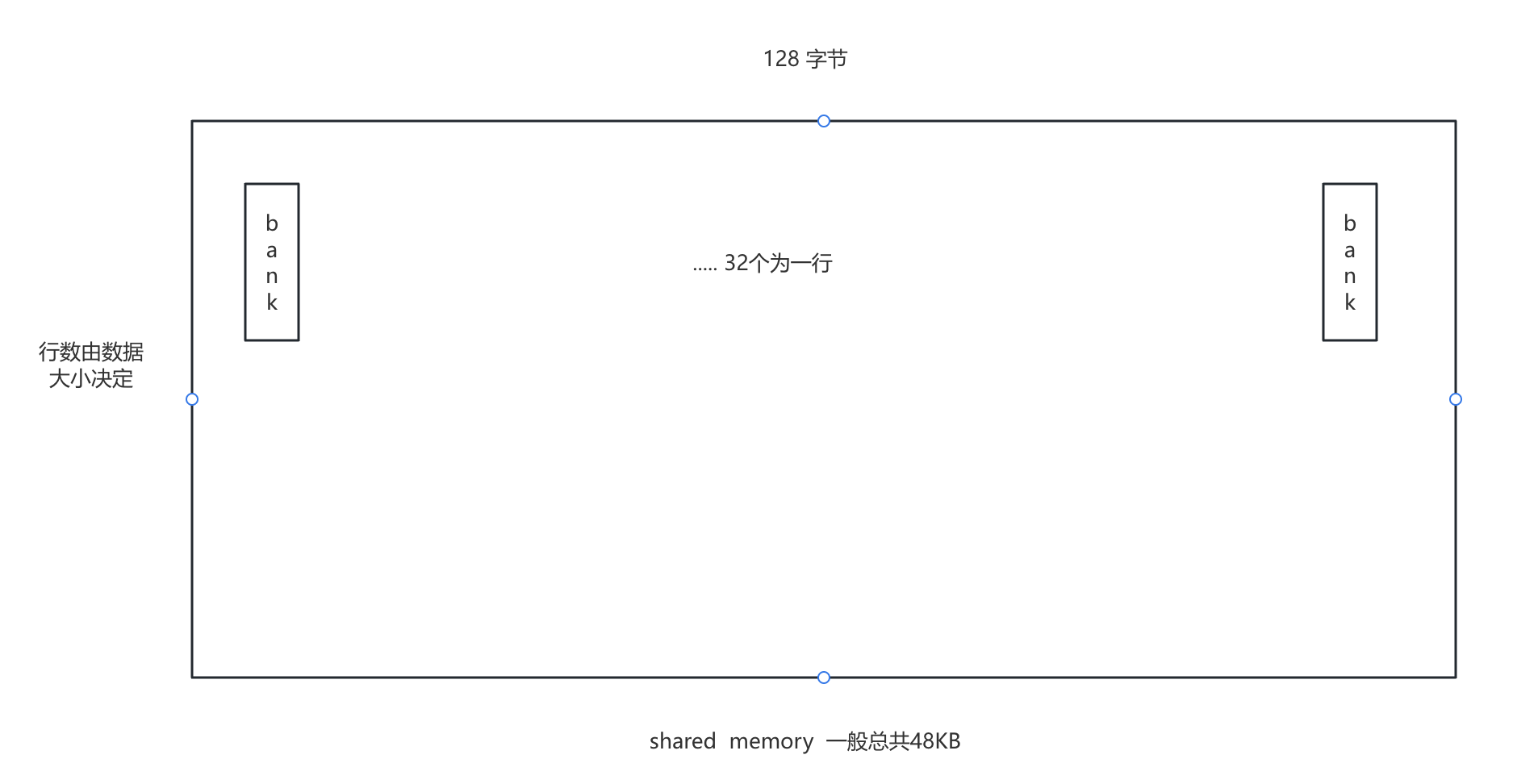
组织结构:
- 32个,4字节宽的bank。
- 连续的4字节字属于不同的bank。
- 通常最多可达48KB共享(或64KB、96KB等)
可以想象成 宽度为 128字节,行数或列数足够构成 48KB 的容量。
- 如果是按bank遍历,共享内存能够以最短的时间完成该加载操作。
- 如果在同一加载事务中请求,假设线程0需要字节0、1、2、3 ,而线程1需要字节 128、129、130、131。这是列式访问,若采用列式访问模式,共享内存将使这些事务串行化。共享内存会表示,在第一个周期,它将为第一个线程提供服务,在第二个周期,我将处理第二个线程,以此类推,直到所有在加载操作中向零号存储体请求项目的线程,即该指令在全 warp范围内发出的所有线程。
- 如果32个线程都访问同一个bank,共享性能最差,
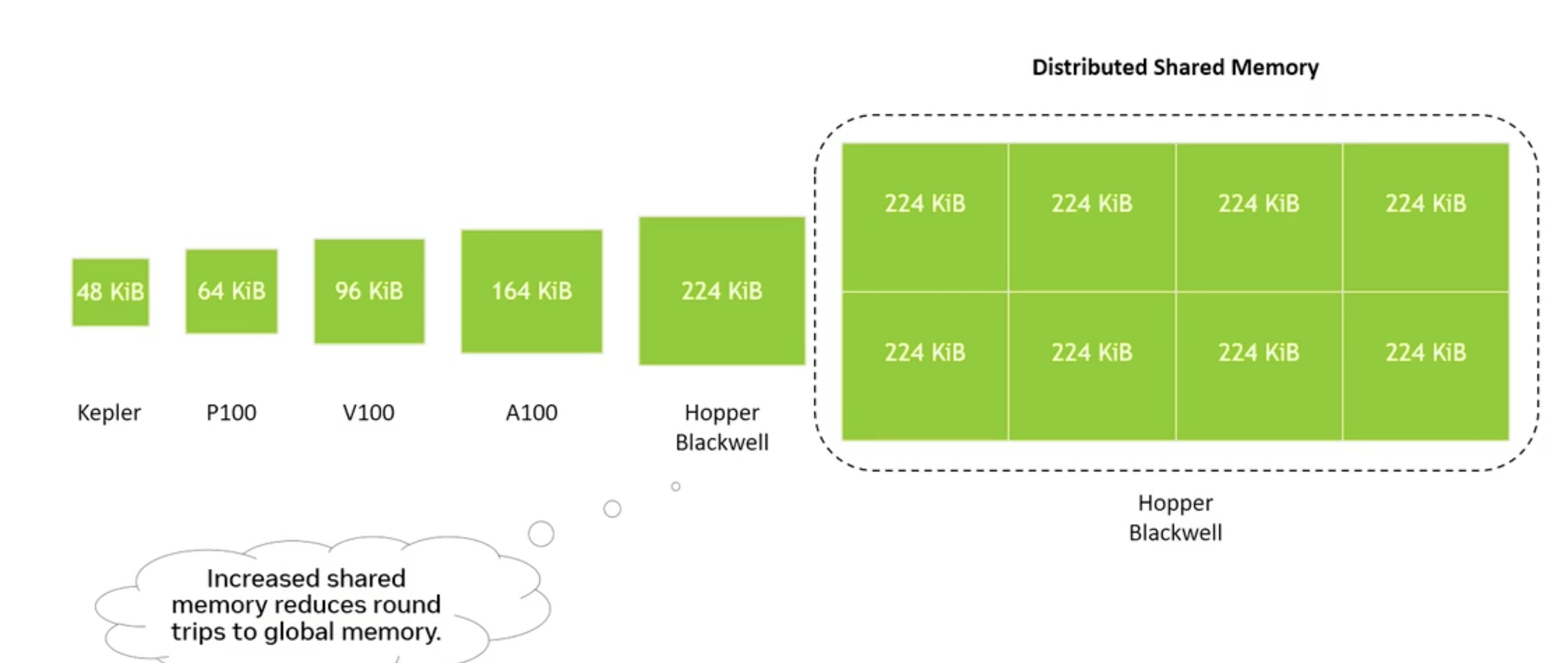
不同架构,共享内存容量变大,允许不同的multi-processor 可以不同的SM的share memory
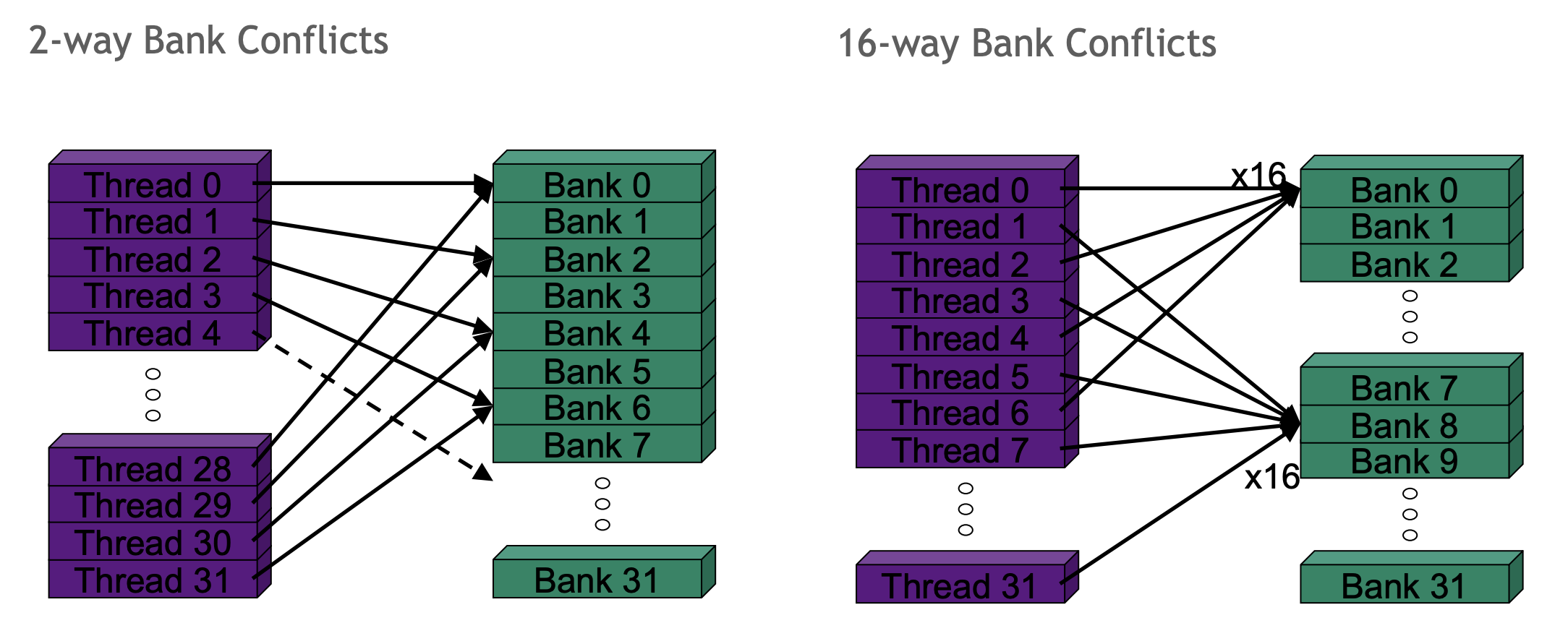
bank conflicts
即两个或多个线程请求同一bank(或可说在共享内存的同一列)中的项。
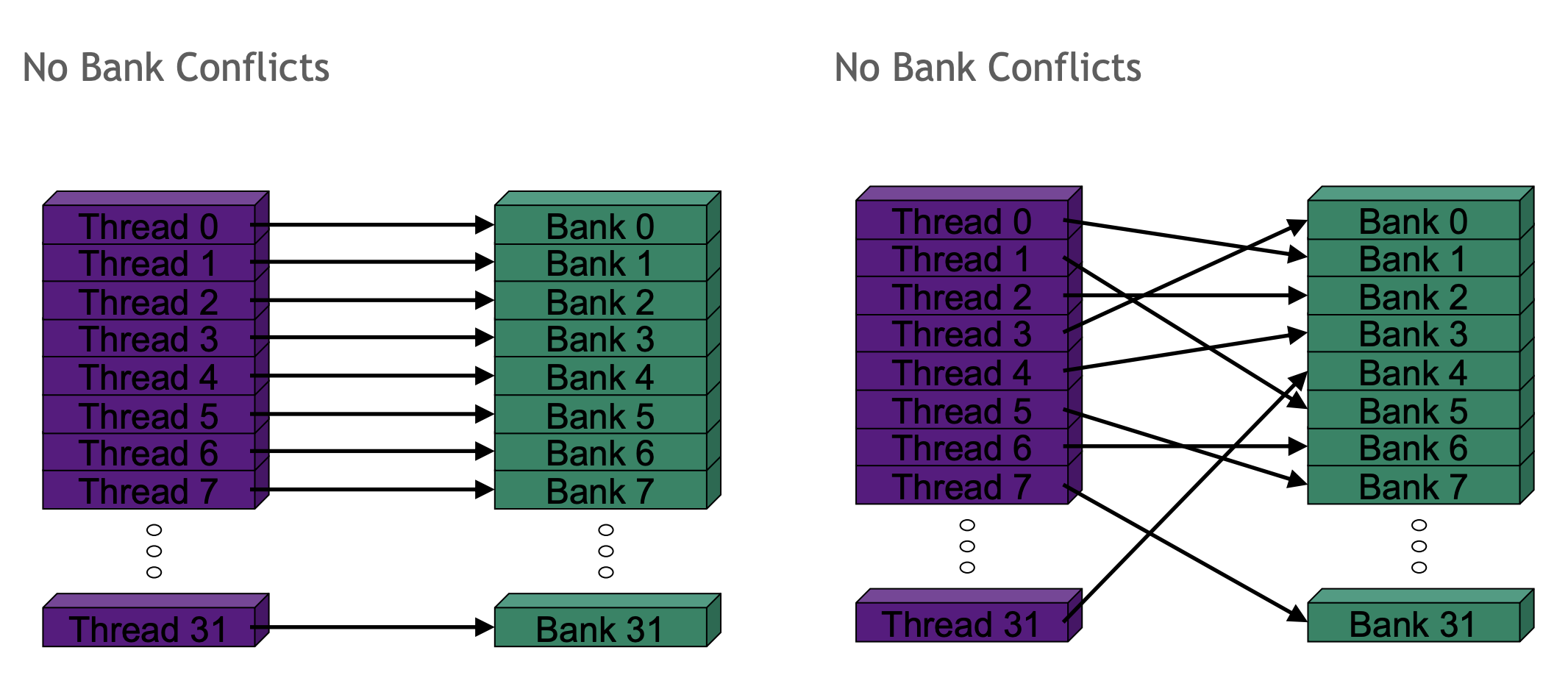
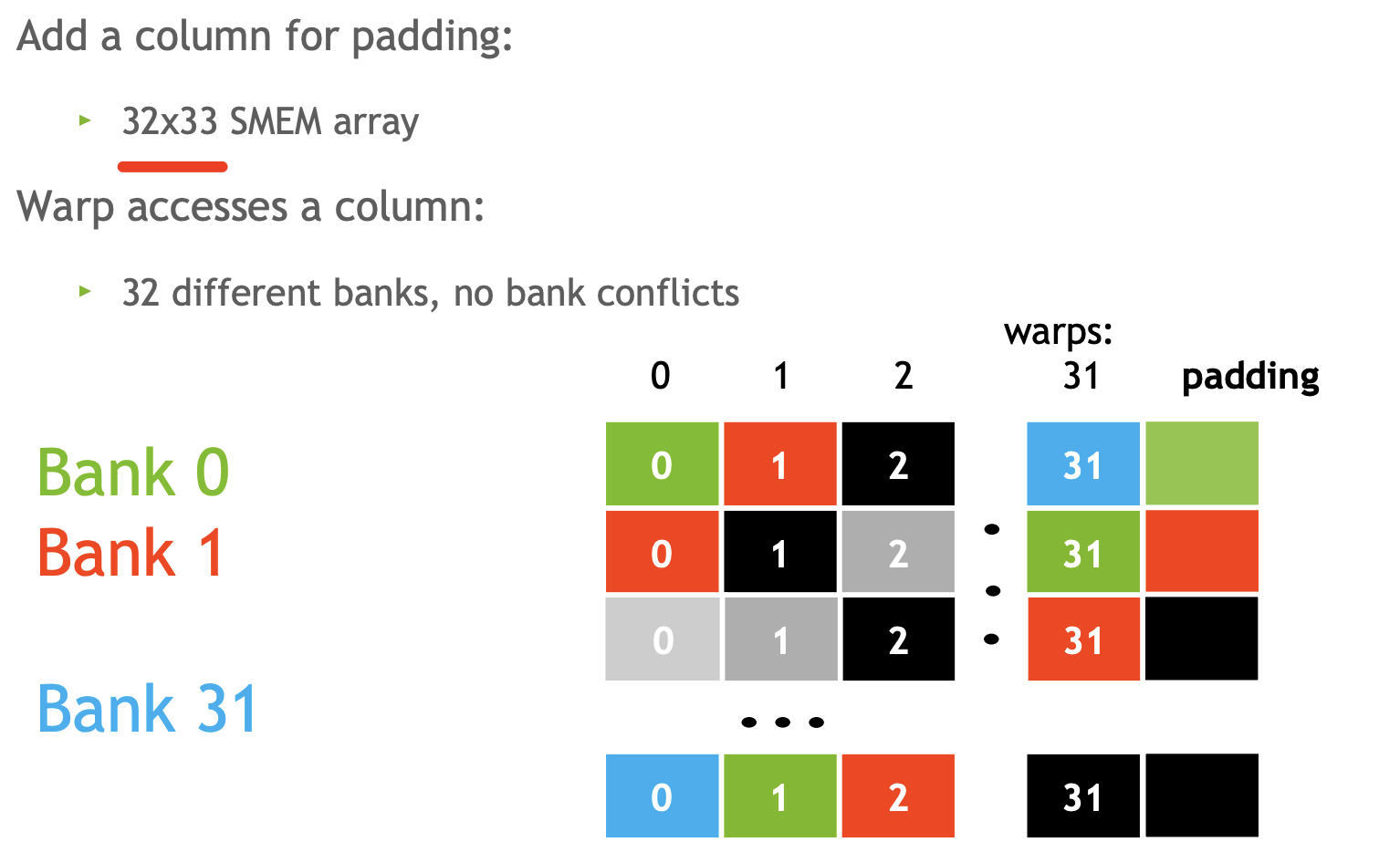
将32*32 改成32*33 使用padding 来避免冲突
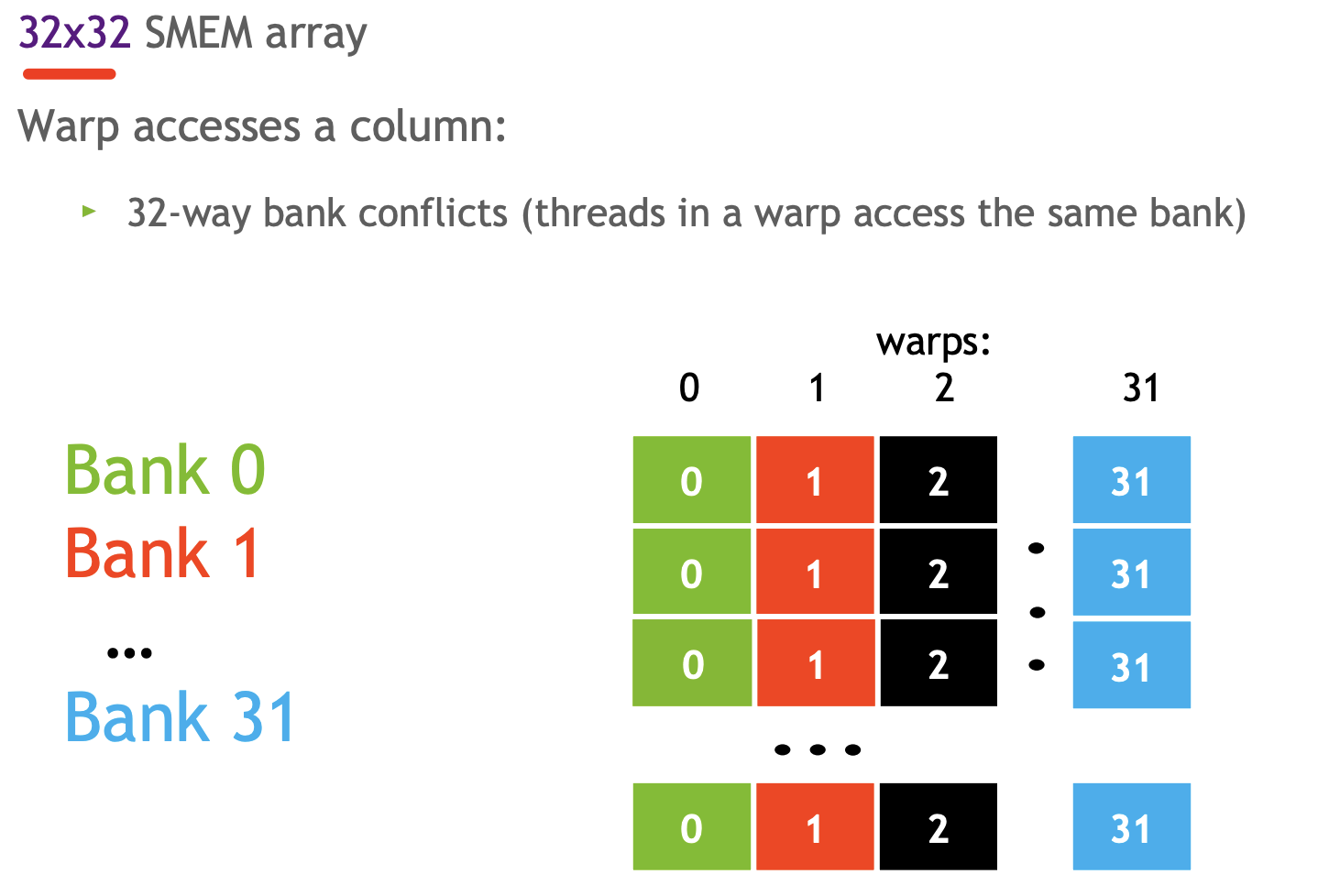
这样做会导致我们的bank布局交错或分散。 物理底层并没有任何变化,我们讨论的是逻辑数组中数据的逻辑排列与共享内存中存储位置的物理排列之间的关系。所以,通过将列数从 32 改为33,而不需要改变我的访问模式。换句话说,当我访问共享内存时,我从未访问过第 33 列。
统一内存 Unified Memory
统一内存提供托管内存来连接主机和设备内存空间。托管内存可作为具有公共地址空间的单一、连贯的内存映像从系统中的所有 CPU 和 GPU 访问。旨在简化编程模型,特别是简化内存模型。
我们并未改变这样一个事实, data DtoH and HtoD 这两个步骤是必须的。使用这个,只是简化编程工作。
cuda runtime是一个执行实体,它基于代码执行 DtoH and HtoD 。所以cuda runtime会关注编写的代码,并影响数据的移动(数据迁移,将数据迁移到需要它的处理器上面,以高效的runtime处理)。这种数据迁移机制:确保数据一次仅有一个处理器访问,保证全局一致性
1 | |
1 | |
数据迁移原理
数据迁移通过page fault 触发:
- page fault on the GPU: data H to D
- page fault on CPU: data D to H
当该页未存在于 GPU上或未驻留时,便发生了页面错误,导致数据迁移。并在GPU内存中物理实例化该页。此后,若发生页面错误,任何触及该页的额外代码将不再引发减速,没有任何开销。它只是以正常的速度继续进行。因此,页面错误通常仅在首次有CUDA 线程访间该页面时发生一次,随后访问该页面的线程通常不会观察到页面错误。
若我以高频率访问代码,无论是在 CPU或者GPU上。此页面将会来回切换。
__managed__ 和 cudaMallocManaged 都用于在 CUDA 中实现统一内存,但它们的使用方式和上下文有所不同。
__managed__
- 用途:用于声明统一内存变量,使得这些变量在 CPU 和 GPU 之间共享。
- 声明方式:在变量声明时直接使用
__managed__关键字。 - 作用范围:适用于全局变量或静态变量。
1 | |
cudaMallocManaged
- 用途:用于动态分配统一内存,允许在运行时分配内存。
- 调用方式:使用
cudaMallocManaged()函数进行分配。 - 作用范围:适用于动态分配的内存,通常用于堆内存。
1 | |
区别
- 声明方式:
__managed__在变量声明时使用。cudaMallocManaged在运行时动态分配内存。
- 使用场景:
__managed__适合于全局、静态变量。cudaMallocManaged更灵活,适合于需要动态分配的内存。
- 内存管理:
__managed__变量的生命周期与程序相同。cudaMallocManaged需要在使用完后调用cudaFree()来释放内存。
超额订阅 GPU Memory Oversubscription
1 | |
作为内核代码,假设触及此分配时,任何尚未物理驻留的页面将通过需求分页系统被引入到 GPU 内存中驻留。现在,当我通过该进程耗尽或超出 GPU 内存时,某些方面必须做出让步。问题在于,那些最近未被访问过的页面将会被驱逐。它们仍然存在于 GPU 内存映射中,只是物理上不驻留在设备上。因此,若代码再次访问被置换的页面,将导致该页面重新迁移回 GPU。
代价:延迟会增加
并发访问
CPU 和 GPU 对同一分配的访问
1 | |
因为运算是异步的,无法判断那个会先发生。所以必须要程序员解决顺序问题
系统级原子操作
1 | |
适用于多处理器
系统级原子操作使您能够以原子方式从所有处理器访问托管分配
特殊操作
统一内存自动做
- 类似于深拷贝的情况
- 编写复制操作的代码很复杂
- 统一内存使得这一过程变得简单
1 | |
性能调优
采用逐页处理的方式,即零散进行,其开销将远高于批量移动数据时的成本。
所以对于大数据量移动或者访问大块显存,使用cuda memcopy效率更好
1 | |
- 可以将数据预取到任何 GPU 或 CPU,这种灵活性有助于优化多设备之间的数据管理。
cudaMemPrefetchAsync是异步的,不会阻塞主机线程。这意味着可以同时进行其他计算或内存传输。- 提前预取数据可以减少后续访问时的延迟,尤其是在数据访问模式已知的情况下,能显著提高性能。专注于数据预取,为后续使用准备数据,而不是立即进行复制。
Advise runtime on expected memory access behaviors with:
cudaMemAdvise(ptr, count, hint, device);
Hints:
cudaMemAdviseSetReadMostly: Specify read duplication , 协商(不强求)只读,保证多处理数据一致,会复制多个副本
一旦某个处理器进行写入,即违反了您的提示,统一内存子系统将介入并使所有相关数据失效,迫使再次进行迁移,以确保数据一致性。
如果准守约定:每个处理器都拥有其本地副本,且不存在任何迁移。若处理器首次触及只读数据,此时将发生迁移,但此后该数据将永久保留,即便其他进程也在读取它。除了首个接触的处理器,其他处理器都可以全速访问。
cudaMemAdviseSetPreferredLocation: suggest best location
当首个 GPU 触及该数据时。数据迁移即刻发生,便在该 GPU 上驻留。第二块 GPU 接触到该数据时,不会将数据迁移至第二块,UM 系统将尝试建立映射,通过处理器间总线(NVLink/PCIe)处理读写请求。
cudaMemAdviseSetAccessedBy: suggest mapping
指定GPU通过映射方式访问数据,而不是数据迁移。映射比普通访问慢,但映射使得你能够通过总线访问它,无需通过页面错误来处理访问请求。若你知晓某个处理器偶尔会访问你确认位于另一处理器上的数据,那么提供这种通过集合访问的额外提示或许是有益的。
CUDA 编程模型通过异步编程模型为内存操作提供加速。异步编程模型定义了异步操作相对于 CUDA 线程的行为。
线程协同
线程协同工作:一种通过通信(通过shared memory,warp shuffle),另一种方式则是通过同步。
原子操作
规约:多个输入,一个输出
*c += a[i];
在GPU编程里面做不到,编译器将这些代码转换成实际可执行的指令
1 | |
当我们跨多个线程执行此操作时。观察到的现象是所有线程都正确完成了第1 步指令。但是后面的步骤:线程们实际上是在相互踩踏, 因为每个线程都在尝试执行或者同时执行,CUDA不会自动为您完成排序。如果代码的正确性依赖于线程执行的顺序,则该代码本身并不正确。
这个时候需要原子操作,将3步转成1步。实际上,它表现为我们所谓的“归约“操作,但归约是机器代码级别上的原子指令形式。在此实现中,不允许其他线程或任何其他活动访问由指针C所指示的位置。让线程间的行为串行化,但这样能确保行为定义明确、可预测且符合预期
原子硬件实际上是在一个名为L2 缓存的地方实现的。当线程发起原示指令时,L2缓存中存在一个协调执行机制,作为协调者它会逐一处理所有这些原子操作。
当多个线程尝试使用原子换作更新同一位置,线程操作的串行化可能导致性能影响。所以,我们通常不应期望原子操作,能以与普通内存操作相同的速率进行
缺点:
原子操作所适用的数据类型及其在不同 GPU 架构上的影响范围可能会有所不同。
技巧
int my_position = atomicAdd(order, 1);- 可用于确定下一个工作项、队列槽等。确定我在顺序中的位置
- 大多数原子操作返回一个值,该值是接收原子更新的位置的“旧”值。
- 预留缓冲区中的空间

线程同步
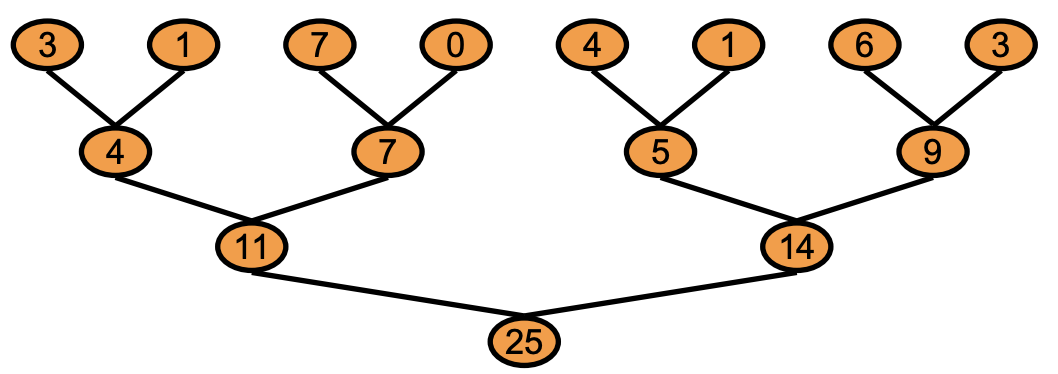
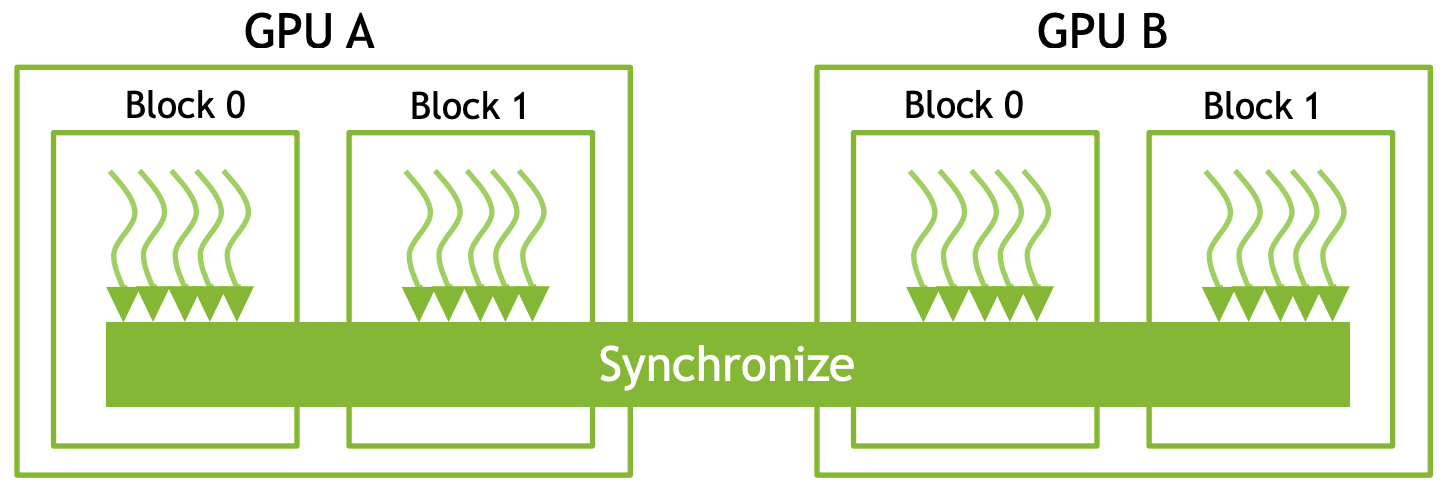
希望树的顶层所有操作,必须在任何低级树操作开始之前完成。
由于这种同步作用于整个树的宽度,类似于作用于整个网格的宽度,我们将其称为全局同步。跨越block级别,作用于grid的线程同步。
- 把任务用kernel切分,kernel会按序完成,当kernel完成就意味着所有线程都完成了,kernel的启动边界提供一个全局同步屏障。
- kernel启动本身存在一定开销,虽然相对于处理时间而言。这一开销通常较低,但如果内核执行大量工作,启动开销可能就不容忽视
- 与内核启动相关联的网格变小了,因为随着我沿树向下移动。树的宽度在缩小。
- 其他方法
- block排空法:kernel结束后,block是一个个退出的,完成一些收尾的工作。通过使用原子操作,跟踪这个活动,知道哪个block是最后完成的。我们就可以将额外的工作给它,因为我们知道其他所有线程块均已完成。cuda sameple threadFenceReduction
- 协作组:CUDA编程模型允许使用相当粗粒度的结构进行分解。主要是解决:CUDA在提供线程协作和线程分解、线程组分解方面的构造或原语不够丰富的问题。协作组提供了一套新的内置函数和基本组件,使我们能够构建规模更为灵活的线程组,这些线程组能够协同工作,共同执行任务。
1 | |
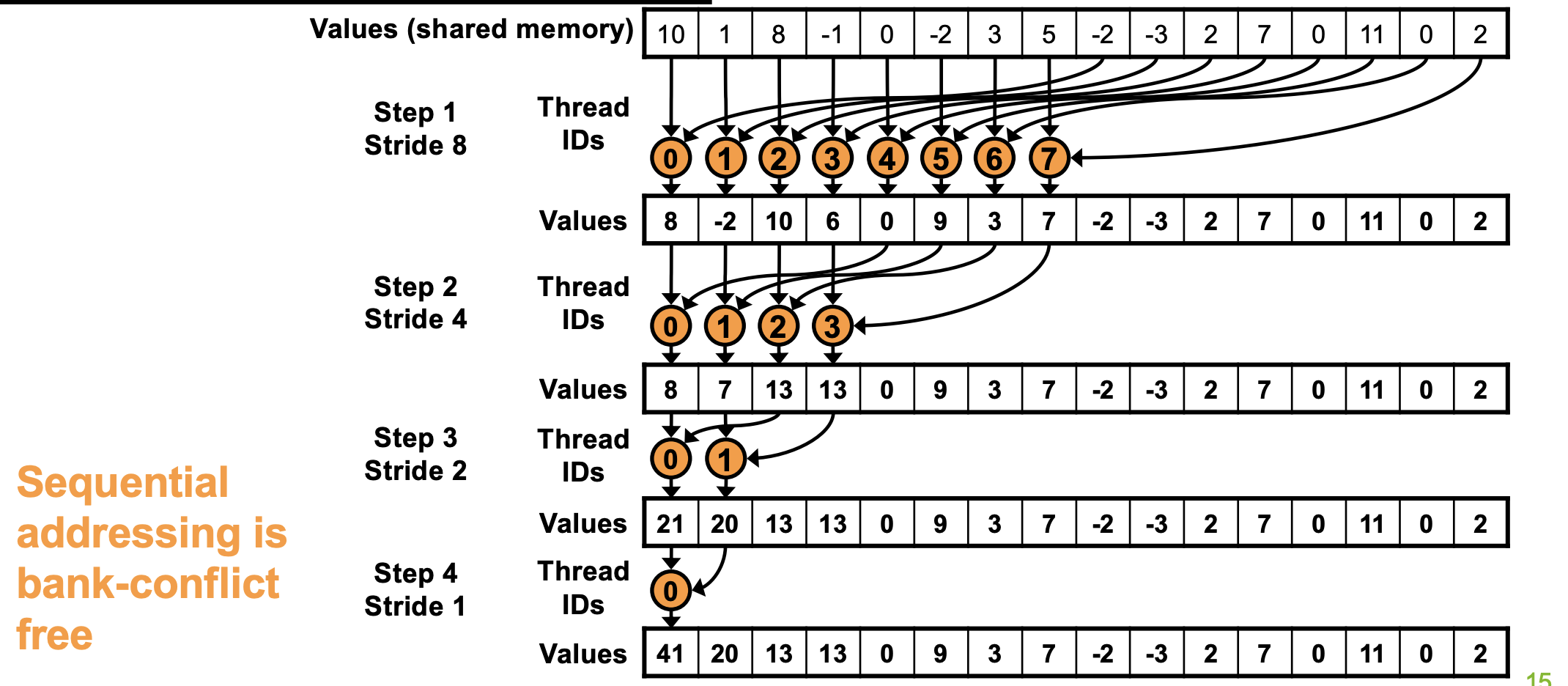
网格跨步循环
希望创建的核函数能够实现一种解耦,即核函数的规模(换言之,网格的大小,即执行操作的线程数量)与数据集大小之间的解耦
能够有效加载和操作任意数据大小的kernel,将初始时对输入数据集大小进行处理,该大小与网格的宽度相对应。
固定数量的线程,等于网格的宽度。即预先确定线程数量。

1 | |
放到一起 规约
1 | |

1 | |
确保线程及其拥有的位置随着时间的推移保持紧密相邻(从缓存局部性获得好处),减少控制分歧
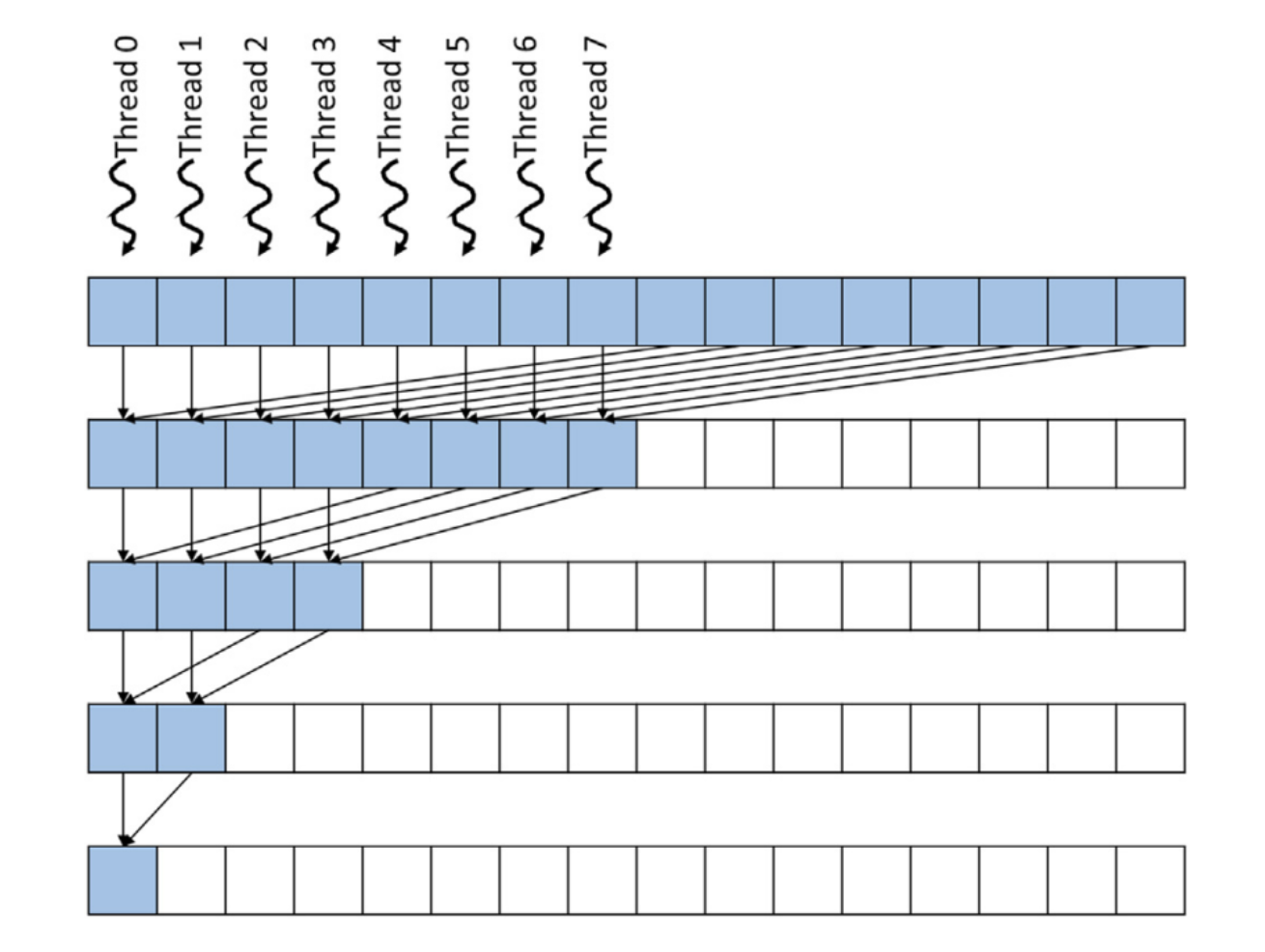
1 | |
减少全局内存读写
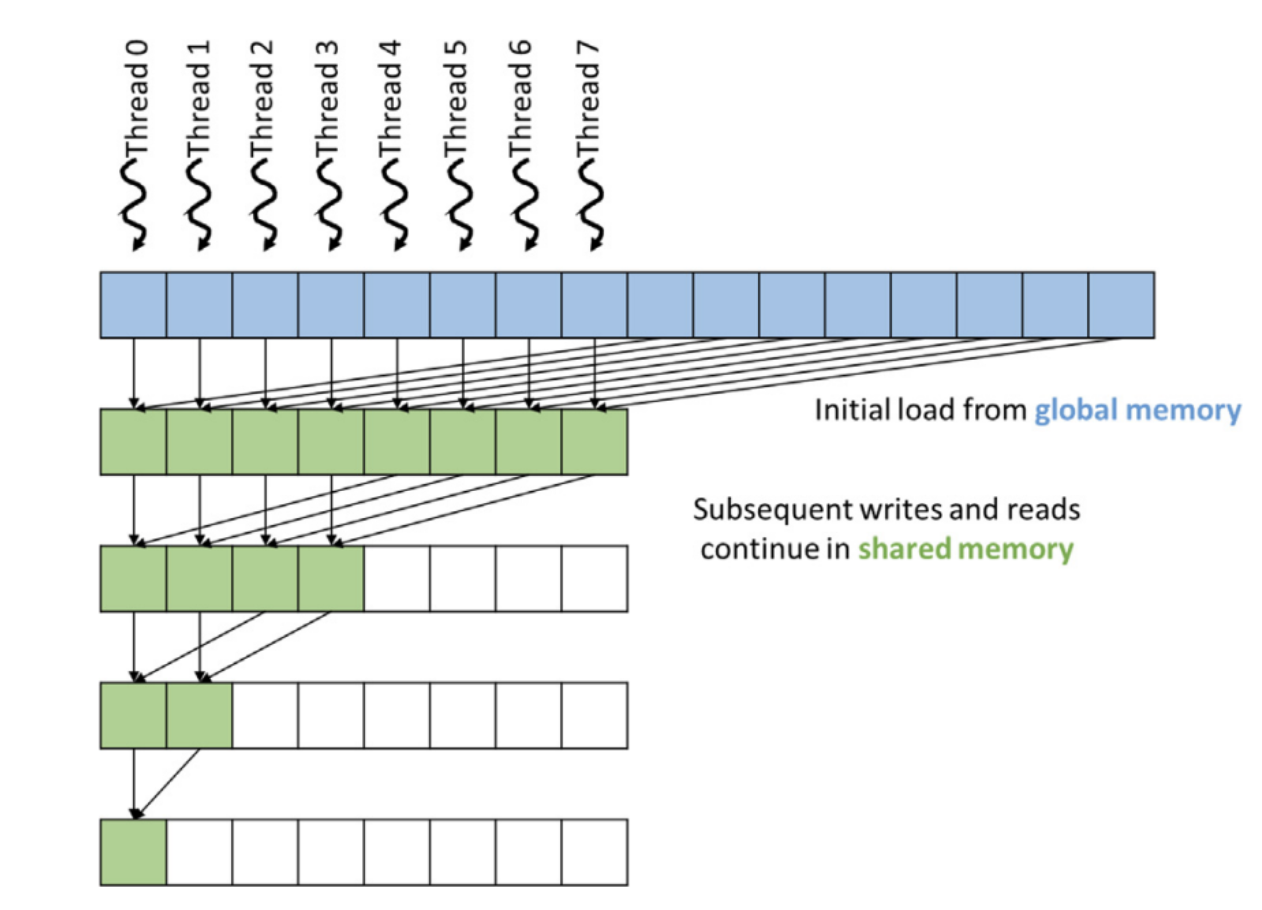
1 | |
上面仅适用于固定大小的输入(每个块处理BLOCK_DIM个元素)。没有考虑总输入大小n,可能导致数据越界。
Hierarchical reduction
- 归约操作分为多个层次,通常包括块内归约和块间归约。
- 每个线程块内部进行局部归约,使用共享内存来存储中间结果。
- 将所有块的结果合并,通常使用原子操作或第二个内核来完成。
- 更强的灵活性和通用性,适用于任意大小的输入数据。
- 处理了边界情况,确保不会越界。
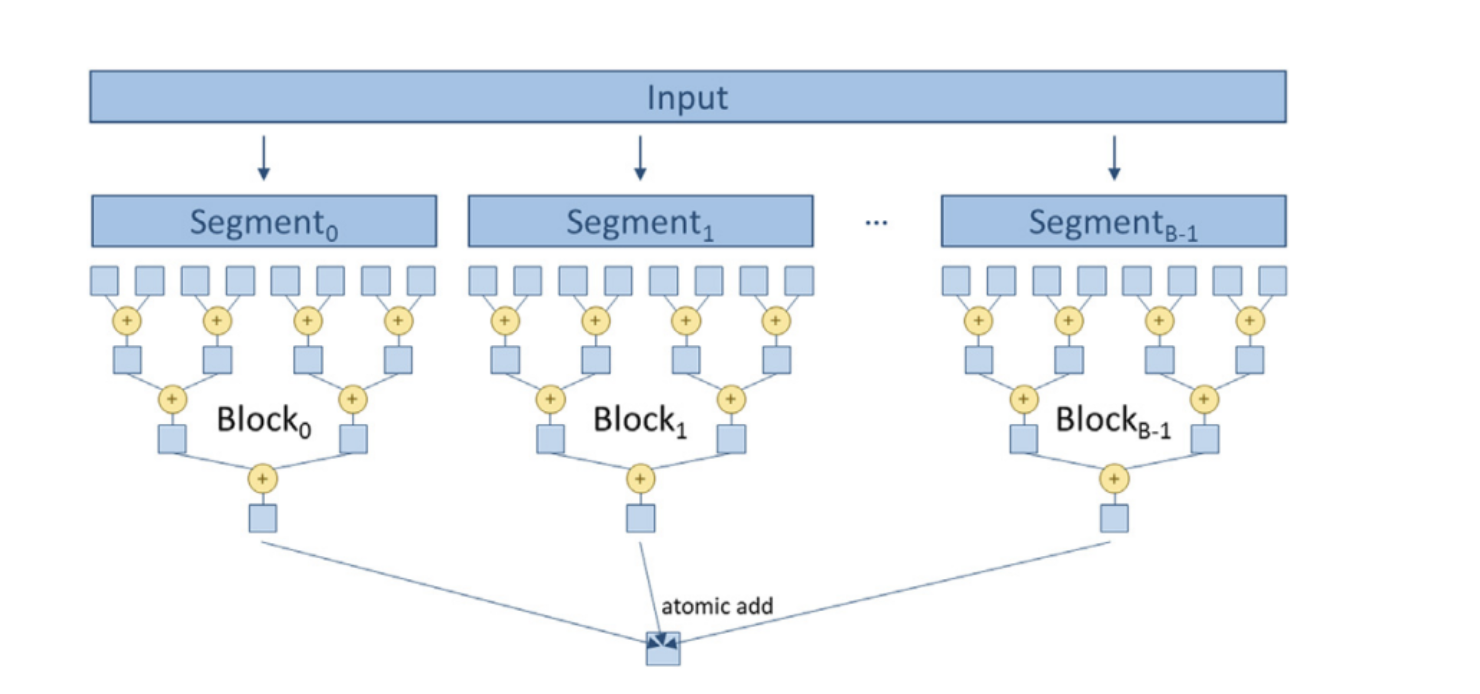
1 | |
CoarsenedReduction 在一个线程里面干更多东西。
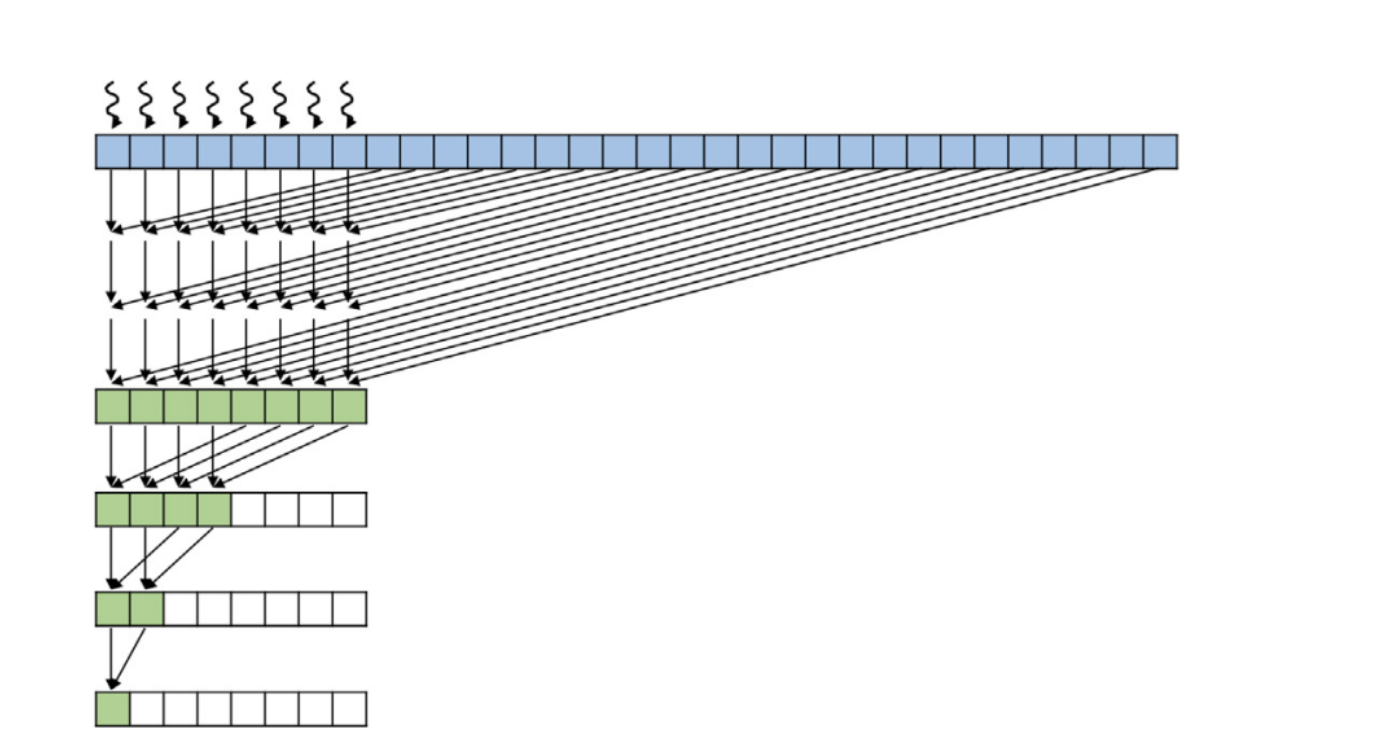
1 | |
warp shuffle
允许Warp内部实现这种直接的线程间通信。
warp 由32个线程组成,同步运行
1 | |
使用同步“mask”掩码用于指定哪些线程参与操作
1 | |
- 减少了每个线程块所需的共享内存量
- wrap shuffle 操作机器码上面是单一指令,减少了指令数量
-
减少了显式同步的频率,相较于共享内存扫描,后者在每次循环迭代中每个扫描操作都需要进行一次同步线程
- 将单一值广播至整个线程束中的所有线程,仅需一条指令
Cooperative Groups 协作组
即在多个执行单元间实现基本合作,Cooperative Groups可以做到全Grid同步
__syncthreads()充当block级别同步屏障,而Cooperative Groups有一个抽象概念thread group:使得一组线程可以通信和同步
thread block: 启动的线程块中所有线程的集合。
32,4 这些值必须小于或等于32,且2必须的幂
1 | |
thread block
1 | |
grid
1 | |
协同启动内核要求
- 硬件支持
- grid size不能超过一定大小,block没有分配到SM, 会造成死锁。一旦block被分配至 SM,它将永久留至任务完成。
multi grid group
1 | |
Coalesced group 合并的线程
一个线程束是一组同步执行的线程集合(SIMD)。当向 warp 中的一个线程发出指令时,该指令也会同时发给 warp 中的所有其他线程。
一旦理解了线程束(warp)的概念,我们可能会问,当存在条件代码导致单个线程束内的线程在条件行为上产生分歧时,存在一个执行引擎,负责处理这种所謂的分岔状态或分岔,即线程束分岔(warp divergence)。它使得一些线程能够遵循“如果”路径,一些线程遵循“那么”路径,还有一些线程遵循“否则”路径,而无需深入细节。存在一个引擎,允许分歧行为。
当我们想象一些线程遵循某一条执行路径,而另一条线程遵循另一条执行路径时,我们能快速意识到,存在某些情况,我们可能无法拥有一个完整的线程束,或者可能无法拥有一个完整的线程束。
Coalesced group就是告诉我那些线程正在同步执行。
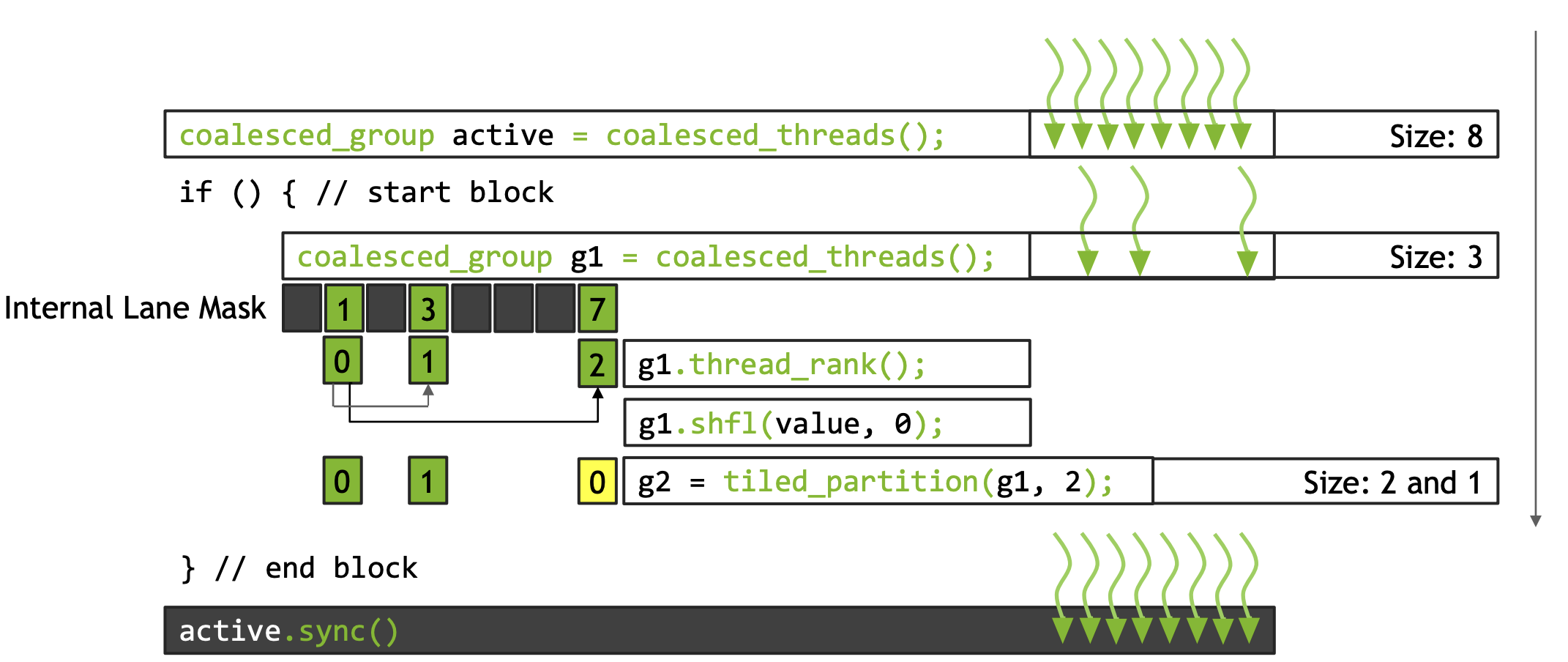
1 | |
并发
PINNED (NON-PAGEABLE) MEMORY 页锁内存
主机端存在虚拟内存,主机内存不足是会将内存数据交换到虚拟内存中,虚拟内存就是主机中的磁盘空间,需要该页时再重新从磁盘加载回来。这样做可以使用比实际内存更大的内存空间。
函数cudaMalloc()将分配标准的,可分页的主机内存。
cudaHostAlloc()将分配页锁定的主机内存。页锁定的主机内存也称为固定内存或不可分页内存,
它的重要属性就是:操作系统将不会对这块内存分页并交换到磁盘上,从而确保了该内存始终驻留在物理内存中。因此,操作系统能够安全的使用应用程序访问该内存的物理地址,因为这块内存将不会被破坏或者重新定位
好处
- 设备内存与锁页内存之间的数据传输可以与内核执行并行处理,方便多流计算
- 锁页内存可以映射到设备内存,减少设备与主机的数据传输。
- 在前端总线的主机系统锁页内存与设备内存之间的数据交换会比较快;并目可以是write-combining的,此时带宽会很大。
cudaMalloc 与 cudaMallocHost 的区别总结
- 内存位置:
cudaMalloc:在设备(GPU)上分配内存,适用于 GPU 计算。cudaMallocHost:在主机(CPU)上分配页锁定内存,主要用于 CPU 与 GPU 之间的数据传输。
- 访问方式:
cudaMalloc:分配的内存只能由 GPU 直接访问,CPU 需要通过cudaMemcpy进行数据传输。cudaMallocHost:分配的内存可以被 GPU 快速访问,适合高效的数据传输。
- 性能:
cudaMallocHost:页锁定内存提高了数据传输性能,但不用于计算。cudaMalloc:设备内存用于 GPU 执行计算。
- 释放方式:
cudaFree:释放通过cudaMalloc分配的内存。cudaFreeHost:释放通过cudaMallocHost分配的内存。
总结
cudaMalloc主要用于 GPU 计算,而cudaMallocHost则用于主机内存,适合高效的数据传输。- 两者各有特定用途,不能相互替代。使用
cudaMalloc进行计算,使用cudaMallocHost进行快速数据传输。
页锁内存(Pinned Memory)的缺点
- 内存限制:
- 页锁内存的使用量通常受到系统限制(上限物理内存总量),过多使用可能导致系统内存不足,影响主机性能。
- 性能开销:
- 尽管页锁内存可以提高数据传输性能,但在某些情况下,使用它可能导致系统整体性能下降,尤其是在 CPU 进行大量内存操作时。
- 资源占用:
- 页锁内存会占用系统内存的页表项,可能影响其他应用程序的性能。
- 分配和释放开销:
- 分配和释放页锁内存的开销通常比普通内存更高,可能导致性能下降。
- 不适合频繁分配:
- 由于分配和释放成本较高,频繁使用页锁内存可能不利于性能。
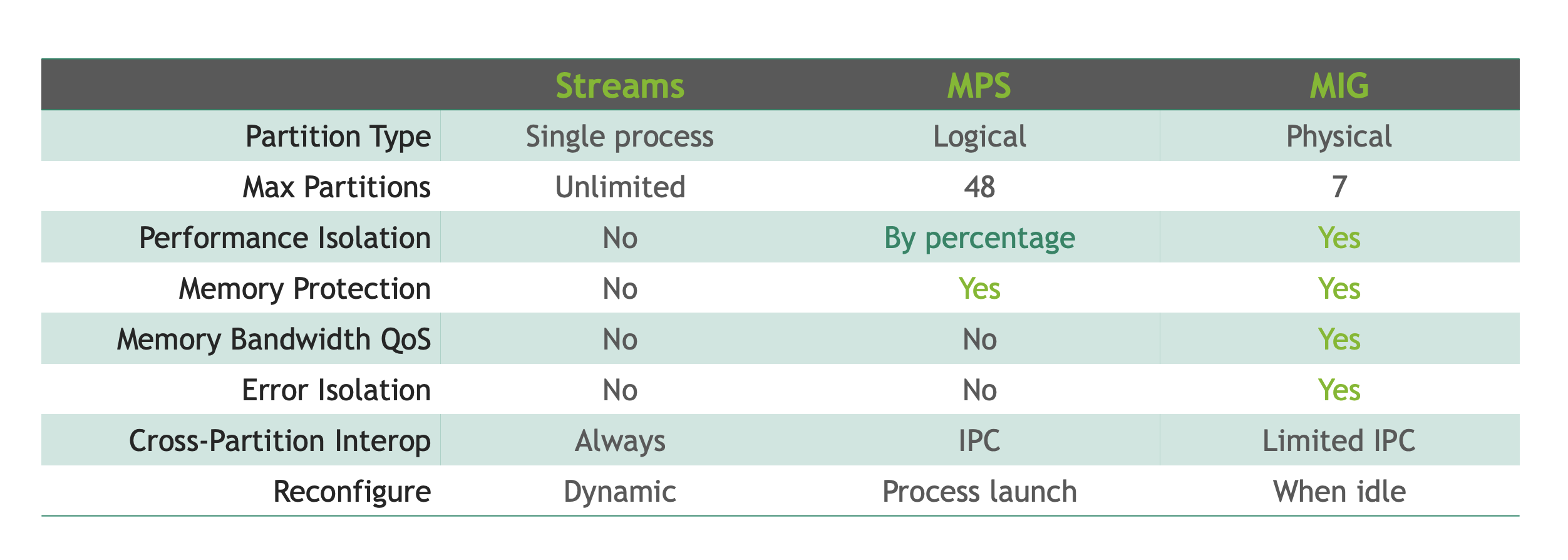
Cuda 流
Stream
是CUDA编程中的一个概念,表示一个GPU操作队列。使用stream可以实现任务的并发执行,从而提高计算效率
- 每个stream中的操作按顺序执行,但不同stream中的操作可以并行执行,形成grid级别的并行。
- 使用多个stream可以重叠计算(kernel)和数据传输(cudaMemcpyAsync),从而隐藏内存访问延迟。时间上重叠
- CUDA流中排队的操作和主机都是异步的,所以排队的过程中并不耽误主机运行其他指令,所以这就隐藏了执行这些操作的开销。
我们主要的并发需求是同时调度从主机到设备以及从设备到主机的数据复制操作。
1 | |
这是深度优先:即我们在完全横向展开操作的宽度之前,先沿着深度方向(三阶段按序入流)进行。
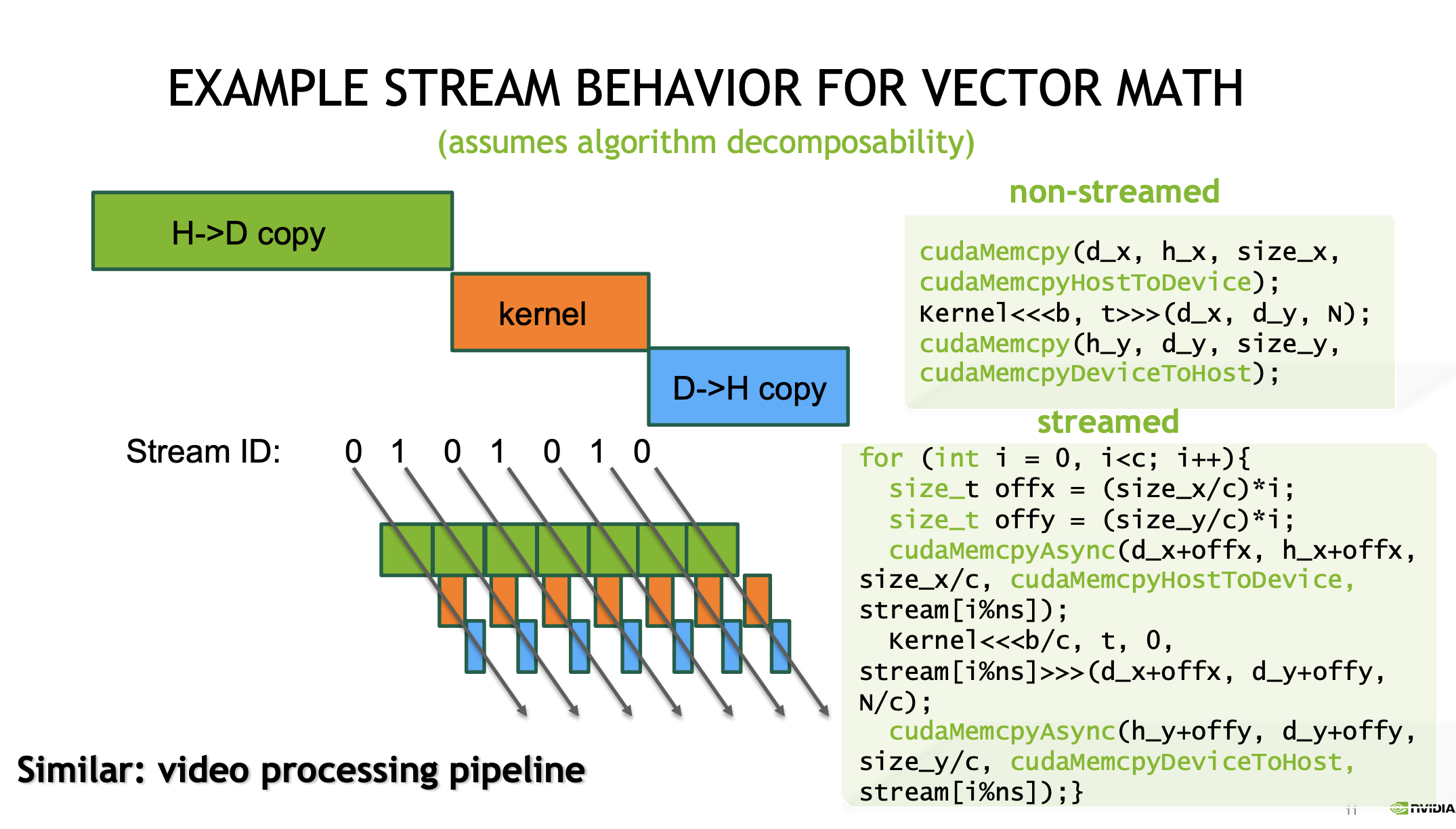
如果三个阶段,按阶段分stream,按块入流。广度优先
默认流
不指定流(或使用0作为流)的内核或 cudaMemcpy 正在使用默认流。当您未使用显式流,也未利用流 API 的任何特性时,所有工作均在默认流中执行。
-
首先,默认流将同步执行,这意味着它会强制所有先前发出的 CUDA 活动(无论在哪个流中发出)完成,然后默认流发出的项才会执行。(红色部分内),默认流有隐式同步
-
此外,默认流要求在发出此默认流项之后发出的任何其他活动,必须等到默认流项完成后方可开始。会阻塞/同步整个流程

- 在复杂的并发场景中,考虑避免使用默认流
- 如果在性能关键循环中遇到没有明显流参数的部分,应立即疑虑其存在的原因及必要性。为什么没用cuda流
1 | |
cudaLaunchHostFunc 流回调 steam callback
函数将在流执行到达该点时被调用。
- 使用由GPU驱动程序生成的线程来执行工作。
- 在函数中不要使用任何CUDA运行时API调用(或内核启动)。
- 对于延迟CPU工作直到GPU结果准备好非常有用。
对统一内存的影响
- 使用cudaMemcpyAsync
1 | |
CUDA流和优先级
- CUDA流允许你可选地定义一个优先级。
- 这会影响并发内核的执行(仅限于并发内核)。
- GPU块调度器会优先调度cudaDeviceGetStreamPriorityRange高优先级(流)内核的块,而不是低优先级块。(值越小,优先级越高)
- 当前实现只有两种优先级。
- 当前实现不支持对块的抢占。
1 | |
cudaDeviceSynchronize 会阻塞到所有流完成,尽量避免频繁调用以减少启动延迟。
推荐使用 cudaStreamSynchronize、cudaMemcpyAsync 等细粒度异步 API。
CUDA 事件 (cudaEventRecord/cudaEventSynchronize/cudaEventQuery/cudaEventElapsedTime) 可用于跨流或计时
合理使用异步拷贝与新引入的 cudaMemcpyBatchAsync (CUDA 12.8) 批量拷贝。
Programmatic Dependent Launch, PDL
在同一流中,后续 Kernel 需等待前驱完成预处理(preamble)才能启动,PDL 允许后续 Kernel 的预处理与前驱 Kernel 的部分计算重叠,加速流水线
使用方式
- 在生产者 (primary) Kernel 中调用
cudaTriggerProgrammaticLaunchCompletion()标记可触发点。 - 在消费者 (secondary) Kernel 中调用
cudaGridDependencySynchronize(),仅在所有 CTA 至少调用一次触发后,才开始依赖部分执行。 - CPU 侧需使用
cudaLaunchKernelEx并设置cudaLaunchAttributeProgrammaticStreamSerialization属性来启动 secondary Kernel 。
注意事项
- 仅在设备架构 Compute Capability ≥ 9.0 上支持。
cudaTriggerProgrammaticLaunchCompletion()不保证内存可见性;需谨慎避免竞态。- 若 work_B (primary 后半部) 比 work_C (secondary 前半部) 更长,secondary 仍可能等待。
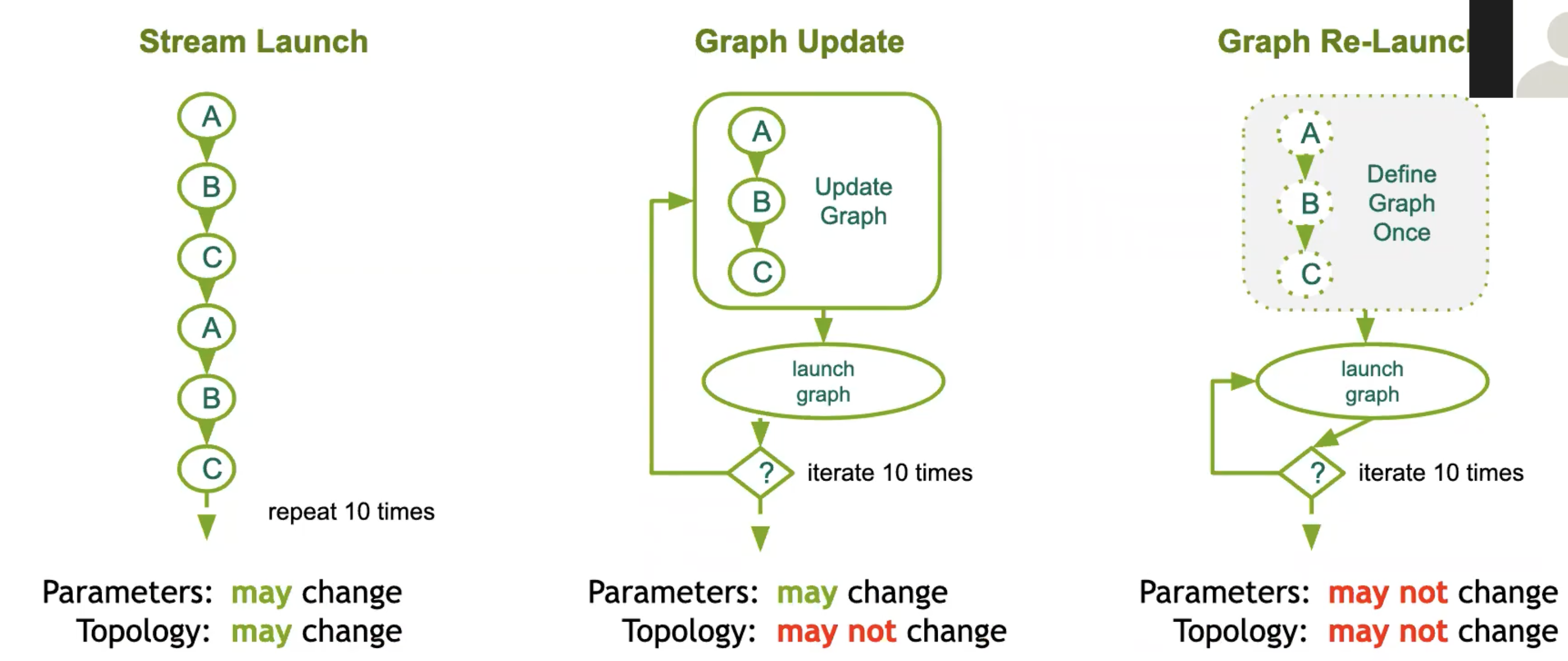
cuda 图 cuda graph
- 允许定义一系列流的工作(内核、内存复制操作、回调(host code)、主机函数、图形)。
- 每个工作项(kernel,内存复制等)在图中是一个节点。
- 允许定义依赖关系(例如,这三个节点必须先完成,才能开始这个节点)。
- 依赖关系实际上是图的边。
- 一旦定义,图可以通过将其启动到一个流中执行。
- 一旦定义,图可以被重新使用。
- 提供手动定义方法和“捕获”方法。
其他并发场景
-
主机/设备执行并发
1
2Kernel<<<b, t>>>(...); // 这个内核执行可以与 cpuFunction(...); // 这段主机代码重叠 -
并发内核
1
2Kernel<<<b, t, 0, streamA>>>(...); // 这些内核有可能 Kernel<<<b, t, 0, streamB>>>(...); // 同时执行 -
在实践中,同一设备上的并发内核执行很难观察到。
-
需要内核具有相对较低的资源利用率和相对较长的执行时间。
-
每个设备对并发内核的数量有硬件限制。(显存容量和SM数量)
-
使用单个内核使设备饱和的效率较低。
multi GPU device manager
多个主机线程可以共享一个设备,单个主机线程可以管理多个设备
1 | |
流(Streams)和事件(cudaEvent)具有隐式/自动的设备关联
-
cudaStreamWaitEvent()可以用来同步不同设备的流,而cudaEventQuery()可以检查一个事件是否“完成”。 - 如果你在一个跟当前设备没关联的流里启动内核,那就会失败。
- 每个设备都有自己独特的默认流。
1 | |
设备之间数据复制
系统拓扑支持,数据可以直接从一个设备复制到另一个设备,使用的是像PCIE或NVLink这样的连接。避免经过主机内存。
两个设备放入一个对等关系(“clique”)中,两种传输方向启用“peering”功能,使用GPUDirect P2P 传输,但是在同一对等组中放置的设备数量存在限制(8~9)
1 | |
peerDevice:指定要访问的设备 ID。flags:通常设为 0,表示没有特殊要求。
1 | |
延迟隐藏
指令按顺序发出。
当一个操作数未准备好时,线程会停止:
- 仅内存读取不会停止执行。内存读取是一项独立指令,内存写入也是如此。一般内存读取本身不会导致执行停滞,操作数通常是内存中的一个位置,而该内存读取的结果则是该位置的数据被放置到 GPU 寄存器中
通过切换线程来隐藏延迟:
- 全局内存延迟(GMEM):>100个周期(因架构/设计而异)
- 算术延迟:<100个周期(因架构/设计而异
需要足够的线程来隐藏延迟。
隐藏算术延迟:
- 需要大约10个warps(约320个线程)每个SM。
- 或者,延迟也可以通过来自同一warp的独立指令来隐藏:如果指令之间没有依赖关系,那么只需要5个warps等。
最大化全局内存吞吐量:
- 取决于访问模式和字大小。
- 足够的内存事务在飞行中以饱和总线:
- 来自同一线程的独立加载和存储。
- 来自不同线程的加载和存储。
- 更大的字大小也可以帮助(例如,float2是float的两倍事务)。
- 需要足够的总线程以保持GPU忙碌:
- 通常,希望每个SM有512个以上的线程(目标是2048 - 最大“占用率”)。
- 如果每个线程处理一个fp32元素,则需要更多线程。
- 当然,也存在例外情况。
- 线程块配置:
- 每个块的线程数应为warp大小(32)的倍数。
- SM可以同时执行至少16个线程块(Maxwell/Pascal/Volta: 32)。
- 非常小的线程块会阻碍良好的占用率。
- 非常大的线程块灵活性较差。
- 通常可以使用128-256个线程/块,但应根据应用选择最佳方案。
OCCUPANCY 占用率
- 占用率是实际线程负载与SM中的峰值理论/可达到负载的一个衡量标准。
- 可实现的占用率受限于占用率的限制因素。
- 每个线程的寄存器数量(可以通过分析工具报告,或在编译时获取)。
- 每个线程块的线程数量。
- 共享内存的使用。
性能分析
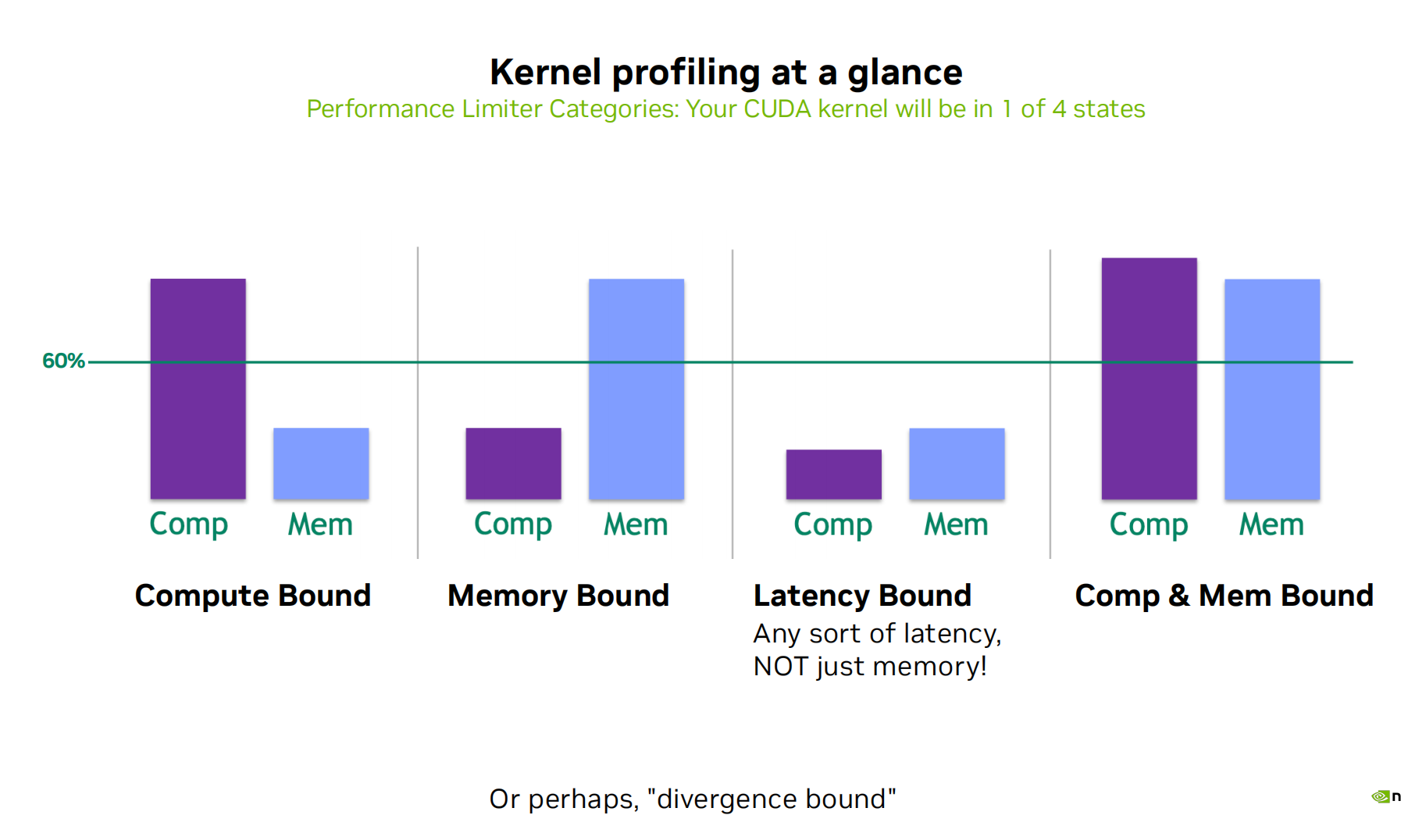
内存,计算,延迟受限 三个角度
- 内存受限:当测量的内存系统性能接近预期最大值时,代码被认为是内存受限(内存总线饱和)。
- 计算受限:当计算指令的吞吐量接近预期最大值时,代码被认为是计算受限。
- 延迟受限:时间间隔(例如:global memory 请求数据尤为漫长),得看延迟是否被隐藏 ,关注GPU上的特定调度器或单元的空间周期数,即其延迟的具体表现。又或者以上两个都不是,那很可能是这个。
- (分析驱动)优化:使用上述判断来指导第一阶段的代码重构工作。
- 代码的限制行为可能会在其执行周期内发生变化。
- 建议分析小段代码,例如一次分析一个内核。
要留意的地方
- 高效利用内存子系统
-
高效使用全局内存(合并访问)(ncu DRAM/L1 cache Throughput,Duration)
努力实现完美的合并(Coalescing):
- (对齐起始地址 - 可能需要填充)。
- 一个warp应在连续区域内进行访问。
确保有足够的并发访问以饱和总线:
- 每个线程处理多个元素。
- 多个加载可以被流水线处理。
- 索引计算通常可以被重用。
启动足够的线程以最大化吞吐量:
- 通过切换线程(warps)来隐藏延迟。
使用所有缓存!
-
智能利用内存层次结构。
- 共享内存、常量内存、纹理内存、缓存等。
-
- 暴露足够的并行性(工作)以饱和机器并隐藏延迟
- 线程/块。
- 占用率。
- 每个线程的工作量。
- 执行效率。
https://docs.nvidia.com/nsight-compute/NsightComputeCli/index.html#metric-comparison
不同指标需要注意的参数
1 | |
带宽利用率
CUDA Techniques to Maximize Memory Bandwidth and Hide Latency
Roofline model
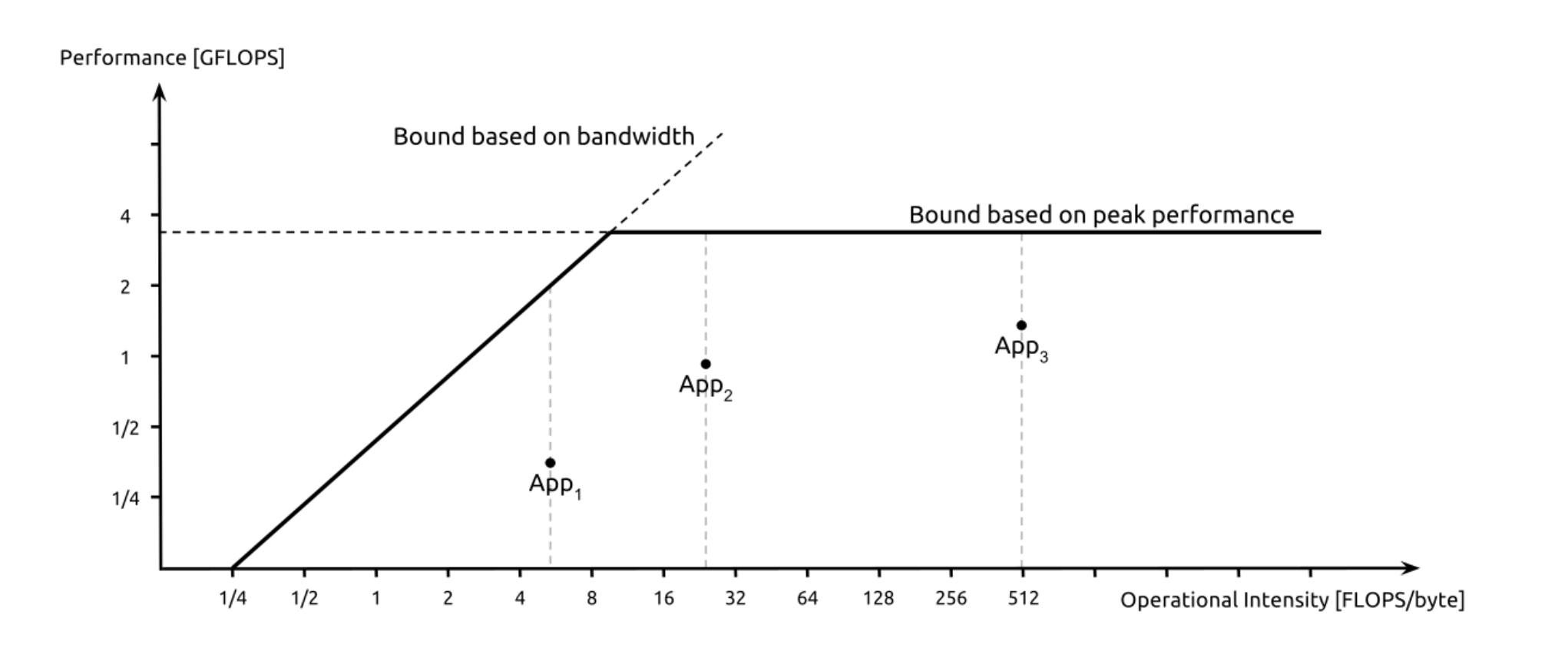
x 是运算强度指标,该指标通过计算总操作数(即加法,乘法、等)该指标通过计算总操作数,然后将其除以总内存访问次数。
y 是性能 运行速度
内存带宽限制:应该输入尽量输入更多,更快发送数据
接近带宽限制线,但仍未达到峰值性能: 通过增加操作强度或优化算法,进一步提高性能。
接近或达到峰值性能线: 操作强度已足够高,性能主要受限于处理器的计算能力。程序在利用硬件资源方面表现优秀。
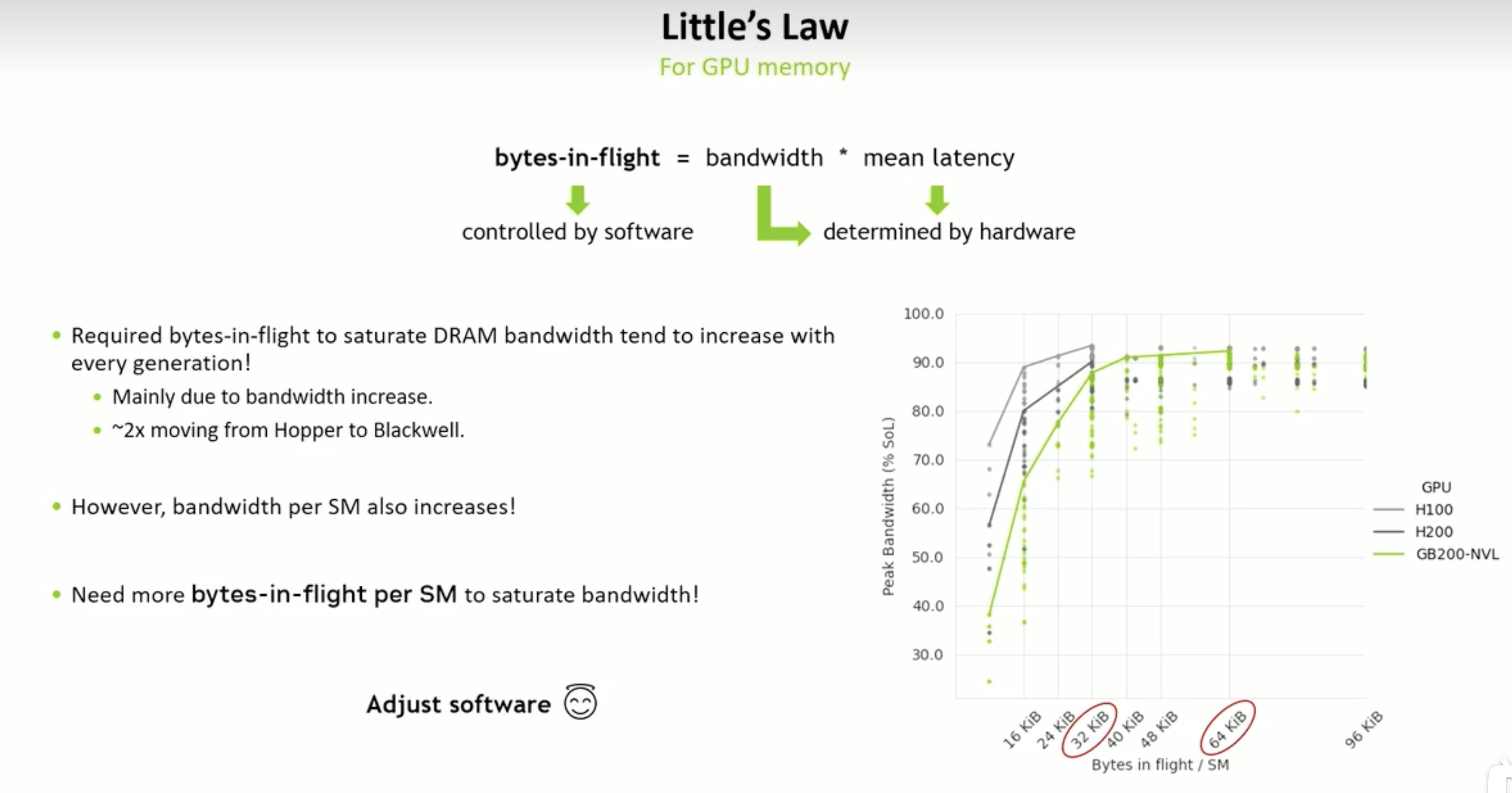
提高每个SM里面的数据量 = 参数个数* 字节数 * 线程数* block 数
“Bytes-in-Flight” 是指:在任意时刻,正在从内存中传输、尚未被处理的数据的总字节数。
它表示 GPU 正在等待/处理中的内存带宽流量,就像网络里“在飞行中的数据包”。
- 从 global memory(全局内存)到 shared memory 或寄存器
- device 和 host 之间
的数据传输并发度。
-
在一个线程内部安排更多彼此独立的内存访问操作,从而利用 GPU 的指令级并行性(ILP)。
1
2
3
4float val1 = input1[idx]; float val2 = input2[idx]; float val3 = input3[idx]; output[idx] = val1 + val2 + val3; -
通过使用向量化(如 float4, int4)的内存操作,提升单条指令加载/存储的数据量,从而利用数据级并行(DLP)。
1
2
3
4
5
6
7float4 val = reinterpret_cast<float4*>(input)[idx]; float4 result; result.x = val.x * 2.0f; result.y = val.y * 2.0f; result.z = val.z * 2.0f; result.w = val.w * 2.0f; reinterpret_cast<float4*>(output)[idx] = result;单次 memory load/store 处理多个数据。
-
通过异步方式在 host 和 device(或 shared memory 与 global memory 之间 可以绕开寄存器)之间进行数据传输,使得数据传输与计算能并行执行。
CUDA 中使用 cudaMemcpyAsync
1
2cudaMemcpyAsync(d_buffer, h_buffer, size, cudaMemcpyHostToDevice, stream); kernel<<<grid, block, 0, stream>>>(d_buffer);- 你并行发起的内存请求越多(高 ILP/DLP),就越多数据在 “飞”(in-flight),那么就需要 更多的寄存器来 hold 这些数据
- 寄存器用光了,就会发生 register spilling 到 local memory(慢得多)
LDGSTS
shared memory 与 global memory 之间 会用的LDGSTS 复制数据(4/8/ BYPASS 16字节ACESS 两种方法)


Tensor Memory Accelerator
批量异步复制一维连续数组、多维数组 shared memory 与 global memory 之间
warp uniform(warp 一致)
对于 TMA 操作而言:
- 最理想的方式是:每个 warp 中只有一个线程调用 TMA。
- 这样编译器能优化代码,避免生成冗余指令;
- 如果 warp 中多个线程都调用 TMA,编译器会“剥离(peel)”这些调用,逐个线程依次执行,这样会 降低性能。
1 | |
这里的 __syncthreads() 就是一个 memory barrier,它确保:
- 所有线程都执行完 shared_mem[threadIdx.x] = val;;
- 然后才允许线程 0 执行 process(shared_mem)。

Memory bound 内存受限
多线程交互
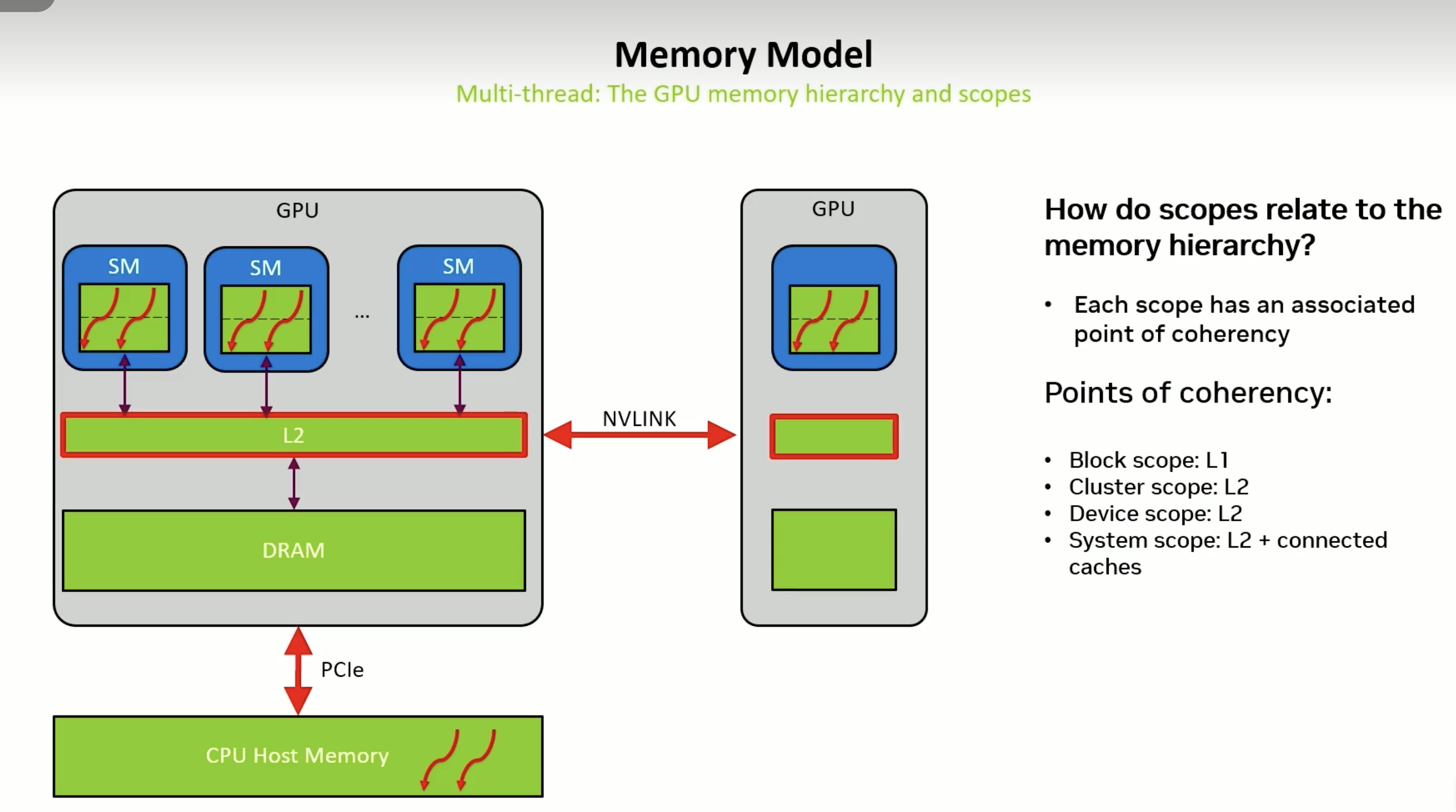
数据共享缓存
- SM内block 靠L1
cuda::thread_scope_block - 多个SM组成Cluster、GPU内部 L2
cuda::thread_scope_device - 系统级别靠内存和L2 通过NVLInk 和 PCIe
通过代码调整作用域
1 | |
两个值先后顺序
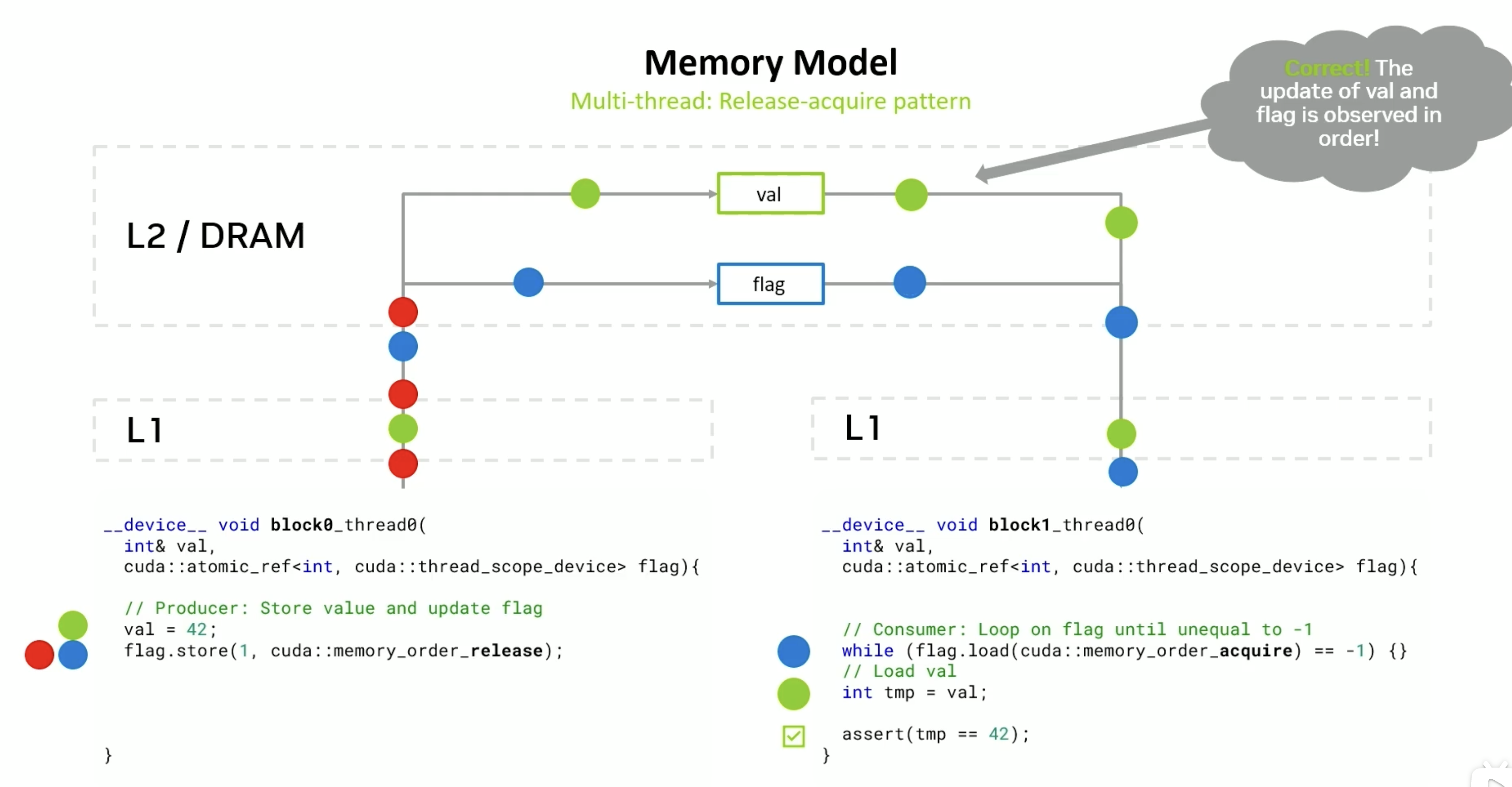

Hopper 异步存储
NVIDIA 的最新 GPU 架构(如 Hopper)中,引入了 分布式共享内存 DSMEM(Distributed Shared Memory) 的概念,使得同一个 Cluster 内的多个 SM(Streaming Multiprocessor) 之间可以直接进行共享内存通信,不需要通过 global memory(全局内存)绕一圈。这对于提升跨 block 通信带宽和降低延迟是非常关键的。
st.async 是 PTX(Parallel Thread Execution)汇编中的一个异步写操作,专门用于将数据写入 其它 SM 的共享内存(即 DSMEM),同时还能触发 远端共享内存的屏障(barrier)更新,这是跨 SM 同步的关键。
1 | |
因为这条指令是 异步执行的,也就是说:
- 发出这条指令后,并不阻塞当前线程继续执行;
- 后续的代码(如读回 remote_addr)可能会先于写入完成执行;
- 所以,需要借助 remote_bar 来通知或等待远程写入完成,否则会有 数据竞争(race condition) 或 读取脏数据 的风险。
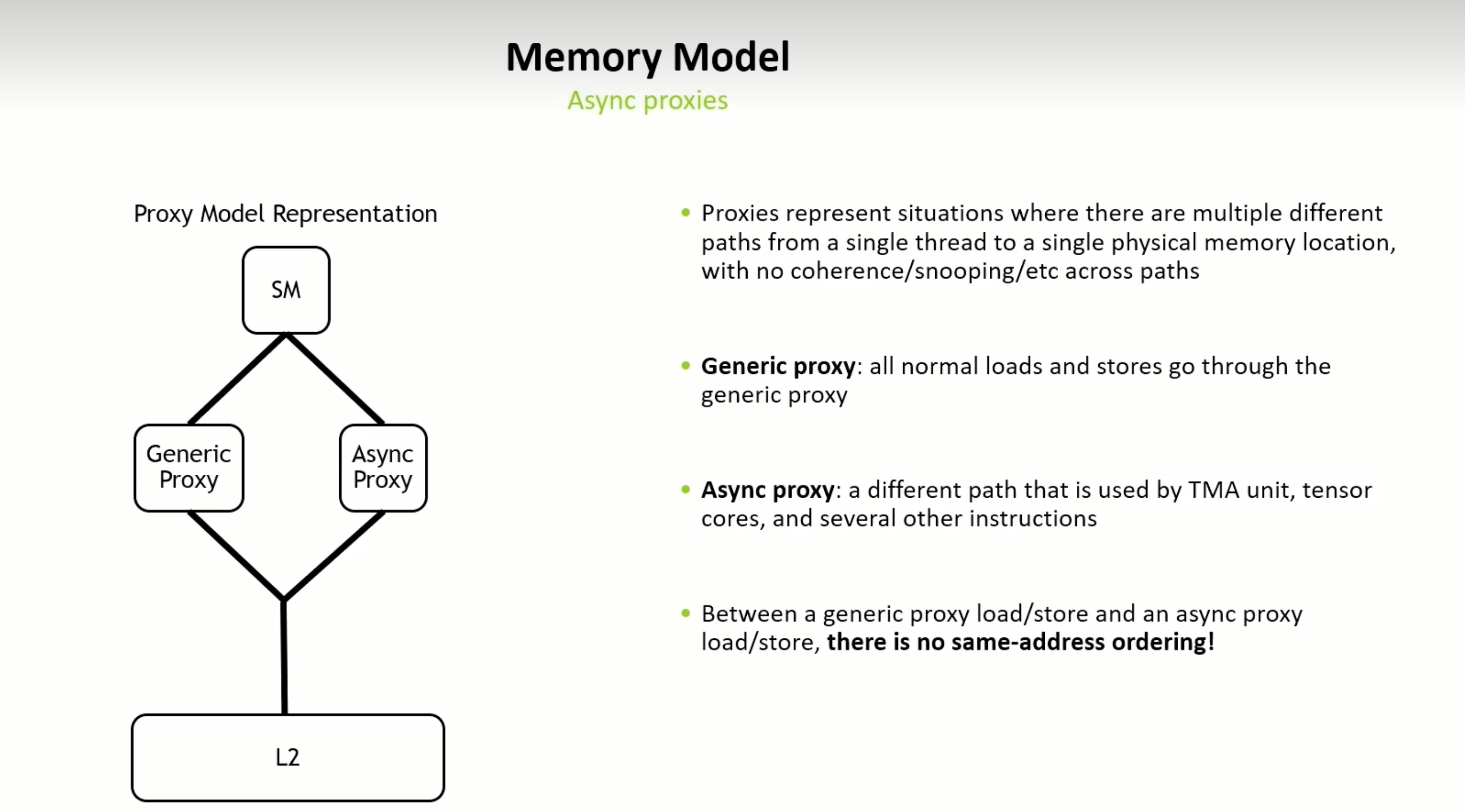
CUDA 的 SM(Streaming Multiprocessor)在执行指令时,有多种方式可以访问物理内存(如 L2):
- 正常的 load/store 指令走传统的 generic proxy 路径
- 一些特殊的指令(如 st.async、TMA、tensor core)则走 async proxy 路径
这两条路径之间是没有一致性保证的(non-coherent),也就是说:
如果你对同一个地址,通过两条路径进行读写,是没有顺序保障的!不同路径不会互相感知对方的读写行为。
- 如果你通过 st.async 写了某个地址,就不要在同一个时间窗口内通过普通 *ptr 去访问它。
- 如果你一定要配合使用 async + normal memory access,要加上 mbarrier.arrive / mbarrier.wait 做同步,确保 memory visibility。
先同步在异步
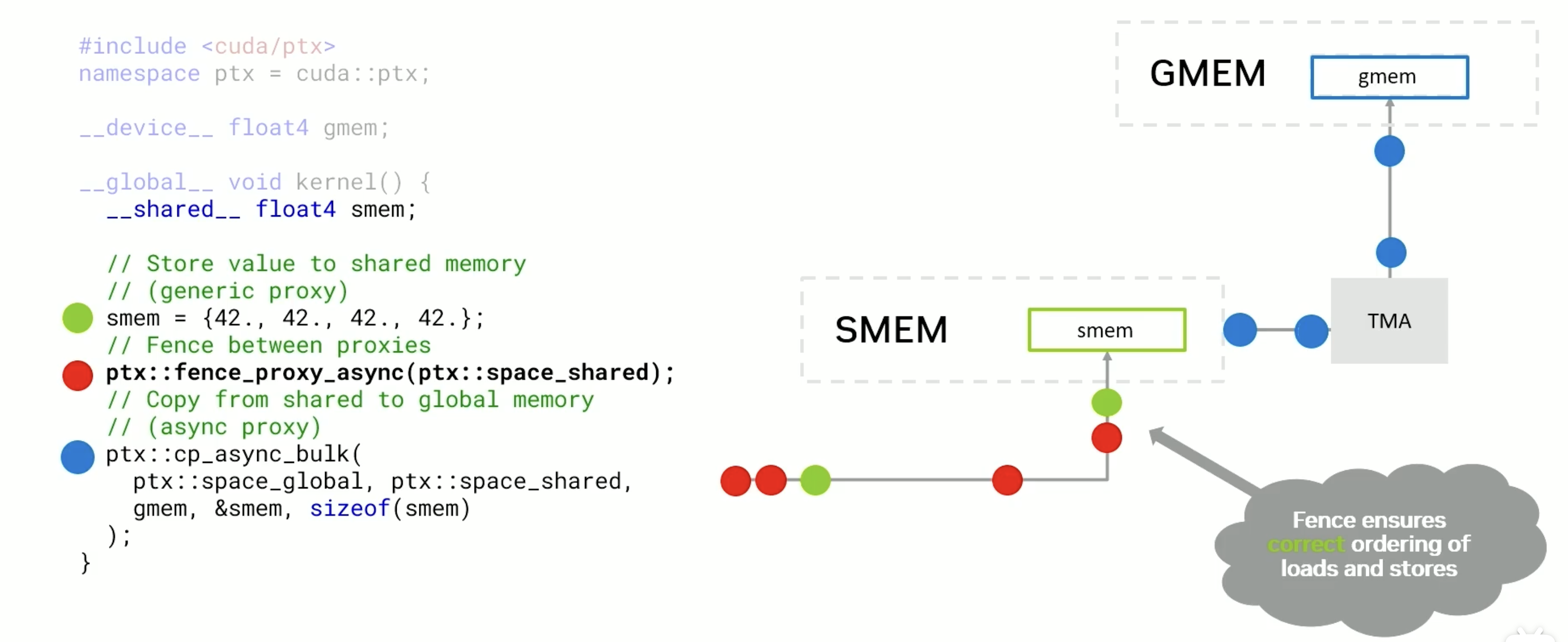
反向
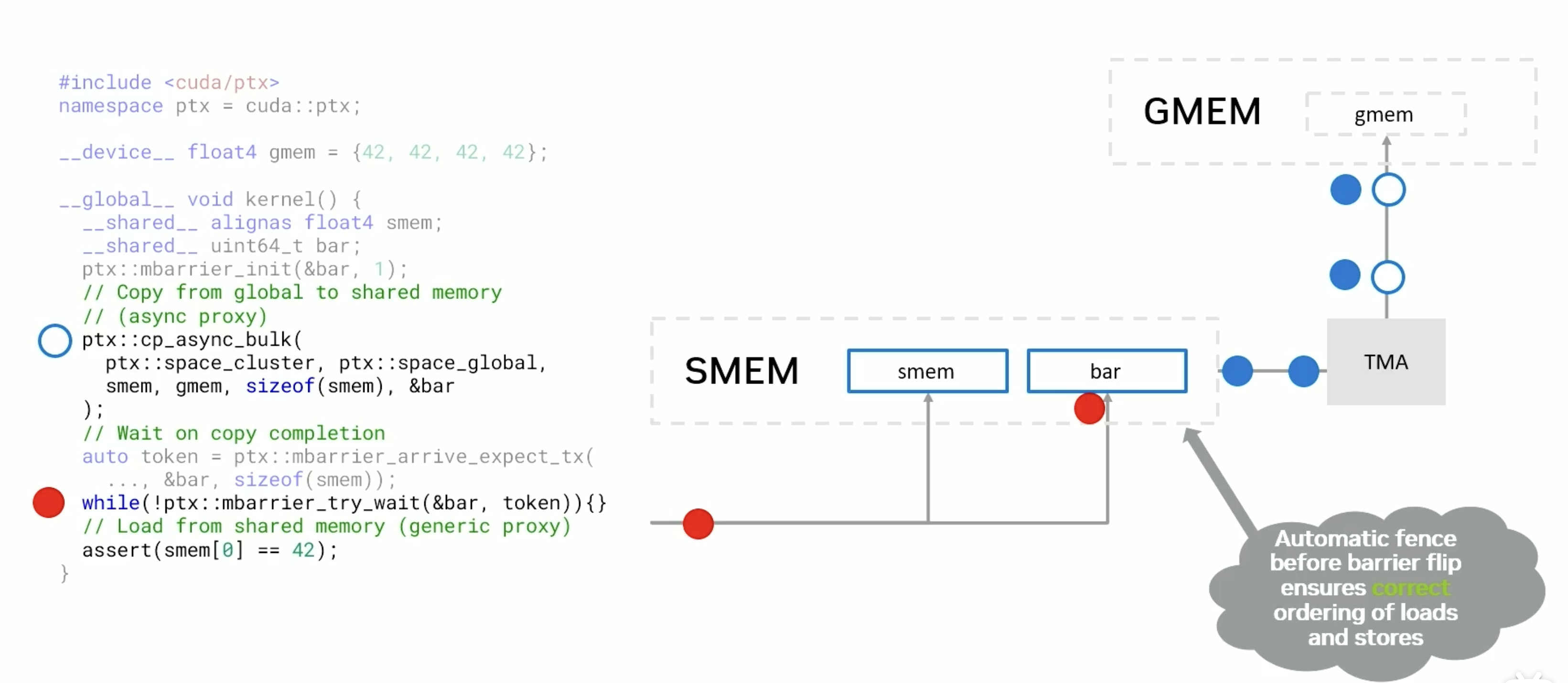
低延迟cluster 同步
cluster.sync()的同步依赖L2,这会非常慢 例如下面
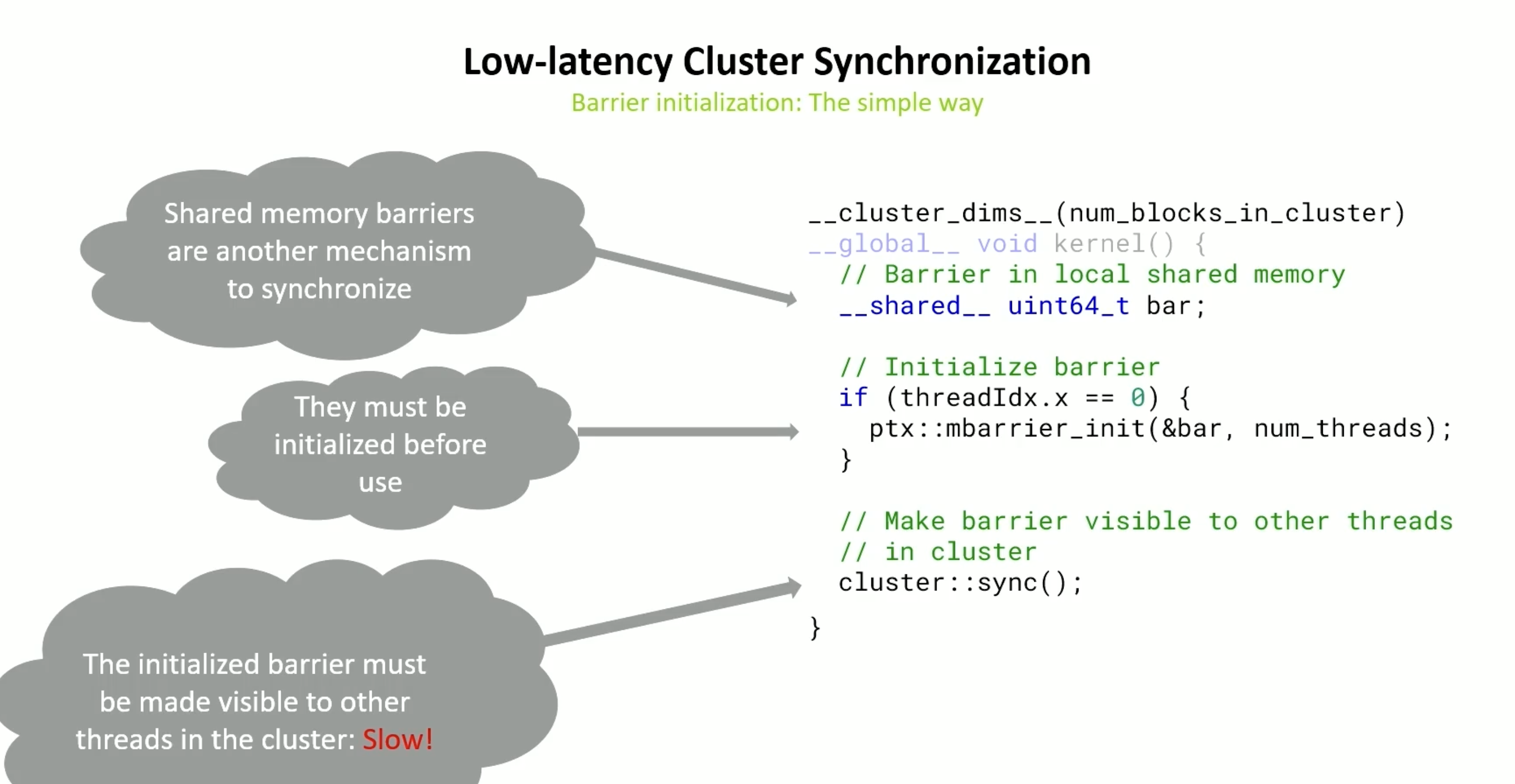
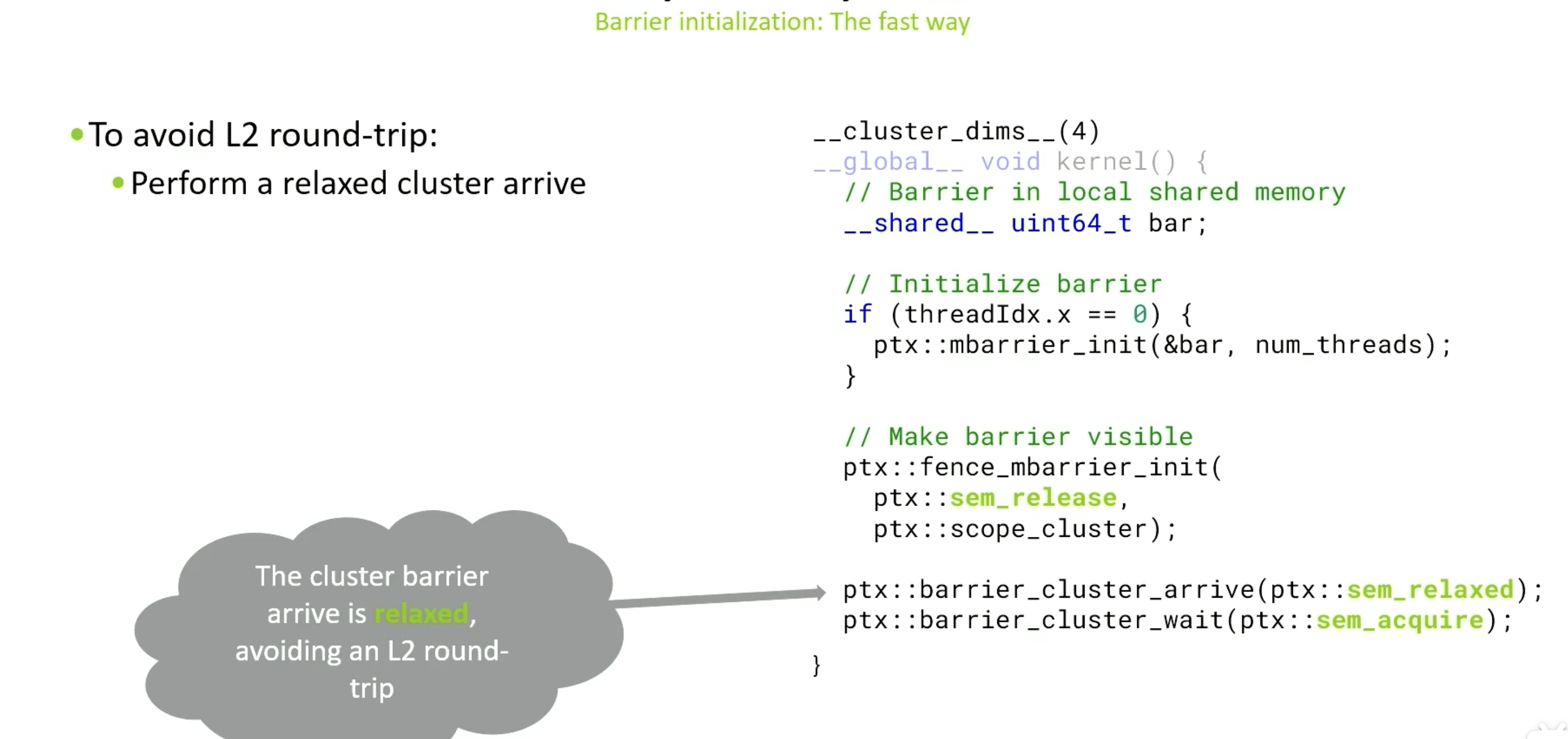
使用relaxed cluster arrive 可以避免, 他使用的代价更低,
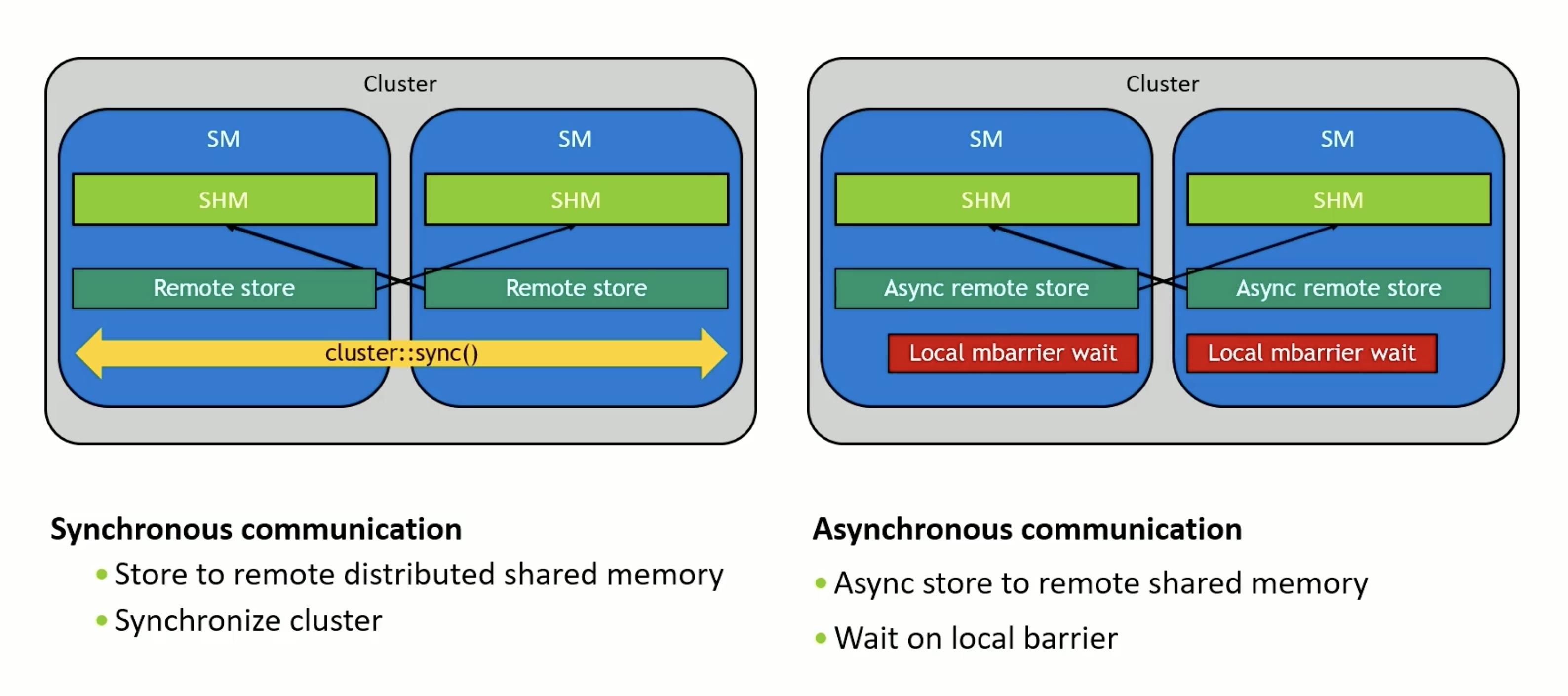
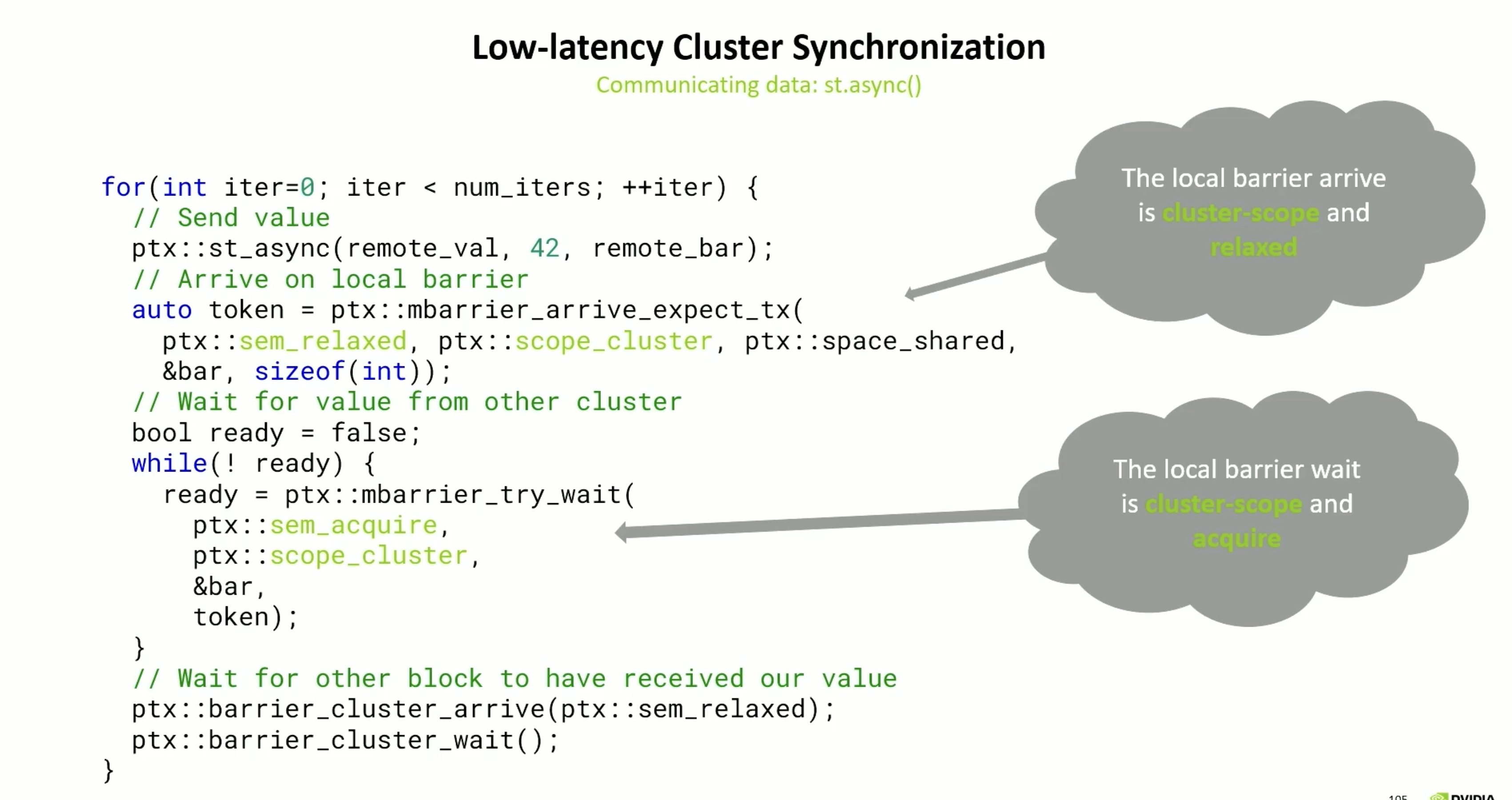
避免使用cluster.sync() 使用st.asnync , 适用热循环加速
其他操作
当代码有内存带宽或延迟的限制,可视为内存受限
-
如果是是延迟问题:我们首先采取的措施是试为 GPU 提供更多的并行工作,以提高占用率,使用大量线程,并可能采用其他策略,从而解决延迟隐藏不足的问题。
- 内存带宽受限:
- 我们首先要确定内存带宽问题所在的位置。(global memory ,L2 cache , shared memory 等)
- 加载和存储所有数据一次的时长理论值= 数据量/内存带宽 ,对比实际吞吐量。接近的话,优化基本完成
-
基本优化策略
-
Thread coarsening(粗化) 增加每个线程处理的数据量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18__global__ void VecAdd(float* A, float* B, float* C, int N) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < N) { C[i] = A[i] + B[i]; } } // Vector addition kernel with thread coarsening // Assuming a coarsening factor of 2 一个线程处理两个数字 __global__ void VecAddCoarsened(float* A, float* B, float* C, int N) { int i = (blockIdx.x * blockDim.x + threadIdx.x) * 2; // Coarsening factor applied here if (i < N) { C[i] = A[i] + B[i]; } if (i + 1 < N) { // Handle the additional element due to coarsening C[i + 1] = A[i + 1] + B[i + 1]; } } -
私有化:将共享数据转变为每个线程或线程块私有的数据副本的过程。这可以减少线程之间的竞争和数据冲突,从而提高性能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39// Kernel without privatization: Direct global memory access __global__ void windowSumDirect(const float *input, float *output, int n, int windowSize) { int idx = blockIdx.x * blockDim.x + threadIdx.x; int halfWindow = windowSize / 2; if (idx < n) { float sum = 0.0f; for (int i = -halfWindow; i <= halfWindow; ++i) { int accessIdx = idx + i; if (accessIdx >= 0 && accessIdx < n) { sum += input[accessIdx]; } } output[idx] = sum; } } // Kernel with privatization: Preload window elements into registers __global__ void windowSumPrivatized(const float *input, float *output, int n, int windowSize) { int idx = blockIdx.x * blockDim.x + threadIdx.x; int halfWindow = windowSize / 2; __shared__ float sharedData[1024]; // Assuming blockDim.x <= 1024 // Load input into shared memory (for demonstration, assuming window fits into shared memory) if (idx < n) { // 每个线程首先将输入数据加载到共享内存中,这样可以减少对全局内存的访问。 sharedData[threadIdx.x] = input[idx]; __syncthreads(); // Ensure all loads are complete float sum = 0.0f; for (int i = -halfWindow; i <= halfWindow; ++i) { int accessIdx = threadIdx.x + i; // Check bounds within shared memory if (accessIdx >= 0 && accessIdx < blockDim.x && (idx + i) < n && (idx + i) >= 0) { sum += sharedData[accessIdx]; } } output[idx] = sum; } } - 量化:减少传输数据量,
- 编译:通过cuda graph之类减少开销)
-
Compute bound 计算受限
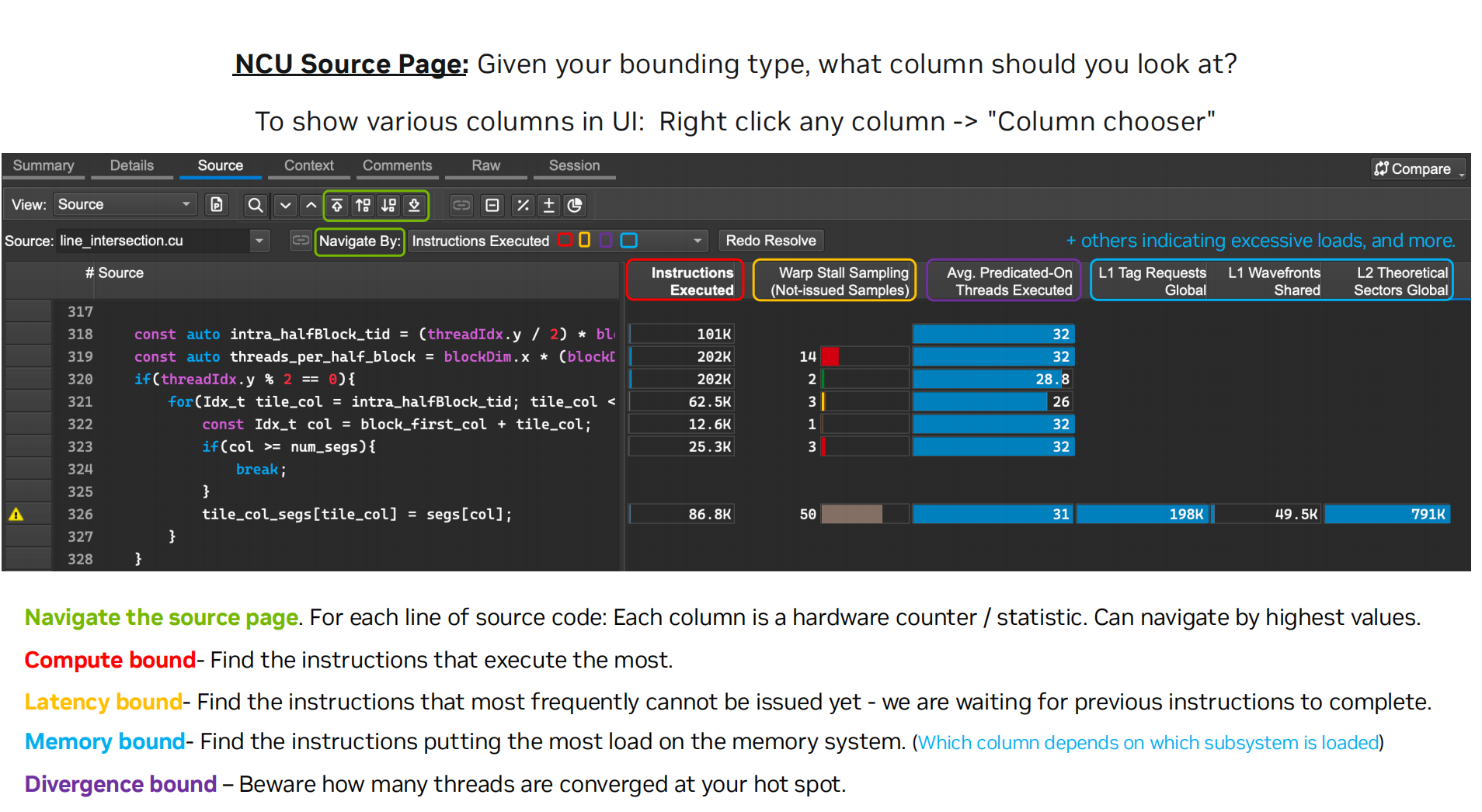
当特定类型的计算单元指令或操作达到或接近该类型服务单元的极限时,代码即处于计算受限状态。
因此,若我使用单精度浮点加法或单精度减法进行运算,乃至加减混合运算,我能够计算出其理论性能,并基于实际执行的浮点操作数及执行时长,评估我接近该性能的程度。
利用率指标高,证明我的代码正以接近机器处理能力极限的速度发出浮点运算指令。
基本优化策略
-
提升特定功能单元的使用效率,即提高对浮点运算或单精度浮点运算的利用率 (改善算法)
-
将计算负载转移到其他类型。 : 经常重用的数据放到 shared memory(flash attention),
-
Minimize control divergence (控制分歧): wrap 内有分歧,就得等慢的,直到所有完成。
-
ncu --set full xxxBranch Intructions (分支指令) -
尽量减少使用条件语句,特别是在同一线程块内的所有线程都需要执行相同操作的情况下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19__global__ void processArrayWithDivergence(int *data, int N) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < N) { if (data[idx] % 2 == 0) { data[idx] = data[idx] * 2; } else { data[idx] = data[idx] + 1; } } } // 优化后 __global__ void processArrayWithoutDivergence(int *data, int N) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < N) { int isEven = data[idx] % 2; data[idx] = isEven * (data[idx] * 2) + (1 - isEven) * (data[idx] + 1); } } -
通过将数据结构或算法重组,使得相似的线程执行相同的代码路径。例如,可以将数据分组,使得同一组的数据在同一线程中处理。
-
-
实际吞吐量与理论峰值的差异
- 到了这个“理论极限”之后,更换算法(比如用 FFT 代替卷积、用压缩表示减少内存访问等)
优化线程分支 (Divergence) 导致 warp 效率低
Work Queueing in Shared Memory
思路分两阶段
| 阶段 | 行为 |
|---|---|
| Scouting phase | 每个线程进行轻量判断,如果需要执行计算,就把任务信息放入共享内存队列 |
| Processing phase | 所有线程一起遍历这个队列,一个个取任务来执行(避免分歧) |
- 队列保存在 shared memory 中(访问快速且线程间共享)
- 使用原子操作保证多线程并发 push 安全性
- 每个任务的信息(例如 index、input 数据等)构成队列元素
- 所有线程 “pull” 出一个任务来执行,从而避免 warp 中 thread 执行路径不一致
其他分支
warp 有好几种状态
| 状态 | 含义 | 说明 |
|---|---|---|
| Unused | 未使用 | 该 warp 尚未被激活,可能尚未分配任务或已经完成任务。 |
| Active | 活跃中 | warp 已驻留在处理器中,处于可调度的状态。 |
| Stalled | 阻塞中 | warp 等待前一条指令完成,或者等待下一条指令所需的数据准备完毕(如内存访问未返回)。 |
| Eligible | 就绪 | warp 所需的数据与资源均已准备好,已具备执行下一条指令的条件。 |
| Selected | 已选中 | warp 已处于就绪状态,并在本周期中被调度器选中执行下一条指令。 |
Achieved occupancy = active / (active + unused)
- Warp 长时间处于 Stalled 状态 → 可能存在内存瓶颈或指令依赖。
- Warp 频繁 Eligible 但未 Selected → 表示调度压力大,可考虑减少并发或提升指令级并行度。
- Active warp 比例高 → 说明资源利用良好。
保持代码尽可能简单,直到性能分析器(profiler)告诉你该优化为止。不要猜测,也不要过早优化。
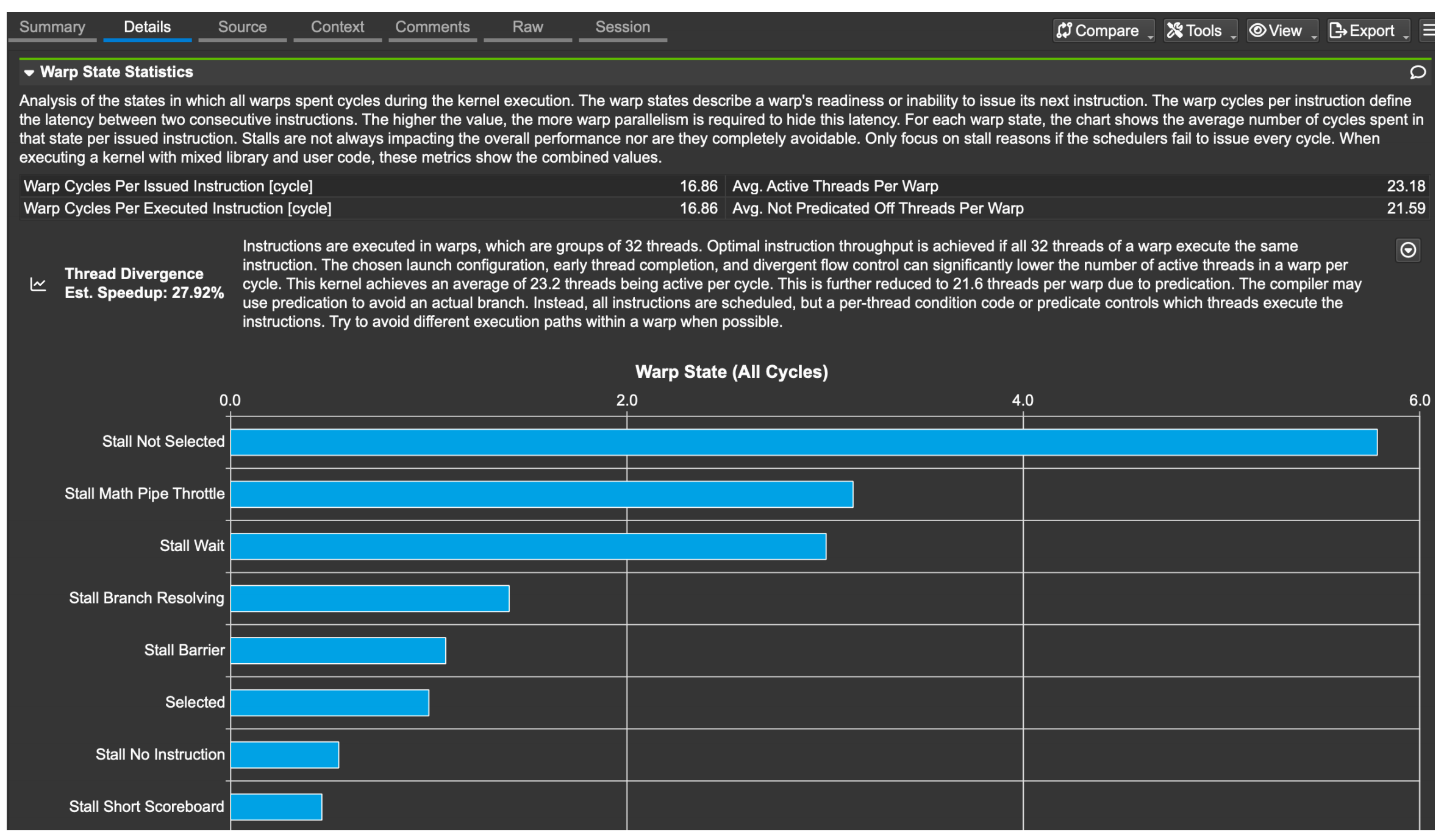
| 类型 | 说明 | 举例 |
|---|---|---|
| Wait | 等待一个在编译期间已知延迟的指令完成 | 比如 __syncthreads() 或 __threadfence() 之后的同步等待 |
| Scoreboard | 等待一个运行时才能确定延迟的指令完成(通常是有数据依赖的) | 一个 warp 读了 global memory 后必须等数据返回才能继续下一条指令 |
| → Long SB | 指令来自全局内存(global memory),延迟长 | global_ptr[i] 这类内存访问后的等待 |
| → Short SB | 指令来自共享内存(shared memory),延迟短 | shared[i] = x 后接着使用 shared[i] |
| Throttle | 等待某个硬件资源的队列有空位(比如纹理单元、LD/ST 单元) | 当前有太多内存请求,导致 load/store pipeline 拥塞 |
| Branch Resolving | 等待分支跳转判断完成 | 遇到 if/else 分支,硬件要等 PC(程序计数器)确定跳转目标 |
| Barrier | 等待 warp 中其他线程到达同步点 | 所有线程要 __syncthreads(),部分线程已到、部分未到时会 stall |
使用 CUDA 的 Cooperative Groups 功能,用户可以定义自定义线程组,实现更灵活的同步。
- 可以 只同步一部分线程组,例如 warp-level。
- 支持在分支中调用,只要属于同一个 group。
__syncthreads(), 确保共享内存(shared)写入已完成再读取。
不能放在不同线程有不同路径的分支中,除非分支在所有线程上都一样,否则会导致 undefined behavior(即程序行为不可预测,可能死锁或崩溃)。

| 方法 | 同步粒度 | 分支中可用 | 使用场景 |
|---|---|---|---|
| __syncthreads() | 整个 thread block | ❌ 除非所有线程都执行 | 大多数共享内存同步需求 |
| cooperative_groups::group.sync() | 用户定义 group(如 block、warp) | ✅ | 精细同步、更灵活逻辑控制 |
Dynamic Block Dimensions Block Divergence
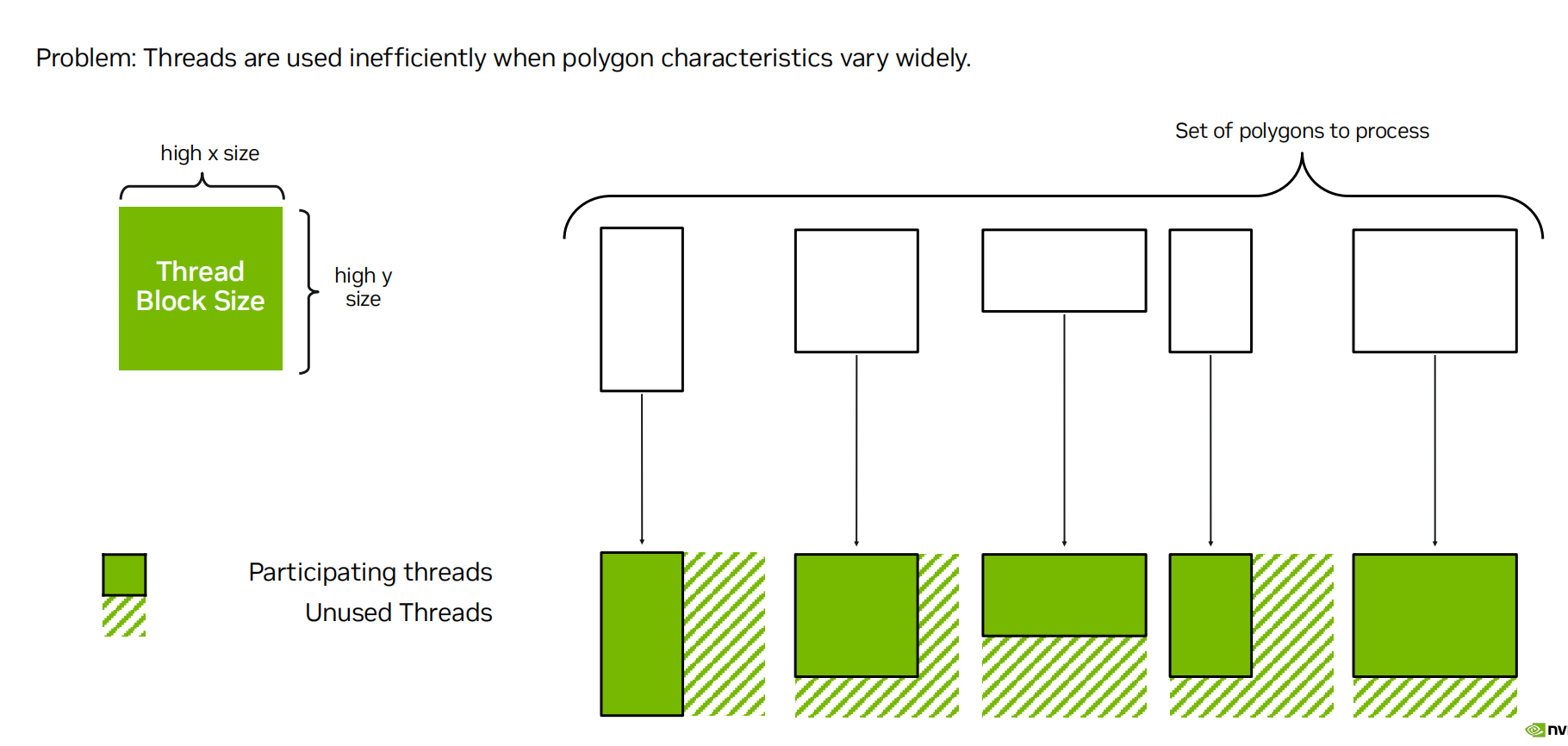

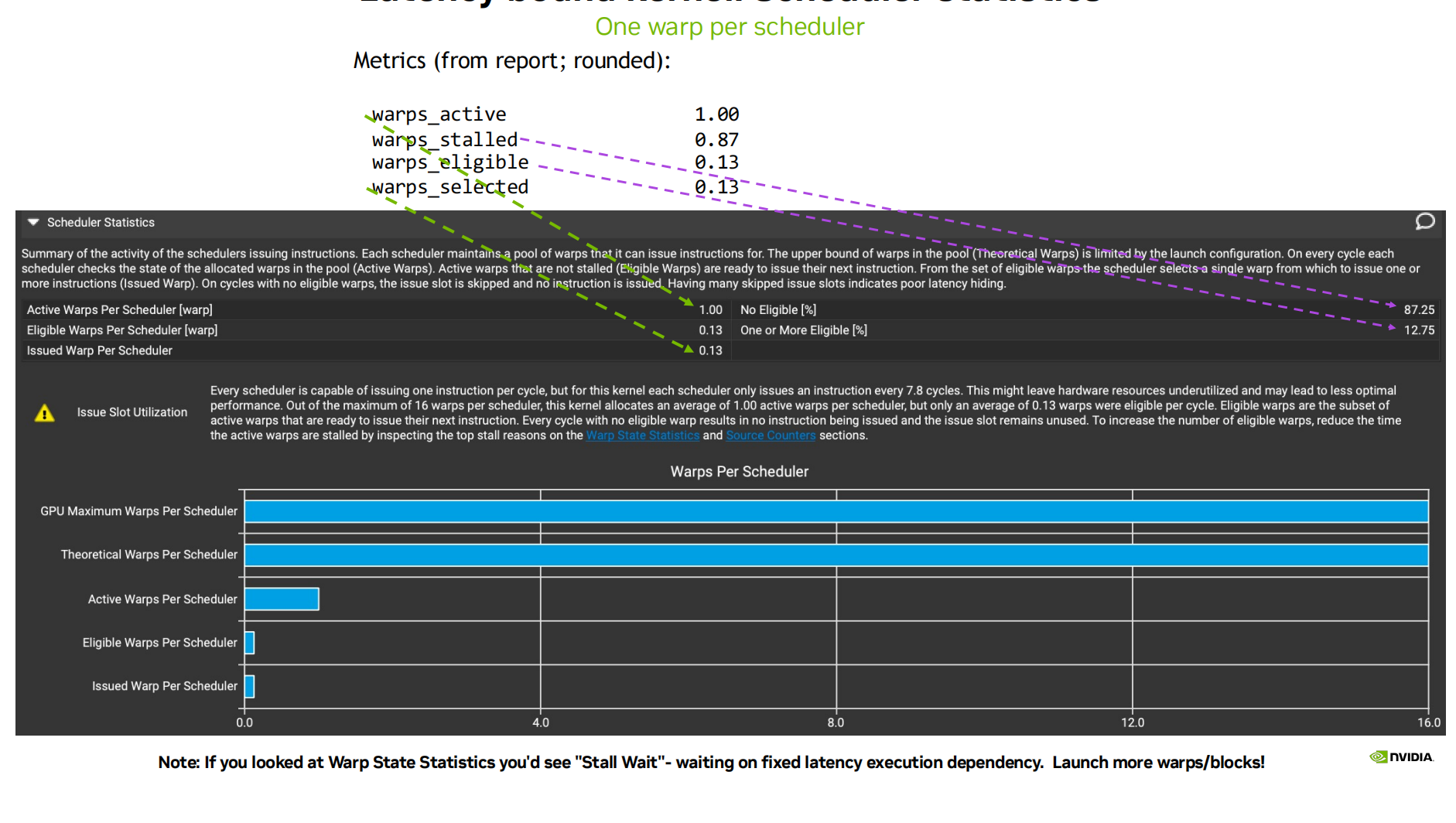
Lantency bound 延迟受限
当 GPU 无法出现有或已暴露的工作保持忙碌状态时,我们基本上已经定义了这种情况。

- 确保启动大量线程
- 增加每个线程的工作量,允许单个线程处理多个输入元素

-
努力最大占用率Occupancy (提高线程/warp 数量等)

warp 有好几种状态
| 状态 | 含义 | 说明 |
|---|---|---|
| Unused | 未使用 | 该 warp 尚未被激活,可能尚未分配任务或已经完成任务。 |
| Active | 活跃中 | warp 已驻留在处理器中,处于可调度的状态。 |
| Stalled | 阻塞中 | warp 等待前一条指令完成,或者等待下一条指令所需的数据准备完毕(如内存访问未返回)。 |
| Eligible | 就绪 | warp 所需的数据与资源均已准备好,已具备执行下一条指令的条件。 |
| Selected | 已选中 | warp 已处于就绪状态,并在本周期中被调度器选中执行下一条指令。 |
SM 或 Memory System 的资源已经满负荷
- 不要担心 stall 或 unused issue slots!,硬件资源已经在满负荷运行,再尝试“更频繁地发出指令”也不会提升性能。
- 停止微调代码逻辑,转向算法变更或减少计算量。
如果资源没有满负荷,但存在较多 stall ** 这就是 **延迟受限(Latency-bound) 的
| 策略 | 含义 | 示例或方法 |
|---|---|---|
| Issue more frequently | 让 warp 更频繁发出指令 | 增加 ILP,增加 Occupancy |
| Stall less frequently | 降低等待情况发生频率 | 减少 global memory 访问、使用共享内存 |
| Busy yourself during stall | 其他 warp 或任务来填补 pipeline 空洞 | 增加并行任务数,提升 warp 数 |
| Decrease stall duration | 使用更低延迟的指令 | 共享内存替代全局内存、常量内存等 |
Occupancy 占有率
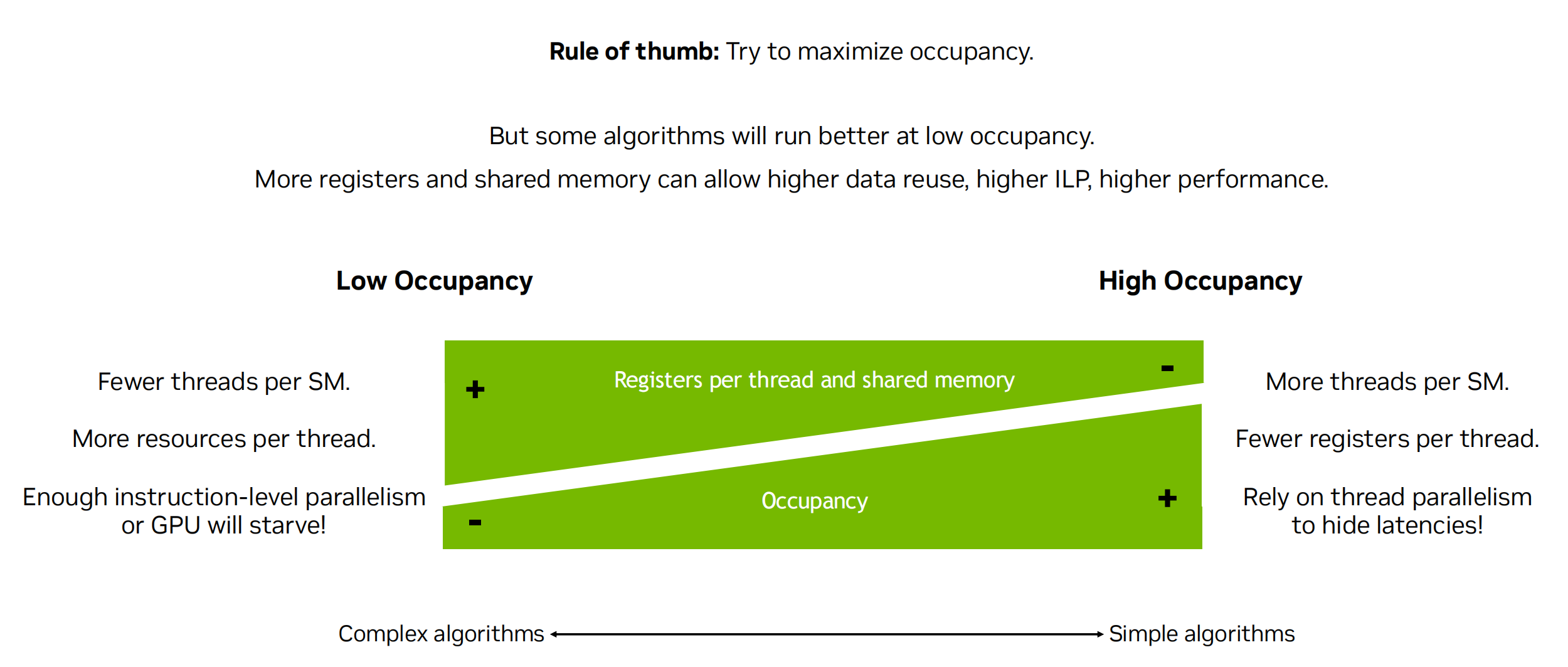
影响活跃 Warp 数的三个层级
| 类别 | 说明 |
|---|---|
| Device 限制 | 由 GPU 的计算能力(Compute Capability)决定的 硬件上限。 |
| Achievable 可实现 | 由 你的 kernel 写法 + 编译器分配资源决定,比如每个线程使用了多少寄存器、共享内存等。 |
| Achieved 实际实现 | 实际运行中由于 grid 配置 或 负载不平衡,决定最终启用了多少 warp。 |
| 限制因素 | 说明 |
|---|---|
| 共享内存 | SM 总共享内存有限,不同 block 间平均分配。每个 block 使用越多,能放的 block 越少。 |
| 寄存器数量 | 每个 SM 有固定数量寄存器。如果每线程用了太多寄存器,也会减少并发 warp 数。 |
| block 配置 | 比如 block size 太大(1024 threads/block),可能导致 block 数无法增加,降低并发度。 block size 不能被最大threads/block 整除,也会降低 Occupancy |
| 硬件其他限制 | 比如:每个 SM 最多只能有 32 个 warps 或最多支持 16 个 blocks 等。 |
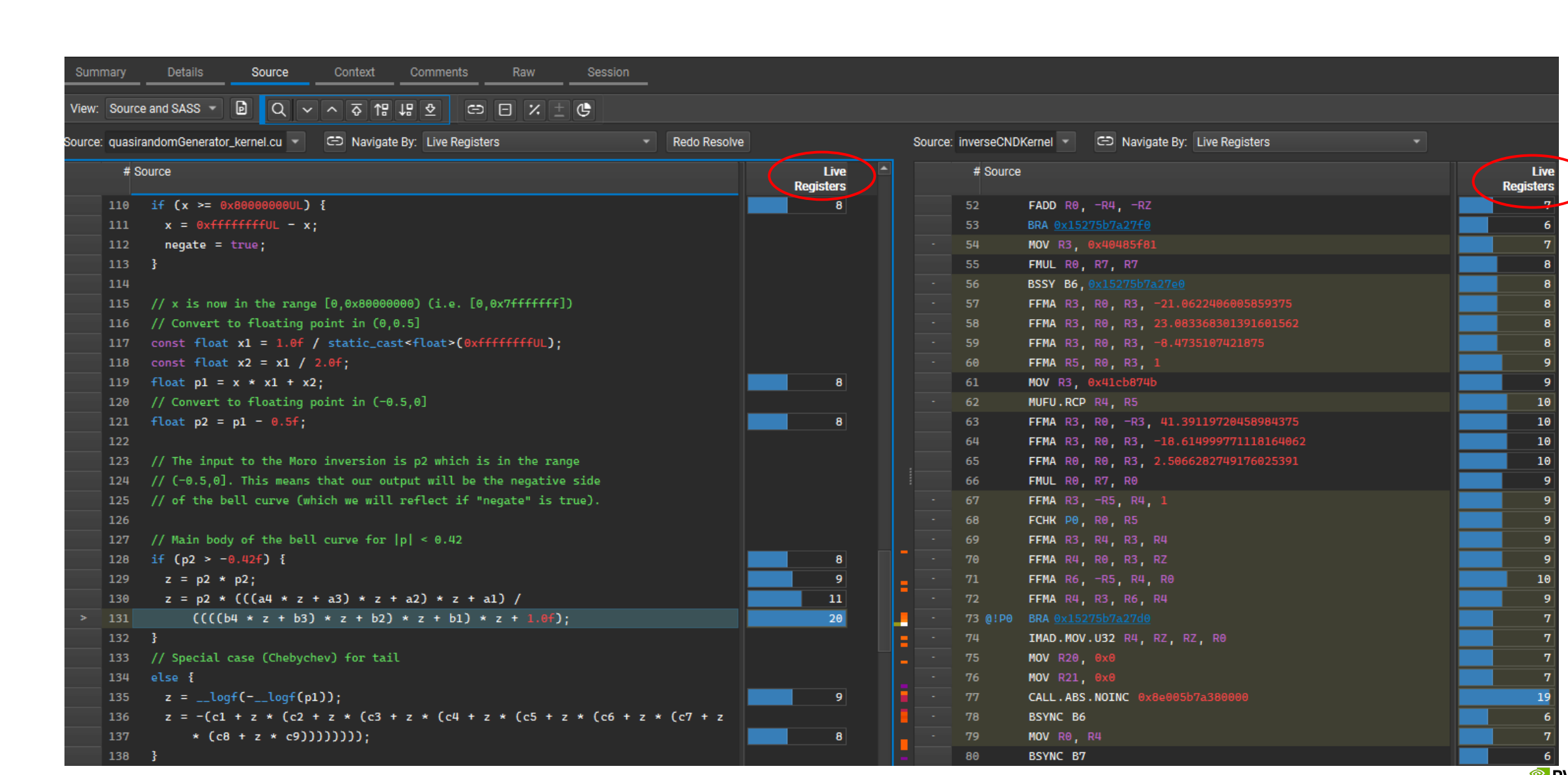
寄存器
使用 nvcc 编译器选项 --ptxas-options=-v 可以输出 , 每个线程使用的寄存器数量(Registers per thread)
| 方法 | 说明 |
|---|---|
| –maxrregcount=N | 在编译期限制某个 .cu 文件中线程可使用的最大寄存器数 |
| launch_bounds | 在函数声明时指定最大线程数和寄存器数限制,例:launch_bounds(maxThreadsPerBlock, minBlocksPerSM) |
| maxnreg(旧) | 已弃用,不推荐使用 |
每个线程使用 63 个寄存器 一个 warp = 32 个线程 , Hopper 架构每个 SM 有 65536 个寄存器
| 策略 | 效果 | 注意事项 |
|---|---|---|
| 减少寄存器使用(如 63 → 48) | 增加 warp 并发数,提高 Occupancy | 过度减少可能导致寄存器溢出,退化为本地内存访问,性能下降 |
| 使用 –maxrregcount 限制寄存器使用 | 控制资源分配,提高并发 | 小心编译器可能溢出到本地内存 如果一个 kernel 使用的寄存器数,超过了硬件上限或者超过了用户设置的限制(如 –maxrregcount 或 launch_bounds),编译器会自动将部分变量溢出(spill)到 local memory。 如果访问的数据被缓存(尤其是 L1 缓存),性能影响较小甚至可能接近寄存器 如果频繁访问非缓存区域,会大大降低性能,因为本质上是访问全局内存 |
分析函数中循环展开#pragma unroll、内联__forceinline__带来的寄存器膨胀 |
避免不必要的寄存器占用 减少分支跳转开销、提高流水线效率和 ILP(指令级并行度) 如果函数太长、或调用次数过多,代码膨胀会导致指令缓存(I-cache)抖动 → 性能下降 |
如果访问的数据被缓存(尤其是 L1 缓存),性能影响较小甚至可能接近寄存器 如果频繁访问非缓存区域,会大大降低性能,因为本质上是访问全局内存尝试不同 unroll 因子(比如 2、4、8),使用 Nsight Compute 对比执行效率 小函数 + 频繁调用:使用 __forceinline__ |
| 64-bit 类型变量, 每个变量占两个寄存器, 造成寄存器压力更高,可能降低 occupancy | 降低寄存器占用 | 使用 float 而非 double,使用 int32_t 而非 int64_t,除非确实需要高精度或大范围 |
| Kernel fusion(融合)可减少 kernel 启动开销、提升数据局部性也可能导致 register 使用激增,从而降低 occupancy。 | 原本简单计算(如 Bonds,只需 28 个寄存器)也被迫使用 72 个,大大降低 occupancy | 此时,适当的 kernel fission(拆分)反而能带来更好的性能。 |
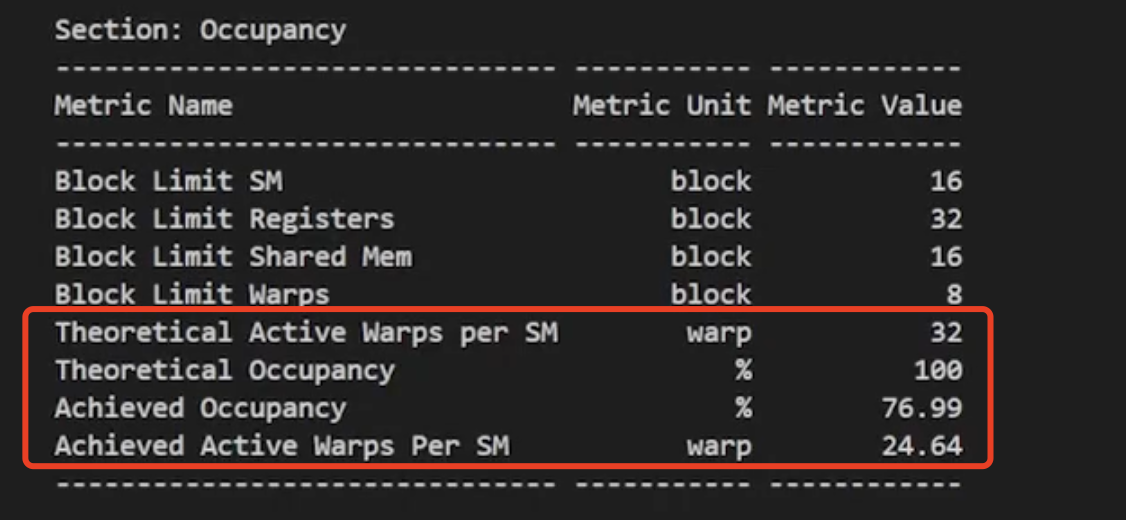
其他操作
更高的占用率,我确保了分配给每个 SM 的线程加载达到了最大值。
衡量一个 SM 是否有足够工作量的标准是,我有多少线程可以选择指令执行。确保 SM 获得最佳隐藏延迟的关键因素之一,便是否为其分配了足够的线程。
因此,占用率是衡量 SM 中实际线程加载与峰值理论加载或峰值可达到加载的指标。若你启动的线程块数量在 256 至 1024 范围内,并且启动了足够多的线程块,通常情况下,只要你的代码允许,便能触及及峰值理论占有率。
可能的限制
- 大多数GPU,每个SM可容纳2048线程 (代码限制其达不到)
- 每个线程的寄存器数量(可以由分析器报告,或者在编译时获取)
- 共享内存使用量 (share memory 大概48KB,可能1024个线程就已经用完了,主要是share memory容量不足)
ncu xxxx
Tile quantization:矩阵分割成较小的块(tiles)进行并行计算时,矩阵的维度并不总是可以被线程块的大小整除。这可能导致某些线程未能充分利用,降低了计算效率。
Wave Quantization:指在 GPU 中,整个计算过程中的 tiles 数量并没有被流处理器(SM,Streaming Multiprocessor)的数量整除。这可能导致某些 SM 不会完全参与计算,影响性能。
如果是pytroch 矩阵乘法 $A_{M\times K}\cdot B_{K\times N}\;=\;C_{M\times N}$ 使用padding 去凑够倍数
| Tensor Cores can be used for… | cuBLAS version < 11.0cuDNN version < 7.6.3 | cuBLAS version ≥ 11.0cuDNN version ≥ 7.6.3 |
|---|---|---|
| INT8 | Multiples(倍数) of 16 | Always but most efficient with multiples of 16; on A100, multiples of 128. |
| FP16 | Multiples of 8 | Always but most efficient with multiples of 8; on A100, multiples of 64. |
| TF32 | N/A | Always but most efficient with multiples of 4; on A100, multiples of 32. |
| FP64 | N/A | Always but most efficient with multiples of 2; on A100, multiples of 16. |
如果是cuda ,可以改变启动kernel的参数。
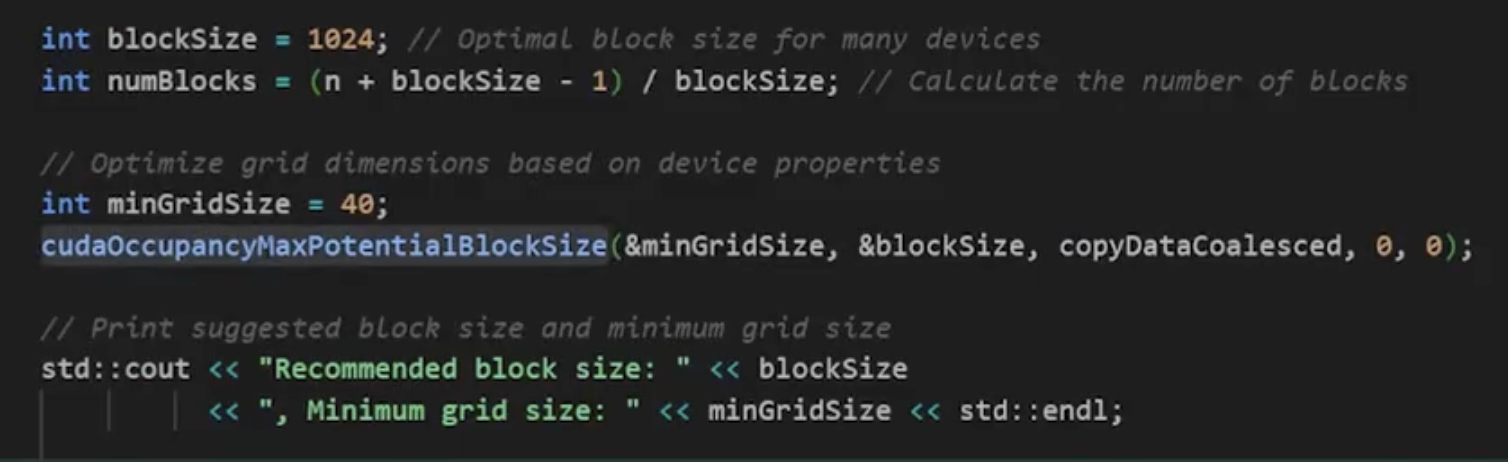
cudaOccupancyMaxPotentialBlockSize 是一个用于优化 CUDA 程序中内核执行的函数。它帮助确定最大潜在的线程块大小和网格大小,以提高内核的占用率。
1 | |
减少不必要指令,增加吞吐
Zoom In(细节):
- CUDA 源代码的小改动(e.g. 改 loop 写法、精简分支)
- 在执行高成本操作前做快速判断,避免不必要的复杂运算 (三角函数、sqrt、除法/取模等)
- 代数优化(Algebraic Optimization),
x * 2 可替换为 x + x 或 x << 1 - 使用 log-space、half-precision、fixed-point 替代 FP32/FP64
- 使用内建高效指令(e.g. vector load/store)
- 利用 CCCL(CUDA C++ Core Libraries)
- 使用向量化指令
Zoom Out(全局):
- 算法设计层面:是否可提前排除不必要的计算?
- 是否可以选择更高效的数学空间来表示问题?
- 是否换个思路就能减少工作量?(剪枝、排序、预处理等)
静态优化(Static Considerations)
1 | |
运行时优化(Runtime Considerations)
- 条件提前、剪枝、表达式变换
- 简化 Kernel
MPI MPS
rank 进程
MPI(Message Passing Interface)是一种用于并行计算的标准接口,主要用于在多个进程之间进行通信。它允许程序在多台计算机或多核处理器上运行,同时支持数据的传输和同步,适用于高性能计算(HPC)和大规模并行计算。
- 并行处理:MPI支持多进程并行执行,适合处理大规模计算任务。
- 数据传输:提供了多种消息传递功能,包括点对点通信和集体通信。
- 可扩展性:能够在从几台到数千台计算机的集群上工作。
局限性
- 在进程间传递消息时,通信延迟和带宽限制可能成为性能瓶颈,尤其在大规模集群中。
- 编程模型较为复杂,需要开发者管理进程间的通信和同步,使得代码编写和调试变得困难。
- 在使用MPI时,数据序列化和反序列化会增加额外的计算时间,尤其是在多线程与CUDA结合时,可能导致性能降低。
怎样知道确定一张卡分配多少rank
基本上是在尽可能地为 GPU 适配更大的问题规模
Nvida多个模式
-
Default:可以同时运行多个进程
-
Exclusive Process 独占进程:每次只能有一个进程在运行
-
Prohibited 禁止:不允许任何进程运行
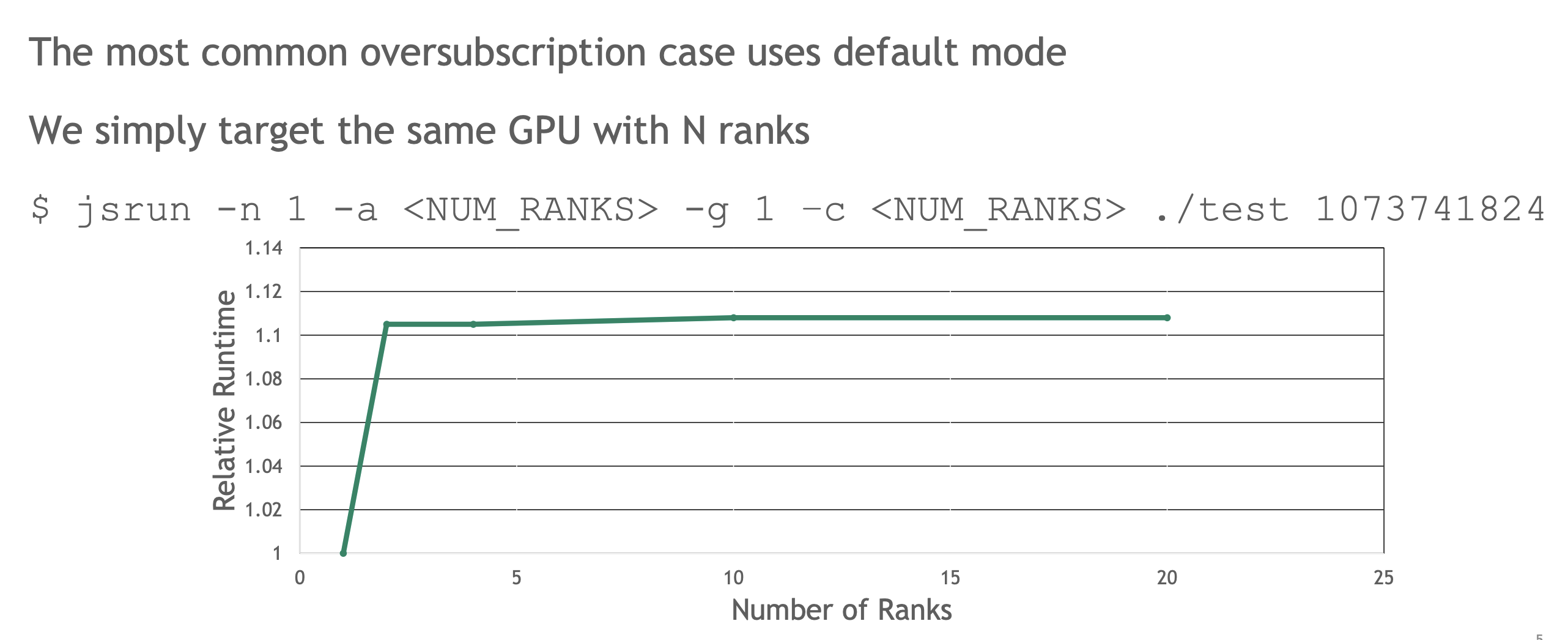
- 多个rank单卡,单个kernel跑得更慢。当rank=4,为什么每个rank的问题模式仅为原来的rank分之一,但平均解决问题所需的时间却大致相同?GPU的SM数量没有变,在任一时刻,这四个内核中的每一个运行时,都必须须以某种方式占用其他 GPU 可用的资源(任意时刻,只有一个MPI rank在SM上运行)
- 当处理较小工作量时,kernel 之间时间间隙变大,即使分配到multiGPU 上,也不会改善,甚至大幅度延长(启动工作相关延迟,或者其他因素将会变得更重要,甚至抵消你试图获得的好处),虽然kernel时间变少
CUDA上下文
- 每个进程都会生成自己的CUDA上下文,上下文是运行CUDA所需的状态对象,当您使用CUDA运行时API时,它会自动为您创建。
- 在V100上,这个上下文的大小大约是300 MB+ 您的GPU代码大小
- 这限制了我们可以在GPU上使用的rank数量,跟应用数据无关,上下文大小部分由cudaLimitStackSize控制
每个等级完全独立于其他所有等级运行。各个进程在时间片中运行。在时间片之间上下文切换时会有性能损失。
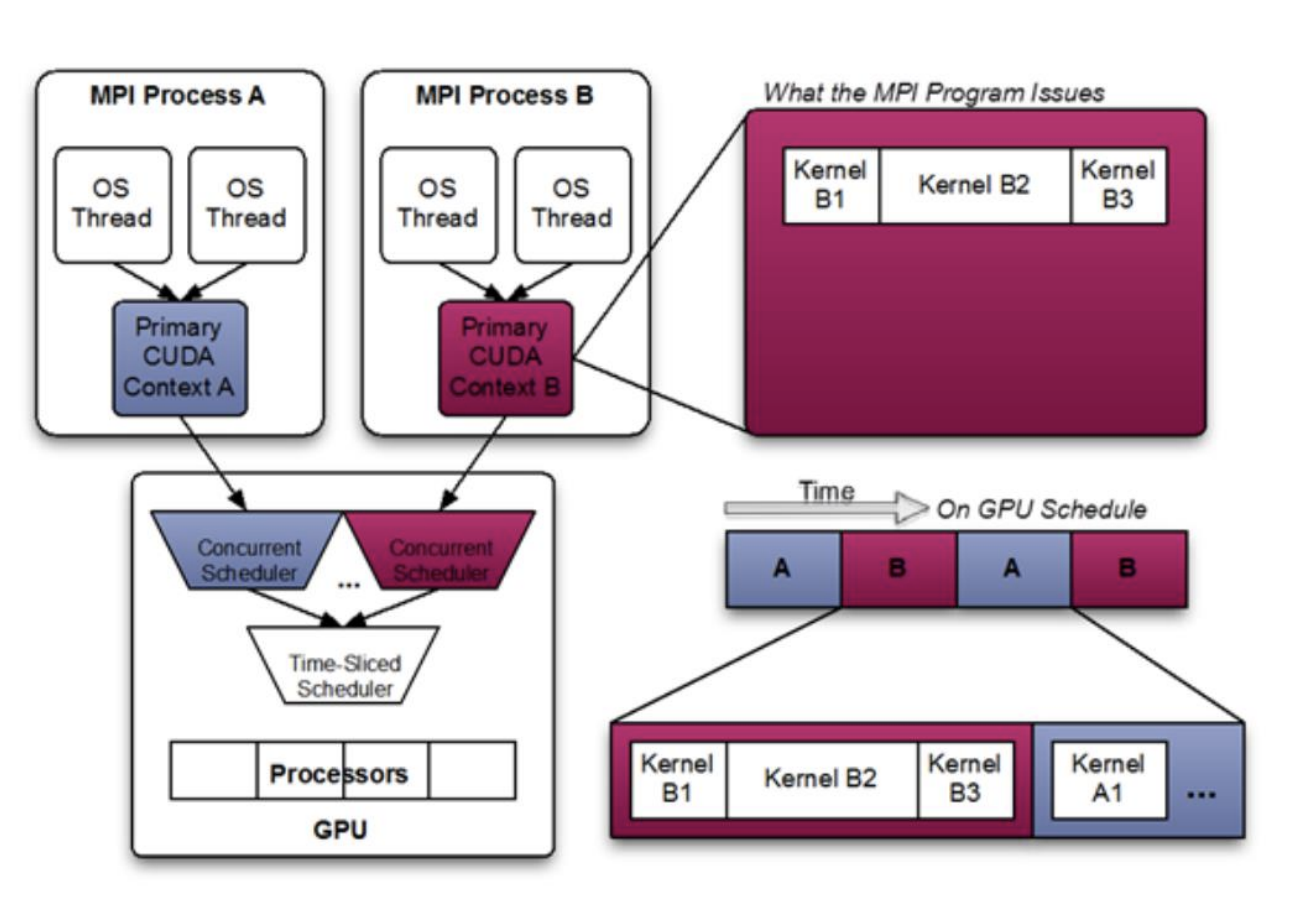
通常情况,不能充分利用GPU资源,在任一时间切片中,对于每个等级的工作量不是以填满 GPU 的情况,我们都在浪费大量 GPU 资源。
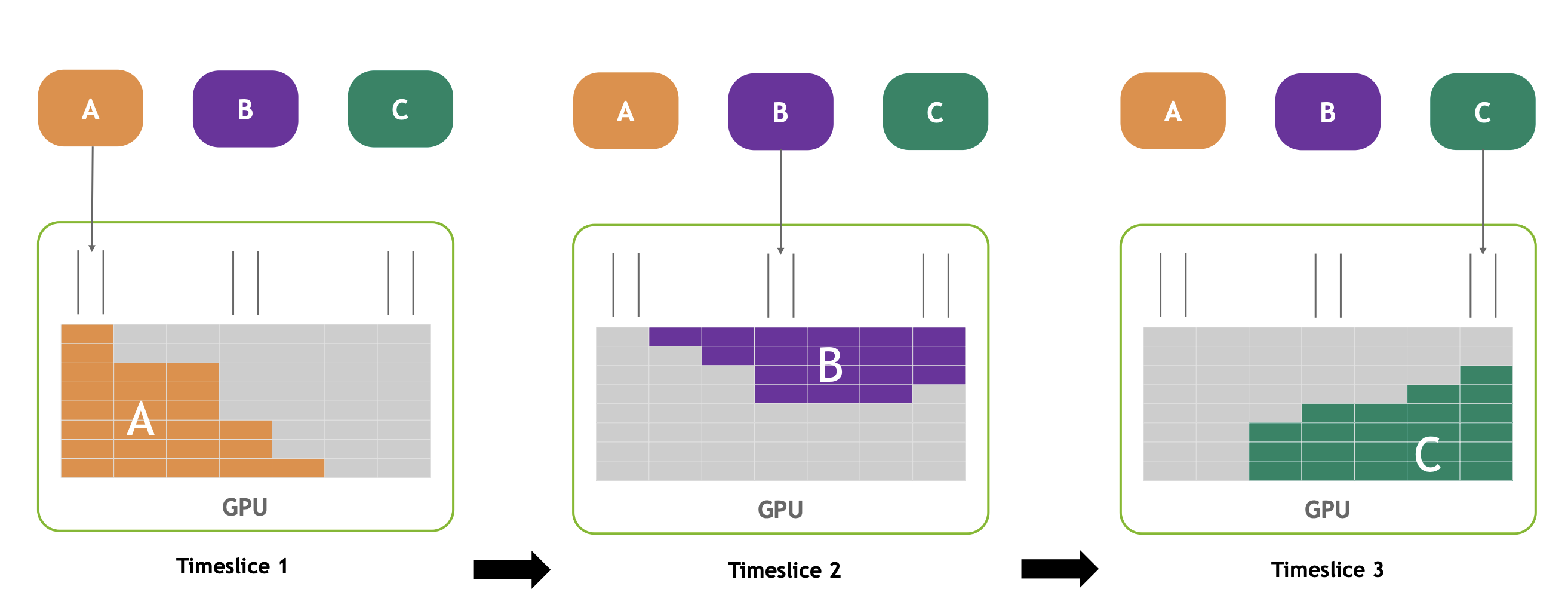
这确保的是,在任意给定的时间片段内,每个进程都能达到峰值吞吐量。它同样确保了进程间的完全隔离,但这也意味着我们无法充分利用所有的计算资源。
综上
- 任意时刻,只有一个MPI rank在SM上运行
- 未完全利用GPU,不能并行
- 对于未完全利用GPU(工作量小)的情况,我们希望填补时间线的空白。但对于仅使用GPU的工作负载,这通常很难达到理想效果。通常在有CPU独占工作时表现更好
MPS MULTI-PROCESS SERVICE
通过允许多个进程(瞬时)共享GPU计算资源(SMs)来改善这种情况。同时将多个 MPI rank映射到单个GPU上,当每个rank太小**,无法单独填满GPU时使用。
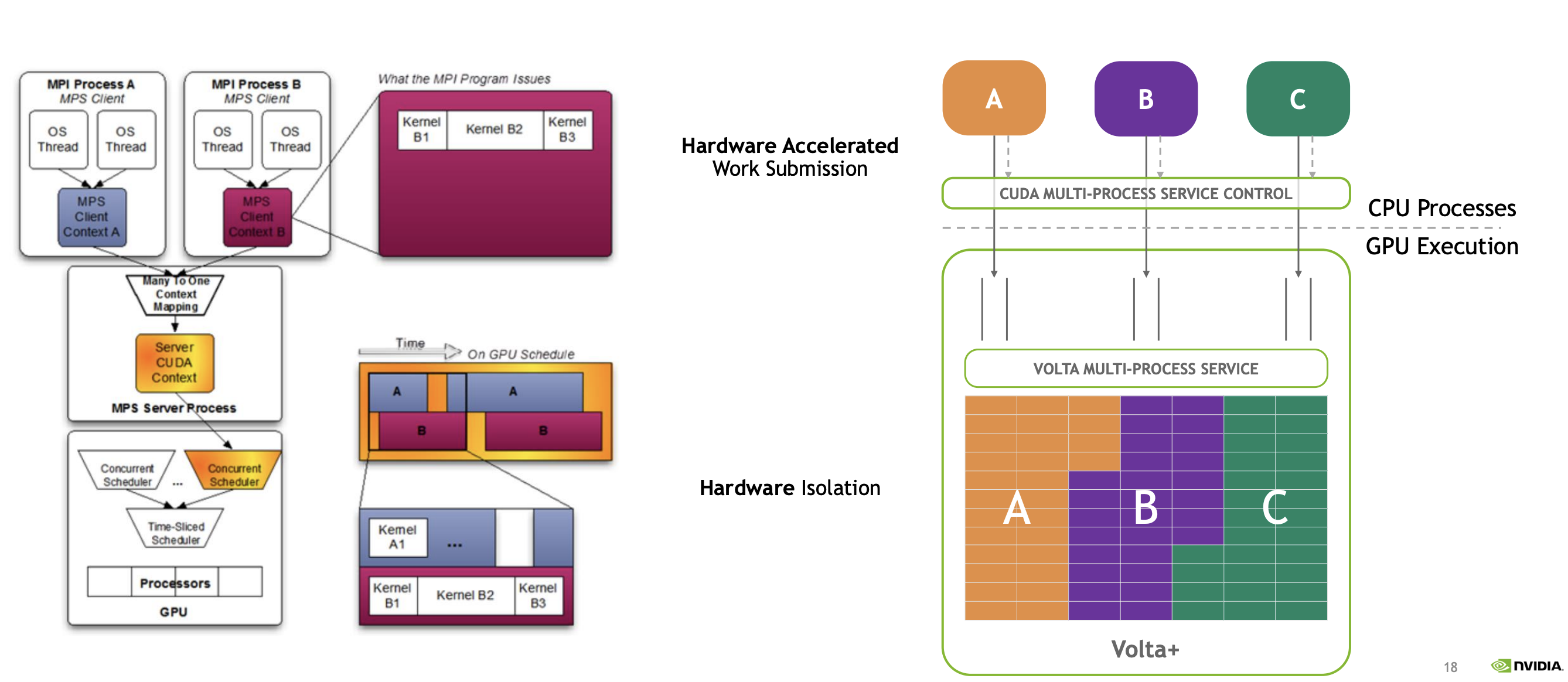
其工作原理是,并非每个 MPI rank都直接在 CUDA 上下文中提交各自的 CUDA 任务,而是我们名为创建一个名为 MPS服务器的机制。该服务器随后接收来自两个 MPI rank的工作请求或内核启动。随后,该服务器上任务负责在 GPU 的 SM(流多处理器)之间分配工作。在这个上下文服务器( MDI 服务器)中,所有魔法般的工作分配发生的地方,使得多个 MPI rank能够并发运行。使得同一个GPU上,多个rank可以使用所有的SM
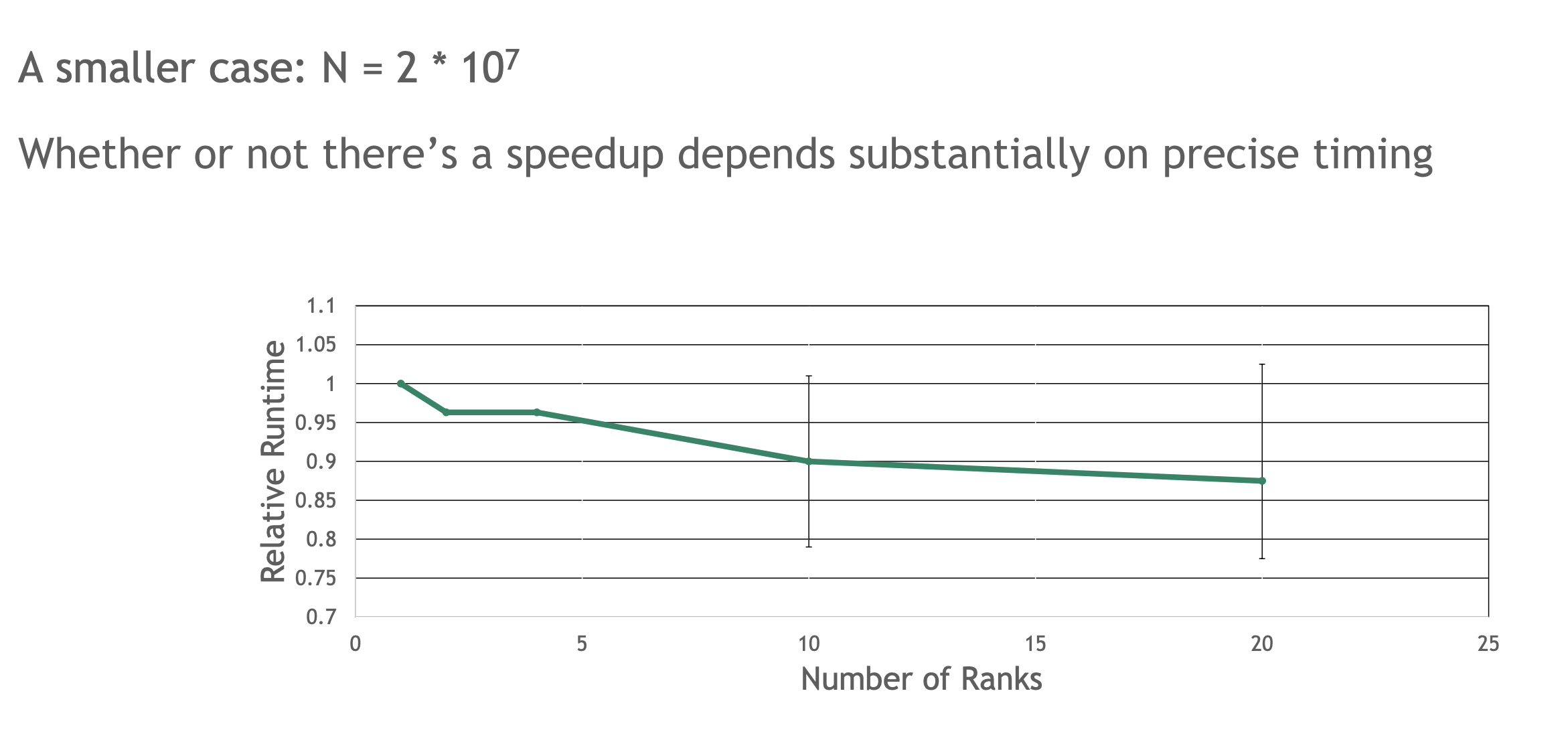
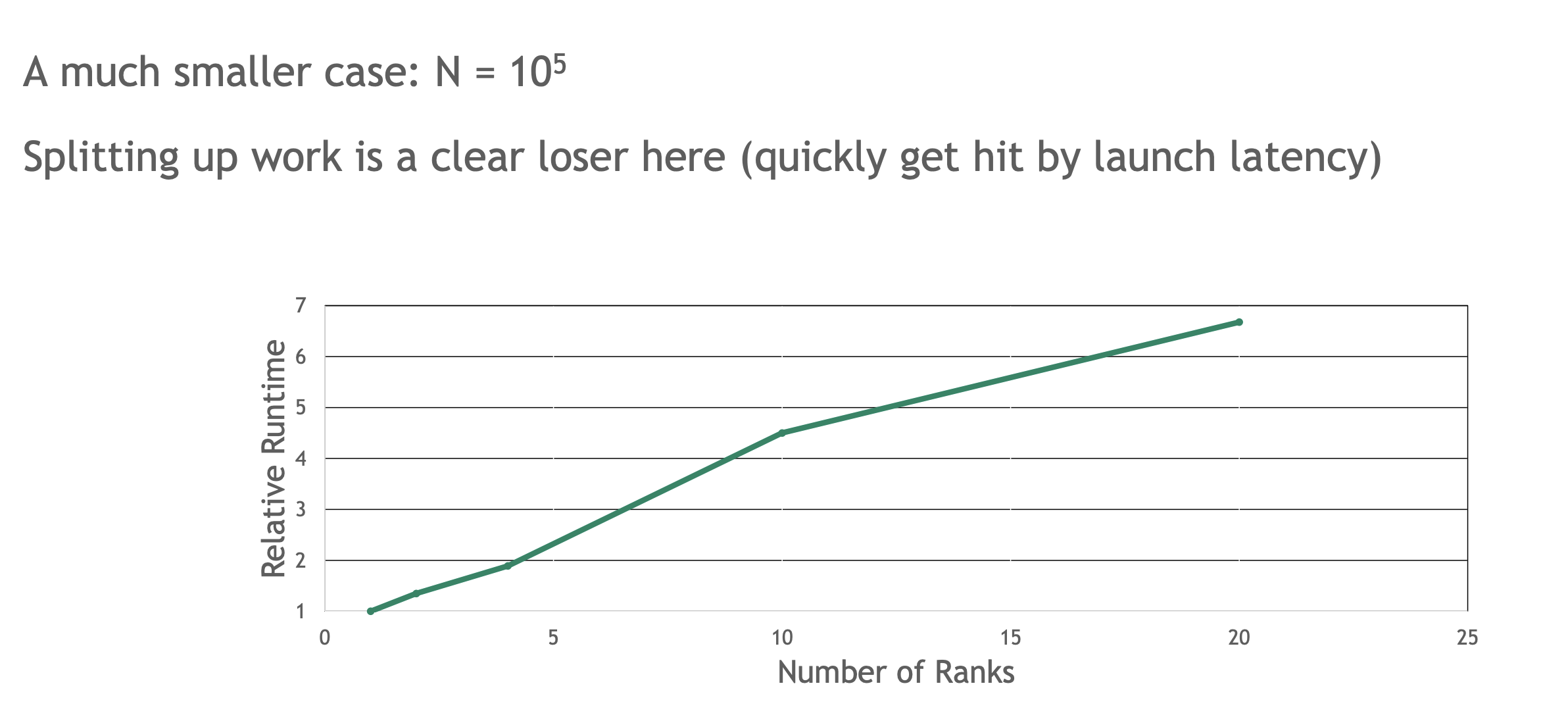
启动少量工作所伴随的延迟消除了多个rank协同工作以填补时间线中空缺所带来的任何好处。每个内核的工作量极小,而启动内核的开销成为主要因素,甚至尝试将此问题分配到多个rank上完全无效。当问题规模较大时,MPS 能帮助您无损性能地分配问题,甚至更优性能
总结
- 努力编写你的应用程序,以便不需要使用MPS。
- 如果你无法编写能充分利用GPU的内核,那么可以考虑过度订阅(多rank),通常在这种情况下开启MPS是值得的。
- 分析你的代码,了解MPS是否有效以及为什么有效或无效。
Use MPS
No application modifications necessary
Not limited to MPI applications
MPS控制守护进程会在CUDA应用程序启动时启动MPS服务器。 分析工具支持MPS;cuda-gdb不支持附加,但你可以生成核心转储文件。
-
nvidia-smi -c EXCLUSIVE_PROCESS (在共享系统中,推荐使用EXCLUSIVE_PROCESS模式,这样可以确保只有一个MPS服务器在使用GPU。)
-
nvidia-cuda-mps-control –d

` export CUDA_MPS_ACTIVE_THREAD_PERCENTAGE=percentage`
配置可供MPS附加进程使用的GPU最大比例
- 确保一个进程最多使用指定的百分比执行资源(SMs)
- 允许进行过度配置:所有MPS进程的总和可以超过100%。
- 仅配置执行资源(SMs),不配置内存带宽或容量。
内存占用
为了提供每个线程的栈空间,CUDA为每个线程保留1kB的GPU内存。 这相当于(2048线程每个SM x 1kB每个线程)= 每个SM使用2 MB,或者每个客户端使用164 MB(V100)(A100为221 MB)。 CUDA_MPS_ACTIVE_THREAD_PERCENTAGE减少了最大SM的使用,从而减少了内存占用。 每个MPS进程还会上传可执行代码的新副本,这会增加内存占用。
工作队列共享
CUDA将流映射到CUDA_DEVICE_MAX_CONNECTIONS硬件工作队列上。 队列通常是每个进程的,但MPS允许96个硬件队列在最多48个客户端之间共享。 MPS会自动减少每个客户端的连接数,除非设置了环境变量。 如果设置了CUDA_DEVICE_MAX_CONNECTIONS(例如,允许在一个进程中更多并发),这可以减少并发客户端的最大数量。
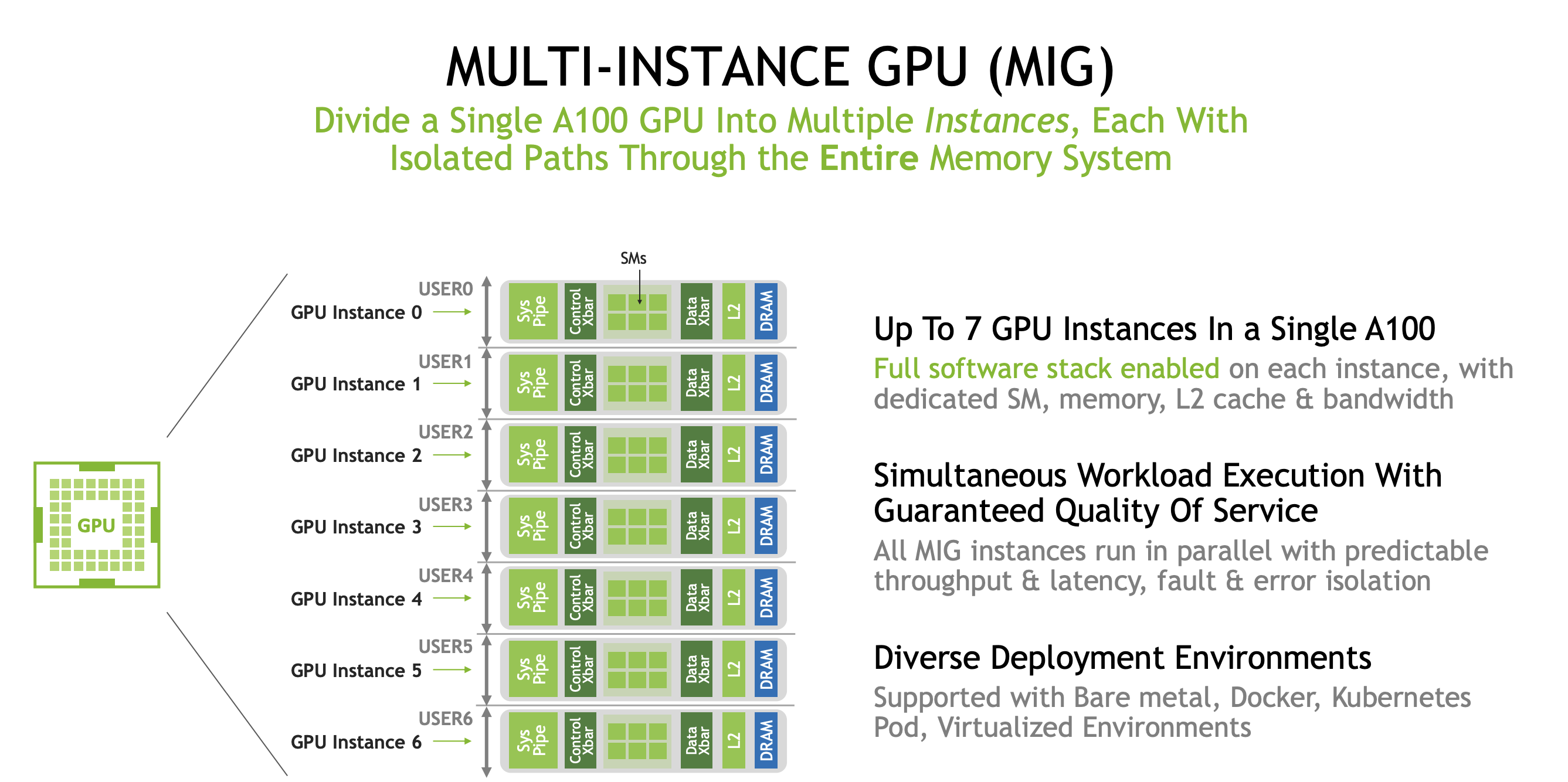
MIG multi instance GPU
从 A100 系列 GPU 开始,我们引入了 MIG(多实例 GPU)的概念,它允许对 GPU 进行物理分区。
使用 MPS 时,资源争夺是动态的,但这是一个接受多个等级工作请求的服务器。随后,该服务器将工作分配到 GPU 上可用的各个系统中。这一结果导致,在服务质量或执行配置方面的保障实际上并不存在,或者说保障程度有限。
在多实例 GPU 中,您能够直接操作 SM 以及内存,并将这些资源分配到 GPU 的多个切片上。因此,可以同时为多个用户运行多个不同的进程。这对于 A100 GPU 来说是相关的,但对于许多 HPC 应用场景而言,相关性并不高。在 AI 推理等应用场景中,这一点变得尤为重要,您可能希望同时运行多个推理过程。
借助 MIG 技术,您可以将 A100 GPU 划分为多达七个独立实例,每个实例均配置专用的 SM 缓存和内存资源。
Event and Error
Error 普通概念
https://github.com/brucefan1983/CUDA-Programming/blob/master/src/04-error-check/error.cuh
方便打印错误信息
运行时会为每个主机线程设置一个错误变量,最开始是cudaSuccess。每当发生错误(不管是参数验证错误还是异步错误),这个变量都会被新的错误代码覆盖。使用cudaPeekAtLastError()可以获取这个变量的值,而cudaGetLastError()则会返回这个变量并把它重置为cudaSuccess。
1 | |
Event
1 | |
CUDA内核启动是异步的
- 内核可能不会立即开始执行
- 启动内核的主机线程会继续执行,而无需等待内核完成
在内核执行期间,可能会检测到CUDA错误
- 一旦检测到错误,它将在下一次 CUDA 调用时报告该错误。
CUDA内核启动可能会产生两种类型的错误:
- Synchronous 同步:在启动时可检测 由 CUDA 运行时 API 调用所引发,并能被 CUDA 运行时检测到的现象。
- 可以使用cudaGetLastError()或cudaPeekAtLastError()来立即检测同步错误
- 例子:ret = cudaMalloc(1000000000000000000000000000000000000000000);(内存不足错误)
- 此类错误不会“破坏CUDA上下文”
- 后续的CUDA运行时API调用正常工作 可恢复的
- Asynchronous 异步:在设备代码执行期间发生 (由内核代码执行错误引起的,不可恢复的)
- 可以通过像cudaDeviceSynchronize()这样的同步调用来强制立即检查,但这会打破异步和并发的结构
- 可以选择使用调试宏
- 还可以选择将CUDA_LAUNCH_BLOCKING环境变量设置为1
- 例子:内核超时、非法指令、地址未对齐、无效地址
- 在该进程中CUDA运行时API不再可用
- 所有后续的CUDA运行时API调用将返回相同的错误
- 唯一的“恢复”过程是终止拥有的主机进程(即结束应用程序)。
Compute Sanitizer
是一个用于功能正确性检查的工具,随CUDA工具包安装。它可以帮助开发者在运行时检测和调试CUDA应用中的潜在错误,提供更高的代码可靠性和性能。
主要功能
- 自动运行时API错误检查:
- 即使您的代码未显式处理错误,Compute Sanitizer也能自动检测运行时错误,帮助开发者及时识别问题。
- 多语言支持:
- 支持多种语言绑定,包括CUDA Fortran、CUDA C++、CUDA Python等,方便不同语言用户使用。
子工具
- memcheck(默认):
- 检测非法代码活动,包括:
- 非法指令
- 非法内存访问
- 访问未对齐的内存
- 检测非法代码活动,包括:
- racecheck:
- 检测共享内存中的竞争条件和潜在危险,包括:
- 读取后写(RAW)
- 写后写(WAW)
- 写后读(WAR)
- 检测共享内存中的竞争条件和潜在危险,包括:
- initcheck:
- 检测对未初始化全局内存的访问,确保所有内存使用前已初始化。
- synccheck:
- 检测对同步原语(如
__syncthreads())的非法使用,确保在正确的上下文中使用同步功能。
- 检测对同步原语(如
Memcheck
是 Compute Sanitizer 中的默认工具,建议在使用其他工具之前先运行它。以下是 Memcheck 的主要特点和功能
compute-sanitizer ./my_executable
- 内核执行错误检测:
- Invalid/out-of-bounds 无效/越界内存访问:检测访问未分配或超出分配范围的内存。
- Invalid PC/Invalid instruction 无效程序计数器/无效指令:检测执行的指令是否有效。
- Misaligned address for data load/store 数据加载/存储的未对齐地址:检测访问未对齐的内存地址。
- 错误定位:
- 当代码使用
-lineinfo编译时,Memcheck 能提供错误定位信息,帮助识别问题所在。 - 此功能也对其他工具有用,例如在分析器(如 Nsight Compute)中的源级工作。
- 当代码使用
- 性能影响:
- Memcheck 对内核执行的速度有一定影响,这需要在调试时考虑。
- 泄漏检查:
- 可以检查设备端内存的分配和释放是否存在内存泄漏问题。
- 更严格的错误检查:
- Memcheck 提供的错误检查比普通的运行时错误检查更为严格,帮助开发者捕捉到更多潜在问题。
1 | |
1 | |
Racecheck
Racecheck 是 Compute Sanitizer 中专门用于检测共享内存竞争条件的工具。以下是 Racecheck 的主要特点和功能:
主要特点
- 线程执行顺序:
- CUDA 不指定线程之间的执行顺序,这使得共享内存中的读写操作顺序对程序的正确性至关重要。
- 共享内存的使用:
- Racecheck 主要检测在共享内存中发生的竞争条件,确保线程间的通信不引发错误。
基本用法
- 运行命令:
compute-sanitizer --tool racecheck ./my_executable
竞争条件类型
- WAW(写后写):
- 两次对同一内存位置的写入操作之间没有进行任何同步。
- RAW(读后写):
- 一次写入操作后,随后没有同步即进行读取。
- WAR(写后读):
- 一次读取操作后,随后没有同步即进行写入。
报告功能
- Racecheck 提供详细的报告,帮助开发者理解竞争条件的发生情况,从而更好地定位和修复问题。
1 | |
1 | |
Initcheck
检测使用未初始化的设备全局内存
1 | |
1 | |
Synccheck
Synccheck 是 Compute Sanitizer 中用于检测同步原语非法使用的工具,主要关注线程间的同步问题。以下是 Synccheck 的主要特点和功能:
主要特点
- 同步原语检测:
- 适用于
__syncthreads()、__syncwarp()和相应的协作组(CG)等函数。 - 主要用于检测不当使用的同步情况,尤其是在未所有必要线程到达同步点时。
- 适用于
- 应用层级:
- 线程块级:检查整个线程块内的同步问题。
- Warp级:检查单个warp内的同步问题。
- 掩码参数:
__syncwarp()内置函数可以接受掩码参数,用于指定预期到达同步点的线程。- 检测掩码的无效使用。
基本用法
- 运行命令:
compute-sanitizer --tool synccheck ./my_executable
适用性
- 在计算能力(cc)7.0 及更高版本中,因Volta执行模型的宽松要求,Synccheck的适用性受到限制。
cuda-gdb Debugger
cuda-gdb 是一个基于广泛使用的 GDB 调试工具(GNU 工具链的一部分),专门用于调试 CUDA 应用程序。以下是其主要特点和功能:
主要特点
- 命令行调试器:
- 提供典型的调试操作,如:
- 设置断点:使用命令
b设置断点。 - 单步执行:使用命令
s逐行执行代码。 - 数据检查:使用命令
p打印变量值。
- 设置断点:使用命令
- 提供典型的调试操作,如:
- 命令语法:
- cuda-gdb 尽可能使用与 GDB 相同的命令语法,并提供某些命令扩展,方便用户上手。
- 调试代码构建:
- 通常需要构建调试版本的代码,以便与调试器配合使用。
- 支持多种语言:
- 支持调试 CUDA C++ 和 CUDA Fortran 应用程序。
在使用 nvcc 编译 CUDA 代码以进行调试时,包含特定的标志是至关重要的。以下是关键选项的总结:
关键编译命令行选项
-g:- 这是标准的 GNU 开关,用于构建主机代码的调试版本。
-G:- 此标志用于编译带调试信息的设备代码。
- 它使调试器能够访问必要的符号信息,支持源级调试。
重要考虑事项
- 性能影响:
-G标志会显著影响设备代码的生成,通常会导致执行速度变慢。- 建议仅在调试时使用
-G,而不是用于性能分析。
- 行为变化:
- 在少数情况下,使用
-G可能会改变代码的行为。
- 在少数情况下,使用
- 目标架构:
- 确保代码使用
-arch标志编译为正确的目标架构(例如-arch=sm_70)。
- 确保代码使用
在使用 cuda-gdb 进行调试时,可以使用以下命令来设置选项、获取信息和更改当前焦点:
命令列表
-
set cuda ...- 用于设置通用选项和高级设置。
-
launch_blocking (on/off)- 控制内核启动时是否暂停主机线程。设置为
on时,每次内核启动将暂停主机。
- 控制内核启动时是否暂停主机线程。设置为
-
break_on_launch (option)- 在每次新的内核启动时是否设置断点。
-
info cuda ...- 获取系统配置的一般信息,包括设备、流处理器(SM)、warp、lane、内核、块和线程等信息。
-
cuda ...- 用于检查或设置当前的调试焦点。
-
cuda device sm warp lane block thread- 显示当前焦点的坐标。例如:
1
block (0,0,0), thread (0,0,0), device 0, sm 0, warp 0, lane 0 -
cuda thread (15)- 更改当前的线程坐标为 15。
确保代码通过 Sanitizer 测试
- 确保您的代码能够顺利通过各类 Sanitizer 工具的测试,以便捕获潜在的内存错误和并发问题。
确保主机代码正常运行
- 确保您的主机代码“健康”,例如,不会出现段错误(segmentation fault)。这可以通过使用调试工具(如
cuda-gdb)来检查。
确保内核被正确启动
-
确保您的 CUDA 内核实际被启动。可以使用以下命令进行性能分析:
1
nsys profile --stats=true ./my_executable -
检查输出中的 “CUDA Kernel Statistics” 部分,以确认内核是否成功启动以及相关的执行统计信息。
cuda-graph
什么是cuda-graph
从 CPU 发起任何 CUDA 操作都会产生通常所说的启动延迟开销。
- 允许定义一系列流的工作(内核、内存复制操作、回调(host code)、主机函数、图形)。
- 每个工作项(kernel,内存复制等)在图中是一个节点。
- 允许定义依赖关系(例如,这三个节点必须先完成,才能开始这个节点)。
- 依赖关系实际上是图的边。
- 提供手动定义方法和“捕获”方法。
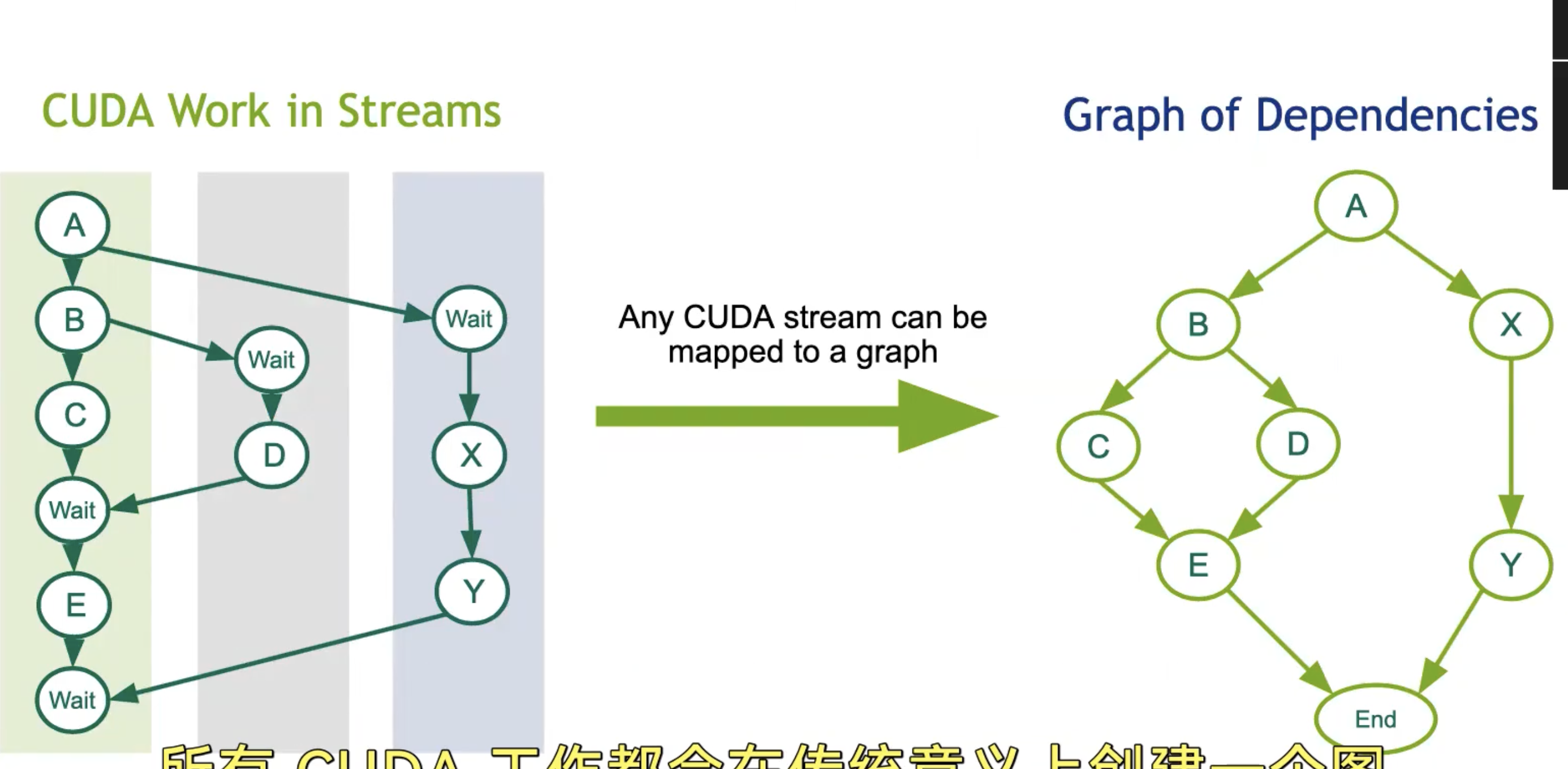
图节点是任何异步的CUDA操作
- Kernel Launch:在GPU上运行的CUDA内核
- CPU Function Call:在CPU上的回调函数
- Memcopy/Memset:GPU数据管理
- Memory Alloc/Free:内联内存分配
- Sub-Graph:图是层次化的
一旦定义,图可以通过将其启动到一个流中执行。图可以被重新使用,同时有助于延迟隐藏
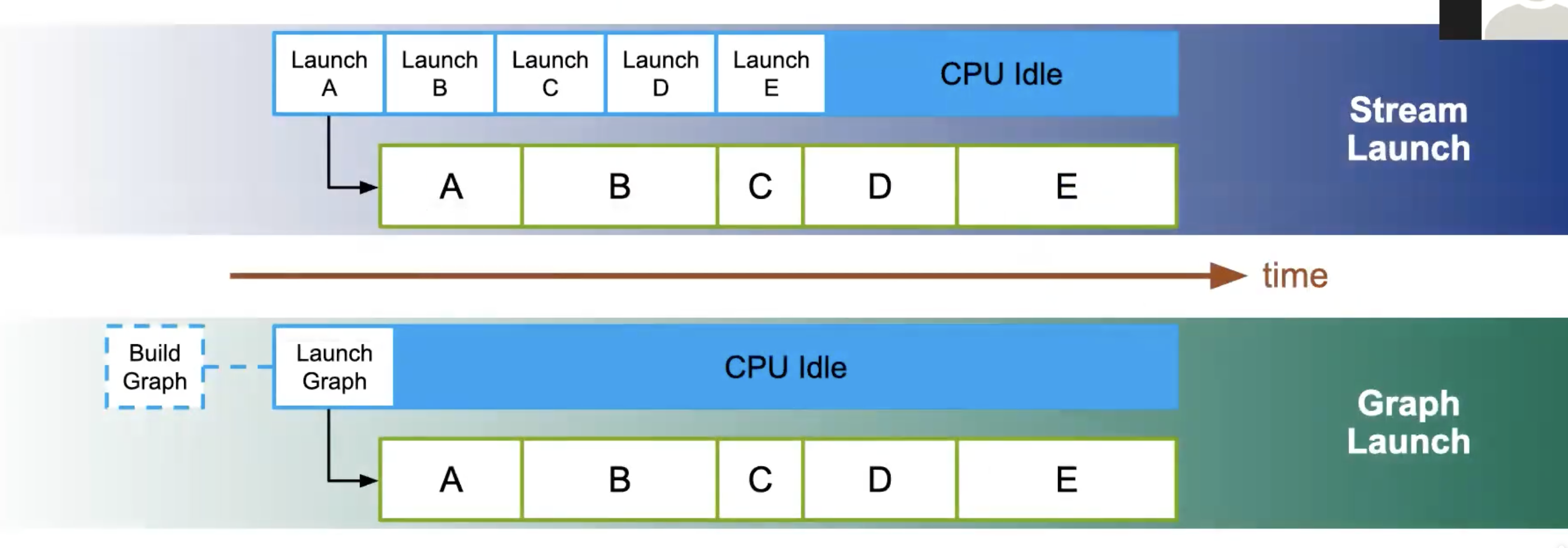
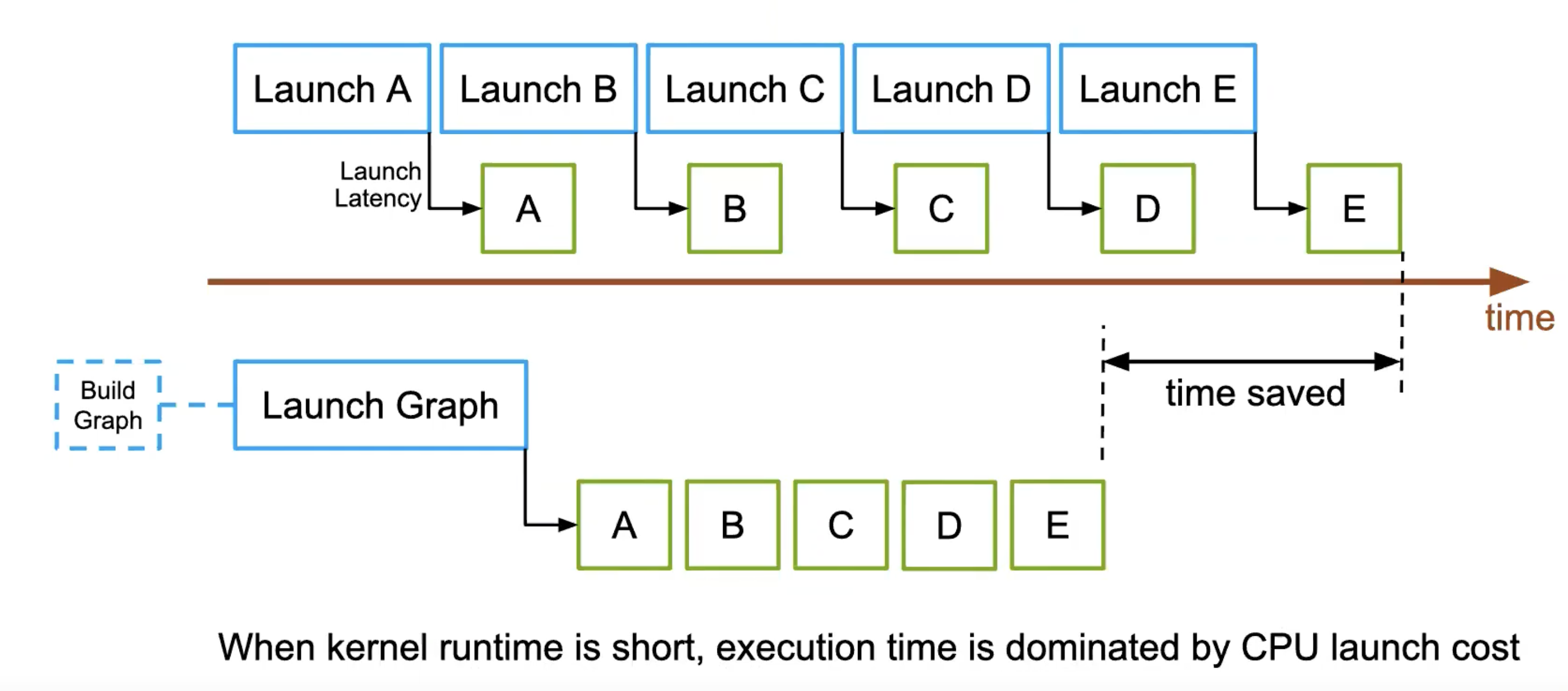
释放CPU时间,CPU可以处理其他工作。同时消除内核间间隙(当内核运行时间较短时,总执行时间主要受 CPU 启动开销影响,而启动开销通常仅为几微秒。)
CUDA Graphs采用三阶段执行模型,我们首先定义图,然后实例化(最耗时),最后在流中执行。
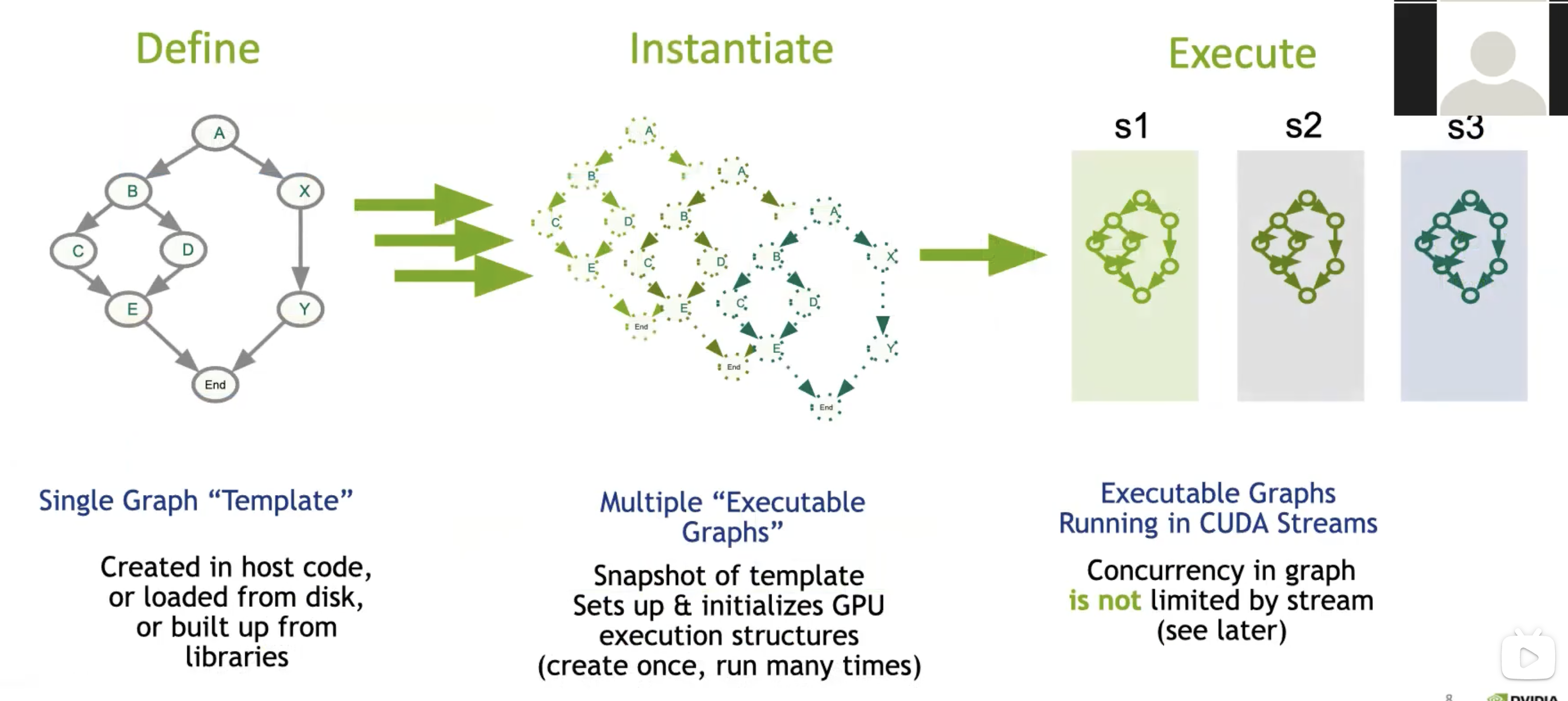
当我们实例化图时,其性能开销与直接在 CUDA 流中启动内核相似,但这仅需支付一次。随后,我们可以多次执行这个图,从而有效地隐藏初始化的设置成本。因此,总体来看,尽管你承担了这一高昂成本,但随着图表的多次重启,你从降低的额外开销中节省的资源将越来越多。
成本并非完全消失,但如果我们能重复使用同一可执行实例,那么相较于零碎启动,我们将降低发送到 GPU 的成本就相对低廉。
右侧所示为理想情况,但通常并非总能 100% 适用,因为代码中存在分支路径和参数变化等情况。
图定义
定义 CUDA 图有两种方式。
stream capture
-
记录了流中的操作,但并未实际向 GPU 发起任何工作任务。
-
之后,当您完成捕获该图对象时,它便可以被实例化。所有节点及其依赖关系均已由 CUDA 为您定义完毕。
-
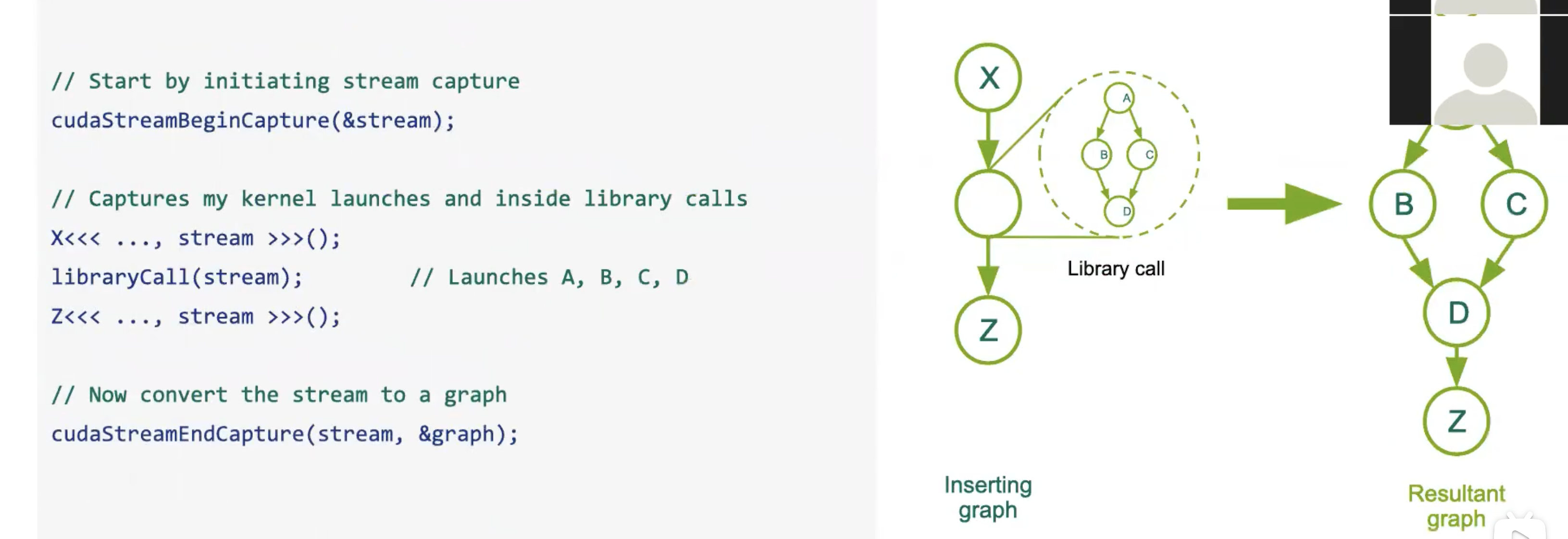
当您调用库函数时,流捕获同样非常实用,例如对 cuBLAS 的调用,或者对 cuFFT 的任何调用。因为作为用户,我们通常并不清楚在库提供的抽象层级背后,具体有哪些工作被启动,以及使用哪些参数等细节来达成结果。流捕获在此非常有助于了解这些细节。此外,需要注意的是,如果库函数调用了 CUDA 流同步,它可能会给您带来问题,因为捕获操作实际上并没有启动任何任务。
使用方式
1 | |
尽管我们仅捕获了steam1,但 CUDA 仍能识别事件记录以等待事件(cudaStreamWaitEvent)和后续节点。如果库调用了cudaStreamSynchronize()或任何其他同步操作的问题捕获并未启动任何内容,因此同步无法等待任何事情。
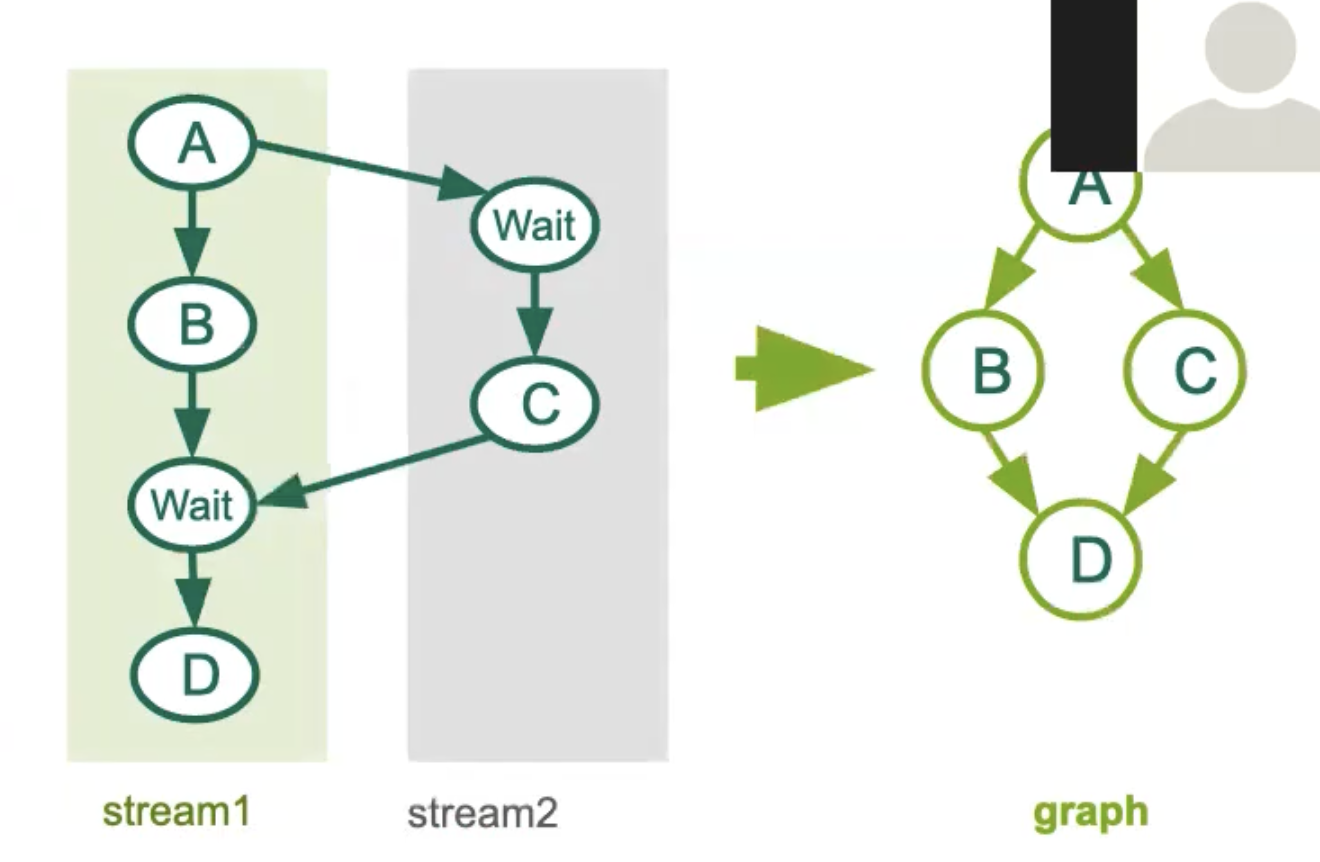
如右侧图片所示,节点 C 位置不同于流中生成的图,这符合预期,这非常好。
这是调用库的代码,stream capture会记录库调用
显式图创建
1 | |

我们已经有一个明确的图表,可以直接将其作为子图节点添加进去,并恰当地融入整个图结构中。

或许绿色的运行在 GPU0上,而蓝色的运行在 GPU 1上,它们可以利用不同的流并执行。
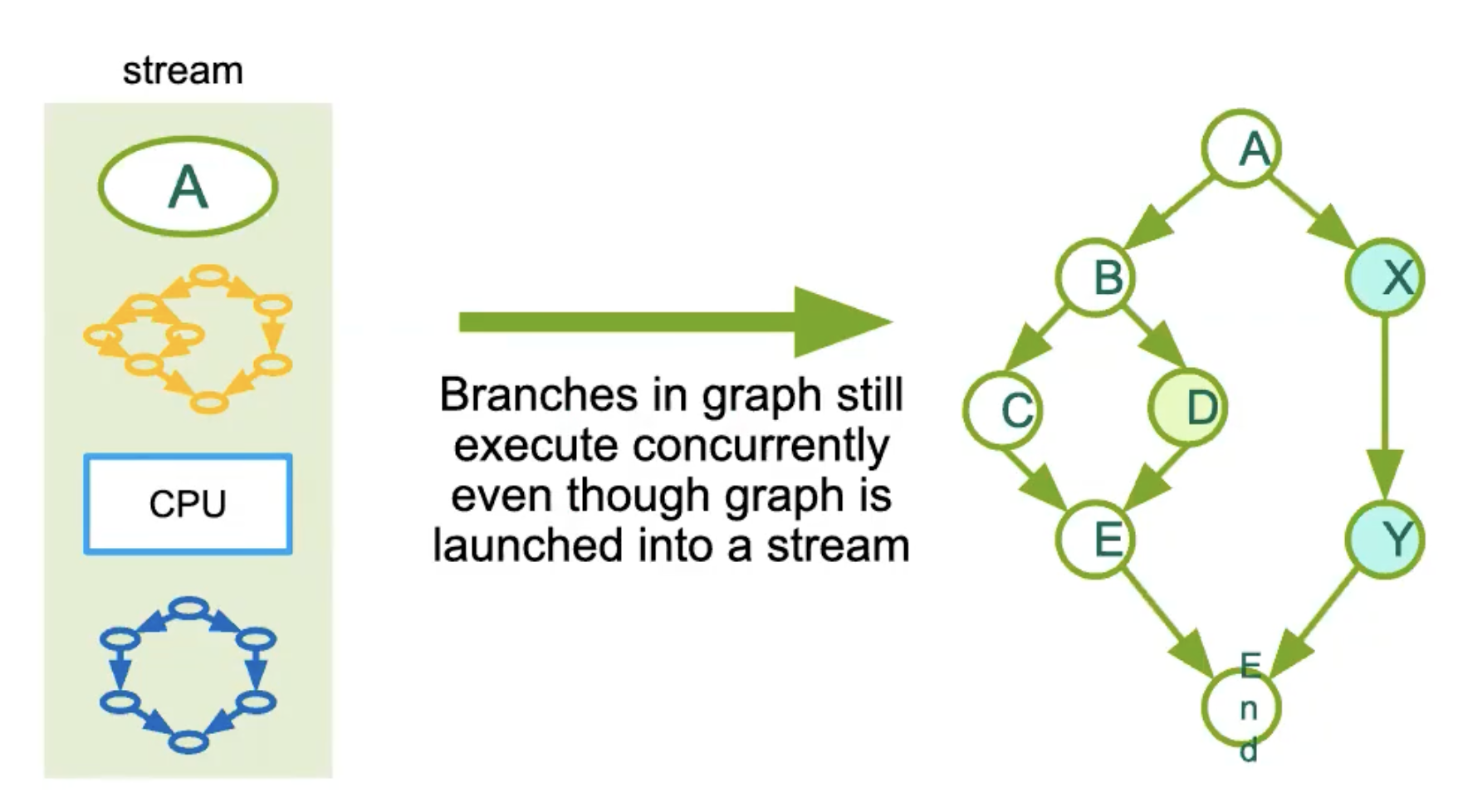
cuda-graph限制
与其他 CUDA 操作一样,CUDA 图不会自动将节点分配到你可用的不同设备上,除非你明确指示它这样做。
因此,在创建图和节点时,你可以决定操作将在何处运行。图算法不会显式处理它。
cuda-graph能力
- 图可以被重新使用
- 对于特定类型的工作负载,图的使用能够优化向 GPU 派发任务时的开销成本。
GPU异构节点类型,图节点包括GPU工作、CPU工作和数据移动。
数据管理可能会被透明地优化
- 预取
- 读取复制
- 细粒度的细分
优化内存访问的带宽和延迟 优化互连的带宽(PCI、QPI、NVLink)
CUDA最接近操作系统和硬件,多GPU间实现同步
- 可以优化多设备依赖
- 可以优化异构依赖
- 特别是在执行图时
GPU communication
GPU 编程中处理生产者和消费者之间数据通信
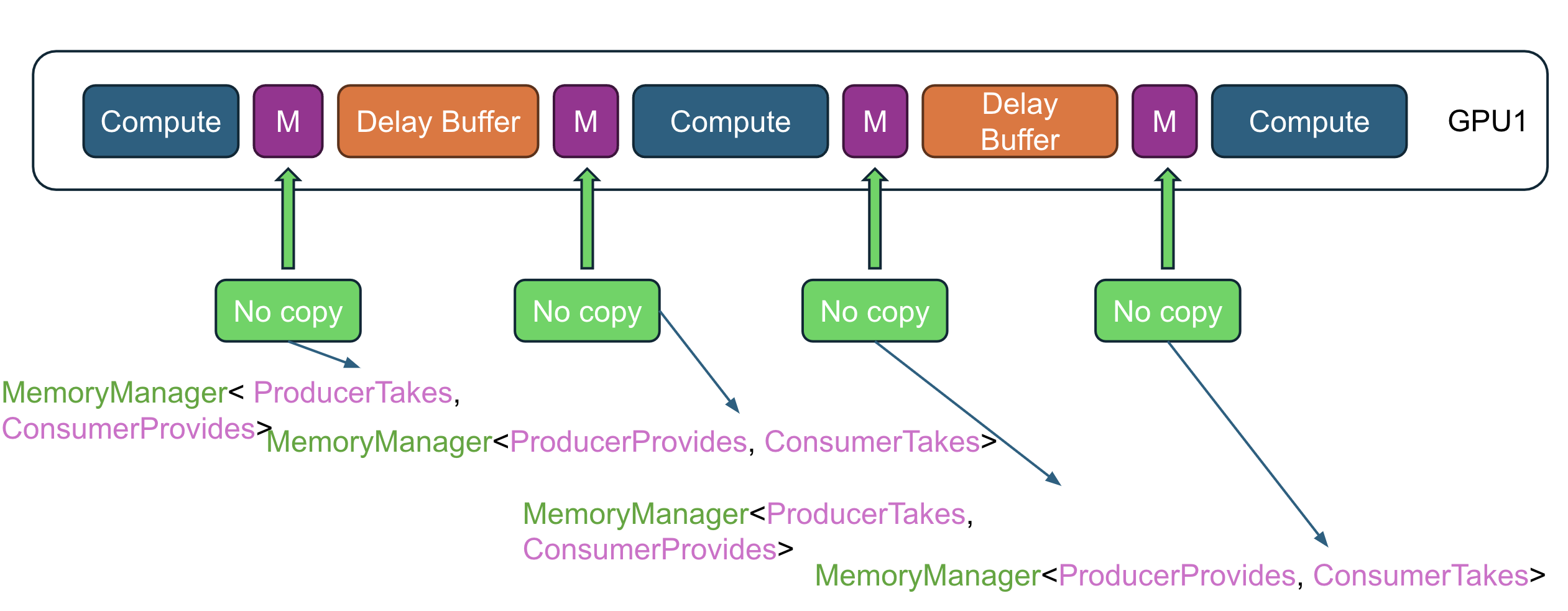
理解 GPU 通信规则
“Provide” 规则
- 何时使用 Provide:
-
生产者作为延迟缓冲区:
如果生产者(即生成数据的代码)是作为延迟缓冲区使用的,这意味着在本次迭代中数据没有被修改。生产者只是将数据传递下去,而不对其进行更改。
-
消费者作为延迟缓冲区:
同样,如果消费者(即消费数据的代码)作为延迟缓冲区使用,它也不会在本次迭代中修改数据。
-
- 操作: 在这两种情况下,生产者或消费者都应该 “Provide” 数据,也就是提供数据以供下一步操作使用。这样可以确保未修改的数据被正确传递。
“Take” 规则
- 何时使用 Take:
-
生产者作为内核或异步 CPU 代码:
如果生产者是一个内核(GPU 代码)或异步 CPU 代码,意味着生产者在本次迭代中会修改数据。这些数据正在被主动处理。
-
消费者作为内核或异步 CPU 代码:
类似地,如果消费者是内核或异步 CPU 代码,这也意味着消费者在本次迭代中会修改数据。
-
- 操作: 在这两种情况下,生产者或消费者都应该 “Take” 数据,也就是获取数据的所有权,以便对其进行必要的修改。
如何理解这些规则
- Provide 用于当数据不被修改而传递时,意味着这是一个只读或传递操作。
- Take 用于当数据被修改时,意味着这是一个写操作或处理操作。
这在 GPU 编程中非常重要,因为它有助于管理数据在管道中如何流动,确保正确的同步和内存管理。如果不遵循这些规则,可能会导致竞争条件、数据损坏或低效的内存使用。
在 GPU 编程中,Kernel Fusion 是一种优化技术,旨在通过将多个内核 (kernels) 合并为一个内核来减少 GPU 上的启动开销、内存访问开销以及内核之间的数据传输。内核融合有两种主要方式:水平融合 (Horizontal Fusion) 和 垂直融合 (Vertical Fusion)。下面我来详细解释一下这两种融合方式及其应用场景。
水平融合 (Horizontal Fusion)
- 水平融合适用于数据独立 (Data Independent) 的内核。
- 将多个数据独立的内核合并为一个内核。这意味着每个内核操作的是相同的数据集,但执行不同的计算任务。通过水平融合,这些任务可以在同一内核中并行完成,从而减少内核启动和数据传输的开销。
- 减少内核启动开销: 合并后,只需启动一次内核,从而减少了内核启动的总开销。
- 提高数据局部性: 由于数据只需要加载一次,随后在不同的计算任务之间共享,可以减少内存访问和数据传输的开销。
垂直融合 (Vertical Fusion)
- 垂直融合适用于数据依赖 (Data Dependent) 的内核。
- 指将具有数据依赖关系的多个内核合并为一个内核。比如,当一个内核的输出直接用作下一个内核的输入时,它们之间存在强数据依赖。通过垂直融合,这些内核可以在同一个内核中顺序执行,避免不必要的数据传输和内存访问。
- 减少全局内存访问: 通过在同一内核中执行多个步骤,可以避免将数据写回全局内存再重新加载,减少了内存访问延迟。
- 提高性能: 数据保存在寄存器或共享内存中,避免了全局内存的读写,可以显著提高计算性能。
稀疏Sparsity
为什么要浪费计算资源来使用许多参数,而几个参数就能解决问题?
- 训练网络直到得到合理的解决方案。
- 移除一部分参数。
- 重新训练模型以恢复丢失的准确性。
- 使用优化的稀疏核运行剪枝后的网络,以加速推理。
- 两部分:
- 准确性:将模型中的参数归零。
- 性能:如何快速进行零乘法。
我们应该如何添加零?
- 不同的稀疏模式
- 我们希望在准确性上有灵活性
- 但为了性能,我们希望有结构化的设计
tensor 怎样表示
-
稀疏表示 + 稀疏核
-
独立存储数据和结构
- COO 表示法
- [ 1 2 3 0 0 0 -> 索引: <(0,0) (0,1) (0,2)> 0 0 0 ] 数据: <1 2 3>
- 稀疏矩阵乘法
- 只有在高稀疏级别(>99%)时更快
不规则稀疏性,保持准确性,但在 GPU 上无法快速处理
- 不容易并行化
- GPU 处理块 - 我们不能在不规则稀疏中有结构块
如何让它在 GPU 上快速运行
- 如果我们去掉一行,而不仅仅是一个参数呢?结构化剪枝
- 我们可以重用稠密核(太好了)
- 但准确性影响很大,且难以处理
针对GPU用的稀疏
Semi-Structured (2:4) Sparsity
- 定义:在这种稀疏性中,每个块包含4个参数,其中2个是非零的,保持50%的稀疏水平。
- 加速效果:理论上可以实现高达2倍的速度提升。
- 准确性恢复:相对容易,通过微调或再训练可以有效恢复模型的准确性。
块稀疏性 (Block Sparsity)
- 定义:在这种方法中,稀疏性是基于块的大小进行组织的,可以在特定的块内保留非零值。
- 加速效果:在90%稀疏水平下,能够实现约3.4倍的速度提升。
- 准确性恢复:需要使用更先进的算法(如DRESS)来帮助恢复准确性,这些算法通常涉及复杂的微调策略。
cutLass
使用CUTLASS的时机
- 从主机调用的库:
- 示例:cuBLAS、cuDNN等。
- 自定义程度有限,需要推断何时使用张量核心。
- 调用这些库时涉及主机和设备之间的数据传输。
- 从设备调用的库:
- 示例:CUTLASS、Thrust、CUB。
- CUTLASS由设备调用,提供低级控制,直接暴露张量核心操作。
- 适用于编码新模型,测试性能和优化。
OpenAI Triton
https://github.com/triton-lang/triton
https://www.youtube.com/watch?v=AtbnRIzpwho&ab_channel=PyTorch
Block 级别编程
LLM speend up for Triton Example
1 | |
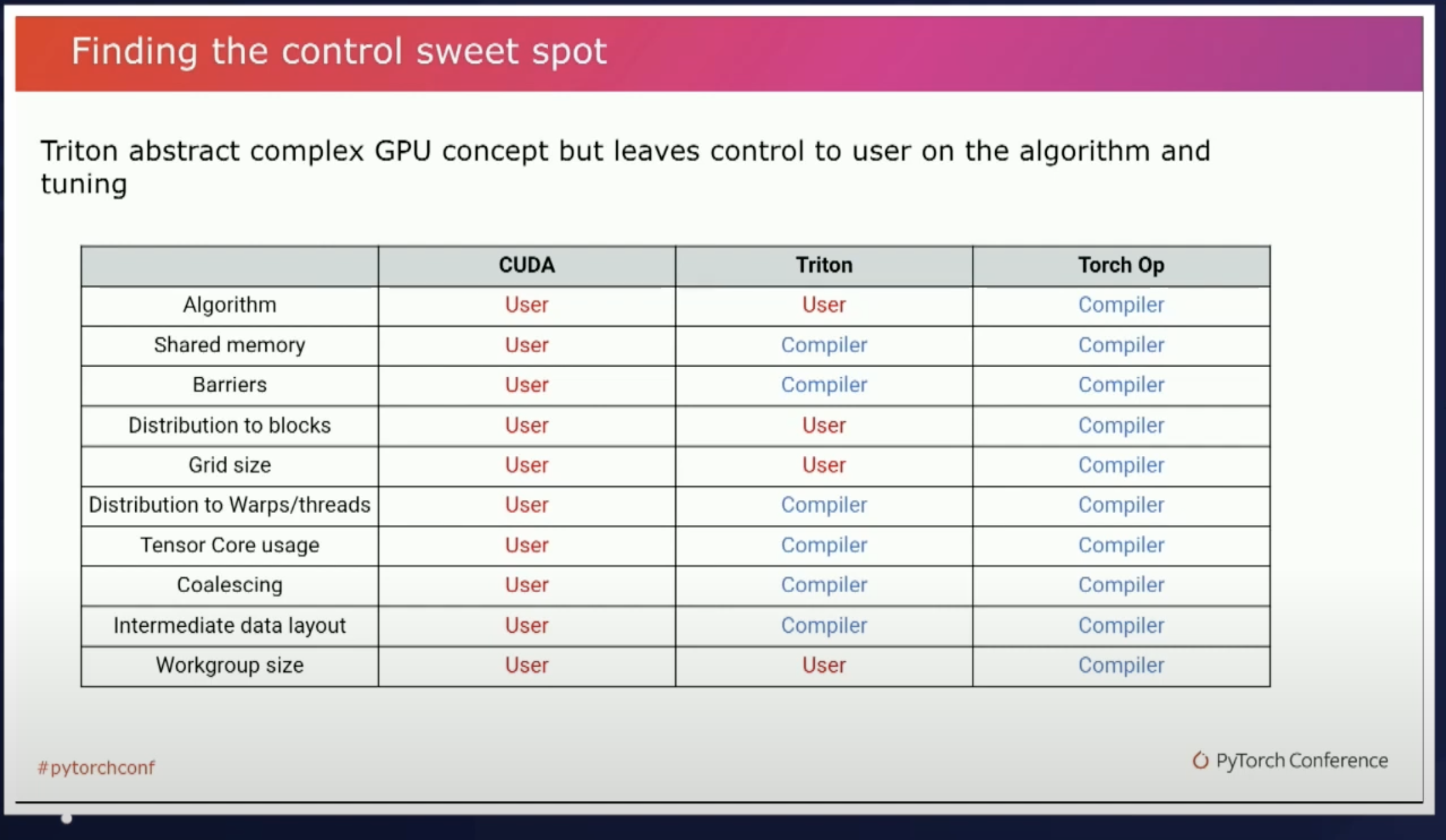
编程模型
使用 CUDA,我们将计算分解为两个级别:首先分解为块,然后每个块进一步分解为线程。块中的所有线程都在同一个 SM 上运行并共享相同的共享内存。并且每个线程都在标量上进行计算。
在 Triton 中,我们仅将计算分解为 1 个级别:分解为块。没有进一步分解为线程。Triton要求我们对向量执行操作。此外,我们不需要也不能管理共享内存。Triton 会自动执行此操作。
每个kernel(处理一个block)称为一个“program”。因此,“block_id”通常称为“pid”(“program id”的缩写),但它是相同的。