VLLM
支持PagedAttention ,张量并行
PagedAttention
KVCache的弱点
autoregressive decoding 过程中, 使用到所有输入的输入token产生KV cache,保留在GPU显存,生成一个token
-
大:对于LLaMA-13B中的单个序列,需要高达1.7GB的内存。
-
动态性:其大小取决于序列长度,而序列长度具有高度可变和不可预测的特性。因此,有效地管理KV缓存是一个巨大的挑战。我们发现,现有系统由于碎片化和过度预留而浪费了60%至80%的内存。
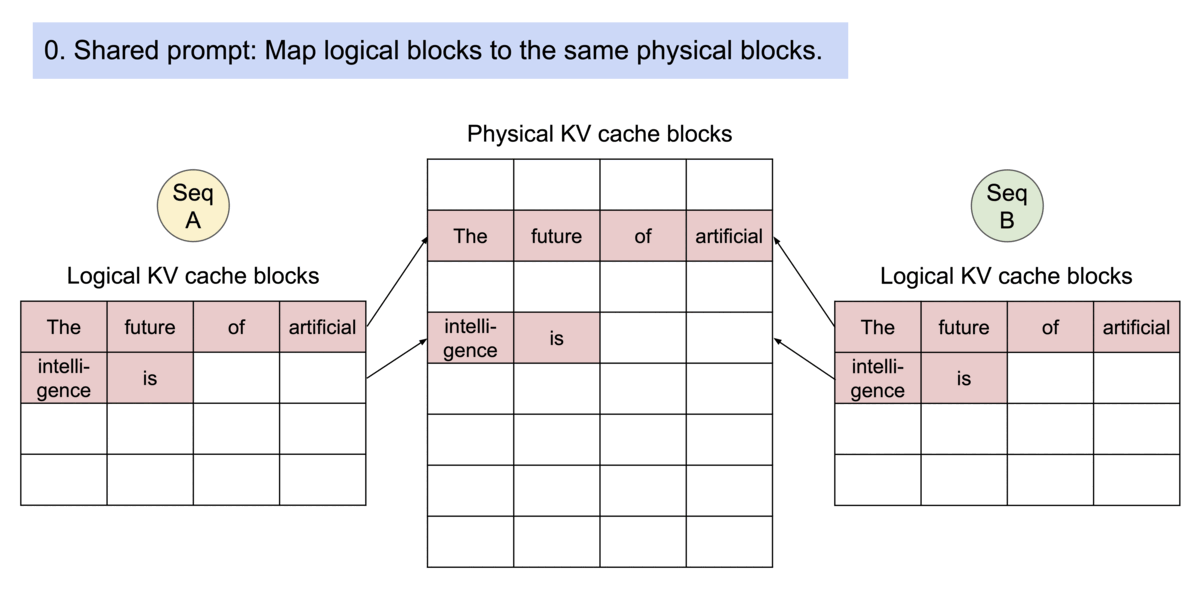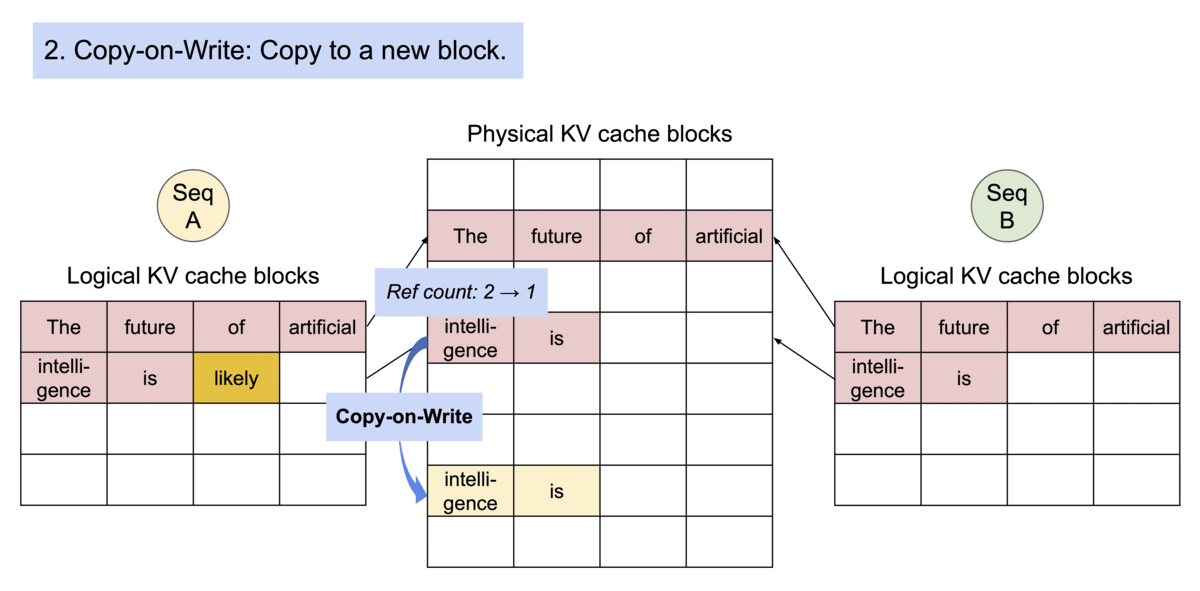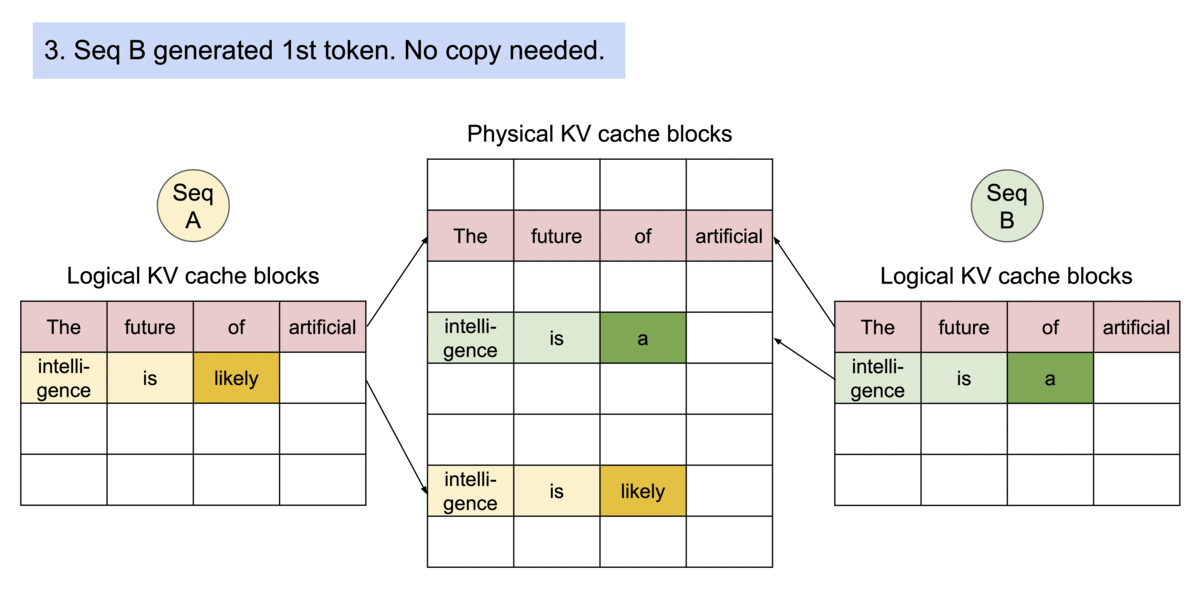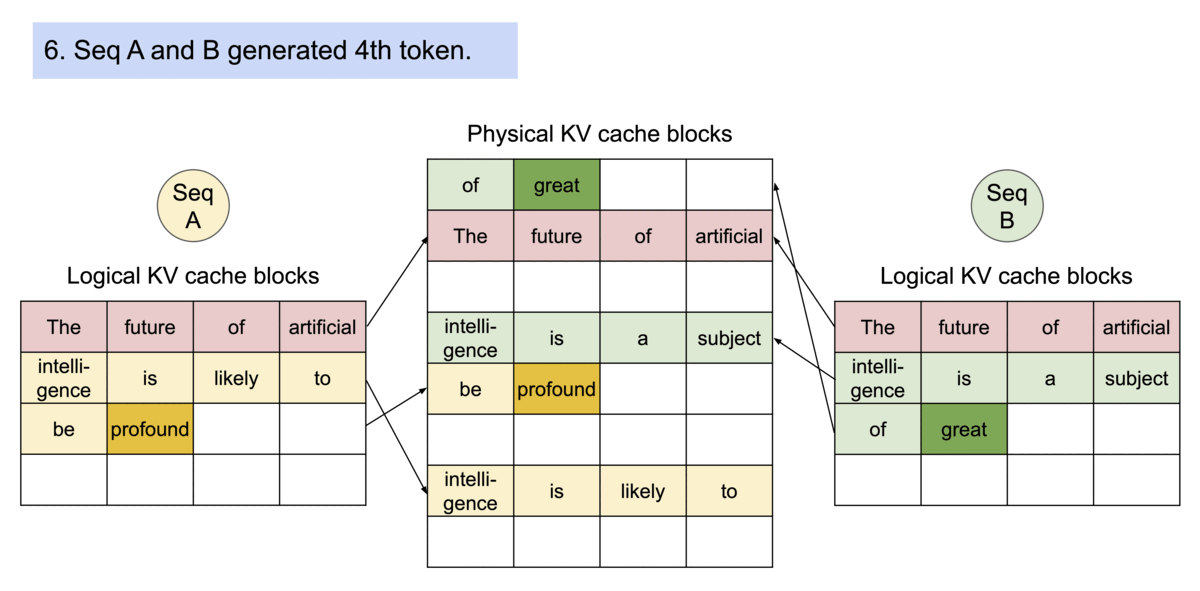
为了解决这个问题,我们引入了PagedAttention,这是一个灵感来自操作系统中虚拟内存和分页的经典思想的注意力算法。与传统的注意力算法不同,PagedAttention允许在非连续的内存空间中存储连续的K和V。具体而言,PagedAttention将每个序列的KV缓存分成块,每个块包含一定数量的token的K和V。在注意力计算过程中,PagedAttention内核能够高效地识别和提取这些块。
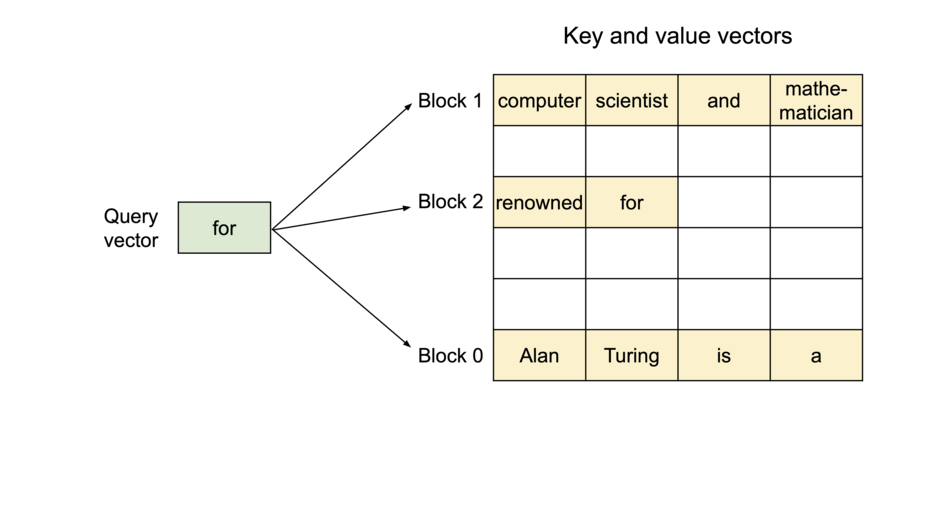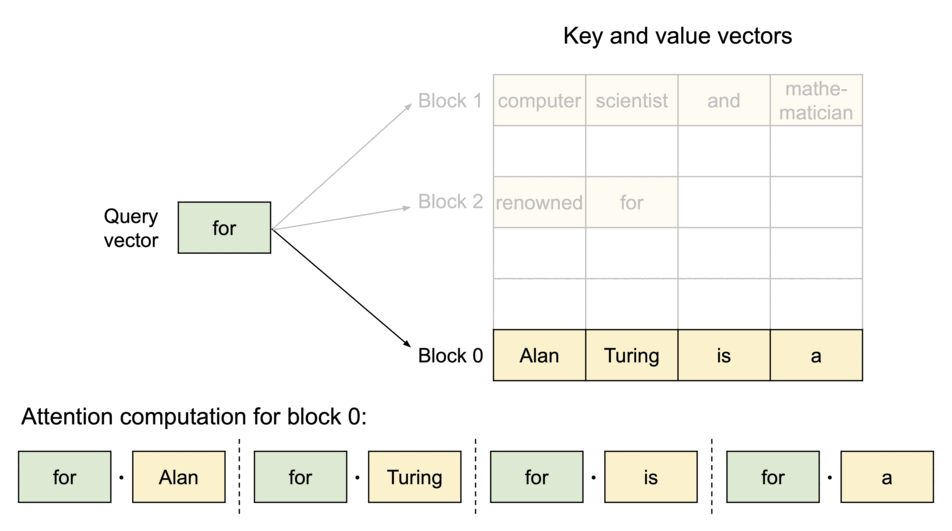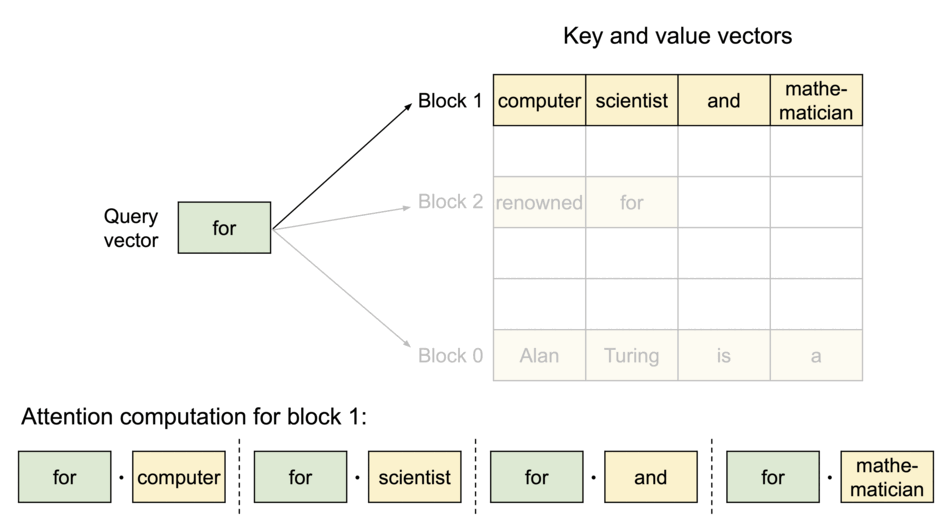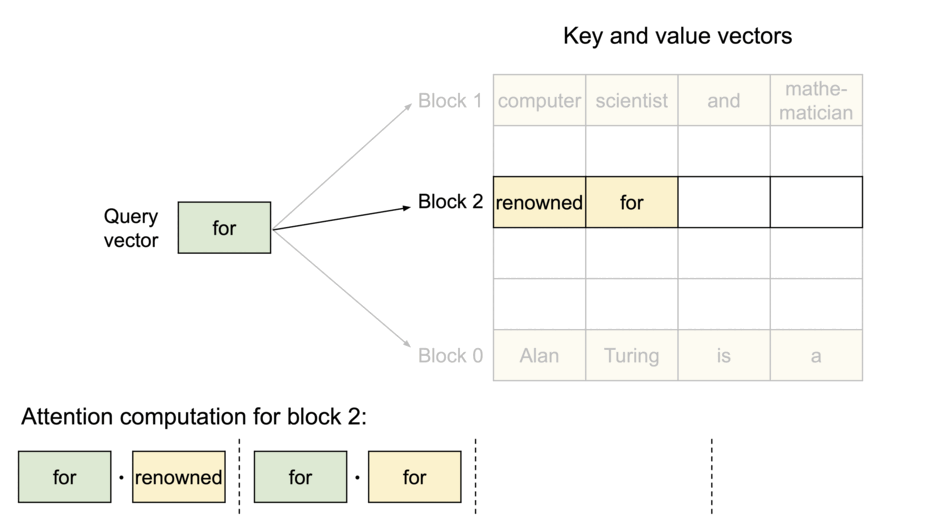
PagedAttention:KV缓存被分成了块。这些块在内存空间中不需要连续。
由于这些块在内存中不需要连续,我们可以像操作系统的虚拟内存那样更加灵活地管理键和值:可以将这些blocks看作pages,token看作byte,sequences看作processes。序列的连续逻辑块通过块表映射到非连续的物理块。随着生成新的标记,物理块会按需进行分配。
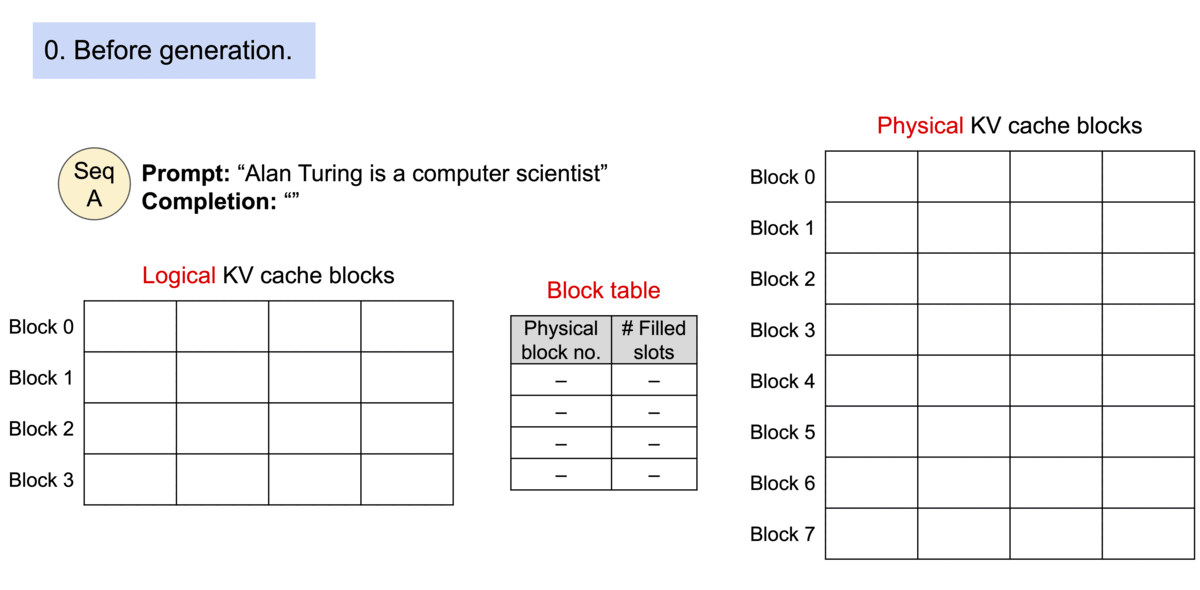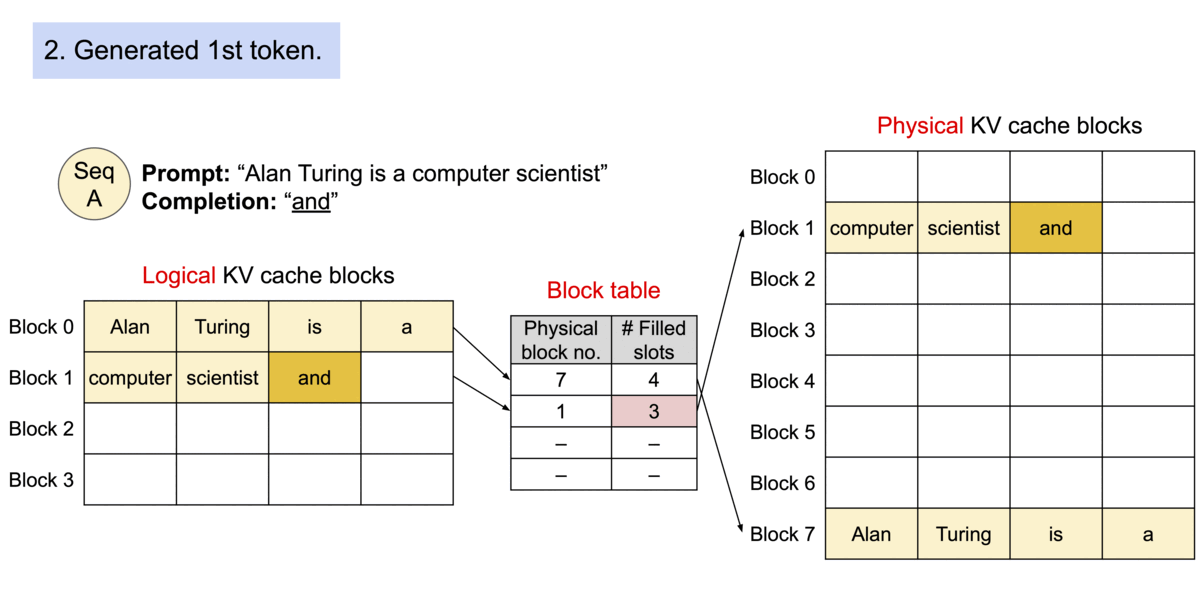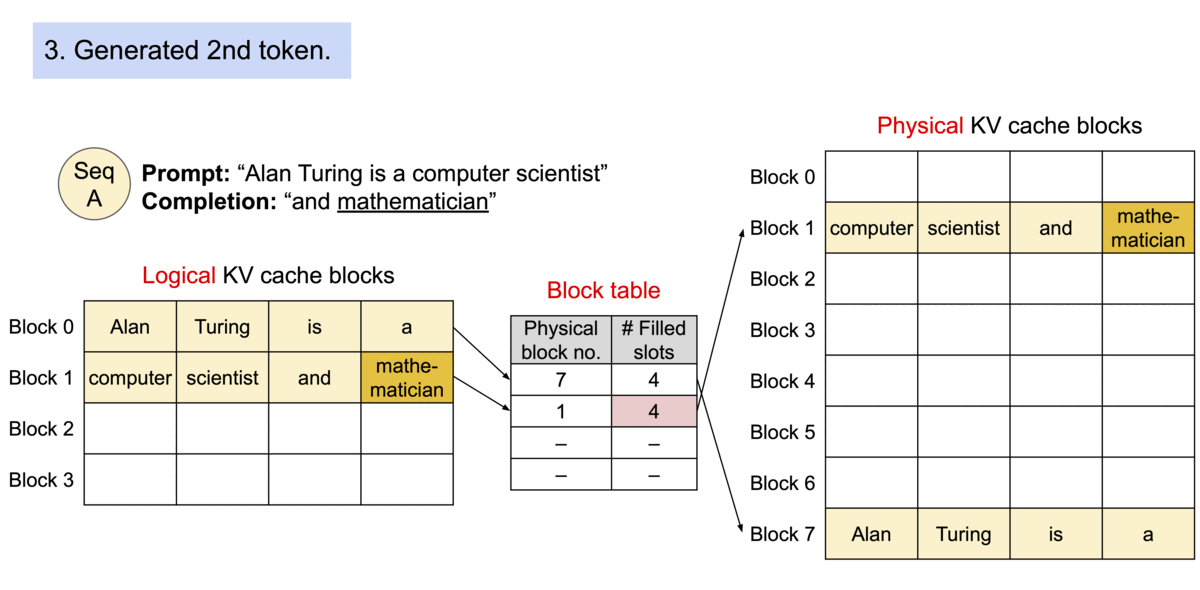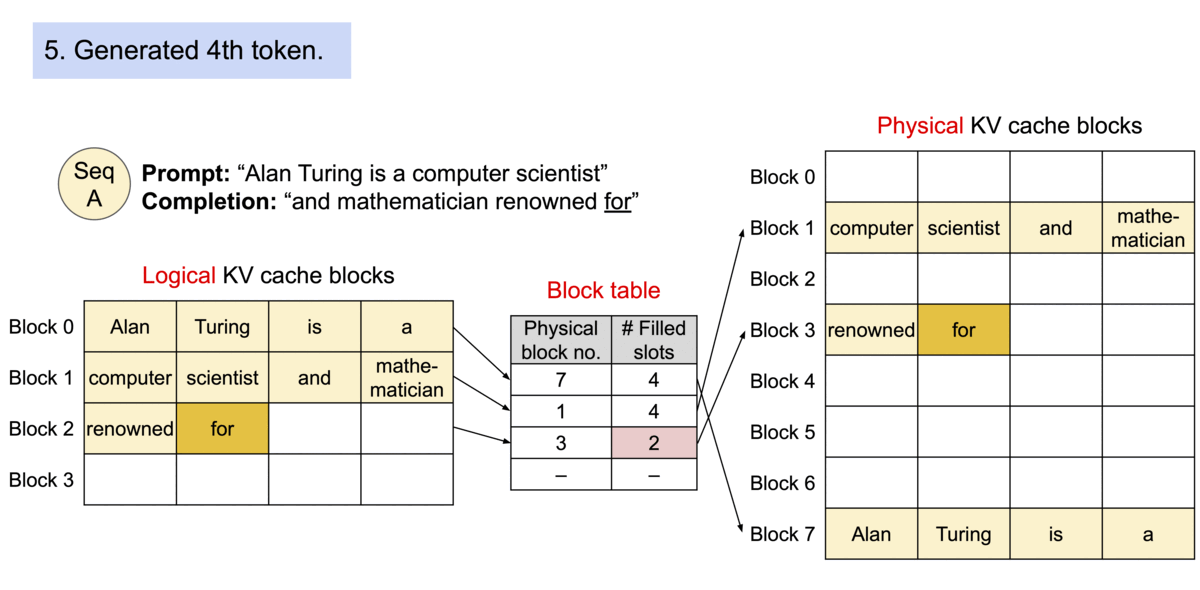
在 PagedAttention 中,内存浪费仅发生在序列的最后一个块中。内存效率的提高非常有益:它允许系统将更多序列一起批处理,提高 GPU 利用率,从而显着提高吞吐量
PagedAttention 还有另一个关键优势:高效的内存共享。例如,在并行采样中,从同一提示生成多个输出序列。
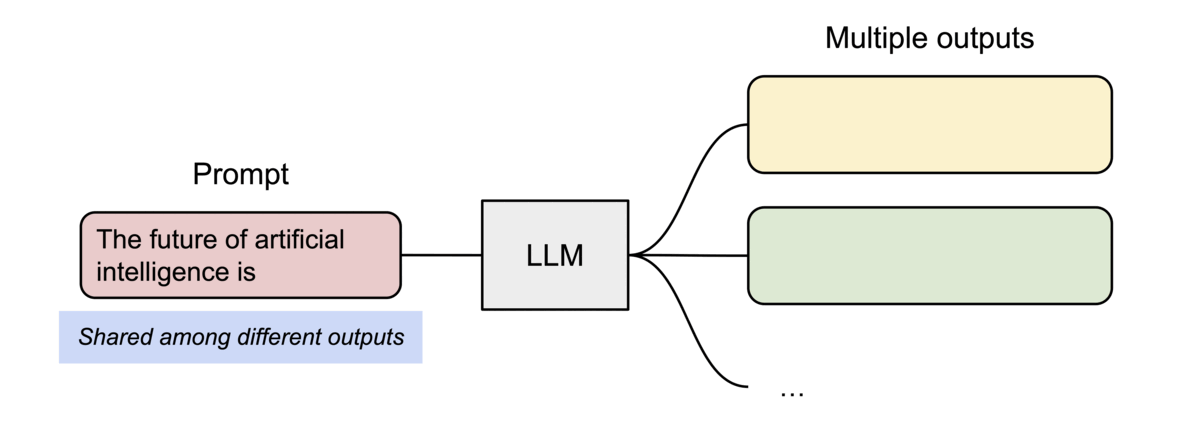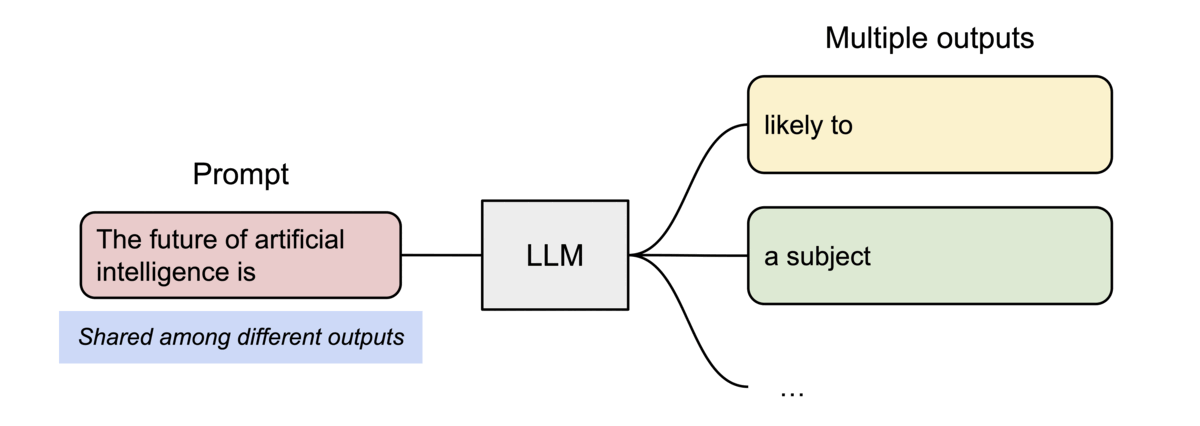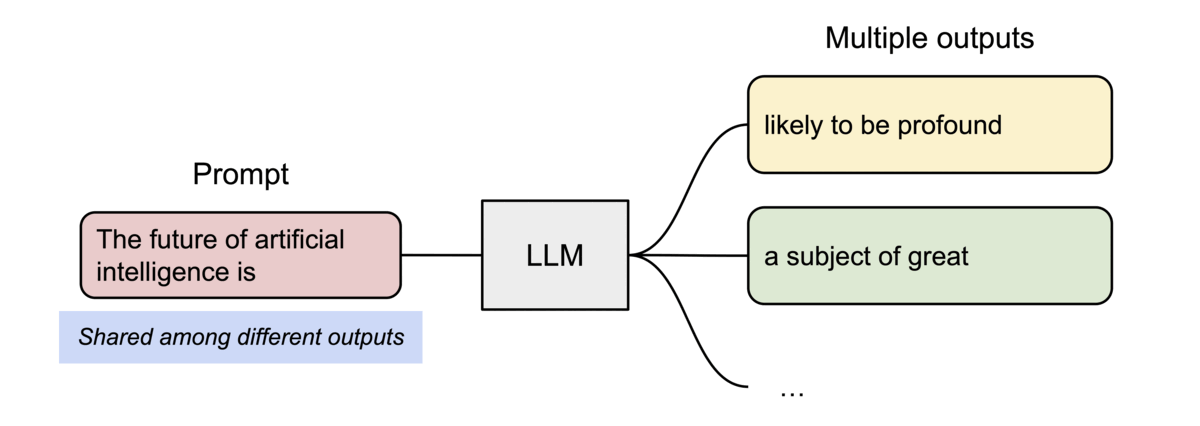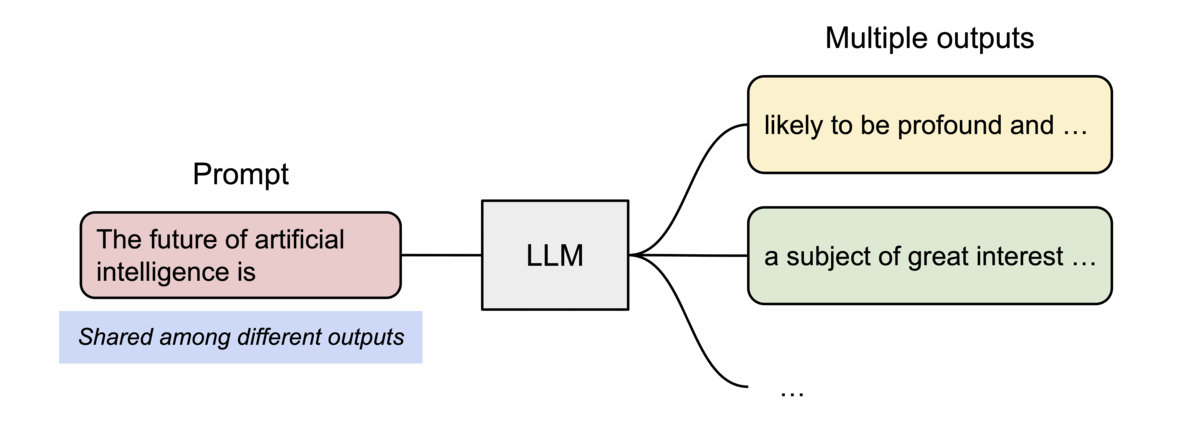
PagedAttention 自然地通过其块表实现内存共享。与进程共享物理页的方式类似,PagedAttention 中的不同序列可以通过将其逻辑块映射到同一物理块来共享块。为了确保安全共享,PagedAttention 跟踪物理块的引用计数并实现Copy-on-Write机制。
调度和抢占
当采用动态分配显存的办法时,虽然明面上同一时刻能处理更多的prompt了,但因为没有为每个prompt预留充足的显存空间,如果在某一时刻整个显存被打满了,而此时所有的prompt都没做完推理,那该怎么办?
当有一堆请求来到vLLM服务器上时,vLLM需要一个调度原则来安排如何执行这些请求,这个调度原则概括如下:
- 先来的请求先被服务(First-Come-First-Serve, FCFS)
- 如有抢占的需要,后来的请求先被抢占(preemption)
- 当一堆请求来到vLLM服务器做推理,导致gpu显存不足时,vLLM会怎么做呢?最直接的办法,就是暂停这堆请求中最后到达的那些请求的推理,同时将它们相关的KV cache从gpu上释放掉,以便为更早到达的请求留出足够的gpu空间,让它们完成推理任务。如果不这样做的话,各个请求间相互争夺gpu资源,最终将导致没有任何一个请求能完成推理任务。等到先来的请求做完了推理,vLLM调度器认为gpu上有足够的空间了,就能恢复那些被中断的请求的执行了。
- 在资源不足的情况下,暂时中断一些任务的执行,这样的举动就被称为“抢占(preemption)”。
终止和恢复被抢占的请求
- 暂停它们的执行,同时将与之相关的KV cache从gpu上释放掉
- 等gpu资源充足时,重新恢复它们的执行
vLLM分别设计了Swapping(交换策略)和Recomputation(重计算策略)来解决。我们来细看这两个策略。
Swapping(交换策略)
- 该释放哪些KV cache
- 由前文PagedAttention原理可知,一个请求可能对应多个block。我们既可以选择释放掉部分block,也可以选择释放掉全部block。在vLLM中,采取的是all-or-nothing策略,即释放被抢占请求的所有block。
- 要把这些KV cache释放到哪里去
- 对于这些被选中要释放的KV block,如果将它们直接丢掉,那未免过于浪费。vLLM采用的做法是将其从gpu上交换(Swap)到cpu上。这样等到gpu显存充份时,再把这些block从cpu上重载回来。
Recomputation(重计算策略)
- 当vLLM调度器任务gpu资源充足时,对于那些被抢占的请求,它会将其卸载到cpu上的KV block重新加载进gpu中,继续完成推理任务。
分布式
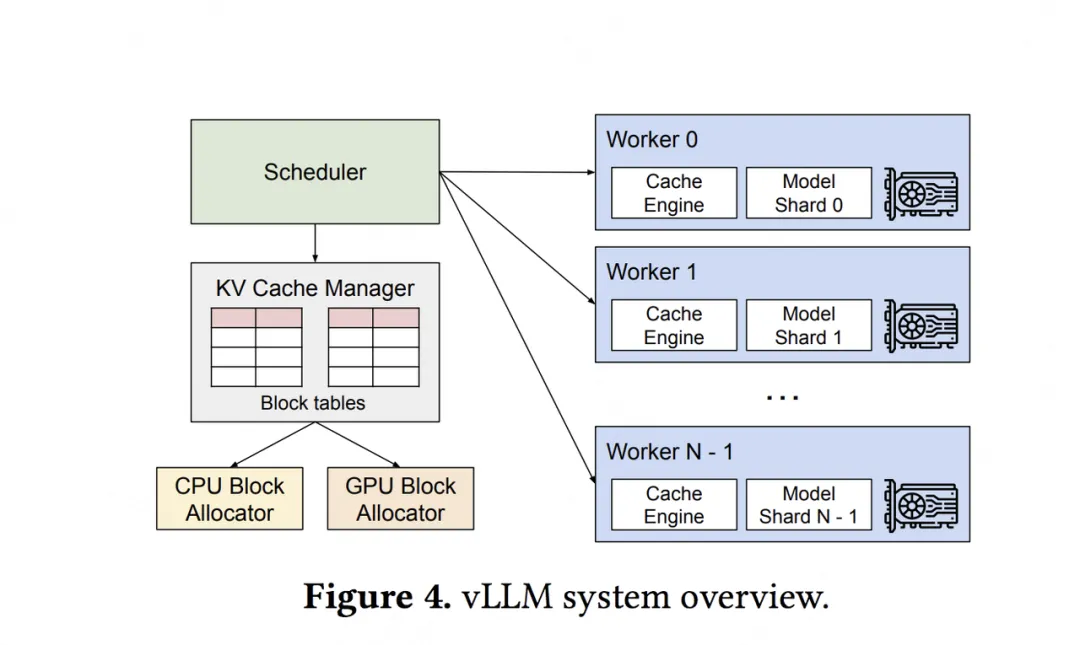
上图显示了在分布式场景下,vLLM的整体运作流程:
- 首先,vLLM有一个中央调度器(Scheduler),它负责计算和管理每张卡上KV cache从逻辑块到物理块的映射表(block tables)
- 在做分布式计算时,Schedular会将映射表广播到各张卡上,每张卡上的Cache engine接收到相关信息后,负责管理各卡上的KV block
上图中给出的例子,是用张量模型并行(megatron-lm)做分布式推理时的情况,所以图中每个worker上写的是model shard。在张量并行中,各卡上的输入数据相同,只是各卡负责计算不同head的KV cache。所以这种情况下,各卡上的逻辑块-物理块的映射关系其实是相同的(用的同一张block table),只是各卡上物理块中实际存储的数据不同而已。
Speculative Decoding
- 在内存受限的 LLM 推理中,GPU 的全部计算能力未得到充分利用。
- 如果我们能找到方法,未使用的计算资源可以被利用。
- 并非每个 token 都需要所有参数进行计算。
适用于小批量
LLM推理阶段
-
预填充阶段。
在这个阶段中,我们把整段prompt喂给模型做forward计算。如果采用KV cache技术,在这个阶段中我们会把prompt过后得到的保存在cache_k和cache_v中。这样在对后面的token计算attention时,我们就不需要对前面的token重复计算了,可以帮助我们节省推理时间。
-
生成response的阶段
在这个阶段中,我们根据prompt的prefill结果,一个token一个token地生成response。同样,如果采用了KV cache,则每走完一个decode过程,我们就把对应response token的KV值存入cache中,以便能加速计算。
由于Decode阶段的是逐一生成token的,因此它不能像prefill阶段那样能做大段prompt的并行计算,所以在LLM推理过程中,Decode阶段的耗时一般是更大的。
从上述过程中,我们可以发现使用KV cache做推理时的一些特点:
- 随着prompt数量变多和序列变长,KV cache也变大,对gpu显存造成压力
- 由于输出的序列长度无法预先知道,所以我们很难提前为KV cache量身定制存储空间
请求处理
在传统离线批处理中,我们每次给模型发送推理请求时,都要:
- 等一个batch的数据齐全后,一起发送
- 整个batch的数据一起做推理
- 等一个batch的数据全部推理完毕后,一起返回推理结果
在vLLM中,当我们使用离线批处理模式时,表面上是在做“同步”推理,也即batch_size是静态固定的。但推理内核引擎(LLMEngine)在实际运作时,batch_size是可以动态变更的:在每一个推理阶段(prefill算1个推理阶段,每个decode各算1个推理阶段)处理的batch size可以根据当下显存的实际使用情况而变动。
- 给定一个很大的batch,此时尽管vLLM采用了PagedAttention这样的显存优化技术,我们的gpu依然无法同时处理这么大的batch。
- 所以batch中的每一条数据,会被先放到一个waiting队列中。vLLM会用自己的调度策略从waiting队列中依次取数,加入running队列中,直到它认为取出的这些数据将会打满它为1个推理阶段分配好的显存。此时waiting队列中可能还会剩一些数据。
- 在每1个推理阶段,vLLM对running队列中的数据做推理。如果这1个推理阶段执行完毕后,有的数据已经完成了生成(比如正常遇到
<eos>了),就将这些完成的数据从running队列中移开,并释放它占据的物理块显存。 - 这时,waiting队列中的数据就可以继续append进running队列中,做下1个阶段的推理。
- 因此在每1个推理阶段,vLLM处理的batch size可能会动态变更。
- 将LLMEngine包装成离线批处理形式后,所有的数据必须等到一起做完推理才能返给我们。
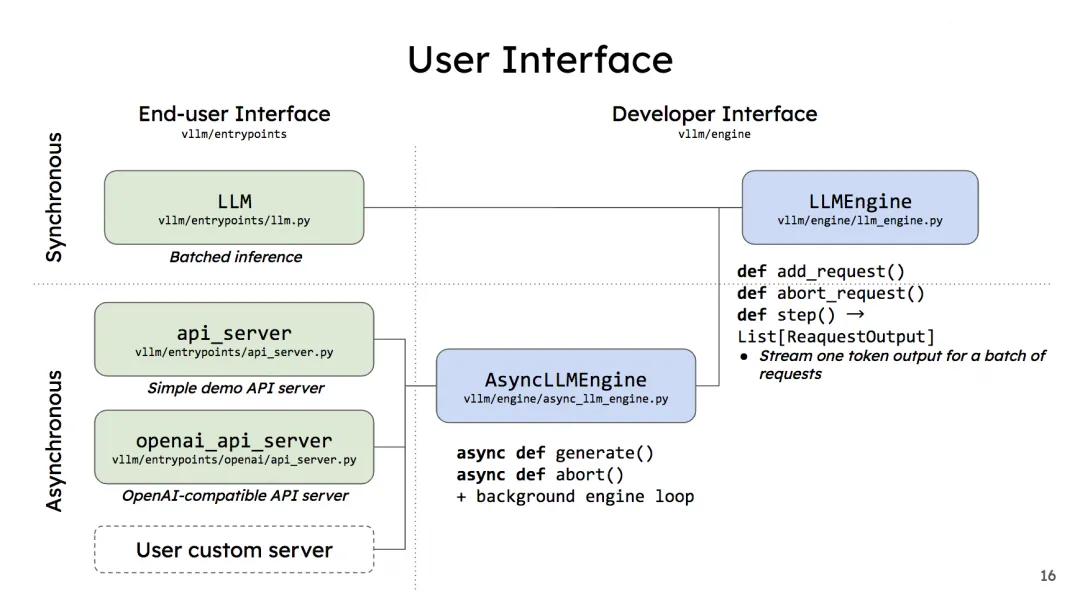
vLLM在实现在线服务时,采用uvicorn部署fastapi app实例,以此实现异步的请求处理。而核心处理逻辑封装在AsyncLLMEngine类中(它继承自LLMEngine)。所以,只要我们搞懂了LLMEngine,对vLLM的这两种调用方式就能举一反三了。
我们来看开发者界面下的几个函数,先来看LLMEngine:
add_request():该方法将每一个请求包装成vLLM能处理的数据类型(SequenceGroup,后面我们会详细解释),并将其加入调度器(Scheduler)的waiting队列中。在LLMEngine中,这个函数是按照“同步”的方式设计的,也就是它被设计为“遍历batch中的每条数据,然后做相应处理”。所以这个函数本身只适合批处理场景。在异步的online serving中将会把它重写成异步的形式。abort_request:在推理过程中,并不是所有的请求都能有返回结果。比如客户端断开连接时,这个请求的推理就可以终止了(abort),这个函数就被用来做这个操作。step():负责执行1次推理过程(1个prefill算1个次推理,每个decode各算1次推理)。在这个函数中,vLLM的调度器会决定要送那些数据去执行本次推理,并负责给这些数据分配好物理块(这些信息都被作为metadata放在要送给模型做推理的数据中)。模型会根据这些信息,采用PagedAttention方法,实际完成推理。
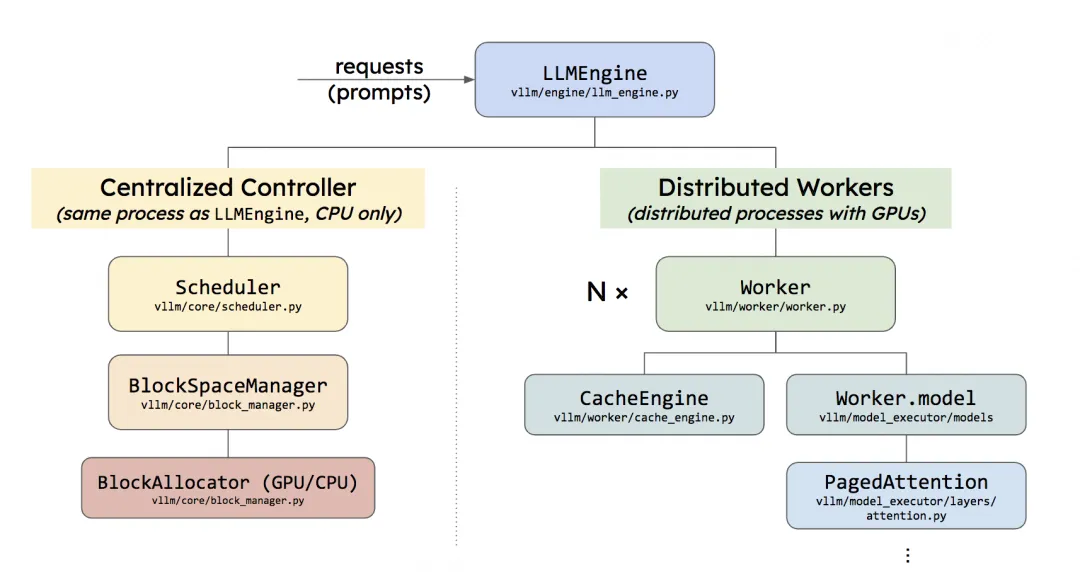
Centralized Controller
它和LLMEngine所在的进程是同一个,且两者都是在CPU上的。
- 调度器Scheduler的主要作用就是,在每1个推理阶段,决定要把哪些数据送给模型做推理,同时负责给这些模型分配KV Cache物理块。但要注意,它只是分配了物理块的id,而不是物理块本身。物理块的实际分配是模型在推理过程中根据物理块id来操作的,也就是CacheEngine做的事情。
- 调度器下维护着BlockSpaceManager。它负责管理BlockAllocator(实际参与分配物理块的类)。BlockAllocator又分成gpu和cpu两种类型,分别管理这两类设备上的物理块。你可能会问,cpu上的物理块是什么呢?你还记得调度器有一个swap策略吗?当gpu上显存不足时,它会把后来的请求抢占,并将其相关的KV cache物理块全部都先swap(置换、卸载)在cpu上,等后续gpu显存充足时,再把它们加载回gpu上继续做相关请求的推理。所以在cpu上我们也需要一个管控物理块的BlockAllocator。
Distributed Workers
你可以将每个worker理解成一块gpu。它的作用是将我们要使用的模型load到各块卡上。
它就是所有Workers的管控中心,它指定了用什么方法管控这些Workers,负责分布式环境的初始化,目前支持的方法有:
-
cpu_executor:(较少用),使用cpu做推理时可考虑
-
gpu_executor:单卡(world_size = 1)的情况下可用
-
ray_gpu_executor:使用ray这个分布式计算框架实现的executor,适用于多卡环境
Worker:在硬件上,它指gpu;在代码上,它指的是Worker实例(每个gpu上的进程维护自己的Worker实例)。在每个Worker实例中又管控着如下两个重要实例:
-
CacheEngine:负责管控gpu/cpu上的KV cache物理块(调度器的block manager只负责物理块id的分配,CacheEngine则是根据这个id分配结果实打实地在管理物理块中的数据)
-
Worker.model:根据vLLM代码,这里写成model_runner会更合适一些。它负责加载模型,并执行推理。调用PagedAttention的相关逻辑,就维护这个实例关联的代码下。
SequenceGroup
为什么要把每个prompt都包装成一个SequenceGroup实例?SequenceGroup又长什么样呢
1 | |
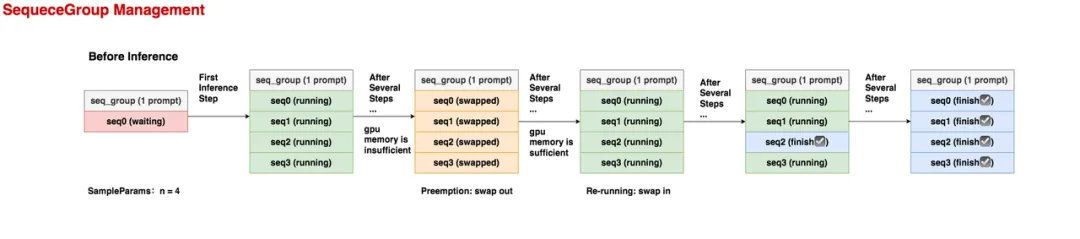
“1个prompt -> 多个outputs“这样的结构组成一个SequenceGroup实例,每组”prompt -> output”组成一个序列(seq,属于Sequence实例)。一个seq_group中的所有seq共享1个prompt
-
在推理开始之前,这个seq_group下只有1条seq,它就是prompt,状态为waiting。
-
在第1个推理阶段,调度器选中了这个seq_group,由于它的采样参数中n = 4,所以在做完prefill之后,它会生成4个seq,它们的状态都是running。
- 在若干个推理阶段后,gpu上的资源不够了,这个seq_group不幸被调度器抢占(preemption),它相关的KV block也被swap out到cpu上。此时所有seq的状态变为swapped。这里要注意,当一个seq_group被抢占时,对它的处理有两种方式:
-
Swap:如果该seq_group下的seq数量 > 1,此时会采取swap策略,即把seq_group下【所有】seq的KV block从gpu上卸载到cpu上。(seq数量比较多,直接把算出的KV block抛弃,比较可惜) -
Recomputation:如果该seq_group下的seq数量 = 1,此时会采取recomputation策略,即把该seq_group相关的物理块都释放掉,然后将它重新放回waiting队列中。等下次它被选中推理时,就是从prefill阶段开始重新推理了,因此被称为“重计算”。(seq数量少,重新计算KV block的成本不高)
-
- 又过了若干个推理阶段,gpu上的资源又充足了,此时执行swap in操作,将卸载到cpu上的KV block重新读到gpu上,继续对该seq_group做推理,此时seq的状态又变为running。
- 又过了若干个推理阶段,该seq_group中有1个seq已经推理完成了,它的状态就被标记为finish,此后这条已经完成的seq将不参与调度。
- 又过了若干个推理阶段,这个seq_group下所有的seq都已经完成推理了,这样就可以把它作为最终output返回了。
逻辑块
对于一个seq,我们重点来看它的属性self.logical_token_blocks(逻辑块)和方法_append_tokens_to_blocks(生成逻辑块的方法)。在vLLM中,每个seq都单独维护一份属于自己的逻辑块,不同的逻辑块可以指向同一个物理块(此刻你一定很关心逻辑块和物理块是如何做映射的,我们会循序渐进地讲解这点,现在你可以先忽略映射方法,把目光聚焦于“一个seq的逻辑块长什么样,怎么初始化它的逻辑块”)
1 | |
Sequence的_append_tokens_to_blocks方法上来:当一个seq只有prompt时,这个方法负责给prompt分配逻辑块;当这个seq开始产出output时,这个方法负责给每一个新生成的token分配逻辑块
1 | |
step 调度器策略
scheduler 概念
所有的seq_group都已经被送入调度器(Scheduler)的waiting队列中了,接下来我们就来看,在1个推理阶段中,调度器是通过什么策略来决定要送哪些seq_group去做推理的
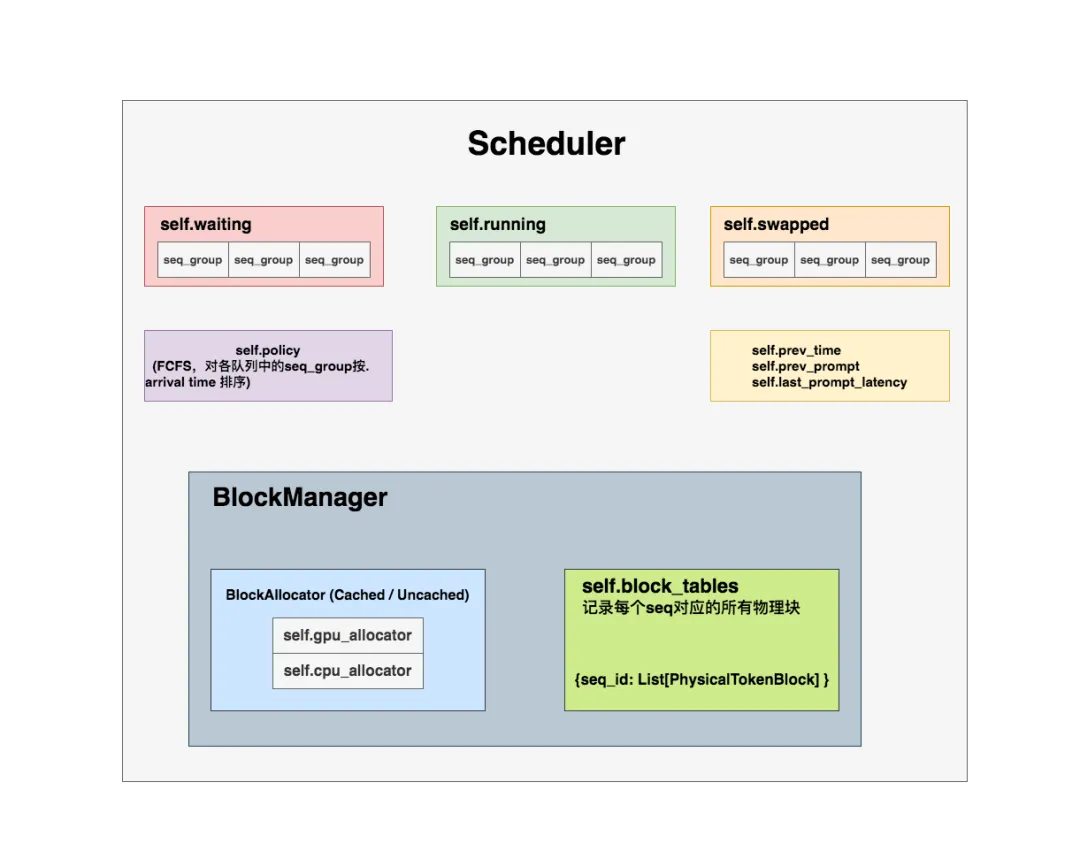
-
self.waiting, self.running, self.swapped这三个都是python的deque()实例(双端队列,允许你从队列两侧添加或删除元素)。
- waiting队列用于存放所有还未开始做推理的seq_group,“未开始”指连prefill阶段都没有经历过。所以waiting队列中的seq_group只有一个seq,即是原始的prompt。
- running队列用于存放当前正在做推理的seq_group。更准确地说,它存放的是上1个推理阶段被送去做推理的seq_group们,在开始新一轮推理阶段时,调度器会根据本轮的筛选结果,更新running队列,即决定本轮要送哪些seq_group去做推理。
- swapped队列用于存放被抢占的seq_group。在2.2节中我们有提过,若一个seq_group被抢占,调度器会对它执行swap或recomputation操作,分别对应着将它送去swapped队列或waiting队列,在后文我们会详细分析抢占处理的代码
self.policy:是vLLM自定义的一个Policy实例,目标是根据调度器总策略(FCFS,First Come First Serve,先来先服务)原则,对各个队列里的seq_group按照其arrival time进行排序。相关代码比较好读,所以这里我们只概述它的作用,后续不再介绍它的代码实现。self.prev_time:上一次调度发起的时间点,初始化为0。我们知道每执行1次推理阶段前,调度器都要做一次调度,这个变量存放的就是上次调度发起的时间点。self.prev_prompt:取值为True/False,初始化为False。若上一次调度时,调度器有从waiting队列中取出seq_group做推理,即为True,否则为False。-
self.last_prompt_latency:记录“当前调度时刻(now) - 最后一次有从waiting队列中取数做推理的那个调度时刻”的差值(并不是每一次调度时,调度器一定都会从waiting队列中取seq_group,它可能依旧继续对running队列中的数据做推理),初始化为0。 -
BlockManager:物理块管理器。这也是vLLM自定义的一个class。截止本文写作时,vLLM提供了BlockSpaceManagerV1和BlockSpaceManagerV2两个版本的块管理器。V1是vLLM默认的版本,V2是改进版本(但还没开发完,例如不支持prefix caching等功能)。所以**本文依然基于BlockSpaceManagerV1进行讲解。物理块管理器这个class下又维护着两个重要属性: -
BlockAllocator:物理块分配者,负责实际为seq做物理块的分配、释放、拷贝等操作。这也是我们后文要解读的对象。其下又分成self.gpu_allocator和self.cpu_allocator两种类型,分别管理gpu和cpu上的物理块。self.block_tables:负责维护每个seq下的物理块列表,本质上它是一个字典,形式如{seq_id: List[PhysicalTokenBlock]}。注意,这里维护者【所有】seq_group下seq的物理块,而不是单独某一个seq的。因为整个调度器都是全局的,其下的BlockManager自然也是全局的。
每个Sequence实例中维护着属于这个seq的逻辑块吗?而我们从self.block_tables中,又能根据seq_id找到这个seq对应的物理块。这就实现了“逻辑块 -> 物理块”的映射。BlockManager就是用来存储逻辑块和物理块映射的,其实它只负责管理和分配物理块,映射关系潜藏在seq中
step 整体调度流程

上图刻画了某次调度步骤中三个队列的情况,再复习一下:
- waiting队列中的数据都没有做过prefill,每个seq_group下只有1个seq(prompt)
- running队列中存放着上一个推理阶段被送去做推理的所有seq_group
- swapped队列中存放着之前调度阶段中被抢占的seq_group
running队列中的seq_group不一定能继续在本次调度中被选中做推理,这是因为gpu上KV cache的使用情况一直在变动,以及waiting队列中持续有新的请求进来的原因。所以调度策略的职责就是要根据这些变动,对送入模型做推理的数据做动态规划。
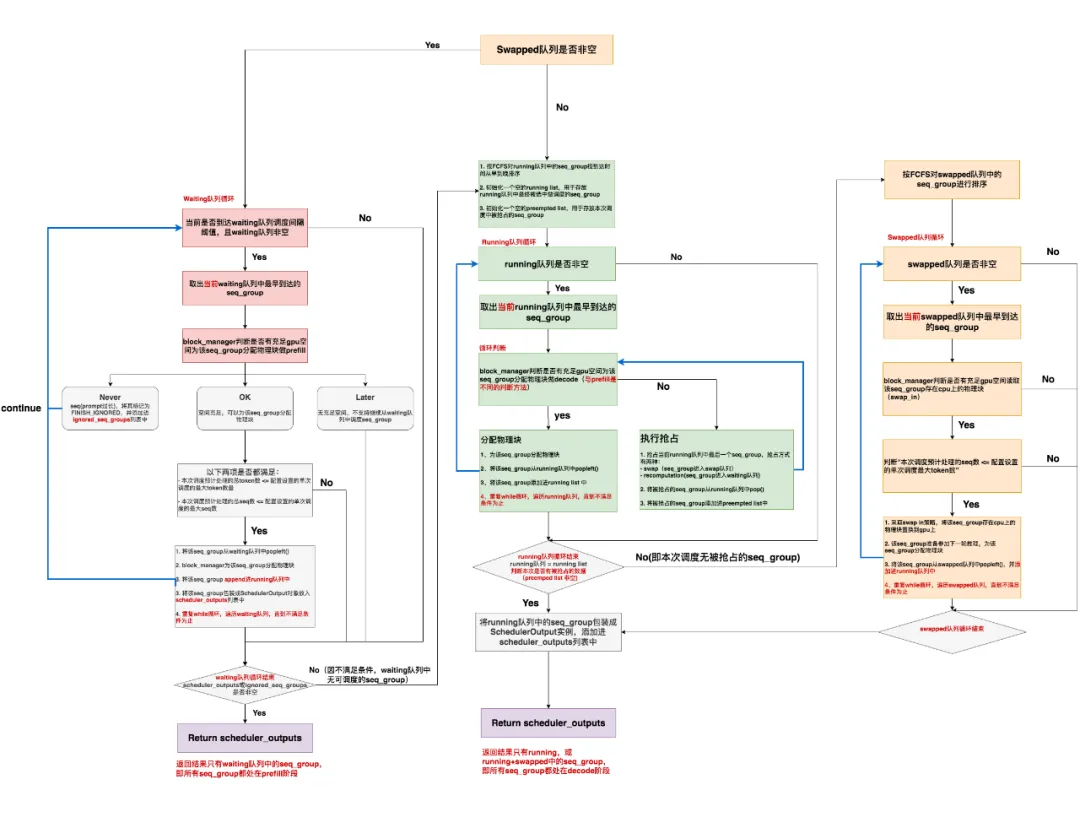
总结来说:
-
如果当前swapped队列为空,那就去检查是否能从waiting队列中调度seq_group,直到不满足调度条件为止(gpu空间不足,或waiting队列已为空等)。此时,1个推理阶段中,所有的seq_group都处在prefill阶段。
-
如果当前swapped队列非空,或者无法从waiting队列中调度任何seq_group时:
-
- 检查是否能从running队列中调度seq_group,直到不满足调度条件为止。
- 若本次无新的被抢占的seq_group,且swapped队列非空,就检查是否能从swapped队列中调度seq_group,直到不满足调度条件为止。
此时,1个推理阶段中,所有的seq_group要么全来自running队列,要么来自running + swapped队列,它们都处在decode阶段。
至此我们要记住vLLM调度中非常重要的一点:\在1个推理阶段中,所有的seq_group要么全部处在prefill阶段。要么全部处在decode阶段。
-
为什么要以swapped是否非空为判断入口呢?
这是因为,如果当前调度步骤中swapped队列非空,说明在之前的调度步骤中这些可怜的seq_group因为资源不足被抢占,而停滞了推理。所以根据FCFS规则,当gpu上有充足资源时,我们应该先考虑它们,而不是考虑waiting队列中新来的那些seq_group。
-
本次调度是否有新的被抢占的seq_group,来决定要不要调度swapped队列中的数据。
在本次调度中,我就是因为考虑到gpu空间不足的风险,才新抢占了一批序列。既然存在这个风险,我就最好不要再去已有的swapped队列中继续调度seq_group了。
-
我们会看到进入waiting循环的判断条件之一是:waiting队列是否达到调度间隔阈值。
我们知道模型在做推理时,waiting队列中是源源不断有seq_group进来的,一旦vLLM选择调度waiting队列,它就会停下对running/swapped中seq_group的decode处理,转而去做waiting中seq_group的prefill,也即vLLM必须在新来的seq_group和已经在做推理的seq_group间取得一种均衡:既不能完全不管新来的请求,也不能耽误正在做推理的请求。所以“waiting队列调度间隔阈值”就是来控制这种均衡的
-
调度间隔设置得太小,每次调度都只关心waiting中的新请求,这样发送旧请求的用户就迟迟得不到反馈结果。且此时waiting队列中积累的新请求数量可能比较少,不利于做batching,浪费了并发处理的能力。
-
调度间隔设置得太大,waiting中的请求持续挤压,同样对vLLM推理的整体吞吐有影响。
-
_passed_delay函数写了阈值判断的相关逻辑
-
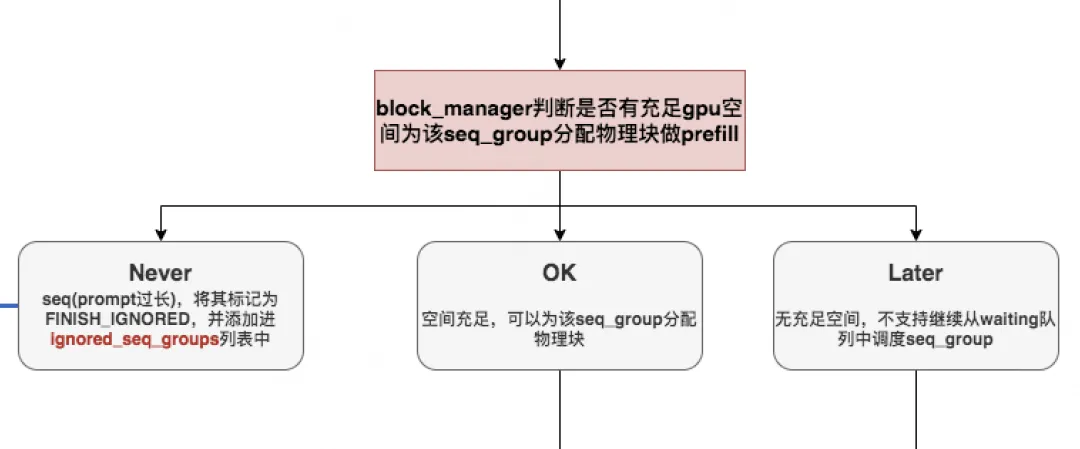
-
can_allocate:能否为seq_group分配物理块做prefill
通过了调度时间阈值的判断条件,现在我们顺利从waiting中取出一个seq_group,我们将对它进行prefill操作。所以这里我们必须先判断:gpu上是否有充足的空间为该seq_group分配物理块做prefill,这个操作当然是由我们的
can_allocate = self.block_manager.can_allocate来做。在vLLM中,gpu_allocator的类型有两种:
-
CachedBlockAllocator:按照prefix caching的思想来分配和管理物理块。在原理篇中,我们提过又些prompts中可能含有类似system message(例如,“假设你是一个能提供帮助的行车导航”)E)等prefix信息,带有这些相同prefix信息的prompt完全可以共享用于存放prefix的物理块,这样既节省显存,也不用再对prefix做推理。 -
UncachedBlockAllocator:正常分配和管理物理块,没有额外实现prefix caching的功能
-
-
can_append_slot:能否为seq_group分配物理块做decode
从running队列中调度seq_group时,我们也会判断是否能为该seq_group分配物理块。但这时,我们的物理块空间是用来做decode的(给每个seq分配1个token的位置),而不是用来做prefill的(给每个seq分配若干个token的位置),所以这里我们采取的是另一种判断方法
can_append_slot。running队列中seq_group下的n个seqs在上1个推理阶段共生成了n个token。在本次调度中,我们要先为这n个token分配物理块空间,用于存放它们在本次调度中即将产生的KV值。好,我们再回到这个seq_group的n个seqs上来,我们知道:
-
当往1个seq的物理块上添加1个token时,可能有两种情况:
-
- 之前的物理块满了,所以我新开1个物理块给它
- 之前的物理块没满,我直接添加在最后一个物理块的空槽位上
- 所以,对于1个seq来说,最坏的情况就是添加1个物理块;对于n个seqs来说,最坏的情况就是添加n个物理块(想想原理篇中讲过的copy-on-write机制)
- 对于1个seq_group,除了那些标记为“finish”的seq外,其余seqs要么一起送去推理,要么一起不送去推理。即它们是集体行动的
所以,判断能否对一个正在running的seq_group继续做推理的最保守的方式,就是判断当前可用的物理块数量是否至少为n。
-
preempt:抢占策略
在若干个推理阶段后,gpu上的资源不够了,这个seq_group不幸被调度器抢占(preemption),它相关的KV block也被swap out到cpu上。此时所有seq的状态变为swapped。这里要注意,当一个seq_group被抢占时,对它的处理有两种方式
- Swap:如果该seq_group剩余生命周期中并行运行的最大seq数量 > 1,此时会采取swap策略,即把seq_group下【所有】seq的KV block从gpu上卸载到cpu上。(seq数量比较多,直接把算出的KV block抛弃,比较可惜)
- Recomputation:如果该seq_group剩余生命周期中并行运行的最大seq数量 = 1,此时会采取recomputation策略,即把该seq_group相关的物理块都释放掉,然后将它重新放回waiting队列中(放在最前面)。等下次它被选中推理时,就是从prefill阶段开始重新推理了,因此被称为“重计算”。(seq数量少,重新计算KV block的成本不高)
总结
vLLM对输入数据做预处理
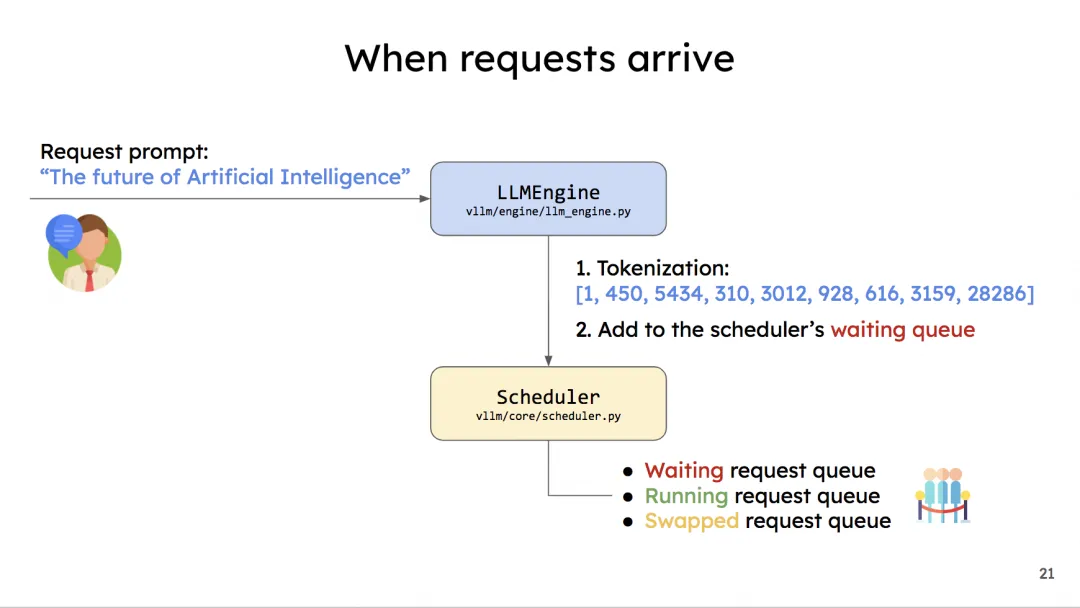
- 在vLLM内部计算逻辑中,1个prompt是1个request
- 每个prompt将被包装成一个SequenceGroup实例提供给调度器做调度
- 1个SequenceGroup实例下维护着若干个Sequence实例,对应着“1个prompt -> 多个outputs”这种更一般性的解码场景。
- 1个Sequence实例下维护着属于自己的逻辑块列表,数据类型为List[LogicalTokenBlock]
vLLM最重要的推理内核引擎是LLMEngine
- LLMEngine下有两个最重要的方法:add_request()和step()
- add_request()负责将每个prompt都包装成一个SequenceGroup对象,送入调度器的waiting队列中等待调度
- step()负责执行1次推理过程,在这个过程中,调度器首先决定哪些seq_group可以被送去推理,然后model_executor负责实际执行推理。
- 在LLMEngine开始处理请求前(实例化阶段),它会先做一次模拟实验,来估计gpu上需要预留多少显存给KV Cache block。
- 当LLMEngine开始处理请求时(add_request),它会把每个prompt当成一个请求,同时把它包装成一个SequenceGroup对象。
- 当LLMEngine开始执行1次调度时(step),调度器策略(Scheduler)会根据实际gpu上KV Cache block的使用情况等要素,来选择要送哪些seq_group去做新一轮推理。注意,在1次推理中,所有seq_group要么一起做prefill,要么一起做decode。
加载模型与预分配显存
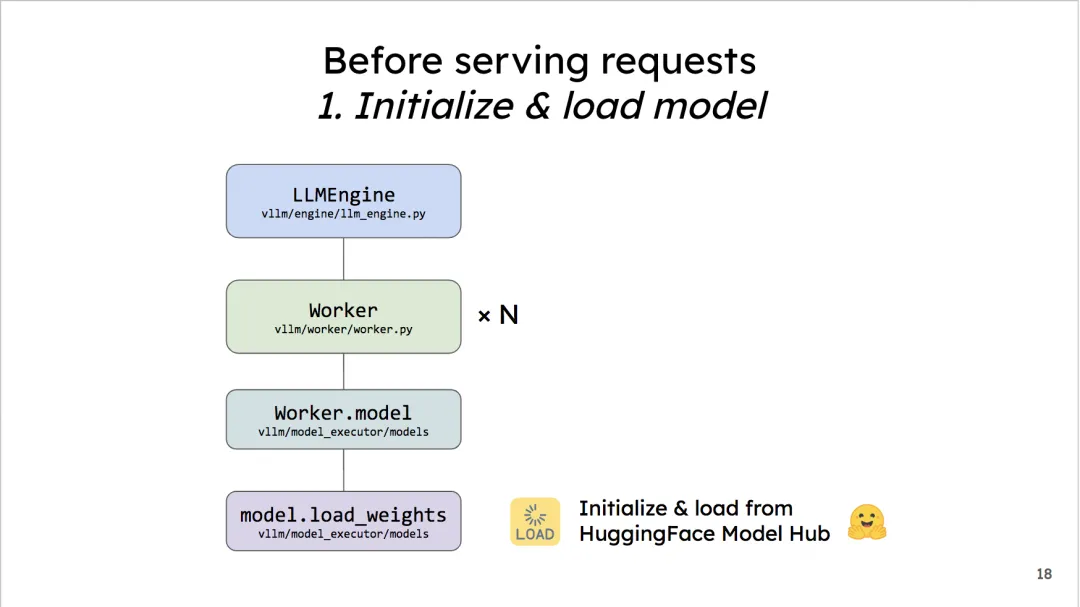
在vLLM正式开始处理1条请求(也就是LLMEngine的调度器正式开始运作时),它需要做两件和初始化相关的事:
-
加载模型
把你的base model加载到worker上。如果你是online加载的,vLLM默认使用HuggingFace,你也可以在环境变量中把相关配置改成ModelScope。
-
预分配显存
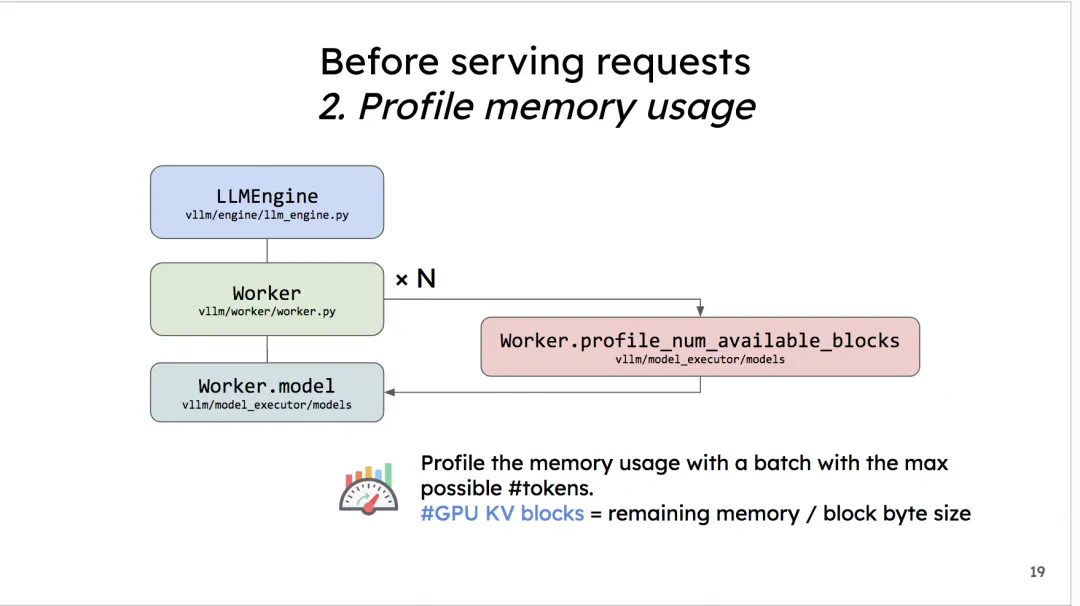
在模型部署的初始化阶段(推理正式开始前),vLLM会通过模拟实验的方式,来决定gpu/cpu上到底有多少个KV cache物理块可以分配给后续的请求们做推理。
vLLM管这个步骤叫
profile_num_available_blocks。我们来看看这个模拟实验是怎么做的:-
杜撰假数据
用户在初始化LLMEngine引擎时,会提供两个重要参数
max_num_seqs:在1个推理阶段中,LLMEngine最多能处理的seq数量(1条seq就是指我们待推理的1条数据)。默认是256max_num_batched_tokens:在1个推理阶段中,LLMEngine最多能处理的token数量。默认是2048
根据这两个参数,我们可以假设在模型推理中,平均一个seq要处理
max_num_batched_tokens // max_num_seqs个token,余数部分我们默认放在第一个seq中。例如,假设max_num_batched_tokens=10,max_num_seqs = 3,那么我们就能杜撰出3条seq,每个seq的长度分别为4,3,3 -
用假数据模拟一次前向推理
我们现在想知道在1次推理过程中,可以分配多少的显存给KV cache。我们可以使用如下公式计算:
分配给KV cache显存 = gpu总显存 - 不使用KV cache情况下做1次FWD时的显存占用(包括模型本身和FWD过程中的中间数据)
对于“不使用KV cache做1次FWD时的显存占用”,我们就可以用杜撰出来的假数据模拟一次FWD来计算得出。在前向推理之后,我们把gpu上的缓存清一次,让它不要影响后续模型的正常推理。
-
计算可分配的KV cache物理块总数
从模拟实验中,我们已经预估了一块卡上“分配给KV Cache的总显存”。现在,我们可以来计算总的物理块数量了。
我们易知:总物理块数量 = 分配给KV Cache的显存大小/ 物理块大小,其中“大小”的单位是bytes。
物理块大小(block_size)也是可以由用户自定义的,vLLM推荐的默认值是block_size = 16。
由大模型中KV值的定义,我们易知:
K_cache_block_size = block_size * num_heads * head_size * num_layers * dtype_size其中dtype_size表示精度对应的大小,例如fp16就是2,fp32就是4同理可知:
V_cache_block_size = K_cache_block_size则最终一个物理块的大小为:
1
cache_block_size = block_size * num_heads * head_size * num_layers * dtype_size * 2知道了物理块的大小,我们就能求出物理块的总数了。
CPU上物理块总数也是同理,但与GPU不同的是,它不需要做模拟实验。CPU上可用的内存总数是用户通过参数传进来的(默认是4G)。也就是我们认为只能在这4G的空间上做swap。将上面公式中“分配给KV Cache的显存大小”替换成4G,就能得到CPU上物理块的数量。
-
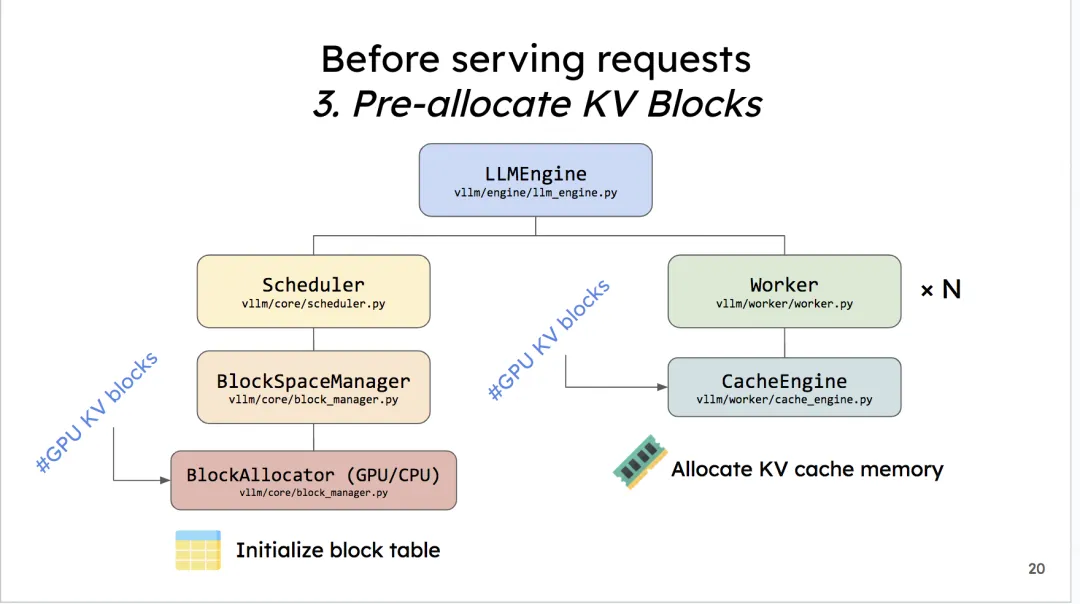
将预分配的KV Cache加载到gpu上
当我们确定好KV Cache block的大小后,我们就可以创建empty tensor,将其先放置到gpu上,实现显存的预分配。以后这块显存就是专门用来做KV Cache的了。也正是因为这种预分配,你可能会发现在vLLM初始化后,显存的占用比你预想地要多(高过模型大小),这就是预分配起的作用。相关代码如下(帮助大家更好看一下KV cache tensor的shape)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20def _allocate_kv_cache( self, num_blocks: int, device: str, ) -> List[torch.Tensor]: """Allocates KV cache on the specified device.""" kv_cache_shape = self.attn_backend.get_kv_cache_shape( num_blocks, self.block_size, self.num_heads, self.head_size) pin_memory = is_pin_memory_available() if device == "cpu" else False kv_cache: List[torch.Tensor] = [] # ======================================================================= # kv_cache_shape: (2, num_blocks, block_size * num_kv_heads * head_size) # ======================================================================= for _ in range(self.num_layers): kv_cache.append( torch.empty(kv_cache_shape, dtype=self.dtype, pin_memory=pin_memory, device=device)) return kv_cache整个预分配的过程,其实也是在提醒我们:当你发现vLLM推理吞吐量可能不及预期,或者出现难以解释的bug时,可以先查查输出日志中pending(waiting)/running/swapped的序列数量,以及此时KV Cache部分的显存利用程度,尝试分析下这些默认的预分配设置是不是很好契合你的推理场景,如果不行,可以先尝试调整这些参数进行解决。
-
Scheduler调度
vLLM所有初始化的工作都完成了,我们现在可以来处理一条请求了。这就是我们调度器发挥作用的时候了,整个调度过程如下
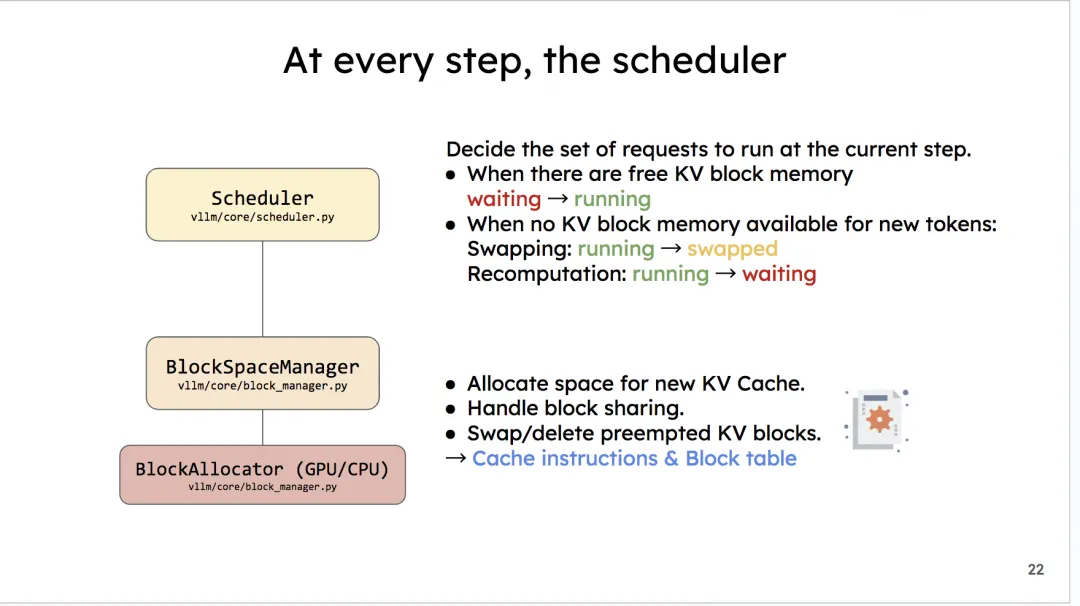
你会发现这出现了叫swapped的队列,这是前文没有提过的。
vLLM的调度策略中有一项叫做:后来先抢占(Preemption)。它是指在准备执行当前这1个推理阶段时,如果gpu上没有足够的资源对running队列中的全部数据完成下1次推理,我们就取出running队列中最后来的数据,将它的KV Cache swapped到CPU上,同时将这个数据从running移到swapped中。我们重复执行这个步骤,直到当前gpu上有足够的KV Cache空间留给剩在running中的全部数据为止。
而存放在Swapped队列中的数据,也会在后续gpu上有足够空间时,被重新加入running计算。
详细的调度策略会更精细复杂,我们放在对Scheduler单独的代码解析中来说。
块管理器 BlockManager
关于逻辑块,它是Sequence实例(seq)下维护的一个属性。我们也提过,在vLLM代码实现中:
BlockManager这个class下又维护着两个重要属性:
BlockAllocator:物理块分配者,负责实际为seq做物理块的分配、释放、拷贝等操作。其下又分成self.gpu_allocator和self.cpu_allocator两种类型,分别管理gpu和cpu上的物理块。self.block_tables:负责维护每个seq下的物理块列表,本质上它是一个字典,形式如{seq_id: List[PhysicalTokenBlock]}。注意,这个字典维护着所有seq_group下seq的物理块,而不是单独某一个seq的。因为调度器是全局的,所以它下面的的BlockManager自然也是全局的。
通过seq这个中介,我们维护起“逻辑块->物理块”的映射。
BlockAllocator又分成两种类型
-
CachedBlockAllocator
按照prefix caching的思想来分配和管理物理块:
- 在prefill阶段,prompts中可能含有类似system message(例如,“假设你是一个能提供帮助的行车导航”)等prefix信息,带有这些相同prefix信息的prompt完全可以共享物理块,实现节省显存、减少重复计算的目的。
- 在decode阶段,我们依然可以用这种prefix的思想,及时发现可以重复利用的物理块。
-
UncachedBlockAllocator :正常分配和管理物理块,没有额外实现prefix caching的功能
为waiting队列中的seq_group分配prefill需要的物理块
- waiting队列中的每个seq_group都还未经历过prefill阶段,因此每个seq_group下只有1个seq,这个seq即为prompt
- 在使用
UncachedBlockAllocator为wating队列中的某个seq_group分配物理块时,我们就是在对初始的这个prompt分配物理块。所以这个prompt有多少个逻辑块,我们就分配多少个可用的空闲物理块,同时注意更新物理块的ref_count。 - 你一定发现了,这里我们做的只是给定一种“物理块的分配方案”,我们只是在制定这个seq_group可以使用哪些物理块,但并没有实际往物理块中添加数据!“添加数据”这一步留到这1步推理实际开始时,由CacheEngine按照这个方案,往物理块中实际添加KV Cache。这个我们留在再后面的系列讲解。
为running/swapped队列中的seq_group分配decode需要的物理块
- 调用
self.block_manager.can_append_slot(seq_group)方法,判断是否至少能为这个seq_group下的每个seq都分配1个空闲物理块。如果可以则认为能调度这个seq_group - 调用
self._append_slot(seq_group, blocks_to_copy)方法,实际分配物理块。