Triton镜像裁剪
完整的nvcr.io/nvidia/tritonserver:24.09-py3镜像大概有16.9GB,非常大。参考官方自定义triton文档
1 | |
需要到的镜像
1 | |
backend 参数可以参考完整镜像里面的/opt/tritonserver/backends/* ,只保留onnxruntime、python、tensorrt
1 | |
会生成Dockerfile.compose文件,由于网络原因,和其他优化之类,对Dockerfile文件修改
1 | |
得到的镜像是12.2GB
调试trip
1 | |
1 | |
warm up
Performance Discrepancy Between Triton Client SDK and perf_analyzer
使用triton async grpc client 基本在客户端和server端交互上,使用内存/显存共享,和gzip 压缩,非常耗时。使用python c api 也耗时在处理返回的地方。直接用
交互优化
服务器配置
| 配置项 | 值 | 描述 |
|---|---|---|
| server_id | triton | 服务器的标识符 |
| server_version | 2.50.0 | Triton Server 的版本号 |
| model_control_mode | MODE_EXPLICIT | 模型控制模式,显式模式下,模型需要通过 API 加载/卸载 |
| pinned_memory_pool_byte_size | 268435456 (256 MB) | 固定内存池的大小,用于加速模型推理 |
| cuda_memory_pool_byte_size{0} | 67108864 (64 MB) | GPU 0 的 CUDA 内存池大小 |
KeepAlive 配置
| 配置项 | 值 | 描述 |
|---|---|---|
| keepalive_time_ms | 7200000 (2小时) | 发送 KeepAlive PING 包的间隔时间(毫秒) |
| keepalive_timeout_ms | 20000 (20秒) | 等待 PING ACK 返回的超时时间(毫秒) |
| keepalive_permit_without_calls | 0 | 是否允许空闲连接发送 PING 请求 |
| http2_max_pings_without_data | 2 | 在发送数据之前允许发送的最大 PING 数量 |
| http2_min_recv_ping_interval_without_data_ms | 300000 (5分钟) | 服务端要求的 PING 接收最小间隔时间 |
| http2_max_ping_strikes | 2 | 超过此数量的无效 PING 后将关闭连接 |
使用aio grpc client,压缩算法,复用client,优化grpc配置,
pinned_memory_pool_byte_size
Pinned memory 是指一种特殊类型的内存,它使得 CPU 和 GPU 之间的数据传输更高效。使用 pinned memory 可以加快 GPU 访问 CPU 内存的速度,减少数据传输的延迟。确保了该内存始终驻留在物理内存中,而不是内存分页并交换到磁盘上。
高设置的优缺点
- 优点:
- 提高数据传输速度:增加 pinned memory 的大小可以提高 CPU 和 GPU 之间数据传输的速度,因为更多的数据可以在高速内存处理。
- 降低传输延迟:有助于减少因频繁数据传输而产生的延迟。
- 缺点:
- 占用更多内存:较大的 pinned memory pool 会占用系统的物理内存,这可能会影响其他应用程序或服务的可用内存。
- 可能导致内存不足:如果系统的物理内存有限,设置过高可能导致内存分配失败或降低整体系统性能。
cuda_memory_pool_byte_size
CUDA memory pool 是用于管理 GPU 内存的一种机制,通过预分配内存块来提高内存使用效率,减少内存分配和释放的开销。
高设置的优缺点
- 优点:
- 减少分配延迟:较大的 CUDA 内存池可以减少在推理期间的内存分配延迟,特别是在高并发请求的情况下。
- 提高吞吐量:有助于在多个推理请求之间高效地重用 GPU 内存,提高整体处理能力。
- 缺点:
- 占用 GPU 内存:设置过高的 CUDA 内存池会占用 GPU 内存,可能导致其他模型的内存不足。
- 可能引起内存碎片:如果请求大小不均,可能导致 GPU 内存的碎片化。
低设置的优缺点
- 优点:
- 节省 GPU 内存:较小的 CUDA memory pool 会释放 GPU 内存,留给其他模型或任务。
- 缺点:
- 增加分配开销:频繁的内存分配和释放可能导致性能下降,特别是在处理高并发请求时。
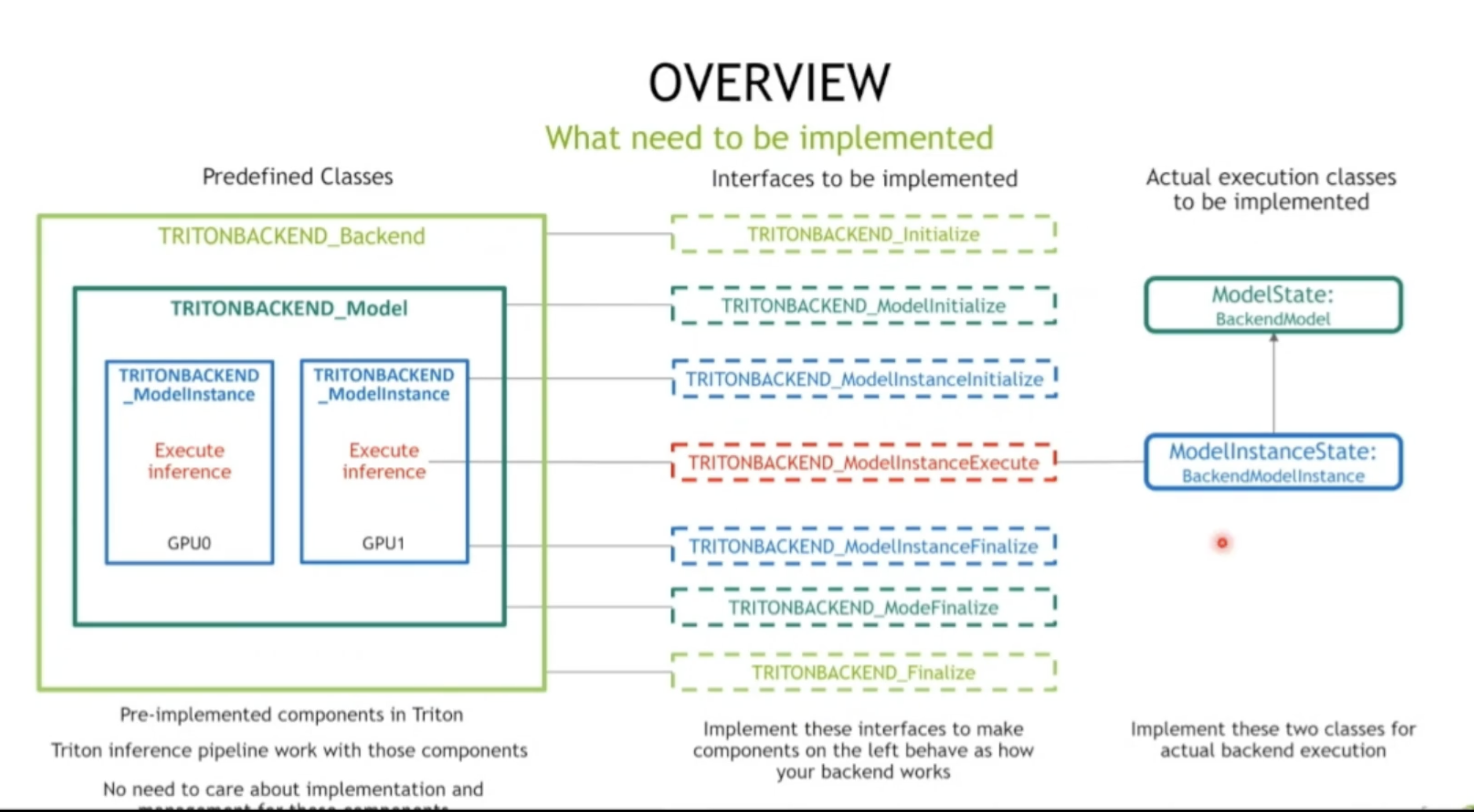
自定义backend
when
- 需要运行Triton不支持的自研框架;
- 需要运行预处理、后处理,还有一些深度学习框架不支持的操作
how
- 三个虚拟类;
-
backend : tensorflow , pytorch 之类
-
model: cnn , 之类
-
不同模型的实例
-
-
七个接口函数 实现这几个接口
- 两个状态类; 真正和执行推理相关 主要功能
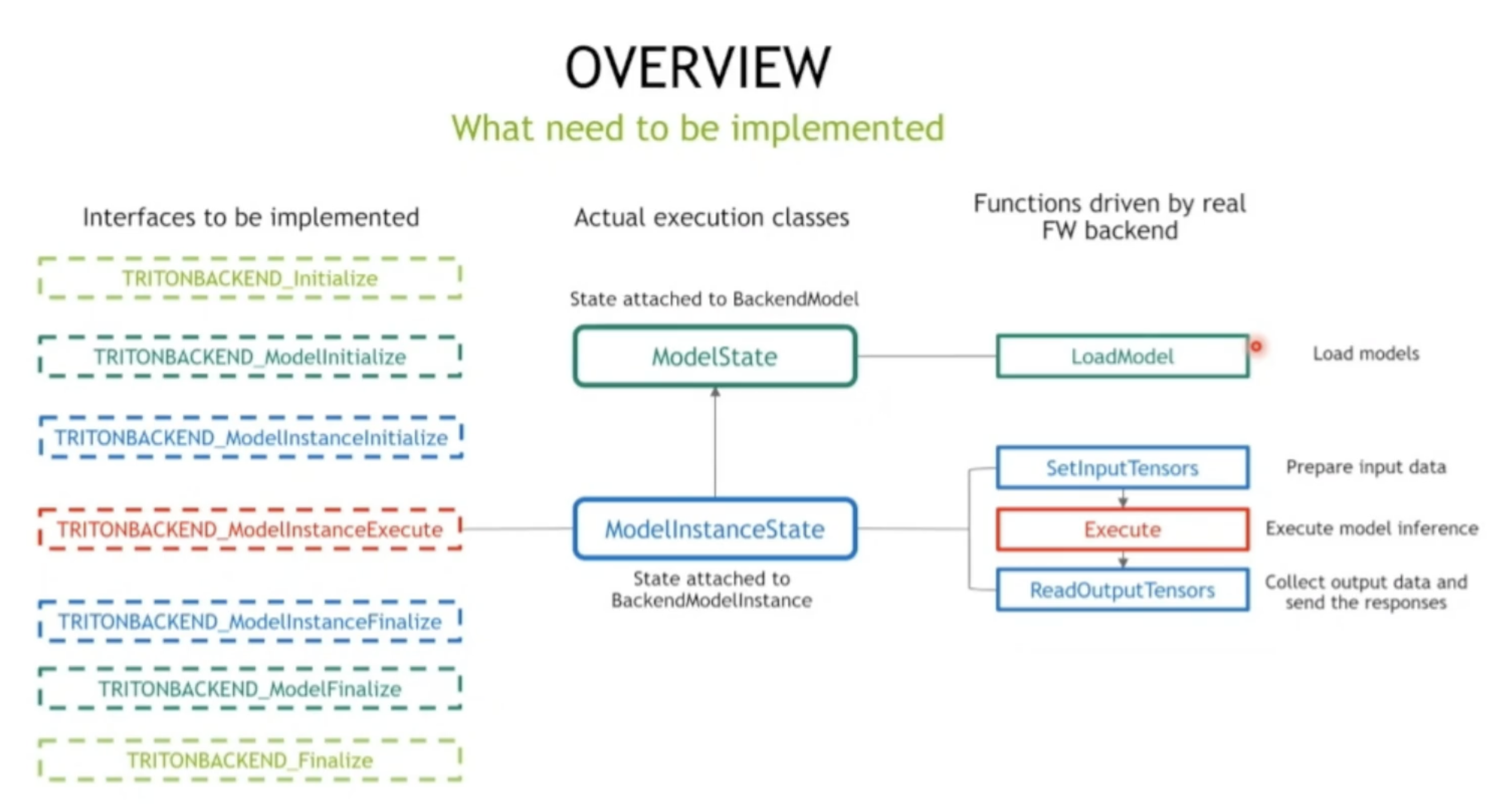
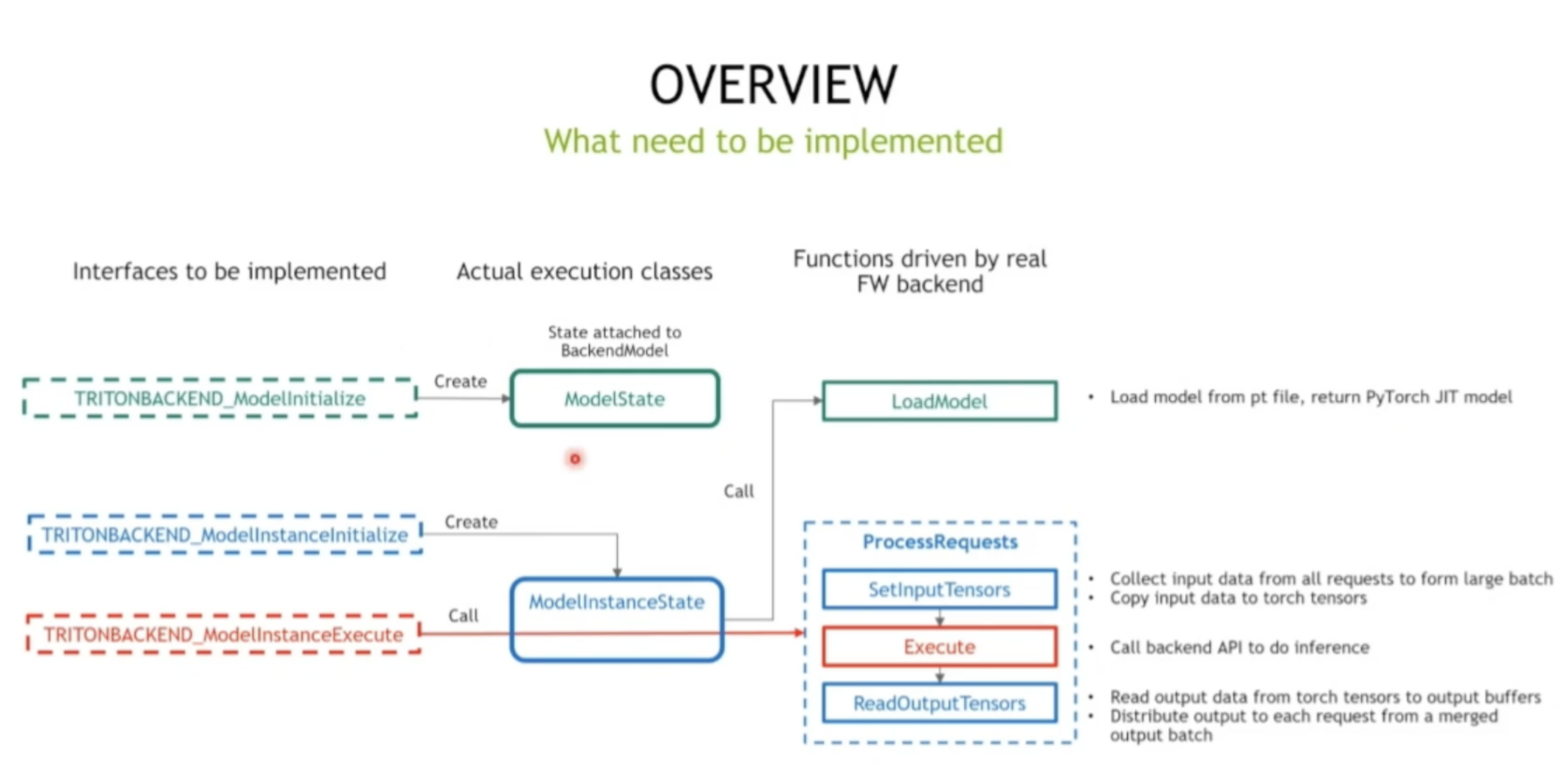
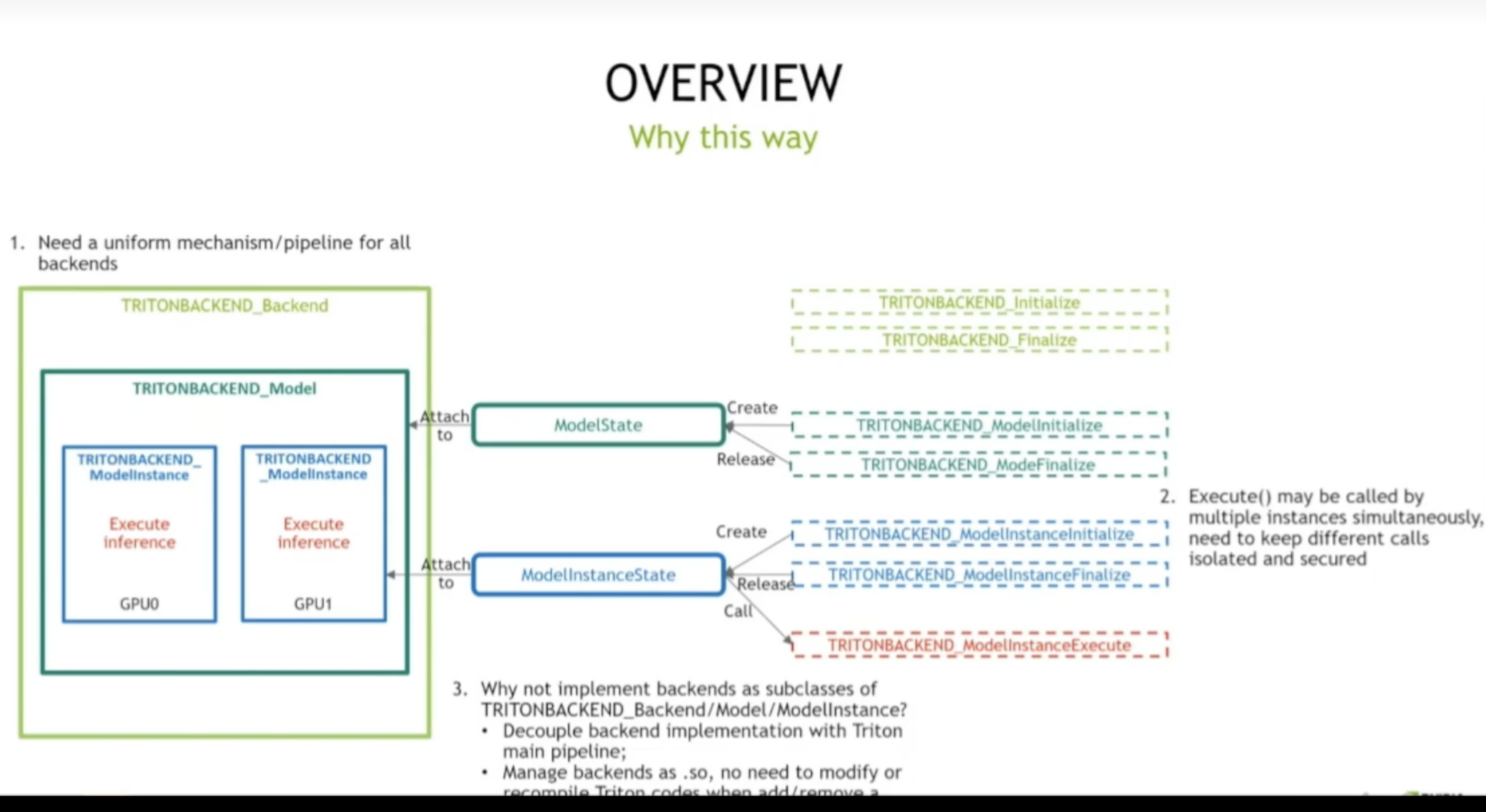
可以很好解耦 拓展功能,不用重新编译整个triton
Python backend
为什么我们需要 Python backend
- 预处理、后处理一般用python
- 已经用python写好的处理单元,需要放Triton上去
- 比C++的更容易实现,无需编译

Python backend(C++)为其实是个agent,Python model(Python)才是真正需要实现的东西,由进程进行管理。两者通过共享内存进行通信;
通信:
- Health flag:标志Python stub process是否是否健康;
- Request MessageQ:消息队列,用来从Python Backend传数据到Python stub process去运行;
- Response MessageQ:消息队列,用来将Python stub process运行完的结果传输给Python Backend;
Python Backend 的tensor 默认放在cpu上
- 如果需要保持在GPU上,需要在config文件中设置参数:
parameters:{ key: "FORCE_CPU_ONLY_INPUT_TENSORS" value: {string_value: "no"}}- 如何查看tensor Placement是否在cpu上:
pb_utils.Tensor.is_cpu()
需要注意的地方
必须手动在代码中指定运行的设备(如GPU)
- 参数”group_instance {KIND:gpu}” 不起作用
- 如果要避免CPU-GPU拷贝设置参数:FORCE_CPU_ONLY_INPUT_TENSORS;
Requests都没有打包成batch,需要自己手动去拼接;
- 每个Request必须对应一个Response;
用于数据传输的共享内存必须足够大 (因为使用share memory 通信)
- 每个实例至少需要65MB
比C++ Backend效率低,特别在循环处理方面
自定义backend需要注意的地方
处理设备 ID
- backend需要根据 device_id 管理设备。
- 确保创建实例对象、分配内存/缓冲区,并在正确的设备上进行推理。
批处理:从所有请求中收集数据以合并成大批量
- 大批量有助于提高吞吐量。
请求管理
- 请求对象在backend外部创建。
- 每次推理后,请求必须在backend内部释放。
- 当发生致命错误(例如某个请求为空、批量大小超过 max_batch_size 或无法获取输入张量)时,请求必须被释放,执行函数必须立即返回。
响应管理
- 响应对象为每个请求在backend内部创建。
- 响应不得在backend释放,响应由 Triton 管道管理。
- 当推理中发生异常时,错误响应将立即由backend发送,但执行函数不得返回。
Build
