Torch 简介
torch 两种模式
-
Eager Mode(即时模式)
- PyTorch 默认的执行方式,代码按照 Python 方式逐行执行,易于调试和开发。
- 适合研究和原型开发,但执行速度相对较慢,不能跨设备(如 C++ 部署)。
- 由于是解释执行,每次调用 forward 都会重新计算计算图,因此不能充分利用编译优化。
-
Graph Mode(图模式)
- 计算图提前构建并优化,提升执行速度,适合部署和优化。
- 主要依赖 TorchScript 进行计算图构建。
- 通过 JIT(Just-In-Time 编译) 来优化执行流程,提高推理速度。
TorchScript
-
一种介于 Eager Mode(动态图) 和 Graph Mode(静态图) 之间的模式。
-
提供了一种将 PyTorch 模型转换为 静态计算图 的方法,适用于优化和跨平台部署。
-
支持两种方式转换:
- Tracing(跟踪)
-
通过示例输入记录模型的计算路径,并构造计算图。
-
适用于大部分 forward 计算路径固定的模型,但如果 if for 语句依赖输入数据,则可能导致错误。
-
- Scripting(脚本化)
- 直接使用 @torch.jit.script 将代码转换为 TorchScript,可处理 Python 逻辑分支。
- 需要对 Python 代码进行约束(如避免 NumPy、列表推导式等, 参数类型),支持完整的 PyTorch 语法。
- Tracing(跟踪)
PyTorch JIT
-
PyTorch 的 JIT(即时编译)技术,是 TorchScript 的核心实现,主要用于加速模型推理和部署。
-
JIT 作用:
- 解析 PyTorch 代码并转换为 TorchScript(静态计算图)。
- 通过优化计算图(如常量折叠、算子融合)提高执行效率。
- 允许模型序列化后在 C++ 端运行(torch.jit.load 加载)。
-
JIT 包含:
- torch.jit.trace(追踪模式)
- torch.jit.script(脚本模式)
- torch.jit.save/load(保存和加载 TorchScript)
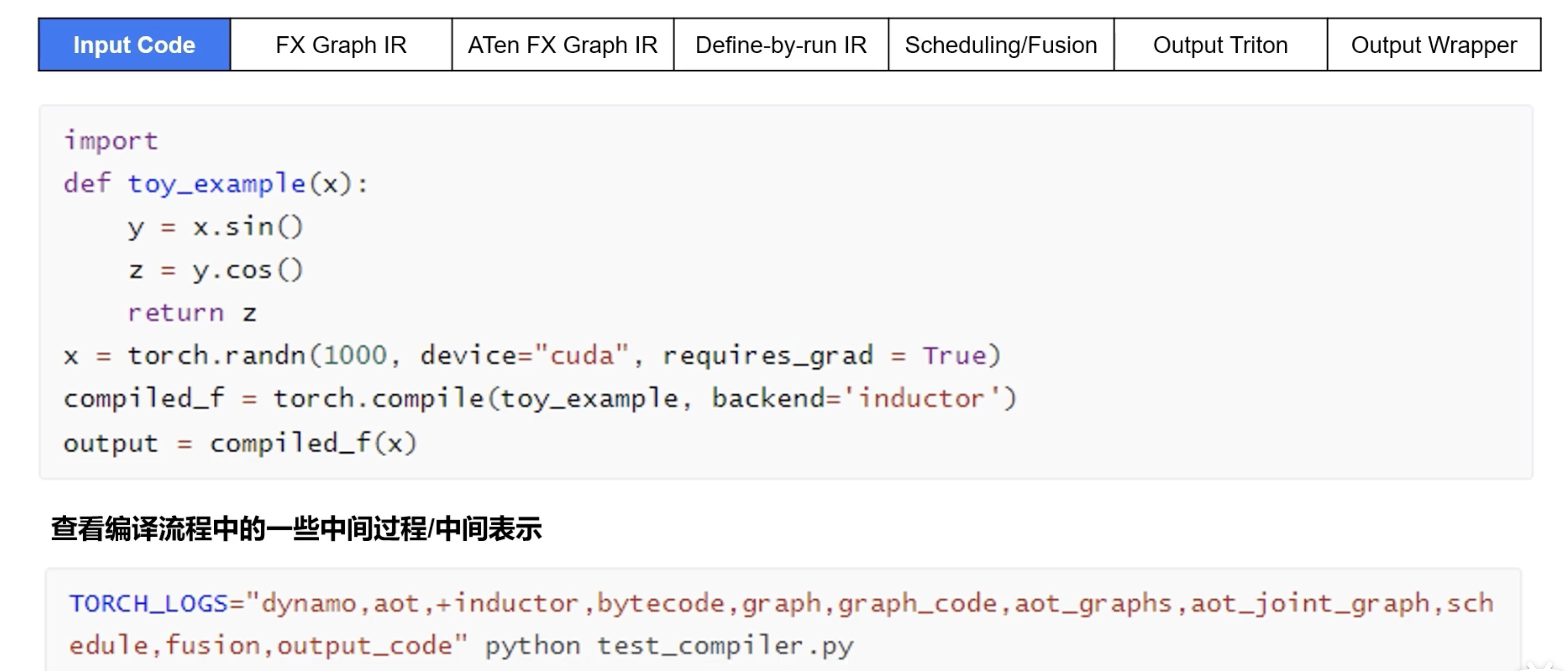
torch.compile
PyTorch 2.0 的 torch.compile 采用了新的 TorchDynamo + AOTAutograd + Inductor 组合优化方式,能够自动将 Eager Mode 代码转换为高性能计算图,并执行深度优化。
- TorchDynamo:这是一个动态捕获工具,能够在不改变原有 Python 代码的情况下,拦截和捕获模型的前向计算图。它通过解析 Python 字节码,识别出模型中的算子和操作,生成对应的静态计算图。
- AOTAutograd:
- 可以在计算前捕获完整的前向和反向传播计算图,并基于该计算图进行优化。其优化方式包括:
- 算子调度:根据计算图中的依赖关系,重新安排算子的执行顺序,以提高计算效率。
- 算子融合:将多个小算子合并为更高效的大算子,减少内存访问和计算开销。
- 层融合:在可能的情况下,将多个计算层合并,以优化整个计算过程。
-
TorchInductor:这是一个深度学习编译器,负责将前向和后向计算图降低(lower)为高效的 GPU (Triton) 或 CPU (C++ / OpenMP)代码。通过融合算子、优化内存访问等方式,生成高性能的计算内核,从而提升模型的执行效率。
这三个组件的协同工作流程如下:
- 捕获前向图:当调用被 torch.compile 装饰的模型时,TorchDynamo 拦截 Python 解释器的执行,捕获前向计算图。
- 生成后向图:AOTAutograd 接收前向计算图,禁用钩子并调用自动微分引擎,生成对应的后向计算图,并重写前向和后向的实现。
- 编译优化:TorchInductor 将前向和后向计算图降低为高效的目标设备代码,进行算子融合和内存优化,生成优化后的计算内核。
- 执行优化后的模型:最终,优化后的计算内核被执行,实现对原始模型的加速。
PrimTorch
-
Prim 算子库:约 250 个较低级别的操作符,适合编译器开发者使用。这些操作符的低级特性意味着需要通过融合等方式来提升性能。
-
ATen 算子库:约 750 个规范化的操作符,适合直接导出,适用于已经在 ATen 层集成的后端,或那些无法通过编译器优化低级操作符性能的后端。 (Triton 算子库 flaggems 平替)
Triton在PyTorch
1 | |
-
mode (str):编译模式,可选值:
- “default”(默认):性能和编译开销之间取得平衡。
- “reduce-overhead”:减少 Python 运行时开销,适用于小 batch 计算,但可能会增加内存占用(通过 CUDA graphs 预分配计算所需的内存)。
- “max-autotune”:启用 Triton 优化的矩阵乘法(matmul)和卷积(convolution),默认启用 CUDA graphs。
- “max-autotune-no-cudagraphs”:类似 “max-autotune”,但不使用 CUDA graphs。
- 可用 torch._inductor.list_mode_options() 查看各模式的具体配置。
-
options (dict):用于配置后端的参数,常见选项包括:
- “epilogue_fusion”:将逐点(pointwise)操作融合到模板中(需启用 “max_autotune”)。
- “max_autotune”:自动分析最优的矩阵乘法配置。
- “fallback_random”:用于调试精度问题。
- “shape_padding”:对矩阵形状进行填充,以优化 GPU 访问(尤其是 Tensor Cores)。
- “triton.cudagraphs”:减少 Python 运行时开销,使用 CUDA graphs。
- “trace.enabled”:开启调试模式,记录编译过程。
- “trace.graph_diagram”:生成优化后计算图的可视化图片。
- 可使用 torch._inductor.list_options() 查看 Inductor 相关的所有选项。
-
disable (bool):如果设置为 True,则 torch.compile() 不执行任何优化,仅用于测试。
triton算子开发
向量加法
1 | |
- tl.program_id(axis=0) 是 当前程序的 ID,类似 CUDA blockIdx.x,用于 并行计算时划分数据范围。
- grid 定义有多少个 program 并行执行,计算方式类似 CUDA gridDim.x = ceil(n_elements / BLOCK_SIZE)。
- 当数据量小,可以不使用 program_id,但当数据量大时,需要 program_id 进行划分并行计算。
| CUDA 术语 | Triton 术语 |
|---|---|
| blockIdx.x | tl.program_id(axis=0) |
| gridDim.x | grid = (num_blocks,) |
| blockDim.x | BLOCK_SIZE |
| threadIdx.x | tl.arange(0, BLOCK_SIZE) |
在 CUDA 里,block 里包含 多个线程,而 Triton 里没有“线程”的概念,直接用 block 处理一段数据,多个 programs 并行执行
对比cuda kernel函数, 每个线程只计算一个元素。
1 | |
共享内存
1 | |
1 | |