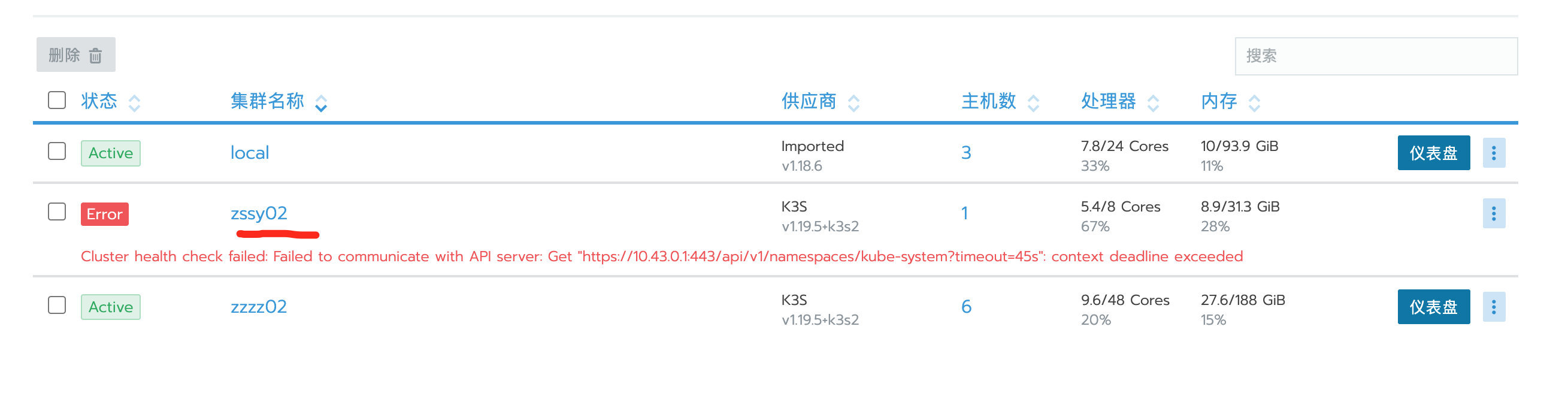
下游集群连不上Rancher排查
-
检查端口连通性,要分段排查,注意数据方向
-
前置机状态
-
前置机nginx状态,端口监听是否异常,nginx配置是否被篡改
-
防火墙是否关闭或者iptable是否很怪
1
2
3
4
5# 防火墙 systemctl status/disable/stop firewalld # 查看iptable,将配置导出到xx方便看 iptables-save > xx
-
-
先尝试连上下游集群主节点是否正常,必要时候重启节点
-
ping 不通
-
ssh 连不上
-
根据提示语(rancher有时候有明确提示语)查看组件log或者重启组件(kubelet,kube-apiserver之类),dokcer重启
1
2docker ps |grep xxx docker logs -f --tail 100 xxx -
查看pod是否正常
1
2
3
4
5# rancher 相关的pod kubectl get pod -n cattle-system # 所有pod kubectl get pod -A遇到域名解析问题,集群需要修改coredns的configmap,然后重启coredns
1
kubectl edit cm coredns -n kube-system参照/etc/hosts修改
1
2
3
4hosts { xxx harbor.xxxx.cn fallthrough }重启coredns
-
记一次apiserver kubelet CPU占用居高不下
背景
拿到一台机子部署好了集群,开始部署kubeflow,部署到一半就开始不太对劲,kubectl命令相应很慢,apply都是慢慢的几秒一行弹出来,代表apiserver已经开始卡了。而且其他命令也开始卡。
30几个核的CPU,不应该才刚部署就卡了,不可能吧
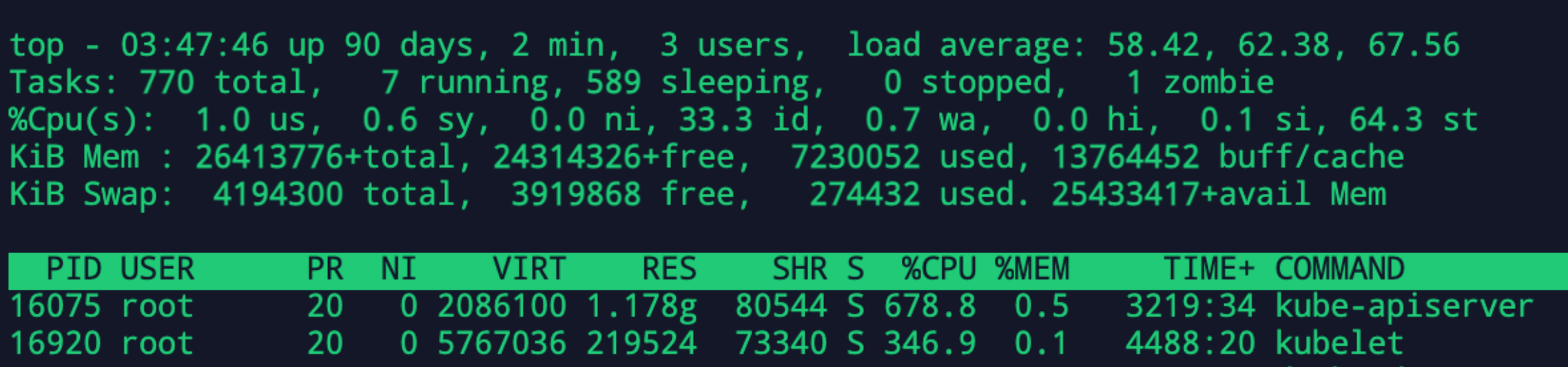
我另外的机器差不多配置的,完全部署才20%不到 load average也非常低
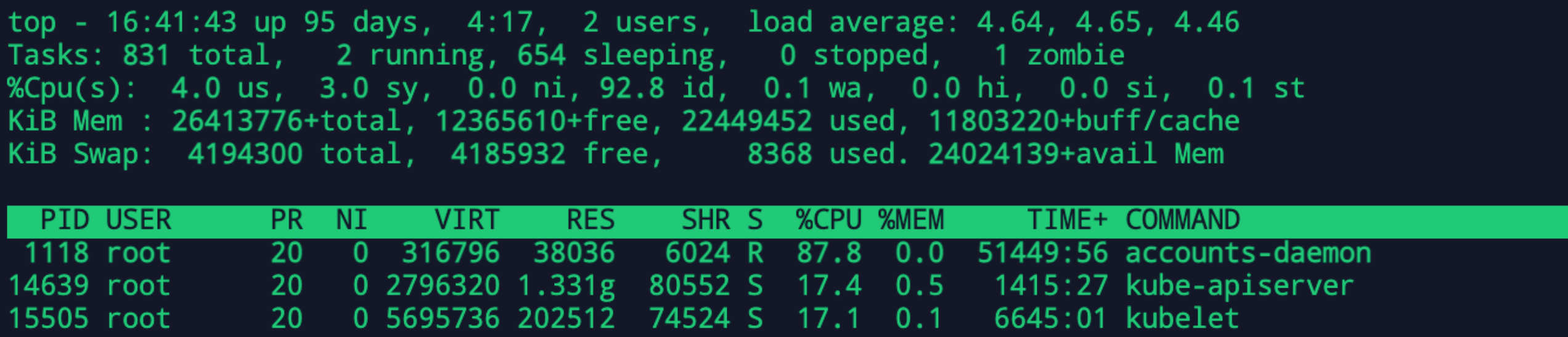
排查开始
查看火焰图
1 | |
宿主机运行用以下命令查看apiserver profile是否开启
1 | |
rke开启
1 | |
svg转换
1 | |
正常的

有问题的

占比大的,对比一下比例都是差不多的。然后对比docker,系统,内核版本,除了使用资源都差不多。
- runtime.gcBgMarkWorker 垃圾回收函数
- runtime.mcall 系统栈中执行调度代码,并且调度代码不会返回,将在运行过程中又一次执行mcall。mcall的流程是保存当前的g的上下文,切换到g0的上下文,传入函数参数,跳转到函数代码执行。
- k8s.io/kubernetes/vendor/github.com/google/cadvisor/manager.(*containerData).housekeeping kubelet 性能监控
strace
strace常用来跟踪进程执行时的系统调用和所接收的信号。 在Linux世界,进程不能直接访问硬件设备,当进程需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通 过系统调用访问硬件设备。strace可以跟踪到一个进程产生的系统调用,包括参数,返回值,执行消耗的时间。
1 | |
- [How to solve “ptrace operation not permitted” when trying to attach GDB to a process](https://stackoverflow.com/questions/19215177/how-to-solve-ptrace-operation-not-permitted-when-trying-to-attach-gdb-to-a-pro)
- https://hub.docker.com/r/sjourdan/strace
1 | |
iostat
-
iotop 看系统上各进程的 IO 读写速度
-
iostat 看 CPU 的 %iowait 时间占比 %util 参数表示磁盘的繁忙程度
1 | |
发现steal出奇地大
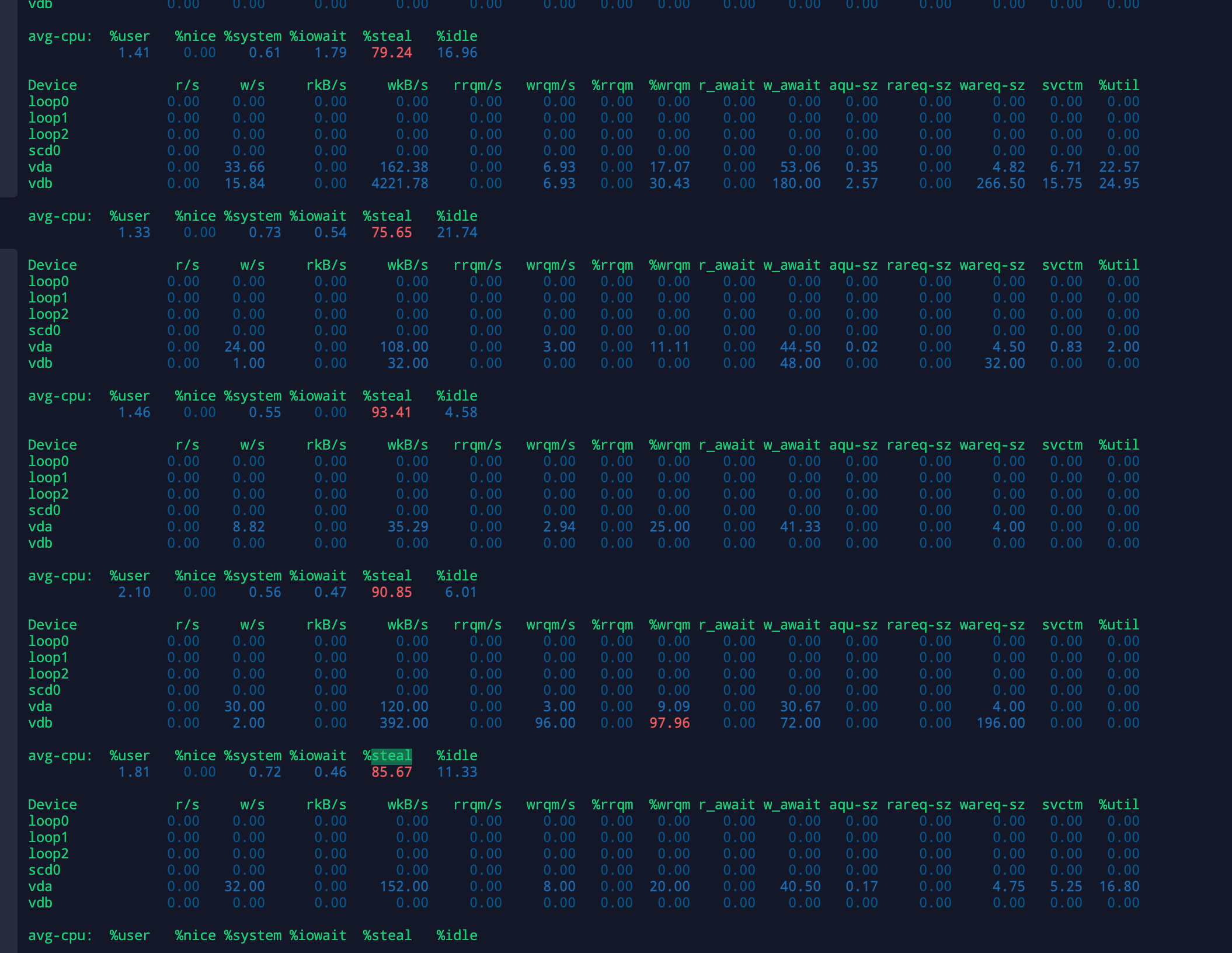
avg-cpu:
%user显示用户级别执行 iostat 命令时,CPU 利用率百分比%nice此参数与 nice 优先级命令有关系,笔者不清楚%system系统级别(kernel)CPU 使用率占比%iowait此参数通常与 top 的%wa参数对应。参数说明,在过去的时间段内(如示例 1,为 1s),有多少时间出现了:CPU(s) 空闲,并且仍然有未完成的 I/O 请求%idleCPU 空闲时间,参数值越小代表目前 CPU 越繁忙
Device:
-
rrqm/s每秒被合并的读 I/O 请求。当 I/O 操作发生在相邻数据块时,它们可以被合并成一个,以提高效率。 -
wrqm/s每秒被合并的写 I/O 请求。 与上边的rrqm/s, 参见:http://linuxperf.com/?p=156 -
%util表示设备有 I/O 请求(即非空闲)的时间比。此参数并不能作为衡量设备饱和程度指标,只能衡量设备的繁忙程度。现代的硬盘具有并行处理多个 I/O 请求的能力,如某硬盘处理单个 I/O 需要 0.1s,如果并行处理 10 个 I/O 请求的话,则 0.1s 可以完成,即在过去 1s 时间内的 %util = 10%;如果 10 个 I/O 请求顺序提交,则 %util = 100%。但是设备并没有饱和。
-
%steal与虚拟机的性能息息相关,如果数值高则机器的状态非常糟糕宿主机 CPU 目前在服务于其它虚拟机,当前虚拟机等待宿主机 CPU 服务的时间占比。如果数值偏大则表示等待时间越长
表明宿主机的负载过高(此种情况往往见于云服务商的超卖)