知识库
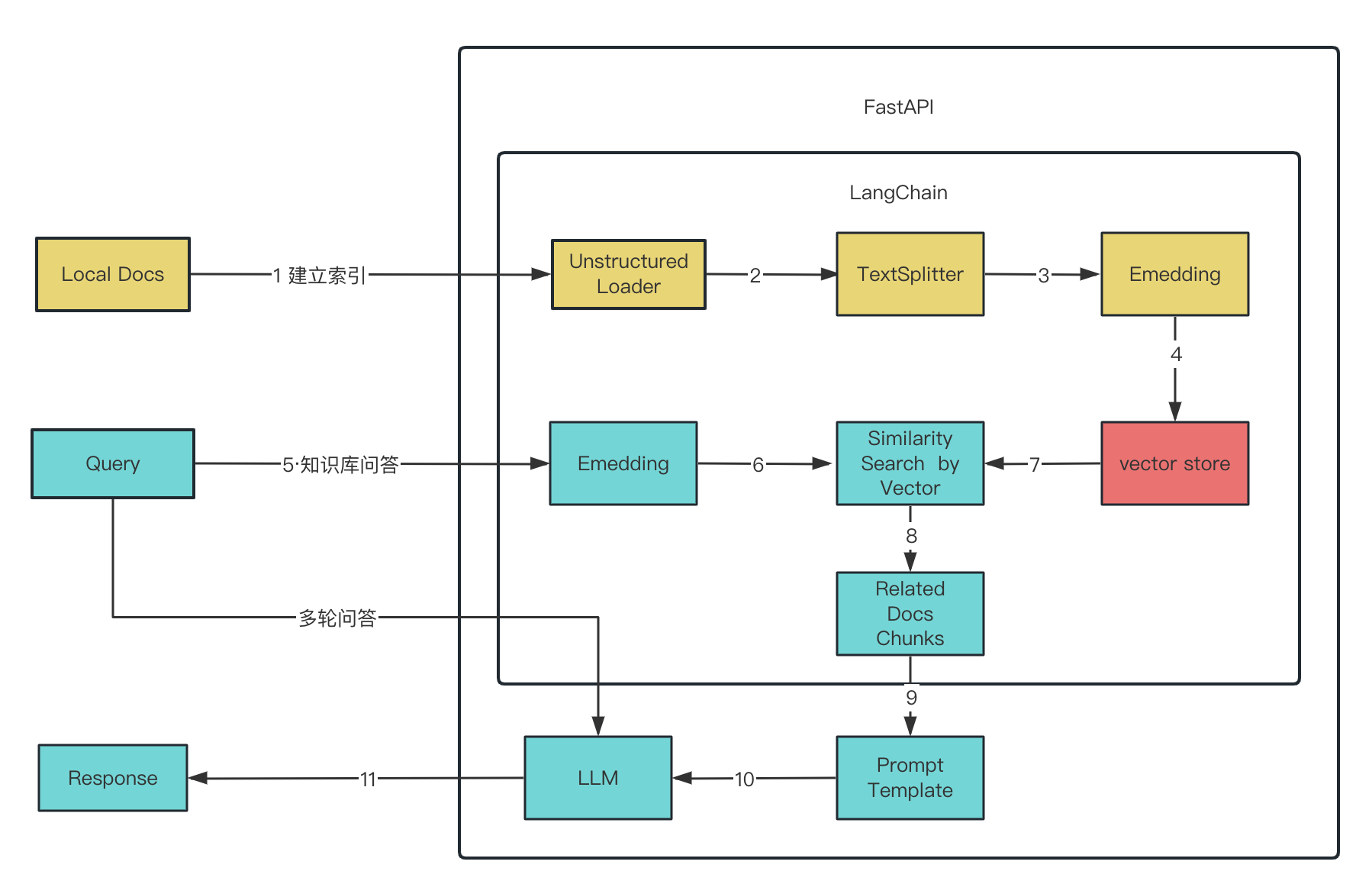
准备数据
-
遍历文件清洗数据,load文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32from langchain.docstore.document import Document data = re.sub(r'!', "!\n", data) data = re.sub(r':', ":\n", data) data = re.sub(r'。', "。\n", data) data = re.sub(r'\r', "\n", data) data = re.sub(r'\n\n', "\n", data) data = re.sub(r"\n\s*\n", "\n", data) docs.append(Document(page_content=data, metadata={"source": file})) _, ext = os.path.splitext(file_path) if ext.lower() == '.pdf': #pdf with pdfplumber.open(file_path) as pdf: data_list = [] for page in pdf.pages: print(page.extract_text()) data_list.append(page.extract_text()) data = "\n".join(data_list) elif ext.lower() == '.txt': # txt with open(file_path, 'rb') as f: b = f.read() result = chardet.detect(b) with open(file_path, 'r', encoding=result['encoding']) as f: data = f.read() -
分批文本块
1
2
3
4
5
6
7
8from langchain.text_splitter import CharacterTextSplitter # chunk_size : 文本分割的滑窗长度 # chunk_overlap:重叠滑窗长度 保留一些重叠可以保持文本块之间的连续性,做一个承上启下 text_splitter = CharacterTextSplitter( chunk_size=int(settings.librarys.rtst.size), chunk_overlap=int(settings.librarys.rtst.overlap), separator='\n') doc_texts = text_splitter.split_documents(docs) -
embedding 文本数据的数字表示。这种数字表示很有用,因为它可以用来查找相似的文档
1
2
3embeddings = HuggingFaceEmbeddings(model_name='') embeddings.client = sentence_transformers.SentenceTransformer("moka-ai/m3e-base", device="cuda") -
VectorStore
向量数据库存放文档和embedding后的vertor
FAISS高效相似性搜索和密集向量聚类的内存库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17from langchain.vectorstores.faiss import FAISS as Vectorstore docs = [] texts = [d.page_content for d in doc_texts] metadatas = [d.metadata for d in doc_texts] # 新增 vectorstore_new = Vectorstore.from_texts(texts, embeddings, metadatas=metadatas) # 合并 vectorstore.merge_from(vectorstore_new) # 加载 vectorstore_old = Vectorstore.load_local( 'memory/default', embeddings=embeddings) # 保存 vectorstore_old.save_local('memory/default')
获取doc
query 向量化,匹配库里向量,查找与之相似度最高的文本块。用户提出的问题与查找到的相关知识将被组合并被LLM处理,最终返回用户所需要的答案。
1 | |
作为system提示词:学习以下文段, 用中文回答用户问题。如果无法从中得到答案,忽略文段内容并用中文回答用户问题。
垂直邻域LLM
参考
由于在训练时训练语料的限制,最终产生的LLM往往只具备通用知识,而不具备特定垂直领域的知识,尤其是企业内部信息。
目前情况
- 如果构建具备特定垂直领域知识的LLM,需要将特定垂直领域的知识作为新的语料来微调通用大模型,不仅耗费大量算力,而且每次信息的更新都需要重新进行模型训练,还无法保证结果的准确性。
- 可以将特定垂直领域的知识作为提示(prompt)输入给通用大模型,由此得到准确的结果。但由于LLM对提示词的长度有限制,其可以获取的信息非常有限,难以记住全部的知识信息,因此无法回答垂直领域的问题。
- 训练会造成通用能力降低,只能回答垂直领域问题。
思考
- 真正垂直领域大模型的做法,应该从Pre-Train做起。SFT只是激发原有大模型的能力,预训练才是真正知识灌输阶段,让模型真正学习领域数据知识,做到适配领域。但目前很多垂直领域大模型还停留在SFT阶段。
- 领域大模型在行业领域上效果是优于通用大模型即可,不需要“即要又要还要”。
- 不应该某些垂直领域大模型效果不如ChatGPT,就否定垂直领域大模型。有没有想过一件可怕的事情,ChatGPT见的垂直领域数据,比你的领域大模型见的还多。但某些领域数据,ChatGPT还是见不到的。
- 纯文本只能用于模型的预训练,真正可以进行后续问答,需要的是指令数据。当然可以采用一些人工智能方法生成一些指数据,但为了保证事实性,还是需要进行人工校对的。高质量SFT数据,才是模型微调的关键。
- 外部知识主要是为了解决模型幻觉、提高模型回复准确。同时,采用外部知识库可以快速进行知识更新,相较于模型训练要快非常多。
解决
- 大模型+知识库,这是目前最简单的办法,构建领域知识库,利用大模型的In Context Learning(基于上下文学习)的能力,通过检索在问答中增强给模型输入的上下文,让大模型可以准确回答特定领域和企业的问题;但是这种方式对准确检索能力要求很高,另外如果模型本身不具备领域知识,即使有准确上下文,也难以给出正确答案。
- PEFT(参数高效的微调),通过P-Tuning或者LoRA等方式对模型进行微调,使其适应领域问题,比如一些法律和医疗的开源模型。但是这种方式微调的模型一般效果不会好,这是因为PEFT并不是用来让模型学会新的知识,而是让模型在特定任务表现更好的方式。类似Prefix Tuning、P-Tuning和LoRA等技术在某种程度上是等价的,目的是让模型适应特定任务,并不是让模型学会新的知识。因此,想通过PEFT方式让模型学会新的知识是南辕北辙。
- 全量微调,这是另外一种比较流行的方式,在某个基座模型的基础上,对模型进行全量微调训练,使其学会领域知识。理论上,全量微调是最佳方式,基座模型已经学会了通用的“世界知识”,通过全量微调可以增强它的专业能力。但是实际上,如果语料不够,知识很难“喂”给模型。现在模型训练的方式,并不存在让模型记住某一本书的方法。其次是,如果拿到的不是预训练好的基座模型,而是经过SFT甚至RLHF的模型,在这些模型的基础上进行训练时,就会产生灾难性遗忘的问题。再者这种方法对算力的要求还是比较高的。
- 从预训练开始定制,这种方式应该是构建垂直领域大模型最有效的方法,从一开始词表的构建,到训练语料的配比,甚至模型的结构都可以进行定制。然后严格遵循OpenAI的Pretrain–>SFT–>RLHF三段训练方法,理论上可以构建出一个优秀的领域大模型。但是这种方法需要的费用极高,除了预训练,还需要考虑模型的迭代,一般的企业根本无力承受。
需要澄清的概念
-
垂直领域和特定任务
很多需求是希望大模型去完成一些特定任务,而并不需要大模型具备专业领域知识。比如文本分类、文本生成等,这些都是特定任务。如果任务和专业领域无关,那么其实并不需要一个垂直领域的大模型。只要对模型进行PEFT微调,甚至是研究一个更好的prompt方式,就可以让模型处理特定任务时表现更好即可。在需要一些知识注入的帮助,一般可以通过外挂知识库的形式进行。除非对专业领域有很高要求,例如医学论文,法律条文解读,需要模型本身具备很强的领域知识,否则都不需要对模型本身进行微调。
-
垂直领域”系统”和”模型”
很多垂直领域需求是一个”系统”而并非一定是一个模型。如果能够利用通用的领域模型,加上其他增强技术构建出一个能够适应特定领域问题的系统,那么也是满足要求的,例如ChatLaw这个开源的项目中,其实也综合使用了其他模型(KeywordLLM)来增强垂直领域能力。
技巧
- 学习长文本,分段summary,LLM生成答案摘要,通过另一个model(Bart)进行扩写
- 经常变化知识,用知识库