项目概览
- 明确目标 如何划定问题,要选择什么算法,评估模型性能的指标是什么 划定问题:监督或非监督,还是强化学习?这是个分类任务、回归任务,还是其它的?要使用批量学习还是线上学习?
- 选择性能指标
- 核实假设
Get Data
。。。。。。spider
Data Explore
了解data概况
- data structure
1
pd.value_counts() .info() scatter_plot .head() .describe() - 可视化数据的分布,趋势,离散,或者相关度,分类的话,填好color and label
- 明确目的,根据以上进一步假设
- EDA Exploratory Data Analysis
Variable Identification
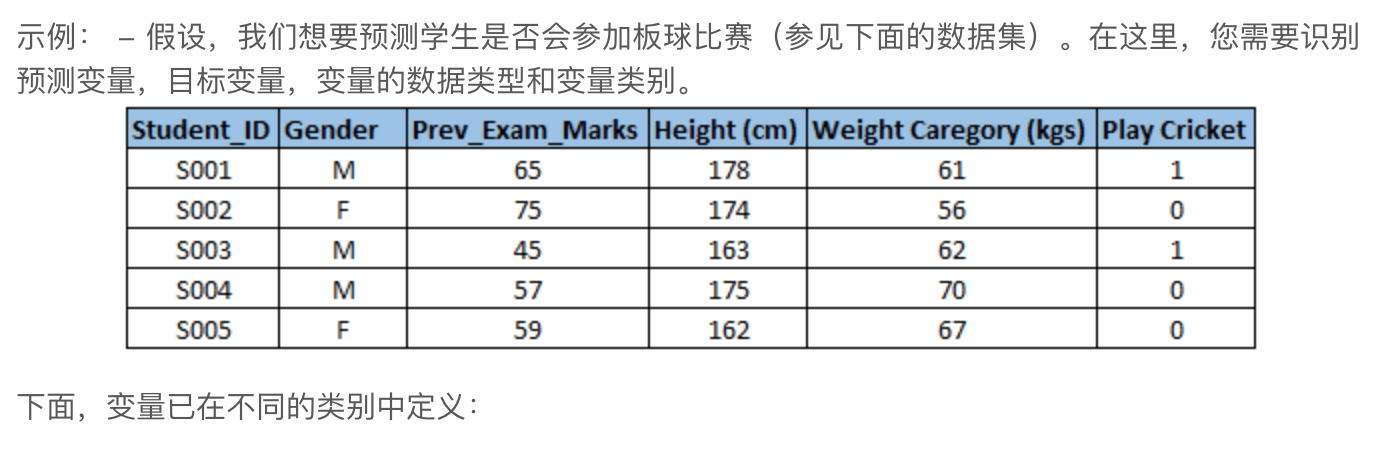
识别预测变量(输入)和目标(输出)变量。接下来,确定变量的数据类型和类别。

Univariate Analysis
逐个探索变量。执行单变量分析的方法将取决于变量类型是分类还是连续。
- 连续变量 在连续变量的情况下,我们需要了解变量的集中趋势和扩散。

- 分类变量 使用频率表来了解每个类别的分布。我们还可以读作每个类别下的值的百分比。 可以使用两个指标(每个类别的计数和计数%)来衡量它。条形图可用作可视化。
Bi-variate Analysis
双变量分析找出两个变量之间的关系。
- 连续和连续 两个连续变量之间进行双变量分析时,我们应该看散点图。
散点图的模式表明变量之间的关系。关系可以是线性的或非线性的。为了找到关系的强度,我们使用
corr()相关系数 - 分类和分类
Data Preprocess
- data nan or noise,异常值 => Techniques of Outlier Detection and Treatment
- 当缺失数据的性质是“完全随机缺失”时, 删除 ,否则非随机缺失值可能会使模型输出产生偏差。
- 平均值/众数/中位数插补 在这种情况下,我们分别计算非缺失值的性别“男性” (29.75)和“女性”(25)的平均值,然后根据性别替换缺失值。对于“男性”,我们将用 29.75 替换人力缺失值,对于“女性”,我们将替换为 25。
- 如果存在大量异常值,我们应该在统计模型中单独处理它们。一种方法是将两个组视为两个不同的组,并为两个组建立单独的模型,然后组合输出。
- 类别特征(categorical features) => numerical features (各种 encode one-hot pd.get_dummies) 如果取值太多 只用取出现频率top n,其他归一类再做encode, 或者这个feature的重要性 干脆不要
- 在预测建模中处理分类变量的简单方法
Feature select
- 凭经验觉得有用的 🤣
- 非线性变换 获得更多feature
- Feature Engineering
- PCA ,Random Forest ,XGBoost ,GDBT
- 归一化
- 标准化
- 文本特征:文本长度、Word Embeddings、TF-IDF、LDA、LSI等,深度学习提取feature
model select
- Gradient Boosting—— GBDT (Xgboost)
- Random Forest
- SVM
- Linear
- Logistic Regression
- Neural Networks 时间model
- ma
- ARIMA
- Markov Model
- LSTM
调参
防止 过拟合
对结果不要想当然,熟悉model参数,确定小范围再grid search
做好训练记录,保存参数,方便重现
Cross Validation
改进 Feature 或 Model 通常 K-Fold CV K=5
Ensemble
选择好的feature 再ensemble get a strong model kaggle-ensembling-guide
Cost Function & Evaluation Fuction
- MSE/RMSE
- L1_Loss(误差接近0的时候不平滑)/L2_Loss
- Hinge_Loss/Margin_Loss
- Cross-entropy_Loss/Sigmoid_Cross-ntropy_Loss/Softmax_Cross-entropy_Loss
- Log_Loss
- ROC/AUC